
Abstract
We propose a simple image high-perception super-resolution reconstruction method based on multi-layer feature fusion model with adaptive compression and parameter tuning. The aim is to further balance the high and low-frequency information of an image, enrich the detailed texture to improve perceptual quality, and improve the adaptive optimization and generalization of the model in the process of super-resolution reconstruction. First, an effective multi-layer fusion super-resolution (MFSR) basic model is constructed by the design of edge enhancement, refine layering, enhanced super-resolution generative adversarial network and other sub-models, and effective multi-layer fusion. This further enriches the image representation of features of different scales and depths and improves the feature representation of high and low-frequency information in a balanced way. Next, a total loss function of the generator is constructed with adaptive parameter tuning performance. The overall adaptability of the model is improved through adaptive weight distribution and fusion of content loss, perceptual loss, and adversarial loss, and improving the error while reducing the edge enhancement model. Finally, a fitness function with the evaluation perceptual function as the optimization strategy is constructed, and the model compression and adaptive tuning of MFSR are carried out based on the multi-mechanism fusion strategy. Consequently, the construction of the adaptive MFSR model is realized. Adaptive MFSR can maintain high peak signal to noise ratio and structural similarity on the test sets Set5, Set14, and BSD100, and achieve high-quality reconstructed images with low learned perceptual image patch similarity and perceptual index, while having good generalization capabilities.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Super-resolution reconstruction is a technology that restores low-resolution images (LR) to super-resolution images (SR), and has been widely used in industrial detection, medical image diagnosis, remote sensing, and other industries [1,2,3]. For example, most of the existing monitoring systems do not have optical zoom capability, and could not provide clear images of key targets to ensure detection efficiency. X-ray detection is often constrained by the resolution of equipment, which reduces the image quality of lesions and defect areas, and increases the difficulty of diagnosis and detection. The remote sensing field is limited by the under-sampling effect of the imaging element and the degradation factor of the link, consequently, the resolution of the remote sensing image is unable to meet the actual demand. Although the current optical zoom can improve the resolution of the image, its application is limited due to the disadvantages of high hardware costs and poor scalability. Therefore, under the conditions of a constant hardware environment, the ability to achieve a super-resolution reconstruction of an image with an efficient image reconstruction model has become a research hotspot in the field of computer vision.
Single-image super-resolution (SISR) reconstruction algorithms can be divided into traditional methods and deep learning-based methods. Traditional SISR methods are mostly implemented by interpolation, reconstruction, etc. However, there are problems of high dependence on small-scale neighborhood information or complex calculations, and it is difficult to guarantee the quality of reconstructed images [4]. The emergence of deep learning is more suitable for recovering high-frequency details of images and the process of high-resolution image reconstruction with larger scaling factors. This is due to the full analysis of the deep features of its convolution model, which provides more research space for the development of super-resolution [5].
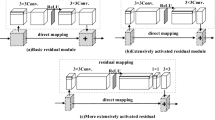
The SRGAN based on deep learning has the advantages of easier recovery of HR and faster reconstruction speed [6]. However, existing studies indicate that there are still some problems that need to be improved: (1) Existing methods mostly focus on the deep feature extraction of single-scale images. As shown in Fig. 1, there is a lack of feature representations of different scales and depths, and a lack of image high and low-frequency information, resulting in missing or blurred edge details of the reconstructed image that affect the quality of the reconstructed image. Furthermore, the balanced reconstruction effect of high- and low-frequency information needs to be improved, and the perceptual quality still needs to be optimized. (2) Currently, super-resolution network structure compression and parameter optimization mostly relies on the subjective experience of developers, which requires professional experience and reliable domain knowledge and optimizes the network structure through a large number of time-consuming “trial and error” experiments to achieve better reconstruction results, lacks the adaptive optimization performance of the model, and often has problems such as structural redundancy and weak model generalization.

The existing problems of super resolution research
In response to the above problems, this study proposes a high-perceptual super-resolution reconstruction method of adaptive multi-layer fusion super-resolution (AMFSR). The effectiveness of the proposed method is proved by comprehensive experiments. The contribution of this article can be summarized in three points:
-
(1)
To further improve the information richness of super-resolution feature extraction and obtain richer high-frequency edge detail information and low-frequency global information, a multi-layer fusion super-resolution (MFSR) model is constructed. Through a single-layer design and multi-layer effective fusion of sub-models such as edge enhancement, refined layering, ESRGAN, etc. The image representation of different scales and different depth of features is further enriched, thereby comprehensively improving the feature representation of images with high and low-frequency information.
-
(2)
To avoid the problem of the subjective weighting of generator loss function weights, a generator total loss function with adaptive tuning performance is constructed. Through the adaptive weight distribution and effective fusion of content loss, perceptual loss, and adversarial loss, the overall adaptability of the model is improved.
-
(3)
To effectively avoid the heavy dependence on professional experience and the high design costs of artificial model compression optimization, the team designed a global optimization strategy based on the multi-mechanism fusion strategy (MFS), and took the constructed perception function, PF, as the fitness function of the optimization strategy. It was successfully applied to the adaptive compression of the MFSR model structure and the adaptive adjustment of key hyperparameters. Finally, the AMFSR model was constructed, which improved the generalization of the model while realizing the model compression optimization.
This paper is arranged as follows. Section 2 discusses related work. Sections 3 and 4 describe the proposed method. Section 5 presents our experiment, and Sect. 6 concludes.
2 Related Work
Many researchers have carried out active research on super resolution reconstruction. In 2014, Dong et al. [7] applied deep learning to image super-resolution for the first time and proposed a super-resolution convolutional neural network (SRCNN) super-resolution model. This algorithm used bicubic interpolation to enlarge LR. After reaching the target size, the super-resolution image (SR) is nonlinearly fitted by 3-layer convolution, and the reconstruction image accuracy and speed are better than traditional super-resolution methods. Subsequently, Kim et al. [8] proposed very deep super-resolution (VDSR). VDSR introduced global residual learning to solve the problem of slow network convergence. In addition, the adjustable structure and gradient clipping technology are applied to the network construction, which deepens the network to 20 layers and improves the network performance and the quality of reconstructed images. At the same time, the receptive field of the feature image was enlarged and the external contour information of the reconstructed image was enhanced. Lim et al. [9] proposed the enhanced deep super-resolution network (EDSR) model, which improves the performance of the model by stacking multiple residual units and eliminates artifacts by removing the batch normalization (BN) layer in the residual block. Kim et al. [10] proposed an efficient unsupervised super-resolution (EUSR), breaking the previous convention of reconstructing super-resolution images through a single scale. EUSR is composed of “enhanced upsampling modules (EUM)”, which splice the output of each EUM module to obtain features of different depth, enhancing feature expression capability. Ledig et al. [11] were the first to propose an image super resolution generative adversarial network (SRGAN) based on a generative adversarial network. This model introduces perceptual loss, adversarial loss, and content loss, and reduces the reconstructed image and ground truth through the mutual game of the generator and the discriminator, so the reconstructed image looks more natural.
Enhanced super-resolution generative adversarial network (ESRGAN) [12] has been widely used because of its residual dense block structure, which can extract the deep features of the image. This method is better at characterizing the high-frequency information of the image and therefore recovers image details and improves the quality of perception. Combining the advantages of ESRGAN and the experimental comparison in Sect. 5.3 of the paper, ESRGAN is selected as the deep feature extractor method in this paper. Figure 2 details the ESRGAN model. After ESRGAN extracts features through 23 residual dense blocks (RRDB), the extracted feature map and the output feature of Conv1 are fused and upsampling is expanded four times. The SR is output after the dimensionality reduction of Conv3 and Conv4. ESRGAN improves the network structure on the basis of SRGAN. It removes the BN blocks in the SRGAN network during the construction of the basic network structure to reduce artifacts in the reconstruction process and converts the sequential connections of the network residual blocks into dense connections. This allows the full use of the features extracted by each layer and enables the generated network to reconstruct images better. However, ESRGAN also has problems. First, ESRGAN focuses on deep feature extraction of single-scale images, and the reconstruction effect of image high- and low-frequency information is not ideal [13]. Second, ESRGAN is relatively large and has low computational efficiency. In addition, the adaptive compression capabilities and generalization ability of the model needs to be further improved.

ESRGAN model structure
3 Multi-layer Fusion Super-Resolution
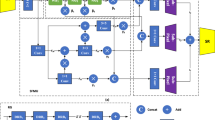
We built a multi-layer fusion super-resolution (MFSR) model. To further verify the optimal combination of each module, we validated the performance of the model through multiple sets of ablation experiments. The ablation experiment can be found in Sect. 5.4. The final experiment shows that both the refine layering module and the edge-enhanced module adopt the parallel method to reconstruct the image with the best quality. Figure 3 shows the model structure of MFSR. We use LR and SR as the low-resolution input image and high-resolution output image of the model, respectively. The following five steps describe the model: Step 1, the low-resolution image LR is used as the input of the edge enhancement module and Conv1, respectively; Step 2, the output of Conv1 is used as the input of the RRDB and the refine layering module, here we use the MFS algorithm to reduce the RRDB; Step 3, to further enrich the high and low-frequency features of ESRGAN, the refine layer module is assisted as the high and low-frequency feature extractor of ESRGAN. The feature map output by the refine layer and the feature map output by Conv2 are concatenated in the channel dimension as the input of the upsampling layer, and the feature map is expanded to four times of the input through the upsampling layer; Step 4, the edge enhancement module is used as a separate branch to enrich the edge features of the image and then expand the extracted feature map to four times the input by the upsampling module, and the features by Conv3 is added to the features by the edge enhancement module; Step 5, through Conv4 a 128 × 128 × 3 SR is reconstructed.

MFSR model structure
3.1 Edge Enhancement Module
The contrast at the edge of the image is directly related to the quality of the image. To further enhance the edge contrast, we chose the edge enhancement-based densely connected convolutional neural network (EDCNN) as proposed by Liang et al. [14] in 2020 as the edge enhancement module of the reconstructed image. EDCNN can perform denoising and edge enhancement on the input image, with better performance of retaining details and suppressing noise, but it is not ideal for reconstructed images with rich structure and texture. Based on the edge enhancement structure of EDCNN, the improvements made in this study include: (1) Deepening the number of layers of convolution 1 × 1 and convolution 3 × 3 to 16, and fully extracting the features of the input image; (2) Adding the upsampling module to make the output image size match the output of other modules, to facilitate image fusion. Figure 4 is a structural diagram of the edge enhancement module. After the input image is first subjected to Sobel convolution [15] to extract edge information of different strengths, 16 identical convolution blocks are used to further extract edge information. Then the extracted edge features are added to the original input to speed up the model convergence. Finally, after upsampling, the output is four times the original input image with clear edge denoising.

Edge enhancement module
3.2 Refine Layer Module
Although Sect. 3.1 described how the edge details are optimized, high-frequency edge detail information must still be distinguished from the low-frequency global information in the image, and the feature information of a single scale will lead to the loss of key image information. In order to further enrich the high-frequency information of the reconstructed images and improve the images of different scales of the characteristics of the receptive field, we designed a refine layer module, as shown in Fig. 5 shows the change of the feature graph of the convolution process. First, the feature map of the low-resolution image LR after 1 × 1 convolution is used as the input of refine layering, and then the feature map is equally divided along the channel direction to obtain the feature map Xi of four different channel scales. Second, four 3 × 3 convolution kernels are used to extract the feature map of each channel to obtain four output features, Yi, where the Yi of each layer has the following relationship:

The convolution kernels of refine layer module
Finally, all output features are spliced in the channel dimension to obtain the recombination feature, Y. Compared with the residual module, each feature subblock Yi of the refined layering module can learn features from Y(i−1). Without consuming a lot of running time, the refine laying module can learn features from the input to obtain more channel information in the image, which helps to further enrich the receptive field, thereby enhancing the high- and low-frequency information of the image.
3.3 Loss Function
To reduce the error between the reconstructed image, SR, and the original high-resolution image, HR, we added the perceptual loss L2 based on the edge enhancement module to the total loss function of the ESRGAN generator. The weight coefficient of the loss function affects the quality of the reconstructed image, and the weight coefficient is often determined by the subjective experience of the designer and lacks adaptability. For this reason, the team built the MFS adaptive algorithm [16] to optimize the weight coefficient of the generator. The specific content expands the narrative in Sect. 4. This study adopts the idea of a generative adversarial network and updates the parameters through the mutual game between the generator and the relative discriminator [17]. Among them, the probability of the relative discriminator [18] to predict the real image xr is higher than that of the generated xf, which is denoted as DRa. The loss function includes two parts: generator loss function and discriminator loss function:
Discriminator loss function:
Generator adversarial loss function:
Equation (4) is the total loss function of the AMFSR generator:
where α, β, γ represent the weight coefficient of \(L_{G}^{Ra}\), L1, L2, respectively.
Lpercep represents the Euclidean distance formula of the G(ILR) feature map of the reconstructed image extracted by the backbone network through the pre-trained VGG network [19] and the IHR feature map of the original image, which can be expressed as:
In formula (5), Conv () represents the feature map after the convolution layer. W and H represent the width and height of the feature map respectively. x is the abscissa of the pixel position, and y is the ordinate of the pixel position.
L1 represents the MSE loss of the HR image Gθ1(ILR) generated by the backbone network and the original image IHR. L1 can be expressed as:
L2 represents the MSE loss of the HR image Gθ2(ILR) generated by the edge enhancement network and the original image IHR. L2 can be expressed as:
4 Model Compression and Adaptive Tuning
To reduce the model redundancy and the subjectivity of hyperparameter adjustment, this paper used the MFS algorithm to optimize the MFSR model. The characteristics of the MFS algorithm are as follows:
-
(1)
Particle swarm optimization (PSO) [20] was used to optimize the key parameters of the sparrow search algorithm (SSA) [21], such as the warning value, the proportion of producers, the proportion of warning sparrows, etc. The search capabilities of SSA were improved.
-
(2)
Tent map [22] combined with chaos operator was used to generate a chaotic sequence to initialize the sparrow population. Tent mapping is as described by Eq. (8):
$$ z_{d}^{i + 1} = \left\{ {\begin{array}{*{20}l} {2z_{d}^{i} ,} \hfill & {0 \le z \le \frac{1}{2}} \hfill \\ {2\left( {1 - z_{d}^{i} } \right),} \hfill & {\frac{1}{2} < z \le 1} \hfill \\ \end{array} } \right.\quad d = 1,2,3, \cdots ,D $$(8)
When i = 1, a d-dimensional chaotic entity is generated. When i = m, an initial chaotic sequence population is formed, and then the chaotic sequence population is transformed into a chaotic individual by Eq. (9). Where Xlb, d and Xub, d represent the upper and lower bounds of the individual with dimension d:
-
(3)
The position of the producers PD, the scroungers, and the vigilant SD is updated iteratively to find the optimal value for solving the problem. The position of the discoverer is updated as follows:
$$ X_{i,j}^{t + 1} = \left\{ {\begin{array}{*{20}l} {X_{i,j}^{t} \cdot \exp \left( { - \frac{i}{{\alpha \cdot iter_{max} }}} \right),} \hfill & {if\;R_{2} < ST} \hfill \\ {X_{i,j}^{t} + Q \cdot L,} \hfill & {if\;R_{2} \ge ST} \hfill \\ \end{array} } \right. $$(10)where t represents the current number of iterations, and itermax is the maximum number of iterations. X represents the position of the i-th sparrow in the j-th dimension. α ∈ [0,1] and Q both represent random numbers. R2 and ST represent the warning value and safety value, respectively. L is a 1 × d-dimensional matrix whose elements are all ones.
The location of the scroungers is updated as follows:
Xp is the best position occupied by the current scroungers. In contrast, Xworst represents the current worst position globally. A represents a 1 × d-dimensional matrix with an element of 1 or − 1. A also satisfies the equation A+ = AT(AAT)−1.
The location of the vigilant SD is updated as follows:
\(X_{best}^{t}\) is the current global optimal position. β is the parameter to control the step length, and K ∈ [− 1,1] is a random number. fi represents the fitness value of the current individual sparrow. fg and fw represent the current global best and worst fitness values, respectively. ε is a constant.
-
(4)
The interference factor p [23] is added to the fusion strategy of SSA and PSO to adaptively change the number of alert sparrows. As shown in Eq. (13):
Based on the above-mentioned MFS adaptive algorithm, to comprehensively improve the perceptual quality of the reconstructed image and make the reconstructed image appear more natural and richer in detail, we constructed the perception function (PF) based on LPIPS [24] and PI [25] as the optimization target of MFS, and PF is as shown in Eq. (14):
vlpips(i) represents the LPIPS value of the i-th picture output by the generator. vPI(i) represents the PI value of the i-th picture output by the generator. Batch is the batch size. When the PF reaches the minimum value, the reconstructed image has better perceptual quality at that time.
This paper uses the MFS adaptive algorithm to compress and adaptively adjust the parameters of the MFSR model. We use the four dimensions of each sparrow to represent the number of RRDB blocks in the MFSR model and the weight coefficients α, β, and γ of the loss function in Eq. (4). First, we initialized the initial position information of each sparrow with chaos as the initial value of the parameters to be optimized for the MFSR network, and train the MFSR network. Then we used Eq. (14) to calculate the fitness value of each sparrow on the test set. Finally, after the MFS adaptive algorithm loop iteration, the fitness value of the global optimal sparrow was selected and assigned to the parameters to be optimized in the MFSR. The specific algorithm flow is in algorithm 1.

MFSR network was optimized by MFS algorithm
5 Experiments
5.1 Training Details
The experimental environment configuration is shown in Table 1. We used the DIV2K [26] public dataset to train our model AMFSR. The LR in the training image is obtained by down-sampling the scale factor × 4. The discriminator uses the standard discriminator in SRGAN. The patch is 16. First, we use pixel loss Eqs. (6) and (7) to pre-train the AMFSR model. The learning rate is initialized to 2 × 104, a total of 1 million steps are performed, and the learning rate is reduced by half every 200,000 steps. Then, we initialize the generator parameters with the pre-training results and use the loss function of Eq. (4) to train the model. The initial learning rate is set to 1 × 10−4. A total of 400,000 steps of training are performed. The learning rate is reduced by half according to the number of steps [5 k, 10 k, 20 k, 30 k]. We use Adam optimizer [27] to optimize the model.
5.2 Evaluation Metrics
To evaluate the quality of the reconstructed images, we used three widely used benchmark datasets: Set5, Set14, and BSDS100. PSNR and SSIM are used to calculate image distortion. The larger the PSNR value and SSIM value, the smaller the image distortion and the better the image quality. PSNR and SSIM are calculated as follows:
where Pmax represents the maximum value of pixels in the image, and MES represents the mean square error values of HR and LR.
where μX and \(\mu_{{\hat{X}}}\) represent the mean value of X and \(\hat{X}\), respectively. \(\sigma_{{X\hat{X}}}\) represents the covariance of X and \(\hat{X}\). σX and \(\sigma_{{\hat{X}}}\) represent the variance of X and \(\hat{X}\) respectively. C1 and C2 are constants to avoid the situation that the denominator is 0 in Eq. (16).
However, some studies have shown that PSNR and SSIM have a low correlation with the human perception of images. Although there are higher PSRN or SSIM values, the reconstructed image lacks high-frequency details and looks unnatural. Some researchers consider perceptual performance metrics such as PI and LPIPS to measure the naturalness of the generated images. LPIPS evaluates image quality by learning the similarity of perceptual image patches, and PI evaluates image quality by non-reference image metrics Ma [28] and NIQE. Such as Eq. (17):
when the LPIPS value and PI value are lower, it indicates that the image perception quality is better.
5.3 Choice of the Base Model
To find a super-resolution reconstruction algorithm with clear reconstruction details, obvious edge contours, no artifacts, and satisfying human senses as our basic model, we compared the performances of a variety of current super-resolution reconstruction algorithms. The upper part of Fig. 6 shows the overall effect of the high-resolution image HR and the reconstructed images of different algorithms, and the lower part is the comparison of the HR details and the reconstruction details corresponding to different algorithms. The black bold font in the figure represents the best. By comparing the PSNR of different algorithms, the PNSR of ESRGAN is only 3.17 dB lower than the highest one. However, some studies have shown that high PSNR has little connection with perceptual quality. The LPIPS of ESRGAN, VDSR [29], EDSR [30] and EnhanceNet [31] are compared, ESRGAN reduces 63.24%, 36.44% and 1.32% respectively, which shows that ESRGAN can obtain the highest perceptual quality while ensuring a higher PSNR value. In addition, from Fig. 5, we can observe that the reconstruction effect of ESRGAN is better than VDSR, EDSR, and EnhanceNet in terms of reconstructed image clarity, edge contour contrast, presence or absence of artifacts, or perceptual quality.

Comparison of the image details of the low-resolution images reconstructed by different algorithms from the Urban100 dataset
In addition to the comparison of the effect of reconstructed images in Sect. 5.6, Fig. 8 compares parameters and average time consumption of single image reconstruction. Although the model parameters of ESRGAN are larger than other models, it can ensure that SR with higher perceptual quality can be reconstructed in a short time. In summary, we choose ESRGAN as our high-resolution reconstruction basic model.
5.4 Ablation Experiment
This section discusses the effectiveness of key operations. We conducted a comprehensive experiment to verify the effectiveness of the refine layering module, edge enhancement module, and L2 loss function, as shown in Table 2. RLM is refine layering module. EEM is the edge enhancement module. SC is the connection mode of RLM or EEM in series connection after Conv2, and PC is the connection mode of RLM or EEM in parallel connection after Conv2. No. 1–4 use a single module series connection or parallel connection, No. 6–9 use RLM and EEM parallel connection or series connection. Comparing the experimental results in the following table, we can find that the PSNR of No. 1–4 is 0.569 higher than that of No. 6–9 on average, and the LPIPS is 0.118 lower on average, which shows that the RLM module and EEM module have an important impact on improving the quality of the reconstructed image. Then we compared RLM and EEM in a series or parallel combination in No. 6–9. By comparing PNSR and LPIPS, the PSNR of No. 9 (RLM and EEM are in parallel) increased 0.1–0.2 dB compared with that of 6, 7, and 8, and the LPIPS decreased by 0.003–0.019. The results show that RLM and EEM have lower distortion and better perception quality. To further verify the effectiveness of the L2 loss function, we selected No. 4 and No. 9 with higher evaluation indicators in No. 1–4 and No. 6–9 to join L2, and found that PSNR increased by 0.069 dB and 0.043 dB, respectively; LPIPS decreased to 0.002 and 0.003, respectively; The effectiveness of L2 is proved.
5.5 The Results of MFSR Optimized by MFS Algorithm
Table 3 is the initialization parameter settings of the MFS optimized MFSR model. We set the population size to 20; the population dimension to 4, which are the number of RRDB blocks and the weights α, β, and γ of the generator loss function. The number of iterations is 10.
Table 4 is the optimal value searched for the optimal individual in the MFS algorithm, where the optimal number of RRDB blocks N is 17, and the optimal weights of the generator loss function α, β, and γ are 5.6e−3, 2e−2, and 1e−4.
Table 5 shows the change process of PSNR and LPIPS in the process of manually compressing the RRDB after fixing the optimal weight searched in Table 4, where N represents the number of RRDB blocks. It can be seen from the table that when the number of RRDB blocks is 17, PSNR and LPIPS are optimal on the Set5, Set14, and BSD100 datasets, and the PSNR on the Set5 dataset is increased by 0.104 dB and LPIPS is decreased by 0.002. On the Set14 dataset, PSNR increased by 0.074 dB and LPIPS decreased by 0.003. On the BSD100 dataset, PSNR increased by 0.084 dB, and LPIPS decreased by 0.002. Table 5 shows that the artificial compression of RRDB with 17 blocks has the best performance, which is the same as the result of MFS adaptive compression, which verifies the effectiveness of the MFS algorithm compression model.
Figure 7 is a comparison of evaluation metrics on Set5, Set14, and BSD100 datasets before and after MFS optimization. PSNR and SSIM are increased on each test set, PI and LPIPS are decreased on each testset. We take LPIPS as the main perceptual measure and the PI value as the secondary measure. It can be seen from the comprehensive metrics that the perceptual quality of the optimized model has been greatly improved.

Comparison of PSNR, SSIM, PI, and LPIPS before and after MFSR optimization
5.6 Comparison with Other Popular Super-Resolution Algorithms
We compared nine super-resolution algorithms with good performance: EnhanceNet, CX [32], SRGAN, RankSRGAN [33], ESRGAN, EUSR, EDSR, VDSR, and PPON [34]. The model parameters, running time, evaluation metrics PSNR and SSIM based on image distortion, evaluation metrics PI and LPIPS based on image perceptual quality, and image detail texture were comprehensively compared.
In Fig. 8, we compare the parameters and average running time per image of five perceptual quality-based super-resolution algorithms in the Set14 dataset. Among them, EnhanceNet has the fewest parameters, and ESRGAN has the most. Compared with the average running time of a single image, the number of parameters of our algorithm is reduced by 23.9%, and by 14.7% for ESRGAN. Tables 6, 7, and 8 compare the quality of the reconstructed images on each dataset. Our model achieves optimal or sub-optimal performance. Therefore, our model has a good balance of parameter quantity, running time, and model performance.

Comparison of different model parameters and running time on the Set14 dataset
The parameters of the model and the average running time of a single image were compared above. To verify that our algorithm has better reconstruction quality, we used PSNR, SSIM, LPIPS, and PI to compare the image reconstruction quality of MFSR and the other eight algorithms on the Set5, Set14, and BSD100 datasets, as shown in Tables 6, 7, 8 and 9. From the tables, we can find that the PSNR or SSIM of our algorithm on Set5 is slightly lower than that of PPON or EUSR, and the PI value is slightly higher than that of EnhanceNet and RankSRGAN, but LPIPS is optimal, which is well balanced on Set5. The relationship between image distortion and perceptual quality on Set14 and BSD100, the algorithms PSNR, SSIM, and LPIPS in this paper have reached optimal, and the PI value is slightly higher than the algorithm. The algorithm in this paper has a poor reconstruction effect on the head image with complex details and close colors in the Set5 dataset, which contains only five test images. As such, the average PSNR and SSIM values on the Set5 dataset are low, but we mainly use LPIPS as the evaluation index to measure the perceptual quality of the reconstructed image. PSNR, SSIM, LPIPS and PI are also superior to other algorithms in DIV2K testset. Overall, our algorithm maintains low distortion and has the best perceptual quality.
For image texture detail evaluation, we compared eight of the latest algorithms. These algorithms were evaluated on the Set5, Set14, and BSD00 datasets. As shown in Fig. 9, on the Set5 dataset, we compared a baby’s upper eyelids and eyelashes. Our algorithm has clearer eyelid contours and eyelashes than other algorithms and has the highest perceptual quality. In the beard part of the Set14 dataset, the SR images of EDSR, VDSR, EUSR are relatively blurry. EnhanceNet has more artifacts. Although the SR images of SRGAN, ESRGAN, RankSRGAN and PPON is relatively clear, many of their texture details are absent or missing from the original image. Compared with several SR algorithms, our SR image is closer to the original image and has a higher perceptual quality. In the BSD100 dataset, the details of bird wings and grass, the SR images of EnhanceNet, SRGAN, ESRGAN, RankSRGAN, and PPON are too smooth, and some high-frequency details are lost and deformed. Our algorithm is more natural for the texture of grass and wings. The algorithm in this paper reduces the distortion and distortion of the image texture and improves the image clarity. At the same time, it can visualize the texture of the image clearly while ensuring a high PSNR. Compared with other algorithms, it is more stable on each tested dataset and obtains the optimal comprehensive metrics score. Meanwhile, in order for readers to subjectively evaluate the effectiveness of the method presented in this paper, we added a visual comparison experiment in PIRM dataset in Fig. 10. The proposed method in this paper has more realistic and natural details than CX, EnhanceNet and ESRGAN.

Comparison of our algorithm and other algorithms in PSNR, PI, and LPIPS

Visual details comparison of various methods on PIRM datasets
6 Conclusion
In this paper, we propose a high-perceptual super-resolution reconstruction method for images with adaptive compression and parameter tuning of multi-layer feature fusion model structure. This method realizes the feature representation of different scales and different depths through the feature fusion of each module so that the reconstructed image can fully recover high and low-frequency information, improve the image perceptual quality, and through the adaptive weight distribution of the loss of content loss, perceptual loss and adversarial loss, reduce the error of the model for edge enhancement. Finally, we constructed an MFS model search strategy and the target perceptual function PF was used to adaptively optimize the MFSR model, and realize the effective compression of the model and the adaptive selection (optimization) of key hyperparameters, the final model AMFSR is constructed. Experiments show that while improving the perceptual quality of the reconstructed image, the constructed AMFSR decreases the parameters of the basic model ESRGAN by 23.9%, and the computational cost is reduced by 14.7%. This paper also compares the current eight super-resolution algorithms with better performance on Set5, Set14, and BSD100 using PSNR, SSIM, LPIPS, etc. as image quality evaluation metrics. The algorithm in this paper is implemented while maintaining a high PSNR and SSIM. To achieve the best LPIPS perceptual quality, a balance is achieved between image distortion and image perceptual quality. We also compare the detailed texture of the reconstructed images. Our algorithm can more truly restore the high and low-frequency information of the LR. Based on the above experimental analysis, the algorithm in this study has been verified to have a certain generalization. In addition to the super-resolution reconstruction of other data sets, the MFS optimization algorithm in this paper has the ability to compress other depth models and optimize hyperparameters.
References
Wang Z, Yi P, Jiang K et al (2019) Multi-memory convolutional neural network for video super-resolution. IEEE Trans Image Process 28(5):2530–2544. https://doi.org/10.1109/TIP.2018.2887017
Schermelleh L, Ferrand A, Huser T, Eggeling C, Sauer M, Biehlmaier O, Drummen GPC (2019) Super-resolution microscopy demystified. Nat Cell Biol 21:72–84. https://doi.org/10.1038/s41556-018-0251-8
Zhang D, Shao J, Li X, Shen HT (2021) Remote sensing image super-resolution via mixed high-order attention network. IEEE Trans Geosci Remote Sens 59(6):5183–5196. https://doi.org/10.1109/TGRS.2020.3009918
Yang W, Zhang X, Tian Y, Wang W, Xue JH, Liao Q (2019) Deep learning for single image super-resolution: a brief review. IEEE Trans Multimedia 21(12):3106–3121. https://doi.org/10.1109/TMM.2019.2919431
Bashir S, Wang Y, Khan M, Niu Y (2021) A comprehensive review of deep learning-based single image super-resolution. PeerJ Comput Sci. https://doi.org/10.7717/peerj-cs.621
Li JC, Wu LM, Wang SM, Wu WH (2019) Super resolution image reconstruction of textile based on SRGAN. In: IEEE international conference on smart internet of things, pp 436–439. https://doi.org/10.1109/SmartIoT.2019.00078
Dong C, Loy CC, He K, Tang X (2016) Image super-resolution using deep convolutional networks. IEEE Trans Pattern Anal Mach Intell 38(2):295–307. https://doi.org/10.1109/TPAMI.2015.2439281
Kim J, Lee JK, Lee KM (2016) Accurate image super-resolution using very deep convolutional networks. In: 2016 IEEE conference on computer vision and pattern recognition (CVPR), pp 1646–1654. https://doi.org/10.1109/CVPR.2016.182
Lim B, Son S, Kim H, Nah S, Lee KM (2017) Enhanced deep residual networks for single image super-resolution. In: 2017 IEEE conference on computer vision and pattern recognition workshops (CVPRW), pp 1132–1140. https://doi.org/10.1109/CVPRW.2017.151
Kim JH, Lee JS (2018) Deep residual network with enhanced upscaling module for super-resolution. In: 2018 IEEE/CVF conference on computer vision and pattern recognition workshops (CVPRW), pp 913–9138. https://doi.org/10.1109/CVPRW.2018.00124
Ledig C, Theis L, Husz’ar F, Caballero J, Cunningham A, Acosta A, Aitken A, Tejani A, Totz J, Wang Z, Shi W (2017) Photo-realistic single image super-resolution using a generative adversarial network. In: 2017 IEEE conference on computer vision and pattern recognition (CVPR), pp 105–114. https://doi.org/10.1109/CVPR.2017.19
Wang X, Yu K, Wu S, Gu J, Liu Y, Dong C, Loy CC, Qiao Y, Tang X (2018) Esrgan: enhanced super-resolution generative adversarial networks. In: ECCV workshops
Kezzoula Z, Gaceb D, Gritli N (2022) Super-resolution of document images using transfer deep learning of an ESRGAN model. In: 2022 5th international symposium on informatics and its applications (ISIA), pp 1–6. https://doi.org/10.1109/ISIA55826.2022.9993497.
Liang T, Jin Y, Li Y, Wang T (2020) Edcnn: edge enhancement-based densely connected network with compound loss for low-dose ct denoising. In: 2020 15th IEEE international conference on signal processing (ICSP), vol. 1, pp 193–198. https://doi.org/10.1109/ICSP48669.2020.9320928
Danial S, Roohallah A, Mohamad R et al (2021) Fusion of convolution neural network, support vector machine and Sobel filter for accurate detection of COVID-19 patients using X-ray images. Biomed Signal Process Control. https://doi.org/10.1016/j.bspc.2021.102622
Zhang R, Bai X, Pan L et al (2021) Zero-small sample classification method with model structure self-optimization and its application in capability evaluation. Appl Intell. https://doi.org/10.1007/s10489-021-02686-8
Goodfellow I, Pouget-Abadie J, Mirza M, et al (2020) Generative adversarial networks. Commun ACM 63(11):139–144
Li Q, Lu L, Li Z, Wu W, Liu Z, Jeon G, Yang X (2021) Coupled gan with relativistic discriminators for infrared and visible images fusion. IEEE Sens J 21(6):7458–7467. https://doi.org/10.1109/JSEN.2019.2921803
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. https://doi.org/10.48550/arXiv.1409.1556
Gülcü A, Kus Z (2020) Hyper-parameter selection in convolutional neural networks using microcanonical optimization algorithm. IEEE Access 8:52528–52540. https://doi.org/10.1109/ACCESS.2020.2981141
Xue J, Shen B (2020) A novel swarm intelligence optimization approach: sparrow search algorithm. Syst Sci Control Eng Open Access J 8(1):22–34
Bhaskar M, Shrey S, Prabhakar K (2019) A secure image encryption scheme based on cellular automata and chaotic skew tent map. J Inf Security Appl 45:117–130. https://doi.org/10.1016/j.jisa.2019.01.010
Pan D, Jiang Z, Maldague X, Gui W (2021) Research on the influence of multiple interference factors on infrared temperature measurement. IEEE Sens J 21(9):10546–10555
Zhang R, Isola P, Efros AA, Shechtman E, Wang O (2018) The unreasonable effectiveness of deep features as a perceptual metric. In: 2018 IEEE/CVF conference on computer vision and pattern recognition, pp 586–595. https://doi.org/10.1109/CVPR.2018.00068
Blau Y, Mechrez R, Timofte R, Michaeli T, Zelnik-Manor L (2018) The 2018 PIRM Challenge on Perceptual Image Super-Resolution. In: Proceedings of the European conference on computer vision (ECCV) workshops, pp 334–355
Timofte R, Agustsson E, et al. (2017) Ntire 2017 challenge on single image super-resolution: methods and results. In: 2017 IEEE conference on computer vision and pattern recognition workshops (CVPRW), pp 1110–1121. https://doi.org/10.1109/CVPRW.2017.149
Yi D, Ahn J, Ji S (2020) An effective optimization method for machine learning based on adam. Appl Sci. https://doi.org/10.3390/app10031073
Ma C, Yang CY, Yang X, Yang MH (2017) Learning a no-reference quality metric for single-image super-resolution. Comput Vis Image Underst 158:1–16. https://doi.org/10.1016/j.cviu.2016.12.009
Jiwon K, Jung KL, Kyoung ML (2015) Accurate image super-resolution using very deep convolutional network. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition, pp 1646–1654. https://doi.org/10.48550/arXiv.1511.04587
Lin K (2022) The performance of single-image super-resolution algorithm: EDSR. In: 2022 IEEE 5th international conference on information systems and computer aided education (ICISCAE), pp 964–968. https://doi.org/10.1109/ICISCAE55891.2022.9927560
Sajjadi MSM, Schölkopf B, Hirsch M (2017) Enhancenet: single image super-resolution through automated texture synthesis. In: 2017 IEEE international conference on computer vision (ICCV), pp 4501–4510. https://doi.org/10.1109/ICCV.2017.481
Mechrez R, Talmi I, Shama F, Zelnik-Manor L (2018) Maintaining natural image statistics with the contextual loss. ACCV 2018. Lecture Notes Comput Sci 11363:209–212. https://doi.org/10.1007/978-3-030-20893-627
Zhang W, Liu Y, Dong C, Qiao Y (2019) Ranksrgan: Generative adversarial networks with ranker for image super-resolution. In: 2019 IEEE/CVF international conference on computer vision (ICCV), pp 3096–3105. https://doi.org/10.1109/ICCV.2019.00319
Hui Z, Li J, Gao X, Wang X (2021) Progressive perception-oriented network for single image super-resolution. Inf Sci 546:769–786. https://doi.org/10.1016/j.ins.2020.08.114
Acknowledgements
We thank International Science Editing (https://www.internationalscienceediting.com) for editing this manuscript.
Funding
This work was supported by the Foundation of Shanxi Province Engineering Research Center for Equipment Digitization and PHM (ZBPHM20201104), in part by the Science and Technology Innovation Project of Higher Education in Shanxi Province (No.2019L0653), in part by the Basic Research Project of Shanxi Province under Grants (No.20210302123216,No.201901D111259), in part by the Shanxi Key Laboratory of Advanced Control and Equipment Intelligence (ACEI202002) and in part by the Excellent Innovation Project for Graduate students in Shanxi Province (No.2021Y699).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, R., Ren, W., Pan, L. et al. A Single Image High-Perception Super-Resolution Reconstruction Method Based on Multi-layer Feature Fusion Model with Adaptive Compression and Parameter Tuning. Neural Process Lett 56, 202 (2024). https://doi.org/10.1007/s11063-024-11660-7
Accepted:
Published:
DOI: https://doi.org/10.1007/s11063-024-11660-7