
Abstract
In order to construct an algorithm for homogeneous diffusive motion that lives on a sphere, we consider the equivalent process of a randomly rotating spin vector of constant length. By introducing appropriate sets of random variables based on cross products, we construct families of methods with increasing efficacy that exactly preserve the spin modulus for every realisation. This is done by exponentiating an antisymmetric matrix whose entries are these random variables that are Gaussian in the simplest case.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction and background
We take a non-standard approach to diffusion on the surface of a sphere, starting with an equation for a three-component spin vector written in Langevin form:
where η is a vector of independent white noises with magnitude σ. Here × denotes the cross product—see Definition 1.
We understand (1) as an Itô stochastic differential equation for the vector-valued process
Equation (1) can then be written as
where \(W(t)=\left (W_{1}(t),W_{2}(t),W_{3}(t)\right )^{\mathrm {T}}\) is a vector of independent Wiener processes. Given the definition of the cross product ×, this can be written as
In matrix form, we can write this as the linear Itô SDE
where I is the 3×3 identity matrix and
Another convenient representation of (3) is
where G(S) is the antisymmetric matrix
Based on (5), we can prove the following theorem.
Theorem 1
With S(t) the solution of (5) then
Proof
The proof is by Itô’s Lemma—see for example Kloeden and Platen [1]. Consider the Itô SDE
where f and G are arbitrary functions satisfying appropriate integrability conditions—see [1] for details. Suppose \(u = h(X) \in \mathbb {R}\), where h has continuous first- and second-order partial derivatives. Then Itô’s Lemma states
where ∇[∇h(X)] is the matrix of second-order spatial derivatives of h. Now when N = d = 3
and G(S) is given by (6).
Hence, du = 0 and so u(t) = S⊤(0)S(0).□
As a consequence of Theorem 1, the vector S(t) lives on the unit sphere of radius 1 for all time.
In this paper, we will construct different classes of numerical methods that preserve \(|| S(t) ||_{2}^{2}\). The starting point is the Stratonovich form of (3) namely
where the Ai are as in (4). This equation is linear, but non-commutative, and we can write the solution as a Magnus expansion [2]:
in terms of iterated commutators of the Ai and stochastic Stratonovich integrals with respect to multiple Wiener processes.
Section 2 reviews the Magnus expansion in the general setting, but we also show that for (8) Ω(t) can be represented as an antisymmetric matrix
where the ξi(σt) are continuous random variables that are to be constructed. Given (9) then by (8)
and so this construction is norm-preserving. We also show in Section 3 that a stepwise implementation by, for example, the Euler-Maruyama method is not norm-preserving.
In Sections 3 and 4, we show how to construct the ξi(σt) based on an expansion of a weighted sum of increasing numbers of appropriate cross products. In Section 5, we estimate these weights based on the following idea: as a particle wanders randomly on the unit sphere, the steady-state distribution at \(z = \cos \limits \theta \) is uniform as the curvature near the pole balances the girth near the equator. We can therefore write down an Itô SDE (2) for z(t) (= S3(t)), namely
This satisfies
We will use these weak forms to compare with S3(t) derived from (8) and (9). In Section 6, we give some results and discussions, and in Section 7 give conclusions on the novelty of this work.
Finally, we note that the problem of a particle diffusing on a sphere has been studied in a number of settings. Yosida [3] in 1949 considered motion on a three-dimensional sphere by solving a certain parabolic partial differential equation in which the generating function of the right-hand side operator can be determined explicitly and is the Laplacian operator in polar co-ordinates. Brillinger [4] looked at this problem in terms of expected travel time to a cap. In a slightly different setting, a number of variants of walks on N-spheres have been constructed for solving the N-dimensional Dirichlet problem. Muller [5] constructed N-dimensional spherical processes through an iterative process extending the ideas of Kakutani [6] who used the exit locations of Brownian motion. Other approaches were introduced in [7, 8]. More recently, Yang et al. [9] showed how a constant-potential, time-independent Schrödinger equation can be solved by a classical walk-on-spheres approach.
2 The Magnus method
The form of the Magnus expansion of the solution for arbitrary matrices A1,A2, and A3 was given in [2], as in Lemma 1.
Lemma 1
with Stratonovich integrals
In fact for any positive integer p, the σp term in the expansion will include iterated commutators of order p that are summed over p summations and multiplied by complicated expressions involving Stratonovich integrals over p Wiener processes.
Theorem 2
With the Ai as in (4), then Ω(t) is the anti-symmetric matrix
Proof
Given (4), then
This means that all high-order commutators of any order p will collapse down to one of A1,A2, or A3. To illustrate this up to σ3, we apply (13) to the expansion in Lemma 1. This gives
Here, we have dropped the dependence on t for ease of notation. Clearly the form for Ω(t) is as in (12).□
Remarks
-
The ξi(σt) are complicated expansions in σ of high-order Stratonovich integrals. However, these are extremely computationally intensive to simulate [1]. Instead, we will approximate them as continuous stochastic processes in some weak sense—see (26).
-
Clearly, the simplest approximation to the ξ(σt) is to take
$$ \xi(\sigma t) = (\xi_{1}(\sigma t),\xi_{2}(\sigma t),\xi_{3}(\sigma t))^{\top} = \sigma J(t) = \sigma W(t), $$(14)where W(t) is a three-vector of independent Wiener processes. This idea will be the basis of our first algorithm presented in Section 3.
3 Stepwise implementations
Before presenting our first method, we show that the Euler-Maruyama method is an inappropriate method in that it does not preserve \(||S(t)||_{2}^{2}\), the spin norm. In fact, the mean drifts and the distribution of values grow rapidly wider with increasing time. An improved algorithm (without Itô correction) can narrow the distribution of values of the norm but will still have a mean that drifts. To see the behaviour of the EM method applied to (3), we have
where, as before,
Hence, with \(N_{k} + N_{k}^{\top } = 0\),
Note N1k,N2k,N3k,k = 1,⋯ ,m are independent Normal random variables with mean 0 and variance 1. Now
Thus
and so
Similarly,
Therefore, if (3) is solved on the time interval (0,T) with m steps h = T/m starting with ||S0||2 = 1 then, as \(m\to \infty \) (h → 0), the value of ||S(t)||2 obtained is a random variable with
and
Thus, the spin modulus is not conserved and the mean error grows linearly with t. More importantly, the variance can be very large so that if the procedure described above is repeated numerous times, the standard deviation of the ensemble of values of ||S(T)||2 obtained is proportional to \(\sqrt {T}\). In fact, the probability density function of \(\log (||S(t)||^{2})\) is Gaussian. This means that, while more than half of the values of ||S(t)||2 obtained will be less than 1, rare large values of ||S(t)||2 dominate the statistics.
In order to construct a simple method that preserves the spin norm, it will be based on (8), (9), and (14), which leads to
with
where in the first instance we take \(J(t) = (\hat {J}_{1}(t), \hat {J}_{2}(t), \hat {J}_{3}(t))^{\top } = (W_{1}(t), W_{2}(t), W_{3}(t))^{\top }\).
Our construction is based on Rodrigues’ formula [10]. Let
Then A3 = −r2A, so that
Now let T = mh; then we can write
This allows us to write a step-by-step method
where Nk is given in (15),
and hence a step-by-step method is, from (18),
Note that this step-by-step method will only be strong order 0.5.
4 A class of Magnus-type methods
A stepwise approach, as constructed previously, will not yield a method that has more than strong order 0.5 and weak order 1 so we will attempt to approximate the ξi(σt) to obtain a better weak order approximation. We will first consider the behaviour of the composition of the Magnus operator over two half steps and require this to be the same as the Magnus approximation over a full step up to some power of the stepsize h. This will give us a clue as to how to choose the ξj(t). In order to simplify the discussion, we will, wolog, take σ = 1.
Let \(\bar {A}_{\xi }\) denote the matrix
with ξ = (ξ1, ξ2, ξ3)⊤.
Suppose on the two half steps, we assume that the random variables behave as
and on the full step
where N1,N2,N and P1,P2,P are 3 vectors of independent random variables that are to be determined in some manner. Furthermore, the matrices generated by these vectors through (19) will be denoted by \(\bar {N}_{1}, \> \bar {N}_{2}, \> \bar {P}_{1}, \> \bar {P}_{2}\).
So from (12) and (16) and setting the composition over two half steps to be equal to the Magnus operator up to the h term implies
Hence
and
Hence from (20) and after some simple algebra
Now with \(\bar {N}_{1}\) and \(\bar {N}_{2}\) generated by the vectors N1 and N2, via (19) it is easy to show that \([\bar {N}_{2},\bar {N}_{1}]\) generates a matrix of the form (19) in which the corresponding vector ξ that generates \(\bar {A}_{\xi }\) is N1 × N2, where the cross product is given through the following definition.
Definition 1
Given vectors B = (B1,B2,B3)⊤, D = (D1,D2,D3)⊤ then
Consequences of Definition 1 are the following well-known results:
Lemma 2
Given two three-vectors B and D, the following results on cross products hold.
Proof
Trivial use of Definition 1.□
Thus, in the vector setting, (20) and (21) and Lemma 2 give
Equation (22) suggests that we take N1 and N2 to be independent N(0,1) 3-vectors, so that N is also a 3-vector with independent N(0,1) components.
Furthermore, if we let u1, u2, v1 and v2 be independent N(0,1) 3-vectors and we take
then from (23) and Lemma 2 we have
Hence N,N1, and N2 have the same distributions as do P,P1, and P2, respectively.
Continuing this line of thought, this suggests that we base our choice of the ξ(t) on a cross product formulation. Thus, we will take for ξ(t) the expansion
where the dj are chosen appropriately and
We can choose any positive integer value for r in (24). But we will see in Section 5 when we attempt to estimate the dj that they become overly sensitive for values of r > 5, and so we will take a specific value of r, namely r = 5.
This will lead to methods that we will denote by M(1,d2,d3,d4,d5). For clarity, we give the form of the ξ(t):
We will show in Section 5 how to calibrate the parameters d2,d3,d4,d5 appropriately, in order to get good performance.
Note if we wish to simulate ξ(t) at some time point t = T, then we generate an equidistant time mesh with stepsize \(h = \frac {T}{m}\). We then simulate two sequences of vectors of length m consisting of independent N(0,1)-3 vectors: G1i,G2i,i = 1,⋯ ,m. We then approximate
and generate ξ(T) by using (26) and the definition of the cross product and related results in Lemma 1.
5 Model calibration
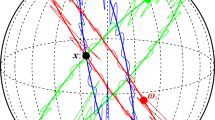
As a particle wanders randomly on a sphere, the steady-state distribution at latitude, \(z = {\cos \limits } \theta \), is uniform as the curvature near the poles balances the greater girth near the equator (see also [4])—by symmetry, the same is true of x and y; see Fig. 1.

Numerical distribution of x, y, and z
If we write the SDE for z alone, we find
Hence, using the property of Itô SDEs
Furthermore, we can show via Itô’s Lemma that with u(t) = z2(t) then u satisfies
Hence
Now we saw that the solution S(t) to (2) is given in (18). Assume S0 = (0, 0, 1)⊤, σ = 1 and let z(t) be the third component of S(t); then
where ξ(t) = (ξ1(t),ξ2(t),ξ3(t))⊤ is to be determined and
Let \(u^{2}(t) = {\xi _{1}^{2}}(t) + {\xi _{2}^{2}}(t)\), then
Since u2(t) is independent from ξ3(t) then with \(\bar {z}(t) = E(z(t))\),
We will compare \(\bar {z}(t)\) with (28) in order to construct effective methods from the class M(1.d2,d3,d4,d5). To commence this, we now analyse the error for method M(1,0,0,0,0) (M1), so that ξ(t) = J1(t). Now for any of the 3 components of ξ(t), say ξ1(t), we know, from the properties of the Normal distribution,
Substituting (31) into (30), we find after some manipulation
Hence
A plot of this error in (33) is given in Fig. 2. We see that (32) is only accurate for modest values of time. So this is a word of caution in using a truncated error estimate for too large a value of t.

Plots of the mean error (solid) and truncated mean error (dotted) for method M1
We will now consider the behaviour of the general class of methods given by M(1,d2,d3,d4,d5) in terms of (30) where ξ(t) is given in (26). It will prove too difficult to get analytical results for the error in (33) so we will have to use a truncated error estimate. First, we will expand \(\bar {z}(t)\) in (30) up to and including the t4 term. It can be shown with some simple expansions that
where
In order to calculate these expectations, we note the following Lemma, where the product of vectors is considered component-wise.
Lemma 3
With the Aj(t) defined previously and ξ(t) given by (26)
Proof
Without loss of generality we will assume p ≥ q = p − r and consider two cases: r = 2k + 1 and r = 2k, (k = 0,1,2,⋯ ). Let us consider the odd case first. Now
It is easy to show by induction that
Now, by definition of the cross product, the ith component of J2 × Ap−(2k+ 1) does not have a corresponding component from Ap−(2k+ 1) and since the powers of J2 appearing in (34) are odd, then
Now let us consider the even case.
Similarly to the odd case, then by induction, for k = 1,2,⋯
Clearly, in each of the 3 components of the vectors on the right-hand side, there will be terms that have even powers in J2 and Ap− 2j and the power of t will behave as k + p − 2k = p − k. Furthermore, each of the 3 components will have the same form. Hence
□
Some algebra and calculations of moments allow us to write
where c2,c3,c4 can be considered to be the error terms when comparing \(\bar {z}(t)\) to e−t. It can be shown that
These results hold true for any component of ξ, i = 1,2, or 3. Some of the expectations in (36) have already been calculated, but we now show the analysis in Lemma 4 for some of the more complicated terms in (36).
Lemma 4
For any i = 1,2 or 3
-
(i)
E(A2(t) ⋅ A4(t))i = 10t3
-
(ii)
E(A1(t) ⋅ A5(t))i = 10t3
-
(iii)
E(A4(t)2)i = 70t4
-
(iv)
E(A3(t) ⋅ A5(t))i = − 70t4.
Proof
We will drop the dependence on t for ease of notation.
-
(i)
As a consequence of Lemma 2 and (34),
$$ \begin{array}{@{}rcl@{}} A_{2} \cdot A_{4} &=& (J_{2} \times J_{1}) \cdot (J_{2} \times (J_{2} \times (J_{2} \times J_{1}))) \\ &=& (J_{2} \times J_{1}) \cdot (J_{2} \times (J_{2} (J_{2}^{\top} J_{1}) - J_{1} (J_{2}^{\top} J_{2}))) \\ &=& -(J_{2} \times J_{1}) \cdot (J_{2} \times J_{1}) (J_{2}^{\top} J_{2}). \end{array} $$With J2 = (B1,B2,B3)⊤, J1 = (N1,N2,N3)⊤ then
$$ J_{2} \times J_{1} = (B_{3} N_{2} -B_{2} N_{3}, \> B_{3} N_{1} - B_{1} N_{3}, \> B_{2} N_{1} - B_{1} N_{2})^{\top}.$$Take any component of the vectors, say the first component, then
$$(A_{2} \cdot A_{4})_{1} = (B_{3}N_{2} - B_{2}N_{3})^{2} ({B_{1}^{2}} + {B_{2}^{2}} + {B_{3}^{2}}).$$Using results on expectation of normals
$$E(A_{2} \cdot A_{4})_{1} = 1 + 1 + 1 + 3 + 3 + 1 = 10 t^{3}.$$ -
(ii)
From (34) and Lemma 2
$$ \begin{array}{@{}rcl@{}} A_{1} \cdot A_{5} &=& J_{1} \cdot (J_{2} \times A_{4}) \\ &=& -J_{1} \cdot (J_{2} \times (J_{2} \times J_{1})) \> (J_{2}^{\top} J_{2}) \\ &=& -(J_{2}^{\top} J_{2}) J_{1} \cdot (J_{2} (J_{2}^{\top} J_{1}) - J_{1} (J_{2}^{\top} J_{2})). \end{array} $$Look at, say, the first component, then
$$ \begin{array}{@{}rcl@{}} (A_{1} \cdot A_{5})_{1} &=& ({B_{1}^{2}} + {B_{2}^{2}} + {B_{3}^{2}})^{2} {N_{1}^{2}} - ({B_{1}^{2}}+{B_{2}^{2}}+{B_{3}^{2}})(B_{1}N_{1}\\ &&+B_{2}N_{2}+B_{3}N_{3})N_{1}B_{1} \\ E(A_{1} \cdot A_{5})_{1} &=& 3 + 3 + 3 + 2 + 2 + 2 - (3 + 1 + 1). \end{array} $$So E(A1A5)1 = 10t3.
-
(iii)
From Lemma 2 and (34)
$$ \begin{array}{@{}rcl@{}} {A_{4}^{2}} &=& (J_{2}^{\top} J_{2})^{2} ((J_{2} \times J_{1}) \cdot (J_{2} \times J_{1})) \\ ({A_{4}^{2}})_{1} &=& ({B_{1}^{2}}+{B_{2}^{2}}+{B_{3}^{2}})^{2} (B_{3} N_{2} - B_{2} N_{3})^{2} \\ E({A_{4}^{2}})_{1} &=& 70 t^{3}. \end{array} $$ -
(iv)
From (34) and Lemma 2
$$ \begin{array}{@{}rcl@{}} A_{3} \cdot A_{5} &=& -(J_{2} \times (J_{2} \times J_{1})) \cdot (J_{2} (J_{2}^{\top} J_{1}) - J_{1} (J_{2}^{\top} J_{2})) (J_{2}^{\top} J_{2}) \\ &=& -(J_{2} (J_{2}^{\top} J_{1}) - J_{1} (J_{2}^{\top} J_{2}))^{2} (J_{2}^{\top} J_{2}). \end{array} $$Look at the first component say, then
$$ \begin{array}{@{}rcl@{}} (A_{3} \cdot A_{5})_{1} &=& -{B_{1}^{2}} ({B_{1}^{2}}+{B_{2}^{2}}+{B_{3}^{2}})(B_{1}N_{1} + B_{2}N_{2} + B_{3} N_{3})^{2} \\ && -{N_{1}^{2}} ({B_{1}^{2}}+{B_{2}^{2}}+{B_{3}^{2}})^{3} \\ && + 2B_{1} N_{1}({B_{1}^{2}}+{B_{2}^{2}}+{B_{3}^{2}})^{2} (B_{1}N_{1} +B_{2}N_{2}+B_{3}N_{3}) \\ E(A_{3} \cdot A_{5})_{1} &=& -35 - 105 + 70 = -70. \end{array} $$
□
From Lemma 4 and (36)
We now consider the behaviour of the error constants as a function of the classes of methods.
Let M2 denote M(1,d2,0,0,0); then clearly c2 and c3 are minimised if d2 = 0, and this reduces to M1 : M(1,0,0,0,0). However, if we allow d2 to be imaginary, then the most effective method within the class M2 is when \({d_{2}^{2}} + \frac {1}{24} = 0\), that is \(M(1,\frac {1}{\sqrt {24}} i, 0, 0, 0)\).
Let M3 denote M(1,d2,d3,0,0); then
in which case from (37)
We now assume (38) holds and choose d3 such that \(c_{4} = \frac {1}{4} c_{3}\) (since the exponential solution for the mean has this property—and it turns out this ansatz is more effective than trying to make some of the error constants equal to zero). This leads to the quadratic
or
Thus, an effective method is \(M_{3} = M(1,\sqrt {2d_{3}-\frac {1}{24}},\frac {1}{53}(1+\frac {1}{12}\sqrt {\frac {23}{2}}),0,0)\). That is,
For the class M4 = M(1,d2,d3,d4,0), then applying the same ansatz as for M3, with \(c_{4} = \frac {1}{4}c_{3}\) then (37) leads to
Taking the negative square root of the right-hand side gives
where d2 is determined from (38). Thus, d3 is a free parameter, but with the caveat that the term under the square root in (39) must be positive, and from (38), \(d_{3} > \frac {1}{48}\).
6 Results and discussion
We now present results for a set of methods, with just up to 4 terms—we do not consider M5; see Remark 5. These methods are M1(1,0,0,0), M2(1,d2,0,0) (d2 > 0), \(M_{2}^{*}(1,\frac {1}{\sqrt {24}}\>i,0,0)\), \(M_{3}(1,\sqrt {\frac {1}{12}(\sqrt {46}-\frac {5}{106})},\frac {1}{53}(1+\frac {1}{12}\sqrt {\frac {23}{2}}))\), M4(1,0.099716,0.025805, − 3.33310− 4), \(M_{4}^{*}(1,0.081984,0.024194,1.366 10^{-6})\). These last two methods were found after a parameter sweep over d3—see Remark 4 below.
In all cases, we give the error in z (E1) and the error in z2 (E2) at T = 1 with 500 steps and 400,000 (1st column) or 1,000,000 (second column) simulations (Table 1).
We can make the following remarks.
-
1.
Although we do not show the results, M1 is always more accurate than the class M2 for any real value of d2 > 0.
-
2.
If we choose \(d_{2} = \frac {1}{\sqrt {24}} \> i\) then \(M_{2}^{*}\) is much more accurate than M1. However, in the case of \(M_{2}^{*}\) the components of S are complex. Nevertheless they still satisfy \({S_{1}^{2}}(t) + {S_{2}^{2}}(t) + {S_{3}^{2}}(t) = 1,\) ∀t. Letting Sj = αj + i βj,j = 1,2,3 and writing
$$ \alpha = (\alpha_{1},\alpha_{2},\alpha_{3})^{\top}, \quad \beta = (\beta_{1},\beta_{2},\beta_{3})^{\top},$$then this conservation property is equivalent to
$$ ||\alpha||^{2} - ||\beta||^{2} = 1, \quad \alpha^{\top} \beta = 0. $$(40)Thus, rather than having a spherical-like structure, the solution to (2) is more akin to a hyperbolic structure.
-
3.
Compared with M1, method M3 performs very well. The error, E1, is approximately 50 times smaller than M1 with 400,000 simulations and much less with 1,000,000 simulations. The errors are also considerably less for E2 and we note that we did not attempt to optimise the parameters for the second moment. However, we do note that there is considerable variation between the results for 400,000 and 1,000,000 simulations.
-
4.
The above remark brings us to the results for M4 and \(M_{4}^{*}\). In finding these results, we did a parameter sweep over the free parameter d3 and we present the best results based on 400,000 and 1,000,000 simulations. M4 is more accurate than M3 with 400,000 simulations (but less accurate with 1,000,000 simulations), while \(M_{4}^{*}\) behaves in the converse with respect to M3. For both M4 and \(M_{4}^{*}\) the corresponding optimal d4 is quite small and so these results are subject to the quality of the normal random number stream.
-
5.
This last point explains why we do not go further and consider M5. Some of the optimal parameters will likely be very small, as is already the case for the values of d4, and the results will be even more sensitive to the normal random number stream.
7 Conclusions
It turns out that a Magnus method given by (16), where the antisymmetric matrix Ω(t) in (17) depends just on the three Wiener processes, guarantees that the solution stays on the surface of the sphere. However, this approach says nothing about the accuracy of the trajectories on the surface.
The novelty of this work is that we construct the continuous random variables ξ1(t), ξ2(t), and ξ3(t) that guarantee that the trajectories lie on the surface but also give good accuracy in a weak sense. This is done by considering a one-dimensional model (27) in which we note that the steady-state distribution of the third variable at \(z = {\cos \limits } \theta \) is uniform as the curvature near the pole balances the girth near the equator. From (27), we can get exact formulations for the first and second moments.
The additional novelty is that we now construct the ξj(t) in terms of a linear combination of iterated cross products (see (26)). We then find the weights dj by comparing the Magnus solution with the above moments. This results in a family of methods with very small weak errors. We describe these methods to be effective in the sense of the above characterisation. This is important for making sure that the paths on the surface of the sphere are highly accurate. It turns out that method M3 is the simplest and the most robust of the methods constructed. The final aspect of innovation is that these ideas can be extended to diffusion on higher dimensional spherical surfaces [11] and we hope to do this in a following paper.
References
Kloeden, P. E., Platen, E.: Numerical Solution of Stochastic Differential Equations. Springer, Berlin (1992)
Burrage, K., Burrage, P. M.: High order strong methods for non-commutative stochastic ordinary differential equation systems and the Magnus formula. Physica D 133, 34–48 (1999)
Yosida, K.: Brownian motion on the surface of the 3-sphere. Ann. Math. Stat. 20(2), 292–296 (1949)
Brillinger, D. R.: A particle migrating randomly on a sphere. J. Theor. Probab. 10(2), 429–443 (1997)
Muller, M. E.: Some continuous Monte Carlo methods for the Dirichlet problem. Ann. Math. Stat. 27, 569–589 (1956)
Kakutani, S.: On Brownian motion in n-space. Proc. Imp. Acad. Tokyo 20(9), 648–652 (1944)
Elepov, B. S., Mihailov, G. A.: The walk on spheres algorithm for the equation δu − cu = −g. Soviet Math. Dokl. 14, 1276–1280 (1973)
Deaconu, M., Herrmann, S., Maire, S.: The walk on moving spheres: a new tool for simulating Brownian motion’s exit time from a domain. Math. Comput. Simul. 135, 23–38 (2017)
Yang, X., Rasila, A., Sottinen, T.: Walk on spheres algorithm for Helmholtz and Yukawa equations via Duffin correspondence. Methodol. Comput. Appl. Probab. 19, 589–602 (2017)
Rodrigues, O.: Memoire sur l’attraction des spheroides. Correspondence sur l’Ecole Polytechnique 3, 361–385 (1816)
Erdogdu, M., Ozdemir, M.: Simple, double and isoclinic rotations with a viable algorithm. Math. Sci. Appl. e-notes 8(1), 1–14 (2020)
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions. The first-named author received funding from the Australian Centre of Excellence (ACEMS) through grant number CE-140100049.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Author contribution
All the authors contributed equally to this work
Data availability
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
Open Access
This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Burrage, K., Burrage, P.M. & Lythe, G. Effective numerical methods for simulating diffusion on a spherical surface in three dimensions. Numer Algor 91, 1577–1596 (2022). https://doi.org/10.1007/s11075-022-01315-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11075-022-01315-w