
Abstract
The paper presents a predefined-time Vector-Field-Orientation (VFO) control law for unicycle-like nonholonomic mobile robots. We consider a set-point control problem in the presence of strict time constraints, which has to guarantee satisfaction of a prescribed upper bound of the settling time for the configuration errors. The control law is based on the VFO methodology, which is characterized by non-oscillatory and well-predictable time evolution of transient states for unicycle-like robots. A formal stability analysis based on the Lyapunov theory is provided for the closed-loop dynamics. Then, the results of extensive numerical simulations as well as experimental tests illustrate the resultant control performance where time constraints are considered. The proposed approach is compared with an alternative predefined-time stabilizer, recently introduced for nonholonomic chained-form systems.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Control of dynamical systems in the presence of strict time constraints is a practically important problem which can be solved in several ways. Apart from a classical time-optimal control, one can find in the literature different alternative approaches to solve this problem. The first approach solves a finite-time stabilization problem, which ensures that there exists a finite upper bound of the settling times of the stabilization errors for any initial condition. The estimated upper bound depends on the initial conditions in this case. The problem of finite-time stability has been discussed, for example, in [1,2,3,4,5].
Another approach, called fixed-time stabilization, also guarantees that the settling time of the system error is no longer than the estimated upper bound, but here the estimated upper bound is independent of the initial conditions. This concept has been discussed and developed, for example, in [6,7,8], while the papers [9,10,11] proposed methods for estimating the upper bound. Moreover, the authors in [12] introduced an estimation method that is less conservative relative to others.
Yet another approach is called the predefined-time stabilization (some authors call this problem the prescribed-time stabilization—see, e.g., [13] and [14]), which is similar to the fixed-time stabilization but assumes a change in the parametrization of the closed-loop system. Namely, the upper bound of the settling time is not estimated in this case but prescribed by a designer, while the controller parameters can be tuned upon a selected value of the upper bound. Predefined-time stability and stabilization have been an area of intensive research, for example, in [15,16,17,18,19,20,21], while in [22] the authors presented several general forms of predefined-time stable systems. From a practical point of view, the predefined-time controllers can be useful in many applications where time is crucial for some reasons like, for example, synchronization or safety issues. A flexible transportation task or a spatio-temporal synchronization for multi-agent systems are examples of practical problems, which can be solved by predefined-time control laws.
The feedback stabilization problem for non-holonomic systems has been widely addressed in the literature (see the fundamental limitations related to this problem presented in [23] and [24]). Among various solutions to the asymptotic stabilization task, the discontinuous control laws represent an important class of solutions. The Vector-Field-Orientation (VFO) controllers belong to this class [25]. According to the practical experience, application of the VFO design methodology leads to control laws which result in non-oscillatory transient states and well-predictable vehicle behavior in its workspace (see, e.g., [26] and [27]). In the literature, one can find also the finite-time (see [28]), and fixed-time (see [29]) versions of the VFO control laws.
The predefined-time control solutions are scarce in the literature, especially for nonholonomic mobile robots (see, e.g., [14, 16, 30]). We try to fill this gap by proposing a feedback set-point control law for unicycle-like mobile robots (modeling not only wheeled mobile robots but also some unmanned aerial vehicles flying on a constant altitude, [31, 32]) which inherits beneficial properties of the VFO control strategy and additionally preserves explicit time-constraints imposed on the closed-loop dynamics. In this work, we propose a predefined-time VFO control law for non-holonomic mobile robots, which is an extension of the fixed-time VFO controller in [29]. It is worth noting that in [29], the upper bound of the settling time cannot be easily prescribed by the designer. In the sequel, apart from a formal stability analysis performed for the closed-loop dynamics, we also present the results of extensive numerical simulations and experimental tests. To reveal the benefits coming from an application of the predefined-time VFO control law, we compare it with an alternative predefined-time stabilizer, recently proposed for nonholonomic chained-form systems in [16].
This paper is organized as follows. Section 2 is devoted to the formulation of the control problem, as well as a discussion of assumptions and prerequisites. Section 3 presents the predefined-time VFO control design. Section 4 provides a formal stability analysis based on the Lyapunov theory, and Sect. 5 presents the results of numerical simulations and experimental tests of the proposed control system.
2 Prerequisites and assumptions
2.1 Model of the mobile robot
Let us consider the kinematic model of a mobile robot:
where \(\varvec{q}= \begin{bmatrix} \theta \ x \ y \end{bmatrix}^\top = \begin{bmatrix} \theta \ \overline{\varvec{q}}^\top \end{bmatrix}^\top \in \mathbb {R}^3\) is the configuration vector consisting of the orientation angle \(\theta \) and the position coordinates (x, y) of a guidance point expressed in a global frame. The control input vector \(\varvec{u}= \begin{bmatrix} u_1 \ u_2 \end{bmatrix}^\top \in \mathbb {R}^2\) contains angular velocity \(u_1\) and longitudinal velocity \(u_2\). The guidance point is located in the middle of the axis connecting the right and left wheels of the unicycle.
2.2 The concept of predefined-time stability
Let us introduce the concept of (nearly) predefined-time stability:
Definition 1
( [15, 33]) The equilibrium point \(\varvec{w}= \textbf{0}\) of a dynamical system \(S: {\dot{\varvec{w}}}(t) = f(\varvec{w}(t), \varvec{p})\), \(\varvec{w}(0) = \varvec{w}_0 \in {\mathbb {R}^{n}}\) is said to be (nearly) predefined-time stable if:
-
it is (nearly) fixed-time stable, i.e., it is Lyapunov stable and for any neighborhood \(M \subset \mathbb {R}^n\) of the origin there exists an upper bound \(T_c\) of the settling time function \(t_s(\varvec{w}_0, \varvec{p})\) of system S such that \(0~<~t_s(\varvec{w}_0, \varvec{p})~<~T_c~<~\infty \), and
$$\begin{aligned} \forall \varvec{w}_0 \in \mathbb {R}^n, \ \forall t \ge T_c, \quad \varvec{w}(t, \varvec{w}_0, \varvec{p}) \in M, \end{aligned}$$ -
and for any predefined \(T_c\) (i.e., prescribed by a designer) there exist some parameters \(\varvec{p}\in \mathbb {R}^l\) of system S such that
$$\begin{aligned} \sup _{\varvec{w}_0 \in \mathbb {R}^n} t_s(\varvec{w}_0, \varvec{p}) \le T_c. \end{aligned}$$
Remark 1
The equilibrium point \(\varvec{w}= \textbf{0}\) of the system S is said to be predefined-time stable if \(M = \{ \textbf{0 }\}\).
Based on the work [12], let us recall the following lemma.
Lemma 1
The equilibrium point \(\varvec{w}= 0\) of a dynamical system \(S: {\dot{\varvec{w}}}(t) = f(\varvec{w}(t), \varvec{p})\), \(\varvec{w}(0) = \varvec{w}_0 \in \mathbb {R}^n\) is said to be predefined-time stable, with a predefined time \(T_c\), if there exists a continuous radially unbounded positive defined function \(V: \mathbb {R}^n \rightarrow \mathbb {R}_+ \cup \{0\}\), and a vector of parameters \(\varvec{p}\), such that any solution \(\varvec{w}(t, \varvec{w}_0, \varvec{p}) \in \mathbb {R}^n \backslash \{ \textbf{0 }\}\) of system S satisfies:
where \(\alpha , \beta , P, R, k > 0\), \(kP < 1\), \(kR >1\) and \(\gamma \) is given by:
with \(m_P = \frac{1-kP}{R-P}\), \(m_R = \frac{kR - 1}{R-P}\) and where \(\Gamma (\cdot )\) is the gamma function defined as \(\Gamma (z)~\triangleq ~\int _{0}^{\infty } e^{-t}t^{z-1}dt\). As a consequence, the settling time function satisfies \(\sup _{\varvec{w}_0 \in \mathbb {R}^n} t_s(\varvec{w}_0, \varvec{p})~\le ~T_c\), and moreover, if (2) is an equality, then \(\sup _{\varvec{w}_0 \in \mathbb {R}^n} t_s(\varvec{w}_0, \varvec{p}) = T_c\).
2.3 Control problem formulation
We are interested in designing a predefined-time control law for the unicycle-like kinematics (1). In order to simplify the reasoning, we assume that the desired configuration is defined as the origin of the global frame (i.e., \(\varvec{q}_d = \begin{bmatrix} \theta _d \ \overline{\varvec{q}}_d^\top \end{bmatrix}^\top \triangleq \begin{bmatrix} 0 \ 0 \ 0 \end{bmatrix}^\top \)), and the error vector can be defined as follows:
where \(f_\theta (\cdot ): \mathbb {R}\rightarrow (-\pi , \pi ]\), i.e., for the angular part we will understand the value of zero modulo \(2 \pi \). The control problem can be formulated as follows:
Problem 1
For system (1), find a feedback control law \(\varvec{u}(\varvec{e}, \varvec{p})\), such that for any initial configuration error \(\varvec{e}(0) = \varvec{e}_0 \in \mathbb {R}^3{\setminus } M\), \(M \triangleq \left\{ \varvec{e}: \Vert \varvec{e}\Vert \le \psi \right\} \), \(\psi \ge 0\), and a prescribed upper bound \(0<T_c<\infty \), there exists a set of controller parameters \(\varvec{p}(T_c)\) which guarantees that the solution \(\varvec{q}(t, \varvec{q}_0, \varvec{p})\) of the closed-loop dynamics \({\dot{\varvec{q}}} = \varvec{G}(\varvec{q})\varvec{u}\left( \varvec{e}, \varvec{p}(T_c)\right) \) implies:
-
\(\forall t \ge 0 \quad \Vert \varvec{e}(t, \varvec{e}_0, \varvec{p}) \Vert < \infty \),
-
\(\forall t \ge t_s(\varvec{e}_0, \varvec{p}) \quad \varvec{e}(t, \varvec{e}_0, \varvec{p}) \in M\),
-
\(\displaystyle {\sup _{\varvec{e}_0 \in \mathbb {R}^3}} \ t_s(\varvec{e}_0, \varvec{p}) \le T_c\),
where \(t_s(\varvec{e}_0, \varvec{p})\) is the settling time function.
Remark 2
If \(\psi > 0\), then Problem 1 corresponds to the predefined-time ultimate boundedness [15], which can be called, the nearly predefined-time stability. If \(\psi = 0\), then \(M~=~\{ \textbf{0 }\}\) and Problem 1 corresponds to the predefined-time stability (see Remark 1).
3 Predefined-time VFO control design
Let us begin the design process of the VFO control law with a decomposition of the kinematic model (1) into the orientation dynamics and the positional dynamics:
where \(\overline{\varvec{g}}_2(\theta ) = \begin{bmatrix} \cos \theta \ \sin \theta \end{bmatrix}^\top \). Next, we introduce the so-called convergence vector field \(\varvec{h}\) defined as follows:
where \(\textrm{sign}(\cdot )\) is a conventional sign function, such that
and
where \(\overline{\varvec{g}}_{2d} = \begin{bmatrix} \cos \theta _d \ \sin \theta _d \end{bmatrix}^\top = \begin{bmatrix} 1 \ 0 \end{bmatrix}^\top \), while
and \(K_a, K_p>0\), \(\eta \in (0,K_p)\) are the design coefficients. The values of \(K_a\) and \(K_p\) will depend on a prescribed upper bound of the settling time, and will be determined in the sequel.
The decision variable \(\sigma \) used in (8) determines the motion strategy: forward if \(\sigma = 1\) and backward if \(\sigma = -1\). Its value can be chosen arbitrarily for almost all initial conditions of the robot configuration, or can depend on the sign of the initial position error as follows:
where
Assuming \(\theta _d \triangleq 0\), one can observe that (10) takes the following form:
Remark 3
The value of the coefficient \(\eta \) can be determined as follows:
where \(\overline{\eta }\) is related to the so-called directing effect (see [25]). Furthermore, it is beneficial to select \(\overline{\eta } \in \left( 0.5, 1\right) \). Moreover, for \(\overline{\eta } = 0.82\) a maximum nominal curvature rate of a robot motion reaches the minimum (for details, see [25] and [34]).
Now, let us define the auxiliary orientation error introduced in (6), namely:
where the term
is an auxiliary orientation angle, while \(\epsilon \ge 0\) is a small vicinity of zero chosen by a designer. A time derivative of the auxiliary orientation angle is defined as follows:
where
and \(\displaystyle {\theta _{a,\epsilon } \triangleq \lim _{\Vert {\overline{\varvec{e}}(t)}\Vert \rightarrow \epsilon } \theta _a\left( \overline{\varvec{h}}(\overline{\varvec{e}})\right) } \). The operator \(\text {Atan2c}\left( {\cdot },{\cdot }\right) :\,\mathbb {R}\times \mathbb {R}\rightarrow \mathbb {R}\), used in (15), is a continuous version of the four-quadrant inverse tangent function \(\text {Atan2}\left( {\cdot },{\cdot }\right) :\,\mathbb {R}\times \mathbb {R}\rightarrow (-\pi ;\pi ]\).
The VFO control formulas are defined as follows:
where the angle \(\alpha \triangleq \angle (\overline{\varvec{h}},\overline{\varvec{g}}_2(\theta ))\) and
with additional design parameters
and where \(\rho _0 > 0\) provides an additional design degree of freedom which will depend on a given upper bound of the settling time, and will be determined in Sect. 4.2.
4 Stability analysis
In order to show that the control law (18)–(19) solves Problem 1, formulated in Sect. 2.3, a stability analysis based on the Lyapunov stability method will be presented separately for the auxiliary orientation error and for the positional error. Next, the convergence of the orientation error will be shown. Note that the analysis will be prepared for \(\epsilon = 0\), which corresponds to \(\psi = 0\) in Problem 1.
4.1 Analysis for the auxiliary orientation error
First, let us derive the dynamics of the auxiliary orientation error (14):
One can conclude, that \(e_a = 0\) is the equilibrium point of (22).
Now, let us consider the positive-definite function \(V_a \triangleq \frac{1}{2}e_a^2\). A time-derivative of \(V_a\) can be computed as follows:
where \(\alpha _a = \sqrt{2}^{\left( \delta _1 + 1\right) },\) \(\beta _a = \sqrt{2}^{\left( \delta _2 + 1\right) },\) \( P_a =\left( \frac{\delta _1 + 1}{2}\right) \), \( R_a = \left( \frac{\delta _2 + 1}{2}\right) \), \( k = 1\), and \(\frac{\displaystyle \gamma _a}{\displaystyle T_{c,a}} = K_a\). By comparing (23) with (2), one can conclude that the equilibrium point \(e_a = 0\) of the auxiliary orientation error dynamics is predefined-time stable. Moreover, upon (3) one can write:
where \(\Gamma \left( \frac{1}{2}\right) = \sqrt{\pi }\), according to [35], and \(\gamma _a\) corresponds to (3) evaluated for the auxiliary orientation error dynamics. Now, the gain \(K_a\), which is used in the control formula (18), can be selected as follows:
where \(T_{c,a}\) means the prescribed upper bound of the settling time \(t_{s,a}\) of the auxiliary orientation error \(e_a\). Since (23) is an equality, then: \(\sup _{e_a(0) \in \mathbb {R}} t_{s,a}(e_a(0)) = T_{c,a}\).
Remark 4
(cf. [28] or [29]) According to the practical experience, one can suggest the following heuristic tuning rule:
4.2 Analysis for the positional error
The positive-definite function \(V_p \triangleq \frac{1}{2} \overline{\varvec{e}}^T \overline{\varvec{e}}\) is chosen to analyze the dynamics of the positional error. First, let us derive the closed-loop positional error equation:
where \(\varvec{r}= \overline{\varvec{h}} - \overline{\varvec{g}}_2(\theta ) \frac{\displaystyle u_2}{\displaystyle \rho }\) and \(\varvec{v}\) is defined in (8).
Remark 5
Let us consider the positional error dynamics (27): \(\dot{\overline{\varvec{e}}} {{\mathop {=}\limits ^{(\small {}5)}}} -\overline{\varvec{g}}_2(\theta ) u_2 {{\mathop {=}\limits ^{(19)}}} \rho \Vert \overline{\varvec{h}}\Vert \cos \alpha {{\mathop {=}\limits ^{(\small {}20)}}} \rho _0 \left( \Vert \overline{\varvec{e}}\Vert ^{\mu _1} \right. \) \(\left. + \Vert \overline{\varvec{e}}\Vert ^{\mu _2}\right) \cos \alpha \) and \(\forall t \ge T_{c,a} \ |\cos \alpha | = |\cos e_a| = 1\). Thus, one can conclude that \(\overline{\varvec{e}} = \textbf{0}\) is the equilibrium point of (27).
Next, let us define the function \(\chi (e_a) {=}\sqrt{1 {-} \cos ^2 e_a} \in [0,1]\). One can observe that:
and \(\Vert \varvec{r}\Vert = \Vert \overline{\varvec{h}}\Vert \chi (e_a) \) (for details, see [28]). Now, let us analyze the time derivative of function \(V_p\):
Based on (28), one can conclude that \(V_p < \infty \) for \(t~\in ~[0,T_{c,a})\), since \(|\xi (\chi )| < \infty \), thus \(\Vert \overline{\varvec{e}} \Vert < \infty \) for \(t~\in ~[0,T_{c,a})\), and consequently the finite-time-escape effect is not possible for dynamics (27).
Note that \(\chi (e_a)\rightarrow 0\) as \(e_a\rightarrow 0\), and as a consequence, \(\xi (\chi (e_a))\rightarrow (K_p-\eta )\) as \(e_a\rightarrow 0\). Thus, for \(t \ge T_{c,a}\) the inequality (28) can be replaced by the following relation:
which depends only on the positional error, and where \(\alpha _p = \sqrt{2}^{\left( \mu _1+1\right) }\), \(\beta _p = \sqrt{2}^{\left( \mu _2+1\right) }\), \( P_p =\left( \frac{\mu _1+1}{2}\right) \), \( R_p = \left( \frac{\mu _2+1}{2}\right) \), and \(\frac{\displaystyle \gamma _p}{\displaystyle T_{c,p}} = \frac{\displaystyle \rho _0(K_p - \eta )}{\displaystyle K_p+\eta }\). Now, by comparing (29) with (2) one can conclude that the equilibrium point \(\overline{\varvec{e}} = \textbf{0}\) of the positional error dynamic is predefined-time stable and, upon (3), one can write:
where \(\gamma _p\) corresponds to (3) evaluated for the positional error dynamics.
When a designer prescribes the upper bound \(T_{c,p}\) on the settling time \(t_{s,p}\) of the positional error, the parameter \(\rho _0\) can be computed as follows:
Remark 6
Note that (29) holds for \(\forall t \ge T_{c,a}\). Thus, assuming that \(T_{c,a}<T_{c,p}\), the total upper bound of the settling time for the error \({\varvec{e}}(t)\) from (4) has to be (conservatively) estimated as
4.3 Convergence of the orientation error
Let us also analyze the convergence of the orientation error \(e_\theta \) as follows. From (4) and (14), one can write:
Next, one can observe that
Assuming that \(T_{c,a} < T_{c,p}\), one can proceed as follows. According to [36], it can be shown that \(h_x(t)~\xrightarrow {t\rightarrow \tau _x}~0\), \(h_y(t)~\xrightarrow {t\rightarrow \tau _y}~0\), for \(\tau _y < \tau _x \le T_{c,p}\), and as a consequence, \(\forall t \ge {T_c} \quad \theta _a {{\mathop {=}\limits ^{(\small {}15)}}} 2k\pi \), \(k \in \mathbb {Z}\), thus one can conclude that \(e_\theta \rightarrow 0\) as \(t \rightarrow {T_c}\).
Remark 7
It should be noted that for \(\epsilon > 0\), \(\theta _a(t)~\rightarrow ~\) \(\theta _{a,\epsilon }\) as \(t \rightarrow {T_c}\), and as a consequence \(e_\theta (t) \rightarrow f_\theta (- \theta _{a,\epsilon })\) as \(t \rightarrow {T_c}\). Moreover, for \(\epsilon > 0\) one gets \(\Vert \overline{\varvec{e}}(t) \Vert = \epsilon \) for \(t \rightarrow {T_c}\).
4.4 Summary of the analysis
Considering the reasoning presented in Sects. 4.1–4.3, and recalling Remark 7, the following corollary can be formulated:
Corollary 1
Prescribing the positive upper bounds \(T_{c,a}< T_{c,p} < \infty \) and if the coefficients \(K_a\), \(K_p\), \(\eta \) and \(\rho _0\) are selected according to (25), (26), (13) and (31), respectively, the control law (18)–(19), when applied to system (1), solves Problem 1 for \(T_c~=~{T_{c,a}+T_{c,p}}\), and such that:
-
taking \(\epsilon = 0 \implies \psi = 0,\)
-
taking \(\epsilon > 0 \implies \psi = \sqrt{ \epsilon ^2 + f_\theta ^2 \left( - \theta _{a,\epsilon } \right) }\).
5 Control system validation
5.1 Simulation results
In order to verify the predefined-time convergence, numerical simulations were prepared with the following parameters: \(\overline{\delta } = \overline{\mu } = 0.2\), \(\epsilon = 10^{-15} \ \text {m}\) and \(\overline{\eta } = 0.82\). The values for the upper bounds of the settling time were chosen as follows: \(T_{c,a} = 5 \ \text {s}\) and \(T_{c,p} = 50 \ \text {s}\). The parameters \(K_a\) and \(\rho _0\) were calculated according to (25) and (31), respectively, while we took \(K_p = \frac{\displaystyle 1}{\displaystyle 2} K_a\).
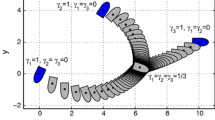
Figure 1 shows the results obtained for the far initial position, i.e., \(\varvec{q}_0 = \begin{bmatrix} -\frac{\displaystyle \pi }{\displaystyle 2} \ -10^3 \ 10^3 \end{bmatrix}^\top \). The following real values of settling times for the auxiliary orientation error and the positional error were obtained: \(t_{s,a} = 2.5 \ \text {s}\) and \(t_{s,p} = 6.77 \ \text {s}\).

Results of a simulation scenario obtained for \(\varvec{q}_0 = \begin{bmatrix} {-\frac{\displaystyle \pi }{\displaystyle 2}} \ {-10^3} \ 10^3 \end{bmatrix}^\top \) (the initial robot configuration is denoted by a solid-line triangle)
The closed-loop system was also tested for a grid of initial conditions determined by the following discrete set of values:
The largest true values of settling times on the grid were obtained as: \(t_{s,a} = 3.37 \ \text {s}\) and \(t_{s,p} = 4.98 \ \text {s}\). The results of the simulations are presented in Fig. 2.
It should be noted that the prescribed upper bounds were satisfied and \(\forall t \ge 0 \ |u_1(t)|,|u_2(t)| < \infty \).

Set of numerical simulation results for \(x_0, y_0 \in \{{-2}, {-\frac{\displaystyle 3}{\displaystyle 2}}, {-1}, {-\frac{\displaystyle 1}{\displaystyle 2}}, 0, \frac{\displaystyle 1}{\displaystyle 2}, 1, \frac{\displaystyle 3}{\displaystyle 2}, 2 \}\) and \(\theta _0 \in \{{-\frac{\displaystyle \pi }{\displaystyle 2}}, 0, \frac{\displaystyle \pi }{\displaystyle 2}, \pi \}\) (the initial robot positions are denoted by red crosses—for each initial position, a simulation was performed with 4 different initial orientations)
In order to study the effect of the settling-time ratio
on the control performance, additional simulations have been conducted (see Fig. 3 and Table 1). The following values of the upper bounds: \(T_{c,p} = 10 \ \text {s}\) and \(T_{c,a} \in \{0.1 \ \text {s}, 1 \ \text {s}, 10 \ \text {s}\}\) were chosen.

Set of numerical simulations obtained for \(T_r~\in ~\{100, 10, 1\}\) and \(\varvec{q}_0 = \begin{bmatrix} 0 \ {-2} \ {-2} \end{bmatrix}^\top \) (the initial robot configuration is denoted by a solid-line triangle)
Upon the results, it can be concluded that the control performance is affected by both the individual values of \(T_{c,a}\) and the ratio \(T_r\). Choosing lower values of \(T_{c,a}\) will lead to faster convergence of the auxiliary orientation error \(e_a\), increasing also the amplitude of the orienting control \(u_1\). Similarly, a selection of smaller values of \(T_{c,p}\) will give a faster convergence of the positional error, though at the expense of higher absolute values of pushing control \(u_2\). The ratio \(T_r\) mainly affects the shapes of paths drawn by the robot’s guidance point, that is, values \(T_r \le 1\) mean that the positional error will converge too fast relative to the auxiliary orientation error, which can lead to a loss of the so-called directing effect, which is crucial for ensuring convergence of the robot’s orientation angle in a terminal motion stage (the lack of orientation convergence can be observed in Fig. 3c).
5.2 Experimental results
The experimental results were obtained using the MTracker—a small differentially driven mobile robot developed in the Institute of Automatic Control and Robotics at the Poznan University of Technology (see Fig. 4). For the experimental validation purposes, the following values of the design parameters were used: \(\overline{\delta } = \overline{\mu } = 0.2\), \(\overline{\eta } = 0.82\), and \(\epsilon = 0.003 \ \text {m}\). In order to guarantee that the control signals are not saturated, the following values of the upper bounds were selected: \(T_{c,a} = 60 \ \text {s}\) and \(T_{c,p} = 600 \ \text {s}\). The experimental tests were prepared for two different initial configurations and movement strategies, namely:
The results for both experimental scenarios are shown in Figs. 5 and 6, respectively. The real values of the settling times obtained during the tests are as follows:
The prescribed upper bounds on the settling times are satisfied and the system errors converge toward zero.

MTracker—differentially driven mobile robot used for the experimental validation

Results of experimental test for case E1: \(\varvec{q}_0 = \begin{bmatrix} 0 \ 0.375 \ 0.4 \end{bmatrix}^\top \) (the initial robot configuration is denoted by a solid-line triangle)

Results of experimental test for case E2: \(\varvec{q}_0~=~\begin{bmatrix} 0 \ {-0.75} \ {{-0.4}} \end{bmatrix}^\top \) (the initial robot configuration is denoted by a solid-line triangle)
5.3 Comparison study
In order to reveal advantages of the proposed predefined-time set-point VFO control law, we compared our solution (using the same control scenario) with the predefined-time stabilizer proposed for the chained-form nonholonomic system in [16].
The control strategy characteristic to the solution shown in [16], and other similar approaches which also use the chained-form transformation [14, 16, 30], can be summarized as follows:
-
a system in the chained form is decomposed into two subsystems:
$$\begin{aligned}&\dot{x}_0 = v_0 \end{aligned}$$(36)and
$$\begin{aligned}&\dot{x}_1 = x_2 v_0, \end{aligned}$$(37)$$\begin{aligned}&\dot{x}_2 = v_1, \end{aligned}$$(38) -
the subsystem (37)–(38) is stabilized first in a predefined time while the subsystem (36) is controlled by some constant value (i.e., \(v_0=a\)) to overcome the loss of controllability of subsystem (37)–(38),
-
when the stabilization process of the subsystem (37)–(38) finishes, then the control law \(v_0\) switches to guarantee the predefined time stabilization of the subsystem (36).
A connection between the chained-form system (36) - (38) and (1) is determined by the following state and input transformations (cf. [16]):
valid for \(\theta \not = \frac{\displaystyle 2k+1}{\displaystyle 2}\pi \), \(k \in \mathbb {Z}\). The authors of [16] proposed the following control law for the chained-form system:
where a is a constant chosen by a designer, and
with
while \(\lfloor z_1 \rceil ^{z_2} \triangleq |z_1|^{z_2} \textrm{sign}{(z_1)}\),
and
Note that the VFO methodology also assumes decomposition of the state dynamics into two subsystems, but at any time instant none of them are controlled by a constant value chosen by a designer, and switching of the pushing control (19) is necessary only in a terminal control stage, i.e., when the positional error enters into a prescribed vicinity \(\epsilon \) (cf. (20)). The comparison shown below has been prepared only with the controller taken from [16] to highlight the benefits of using the VFO design methodology over the representative one proposed for the chained-form system in [16].

Results obtained for the comparison of the predefined-time VFO controller with the controller proposed in [16]: \(\varvec{q}_0~=~\begin{bmatrix} 0 \ 3 \ {-1} \end{bmatrix}^\top \) (the initial robot configuration is denoted by a solid-line triangle).
For the control law (40)–(41), the simulation was conducted with the following parameters: \(T_{c1} = 50 \ \text {s}\), \(T_{c2} = 9 \ \text {s}\), \(T_{c3} = 41 \ \text {s}\), \(p_1 = 1\), \(q_1 = 1.2\), \(p_2 = 1\), \(q_2 = 0.8\), \(\alpha _2 = 10^{-3}\), \(\zeta _0 = 0.1\), \(\zeta = 0.03\), \(\beta _2 = 1\), \(a = 0.01\) and \(\gamma = 0.3\). For the VFO control law, the upper bounds were chosen as: \(T_{c,a} = 10 \ \text {s}\), \(T_{c,p} = 90 \ \text {s}\) and other parameters were selected as in Sect. 5.1. The obtained comparative results are shown in Fig. 7 and are summarized in Table 2.
In both cases, the total upper bound on the settling time of the stabilization errors is 100 s—for the VFO control law \(T_c = T_{c,p} + T_{c,a}\), and for the controller from [16] the total upper bound is \(T_c = T_{c1} + T_{c2} + T_{c3} \). One can observe that the configuration errors converge faster for the VFO controller than for the controller from [16]. Moreover, the control design proposed in [16] is characterized by a control-chattering effect observed in the plots of the control signals. The control oscillations are caused by the use of a discontinuous sign function in (41) and (43). One can replace the sign function, e.g., by a sigmoid function to reduce the chattering phenomenon, however, at the cost of significant performance degradation (robustness and accuracy issues). In contrast, the VFO controller is characterized by non-oscillatory time evolution of transient states, which can be also observed in Fig. 7.
Moreover, the controller from [16] is characterized by discontinuities in \(u_2\) and higher supremum values of \({u_1}\) (see Table 2). Hence, the controller from [16] provides control inputs which will be saturated due to physical limitations on the robot actuators contrary to our proposed scheme. The switching scheme in [16] significantly impacts the transient states. It is also worth mentioning, that the proposed predefined-time VFO controller generates noticeably smaller absolute value of \(u_1\) and a well predictable time evolution of transient states. Moreover, for the VFO controller, the path taken by the robot is shorter, is characterized by a smaller maximum curvature, and needs less movement direction changes.
6 Conclusions
In the paper, the predefined-time VFO control law has been proposed for the nonholonomic unicycle-like mobile robots, based on the definition of global predefined-time stability proposed in [12], which guarantees less conservative estimation of the upper bounds for the settling time of configuration errors relative to alternative estimation approaches introduced in [9,10,11]. For the predefined-time VFO control law, the well-predictable and non-oscillatory transient behavior (characteristic to the previous versions of VFO controllers) has been preserved. Some practical benefits of the proposed control law relative to the predefined-time chained-form stabilizer proposed in [16] have been highlighted in this paper.
It is worth noting that despite the less conservative method of the upper bound estimation for settling times utilized during the VFO control design, the differences between achieved settling times and the predefined upper bounds are still noticeable (some level of conservatism seems to be unavoidable for the global stability results). In order to decrease the conservatism, local versions of fixed- and predefined-time stability concepts seem to be necessary. A combination of time constraints with control input constraints for mobile robots is the next interesting and practically important research problem, which the authors are going to address in their future investigations.
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Bhat, S., Bernstein, D.: Finite-time stability of continuous autonomous systems. SIAM J. Control Optim. 38(3), 751–766 (2000)
Moulay, E., Perruquetti, W.: Finite-time stability and stabilization: state of the art. In: Advances in Variable Structure. LNCIS, vol. 334, pp. 23–41. Springer, Berlin (2006)
Chen, H., Cao, H., Wang, Y., Lei, Y., Chen, W.: Global finite-time stabilization for a class of extended nonholonomic chained system. In: 2014 International Conference on Mechatronics and Control (ICMC), Jinzhou, China, pp. 2211–2214 (2014)
Galicki, M.: Finite-time control of omnidirectional mobile robots. In: Nonlinear Dynamic and Control, vol. II. Springer, Rome (2020)
Xie, H., Zheng, J., Sun, Z., Wang, H., Chai, R.: Finite-time tracking control for nonholonomic wheeled mobile robot using adaptive fast nonsingular terminal sliding mode. Nonlinear Dyn. 110(2), 1437–1453 (2022)
Lopez-Ramirez, F., Efimov, D., Polyakov, A., Perruquetti, W.: On necessary and sufficient conditions for fixed-time stability of continuous autonomous systems. In: 2018 European Control Conference (ECC), Limassol, Cyprus, pp. 197–200 (2018)
Lopez-Ramirez, F., Efimov, D., Polyakov, A., Perruquetti, W.: Conditions for fixed-time stability and stabilization of continuous autonomous systems. Syst. Control Lett. 129, 26–35 (2019)
Ou, M., Sun, H., Zhang, Z., Gu, S.: Fixed-time trajectory tracking control for nonholonomic mobile robot based on visual servoing. Nonlinear Dyn. 108(1), 251–263 (2022)
Polyakov, A.: Nonlinear feedback design for fixed-time stabilization of linear control systems. IEEE Trans. Autom. Control 57(8), 2106–2110 (2012)
Parsegov, S., Polyakov, A., Shcherbakov, P.: Nonlinear fixed-time control protocol for uniform allocation of agents on a segment. In: 51st IEEE Conference on Decision and Control (CDC), Maui, Hawaii, USA, pp. 7732–7737 (2012)
Zuo, Z., Tie, L.: Distributed robust finite-time nonlinear consensus protocols for multi-agent systems. Int. J. Syst. Sci. 47(6), 1366–1375 (2016)
Aldana-López, R., Gómez-Gutiérrez, D., Jiménez-Rodríguez, E., Sánchez-Torres, J.D., Defoort, M.: Enhancing the settling time estimation of a class of fixed-time stable systems. Int. J. Robust Nonlinear Control 29(12), 4135–4148 (2019)
Song, Y., Wang, Y., Holloway, J., Krstic, M.: Time-varying feedback for regulation of normal-form nonlinear systems in prescribed finite time. Automatica 83, 243–251 (2017)
Gao, F., Huang, J., Wu, Y., Zhao, X.: A time-scale transformation approach to prescribed-time stabilisation of non-holonomic systems with inputs quantisation. Int. J. Syst. Sci. 53(8), 1796–1808 (2022)
Jiménez-Rodríguez, E., Muñoz-Vázquez, A.J., Sánchez-Torres, J.D., Defoort, M., Loukianov, A.G.: A Lyapunov-like characterization of predefined-time stability. IEEE Trans. Autom. Control 65(11), 4922–4927 (2020)
Sánchez-Torres, J.D., Defoort, M., Muñoz-Vázquez, A.J.: Predefined-time stabilisation of a class of nonholonomic systems. Int. J. Control 93(12), 2941–2948 (2020)
Sánchez-Torres, J.D., Sanchez, E.N., Loukianov, A.G.: Predefined-time stability of dynamical systems with sliding modes. In: 2015 American Control Conference (ACC), Chicago, pp. 5842–5846 (2015)
Krishnamurthy, P., Khorrami, F., Krstic, M.: A dynamic high-gain design for prescribed-time regulation of nonlinear systems. Automatica 115, 108860 (2020)
Lin, L., Wu, P., He, B., Chen, Y., Zheng, J., Peng, X.: The sliding mode control approach design for nonholonomic mobile robots based on non-negative piecewise predefined-time control law. IET Control Theory Appl. 15(9), 1286–1296 (2021)
Liang, C.-D., Ge, M.-F., Liu, Z.-W., Ling, G., Zhao, X.-W.: A novel sliding surface design for predefined-time stabilization of Euler-lagrange systems. Nonlinear Dyn. 106(1), 445–458 (2021)
Yang, X.-W., Fan, X.-P., Long, F., Li, G.-R.: Predefined-time robust control with formation constraints and saturated controls. Nonlinear Dyn. 110(3), 2535–2554 (2022)
Aldana-López, R., Gómez-Gutiérrez, D., Jiménez-Rodríguez, E., Sánchez-Torres, J.D., Defoort, M.: Generating new classes of fixed-time stable systems with predefined upper bound for the settling time. Int. J. Control 95(10), 2802–2814 (2022)
Brockett, R.W., et al.: Asymptotic stability and feedback stabilization. Differ. Geom. Control Theory 27(1), 181–191 (1983)
Zabczyk, J.: Some comments on stabilizability. Appl. Math. Optim. 19(1), 1–9 (1989)
Michałek, M., Kozłowski, K.: Vector-field-orientation feedback control method for a differentially driven vehicle. IEEE Trans. Control Syst. Technol. 18(1), 45–65 (2010)
Panahandeh, P., Alipour, K., Tarvirdizadeh, B., Hadi, A.: A kinematic Lyapunov-based controller to posture stabilization of wheeled mobile robots. Mech. Syst. Signal Process. 134, 106319 (2019)
Ghaffari, A., Desai, M.: Exponential barrier functions for safe steering of nonholonomic vehicles with actuator time-delay. IEEE Access 10, 9184–9197 (2022)
Michałek, M., Kozłowski, K.: Finite-time VFO stabilizers for the unicycle with constrained control input. In: Robot Motion and Control. LNCIS, vol. 396, pp. 23–34. Springer, London (2009)
Michałek, M.M., Sobański, R.M., Defoort, M.: Fixed-time VFO control for a unicycle. In: Prace Naukowe. Elektronika, Tom I, vol. 197, pp. 191–200. Oficyna Wydawnicza Politechniki Warszawskiej, Warszawa (2022)
Gao, F., Wu, Y., Huang, J., Liu, Y.: Output feedback stabilization within prescribed finite time of asymmetric time-varying constrained nonholonomic systems. Int. J. Robust Nonlinear Control 31(2), 427–446 (2021)
Panyakeow, P., Mesbahi, M.: Decentralized deconfliction algorithms for unicycle UAVs. In: Proceedings of the 2010 American Control Conference, pp. 794–799 (2010)
Yan, J., Yu, Y., Wang, X.: Distance-based formation control for fixed-wing UAVs with input constraints: a low gain method. Drones 6(7), 159 (2022)
Braidiz, Y., Polyakov, A., Efimov, D., Perruquetti, W.: On finite-time stability analysis of homogeneous vector fields with multiplicative perturbations. Int. J. Robust Nonlinear Control 32(15), 8280–8292 (2022)
Gawron, T., Michałek, M.M.: A G3-continuous extend procedure for path planning of mobile robots with limited motion curvature and state constraints. Appl. Sci. 8(11), 2127 (2018)
Sebah, P., Gourdon, X.: Introduction to the gamma function. Am. J. Sci. Res., 2–18 (2002)
Michałek, M., Kozłowski, K.: Convergence analysis for the orientation error of the unicycle in the VFO set-point control system. Complementary note available on https://maciej.michalek.pracownik.put.poznan.pl/PublikacjePliki/UMRComplementaryNote.pdf (2014)
Funding
The research leading to these results received funding from Poznan University of Technology under research subvention No. 0211/SBAD/0123.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sobański, R.M., Michałek, M.M. & Defoort, M. Predefined-time VFO control design for unicycle-like mobile robots. Nonlinear Dyn 112, 3591–3603 (2024). https://doi.org/10.1007/s11071-023-09153-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11071-023-09153-8