
Abstract
Object trackers based on Siamese networks view tracking as a similarity-matching process. However, the correlation operation operates as a local linear matching process, limiting the tracker’s ability to capture the intricate nonlinear relationship between the template and search region branches. Moreover, most trackers don’t update the template and often use the first frame of an image as the initial template, which will easily lead to poor tracking performance of the algorithm when facing instances of deformation, scale variation, and occlusion of the tracking target. To this end, we propose a Simases tracking network with a multi-attention mechanism, including a template branch and a search branch. To adapt to changes in target appearance, we integrate dynamic templates and multi-attention mechanisms in the template branch to obtain more effective feature representation by fusing the features of initial templates and dynamic templates. To enhance the robustness of the tracking model, we utilize a multi-attention mechanism in the search branch that shares weights with the template branch to obtain multi-scale feature representation by fusing search region features at different scales. In addition, we design a lightweight and simple feature fusion mechanism, in which the Transformer encoder structure is utilized to fuse the information of the template area and search area, and the dynamic template is updated online based on confidence. Experimental results on publicly tracking datasets show that the proposed method achieves competitive results compared to several state-of-the-art trackers.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Object tracking plays a vital role in the field of computer vision, finding wide-ranging applications in areas such as video surveillance, human-computer interaction, vehicle navigation, animal behavior analysis, and military observation [1, 2]. However, owing to the intricacies in real-world scenarios, during the tracking process, factors such as deformation, occlusion, fast motion, and background clutter have the potential to exacerbate the disparity between the current target and the template to a certain extent, leading to bounding box deviations and even tracking failure [3, 4].
Siamese-based trackers have significantly progressed in recent years and attained outstanding performance across various datasets. SiamFC [5] comprehensively and thoroughly integrates the Siamese network into object tracking, treating object tracking as a straightforward similarity measurement problem. Li et al. [6] introduced the Region Proposal Network (RPN) [7] from object detection into the object tracking task, proposing the SiamRPN. On this basis, the proposed classic trackers DaSiamRPN [8], SiamDW [9], SiamRPN++ [10] and SiamMask [11] all have demonstrated exceptional performance.
Although these works have significantly advanced the development of visual tracking in many ways, there are still certain limitations. One issue is that they use the correlation operation to fuse information from the template branch with information from the search branch to accomplish similarity matching. However, the correlation operation is a local linear matching process that overlooks crucial semantic information. During the information fusion process, this will significantly lose valuable tracking information from the template feature map and the search region feature map. Another issue is that the majority of trackers utilize offline training approaches and solely incorporate the object’s initial information. They only used the first frame of the image as the initial template, and tracking drift is prone to occur when facing deformation, appearance change, and occlusion of the tracking target.
In view of this, we present a Simases tracking network with multi-attention mechanism. To address the issues related to semantic information loss, detailed feature loss, and limited global modeling capability, the hybrid architecture of CNN-Transformer is adopted to perform feature extraction through CNN as the backbone network, and the attention mechanism of Transformer is used for feature enhancement and feature integration of target template and search region. The network structure contains a template branch and a search branch. The template branch adapts to changes in the target’s appearance by adding dynamic templates and introduces a multi-attention mechanism to obtain a more effective feature representation by fusing the initial template and dynamic template features. The search branch, on the other hand, employs a multi-scale feature fusion approach to capture information from different scales within the search region. As a result, the tracking model’s robustness is significantly enhanced by leveraging these multi-scale features. Moreover, a lightweight and streamlined feature fusion mechanism is given rather than relying on traditional cross-correlation operations. Specifically, the Transformer encoder structure fuses information from the template and search regions. This approach simplifies the network structure, improving tracking speed without sacrificing performance.
To summarize, this work has the following three main contributions:
-
(1)
We emphasize the importance of adapting to target appearance changes for accurate tracking and propose an online dynamic template updating mechanism and a multi-template feature fusion module. The real-time updated dynamic templates provide rich temporal and spatial feature information, and the adopted multi-attention mechanism helps to obtain effective multi-template feature representations, thereby improving the tracking performance of the network.
-
(2)
We develop a tracking network oriented to unique feature information of the target at different scales, in which a multi-scale feature fusion module is presented to couple the feature information of different scales in the search region to obtain more robust multi-scale fusion features, therefore improving the algorithm’s accuracy.
-
(3)
We design a lightweight and simple fusion mechanism based on the Transformer encoder-decoder structure to integrate information from the template region and search region. Due to abandoning the tedious encoding-decoding process, the computational complexity of the model has been greatly reduced.
2 Related Work
This section provides a brief overview of the object tracking methods, encompassing Siamese network-based and Transformer-based approaches.
2.1 Tracking Methods Based on Siamese Network
In recent years, Siamese-based networks have garnered widespread attention in visual tracking due to their high accuracy and real-time speed. Tao et al. [12] introduced SINT, as the pioneering work of Siamese tracking, the SINT algorithm first transforms the target tracking task into a target matching problem, effectively improving the tracking performance. SiamFC [5] is the first fully convolutional tracking network in the target tracking task. It designs a simple model structure to accurately predict the target position by calculating the similarity between different positions in the search area and target features. In SiamRPN++ [10], deep cross-correlation is proposed to fuse the template and search branches. Anchor-free trackers to solve the limitation of anchors, such as SiamFC++ [13], Ocean [14], SiamBAN [15], SiamCAR [16] and SiamADT [17] introduce the anchor-free strategy in target detection into the tracking field, which alleviates the problem of hyperparameter sensitivity and improves tracking accuracy. However, some issues in the correlation operation have been overlooked: (1) Correlation operations do not fully use the global context information and easily fall into local optima; (2) During the information fusion process, valuable tracking semantic information is lost; (3) The correlation operation restricts the tracker from capturing the intricate nonlinear relationship between the template and search branches. Therefore, we design an attention-based feature fusion approach to replace conventional cross-correlation operations, yielding highly effective results.
Siamese-based trackers are susceptible to interference from occlusions, appearance deformations, and similar objects. If the template is not updated promptly, the tracker may fail. Therefore, the latest trackers are working on the issue of template updating. MLT [18] proposes a meta-learning network for template updating. Grad-Net [19] generates an optimal template for the next frame by updating the template based on gradients. Update-Net [20] combines the initial, accumulated, and current frame templates, using a convolutional neural network to predict the best template for the next frame. In this study, an attention mechanism is employed to fuse features from the initial template and dynamic templates, yielding a multi-template feature information representation to enhance the network’s tracking performance.
2.2 Tracking Methods Based on Transformer
Transformer is a well-known deep-learning model that utilizes an encoder–decoder architecture with attention mechanisms to process sequential data.
Some cutting-edge research has begun to explore the great potential of Transformer in improving tracking algorithms. For instance, Chen et al. [21] introduced TransT, which integrates the Transformer’s encoder-decoder architecture into the Siamese network structure, uses the attention mechanism to focus on useful contextual information, and enhances and fuses template and search area features. Sun et al. improved TransT by introducing an image quality assessment module and an image deblurring module, which boosted the performance in dealing with motion blur. Wang et al. [22] introduced TrDiMP, which uses Transformer to strengthen the template features and search features based on DiMP [23] and improves the matching accuracy of the Siamese network structure. Yan et al. [24] introduced STARK, utilizing the Transformer’s encoder-decoder architecture to model the global dependence between the target and search region. This enables the prediction of the target’s spatial location. SimTrack [25] which uses Transformer’s own capabilities in feature extraction and decoding prediction, and utilizes it as a backbone network to enhance accurate target localization. SparseTT [26] which employs Transformers to enhance the template-search region interaction. Cui et al. [27] used the flexibility of attention operation to propose a Mixed Attention Module (MAM), which simultaneously extracts and integrates target information and obtains a more streamlined tracking approach. Song et al. [28] introduced a novel Transformer architecture featuring multi-scale cyclic shift window attention for visual object tracking, elevating the attention from pixel level to window level. Zhao et al. [29] introduced a new tracking algorithm, using the Transformer encoder and decoder network architecture, giving full play to its powerful attention mechanism, it can capture more contextual information and perform well in large-scale experiments. Lin et al. [30] introduced SwinTrack, which uses Swin-Transformer as the backbone network to extract and fuse image features, achieving high precision and running at real-time speed.
While the Transformer has showcased its exceptional performance, it also confronts challenges such as a high volume of parameters and intricate structure. Drawing inspiration from Transformer [31] within the context of visual applications [32,33,34], in this paper, only one Transformer encoder structure is adopted to fuse the information of the template region and the search region to replace the correlation for similarity matching. Abandon the tedious encoding-decoding process, thereby reducing the amount of model calculation.
2.3 Prompt Learning
Recently, with the emergence of prompt learning methods in the field of natural language processing, researchers have also explored prompt learning-based tracking methods. Cai et al. [35] proposed the Historical Information Prompter (HIP), to effectively incorporate the historical appearance and position information of the target. By integrating historical information prompts, HIPTrack significantly enhances tracking performance without the need to retrain the backbone. UTrack [36] can explicitly perform tracking using target cues and obtain high-level semantic information for robust tracking. Luo et al. [37] proposed MPLT, an RGB-T tracking method based on multi-modal mutual prompt learning. It successfully transfers the object tracking foundation model trained on single-modal images to downstream tasks, achieving high performance. This paper proposes an online template update mechanism. To adapt to the rapidly changing appearance of the target, the dynamic template that changes over time provides temporal information prompts for the tracking framework. By designing a multi-template feature fusion module, the information fusion of dynamic templates and initial templates is used to obtain a richer multi-template feature representation, thereby improving tracking robustness.
3 Method
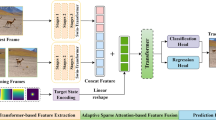
Inspired by the STARK [24], we propose a Simases tracking network with multi-attention mechanism, named SiamSC. The overall framework of the algorithm is shown in Fig. 1. Firstly, in the feature extraction part, a shared-weight ResNet50 [38] is employed as the backbone network to extract features from the initial template, dynamic template, and the current search frame (search region) separately. In the template branch, we propose a Multi-template Feature Fusion (MTFF) module, which utilizes the SA–CA (Self Attention–Cross Attention) mechanism to fuse the initial template’s features and the dynamic template’s features to obtain a richer and more accurate multi-template feature representation. In the search branch, we propose a multi-scale feature fusion (MSFF) module, which extracts feature maps of different scales in the search region from the backbone network and obtains more robust search features through the SA-CA feature fusion network that shares weights with the template branch. Secondly, in the feature fusion module, after the two branches pass through the SA mechanism to enhance the feature representation respectively, only the encoder structure of the Transformer is used to fuse the template and search features, simplifying the fusion mechanism and reducing the computational complexity of the model. Finally, a prediction head that estimates the probability distribution of object corners is used to perform bounding box prediction to obtain tracking results directly. At the same time, after the running frame number of the tracker reaches the update interval and the confidence score in the score prediction head is higher than the threshold \(\tau \), the dynamic template will be updated.

The overall structure of SiamSC. It consists of three parts, the first part is the feature extraction module, the second part is the feature fusion module, and the third part is the prediction head
3.1 Feature Extraction Network
Object tracking encounters various challenges in real-world application scenarios, including target deformation, motion blur, scale change, occlusion, and other factors. These challenges significantly affect the robustness of the tracker. The Siamese tracking network employs the ResNet50 deep residual network as the backbone for feature extraction. The template branch introduces a multi-template feature fusion module to capture rich multi-template features. The search branch proposes a multi-scale feature fusion module to obtain a more robust representation of the search region features, consequently enhancing the algorithm’s accuracy.
The initial template image \(Z_0\in R^{3\times H_{z_0}\times W_{z_0}}\), the dynamic template image \(Z_1\in R^{3\times H_{z_0}\times W_{z_0}}\) and the search region \(X\in R^{3\times H_{z_{0}}\times W_{z_{0}}}\) are taken as input, where \(H_{z_0}\) and \(W_{z_0}\) are the height and width of the initial template area, and the dynamic template is the same as the initial template region in height and width. The final output is the size of the multi-template feature map is \(f_t\in R^{C\times \frac{H_z}{s}\times \frac{W_z}{s}}\), and the size of the multi-scale search region feature map is \(f_{s}\in R^{C\times \frac{H_{x}}{s}\times \frac{W_{x}}{s}}\). Here, s is 16, and C is 384.
3.1.1 Multi-template Feature Fusion Module (MTFF)
The attention mechanism serves as a foundational element in the design of multi-template feature fusion modules. Given queries(Q), keys(K), and values(V), the attention function is formulated as follows:
where Q, K and V represent three input feature vector groups, and \(\sqrt{d_k}\) is the key vector dimension. To allow the model to pay attention to information in different positions, the single-head attention module is extended to the multi-head attention module, which is defined as follows:
where \(W_i^Q\in R^{d_m\times d_k}\), \(W_i^K\in R^{d_m\times d_k}\), \(W_i^V\in R^{d_m\times d_v}\) and \(W^o\in R^{n_hd_v\times d_m}\) are parameter matrices, and \(n_{h}\) is the number of attention heads, which in our work is set to 6.
-
(1)
Self Attention mechanism (SA) The initial template in the template branch is static. To address the issue of poor frame tracking performance when only using the initial template of the first frame as a template, a dynamic template is added based on it, and the dynamic template will adjust to variations in the target’s appearance. The initial template feature map \(f_{z_0}\in R^{d\times \frac{H_{z_0}}{s}\times \frac{W_{z_0}}{s}}\) and the dynamic template feature map \(f_{z_1}\in R^{d\times \frac{H_{z_1}}{s}\times \frac{W_{z_1}}{s}}\) are used as input, respectively. The mechanism of action of SA can be summarized as follows:
$$\begin{aligned}{} & {} \hat{f}_{z_0}=f_{z_0}+\text {MultiHead }(Q_0,K_0,V_0) \end{aligned}$$(4)$$\begin{aligned}{} & {} \hat{f}_{z_1}=f_{z_1}+\text {MultiHead}\left( Q_1,K_1,V_1\right) \end{aligned}$$(5) -
(2)
Cross Attention mechanism (CA) This paper fuses the initial and dynamic templates’ features to obtain multi-template features with rich semantic information. The output initial template features from the SA mechanism are used as query vectors, while the dynamic template features serve as key and value vectors. The output is the fused template feature map \(f_z\in R^{d\times \frac{H_z}{s}\times \frac{W_z}{s}}\). This process can be summarized as follows:
$$\begin{aligned} Q= & {} \hat{f}_{z_0}W_q,K=\hat{f}_{z_1}W_k,V=\hat{f}_{z_1}W_v \end{aligned}$$(6)$$\begin{aligned} f_z= & {} \hat{f}_{z_0}+\text {Multi}\textrm{Head}(Q,K,V) \end{aligned}$$(7)
Thus, the model can effectively use the correlation information between the initial and dynamic templates, and obtain a more accurate and complete multi-template target representation, thereby enhancing the model’s adaptability to different scenarios to enhance the robustness of the tracking task.
The MTFF module achieves the multi-template feature representation by employing the SA–CA mechanism, which operates as follows: Firstly, the initial template feature map \(f_{z_0}\) and dynamic template feature map \(f_{z_1}\) in the template branch are enhanced through the SA mechanism. Secondly, the CA mechanism simultaneously receives the feature mappings of the initial template and dynamic template and performs feature fusion to form a fusion layer. The ultimate output is the feature map \(f_z\in R^{d\times \frac{H_z}{s}\times \frac{W_z}{s}}\) obtained through the SA-CA mechanism, where d is 192. As shown in the black dashed box in Fig. 2, the SA and CA mechanisms are repeated N times, with N being 2.
In the multi-template feature fusion module, we use the self-attention mechanism to enhance the features of the initial template and the dynamic template respectively, and the cross-attention mechanism to perform feature fusion of multiple templates. The purpose of fusion is to effectively retain the feature information of the initial template while fusing the temporal information of the dynamic template to obtain a rich multi-template feature representation and provide reliable information for subsequent tracking tasks.

The structure of SA-CA mechanism
3.1.2 Multi-scale Feature Fusion Module (MSFF)
Features of varying scales encompass distinct feature information about the target object across different scales. Among them, the small-scale features output by the high-level backbone network have low resolution and rich semantic information but are not sensitive enough to the target location information; the large-scale features output by the low-level network have high resolution and contain some shallow features such as color and shape. It has rich positional information but ambiguous semantic information. Therefore, effectively performing multi-scale feature fusion can enhance the tracking performance of target objects.
This paper proposes the MSFF module in the search branch to extract richer multi-scale features from the search area to adapt to the tracking task. The MSFF module obtains multi-scale feature representation by designing the SA-CA mechanism, improving the algorithm’s accuracy. Referring to the SA-CA network structure of the MtFF module, the search feature maps \(f_{x_0}\in R^{d\times \frac{H_{x_0}}{s}\times \frac{W_{x_0}}{s}}\) and \(f_{x_1}\in R^{d\times \frac{H_{x_0}}{s}\times \frac{W_{x_0}}{s}}\) of different scales, extracted via the backbone network, are employed as inputs for the module, and through the SA-CA mechanism which shares weights with the template branch outputs a feature map \(f_{x}\in R^{d\times \frac{H_{x}}{s}\times \frac{W_{x}}{s}}\).
The specific process is as follows: first, two feature maps of different scales generate more discriminative search region feature representations through the SA mechanism, thereby obtaining two feature maps rich in context information. And then through the CA mechanism. The idea of residual learning is used to perform adaptive feature fusion on feature maps of different scales. The multi-scale feature fusion module adopted can further mine the effective information of different scale features in the search area, thereby obtaining more robust multi-scale fusion features.
In the multi-scale feature fusion module, we use the self-attention mechanism shared with the template branch weight to enhance the features of the search area at different scales and then use the cross-attention mechanism to perform multi-scale feature fusion. Different from the multi-template feature fusion module in the template branch that uses the attention mechanism for fusion purposes, to obtain the unique feature information of the target object at different scales, the multi-head attention mechanism is used to fuse the multi-scale features of the search area to adapt to the tracking task.
3.1.3 Channel Splicing
Channel stitching is performed separately in the template and search branches to obtain rich vertical feature information. In the template branch, the process of channel splicing between the initial template feature map \(f_{z_0}\in R^{d\times \frac{H_{z_0}}{s}\times \frac{W_{z_0}}{s}}\) and the feature map \(f_{z}\in R^{d\times \frac{H_{z}}{s}\times \frac{W_{z}}{s}}\) generated by the MTFF module is shown in Fig. 3. The feature map \(f_{z}\in R^{d\times \frac{H_{z}}{s}\times \frac{W_{z}}{s}}\) is split into \(n_{i}\) \(\left( n_i=\frac{d}{m_i}\right) \) groups along the channel dimension, resulting in a multi-template feature map \(f_{t}\in R^{C\times \frac{H_{z}}{s}\times \frac{W_{z}}{s}}\) with enriched feature information. After splicing, the channel dimension changes from d (192) to C (384). Similarly, in the search branch, the search region feature map \(f_{x_0}\in R^{d\times \frac{H_{x_0}}{s}\times \frac{W_{x_0}}{s}}\) is spliced with the feature generated by the MSFF module across the channel dimension, resulting in the concatenated multi-scale fused feature map \(f_{x}\in R^{d\times \frac{H_{x}}{s}\times \frac{W_{x}}{s}}\). The multi-template feature \(f_{t}\) and multi-scale fusion search feature \(f_{s}\) obtained after channel splicing are used to complete the subsequent Transformer feature fusion operation.

The structure of channel splicing
3.2 Transformer Feature Fusion Network
The module consists of two parts: the SA mechanism and the Transformer encoder. As shown in the Transformer feature fusion module in Fig. 1, firstly, the multi-template fusion features and multi-scale fusion features extracted from the feature extraction network are respectively passed through the SA mechanism to enhance their feature representation, and then input to the Transformer encoder for feature fusion.
Instead of traditional methods using cross-correlation operations for feature fusion, a lightweight and simple fusion mechanism is designed based on the encoder-decoder structure, which only uses the Transformer encoder structure to fuse template region and search region information. The structure of the Transformer encoder proposed is shown in Fig. 4. After the SA mechanism, the multi-template feature map \(f_t\in R^{C\times \frac{H_z}{s}\times \frac{W_z}{s}}\) and the multi-scale feature map \(f_{s}\in R^{C\times \frac{H_{x}}{s}\times \frac{W_{x}}{s}}\) use a \(1\times 1\) convolutional layer for dimension reduction to reduce the number of parameters and obtain two lower-dimensional feature maps \(f_z\in R^{d\times \frac{H_z}{s}\times \frac{W_z}{s}}\) and \(f_{x}\in R^{d\times \frac{H_{x}}{s}\times \frac{W_{x}}{s}}\). The number of channels is reduced from C to d. The feature maps of the template and the search regions are flattened into feature vectors along the spatial dimension and then spliced, and the spliced feature vectors \(f\in R^{d\times (\frac{H_{z}}{s}\times \frac{W_{z}}{s}+\frac{H_{x}}{s}\times \frac{W_{x}}{s})}\) is obtained as the input of the encoder. Since the attention mechanism cannot distinguish the position information of the input feature sequence, a sine function is employed for generating the spatial position code, and the spatial position code is introduced into the input feature to ensure that the model knows the position and branch of the feature mark in the process of calculating attention. As shown in Fig. 4, the encoder is designed using a residual network combined with a multi-head self-attention, normalization, and feedforward neural network. The Transformer feature fusion module is repeated N times, where N is 6.

The structure of transformer encoder
The multi-head attention module of the encoder fuses the information from both the template branch and the search branch. Then it strengthens the features through addition, normalization, and fully connected feed-forward networks. The computation process can be described as follows:
The proposed feature fusion method based on the Transformer attention mechanism abandons the cumbersome encoder-decoder process and effectively combines the template and search region features through the encoder structure. Compared to the repetitive and cumbersome encoder–decoder structures of STARK [24] and TrDiMP [22], it has lower computational complexity and improves tracking speed.
In the Transformer feature fusion network, the self-attention mechanism in the encoder can perform global information interaction. Under its action, the features of the template and the search area are deeply fused, and the resulting mixed feature sequence is input to the prediction head for more accurate positioning.
3.3 Online Template Update
In complex real-world scenes, the target’s appearance will also change significantly over time, such as being affected by interference factors such as target deformation, scale variation, and occlusion. Relying solely on the target’s first frame as the template frame can undermine the robustness of the tracker. Hence, this paper introduces an online update template strategy to adjust the template appearance state, thereby improving the robustness of the tracker. As shown in Fig. 1, the template branch adds a dynamic template based on the first frame of the initial target. Specifically, the Siamese network performs feature extraction on the first frame of the template and the dynamic template frame to obtain the initial template feature map and the dynamic template feature map. Then it obtains a richer and more accurate multi-template feature representation through the multi-template feature fusion module. After splicing the multi-template feature vector and the multi-scale search feature vector, the feature fusion is performed through the Transformer feature fusion module. Finally, the feature vector outputted by the Transformer feature fusion module is fed into a score prediction head to decide whether the template should be updated.
While in the tracking process, the cropped dynamic template becomes unreliable in cases where the target is wholly occluded or when the tracker experiences drift. Therefore, the template does not need to be updated when encountering extreme interference factors, and the template can only be updated when the search region encompasses the target object. A straightforward score prediction head is proposed to determine whether the current state is reliable, which is a three-layer perceptron followed by a sigmoid activation. Once the confidence score exceeds the threshold \(\tau \), the present state is deemed dependable, and the target in the current search area is cropped as a dynamic template frame; otherwise, the template does not need to be updated. To enhance efficiency, we set the update interval to \(T_{s}\) frames.
The initial frame template and search region are cropped during inference and input to the tracking network to obtain bounding box results and scores. The dynamic template is updated once the update interval is reached and the confidence score exceeds the threshold \(\tau \).
3.4 Prediction Header
After the encoder is output, the fused total feature representation F is obtained, and then it is separated to derive the enhanced template feature \(f_{z}\) and search feature \(f_{x}\). Referring to the design of the STARK prediction head, the difference from STARK is that the feature fusion in this paper only uses the Transformer encoder structure. Therefore, from the sequence outputted by the encoder, a search feature map \(f_x\in R^{d\times \frac{H_x}{s}\times \frac{W_x}{s}}\) relevant to the target is extracted as the input to the prediction head. Subsequently, the search feature sequence is reshaped to a feature map \(F_x\in R^{d\times \frac{H_x}{s}\times \frac{W_x}{s}}\) and inputted into a basic fully-convolutional network (FCN) for corner heat map prediction. The structure of the box prediction header is shown in Fig. 5.

The structure of the box prediction head
The FCN comprises of L stacked Conv-BN-ReLU layers, generating two probability maps denoted as \(p_l(x,y)\) and \(p_r(x,y)\). These maps correspond to object bounding boxes’ top-left and bottom-right corners. Finally, the predicted box coordinates \((x_l,y_l)\) and \((x_r,y_r)\) are derived by calculating the expected value of the probability distribution of corners as follows:
Compared to regressing bounding box coordinates with a multi-layer perceptron, our network addresses coordinate estimation uncertainty by implementing a prediction head based on corners. This approach contributes to more accurate localization. This representation is more robust to challenges such as occlusion and background clutter in object tracking.
3.5 Loss Function
-
(1)
The first stage Aside from the score prediction head, the entire network is trained end-to-end offline. After the prediction box \(\hat{B}\) is obtained on the search frame, the prediction result of the bounding box is supervised by using the \(L_{1}\) loss and the generalized IoU loss, which is defined as follows:
$$\begin{aligned} L=\lambda _{L_1}L_1(B,\hat{B})+\lambda _{iou}L_{iou}\left( B,\hat{B}\right) \end{aligned}$$(12)where B and \(\hat{B}\) represent the groundtruth and the predicted box respectively and \(\lambda _{L_1}\), \(\lambda _{iou}\) are hyperparameters. We simplify the training process by not using classification loss and the Hungarian algorithm. Ensure that all search images encompass the target object to train the model’s localization capability effectively. Throughout the track, the network accepts a search region extracted from the current frame as input for each frame and generates the predicted box as the ultimate outcome. This is achieved without additional post-processing steps like a cosine window or bounding box smoothing.
-
(2)
The second stage The score head is trained using a binary cross-entropy loss function, which is defined as follows:
$$\begin{aligned} L_c=y_i\textrm{log}\left( P_i\right) +(1-y_i)\textrm{log}\left( 1-P_i\right) \end{aligned}$$(13)where \({y_i}\) represents the ground truth label, and \(P_{i}\) represents the predicted confidence while keeping all other parameters frozen to prevent any interference with the localization capacity. This approach ensures that the final model acquires both localization and classification capabilities simultaneously through a two-stage training process.
4 Experimental Results
4.1 Implementation Details
Our proposed SiamSC is developed using PyTorch 1.7 and Python 3.8. The training is conducted on a workstation with a GTX 3090Ti GPU and an Intel(R) Xeon(R) Silver 4316 CPU @ 2.30 GHz.
The experiment selects the GOT10K, LaSOT, COCO, and TrackingNet as the training dataset and samples the video sequences of the dataset to generate training sample pairs. The training sample pairs include the template images and the search images. The size of the template images is \(128\times 128\). The search images are \(320\times 320\). The complete training procedure of SiamSC involves two stages, with the localization stage spanning 500 epochs and the classification stage spanning 50 epochs. The batch sizes are set to 16, the model optimizer is AdamW, and weight decay \(10^{-4}\). The loss weights \(\lambda _{L_1}\) and \(\lambda _{iou}\) are configured as 5 and 2, respectively. The initial learning rates for the backbone and other components are set at \(10^{-5}\) and \(10^{-4}\), respectively. The learning rate is reduced by 10 after 400 epochs in the first stage and after 40 epochs in the second stage. In the online template update mechanism, the update interval \(T_{s}\) is set to 200 frames, and the confidence score threshold \(\tau \) is set to 0.5.
4.2 Quantitative Analysis
To verify the effectiveness of the algorithm in this paper, the advanced mainstream tracking algorithms (Ocean, SiamRPN++, SiamBAN, TransT, DiMP, STARK, SimTrack, MixFormer, SparseTT, UTT, SBT, CTTrack) for comparative experiments. Experimental results show that the proposed algorithm exhibits good tracking performance.
4.2.1 Results on UAV123
UAV123 is a data set completely taken by drones. It contains a total of 123 video sequences, including 20 long videos, and these sequences have 12 challenges. These challenges are aspect ratio change (ARC), background clutter (BC), camera motion (CM), fast motion (FM), partial occlusion (POC), full occlusion (FOC), illumination variation (IV), low resolution (LR), out-of-view (OV), similar object (SOB), scale variation (SV), viewpoint change (VC). The target object is relatively small in the air tracking sequence, and it is more difficult to track than other benchmark datasets. Evaluation indicators use precision and success rates to evaluate the tracking performance of the algorithm. The precision and success plots from UAV123 visually present the experimental outcomes of the tracker.
The specific test results are shown in Table 1. The table shows that our algorithm achieves the best performance with a significant advantage in both success rate and precision, outperforming mainstream tracking algorithms. Specifically, our tracker achieves a \(1.9\%\) higher success rate and a \(2.5\%\) higher precision than the baseline tracker STARK. Furthermore, our algorithm improves the success rate by 10 to \(15\%\) compared to full-CNN trackers such as DiMP and SiamRPN++ and achieves a \(1.7\%\) improvement compared to full-Transformer trackers like SiamTrack and MixFormer. Compared with the second-ranked fully transformer-based tracker CTTrack and SparseTT, the success rate is \(1.6\%\) higher. Figure 6 depicts the success and precision plots obtained on UAV123.

Success and precision plots on UAV123
To explore whether the rich feature information obtained by the method in feature extraction and whether the introduction of the online template update mechanism can improve the robustness of the tracker, the evaluation is performed separately on similar object, partial occlusion, and scale variation challenge attributes. Figure 7 illustrates the success and precision plots with similar object. Compared with the baseline tracker STARK, the tracking success rate is increased by \(2.6\%\), and the tracking precision is increased by \(2.1\%\). Figure 8 shows the success and precision plots with partial occlusion. Our tracker surpasses STARK by \(2.5\%\) and \(2.6\%\) or success rate and precision, respectively. Figure 9 illustrates the success and precision plots with scale variation. Our tracker also achieves outstanding performance and outperforms STARK with a gain of \(2.2\%\) in success rate.
Furthermore, it can be observed that our tracker achieves the best performance in terms of partial occlusion (POC) and scale variation (SV), surpassing the second-ranked tracker, by \(1.7\%\) and \(1.2\%\) in success rate and by \(1.5\%\) and \(1.2\%\) in precision, respectively. This demonstrates that the introduced online template update mechanism can adjust the template appearance state, and the attention mechanism proposed in the feature extraction part effectively integrates the information from the initial and dynamic template features, thereby enhancing the robustness of the tracker.

Success and precision plots with similar object on UAV123

Success and precision plots with partial occlusion on UAV123

Success and precision plots with scale variation on UAV123
4.2.2 Results on GOT-10K
The GOT-10k provides a rich and challenging environment for object tracking, consisting of over 10,000 real-world video sequences and more than 1.5 million manually annotated bounding boxes across 563 object categories. It is currently one of the mainstream benchmark datasets for evaluating object-tracking algorithms. The evaluation metrics used in this dataset include Average Overlap (AO) and Success Rate (SR).
Table 2 exhibits the detailed experiment results of test trackers. The Average Overlap (AO) is adopted as the primary evaluation metric. Our tracker’s average overlap reaches 0.703, a significant improvement of \(15\%\) to \(35\%\) compared to fully-CNN trackers such as SiamRPN++ and Ocean. This demonstrates that the Transformer-based feature fusion module used in this paper effectively integrates information from both the template region and the search region, enabling the algorithm to more decisively differentiate between background and target features. Compared to CNN-Transformer trackers like STARK and TransT, our tracker improves \(4.6\%\) and \(4.8\%\), respectively, and surpasses the fully-Transformer tracker SimTrack by \(2.5\%\). Compared to CNN-Transformer trackers like UTT, STARK, and TransT, our tracker improves \(4.6\%\), \(4.6\%\) and \(4.8\%\), respectively, and surpassed the fully-Transformer trackers SBT, SpareTT, and SimTrack, increasing by 0.6, 1.4 and \(2.5\%\) respectively.
4.2.3 Results on LaSOT
LaSOT is a large-scale, long-term tracking dataset and evaluation benchmark. It contains 1400 video sequences, including 1120 sequences in the training set and 280 sequences in the test set, with an average of more than 2500 frames per sequence and a total of 3.52 million high-quality manually annotated bounding boxes. Evaluation indicators are success rate and normalized precision.
Table 3 shows that the success rate reaches 0.662 and the normalized precision reaches 0.757, surpassing all fully-CNN trackers by a significant margin. This is attributed to the use of a Transformer encoder in the feature fusion network of this paper, replacing traditional linear cross-correlation operations. Our tracker achieves optimal performance in the CNN-Transformer network architecture, with a \(0.8\%\) improvement in success rate compared to the baseline tracker STARK and a \(2.0\%\) improvement compared to the TransT. Finally, our tracker ranks second in success rate, just behind the fully-Transformer tracker MixFormer and CTTrack. This demonstrates that while using CNN for feature extraction has limitations, the proposed multi-template feature fusion module and multi-scale feature fusion strategy in the feature extraction part can further capture global feature representations. Therefore, our tracker performs considerably on such a large-scale outdoor tracking dataset.
The backbones, parameters, and FLOPs of various trackers are shown in Table 4. Our tracker and other CNN-Transformer trackers such as TransT and STARK successfully balance tracking computational efficiency and robustness. The number of Params and FLOPS is relatively low and it achieves quite good tracking performance. Among them, the tracker in this paper has 33.53 million parameters and obtains high-efficiency results. Although fully-Transformer trackers like CTTrack, SimTrack, and MixFormer utilize Transformers (such as ViT, and CVT) to capture global feature representations to show excellent tracking robustness, their efficiency is much lower than our tracker’s.
Table 5 displays the frame rates for each approach evaluated on the LaSOT dataset. Our proposed SiamSC achieves an average frame rate of 15 frames per second (FPS). As can be observed, without performing online template updates and multi-template feature fusion operations, the tracking speed is 30 FPS, which is similar to the speed of the baseline algorithm.
4.3 Qualitative Analysis
In this section, a comparison is conducted to the advanced trackers about POC, BC, IV, and SV. The objective is to provide a more distinct presentation of SiamSC’s advantages over other object-trackers. The visualization of the tracking outcomes is illustrated in Fig. 10.

A visual comparison of the tracking results of the eight trackers on some sequences. -GroundTruth purple, -SiamSC red, -SimTrack blue, -MixFormer orange, -STARK green
-
(1)
Partial occlusion From Fig. 10a, in the UAV123-car12 sequence, occlusions occur between the car and trees. In the 74th frame, when the target is partially occluded, only SiamSC accurately localizes it, while other methods lose track of it. In the 195th frame, SiamSC maintains stable tracking throughout when the target is heavily occluded again. This demonstrates that adopting the multi-template feature fusion module in the feature extraction stage yields richer semantic information, enhancing the algorithm’s robustness. Additionally, introducing the Transformer encoder structure in the feature fusion stage enables global modeling, further strengthening the robustness of the tracking algorithm in complex scenes. Consequently, our method achieves superior localization accuracy compared to other methods.
-
(2)
Background clutter Video sequences uav7 are susceptible to interference from background clutters. This is evident in Fig. 10b, In the 84th, 118th, and 131st frames, only SiamSC achieves precise localization, while other methods mistakenly identify parts of the occluders as the target, leading to misjudgment. This is because the extracted feature information in the comparative methods is not sufficiently rich to distinguish between the target and background occluders, resulting in tracking failures. From the 110th frame, it can be observed that MixFormer recovers the target, but throughout the tracking process, SiamSC demonstrates more excellent stability and more precise localization compared to MixFormer. This verifies that our proposed multi-scale feature fusion module can mine valuable information from different scale features of the search region to effectively distinguish object features from background features and make bounding box estimation more accurate.
-
(3)
Illumination variation As can be seen from Fig. 10c, when the scene experiences lighting variations, the tracking performance of comparative algorithms deteriorates to varying degrees, and even tracking drift may occur. However, SiamSC can consistently track the target accurately. As shown in the 163rd and 195th frames, the comparative algorithms STARK and SimTrack produce predicted bounding boxes significantly larger than the groundtruth, indicating inaccurate localization.
-
(4)
Scale variation bird1 contains SV. As can be seen from Fig. 10d, In the 65th frame, STARK fails to accurately localize the target when the target undergoes a pose change. In the 72nd frame, STARK re-detects the target and captures some features. However, MixFormer experiences a target transfer and suffers severe tracking drift. In the 107th frame, when the target changes drastically, only SiamSC successfully locates the target, and all the comparison methods lose the object. In contrast, the comparative methods make it difficult to make effective adjustments according to the target’s posture changes. On the other hand, our proposed method can adaptively adjust the predicted bounding box size to track the target robustly, thanks to the online template update strategy and the multi-template feature fusion module introduced in this paper.
4.4 Ablation Experiment
To validate the impact of the multi-template feature fusion module, multi-scale feature fusion module, and the Transformer encoder structure in the SiamSC algorithm on the performance of our method, we conducted ablation experiments on the LaSOT. The results are shown in Table 6.
We adopt STARK-S50 as a baseline, which uses ResNet50 as the backbone network, adopts the feature fusion method of the encoder-decoder structure, and uses the corner prediction head to obtain the tracking results directly. The algorithm has achieved a success rate of 0.657.
Model 1 represents removing the decoder structure, where only the Transformer encoder structure is used for feature fusion in the template branch and search branch. It directly utilizes the search region information obtained from the encoder for bounding box prediction. Compared with the baseline model, it can be observed that removing the entire decoder structure has little impact on the overall performance. Instead, it saves parameters and computational resources. It is reflected from the side that the decoder information is not fully utilized in the baseline structure, which inspired us to use only the Transformer encoder structure in the Transformer feature fusion module.
Model 2 means adding a multi-scale feature fusion module based on Model 1. By combining the features output by the high-level network and the features output by the low-level network, that is, multi-scale feature fusion, more discriminative search area features are obtained, thereby improving the algorithm’s accuracy. This validates the effectiveness of the multi-scale feature fusion module with a minimal computational cost.
Model 3 represents the introduction of an online template updating mechanism and the proposal of a multi-template feature fusion module based on Model 2. By employing the SA-CA mechanism, the model effectively utilizes the correlation information between the initial and dynamic templates, extracting rich semantic information from multiple templates. It achieves a performance improvement of \(0.8\%\) on the LaSOT, demonstrating the effectiveness of this model structure enhancement.
Drawing from the preceding analysis, the LaSOT dataset’s experimental findings confirm each module’s impact within our proposed SiamSC.
5 Conclusion
We propose a Simases tracking network with multi-attention mechanism. Firstly, we introduce an online template updating mechanism to address the issue of poor tracking performance when only using the initial template from the first frame. The template branch incorporates dynamic templates in addition to the initial template, and a multi-template feature fusion module is designed to effectively combine the features from the initial template and dynamic templates, obtaining more informative feature representations. Meanwhile, the search branch utilizes a multi-scale feature fusion approach to obtain rich feature information in the search region, enhancing the tracking capability in complex scenes. Secondly, Instead of traditional correlation operations, we employ a Transformer encoder as the feature fusion module to fuse the features of the template branch and search branches’ features. Additionally, the dynamic templates are updated online based on confidence scores. Finally, the tracking results are directly obtained using a corner-based prediction head. The experimental results show that our algorithm achieves excellent tracking accuracy and speed compared to the advanced tracking algorithm on the UAV123, GOT-10k, and LaSOT, indicating its practical value and potential for further development.
Data Availability
The datasets used in this study are publicly available online. The codes and datasets included during the current study are available in the project website: https://github.com/X-yuzhuo/SiamSC.
References
You S, Zhu H, Li M, Li Y (2019) A review of visual trackers and analysis of its application to mobile robot. arXiv preprint arXiv:1910.09761
Wang F, Cao P, Li F, Wang X, He B, Sun F (2023) Watb: wild animal tracking benchmark. Int J Comput Vis 131:899–917
Ciaparrone G, Sánchez FL, Tabik S, Troiano L, Tagliaferri R (2020) Herrera F Deep learning in video multi-object tracking: a survey. Neurocomputing 381:61–88
Li P, Wang D, Wang L (2018) Deep visual tracking: review and experimental comparison. Pattern Recogn 76:323–338
Bertinetto L, Valmadre J, Henriques J.F, Vedaldi A, Torr P.H Fully-convolutional siamese networks for object tracking. In: Computer Vision–ECCV 2016 Workshops: Amsterdam, The Netherlands, October 8-10 and 15-16, 2016, Proceedings, Part II 14, pp. 850–865 (2016)
Li B, Yan J, Wu W, Zhu Z, Hu X (2018) High performance visual tracking with siamese region proposal network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8971–8980
Ren S, He K, Girshick R (2015) Faster R-CNN: towards real-time object detection with region proposal networks. Adv Neural Inf Process Syst 28:2969239
Zhu Z, Wang Q, Li B, Wu W, Yan J, Hu W (2018) Distractor-aware siamese networks for visual object tracking. In: Proceedings of the European conference on computer vision (ECCV), pp. 101–117
Zhang Z, Peng H (2019) Deeper and wider siamese networks for real-time visual tracking. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 4591–4600
Li B, Wu W, Wang Q, Zhang F, Xing J, Yan J (2019) Siamrpn++: evolution of siamese visual tracking with very deep networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 4282–4291
Wang Q, Zhang L, Bertinetto L, Hu W, Torr PH (2019) Fast online object tracking and segmentation: a unifying approach. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 1328–1338
Tao R, Gavves E, Smeulders AW (2016) Siamese instance search for tracking. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1420–1429
Xu Y, Wang Z, Li Z, Yuan Y, Yu G (2020) Siamfc++: towards robust and accurate visual tracking with target estimation guidelines. In: Proceedings of the AAAI conference on artificial intelligence, vol. 34, pp. 12549–12556
Zhang Z, Peng H, Fu J, Li B, Hu W (2020) Ocean: object-aware anchor-free tracking. In: Computer Vision–ECCV 2020: 16th European conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXI 16, pp. 771–787
Chen Z, Zhong B, Li G, Zhang S, Ji R (2020) Siamese box adaptive network for visual tracking. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 6668–6677
Guo D, Wang J, Cui Y, Wang Z, Chen S (2020) Siamcar: siamese fully convolutional classification and regression for visual tracking. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 6269–6277
Wang F, Cao P, Wang X, He B (2023) Siamadt: siamese attention and deformable features fusion network for visual object tracking. Neural Process Lett. https://doi.org/10.1007/s11063-023-11290-5
Choi J, Kwon J, Lee KM (2019) Deep meta learning for real-time target-aware visual tracking. In: Proceedings of the IEEE/CVF international conference on computer vision, pp. 911–920
Li P, Chen B, Ouyang W, Wang D, Yang X, Lu H (2019) Gradnet: gradient-guided network for visual object tracking. In: Proceedings of the IEEE/CVF international conference on computer vision, pp. 6162–6171
Zhang L, Gonzalez-Garcia A, Weijer JVD, Danelljan M, Khan FS (2019) Learning the model update for siamese trackers. In: Proceedings of the IEEE/CVF international conference on computer vision, pp. 4010–4019
Chen X, Yan B, Zhu J, Wang D, Yang X, Lu H (2021) Transformer tracking. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 8126–8135
Wang N, Zhou W, Wang J, Li H (2021) Transformer meets tracker: exploiting temporal context for robust visual tracking. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 1571–1580
Bhat G, Danelljan M, Gool L.V, Timofte R (2019) Learning discriminative model prediction for tracking. In: Proceedings of the IEEE/CVF international conference on computer vision, pp. 6182–6191
Yan B, Peng H, Fu J, Wang D, Lu H (2021) Learning spatio-temporal transformer for visual tracking. In: Proceedings of the IEEE/CVF international conference on computer vision, pp. 10448–10457
Chen B, Li P, Bai L, Qiao L, Shen Q, Li B, Gan W, Wu W, Ouyang W (2022) Backbone is all your need: a simplified architecture for visual object tracking. In: European conference on computer vision, pp. 375–392
Fu Z, Fu Z, Liu Q, Cai W, Wang Y (2022) Sparsett: visual tracking with sparse transformers. arXiv preprint arXiv:2205.03776
Cui Y, Jiang C, Wang L, Wu G (2022) Mixformer: end-to-end tracking with iterative mixed attention. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 13608–13618
Song Z, Yu J, Chen Y.-P.P, Yang W (2022) Transformer tracking with cyclic shifting window attention. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 8791–8800
Zhao M, Okada K, Inaba M (2021) Trtr: visual tracking with transformer. arXiv preprint arXiv:2105.03817
Lin L, Fan H, Zhang Z, Xu Y (2022) Swintrack: a simple and strong baseline for transformer tracking. Adv Neural Inf Process Syst 35:16743–16754
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A.N, Kaiser Ł, Polosukhin I (2017)Attention is all you need. Advances in neural information processing systems. 30
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S et al (2020) An image is worth 16x16 words: transformers for image recognition at scale. arXiv preprint arXiv:2010.11929
Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, Lin S, Guo B (2021) Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF international conference on computer vision, pp. 10012–10022
Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S (2020) End-to-end object detection with transformers. In: European conference on computer vision, pp. 213–229
Cai W, Liu Q, Wang Y (2023) Learning historical status prompt for accurate and robust visual tracking. arXiv preprint arXiv:2311.02072
Gao J, Zhong B, Chen Y (2023) Unambiguous object tracking by exploiting target cues. In: Proceedings of the 31st ACM international conference on multimedia, pp. 1997–2005
Luo Y, Guo X, Feng H, Ao L (2023) Rgb-t tracking via multi-modal mutual prompt learning. arXiv preprint arXiv:2308.16386
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778
Ma F, Shou M.Z, Zhu L, Fan H, Xu Y, Yang Y, Yan Z (2022) Unified transformer tracker for object tracking. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 8781–8790
Xie F, Wang C, Wang G, Cao Y, Yang W, Zeng W (2012) Correlation-aware deep tracking. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 8751–8760
Song Z, Luo R, Yu J, Chen Y-PP, Yang W (2023) Compact transformer tracker with correlative masked modeling. arXiv preprint arXiv:2301.10938
Acknowledgements
This work was supported by the National Natural Science Foundation of China under Grant 62172137 and 61976042, by the Innovative Talents Program for Liaoning Universities under Grant LR2019020, by the Liaoning Revitalization Talents Program under Grant XLYC2007023 and by the Joint Funds of Liaoning Science and Technology Program under Grant 2023JH2/101800032.
Author information
Authors and Affiliations
Contributions
F. Sun and B. Zhu conceived this study. Y. Xu and F. Sun conducted the experiment and wrote the initial manuscript. T. Li and F. W reviewed and edited it.
Corresponding author
Ethics declarations
Conflict of interest
All authors certify that they have no affiliations with or involvement in any organization or entity with any financial interest or non-financial interest in the subject matter or materials discussed in this manuscript.
Ethics Approval
There is no ethical approval needed in the present study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Xu, Y., Li, T., Zhu, B. et al. Siamese Tracking Network with Multi-attention Mechanism. Neural Process Lett 56, 222 (2024). https://doi.org/10.1007/s11063-024-11670-5
Accepted:
Published:
DOI: https://doi.org/10.1007/s11063-024-11670-5