
Abstract
Signomial Programming (SP) has proven to be a powerful tool for engineering design optimization, striking a balance between the computational efficiency of Geometric Programming (GP) and the extensibility of more general methods for optimization. While techniques exist for fitting GP compatible models to data, no models have been proposed that take advantage of the increased modeling flexibility available in SP. Here, a new Difference of Softmax Affine function is constructed by utilizing existing methods of GP compatible fitting in Difference of Convex (DC) functions. This new function class is fit to data in log–log space and becomes either a signomial or a set of signomials upon inverse transformation. Examples presented here include simple test cases in 1D and 2D, and a fit to the performance data of the NACA 24xx family of airfoils. In each case, RMS error is driven to less than 1%.
Similar content being viewed by others
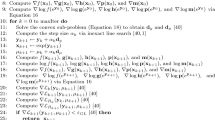

Avoid common mistakes on your manuscript.
1 Motivation
Geometric Programming (GP) and Signomial Programming (SP) are two related classes of non-linear optimization that have recently been applied with great success to the field of aircraft design (Hoburg and Abbeel 2014; Torenbeek 2013; Hoburg and Abbeel 2013; Kirschen et al. 2016; Brown and Harris 2018; York et al. 2018; Burton and Hoburg 2018; Lin et al. 2020; Kirschen et al. 2018; York et al. 2018; Saab et al. 2018; Hall et al. 2018). Despite these developments, the GP and SP formulations do not allow the use of black box analysis tools that are common in practical design problems (Hall et al. 2018; Martins and Lambe 2013). One method proposed by Hoburg et al. (2016) to overcome this limitation is to fit a GP compatible function to a set of training data that represents the black-box relationship, and then to impose this fitted function as a constraint in the GP formulation. In cases where the black-box relationship is log–log convexFootnote 1, the three functions proposed in Hoburg et al. are capable of capturing the true relationship with a high degree of accuracy (Hoburg et al. 2016). But when black-box relationships between inputs and outputs are not log–log convex, as might be the case with high fidelity CFD or FEA, then GP compatible functions lack the ability to model the relationship with sufficient accuracy. Unlike Geometric Programming, Signomial Programming is not limited to log–log convex relationships, but no SP compatible functions exist for the purpose of data fitting. This work fills this gap by developing a SP compatible function capable of capturing black-box relationships that are not log–log convex.
2 Geometric programming and signomial programming
2.1 Geometric programming
Geometric Programs (GPs) are built upon two fundamental building blocks: monomial and posynomial functions. A monomial function is defined as the product of a leading constant with each variable raised to a real power (Boyd et al. 2007):
A posynomial is the sum of monomials (Boyd et al. 2007), which can be defined in notation as:
From these two building blocks, it is possible to construct the definition of a GP in standard form (Boyd et al. 2007):
When constraints and objectives can be written in the form specified in Eq. 3 it is said that the problem is GP compatible.
2.2 Signomial programming
Signomal Programs (SPs) are a logical extension of Geometric Programs that allow the inclusion of negative leading constants and a broader set of equality constraints. The key building blocks of Signomial Programing are signomials, defined as the difference between two posynomials \(p(\mathbf{x} )\) and \(n(\mathbf{x} )\):
The posynomial \(n(\mathbf{x} )\) is often referred to as a ‘neginomial’ because it is made up of all of the terms with negative leading coefficients. From this definition, it is now possible to write the standard form for a Signomial Program (Kirschen et al. 2016):
however, another useful form is:
In this alternative form, the neginomial is added to both sides, and then used as a divisor to construct an expression either equal to or constrained by a value of one.
SPs are not convex upon transformation to log–log space, unlike their GP counterparts, and therefore must be solved using general non-linear methods. However many signomial programs of interest still exhibit an underlying structure which is well approximated by a log–log convex formulation, and as a result can be efficiently solved by a series of GP approximations via the Difference of Convex Algorithm (DCA). In this process the various neginomials \(n(\mathbf{x} )\) are replaced with local monomial approximations, yielding substantial benefits over other non-linear solution methods (see Kirschen et al. 2018 and York et al. 2018 for discussion).
3 Difference of convex functions for data fitting
3.1 Difference of convex (DC) functions
Most continuous functionsFootnote 2 (\(f(\mathbf {x})\)) can be written as the difference of two convex functions (\(g(\mathbf {x})\) and \(h(\mathbf {x})\)) (Hartman 1959):
Functions of the form in Eq. 7 are said to be Difference of Convex (DC) functions.
By extension, it follows that most datasets that can be well approximated by a continuous function should also be well approximated by the difference between two convex functions. In other words, if there is some continuous function (or more precisely some function of bounded variation) \(f(\mathbf {x})\) that fits some data set sampled from a mapping from \(\mathbb {R}^N \rightarrow \mathbb {R}\), then there also exist functions \(g(\mathbf {x})\) and \(h(\mathbf {x})\) such that \(g(\mathbf {x})\) and \(h(\mathbf {x})\) are both convex and \(g(\mathbf {x}) - h(\mathbf {x})\) is an equally good fit to the mapping as the original function \(f(\mathbf {x})\). Taking functions \(g(\mathbf {x})\) and \(h(\mathbf {x})\) to be log–log convex functions such as those proposed in Hoburg et. al. (2016), it is possible to fit approximations for these functions \(g(\mathbf {x})\) and \(h(\mathbf {x})\) to data sets from mappings which are not log–log convex.
3.2 Function definitions
3.2.1 Notation
Consider a data set sampled from a black box mapping from \(\mathbb {R}^N \rightarrow \mathbb {R}\). Consistent with the notation in Hoburg et al. (2016) let the vector \(\mathbf {u}_j\) represent the independent variables in \(\mathbb {R}^N\) for data point j and the scalar \(w_j\) represent the output in \(\mathbb {R}\) for data point j. The log–log space variables are then represented as \(\mathbf {x}_j = \log \mathbf {u}_j\) and \(y_j = \log w_j\).
3.2.2 Difference of max affine (DMA) functions
The first function proposed by Hoburg et al. (2016) is the Max Affine (MA) function:
This function class is known to create a convex epigraph. In fact, any convex function can be reasonably approximated as a Max Affine function given a sufficient number of affine functions, K (Bertsimas 2009). Upon transformation back to variables \(\mathbf {u}_j\) and \(w_j\), the Max Affine function becomes Max Monomial, which can be implemented as a set of monomial constraints in the Geometric Program.
Now consider the difference between two of these max affine functions (Eq. 8), which henceforth will be called the Difference of Max Affine (DMA) function:
The subtracted term is represented by an entirely separable Max Affine function defined by fitting parameters M, h, and \(\mathbf {g}\). Based on an understanding of DC functions, and the fact that convex functions can be well approximated as Max Affine for large K or M, this DMA function should be highly versatile as a fitting function.
While the Max Affine function has a realizable transformation back from log–log space, the Difference of Max Affine function has no such transformation due to the inability to readily construct a meaningful epigraph or subgraph using a set of separable inequalities, making it somewhat impractical for use in optimization. Despite this, the DMA function is quite rapid to fit, and could be of application in other areas where a cheap surrogate is desired for non-convex fitting. Here, the DMA function is a used as an intellectual building block to the next function class, and as a seed function for the fitting process.
3.2.3 Difference of softmax affine (DSMA) functions
The second function proposed by Hoburg et al. (2016) is the Softmax Affine (SMA) function:
The SMA function uses a global softening parameter (\(\alpha\)) to ‘smooth’ the sharp corners of the Max Affine function and has the benefit of requiring far fewer affine terms K to capture smooth convex functions with reasonable accuracy (Hoburg et al. 2016). However, the global softening parameter results in a poor representation in regions where the curvature deviates substantially from the global average (Hoburg et al. 2016).
Consider the following function which is the difference between two Softmax Affine functions (Eq. 10):
In the same way that an individual SMA function requires fewer terms K than the Max Affine function, the two SMA functions of DSMA require fewer terms K and M to fit smooth convex functions Hoburg et al. (2016). Thus, the DSMA function will generally require fewer terms \(K+M\) than the DMA function to obtain an accurate fit to DC functions.
Transforming the DSMA function back to the optimization variables \(\mathbf {u}_j\) and \(w_j\) proceeds as follows:
At this point it is obvious from the definition of a posynomial function that the form will reduce to:
Though Eq. 13 is not compatible with the SP formulation, consider the following substitutions:
which then reduces Eq. 13 to:
Thus, taking the three constraints Eqs. 14, 15, 16 as a set does result in an SP compatible scheme. This method of substitution is consistent with other approaches to constructing GP and SP compatible constraints (Boyd et al. 2007).
3.2.4 Consideration of implicit difference of softmax affine (IDSMA) functions
Hoburg et al. (2016) proposes a third function class called Implicit Softmax Affine (ISMA). Unlike MA and SMA, the ISMA function class is an implicit function of y:
Since the ISMA function proved superior to the SMA function, particularly for functions with corners, cusps, and highly varying curvature, it is tempting to write an Implicit Difference of Softmax Affine function as follows:
However, this function is not a one to one mapping in that there are multiple possible values y for each vector \(\mathbf {x}\). To demonstrate this, consider the case where \(K = M = 1\), \(\alpha _k = \beta _m = 1\), and all other constants are zero. Substituting these values into Eq. 18 yields the expression \(y-y = 0\), which holds true for all values of y. It is therefore not generally possible to solve for a unique y for any given \(\mathbf {x}\). Fortunately, in practice the DSMA function performs well in regions that proved challenging to SMA functions due to the DC construction, somewhat negating the desire for IDSMA functions in the first place.
4 Process for using the DSMA function in an optimization formulation
Consider a constraint that might be posed in an optimization problem:
where function \(g(\mathbf {u})\) represents the black box mapping from \(\mathbb {R}^N \rightarrow \mathbb {R}\) discussed above in Sect. 3.2.1. The steps to model this constraint in a Signomial Programming compatible form are as follows:
-
1.
Select a set of trial points \(\{\mathbf {u}_j\) | \(j\in J\}\)
-
2.
Generate dataset \(\{\mathbf {u}_j, w_j\) | \(j \in J, w_j = g(\mathbf {u}_j)\}\) by evaluating each \(\mathbf {u}_j\) using the black box function
-
3.
Apply the log transformation \(\{\mathbf {x}_j, y_j\} = \{\log \mathbf {u}_j, \log w_j\}\)
-
4.
Fit a DSMA function f to the transformed data such that \(y_j \approx f(\mathbf {x}_j)\)
-
5.
Use the fit parameters from the DSMA function f to construct Eqs. 14, 15, and 16
-
6.
Relax the equalities in Eqs. 14, 15, and 16 as appropriate to construct the desired constraint (See Table 1)
The first three steps are trivial, so discussion here will focus on fitting and constraint construction.
4.1 Fitting method
For a set of m number of data points (ie, if there are m number of data points in set J), the fitting problem can be written as an unconstrained least squares optimization problem with objective function:
where the fitting parameters are stacked in the vector \(\gamma\) (Hoburg et al. 2016).
This problem is solved using the Levenberg–Marquardt (LM) algorithm presented by Hoburg et al. (2016). The LM algorithm computes a step size at each iteration but requires a Jacobian to be computed at each step, and so relevant analytical derivatives are presented in the following Sects. 4.3 and 4.4. The gradient based nature of the LM algorithm requires a number of random restarts to be performed from varying initial guesses. The cases presented below utilize between 30 and 100 random restarts, though the required number will be problem dependent.
When fitting a DSMA function, a DMA function is first fit in order to provide an initial guess for the DSMA fitting algorithm when combined with a relatively large softening parameter. The ability to quickly achieve a DMA initial guess is critical to the success of fitting DSMA functions, as starting from random starting conditions does not typically yield a satisfactory result.
4.2 Constraint construction
Equations 14, 15, and 16 combine to represent the function \(g(\mathbf {u})\) in a form that is compatible with Signomial Programming, but a constraint in an optimization problem (Eq. 19) is defined by both the function \(g(\mathbf {u})\) and the relationship between \(g(\mathbf {u})\) and w as defined by a relational operator (\(=,\ge ,\le\)). Eqs. 14, 15, and 16 must therefore be modified to contain this relational information.
For example, if as presented in Eq. 19, w is lower bounded by the function \(g(\mathbf {u})\), then Eq. 16 must similarly present a lower bound on w. Since softening parameters are strictly positive by definition (Hoburg et al. 2016), intermediate variable \(p_{\text {convex}}\) must also be lower bounded in Eq. 14 since it appears in the numerator of Eq. 16. However, intermediate variable \(p_{\text {concave}}\) must be upper bounded to prevent the denominator of Eq. 16 from growing too large. This case corresponds to the second column of Table 1. Similar cases are presented for all three possible relational operators of the original constraintFootnote 3.
4.3 Derivatives for the DMA function
4.4 Derivatives for the DSMA function
5 Demonstrations of the fitting models
5.1 A 1D fitting problem
Consider the 1D function, which uses the log transformed variables \(\mathbf {x}\) and y:
This function is used as a test case due to a non-differentiable corner along with significant variations of curvature. Log–log convex methods (MA, SMA, ISMA) are unable to capture the highly non-convex region of the data, essentially approximating this portion of the curve as a straight line (Fig. 1).

Fifth order fits to the simple 1D function. RMS Error is as follows: MA: 44.6%, SMA: 44.6%, ISMA: 44.8%, DSMA: 0.019%
As a result, the convex fitting methods all converge to nearly identical representations with an RMS error of between 44–45%. In contrast, the DSMA function captures all of the major features of the function, including the non-differential corner. Unlike SMA functions, which can only capture a single curvature due to the single parameter \(\alpha\), the DSMA function can capture complex, multi-radius curvature as a direct result of the DC construction. Fitting this function with functions of increasing order substantially improves the RMS error, largely driven by the error at the non-differentiable corner point (Fig. 2).

The log of RMS error with increasing fit order
5.2 A 2D fitting problem
Consider the 2D test case shown in Fig. 3, which is an eigenfunction of the wave equation with a clamped lower right quadrant.

An eigenfunction of the wave equation with clamped lower right quadrant
This function features complex regions of both convex and concave curvature, an entirely flat quadrant, and a sharp non-differentiable cusp at the origin. Though this particular function has no explicit form, the Matlab ‘membrane’ function produces the necessary data.
Fitting this function with an DSMA function yields a reasonably accurate surrogate (See Fig. 4 for a 9th order fit). As might be expected, the fitting scheme struggles along the non-differentiable L-shaped curve, and at origin specifically. Error near the point (0,1) is due to an inflection in the data where curvature changes from concave to convex in a very small region, which proves a difficult feature to capture in the fit. As with the previous example, increasing the fit order improves the fit quality (Fig. 5).

The fitted 9th order function and associated absolute error

The log of RMS error with increasing fit order
5.3 Fitting XFOIL performance data of the NACA 24xx family of airfoils
Hoburg et al. (2016) fit performance data for NACA 24xx airfoils generated from XFOIL (Drela 1989), but only by considering curves of lift coefficient vs. drag coefficient. In many cases, it is more useful to have two separate curves of lift coefficient vs. angle of attack and drag coefficient vs. angle of attack, but the CL vs. \(\alpha\) curve is not compatible with log–log convex fitting techniques.
Consider the problem of fitting the following function:
where \(C_L\) is the airfoil lift coefficient, \(\alpha\) is the airfoil angle of attack, Re is the Reynolds number, and \(\tau\) is the airfoil thickness (ex, a \(\tau =0.12\) would be a NACA 2412 airfoil).
Sweeping with XFOIL over a grid from \(\alpha =[1,23]\), \(Re=[10^6,10^7]\), and \(\tau =[.09,.21]\) yields a training set of untransformed variables \(\mathbf {u}_j\) and \(w_j\). This data is then transformed, fit with a DSMA function, and then used to construct a SP compatible equation set as described in Sect. 4.2, with the results shown in Fig. 6. Once again, increasing fit order improves the overall quality of the fit (Fig. 7).

5th order DSMA fits representing Lift Coefficient vs. Angle of Attack for the NACA 24xx family of airfoils, plotted with the sampled data from XFOIL

The log of RMS error with increasing fit order
6 Conclusions
This work serves to develop and validate a Signomial Programming compatible method for fitting black-box data when the underlying mathematical relationships are not log–log convex. The Difference of Softmax Affine (DSMA) function is a key link in the chain from Geometric Programming, where analysis models are predominately limited to either simple explicit relationships or log–log convex data fits, to more traditional MDAO methods like Sequential Quadratic Programming, where the mathematical form of an analysis model has few limitations.
Notes
The log–log transformation discussed in this work is sometimes shortened to log-transformation for practical reasons, and appears in the literature both ways. In all cases here, the terms log–log convexity, log–log transformation, log–log space, etcetera could alternatively be called log-convexity, log-transformation, logspace, and similar.
The precise statement in Hartman et. al. is that any function of bounded variation can be decomposed into the difference between two convex functions. For practical engineering purposes, this translates to most differentiable and non-differentiable continuous functions.
References
Bertsimas D (2009) 15.093J/6.255J optimization methods. Massachusetts Institute of Technology: MIT OpenCouseWare, https://ocw.mit.edu/. License: Creative Commons BY-NC-SA (Fall). https://ocw.mit.edu/courses/sloan-school-of-management/15-093j-optimization-methods-fall-2009/lecture-notes/
Boyd S, Kim SJ, Vandenberghe L, Hassibi A (2007) A tutorial on geometric programming. Optim Eng 8(1):67–127. https://doi.org/10.1007/s11081-007-9001-7
Brown A, Harris W (2018) A vehicle design and optimization model for on-demand aviation. In: 2018 AIAA/ASCE/AHS/ASC structures, structural dynamics, and materials conference, pp. 1–46. American Institute of Aeronautics and Astronautics, Reston. https://doi.org/10.2514/6.2018-0105
Burton M, Hoburg W (2018) Solar and gas powered long-endurance unmanned aircraft sizing via geometric programming. J Aircraft 55(1):212–225. https://doi.org/10.2514/1.C034405
Drela M, Drela M (1989) Xfoil: an analysis and design system for low Reynolds number airfoils. In: Mueller TJ (ed) Low Reynolds number aerodynamics. Springer, Berlin, pp 1–12. https://doi.org/10.1007/978-3-642-84010-4_1
Hall DK, Dowdle A, Gonzalez J, Trollinger L, Thalheimer W (2018) Assessment of a boundary layer ingesting turboelectric aircraft configuration using signomial programming. In: 2018 aviation technology, integration, and operations conference, pp. 1–16. American Institute of Aeronautics and Astronautics, Reston. https://doi.org/10.2514/6.2018-3973
Hartman P (1959) On functions representable as a difference of convex functions. Pac J Math 9(3):707–713. https://doi.org/10.2140/pjm.1959.9.707
Hoburg W, Abbeel P (2013) Fast wind turbine design via geometric programming. In: 54th AIAA/ASME/ASCE/AHS/ASC structures, structural dynamics, and materials conference, pp. 1–9. American Institute of Aeronautics and Astronautics, Reston. https://doi.org/10.2514/6.2013-1532
Hoburg W, Abbeel P (2014) Geometric programming for aircraft design optimization. AIAA J 52(11):2414–2426. https://doi.org/10.2514/1.J052732
Hoburg W, Kirschen P, Abbeel P (2016) Data fitting with geometric-programming-compatible softmax functions. Optim Eng 17(4):897–918. https://doi.org/10.1007/s11081-016-9332-3
Kirschen PG, Burnell E, Hoburg W (2016) Signomial programming models for aircraft design. In: 54th AIAA Aerospace Sciences Meeting, pp. 1–26. American Institute of Aeronautics and Astronautics, Reston. https://doi.org/10.2514/6.2016-2003
Kirschen PG, York MA, Ozturk B, Hoburg WW (2018) Application of signomial programming to aircraft design. J Aircraft 55(3):965–987. https://doi.org/10.2514/1.C034378
Lin B, Carpenter M, de Weck O (2020) Simultaneous vehicle and trajectory design using convex optimization. In: AIAA Scitech 2020 Forum, pp. 1–18. American Institute of Aeronautics and Astronautics, Reston. https://doi.org/10.2514/6.2020-0160
Martins JRRA, Lambe AB (2013) Multidisciplinary design optimization: a survey of architectures. AIAA J 51(9):2049–2075. https://doi.org/10.2514/1.J051895
Opgenoord MMJ, Cohen BS, Hoburg WW (2017) Comparison of algorithms for including equality constraints in signomial programming. Technical Report ACDL TR-2017-1, Massachusetts Institute of Technology. https://convex.mit.edu/publications/SignomialEquality.pdf
Saab A, Burnell E, Hoburg WW (2018) Robust designs via geometric programming. arXiv. https://arxiv.org/abs/1808.07192
Torenbeek E (2013) Advanced aircraft design: conceptual design, analysis and optimization of subsonic civil airplanes. Wiley, New York
York MA, Hoburg WW, Drela M (2018) Turbofan engine sizing and tradeoff analysis via signomial programming. J Aircraft 55(3):988–1003. https://doi.org/10.2514/1.C034463
York MA, Öztürk B, Burnell E, Hoburg WW (2018) Efficient aircraft multidisciplinary design optimization and sensitivity analysis via signomial programming. AIAA J 56(11):4546–4561. https://doi.org/10.2514/1.J057020
Acknowledgements
This material is based on research sponsored by the U.S. Air Force under agreement number FA8650-20-2-2002. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright notation thereon. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of the U.S. Air Force or the U.S. Government. The author would like to thank Mark Drela, Bob Haimes, Woody Hoburg, and Berk Ozturk for their input into the technical matter, the EnCAPS Technical Monitor Ryan Durscher, and the anonymous reviewer who provided comments and suggestions.
Funding
Open Access funding provided by the MIT Libraries.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Karcher, C.J. Data fitting with signomial programming compatible difference of convex functions. Optim Eng 24, 973–987 (2023). https://doi.org/10.1007/s11081-022-09717-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11081-022-09717-4