
Abstract
In this paper, we consider maximum likelihood estimations of the degree of freedom parameter ν, the location parameter μ and the scatter matrix Σ of the multivariate Student t distribution. In particular, we are interested in estimating the degree of freedom parameter ν that determines the tails of the corresponding probability density function and was rarely considered in detail in the literature so far. We prove that under certain assumptions a minimizer of the negative log-likelihood function exists, where we have to take special care of the case \(\nu \rightarrow \infty \), for which the Student t distribution approaches the Gaussian distribution. As alternatives to the classical EM algorithm we propose three other algorithms which cannot be interpreted as EM algorithm. For fixed ν, the first algorithm is an accelerated EM algorithm known from the literature. However, since we do not fix ν, we cannot apply standard convergence results for the EM algorithm. The other two algorithms differ from this algorithm in the iteration step for ν. We show how the objective function behaves for the different updates of ν and prove for all three algorithms that it decreases in each iteration step. We compare the algorithms as well as some accelerated versions by numerical simulation and apply one of them for estimating the degree of freedom parameter in images corrupted by Student t noise.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The motivation for this work arises from certain tasks in image processing, where the robustness of methods plays an important role. In this context, the Student t distribution and the closely related Student t mixture models became popular in various image processing tasks. In [31] it has been shown that Student t mixture models are superior to Gaussian mixture models for modeling image patches and the authors proposed an application in image compression. Image denoising based on Student t models was addressed in [17] and image deblurring in [6, 34]. Further applications include robust image segmentation [4, 25, 29] as well as robust registration [8, 35].
In one dimension and for ν = 1, the Student t distribution coincides with the one-dimensional Cauchy distribution. This distribution has been proposed to model a very impulsive noise behavior and one of the first papers which suggested a variational approach in connection with wavelet shrinkage for denoising of images corrupted by Cauchy noise was [3]. A variational method consisting of a data term that resembles the noise statistics and a total variation regularization term has been introduced in [23, 28]. Based on an ML approach the authors of [16] introduced a so-called generalized myriad filter that estimates both the location and the scale parameter of the Cauchy distribution. They used the filter in a nonlocal denoising approach, where for each pixel of the image they chose as samples of the distribution those pixels having a similar neighborhood and replaced the initial pixel by its filtered version. We also want to mention that a unified framework for images corrupted by white noise that can handle (range constrained) Cauchy noise as well was suggested in [14].
In contrast to the above pixelwise replacement, the state-of-the-art algorithm of Lebrun et al. [18] for denoising images corrupted by white Gaussian noise restores the image patchwise based on a maximum a posteriori approach. In the Gaussian setting, their approach is equivalent to minimum mean square error estimation, and more general, the resulting estimator can be seen as a particular instance of a best linear unbiased estimator (BLUE). For denoising images corrupted by additive Cauchy noise, a similar approach was addressed in [17] based on ML estimation for the family of Student t distributions, of which the Cauchy distribution forms a special case. The authors call this approach generalized multivariate myriad filter.
However, all these approaches assume that the degree of freedom parameter ν of the Student t distribution is known, which might not be the case in practice. In this paper we consider the estimation of the degree of freedom parameter based on an ML approach. In contrast to maximum likelihood estimators of the location and/or scatter parameter(s) μ and Σ, to the best of our knowledge the question of existence of a joint maximum likelihood estimator has not been analyzed before and in this paper we provide first results in this direction. Usually the likelihood function of the Student t distributions and mixture models are minimized using the EM algorithm derived e.g. in [13, 21, 22, 26]. For fixed ν, there exists an accelerated EM algorithm [12, 24, 32] which appears to be more efficient than the classical one for smaller parameters ν. We examine the convergence of the accelerated version if also the degree of freedom parameter ν has to be estimated. Also for unknown degrees of freedom, there exist an accelerated version of the EM algorithm, the so-called ECME algorithm [20] which differs from our algorithm. Further, we propose two modifications of the ν iteration step which lead to efficient algorithms for a wide range of parameters ν. Finally, we address further accelerations of our algorithms by the squared iterative methods (SQUAREM) [33] and the damped Anderson acceleration with restarts and 𝜖-monotonicity (DAAREM) [9].
The paper is organized as follows: In Section 2 we introduce the Student t distribution, the negative \(\log \)-likelihood function L and their derivatives. The question of the existence of a minimizer of L is addressed in Section 3. Section 4 deals with the solution of the equation arising when setting the gradient of L with respect to ν to zero. The results of this section will be important for the convergence consideration of our algorithms in the Section 5. We propose three alternatives of the classical EM algorithm and prove that the objective function L decreases for the iterates produced by these algorithms. Finally, we provide two kinds of numerical results in Section 5. First, we compare the different algorithms by numerical examples which indicate that the new ν iterations are very efficient for estimating ν of different magnitudes. Second, we come back to the original motivation of this paper and estimate the degree of freedom parameter ν from images corrupted by one-dimensional Student t noise. The code is provided onlineFootnote 1.
2 Likelihood of the multivariate student t distribution
The density function of the d-dimensional Student t distribution Tν(μ, Σ) with ν > 0 degrees of freedom, location paramter \(\mu \in \mathbb {R}^{d}\) and symmetric, positive definite scatter matrixΣ ∈ SPD(d) is given by
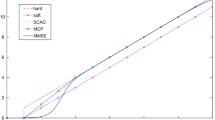
with the Gamma function \( {\Gamma }(s) := {\int \limits }_{0}^{\infty } t^{s-1}\mathrm {e}^{-t} \mathrm {d}t \). The expectation of the Student t distribution is \(\mathbb {E}(X) = \mu \) for ν > 1 and the covariance matrix is given by \(Cov(X) =\frac {\nu }{\nu -2} {\varSigma }\) for ν > 2; otherwise, the quantities are undefined. The smaller the value of ν, the heavier the tails of the Tν(μ, Σ) distribution. For \(\nu \to \infty \), the Student t distribution Tν(μ, Σ) converges to the normal distribution \(\mathcal {N}(\mu ,{\varSigma })\) and for ν = 0 it is related to the projected normal distribution on the sphere \(\mathbb {S}^{d-1}\subset \mathbb {R}^{d}\). Figure 1 illustrates this behavior for the one-dimensional standard Student t distribution.

Standard Student t distribution Tν(0,1) for different values of ν in comparison with the standard normal distribution \(\mathcal {N}(0,1)\)
As the normal distribution, the d-dimensional Student t distribution belongs to the class of elliptically symmetric distributions. These distributions are stable under linear transforms in the following sense: Let \(X\sim T_{\nu }(\mu ,{\varSigma })\) and \(A\in \mathbb {R}^{d\times d}\) be an invertible matrix and let \(b\in \mathbb {R}^{d}\). Then \(AX + b\sim T_{\nu }\left (A\mu + b, A{\varSigma } A^{\mathrm {T}}\right )\). Furthermore, the Student t distribution Tν(μ, Σ) admits the following stochastic representation, which can be used to generate samples from Tν(μ, Σ) based on samples from the multivariate standard normal distribution \(\mathcal {N}(0,I)\) and the Gamma distribution \({\Gamma }\left (\tfrac {\nu }{2},\tfrac {\nu }{2}\right )\): Let \(Z\sim \mathcal {N}(0,I)\) and \(Y\sim {\Gamma }\left (\tfrac {\nu }{2},\tfrac {\nu }{2}\right )\) be independent, then
For i.i.d. samples \(x_{i} \in \mathbb R^{d}\), i = 1,…,n, the likelihood function of the Student t distribution Tν(μ, Σ) is given by
and the log-likelihood function by
In the following, we are interested in the negative log-likelihood function, which up to the factor \(\frac {2}{n}\) and weights \(w_{i} = \frac {1}{n}\) reads as
In this paper, we allow for arbitrary weights from the open probability simplex \( \mathring {\Delta }_{n} := \left \{w = (w_{1},\ldots ,w_{n}) \in \mathbb R_{>0}^{n}: {\sum }_{i=1}^{n} w_{i} = 1 \right \} \). In this way, we might express different levels of confidence in single samples or handle the occurrence of multiple samples. Using \( \frac {\partial \log (\left | X \right |)}{\partial X} = X^{-1} \) and \( \frac {\partial a^{\mathrm {T}} X^{-1}b }{\partial X} =- {\left (X^{-\mathrm {T}}\right )}a b^{\mathrm {T}} {\left (X^{-\mathrm {T}}\right )} \) (see [27]), the derivatives of L with respect to μ, Σ and ν are given by
with
and the digamma function
Setting the derivatives to zero results in the equations
Computing the trace of both sides of (3) and using the linearity and permutation invariance of the trace operator we obtain
which yields
We are interested in critical points of the negative log-likelihood function L, i.e., in solutions (μ, Σ, ν) of (2)–(4), and in particular in minimizers of L.
3 Existence of critical points
In this section, we examine whether the negative log-likelihood function L has a minimizer, where we restrict our attention to the case μ = 0. For an approach how to extend the results to arbitrary μ for fixed ν we refer to [17]. To the best of our knowledge, this is the first work that provides results in this direction. The question of existence is, however, crucial in the context of ML estimation, since it lays the foundation for any convergence result for the EM algorithm or its variants. In fact, the authors of [13] observed the divergence of the EM algorithm in some of their numerical experiments, which is in accordance with our observations.
For fixed ν > 0, it is known that there exists a unique solution of (3) and for ν = 0 that there exist solutions of (3) which differ only by a multiplicative positive constant (see, e.g., [17]). In contrast, if we do not fix ν, we have roughly to distinguish between the two cases that the samples tend to come from a Gaussian distribution, i.e., HCode \(\nu \to \infty \), or not. The results are presented in Theorem 1.
We make the following general assumption:
Assumption 1
Any subset of less or equal d samples xi, i ∈{1,…,n} is linearly independent and \(\max \limits \{w_{i}:i=1,\ldots ,n\}<\frac {1}{d }\).
For μ = 0, the negative log-likelihood function becomes
Further, for a fixed ν > 0, set
To prove the next existence theorem we will need two lemmas, whose proofs are given in the Appendix.
Theorem 1
Let \(x_{i} \in \mathbb R^{d}\), i = 1,…,n and w ∈Δ̈n fulfill Assumption 1. Then exactly one of the following statements holds:
-
(i)
There exists a minimizing sequence (νr,Σr)r of L, such that \(\{\nu _{r}:r\in \mathbb N\}\) has a finite cluster point. Then we have \(argmin_{(\nu ,{\varSigma })\in \mathbb {R}_{>0}\times \text {SPD}(d)} L(\nu ,{\varSigma })\neq \emptyset \) and every \((\hat \nu ,\hat {\varSigma })\in argmin_{(\nu ,{\varSigma })\in \mathbb {R}_{>0}\times \text {SPD}(d)}L(\nu ,{\varSigma })\) is a critical point of L.
-
(ii)
For every minimizing sequence (νr,Σr)r of L(ν, Σ) we have \(\underset {r\to \infty }{\lim } \nu _{r}=\infty \). Then (Σr)r converges to the maximum likelihood estimator \(\hat {\varSigma }={\sum }_{i=1}^{n} w_{i}x_{i}x_{i}^{\mathrm {T}}\) of the normal distribution \(\mathcal {N}(0,{\varSigma })\).
Proof
Case 1: Assume that there exists a minimizing sequence (νr,Σr)r of L, such that (νr)r has a bounded subsequence. In particular, using Lemma 4, we have that (νr)r has a cluster point ν∗ > 0 and a subsequence \((\nu _{r_{k}})_{k}\) converging to ν∗. Clearly, the sequence \((\nu _{r_{k}},{\varSigma }_{r_{k}})_{k}\) is again a minimizing sequence so that we skip the second index in the following. By Lemma 5, the set \(\overline {\{{\varSigma }_{r}:r\in \mathbb N\}}\) is a compact subset of SPD(d). Therefore there exists a subsequence \(({\varSigma }_{r_{k}})_{k}\) which converges to some Σ∗∈SPD(d). Now we have by continuity of L(ν, Σ) that
Case 2: Assume that for every minimizing sequence (νr,Σr)r it holds that \(\nu _{r}\to \infty \) as \(r\to \infty \). We rewrite the likelihood function as
Since
we obtain
Next we show by contradiction that \(\overline {\{{\varSigma }_{r}:r\in \mathbb N\}}\) is in SPD(d) and bounded: Denote the eigenvalues of Σr by λr1 ≥⋯ ≥ λrd. Assume that either \(\{\lambda _{r1}:r\in \mathbb N\}\) is unbounded or that \(\{\lambda _{rd}:r\in \mathbb N\}\) has zero as a cluster point. Then, we know by [17, Theorem 4.3] that there exists a subsequence of (Σr)r, which we again denote by (Σr)r, such that for any fixed ν > 0 it holds
Since \(k\mapsto \left (1+\frac {k}{x}\right )^{k}\) is monotone increasing, for νr ≥ d + 1 we have
By (5) this yields
This contradicts the assumption that (νr,Σr)r is a minimizing sequence of L. Hence, \(\overline {\{{\varSigma }_{r}:r\in \mathbb N\}}\) is a bounded subset of SPD(d). Finally, we show that any subsequence of (Σr)r has a subsequence which converges to \(\hat {\varSigma }={\sum }_{i=1}^{n} w_{i} x_{i}x_{i}^{\mathrm {T}}\). Then the whole sequence (Σr)r converges to \(\hat {\varSigma }\). Let \(\left ({\varSigma }_{r_{k}}\right )_{k}\) be a subsequence of (Σr)r. Since it is bounded, it has a convergent subsequence \(\left ({\varSigma }_{r_{k_{l}}}\right )_{l}\) which converges to some \(\tilde {\varSigma }\in \overline {\{{\varSigma }_{r}:r\in \mathbb N\}}\subset \text {SPD}(d)\). For simplicity, we denote \(\left ({\varSigma }_{r_{k_{l}}}\right )_{l}\) again by (Σr)r. Since (Σr)r is converges, we know that also \(\left (x_{i}^{\mathrm {T}} {\varSigma }_{r}^{-1}x_{i}\right )_{r}\) converges and is bounded. By \(\underset {r\to \infty }{\lim }\nu _{r}=\infty \) we know that the functions \(x\mapsto \left (1+\frac {x}{\nu _{r}}\right )^{\nu _{r}}\) converge locally uniformly to \(x\mapsto \exp (x)\) as \(r\to \infty \). Thus we obtain
Hence, we have
By taking the derivative with respect to Σ we see that the right-hand side is minimal if and only if \({\varSigma }=\hat {\varSigma }={\sum }_{i=1}^{n}w_{i}x_{i}x_{i}^{\mathrm {T}}\). On the other hand, by similar computations as above we get
so that \(\tilde {\varSigma }=\hat {\varSigma }\). This finishes the proof. □
4 Zeros of F
In this section, we are interested in the existence of solutions of (4), i.e., in zeros of F for arbitrary fixed μ and Σ. Setting \(x := \frac {\nu }{2} > 0\), \(t := \frac {d}{2}\) and
we rewrite the function F in (4) as
where
and
The digamma function ψ and \(\phi = \psi - \log (\cdot )\) are well examined in the literature (see [1]). The function ϕ(x) is the expectation value of a random variable which is Γ(x, x) distributed. It holds \(-\frac {1}{x} < \phi (x) < - \frac {1}{2x}\) and it is well-known that − ϕ is completely monotone. This implies that the negative of A is also completely monotone, i.e., for all x > 0 and \(m \in \mathbb N_{0}\) we have
in particular A < 0, \(A^{\prime } > 0\) and \(A^{\prime \prime } < 0\). Further, it is easy to check that
On the other hand, we have that B(x) ≡ 0 if s = t in which case Fs = A < 0 and has therefore no zero. If s≠t, then Bs is completely monotone, i.e., for all x > 0 and \(m \in \mathbb N_{0}\),
in particular Bs > 0, \(B_{s}^{\prime } < 0\) and \(B_{s}^{\prime \prime } >0\), and
Hence, we have
If \(X \sim {\mathcal N}(\mu ,{\varSigma })\) is a d-dimensional random vector, then \(Y := (X-\mu )^{\mathrm {T}} {\varSigma }^{-1} (X-\mu ) \sim {\chi _{d}^{2}}\) with \(\mathbb E (Y) = d\) and V ar(Y ) = 2d. Thus, we would expect that for samples xi from such a random variable X the corresponding values \((x_{i} - \mu )^{\mathrm {T}} {\varSigma }^{-1} (x_{i} - \mu )\) lie with high probability in the interval \([d - \sqrt {2d},d+ \sqrt {2d}]\), respective \(s_{i} \in [t -\sqrt {t}, t + \sqrt {t}]\). These considerations are reflected in the following theorem and corollary.
Theorem 2
For \(F_{s}: \mathbb {R}_{>0} \rightarrow \mathbb {R}\) given by (7) the following relations hold true:
-
i) If \(s \in [t - \sqrt {t},t+ \sqrt {t}] \cap \mathbb R_{>0}\), then Fs(x) < 0 for all x > 0 so that Fs has no zero.
-
ii) If s > 0 and \(s \not \in [t - \sqrt {t},t+ \sqrt {t}]\), then there exists x+ such that Fs(x) > 0 for all x ≥ x+. In particular, Fs has a zero.
Proof
We have
We want to sandwich \(F^{\prime }_{s}\) between two rational functions Ps and Ps + Q which zeros can easily be described.
Since the trigamma function \(\psi ^{\prime }\) has the series representation
see [1], we obtain
For x > 0, we have
Let R(x) and T(x) denote the rectangular and trapezoidal rule, respectively, for computing the integral with step size 1. Then, we verify
so that
By considering the first and second derivatives of g we see the integrand in I(x) is strictly decreasing and strictly convex. Thus, \( P_{s}(x) < F_{s}^{\prime }(x) \), where
with ps(x) : = a3x3 + a2x2 + a1x + a0 and
For t ≥ 1, we have
and
For \(t=\frac 12\), it holds \([t+2-\sqrt {4+ 5t}, t+2 + \sqrt {4+ 5t}]\supset [0,t+\sqrt {t}]\).
Thus, for \(s \in [t - \sqrt {t}, t + \sqrt {t}]\), by the sign rule of Descartes, ps(x) has no positive zero which implies
Hence, the continuous function Fs is monotone increasing and by (10) we obtain Fs(x) < 0 for all x > 0 if \(s \in [t - \sqrt {t}, t + \sqrt {t}] \cap \mathbb R_{>0}\). Let s > 0 and \(s \not \in [t - \sqrt {t}, t + \sqrt {t}]\). By
and Euler’s summation formula, we obtain
with \(g^{\prime }(u) = -\frac {2}{(x+u)^{3}}+\frac {2}{(x+u+t)^{3}}\) and \(g^{(4)}(u) = \frac {5!}{(x+u)^{6}}-\frac {5!}{(x+u+t)^{6}}\), so that
Therefore, we conclude
The main coefficient of x5 of the polynomial in the numerator is \(2\left (t-(s-t)^{2}\right )\) which fulfills (12). Therefore, if \(s \not \in [t - \sqrt {t}, t + \sqrt {t}]\), then there exists x+ large enough such that the numerator becomes smaller than zero for all x ≥ x+. Consequently, \(F^{\prime }_{s}(x) \leq P_{s}(x) + Q(x)<0\) for all x ≥ x+. Thus, Fs is decreasing on \([x_{+},\infty )\). By (10), we conclude that Fs has a zero. □
The following corollary states that Fs has exactly one zero if \(s > t+ \sqrt {t}\). Unfortunately we do not have such a results for \(s < t - \sqrt {t}\).
Corollary 1
Let \(F_{s}: \mathbb {R}_{>0} \rightarrow \mathbb {R}\) be given by (7). If \(s >t + \sqrt {t}\), t ≥ 1, then Fs has exactly one zero.
Proof
By Theorem 2ii) and since \(\lim _{x\rightarrow 0} F_{s}(x) = -\infty \) and \(\lim _{x\rightarrow \infty } = 0^{+}\), it remains to prove that \(F_{s}^{\prime }\) has at most one zero. Let x0 > 0 be the smallest number such that \(F_{s}^{\prime }(x_{0})=0\). We prove that \(F_{s}^{\prime }(x)<0\) for all x > x0. To this end, we show that \(h_{s}(x):= F_{s}^{\prime }(x)(x+s)^{2}(x+t)\) is strictly decreasing. By (11) we have
and for s > t further
where I(x) is the integral and R(x) the corresponding rectangular rule with step size 1 of the function g : = g1 + g2 defined as
We show that R(x) − I(x) < 0 for all x > 0. Let T(x), Ti(x) be the trapezoidal rules with step size 1 corresponding to I(x) and \(I_{i}(x)={\int \limits }_{0}^{\infty } g_{i}(u)du\), i = 1,2. Then it follows
Since g2 is a decreasing, concave function, we conclude T2(x) − I2(x) < 0. Using Euler’s summation formula in (13) for g1, we get
Since \(g_{1}^{(4)}\) is a positive function, we can write
All coefficients of x are smaller or equal than zero for t ≥ 1 which implies that hs is strictly decreasing. □
Theorem 2 implies the following corollary.
Corollary 2
For \(F: \mathbb {R}_{>0} \rightarrow \mathbb {R}\) given by (6) and \(\delta _{i} := (x_{i} - \mu )^{\mathrm {T}} {\varSigma }^{-1} (x_{i} - \mu )\), i = 1,…,n, the following relations hold true:
-
i) If \(\delta _{i} \in [d - \sqrt {2d},d+ \sqrt {2d}] \cap \mathbb R_{>0}\) for all i ∈{1,…,n}, then F(x) < 0 for all x > 0 so that F has no zero.
-
ii) If δi > 0 and \(\delta _{i} \not \in [d - \sqrt {2d},d+ \sqrt {2d}]\) for all i ∈{1,…,n}, there exists x+ such that F(x) > 0 for all x ≥ x+. In particular, F has a zero.
Proof
Consider \(F = {\sum }_{i=1}^{n} F_{s_{i}}\). If \(\delta _{i} \in [d - \sqrt {2d},d+ \sqrt {2d}] \cap \mathbb R_{>0}\) for all i ∈{1,…,n}, then we have by Theorem 2 that \(F_{s_{i}} (x) < 0\) for all x > 0. Clearly, the same holds true for the whole function F such that it cannot have a zero.
If \(\delta _{i} \not \in [d - \sqrt {2d},d+ \sqrt {2d}]\) for all i ∈{1,…,n}, then we know by Theorem 2 that there exist xi+ > 0 such that \(F_{s_{i}} (x) > 0\) for x ≥ xi+. Thus, F(x) > 0 for \(x \ge x_{+} := \max \limits _{i}(x_{i+})\). Since \(\lim _{x \rightarrow 0} F(x) = -\infty \) this implies that F has a zero. □
5 Algorithms
In this section, we propose an alternative of the classical EM algorithm for computing the parameters of the Student t distribution along with convergence results. In particular, we are interested in estimating the degree of freedom parameter ν, where the function F is of particular interest.
Algorithm 1 with weights \(w_{i} = \frac {1}{n}\), i = 1,…,n, is the classical EM algorithm. Note that the function in the third M-Step
has a unique zero since by (8) the function ϕ < 0 is monotone increasing with \(\lim _{x \rightarrow \infty } \phi (x) = 0^{-}\) and cr > 0. Concerning the convergence of the EM algorithm it is known that the values of the objective function L(νr,μr,Σr) are monotone decreasing in r and that a subsequence of the iterates converges to a critical point of L(ν, μ, Σ) if such a point exists, see [5].

Algorithm 2 distinguishes from the EM algorithm in the iteration of Σ, where the factor \(\frac {1}{\sum \limits _{i=1}^{n} w_{i} \gamma _{i,r}}\) is incorporated now. The computation of this factor requires no additional computational effort, but speeds up the performance in particular for smaller ν. Such kind of acceleration was suggested in [12, 24]. For fixed ν ≥ 1, it was shown in [32] that this algorithm is indeed an EM algorithm arising from another choice of the hidden variable than used in the standard approach, see also [15]. Thus, it follows for fixed ν ≥ 1 that the sequence L(ν, μr,Σr) is monotone decreasing. However, we also iterate over ν. In contrast to the EM Algorithm 1 our ν iteration step depends on μr+ 1 and Σr+ 1 instead of μr and Σr. This is important for our convergence results. Note that for both cases, the accelerated algorithm can no longer be interpreted as an EM algorithm, so that the convergence results of the classical EM approach are no longer available.
Let us mention that a Jacobi variant of Algorithm 2 for fixedν, i.e.,
with μr instead of μr+ 1 including a convergence proof was suggested in [17]. The main reason for this index choice was that we were able to prove monotone convergence of a simplified version of the algorithm for estimating the location and scale of Cauchy noise (d = 1, ν = 1) which could be not achieved with the variant incorporating μr+ 1 (see [16]). This simplified version is known as myriad filter in image processing. In this paper, we keep the original variant from the EM algorithm (14) since we are mainly interested in the computation of ν.
Instead of the above algorithms we suggest to take the critical point (4) more directly into account in the next two algorithms.


Finally, Algorithm 4 computes the update of ν by directly finding a zero of the whole function F in (4) given μr and Σr. The existence of such a zero was discussed in the previous section. The zero computation is done by an inner loop which iterates the update step of ν from Algorithm 3. We will see that the iteration converge indeed to a zero of F.

In the rest of this section, we prove that the sequence (L(νr,μ, r, Σr))r generated by Algorithms 2 and 3 decreases in each iteration step and that there exists a subsequence of the iterates which converges to a critical point.
We will need the following auxiliary lemma.
Lemma 1
Let \(F_{a},F_{b}\colon \mathbb {R}_{>0}\to \mathbb {R}\) be continuous functions, where Fa is strictly increasing and Fb is strictly decreasing. Define F : = Fa + Fb. For any initial value x0 > 0 assume that the sequence generated by
is uniquely determined, i.e., the functions on the right-hand side have a unique zero. Then it holds
-
i)
If F(x0) < 0, then (xl)l is strictly increasing and F(x) < 0 for all x ∈ [xl,xl+ 1], \(l \in \mathbb N_{0}\).
-
ii)
If F(x0) > 0, then (xl)l is strictly decreasing and F(x) > 0 for all x ∈ [xl+ 1,xl], \(l \in \mathbb N_{0}\).
Furthermore, assume that there exists x− > 0 with F(x) < 0 for all x < x− and x+ > 0 with F(x) > 0 for all x > x+. Then, the sequence (xl)l converges to a zero x∗ of F.
Proof
We consider the case i) that F(x0) < 0. Case ii) follows in a similar way.
We show by induction that F(xl) < 0 and that xl+ 1 > xl for all \(l \in \mathbb N\). Then it holds for all \(l\in \mathbb N\) and x ∈ (xl,xl+ 1) that Fa(x) + Fb(x) < Fa(x) + Fb(xl) < Fa(xl+ 1) + Fb(xl) = 0. Thus F(x) < 0 for all x ∈ [xl,xl+ 1], \(l \in \mathbb N_{0}\).
Induction step. Let Fa(xl) + Fb(xl) < 0. Since Fa(xl+ 1) + Fb(xl) = 0 > Fa(xl) + Fb(xl) and Fa is strictly increasing, we have xl+ 1 > xl. Using that Fb is strictly decreasing, we get Fb(xl+ 1) < Fb(xl) and consequently
Assume now that F(x) > 0 for all x > x+. Since the sequence (xl)l is strictly increasing and F(xl) < 0 it must be bounded from above by x+. Therefore it converges to some \(x^{*}\in \mathbb {R}_{>0}\). Now, it holds by the continuity of Fa and Fb that
Hence x∗ is a zero of F. □
For the setting in Algorithm 4, Lemma 1 implies the following corollary.
Corollary 3
Let \(F_{a} (\nu ) := \phi \left (\frac {\nu }{2} \right ) - \phi \left (\frac {\nu +d}{2} \right )\) and
Assume that there exists ν+ > 0 such that F : = Fa + Fb > 0 for all ν ≥ ν+. Then the sequence (νr, l)l generated by the r th inner loop of Algorithm 4 converges to a zero of F.
Note that by Corollary 2 the above condition on F is fulfilled in each iteration step, e.g., if \(\delta _{i,r} \not \in [d - \sqrt {2d} , d + \sqrt {2d}]\) for i = 1,…,n and \(r \in \mathbb {N}_{0}\).
Proof
From the previous section we know that Fa is strictly increasing and Fb is strictly decreasing. Both functions are continuous. If F(νr) < 0, then we know from Lemma 1 that (νr, l)l is increasing and converges to a zero \(\nu _{r}^{*}\) of F.
If F(νr) > 0, then we know from Lemma 1 that (νr, l)l is decreasing. The condition that there exists \(x_{-}\in \mathbb {R}_{>0}\) with F(x) < 0 for all x < x− is fulfilled since \(\lim _{x \rightarrow 0} F(x) = -\infty \). Hence, by Lemma 1, the sequence converges to a zero \(\nu _{r}^{*}\) of F. □
To prove that the objective function decreases in each step of the Algorithms 2–4 we need the following lemma.
Lemma 2
Let \(F_{a},F_{b}\colon \mathbb {R}_{>0}\to \mathbb {R}\) be continuous functions, where Fa is strictly increasing and Fb is strictly decreasing. Define F : = Fa + Fb and let \(G\colon \mathbb {R}_{>0}\to \mathbb {R}\) be an antiderivative of F, i.e., \(F= \frac {\mathrm {d}}{\mathrm {d}x} G\). For an arbitrary x0 > 0, let (xl)l be the sequence generated by
Then the following holds true:
-
i)
The sequence (G(xl))l is monotone decreasing with G(xl) = G(xl+ 1) if and only if x0 is a critical point of G. If (xl)l converges, then the limit x∗ fulfills
$$ G(x_{0}) \geq G(x_{1}) \geq G(x^{*}), $$with equality if and only if x0 is a critical point of G.
-
ii)
Let \(F = \tilde F_{a} + \tilde F_{b}\) be another splitting of F with continuous functions \(\tilde F_{a}, \tilde F_{b}\), where the first one is strictly increasing and the second one strictly decreasing. Assume that \(\tilde F_{a}^{\prime }(x) > F_{a}^{\prime }(x)\) for all x > 0. Then holds for \(y_{1} := \text { zero of } \tilde F_{a}(x) + \tilde F_{b}(x_{0})\) that G(x0) ≥ G(y1) ≥ G(x1) with equality if and only if x0 is a critical point of G.
Proof
i) If F(x0) = 0, then x0 is a critical point of G.
Let F(x0) < 0. By Lemma 1 we know that (xl)l is strictly increasing and that F(x) < 0 for x ∈ [xr,xr+ 1], \(r \in \mathbb {N}_{0}\). By the Fundamental Theorem of calculus it holds
Thus, G(xl+ 1) < G(xl).
Let F(x0) > 0. By Lemma 1 we know that (xl)l is strictly decreasing and that F(x) > 0 for x ∈ [xr+ 1,xr], \(r \in \mathbb {N}_{0}\). Then
implies G(xl+ 1) < G(xl). Now, the rest of assertion i) follows immediately. ii) It remains to show that G(x1) ≤ G(y1). Let F(x0) < 0. Then we have y1 ≥ x0 and x1 ≥ x0. By the Fundamental Theorem of calculus we obtain
and
This yields
and since \(\tilde F^{\prime }_{a}(x) > F^{\prime }_{a}(x)\) further y1 ≤ x1 with equality if and only if x0 = x1, i.e., if x0 is a critical point of G. Since F(x) < 0 on (x0,x1) it holds
with equality if and only if x0 = x1. The case F(x0) > 0 can be handled similarly. □
Lemma 2 implies the following relation between the values of the objective function L for Algorithms 2–4.
Corollary 4
For the same fixed \(\nu _{r}>0, \mu _{r}\in \mathbb {R}^{d}, {\varSigma }_{r}\in \text {SPD}(d)\) define μr+ 1, Σr+ 1, \(\nu _{r+1}^{\text {aEM}}\), \(\nu _{r+1}^{\text {MMF}}\) and \(\nu _{r+1}^{\text {GMMF}}\) by Algorithm 2, 3 and 4, respectively. For the GMMF algorithm assume that the inner loop converges. Then it holds
Equality holds true if and only if \(\frac {\mathrm {d}}{\mathrm {d}\nu }L(\nu _{r},\mu _{r+1},{\varSigma }_{r+1})=0\) and in this case \(\nu _{r} = \nu _{r+1}^{\text {aEM}} = \nu _{r+1}^{\text {MMF}} = \nu _{r+1}^{\text {GMMF}}\).
Proof
For G(ν) : = L(ν, μr+ 1,Σr+ 1), we have \(\frac {\mathrm {d}}{\mathrm {d}\nu } L(\nu ,\mu _{r+1},{\varSigma }_{r+1}) = F(\nu )\), where
We use the splitting
with
and
By the considerations in the previous section we know that Fa, \(\tilde F_{a}\) are strictly increasing and Fb, \(\tilde F_{b}\) are strictly decreasing. Moreover, since \(\phi ^{\prime } > 0\) we have \(\tilde F^{\prime }_{a} > F^{\prime }_{a}\). Hence it follows from Lemma 2(ii) that
Finally, we conclude by Lemma 2(i) that
□
Concerning the convergence of the three algorithms we have the following result.
Theorem 3
Let (νr,μr,Σr)r be sequence generated by Algorithm 2, 3 or 4, respectively starting with arbitrary initial values \(\nu _{0} >0,\mu _{0}\in \mathbb {R}^{d},{\varSigma }_{0}\in \text {SPD}(d)\). For the GMMF algorithm we assume that in each step the inner loop converges. Then it holds for all \(r\in \mathbb N_{0}\) that
with equality if and only if (νr,μr,Σr) = (νr+ 1,μr+ 1,Σr+ 1).
Proof
By the general convergence results of the accelerated EM algorithm for fixed ν, see also [17], it holds
with equality if and only if (μr,Σr) = (μr+ 1,Σr+ 1). By Corollary 4 it holds
with equality if and only if νr = νr+ 1. The combination of both results proves the claim. □
Lemma 3
Let \(T = (T_{1}, T_{2}, T_{3}): \mathbb {R}_{>0} \times \mathbb {R}^{d} \times SPD(d) \rightarrow \mathbb {R}_{>0} \times \mathbb {R}^{d} \times SPD(d)\) be the operator of one iteration step of Algorithm 2 (or 3). Then T is continuous.
Proof
We show the statement for Algorithm 3. For Algorithm 2 it can be shown analogously. Clearly the mapping (T2,T3)(ν, μ, Σ) is continuous. Since
where
It is sufficient to show that the zero of Ψ depends continuously on ν, T2 and T3. Now the continuously differentiable function Ψ is strictly increasing in x, so that \(\frac {\partial }{\partial x} {\varPsi }(x,\nu ,T_{2},T_{3})>0\). By Ψ(T1,ν, T2,T3) = 0, the Implicit Function Theorem yields the following statement: There exists an open neighborhood U × V of (T1,ν, T2,T3) with \(U\subset \mathbb {R}_{>0}\) and \(V\subset \mathbb {R}_{>0}\times \mathbb {R}^{d}\times SPD(d)\) and a continuously differentiable function G: V → U such that for all (x, ν, μ, Σ) ∈ U × V it holds
Thus the zero of Ψ depends continuously on ν, T2 and T3. □
This implies the following theorem.
Theorem 4
Let (νr,μr,Σr)r be the sequence generated by Algorithm 2 or 3 with arbitrary initial values \(\nu _{0} >0,\mu _{0}\in \mathbb {R}^{d},{\varSigma }_{0}\in \text {SPD}(d)\). Then every cluster point of (νr,μr,Σr)r is a critical point of L.
Proof
The mapping T defined in Lemma 3 is continuous. Further we know from its definition that (ν, μ, Σ) is a critical point of L if and only if it is a fixed point of T. Let \((\hat \nu ,\hat \mu ,\hat {\varSigma })\) be a cluster point of (νr,μr,Σr)r. Then there exists a subsequence \((\nu _{r_{s}},\mu _{r_{s}},{\varSigma }_{r_{s}})_{s}\) which converges to \((\hat \nu ,\hat \mu ,\hat {\varSigma })\). Further we know by Theorem 3 that Lr = L(νr,μr,Σr) is decreasing. Since (Lr)r is bounded from below, it converges. Now it holds
By Theorem 3 and the definition of T we have that L(ν, μ, Σ) = L(T(ν, μ, Σ)) if and only if (ν, μ, Σ) = T(ν, μ, Σ). By the definition of the algorithm this is the case if and only if (ν, μ, Σ) is a critical point of L. Thus \((\hat \nu ,\hat \mu ,\hat {\varSigma })\) is a critical point of L. □
6 Numerical results
In this section we give two numerical examples of the developed theory. First, we compare the four different algorithms in Section 6.1. Then, in Section 6.2, we address further accelerations of our algorithms by SQUAREM [33] and DAAREM [9] and show also a comparison with the ECME algorithm [20]. Finally, in Section 6.3, we provide an application in image analysis by determining the degree of freedom parameter in images corrupted by Student t noise. We run all experiments on a HP Probook with Intel i7-8550U Quad Core processor. The code is provided onlineFootnote 2.
6.1 Comparison of algorithms
In this section, we compare the numerical performance of the classical EM algorithm 1 and the proposed Algorithms 2, 3, and 4. To this aim, we did the following Monte Carlo simulation: Based on the stochastic representation of the Student t distribution, see (1), we draw n = 1000 i.i.d. realizations of the Tν(μ, Σ) distribution with location parameter μ = 0 and different scatter matrices Σ and degrees of freedom parameters ν. Then, we used Algorithms 2, 3, and 4 to compute the ML estimator \((\hat \nu ,\hat \mu ,\hat {\varSigma })\).
We initialize all algorithms with the sample mean for μ and the sample covariance matrix for Σ. Furthermore, we set ν = 3 and in all algorithms the zero of the respective function is computed by Newton’s method. As a stopping criterion we use the following relative distance:
We take the logarithm of ν in the stopping criterion, because Tν(μ, Σ) converges to the normal distribution as \(\nu \to \infty \) and therefore the difference between Tν(μ, Σ) and Tν+ 1(μ, Σ) becomes small for large ν.
To quantify the performance of the algorithms, we count the number of iterations until the stopping criterion is reached. Since the inner loop of the GMMF is potentially time consuming we additionally measure the execution time until the stopping criterion is reached. This experiment is repeated N = 10.000 times for different values of ν ∈{1,2,5,10}. Afterward we calculate the average number of iterations and the average execution times. The results are given in Tables 1 and 2. We observe that the performance of the algorithms depends on Σ. Further we see, that the performance of the aEM algorithm is always better than those of the classical EM algorithm. Further all algorithms need a longer time to estimate large ν. This seems to be natural since the likelihood function becomes very flat for large ν. Further, the GMMF needs the lowest number of iterations. But for small ν the execution time of the GMMF is larger than those of the MMF and the aEM algorithm. This can be explained by the fact, that the ν step has a smaller relevance for small ν but is still time consuming in the GMMF. The MMF needs slightly more iterations than the GMMF but if ν is not extremely large the execution time is smaller than for the GMMF and for the aEM algorithm. In summary, the MMF algorithm is proposed as algorithm of choice.
In Fig. 2 we exemplarily show the functional values L(νr,μr,Σr) of the four algorithms and samples generated for different values of ν and Σ = I. Note that the x-axis of the plots is in log-scale. We see that the convergence speed (in terms of number of iterations) of the EM algorithm is much slower than those of the MMF/GMMF. For small ν the convergence speed of the aEM algorithm is close to the GMMF/MMF, but for large ν it is close to the EM algorithm.

Plots of L(νr,μr,Σr) on the y-axis and r on the x-axis for all algorithms
In Fig. 3 we show the histograms of the ν-output of 1000 runs for different values of ν and Σ = I. Since the ν-outputs of all algorithms are very close together we only plot the output of the GMMF. We see that the accuracy of the estimation of ν decreases for increasing ν. This can be explained by the fact, that the likelihood function becomes very flat for large ν such that the estimation of ν becomes much harder.

Histograms of the output ν from the algorithms
6.2 Comparison with other accelerations of the EM algortihm
In this section, we compare our algorithms with the Expectation/Conditional Maximization Either (ECME) algorithm [19, 20] and apply the SQUAREM acceleration [33] as well as the damped Anderson Acceleration (DAAREM) [9] to our algorithms.
ECME algorithm:
The ECME algorithm was first proposed in [19]. Some numerical examples of the behavior of the ECME algorithm for estimating the parameters (ν, μ, Σ) of a Student t distribution Tν(μ, Σ) are given in [20]. The idea of ECME is first to replace the M-Step of the EM algorithm by the following update of the parameters (νr,μr,Σr): first, we fix ν = νr and compute the update (μr+ 1,Σr+ 1) of the parameters (μr,Σr) by performing one step of the EM algorithm for fixed degree of freedom (CM1-Step). Second, we fix (μ, Σ) = (μr,Σr) and compute the update νr+ 1 of νr by maximizing the likelihood function with respect to ν (CM2-Step). The resulting algorithm is given in Algorithm 5. It is similar to the GMMF (Algorithm 4), but uses the Σ-update of the EM algorithm (Algorithm 5) instead of the Σ-update of the aEM algorithm (Algorithm 2). The authors of [19] showed a similar convergence result as for the EM algorithm. Alternatively, we could prove Theorem 3 for the ECME algorithm analogously as for the GMMF algorithm.

Next, we consider two acceleration schemes of arbitrary fixed point algorithms 𝜗r+ 1 = G(𝜗r). In our case \(\vartheta \in \mathbb {R}^{p}\) is given by (ν, μ, Σ) and G is given by one step of Algorithm 1, 2, 3, 4, or 5.
SQUAREM Acceleration:
The first acceleration scheme, called squared iterative methods (SQUAREM) was proposed in [33]. The idea of SQUAREM is to update the parameters 𝜗r = (νr,μr,Σr) in the following way: we compute 𝜗r,1 = G(𝜗r) and 𝜗r,2 = G(𝜗r,1). Then, we calculate s = 𝜗r,1 − 𝜗r and v = (𝜗r,2 − 𝜗r,1) − s. Now we set \(\vartheta ^{\prime }=\vartheta _{r}-2\alpha r+\alpha ^{2} v\) and define the update \(\vartheta _{r+1}=G(\vartheta ^{\prime })\), where α is chosen as follows. First, we set \(\alpha =\min \limits (-\tfrac {\|r\|_{2}}{\|v\|_{2}},-1)\). Then we compute \(\vartheta ^{\prime }\) as described before. If \(L(\vartheta ^{\prime })<L(\vartheta _{r})\), we keep our choice of α. Otherwise we update α by \(\alpha =\tfrac {\alpha -1}{2}\). Note that this scheme terminates as long a 𝜗r is not a critical point of L by the following argument: it holds that 𝜗r + 2r + v = 𝜗r,2, which implies that it holds that \(\lim _{\alpha \to -1}L(\vartheta _{r}-2\alpha +\alpha ^{2}v)=L(\vartheta _{r,2})\leq L(\vartheta _{r})\) with equality if and only if 𝜗r is a critical point of L, since all our algorithms have the property that L(𝜗) ≥ L(G(𝜗)) with equality if and only if 𝜗 is a critical point of L. By construction this scheme ensures that the negative log-likelihood values of the iterates are decreasing.
Damped Anderson Acceleration with Restarts and 𝜖-Monotonicity (DAAREM):
The DAAREM acceleration was proposed in [9]. It is based on the Anderson acceleration, which was introduced in [2]. As for the SQUAREM acceleration want to solve the fixed point equation 𝜗 = G(𝜗) with 𝜗 = (ν, μ, Σ) using the iteration 𝜗r+ 1 = G(𝜗r). We also use the equivalent formulation to solve f(𝜗) = 0, where f(𝜗) = G(𝜗) − 𝜗. For a fixed parameter \(m\in \mathbb {N}_{>0}\), we define \(m_{r}=\min \limits (m,r)\). Then, one update of 𝜗r using the Anderson Acceleration is given by
with \(\gamma ^{(r)}=\left (\mathcal {F}_{r}^{\mathrm {T}}\mathcal {F}_{r}\right )^{-1}\mathcal {F}_{r}^{\mathrm {T}} f(\vartheta _{r})\), where the columns of \(\mathcal {F}_{r}\in \mathbb {R}^{p\times m_{r}}\) are given by \(f(\vartheta _{r-m_{r}+j+1})-f(\vartheta _{r-m_{r}+j})\) for j = 0,…,mr − 1. An equivalent formulation of update step (14) is given by
where the columns of \(\mathcal {X}_{r}\in \mathbb {R}^{p\times m_{r}}\) are given by \(\vartheta _{r-m_{r}+j+1}-\vartheta _{r-m_{r}+j}\) for j = 0,…,mr − 1. The Anderson acceleration can be viewed as a special case of a multisecant quasi-Newton procedure to solve f(𝜗) = 0. For more details we refer to [7, 9].
The DAAREM acceleration modifies the Anderson acceleration in three points. The first modification is to restart the algorithm after m steps. That is, to set \(m_{r}=\min \limits (m,c_{r})\) instead of \(m_{r}=\min \limits (m,r)\), where cr ∈{1,…,m} is defined by cr = r modm. The second modification is to add damping term in the computation coefficients γ(r). This means, that γ(r) is given by \(\gamma ^{(r)}=(\mathcal {F}_{r}^{\mathrm {T}}\mathcal {F}_{r}+\lambda _{r} I)^{-1}\mathcal {F}_{r}^{\mathrm {T}} f(\vartheta _{r})\) instead of \(\gamma ^{(r)}=(\mathcal {F}_{r}^{\mathrm {T}}\mathcal {F})^{-1}\mathcal {F}_{r}^{\mathrm {T}} f(\vartheta _{r})\). The parameter λr is chosen such that
for some damping parameters δr. We initialize the δr by \(\delta _{1}=\tfrac 1{1+\alpha ^{\kappa }}\) and decrease the exponent of α in each step by 1 up to a minimum of κ − D for some parameter \(D\in \mathbb {N}_{>0}\). The third modification is to enforce that for the negative log-likelihood function L does not increase more than 𝜖 in one iteration step. To do this, we compute the update 𝜗r+ 1 using the Anderson acceleration. If L(𝜗r+ 1) > L(𝜗r) + 𝜖, we use our original fixed point algorithm in this step, i.e., we set 𝜗r+ 1 = G(𝜗r).
We summarize the DAAREM acceleration in Algorithm 6. In our numerical experiments we use for the parameters the values suggested by [9], that is 𝜖 = 0.01, 𝜖c = 0, α = 1.2, κ = 25, D = 2κ and \(m=\min \limits (\lceil \tfrac {p}2\rceil ,10)\), where p is the number of parameters in 𝜗.

Simulation Study:
To compare the performance of all of these algorithms we perform again a Monte Carlo simulation. As in the previous section we draw n = 100 i.i.d. realizations of Tν(μ, Σ) with μ = 0, Σ = 0.1Id and ν ∈{1,2,5,10,100}. Then, we use each of the Algorithms 1, 2, 3, 4 and 5 to compute the ML estimator \((\hat \nu ,\hat \mu ,\hat {\varSigma })\). We use each of these algorithms with no acceleration, with SQUAREM acceleration and with DAAREM acceleration.
We use the same initialization and stopping criteria as in the previous section and repeat this experiment N = 1.000 times. To quantify the performance of the algorithms, we count the number of iterations and measure the execution time. The results are given in Tables 3 and 4. Since the DAAREM and SQUAREM accelerations were proposed originally for an absolute stopping criteria, we redo the experiments with the stopping criteria
The results are given in Tables 5 and 6.
We observe that for nearly any choice of the parameters the performance of the GMMF is better than the performance of the ECME. For small ν, the performance of the SQUAREM-aEM is also very good. On the other hand, for large ν the SQUAREM-GMMF behaves very well. Further, for any choice of ν the performance of the SQUAREM-MMF is close to the best algorithm.
6.3 Unsupervised estimation of noise parameters
Next, we provide an application in image analysis. To this aim, we consider images corrupted by one-dimensional Student t noise with μ = 0 and unknown Σ ≡ σ2 and ν. We provide a method that allows to estimate ν and σ in an unsupervised way. The basic idea is to consider constant areas of an image, where the signal to noise ratio is weak and differences between pixel values are solely caused by the noise.
Constant area detection:
In order to detect constant regions in an image, we adopt an idea presented in [30]. It is based on Kendall’s τ-coefficient, which is a measure of rank correlation, and the associated z-score, see [10, 11]. In the following, we briefly summarize the main ideas behind this approach. For finding constant regions we proceed as follows: First, the image grid \(\mathcal {G}\) is partitioned into K small, non-overlapping regions \(\mathcal {G}= \bigcup _{k=1}^{K} R_{k}\), and for each region we consider the hypothesis testing problem
To decide whether to reject \({\mathscr{H}}_{0}\) or not, we observe the following: Consider a fixed region Rk and let \(I, J\subseteq R_{k}\) be two disjoint subsets of Rk with the same cardinality. Denote with uI and uJ the vectors containing the values of u at the positions indexed by I and J. Then, under \({\mathscr{H}}_{0}\), the vectors uI and uJ are uncorrelated (in fact even independent) for all choices of \(I, J\subseteq R_{k}\) with I ∩ J = ∅ and |I| = |J|. As a consequence, the rejection of \({\mathscr{H}}_{0}\) can be reformulated as the question whether we can find I, J such that uI and uJ are significantly correlated, since in this case there has to be some structure in the image region Rk and it cannot be constant. Now, in order to quantify the correlation, we adopt an idea presented in [30] and make use of Kendall’s τ-coefficient, which is a measure of rank correlation, and the associated z-score, see [10, 11]. The key idea is to focus on the rank (i.e., on the relative order) of the values rather than on the values themselves. In this vein, a block is considered homogeneous if the ranking of the pixel values is uniformly distributed, regardless of the spatial arrangement of the pixels. In the following, we assume that we have extracted two disjoint subsequences x = uI and y = uJ from a region Rk with I and J as above. Let (xi,yi) and (xj,yj) be two pairs of observations. Then, the pairs are said to be
Next, let \(x,y\in \mathbb {R}^{n}\) be two sequences without tied pairs and let nc and nd be the number of concordant and discordant pairs, respectively. Then, Kendall’s τ coefficient [10] is defined as \(\tau \colon \mathbb {R}^{n}\times \mathbb {R}^{n}\to [-1,1]\),
From this definition we see that if the agreement between the two rankings is perfect, i.e., the two rankings are the same, then the coefficient attains its maximal value 1. On the other extreme, if the disagreement between the two rankings is perfect, that is, one ranking is the reverse of the other, then the coefficient has value − 1. If the sequences x and y are uncorrelated, we expect the coefficient to be approximately zero. Denoting with X and Y the underlying random variables that generated the sequences x and y, we have the following result, whose proof can be found in [10].
Theorem 5
Let X and Y be two arbitrary sequences under \({\mathscr{H}}_{0}\) without tied pairs. Then, the random variable τ(X, Y ) has an expected value of 0 and a variance of \(\frac {2(2n+5)}{9n(n-1)}\). Moreover, for \(n\to \infty \), the associated z-score \(z\colon \mathbb {R}^{n}\times \mathbb {R}^{n}\to \mathbb {R}\),
is asymptotically standard normal distributed,
With slight adaption, Kendall’s τ coefficient can be generalized to sequences with tied pairs (see [11]). As a consequence of Theorem 5, for a given significance level α ∈ (0,1), we can use the quantiles of the standard normal distribution to decide whether to reject \({\mathscr{H}}_{0}\) or not. In practice, we cannot test any kind of region and any kind of disjoint sequences. As in [30], we restrict our attention to quadratic regions and pairwise comparisons of neighboring pixels. We use four kinds of neighboring relations (horizontal, vertical and two diagonal neighbors) thus perform in total four tests. We reject the hypothesis \({\mathscr{H}}_{0}\) that the region is constant as soon as one of the four tests rejects it. Note that by doing so, the final significance level is smaller than the initially chosen one. We start with blocks of size 64 × 64 whose side-length is incrementally decreased until enough constant areas are found.
Parameter estimation.
In each constant region we consider the pixel values in the region as i.i.d. samples of a univariate Student t distribution Tν(μ, σ2), where we estimate the parameters using Algorithm 3.
After estimating the parameters in each found constant region, the estimated location parameters μ are discarded, while the estimated scale and degrees of freedom parameters σ respective ν are averaged to obtain the final estimate of the global noise parameters. At this point, as both ν and σ influence the resulting distribution in a multiplicative way, instead of an arithmetic mean, one might use a geometric which is slightly less affected by outliers.
In Fig. 4 we illustrate this procedure for two different noise scenarios. The left column in each figure depicts the detected constant areas. The middle and right column show histograms of the estimated values for ν respective σ. For the constant area detection we use the code of [30]Footnote 3. The true parameters used to generate the noisy images where ν = 1 and σ = 10 for the top row and ν = 5 and σ = 10 for the bottom row, while the obtained estimates are (geometric mean in brackets) \(\hat {\nu } = 1.0437\) (1.0291) and \(\hat {\sigma }= 10.3845\) (10.3111) for the top row and \(\hat {\nu }= 5.4140\) (5.0423) and \(\hat {\sigma }=10.5500\) (10.1897) for the bottom row.

Unsupervised estimation of the noise parameters ν and σ2
A further example is given in Fig. 5. Here, the obtained estimates are (geometric mean in brackets) \(\hat {\nu } = 1.0075\) (0.99799) and \(\hat {\sigma }= 10.2969\) (10.1508) for the top row and \(\hat {\nu }= 5.4184\) (5.1255) and \(\hat {\sigma }=10.2295\) (10.1669) for the bottom row.

Unsupervised estimation of the noise parameters ν and σ2
Change history
15 July 2021
A Correction to this paper has been published: https://doi.org/10.1007/s11075-021-01156-z
References
Abramowitz, M., Stegun, I.A.: Handbook of mathematical functions: with formulas, graphs, and mathematical tables, volume 55 Courier Corporation (1965)
Anderson, D.G.: Iterative procedures for nonlinear integral equations. J. Assoc. Comput. Mach. 12, 547–560 (1965)
Antoniadis, A., Leporini, D., Pesquet, J.-C.: Wavelet thresholding for some classes of non-Gaussian noise. Statis. Neerlandica 56(4), 434–453 (2002)
Banerjee, A., Maji, P.: Spatially constrained Student’s t-distribution based mixture model for robust image segmentation. J. Mathe. Imag. Vision 60(3), 355–381 (2018)
Byrne, C.L.: The EM algorithm: theory, applications and related methods. Lecture notes university of massachusetts (2017)
Ding, M., Huang, T., Wang, S., Mei, J., Zhao, X.: Total variation with overlapping group sparsity for deblurring images under Cauchy noise. Appl. Math. Comput. 341, 128–147 (2019)
Fang, H.-R., Saad, Y.: Two classes of multisecant methods for nonlinear acceleration. Numer. Linear Algebra Appli. 16(3), 197–221 (2009)
Gerogiannis, D., Nikou, C., Likas, A.: The mixtures of Student’s t-distributions as a robust framework for rigid registration. Image Vis. Comput. 27(9), 1285–1294 (2009)
Henderson, N.C., Varadhan, R.: Damped Anderson acceleration with restarts and monotonicity control for accelerating EM and EM-like algorithms. J. Comput. Graph. Stat. 28(4), 834–846 (2019)
Kendall, M.G.: A new measure of rank correlation. Biometrika 30(1/2), 81–93 (1938)
Kendall, M.G.: The treatment of ties in ranking problems. Biometrika 239–251 (1945)
Kent, J.T., Tyler, D.E., Vard, Y.: A curious likelihood identity for the multivariate t-distribution. Communications in Statistics-Simulation and Computation 23(2), 441–453 (1994)
Lange, K.L., Little, R.J., Taylor, J.M.: Robust statistical modeling using the t distribution. J. Am. Stat. Assoc. 84(408), 881–896 (1989)
Lanza, A., Morigi, S., Sciacchitano, F., Sgallari, F.: Whiteness constraints in a unified variational framework for image restoration. J. Mathe. Imag. Vision 60(9), 1503–1526 (2018)
Laus, F.: Statistical Analysis and Optimal Transport for Euclidean and Manifold-Valued Data. PhD Thesis, TU Kaiserslautern (2020)
Laus, F., Pierre, F., Steidl, G.: Nonlocal myriad filters for Cauchy noise removal. J. Math. Imag. Vision 60(8), 1324–1354 (2018)
Laus, F., Steidl, G.: Multivariate myriad filters based on parameter estimation of student-t distributions. SIAM J Imaging Sci 12(4), 1864–1904 (2019)
Lebrun, M., Buades, A., Morel, J.-M.: A nonlocal Bayesian image denoising algorithm. SIAM J. Imag. Sci. 6(3), 1665–1688 (2013)
Liu, C., Rubin, D.B.: The ECME algorithm: a simple extension of EM and ECM with faster monotone convergence. Biometrika 81(4), 633–648 (1994)
Liu, C., Rubin, D.B.: ML estimation of the t distribution using EM and its extensions, ECM and ECME. Stat. Sin. 5(1), 19–39 (1995)
McLachlan, G., Krishnan, T.: The EM algorithm and extensions. John wiley and sons inc (1997)
McLachlan, G., Peel, D.: Robust cluster analysis via mixtures of multivariate t-distributions. volume 1451 of Lecture Notes in Computer Science. Springer, New York (1998)
Mei, J.-J., Dong, Y., Huang, T.-Z., Yin, W.: Cauchy noise removal by nonconvex ADMM with convergence guarantees. J. Sci. Comput. 74(2), 743–766 (2018)
Meng, X.-L., Van Dyk, D.: The EM algorithm - an old folk-song sung to a fast new tune. J. Royal Statis. Soc. :, Series B (Statis. Methodol.) 59 (3), 511–567 (1997)
Nguyen, T.M., Wu, Q.J.: Robust Student’s-t mixture model with spatial constraints and its application in medical image segmentation. IEEE Trans. Med. Imaging 31(1), 103–116 (2012)
Peel, D., McLachlan, G.J.: Robust mixture modelling using the t distribution. Stat. Comput. 10(4), 339–348 (2000)
Petersen, K.B., Pedersen, M.S.: The Matrix Cookbook. Technical University of Denmark, Lecture Notes (2008)
Sciacchitano, F., Dong, Y., Zeng, T.: Variational approach for restoring blurred images with Cauchy noise. SIAM J. Imag. Sci. 8(3), 1894–1922 (2015)
Sfikas, G., Nikou, C., Galatsanos, N.: Robust image segmentation with mixtures of Student’s t-distributions. In: 2007 IEEE International Conference on Image Processing, volume 1, pages I – 273–I –276 (2007)
Sutour, C., Deledalle, C.-A., Aujol, J.-F.: Estimation of the noise level function based on a nonparametric detection of homogeneous image regions. SIAM J. Imag. Sci. 8(4), 2622–2661 (2015)
Van Den Oord, A., Schrauwen, B.: The Student-t mixture as a natural image patch prior with application to image compression. J. Mach. Learn. Res. 15(1), 2061–2086 (2014)
Van Dyk, D.A.: Construction, Implementation, and Theory of Algorithms Based on Data Augmentation and Model Reduction. The University of Chicago, PhD Thesis (1995)
Varadhan, R., Roland, C.: Simple and globally convergent methods for accelerating the convergence of any EM algorithm. Scandinavian. J. Statis. Theory Appli 35(2), 335–353 (2008)
Yang, Z., Yang, Z., Gui, G.: A convex constraint variational method for restoring blurred images in the presence of alpha-stable noises. Sensors 18(4), 1175 (2018)
Zhou, Z., Zheng, J., Dai, Y., Zhou, Z., Chen, S.: Robust non-rigid point set registration using Student’s-t mixture model. PloS one 9(3), e91381 (2014)
Acknowledgments
The authors want to thank the anonymous referees for bringing certain accelerations of the EM algorithm to our attention.
Funding
Open Access funding enabled and organized by Projekt DEAL. This work received funding from the German Research Foundation (DFG) within the project STE 571/16-1.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this article was revised due to a retrospective Open Access order.
Appendix. Auxiliary lemmas
Appendix. Auxiliary lemmas
Lemma 4
Let \(x_{i} \in \mathbb R^{d}\), i = 1,…,n and w ∈Δ̈n fulfill Assumption 1. Let (νr,Σr)r be a sequence in \(\mathbb {R}_{>0} \times \text {SPD} (d)\) with \(\nu _{r} \rightarrow 0\) as \(r\rightarrow \infty \) (or if {νr}r has a subsequence which converges to zero). Then (νr,Σr)r cannot be a minimizing sequence of L(ν, Σ).
Proof
We write
where
Then it holds \(\lim _{\nu \to 0}g(\nu )=\infty \). Hence it is sufficient to show that (νr,Σr)r has a subsequence \((\nu _{r_{k}},{\varSigma }_{r_{k}})\) such that \(\left (L_{\nu _{r_{k}}}({\varSigma }_{r_{k}}) \right )_{r}\) is bounded from below. Denote by λr1 ≥… ≥ λrd the eigenvalues of Σr.
Case 1: Let \(\{\lambda _{r,i}:r\in \mathbb N,i=1,\ldots ,d\}\subseteq [a,b]\) for some \(0<a\leq b<\infty \). Then it holds \(\liminf _{r\to \infty }\log \left | {\varSigma }_{r} \right |\geq \log (a^{d})=d\log (a)\) and
Note that Assumption 1 ensures xi≠ 0 and \(x_{i}^{\mathrm {T}} x_{i}>0\) for i = 1,…,n. Then we get
Hence \((L_{\nu _{r}}({\varSigma }_{r}))_{r}\) is bounded from below and (νr,Σr) cannot be a minimizing sequence.
Case 2: Let \(\{\lambda _{r,i}:r\in \mathbb N,i=1,\ldots ,d\}\not \subseteq [a,b]\) for all \(0<a\leq b<\infty \). Define ρr = ∥Σr∥F and \(P_{r}=\frac {{\varSigma }_{r}}{\rho _{r}}\). Then, by concavity of the logarithm, it holds
Denote by pr,1 ≥… ≥ pr, d > 0 the eigenvalues of Pr. Since \(\{P_{r}:r\in \mathbb N\}\) is bounded there exists some C > 0 with C ≥ pr,1 for all \(r\in \mathbb N\). Thus one of the following cases is fulfilled:
-
i)
There exists a constant c > 0 such that pr, d > c for all \(r\in \mathbb N\).
-
ii)
There exists a subsequence \((P_{r_{k}})_{k}\) of (Pr)r which converges to some P ∈ ∂SPD(d).
Case 2i) Let c > 0 with pr, d ≥ c for all \(r\in \mathbb N\). Then \(\underset {r\to \infty }{\liminf } \log (\left | P_{r} \right |) \geq \log (c^{d})=d\log (c)\) and
By (16) this yields
Hence, \((L_{\nu _{r}}({\varSigma }_{r}))_{r}\) is bounded from below and (νr,Σr) cannot be a minimizing sequence.
Case 2ii) We use similar arguments as in the proof of [17, Theorem 4.3]. Let \((P_{r_{k}})_{k}\) be a subsequence of (Pr)r which converges to some P ∈ ∂SPD(d). For simplicity we denote \((P_{r_{k}})_{k}\) again by (Pr)r. Let p1 ≥… ≥ pd ≥ 0 be the eigenvalues of P. Since \(\|P\|_{F}=\lim \limits _{r\to \infty } \| P_{r}\|_{F}=1\) it holds p1 > 0. Let q ∈ 1,…,d − 1 such that
By er,1,…,e,rd, we denote the orthonormal eigenvectors corresponding to pr,1,…,pr, d. Since \((\mathbb S^{d})^{d}\) is compact we can assume (by going over to a subsequence) that (er,1,…,er, d)r converges to orthonormal vectors (e1,…,ed). Define S0 : = {0} and for k = 1,…,d set Sk : = span{e1,…,ek}. Now, for k = 1,…,d define
Further, let
Because of \(S_{k}=W_{k}\dot \cup S_{k-1}\) we have \(\tilde I_{k}=I_{k}\dot \cup \tilde I_{k-1}\) for k = 1,…,d. Due to Assumption 1 we have \(\left | I_{k} \right |\leq \left | \tilde I_{k} \right |\leq \dim (S_{k})=k\) for k = 1,…,d − 1. Defining for j = 1,…,d,
it holds \(L_{0}(P_{r})={\sum }_{j=1}^{d} L_{j}\). For j ≤ q we get
Since for k ∈{1,…,d} and i ∈ Ik,
and \(\lim _{r\to \infty }\left \langle x_{i}, e_{rk} \right \rangle = \left \langle x_{i}, e_{k} \right \rangle \neq 0\), we obtain
Hence, it holds for j ≥ q + 1 that
Thus, we conclude
It remains to show that there exist \(\tilde c > 0\) such that
We prove for k ≥ q + 1 by induction that for sufficiently large \(r\in \mathbb N\) it holds
Induction basis k = d: Since \(\tilde I_{k}=I_{k}\cup \tilde I_{k-1}\) we have
and further
If we multiply both sides with \(\log (p_{rd})\) this yields (18) for k = d. Induction step: Assume that (18) holds for some k + 1 with d ≥ k + 1 > q + 1, i.e.,
Then we obtain
and since \({\sum }_{i\in \tilde I_{k}}w_{i}<\left | \tilde I_{k} \right |\frac 1d\leq \frac {k}{d}\) by Assumption 1 and pr, k+ 1 ≤ pr, k < 1 finally
This shows (18) for k ≥ q + 1. Using k = q + 1 in (17) we get
This finishes the proof. □
Lemma 5
Let (νr,Σr)r be a sequence in \(\mathbb {R}_{>0}\times \text {SPD}(d)\) such that there exists \(\nu _{-}\in \mathbb {R}_{>0}\) with ν−≤ νr for all \(r\in \mathbb N\). Denote by λr,1 ≥⋯ ≥ λr, d the eigenvalues of Σr. If \(\{\lambda _{1,r}:r\in \mathbb N\}\) is unbounded or \(\{\lambda _{d,r}:r\in \mathbb N\}\) has zero as a cluster point, then there exists a subsequence \((\nu _{r_{k}},{\varSigma }_{r_{k}})_{k}\) of (νr,Σr)r, such that \(\lim \limits _{k\to \infty }L(\nu _{r_{k}},{\varSigma }_{r_{k}})=\infty \).
Proof
Without loss of generality we assume (by considering a subsequence) that either \(\lambda _{r1}\to \infty \) as \(r\to \infty \) and λrd ≥ c > 0 for all \(r\in \mathbb N\) or that λrd → 0 as \(r\to \infty \). By [17, Theorem 4.3] for fixed ν = ν−, we have \(L_{\nu _{-}}({\varSigma }_{r}) \to \infty \) as \(r\to \infty \).
The function \(h\colon \mathbb {R}_{>0}\to \mathbb {R}\) defined by \(\nu \mapsto (d+\nu )\log (\nu +k)\) is monotone increasing for all \(k\in \mathbb {R}_{\geq 0}\). This can be seen as follows: The derivative of h fulfills
and since
the later function is minimal for k = 1, so that
Using this relation, we obtain
and further
□
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hasannasab, M., Hertrich, J., Laus, F. et al. Alternatives to the EM algorithm for ML estimation of location, scatter matrix, and degree of freedom of the Student t distribution. Numer Algor 87, 77–118 (2021). https://doi.org/10.1007/s11075-020-00959-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11075-020-00959-w