
Abstract
Video anomaly event detection is crucial for analyzing surveillance videos. Existing methods have limitations: frame-level detection fails to remove background interference, and object-level methods overlook object-environment interaction. To address these issues, this paper proposes a novel video anomaly event detection algorithm based on a dual-channel autoencoder with key region feature enhancement. The goal is to preserve valuable information in the global context while focusing on regions with a high anomaly occurrence. Firstly, a key region extraction network is proposed to perform foreground segmentation on video frames, eliminating background redundancy. Secondly, a dual-channel autoencoder is designed to enhance the features of key regions, enabling the model to extract more representative features. Finally, channel attention modules are inserted between each deconvolution layer of the decoder to enhance the model’s perception and discrimination of valuable information. Compared to existing methods, our approach accurately locates and focuses on regions with a high anomaly occurrence, improving the accuracy of anomaly event detection. Extensive experiments are conducted on the UCSD ped2, CUHK Avenue, and SHTech Campus datasets, and the results validate the effectiveness of the proposed method.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Anomalous event detection in videos refers to the identification of unexpected events or objects in specific scenarios, aiming to discover and locate abnormal events that may pose a threat to public safety, such as robbery, fighting, and traffic accidents. The rarity of anomalous event samples in videos and the scene-dependent definition of abnormal events pose significant challenges in meeting the requirements of efficient and accurate anomaly detection. The emergence of deep learning techniques has provided new insights and greatly advanced the development of video anomalous event detection. Early methods for video anomalous event detection mostly relied on traditional supervised learning techniques [1]. However, due to the scarcity of anomalous event samples, the training data is limited to normal events, which ultimately hampers the effectiveness of supervised learning. Therefore, contemporary researchers widely adopt unsupervised deep learning approaches that only require normal samples.
The key to unsupervised learning-based methods lies in extracting representative, discriminative, and accurate features that reflect the actual characteristics of video data. To address this issue, some researchers [2,3,4,5,6] have employed approaches that focus on extracting local features for anomaly detection. Additionally, there is a portion of researchers who have concentrated their attention on global information. Lee et al. [7] proposed a method based on a bidirectional multi-scale aggregation network, which learns the correspondence between appearance and motion patterns in video information. It utilizes bidirectional multi-scale feature aggregation and appearance-motion joint detection for efficient spatiotemporal feature encoding. Nguyen et al. [8] designed a video anomaly detection method based on the correspondence between pattern appearance and motion. This method consists of two streams: the first stream reconstructs appearance using an autoencoder architecture, while the second stream predicts the motion of input video frames using a U-Net structure, with both streams sharing an encoder. Park et al. [9] also leveraged the power of global information but overlooked the interference caused by the background, resulting in limited utilization of local target information.
Most of the aforementioned methods primarily utilize global or local information without considering the regions of interest. In reality, anomalous events often occur or manifest on individuals or objects within video frames, making the moving entities in the foreground crucial for anomaly detection. As a result, many researchers have shifted their focus towards objects within the scene. Ionescu et al. [10] employed a single-shot detector [11] on every frame of the video. After isolating the objects, they utilized convolutional autoencoder to learn deep unsupervised features, thus directing the algorithm’s attention towards the objects in the scene. Furthermore, they reframed the anomaly detection problem as a multi-class classification task rather than an imbalanced binary classification problem. Doshi et al. [12, 13] proposed a statistical framework for sequential anomaly detection, leveraging efficient object detectors to extract more meaningful features and enhancing model training efficiency through transfer learning. Wang et al. [14] employed a self-supervised approach for deep outlier detection, addressing the limitations of supervised methods while allowing discriminative deep neural networks to be directly applied to deep outlier detection problems. Barbalau et al. [15] further explored the existing self-supervised multi-task learning (SSMTL) framework for video anomaly detection by introducing additional detection methods centered around objects, aiming to improve the accuracy of object detectors within SSMTL. Although these methods to some extent mitigate the interference caused by complex background information in anomaly recognition, they often overlook the association between anomalous events and their contextual information due to their excessive focus on objects.
To enhance the accuracy of anomaly event detection by fully utilizing the informative key region information with high anomaly occurrence, this paper proposes a Key Region Feature Enhancement Dual-channel Autoencoder (KRFE-DAE). Unlike existing methods, KRFE-DAE not only focuses on anomalous key regions for video anomaly event detection but also considers the interaction between foreground objects and global context, avoiding the oversight of anomalous events that may occur in the background. Specifically, we design a Key Region Extraction Network (KREN) to separate the foreground motion regions with high anomaly occurrence from the video background, reducing the interference of background redundancy. Furthermore, we introduce a dual-channel autoencoder with an attention mechanism to fuse the information from key region images and complete video frames, enhancing the key region features and improving the detection accuracy of the model.
In summary, our work makes the following contributions:
-
We propose a well-designed Key Region Extraction Network (KREN) to separate background information and perform pixel-level segmentation of frequently occurring key regions, mitigating the interference from complex backgrounds.
-
We design a dual-channel autoencoder structure that highlights disturbances caused by anomalous data from both global context and key regions. The dual-channel structure preserves information that may trigger anomalies in the global context while enhancing the features of key regions.
-
We incorporate attention mechanisms into the decoder. During the feature reconstruction process, the attention decoder effectively utilizes inter-channel correlation information to suppress noise diffusion and focuses the model’s attention on anomalous key regions, thereby improving the reconstruction error of anomalous samples.
-
We conduct extensive experiments to demonstrate the generalization and effectiveness of the proposed dual-channel autoencoder network on three benchmark datasets.
The rest parts of this paper are organized as follows. Section 2 provides a brief overview of recent relevant work. Section 3 gives the overall and detailed description of the proposed KRFE-DAE. Section 4 showcases the experimental results of our approach for anomalous event detection on benchmark datasets. The conclusion and discuss about future work are finally summarized in Sect. 5.
2 Related Work
Currently, in the field of video anomalous event detection, numerous methods have been proposed. Among them, prediction-based methods and reconstruction-based methods are widely researched and applied as mainstream approaches.
2.1 Prediction-Based Methods
The principle of prediction model is to forecast future data using a training set and detect anomalies by analyzing the errors between the predicted values and actual data. Previous studies [16,17,18] have demonstrated the effectiveness of prediction-based anomalous event detection methods. Liu et al. [19] argued that since anomalies can be seen as events that deviate from certain expectations, predicting future frames could provide a more natural perspective. They employed a generator-discriminator structure similar to generative adversarial networks, with the U-Net architecture chosen as the generator for future frame prediction, and a discriminator at the end of the network to determine if the predicted frames are anomalous. Inspired by the predictive coding mechanism, Ye et al. [20] proposed a novel deep predictive coding network called AnoPCN to address the issue of narrow regularity score intervals in anomaly detection. The network consists of a predictive coding module and an error refinement module. The predictive coding module utilizes a convolutional recurrent neural network to achieve prediction and incorporates explicit motion information for improved prediction performance. However, this model has limitations in modeling temporal information and utilizing adversarial techniques, resulting in poor training effectiveness.
To address this issue, Wang et al. [21] employed a multi-path structure and noise-tolerant loss to enhance the performance of anomaly detection in surveillance videos, avoiding the need for complex variational methods and additional loss functions. This approach effectively improves the training efficiency and robustness of the model. In another study [22], improvements were made to the LSTM model to achieve higher prediction accuracy for time series datasets with different distributions. They also proposed a pruning algorithm to dynamically determine the prediction error threshold for identifying anomalies, reducing false positives, and avoiding reliance on scarce anomaly labels, thereby further enhancing anomaly detection performance. Additionally, Li et al. [23] proposed an unsupervised traffic video anomaly detection method based on future object localization. They improved upon the traditional adversarial generative network by introducing a single encoder-dual decoder architecture with multiple fully convolutional layers. This architecture enables the network to predict future skeletal trajectories while simultaneously reconstructing past input trajectories. Although the aforementioned prediction-based video anomaly detection methods have made significant progress in detection results, their drawbacks should not be overlooked. Firstly, they excessively emphasize the unpredictability of anomalous events, and secondly, they overlook the fact that many normal events are also unpredictable, leading to high false alarm rates.
2.2 Reconstruction-Based Methods
Many researchers [24, 25] have chosen to address the challenge of video anomalous event detection using reconstruction-based methods. Reconstruction-based methods can more accurately restore the original video content and are less susceptible to detection performance degradation caused by prediction errors. Lu et al. [26] recognized the limitations of traditional autoencoders and introduced convolutional autoencoders to reduce the loss of spatial information. They proposed a sparse combination learning framework that decomposes complex problems into several easily solvable sub-problems. This approach significantly improves the detection speed without compromising the detection quality. However, sparse coding requires significant computational power when dealing with large-scale data. Based on this, Shi et al. [27] proposed a Conv-LSTM network based on reconstruction error for video anomalous event detection. This method utilizes a neural network, Long Short-Term Memory (LSTM), capable of learning long-term dependencies in data to construct an encoder-decoder structured Conv-LSTM network for video anomalous event detection research. On the other hand, Chong et al. [28] integrated the aforementioned two methods. Specifically, they designed a convolutional autoencoder with CLSTM layers to preserve temporal information in frame sequences during model training, addressing the issue of temporal information loss. Furthermore, there have been many recent studies [29, 30] exploring additional possibilities of reconstruction-based methods.
In general, reconstruction-based methods for anomalous event detection have been proven effective, exhibiting good generalization capability and scalability. However, most of these methods only utilize complete video frames to learn normal patterns. These models often suffer from a lack of focus, as they do not prioritize the learning and reconstruction of complex regions that pose challenges during training. Consequently, their performance in detecting anomalous events is compromised when confronted with complex background interferences. To address this issue, this paper proposes KRFE-DAE, which employs a reconstruction-based anomaly discrimination approach. By incorporating key region feature enhancement, the network is directed to focus on regions that are more likely to exhibit anomalies, thereby improving the accuracy of anomalous event detection.
3 Methodology
3.1 Overall Architecture
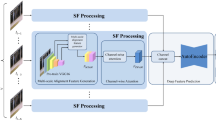
In this paper, we propose a KRFE-DAE to detect anomalous events in videos. Figure 1 describes the architecture of our algorithm, which consists of three main components: KREN, dual-channel encoders, and attention decoder.

The overall framework of the video anomalous event detection algorithm based on KRFE-DAE. Firstly, key region extraction is performed on the video frame sequence. Next, the key regions and original frames are fed into two separate encoders of a dual-channel autoencoder, extracting features from both the key regions and the original video frames. The fused features are then inputted into a self-attention decoder for frame reconstruction. Finally, the reconstruction error between the original and reconstructed video frames is computed to accomplish anomalous event detection in the video
We propose a video anomalous event detection algorithm based on KRFE-DAE. The algorithm shifts the focus of detection from the entire frame to key regions that are prone to anomalies. It adopts a dual-stream architecture, utilizing two encoders to process both the original images and the key region images. After feature extraction, feature fusion is employed to enhance the key region features, enabling the network to learn the anomaly-prone regions while preserving the global contextual information. To emphasize important features during decoding, an attention decoder is introduced, incorporating channel attention modules between each layer of the decoder network to enhance reconstruction performance. As the training data consists only of normal samples, the model struggles to reconstruct anomalous samples effectively. For anomalous samples, there exist substantial disparities between the reconstructed images and their corresponding original images, thereby facilitating anomaly detection by evaluating the reconstruction error.
3.2 Key Region Extraction
Anomalous events often occur on rapidly moving foreground objects, such as suddenly running individuals or vehicles abruptly entering the scene. Therefore, foreground motion targets serve as crucial regions for video anomaly detection. The purpose of key region extraction is to eliminate complex background information and retain only the highly anomalous regions. This aims to enhance the model’s sensitivity and accuracy in detecting abnormal events while reducing the possibilities of false positives and false negatives. The process of KREN proposed in this paper for extracting abnormal key regions is illustrated in Fig. 2.

The process of KREN. When video frames are input to the KREN, the process begins with object detection and foreground detection to extract collections of human and object targets and foreground motion objects from the video frames, respectively. Subsequently, a comparison is performed between the objects in the two collections, eliminating background regions and objects with low anomaly occurrence rates. This results in the identification of key regions that significantly impact video anomaly detection. Finally, random occlusion is applied to the key regions to reduce interference from redundant targets
First, the KREN performs object detection on the original video frames using Mask R-CNN [31], enabling precise localization of targets and pixel-level segmentation from the background. To avoid the loss of anomalous targets caused by missed detections, this study reasonably lowers the threshold for object detection, aiming to capture as many potential targets as possible. Although the obtained object detection results have already removed a significant amount of background information and narrowed down the scope of key regions, there still exist numerous static redundant objects. To further pinpoint the key regions in the video frames, this paper employs ViBe [32] to extract foreground motion information. Subsequently, a one-to-one comparison is conducted between the objects obtained from object detection and foreground detection. The target box to be compared is denoted as \(B _{o}\), and the corresponding region in the foreground motion target image is denoted as \(B_{f}\).
The probability of key region determination, \(P_{k}\), is calculated based on Eq. (1). When \(P_{k}\) exceeds the detection threshold, the target box \(B_{o}\) is classified as a key region. The process described in Eq. (1) is repeated until all target boxes have been compared. Since the proportion of anomalous targets is relatively low compared to the overall targets, in order to better focus the detection on potential anomalous targets, this study employs random occlusion to convert a certain proportion of the compared foreground targets into background. In this way, KREN can effectively mitigate the interference caused by redundant information and extract pixel-level key regions that have the most significant impact on anomaly detection.
3.3 Dual-Channel Autoencoder
Due to the close association between the definition of abnormal event and the environment, it is not feasible to simply remove the background completely when considering how to mitigate the interference caused by complex environmental factors in the detection process. In order to enhance the foreground information while preserving the global contextual information, we propose a dual-channel autoencoder that effectively utilizes both global information and key region information.
The proposed dual-channel autoencoder network architecture is illustrated in Fig. 3. Both the global encoder and the key region encoder in the network employ the same structure of 3D-CNN, where each layer consists of a convolutional layer, a Batch Normalization layer, and a Leaky ReLU activation function. After extracting global and key region features using the two branch encoders, the features are fused and inputted into the decoder. The decoder consists of 3D deconvolutional layers, Batch Normalization layers, and Leaky ReLU activations, except for the last layer. The detailed configuration of the proposed dual-channel autoencoder is presented in Table 1, where \(C_{in}\) and \(C_{out}\) represent the input and output channels of each layer, respectively. \(N_{k}\), \(N_{s}\), and \(N_{p}\) denote the kernel size, stride, and padding size, respectively. \(SHAPE_{out}\) represents the output size.

The framework of dual-channel autoencoder
3.4 Decoder Based on Attention Mechanism
To enhance the network’s focus on important features, we introduced a channel attention module [33] to calculate the importance of each feature map. A channel attention module was incorporated between each deconvolutional layer of the decoder, aiming to enhance the model’s perception and discriminative ability for the target task, thereby improving its generalization capability. The structure of this module is illustrated in Fig. 4.

The framework of attention-based decoder
The purpose of incorporating channel attention is to improve the model’s focus on different channels by learning attention weights, with the core being the Squeeze-and-Excitation (SE) module. The SE module is a computational unit that can be built upon a transformation convolution operator, denoted as \(F_{tr}\), which maps an input \(X\ (X\in R^{H'\times W'\times C'})\) to a feature map \(U\ (U\in R^{H\times W\times C} )\). In Eq. (2), \(V=[v_{1},v_{2},\cdots ,v_{c} ]\) represents the collection of filter kernels, where \(v_{c}\) denotes the parameters of the c-th filter. The output is denoted as \(u_{c}\).
In Eq. (2), \(\times \) denotes convolution, and \(v_{c}\) is a two-dimensional spatial kernel. The SE module consists of two steps, squeeze and excitation, to calibrate the filter responses and provide global information. Squeeze is performed by global average pooling, which compresses the input feature map into a one-dimensional vector. This vector contains global information of the input feature map across different channels. Formally, the statistic \(z \ (z\in R^{C})\) is generated by compressing the spatial dimensions \(H \times W\) of U. Each \(z_{c}\) is computed using Eq. (3):
To utilize the aggregated information after sufficient squeezing, an excitation operation is performed. It maps the one-dimensional vector to a lower-dimensional vector through a fully connected layer and uses the Sigmoid activation function to generate channel attention weights, as shown in Eq. (4):
In Eq. (4), \(\sigma \) denotes the ReLU [34] function, \(W_{1}\in R^{\frac{c}{r} \times c},W_{2}\in R^{\frac{c}{r} \times c}\). To limit the model’s complexity and improve its generalization, this study employs a dimension reduction layer with a reduction ratio r, ReLU, and an expansion layer for parameterized gating. The final output of the SE module is obtained by re-scaling U with the activated s.
3.5 Anomaly Discrimination
This paper employs reconstruction error for anomaly discrimination. The basic idea of reconstruction error is that normal samples, when input into a well-trained model, will produce outputs that are closer to the inputs, resulting in lower reconstruction error because they are more similar to the training data. On the other hand, anomalous samples, due to their significant differences from the training data, will exhibit higher reconstruction error.
Let \(x_{t}\) denote the video segment or frame at time t, g represent the neural network that reconstructs x, g(x) denote the reconstructed equation, and \(g_{t}(x)\) represent the reconstructed video segment or frame. The reconstruction error can be defined as the function R, which calculates the error between x (the original input) and g(x), as shown in Eq. (5).
The reconstruction error formula represents the L2 norm error between the original and reconstructed inputs. During the testing phase, when the model reconstructs frames of anomalous events, it typically exhibits larger reconstruction errors. If the error value exceeds a predefined threshold, the current video frame is considered to contain an anomalous event. To facilitate further computations, after obtaining the reconstruction scores for all frames of the video, this paper normalizes the reconstruction scores of all frames. Let \(R_{u}\) denote the score of the u-th frame, where \(min(R_{u})\) represents the minimum score among all scores, and \(max(R_{u})\) represents the maximum score among all scores. The normalized reconstruction score for the u-th frame is calculated as shown in Eq. (6).
4 Experiments
4.1 Comparison with State-of-the-Art Methods
To validate the effectiveness of the proposed KRFE-DAE, experiments were conducted on the UCSD ped2, CUHK Avenue, and SHTech Campus datasets for video anomaly event detection. The performance of KRFE-DAE was compared with handcrafted feature-based methods [45,46,47] and deep learning-based methods [35,36,37,38,39,40,41,42,43,44] in terms of frame-level AUC. The experimental results are presented in Table 2.
Existing methods can be broadly categorized into handcrafted feature-based methods and deep learning-based methods. As shown in Table 2, our proposed method achieves significantly higher AUC scores on the UCSD Ped2, CUHK Avenue, and SHTech Campus datasets, with values of 97.1%, 82.9%, and 73.8%, respectively, surpassing the performance of handcrafted feature-based methods. Among the deep learning-based methods, compared to the traditional 3D convolutional autoencoder method [35], KRFE-DAE improves the accuracy by 5.9%, 5.5%, and 4.1% on the UCSD Ped2, CUHK Avenue, and SHTech Campus datasets, respectively, and achieves the best performance on the UCSD Ped2 and SHTech Campus datasets.
In the CUHK Avenue dataset, our method does not perform the best, primarily due to the presence of various abnormal behaviors such as throwing backpacks and papers. These throwing actions result in blurred objects that are challenging to extract using the proposed KREN in this paper. In future work, we will further optimize KREN to enhance its ability to capture rapidly moving objects. In fact, as shown in Table 2, most methods do not achieve the best performance across all three datasets. For example, ME [40] outperforms our method in the CUHK Avenue dataset, but its accuracy is lower than ours in the other two datasets. Overall, our method has significantly improved accuracy compared to traditional deep learning-based approaches, providing sufficient evidence for the effectiveness of KRFE-DAE.
We empirically study the computing complexity of the proposed KRFE-DAE with an NVIDIA GTX 1080 Ti GPU. As shown in Table 3, KRFE-DAE achieves an frames per second (FPS) of 26.2, demonstrating better real-time feasibility compared to other existing methods. This further validates the effectiveness of our proposed approach.
4.2 Ablation Study
A series of ablation experiments were conducted in this study to investigate the effects of selecting different parameters and modules, aiming to validate the effectiveness of the proposed method.
4.2.1 Selection of Parameters
The selection of the key region occlusion rate determines the number of preserved targets in the key region, which significantly affects the effectiveness of key region feature enhancement and the final results of anomaly detection. Therefore, in this paper, we conducted occlusion rate selection experiments on the UCSD ped2 dataset using a single autoencoder. The experiments tested the model’s anomaly detection performance with different values of occlusion rate ranging from 0 to 1. The experimental results are shown in Table 4.
According to Table 4, it can be observed that the KREN performs the best on the UCSD ped2 dataset when the occlusion rate is set to 0.2. Moreover, the performance of KREN with an occlusion rate of 0.2 surpasses that of the model without any occlusion (occlusion rate of 0), thereby demonstrating the effectiveness of the proposed random occlusion module.
For the task of video anomaly event detection, in addition to improving the accuracy of anomaly detection, it is also necessary to fully consider the real-time requirements of detection and strive to enhance the speed of detection. In order to maximize the real-time potential of the proposed method while ensuring accuracy, this paper adopts a linear fusion approach during feature fusion to reduce the computational cost of the model and thereby improve the detection speed.
In the dual-channel autoencoder, the feature fusion method is shown in Eq. (7), where \(F_{1}\) and \(F_{2}\) represent the extracted key region feature and global contextual feature from two encoders, respectively. \(\alpha \) and \(\beta \) are weight coefficients used to adjust the relative importance of the two features, with a linear relationship between them as depicted in Eq. (8). In this paper, experiments were conducted to select the value of \(\alpha \) on the UCSD ped2 and CUHK Avenue datasets, and the experimental results are shown in Fig. 5. Due to the linear relationship between \(\alpha \) and \(\beta \), as shown in Eq. (8), when \(\alpha \) is 0.5, \(\beta \) is also 0.5. As can be seen from Fig. 5, the dual-channel autoencoder achieves optimal accuracy on both datasets at this point. Therefore, in the experiments, we assign equal weights to the key region feature and global context feature, achieving a good balance and improving the accuracy of detection.

Accuracy of anomaly detection in dual-channel autoencoder at different values of \(\alpha \)
In future work, we will continue to refine the feature fusion method and employ a learnable approach to further improve the model’s performance.
4.2.2 Analysis of the Effectiveness of Different Modules
We have also examined the impact of different components of KRFE-DAE in terms of AUC, as shown in Table 5.
Comparing with the traditional approach that only utilizes autoencoders, Table 5 reveals a slight performance improvement with the addition of the attention module, resulting in a 1.3% increase in accuracy on the UCSD ped2 dataset. Moreover, incorporating KREN on top of the autoencoder leads to a significant performance boost, with a 4.7% increase in accuracy on UCSD ped2. This demonstrates the importance and high detection value of key region information for anomaly detection. By integrating KREN and the attention module into a single autoencoder, the accuracy on UCSD ped2 is further improved by 5.3%. The combination of a dual-channel autoencoder with the key region feature extraction network, incorporating the attention mechanism (KRFE-DAE), achieves the optimal detection performance with an accuracy of 97.1%, representing a 5.9% accuracy improvement. These experimental results validate the effectiveness of the proposed approach in this paper.
4.3 Analysis of Visual Results
This paper presents a visual analysis of the experimental results of each module of KRFE-DAE on an abnormal event detection dataset.
4.3.1 Visual Analysis of KREN’s Results
Figure 6 illustrates the key region extraction performance of KREN on different datasets.

Key region extraction results of KREN on normal and abnormal video frames in the UCSD ped2 dataset, CUHK Avenue dataset, and SHTech Campus dataset
As depicted in Fig. 6, KREN demonstrates efficient extraction of pixel-level key regions for video abnormal events, which helps mitigate background interference and extract more discriminative features.
4.3.2 Visual Analysis of Attention-Based Autoencoder
In order to further validate the effectiveness of the attention-based autoencoder, this study conducted experiments on the UCSD ped2 and CUHK Avenue dataset using both a traditional autoencoder without attention mechanism and an attention-based autoencoder. As shown in Fig. 7, it can be observed that the attention-based autoencoder converges faster and achieves a lower loss function value compared to the traditional autoencoder, providing evidence for the effectiveness of the attention module.

Comparison of loss functions during training of attention-based autoencoder and traditional autoencoder without attention mechanism on different dataset
4.3.3 Visual Analysis of KRFE-DAE’s Results
We conducted video anomaly event detection on the UCSD ped2 and CUHK Avenue datasets using both a traditional autoencoder and the proposed KRFE-DAE. The detection results were visualized and analyzed. Figure 8a and b show the test results of the same video segment from UCSD ped2 using the traditional autoencoder method and the KRFE-DAE, respectively. A comparison between Fig. 8a and b reveals that the traditional method exhibits numerous false negatives, while the KRFE-DAE successfully detects all anomaly events with a true positive rate (TPR) of 100%.

Visualization images of detection results obtained using both the traditional autoencoder and KRFE-DAE on a specific testing video from the UCSD ped2 dataset. The images include reconstructed score curves for detection, as well as annotations for false positives and false negatives
Comparing Fig. 9a and b, it can be observed that in the video segments of the CUHK Avenue dataset, although the traditional method does not have false negatives, it suffers from significant false positives. In the real world, false alarms caused by false positives can lead to substantial resource wastage and have detrimental effects. In contrast, the KRFE-DAE achieves a false positive rate (FPR) of 0 and a TPR of 96.8% for this video segment, with only a minimal number of missed abnormal frames. Overall, the proposed method demonstrates effectiveness and practicality, outperforming traditional method.

Visualization images of detection results obtained using both the traditional autoencoder and KRFE-DAE on a specific testing video from the CUHK Avenue dataset. The images include reconstructed score curves for detection, as well as annotations for false positives and false negatives
5 Conclusion
In traditional video anomaly event detection based on autoencoders, the autoencoder lacks focus during feature extraction and overlooks the importance of key regions where anomaly events are likely to occur. To address this issue, we propose a video anomaly event detection algorithm based on KRFE-DAE. KRFE-DAE precisely extracts pixel-level key regions using KREN, reducing interference from redundant information. To avoid missing contextual information, KRFE-DAE adopts a dual-stream structure to simultaneously extract key region information and global contextual information, achieving enhanced key region feature fusion. Additionally, we incorporate an attention mechanism into the decoder to improve the reconstruction performance of the network. Extensive experiments on three video anomaly event detection datasets, namely UCSD ped2, CUHK Avenue, and SHTech Campus, validate the effectiveness of the proposed KRFE-DAE in this paper. In future work, we will further investigate how to better apply video anomaly event detection in real-world scenarios and improve our method in terms of extracting motion features and enhancing real-time feasibility.
References
Hinami R, Mei T, Satoh S (2017) Joint detection and recounting of abnormal events by learning deep generic knowledge. In: Proceedings of the IEEE international conference on computer vision, pp 3619–3627
Chen My, Hauptmann A (2009) Mosift: Recognizing human actions in surveillance videos. Computer Science Department, p 929
Kim J, Grauman K (2009) Observe locally, infer globally: a space-time mrf for detecting abnormal activities with incremental updates. In: 2009 IEEE conference on computer vision and pattern recognition. IEEE, pp 2921–2928
Xu L, Gong C, Yang J, Wu Q, Yao L (2014) Violent video detection based on mosift feature and sparse coding. In: 2014 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, pp 3538-3542
Sabokrou M, Fayyaz M, Fathy M, Klette R (2017) Deep-cascade: Cascading 3d deep neural networks for fast anomaly detection and localization in crowded scenes. IEEE Trans Image Process 26(4):1992–2004
Wu P, Liu J, Shen F (2019) A deep one-class neural network for anomalous event detection in complex scenes. IEEE Trans Neural Netw Learn Syst 31(7):2609–2622
Lee S, Kim HG, Ro YM (2019) Bman: bidirectional multi-scale aggregation networks for abnormal event detection. IEEE Trans Image Process 29:2395–2408
Nguyen TN, Meunier J (2019) Anomaly detection in video sequence with appearancemotion correspondence. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 1273–1283
Park H, Noh J, Ham B (2020) Learning memory-guided normality for anomaly detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 14372–14381
Ionescu RT, Khan FS, Georgescu MI, Shao L (2019) Object-centric auto-encoders and dummy anomalies for abnormal event detection in video. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 7842–7851
Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu CY, Berg AC (2016) Ssd: Single shot multibox detector. In: Computer Vision-ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part I 14. Springer, pp 21–37
Doshi K, Yilmaz Y (2020) Any-shot sequential anomaly detection in surveillance videos. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pp 934–935
Doshi K, Yilmaz Y (2020) Continual learning for anomaly detection in surveillance videos. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pp 254–255
Wang S, Zeng Y, Yu G, Cheng Z, Liu X, Zhou S, Zhu E, Kloft M, Yin J, Liao Q (2022) E(3)outlier: a self-supervised framework for unsupervised deep outlier detection. IEEE Trans Pattern Anal Mach Intell 45(3):2952–2969
Barbalau A, Ionescu RT, Georgescu MI, Dueholm J, Ramachandra B, Nasrollahi K, Khan FS, Moeslund TB, Shah M (2023) Ssmtl++: revisiting self-supervised multi-task learning for video anomaly detection. Comput Vis Image Underst 229:103656
Mahadevan V, Li W, Bhalodia V, Vasconcelos N (2010) Anomaly detection in crowded scenes. In: 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp 1975–1981
Cheng KW, Chen YT, Fang WH (2015) Video anomaly detection and localization using hierarchical feature representation and gaussian process regression. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2909–2917
Feng Y, Yuan Y, Lu X (2017) Learning deep event models for crowd anomaly detection. Neurocomputing 219:548–556
Liu W, Luo W, Lian D, Gao S (2018) Future frame prediction for anomaly detection-a new baseline. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 6536–6545
Ye M, Peng X, Gan W, Wu W, Qiao Y (2019) Anopcn: Video anomaly detection via deep predictive coding network. In: Proceedings of the 27th acm international conference on multimedia, pp 1805–1813
Wang X, Che Z, Jiang B, Xiao N, Yang K, Tang J, Ye J, Wang J, Qi Q (2021) Robust unsupervised video anomaly detection by multipath frame prediction. IEEE Trans Neural Netw Learn Syst 33(6):2301–2312
Wang Y, Du X, Lu Z, Duan Q, Wu J (2022) Improved lstm-based time-series anomaly detection in rail transit operation environments. IEEE Trans Industr Inf 18(12):9027–9036
Chang Y, Tu Z, Xie W, Luo B, Zhang S, Sui H, Yuan J (2022) Video anomaly detection with spatio-temporal dissociation. Pattern Recogn 122:108213
Xu D, Yan Y, Ricci E, Sebe N (2017) Detecting anomalous events in videos by learning deep representations of appearance and motion. Comput Vis Image Underst 156:117–127
Ribeiro M, Lazzaretti AE, Lopes HS (2018) A study of deep convolutional autoencoders for anomaly detection in videos. Pattern Recogn Lett 105:13–22
Lu C, Shi J, Jia J (2013) Abnormal event detection at 150 fps in matlab. In: Proceedings of the IEEE international conference on computer vision, pp 2720–2727
Shi X, Chen Z, Wang H, Yeung DY, Wong WK, Woo Wc (2015) Convolutional lstm network: A machine learning approach for precipitation nowcasting. Adv Neural Inform Process Syst 28
Chong YS, Tay YH (2017) Abnormal event detection in videos using spatiotemporal autoencoder. In: International symposium on neural networks, pp 189–196
Jiang Z, Song G, Qian Y, Wang Y (2022) A deep learning framework for detecting and localizing abnormal pedestrian behaviors at grade crossings. Neural Comput Appl 34(24):22099–22113
Zhao R, Wang Y, Jia P, Zhu W, Li C, Ma Y, Li M (2023) Abnormal behavior detection based on dynamic pedestrian centroid model: Case study on u-turn and fall-down. IEEE Trans Intell Transp Syst
He K, Gkioxari G, Dollár P, Girshick R (2017) Mask R-CNN. In: Proceedings of the IEEE international conference on computer vision, pp 2961–2969
Barnich O, Van Droogenbroeck M (2010) ViBe: a universal background subtraction algorithm for video sequences. IEEE Trans Image Process 20(6):1709–1724
Hu J, Shen L, Sun G (2018) Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 7132–7141
He J, Li L, Xu J (2022) Relu deep neural networks from the hierarchical basis perspective. Comput Math Appl 120:105–114
Hasan M, Choi J, Neumann J, Roy-Chowdhury AK, Davis LS (2016) Learning temporal regularity in video sequences. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 733–742
Deepak K, Chandrakala S, Mohan CK (2021) Residual spatiotemporal autoencoder for unsupervised video anomaly detection. SIViP 15(1):215–222
Hu X, Lian J, Zhang D, Gao X, Jiang L, Chen W (2022) Video anomaly detection based on 3d convolutional auto-encoder. SIViP 16(7):1885–1893
Luo W, Liu W, Lian D, Tang J, Duan L, Peng X, Gao S (2019) Video anomaly detection with sparse coding inspired deep neural networks. IEEE Trans Pattern Anal Mach Intell 43(3):1070–1084
Gong D, Liu L, Le V, Saha B, Mansour MR, Venkatesh S, Hengel Avd (2019) Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 1705–1714
Fang Z, Zhou JT, Xiao Y, Li Y, Yang F (2020) Multi-encoder towards effective anomaly detection in videos. IEEE Trans Multim 23:4106–4116
Tang Y, Zhao L, Zhang S, Gong C, Li G, Yang J (2020) Integrating prediction and reconstruction for anomaly detection. Pattern Recogn Lett 129:123–130
Shao W, Rajapaksha P, Wei Y, Li D, Crespi N, Luo Z (2023) Covad: contentoriented video anomaly detection using a self-attention based deep learning model. Virtual Reality Intell Hardware 5(1):24–41
Zhang H, Fang X, Zhuang X (2023) Autoencoder video human abnormal behavior detection model combined with attention mechanism. Laster J 44:69–75
Xiao J, Guo H, Xie H, Zhao T, Shen M, Wang Y (2023) Probabilistic memory autoencoding network for abnormal behavior detection in surveillance videos. Ruan Jian Xue Bao 1–16
Poppla O, Wang K (2012) Video-based abnormal human behavior recognition-a review. IEEE Trans Syst Man Cybernet C (Appl Rev) 42(6):865–878
Wang Y, Qin C, Bai Y, Xu Y, Ma X, Fu Y (2023) Making reconstruction-based method great again for video anomaly detection. In: IEEE International conference on data mining (ICDM), pp 1215–1220
Purwanto D, Pramono R, Chen Y, Fang W (2019) Three-stream network with bidirectional self-attention for action recognition in extreme low resolution videos. IEEE Signal Process Lett 26(8):1187–1191
Taghinezhad N, Yazdi M (2023) A new unsupervised video anomaly detection using multi-scale feature memorization and multipath temporal information prediction. IEEE Access 11:9295–9310
Slavic G, Baydoun M, Campo D, Marcenaro L, Regazzoni C (2021) Multilevel anomaly detection through variational autoencoders and bayesian models for self-aware embodied agents. IEEE Trans Multim 24:1399–1414
Huang C, Liu Y, Zhang Z, Liu C, Wen J, Xu Y, Wang Y (2022) Hierarchical graph embedded pose regularity learning via spatio-temporal transformer for abnormal behavior detection. In Proceedings of the 30th ACM international conference on multimedia, pp 307–315
Cho M, Kim T, Kim WJ, Cho S, Lee S (2022) Unsupervised video anomaly detection via normalizing flows with implicit latent features. Pattern Recogn 129:108703
Acknowledgements
This paper is supported by Key Research and Development Program (No.2020YFC0811004), Technology Project of Beijing Municipal Education Commission (No. SQKM201810009002), Beijing Innovation Team, Key scientific research direction construction project of North China University of Technology. The authors also gratefully acknowledge the helpful comments and suggestions of the reviewers, which have improved the presentation.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant Conflict of interest to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ye, Q., Song, Z., Zhao, Y. et al. Dual-Channel Autoencoder with Key Region Feature Enhancement for Video Anomalous Event Detection. Neural Process Lett 56, 186 (2024). https://doi.org/10.1007/s11063-024-11634-9
Accepted:
Published:
DOI: https://doi.org/10.1007/s11063-024-11634-9