
Abstract
Intelligent manufacturing process needs to adopt distributed monitoring scenario due to its massive, high-dimensional and complex data. Distributed process monitoring has been introduced into global monitoring and local monitoring to analyze the characteristic relationship between process data. However, the existing framework methods ignore or suppress the fault information and thus cannot effectively identify the local faults and the time sequence characteristics between units in the batch production system. This paper proposes a novel distributed process monitoring framework based on Girvan-Newman algorithm modular subunit partitioning and probabilistic learning model with deep neural networks. First, Girvan-Newman algorithm is used to divide the complex manufacturing system modularized to reduce the latitude of data processing. Second, variational autoencoder (VAE) is adopted to ensure the stability of local analysis, and long short-term memory is adopted to improve the VAE model to detect global multi-time scale anomalies. Finally, distributed process fault detection is carried out for each subunit in a separate and integrated manner, and the performance of the framework in distributed process monitoring is analyzed through two fault detection indicators T2 and SPE statistics. A case study of the Tennessee Eastman Process is used to demonstrate the performance and applicability of the proposed framework. Results show that the proposed VAE enhancement framework based on the DNN could accurately identify faults in distributed process monitoring and locate the specific sub-units where the fault occurs. Compared with VAE-DNN method and traditional process monitoring methods, the framework proposed in this paper has higher fault detection rate and lower false alarm rate, and the detection rate of some faults can reach 100%.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The quality control issues in the modern industrial production process have gained significant attention in recent years [2], especially in large-scale production processes [4]. The implementation of real-time process monitoring methods could detect faults in time, reduce damage to industrial instruments, and effectively improve production efficiency [5]. However, with the development of intelligent manufacturing, large-scale, multi-unit production systems are more widely used [7]. Traditional simple monitoring methods, such as principal component analysis (PCA), kernel principal component analysis (KPCA), and canonical correlation analysis (CCA), are unable to explain the status and relationship between the units in the production process. The distributed process quality monitoring method divides the entire production process into multiple sub-units to reduce the complexity of monitoring and then monitors the status of each sub-block to analyze whether failure occurs in the process [10]. Thus, the use of distributed process quality monitoring in large-scale industrial production processes has become particularly important.
The method of multivariate statistical process monitoring is usually used for distributed quality inspection. If the statistical amount exceeds the threshold, the production process has failed. Traditional multivariate statistical methods have a deep theoretical foundation and wide application in distributed process monitoring modeling, such as CCA [13], PCA, and partial least squares (PLS) [12]. These distributed process monitoring methods provide research ideas for complex distributed process monitoring. Two sets of variables are involved in process quality monitoring: process and quality variables. As a data-driven method, the PLS method performs process monitoring by analyzing the correlation between process and quality variables [14]. However, as a kind of oblique projection technology, PLS may contain useless information in the quality-related variables in the monitoring process [15]. Some studies have extended it to improve the monitoring performance of PLS [16]. Qin et al. proposed the concurrent partial least squares method, which further decomposes the output residual space into secondary principal component subspace and secondary residual subspace through PCA [17]. Zhou et al. proposed integrated partial least squares to decompose the output residual space into potential structures [16]. These methods are all post-processing strategies; data processing is performed after PLS. Wang et al. used quadrature signal correction and combined it with improved PLS for process monitoring to improve detection stability [18].
Most multivariate statistical process monitoring methods are used for centralized monitoring of static processes, whereas the actual factory production process changes dynamically and in real-time. Researchers have proposed a dynamic PCA method for modeling by enhancing the data matrix [19]. Li et al. proposed the dynamic latent variable framework by analyzing the autocorrelation and cross-correlation between process data and quality data [20]. However, problems such as communication delay or data loss are likely to occur during the centralized monitoring process, which causes the entire process monitoring framework to malfunction. Some data security issues are encountered; that is, in the case of complex geographical distribution and complex structure, some data may not be shared [3]. Fortunately, strong coupling and correlation between different operating units in a large-scale production process provide the possibility to build a distributed monitoring framework. Distributed process monitoring usually decomposes the factory process into multiple sub-units or blocks, monitors the quality of the sub-units according to local data and information in each block area, and finally performs data fusion to realize the entire process monitoring. However, the lack of data in large-scale production processes is common, and this problem will affect the stability of the framework used to monitor the process. Lin, Pan, Sun et al., and Jiang et al. considered building a framework using variational Bayesian PCA (VBPCA) to improve the stability of the data missing framework in the process [21]. With the development of data-driven distributed monitoring models, Jiang et al. proposed a distributed detection method of VBPCA-CCA on the basis of VBPCA, which uses VBPCA to deal with missing values and CCA to analyze the correlation between variables. However, only relying on VBPCA and CCA regression cannot easily obtain the correlation between operating variables in a complex system.
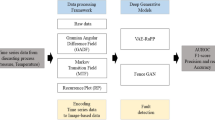
To solve the problem of affecting the stability of the quality monitoring framework because of the loss of data in the distributed production process, the correlations between manipulated variables in large-scale systems. This study proposes a novel distributed process monitoring framework of VAE-enhanced with deep neural network (DNN) for complex industrial fault detection. First, we divide the complex production process into multiple simple production units using the Girvan-Newman algorithm. For complex processes with strong non-linearity, variational autoencoder (VAE) could solve the problem of generating probability functions through neural networks. Therefore, when building a DNN probabilistic learning model for distributed process quality monitoring, we use long short-term memory (LSTM) DNNs to improve VAE to process the time series data between various operating units in the actual factory process. In the overall distributed monitoring process, process monitoring is performed on each sub-block, and information fusion is performed to integrate monitoring of failures in the production process. Finally, we could directly diagnose the fault by constructing two statistics.
The rest of this paper is structured as follows: Sect. 2 reviews the literature in distributed process monitoring. Section 3 proposes a distributed sub-unit division method based on the Girvan-Newman algorithm and illustrates the detailed process of distributed process monitoring based on VAE-LSTM. Section 4 compares, analyzes, and discusses the results by applying the model to the Tennessee Eastman process instance. Section 5 gives the conclusions of this study and prospects.
2 Literature Review
Distributed process monitoring reduces the dimensionality of monitoring targets by decomposing the integrated system into multiple sub-units. Existing research has mostly carried out distributed process monitoring from the perspective of missing unit data. Lin, Pan, and Sun et al. proposed a variational Bayes-based PCA (VBPCA) method for fault detection, which improved the problem of missing data in process monitoring [21]. Furthermore, to analyze the information between adjacent units in the distributed process, Jiang et al. proposed a framework based on domain variational Bayesian principal component analysis (NVBPCA) and canonical correlation analysis (CCA) [22]. The NVBPCA method is used to reconstruct the missing values of the local unit. Combined with the local CCA monitor, it uses the information of the local and neighboring units to identify the state of the local unit and detect faults. However, only relying on VBPCA cannot easily obtain the correlation between units. Ge and Song et al. proposed a principal component analysis model for the whole plant process monitoring sub-block [10]. This method constructs different sub-blocks through PCA principal components, automatically divides the original feature space into multiple sub-feature spaces, and finally combines the sub-spaces to monitor local behaviors to enhance monitoring performance. The framework based on feature division only obtains the original features of variables and ignores the feature relationship between hidden variables. To analyze the relationship between unit variables further, Jiashi Jiang and Qingchao Jiang proposed a variational Bayesian framework for distributed process monitoring [41]. Variational Bayes is used to extract latent variables between units to construct a variational Bayesian regression model and characterize the relationship between variables between units. However, the above quotes do not consider the timing characteristics between process variables in the distributed process but only discuss the model's overall performance or the correlation between process variables in local units, which will cause the fault information to be ignored.
Traditional distributed process monitoring methods mostly use feature extraction and data-driven methods for data analysis. However, traditional process monitoring methods cannot effectively mine information and ignore some fault messages in the face of powerful low-dimensional nonlinear systems and powerful time-series data. The deep learning network model is gradually applied to industrial process monitoring because of its good adaptability. More and more researchers are applying deep learning network models to monitor, detect, and classify faults. For example, Chengyi Zhang et al. proposed a sparse and manifold-regularized convolutional autoencoder method for fault detection in complex multivariate processes [23]. This method effectively retains fault features through DNN and sparse matrix and extracts comprehensive features from process signals to achieve process fault detection. The unsupervised learning method has better performance for the data balancing method. However, if the sampling rate of the quality variable decreases in the process, the unsupervised learning method will need to be adjusted. In complex production systems, process variables usually have complex timing characteristics. The unique gate unit loop in the LSTM network can filter noise, separate fault information, and capture the long-term dependence of sequential characteristic data. Many recent studies have used the LSTM network to process time-series data [24]. Arunthavanathan et al. proposed a CNN-LSTM model for process fault prediction, which predicts the system parameters in the future sampling window recognition by checking the fault conditions in the multi-complex process system [25]. Yao, Yang, and Li addressed the problem that traditional data-driven diagnosis methods have difficulty extracting effective features adaptively from industrial process data; they proposed a fault diagnosis method based on residual convolution combined with the LSTM extraction process's time characteristics of variables for fault diagnosis [26]. Although these methods consider the time series characteristics of variables as a whole, they lack the monitoring and analysis of regional sub-units for distributed process monitoring and thus cannot accurately locate the location of the fault. Furthermore, the LSTM model has been widely used in other fields because of its superior time series analysis capabilities, such as (1) solar power plant power detection [27], (2) telecommunication network traffic and mobility [28], and (3) the medical field [29]. This study combined the LSTM method with the VAE model for distributed process monitoring.
3 VAE-LSTM Distributed Process Monitoring Framework
Unlike the traditional process monitoring process, to realize a distributed process, the entire production unit should be divided first, and each sub-unit should be monitored. This section first introduces the modular sub-unit division using the Girvan-Newman algorithm. It then proposes a VAE-LSTM model to monitor and diagnose the process of each sub-unit.
4 Modularized Sub-unit Partition with Girvan-Newman Algorithm
Given that the large-scale process system data has high-dimensional complexity, and the normal variables in the centralized production process still dominate, causing some fault information to be ignored [30]. By introducing a distributed process monitoring strategy, the complexity of data in process monitoring can be reduced, and the detection efficiency can be improved. Furthermore, some local fault information exists, and these faults may be early. Distributed process monitoring has a more sensitive detection effect for this type of fault. Thus, this study focuses on dividing the complex whole-process production process into low-dimensional sub-units through multi-block division. However, common clustering methods cannot effectively cluster big data [31], whereas the Girvan-Newman algorithm solves the problem of big data and complex network partitioning [32]. Thus, the Girvan-Newman algorithm is used to divide the sub-units in this section.
The Girvan-Newman algorithm is a classic community division algorithm proposed by Girvan and Newman [33]. In the complex production process, a large-scale network structure generally exists, in which a community corresponds to a collection of nodes with the same function, similar nature, or relatively close relationship. Inspired by the above, we regard the process variable as a node and connect the nodes with greater correlation with each node to form the network's edge. Thus, the entire complex process can be divided into sub-units through the Girvan-Newman algorithm. The schematic diagram of the unit division of the Girvan-Newman algorithm is shown in Fig. 1.

The schematic diagram of the unit division of Girvan-Newman
Considering that the connection between communities is relatively small, at least one connection is required from one community to another. Thus, the network will naturally be successfully divided after finding these important channels and removing the unimportant edges. The Girvan-Newman algorithm measures the importance of these edges by introducing edge betweenness [33]. The number of shortest paths through this edge in the network is called edge betweenness. Although the number of shortest paths passing through the inner edges of the community is small, the number of shortest paths passing through the connecting edges between different communities is large, which also provides an opportunity for the module division of the algorithm. However, a network community can be divided into many forms, and determining how many blocks a network should be divided into directly using the Girvan-Newman algorithm is impossible. Thus, the module degree Q is introduced for measurement. The meaning of modularity is the difference between a network and a random network under a certain community division because a random network does not have a community structure. Thus, in the end, the greater the corresponding difference between the two, the better the result of the community division. For a network X that can be expressed as an M*N matrix, the modularity Q is defined as follows:
where i represents the i-th community, eii represents the ratio of community i to all edges of the original network, and ai represents the ratio of the number of vertices connected to community i to the total number of edges. In general, modularity is the ratio of the number of edges within the sub-block to the total number of edges in the network, minus the expectation. The value of modularity Q ranges from − 0.5 to 1 [34] after consulting data.
This study is based on the Girvan-Newman algorithm for sub-block division. The flow of the algorithm can be seen in Fig. 2. The specific division procedure steps are as follows:
-
1.
Calculate the correlation coefficient, that is, the correlation coefficient matrix in the variable data set in the production process
-
2.
Construct a network to connect each process variable with the process variable with the largest correlation coefficient to form a connected network
-
3.
Calculate the edge betweenness of each edge, that is, the number of the shortest path through that edge
-
4.
Find the edge with the largest betweenness and remove it
-
5.
Calculate the modularity Q value in the obtained community network and find the largest Q value
-
6.
Recalculate the edge betweenness of the remaining edges in the network, repeat the removal until all edges are removed, and get the division result of multiple sub-blocks: X = {X1,X2,…,Xn}.

The flow chart of the Girvan-Newman algorithm
5 Process monitoring with VAE-LSTM
In the large-scale industrial production process, each operating unit has time sequence characteristics. In addition to its structure or function, each unit is also related to other units and affects each other [7]. That is, the process quality of an operating unit may affect the production quality of adjacent sub-blocks, and some local failures occur in the early stages of the entire production process. Fine monitoring of multi-unit processes, focusing on the operating status of the units and the entire process, and timely judgment of partial processes or overall abnormalities have important theoretical significance and value in actual production. The LSTM network is a deep learning network with memory, and its good time-series processing capabilities make it have better performance when processing time-series data. Thus, this study focuses on the network model to optimize the VAE model to realize distributed process monitoring.
In distributed process monitoring, a given production process contains N process variables (units) Xi ∈ Rm, i = 1,2,…,N. A local unit can be expressed as X = [X1,…,Xn]T, and the corresponding quality observation variable can be expressed as Yi ∈ Rp. Thus, the input for this study to monitor through process variables and quality variables is \((X,Y) = \{ (x_{i} ,y_{i} )\}_{i = 1}^{N}\), and the measurement variables in other units are structured as Z = [Z1,…,Zq]T. The new measurement value between the local and neighbouring units can be expressed as U = [U1,…,UN]T, and U = [XT,YT,ZT]. In the distributed process quality monitoring process, the failure of product quality is usually affected by some independent factors, defined as latent variables (LVs), LVi ∈ Rn. This study provides noise factors to generate observations that affect the process ei, ei ∈ Rm, i = 1,2,…,N. At the same time, considering the observations that affect the quality variables, this study introduces a noise factor ti, ti ∈ Rp, i = 1,2,…,N. to represent. These noises include operational changes, process fluctuations, and some feedback activities in the process. Based on the aboves, the model can be expressed as follows:
where f(LV) means Rn → Rm, which is used to describe the nonlinear mapping function of LV to the process variable, g represents Rn → Rp,, which is another nonlinear function used to describe how to generate measured observations based on LVs. This study believes that the noise e is a Gaussian distribution with a 0 mean, that is, e ~ N(0, ∑e), t ~ N(0, ∑t), and z ~ (0, ∑z), zi ∈ Rq, i = 1,2,…,N, the probability generation model study can be obtained:
Model 3 can be represented by the probability graph model in Fig. 3. According to the VAE process monitoring model, we assume that X and Y are the standard normal distribution of LV, that is, p(LV) = N(0,1). Then, according to the standard continuous model, this study assumes that each pair of inputs (xi,yi) is independent and uniformly distributed and uses the expected maximum (EM) algorithm to maximize its log likelihood. The study uses SN(X,Y) to represent the log likelihood.

Probabilistic graphical model

LSTM encoder unit structure
According to the calculation process of maximum likelihood estimation, directly maximizing SN(xi,yi) is usually difficult because of the complexity of the marginal distribution p(x,y). On the contrary, maximizing the lower bound of variation LSN(xi,yi) is easier to maximize estimation, where LSN(xi,yi) ≤ SN(xi,yi). However, according to Fig. 3, X and Y are independent of LV, so we can finally get Formula 6:
where Eq(LV) is the expectation of distribution q. KL in Eq. 6 represents KL (Kullback–Leibler) divergence, which can measure the similarity between the distribution q and p of a random vector with respect to a random measurement value, as shown in Eq. 7. What needs special attention here is that, in the E step of the EM algorithm, the model's parameters are obtained in the last iteration to calculate the posterior p(LV|xi,yi). Then, LSN(xi,yi) is maximized in the process of algorithm M to update the parameters to maximize SN(xi,yi) and finally cyclically execute the EM algorithm until the parameters converge (Fig. 4).
This study first needs to solve the distribution formulation in the probability model to train the established model in the distributed process. Specifically, given the complex non-linearity of f(LV) and g(LV), the traditional linear regression method is inefficient. Still, it maintains close timing characteristics among the sub-units in the distributed production process. Thus, this study uses LSTM to formulate the generation distributions p(x|LV) and p(y|LV) based on the VAE model. This process is called the decoding process in this research. Similarly, there is no specific analytical form in the posterior distribution p(LV|x,y). In this study, the local Gauss theorem is considered in the VAE model to express the posterior distribution of each sample. The formula is as follows:
where Λ(x,y) is the covariance matrix, which can limit the diagonal of the matrix to express the orthogonality of LV. The advantage of Eq. 13 is that the KL divergence is analytical, and the LSTM in a similar encoder is designed to encode the data set (x, y). Taking the encoder as an example, the LSTM coding structure in this study is as follows:
This study inputs the data set (x, y) into the encoder LSTM, choosing ln(1 + ex) as the sigmoid activation function. The structure of the decoder and the encoder is similar. For x-decoder, when the input of LSTM is LV, the output f(LV) is an average constant, and the output of the corresponding y-decoder is g(LV). The LSTM network expresses distributed process data through its network structure. Considering the situation that the expectation of the sampling process is difficult to determine, this study approximates the sampling process in the VAE:
where S is the number of samples, LV(s) can be obtained from the distribution (LV|xi,yi). Sampling variational sampling is performed through the initial sample, giving ε(s), which comes from the unit Gaussian distribution p(ε) = N(0,1), and bringing it into LV(s) to obtain Eq. 10:
The previous step is also called reparameterization in the process of VAE. The overall model structure of the VAE-LSTM in this study is shown in Fig. 5.

VAE-LSTM model structure diagram
The encoder in the model includes a stack of multiple neurons. Each unit must accept a single element of the input sequence, save the element information, and propagate forward simultaneously. The input of the model during training is a set of operation sequence parameters of the data set. Xi represents the sequence of operations, and hi represents the transition of the hidden state. The encoder will generate an intermediate vector after encoding, as shown in Fig. 6. It is the final hidden state generated from the model encoder part. This vector encapsulates the information of the input element to help the decoder make more accurate data generation and to ensure the initial input state of the model decoder. The decoder part is also composed of several cyclic stack units, and each cyclic unit makes a prediction output Yi on its step size. Each unit must accept the hidden state of the previous unit and finally generate and output its own hidden state. The structure of the decoder and encoder parts is similar.

Schematic diagram of VAE-LSTM process monitoring process
6 Fault Detection in the Distributed Process
Research also needs to monitor failure conditions to perform distributed process quality monitoring. Thus, this study first designs fault detection indicators to capture the faults of different timings in each sub-unit in distributed production during the model training process. The abnormal sample is usually perceived to be caused by the destruction of the correlation of the variables defined in the equation. Furthermore, it may be beyond the boundary defined by the training data set to cause significant changes. Two index variables, T2 and SPE, were developed based on the PCA monitoring process [37]. The SPE index is used to measure the projection change of the sample vector in the residual space, and the T2 statistic is used to measure the change of the sample vector in the principal component space. If the final result exceeds the statistical control limit, then the fault is detected.
Suppose X represents a measurement sample containing m sensors, and each sensor contains n independent samples to construct a data set. The calculation formulas for two statistics are as follows:
where Λ is the diagonal matrix; V is the eigenvector matrix of S; and P is the first A column of matrix V, \(\sigma_{\alpha }^{2}\) and \({\text{T}}_{\alpha }^{2}\) which represent the control limits of confidence α, and Λ = diag{λ1, λ2, …, λA}. The following methods usually calculate the control limit:
where \(F_{A,n - A,\alpha }\) is the distribution value with A and n-A degrees of freedom and confidence α. The control limits of these two indicators can also be referred to [38]. The limits in the literature are calculated according to the hypothesis test program. These two indicators also represent different functions in detecting different types of faults. Given the influence of LVs on the processing system, the T2 indicator will be used to capture the main process fluctuations. The imbalance of the SPE indicator means that the process or quality structure has exceeded the control limit.
This study uses two indicators to evaluate fault detection performance: fault detection rate (FDR) and false alarm rate (FAR). FDR represents the ratio of samples whose detection index exceeds the control limit to total samples. FAR represents the ratio of false alarms to the total number of normal data. The specific description is as follows:
7 Case Study and Discussion
Numerical simulation and Tennessee Eastman process are used as the benchmark processes for distributed process monitoring. The modular subunit division based on Girvan-Newman algorithm is applied and validated and the performance of the VAE-LSTM process monitoring model is verified based on these foundations, followed by result analysis and discussion.
8 Numerical Simulation
A numerical simulation case is utilized in this section, constructed based on the multivariate coupled characteristics of a nonlinear system, to validate the effectiveness of the proposed method. The specific description of the numerical simulation nonlinear system is given by Eq. 16:
where \(x \in [0.01,2]\) serves as the system input variable, uniformly distributed within the specified range; \(\varepsilon_{1} ,\varepsilon_{2} ,\varepsilon_{3} ,\varepsilon_{4} ,\varepsilon_{5} ,\varepsilon_{6} ,\varepsilon_{7}\) acts as the system input noise variable, independently and identically distributed according to a Gaussian distribution with parameters \(N(0,0.01)\); \(Y = \{ y_{1} ,y_{2} ,y_{3} ,y_{4} ,y_{5} ,y_{6} ,y_{7} \}\) serves as the system's output variable, exhibiting significant nonlinearity and multivariate coupling relationships within the variable set, with \(x,y_{1} ,y_{2} ,y_{3} ,y_{4} ,y_{5} ,y_{6} ,y_{7}\) being monitored variables during the system simulation process.
The above represents normal operating data for the system under controlled conditions. Based on the above formula, all controlled state data samples required for validation can be generated, including a total of 960 monitoring samples. In addition to this, this study introduces different fault noise factors denoted as \(fault\_factor\) to create fault samples for the system under uncontrolled conditions. The specific fault settings are as follows:
Fault 1: Inject a fault at the 161st training sample with \(\varepsilon_{1} = \varepsilon_{1} {*}fault\_factor\), where \(fault\_factor = 10\) is used to represent a step-type fault.
Fault 2: Inject a fault at the 161st training sample with \(\varepsilon_{2} = fault\_factor*0.5 + 5\), where \(fault\_factor\) serves as a random factor and follows a Gaussian distribution with parameters \(N(0,0.01)\), representing a random fault type.
Fault 3: Inject a fault at the 161st training sample with \(\varepsilon_{3} = 5 + 0.01{*}fault\_factor{ - }161\), where \(fault\_factor\) represents the time step and is used to indicate a slow drift fault type.
Fault 4 and 5: Data random loss rates of 0.1 and 0.7 were employed, along with the injection of gradual drift fault noise, to simulate scenarios of moderate and significant data loss during normal operational processes.
In this study, we used controlled state data as the training set and fault data as the test set to validate the effectiveness of the proposed process monitoring model. We constructed process monitoring models based on VAE-LSTM, PCA, and KPCA, with KPCA using a Gaussian kernel function. The results of three models are shown in Table 1. We found that VAE-LSTM achieved a higher fault detection rate compared to traditional models, and it was more sensitive to the specific faults we set. The VAE-LSTM-based process monitoring models were able to identify all five types of faults and demonstrated excellent performance, surpassing both PCA and KPCA in terms of monitoring statistics. The average fault detection rate based on monitoring statistics reached as high as 0.962, significantly outperforming baselines. Additionally, except for some fluctuations in the false alarm rate for KPCA, both VAE-LSTM and PCA process monitoring models exhibited low false alarm rates, meeting the requirements of practical applications. In this study, we used the modular Girvan-Newman algorithm to partition the nonlinear system with seven output variables into subunits, constructing a distributed nonlinear system. The partitioned subunit results are shown in Fig. 7. Below, we provide specific results for the VAE-LSTM model based on five types of faults.

Process variable partitioning results
Fault 1, as a step-type fault, was introduced at time step 161. The detection results for the step-type fault based on VAE-LSTM, as shown in Fig. 8, indicate that an alarm is immediately triggered when the fault is introduced at time step 161. From a mathematical perspective, introducing step-type fault noise at time step 161 results in a step-type fault. Analyzing the process monitoring results, the proposed model demonstrates the effective monitoring ability for fault 1 in both distributed subunit 1 and subunit 2. In contrast, centralized monitoring is able to detect the fault promptly while still lacks of accurate fault representation. The distributed process monitoring methods provides more accurate results for nonlinear manufacturing systems.

Step-type fault detection results based on VAE-LSTM. a Subunit 1, b Subunit 2, c Overall process monitoring results (Left: fault detection, right: statistics sampling distribution)
Fault 2, as a random fault type, is analyzed based on the step-type fault detection results using VAE-LSTM, as shown in Fig. 9. When the fault is introduced at time step 161, the variables of the entire system exhibit unpredictable fluctuations due to random noise. From the analysis of the nonlinear system itself, this random fault affects the entire manufacturing system, and the effects observed in subunit 1 and subunit 2 are similar to the results of centralized process monitoring. However, the monitoring results in subunit 1, when analyzed, show that the distributed process monitoring method can capture process variable faults on a finer dimension. Therefore, the distributed process monitoring method in detecting random fault types shows its effectiveness.

Random-type fault detection results based on VAE-LSTM. a Subunit 1, b Subunit 2, c Overall process monitoring results (Left: fault detection, right: statistics sampling distribution)
Fault 3, as a slow drift fault type, is analyzed based on the step-type fault detection results using VAE-LSTM, as shown in Fig. 10. Similarly, when the fault is introduced at time step 161, it does not immediately result in significant fault conditions, but gradually affects the entire system over time. However, the analysis of process monitoring results in subunit 1 shows that the entire system experiences faults after the fault is introduced at time step 161. In contrast, the process monitoring results in subunit 2 indicate that the fault gradually drifts to 750 variables and then returns to normal over time. This result aligns with the performance of centralized process monitoring and compensates for the missing process monitoring results in subunit 1.

Slow drift-type fault detection results based on VAE-LSTM. a Subunit 1, b Subunit 2, c Overall process monitoring results (Left: fault detection, right: statistics sampling distribution)
Fault 4, representing a fault type characterized by partial data loss and slow drift noise (with a random data loss rate of 0.1), was analyzed for fault detection using the VAE-LSTM model, as illustrated in Fig. 11. When random data loss noise is introduced at time step 161, the process monitoring model immediately issues a fault alarm. Analysis of the process monitoring results from subunit 1 and subunit 2 reveals that the fault gradually increases over time, exhibiting a slow upward trend. This trend aligns with the characteristics of slow drift fault types, which are less represented in centralized process monitoring. This indicates that when a small amount of data is lost, it will not affect the stability of the framework proposed in this study. Therefore, the distributed process monitoring based on the VAE-LSTM model exhibits higher fault detection performance for faults representing partial data loss and slow drift noise.

Data loss-type (0.1) fault detection results based on VAE-LSTM. a Subunit 1, b Subunit 2, c Overall process monitoring results (Left: fault detection, right: statistics sampling distribution)
Fault 5, representing a fault type characterized by extensive data loss and slow drift noise (with a random data loss rate of 0.7), was monitored using the VAE-LSTM model, and the fault detection results are shown in Fig. 12. When the fault was introduced at time step 161, the VAE-LSTM model proposed in this study promptly issued a fault warning, and fault occurrences were detected in both subunit 1 and subunit 2. However, due to the extensive data loss, there were significant fluctuations in the final fault detection results. This indicates that the impact of this data loss condition on the ultimate product quality is substantial. Additionally, from the detection results, the upward trend observed from time step 161 to 300 aligns with the characteristics of slow drift fault situations. However, as time progresses, it remains consistent in the later stages. This suggests that when significant data loss occurs and control faults are not promptly detected, uncontrollable production faults may occur later on. This means that even when a large amount of data is lost, it will not affect the stability of the framework proposed in this study. However, in actual manufacturing processes, it is important to proactively control faults that result in the loss of a significant amount of data to prevent uncontrollable fault situations. This demonstrates that the distributed process monitoring model based on the VAE-LSTM has good monitoring capabilities for faults involving extensive data loss and slow drift noise.

Data loss-type (0.7) fault detection results based on VAE-LSTM. a Subunit 1, b Subunit 2, c Overall process monitoring results (Left: fault detection, right: statistics sampling distribution)
Based on the analysis of specific faults mentioned above, it is evident that the process monitoring model based on VAE-LSTM outperforms traditional PCA and KPCA models in terms of both fault detection rate and false alarm rate. The VAE-LSTM process monitoring model effectively perform process monitoring tasks for nonlinear systems and exhibits good sensitivity to various types of faults. From the experimental results, it is clear that the VAE-LSTM-based process monitoring model can be applied to nonlinear process industrial scenarios. It can monitor the current system's operational status from the perspectives of the distribution characteristics of monitoring data and temporal features, effectively addressing the issue of fault time monitoring samples caused by data loss.
9 Application to Tennessee Eastman Process
The data acquired by the Tennessee-Eastman (TE) process [39] has the characteristics of time-varying, evident non-linearity, and strong coupling. It is widely used to control complex, large-scale industrial processes and test fault diagnosis models. As a well-known process monitoring benchmark [35], it has also been verified to evaluate the performance of distributed process quality monitoring strategies. The TE process consists of five main operating units: reactor, condenser, compressor, separator, and stripper. The four main reactants, A, C, D, E, and an inert feed B, are input into the reactor in the production process. Finally, two required products, G and H, and the by-product F are formed. The production flow of the TE process is shown in Fig. 13. For a detailed introduction of the specific TE process, refer to Zhong et al. [24].

TE process flow chart
The process contains 41 measurement variables, 22 continuous process measurement values, 19 component measurement values, and 11 manipulated variables. A total of 21 faults are introduced during the simulation. The TE process can provide one set of normal data sets for training and testing and 21 different fault data sets for distributed process monitoring. In all 21 types of faults, 15 fault types are known. The specific fault information can be found in the references [37]. This study obtains 500 offline samples through simulation To monitor the distributed process better. At the same time, for the online testing process, this study presets 960 samples for each type of fault and introduces the fault attributes at the 161st simulation sample. Figure 14 shows that the modularized Girvan-Newman algorithm divides all variables into five sub-blocks. Table 2 shows the specific division of each sub-block. The following conclusions can be obtained by analyzing the attributes and functions of the internal variables of each unit: Generally, variables with high correlation between process variables are divided into the same sub-block. These operating variables have similar production effects in the entire production process.

The schematic diagram of process variable division
To validate the effectiveness of Girvan-Newman algorithm in both high-dimensional and low-dimensional manufacturing processes, we used the VAE-LSTM model to generate network datasets with node sizes of 10, 50, 100, 200, and 500, all having the same distribution characteristics based on TE process data. Subunit divisions were then applied using the Girvan-Newman algorithm to each of these datasets. To comprehensively analyze the performance of this method, we evaluated the algorithm's modularity calculation, runtime, and memory consumption from three aspects. The results are shown in Fig. 15, and the specific numerical algorithm results are presented in Table 3. Upon analysis, the algorithm's modularity calculation performed well across different dimensions, increasing as the number of nodes increased. This indicates that the GN algorithm is more effective in detecting community structures as the node count increases. Runtime was very fast in smaller data dimensions, but it significantly increased with the number of nodes, reaching approximately 242 s at 500 nodes. This suggests that the GN algorithm may require more time on larger networks, although this depends on the hardware infrastructure. In this study, an Intel(R) Core(TM) i7-7500U CPU @ 2.70 GHz 2.90 GHz with a GeForce 940MX GPU was used. Improving the computer's hardware can enhance the algorithm's computational time. Furthermore, the algorithm's memory consumption remained relatively stable, showing a slight increase with the number of nodes, but the increase was not significant. Therefore, the GN algorithm exhibited good performance in terms of memory consumption and can handle common-scale networks in intelligent manufacturing processes.

Girvan-Newman applicability analysis
Finally, the results of subunit division are compared with the complete TE process. The subdivided units are as follows: Subunit 1 is the reactor, Subunit 2 is the separator, Subunit 3 is the stripper, and Subunit 4 is the compressor. Through comparative analysis and based on Fig. 10, it can be observed that there is no connection between Unit 5 and the other four subunits, indicating that variables contained in Subunit 5 are unrelated to the process variables. There is an intersection of operating variables between Subunit 1 and Subunit 3, indicating that the variables with overlap play important roles in both units. Specifically, the overlapping unit variables are 36, 37, 38, and 39, and it is known from reference [37] that they all represent variables related to product quality components. Figure 14 shows that the reactor inputs output variables into both the condenser and the separator. Then, after the reaction process, they each produce products, flows 6 and 9, which are quality variables of the products. This confirms that the partitioning results match the actual TE process and also demonstrates the reliability of the modular subunit partitioning algorithm based on Girvan-Newman in this study.
Faults in the actual production system will propagate forward with time, and the corresponding process variables should be affected. However, this study found that, when some faults occur in the experiment process, most variables in the entire generation process can still be stable and normal, which increases the difficulty of fault detection. Thus, to compare and analyze the impact of 15 known faults on distributed process monitoring, this research should determine the relationship between each fault and quality. According to the statistical analysis set in Sect. 3.3, when the statistics SPE and T2 corresponding to the current fault are greater than the control limit, the fault is related to quality. Faults 3, 9, and 15, which are not related to quality, are usually excluded because of their small fault magnitude and greater difficulty in detection [31]. Based on the above analysis and calculation, the quality-related fault is [IDV(1, 2, 5, 6, 7, 8, 10, 12, 13)], and the quality-independent fault is [IDV(4, 11, 14)] [32]. In this study, quality-related faults and quality-independent faults are compared with normal process variables for distributed process monitoring and analysis, and the VAE-LSTM process monitoring results are compared with VAE-DNN, PCA, and KPCA methods.
10 Results and Discussion
To prove the accuracy of the model in this study, this section first compares the performance of distributed process monitoring based on the VAE-LSTM and VAE-DNN models and selects the normal data set d00 and the faulty data set d10 for training. Although the two methods have high accuracy in normal data set process monitoring, the results generated by the VAE-DNN model after the introduction of faults are unsatisfactory, and the peak situations are extreme. The proposed VAE-LSTM method has good generating ability for normal data set d01 and data set d10 with faults, which also proves the reliability of the proposed model. The specific monitoring process of the model can be seen in Fig. 16, where (a) is the generation result of the VAE-DNN model for the d00 data set process variables, (b) is the VAE-DNN model d10 data set quality variable generation result, and (c) is the VAE LSTM model that generates the result of the process variables in the d00 data set, (d) is the generated result of the VAE-LSTM model in the d10 data set (Fig. 16 [a, b], the left figure is the original data, and the right figure is the generated data; [c, d] the red figure in is the generated result, and the blue figure is the original data).

The distributed process monitoring results of fault 10 using VAE-DNN and VAE-LSTM [VAE-DNN: (a, b), VAE-LSTM: (c, d)]
Fault 13 is a change in the reaction kinetic characteristics, which occurs at the reactor. According to the meaning of TE process, the fault type is a slow drift. T2 and SPE statistics are both standard statistics in process monitoring and fault detection. Among them, the T2 statistic considers the relationships and joint variations among multiple variables. The T2 statistic uses covariance information between variables, which means it can detect linear and nonlinear relationships between variables, while the SPE statistic typically only considers the dispersion of each variable.The T2 statistic usually operates on high-dimensional datasets, considering multiple variables, whereas the SPE statistic typically operates on low-dimensional datasets, focusing on the variability of individual variables. During the experimental process, this study found that the T2 statistic is more sensitive in fault detection compared to the SPE statistic. For some fault scenarios, the SPE statistic is unable to characterize the fault, which is why this study utilizes the T2 statistic to assess faults. According to Fig. 17a, b, after the fault is introduced at the 161st sample, the fault becomes more and more apparent and fluctuates with the change of time, which conforms to the characteristic of slow drifting fault. It occurs simultaneously in the first sub-unit of the entire production process, which also causes subsequent process variables related to product quality to fail. Fault 1 means that the A/C feed flow ratio changes, and component B remains unchanged. This fault is a step fault. According to Fig. 17c, d, after the fault is introduced at 161, the reactor fails, and the process variable undergoes a step change and gradually stabilizes over time, which is consistent with the step category of Fault 1.

The distributed process monitoring results of Fault 13 using PCA and KPCA [PCA: (a, c), KPCA: (b, d), Fault 13 (a, b), and Fault 1 (c, d)]
For some local faults, for example, in the fault detection process of Fault 1, this study found that the fault detection efficiency of the overall production process is low. Thus, this study focuses on monitoring the divided sub-units and then performs the process monitoring on the sub-units. AE feature fusion for overall detection. Fault 11 is a change in the temperature of the cooling water inlet of the reactor. The fault is a random change, and the quality is irrelevant. Then, fault in subunit 1 should be detected. Figure 13 shows each subunit's fault detection and detection status, sampling distribution, and data distribution results for distributed process monitoring. Figure 18a is the fault detection situation in subunit 1, and Figs. 18b, c, and d are the fault detection situation of subunits 2, 3, and 4 after the introduction of Fault 11. Comparative analysis reveals that, when the reactor fails, other sub-units associated with its timing also have failures. Figure 18e shows the overall fault detection results after subunit fusion. In this study, the AE encoder uses the hidden variables generated by it to perform feature reduction; finally, the four subunits are fused. The comparative analysis shows that the change of random faults is unstable. When 161 samples are introduced, the process variables start to float after the distributed process detection research. Furthermore, the introduction of Fault 11 has a small impact on the quality variables, proving that the fault is a quality-independent fault. Finally, Fig. 18e shows the fault detection results of the fusion sub-block. The analysis shows that the distributed process monitoring model proposed in this study can determine the location of the fault. Through the distributed process detection distribution diagram of each sub-unit in Fig. 18, this research model's detection accuracy can be obtained.


The distributed process monitoring results of Fault 11. a reactor, b separator, c stripper, d compressor, e fusion sub-block (Left: fault detection, right: statistics sampling distribution, bottom: process monitoring)
This study also selected Fault 12, the condenser cooling water inlet temperature change fault for analysis. Figures 19a, b, c, and d correspond to the fault 12 detection results of subunits 1, 2, 3, and 4, respectively; they illustrate a statistical sampling diagram and distributed process monitoring data distribution. The analysis in Figs. 14a and c reveal that the failure occurred in the later stage of the entire production process. No obvious step change is found in the failure of subunits 1 and 3 after the failure was introduced in the sample at 161. Furthermore, in Fig. 14b and d, after the fault is introduced in the sample at 161, the process variable of subunit 4 immediately undergoes a step change, which indicates that the model detects that Fault 12 has occurred in the condenser of subunit 4. Furthermore, the result of sub-unit division in Fig. 19 shows that subunits 2 and 3 are adjacent subunits of the condenser. Thus, this study focuses on the change in inlet temperature during actual production, which the failure of the upstream unit may also cause. Finally, Fig. 19e shows the detection results of sub-block fusion. It reveals that the proposed distributed process detection model determines the location of the fault. Through the process monitoring results of each subunit in the distributed process shown in Fig. 19, we can obtain that the fault detection proposed in this study has a certain accuracy.


The distributed process monitoring results of Fault 12. a reactor, b separator, c stripper, d compressor, e fusion sub-block (Left: fault detection, right: statistics sampling distribution, bottom: process monitoring)
This study analyzes the detection and analysis of 15 known types of faults. Given that the fault levels of Faults 3, 9, and 15 are relatively small, they are not sensitive enough to the statistic T2 in the detection process. Thus, this study lists 12 known types of fault distributed process detection results, and the specific fault detection rates are shown in Table 4. In the above analysis, this study found that the quality of the manufacturing process with the introduction of Failure 1 can be restored. That is, when this type of failure occurs and the product quality fluctuates for a period, the quality will eventually return to normal. This study found that this type of failure includes Failures 1, 5, and 7. Thus, distributed detection can identify failures, which are difficult to find in the centralized detection process. According to Table 4, the fault detection rate of the VAE-LSTM model proposed in this study has been greatly improved compared with the traditional PCA and KPCA methods, and the fault detection accuracy of the VAE-DNN method is also improved to a certain extent. The false alarm rate of Fault 1 selected in this study is representative. The comparison shows that this study's false alarm rate of faults in distributed process monitoring is also the lowest.
11 Conclusions and Outlooks
This study proposes a distributed process monitoring framework for the complex industrial manufacturing system. The framework first uses the Girvan-Newman algorithm to realize the modularization of the complex factory system. The LSTM method is innovatively proposed to improve the VAE model and analyze the complex timing characteristics between different sub-blocks and between the internal variables of the sub-blocks. The gate control unit contained in the network is used to filter noise and separate fault information. The timing relationship between the data is fully analyzed to realize distributed process monitoring. The distributed process fault detection is also carried out separately and integratedly for each sub-unit, and the performance of the distributed process is monitored by the two fault detection indicators T2 and SPE analysis framework. Finally, through the TE process as a case study analysis and verification, this study finds that the proposed VAE-LSTM-based process monitoring model can accurately locate the specific subunit where the fault occurs and identify the fault location, reducing communication costs and risks in centralized process monitoring method. At the same time, compared with the VAE-DNN, PCA, and KPCA methods, the proposed method has a higher fault detection rate and a lower fault false alarm rate. Therefore, this study's distributed process monitoring framework has excellent monitoring performance.
Given that distributed process monitoring has attracted more and more attention, especially in large-scale industrial systems, the proposed framework has high theoretical value and practical significance. This framework reduces the data latitude in the manufacturing process through subunit division and improves the efficiency of distributed process monitoring. By extracting the timing characteristics between units, the relationship between unit variables can be deeply analysed, potential fault information can be determined, and local faults can be found to solve the faults immediately. The framework proposed in this study has more sensitive fault detection capabilities than traditional process monitoring methods and has more efficient process monitoring capabilities in the industrial manufacturing process.
However, the probability generation model used in this study can generate any type of data, such as images and sounds. Thus, this article considers expanding the data source type and popularizing the model in future research. The problem of variable overlap between different subunits in subunit division should also be considered in distributed process monitoring. Changing the redundancy of variables between several of these units will enhance the coupling between the operating units, which is in line with the strong coupling of industrial operating blocks. On the basis of fault detection, managing faults is important and requires the classification of faults. Thus, further research will continue to expand the fault classification. In the case study based on the TE process, we found that although ideal monitoring performance was achieved for most faults, there were still a few challenging faults to monitor. In future work, we will consider the characteristics of typical faults and enhance sensitivity to these minor faults. The process monitoring model should exhibit greater adaptability to different types of faults.Furthermore, real-world industrial processes are becoming increasingly complex, and this trend is more pronounced with the advancement of industrial technology. In this study, we primarily validated the process monitoring performance for single fault states. In future research, it should be considered that multiple fault scenarios based on time or production units may occur. These multi-fault scenarios manifest in monitoring variables not as simple additions or cancellations, but potentially interact with each other, posing greater challenges and difficulties for process monitoring tasks.
References
Tang P, Peng K, Jiao R (2022) A process monitoring and fault isolation framework based on variational autoencoders and branch and bound method. J Franklin Inst 359(2):1667–1691
Samandari Masooleh L, Arbogast JE, Seider WD et al (2022) Distributed state estimation in large-scale processes decomposed into observable subsystems using community detection. Comput Chem Eng 156:107544
Peng X, Li Z, Zhong W, Qian F, Tian Y (2020) Concurrent quality-relevant canonical correlation analysis for nonlinear continuous process decomposition and monitoring. Ind Eng Chem Res 59(18):8757–8768
Peng X, Tang Y, Du W, Qian F (2017) Multimode process monitoring and fault detection: a sparse modeling and dictionary learning method. IEEE Trans Industr Electron 64(6):4866–4875
Huang K, Wu Y, Wen H, Liu Y, Yang C, Gui W (2020) Distributed dictionary learning for high-dimensional process monitoring. Control Eng Pract 98
Tong C, Lan T, Yu H, Peng X (2019) Distributed partial least squares based residual generation for statistical process monitoring. J Process Control 75:77–85
Jiang Q, Huang B (2016) Distributed monitoring for large-scale processes based on multivariate statistical analysis and Bayesian method. J Process Control 46:75–83
Li W, Zhao C (2019) Hybrid fault characteristics decomposition based probabilistic distributed fault diagnosis for large-scale industrial processes. Control Eng Pract 84:377–388
Shang C, Ji H, Huang X, Yang F, Huang D (2019) Generalized grouped contributions for hierarchical fault diagnosis with group Lasso. Control Eng Pract 93
Ge Z, Song Z (2013) Distributed PCA model for plant-wide process monitoring. Ind Eng Chem Res 52(5):1947–1957
Ge Z (2017) Review on data-driven modeling and monitoring for plant-wide industrial processes. Chemom Intell Lab Syst 171:16–25
Lu W, Yan X (2021) Variable-weighted FDA combined with t-SNE and multiple extreme learning machines for visual industrial process monitoring. ISA Trans
Chen Z, Ding SX, Zhang K, Li Z, Hu Z (2016) Canonical correlation analysis-based fault detection methods with application to alumina evaporation process. Control Eng Pract 46:51–58
Wu P, Zhang X, He J et al (2021) Locality preserving randomized canonical correlation analysis for real-time nonlinear process monitoring[J]. Process Saf Environ Prot 147:1088–1100
Hu Y, Ma H, Shi H (2013) Enhanced batch process monitoring using just-in-time-learning based kernel partial least squares. Chemom Intell Lab Syst 123:15–27
Zhong M, Xue T, Song Y et al (2021) Parity space vector machine approach to robust fault detection for linear discrete-time systems. IEEE Trans Syst Man Cybernet Syst 51(7):4251–4261
Qin SJ, Zheng Y (2013) Quality-relevant and process-relevant fault monitoring with concurrent projection to latent structures. AIChE J 59(2):496–504
Wang K, Hatchell P, Chalenski D, Lopez J (eds) (2017) Advances in 4D seismic and geophysical monitoring of deepwater fields. In: Proceedings of the annual offshore technology conference
Ku W, Storer RH, Georgakis C (1995) Disturbance detection and isolation by dynamic principal component analysis. Chemom Intell Lab Syst 30(1):179–196
Li G, Qin SJ, Zhou D (2014) A new method of dynamic latent-variable modeling for process monitoring. IEEE Trans Industr Electron 61(11):6438–6445
Liu Y, Pan Y, Sun Z, Huang D (2014) Statistical monitoring of wastewater treatment plants using variational Bayesian PCA. Ind Eng Chem Res 53(8):3272–3282
Jiang Q, Yan X, Huang B (2019) Neighborhood variational bayesian multivariate analysis for distributed process monitoring with missing data. IEEE Trans Control Syst Technol 27(6):2330–2339
Zhang C, Yu J, Ye L (2021) Sparsity and manifold regularized convolutional auto-encoders-based feature learning for fault detection of multivariate processes. Control Eng Pract 111:104811
Zhang J, Zhong Y, Huai W (2018) Transverse distribution of streamwise velocity in open-channel flow with artificial emergent vegetation. Ecol Eng 110:78–86
Arunthavanathan R, Khan F, Ahmed S, Imtiaz S (2021) A deep learning model for process fault prognosis. Process Saf Environ Prot 154:467–479
Yao P, Yang S, Li P (eds) (2021) Fault diagnosis based on RseNet-LSTM for industrial process. IEEE Adv Inf Technol Electronic Autom Control Conf (IAEAC)
Zheng J, Zhang H, Dai Y, Wang B, Zheng T, Liao Q et al (2020) Time series prediction for output of multi-region solar power plants. Appl Energy, 257
Hua Y, Zhao Z, Li R, Chen X, Liu Z, Zhang H (2019) Deep learning with long short-term memory for time series prediction. IEEE Commun Mag 57(6):114–119
Ahmed I, Ahmad M, Chehri A, Jeon G (2023) A heterogeneous network embedded medicine recommendation system based on LSTM. Futur Gener Comput Syst 149:1–11
Huang J, Yan X (2018) Relevant and independent multi-block approach for plant-wide process and quality-related monitoring based on KPCA and SVDD. ISA Trans 73:257–267
Rokach L (2010) A survey of clustering algorithms. Data mining and knowledge discovery handbook, 269–298
Moon H-J, Bu S-J, Cho S-B (2023) A graph convolution network with subgraph embedding for mutagenic prediction in aromatic hydrocarbons. Neurocomputing 530:60–68
Gayathri RG, Nair JJ, Kaimal MR (eds) (2016) Extending full transitive closure to rank removable edges in GN algorithm. Proc Comput Sci
Song L, Wu Y, Wu M, Ma J, Cao W (2023) An integrated approach to model connectivity and identify modules for habitat networks. Ecol Model 483:110446
Ali M, Hassan M, Kifayat K, Kim JY, Hakak S, Khan MK (2023) Social media content classification and community detection using deep learning and graph analytics. Technol Forecast Soc Chang 188:122252
Zhou L, Liao Z, Wang J, Jiang B, Yang Y (2014) MPEC strategies for efficient and stable scheduling of hydrogen pipeline network operation. Appl Energy 119:296–305
Zhou L, Chen J, Song Z et al (2015) Semi-supervised PLVR models for process monitoring with unequal sample sizes of process variables and quality variables. J Process Control 26:1–16
Cao Y, Yuan X, Wang Y et al (2021) Hierarchical hybrid distributed PCA for plant-wide monitoring of chemical processes. Control Eng Pract 111:104784
Linzhe H, Yuping C, Xuemin T, Xiaogang D (2015) A nonlinear quality-relevant process monitoring method with kernel input-output canonical variate analysis. IFAC-PapersOnLine 48(8):611–635
Wang K, Yuan X, Chen J, Wang Y (2021) Supervised and semi-supervised probabilistic learning with deep neural networks for concurrent process-quality monitoring. Neural Netw 136:54–62
Jiang J, Jiang Q (2021) Variational Bayesian probabilistic modeling framework for data-driven distributed process monitoring. Control Eng Pract 110:104778
Funding
The work reported herein was supported by Shaanxi Province Natural Science Foundation Research Project (2023-JC-YB-615), the Practical Innovation Ability Cultivation Fund for Master Students (06410-23GH01050101) and Shaanxi Social Science Fund in China (Program No.2023R102). The authors thank all the participants in the experiment and the professors for their advice. The authors would like to thank the anonymous reviewers for their valuable suggestion and constructive comments.
Author information
Authors and Affiliations
Contributions
JiaYi Tian and Ming Yin wrote the main manuscript text. YiBo Wang and JiJiao Jiang prepared figures. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Conflict of interest
We declare that we have no financial and personal relationships with other people or organizations that can inappropriately influence our work, there is no professional or other personal interest of any nature or kind in any product, service and/or company that could be construed as influencing the position presented in, or the review of, the manuscript entitled.
Data in Brief
The datasets generated during and/or analysed during the current study are available in the Washington repository, [http://depts.washington.edu/control/LARRY/TE/download.html#Basic_TE_Code].
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yin, M., Tian, J., Wang, Y. et al. A Novel Distributed Process Monitoring Framework of VAE-Enhanced with Deep Neural Network. Neural Process Lett 56, 118 (2024). https://doi.org/10.1007/s11063-024-11577-1
Accepted:
Published:
DOI: https://doi.org/10.1007/s11063-024-11577-1