
Abstract
Population contact pattern plays an important role in the spread of an infectious disease. This can be described in the framework of a complex network approach. In this paper network epidemic models for influenza-like diseases that may have infectious force in incubative or asymptomatic stage are formulated and studied. Two general types of network models are considered: the annealed and the quenched networks. The next-generation matrix approach is employed to compute the basic reproduction number of our network-based models. The implicit equations for the final epidemic size are derived, and the existence and uniqueness of solutions for implicit equations are studied by rewriting implicit equations as suitable fixed-point problems. In particular, for networks with no degree correlation, low-dimensional systems of nonlinear ordinary differential model are derived by employing an edge-based compartmental approach. Due to their low dimension, a gap between the parameter identification problem for influenza-like diseases or network inference and network epidemic models may be built through our results. The analysis is applied to an example of influenza epidemic based on the final epidemic size, from which the transmission rate and the basic reproduction number can be estimated.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Seasonal influenza, caused by influenza viruses, is an acute respiratory infection circulating in all parts of the world. There are four types (A, B, C, and D) of seasonal influenza viruses, among which type A and B viruses are mainly responsible for the circulation and cause of seasonal epidemics [1]. Seasonal influenza poses a huge health threat to human, with the World Health Organization (WHO) estimation of 3–5 million infected cases every year killing up to 650,000 people [2]. In modern history, one of the most catastrophic public health crises is the 1918 influenza pandemic, known colloquially as “Spanish flu”, infecting one-third of the global population and resulting in millions of deaths. On 11 March 2019, WHO released a Global Influenza Strategy for 2019–2030 to protect people in all countries from the threat of influenza [3].
Based on the classical susceptible-infectious-recovered (SIR) model, first formulated by Kermack and McKendrick [4], many scholars have extended it to investigate the spread and control of influenza (see, e.g., [5,6,7,8,9,10,11,12,13,14]). Before introducing the models in detail, we briefly describe two main epidemiological concepts involved in the infection of an individual [15]. One is latent period, and the other is incubation period. Once an individual has been infected by some causative organisms, a complicated process is initiated in the body, and the time interval, during which the infectious material in general is not discharged, is called the latent period. This period is immediately followed by the infectious period. The time interval between the instant of infection and the onset of symptoms is called the incubation period, after which time preventive measures such as isolation can be implemented. It should be mentioned that there is some overlap between the incubation period and the infectious period. That is, even an individual does not show any symptom, he/she may transmit the disease. This characteristic is very important for epidemiologists, public health specialists, or government officials. For example, the ongoing Coronavirus Disease 2019 (COVID-2019), similar to influenza, has the feature that carriers can transmit the disease whether or not they develop symptoms [16, 17], with the WHO estimating 13,616,593 confirmed cases by July 17, 2020 resulting in 585,727 deaths globally [18].
In this work, we consider modeling the dynamics of influenza-like diseases spread through both infectious period and incubation period. Arino et al. [19] suggested a deterministic compartmental model of SLIAR form to describe this process. They assumed bilinear incidence rates, changing individuals from susceptible class to incubation class due to contacts with individuals in infectious class, incubation class, or asymptomatic class having reduced infectivity. Individuals in the incubation stage can go to either an infectious stage with probability q (\(0<q<1\)) or an asymptomatic stage with probability \(1-q\). Also, individuals in the incubation stage and asymptomatic stage have some reduced infectivity, denoted by factors \(0\le \delta _{1}<1\) and \(0\le \delta _{2}<1\), respectively. There may exist disease-induced deaths in the infectious stage, and it is assumed that there is a fraction \(0\le \sigma \le 1\) of infectious individuals recovering. The mean incubation, infectious and asymptomatic periods are supposed to be \(1/\kappa \), \(1/\gamma \) and \(1/\eta \), respectively. The fraction of the susceptible, incubative, infectious, asymptomatic, and recovered individuals is denoted as S, L, I, A and R, respectively. As in equations (13) of Ref. [19], a five-dimensional system of the SLIAR model could be given by the following ordinary differential equations (ODEs):
where \(\beta \) is the transmission rate in unit time per infectious individual. Note that different from the model in [19], we use standard incidence rates in our model for more realistic and subsequent extensions. Moreover, a flowchart for model (1) is depicted in Fig. 1.

Flowchart for the homogeneous mixing SLIAR epidemic model. The possible transition rates between different stages are labeled on the arrows
The basic reproduction number, a key concept in epidemiology and usually denoted as \(R_{0}\), is defined as the mean number of new cases produced by introducing one infectious individual into a completely susceptible population over the course of its infectious period [20]. Using the next-generation matrix method [21], Arino et al. [19] calculated the basic reproduction number for model (1) as
If \(R_{0}<1\), then the disease cannot invade a susceptible population, whereas if \(R_{0}>1\), then there is an outbreak. Note that \(R_{0}\) is the sum of three contributions, i.e., the contribution from individuals in incubation stage \(\delta _{1}\beta /\kappa \), from individuals in infectious stage \(q\beta /\gamma \) and from individuals in asymptomatic stage \((1-q)\delta _{2}\beta /\eta \). Another key quantity of immediate interest is the likely magnitude of the outbreak at the end of an epidemic [4], usually called the expected final size of an epidemic and denoted as Z [22]. The expected final size Z depends on the initial conditions of the model, the basic reproduction number, and the disease parameters. Considering the initial conditions \(S(0)=1-\epsilon \), \(I(0)=\epsilon \) (\(0<\epsilon \ll 1\)), \(L(0)=A(0)=R(0)=0\), Arino et al. [19] derived the final size relation for model (1) as
which holds for all \(R_{0}\), since it reflects the solution behavior of model (1) as \(t\rightarrow +\infty \). In particular, when the limit \(\epsilon \rightarrow 0\), i.e., \(I(0)\rightarrow 0\) and \(S(0)\rightarrow 1\), rewriting Eq. (3) yields (noting that \(Z=S(0)-S(\infty )\approx 1-S(\infty )\))
which is the classical final size relation and is valid for most compartmental epidemic models [4, 22].
The model (1) assumes that the population is homogeneous mixing, that is, each individual has exact the same number of contacts with every other individual. Obviously, this is an oversimplified assumption, and each individual may have different number of contacts that is varying widely. A possible treatment of this problem is the usage of complex networks [23], in which nodes represent individuals, and edges represent interactions among individuals. It is very interesting to investigate how dynamical processes unfolding on complex networks are affected by the connectivity pattern or topological heterogeneities [24, 25]. In particular, network topology can have great impact on disease spreading. For example, Pastor-Satorras and Vespignani [26] first pointed out that for networks with a power-law degree distribution with power exponent in the interval (2, 3], there exists no epidemic threshold if the second moment of the degree distribution tends to infinity in the limit of infinite network size. Yuan et al. [27] found that for slowly evolving contact networks, the basic reproduction number may attain its peak value when the population is still growing, in contrast to at equilibrium for classical homogeneous mixing epidemic models. Jaramillo et al. [13] showed that by incorporating a contact network structure, the establishment of a new strain is possible for much higher immunity levels of previously infected individuals than that predicted by the homogeneous mixing assumption.
Homogeneous epidemic models are also widely used to understand the spread and control of the ongoing COVID-19. Most of these models are based on the so-called SIR or SEIR model. Typically, Hao et al. [28] proposed a conceptual model to reconstruct the full-spectrum dynamics of COVID-19 between January 1, 2020, and March 8, 2020, across five periods marked by events and interventions based on many laboratory-confirmed cases. Tian et al. [29] showed that the Wuhan shutdown delays arrival of COVID-19 in other cities by 2.91 days using an SEIR epidemic model. Tang et al. [30] studied the influence of quarantine and isolation on the trend of the COVID-19 epidemics in China. Acuña-Zegarra [31] presented a COVID-19 model to explore the effect of behavioral changes required to reduce transmission, and obtained an optimum value of the lockdown proportion minimizing incidence. Sun et al. [32] proposed an SEIQR model in consideration of the effects of lockdown and medical resources on the spread of COVID-19. However, to the best of our knowledge, little attention has been paid to the effect of contact heterogeneity of a population on the spread of COVID-19. Liu et al. [33] proposed a network-based SAIR model to describe the spread of COVID-19 and analyzed the outbreak using the epidemic data of Wuhan from January 24 to March 2. Xue et al. [34] developed a network-based COVID-19 model and fitted the outbreaks for the three selected places. These network-based epidemic models use the so-called annealed networks, as we will introduce in Sect. 2, and are not suitable for describing the disease spread in a population with fixed contact pattern, for example, members in a shutdown community.
Our main aim in this paper is to investigate how contact heterogeneity affects the dynamics of influenza-like diseases, especially on the basic reproduction number and the final size relation. For this reason, we first derive degree-based epidemic models in two general types of network. The model also allows for biased mixing, rather than random mixing, among individuals, which is captured by a conditional probability between different degree classes. Moreover, the solvability of final size equations is studied in detail, including the existence and uniqueness of the solution.
The paper is organized as follows. In Sect. 2, we present the model in annealed networks with degree correlation, derive the basic reproduction number and final size implicit equations, and prove the solvability of these implicit equations. In Sect. 3, we derive the model in static networks with no degree correlation by using an edge-based compartmental modeling approach, and obtain the basic reproduction number and the implicit final size equation. In Sect. 4, we give an example of influenza epidemic with final epidemic size and some known model parameters and determine the transmission rate and the basic reproduction number. We end the paper in Sect. 5 with some concluding remarks.
2 Epidemic dynamics of influenza in annealed networks
Annealed networks assume that the evolution of the network topology is much faster than that of the dynamical processes unfolding on it. That is, networks are constantly rewired such that they can be captured by a mean-field version of the adjacency matrix [25]. Specifically, whether an edge in the average network appears or not is dependent on the degree distribution P(k) (the probability that a randomly selected node has degree k) and the two-node degree correlation P(j|k) (the probability that a node of degree k links to a node of degree j).
2.1 Degree-based mean-field (DBMF) epidemic dynamics of influenza
Considering the heterogeneous number of contacts, individuals are classified according to both statuses and the number of contacts. Let \(S_{k}\), \(L_{k}\), \(I_{k}\), \(A_{k}\) and \(R_{k}\) represent the relative density of susceptible, incubative, infectious, asymptomatic and recovered individuals with k contacts per unit time, respectively. The DBMF theory assumes that all nodes of degree k are statistically equivalent, and uses relevant variable to specify the status of nodes in degree class k. Let \(\Theta _{I}=\sum _{j}P(j|k)I_{j}\), \(\Theta _{L}=\sum _{j}P(j|k)L_{j}\) and \(\Theta _{A}=\sum _{j}P(j|k)A_{j}\) be the probability that a node of degree k is connected to a node of degree j with infectious, incubative and asymptomatic state, respectively. Let \(\tau \) be the transmission rate per infectious contact, and other parameters be the same as in model (1). Then, the dynamics is given by the following ODEs
If the fraction of disease-induced deaths is very small, i.e., \(\sigma \approx 1\), we can ignore the population demography and obtain the conservation equation
for any k. The following general initial conditions are used
where \(\epsilon ^{L}_{k}\), \(\epsilon ^{I}_{k}\) and \(\epsilon ^{A}_{k}\) are non-negative constants, and \(\epsilon ^{L}_{k}+\epsilon ^{I}_{k}+\epsilon ^{A}_{k}<1\).
Since variable \(R_{k}\) is decoupled from the first four equations of model (5), we drop it from (5). Let \(\mathcal {S}=(S_{1}, L_{1}, I_{1}, A_{1}, \ldots , S_{n}, L_{n}, I_{n}, A_{n})\) be a solution of (5), where n is the maximum number of contacts or degree due to finite population size or network size effect [35].
Denote
Then, we first obtain the following preliminary results.
Lemma 2.1
System (5) is positively invariant with respect to the set \(\Omega \), and it has a unique global nonnegative solution for \(t\ge 0\).
Proof
It is easy to see that the vector field defined by the right-hand side of (5) is locally Lipschitz on \(R_{+}^{4n}\), so there admits a unique solution of system (5) for \(t\ge 0\). The proof of the nonnegativity of each state variable is similar to Lemma 2.1 in Wang et al. [36], so it is omitted here. \(\square \)
Lemma 2.1 tells that model (5) is well-posed epidemiologically and mathematically. Concerning the long-time behavior of solutions, we have the following lemma.
Lemma 2.2
For any \(\epsilon ^{L}_{k}, \epsilon ^{I}_{k}, \epsilon ^{A}_{k}\ge 0\), \(\epsilon ^{L}_{k}+\epsilon ^{I}_{k}+\epsilon ^{A}_{k}<1\) and \(k=1, \ldots , n\), it follows that
Proof
Based on the first equation of (5) and Lemma 2.1, we know \(S'_{k}(t)\le 0\) for \(t\ge 0\). Since \(S_{k}\) is bounded below by 0, the limit \(S_{k}(\infty )\) exists for any k. Summing the first two equations of (5) gives
It can be seen that \(S_{k}+L_{k}\) is decreasing strictly whenever \(L_{k}>0\). Also, \(S_{k}+L_{k}\) is bounded below by 0, and hence it admits a limit. Meanwhile, the above equation tells that \((S_{k}+L_{k})'\) is bounded since \(L_{k}\) is bounded. Therefore, it follows that \(\lim _{t\rightarrow +\infty }(S_{k}+L_{k})'=0\), leading to \(L_{k}(\infty )=\lim _{t\rightarrow +\infty }L_{k}(t)=0\).
Summing the first three equations of (5) leads to
It can be seen that \(S_{k}+L_{k}+I_{k}\) is decreasing strictly whenever \(L_{k}>0\) or \(I_{k}>0\). Moreover, \((S_{k}+L_{k}+I_{k})'\) is bounded because \(L_{k}\) and \(I_{k}\) are bounded. Hence, it follows that \(\lim _{t\rightarrow +\infty }(S_{k}+L_{k}+I_{k})'=0\). Combing it with \(L_{k}(\infty )=0\), we obtain \(I_{k}(\infty )=0\).
Proceeding as above, we can verify \(A_{k}(\infty )=0\). In addition, using the conservation equation, we have \(R_{k}(\infty )=1-S_{k}(\infty )\), \(k=1, \ldots , n\), and thus \(Z=R(\infty )=\sum _{k=1}^{n}P(k)R_{k}(\infty )=1-\sum _{k=1}^{n}P(k)S_{k}(\infty )\). \(\square \)
2.2 Basic reproduction number and implicit final size equations
First, we compute the basic reproduction number \(R_{0}\), and in particular, we give the explicit formula of \(R_{0}\) for annealed networks with no degree correlation. Then, we derive implicit equations for the final epidemic size. Finally, we prove the existence and uniqueness of the solution for these implicit equations, and present a numerical iteration that converges to the unique solution.
To obtain the basic reproduction number \(R_{0}\) for the model (5), we use the straightforward next-generation matrix approach of van den Driessche and Watmough [21]. Ordering the infected compartments first by infection status, then by degree, i.e.,
we get the following new infection matrix F and the transition matrix V
where \(B_{11}=(\delta _{1}\tau kP(j|k))_{n\times n}\), \(B_{12}=(\tau kP(j|k))_{n\times n}\) and \(B_{13}=(\delta _{2}\tau kP(j|k))_{n\times n}\), and \(E_{n}\) is the \(n\hbox {th}\)-order identity matrix.
Following the recipe in [21], \(R_{0}\) is calculated as the dominant eigenvalue of the matrix \(FV^{-1}\), i.e., \(R_{0}=\rho (FV^{-1})\), where \(\rho (\cdot )\) denotes the spectral radius of a square matrix. Direct computation yields
Noting that matrix \(FV^{-1}\) has rank n, we obtain the dominant eigenvalue as
where \(B=(kP(j|k))_{n\times n}\). The terms in big parenthesis have similar explanations as those in (2), and the network information is encapsulated in \(\rho (B)\).
For model (5), the disease-free equilibrium (DFE) \(E_{0}\) is \(L_{k}=I_{k}=A_{k}=0\) and \(S_{k}=1\), \(k=1, \ldots , n\). According to Theorem 2 in van den Driessche and Watmough [21], the local stability of \(E_{0}\) is determined by \(R_{0}=1\). That is, \(R_{0}=1\) is a disease threshold condition. In particular, if \(R_{0}<1\), the density of infectious individuals decreases directly, and there is only sporadic infection, whereas if \(R_{0}>1\), the density of infectious individuals would increase, and there is a major outbreak.
Example
If there is no degree correlation in annealed networks, the probability that a ‘stub’ is connected to a node of degree j only proportionates to the total number of ‘stubs’ it has, i.e., \(P(j|k)=jP(j)/\langle k\rangle \). Then the dominant eigenvalue of B is \(\rho (B)=\langle k^{2}\rangle /\langle k\rangle \). Here, \(\langle k\rangle =\sum _{j}jP(j)\) is the average degree of a network, and \(\langle k^{2}\rangle =\sum _{j}j^{2}P(j)\) is the second moment of degree distribution P(k). Thus, \(R_{0}\) in (6) reduces to
Noting that \(\langle k^{2}\rangle /\langle k\rangle =Var(k)/\langle k\rangle +\langle k\rangle \), where Var(k) is the variance of degree distribution, we can easily see that degree heterogeneity or fluctuation enlarges \(R_{0}\), namely the disease can invade a population with heterogeneous number of contacts more easily if the average degree is fixed.
We next derive the implicit equations for final epidemic size [37]. From Lemma 2.2, we know \(R_{k}(\infty )=1-S_{k}(\infty )\). Now we find implicit equations for \(S_{k}(\infty )\), \(k=1,\ldots , n\). To simplify calculations below, we denote \(\beta _{kj}=kP(j|k)\), and let \(\epsilon _{k}^{L}=\epsilon _{k}^{A}=0\). This assumption is reasonable and easily relaxed to more general initial conditions. Rewriting the first equation of (5) gives
or equivalently
Integrating Eq. (8) on (0, t), we have
Adding up the equations for \(S_{k}'\) and \(L_{k}'\), we get
Integrating Eq. (10) on (0, t), we have
Adding up the equations for \(S_{k}'\), \(L_{k}'\) and \(I_{k}'\), we get
and then integrating the equation on (0, t), we have
Similarly, adding up the equations for \(S_{k}'\), \(L_{k}'\), \(I_{k}'\) and \(A_{k}'\), and integrating the equation on (0, t), we have
Then, from Eq. (11), we obtain
Substituting (14) into Eq. (12), we obtain
Substituting (15) into Eq. (13), we obtain
Substituting Eqs. (14)–(16) into Eq. (9) and taking the limit \(t\rightarrow +\infty \), we conclude
where \(a=\delta _{1}\tau /\kappa +q\tau /\gamma +(1-q)\delta _{2}\tau /\eta \).
Specifically, the implicit equations for final epidemic size are given by
Next, our aim is to verify that (17) has a unique positive solution \(S_{k}(\infty )\) for any \(\epsilon _{k}^{I}\in [0, 1)\), \(k=1,\ldots ,n\). To this end, we define the map \(H: R^{n}\rightarrow R^{n}\) as
where T denotes the transpose of a vector or matrix, and the element of H(X) is
For arbitrary \(X, Y\in R^{n}\), we use the following notations. If \(X_{j}\le Y_{j}\), \(j=1, \ldots , n\), we denote it by \(X\le Y\). If \(X\le Y\) and \(X_{j}< Y_{j}\) for some \(j=1, \ldots , n\), we denote it by \(X<Y\). If \(X_{j}< Y_{j}\), \(j=1, \ldots , n\), we denote it by \(X\ll Y\).
It is easy to see that H is monotone increasing, that is, if \(X\le Y\), then \(H(X)\le H(Y)\). In particular, if \(0\le \epsilon _{k}^{I}<1\), \(k=1, \ldots , n\), namely, \(0<S_{k}(0)\) and \(0\le I_{k}(0)\), we have
where \(\zeta =(S_{1}(0), \ldots , S_{n}(0))^\mathrm{T}=(1-\epsilon _{1}^{I}, \ldots , 1-\epsilon _{n}^{I})^\mathrm{T}\).
Moreover, using the mathematical induction, we conclude that
for any \(l\ge 1\). In the light of the criterion for monotone bounded sequence, taking the limit \(l\rightarrow +\infty \) yields
Because H is continuous, we obtain
leading to the following lemma.
Lemma 2.3
If \(\kappa , \gamma , \eta >0\) and \(\epsilon _{k}^{I}\in [0, 1)\), \(k=1, \ldots , n\), then all the fixed points of H in \([0, \zeta ]\) are actually located in the interval \([\zeta ^{-}, \zeta ^{+}]\).
Noting that H is continuously differentiable, we obtain the partial derivative of \(H_{k}(X)\) with respect to \(X_{j}\), i.e.,
and we can rewrite it as a compact matrix form
where DH(X) denotes the Jacobian matrix, and \({{ diag}}(\cdot )\) denotes the diagonal matrix (whose diagonal elements are elements of a vector).
From (18), we deduce that the monotony of H implies the monotony of DH; in other words, for any \(0\le X\le Y\le \zeta \) and vector \(0\le C\)
Returning to the fact \(H(\zeta ^{+})=\zeta ^{+}\) and \(H(\zeta ^{-})=\zeta ^{-}\), we get \(DH(\zeta ^{+})={{ diag}}(\zeta ^{+})a B\) and \(DH(\zeta ^{-})={{ diag}}(\zeta ^{-})a B\).
The uniqueness of the solution of Eq. (17) is given in the following theorem.
Theorem 2.1
Let \(\tau , \kappa , \gamma , \eta >0\) and \(\epsilon _{k}^{I}\in [0, 1)\), \(k=1, \ldots , n\). If matrix B is nonnegative and irreducible, that is, a degree k node can be reached from any other degree j node (\(j\ne k\)) via a path, then the following statements hold
-
1.
\(H(\zeta )=\zeta \) is equivalent to \(\epsilon _{k}^{I}=0\), \(k=1, \ldots , n\);
-
2.
If \(\epsilon _{k}^{I}>0\) for some \(k=1, \ldots , n\), then Eq. (17) has a unique positive solution \(0<S_{k}(\infty )\le 1-\epsilon _{k}^{I}\), \(k=1, \ldots , n\), i.e., a unique fixed point \(\zeta ^{*}\) of H.
Proof
Since matrix B is nonnegative and irreducible, and \(\zeta ^{+}\gg 0\), we know that \(DH(\zeta ^{+})={\text {diag}}(\zeta ^{+})a B\) is also nonnegative and irreducible.
1. Letting \(H(\zeta )=\zeta \) leads to the following equalities
and this is equivalent to
Considering the fact that matrix B is nonnegative and irreducible, and \(\epsilon _{k}^{I}\in [0, 1)\), \(k=1, \ldots , n\), we obtain \(B(1-\zeta )=0\Leftrightarrow 1-\zeta =0\), i.e., \(\epsilon _{k}^{I}=0\), \(k=1, \ldots , n\). This means that H has a trivial fixed point \(\zeta \gg 0\) if and only if \(\epsilon _{k}^{I}=0\), \(k=1, \ldots , n\), namely, there is no initial infection in the network.
2. Since \(\epsilon _{k}^{I}>0\) for some \(k=1, \ldots , n\). By the definition of H, we have \(0\ll H(\zeta )<\zeta \) and \(\zeta ^{+}<\zeta \). In addition, by the monotony of H, we get \(\zeta ^{+}=H(\zeta ^{+})\le H(\zeta )\).
For the uniqueness of the positive solution \(S_{k}(\infty )\), \(k=1, \ldots , n\), it is enough to verify that \(\zeta ^{-}=\zeta ^{+}\). If it is not so, we have \(\zeta ^{-}<\zeta ^{+}\). Then, it follows that
Noting that DH is monotone increasing for any \(\nu \in [0,1]\), we obtain
and thus
Moreover, according to the Perron-Frobenius theorem [38], there is a left eigenvector \(\omega \gg 0\) of \(DH(\zeta ^{+})\) corresponding to the dominant eigenvalue \(\rho (DH(\zeta ^{+}))\) such that
This implies \(\rho (DH(\zeta ^{+}))\ge 1\) by using the assumption \(\zeta ^{-}<\zeta ^{+}\).
On the other hand, noting the fact that
and for any \(\nu \in [0,1]\)
we deduce
Combining this with \(\rho (DH(\zeta ^{+}))\ge 1\), we have
which is contradictory with \(0\ll H(\zeta )<\zeta \). This completes the proof. \(\square \)
Remark 2.1
From a mathematical point of view, we consider the implicit equations (17) as a fixed point problem. From a biological point of view, there is no infection eventually if and only if no initial infection is introduced into the network, and there is a sporadic infection or major outbreak (depending on if the basic reproduction number \(R_{0}\) is above one) in the end if initial infectious node of any degree is introduced into the network.
Remark 2.2
Based on the above theorem, we can estimate the final epidemic size numerically by iterating the fixed-point equation. Specifically,
for initial infectious nodes of arbitrary degree k. Moreover, if \(\epsilon _{k}^{I}>0\) for some \(k=1, \ldots , n\), the final density of the susceptible nodes with degree k may also be estimated as \(S_{k}(\infty )=\lim _{l\rightarrow +\infty }H_{k}^{l}(0)\). Thus, the final epidemic size is estimated numerically as \(Z=R(\infty )=1-\sum _{k=1}^{n}P(k)S_{k}(\infty )\). In addition, if the network is disconnected, that is, matrix B is non-irreducible, the above theorem can be used to estimate final epidemic size in each connected component.
2.3 Edge-based dynamics of influenza in degree uncorrelated networks
When there is no degree correlation, i.e., \(\beta _{kj}=kjP(j)/\langle k\rangle \), a low-dimensional counterpart of system (5) is derived. To see this, we rewrite Eq. (9) as
which is the probability that a degree k node remains susceptible by time t. This comprises two parts, the probability \(1-\epsilon _{k}^{I}\) that a degree k node is susceptible initially, and the probability
that it does not receive any infection through its k stubs by time t. Denote
by \(\theta (t)\), i.e., the probability that a randomly chosen stub has never transmitted infection, then we have \(S_{k}(t)=\left( 1-\epsilon _{k}^{I}\right) \theta ^{k}(t)\) and \(S(t)=\sum _{k=1}^{n}\left( 1-\epsilon _{k}^{I}\right) P(k)\theta ^{k}(t)\).
Now we are in a position to find the equation for \(\theta (t)\). Let \(\phi _{S}\), \(\phi _{L}\), \(\phi _{I}\), \(\phi _{A}\) and \(\phi _{R}\) be the probability that a randomly chosen stub of a node has never transmitted infection to the node and currently connects to a susceptible, incubative, infectious, asymptomatic, and recovered node, respectively. For annealed networks without degree correlation, since networks are constantly rewired, the probability that a randomly selected stub connects to a node with given status equals the fraction of all stubs pertaining to nodes of that status. Thus, we must take the fraction of stubs that pertain to susceptible, incubative, infectious, asymptomatic, or recovered nodes \(\Theta _{S}\), \(\Theta _{L}\), \(\Theta _{I}\), \(\Theta _{A}\) and \(\Theta _{R}\) into consideration. It follows that \(\phi _{i}=\theta \Theta _{i}\), \(i\in \{S, L, I, A, R\}\). For instance, \(\phi _{I}\) is the product of the probability \(\theta \) that a stub has never transmitted infection with the probability \(\Theta _{I}\) that it connects to a infectious node at the moment.
Assuming that the neighbors pertained to a single stub anytime are independent, no explicit fluxes among \(\phi _{S}\), \(\phi _{L}\), \(\phi _{I}\), \(\phi _{A}\) and \(\phi _{R}\) exist. The change for status of a neighbor is due to pairing and terminating of stubs, rather than infection or transition of the neighbor. We need a transition chart for \(\Theta _{S}\), \(\Theta _{L}\), \(\Theta _{I}\), \(\Theta _{A}\) and \(\Theta _{R}\), which is similar to the flowchart for S, L, I, A and R. The transition chart is shown in Fig. 2. Stubs belonging to incubative nodes become stubs belonging to infectious nodes at rate \(q\kappa \), and stubs belonging to infectious nodes become stubs belonging to removed nodes at rate \(\gamma \), thus \(\Theta '_{I}=q\kappa \Theta _{L}-\gamma \Theta _{I}\). Similarly, we get \(\Theta '_{A}=(1-q)\kappa \Theta _{L}-\eta \Theta _{A}\).

Flowchart for the heterogeneous mixing SLIAR epidemic model in annealed networks with no degree correlation. Compartments \(\Theta _{S}\), \(\Theta _{L}\), \(\Theta _{I}\), \(\Theta _{A}\) and \(\Theta _{R}\) correspond to the fraction of stubs belonging to susceptible, incubative, infectious, asymptomatic, and removed nodes, respectively
To calculate the probability \(\theta \), noting that it decreases owing to the infection transmitted along a stub that belongs to incubative, infectious or asymptomatic nodes, we have
Noting that \(\Theta '_{L}=-\Theta '_{S}-\kappa \Theta _{L}\), we need calculate \(\Theta _{S}\). Because the probability a stub emanates from a node of degree k is \(kP(k)/\langle k\rangle \), and the probability the node remains susceptible by time t is \(\left( 1-\epsilon _{k}^{I}\right) \theta ^{k}\), we obtain
leading to
Therefore, the full system can be summarized in the following form
The above system is finished with initial conditions: \(\theta (0)=1\), \(\Theta _{I}(0)=\sum _{k=1}^{n}kP(k)\epsilon _{k}^{I}/\langle k\rangle \), \(\Theta _{L}(0)=\Theta _{A}(0)=0\), \(I(0)=\sum _{k=1}^{n}P(k)\epsilon _{k}^{I}\) and \(L(0)=A(0)=0\).
To calculate the basic reproduction number \(R_{0}\) for model (22), we use the next-generation matrix approach involving only variables \(\Theta _{L}\), \(\Theta _{I}\) and \(\Theta _{A}\). Linearizing the equations associated with these variables around the DFE (\(\theta =1\) and \(\Theta _{L}=\Theta _{I}=\Theta _{A}=0\)) gives
Assuming \(\epsilon _{k}^{I}\rightarrow 0\), \(k=1, \ldots , n\), we rewrite (23) as a compact matrix form
where
Then, the basic reproduction number is given by
which is equivalent to that from Eq. (6).
To derive the implicit equation for final epidemic size, we have to find \(\theta (\infty )\). We can rewrite Eq. (20) as
Using \(\Theta '_{S}+\Theta '_{L}=-\kappa \Theta _{L}\) and integrating it on (0, t) yield
Using \(\Theta '_{S}+\Theta '_{L}+\Theta '_{I}=-(1-q)\kappa \Theta _{L}-\gamma \Theta _{I}\) and integrating it on (0, t) yield
Similarly, using \(\Theta '_{S}+\Theta '_{L}+\Theta '_{I}+\Theta '_{A}=-\gamma \Theta _{I}-\eta \Theta _{A}\) leads to
Based on (25), we get
Similarly, based on (26), (27) and (28), we solve \(\int _{0}^{t}\Theta _{I}(s){\text {d}}s\) and \(\int _{0}^{t}\Theta _{A}(s){\text {d}}s\), respectively. Substituting these expressions into Eq. (24), we have
Taking the limit \(t\rightarrow +\infty \) and using \(\Theta _{L}(\infty )=\Theta _{I}(\infty )=\Theta _{A}(\infty )=0\), we get
Using \(\Theta _{S}(\infty )=\sum _{k=1}^{n}kP(k)\left( 1-\epsilon _{k}^{I}\right) \theta ^{k}(\infty )/\langle k\rangle \) and \(\Theta _{S}(0)=1-\sum _{k=1}^{n}kP(k)\epsilon _{k}^{I}/\langle k\rangle \), we rewrite Eq. (30) as
\(Z=R(\infty )=1-\sum _{k=1}^{n}\left( 1-\epsilon _{k}^{I}\right) P(k)\theta ^{k}(\infty )\), where \(\theta (\infty )\) can be estimated numerically from Eq. (31).
Define the function
which allows us to consider the fixed point of the function f. It is easy to verify that \(f'(x)>0\) and \(f''(x)>0\), leading to the following theorem.
Theorem 2.2
If \(\tau , \kappa , \gamma , \eta >0\) and \(\epsilon _{k}^{I}\in [0, 1)\), \(k=1, \ldots , n\), then the following statements hold
-
1.
\(f(1)=1\) is equivalent to \(\epsilon _{k}^{I}=0\), \(k=1, \ldots , n\);
-
2.
If \(\epsilon _{k}^{I}>0\) for some \(k=1, \ldots , n\), then f has a unique fixed point \(x^{*}\in (0, 1)\).
Proof
Since \(f'(x)>0\) and \(f''(x)>0\), f is strictly increasing and convex in the interval [0, 1].
1. Letting \(f(1)=1\), we have
Recalling \(\Theta _{S}(0)=1-\sum _{k=1}^{n}kP(k)\epsilon _{k}^{I}/\langle k\rangle \) and substituting it into the above equation leads to \(\Theta _{S}(0)=1\), which is equivalent to
2. If \(\epsilon _{k}^{I}>0\) for some \(k=1, \ldots , n\), then it follows that \(0<\Theta _{S}(0)<1\). Thus, we have
which shows that the graph of f initiates above and terminates below the diagonal (the line segment linking two points (0, 0) and (1, 1)). Because f is strictly increasing and convex in the interval [0, 1], it has a unique fixed point \(x^{*}\in (0, 1)\). Moreover, it follows that \(f(x)>x\) in \([0, x^{*})\) and \(f(x)<x\) in \((x^{*}, 1]\). \(\square \)
Remark 2.3
For annealed networks with no degree correlation, the implicit equations (17) of final epidemic size are of n dimension, and Theorem 2.2 assumes that the connectivity matrix B is irreducible. However, Theorem 2.2 has no such assumption, and thus it is more general in a way.
Remark 2.4
The edge-based approach can be easily extended to annealed networks with degree correlation, see, for example [39]. Specifically, the probability \(\theta (t)\) that a randomly selected stub has never transmitted infection by time t should be depended on the degree k of a node, i.e., \(\theta _{k}(t)\). Then, the implicit equations for final epidemic size are of n dimension.
To show how the solution of (31) can be obtained by using a natural iteration, i.e., \(x_{l+1}=f(x_{l})\), \(l=0, 1, 2, \ldots \), we first recall the following lemma from [40].
Lemma 2.4
If \(f: J\rightarrow J\) is a strictly increasing continuous function on the interval J, and has a unique fixed point \(x^{*}\in J\), i.e., \(x^{*}=f(x^{*})\), and if \(f(x)>x\) for \(x<x^{*}\) and \(f(x)<x\) for \(x>x^{*}\), then for any \(x_{0}\in J\), the sequence defined by the iteration \(x_{l+1}=f(x_{l})\) converges to the fixed point \(x^{*}\).
Proof
The proof is provided in Lemma 1 of [40]. \(\square \)
Using the above lemma, we immediately have the following result on the solvability of Eq. (31).
Theorem 2.3
If \(\tau , \kappa , \gamma , \eta >0\) and \(\epsilon _{k}^{I}\in [0, 1)\), \(k=1, \ldots , n\), then for any \(\theta _{0}\in (0, 1)\), the sequence defined by the iteration \(\theta _{l+1}=f(\theta _{l})\) converges to \(x^{*}=\theta (\infty )\).
Proof
From Theorem 2.2, f is strictly increasing on the interval [0, 1], which has a unique fixed point \(x^{*}\in (0, 1]\), and \(f(x)>x\) for \(x<x^{*}\) while \(f(x)<x\) for \(x>x^{*}\). In other words, the function f satisfies the conditions of Lemma 2.4, thus the sequence induced by \(\theta _{l+1}=f(\theta _{l})\) converges to \(x^{*}=\theta (\infty )\). \(\square \)
3 Epidemic dynamics of influenza in quenched networks
Quenched networks assume that the evolution of the network topology is much slower than that of the dynamical processes unfolding on it. Thus, the networks can be considered as fixed or static, and the correlations among nodes may appear. Generally speaking, these correlations can be captured by quenched mean-field [41,42,43] or N-intertwined mean-field approximation [44].
3.1 Edge-based dynamics of influenza in quenched networks
On quenched networks with no degree correlation, we employ an edge-based compartmental modeling approach [42, 43] for influenza. In particular, we derive a low-dimensional system of ODEs.
To begin with, a susceptible node of degree k is infected only through its k direct neighbors, whose statuses may be incubative, infectious or asymptomatic. Assuming that all nodes of degree k are statistically equivalent, we obtain the dynamical equation for all susceptible nodes of degree k as
where \(p_{I}=M_{SI}/M_{S}\), \(p_{L}=M_{SL}/M_{S}\) and \(p_{A}=M_{SA}/M_{S}\) is the probability that an arc (each undirected edge is considered as two directed arcs) associated with a susceptible ego links to an incubative, infectious or asymptomatic alter, respectively.
Rewriting Eq. (32) and integrating it on (0, t) gives
where \(\theta (t)\doteq \text {e}^{-\tau \int _{0}^{t}(p_{I}(s)+\delta _{1} p_{L}(s)+\delta _{2} p_{A}(s)){\text {d}}s}\) is the probability that a randomly chosen edge has never transmitted infection by time t. Thus, we get \(S_{k}(t)=\left( 1-\epsilon _{k}^{I}\right) \theta ^{k}(t)\) and \(S(t)=\sum _{k=1}^{n}\left( 1-\epsilon _{k}^{I}\right) P(k)\theta ^{k}(t)\).
To find the equation for \(\theta (t)\), we denote by \(\varphi _{S}\), \(\varphi _{L}\), \(\varphi _{I}\), \(\varphi _{A}\) and \(\varphi _{R}\) the probability that the alter node of an arc is susceptible, incubative, infectious, asymptomatic and recovered, and has not transmitted infection by time t, for example, \(\varphi _{L}(t)=\theta (t) p_{L}(t)\). Clearly, arcs that satisfies the definition of \(\varphi _{i}\), \(i\in \{S, L, I, A, R\}\), is a subset of arcs that satisfy the definition of \(\theta \), namely \(\theta (t)=\varphi _{S}(t)+\varphi _{L}(t)+\varphi _{I}(t)+\varphi _{A}(t)+\varphi _{R}(t)\).
The infection transmitting along an arc decreases the probability \(\theta \), thus
Now we need equations for \(\varphi _{L}\), \(\varphi _{I}\) and \(\varphi _{A}\). The probability \(\varphi _{L}\) increases when the susceptible alter becomes newly incubative, whereas it decreases when the infection transmits along the arc or when the incubative alter becomes infectious or asymptomatic. Then, it follows that
The probability \(\varphi _{S}\) can be calculated directly. Since the probability a randomly selected arc points to a degree k node is proportional to \(kP(k)/\langle k\rangle \) in quenched networks of configuration type, and the susceptible ego of degree k can be infected only through other \(k-1\) arcs except the one we followed, thus we get \(\varphi _{S}=\langle k\rangle ^{-1}\sum _{k=1}^{n}kP(k)\left( 1-\epsilon _{k}^{I}\right) \theta ^{k-1}\). Then, the equation of \(\varphi '_{L}\) becomes
The probability \(\varphi _{I}\) increases when the incubative alter becomes infectious, while it decreases when the infection transmits along the arc or when the infectious alter becomes recovered. Then, \(\varphi '_{I}=q\kappa \varphi _{L}-(\tau +\gamma )\varphi _{I}\). Similarly, it follows that \(\varphi '_{A}=(1-q)\kappa \varphi _{L}-(\delta _{2}\tau +\eta )\varphi _{A}\).
Therefore, the full system can be summarized as follows
with the initial conditions: \(\theta (0)=1\), \(\varphi _{I}(0)=\sum _{k=1}^{n}kP(k)\epsilon _{k}^{I}/\langle k\rangle \), \(\varphi _{L}(0)=\varphi _{A}(0)=0\), \(I(0)=\sum _{k=1}^{n}P(k)\epsilon _{k}^{I}\) and \(L(0)=A(0)=0\).
3.2 Basic reproduction number
To compute the basic reproduction number \(R_{0}\) for model (36), we employ the next-generation matrix approach involving only variables \(\varphi _{L}\), \(\varphi _{I}\) and \(\varphi _{A}\). Linearizing the equations associated with these variables about the DFE (\(\theta =1\), and \(\varphi _{L}=\varphi _{I}=\varphi _{A}=0\)) yields
Letting \(\epsilon _{k}^{I}\rightarrow 0\), \(k=1, \ldots , n\) and rewriting (37) in a compact matrix form, we obtain
where
Thus, the basic reproduction number is given by \(R_{0}=\rho (F_{2}V_{2}^{-1})\), i.e.,
where \(R_{L}=\frac{\delta _{1}\tau }{\delta _{1}\tau +\kappa }\frac{\langle k(k-1)\rangle }{\langle k\rangle }\) is the basic reproduction number of the incubative individual-infected individuals, \(R_{I}=\frac{q\kappa }{\delta _{1}\tau +\kappa }\frac{\tau }{\tau +\gamma }\frac{\langle k(k-1)\rangle }{\langle k\rangle }\) is the basic reproduction number of the infectious individual-infected individuals, and \(R_{A}=\frac{(1-q)\kappa }{\delta _{1}\tau +\kappa }\frac{\delta _{2}\tau }{\delta _{2}\tau +\eta }\frac{\langle k(k-1)\rangle }{\langle k\rangle }\) is the basic reproduction number of the asymptomatic individual-infected individuals. Here, \(\frac{\delta _{1}\tau }{\delta _{1}\tau +\kappa }\) is the probability that an incubative neighbor has transmitted infection before it becomes infectious or asymptomatic, \(\frac{q\kappa }{\delta _{1}\tau +\kappa }\) is the probability that an incubative neighbor has become infectious, \(\frac{\tau }{\tau +\gamma }\) is the probability that an infectious neighbor has transmitted infection before it becomes recovered, \(\frac{(1-q)\kappa }{\delta _{1}\tau +\kappa }\) is the probability that an incubative neighbor has become asymptomatic, \(\frac{\delta _{2}\tau }{\delta _{2}\tau +\eta }\) is the probability that an asymptomatic neighbor has transmitted infection before it becomes recovered, and \(\frac{\langle k(k-1)\rangle }{\langle k\rangle }\) is the mean excess degree of the contact network (the degree of a node reached by following a random edge minus the edge that is followed).
3.3 Implicit equation for the final epidemic size
We now derive the implicit equation for the final epidemic size. Since \(S(\infty )=\sum _{k=1}^{n}\left( 1-\epsilon _{k}^{I}\right) P(k)\theta ^{k}(\infty )\), we need \(\theta (\infty )\). Noting that \(\theta '\le 0\) and \(\theta \in [0, 1]\), we know \(\theta (\infty )\) exists. Integrating the first equation of (36) on (0, t), we obtain
Observing \(\varphi '_{S}+\varphi '_{L}=-(\delta _{1}\tau +\kappa )\varphi _{L}\) and integrating it on (0, t), we have
Observing \(\varphi '_{S}+\varphi '_{L}+\varphi '_{I}=-(\delta _{1}\tau +(1-q)\kappa )\varphi _{L}-(\tau +\gamma )\varphi _{I}\) and integrating it on (0, t), we have
Similarly, observing \(\varphi '_{S}+\varphi '_{L}+\varphi '_{I}+\varphi '_{A}=-\delta _{1}\tau \varphi _{L}-(\tau +\gamma )\varphi _{I}-(\delta _{2}\tau +\eta )\varphi _{A}\), we have
for any \(t>0\).
From (40), we solve
Similarly, from (41), (42) and (43), we solve \(\int _{0}^{t}\varphi _{I}(s){\text {d}}s\) and \(\int _{0}^{t}\varphi _{A}(s){\text {d}}s\), respectively. Substituting these expressions into Eq. (39), we can obtain
where \(b=\frac{\delta _{1}\tau }{\delta _{1}\tau +\kappa }+\frac{q\kappa }{\delta _{1}\tau +\kappa }\frac{\tau }{\tau +\gamma }+\frac{(1-q)\kappa }{\delta _{1}\tau +\kappa }\frac{\delta _{2}\tau }{\delta _{2}\tau +\eta }\).
Taking the limit \(t\rightarrow +\infty \) and using \(\varphi _{L}(\infty )=\varphi _{I}(\infty )=\varphi _{A}(\infty )=0\), we conclude
Substituting \(\varphi _{S}(\infty )=\frac{1}{\langle k\rangle }\sum _{k=1}^{n}kP(k)\left( 1-\epsilon _{k}^{I}\right) \theta ^{k-1}(\infty )\) into (45) yields
Thus, the final epidemic size is given by \(Z=R(\infty )=1-\sum _{k=1}^{n}\left( 1-\epsilon _{k}^{I}\right) P(k)\theta ^{k}(\infty )\), where \(\theta (\infty )\) can be solved numerically from Eq. (46).
To show Eq. (46) has a unique solution \(\theta (\infty )\in (0, 1]\) for any \(\epsilon _{k}^{I}\ge 0\), \(k=1, \ldots , n\), we consider the fixed point of the following function g, i.e.,
Clearly, it can be verified that \(g'(y)>0\) and \(g''(y)>0\), giving the following result.
Theorem 2.4
If \(\tau , \kappa , \gamma , \eta >0\), and \(\epsilon _{k}^{I}\in [0, 1)\), \(k=1, \ldots , n\), then the following properties of g hold
-
1.
\(g(1)=1\) is equivalent to \(\epsilon _{k}^{I}\), \(k=1, \ldots , n\);
-
2.
If \(\epsilon _{k}^{I}>0\) for some \(k=1, \ldots , n\), then g has a unique fixed point \(y^{*}\in (0, 1)\).
Proof
Based on \(g'(y)>0\) and \(g''(y)>0\), we know g is strictly increasing and convex in the interval [0, 1].
-
1.
Letting \(g(1)=1\), we obtain
$$\begin{aligned}&-b\big (\varphi _{S}(0)-\sum _{k=1}^{n}kP(k)\left( 1-\epsilon _{k}^{I}\right) /\langle k\rangle \big )\\&\quad -\frac{\tau }{\tau +\gamma }(1-\varphi _{S}(0))=0. \end{aligned}$$Recalling \(\varphi _{S}(0)=1-\sum _{k=1}^{n}kP(k)\epsilon _{k}^{I}/\langle k\rangle \) and substituting it into the above equation, we obtain \(\varphi _{S}(0)=1\), which is equivalent to
$$\begin{aligned} \sum _{k=1}^{n}kP(k)\epsilon _{k}^{I}/\langle k\rangle =0\Leftrightarrow \epsilon _{k}^{I}=0,\ k=1, \ldots , n. \end{aligned}$$ -
2.
If \(\epsilon _{k}^{I}>0\) for some \(k=1, \ldots , n\), i.e., \(\varphi _{S}(0)\in (0, 1)\), then we obtain
$$\begin{aligned} g(0)=1-b\varphi _{S}(0)-\frac{\tau }{\tau +\gamma }(1-\varphi _{S}(0)), \end{aligned}$$and
$$\begin{aligned} 0<\frac{\gamma }{\tau +\gamma }<g(1)=1-\frac{\tau }{\tau +\gamma }(1-\varphi _{S}(0))<1. \end{aligned}$$Noting that
$$\begin{aligned} 0<b<\frac{\delta _{1}\tau }{\delta _{1}\tau +\kappa }+\frac{q\kappa }{\delta _{1}\tau +\kappa }+\frac{(1-q)\kappa }{\delta _{1}\tau +\kappa }=1, \end{aligned}$$then we have
$$\begin{aligned} g(0){>}1{-}\varphi _{S}(0){-}\frac{\tau }{\tau {+}\gamma }(1{-}\varphi _{S}(0))=\frac{\gamma }{\tau +\gamma }(1-\varphi _{S}(0))>0, \end{aligned}$$and \(g(0)<1\). This means that the graph of g initiates above and terminates below the diagonal (the line segment linking two points (0, 0) and (1, 1)). Since g is strictly increasing and convex in the interval [0, 1], it has a unique intersection with the diagonal, that is, a unique fixed point \(y^{*}\in (0, 1)\) exists. In addition, it holds that \(g(y)>y\) in \([0, y^{*})\) and \(g(y)<y\) in \((y^{*}, 1]\). \(\square \)
Remark 2.5
Similar to the approach in [39], model (36) could be directly extended to influenza-like diseases in quenched networks with degree correlation. In particular, the probability \(\theta (t)\) that a randomly chosen edge has never transmitted infection by time t should be associated with the degree k of a node, i.e., \(\theta _{k}(t)\). Thus, the implicit equations of n dimension for final epidemic size are obtained.
The solution of (46) can be acquired by using an iteration method. In fact, according to Lemma 2.4, we immediately have the following result on the solvability of Eq. (46). The proof is similar to Theorem 2.3, so we omit it here.
Theorem 2.5
If \(\tau , \kappa , \gamma , \eta >0\), and \(\epsilon _{k}^{I}\in [0, 1)\), \(k=1, \ldots , n\), then for any \(y_{0}\in (0, 1)\), the sequence defined by the iteration \(y_{l+1}=g(y_{l})\) converges to \(y^{*}=\theta (\infty )\).
4 Numerical simulations
In this section, we numerically investigate the effect of network topology and infection rate on the spread of an influenza epidemic.
Noting that if \(\delta _{2}=0\) and \(q=1\), our model reduces to the SEIR model with infectious force in latent period in [45]. In [45], the model agrees well with the ensemble means of stochastic simulations, including different initial distribution of infectious seeds, length of latent period and types of networks. Hence, we will not compare our model with the ensemble means of stochastic simulations here. Alternatively, we briefly introduce the algorithms for contact networks generated and stochastic epidemic simulations. To generate the idealized networks, we use the configuration model, also called the Molloy–Reed model [46]. Specifically, for a network with N nodes and given degree distribution P(k), each node is assigned a number of k “stubs” which is randomly drawn from P(k), then two randomly selected stubs from nodes that are not same or not already neighbors are paired. This pairing procedure is repeated until no more stubs can be paired, and the remaining stubs are given up. Contact networks of configuration type can well capture the network of interest if the only available network statistic is its degree distribution.
To simulate the epidemic process on contact networks, we use the Gillespie numerical method [47]. Specifically, each node is labeled by its infection status, namely, susceptible, incubative, infectious with symptom, infectious without symptom and recovered. Once a node gets infection, it enters an incubation phase and is associated with an exponentially distributed incubation period with mean \(1/\kappa \), after which it develops symptom with probability q and is associated with an exponentially distributed infectious period with mean \(1/\gamma \), or it has no symptom with probability \(1-q\) and is associated with an exponentially distributed asymptomatic period with mean \(1/\eta \). After the infectious period or asymptomatic period, its infection status becomes recovered. During the period that a node has some infectivity, contact events are generated for each of its edges emanating from the node. In particular, the waiting times for the contacts along each edge emanating from infectious nodes are exponentially distributed with mean \(1/\tau \), the waiting times for the contacts along each edge emanating from incubative nodes are exponentially distributed with mean \(1/(\delta _{1}\tau )\), and the waiting times for the contacts along each edge emanating from asymptomatic nodes are exponentially distributed with mean \(1/(\delta _{2}\tau )\). If the contacting node is susceptible, then it becomes incubative, otherwise, the contact event is ignored and a new contact event is generated. The process stops when it reaches a predetermined terminal time, for example, when there is no any node with infectivity left.
The disease parameters are mainly based on the spread and epidemiology of the 1957 influenza epidemic with per day as the default time unit [5]. In particular, the parameters used for influenza are \(\delta _{1}=0\), \(\delta _{2}=0.5\), \(\kappa =0.526\), \(q=0.667\) and \(\gamma =\eta =0.244\), and the initial conditions are \(S(0)=1988/2000\), \(I(0)=12/2000\) (initial infectious nodes are randomly selected in a network) and \(L(0)=A(0)=R(0)=0\). The attack rate is defined as the proportion of the susceptible population that develops infection symptoms over the course of the epidemic, and in our notation this is \(q(1-S(\infty )/S(0))\). In [5], the average attack rate for the entire population is estimated to be 0.326. If we use an attack rate of 0.326, i.e., \(q(1-S(\infty )/S(0))=0.326\), the final density of susceptible population is \(S(\infty )=0.508\). Furthermore, if we specify the degree distribution, we can use the final size relation to estimate the infection rate \(\tau \) and the basic reproduction number \(R_{0}\).
Example 4.1
(Poisson degree distribution) Consider the network with \(N=2000\) and \(P(k)=\langle k\rangle ^{k}\text {e}^{-\langle k\rangle }/k!\). Both the expectation and variance of the Poisson degree distribution are \(\langle k\rangle \). For the model (22), it follows that \(S(\infty )=(1-I(0))\text {e}^{-\langle k\rangle (1-\theta (\infty ))}=0.508\). Given \(\langle k\rangle \), it yields
Then, it follows from (30) that
solving \(\tau \). We show the results in Table 1 for the probability \(\theta (\infty )\) of a stub never transmitted infection at the end of the epidemic, the transmission rate \(\tau \), and the basic reproduction number \(R_{0}\).
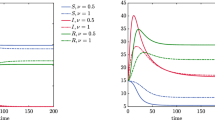
It can be seen in Table 1, as the mean degree \(\langle k\rangle \) increases, the probability \(\theta (\infty )\) increases, however, the transmission rate \(\tau \) and basic reproduction number \(R_{0}\) decrease. In Fig. 3, we show the time series of the infectious and asymptomatic individuals in annealed networks with Poisson degree distribution. Although the final epidemic size is the same in a population, the epidemic peak and the arrival time of the peak differ significantly.

Time series of the number of the infectious (a) and asymptomatic (b) nodes in annealed networks with Poisson degree distribution. Disease parameters except \(\tau \) for model (22) are given in the main text
Example 4.2
(Delta degree distribution) Consider the network with \(N=2000\) and \(P(k)=1\) when \(k=k_{0}\) (zero otherwise). This type of network is regular, including the complete graph as a special case. For the model (22), it follows that \(S(\infty )=(1-I(0))\theta ^{k_{0}}(\infty )=0.508\). Given \(k_{0}\), it yields
Then, it follows from (30) that
solving \(\tau \). We show the results in Table 2 for the probability \(\theta (\infty )\) of a stub never transmitted infection at the end of the epidemic, the transmission rate \(\tau \), and the basic reproduction number \(R_{0}\).
It can be seen in Table 2, as the regular degree \(k_{0}\) increases, the probability \(\theta (\infty )\) increases, and the transmission rate \(\tau \) decreases. However, the basic reproduction number \(R_{0}\) keeps constant. In fact, combining Eq. (49) with Eq. (50), we have
where \(c=q/\gamma +(1-q)\delta _{2}/\eta \) and \(R_{0}=c\tau k_{0}\). It is obvious that for the fixed disease parameters of influenza except \(\tau \) and final epidemic size \(R(\infty )\), the basic reproduction number \(R_{0}\) is determined uniquely by Eq. (51). In particular, if I(0) tends to zero, we obtain the classical final size relation \(R(\infty )=1-\text {e}^{-R_{0}R(\infty )}\). Figure 4 depicts the time series of the infectious and asymptomatic individuals in annealed networks with Delta degree distribution.

Example 4.3
(Scale-free degree distribution) Consider the network with \(N=2000\) and \(P(k)=Ck^{-\iota }\) (\(2<\iota \le 3\)), where C is a normalized constant. Assuming that the minimum degree \(k_{min}=1\) and the maximum degree \(k_{max}=45\), we have \(\langle k\rangle =\sum _{k=k_{min}}^{k_{max}}kP(k)\). Given \(\iota \), one obtains \(\langle k\rangle \). However, it is very difficult to solve \(\theta (\infty )\) from \(S(\infty )=C(1-I(0))\sum _{k=1}^{45}k^{-\iota }\theta ^{k}(\infty )=0.508\). We show some numerical results in Table 3 for several degree exponent \(\iota \).
It can be seen in Table 3, as the degree exponent \(\iota \) increases, that is, the contact heterogeneity decreases, the mean degree \(\langle k\rangle \) and the basic reproduction number \(R_{0}\) decrease, however, the transmission rate \(\tau \) increases. This is not surprising, since as the mean degree \(\langle k\rangle \) decreases, most nodes are not in the largest connected components and form isolated pairs. Thus, larger transmission rate \(\tau \) is required to achieve the same size of final epidemic. Moreover, it can be found that, for a population with the same mean degree \(\langle k\rangle \) and final epidemic size, the network with scale-free degree distribution yields larger basic reproduction number \(R_{0}\). The time series of the infectious and asymptomatic individuals in annealed networks with scale-free degree distribution are shown in Fig. 5.

Similarly, for the model (36), if a population has a fixed contact structure, we may use the final size relation (46) to estimate the transmission rate \(\tau \) and thus the basic reproduction number \(R_{0}\). The procedure proceeds as in annealed networks, though the calculations are more complex and cumbersome.
5 Concluding remarks
We have formulated models for influenza-like diseases in which the individual contacts are represented by contact networks. These models allow for heterogeneous number of contacts, and thus are more general than the classical homogeneous mixing model. We obtained the basic reproduction number, implicit equations for the final epidemic size and the solvability of them for arbitrary network degree distribution. In the case of disease in annealed networks with degree correlation, we derived the formula of basic reproduction number, the implicit equations for final epidemic size and the existence and uniqueness for solutions of final size equations. For annealed networks with no degree correlation, we got a low-dimensional nonlinear system of ODEs by using an edge-based approach and derived the implicit equation for final epidemic size. Moreover, we proved the existence and uniqueness of a fixed point \(x^{*}\), which could be found by iteration. In the case of disease in quenched networks with no degree correlation, we derived a low-dimensional system of nonlinear ODEs by using an edge-based compartmental modeling approach, and obtained the basic reproduction number and the implicit equation for final epidemic size. Also, we proved the existence and uniqueness of a fixed point \(y^{*}\), which could be found by iteration. If network parameters and some epidemiological parameters are known, then the final size relation is helpful for identifying the transmission rate and the basic reproduction number of a disease using the known final epidemic size. Numerical evidence showed that the network topology has great impact on the estimated transmission rate and basic reproduction number, and thus on the spreading behavior of infectious diseases.
It should be noted that annealed networks and quenched networks are two extreme types of network in reality. However, they also provide useful information on the spread and control of diseases such as the epidemic peak, arrival time of the peak and the final epidemic size, etc. If the disease parameters are known, the final epidemic size is dependent on network topology. Furthermore, if the only available information about the network is its degree distribution, the final epidemic size can be estimated from our models, especially for diseases with infectious force in incubative or asymptomatic stage. On the other hand, if the reported case data are collected from public health sources, the parameter identification problem [48] for influenza-like diseases may be addressed based on our results, and then the underlying network structure may be inferred. For example, the population-level epidemic daily data on COVID-2019 is available, so our models could be used to address the parameter identification problem and infer the network structure in a community or population. We leave these topics for further research.
Other interesting extensions of our models include comparable timescales between network dynamics and epidemic processes or movement of population. This requires a dynamic network approach [49], which is a highly challenging and interesting problem in future exploration.
References
https://www.who.int/news-room/fact-sheets/detail/influenza-(seasonal)
https://www.who.int/news-room/detail/11-03-2019-who-launches-new-global-influenza-strategy
Kermack, W.O., McKendrick, A.G.: A contribution to the mathematical theory of epidemics. Proc. R. Soc. Lond. Ser. A 115, 700–721 (1927)
Longini, I.M., Halloran, M.E., Nizam, A., Yang, Y.: Containing pandemic influenza with antiviral agents. Am. J. Epidemiol. 159, 623–633 (2004)
Longini, I.M., Nizam, A., Xu, S.F., et al.: Containing pandemic influenza at the source. Science 309, 1083–1087 (2005)
Arino, J., Brauer, F., van den Driessche, P., Watmough, J., Wu, J.H.: Simple models for containment of a pandemic. J. R. Soc. Interface 3, 453–457 (2006)
Goldstein, E., Dushoff, J., Ma, J.L., et al.: Reconstructing influenza incidence by deconvolution of daily mortality time series. Proc. Nat. Acad. Sci. USA 106, 21825–21829 (2009)
Ma, J.L., Dushoff, J., Earn, D.J.D.: Age-specific mortality risk from pandemic influenza. J. Theor. Biol. 288, 29–34 (2011)
He, D.H., Dushoff, J., Day, T., Ma, J.L., Earn, D.J.D.: Mechanistic modelling of the three waves of the 1918 influenza pandemic. Theor. Ecol. 4, 283–288 (2011)
Asaduzzaman, S.M., Ma, J.L., van den Driessche, P.: The coexistence or replacement of two subtypes of influenza. Math. Biosci. 270, 1–9 (2015)
Asaduzzaman, S.M., Ma, J.L., van den Driessche, P.: Estimation of cross-immunity between drifted strains of influenza A/H3N2. Bull. Math. Biol. 80, 657–669 (2018)
Jaramillo, J.M., Ma, J.L., van den Driessche, P., Yuan, S.L.: Host contact structure is important for the recurrence of Influenza A. J. Math. Biol. 77, 1563–1588 (2018)
Li, M.L., Wang, H., Sun, B.J., Ma, J.L.: The spread of influenza-like-illness within the household in Shanghai, China. Math. Biosci. Eng. 17, 1889–1900 (2020)
Dietz, K.: Epidemics and rumours: a survey. J. R. Stat. Soc. A 130, 505–528 (1967)
Huang, C.L., Wang, Y.M., Li, X.W., et al.: Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. The Lancet 395, 497–506 (2020)
Rothe, C., Schunk, M., Sothmann, P., et al.: Transmission of 2019-nCoV infection from an asymptomatic contact in Germany. N. Engl. J. Med. 382, 970–971 (2020)
WHO: Coronavirus disease 2019 (COVID-2019) situation report—179, WHO (2020)
Arino, J., Brauer, F., van den Driessche, P., Watmough, J., Wu, J.H.: A final size relation for epidemic models. Math. Biosci. Eng. 4, 159–175 (2007)
Diekmann, O., Heesterbeek, J.A.P., Metz, J.A.J.: On the definition and the computation of the basic reproduction ratio \(R_{0}\) in models for infectious diseases in heterogeneous populations. J. Math. Biol. 28, 365–382 (1990)
van den Driessche, P., Watmough, J.: Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmission. Math. Biosci. 180, 29–48 (2002)
Ma, J.L., Earn, D.J.D.: Generality of the final size formula for an epidemic of a newly invading infectious disease. Bull. Math. Biol. 68, 679–702 (2006)
Newman, M.E.J.: Networks: An Introduction. Oxford University Press, Oxford (2010)
Barrat, A., Barthelemy, M., Vespignani, A.: Dynamical Processes on Complex Networks. Cambridge University Press, New York (2008)
Pastor-Satorras, R., Castellano, C., Van Mieghem, P., Vespignani, A.: Epidemic processes in complex networks. Rev. Mod. Phys. 87, 925–979 (2015)
Pastor-Satorras, R., Vespignani, A.: Epidemic spreading in scale-free networks. Phys. Rev. Lett. 86, 200–3203 (2001)
Yuan, S.L., van den Driessche, P., Willeboordse, F.H., Shuai, Z.S., Ma, J.L.: Disease invasion risk in a growing population. J. Math. Biol. 73, 665–681 (2016)
Hao, X., Cheng, S., Wu, D., et al.: Reconstruction of the full transmission dynamics of COVID-19 in Wuhan. Nature (2020). https://doi.org/10.1038/s41586-020-2554-8
Tian, H., Liu, Y., Li, Y., et al.: An investigation of transmission control measures during the first 50 days of the COVID-19 epidemic in China. Science 368, 638–642 (2020)
Tang, B., Xia, F., Tang, S., et al.: The effectiveness of quarantine and isolation determine the trend of the COVID-19 epidemics in the final phase of the current outbreak in China. Int. J. Infect. Dis. 95, 288–293 (2020)
Acuña-Zegarra, M., Santana-Cibrian, M., Velasco-Hernandez, J.: Modeling behavioral change and COVID-19 containment in Mexico: a trade-off between lockdown and compliance. Math. Biosci. 325, 108370 (2020)
Sun, G., Wang, S., Li, M., et al.: Transmission dynamics of COVID-19 in Wuhan, China: effects of lockdown and medical resources. Nonlinear Dyn. (2020). https://doi.org/10.1007/s11071-020-05770-9
Liu, C., Wu, X., Niu, R., et al.: A new SAIR model on complex networks for analysing the 2019 novel coronavirus (COVID-19). Nonlinear Dyn. (2020). https://doi.org/10.1007/s11071-020-05704-5
Xue, L., Jing, S., Miller, J.C., et al.: A data-driven network model for the emerging COVID-19 epidemics in Wuhan, Toronto and Italy. Math. Biosci. 326, 108391 (2020)
Pastor-Satorras, R., Vespignani, A.: Epidemic dynamics in finite size scale-free networks. Phys. Rev. E 65, 035108(R) (2002)
Wang, Y., Cao, J.D., Li, M.Q., Li, L.: Global behavior of a two-stage contact process on complex networks. J. Frankl. I(356), 3571–3589 (2019)
Wang, Y., Cao, J.D., Huang, G.: Further dynamic analysis for a network sexually transmitted disease model with birth and death. Appl. Math. Comput. 363, 124635 (2019)
Berman, A., Plemmons, R.J.: Nonnegative Matrices in the Mathematical Sciences. SIAM, Philadelphia (1994)
Wang, Y., Ma, J.L., Cao, J.D., Li, L.: Edge-based epidemic spreading in degree-correlated complex networks. J. Theor. Biol. 454, 164–181 (2018)
Bidari, S., Chen, X.Y., Peters, D., Pittman, D., Simon, P.L.: Solvability of implicit final size equations for SIR epidemic models. Math. Biosci. 282, 181–190 (2016)
Volz, E.: SIR dynamics in random networks with heterogeneous connectivity. J. Math. Biol. 56, 293–310 (2008)
Miller, J.C., Slim, A.C., Volz, E.: Edge-based compartmental modelling for infectious disease spread. J. R. Soc. Interface 9, 890–906 (2012)
Wang, Y., Cao, J.D., Li, X., Alsaedi, A.: Edge-based epidemic dynamics with multiple routes of transmission on random networks. Nonlinear Dyn. 91, 403–420 (2018)
Mieghem, P.V., Omic, J., Kooij, R.: Virus spread in networks. IEEE/ACM Trans. Netw. 17, 1–14 (2009)
Wang, Y., Cao, J.D., Alsaedi, A., Ahmad, B.: Edge-based SEIR dynamics with or without infectious force in latent period on random networks. Commun. Nonlinear Sci. Numer. Simul. 45, 35–54 (2017)
Molloy, M., Reed, B.: A critical point for random graphs with a given degree sequence. Random Struct. Algorithms 6, 161–179 (1995)
Gillespie, D.T.: A general method for numerically simulating the stochastic time evolution of coupled chemical reactions. J. Comput. Phys. 22, 403–434 (1976)
Magal, P., Webb, G.: The parameter identification problem for SIR epidemic models: identifying unreported cases. J. Math. Biol. 77, 1629–1648 (2018)
Holme, P., Saramäki, J.: Temporal networks. Phys. Rep. 519, 97–125 (2012)
Acknowledgements
The authors are grateful to two anonymous referees for their valuable comments improving the presentation of the paper. This project was partly supported by (i) Fundamental Research Funds for the Central Universities, China University of Geosciences (Wuhan) under Grant CUGGC05, (ii) National Natural Science Foundation of China under Grants 11801532 and 11772306, (iii) China Postdoctoral Science Foundation under Grants 2019T120372 and 2018M630490, (iv) Key Project of Natural Science Foundation of China under Grant 61833005.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Wang, Y., Wei, Z. & Cao, J. Epidemic dynamics of influenza-like diseases spreading in complex networks. Nonlinear Dyn 101, 1801–1820 (2020). https://doi.org/10.1007/s11071-020-05867-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11071-020-05867-1