
Abstract
Neural networks as differential equation solvers are a good choice of numerical technique because of their fast solutions and their nature in tackling some classical problems which traditional numerical solvers faced. In this article, we look at the famous gradient descent optimization technique, which trains the network by updating parameters which minimizes the loss function. We look at the theoretical part of gradient descent to understand why the network works great for some terms of the loss function and not so much for other terms. The loss function considered here is built in such a way that it incorporates the differential equation as well as the derivative of the differential equation. The fully connected feed-forward network is designed in such a way that, without training at boundary points, it automatically satisfies the boundary conditions. The neural tangent kernel for gradient enhanced physics informed neural networks is examined in this work, and we demonstrate how it may be used to generate a closed-form expression for the kernel function. We also provide numerical experiments demonstrating the effectiveness of the new approach for several two point boundary value problems. Our results suggest that the neural tangent kernel based approach can significantly improve the computational accuracy of the gradient enhanced physics informed neural network while reducing the computational cost of training these models.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In recent years scientific machine learning has been on the rise many problems have been solved using scientific machine learning. The algorithms of these methods are solely based on the mathematical structure of optimisation. Daily new methods are coming up that work with different techniques of optimisation [1, 2]. Neural networks are the base for scientific machine learning. They are a graph structure in which, when given a set of inputs and outputs, the structure learns the behaviour between these inputs and outputs then it can predict the output for any given input. After recent work in this field, an algorithm called automatic differentiation has come up in which the computer can differentiate any functions at any point quickly [3]. This method is not numerical, so even for complex structures, the algorithm can find its derivatives with really low errors. Then with the help of automatic differentiation, the problem of differential equations was looked at using the neural networks. These methods were referred to as physics-informed neural networks (PINNs) as the neural network train using the physical properties of the equations like in [4,5,6,7,8,9,10,11]. It was seen that using PINNs, a few of the classical problems in the field of numerical methods for differential equations were solved. One of them was the problem of dimensionality. Also, it was seen that using automatic differentiation to solve differential equations was faster than traditional numerical techniques. PINNs have been made even faster, such as conservative physics-informed neural networks (cPINN), where the neural networks constructed are such that they are deep in complex sub-domains and shallow in relatively simple and smooth sub-domains [12]. In other methods like XPINNs, where domain decomposition results in several sub-problems on subdomains, the individual networks can solve each sub-problem parallelly to accelerate convergence and improve generalization empirically [13,14,15]. Furthermore, [16,17,18] recently presented a detailed error analysis for PINNs.
The use of PINNs in modelling has shown promising results in a variety of fields. PINNs are advantageous as they need less data to predict solutions. They are practically useful when experimental data is scarce or expensive to obtain. For finding microstructure properties of polycrystalline Nickel so that we can infer the spatial variation of compliance coefficients of the material using ultrasound data, we find that traditional methods face problems as the wavefield data acquired experimentally or numerically are often sparse and high-dimensional in nature; the PINNs method provides a promising approach for solving inverse problems, where free parameters can be inferred, or missing physics can be recovered using noisy, sparse, and multi-fidelity scattered data sets [19]. Inverse water wave problems refer to the problem of obtaining the ocean floor deviation from the surface wave elevation. These problems are ill-posed since the direct problem that maps ocean floor deformations to sur- face water waves is not one-to-one, and thus small changes in the boundary conditions can cause significant differences in the outputs. PINNs can be used to generate solutions to such ill-posed problems using only data on the free surface elevation and depth of the water [20]. The use of shock waves in supersonic compressible flow is essential in many engineering applications, such as in the design of high-speed aircraft and spacecraft. The shock wave causes the solutions to become locally discontinuous and challenging to approximate using traditional numerical methods. However, PINNs can tackle such problems since they can approximate local discontinuities and extract relevant features from the data even in the presence of discontinuities [21]. High-speed aerodynamic flow can be modelled by the Euler equations, which follow the conservation of mass, momentum, and energy for compressible flow in the inviscid limit. Solutions of these conservation laws often develop discontinuities in some finite time, even though the initial conditions may be smooth. Still, PINNs can get a relatively stable solution without any regularization [22]. Black Scholes equation is a famous equation predicting options value in financial trading, these equations involve many variables and are difficult to solve numerically using standard mesh based numerical methods PINNs are good numerical techniques to tackle such problems [23]. PINNS have also been used in solving some families of fractional differential equations which are hard to solve using standard methods [24]. Overall, the use of PINNs in modelling has shown great potential in a wide range of fields. As the field continues to develop, PINNs will likely become an increasingly important tool for scientists and engineers seeking to understand better and predict the behaviour of complex systems.
In Sect. 2, we work with a fully connected neural network which not only tries to solve the differential equation but also tries to predict the gradient of the differential equation called gradient-enhanced physics-informed neural networks (GPINNs) [25]. We look at the neural tangent kernel (NTK) technique, which is a famous technique used to understand the behaviour of a neural network for the GPINN [26,27,28,29]. We look at the popular optimisation technique of stochastic gradient descent and try to understand the behaviour of the neural network when it uses this optimisation technique. We come across the problem of frequency bias, also called the F-Principle and try to work our way around the problem [30,31,32,33,34,35,36]. In Sect. 3, we provide some numerical results for different kinds of two point boundary value problems using techniques discussed in Sect. 2.
2 The GPINN-NTK Method
In this section, we discuss how the weights associated with individual terms of the loss function affect network training. For this, we will consider a single hidden layer feed-forward neural network. Theoretically, we will demonstrate that for a sufficiently large number of neurons in the hidden layer, the neural network solution approaches the exact solution as training time increases. Consider the nonlinear boundary value problem
We construct a neural network that automatically satisfies the boundary condition. There are further methods for creating these neural networks, such as creating a differential equation solution and multiplying it with an approximate distance function to the boundary that perfectly meets the boundary constraints [37]. The method also uses generalized barycentric coordinates to construct the distance function. Here we construct the distance function using linear Lagrange interpolation. The function N outputs the value
where \(\mathcal {N}\) is a feedforward neural network with initialised parameters that will be trained also it can be seen that at \(x=a\) and \(x=b\), the network N depends only on the Lagrange interpolant and hence satisfies the boundary conditions exactly. Further, the loss function \(L(\Theta )\) is taken in such a way that the neural network N(x) satisfies Eq. (1).
where \(w_{r}\) and \(w_{s}\) are the associated weights and
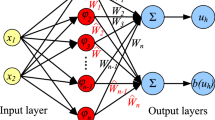
Here, the loss term \({L}_{s}(\Theta )\) is the \({l}_{2}\)-error of the neural network trying to fit the gradient of the differential equation. For the differential operator \(\mathcal {L}\) and the spatial derivative operator \(\mathcal {L}_x\). The term \({L}_{s}(\Theta )\) helps the network better understand the properties of the equation, mainly their derivatives. The graphical representation of the proposed network can be found in Fig. 1.
We use the NTK method for our constructed GPINN which satisfies the boundary condition automatically. The theory of NTK for PINNs has already been developed in [26], where the convergence of PINNs has been shown theoretically considering the boundary condition in their loss term. Here the theory of NTK has been developed for a network which does not contain the boundary term but contains a gradient loss term. Also, the network constructed here depends on the distance function created using Lagrange interpolation.
2.1 The Network Architecture
Consider a neural network having a single hidden layer with N nodes. Assuming weight parameters in the network be \(\mathcal {W} = \{{W}_{0},{W}_{1}\}\) where both \({W}_{0}\) and \({W}_{1}\) are \(N\times 1\) matrices. The bias parameters are \(\mathcal {B} = \{b_{0},b_{1}\}\), \(b_{0}\) and \(b_{1}\) are \(N\times 1\) and \(1\times 1\) matrix respectively. Define \(\Theta \) as the collection of all weights and biases. The network’s activation function is selected to be the hyperbolic tangent function, which is provided by
Then, for an input vector X, the network results the output
where k is the index of the k th row of the matrices \(W_0,W_1\) and \(b_0\).

Model of the network with gradient descent
2.2 Training of the Network
The gradient descent optimization approach is used to train the neural network. The algorithm for which is provided by
where \(j=0,1\) and \(\eta \) is the learning rate for the algorithm. For infinitesimally small values of \(\eta \), and a large number of neurons, the above discrete equation shows continuous behaviour, and the algorithm can be seen as
where the discrete iteration steps become a continuous domain of time and each \(W_{jk}\) is a continuous function over time t. In general, for all weights and biases, we can write this relation as
The gradient descent shows a learning bias known as the F-principle. The network shows a bias toward the loss term having lower frequencies, and it trains the term with lower frequencies first and then the terms with higher frequencies. Let
Consider the loss function
Then, according to the definition, we obtain
Now, for \(0 \le j \le N_b\), consider
Substituting the value of \(\frac{d \Theta }{d t}\), we find
and
Therefore, the matrix multiplication
yields
which is equivalent to
We know that \(\Theta \) are weights and biases, therefore, one obtains
As a result, \(\forall \theta \in \Theta \), we can write
As a result, now we define a matrix \(\varvec{k}_{rr}\), with dimension \( Nr \times Nr\), whose (i, j)th element is defined as the inner product representation
Similarly, the matrix multiplication
yields
where
Therefore, for an input vector of collocation points \(\varvec{x}_r\), we have
where the dimensions of the matrices are
Similarly, we can show that
where \(\varvec{k}_{tr}=\varvec{k}_{rt}^{\top }\), and
The above algebraic simplification provides us with a complete system, given by
The matrix
is called the neural tangent kernel. It follows that
and
From Eq. (2), using the structure of \(\mathcal {N}(x)\), we have the output of N(x). Differentiating N(x) in the spatial domain, we find
Upon using the structure of \(\mathcal {N}(x)\), we have




Here \(\dot{\sigma }\), \(\ddot{\sigma }\) and  denote the first, second and third derivative of the hyperbolic tangent activation function. This is possible to do since the hyperbolic tangent function is a \(C^{\infty }\) function. Here it can be seen that the derivatives \(\frac{dN_{xx}}{d\Theta }\) and \(\frac{dN_{xxx}}{d\Theta }\) depend only on the network \(\mathcal {N}\) and its spatial derivative.
denote the first, second and third derivative of the hyperbolic tangent activation function. This is possible to do since the hyperbolic tangent function is a \(C^{\infty }\) function. Here it can be seen that the derivatives \(\frac{dN_{xx}}{d\Theta }\) and \(\frac{dN_{xxx}}{d\Theta }\) depend only on the network \(\mathcal {N}\) and its spatial derivative.
2.3 Initialisation of Parameters
The behaviour of the neural network relies heavily on the initial values of the hyperparameters. The number of layers defines the depth of a network; deeper networks can capture more complex relationships in the data. However, striking a balance is essential as deeper networks might also suffer from vanishing or exploding gradients, making them harder to train. The width of a network is defined by the number of neurons in the hidden layer. Wider networks help better approximate the solution of the physical equation, especially for problems with high-dimensional input or complex dynamics. Still, they may also increase overfitting and require more computational resources. Learning rate is the rate by which weights and bias hyperparameters are updated. A higher learning rate can lead to fast convergence but may result in overshooting and instability. On the other hand, a very low learning rate can cause slow convergence and might get stuck in local minima. Weights and bias hyperparameters are responsible for the output of the neural network. Since we need to optimize the loss function, the network would converge to the solution faster if we choose the biases and weights close to the minima. The learning rate is another crucial factor of the gradient descent optimization technique. If the initial parameters are not close to the minimum, the initial loss would be higher, and the value of \({\delta \mathcal {L}^t}/{\delta W_{jk}^{t}}\) may blow up. Hence, we need a small learning rate to control the change in the weight and bias so that it does not diverge. Controlling the relation between initial weights and the learning rate makes neural network training more successful.
It is always advised to take small initial parameters and a small learning rate and train the network over a bigger data set for a longer number of iterations so that the network converges. As for a small learning rate, more information and more training iterations are required. We need the initial loss term to be small so that the Jacobian \({\delta \mathcal {L}^t}/{\delta W_{jk}^{t}}\) does not blow up. Consider the mean square error (MSE) loss term
where \(w_{r}\) and \(w_{s}\) are the weights associated with the loss term in the differential equation and their gradient. To have a good initial loss which will be easy to minimize, we need to choose appropriate values of these weights. Which will be the main aim of the algorithm.
3 Convergence of Neural Network Through Neural Tangent Kernels
If we assume the initial parameter \(\Theta \) to be a Gaussian process N(0, 1) (see [26]), then it can be shown that
and
where
and

In other words if the initial parameters are taken from the normal distribution then the resulting output of the network, and its derivatives also follow a Gaussian process. We will demonstrate that as the number of neurons in the single hidden layer are sufficiently large then, the initial tangent kernel approaches a deterministic value.
Firstly, let us consider the derivatives of the output of the network and the spatial derivative of the output of the network with respect to the parameters of the network. For \(t=0,1\), we have
where \(\mathcal {N}_{x}\), \(\mathcal {N}_{xx}\) and \(\mathcal {N}_{xxx}\) are defined in Eqs. (35)–(37). The derivatives of the output \(\mathcal {N}\) of the network and the derivatives of the spatial derivatives \(\mathcal {N}_{x}\), \(\mathcal {N}_{xx}\) and \(\mathcal {N}_{xxx}\) of the network with respect to the parameters of the network are given in Appendix A. After that, we may update the weights and biases in the gradient descent iterative method using the above-provided derivatives for the backpropagation technique.
We assume the weights and biases parameters to be bounded by some constant to achieve bounded numerical data from the network and their derivatives with respect to the parameters. Moreover, the bounded derivatives yield a deterministic value in each iteration from the tangent kernel and render a convergent algorithm.
Theorem 3.1
For a fully connected single-layer neural network having N neurons, if there exists a constant \(C>0\) such that \(\sup _{t \in [0, T]}\Vert \Theta (t)\Vert _{\infty } \le C\), and \(D^{2}f \in C^{\infty }([a,b])\). Then, the following holds
for \(N \xrightarrow {} \infty \), \(t=0,1\). Here, D denotes the partial differentiation with respect to arguments.
Proof
Combining the Eqs. (31)–(37), it can be seen that the derivatives of \(N_{xx}\) and \(N_{xxx}\) with respect to the parameter depend only on some finite algebraic relations between the weights \(W_0,W_1\) biases \(b_0\) and the hyperbolic tangent activation function and its derivatives. The initial assumption of the theorem was \(\sup _{t \in [0, T]}\Vert {\Theta }(t)\Vert _{\infty } \le C\). This implies, \( \sup _{t \in [0, T]}\Vert {W}_{t}(t)\Vert _{\infty } \le C, \sup _{t \in [0, T]}\Vert {b}_{0}(t)\Vert _{\infty } \le C \). Moreover, by the definition of the hyperbolic tangent function, we have \(\Vert \sigma ^{k}(x)\Vert _{\infty } \le 1\), for its \(k^{th}\) derivative \(k=0,1,...\) and \(x \in [a,b]\). By the second assumption of the theorem, we have that \(\Vert \frac{df}{du}\Vert _{\infty } \le M\), \(\Vert \frac{d^2f}{du^2}\Vert _{\infty } \le M\) and \(\Vert \frac{df}{du_{x}}\Vert _{\infty } \le M\), \(\Vert \frac{d^2f}{du_{x}^2}\Vert _{\infty } \le M\). Taking (41)–(46), substituting the bounds of (47) and (48) and using them for Eqs. (34)–(37) we have that
Now substituting the values of the spatial derivatives of the equation in Eqs. (31)–(33) we find
Further substituting the values of (50), (51) and (52), in (29) and (30), we have
This completes the proof. \(\square \)
Consequently, by employing the definition of the neural tangent kernel from Eq. (28) and Theorem 3.1 it can be shown that
Therefore, the kernel tangents approaches zero as the number of nodes in the hidden layer tends to infinity. This also shows that the NTK is bounded and has a definite value. In Wang et al. [26] it can be seen that the change in the NTK is negligible over the training process. Meaning that the NTK behaves similarly to the initial NTK. Denote the initial NTK as \(\varvec{k}(0) = \varvec{k}^*\) then we have that \(\varvec{k}(t) \approx \varvec{k}^*\), \(\forall t \in [0,T]\).
Now, consider the first row of the matrix Eq. (28) where we denote the parameters \(\Theta \) as a function of time as they evolve over time by the gradient descent algorithm.
Replacing \(\varvec{k}(t)\) with its approximate value
Let \(\mathcal {L} N\left( \varvec{x}_r, \Theta (t)\right) =y(t)\), then solving the differential equation
we obtain,
where \(c=\mathcal {L} N(0)\). Replacing the value of c in (58), we obtain
Similarly, it can be shown that
so we have
If the kernel matrix \(\varvec{k}^*\) was invertible, then values of \(\mathcal {L} N\) and \(\mathcal {L}_{x} N\) can be found in Eqs. (59) and (60) using kernel regression for some created test data at points \(x_{\text {test}}\). But in numerical results, the matrix \(\varvec{k}^*\) is close to a singular matrix and hence finding its inverse is difficult. This is called kernel regression.
3.1 Frequency Bias
Consider the matrix \(\varvec{k}_{rr}\) given in Eq. (22) it can be written as the multiplication of two matrices
Then, we have that
Similarly for
we have obtained
It is also true that for \(\varvec{J} = [\varvec{J}_1 \quad \varvec{J}_2],\)
Remark 1
For a matrix \(\varvec{A}\) having full rank it is true that \(\varvec{A}\varvec{A}^{\top }\) is always positive semi definite.
From the given remark we have that the matrices \(\varvec{k}_{rr}\), \(\varvec{k}_{tt}\) and \(\varvec{k}\) are all positive semi definite. Matrix \(\varvec{k*}\) has real positive eigenvalues means that matrix \(\varvec{k*}\) can be decomposed into the multiplication of two orthogonal matrices and one diagonal matrix. Consequently the spectral decomposition of the neural tangent kernel gives us
where Q is a orthogonal matrix \(Q^{-1} = Q^{\top }\), and \(\Lambda \) is a diagonal matrix having positive eigenvalues \(\lambda _i\) corresponding to the neural tangent matrix \(\varvec{k}^*\). Further, replacing (66) in (61), we get
and
As \(t \xrightarrow {} \infty \), it can be seen that the right side approaches 0, indicating that \(\mathcal {L} N (x_r)\xrightarrow {} 0\).
The convergence of \(\mathcal {L} N\) at the point \(x_i\) depends on the respective eigenvalue \(\lambda _i\). Moreover, it exhibits a faster rate of convergence for the large eigenvalues associated with the neural tangent kernel matrix. The eigenvalues with larger magnitudes correspond to eigenvectors having lower frequencies. The neural network first learns the part of the loss function with lower frequencies and then learns the part with higher frequencies since the convergence rate is faster for smaller frequencies. This is known as the frequency bias performed by the neural network. In order to solve this issue, it is necessary to ensure that the loss function does not contain a part with higher and lower frequencies.
In general, it is observed that the greater magnitude eigenvalues of the NTK matrix correspond to the portion of the loss function that deals with the derivative of the differential equation. The weights \(w_r\) and \(w_s\) multiplied by each part of the loss function are the parameters that can be altered to make the eigenvalues of both parts of the loss function equal. Increase the weight \(w_r\) or reduce the weight \(w_s\) to ensure that the eigenvalues of both terms remain identical, the neural network does not exhibit frequency bias, and the network is trained simultaneously for both parts of the loss function. We define the algorithm which will be used in the numerical simulations.

The GPINN method
4 Numerical Simulations
We will solve a few differential equations where our loss term to be optimized is given by Eqs. (4) and (5). We take a network with a single hidden layer to compare the results between different values of weights for loss terms. By doing so, we reduce computational time. We take 1000 neurons in the hidden layer so that the network can understand the complex dynamics of the differential equation. We use Xavier initialization as it helps set the initial weights so that the gradients in the network remain well-behaved during training. This helps prevent vanishing and exploding gradient problems, which can hinder the convergence of deep neural networks. Experimental results show that taking the learning rate as \(10^{-3}\) suits optimizing the loss function created. The activation function for the hidden layer is an important hyperparameter as it converts the linear network into a non-linear model. One can refer to the detailed description of the activation and adaptive activation functions in [38,39,40,41]. Here a scalable hyperparameter a is used in the activation function to optimize the network’s performance, resulting in better learning capabilities and a vastly improved convergence rate, especially at the early stages of training. A change in the parameter results in a change in the slope of the activation function. In these examples, we use the Swish activation function, which is a scalable sigmoidal function given by
Experiments show that parameter value \(a=1\) gives the best results. We first train the network using LBFGS optimizer and then use ADAM optimization for 20000 iterations.
The results are calculated for different values of the weights \(w_s\) and \(w_r\). All the problems have been solved on Python 3.0 using Tensorflow and Deepxde library see [42]. The relative error in \(l_2\) norm is calculated for 1000 points in the domain and the \(l_{\infty }\) error representing the maximum error value are computed with 1000 points in the domain. For all the examples, we take the parameters as shown in Table 1. Results have been shown for different residual points for all examples.
Example 4.1
[43] Consider the convection-diffusion concentration equation given by
with the boundary data \(u(0)=0\) and \(u(1)=1\). The analytical solution to the problem is given by
Table 2 shows the \(l_2-\)errors and relative \(l_{\infty }-\)errors at different weights and different nodes 10, 20 and 40 respectively, for \(a=6\) and \(b=20\).
Example 4.2
[44] Consider the finite deflection of elastic string equation given by
with the boundary data \(u(0)=0\) and \(u(1)=0\). The analytical solution is given by
Table 3 shows the relative \(l_2-\)errors and \(l_{\infty }-\)errors at different weights and different nodes 10, 20 and 40 respectively.
Example 4.3
Consider the Bessel differential equation given by
The analytical solution to the problem is given by the BesselJ(x) function. Table 4 shows the relative \(l_2-\)errors and \(l_{\infty }-\)errors at different weights and different nodes 10, 20 and 40 respectively, for \(\tau =8\).
Example 4.4
Consider a nonlinear Burger’s equation given by
with the boundary data \(u(0)=0\) and \(u(1)=0\).The analytical solution to the problem is given by
where \(R_e\) is the Reynolds number [45]. Table 5 shows the relative \(l_2-\)errors and \(l_{\infty }-\)errors at different weights and different nodes 10, 20 and 40 respectively, for \(R_e=100\) and \(\alpha =0.1\).
Example 4.5
Consider a boundary value problem given by
with the boundary data \(u(0)=-3\), \(u(1)=-2.2642421\). The analytical solution to the problem is given by \(u(x)= 2xe^{x-2} -3\). A comparison report is given in Table 6 for the exact and numerical solutions values at various grid points and \(w_r = 100\) and \(w_s=0.001\). The proposed GPINN technique exhibits superiority over the existing biologically inspired differential evolution algorithm [46].
Example 4.6
[47] Consider the Poisson’s equation given by
with the boundary data \(u(0,y)=1\), \(u(x,0)=1\), \(u(x,1)=e^{x}\) and \(u(2,y)=e^{2y}\). The analytical solution to the problem is given by \(u(x,y)= e^{xy}\). Table 7 shows the relative \(l_2-\)errors and \(l_{\infty }-\)errors at different weights and different nodes 10, 20 and 40 respectively.

Exact and approximate solution plot at different values of weights for Example 4.1

Log log plot for error vs number of grid points
5 Conclusion
Understanding why neural networks with some specific structure work better in a few places of the solution domain and not so well in other places is important for training the network well. Here we construct a network that automatically meets the boundary data, which reduces the cost of training the network on the boundary and gives the exact value at the boundary. We then introduce a loss term where the network tries to fit the derivative of the differential equation; this helps the network in problems where the derivative is steep (see Burger’s equation). Adding the loss component raises the back-propagated derivatives of the neural network with respect to its parameters, which causes the weights to change with each iteration rapidly. We look at this problem through the lens of NTK and then see that this problem can be solved just by adjusting the weights of each loss term. Results show that increasing the weight of the loss term containing the residual of the differential equation and decreasing the weight of the loss term containing the residual of the gradient of the differential equation helps in better solutions. The proposed method can be deployed on different network architectures as each of them might have another problem with training and can be seen easily with the help of NTK.
Data Availability
The Python codes are available on request to the corresponding author.
References
Al-Majidi SD, Abbod MF, Al-Raweshidy HS (2020) A particle swarm optimisation-trained feedforward neural network for predicting the maximum power point of a photovoltaic array. Eng Appl Artif Intel 92:103688
Kowalski PA, Łukasik S (2016) Training neural networks with krill herd algorithm. Neural Process Lett 44:5–17
Baydin AG, Pearlmutter BA, Radul AA, Siskind JM (2018) Automatic differentiation in machine learning: a survey. Mach Learn Res 18:1–43
Raissi M, Perdikaris P, Karniadakis GE (2017) Inferring solutions of differential equations using noisy multi-fidelity data. J Comput Phys 335:736–746
Raissi M, Perdikaris P, Karniadakis GE (2017) Physics Informed deep learning (Part I): data-driven solutions of nonlinear partial differential equations. arXiv:1711.10561
Raissi M, Perdikaris P, Karniadakis GE (2017) Physics informed deep learning (Part II): data-driven discovery of nonlinear partial differential equations. arXiv:1711.10566
Raissi M, Perdikaris P, Karniadakis GE (2018) Numerical gaussian processes for time-dependent and nonlinear partial differential equations. SIAM J Sci Comput 40(1):172–198
Raissi M, Perdikaris P, Karniadakis GE (2019) Physics-informed neural networks: a deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J Comput Phys 378:686–707
Zhang D, Lu L, Guo L, Karniadakis GE (2019) Quantifying total uncertainty in physics-informed neural networks for solving forward and inverse stochastic problems. J Comput Phys 397:108850
Mall S, Chakraverty S (2016) Single layer Chebyshev neural network model for solving elliptic partial differential equations. Neural Process Lett 45:825–840
Lu L, Jin P, Pang G, Zhang Z, Karniadakis GE (2021) Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nat Mach Intell 3(3):218–229
Jagtap AD, Kharazmi E, Karniadakis GE (2020) Conservative physics informed neural networks on discrete domains for conservation laws: applications to forward and inverse problems. Comput Methods Appl Mech Engrg 365:113028
Jagtap AD, Karniadakis GE (2020) Extended physics informed neural networks (XPINNs): a generalized space-time domain decomposition based deep learning framework for nonlinear partial differential equations. Commun Comput Phys 28(5):2002–2041
Shukla K, Jagtap AD, Karniadakis GE (2021) Parallel physics-informed neural networks via domain decomposition. J Comput Phys 447:110683
Hu Z, Jagtap A.D, Karniadakis G.E, Kawaguchi K (2022) Augmented physics-informed neural networks (APINNs): a gating network-based soft domain decomposition methodology. arXiv:2211.08939
Mishra S, Molinaro R (2022) Estimates on the generalization error of physics-informed neural networks for approximating a class of inverse problems for PDEs. IMAJNA 42(2):981–1022
De Ryck T, Jagtap AD, Mishra S (2023) Error estimates for physics-informed neural networks approximating the Navier–Stokes equations. IMAJNA 44(1):83–119
Hu Z, Jagtap AD, Karniadakis GE, Kawaguchi K (2022) When do extended physics-informed neural networks (XPINNs) improve generalization? SIAM J Sci Comput 44(5):A3158–A3182
Shukla K, Jagtap AD, Blackshire JL, Sparkman D, Karniadakis GE (2021) A physics-informed neural network for quantifying the microstructural properties of polycrystalline nickel using ultrasound data: a promising approach for solving inverse problems. IEEE Signal Process Mag 39(1):68–77
Jagtap AD, Mitsotakis D, Karniadakis GE (2022) Deep learning of inverse water waves problems using multi-fidelity data: application to Serre–Green–Naghdi equations. Ocean Eng 248:110775
Jagtap AD, Mao Z, Adams N, Karniadakis GE (2022) Physics-informed neural networks for inverse problems in supersonic flows. J Comput Phys 466:111402
Mao Z, Jagtap AD, Karniadakis GE (2020) Physics-informed neural networks for high-speed flows. Comput Methods Appl Mech Engrg 360:112789
Gençay R, Qi M (2001) Pricing and hedging derivative securities with neural networks: Bayesian regularization, early stopping, and bagging. IEEE Trans Neural Netw 12(4):726–734
Pang G, Lu L, Karniadakis GE (2019) fPINNs: fractional physics-informed neural networks. SIAM J Sci Comput 41(4):2603–2626
Yu J, Lu L, Meng X, Karniadakis GE (2022) Gradient-enhanced physics-informed neural networks for forward and inverse PDE problems. Comput Methods Appl Mech Engrg 393:114823
Wang S, Yu X, Perdikaris P (2022) When and why PINNS fail to train: a neural tangent kernel perspective. J Comput Phys 449:110768
Jacot A, Gabriel F, Hongler C (2018) Neural tangent kernel: convergence and generalization in neural networks. Adv Neural Inf Process Syst 31:1–10
Saadat M.H, Gjorgiev B, Das L, Sansavini G (2022) Neural tangent kernel analysis of PINN for advection-diffusion equation. arXiv:2211.11716
McClenny LD, Braga-Neto UM (2023) Self-adaptive physics-informed neural networks. J Comput Phys 474:111722
Penwarden M, Jagtap AD, Zhe S, Karniadakis GE, Kirby RM (2023) A unified scalable framework for causal sweeping strategies for physics-informed neural networks (PINNs) and their temporal decompositions. arXiv:2302.14227
Canatar A, Bordelon B, Pehlevan C (2021) Spectral bias and task-model alignment explain generalization in kernel regression and infinitely wide neural networks. Nat Commun 12(1):2914
Tancik M, Srinivasan P, Mildenhall B, Fridovich-Keil S, Raghavan N, Singhal U, Ramamoorthi R, Barron J, Ng R (2020) Fourier features let networks learn high frequency functions in low dimensional domains. Adv Neural Inf Process Syst 33:7537–7547
Wang S, Wang H, Perdikaris P (2021) On the eigenvector bias of Fourier feature networks: from regression to solving multi-scale PDEs with physics-informed neural networks. Comput Methods Appl Mech Engrg 384:113938
Xiang Z, Peng W, Liu X, Yao W (2022) Self-adaptive loss balanced physics-informed neural networks. Neurocomputing 496:11–34
Xu Z.Q.J, Zhang Y, Luo T, Xiao Y, Ma Z (2019) Frequency principle: fourier analysis sheds light on deep neural networks. arXiv:1901.06523
Poggio T, Banburski A, Liao Q (2020) Theoretical issues in deep networks. PNAS 117(48):30039–30045
Sukumar N, Srivastava A (2022) Exact imposition of boundary conditions with distance functions in physics-informed deep neural networks. Comput Methods Appl Mech Engrg 389:114333
Jagtap AD, Kawaguchi K, Karniadakis GE (2020) Adaptive activation functions accelerate convergence in deep and physics-informed neural networks. J Comput Phys 404:109136
Jagtap AD, Kawaguchi K, Karniadakis GE (2020) Locally adaptive activation functions with slope recovery for deep and physics-informed neural networks. Proc Math Phys Eng Sci 476(2239):20200334
Jagtap AD, Shin Y, Kawaguchi K, Karniadakis GE (2022) Deep Kronecker neural networks: a general framework for neural networks with adaptive activation functions. Neurocomputing 468:165–180
Jagtap AD, Karniadakis GE (2023) How important are activation functions in regression and classification? A survey, performance comparison, and future directions. JMLMC 4(1):21–75
Lu L, Meng X, Mao Z, Karniadakis GE (2021) DeepXDE: a deep learning library for solving differential equations. SIAM Rev 63(1):208–228
Agarwal RP, Hodis S, O’Regan D (2019) 500 Examples and problems of applied differential equations. Springer, Berlin
Cuomo S, Marasco A (2008) A numerical approach to nonlinear two-point boundary value problems for ODEs. Comput Math Appl 55:2476–2489
Jha N (2013) A fifth order accurate geometric mesh finite difference method for general nonlinear two point boundary value problems. Appl Math Comput 219:8425–8434
Fateh MF, Zameer A, Mirza NM, Mirza SM, Raja MAZ (2017) Biologically inspired computing framework for solving two-point boundary value problems using differential evolution. Neural Comput Appl 28:2165–2179
Jha N, Perfilieva I, Kritika (2023) A high-resolution fuzzy transform combined compact scheme for 2D nonlinear elliptic partial differential equations. MethodsX 10:102206
Acknowledgements
E. Mallik acknowledges the Council of Scientific & Industrial Research Grant-in-aid (No.09/1112(13710)/2022-EMR-I) in the form of a research fellowship and N. Jha is supported by the research grant from the Department of Atomic Energy, Government of India (No. 02011/1/2023NBHM(R.P.)/R & D II/1631).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no Conflict of interest regarding the publication of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A Few Derivative Results
Appendix A Few Derivative Results
See Table 8.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jha, N., Mallik, E. GPINN with Neural Tangent Kernel Technique for Nonlinear Two Point Boundary Value Problems. Neural Process Lett 56, 192 (2024). https://doi.org/10.1007/s11063-024-11644-7
Accepted:
Published:
DOI: https://doi.org/10.1007/s11063-024-11644-7