
Abstract
We present some accelerated variants of fixed point iterations for computing the minimal non-negative solution of the unilateral matrix equation associated with an M/G/1-type Markov chain. These variants derive from certain staircase regular splittings of the block Hessenberg M-matrix associated with the Markov chain. By exploiting the staircase profile, we introduce a two-step fixed point iteration. The iteration can be further accelerated by computing a weighted average between the approximations obtained at two consecutive steps. The convergence of the basic two-step fixed point iteration and of its relaxed modification is proved. Our theoretical analysis, along with several numerical experiments, shows that the proposed variants generally outperform the classical iterations.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The transition probability matrix of an M/G/1-type Markov chain is a block Hessenberg matrix P of the form
with \(A_{i}, B_{i} \in \mathbb R^{n\times n}\geq 0\) and \({\sum }_{i=0}^{\infty } B_{i}\) and \({\sum }_{i=-1}^{\infty } A_{i}\) stochastic matrices.
In the sequel, given a real matrix A = (aij)i= 1,…,m,j= 1,…,n, we write A ≥ 0 (A > 0) if aij ≥ 0 (aij > 0) for any i,j. A stochastic matrix is a matrix A ≥ 0 such that Ae = e, where e is the column vector having all the entries equal to 1.
In the positive recurrent case, the computation of the steady state vector π of P, such that
is related with the solution of the unilateral power series matrix equation
Indeed, this equation has a componentwise minimal non-negative solution G which determines, by means of Ramaswami’s formula [1], the vector π.
Among the easy-to-use, but still effective, tools for numerically solving (3), there are fixed point iterations (see [2] and the references given therein for a general review of these methods). The intrinsic simplicity of such schemes makes them attractive in domains where high performance computing is crucial. But they come at a price: the convergence can become very slow especially for problems which are close to null recurrent. The design of acceleration methods (also known as extrapolation methods) for fixed point iterations is a classical topic in numerical analysis [3]. Relaxation techniques are commonly used for the acceleration of classical stationary iterative solvers for large systems. In this paper, we introduce some new coupled fixed point iterations for solving (3), which can be combined with relaxation techniques to speed up their convergence. More specifically, we first observe that computing the solution of the matrix (3) is formally equivalent to solving a semi-infinite block Toeplitz, block Hessenberg linear system. Customary block iterative algorithms applied for the solution of this system yield classical fixed point iterations. In particular, the traditional and the U-based fixed point iterations [2] originate from the block Jacobi and the block Gauss-Seidel method, respectively. Recently, in [4], the authors show that some iterative solvers based on a block staircase partitioning outperform the block Jacobi and the block Gauss-Seidel method for M-matrix linear systems in block Hessenberg form. Indeed, the application of the staircase splitting to the block Toeplitz, block Hessenberg linear system associated with (3) yields the new coupled fixed point iteration (10), starting from an initial approximation X0. The contribution of this paper is aimed at highlighting the properties of the sequences defined in (10).
We show that, if X0 = 0, the sequence {Xk}k defined in (10) converges to G faster than the traditional fixed point iteration. In the case where the starting matrix X0 of (10) is any row stochastic matrix and G is also row stochastic, we prove that the sequence {Xk}k still converges to G. Moreover, by comparing the mean asymptotic rates of convergence, we conclude that (10) is asymptotically faster than the traditional fixed point iteration.
Since, at each iteration, the scheme (10) determines two approximations, we propose to combine them by using a relaxation technique. Therefore, the approximation computed at the k th step takes the form of a weighted average between Yk and Xk+ 1. The modified relaxed variant is defined by the sequence (11), where ωk+ 1 is the relaxation parameter. The convergence results proved for the sequences (10) can be easily extended to the modified scheme in the case of under-relaxation, that is, when the parameter ωk is such that 0 ≤ ωk ≤ 1. Heuristically, it is argued that over-relaxation values (ωk > 1) can improve the convergence. If X0 = 0, under some suitable assumptions, a theoretical estimate of the asymptotic convergence rate of (11) is given, which confirms this heuristic. Moreover, an adaptive strategy is devised, which makes possible to perform over-relaxed iterations of (11), by still ensuring the convergence of the overall iterative process. The results of an extensive numerical experimentation confirm the effectiveness of the proposed variants, which generally outperform the U-based fixed point iteration for nearly null recurrent problems. In particular, the over-relaxed scheme (11) with X0 = 0, combined with the adaptive strategy for parameter estimation, is capable to significantly improve the convergence, without increasing the computational cost.
The paper is organized as follows. In Section 2, we set up the theoretical framework, by briefly recalling some preliminary properties and assumptions. In Section 3, we revisit classical fixed point iterations for solving (3), by establishing the link with the iterative solution of an associated block Toeplitz block Hessenberg linear system. In Section 4, we introduce the new fixed point iteration (10) and we prove some convergence results. The relaxed variant (11), as well as the generalizations of convergence results for this variant, are described in Section 5. Section 6 deals with a formal analysis of the asymptotic convergence rate of both (10) and (11). Adaptive strategies for the choice of the relaxation parameter are discussed in Section 7, together with their cost analysis, under some simplified assumptions. Finally, the results of an extensive numerical experimentation are presented in Section 8, whereas conclusions and future work are the subjects of Section 9.
2 Preliminaries and assumptions
Throughout the paper, we assume that Ai, i ≥− 1, are n × n nonnegative matrices, such that their sum \(A={\sum }_{i=-1}^{\infty } A_{i}\) is irreducible and row stochastic, that is, Ae = e, \(\boldsymbol {e}=\left [1, \ldots , 1\right ]^{T}\). According to the results of [2, Chapter 4], such assumption implies that (3) has a unique componentwise minimal nonnegative solution G; moreover, In − A0 is a nonsingular M-matrix and, hence, (I − A0)− 1 ≥ 0.
Furthermore, in view of the Perron Frobenius Theorem, there exists a unique vector v such that vTA = vT and vTe = 1, v > 0. If the series \({\sum }_{i=-1}^{\infty } iA_{i}\) is convergent, we may define the vector \(\boldsymbol {w}={\sum }_{i=-1}^{\infty } iA_{i}\boldsymbol {e}\in \mathbb { R}^{n}\). In the study of M/G/1-type Markov chains, the drift is the scalar number η = vTw [5]. The sign of the drift determines the positive recurrence of the M/G/1-type Markov chain [2].
When explicitly stated, we will assume the following additional condition:
- A1.:
-
The series \({\sum }_{i=-1}^{\infty } iA_{i}\) is convergent and η < 0.
Under assumption [A1], the componentwise minimal nonnegative solution G of (3) is stochastic, i.e., Ge = e ([2]). Moreover, G is the only stochastic solution.
3 Nonlinear matrix equations and structured linear systems
In this section, we reinterpret classical fixed point iterations for solving the matrix (3) in terms of iterative methods for solving a structured linear system.
Formally, the power series matrix (3) can be rewritten as the following block Toeplitz, block Hessenberg linear system
The above linear system can be expressed in compact form as
where \(\hat {\mathbf {X}}=\left [X^{T}, (X^{T})^{2}, \ldots \right ]^{T}\), \(\tilde P\) is the matrix obtained from P in (1) by removing its first block row and block column, and \(\boldsymbol {E}=\left [I_{n}, 0_{n}, \ldots \right ]^{T}\).
Classical fixed point iterations for solving (3) can be interpreted as iterative methods for solving (4), based on suitable partitionings of the matrix H. For instance, from the partitioning H = M − N, where M = I and \(N=\tilde P\), we find that the block vector \(\hat X\) is a solution of the fixed point problem
From this equation, we may generate the sequence of block vectors
such that
We may easily verify that the sequence {Xk}k coincides with the sequence generated by the so-called natural fixed point iteration \(X_{k+1}={\sum }_{i=-1}^{\infty } A_{i} X_{k}^{i+1}\), k = 0,1,,…, applied to (3).
Similarly, the Jacobi partitioning, where M = I ⊗ (In − A0) and N = M − H, which leads to the sequence
corresponds to the traditional fixed point iteration
The anti-Gauss-Seidel partitioning, where M is the block upper triangular part of H and N = M − H, determines the fixed point iteration
introduced and named U-based iteration in [6]. In some references (see for instance [7]), the fixed point iteration (7) is called SS iteration, where the acronym SS stands for Successive Substitution.
The convergence properties of these three fixed point iterations are analyzed in [2]. Among the three iterations, (7) is the fastest and also the most expensive since it requires the solution of a linear system (with multiple right-hand sides) at each iteration. Moreover, it turns out that fixed point iterations exhibit arbitrarily slow convergence for problems which are close to null recurrence. In particular, for positive recurrent Markov chains having a drift η close to zero, the convergence slows down and the number of iterations becomes arbitrarily large. In the next sections, we present some new fixed point iterations which offer several advantages in terms of computational efficiency and convergence properties when compared with (7).
4 A new fixed point iteration
Recently, in [4], a comparative analysis has been performed for the asymptotic convergence rates of some regular splittings of a non-singular block upper Hessenberg M-matrix of finite size. The conclusion is that the staircase splitting is faster than the anti-Gauss-Seidel splitting, that in turn is faster than the Jacobi splitting. The second result is classical, while the first one is somehow surprising since the matrix M in the staircase splitting is much more sparse than the corresponding matrix in the anti-Gauss-Seidel partitioning and the splittings are not comparable. Inspired from these convergence properties, we introduce a new fixed point iteration for solving (3), based on the staircase partitioning of H, namely,
The splitting has attracted interest for applications in parallel computing environments [8, 9]. In principle, the alternating structure of the matrix M in (8) suggests several different iterative schemes.
From one hand, the odd block entries of the system \(M \boldsymbol {Z}_{k+1}=N\boldsymbol {\hat X_{k}} + \boldsymbol {E} A_{-1}\) yield the traditional fixed point iteration. On the other hand, the even block entries lead to the implicit scheme \(-A_{-1} + (I_{n}-A_{0})X_{k+1} -A_{1} X_{k+1} X_{k} ={\sum }_{i=2}^{\infty } A_{i}X_{k}^{i+1}\), where a Sylvester equation should be solved at each step. Differently, by looking at the structure of the matrix M on the whole, we introduce the following composite two-stage iteration:
or, equivalently,
starting from an initial approximation X0. At each step k, this scheme consists of a traditional fixed point iteration, as (6), that computes Yk from Xk, followed by a cheap correction step for computing the new approximation Xk+ 1.
Observe that, in the QBD case where Ai = 0 for i ≥ 2, then \(Y_{k}=(I-A_{0})^{-1}(A_{-1}+A_{1} {X_{k}^{2}})\) and \(X_{k+1}=Y_{k}+(I-A_{0})^{-1}({Y_{k}^{2}}-{X_{k}^{2}})\). By replacing Yk in the latter expression, we find that Xk+ 1 coincides with the matrix obtained by applying two steps of the traditional fixed point iteration (6), starting from Xk. In the general case, the matrix Xk+ 1 can be interpreted as a refinement of the approximation obtained by the traditional fixed point iteration (6). The computation of such refinement is generally (except for the QBD case) cheaper than applying a second step of traditional fixed point iteration.
As for classical fixed point iterations, the convergence is guaranteed when X0 = 0.
Proposition 1
Assume that X0 = 0. Then the sequence \(\{X_{k}\}_{k\in \mathbb N}\) generated by (10) converges monotonically to G.
Proof 1
We show by induction on k that 0 ≤ Xk ≤ Yk ≤ Xk+ 1 ≤ G for any k ≥ 0. For k = 0, we verify easily that
which gives G ≥ X1. Suppose now that G ≥ Xk ≥ Yk− 1 ≥ Xk− 1, k ≥ 1. We find that
and
By multiplying both sides by the inverse of I − A0, we obtain that G ≥ Yk ≥ Xk. This also implies that \({Y_{k}^{2}}-{X_{k}^{2}}\geq 0\) and therefore Xk+ 1 ≥ Yk. Since
we prove similarly that G ≥ Xk+ 1. It follows that \(\{X_{k}\}_{k\in \mathbb N}\) is convergent, the limit solves (3) by continuity, and, hence, the limit coincides with the matrix G, since G is the minimal nonnegative solution. □
A similar result is valid also in the case where X0 is a stochastic matrix, assuming that [A1] holds, so that G is stochastic.
Proposition 2
Assume that condition [A1] is fulfilled and that X0 is a stochastic matrix. Then, the sequence \(\{X_{k}\}_{k\in \mathbb N}\) generated by (10) converges to G.
Proof 2
From (9), we obtain that
which gives that Xk ≥ 0 and Yk ≥ 0, for any \(k\in \mathbb N\), since X0 ≥ 0. By assuming that X0e = e, we may easily show by induction that Yke = Xke = e for any k ≥ 0. Therefore, all the matrices Xk and Yk, \(k\in \mathbb N\), are stochastic. Let \(\{\hat X_{k}\}_{k\in \mathbb N}\) be the sequence generated by (10) with \(\hat X_{0}=0\). We can easily show by induction that \(X_{k}\geq \hat X_{k}\) for any \(k\in \mathbb N\). Since \(\lim _{k\to \infty }\hat X_{k}=G\), then any convergent subsequence of \(\{X_{k}\}_{k\in \mathbb N}\) converges to a stochastic matrix S such that S ≥ G. Since G is also stochastic, it follows that S = G and therefore, by compactness, we conclude that the sequence \(\{X_{k}\}_{k\in \mathbb N}\) is also convergent to G. □
Propositions 1 and 2 are global convergence results. An estimate of the rate of convergence of (10) will be provided in Section 6, together with a comparison with other existing methods.
5 A relaxed variant
At each iteration, the scheme (10) determines two approximations which can be combined by using a relaxation technique, that is, the approximation computed at the k-th step takes the form of a weighted average between Yk and Xk+ 1:
In matrix terms, the resulting relaxed variant of (10) can be written as
If ωk = 0, for k ≥ 1, the relaxed scheme reduces to the traditional fixed point iteration (6). If ωk = 1, for k ≥ 1, the relaxed scheme coincides with (10). Values of ωk greater than 1 can speed up the convergence of the iterative scheme.
Concerning convergence, the proof of Proposition 1 can immediately be generalized to show that the sequence {Xk}k defined by (11), with X0 = 0, converges for any ωk = ω, k ≥ 1, such that 0 ≤ ω ≤ 1. Moreover, let \(\{X_{k}\}_{k\in \mathbb N}\) and \(\{\hat X_{k}\}_{k\in \mathbb N}\) be the sequences generated by (11) for ωk = ω and \(\omega _{k}=\hat \omega \) with \(0\leq \omega \leq \hat \omega \leq 1\), respectively. It can be easily shown that \(G\geq \hat X_{k} \geq X_{k}\) for any k and, hence, that the iterative scheme (10) converges faster than (11) if 0 ≤ ωk = ω < 1.
The convergence analysis of the modified scheme (11) for ωk > 1 is much more involved since the choice of a relaxation parameter ωk > 1 can destroy the monotonicity and the nonnegativity of the approximation sequence, which are at the core of the proofs of Propositions 1 and 2 . In order to maintain the convergence properties of the modified scheme we introduce the following definition.
Definition 1
The sequence {ωk}k≥ 1 is eligible for the scheme (11) if ωk ≥ 0, k ≥ 1, and the following two conditions are satisfied:
and
It is worth noting that condition (12) is implicit since the construction of Xk+ 1 also depends on the value of ωk+ 1. By replacing Xk+ 1 in (12) with the expression in the right-hand side of (11), we obtain a quadratic inequality with matrix coefficients in the variable ωk+ 1. Obviously the constant sequence ωk = ω, k ≥ 1, with 0 ≤ ω ≤ 1, is an eligible sequence.
The following generalization of Proposition 1 holds.
Proposition 3
Set X0 = 0 and let condition [A1] be satisfied. If {ωk}k≥ 1 is eligible then the sequence \(\{X_{k}\}_{k\in \mathbb N} \) generated by (11) converges monotonically to G.
Proof 3
We show by induction that 0 ≤ Xk ≤ Yk ≤ Xk+ 1 ≤ G. For k = 0, we have
which gives immediately X1 ≥ Y0 ≥ 0. Moreover, X1e ≤e. Suppose now that Xk ≥ Yk− 1 ≥ Xk− 1 ≥ 0, k ≥ 1. We find that
from which it follows Yk ≥ Xk ≥ 0. This also implies that Xk+ 1 ≥ Yk. From (13), it follows that Xke ≤e for all k ≥ 0 and therefore the sequence of approximations is upper bounded and it has a finite limit H. By continuity, we find that H solves the matrix (3) and He ≤e. Since G is the unique stochastic solution, then H = G. □
Remark 1
As previously mentioned, condition (12) is implicit, since Xk+ 1 also depends on ωk+ 1. An explicit condition can be derived by noting that
with \({\Gamma }_{k}=(I_{n}-A_{0})^{-1} A_{1} ({Y_{k}^{2}}-{X_{k}^{2}})\). There follows that (12) is fulfilled whenever
which can be reduced to a linear inequality in ωk+ 1 over a fixed search interval. Let \(\omega \in [1, \hat \omega ]\) be such that
Then we can impose that
From a computational viewpoint, the strategy based on (14) and (15) for the choice of the value of ωk+ 1 can be too much expensive and some weakened criterion should be considered (compare with Section 7 below).
In the following section, we perform a convergence analysis to estimate the convergence rate of (11) in the stationary case ωk = ω, k ≥ 1, as a function of the relaxation parameter.
6 Estimate of the convergence rate
Relaxation techniques are usually aimed at accelerating the convergence speed of frustratingly slow iterative solvers. Such inefficient behavior is typically exhibited when the solver is applied to a nearly singular problem. Incorporating some relaxation parameter into the iterative scheme (3) can greatly improve its convergence rate. Preliminary insights on the effectiveness of relaxation techniques applied for the solution of the fixed point problem (5) come from the classical analysis for stationary iterative solvers and are developed in Section 6.1. A precise convergence analysis is presented in Section 6.2.
6.1 Finite dimensional convergence analysis
Suppose that H in (5) is block tridiagonal of finite size m = nℓ, ℓ even. We are interested in comparing the iterative algorithm based on the splitting (8) with other classical iterative solvers for the solution of a linear system with coefficient matrix H. As usual, we can write H = D − P1 − P2, where D is block diagonal, while P1 and P2 are staircase matrices with zero block diagonal. The eigenvalues λi of the Jacobi iteration matrix satisfy
Let us consider a relaxed scheme where the matrix M is obtained from (8) by multiplying the off-diagonal blocks by ω. The eigenvalues μi of the iteration matrix associated with the relaxed staircase regular splitting are such that
and, equivalently,
By using a similarity transformation induced by the matrix \(S=I_{\ell /2} \otimes diag\left [I_{n},\alpha I_{n}\right ]\), we find that
There follows that
whenever α fulfills
Therefore, the eigenvalues of the Jacobi and relaxed staircase regular splittings are related by
For ω = 0, the staircase splitting reduces to the Jacobi partitioning. For ω = 1, we find that \(\mu _{i}={\lambda _{i}^{2}}\), which yields the classical relation between the spectral radii of Jacobi and Gauss-Seidel methods. It is well known that the asymptotic convergence rates of Gauss-Seidel and the staircase iteration coincide, when applied to a block tridiagonal matrix [11]. For ω > 1, the spectral radius of the relaxed staircase scheme can be significantly smaller than the spectral radius of the same scheme for ω = 1. In Fig. 1, we illustrate the plot of the function
for a fixed λ = 0.999. For the best choice \(\omega =\omega ^{\star }=2 \frac { 1 + \sqrt {1-\lambda ^{2}}}{\lambda ^{2}}\), we find \(\rho _{S}(\omega ^{\star })=1-\sqrt {1-\lambda ^{2}} =\frac {\lambda ^{2}}{1+\sqrt {1-\lambda ^{2}}}\).

Plot of ρS(ω) for ω ∈ [1,2] and λ = 0.999
6.2 Asymptotic convergence rate
A formal analysis of the asymptotic convergence rate of the relaxed variants (11) can be carried out by using the tools described in [12]. In this section, we relate the approximation error at two subsequent steps and we provide an estimate of the asymptotic rate of convergence, expressed as the spectral radius of a suitable matrix depending on ω.
Hereafter, it is assumed that assumption [A1] is verified.
6.2.1 The case X 0 = 0
Let us introduce the error matrix Ek = G − Xk, where \(\{X_{k}\}_{k\in \mathbb N}\) is generated by (11) with X0 = 0. We also define Ek+ 1/2 = G − Yk, for k = 0,1,2,…. Suppose that
- C0.:
-
{ωk}k is an eligible sequence according to Definition 1.
Under this assumption, from Proposition 3, the sequence {Xk}k converges monotonically to G and Ek ≥ 0, Ek+ 1/2 ≥ 0. Since Ek ≥ 0 and \(\Vert E_{k}\Vert _{\infty }=\Vert E_{k}\boldsymbol {e}\Vert _{\infty }\), we analyze the convergence of the vector 𝜖k = Eke, k ≥ 0.
We have
Similarly, for the second equation of (11), we find that
which gives
Denote by Rk the matrix on the right-hand side of (16), i.e.,
Since Ge = e, (17), together with the monotonicity, yields
Observe that Rke ≤ WEke, where
hence
where
The matrix P(ω) can be written as P(ω) = M− 1N(ω) where
and
Let us assume the following condition holds:
- C1.:
-
The relaxation parameter ω satisfies \(\omega \in [0,\hat \omega ]\), with \(\hat \omega \ge 1 \) such that
$$ \hat \omega A_{1}(I_{n}+G)(I_{n}-A_{0})^{-1}(I_{n}-A_{0}-W)\leq W. $$
Assumption [C1] ensures that N(ω) ≥ 0 and, therefore, P(ω) ≥ 0 and M − N(ω) = A(ω) is a regular splitting of A(ω). If [C1] is satisfied at each iteration of (11), then from (19) we obtain that
Therefore, the asymptotic rate of convergence, defined as
where ∥⋅∥ is any vector norm, is such that
The above properties can be summarized in the following result that gives a convergence rate estimate for iteration (11).
Proposition 4
Under Assumptions [A1], [C0] and [C1], for the fixed point iteration (11) applied with ωk = ω for any k ≥ 0, we have the following convergence rate estimate:
where P(ω) is defined in (20) and ρω = ρ(P(ω)) is the spectral radius of P(ω).
When ω = 0, we find that A(0) = In − A0 − W = In − V, where \(V={\sum }_{i=0}^{\infty } A_{i}{\sum }_{j=0}^{i} G^{j}\). According to Theorem 4.14 in [2], I − V is a nonsingular M-matrix and therefore, since N(0) ≥ 0 and M− 1 ≥ 0, A(0) = M − N(0) is a regular splitting. Hence, the spectral radius ρ0 of P(0) is less than 1. More generally, under Assumption [C1] since
from characterization F20 in [13], we find that A(ω) is a nonsingular M-matrix and A(ω) = M − N(ω) is a regular splitting. Hence, we deduce that ρω < 1. The following result gives an estimate of ρω, by showing its dependence as function of the relaxation parameter.
Proposition 5
Let ω be such that \(0\le \omega \le \hat \omega \) and assume that condition [C1] holds. Assume that the Perron eigenvector v of P(0) is positive. Then we have
where \(\sigma _{\min \limits }=\min \limits _{i} \frac {u_{i}}{v_{i}}\) and \(\sigma _{\max \limits }=\max \limits _{i} \frac {u_{i}}{v_{i}}\), with u = (In − A0)− 1A1(I + G)v. Moreover, \(0\le \sigma _{\min \limits },\sigma _{\max \limits }\le \rho _{0}\).
Proof 4
In view of the classical Collatz-Wielandt formula (see [14], Chapter 8), if P(ω)v = w, where v > 0 and w ≥ 0, then
Observe that
which leads to (21), since u ≥ 0. Moreover, since A1(In + G) ≤ W, then
hence ui/vi ≤ ρ0 for any i. □
Observe that, in the quasi-birth-and-death case, where Ai = 0 for i ≥ 2, we have A1(In + G) = W and, from the proof above, u = ρ0v. Therefore, we have \(\sigma _{\min \limits }=\sigma _{\max \limits }=\rho _{0}\) and, hence, ρω = ρ0(1 − ω(1 − ρ0)). In particular, ρω linearly decreases with ω, and \(\rho _{1}={\rho _{0}^{2}}\). In the general case, inequality (21) shows that the upper bound to ρω linearly decreases as a function of ω. Therefore, the choice \(\omega =\hat \omega \) gives the fastest convergence rate.
Remark 2
For the sake of illustration, we consider a quadratic equation associated with a block tridiagonal Markov chain taken from [15]. We set A− 1 = W + δI, A0 = A1 = W where 0 < δ < 1 and \(W\in \mathbb R^{n\times n}\) has zero diagonal entries and all off-diagonal entries equal to a given value α determined so that A− 1 + A0 + A1 is stochastic. We find that N(ω) ≥ 0 for ωk = ω ∈ [0,6]. In Fig. 2, we plot the spectral radius of P = P(ω). The linear plot is in accordance with Proposition 5.

Plot of ρ(P(ω)) for ω ∈ [0,6]
6.2.2 The case X 0 stochastic
In this section, we analyze the convergence of the iterative method (11) starting with a stochastic matrix X0, that is, X0 ≥ 0 and X0e = e. Eligible sequences {ωk}k are such that Xk ≥ 0 for any k ≥ 0. This happens for 0 ≤ ωk ≤ 1, k ≥ 1. Suppose that:
- S0.:
-
The sequence {ωk}k in (11) is determined so that ωk ≥ 0 and Xk ≥ 0 for any k ≥ 1.
Observe that the property Xke = e, k ≥ 0 is automatically satisfied. Hence, under assumption [S0], all the approximations generated by the iterative scheme (11) are stochastic matrices and therefore, Proposition 2 can be extended in order to prove that the sequence \(\{X_{k}\}_{k\in \mathbb N}\) is convergent to G.
The analysis of the speed of convergence follows from relation (17). Let us denote as \(\text {vec}(A)\in \mathbb R^{n^{2}}\) the vector obtained by stacking the columns of the matrix \(A\in \mathbb R^{n\times n}\) on top of one another. Recall that vec(ABC) = (CT ⊗ A)vec(B) for any \(A,B,C \in \mathbb R^{n\times n}\). By using this property, we can rewrite (17) as follows:
for k ≥ 0. The convergence of {vec(Ek)}k depends on the choice of ωk+ 1, k ≥ 0. Suppose that ωk = ω for any k ≥ 0 and [S0] holds. Then (22) can be rewritten in a compact form as
where Hk = Hω(Xk,Yk) and
It can be shown that the asymptotic rate of convergence σ satisfies
In the sequel, we compare the cases ωk = 0, which corresponds with the traditional fixed point iteration (6), and ωk = 1 which reduces to the staircase fixed point iteration (10).
For ωk+ 1 = 0, k ≥ 0, we find that
which means that
Let UHGTU = T be the Schur form of GT and set W = (UH ⊗ In). Then
which means that H0 is similar to the matrix on the right-hand side. There follows that the eigenvalues of H0 belong to the set
with λ eigenvalue of G. Since G is stochastic we have |λ|≤ 1. Thus, from
we conclude that ρ(H0) ≤ ρ(P(0)) in view of the Wielandt theorem [14].
A similar analysis can be performed in the case ωk = 1, k ≥ 0. We find that
By the same arguments as above, we find that the eigenvalues of H1 belong to the set
with λ eigenvalue of GT, and
Since
we conclude that
Therefore, in the application of (10), we expect a faster convergence when X0 is a stochastic matrix, rather than X0 = 0. Indeed, numerical results shown in Section 5 exhibit a very rapid convergence profile when X0 is stochastic, even better than the one predicted by ρ(H1). This might be explained with the dependence of the asymptotic convergence rate on the second eigenvalue of the corresponding iteration matrices as reported in [12].
7 Adaptive strategies and efficiency analysis
The efficiency of fixed point iterations depends on both speed of convergence and complexity properties. Markov chains are generally defined in terms of sparse matrices. To take into account this feature we assume that γn2, γ = γ(n), multiplications/divisions are sufficient to perform the following tasks:
-
1.
to compute a matrix multiplication of the form Ai ⋅ W, where \(A_{i}, W \in \mathbb R^{n\times n}\);
-
2.
to solve a linear system of the form (I − A0)Z = W, where \(A_{0}, W \in \mathbb R^{n\times n}\).
We also suppose that the transition matrix P in (1) is banded, hence Ai = 0 for i > q. This is always the case in numerical computations where the matrix power series \({\sum }_{i=-1}^{\infty } A_{i} X_{k}^{i+1}\) has to be approximated by some finite partial sum \({\sum }_{i=-1}^{q} A_{i} X_{k}^{i+1}\). Under these assumptions, we obtain the following cost estimates per step:
-
1.
the traditional fixed point iteration (6) requires qn3 + 2γn2 + O(n2) multiplicative operations;
-
2.
the U-based fixed point iteration (7) requires (q + 4/3)n3 + γn2 + O(n2) multiplicative operations;
-
3.
the staircase-based (S-based) fixed point iteration (10) requires (q + 1)n3 + 4γn2 + O(n2) multiplicative operations.
Observe that the cost of the S-based fixed point iteration is comparable with the cost of the U-based iteration, which is the fastest among classical iterations [2]. Therefore, in the cases where the U/S-based fixed point iterative schemes require significantly less iterations to converge, these algorithms are more efficient than the traditional fixed point iteration.
Concerning the relaxed versions (11) of the S-based fixed point iteration for a given fixed choice of ωk = ω, we get the same complexity of the unmodified scheme (10) obtained with ωk = ω = 1. The adaptive selection of ωk+ 1 exploited in Proposition 3 and Remark 1 with X0 = 0 requires more care.
The strategy (14) is computationally unfeasible since it needs the additional computation of \({\sum }_{i=2}^{q} A_{i}Y_{k}^{i+1}\). To approximate this quantity, we recall that
Let 𝜃k+ 1 be such that
Then condition (14) can be replaced with
The iterative scheme (11), complemented with the strategy based on (23) for the selection of the parameter ωk+ 1, requires no more than (q + 3)n3 + 4γn2 + O(n2) multiplicative operations. The efficiency of this scheme will be investigated experimentally in the next section.
8 Numerical results
In this section, we present the results of some numerical experiments which confirm the effectiveness of the proposed schemes. All the algorithms have been implemented in Matlab and tested on a PC i9-9900K CPU 3.60GHz with 8 cores. Our test suite includes:
-
1.
Synthetic Examples:
-
(a)
The block tridiagonal Markov chain of Remark 2. Observe that the drift of the Markov chain is exactly equal to − δ.
-
(b)
A numerical example considered in [7, 16] for testing a suitable modification — named SSM — of the U-based fixed point iteration that avoids the matrix inversion at each step. The Markov chain of the M/G/1 type has blocks given by
$$ A_{-1}=\frac{4(1-p)}{3} \left[\begin{array}{ccccc} 0.05 & 0.1 & 0.2 & 0.3 & 0.1\\ 0.2 & 0.05 & 0.1 & 0.1 & 0.3\\ 0.1 & 0.2 & 0.3 & 0.05 & 0.1\\ 0.1 & 0.05 & 0.2 & 0.1 & 0.3\\ 0.3 & 0.1 & 0.1 & 0.2 & 0.05 \end{array}\right], \quad A_{i}=p A_{i-1}, ~~i\geq 0. $$The Markov chain is positive recurrent, null recurrent or transient according as 0 < p < 0.5, p = 0.5, or p > 0.5, respectively. In our computations, we have chosen different values of p, in the range 0 < p < 0.6 and the matrices Ai are treated as zero matrix for i ≥ 51.
-
(c)
Synthetic examples of M/G/1-type Markov chains described in [10]. These examples are constructed in such a way that the drift of the associated Markov chain is close to a given negative value. We do not describe in detail the construction, as it would take some space, but we refer the reader to [10, Sections 7.1].
-
(a)
-
2.
Application Examples:
-
(a)
Some examples of PH/PH/1 queues collected in [10, Sections 7.1] for testing purposes. The construction depends on a parameter ρ with 0 ≤ ρ ≤ 1. In this case the drift is η = 1 − ρ.
-
(b)
The Markov chain of M/G/1 type associated with the infinitesimal generator matrix Q from the queuing model described in [17]. This is a complex queuing model, a BMAP/PHF/1/N model with retrial system with finite buffer of capacity N and non-persistent customers. For the construction of the matrix Q, we refer the reader to [17, Sections 4.3 and 4.5].
-
(a)
8.1 Synthetic examples
The first test concerns the validation of the analysis performed in the previous sections, regarding the convergence of fixed point iterations. In Table 1, we report the number of iterations required by different iterative schemes on Example 1.(a) with n = 100. Specifically, we compare the traditional fixed point iteration, the U-based fixed point iteration, the S-based fixed point iteration (10), and the relaxed fixed point iterations (11). For the latter case, we consider the Sω-based iteration where ωk+ 1 = ω is a priori fixed and the S\(_{\omega _{k}}\)-based iteration where the value of ωk+ 1 is dynamically adjusted at any step according to the strategy (23), complemented with condition (13). The relaxed stationary iteration is applied for ω = 1.8,1.9,2. The relaxed adaptive iteration is applied with \(\hat \omega =10\). The iterations are stopped when the residual error \(\Vert X_{k}-{\sum }_{i=-1}^{q} A_{i} X_{k}^{i+1}\Vert _{\infty }\) is smaller than tol = 10− 13.
The first four columns of Table 1 confirm the theoretical comparison of asymptotic convergence rates of classical fixed point iterations applied to a block tridiagonal matrix. Specifically, the U-based and the S-based iterations are twice faster than the traditional iteration. Also, the relaxed stationary variants greatly improve the convergence speed. An additional remarkable improvement is obtained by adjusting dynamically the value of the relaxation parameter. Also notice that the S\(_{\omega _{k}}\)-based iteration is guaranteed to converge, differently from the stationary Sω-based iteration.
The superiority of the adaptive implementation over the other fixed point iterations is confirmed by numerical results on Example 1.(b) In Table 2, for different values of p, we show the number of iterations required by different iterative schemes including also the successive-substitution Moser (SSM) method introduced in [7] and further analyzed in [16]. This algorithm avoids the explicit computation of the inverse matrix in the U-based iteration (7), by successively approximating it by the Moser formula. For a fair comparison with the results in [16], here we set tol = 10− 8 in the stopping criterion, as in [16]. In [7], the same approach is also exploited to develop an inversion-free modification of the Newton iteration (Newton-Moser method — NM), applied for solving the nonlinear matrix (3). We have implemented the resulting iterative scheme. Although it is very fast and efficient for p ∈{0.3,0.48,0.55}, numerical difficulties occur when p is close to 0.5, due to the bad conditioning of the Jacobian matrix. In particular, for p = 0.5, our implementation fails to get the desired accuracy of tol = 10− 8 and the iteration diverges.
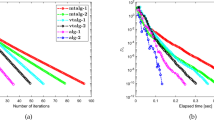
Finally, we compare the convergence speed of the traditional, U-based, S-based, and S\(_{\omega _{k}}\)-based fixed point iterations applied on the synthetic example 1.(c) of M/G/1-type Markov chains described in [10]. In Fig. 3, we report the semilogarithmic plot of the residual error in the infinity norm generated by the four fixed point iterations, for two different values of the drift η.

Residual errors generated by the four fixed point iterations applied to the synthetic example 1.(c) with drift η = − 0.1 and η = − 0.005
Observe that the adaptive relaxed iteration is about twice faster than the traditional fixed point iteration. The observation is confirmed in in Table 3 where we indicate the speed-up in terms of CPU-time, with respect to the traditional fixed point iteration, for different values of the drift η.
In Fig. 4, we repeat the set of experiments of Fig. 3 with a starting stochastic matrix \(X_{0}= \boldsymbol {e}\boldsymbol {e}^{T}/n\). Here the adaptive strategy is basically the same as used before where we select ωk+ 1 in the interval [0,ωk] as the maximum value which maintains the nonnegativity of Xk+ 1.

Residual errors generated by the four fixed point iterations applied to the synthetic example with drift η = − 0.1 and η = − 0.005
In this case the adaptive strategy seems to be quite effective in reducing the number of iterations. Other results are not so favorable and we believe that in the stochastic case, the design of a general efficient strategy for the choice of the relaxation parameter ωk is still an open problem.
8.2 Application examples
The first set 2.(a) of examples from applications includes several cases of PH/PH/1 queues collected in [10]. The construction of the Markov chain depends on a parameter ρ, with 0 ≤ ρ ≤ 1, and two integers (i,j) which specify the PH distributions of the model. The Markov chain generated in this way is denoted as Example (i,j). Its drift is η = 1 − ρ. In Tables 4, 5, and 6, we compare the number of iterations for different values of ρ. Here and hereafter the relaxed stationary Sω-based iteration is applied with ω = 2.
In Table 7, we report the number of iterations on Example (8,3) of Table 5, starting with X0 a stochastic matrix. We compare the traditional, U-based and S-based iterations. We observe a rapid convergence profile and the fact that the number of iterations is independent of the drift value.
For a more challenging example 2.(b) from applications, we consider the generator matrix Q from the queuing model described in [17]. The corresponding matrix H in (4), as well as the solution matrix G, is very sparse, so that this example is particularly suited for fixed point iterations. For N = 5, the nonzero blocks are 42 (i.e., q= 40), and have size 48 × 48. In Fig. 5, we show the Matlab spy plots of the leading principal submatrix of order 256 of H and of the solution matrix G.

Matlab spy plots of H(1 : 256,1 : 256) and the solution matrix G for test 2.b with N = 5
In Table 8, we indicate the number of iterations for different values of the capacity N.
Our implementation of the Newton method, incorporating the Moser iteration for computing the approximation of the inverse of the Jacobian matrix (NM method), again fails to get the desired accuracy of tol = 1.0e − 13 in all the cases. Finally, in Table 9, for N = 5 and different threshold values of accuracy, we report the timings of our proposed method compared with the cyclic reduction algorithm for M/G/1 type Markov chain implemented in the SMCSolver Matlab toolbox [18].
This table indicates that for a large and sparse Markov Chain in a multithread computing environment, the proposed approach can be a valid option.
9 Conclusions and future work
In this paper, we have introduced a novel fixed point iteration for solving M/G/1-type Markov chains. It is shown that this iteration complemented with suitable adaptive relaxation techniques is generally more efficient than other classical iterations. Incorporating relaxation techniques into other different inner-outer iterative schemes as the ones introduced in [10] is an ongoing research.
Data Availability
Not applicable.
References
Ramaswami, V.: A stable recursion for the steady state vector in Markov chains of M/G/1 type. Comm. Statist. Stochastic Models 4(1), 183–188 (1988). https://doi.org/10.1080/15326348808807077
Bini, D.A., Latouche, G., Meini, B.: Numerical Methods for Structured Markov Chains. Oxford University Press, New York (2005). https://doi.org/10.1093/acprof:oso/9780198527688.001.0001
Brezinski, C., Redivo Zaglia, M.: Extrapolation Methods. Theory and Practice. Studies in Computational Mathematics, vol. 2, p 464. North-Holland Publishing Co, Amsterdam (1991)
Gemignani, L., Poloni, F.: Comparison theorems for splittings of M-matrices in (block) Hessenberg form. BIT Numerical Mathematics. https://doi.org/10.1007/s10543-021-00899-4 (2022)
Neuts, M.F.: Matrix-geometric Solutions in Stochastic Models. An algorithmic approach. Johns Hopkins Series in the Mathematical Sciences, vol. 2 (1981)
Latouche, G.: Algorithms for infinite Markov chains with repeating columns. In: Linear Algebra, Markov Chains, and Queueing Models (Minneapolis, MN, 1992). IMA Vol. Math. Appl. https://doi.org/10.1007/978-1-4613-8351-2_15, vol. 48, pp 231–265. Springer (1993)
Bai, Z. -Z.: A class of iteration methods based on the Moser formula for nonlinear equations in Markov chains. Linear Algebra Appl. 266, 219–241 (1997). https://doi.org/10.1016/S0024-3795(97)86522-6
Meurant, G.: Domain decomposition preconditioners for the conjugate gradient method. Calcolo 25(1-2), 103–119 (1988). https://doi.org/10.1007/BF02575749
Lu, H.: Stair matrices and their generalizations with applications to iterative methods. I. A generalization of the successive overrelaxation method. SIAM J. Numer. Anal. 37(1), 1–17 (1999). https://doi.org/10.1137/S0036142998343294
Bini, D.A., Latouche, G., Meini, B.: A family of fast fixed point iterations for M/G/1-type Markov chains. IMA J. Numer. Anal. 42(2), 1454–1477 (2021). https://doi.org/10.1093/imanum/drab009
Amodio, P., Mazzia, F.: A parallel Gauss-Seidel method for block tridiagonal linear systems. SIAM J. Sci. Comput. 16(6), 1451–1461 (1995). https://doi.org/10.1137/0916084
Meini, B.: New convergence results on functional iteration techniques for the numerical solution of M/G/1 type Markov chains. Numer. Math. 78 (1), 39–58 (1997). https://doi.org/10.1007/s002110050303
Plemmons, R.J.: M-matrix characterizations. I. Nonsingular M-matrices. Linear Algebra Appl. 18(2), 175–188 (1977). https://doi.org/10.1016/0024-3795(77)90073-8
Meyer, C.: Matrix analysis and applied linear algebra. Society for industrial and applied mathematics (SIAM), Philadelphia PA. (2000) https://doi.org/10.1137/1.9780898719512
Latouche, G., Ramaswami, V.: A logarithmic reduction algorithm for quasi-birth-death processes. J. Appl. Probab. 30(3), 650–674 (1993). https://doi.org/10.2307/3214773
Guo, C.-H.: On the numerical solution of a nonlinear matrix equation in Markov chains. Linear Algebra Appl. 288(1-3), 175–186 (1999). https://doi.org/10.1016/S0024-3795(98)10190-8
Dudin, S., Dudin, A., Kostyukova, O., Dudina, O.: Effective algorithm for computation of the stationary distribution of multi-dimensional level-dependent Markov chains with upper block-Hessenberg structure of the generator. J. Comput. Appl. Math. 366, 112425 (2020). https://doi.org/10.1016/j.cam.2019.112425
Bini, D.A., Meini, B., Steffè, S., Van Houdt, B.: Structured Markov Chains Solver: Software Tools. In: Proceeding from the 2006 Workshop on Tools for Solving Structured Markov Chains. SMCtools ’06, pp. 14-Es. Association for Computing Machinery. https://doi.org/10.1145/1190366.1190379 (2006)
Acknowledgements
The authors wish to thank the anonymous referees for their remarks that contributed to improve the presentation.
Funding
Open access funding provided by Università di Pisa within the CRUI-CARE Agreement. This work has been partially supported by GNCS of INdAM.
Author information
Authors and Affiliations
Contributions
The contribution of the authors is parithetic.
Corresponding author
Ethics declarations
Ethics approval
Not applicable.
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gemignani, L., Meini, B. Relaxed fixed point iterations for matrix equations arising in Markov chain modeling. Numer Algor 94, 149–173 (2023). https://doi.org/10.1007/s11075-023-01496-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11075-023-01496-y