
Abstract
Neural radiance field (NeRF) is an emerging view synthesis method that samples points in a three-dimensional (3D) space and estimates their existence and color probabilities. The disadvantage of NeRF is that it requires a long training time since it samples many 3D points. In addition, if one samples points from occluded regions or in the space where an object is unlikely to exist, the rendering quality of NeRF can be degraded. These issues can be solved by estimating the geometry of 3D scene. This paper proposes a near-surface sampling framework to improve the rendering quality of NeRF. To this end, the proposed method estimates the surface of a 3D object using depth images of the training set and performs sampling only near the estimated surface. To obtain depth information on a novel view, the paper proposes a 3D point cloud generation method and a simple refining method for projected depth from a point cloud. Experimental results show that the proposed near-surface sampling NeRF framework can significantly improve the rendering quality, compared to the original NeRF and three different state-of-the-art NeRF methods. In addition, one can significantly accelerate the training time of a NeRF model with the proposed near-surface sampling framework.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Recently, metaverse and virtual reality applications are rapidly drawing attention. In such applications, it is important to generate novel views accurately. One way to achieve this goal is to generate a three-dimensional (3D) model first and follow a conventional rendering pipeline [1]. However, generating a 3D model needs a lot of time and effort.
Image-based rendering (IBR) is another approach that generates novel views without explicitly generating a 3D model. Several methods generate a novel view using image morphing [4]. The Layered Depth Images method [24] stores multiple depth and color values for each pixel to effectively fill the hole behind the foreground object in a novel view. Light fields [11] and Lumigraph [7] that express light rays as a function were also proposed.
Recently, among IBR methods, neural radiance field (NeRF) [17] has been rapidly gaining attention. Ray, a core concept of NeRF, means lines shot in a straight line from the camera position to an object. A NeRF network predicts the color and density of each point utilizing 3D points sampled from each ray. Then a novel view is obtained by performing a line integral using this color and density.

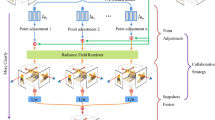
The brief overview of the proposed NeRF framework that samples points near the estimated surface from a point cloud
The original NeRF [17] performs sampling within a range that includes the entire 3D object. This paper proposes to use depth information to sample 3D points only around surface of an object in NeRF, where we consider the practical scenario that depth information is only available at hands (from depth cameras) in a training dataset. To consider that measured/estimated depths maps may be inaccurate due to capturing environments, we propose to generate a 3D point cloud using available (inaccurate) depth information in training, and to use this 3D point cloud to estimate a depth image for each novel view in test (i.e., inference). Figure 1 illustrates the brief overview of the proposed NeRF framework. Simply projecting a 3D point cloud onto a novel view generates a rather rough depth image. To obtain more accurate depth images, we additionally propose a refining method that removes unnecessary 3D points in generating a point cloud and fills the hole of the projected depth image. Simply put, to improve NeRF, the paper proposes an advanced sampling method around the surface of an object/a scene using estimated depth images from generated point cloud. Our experimental results with different datasets demonstrate that the proposed framework outperforms original NeRF and three different state-of-the-art NeRF methods.
The rest of the paper is organized as follow. Section 2 reviews NeRF and its follow-up works with particularly related works with ours, and presents differences between the proposed NeRF and existing depth-based NeRFs. Section 3 provides motivation and detail of the proposed method, Sect. 4 reports experiments and analysis, and Sect. 5 discusses conclusions, limitation and future work.
2 Related Works
2.1 NeRF
NeRF [17] is a state-of-the-art view synthesis technology that samples points on rays and synthesizes views through differentiable volume rendering. The input of this algorithm is a single continuous five-dimensional (5D) coordinate consisting of a 3D spatial location and a two-dimensional viewing direction. The output is a volume density and view-dependent emitted radiance at the corresponding spatial location. In other words, the key idea of NeRF is to train a neural network that predicts a view-dependent color value and a volume probability value by taking a 5D coordinate. Using those two predicted values, a final rendered color value is determined by performing a line integral with classical volume rendering. To further improve the rendering quality, NeRF uses the following two techniques: positional encoding and hierarchical volume sampling. Positional encoding increases the dimension of input data; the hierarchical volume sampling technique allocates more samples to regions that are expected to include visible content. Hierarchical volume sampling is named as it performs sampling with two different networks, “coarse” one and “fine” one. For each ray, a coarse network gives a view-dependent emitted color and volume density using \(N_\text {c}\) points that are sampled with stratified sampling method along the ray. A piecewise-constant probability density function (PDF) is generated (along each ray) by normalizing contribution weights that are calculated with volume densities and the distances between adjacent samples of \(N_\text {c}\) points. After integrating the generated PDF to calculate cumulative distribution function, \(N_\text {f}\) points are sampled through inverse transform sampling. A fine network gives a view-dependent color value and volume density using \(N_\text {c}\) points and those more informed \(N_\text {f}\) points. After all, one calculates the final rendering of the corresponding ray with \(N_\text {c} + N_\text {f}\) points. Through this process, NeRF can represent a 3D object (in \(360^{\circ }\)) and forward-facing scenes with continuous views. However, NeRF in its original form has several limitations. For example, it can represent only static scenes; its training and inference is slow; one NeRF network represents only one object/scene.
2.2 Follow-Up Works of NeRF
Researchers has been improving the original NeRF model [17] in various aspects. The first aspect is to reduce training time of NeRF models while maintaining rendering accuracy [5, 9, 18, 27]. [9] reduces training time by proposing a new sampling method to use less number of samples per ray. Deng et al. [5] supervises depth to use a smaller number of views in training. Xu et al. [27] can accelerate training by quickly generating an initial rough point cloud and refining it in an iterative manner. Müller et al. [18] uses a learnable encoding method instead of positional encoding, and update only parameters related to sampling positions instead of updating all parameters.
The second aspect is to improve inference time of NeRF models [13, 14, 18, 19, 23]. Liu et al. [14] and Rebain et al. [23] reduces inference time by spatially decomposing and processing the scene: [23] uses a spatially decomposed scene and a small network for each space; [14] skips spaces with irrelevant scenes among the decomposed spaces during inference. Lindell et al. [13] uses volume integral calculation network instead of the classical integral calculation method to shorten inference. Neff et al. [19] uses a rendering pipeline that includes a network to predict the optimal sample locations on rays to reduce inference time. Using learnable encoding method instead of positional encoding [18] can accelerate inference.
Third aspect is to consider different scenarios with NeRF models [2, 10, 12, 16, 20,21,22, 25, 26, 29]. [29] additionally estimates camera pose. Lin et al. [12] considers the case that camera poses are imperfect or unknown. Johari et al. [26], Niemeyer and Geiger[20], Xie et al. [10] consider multi-object/scene representation. In particular, [26] disentangles foreground and background. Dynamic scene representation [21, 22] and relighting [2, 16, 25] makes NeRF to be applicable to changing scenes rather than static scenes.
2.3 Depth-Based NeRFs and Their Relations with the Proposed NeRF Framework
Depth oracle neural radiance field (DONeRF) [19] uses ground-truth depth images of the training set to train ideal sample locations on rays, and performs sampling in the estimated locations. However, DONeRF works only on forward-facing scenes where all camera poses belong to a bounding box called the view cell. Depth supervised neural radiance field (DSNeRF) [5] uses a sparse depth map estimated with the structure from motion technique and adds an optimization process to the original NeRF using estimated depth information, to achieve the best rendering performance of original NeRF with fewer training iterations and images.
Similar to DONeRF, we aim to improve the quality of rendered images by using depth images available at hand in a training dataset. Note, however, that different from DONeRF, the proposed method does not use the view cell information that is required in DONeRF, and is applicable with less restricted camera positions. Similar to DSNeRF, we use depth information by leveraging a point cloud. However, the proposed framework and DSNeRF use a point cloud in a different way. DSNeRF uses a point cloud to adjust the volume density function of NeRF. Different from this, the proposed framework uses a point cloud to directly estimate the distance to the surface of an object from a camera.
3 Proposed Method
3.1 Motivation
In NeRF [17], there exists a room for improvement of rendering accuracy. NeRF uses a hierarchical volume sampling method that performs sampling twice: “rough” sampling with a stratified sampling approach and “fine” sampling in the space where an object is likely to exist. See details in Sect. 2.1. The stratified sampling approach in NeRF divides a specified range into many bins and selects a sample uniformly a random from each bin. In the stratified sampling process, sampling is performed not only in the space where the object exists, but also in the free space or the occluded region. Sampling in free space and occluded region may degrade rendering quality. If one can sample points only around an object in the rough sampling stage, the rendering performance might improve even without the fine sampling process.
To show the effects of the sampling density around an object on the rendering quality, we ran simple experiments with different sampling ranges around the surface of an object. Figure 2 shows the rendering accuracy with peak signal-to-noise ratio (PSNR) values with different sampling range, where we increased the default sampling range of NeRF by a factor of 2, 4 and 8 by increasing distances between two samples. As the sampling range increases, i.e., sampling density around an object decreases, the rendering accuracy rapidly degrades. We observed from these experiments that narrowing the sampling range around an object can improve the rendering quality in NeRF. This corresponds to the hierarchical volume sampling scheme of original NeRF that re-extracts samples with high volume density values to increase rendering efficiency.

The NeRF rendering accuracy comparisons with different sampling ranges. Here, d denotes the default sampling range of NeRF

The overall diagram of the proposed NeRF framework. The red words highlight proposed modules. (Color figure online)
Recently, diverse low-cost depth cameras with high accuracy have been proposed [6, 15]. Depth cameras (using multi-view) can measure the distance between an object and the device, giving additional 3D information of an object. We conjecture that if we sample points on 3D ray only around the surface of an object, the rendering quality of NeRF improves.
3.2 Overview
Figure 3 illustrates the overall process of the proposed framework. A training set consists of color images and depth images, and at the train stage we use both. In particular, we use depth images to sample in the area close to the surface of the object in a 3D space, and we refer to this sampling strategy as surface-based sampling. By using those sample points obtained through surface-based sampling, we train the NeRF model. At the offline stage, we use depth images of the training set to generate a point cloud and save this point cloud for inference. At the test stage, we use the saved point cloud at the offline stage to generate a depth image corresponding to a novel view. We further refine depth images through computationally efficient hole filling for surface-based sampling. Using sampled points only around the surface of an object that is estimated with a refined depth, we render images of novel views with a single NeRF network.
3.3 Surface-Based Sampling
Figure 4 illustrates the difference between the sampling range of the original NeRF’s sampling method (blue) and that of the surface-based sampling method (orange). Different from original NeRF that samples 3D points at a wide range that includes the entire 3D object, the proposed surface-based sampling method mainly samples those around the surface of the object.

Sampling range comparisons between the original NeRF (blue) and the proposed surface-based sampling scheme (orange). The solid line represents the surface of an object, and the dotted lines inside the blue fan represent rays. The area within two dotted lines outside the blue region corresponds to the field of view of a camera. Different the original NeRF, the proposed method samples only around the surface of an object. (Color figure online)
We now describe the geometry of the proposed surface-based sampling method for each ray of each view. As in the original NeRF, we assume that each ray is propagated from the location of a camera (see Fig. 4). We define the location of a camera in each ray as 0. The distance between the locations of a camera and an object is the depth value from a depth image, and we denote it as d. Let the half of some specified sampling range be \(\alpha \). Then, the location of a point nearest to the camera within the sampling range can be calculated as follows:
Now, we determine the location of the nth sample for each ray (considering that a ray is originated from the camera location, 0) by
where N is the number of sample points for each ray, and \(\gamma \) is a random number generated between 0 and \(2\alpha /N\). We perform stratified sampling near the surface of an object, where we determine the sample locations by (2). In (2), \([0, 2\alpha /N]\) is the length of each bin in stratified sampling of the original NeRF method. Here, the parameter \(\alpha \) determines the sampling range; if N is fixed, \(\alpha \) ultimately affects the sampling density around the surface. As \(\alpha \) decreases, the length of each bin is shorter and distances between sample points are expected to become close, so the sampling density near the surface increases. As \(\alpha \) increases, the length of each bin is longer and distances between sample points are expected to become far, so the sampling density near the surface decreases.

An example of the proposed point cloud refinement. In the first step, we generate a point cloud from a depth image of a viewpoint. In the second step, we project the generated point cloud onto the next viewpoint. In the third step, we use the depth thresholding scheme (3) using projected points in the next viewpoint and ground-truth depth values. If a projected point in the next viewpoint has a similar value to the ground-truth, we consider that the corresponding 3D point is redundant to generate. We then generate new 3D points in the next viewpoint if they are determined to be necessary. We repeat the above steps
Different from the two-step network sampling scheme in original NeRF, the proposed framework directly samples points near the surface of an object by using depth information in the near-surface sampling scheme (2) in a single step, i.e., it uses a single network. We expect that if the depth to the surface of a 3D object d is accurately estimated, the rendering quality improves by using small \(\alpha \), i.e., densely sampling 3D points. If it is poorly estimated, we expect that small \(\alpha \) rather degrades the rendering quality. With fixed N, we recommend setting \(\alpha \) considering the accuracy of depth images.
3.4 Depth Image Generation for Novel Views
In the training stage, we perform surface-based sampling without any additional process, assuming that a depth image for each view is available. In the test stage, however, we assume that depth images are unavailable, so we perform depth estimation for a novel view for surface-based sampling. For depth estimation, in the offline stage, we generate and save a point cloud as shown in Fig. 3. In the test stage, we use this point cloud to estimate depth images for novel views. Using this depth estimation process, surface-based sampling can be performed without a ground truth depth image in the test stage.
3.4.1 Point Cloud Generation and Refinement in the Offline Stage
Figure 5 illustrates the key concept of the proposed point cloud generation and refinement method. To improve the accuracy of depth estimation, we generate 3D points with a subset of training images, by repeatedly eliminating inaccurate points. In constructing a subset of training images, we give a sufficient and uniform distance between their adjacent viewpoints. This setup is more efficient in constructing a 3D point cloud, compared to the setup that uses the entire training views. See details of this experimental setup later in Sect. 4.2.
Each iteration consists of the following four steps and we repeat them with the cardinality of a subset of training images, where we sequentially follow the trajectory of viewpoints in a subset of training data:
-
(1)
We generate a point cloud using a depth image from a viewpoint.
-
(2)
We project 3D points of the generated point cloud onto an image plane of the next viewpoint, and obtain the distance between each 3D point and the camera location of the next viewpoint by using the multiple view geometry calculation method [8].
-
(3)
We compare each calculated distance to a ground-truth depth value from the depth image at the next viewpoint, and identify if the following condition is satisfied:
$$\begin{aligned} \big | \tilde{d} - d_{\text {GT}} \big | \le \tau , \end{aligned}$$(3)where \(\tilde{d}\) denotes the calculated distance using the second step above, \(d_{\text {GT}}\) denotes the ground-truth depth value of a pixel position where the 3D point is projected, and \(\tau \) denotes some specified threshold.
-
(4)
If the condition (3) is not satisfied, we generate a new 3D point by back-projecting a pixel of the value \(d_{\text {GT}}\).
Setting \(\tau \) appropriately is important to generate an accurate point cloud. If \(\tau \) is too large, 3D points with similar locations will be considered as the same point. Consequently, fewer 3D points are generated, leading to faster rendering times; however, estimated depth images may contain many holes. Conversely, if \(\tau \) is too small, the number of 3D points increases since point clouds can be generated with overlapping. This decreases the number of holes in depth images, but it takes a long time for the rendering process.
Throughout the paper, we use a subset of training views for point cloud generation and refinement.
Difference with multi-view stereo (MVS) in point cloud generation. MVS is a standard approach for generating a cloud or mesh, from a set of images captured from many different views. We observed that the proposed point cloud generation method can generate more points than the standard MVS method [3] for similar computational timeFootnote 1 This leads to the consequence that a point cloud generated by the proposed method above can improve rendering quality compared to that generated by MVS. Within the proposed NeRF framework, a point cloud generated by the proposed point cloud generation method and that given by the standard MVS method resulted in 31.44 dB and 30.27 dB in PSNR, respectively (for the Pavillon dataset [19]; \(\alpha =1/2\), \(N=8\)).
3.4.2 Depth Estimation from a Point Cloud in the Test Stage
To obtain a depth image at a novel viewpoint using a point cloud, we calculate the distance from a 3D point to the camera location by projecting a generated point cloud in Sect. 3.4.1 to the image plane. If more than one 3D point is projected onto the same pixel location, we use the closest 3D point to the camera location for distance calculations.
At a novel viewpoint, a projected depth image from a point cloud could have “holes”, i.e., pixels with zero values, if those do not have corresponding 3D point(s) in a point cloud. In projected depth images, however, one cannot identify if such holes correspond to background areas or are missing information on the surface of a foreground object due to limited 3D points.
In this section, we aim to fill-up missing information on the object surface while maintaining background areas. To distinguish whether holes in projected depth images correspond to background area(s) or missing information on the surface of a foreground object, we use the following condition for a pixel of value p:
where \(\mu \) and \(\sigma \) are the average and the standard deviation calculated from \(M \times M\) neighboring pixels in a projected depth image—whose center is the pixel of p value—respectively, and \(\kappa \) is some specified threshold. If the condition (4) is satisfied, we determine that a hole is missing information on the surface, and fill that hole by applying the moving average filter with a kernel of size \(M \times M\). If \(\kappa \) is too large, there still may exist many holes with missing information on the surface of an object (not in background area(s)) even after the hole filling process. If \(\kappa \) is too small, however, one may even fill holes in background area(s) and blur depth images. Selecting an appropriate \(\kappa \) value can generate more accurate/useful depth images by minimizing missing information on the object surface and mitigating hole-filling the background areas.

Comparisons of estimated depth and rendered images by the proposed method without hole filling and with hole filling using different \(\kappa \) values (DONeRF Lego dataset [19], \(\{ N=8, \alpha = 1/16 \}\); we zoomed-in images by a factor of 4, and measured PSNR for all novel views.)
Figure 6 and Table 1 support our expectation regarding \(\kappa \) in depth estimation. Fig. 6 with the extreme case \(N=8\) shows examples of estimated depth images without and with the proposed hole filling process using different \(\kappa \) values, and the corresponding rendered images by the proposed NeRF model. Table 1 reports the corresponding PSNR results across different \(\kappa \) values. We observed that the proposed hole filling scheme with appropriate \(\kappa \) (e.g., \(\kappa = 2\) in Fig. 6) estimates missing depth information for a foreground object, giving more appropriate depth maps. However, a few regions of the background that are supposed to have zero values are filled with some non-zero values. It is suboptimal in the perspective of depth estimation, but it is a simple method that can provide sufficiently useful information for proposed near-surface sampling in Sect. 3.3. Finally, we empirically found with results in Fig. 6 that \(\kappa = 2\) gives the highest accuracy among \(\{ \kappa = 0.25, 0.5, 1, 2, 3, 4 \}\) in the rendering perspective.
4 Results and Discussion
4.1 Datasets
We used the synthetic Lego and Ship datasets in original NeRF [17],Footnote 2 the real dataset with the identifier 5a8aa0fab18050187cbe060e in BlendedMVS [28], and the Pavillon scene dataset. Figure 7 shows these datasets. For each synthetic dataset, we used 150 training images and 50 test images, all with the spatial resolution of \(800 \times 800\). In generating a point cloud (Sect. 3.4.1) for each synthetic dataset, we used 20 of 100 training images from the original dataset.Footnote 3 In constructing a training dataset for each synthetic data, we selected 50 of 100 original test images by skipping one view by one view and added them to the original training dataset. For the real dataset, we used 100 training images and 11 test images, all with the resolution of \(574 \times 475\). In generating a point cloud, we used 20 of 100 training images.\(^{3}\) For all datasets, each instance has a different viewpoint. If not further specified, we used the above experimental setup throughout all experiments.
The chosen real data contains multi-view images taken around an object and several images are captured from closer viewpoints to an object. In our experiments, we used included depth images in [28], and used blended color images reflecting view-dependent lighting [28], as the ground truth color images.
We compared the proposed NeRF framework using near-surface sampling with a point cloud, with original NeRF, DONeRF [19], DSNeRF [5], and Instant-NGP [18]. For comparing performances between all five methods, we used the re-rendered Lego dataset and Pavillon scene dataset to better fit the view cell methodology of DONeRF that uses additional configurations for view cell generation, and is forward-facing. We used 210 training images and 60 test images, for these comparison experiments. For a point cloud generation, we used 20 training images. For comparing performances between the proposed and original NeRF, we used all three different datasets (Lego, Ship, and BlendedMVS) that are not necessarily forward-facing.
4.2 Experimental Setup
Throughout experiments with different sampling ranges of the proposed surface-based sampling method, we assumed that the full sampling range of original NeRF [17], i.e., the radius of the blue fan-shape in Fig. 4, is 4 (unitless). For synthetic datasets, we set half of the sampling range of the proposed NeRF, i.e., \(\alpha \) in (1)–(2), as 1/2, 1/4, 1/8, and 1/16. For the real dataset, we set \(\alpha \) as 1, 1/2, 1/4, and 1/8. (We used larger sampling ranges in real dataset experiments compared to synthetic dataset experiments, since the depth quality of the real dataset is relatively poorer than that of the synthetic dataset.)Footnote 4 To see the effects of depth estimation accuracy in the proposed NeRF framework, we also ran experiments with ground-truth depth images and estimated depth images via the proposed method. We set the number of sample points \(N=64\), except for experiments using different N’s.

The Lego (1st), Ship (2nd), BlendedMVS (3rd), and Pavillon (4th) datasets
In experiments comparing different NeRF methods, we used different numbers of sampling points, i.e., N in (2). For fair comparisons, the total number of sampling points per ray of original NeRF is set identical to those of proposed NeRF, DONeRF [19], DSNeRF [5], and Instant-NGP [18]. In the original NeRF approach, for each coarse and fine network, we set the number of sample points per ray to 4, 8, 16, and 32. For the proposed NeRF, DONeRF, DSNeRF, we set N as 8, 16, 32, and 64, and used only one rendering network. Different from original NeRF that uses samples with different locations for two different networks, Instant-NGP uses two networks that estimate color and density respectively, but use samples with the same locations. For Instant-NGP, we set the number of samples per ray to 8, 16, 32, and 64. That is, in comparing different NeRF methods, we set the total number of sample points per ray as 8, 16, 32, and 64 consistently for all the NeRF methods.
The remaining hyperparameters of the proposed NeRF approach are listed as follows. In determining sampling locations (2), we randomly sampled \(\gamma \) via the uniform distribution between 0 and \(2\alpha /N\). In the point cloud refinement condition (3), we set \(\tau \) as 0.1. In the hole filling condition (4), we set \(\kappa \) as 2 using the preliminary results in Fig. 6 with the extreme case \(N=8\), and set M as 11.
We used the following hyperparameters throughout all experiments. We set the total number of training iterations as \(400,\!000\), as the training losses tend to converge after \(400,\!000\) iterations. For each iteration, we set the batch size of input rays as 1024. We used the learning rate of \(5 \times 10^{-4}\) until \(250,\!000\) iterations, and reduced it to \(5 \times 10^{-5}\) after \(250,\!000\) iterations. We used the ADAM optimizer.
For quantitative comparisons, we used the most representative measure, PSNR in dB, structural similarity index measure (SSIM), and learned perceptual image patch similarity (LPIPS), excluding the background area (if available). We used an NVIDIA GeForce RTX 4090 GPU with 24 GB GDDR6X VRAM and 2.31 GHz, Intel(R) Xeon(R) Gold 6326 CPU with 2.90 GHz, and main memory of 503 GB RAM.
4.3 Comparisons with Different Sampling Ranges in the Proposed NeRF Framework
Using the proposed surface-based sampling method, we compared results between different sampling ranges, either with ground-truth or estimated depth images. First, we compare performances between different sampling ranges, with the ground-truth depth images. Figure 8 with dotted lines compares the rendering quality of the proposed NeRF with different sampling ranges, for three different datasets. It demonstrates that as the sampling range becomes narrow, the rendering quality of NeRF improves. With the ground truth depth information, the rendering accuracy improved as the sampling range becomes narrow. This is natural as the narrower the sampling range, the more sample points are located near the surface of an object.

PSNR (dB) comparisons with different sampling ranges, for three different datasets (\(N = 64\)). The dotted and solid lines denote the rendering accuracy in PSNR values of proposed NeRF, with the ground-truth and estimated depth images, respectively

Comparisons of rendered images via proposed NeRF for the Lego (1st row), Ship (2nd row), and BlendedMVS (3rd row) datasets, with different sampling ranges (we used estimated depth images via the proposed method; \(N = 64\)). The sampling ranges are scaled versions of the original NeRF’s with \(\alpha \)’s in (2). Images in the 4th column are ground truths
Next, we compare performances between different sampling ranges, with the estimated depth images via the proposed point cloud generation and hole filling approaches. Figures 8 (solid lines) and 9 compare the rendering quality of proposed NeRF with different sampling ranges, for three different datasets. In Fig. 9, different columns show rendered images with different sampling ranges; in the last column, the ground truth images are presented; different rows show rendered images with different datasets. Figures 8 and 9 demonstrate that the rendering quality of the proposed NeRF improves, as the sampling range becomes narrow, but only up to the certain sampling range, e.g., 1/8 and 1/2 of the full sampling range of original NeRF for synthetic data and real data, respectively. If the sampling range is too narrow, e.g., 1/16 and 1/4 for synthetic data and real data, respectively, the rendering accuracy degraded. This is because some estimated depth information is inaccurate, but we sample points too near the corresponding inaccurate regions where actual surfaces do not exist.

Comparisons of rendered images with different NeRFs (the Lego dataset [19]; \(N=8\), \(\alpha = 1/16\))
Finally, we compare the rendering accuracy between the two proposed NeRF methods using ground truth and estimated depth images respectively. Figure 8 demonstrates that in the proposed NeRF framework, using estimated depth images degrades the overall rendering accuracy compared to using the ground truth depth, as one may expect. In particular, points sampled around the inaccurately estimated surface of an object degrade the rendering accuracy.
4.4 Rendering Quality Comparisons Between Different NeRF Models
4.4.1 Comparisons Between Five Different NeRF Models
Table 2 and Figs. 10 and 11 compare the rendering quality between the five different NeRF models, with different number of samples. They demonstrate that the proposed NeRF outperforms original NeRF, DONeRF, DSNeRF, and Instant-NGP, regardless of the number of sample points per ray. Figures 10 and 11 show that the proposed NeRF framework produces significantly better details of a 3D object, compared to the original NeRF, DONeRF, DSNeRF and Instant-NGP. Table 2 with two different datasets shows that rendering accuracy reduces as the number of sample points per ray decreases. This is similarly observed in all the five different NeRF models. This is because as the number of sample points decreases, we have less information to model a 3D object via networks.

Comparisons of rendered images with different NeRFs (the Pavillon scene dataset [19]; \(N=8\), \(\alpha = 1/2\))
4.4.2 A Closer Look at Original NeRF versus Proposed NeRF
Figure 12 compares the rendering performance particularly between original and proposed NeRFs, with different numbers of samples per ray. The figure demonstrates for the three different datasets that the proposed NeRF framework gives significantly better rendering accuracy compared to original NeRF, regardless of the number of sample points per ray. More importantly, Fig. 12 shows that in the proposed NeRF framework, the performance degradation according to reduction of the number of samples per ray is significantly less, compared to original NeRF. In other words, proposed NeRF can maintain the rendering quality, while reducing the number of samples per ray. Consequently, we conclude that only with a limited number of samples per ray, the proposed NerF model can achieve significantly better rendering accuracy, compared to the original NeRF model using many samples per ray. For the synthetic datasets, the proposed framework using 16 samples per ray outperformed original NeRF using 64 samples per ray; for the real data, the rendering accuracy of the proposed NeRF model using 16 samples per ray is comparable with that of original NeRF using 64 samples per ray. We expect that the smaller the error in estimated depth at a novel view, the narrower sampling range can be used while reducing the number of samples.

PSNR (dB) comparisons with different numbers of samples per ray, for for three different datasets (for Lego and Ship, \(\alpha = 1/16\); for BlendedMVS, \(\alpha = 1/4\)). The green line with squares and yellow line with triangles denote the rendering accuracy of proposed and original NeRF, respectively. (Color figure online)
Figure 13 shows rendered images by the proposed framework for different numbers of sample points per ray, with three different datasets. Except for the extreme case of using only eight samples per ray (\(N=8\)), the image quality of rendered images by the proposed framework gradually degraded as the number of samples per ray reduces. (When \(N = 8\), the rendering quality significantly degraded.) This with the above results from Fig. 12 underscores the importance of the near-surface sampling approach.

Comparisons of rendered images via proposed NeRF for the Lego (1st row), Ship (2nd row), and BlendedMVS (3rd row) datasets, with different numbers of samples per ray (for Lego and Ship, \(\alpha = 1/16\); for BlendedMVS, \(\alpha = 1/4\)). Images in the 5th column are ground truths
Figure 14 compares rendered images by the original and proposed NeRF methods when \(N=64\). Particularly in the proposed NeRF framework, we used the worst sampling range for the BlendedMVS dataset. The proposed surface-based sampling method significantly improves the overall rendering quality of NeRF, but there exist some dot artifacts. This is because some missing information still exists or filled holes have inaccurate depth information, after the hole filling. We conjecture that if one uses a fancier depth estimation method than the proposed simple hole filling scheme, one can remove those artifacts.

A closer look at rendered images by the original NeRF and proposed NeRF method for a real dataset in BlendedMVS [28] (\(N = 64\); we used the worst sampling range for the \(N = 64\) case, \(\alpha = 1/8\))
Table 3 summarizes PSNR values of the original and proposed NeRF models, for different numbers of samples per ray (N) and different sampling ranges (\(2\alpha \)). For each setup using an identical N value, the proposed NeRF framework outperformed the original NeRF model, regardless of \(\alpha \).
4.5 Training Time Comparisons Between Different NeRF Models
Table 4 compares the training time between the five different NeRF methods, with different numbers of samples. The Instant-NGP model showed the fastest training time among the five NeRF models—note, however, that its rendering accuracy is significantly worse than the proposed NeRF method (see Table 2). Except for Instant-NGP, the proposed NeRF method showed the fastest training time. Particularly compared to the original NeRF, the proposed NeRF was about two times faster. The reason is that we trained a single fully-connected network in the proposed NeRF framework, whereas the original NeRF approach trained two fully-connected networks. It took longer in training DONeRF and DSNeRF than the proposed NeRF model (with the same number of iterations). This is natural because DONeRF and DSNeRF train an extra depth estimation network.
Regardless of the models, the smaller the number of sample points, it took the less training time.
5 Conclusion
In NeRF methods, it is important to reduce the number of sample points per ray while maintaining the rendering quality, as using less samples can reduce training/inference time. Based on the assumption that the closer the sample point is to the surface of an object, the more important it is for rendering, we propose a near-surface sampling method for NeRF. The proposed framework samples 3D points only near the surface of an object, by estimating depth images from a 3D point cloud generated with a subset of training data and a simple hole filling method. For different datasets, the proposed NeRF framework significantly improves the original NeRF [17] and three state-of-the-art NeRF methods, DONeRF [19], DSNeRF [5], and Instant-NGP [18]. Particularly compared to the original NeRF method, the proposed framework can achieve significantly better rendering accuracy, with only a quarter of sample points per ray. In addition, the proposed near-surface sampling framework can accelerate the NeRF training time twice as fast, while improving the rendering quality with an appropriate sampling range parameter. The proposed method would be useful particularly for applications/technologies where visualizing details is important in novel views.
There are a number of avenues for future work to improve the proposed framework. First, the proposed framework takes a longer inference time compared to the original NeRF model, because projecting many 3D points to a view plane and estimating a depth image is slower than inference via coarse network in original NeRF. We expect to reduce rendering time by speeding up the point cloud projection process. Second, the proposed NeRF framework is not completely end-to-end. In particular, the point cloud generation and refinement process is in the offline stage and not yet optimized for rendering. Therefore, we expect to improve the performance of the NeRF model by modifying it with the fully end-to-end approach, incorporating point cloud generation and refinement process into training. Finally, we expect to further improve the rendering performance of the proposed method by using a more accurate depth estimation method.
Data Availability
The NeRF dataset and BlendedMVS dataset are publicly available at https://paperswithcode.com/dataset/nerf and https://paperswithcode.com/dataset/blendedmvs.
Code availability
The code in this study is available from the corresponding author on reasonable request.
Notes
With a standard graphics processing unit (GPU), the processing time of standard MVS is 86.78 s (s) and that of the proposed point cloud generation is 87.12 s, both with 20 views.
Each original synthetic dataset consist of 100 training images and 100 test images; viewpoints are sampled on the upper hemisphere (with fixed diameter) around an object.
We generated a point cloud with 20 viewpoints by sequentially using the every fifth viewpoint from 100 viewpoints. We repeated the point cloud generation process 20 times, where each iteration consists of four steps in Sect. 3.4.1. (Sect. 3.4.1 describes the relation between the numbers of viewpoints and repetitions.)
For the synthetic Lego and Ship datasets and real BlendedMVS dataset, the PSNR value (in dB) for estimated depth in inference is 19.3, 16.8, and 10.4, respectively.
References
Alan W (1993) 3D Computer graphics. Addison-Wesley, Boston
Boss M, Braun R, Jampani V, et al (2021) NeRD: neural reflectance decomposition from image collections. In: IEEE/CVF international conference on computer vision, pp 12664–12674. https://doi.org/10.1109/ICCV48922.2021.01245
Cernea D (2020) OpenMVS: multi-view stereo reconstruction library. https://cdcseacave.github.io/openMVS
Chen SE, Williams L (1993) View interpolation for image synthesis. In: Proceedings of the conference on computer graphics and interactive techniques, pp 279–288. https://doi.org/10.1145/166117.166153
Deng K, Liu A, Zhu JY, et al (2022) Depth-supervised NeRF: fewer views and faster training for free. In: IEEE/CVF conference on computer vision and pattern recognition, pp 12872–12881. https://doi.org/10.1109/CVPR52688.2022.01254
Draelos M, Qiu Q, Bronstein A, et al (2015) Intel realsense = real low cost gaze. In: IEEE international conference on image processing, pp 2520–2524. https://doi.org/10.1109/ICIP.2015.7351256
Gortler SJ, Grzeszczuk R, Szeliski R, et al (1996) The lumigraph. In: Proceedings of the conference on computer graphics and interactive techniques, pp 43–54. https://doi.org/10.1145/237170.237200
Hartley R, Zisserman A (2003) Multiple view geometry in computer vision, 2nd edn. Cambridge University Press, Cambridge
Hu T, Liu S, Chen Y, et al (2022) EfficientNeRF efficient neural radiance fields. In: IEEE/CVF conference on computer vision and pattern recognition, pp 12902–12911. https://doi.org/10.1109/CVPR52688.2022.01256
Johari MM, Lepoittevin Y, Fleuret F (2022) GeoNeRF: generalizing nerf with geometry priors. In: IEEE/CVF conference on computer vision and pattern recognition, pp 18344–18347. https://doi.org/10.1109/CVPR52688.2022.01782
Levoy M, Hanrahan P (1996) Light field rendering. In: Proceedings of the conference on computer graphics and interactive techniques, pp 31–42. https://doi.org/10.1145/237170.237199
Lin CH, Ma WC, Torralba A, et al (2021) BARF: bundle-adjusting neural radiance fields. In: IEEE/CVF international conference on computer vision, pp 5721–5731. https://doi.org/10.1109/ICCV48922.2021.00569
Lindell DB, Martel JNP, Wetzstein G (2021) AutoInt: automatic integration for fast neural volume rendering. In: IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 14551–14560. https://doi.org/10.1109/CVPR46437.2021.01432
Liu L, Gu J, Lin KZ, et al (2020) Neural sparse voxel fields. In: Proceedings of the international conference on neural information processing systems, pp 15651–15663
Mankoff K, Russo T (2013) The Kinect: a low-cost, high-resolution, short-range 3d camera. Earth Surf Proc Land 38:926–936. https://doi.org/10.1002/esp.3332
Martin-Brualla R, Radwan N, Sajjadi MSM, et al (2021) NeRF in the wild: neural radiance fields for unconstrained photo collections. In: IEEE/CVF conference on computer vision and pattern recognition, pp 7206–7215. https://doi.org/10.1109/CVPR46437.2021.00713
Mildenhall B, Srinivasan PP, Tancik M, et al (2020) NeRF: Representing scenes as neural radiance fields for view synthesis. In: Proceedings of the European conference on computer vision, pp 405–421. https://doi.org/10.1007/978-3-030-58452-8_24
Müller T, Evans A, Schied C et al (2022) Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans Graph 41:1–15. https://doi.org/10.1145/3528223.3530127
Neff T, Stadlbauer P, Parger M et al (2021) DONeRF: towards real-time rendering of neural radiance fields using depth oracle networks. Comput Graph Forum 40:45–49. https://doi.org/10.1111/cgf.14340
Niemeyer M, Geiger A (2021) GIRAFFE: representing scenes as compositional generative neural feature fields. In: IEEE/CVF conference on computer vision and pattern recognition, pp 11448–11459. https://doi.org/10.1109/CVPR46437.2021.01129
Park K, Sinha U, Barron JT, et al (2021) Nerfies: deformable neural radiance fields. In: IEEE/CVF international conference on computer vision, pp 5845–5854. https://doi.org/10.1109/ICCV48922.2021.00581
Pumarola A, Corona E, Pons-Moll G, et al (2021) D-NeRF: neural radiance fields for dynamic scenes. In: IEEE/CVF conference on computer vision and pattern recognition, pp 10313–10322. https://doi.org/10.1109/CVPR46437.2021.01018
Rebain D, Jiang W, Yazdani S, et al (2021) DeRF: decomposed radiance fields. In: IEEE/CVF conference on computer vision and pattern recognition, pp 14148–14156. https://doi.org/10.1109/CVPR46437.2021.01393
Shade J, Gortler S, He Lw, et al (1998) Layered depth images. In: Proceedings of the conference on computer graphics and interactive techniques, pp 231–242. https://doi.org/10.1145/280814.280882
Srinivasan PP, Deng B, Zhang X, et al (2021) NeRV: neural reflectance and visibility fields for relighting and view synthesis. In: IEEE/CVF conference on computer vision and pattern recognition, pp 7491–7500, https://doi.org/10.1109/CVPR46437.2021.00741
Xie C, Park K, Martin-Brualla R, et al (2021) Fig-NeRF: figure-ground neural radiance fields for 3d object category modelling. In: International conference on 3D vision, pp 962–971. https://doi.org/10.1109/3DV53792.2021.00104
Xu Q, Xu Z, Philip J, et al (2022) Point-NeRF: point-based neural radiance fields. In: IEEE/CVF conference on computer vision and pattern recognition, pp 5438–5448. https://doi.org/10.1109/CVPR52688.2022.00536
Yao Y, Luo Z, Li S, et al (2020) BlendedMVS: a large-scale dataset for generalized multi-view stereo networks. In: IEEE/CVF conference on computer vision and pattern recognition, pp 1787–1796. https://doi.org/10.1109/cvpr42600.2020.00186
Yen-Chen L, Florence P, Barron JT, et al (2021) iNeRF: inverting neural radiance fields for pose estimation. In: IEEE/RSJ international conference on intelligent robots and systems (IROS), pp 1323–1330. https://doi.org/10.1109/IROS51168.2021.9636708
Funding
The work of H. B. Yoo and I. Y. Chun was supported in part by NRF Grants 2022R1F1A1074546 and RS-2023-00213455 Funded by MSIT, and the BK21 FOUR Project. The work of I. Y. Chun was additionally supported in part by IITP Grant 2019-0-00421 funded by MSIT, IBS-R015-D1, KIAT Grant P0022098 funded by MOTIE, the KEIT Technology Innovation program Grant 20014967 funded by MOTIE, SKKU-SMC and SKKU-KBSMC Future Convergence Research Program grants, and SKKU seed grants. The work of H. M. Han and S. S. Hwang was supported the NRF Grant NRF-2022R1C1C1011084 funded by MSIT.
Author information
Authors and Affiliations
Contributions
Conceptualization, H. B. Y., H. M. H., S. S. H., and I. Y. C.; data curation, H. M. H.; formal analysis, H. B. Y. and I. Y. C.; funding acquisition, S. S. H. and I. Y. C.; investigation, H. B. Y. and H. M. H.; methodology, H. B. Y., H. M. H., S. S. H., and I. Y. C.; project administration, S. S. H. and I. Y. C.; resources, I. Y. C.; software, H. B. Y. and H. M. H.; supervision, S. S. H. and I. Y. C.; validation, H. M. H., S. S. H., and I. Y. C.; visualization, H. M. H.; writing—original draft preparation, H. B. Y. and H. M. H.; writing—review and editing, I. Y. C. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that they have no Conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yoo, H.B., Han, H.M., Hwang, S.S. et al. Improving Neural Radiance Fields Using Near-Surface Sampling with Point Cloud Generation. Neural Process Lett 56, 214 (2024). https://doi.org/10.1007/s11063-024-11654-5
Accepted:
Published:
DOI: https://doi.org/10.1007/s11063-024-11654-5