
Abstract
Dropout is perhaps the most popular regularization method for deep learning. Due to the stochastic nature of the Dropout mechanism, the convergence analysis of Dropout learning is challenging and the existing convergence results are mainly of probability nature. In this paper, we investigate the deterministic convergence of the mini-batch gradient learning method with Dropconnect and penalty. By drawing and presenting a set of samples of the mask matrix of Dropconnect regularization into the learning process in a cyclic manner, we establish an upper bound of the norm of the weight vector sequence and prove that the gradient of the cost function, the cost function itself, and the weight vector sequence deterministically converge to zero, a constant, and a fixed point respectively. Considering Dropout is mathematically a specific realization of Dropconnect, the established theoretical results in this paper are also valid for Dropout learning. Illustrative simulations on the MNIST dataset are provided to verify the theoretical analysis.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Thanks to the availability of big data and advanced computation resources, in recent years deep neural networks (DNNs) have gained popularity in a wide range of real applications [1,2,3,4]. The hierarchy structure endows DNNs with powerful capability in extracting higher-level features, but also makes DNNs prone to overfitting [5]. Dropout is almost the most widely used regularization technique to tackle the overfitting problem for DNNs [6]. By randomly dropping a certain proportion of hidden units during the training process, Dropout implicitly performs network ensemble and thus improves the generalization performance. As a generalization of Dropout, DropConnect randomly forces a portion of the weights of the network to zero and obtains the state-of-the-art results at that time [7]. To cater to the diverse network structures of DNNs, many variants of Dropout have been proposed, such as Standout [8], Maxout [9], RNNdrop [10], and Dropout for RNNs [11]. Besides extensively reported empirical evidence, many insightful theoretical investigations have also been carried out concerning the approximation capability [12], generalization bound [7], and working mechanism [13].
As a classical training strategy for neural networks, the gradient method is also prevalent in training DNNs. The gradient method can be executed in three modes: batch learning [14, 15], online learning [16], and mini-batch learning [17]. Batch learning updates the network weights based on the whole training data set, while online learning updates the weights immediately after a sample is presented to the network. As a result, batch learning requires a large memory cost for DNNs and online learning usually requires a large number of iterations to converge. As an intermediate mode, mini-batch learning updates the network weights each time based on a chunk of data, thus can efficiently balance the tradeoff between the memory cost and the learning speed.
Convergence is a prerequisite for gradient-based learning algorithms to be used in real applications [18]. Batch gradient learning corresponds to the standard gradient descent algorithm and its deterministic convergence nature can be easily obtained from traditional optimization theory. However, online learning and mini-batch learning are basically of stochastic nature and accordingly their convergence was usually established in the sense of probability [16]. It is interesting to find that when the training samples are presented to networks in a certain fixed sequence, the deterministic convergence for online learning [19] and mini-batch learning [17] can also be guaranteed. Moreover, the deterministic convergence results for some other variants of gradient method, such as gradient method with momentum [20], chaos injection-based gradient method [21], and complex gradient method [17, 22], have also been established.
Due to the uncertainty brought to the network structure and the learning process, the convergence analysis of Dropout learning is challenging work. By utilizing the stochastic approximation theory, a probability convergence result for the stochastic gradient learning algorithm with Dropout was established in [23]. Moreover, a convergence theorem for SpikeProp with Dropout is given in [24]. However, the deterministic convergence for mini-batch gradient learning with dropout is still unknown in the literature. To this end, in this paper, we consider establishing the deterministic convergence of the mini-batch gradient method with cyclic Dropconnect and penalty (MBGMCDP). The main contribution of this paper is listed as follows.
-
(i)
In [7, 23, 24], the boundedness of the network weights is implicitly or explicitly required. In this paper, by including a penalty term in the cost function, we prove that the network weights are bounded during the learning process. Thus this condition is not extra required in our convergence analysis. From the viewpoint of real application, the combination of the dropout and the weight decay is also helpful to enhance the generalization performance.
-
(ii)
By presenting the samples of the mask matrix of Dropconnect into the network in a cyclic way, we prove the deterministic convergence, covering both the weak convergence and strong convergence, of the mini-batch gradient learning method with Dropconnect and penalty. Considering Dropout can be mathematically viewed as a specific realization of Dropconnect by setting the mask matrix in a certain form, our convergence results can also be applied to Dropout learning.
-
(iii)
The theoretical findings and the efficiency of MBGMCDP are validated by simulations of MNIST problems.
The remainder of this paper is structured as follows. The MBGMCDP algorithm is formally described in Sect. 2. The main theoretical results are provided in Sect. 3. Section 4 provides the simulation results to validate our theoretical findings and the efficiency of MBGMCDP. Finally, we summarize our work in Sect. 5. The proof of the theorems in Sect. 3 is shown in the appendix. In this paper, we use \(|| \cdot ||\) to denote the Euclidean norm.
2 Mini-batch Gradient Method with Cyclic Dropconnect and Penalty
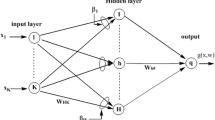
Given a set of training samples \(\left\{ {\xi ^{j},O^{j}} \right\} _{j = 0}^{J - 1}\), where \(\xi ^{j}\) is the jth input vector, and \(O^{j}\) is the corresponding objective output of the network, the training of neural networks is mathematically equivalent to solving the following optimization problem
where \({\textbf {w}}\) is the network weight vector, \(e({\textbf {w}},\xi ^{j})\) is a function to measure the discrepancy between the desired output \(O^{j}\) and the corresponding actual output of the network with respect to the jth input \(\xi ^{j}\). In real applications, such a function can be the square error function or the cross-entropy loss function.
In order to prevent the neural network from overfitting, Dropconnect introduces dynamic sparsity in the network weight vector by randomly dropping some weights during the training stage. To implement the Dropconnect learning, we define a modified cost function as follows
where \({\textbf {m}}\) is a binary mask vector whose elements are randomly drawn to be 0 or 1 according to a certain probability distribution, \(\mathbb {E}\) denotes the mathematical expectation operation with respect to the random vector \({\textbf {m}}\), "\(\star \)" denotes the Hadamard product operation, and \(\lambda \) is a penalty coefficient.
In order to balance the tradeoff between memory overheads and computational efficiency, the mini-batch learning allows the network weights to be updated once a block of training samples are available. Suppose that the training samples are presented cyclically in a fixed order of b blocks: \(B_{0},B_{1},\ldots ,B_{b-1}\), where \(B_{0} = \left\{ {\xi ^{j},O^{j}} \right\} _{j = 0}^{j_{1}},B_{1} = \left\{ {\xi ^{j},O^{j}} \right\} _{j = j_{1} + 1}^{j_{2}},\ldots ,\) and \( B_{b-1} = \left\{ {\xi ^{j},O^{j}} \right\} _{j = j_{b - 1} + 1}^{J-1}\). Accordingly, suppose \({\textbf {m}}^0\),\({\textbf {m}}^1\),\(\ldots \), and \({\textbf {m}}^{b-1}\) are b samples of the mask vector, then we have a practical realization of the cost function (2)
where
is an instant error defined based on a block of samples \(B_{k}\).
Starting from an arbitrary initial value \({\textbf {w}}^{0}\), the mini-batch gradient method with cyclic Dropconnect and penalty updates the weights iteratively by
where n denotes the cycle (epoch) number, k denotes the block number and \(\eta _{n}\) is the step size for the nth cycle. Write \(m=nb+k\), then a weight vector sequence \(\{{\textbf {w}}^m\}\) can be generated using (5).
3 Main Results
We will establish the main theoretical results for MBGMCDP in this section.
Let \(\Phi = \left\{ {\textbf {w}}:\nabla _{{\textbf {w}}}E({\textbf {w}}) = 0 \right\} \) be the stationary point set of the cost function \(E({\textbf {w}})\), and \(\Phi _{s} \in R\) be the projection of \(\Phi \) onto the sth coordinate axis.
The following assumptions will be used in our theoretical analysis.
-
(A1)
The function \(e\left( {{\textbf {w}},\xi } \right) \) is twice continuously differentiable with respect to \({\textbf {w}}\). Moreover, \(e\left( {{\textbf {w}},\xi } \right) \), \(\frac{\partial e\left( {{\textbf {w}},\xi } \right) }{\partial {\textbf {w}}}\), and \(\frac{\partial ^{2}e\left( {{\textbf {w}},\xi } \right) }{\partial {\textbf {w}}^{2}}\) are uniformly bounded.
-
(A2)
There exists an \(\alpha \in (0,1)\), such that \(\left\| {{\textbf {m}}\star {\textbf {w}}} \right\| \ge \alpha \left\| {\textbf {w}} \right\| \).
-
(A3)
\(\eta _{n} > 0,{\sum \limits _{n = 0}^{\infty }\eta _{n}} = \infty ,{\sum \limits _{n = 0}^{\infty }\eta _{n}^{2}} < \infty \).
-
(A4)
\(\Phi _{s}\) does not contain any interior points for any s.
Theorem 1
Suppose that \(\left\{ {\textbf {w}}^{m} \right\} \) is the weight sequence generated by (5) from an arbitrary initial value \({\textbf {w}}^{0}\). Then \(\left\{ {\textbf {w}}^{m} \right\} \) is uniformly bounded under Assumptions \((A1)-(A3)\) and condition \(0< 2\lambda \alpha ^{2}\left( {1 - \lambda } \right) \eta _{n} < 1\).
Theorem 2
Suppose that \(E({\textbf {w}})\) is the cost function defined by (3), that \(\left\{ {\textbf {w}}^{m} \right\} \) is the weight sequence generated by (5) from an arbitrary initial value \({\textbf {w}}^{0}\), and the Assumptions \((A1)-(A3)\) are valid. Then
-
(a)
There exists a constant \(E^{*}\) such that
$$\begin{aligned} {\lim \limits _{n\rightarrow \infty }{E({\textbf {w}}^{nb})}} = E^{*}; \end{aligned}$$(6) -
(b)
There holds that
$$\begin{aligned} {\lim \limits _{n\rightarrow \infty }\left\| {\nabla _{{\textbf {w}}}E({\textbf {w}}^{nb})} \right\| } = 0. \end{aligned}$$(7) -
(c)
Furthermore, if Assumption (A4) is valid, then there exists a point \({\textbf {w}}^{*} \in \Phi \) such that
$$\begin{aligned} {\lim \limits _{m\rightarrow \infty }{} {\textbf {w}}^{nb}} = {\textbf {w}}^{*}. \end{aligned}$$(8)
Remark 1
Assumption (A1) can be satisfied by typical square error function or cross-entropy loss function for neural networks with activation functions such as softmax function and sigmoid functions. Assumption (A2) is listed only for the sake of mathematical deduction and is certainly satisfied in real applications. Assumption (A3) is a typical condition of the step size for the convergence analysis of gradient learning method. Assumption (A4) is used to establish the strong convergence of the MBGMCDP algorithm. Equations (6) and (7) mean the weak convergence, while (8) means the strong convergence.
Remark 2
The additional condition for the step size \(\eta _{n}\) and the penalty parameter \(\lambda \) required in Theorem 1 is not restrictive. In real applications, \(\eta _{n}\) and \(\lambda \) are usually small enough to satisfy \(0< 2\lambda \alpha ^{2}\left( {1 - \lambda } \right) \eta _{n} < 1\).
4 Experiments
In this section, the theoretical findings and the efficiency of MBGMCDP will be validated through simulations on MNIST and CIFAR-10 datasets, which are two benchmark classification problems.
MNIST dataset is composed of 60,000 gray-scale images of handwritten digits (0–9), each of which is made up of \(28\times 28\) pixels. We randomly selected 5000 images for training and 1000 images for testing. The network used was a four-layer fully connected network of structure 784-128-32-10. The activation function was set as the sigmoid function, the batch size was set to 200, the step size \(\eta _{n} = \frac{1}{(n + 1)^{0.51}}\), and the penalty coefficient \(\lambda = 0.001\). The simulation results illustrated were obtained by averaging over 50 independent trials.
Figures 1, 2, and 3 illustrate the learning curves of MBGMCDP. It can be observed from Fig. 1 and Fig. 2 that the gradient tends to zero and the cost function tends to a constant as the epoch increases. This validates our theoretical findings in Theorem 2. Figure 3 reveals that there are oscillations for the instant cost curves with respect to the number of iterations during the Dropconnect learning, while the oscillations vanish for the loss curves for the whole network with respect to the number of epochs as shown in Fig. 2. It can be observed from Fig. 4 that, if the training set is shuffled at each epoch, the oscillations occur again for the loss curves of the whole network with respect to the number of epochs. Tables 1 and 2 illustrate the testing results for \(\lambda =0\) and \(\lambda =0.001\), respectively, where the drop rate varies as 0, 0.1, 0.2 and 0.5. It can be observed from the two tables that, the testing accuracy obtained here is close to the state-of-the-art results [25], and both the Dropconnect and the penalty contribute to enhancing the generalization capability of the network. However, if the drop rate is too large, the trained network may be underfitting, which also degrades the performance.

Learning curves of the norm of gradient with respect the number of epochs

Learning curves of the training cost with respect the number of epochs

Learning curves of the instant cost with respect the number of iterations

Learning curves of the training cost with respect the number of epochs for MBGMCDP with shuffled training data
The CIFAR-10 dataset is composed of 60,000 \(32\times 32\) colour images in 10 classes, with 6000 images per class. We randomly selected 50,000 images for training and 10,000 images for testing. The network used was a pretrained Alexnet network with three linear layers of structure 9126-4096-10 to be retrained. The batch size was set to 64. The testing loss and testing accuracy are listed in Table 3, from which the contribution of the dropout method with different drop rate can also be observed.
5 Conclusion
In this paper, we investigated the mini-batch gradient method with Dropconnect and the penalty for the regularization learning of deep neural networks. By presenting a set of samples of the mask matrix of Dropconnect to the learning process in a cyclic manner and adding a penalty term to the cost function, the boundedness of the weight sequence and the deterministic convergence of the MBGMCDP, including both the weak convergence and strong convergence, were theoretically established. Illustrative simulation on the MNIST dataset verified the theoretical findings and justified that both the Dropconnect and the penalty contributed to the generalization performance promotion. However, in this paper, we only consider the case that the training samples are presented cyclically and the activation functions are twice continuously differentiable. In the future, we will extend our work to a more general case where the training samples are shuffled in each epoch and the ReLU activation function is used.
Data Availibility Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
References
Meiyin Wu, Li Chen (2015) Image recognition based on deep learning. In: CAC, pp 542–546. IEEE. https://doi.org/10.1109/CAC.2015.7382560
Zhao Z-Q, Zheng P, Shou-tao X, Xindong W (2019) Object detection with deep learning: a review. IEEE Trans Neural Networks Learn Syst 30(11):3212–3232. https://doi.org/10.1109/TNNLS.2018.2876865
Qing R, Jelena F (2018) Deep learning for self-driving cars: chances and challenges. In: Proceedings of the 1st international workshop on software engineering for AI in autonomous systems, pp 35–38. https://doi.org/10.1145/3194085.3194087
Sharada PM, David P, Marcel S (2016) Using deep learning for image-based plant disease detection. Front in Plant SCI, 7:1419. https://doi.org/10.3389/fpls.2016.01419
Mei G, Yurui S, Yongliang Z, Mingqiao H, Gang D, Shiping W (2023) Pruning and quantization algorithm with applications in memristor-based convolutional neural network. Cogn Neurodyn, pp 1–13. https://doi.org/10.1007/s11571-022-09927-7
Nitish S, Geoffrey H, Alex K, Ilya S, Ruslan S (2014) Dropout: a simple way to prevent neural networks from overfitting. Mach Learn Res 15(1):1929–1958. https://www.jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf
Li W, Matthew Z, Sixin Z, Yann LC, Rob F (2013) Regularization of neural networks using dropconnect. In: ICML, pp 1058–1066. PMLR. http://proceedings.mlr.press/v28/wan13.pdf
Jimmy Ba, Brendan Frey (2013) Adaptive dropout for training deep neural networks. Adv Neural Inf Process Syst, 26. https://proceedings.neurips.cc/paper_files/paper/2013/file/7b5b23f4aadf9513306bcd59afb6e4c9-Paper.pdf
Ian G, David W-F, Mehdi M, Aaron C, Yoshua B (2013) Maxout networks. In: ICML, pp 1319–1327. PMLR. https://doi.org/10.48550/arXiv.1302.4389
Taesup M, Heeyoul C, Hoshik L, Inchul S (2015) Rnndrop: a novel dropout for RNNS in ASR. In: IEEE workshop on ASRU, pp 65–70. IEEE. https://doi.org/10.1109/ASRU.2015.7404775
Sungrae P, JunKeon P, Su-Jin S, Il-Chul M (2018) Adversarial dropout for supervised and semi-supervised learning. In: Proc AAAI Conf Artif Intell, vol 32. https://doi.org/10.1609/aaai.v32i1.11634
Oxana AM, Mark AP, Jacobus WP, Jaron S, Albert S-C (2020) Universal approximation in dropout neural networks. arXiv preprint arXiv:2012.10351. https://doi.org/10.48550/arXiv.2012.10351
Baldi P, Sadowski P (2014) The dropout learning algorithm. Artif Intell 210:78–122. https://doi.org/10.1016/j.artint.2014.02.004
Ying Z, Jianing W, Dongpo X, Huisheng Z (2022) Batch gradient training method with smoothing group l 0 regularization for feedfoward neural networks. Neural Process Lett, pp 1–17. https://link.springer.com/article/10.1007/s11063-022-10956-w#citeas
Qinwei F, Le L, Qian K, Li Z (2022) Convergence of batch gradient method for training of pi-sigma neural network with regularizer and adaptive momentum term. Neural Process Lett, pp 1–18. https://doi.org/10.1007/s11063-022-11069-0
Zhang H, Wei W, Liu F, Yao M (2009) Boundedness and convergence of online gradient method with penalty for feedforward neural networks. IEEE Trans on Neural Netw 20(6):1050–1054. https://doi.org/10.1109/TNN.2009.2020848
Zhang H, Zhang Y, Zhu S, Dongpo X (2020) Deterministic convergence of complex mini-batch gradient learning algorithm for fully complex-valued neural networks. Neurocomputing 407:185–193. https://doi.org/10.1016/j.neucom.2020.04.114
Jinlan L, Dongpo X, Huisheng Z, Danilo M (2022) On hyper-parameter selection for guaranteed convergence of rmsprop. Cogn Neurodyn, pp 1–11. https://doi.org/10.1007/s11571-022-09845-8
Wei W, Wang J, Cheng M, Li Z (2011) Convergence analysis of online gradient method for bp neural networks. Neural Netw 24(1):91–98. https://doi.org/10.1016/j.neunet.2010.09.007
Fan Q, Zhang Z, Huang X (2022) Parameter conjugate gradient with secant equation based elman neural network and its convergence analysis. Adv Theory Simul 5(9):2200047. https://doi.org/10.1002/adts.202200047
Huisheng Z, Ying Z, Dongpo X, Xiaodong L (2015) Deterministic convergence of chaos injection-based gradient method for training feedforward neural networks. Cogn Neurodyn 9:331–340. https://link.springer.com/article/10.1007/s11571-014-9323-z#citeas
Zhang H, Mandic DP (2015) Is a complex-valued stepsize advantageous in complex-valued gradient learning algorithms? IEEE Trans Neural Networks Learn Syst 27(12):2730–2735. https://doi.org/10.1109/TNNLS.2015.2494361
Albert S-C, Jaron S (2020) Almost sure convergence of dropout algorithms for neural networks. arXiv preprint arXiv:2002.02247. https://doi.org/10.48550/arXiv.2002.02247
Zhao J, Yang J, Wang J, Wei W (2021) Spiking neural network regularization with fixed and adaptive drop-keep probabilities. IEEE Trans Neural Networks Learn Syst 33(8):4096–4109. https://doi.org/10.1109/TNNLS.2021.3055825
Ting W, Mingyang Z, Jianjun Z, Wing W, Ng Y, Philip Chen CL (2022) Bass: broad network based on localized stochastic sensitivity. IEEE Trans Neural Netw Early Acess, pp 1–15. https://ieeexplore.ieee.org/document/9829395
Bertsekas DP, Tsitsiklis JN (2000) Gradient convergence in gradient methods with errors. SIAM J Optimiz 10(3):627–642. https://doi.org/10.1137/S1052623497331063
Wang J, Wei W, Zurada JM (2011) Deterministic convergence of conjugate gradient method for feedforward neural networks. Neurocomputing 74(14–15):2368–2376. https://doi.org/10.1016/j.neucom.2011.03.016
Acknowledgements
This work is supported by the National Natural Science Foundation of China (No.61671099).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 Proof of Theorem 1
In the following we will show that there exists a constant \(C_{1}\) such that for any nonnegative integer n and k
According to Assumption (A3), we know that \({\lim \limits _{n\rightarrow \infty }\eta _{n}} = 0\) and \(\eta _n<1\) for sufficiently large n. By \(0< 2\lambda \alpha ^{2}\left( {1 - \lambda } \right) \eta _{n} < 1\), we have
Equation (5) can be rewritten as:
where 1 represents a vector of all-ones.
According to Assumption (A1), there exists a constant \(C_{2} > 0\), such that for all \(n \in N\) and \(k=0,\ldots ,b-1\), there holds that
Using Assumption (A3), Equs. (10)–(12), and the triangle inequality, we have that
Now, we proceed to show (9) is always true by considering the following two cases.
Case (i): For any m (or \(nb+k)\), there always holds that
In this case, we can simply set \(C_{1} = \frac{C_{2}}{2\lambda \alpha ^{2}\left( {1 - \lambda } \right) }\) to validate (9).
Case (ii): There exists an integer \(N(N \ge 0)\) such that
In this case, we shall prove by induction on m to show that
Equation (15) evidently holds for \(m = N\). Then we suppose that (15) holds for an integer \(m(m \ge N)\), and we try to show that (15) also holds for \(m+1\).
1. If \(\left\| {\textbf {w}}^{m} \right\| < \frac{C_{2}}{2\lambda \alpha ^{2}\left( {1 - \lambda } \right) }\), by (10), (13), and (14) we have
2. On the other hand, if \(\left\| {\textbf {w}}^{m} \right\| \ge \frac{C_{2}}{2\lambda \alpha ^{2}\left( {1 - \lambda } \right) }\), a combination of (10), (13), and (14) produces
Now we have shown by induction that (15) always holds for Case (ii). Hence, (9) is valid in this case by setting
Thus, (9) is true for both Cases (i) and (ii), and this completes the proof of Theorem 1. \(\square \)
1.2 Proof of Theorem 2
Lemma 1
([26]) Suppose that the step size \({\eta _n}\) satisfies the Assumption (A3) and the sequence \(\{a_n\}(n \in N)\) satisfies \({a_n} \ge 0\), \(\sum \limits _{n = 0}^\infty {{\eta _n}a_n^\beta } < \infty \) and \(\left| {{a_{n + 1}} - {a_n}} \right| \le \mu {\eta _n}\) for some positive constants \(\beta \) and \(\mu \). Then we have
Lemma 2
([27]) Let \(\{Y_n\}\), \(\{W_n\}\), \(\{Z_n\}\) be three sequences, where \({W_n}\) is nonnegative and \(\{Y_n\}\) is bounded for all n. Assume that \({Y_{n + 1}} \le {Y_n} - {W_n} + {Z_n}\) and \(\sum \limits _{n = 0}^\infty {{Z_n}} \) is convergent. Then either \({Y_n} \rightarrow - \infty \) or else \({Y_n}\) converges to a finite value and \(\sum \limits _{n = 0}^\infty {{W_n}} < \infty \).
Lemma 3
([27]) Let \(G:\phi \in {R^m} \rightarrow R(m \ge 1)\) be continuous for a bounded closed region \(\phi \), and \({\phi _0} = \{ {\textbf {x}} \in \phi :G({\textbf {x}}) = 0\} \). Suppose the projection of \({\phi _0}\) on each coordinate axis does not contain any interior points. If the sequence \(\{ {{\textbf {x}}^q}\} \) satisfies
-
(a)
\(\mathop {\lim }\limits _{q \rightarrow \infty } G({{\textbf {x}}^q}) = 0\),
-
(b)
\(\mathop {\lim }\limits _{q \rightarrow \infty } \left\| {{{\textbf {x}}^{q + 1}} - {{\textbf {x}}^q}} \right\| = 0\),
then there exists a unique \({{\textbf {x}}^ * } \in {\phi _0}\) such that \(\mathop {\lim }\limits _{q \rightarrow \infty } {{\textbf {x}}^q} = {{\textbf {x}}^ * }\).
Lemma 4
Suppose that the sequence \(\left\{ {\textbf {w}}^{nb+k} \right\} \) is generated by (5) and that conditions (A1) and (A2) are satisfied, then there holds that
where the constant \({C_3} > 0\) is independent of n and \({\eta _n}\).
Proof
According to Equation (3), we have
where
The first term of (21) can be rewritten as follows
where
Using Assumption (A1) and Theorem 1, we know that there exists a constant \({C_4}\) such that
Similarly, there exists a constant \(C_5\) such that
Using Assumption (A1) and the mean value theorem, we can deduce that there exists a constant L such that
In this way, based on Eqs. (24) and (25), we know that there exists a constant \(C_6\) such that
Using (25), the third term of (21) can be reformulated and estimated as
where \({C_7}\) is a positive constant. Now, combining (21)–(29), we can obtain that
This completes the proof by simply setting \(C_{3} = C_{5} + C_{6} + C_{7}\). \(\square \)
Proof of (6) and (7). Applying Lemma 2 to (20), we can conclude that
and \(E\left( {\textbf {w}}^{nb} \right) \rightarrow - \infty \) or converges to a constant \(E^{*}\) as \(n\rightarrow + \infty \). Since \(E\left( {\textbf {w}}^{nb} \right) > 0\), then we have
Combining (27) and (25), we have
where D is a positive constant. Then we have
A combination of (31), (33) and lemma 1 immediately gives
\(\square \)
Proof of (8). According to Equ. (5) and Assumptions (A1) and (A3), we have
Therefore, based on (6), (34), and Assumption (A4), we can conclude from Lemma 3 that there exists a unique \({\textbf {w}}^{*} \in \Phi \) such that
\(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jing, J., Jinhang, C., Zhang, H. et al. Boundedness and Convergence of Mini-batch Gradient Method with Cyclic Dropconnect and Penalty. Neural Process Lett 56, 113 (2024). https://doi.org/10.1007/s11063-024-11581-5
Accepted:
Published:
DOI: https://doi.org/10.1007/s11063-024-11581-5