
Abstract
Current fire danger scales do not adequately reflect the potential destructive force of a bushfire in Australia and, therefore, do not provide fire prone communities with an adequate warning for the potential loss of human life and property. To determine options for developing a bushfire severity scale based on community impact and whether a link exists between the energy release rate (power) of a fire and community loss, this paper reviewed observations of 79 wildfires (from 1939 to 2009) across Victoria and other southern states of Australia. A methodology for estimating fire power based on fuel loading, fire size and progression rate is presented. McArthur’s existing fire danger indices (FDIs) as well as fuel- and slope-adjusted FDIs were calculated using fire weather data. Analysis of possible relationships between fire power, FDIs, rate of spread and Byram’s fireline intensity and community loss was performed using exposure as a covariate. Preliminary results showed that a stronger relationship exists between community loss and the power of the fire than between loss and FDI, although fuel-adjusted FDI was also a good predictor of loss. The database developed for this study and the relationships established are essential for undertaking future studies that require observations of past fire behaviour and losses and also to form the basis of developing a new severity scale.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Since European settlement, Australia has a long history of destructive fires, particularly in the inhabited forest and grasslands of the southern states. Some of the most destructive fires of Australia recorded include Black Friday (1939), Dwellingup (1961), Hobart (1967), Western District (1977), Ash Wednesday (1983), Como/Jannali (1994), Canberra (2003) and, more recently, Black Saturday (2009). These fires impacted communities for many reasons described in a number of inquiries and commissions, the latest being the Royal Commission established to investigate the Black Saturday bushfires (see Teague et al. 2010). These fires were destructive in nature because of the catastrophic losses incurred to communities through the loss of human life, property, assets and infrastructure. Underpinning all of these events are particular weather conditions, fuel type and fuel condition, and how the fire impacts the community, as well as the vulnerability and response of communities.
The way in which destructive and other fires evolve and behave has, in some cases, been well researched and documented in the literature. At the forefront of the research into fire behaviour was the work conducted by McArthur (1962, 1966, 1967) in the 1950s and 1960s on grasslands and forests of southern Australia and simultaneously by Peet (1965, 1967) on forests in Western Australia. More recently, improvements in models relating to fire behaviour have been made for grasslands by Cheney et al. (1993,1998) and for dry eucalypt forests by Gould et al. (2007a, b) as part of Project Vesta that aimed to comprehensively understand and model bushfire behaviour in eucalypt forests in Australia.
Fire danger rating systems (FDRS) are used to assess the potential for bushfire occurrence, fire spread and difficulty of suppression (McArthur 1967; Sharples et al. 2009). Although many examples of fire danger ratings systems exist internationally, this paper focuses on the McArthur fire danger metres because they are widely used in southern Australia for declaring fire bans, informing people of the emerging risk of fire and for planning and allocating resources (McArthur 1966; Luke and McArthur 1978). The McArthur forest and grass FDRS are based on forest and grass fire danger indices (FFDI and GFDI, respectively), which were developed in the 1950s and 1960s using available science, case study evidence and expert opinion (Luke and McArthur 1978). The FFDI and GFDI are proportional to the predicted rate of spread of a fire on flat ground in standard fuel and so are linked to the McArthur fire spread predictions.
The Fire Danger Indices (FDIs) are non-linear functions of simple weather and drought variables that include temperature, relative humidity, wind speed and either drought factor (DF) for forests or curing for grasslands. The forest and grassland fire danger ratings (FFDR and GFDR) are categorical ratings determined from non-linearly increasing ranges of the FFDI and GFDI. Although the McArthur FDRS has been in use for over 50 years, there are some weaknesses in the underlying system. Firstly, experimental studies largely focused on many small scale fires in dry and wet sclerophyll forests in New South Wales and the Australian Capital Territory (ACT) under moderate weather conditions and on a number of experimental fires conducted in dry open sclerophyll jarrah forest in Western Australia (McArthur 1962), but the data were not published (Cheney et al. 1998). These experimental fires were supplemented with observations on three well-documented large wildfires (McArthur 1962) and field observations of small wildfires. Secondly, the most severe conditions represented by both forest and grass metres (FFDI and GFDI values of 100) were based on known worst case fires, the 1939 Black Friday for forests (Cheney et al. 1990) and the 1952 Mangoplah for grasslands. Weather conditions for these fires have since been exceeded a number of times (e.g. Ash Wednesday 1983, Black Saturday 2009). These two weaknesses limit the applicability of the McArthur FDRS in situations where the conditions may be out of the range of those in the fire danger metres. A third problem arises when relating fire danger to community losses because fire danger is determined over broad regional areas, and so factors that affect fire behaviour such as topography, atmospheric conditions and fuel hazard are not included in the FDRS. Finally, FDRS are designed to assess the potential for bushfire occurrence, fire spread and difficulty of suppression (McArthur 1967; Sharples et al. 2009) and not designed for determining the impact on communities.
While the McArthur FDRS has been an essential component of fire danger warnings in Australia, a fire danger rating system is needed that transparently reflects how fire behaviour characteristics determine not only difficulty of suppression, but also the potential for damage to a community. This topic is of fundamental importance for disaster prevention programmes, but has not received much attention in Australia. In establishing such a programme, it is critical to predict the scale of damage caused by the bushfire of a given severity. Although researchers have attempted to address this problem for earthquakes (Samardjieva and Badal 2002) and hurricanes (Pielke et al. 2008), no such study exists for the case of bushfires. Many natural hazards have a scale or rating that can be directly related to the destructive force or potential power of the hazard. For example, earthquakes use the open ended Richter scale, which is based on the amount of seismic energy released by the earthquake (USGS 2010). Additionally, a Mercalli rating was created to measure or rate the effects of an earthquake (USGS 2011) on the Earth’s surface, humans, objects and structures. For hurricanes, the Saffir Simpson Hurricane Wind Scale is used. This scale is made up of five categories distinguished by the intensities of their sustained winds and is primarily used for measuring the potential damage upon landfall (NOAA 2010). Both of these increase by orders of magnitude in impact from one level to another and are potentially linked to the amount of damage caused by the hazard (Simpson and Riehl 1981). In order to establish a link between the scale of the disaster and the amount of damage, a number of studies have attempted to find an empirical relationship between the magnitude of the hazard and the extent of damage to human life and infrastructure by investigating case studies of past hazards (Mizutani 1984; Samardjieva and Oike 1992; Samardjieva and Badal 2002; Pielke et al. 2008; Jaiswal et al. 2010). While these rating systems are measures during or after an event (not a forecast of conditions prior to one eventuating), methods of linking the destructive force to the amount of damage should be considered for categorising bushfire events. A scale that refers to the impact of a bushfire is logical for consistently assessing each event. Such information would be important for disaster prevention and risk reduction purposes in managing and preparing for future bushfires. It is also essential for any future attempts to create or improve the fire danger rating scale in Australia.
The proposal of linking loss and a fire strength metric is not a new idea. Recently, Blanchi et al. (2010) demonstrated that a relationship between fire weather severity and house loss does exist. Furthermore, Gill (1998) theorised developing a ‘Richter-like’ scale for fires based on fireline intensity as the variable associated with destructive force and loss, and other studies have suggested a link between fireline intensity and community loss (e.g. Middelmann 2007; Wang 2006). Fireline intensity is defined as the rate of heat released per unit length of fire front (Byram 1959). Because fire intensity represents an important characteristic for fire propagation, it provides critical information on fire suppression, ecological damage and fire planning (Salazar and Bradshaw 1986). Byram’s fireline intensity is often presented as the only measure of fire intensity (Chandler et al. 1983; Johnson and Miyanishi 2001), but this fails to acknowledge that other measures of energy release from bushfires may provide a better metric for fire impact. For example, losses in communities are typically caused by a combination of wind- and plume-driven fires, which is not reflected in Byram’s fireline intensity. An alternative approach to better capture the plume convective energy is to measure the rate of energy release around the fire perimeter. This presents a surrogate to describe the potential energy that could drive convective plume-driven fires and their consequent impact on communities. The energy release rate in this paper is known as Power—this is not to be confused with Byram’s use of ‘power’ which is ‘the rate at which buoyant air does work in ascending unit vertical distance of the convection column’ (Nelson 2003). ‘Power’ is used in the combustion science sense, where power is the energy released from combustion per unit time (Drysdale 1999) and not in a physics sense, where power is the rate at which work is performed for a given unit of time (Semat and Baumel 1974).
While relationships between fire strength and community impacts have been hypothesised to exist, no data have previously been compiled and analysed to support this theory. However, with a growing, and increasingly improving database of fire statistics covering Australia’s long history of destructive fires, a review of current fire danger ratings can now be conducted using the latest observations and estimates of fire behaviour and fire weather, and an investigation can be made of how these relate to community losses. Therefore, in this study, a comprehensive spatial database of forest and grass fires in Australia has been assembled, which includes fire danger indices (FFDI and GFDI), measures of fire severity (Byram’s fireline intensity and fire power), fire behaviour characteristics (e.g. rate of spread, fire area), community loss (number of fatalities, houses destroyed and economic cost of the fire), site information (e.g. vegetation type and fuel loading) and ancillary information such as weather characteristics. Such a database that combines vital information is necessary to investigate options to develop a bushfire severity scale so that better fire management processes, including community information and warnings, can be put in place.
The aim of this paper is to develop a measure of fire severity, or potential destructive force, focused on community impact, either by improving current FDRS (by accounting for fuel and slope variability), or as a standalone scale. Therefore, a new methodology was established to assess how various measures of fire severity impact on community loss. The paper summarises the procedures developed and explores the relationship between fire behaviour indices/measures of fire power and community loss.
2 Study area
South-eastern Australia experiences relatively frequent major fires with the bushfire danger becoming serious in some parts of Victoria every two to three years (Luke and McArthur 1978). This is because of the regular occurrence of extreme weather (Long 2006), the steep topography and the accumulation of flammable vegetation as well as occasional severe droughts (all of which influence fire behaviour). Eucalypts are the dominant forest type (McArthur 1967), but there are a range of other flammable vegetation types such as mallee heath and coastal heathland (Billing 1987). Due to the natural climate variability in Australia, and specifically in Victoria, large areas are prone to bushfires. Long periods of hot weather, coupled with low rainfall affect vegetation dryness and often cause drought and tinder conditions throughout the state (Bureau of Meteorology 2009). Additionally, if these drought conditions are preceded by high spring rains, the summer bushfires in more grassy communities can be intense due to high grass curing and additional fuel load on the surface (Bureau of Meteorology 2009).
3 Data and methods
To assess the relationship between loss and the destructive power of the fires studied, several data sets were required. Fire weather, fire behaviour, vegetation type, fuel loading, topography, community loss and house and population density information were collected for each fire. The data sets were compiled from a range of sources and each data set is discussed separately. The spatial layers and the tabular data were linked spatially so that where possible spatial information could be extracted for analysis. Several fires were included for which no community loss was recorded so that the risk of loss could be assessed for given weather conditions.
3.1 Summary of fires in the southern states of Australia
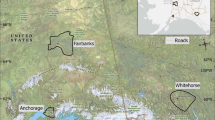
A total of 79 fires were analysed in this study. The number of fires included was largely restricted by data availability. Most of the fires were in Victoria (72); one in Western Australia, two in South Australia, two in New South Wales and two in the ACT. Of the 79 fires, 47 of these were in forested regions and 32 were in grass. Of the fires studied, 35 had one or more fatalities during the event, 25 of these fires occurred in forest and 10 in grass. In terms of house loss, 57 of the 75 fires with house loss information had one or more houses destroyed, 34 of these being in forest and 23 in grass. The locations of the bushfires analysed in this paper are shown in Fig. 1.

The locations of the major bushfires analysed in this study
3.2 Fire perimeters and fire behaviour mapping
A Victorian fire history database created by the Country Fire Authority (CFA) and the Department of Sustainability and Environment (DSE) containing a digital perimeter for many fires was used; however, for some older fires (pre-1980s) and fires from other states, perimeters were only available as paper maps so they were scanned, digitised, geometrically rectified and then added to the geographical information systems (GIS) spatial database.
Many of the fires occurred over several days or were several fires that eventually coalesced. Where it was known, the fire perimeter on the day the damage was incurred was used in the analysis. Isochrones, or the locations of the fire perimeter at known times, were obtained where possible for each fire. These contours detail the spatial spread of the fire perimeter over temporal scales ranging from 10 minutes to daily intervals. Such detailed information is essential for understanding how the fire propagated pre- and post-frontal change, as well as quantifying the rate of spread at various points across the fire. The level of detail for each fire varied depending on the source and age of the fire, and unfortunately, very few fires had highly detailed isochrone information (such as those available for the 2009 fires).
3.3 Fire weather variables
Weather variables were obtained from the Bureau of Meteorology’s automatic weather station data and government reports that described data from manual and automatic weather stations. These data included temperature, relative humidity, rainfall and wind speed and direction. Often the weather stations were a long distance from where the fire occurred and the conditions (topography/elevation) may have been very different. Therefore, the distance between the fire and the weather station was calculated so that this could be incorporated into the analysis.
3.4 Slope
Slope data were calculated from the VicMap DEM20 (resolution of 20 m) for Victorian fires and GEODATA 9 Second digital elevation model (DEM-9S) version 3 (www.ga.gov.au/meta/ANZCW0703011541.html) (resolution approximately 250 m) for all other states.
3.5 Fuel types and loads
Best estimates of fuel load were taken from the literature (including case study reports, journal articles and government agency documents), although some areas lacked any estimate, so modelled fuel loads were used. Modelled fuel loads were created using fuel types, fire history and accumulation curves. Information about the grouping of fuel types and the fuel accumulation rates can be found in Tolhurst (2005) and McCarthy et al. (2009). These data were used to produce estimates of the bark load, surface load and elevated load. For consistency with the literature data, only surface fuel loads estimates from the modelled data were incorporated into the analysis. Where there were no estimates for fuel load in the literature or modelled data, estimates were taken from Gellie et al. (2011).
3.6 Community loss and density
Community loss data were collected from a range of sources many of which were already compiled by the CFA. Estimates of economic loss were also used in the analyses. For the Victorian fires in this study that occurred between 1939 and 2008, economic figures were acquired from the CFA and DSE. These data were constructed according to the State Emergency Risk Assessment Methodology (State Emergency Mitigation Committee 2005) and were corrected to 2008 Australian dollars. Economic data for the 2009 fires were acquired from a recent economic loss assessment (Stephenson 2011), which is based on methods developed by the OESC (2008). These economic figures were also converted to 2008 Australian dollars. This framework was also used to calculate simple economic costs for fires other than those in Victoria.
To assess the community loss in relation to the community affected, house and population density information were required. In order to be more representative in describing the impact of house loss, fatalities and economic loss in fire-affected communities, average densities were calculated over the fire-affected area only. For house density, where possible, aerial photography obtained over a fire-affected region around the time of the fire was collected. These images were georectified, collated as a mosaic, and then each property was digitised to establish the housing density.
Aerial photography was not available for all regions and was not always feasible for ascertaining house density and for estimating the population density; consequently, Australian Bureau of Statistics (ABS) population and housing census data were incorporated. This was achieved by using statistical local boundaries, local government or census districts to provide the best available estimate of broad population and housing densities using the proportion of area burnt and proximity to towns. The ABS data set at the closest time to the fire event was used.
A comparison of the orthophoto and ABS data method was conducted for the 2009 fires to assess how well the two methods compared in capturing housing density. This analysis showed that in the 2009 case, the ABS method overestimated housing density, and for this reason, we weighted the different methods, giving lower weighting to the ABS data (see Table 1).
3.7 Fire danger indices
McArthur’s FDIs were calculated using the weather data from Bureau of Meteorology and government reports. The data were taken when the FFDI was highest for the day. To test the applicability of McArthur’s fire danger metre on community loss, FFDI (Mk V) and GFDI (Mk IV) were calculated for each fire using the same methods as used by the Bureau of Meteorology (2006).
Both FFDI and GFDI are functions of temperature, humidity and wind speed at a height of 10 m. The GFDI includes a measure of grassland curing, whereas the FFDI includes a measure of ‘fuel availability’ reflected in the DF, which is a measure of long-term drying. The DF is a function of the Keetch–Byram Drought Index (KBDI), which estimates the cumulative moisture deficiency in the upper soil layers, and it also incorporates information about the rainfall record (Keetch and Byram 1968). Equations used to determine FFDI were those given in Noble et al. (1980), but with the equation to determine the DF replaced by Griffiths’ algorithm (Griffiths 1999). The equation to determine the GFDI was that given in Purton (1982). Because the indices are used for broad scale applications, both forms of the indices assume standard fuel loadings, being 4.5 t/ha for grasslands (Luke and McArthur 1978) and 12.5 t/ha for forests (McArthur 1967).
3.8 Adjusted fire danger indices
Slope and fuel loading/structure affect fire behaviour (Luke and McArthur 1978). However, these factors are not included in the McArthur FDIs. To better reflect the fire behaviour over the fire area, FFDI and GFDI were adjusted to account for fuel loading and slope in a way that reflects the Mark V Forest Meter and Mark V Grassland Meter spread rate predictions. Equations 1 and 2 are the fuel-adjusted FFDI and GFDI (FFDIF and GFDIF, respectively)
where w is the average fuel load over the fire area in kg/m2, 1.25 is the standard fuel loading for the FFDI (12.5 t/ha) converted to kg/m2, and 0.45 is the standard fuel loading for the GFDI (4.5 t/ha) converted to kg/m2. Equations 3 and 4 are the slope-adjusted FFDI and GFDI (FFDIS and GFDIS, respectively)
where θ is the average slope encountered by the head fire in degrees. The multiplier exp (0.069θ) is given in Noble et al. (1980) as an approximation to the increase in no-slope rate of spread in the Mark V Forest Meter when the slope angle is θ degrees. Adjustments for both fuel and slope are given by Eqs. 5 and 6
These adjustments were used as predictor variables for community loss to see whether they would be better predictors than the unadjusted FFDI or GFDI.
3.9 Intensity and power measures
The most commonly used measure of the ‘strength’ of a fire is Byram’s fireline intensity, I B , which is the rate of heat release per unit length of the active fire front (Byram 1959). It is calculated as
where w a (kg/m2) is the fuel available for burning in the fire front, h (kJ/kg) is the heat yield of the available fuel, and R is the forward rate of spread (m/s). Fireline intensity is thus the rate of energy release over the depth of flame behind unit length of the fire front.
To create a measure describing the energy release rate, two methods were considered. The first method was to multiply the energy release rate per unit length by some characteristic fireline length for which the intensity is reasonably large. This gives an estimate of the power of the fire, PWR1, in the form
where P is the perimeter of the fire, and α is the characteristic fireline length. Three values of α were used, which were equal to the fraction of the ellipse perimeter at which the intensity drops to 0.75, 0.5, and 0.25, respectively, of the maximum intensity, each of which can be shown to be dependent on length-to-breadth ratio, LB. Regressions of log(α) on functions of LB gave
with minimum R 2 of 0.98. The resulting variables are denoted as PWR1(0.25), PWR1(0.50) and PWR1(0.75).
Catchpole et al. (1982) extended the definition of intensity in Eq. 7 to intensity around the perimeter of a fire, where R is replaced by the rate of spread normal to the perimeter. The spread rate, and thus the intensity, varies around the perimeter, as discussed in Catchpole et al. (1982). An estimate of the power of the fire, PWR2, is given by integrating the intensity around the fire perimeter, which is shown in Catchpole et al. (1982) to be
where dA/dT is the rate of area growth with time. It is shown in Harris et al. (2011) that for an elliptical fire with length D T , length-to-breadth ratio LB, at a time T after ignition.
Note that this assumes that the heat yield and available fuel remain constant around the fire, whereas recent studies (e.g. Linn and Cunningham 2005) suggest that the combustion processes are different for heading, flanking and backing fires, thus h and w a would vary somewhat around the perimeter.
The use of the whole fire was necessary as the position of losses for older fires was unknown. However, as stated in Wade and Ward (1973), fires are a function of fire size and the rate at which they spread since this drives the convective phases of the fire. This process draws energy from all sides of the fire perimeter. Having a better account of fire intensity along the total fire perimeter and therefore the total energy output better describes the potential of increased convective energy.
To calculate the power of the fire for fires that have a ‘blow-out’ due to a wind change, a number of different equations are required. Blow-outs in this study are defined as the rapid spread of fire following a major wind change when the flank turns into the head fire. The methods used to calculate the power of the fire from these blow-outs can be found in the Appendix of Harris et al. (2011). The equations are just variations on the equation for an ellipse and cover square, rectangular and triangular blow-outs. This is explained further in the next section.
3.10 Extracting data for calculating power and intensity
To calculate PWR1 and PWR2, each fire was divided into sections that are described by fitting the best geometric shape (e.g. ellipse to represent the main run of the fire). For these geometric shapes, the fire length and width were measured in a GIS platform, and the corresponding length-to-breadth ratio and fire area were calculated (Fig. 2). While each fire does not follow a precise shape, this method was the most consistent and efficient at encapsulating and representing each fire event. Fire start and end times of the ellipse and blow-out were also necessary to calculate the rate of spread (R) of each part of the fire.

One example of applying shapes to actual fire events, in this case the Murrindindi fire: B is breadth of ellipse, L is length of ellipse, B B is the breadth of the blow-out (in this case a rectangle), and L B is the length of the blow-out
The average fine fuel load (w) was extracted from either the literature or the modelled data for the fire-affected area and assumed to equal the available fuel. For the heat yield (h), 20,000 kJ/kg is regarded as a reasonable average for the range of fuels commonly consumed by bushfires (Luke and McArthur 1978). Following Nelson and Adkins (1986), this was corrected for a nominal 20 % energy loss due to radiation and a nominal 5 % loss due to the evaporation of moisture (assuming a moisture content of 5 %) from Table 3.2 in Byram (1959). The power and intensity values were then calculated using the various dimension measurements, rate of spread, fuel load estimates and heat yield. Finally, the average slope was calculated by taking the mean slope within the fire perimeter in a GIS. Average values over the fire were used because the position of the losses was largely unknown. For the power variables, the total power from ellipse and blow-out was used. However, for fires with triangular blow-outs, PWR1 was not applicable, as a characteristic distance for a triangular blow-out is hard to determine. For rate of spread and intensity, the maximum ROS and IB over the ellipse and blow-out were used to be consistent with using the highest FDI values. As PWR1 could not be calculated for triangular blow-outs, only data with PWR1 values were used for comparison of variables.
3.11 Data accuracy classification system
The data were classified into categories that represented the reliability and uncertainties of the data used in the analysis (Table 1). These classifications were based on previous studies such as Cheney et al. (1998) and Bushfire CRC (2009). The numerical weights associated with each category were estimates of the relative reliability determined when setting up the database. These weights were used in the statistical analysis of the relationships, as described in the statistical methods section.
3.12 Statistical methods
The aim was to establish whether there was a relationship between any of the FDIs (raw or adjusted) or any of the measures of the strength of the fire (the independent variable x) and community loss (the dependent variable Y), and if so, which measure of strength (or FDI) gave the strongest relationship.
The data were analysed using generalised linear models (McCullagh and Nelder 1989). To deal with the overly large variation (overdispersion) often found in count data, a quasi-Poisson was assumed. Another possible model that can cope with overdispersion is the negative binomial model, but as pointed out by Ver Hoef and Boveng (2007), the quasi-Poisson model gives more weight to larger losses. Since it is critical to model high losses accurately, the quasi-Poisson model was considered to be preferable.
In addition to overly large variation, count data may contain more zeros than would be allowed for by the standard distributions, and there is also a possibility of underrepresentation of zeros because of the bias towards including fires with some losses in the database. To deal with these situations, a hurdle model (Mullahy 1986; Zeileis et al. 2008) was used. In the hurdle model, there are two component models: a truncated count model that is used for the positive counts and a hurdle component that models zero versus positive counts. In the case of fatalities, for example, the hurdle model may be interpreted as there being one process that determines whether there was a fatality on a fire and another process that determines how many fatalities there were, given that there was at least one fatality.
For the count model with two regressor variables x 1 and x 2, the regression equation with a log link is
where μ is the conditional mean of Y, and b 0, b 1 and b 2 are regression coefficients. A binomial model was used for the zero-hurdle component. For two regression variables, this is
where π is the probability of a non-zero loss, and c 0, c 1, and c 2 are regression coefficients. For the hurdle model with log link, the mean regression relationship is given by
where Μ is the mean loss, η is the function of the regression coefficients in Eq. 12, f z (0,π) is the probability of no losses in the zero-hurdle model, and f z (0, μ) is the probability of no losses in the positive count model. For example, in the case of the hurdle model with a Poisson positive count model and a binomial zero-hurdle model, f z (0, π) = (1−π) and f z (0, μ) = exp(−μ). Equation 14 is used to predict mean loss.
The software did not allow a quasi-Poisson hurdle model. However, the estimates of the coefficients from the quasi-Poisson model are the same as those for the Poisson model, but the standard errors are larger (Agresti 2002). Thus, the hurdle Poisson model was used to fit the data, and the standard errors were calculated using the sandwich covariance matrix estimator (White 1994), to test for the significance of the coefficients. The models were fitted using the software R (R Development Core Team 2011) with the extra packages pscl (Jackman 2011), lmtest (Zeileis and Hothorn 2002) and sandwich (Zeileis 2004, 2006) included for analysis of the hurdle model and for the sandwich covariance estimator.
The economic loss data were continuous and highly skewed to the right. One method of analysing this type of data is to use a generalised linear model with a Gaussian distribution and a log link which essentially assumes a Gaussian distribution of the logarithm of the data. On the other hand, economic loss is highly correlated with house loss and fatalities. As an approximation, the economic loss was rounded to the nearest million dollars and hurdle Poisson models were fitted, as the Gaussian model gave poor regression diagnostics.
The models were assessed using three goodness of fit statistics: the root mean squared error (RMSE), the mean bias error (MBE) (Willmott 1982), and for a non-dimensional standardised measure of goodness of fit, the correlation, r, between the observed values and the fitted model predictions, as recommended by Agresti (2002).
Untransformed regressor variables were fitted as this provided better error statistics than using a logarithmic transformation. The logarithm of house or population exposure (fire area multiplied by density) was used as a covariate regressor variable depending on whether the independent variable was house loss, fatalities or economic loss. For comparison of models, the regressions were unweighted (apart for economic loss that had different reliabilities in the Y variable), but in the final model development, the regressions were weighted. The weighting was done using the product of the relevant fuel, fire behaviour and density weights (as given in Table 1) as this was presumed to reflect the way the errors compounded in the variables. If spread rate was estimated from the McArthur equations, or if one of the FDIs (raw or adjusted) was the regressor variable, the weather reliability weighting was included in the weighting. Sensitivity to the weighting was examined by fitting a non-weighted model and comparing the results.
The analyses were supplemented by residual plots: residuals against fitted values, normal quantile plots of the standardised deviance residuals, square root standardised deviance residuals against fitted values and standardised Pearson residuals against leverage (see Davison and Snell (1991) for details).
4 Results: statistical relationship between loss and fire-related variables
4.1 House loss
Table 2 shows the results of fitting hurdle Poisson models using each fire behaviour measure in turn as the independent variable. The fuel-adjusted FFDI and GFDI were better than the unadjusted values, but the slope-adjusted FDIs were worse. The best predictors were FFDI, GFDI, IB, PWR1(0.50), PWR1(0.75) and PWR2. Of these, the performance of PWR1(0.75) was marginally the best. PWR1 improved with increasing α (smaller fraction of the perimeter) and was better than PWR2 for α > 0.25. ROS was a relatively poor predictor.
In the following analyses for house loss, the best models for the combined data set are developed using weighted data, as appropriate, and the terms in the zero-hurdle model are tested for significance.
4.1.1 Using PWR1(α = 0.75) as the predictor variable
A hurdle Poisson model was fitted using PWR1(0.75) as the predictor variable. The positive count component of the hurdle model was of the form
where the subscript Η indicates house loss, HEXP is the house exposure (fire area times house density), and b 0, b 1 and b 2 are regression coefficients. Note that to predict the mean number of houses lost, Μ H , it is necessary to add the hurdle component to the right hand side of Eq. 15 as in Eq. 14. Only the covariate was significant in the zero-hurdle model. All coefficients in the positive count part of the hurdle model were significant (using a sandwich test for the Poisson model). The predicted values are plotted against the observed values in Fig. 3.

Predicted values plotted against observed values for the prediction equation for house loss in terms of PWR1(0.75) and HEXP (Eq. 15). Fire reliability is shown by shading in the symbols: black filled circles weight greater or equal to 0.55, grey filled circles weight less than 0.55 and greater or equal to 0.35, and open circles weight less than 0.35
The goodness of fit statistics (and for the models developed for fatalities and economic loss) are given in Table 3, and the regression coefficients (and their standard errors) are given in Table 4 (V is the fire-related variable considered and CV is the risk covariate used).
4.1.2 Effect of weighting
The effect of weighting was examined on the house loss model in Eq. 15 by comparing the weighting used with equal weighting. The change had only a small effect on the resulting model coefficients. The coefficient for the intercept, for instance, changed from 1.4873 to 1.4591, a difference of about 2 %. The r values, RMSE and MAE were quite similar, but the bias was less in the unweighted model (1.9 as opposed to −7.7).
4.1.3 Using FFDIF as the predictor variable
A model was also created using FFDIF. It was used in preference to GFDIF as there are generally more house losses in forested areas. The positive count component of the hurdle model was of the form
Only the covariate was significant in the zero-hurdle part of the model. The goodness of fit statistics were similar to those of Eq. 15: r and the RMSE were slightly worse, but the MAE and the MBE were slightly better. Predicted values are plotted against the observed values in Fig. 4.

Predicted values plotted against observed values for the prediction equation for house loss in terms of FFDIF and HEXP (Eq. 16). Fire reliability is shown by shading in the symbols: black filled circles weight greater or equal to 0.55, grey filled circles weight less than 0.55 and greater or equal to 0.35, and open circles weight less than 0.35
4.2 Fatalities
Models were fitted using each fire-related variable in turn, and the results are shown in Table 5. Again, the fuel-adjusted FFDI and GFDI were better than the unadjusted values, but the slope-adjusted FDIs were generally worse. The best predictors were FFDI, GFDI, PWR1(0.50), PWR1(0.75) and PWR2. Of these, the performance of PWR1(0.75) was the best. PWR1 improved with increasing α and was better than PWR2 for α > 0.25. ROS was a relatively poor predictor. IB was similar to the worst of the alternative formulations for PWR1. Note that the data set was dominated by three high fatality fires (Murrindindi, Kilmore and Black Friday—Central and North); thus, any model for fatalities may not be robust. A model was created using PWR1(0.75), but it should be regarded with caution.
The fitted model was of the form
where PEXP is the population exposure. None of the hurdle model coefficients were significant so a quasi-Poisson model was used. The predicted values are plotted against the observed values in Fig. 5.

Predicted values plotted against observed values for the prediction equation for fatalities in terms of PWR1(0.75) and PEXP (Eq. 17). Fire reliability is shown by shading in the symbols: black filled circles weight greater or equal to 0.55, grey filled circles weight less than 0.55 and greater or equal to 0.35, and open circles weight less than 0.35
4.3 Economic loss
House exposure performed slightly better than population exposure, so it was used as a covariate. Loss was also weighted by the economic reliability given in Table 1. Models were fitted using each fire variable in turn, and the results are shown in Table 6. Again, the fuel- and slope-adjusted FFDI and GFDI were better than the unadjusted values. In this case, the slope-adjusted FDIs had similar predictive power to the fuel-adjusted FDIs. The best predictors were the power variables. PWR1 improved with increasing α and was again better than PWR2 for α > 0.25. ROS and IB were relatively poor predictors. The combined data set was dominated by two economic loss fires (Murrindindi and Kilmore); thus, any model for economic loss may not be robust. A model was created using PWR1(0.75), but it should be regarded with caution.
The positive count regression model was of the form
where the subscript Ε refers to economic loss that is measured in millions of dollars. For this model, only the intercept was significant in the zero-hurdle model. The predicted values are plotted against the observed values for this model in Fig. 6.

Predicted values plotted against observed values for the prediction equation for economic loss in terms of PWR1(0.75) and HEXP (Eq. 18). Fire reliability is shown by shading in the symbols: black filled circles weight greater or equal to 0.55, grey filled circles weight less than 0.55 and greater or equal to 0.35, and open circles weight less than 0.35
5 Discussion
5.1 Fire characterisation and limitations
Effort was made to obtain the most reliable data for each fire, but in some cases, this was not possible. Continued development and improvement in the data quality will be made, which may alter some of the findings from this research. To add significant value and improve its use for analysis, additional bushfire case studies should be added, particularly from the national and international scene. The lack of fires from other states obviously biases the analysis as the sampling is not random. The analysis is also biased because a disproportionately small number of fires that did not cause damage are in the database. These fires would be generally smaller fires, and the bias would affect the estimation of the hurdle model parameters, in that the probability of no losses would be underestimated. In addition to this, the modelling is conditional on there being an ignition. This could be extended in future work.
The method of down-weighting poor data is crude and neither takes account of whether the error was in the dependent or independent variable nor uses an estimate of the magnitude of the error. Doing these things would complicate the analysis considerably. Future analysis should cover these aspects.
Using the independent variable (power of the fire or the adjusted FFDI) in a linear form in the equation for the logarithm of loss (such as Eq. 15) results in an exponential form of the independent variable in the prediction equation for loss. Thus, non-zero loss is predicted for zero-values of the independent variable which is obviously incorrect. The problem is exacerbated as the values of the covariate (density or exposure) are increased. However, it is not unusual to get quite high losses for small values of power when the house or population density is high or the fire area is large. As an example, the Como/Jannali fire had a low value of PWR1(0.75) of 6.7 GW but a high house density of 145 houses km−2 (median 1.57 in the data set). It had an economic loss of 51 million dollars (median 10 in the data set), and the model in Eq. 18 predicted 34 million dollars.
To develop a more thorough understanding of the impacts of fire on communities, future estimates of the power of a fire would benefit from focusing on the region of the fire that caused the damage to a community. An estimate of the power of the fire along a given isochrone could be obtained by integrating Eq. 7 in Catchpole et al. (1982) for the rate of spread (and hence intensity) of a point on an arbitrary fire front along the isochrone. Also, more complete measurements of fire behaviour could be made by improving fuel accumulation and fuel load models and by adding fuel estimates for near surface and elevated fuel components, medium woody debris, canopy and live/dead components like those modelled by Keith et al. (2010). This would better quantify the energy release rate of the fire as it considers all available fuels rather than only surface fuels. Furthermore, the vertical atmospheric structure, and how that plays a role in influencing the power of fire (Potter 2002) should be incorporated. Other methods of estimating the energy released during a fire event should also be further investigated, such as those methods developed by Wooster et al. (2005), which estimate fire radiative energy (FRE) and fire radiative power (FRP) from remotely sensed data. Finally, how the scale of a fire event alters the ability of mitigation strategies such as planned burning to alter impacts, and of communities and fire agencies to respond are also important gaps in our knowledge that need to be addressed.
5.2 Performance of the predictor variables
This paper introduced two new methodologies to estimate fire severity, or potential destructive force, through measuring the power of fire. Here, an assessment of the variables used in this paper is made, especially of how they compared and performed with respect to predicting community loss.
5.2.1 FFDI and GFDI
Generally, FFDI and GFDI were found to perform poorly in relation to community loss when compared with the adjusted values and with the measures of power. This is almost certainly due to inherent limitations of the FFDI and GFDI which are meant for broadscale application and solely rely on meteorological input data and are therefore not suitable for a range of fuel loads and topographic regions. It should also be noted that FFDI and GFDI were designed as a predictor of fire initiation, fire spread, ease of suppression and impact on forest and rural farmland values, and not for community loss.
5.2.2 FFDI and GFDI adjusted
The adjustment to the FFDI and GFDI which gave the best predictions was that for fuel alone. Adjusting for slope and fuel provided better predictions than the unadjusted indices but generally not as well as those for fuel alone. The problem may be that the adjustment for average slope over the whole fire does not capture the fire behaviour at the site of the losses. The fuel-adjusted indices were almost equal to or better than the power variables in predicting community loss.
5.2.3 Byram’s intensity and rate of spread
Byram’s fireline intensity has been shown to have great practical value as an indicator of fire severity for fire control purposes (Catchpole et al. 1982), and ecologically, the index has been used to relate damage of trees to fire severity (McArthur and Cheney 1966; Van Wagner 1973). For house loss, it was a possible contender as a predictor variable, but it was not quite as good as the best of the power variables. Rate of spread was a generally a worse predictor of loss than the fuel-adjusted FDIs, IB or the power variables.
5.2.4 Power of the fire
PWR1(0.75) was the best predictor of community loss, although FFDIF came close to it for predicting house loss. It was always slightly better than PWR2. The predictive power increased as less of the perimeter was used, but as it was better than IB that only considers unit length of the perimeter, there is obviously merit in including some characteristic length which is assumed to have burned at a reasonably high intensity.
PWR1(0.75) needs predictions of time since ignition and fire area, and the exposure covariate model needs predictions of fire area. Emerging tools such as Phoenix RapidFire, which is a research and development tool developed by the University of Melbourne and Bushfire CRC, can now be used to estimate the area and time since ignition of a fire through simulation and fire behaviour prediction models. This could be used to provide predictions of possible loss on a local area basis.
5.3 Implications for developing a bushfire severity scale
The current FDRS based on FFDI and GFDI is not adequate for predicting community loss. This report suggested simple modifications to the FFDI through incorporating slope and fuel-loading factors (especially fuel) to increase the predictive power of FFDI. Furthermore, power of fire measures, with continued improvement, could be further explored as a basis for developing a bushfire severity scale. This paper provides an initial insight into establishing a new methodology to describe fire through reconstructing the power released at certain parts of the fire. However, to fully understand and make use of this methodology as a fire severity scale, it is necessary to move from reconstruction to prediction.
The implications that this research, combined with further work, will have on policy decisions is considerable. The ability to calculate the power of the fire, and then at a local scale use it to predict the number of fatalities and house losses (within a range) will have implications for providing communities with more targeted advice to leave in advance of Code Red bushfire days and therefore may result in reducing the number of fatalities. Furthermore, these finding could have implications on fuel management such as prescribed burning for reducing fuel hazard and fuel loads therefore impacting the destructive power of the fire.
Predicting the behaviour of natural phenomena such as fire requires robust fire behaviour models. Computationally, local fire behaviour prediction is becoming more achievable through advancements such as Phoenix RapidFire, but the predictions produced are still only a function of the quality of the data and models that underpin them. This research highlighted the importance of this knowledge in informing fire agencies and community decision-making. Such knowledge is especially important when events of unprecedented scale and magnitude occur. Additionally, events such as those on Black Saturday will invariably occur in a warming and drying climate (Lucas et al. 2007), and making predictions about what might happen involves considerable uncertainty. This uncertainty can be reduced if a solid scientific base can be built that captures what is known from past events (which is not currently the case), and a contemporary view and understanding of fire, how it behaves, how it can be described, and how it can impact communities are therefore needed.
The paper highlights the need for further research into a contemporary fire danger rating system that not only meets traditional fire agency needs relating to preparedness decision-making and impact of forest and rural values, but also includes the potential for bushfires to impact communities. It shows that physical measures that relate to community impact exist and are an improvement on existing FDIs and the standard Byram’s fireline intensity. It also confirms that bushfire behaviour (rate of spread, fire shape and size, fuel consumption and power) and community (settlement patterns) attributes affect bushfire risk and that improved science and data will improve fire danger rating and risk assessments.
6 Conclusion
Developing more robust theories and models of fire behaviour and the impacts of fire on communities is critical for current and future fire risk management. To date, much of Australia’s fire history had not been collated and considered in an integrated way, and yet, this information provides an insight in to the nature and intensity of fires that result in the loss of life and assets or have the potential to do so. This study compiled the most comprehensive database of observations and estimates on fires that have occurred in Victoria and elsewhere in Australia available today. While vast improvements could be made to both the data analysed and the measurements of power of fire, results from the statistical analysis suggest that the current FDRS could be adjusted to improve the warning system, so it better relates to community loss. However, a better approach would be to continue exploring how to measure the power of fire and begin investigating how to base a new bushfire threat warning system on these measures. Given the importance of accurately predicting bushfire threats, improving the measures and predictability of fire power should be a priority in bushfire research in Australia.
References
Agresti A (2002) Categorical data analysis. Wiley, New York
Billing P (1987) Flammability of heaths. In: Bushfires in heathlands conference. Australian Defence Force, Canberra
Blanchi R, Lucas C, Leonard J, Finkele K (2010) Meteorological conditions and wildfire-related house loss in Australia. Int J Wildland Fire 19:914–926
Bureau of Meteorology (2006) Fire weather directive. Victoria Regional Office, Bureau of Meteorology, Australian Government, Australia
Bureau of Meteorology (2009) Bushfire weather. Available from http://www.bom.gov.au/weather-services/bushfire/about-bushfire-weather.shtml. Accessed 17 Oct 2010
Bushfire CRC (2009) Victorian 2009 bushfire research response final report. Available from http://www.bushfirecrc.com/managed/resource/victorian-2009-bushfire-research-response-report-_-overview.pdf. Accessed 4 June 2010
Byram GM (1959) Forest fire behaviour. In: Davis KP (ed) Forest fire control and use. McGraw-Hill, New York
Catchpole EA, deMestre NJ, Gill AM (1982) Intensity of fire at its perimeter. Aust For Res 12:47–54
Chandler C, Cheney NP, Thomas P, Trabaud L, Williams D (1983) Fire in forestry 1. Forest fire behaviour and effects. Wiley, New York
Cheney NP, Wilson AAG, McCaw L (1990) Development of an Australian fire danger rating system. Rural Industries Research and Development Corporations, Project No. CSF-35A Report, Canberra, p 24
Cheney NP, Gould JS, Catchpole WR (1993) The influence of fuel, weather and fire shape variables on fire spread in grasslands. Int J Wildland Fire 3:31–44
Cheney NP, Gould JS, Catchpole WR (1998) Prediction of fire spread in grasslands. Int J Wildland Fire 8(1):1–13
Country Fire Authority (2010) Victorian fire history database. CFA, Victoria
Davison AC, Snell EJ (1991) Residuals and diagnostics. In: Hinkley DV, Reid N, Snell EJ (eds) Statistical theory and modelling: in honour of Sir David Cox. Chapman and Hall, London, pp 83–106
Drysdale D (1999) An introduction to fire dynamics, 2nd edn. Wiley, Chichester
Gellie N, Gibos K, Mattingley G, Wells T, Salkin O (2011) Reconstruction of the spread and behaviour of the Black Saturday fires, 7th February 2009. Fire Division, Department of Sustainability and Environment. Government of Victoria, Melbourne, VIC. (submitted)
Gill M (1998) A richter-type scale for fires? Available from http://www.firebreak.com.au/reslet2.html. Accessed 16 June 2010
Gould JS, McCaw WL, Cheney NP, Ellis PF, Knight IK, Sullivan AL (2007a) Field guide—fuel assessment and fire behaviour prediction in dry eucalypt forest. Ensis-CSIRO, Canberra ACT, and Department of Environment and Conservation, Perth, WA
Gould JS, McCaw WL, Cheney NP, Ellis PF, Knight IK, Sullivan AL (2007b) Project Vesta—fire in dry eucalypts forest: fuel structure, fuel dynamics and fire behaviour. Ensis-CSIRO, Canberra ACT, and Department of Environment and Conservation, Perth WA
Griffiths D (1999) Improved formula for the drought factor in McArthur’s forest fire danger meter. Aust For 62:210–214
Harris S, Anderson A, Kilinc M, Fogarty L (2011) Establishing a link between the power of fire and community loss: the first step towards developing a bushfire severity scale. Fire and Adaptive Management Report Series No 89, Department of Sustainability and Environment
Jackman S (2011) pscl: classes and methods for R developed in the political science computational laboratory, Stanford University. Department of Political Science, Stanford University, Stanford, California. R package version 1.03.10. http://pscl.stanford.edu/
Jaiswal K, Wald D, Porter K (2010) A global building inventory for earthquake loss estimation and risk management. Earthq Spectra 26:731–748
Johnson EA, Miyanishi K (eds) (2001) Forest fires: behavior and ecological effects. Academic Press, San Diego
Keetch JJ, Byram GM (1968) A drought index for forest fire control. Research Paper SE-38. USDA Forest Service
Keith H, Mackey B, Berry S, Lindenmayer D, Gibbons P (2010) Estimating carbon carrying capacity in natural forest ecosystem across heterogenous landscapes: address sources of error. Glob Change Biol 16(11):2971–2989
Linn RR, Cunningham P (2005) Numerical simulations of grass fires using a coupled atmosphere–fire model: basic fire behavior and dependence on wind speed. J Geophys Res 110:D13107
Long M (2006) A climatology of extreme fire weather days in Victoria. Aust Meteorol Mag 55:3–18
Lucas C, Hennessy K, Mills G, Bathols J (2007) Bushfire weather in Southeast Australia: recent trends and projected climate change impacts. Bushfire CRC and Australian Bureau of Meteorology and CSIRO Marine and Atmospheric Research
Luke RH, McArthur AG (1978) Bushfires in Australia. Australian Government Publishing Services, Canberra
McArthur AG (1962) Control burning in eucalypt forests. Forestry and Timber Bureau Australia Leaflet No. 80, Canberra
McArthur AG (1966) Weather and grassland fire behaviour. Forestry and Timber Bureau Australia Leaflet No. 100, 23 pp
McArthur AG (1967) Fire behaviour in eucalypt fuels. Forestry and Timber Bureau Australia Leaflet No. 107, 36 pp
McArthur AG, Cheney NP (1966) The characterization of fires in relation to ecological studies. Aust For Res 2:36–45
McCarthy GJ, Tolhurst KG, Chatto K (2009) Overall fuel hazard guide. Department of Sustainability and Environment
McCullagh P, Nelder JA (1989) Generalized Linear Models. Chapman and Hall, London
Middelmann MH (2007) Natural hazards in Australia: identifying risk analysis requirements. Department of Industry, Tourism & Resources. Commonwealth of Australia, Australia
Mizutani T (1984) Some relationships between intensity of hazardous natural events and amount of disaster damage. Department Bulletin Paper, Tokyo Metropolitan University, Tokyo, p 10
Mullahy J (1986) Specification and testing of some modified count data models. J Econom 33:341–365
Nelson RM Jr (2003) Power of the fire—a thermodynamic analysis. Int J Wildland Fire 12(1):51–65
Nelson RM Jr, Adkins CW (1986) Flame characteristics of wind-driven surface fires. Can J For Res 16:1293–1300
NOAA (2010) The Saffir-Simpson hurricane wind scale. Available from http://www.nhc.noaa.gov/sshws.shtml. Accessed 14 Nov 2010
Noble IR, Bary GAV, Gill AM (1980) McArthur’s fire-danger meters expressed as equations. Aust J Ecol 5:201–203
OESC (2008) The development of a socio-economic impact assessment model for emergencies. Office of Emergency Services Commissioner (draft version)
Peet GB (1965) A fire danger rating and controlled burning guide for the northern Jarrah (Euc. Marginata) forest of Western Australia. Department of Western Australia Bulletin: 74
Peet GB (1967) Controlled burning in the forests of Western Australia. In: Ninth commonwealth forestry conference, India
Pielke RA Jr, Gratz J, Landsea CW, Collins D, Saunders MA, Musulin R (2008) Normalized hurricane damage in the United States: 1900–2005. Nat Hazards Rev 31:29–42
Potter BE (2002) A dynamics-based view of fire-atmosphere interactions. Int J Wildland Fire 11:247–255
Purton CM (1982) Equations for the McArthur Mark 4 fire danger meter. Regional Office, Bureau of Meteorology
R Development Core Team (2011) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. ISBN 3-900051-07-0. http://www.R-project.org
Salazar LA, Bradshaw LS (1986) Display and interpretation of fire behavior probabilities for long-term planning. Environ Manage 10:393–402
Samardjieva E, Badal J (2002) Estimation of the expected number of casualties caused by strong earthquakes. Bull Seismol Soc Am 92:2310–2322
Samardjieva E, Oike K (1992) Modelling the number of casualties from earthquakes. J Nat Disaster Sci 1:17–28
Semat H, Baumel P (1974) Fundamentals of physics. Holt, Rinehart and Winston, New York
Sharples JJ, McRae RHD, Weber RO, Gill AM (2009) A simple index for assessing fire danger rating. Environ Model Softw 24:764–774
Simpson RH, Riehl H (1981) The hurricane and its impact. Louisiana State University, Baton Rouge
State Emergency Mitigation Committee (2005) State emergency risk assessment methodology. Department of Justice
Stephenson C (2011) The impacts, losses and benefits sustained from five severe bushfires in south-eastern Australia. Fire and adaptive management report series No 88. Department of Sustainability and Environment
Teague B, McLeod R, Pascoe S (2010) Victorian Bushfires Royal Commission: final report. Parliament of Victoria
Tolhurst K (2005) Conversion of ecological vegetation classes (EVCs) to fuel types and calculation of equivalent fine fuel loads with time since fire, in Victoria, pp 1–7
USGS (2010) The Richter magnitude scale. Available from http://earthquake.usgs.gov/learn/topics/richter.php. Accessed 14 Nov 2010
USGS (2011) The modified Mercalli intensity scale. Available from http://earthquake.usgs.gov/learn/topics/mercalli.php. Accessed 30 Nov 2011
Van Wagner CE (1973) Height of crown scorch in forest fires. Can J For Res 3:373–378
Ver Hoef JM, Boveng PL (2007) Quasi-Poisson vs negative binomial regression: how should we model overdispersed count data. Ecology 88:2766–2772
Wade DD, Ward DE (1973) An analysis of the air force bomb range fire. Research paper SE-105. USDA Forest Service—Southeastern Forest Experiment Station, Asheville, p 41
Wang H (2006) Ember attack: its role in the destruction of houses during ACT bushfires in 2003. In: Bushfire conference 2006, Brisbane, 6–9 June 2006
White H (1994) Estimation, inference and specification analysis. Cambridge University Press, Cambridge
Willmott CJ (1982) Some comments on the evaluation of model performance. Bull Am Meteorol Soc 63:1309–1313
Wooster MJ, Roberts G, Perry GLW, Kaufman YJ (2005) Retrieval of biomass combustion rates and totals from fire radiative power observations: FRP derivation and calibration relationships between biomass consumption and fire radiative energy release. J Geophys Res 110(D24311):1–19. doi:10.1029/2005JD006318
Zeileis A (2004) Econometric computing with HC and HAC covariance matrix estimators. J Stat Softw 11(10):1–17. http://www.jstatsoft.org/v11/i10/
Zeileis A (2006) Object-oriented computation of sandwich estimators. J Stat Softw 16(9):1–16. http://www.jstatsoft.org/v16/i09/
Zeileis A, Hothorn T (2002) Diagnostic checking in regression relationships. R News 2(3):7–10. http://CRAN.R-project.org/doc/Rnews/
Zeileis A, Kleiber C, Jackman S (2008) Regression models for count data in R. J Stat Softw 27:1–25
Acknowledgments
We acknowledge funding from the Department of Sustainability and Environment (DSE) and the Office of Emergency Services Commissioner (OESC)–Department of Justice, through the Bushfire Cooperative Research Centre (CRC) and to Project Management and Facilitation by Bushfire CRC, DSE, Country Fire Authority (CFA) and Monash University. Thanks to the invaluable comments from Lachie McCaw (Department of Environment and Conservation), Andrew Sullivan (Commonwealth Scientific and Industrial Research Organisation (CSIRO)), Jim Gould (CSIRO), Miguel Cruz (CSIRO), Robin Hicks (Bureau of Meteorology), David Packham (Monash University), Richard Thornton (Bushfire CRC), Graham Hepworth (Melbourne University, Statistical Consulting Centre), Ralph Nelson (United States Forest Service (USFS), retired) and Brian Potter (USFS), and to Dave Anderson for additional statistical methods and ideas. Finally, thanks to Neil Burrows and three anonymous reviewers for their constructive review of the manuscript.
Open Access
This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Harris, S., Anderson, W., Kilinc, M. et al. The relationship between fire behaviour measures and community loss: an exploratory analysis for developing a bushfire severity scale. Nat Hazards 63, 391–415 (2012). https://doi.org/10.1007/s11069-012-0156-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-012-0156-y