
Abstract
Membrane computing is a type of parallel computing system (generally called P system) abstracted from information exchange mechanisms in biological cells, tissues, or neurons, which can process data in a distributed and interpretable manner. LSTM-SNP, the first model of long short-term memory networks based on parameterized nonlinear Spiking neural P systems, was proposed recently. However, a systematic understanding and leveraging of the LSTM-SNP model to address named entity recognition (NER) and other natural language processing (NLP) tasks are still lacking. The bottleneck of the NER task lies in the scarcity of data and the vague definition of entity edges. Most approaches center on dataset handling, and there have been few attempts to address the issue in Spiking neural P (SNP) systems. This paper proposes a model named CLSTM-SNP based on the LSTM-SNP, aiming to tackle the NER problem in the field of SNP systems for the first time. First, this study employs a CNN layer to obtain character-level characteristics. Second, GloVe word vectors are utilized as word representations. Third, the research employs the LSTM-SNP to analyze textual features. We subsequently studied CLSTM-SNP’s effectiveness in addressing NER problems on CoNLL-2003 and OntoNotes 5.0 datasets and compared it to the results of five other baseline methods. Our model CLSTM-SNP achieved a macro F1-score of 89.2 \(\%\) on CoNLL-2003 and 75.5\(\%\) on OntoNotes 5.0, respectively. The performance of CLSTM-SNP and LSTM-SNP indicates a great potential for handling named entity recognition or other sequential tasks in NLP.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Membrane computing, known as the P system, was proposed by academician Gheorghe Pǎun [1] at Turku Computing Research Center. P systems are theoretical calculation models derived from the architecture and information interaction mechanisms of biological cells, tissues, and organs. As an emerging research field, the significant influence of membrane computing is mainly reflected in the following two aspects [2,3,4]. First, the computing capacity of membrane computing models is theoretically as powerful as the Turing machine. Second, the models offer high computation efficiency due to their inherent maximum parallelism. Accordingly, some computationally complex problems, e.g., NP problems, can be processed using membrane computing in a feasible time frame.
Extensive research has shown the advent of membrane computing in various applications such as biology and bio-medicine [5], computer graphics [6], cryptography [7], robot control [8], image processing [9], power system fault diagnosis [10] and other real-life complex problems. How to make membrane computing with excellent learning and application capabilities is still one of the research hotspots nowadays. Recent researches are committed to implementing learning algorithms, similar to back-propagation algorithms, within membrane computing [11, 12]. The study on applying membrane computing with learning functions to practical problems is also in progress. These papers are primarily based on the Spiking neural P (SNP) system, a significant branch of membrane computing. For instance, Wu and Pan [12]designed a numerical SNP system based on the SNP system, which possesses fine favorable numerical representation abilities. Song and Pang [13] proposed an SNP model with learning functions to successfully resolve the task of English letter recognition.
SNP systems can be expressed by a directed graph, in which the nodes represent neurons, and the arcs characterize synapses between them. Each neuron in an SNP system has two components: data and spiking rules. The data reflect the internal state, and the spiking rules describe the system’s dynamic behaviors. The working mechanism of spiking rules involves two processes: spike consumption and spike generation. Additionally, various biological mechanisms have been introduced previously, referring to a delay on synapses [14], dynamic threshold mechanism [15], nonlinear coupled mechanism [16], inhibitory rules [17], communication on request [18], etc. NSNP systems [19], referred to as nonlinear versions of traditional SNPs, are currently being investigated, in which neurons consume and generate spikes via predefined nonlinear functions of the neuron’s states. Therefore, NSNP systems are appropriate for capturing nonlinear characteristics in complex systems.
Long short-term memory network (LSTM) [20] is a class of RNN with the ability to extract data features with long-term dependency. An LSTM model incorporates a hidden state that records information about the current time step and passes it on to the next time step. The network has three gates, i.e., forget gate, input gate, and output gate, which regulate the information transmission of neurons. As previously mentioned, each spiking neuron in an SNP system has an internal state and two spiking mechanisms (spike consumption and spike generation). Motivated by the state and mechanisms of NSNP and LSTM models, Liu and Peng [21] develop the LSTM-SNP model, a parameterized NSNP system, to solve the time series prediction problem effectively. An LSTM-SNP consists of only one nonlinear spiking neuron with nonlinear spiking mechanisms (nonlinear spike consumption and nonlinear spike generation) and nonlinear gate functions (reset, consumption, and generation).
Surveys such as that conducted by Ma et al. [22] have shown that recurrent-type models perform exceptionally well on sequence problems, such as time series forecasting problems. The LSTM-SNPs are a generic term that refers to recurrent-type NSNP systems based on nonlinear spiking neuron mechanisms. Their ability to deal with time-series issues is also to be expected. Named entity recognition (NER) is a critical task in many natural language processing (NLP) time-series applications, such as information extraction, question answering, and machine translation. However, a systematic understanding and leveraging of the LSTM-SNP to address NER or other NLP time-series tasks are still lacking. Hence, this paper designed a convolutional LSTM-SNP (CLSTM-SNP) model to study the adaptability of the latest general neural networks LSTM-SNP in the NER issues. In this study, the CLSTM-SNP approach utilizes the text representation ability of GloVe vectors [23] and character feature representation of convolutional neural networks [24].
Recently, the development of LLMs has shifted from in-context learning to addressing task-specific challenges [25,26,27], particularly in the domains of NER and RE. The paradigm shift represented by targeted distillation, as exemplified by UniversalNER, provides valuable insights into the future landscape of utilizing LLMs for a myriad of applications in NLP, ranging from diverse to complex and resource-intensive scenarios. Despite the progress, LLMs’ performances on the task of NER are still well below supervised baselines. This is because of the intrinsic gap between the two tasks of NER and LLMs: NER is a sequence labeling task in nature, where the model needs to assign an entity-type label to each token within a sentence, while LLMs are formalized under a text generation task. The gap between the semantic labeling task and the text generation model leads to inferior performance when applying LLMs to resolve the NER task.
Bottlenecks in NER lie in the scarcity of data and the vague definition of entity edges. Most current NER solutions focus on data processing to compensate for scarce data, which is commonly achieved by transforming text words into graphs prior to processing [28], active learning [29], or adversarial learning strategies [30]. Are there ways to use the existing dataset of named entities in conjunction with more substantial model computing power in order to find a feasible solution? A membrane system is accurately defined as a computational model derived from biology [1]. The computational power of membrane systems can be comparable with that of the Turing machine in theory. Another purpose of this paper is to investigate a competent method to work out the NER problems in the field of membrane computing. The code is available at this website.Footnote 1 The main motivations and contribution of this study can be summarised as follows:
-
A model CLSTM-SNP combining LSTM-SNP with convolutional neural networks (CNNs) has been proposed. CLSTM-SNPs are the first attempt to combine the CNN to enhance the capability of LSTM-SNP for characteristic extraction. CLSTM-SNPs are able to extract characteristics from text data sets with a high level of sparse data more accurately than LSTM-SNPs.
-
This research examines the emerging role of CLSTM-SNP and LSTM-SNP models in the task of named entity recognition for the first time, aiming at extending the application of membrane computing to natural language processing. Both models have the potential to provide powerful computing capabilities in theory but suffer from difficulty in application. Our model-constructed approach is designed to overcome the difficulties of applying the SNP systems. The training processing recommended in this article provides new insights into SNP applications.
-
Our research shows that membrane computing is viable for solving NER, even with sparse data scenarios. While more research is needed to perfect this technique, it offers enormous potential for the future of NER research.
2 Related Work
Named entity recognition (NER) is an NLP mission that identifies and classifies named entities in text. Several entities can be considered, including people, organizations, locations, events, etc. NER is a versatile tool that can be used for many downstream applications, such as information extraction and question-answering. NER can be accomplished through the utilization of rule-based approaches, machine learning approaches, or deep learning approaches. Rule-based approaches involve the use of hand-crafted rules to identify named entities in text. These rules are typically based on patterns in the text, such as specific character sequences or word forms. Machine learning methods use the algorithm, such as a hidden Markov model (HMM) [31] or a conditional random field (CRF) [32], to identify named entities based on labeled training data. Such statistical methods can be effective but require a large training corpus. Deep learning methods apply neural networks to learn how to identify named entities from text. These methods can be effective with little training data but require more computational resources. This section provides a brief overview of each type of NER method.
2.1 Rules-Based NER
A few different approaches to NER primarily rely on grammar rules. Two classic methods can be found in the studies [33] and [34], referring to the rules according to place name dictionaries and lexical-syntactic patterns, respectively. These approaches can be practical in many cases, but there are also some limitations. One of the main drawbacks is that these approaches can be complex and rely heavily on the annotation of domain experts as part of the learning process. Developing comprehensive rules that cover all potential entities can take time and effort. In addition, entities can be intricate and may only sometimes adhere to standard grammar regulations.
2.2 Machine Learning NER
Machine learning algorithms have become increasingly sophisticated and are now able to learn from data much more effectively than before. This has made them extremely powerful tools for solving NER problems that are generally considered a multi-classification sequence annotation issue. The typical approaches include maximum entropy (MaxEnt) [35], support vector machines (SVMs) [36] hidden Markov models (HMMs) [31], and conditional random fields (CRFs) [32]. For example, Makino et al. [37] construct artificial features based on speech and word forms, extract the features with an HMM, combine them, and calculate entity recognition results using an SVM. Krishnan et al. [38] use two CRFs to access local feature extraction in entity recognition and output feature information obtained by the logic forward CRF. These models overcome the defaults of the rule design. However, their performance declines when the sentence is too long due to the inability to capture more contextual information.
2.3 Deep Learning NER
Many studies on NLP underline the significance of neural network approaches in deep learning to address NER difficulties. Long short-term memory networks (LSTMs) and convolutional neural networks (CNNs) are two popular types of neural networks that have been used to achieve excellent results on NER tasks. LSTMs are more effective when dealing with data that has a temporal component, while CNNs are more suitable for data that has a spatial structure. Neural network approaches do not necessitate a manual feature extraction process. Some related work has achieved beneficial model performance gains by updating the two types of models. Luo et al. [39] developed an attention-based bidirectional LSTM with a CRF-layer (Att-BiLSTM-CRF) to train a robust model for NER issues. BiLSTM-CNN model conducted by Li et al. [40] has shown that CNN as a model component can significantly improve entity recognition accuracy. The research conducted by Devlin et al. [41] indicates that utilizing Bert as a pretraining language model can significantly enhance the performance of NER approaches. Yang et al. [42] proposed a language model xlnet based on auto-regressive pretraining, eliminating Bert’s disadvantage in ignoring location dependence. Li et al. [28] presented a novel alternative, namely W2NER, by modeling the unified NER as word-word relation classification. NER problems can be optimally solved by combining Bert, LSTM, and multiple two-dimensional extended convolutions (DConv).
Recurrent neural networks (RNNs) are suitable for processing sequential data, especially in named entity recognition issues. Some RNN-like architectures have been developed, such as LSTMs [20] and gated recurrent units (GRUs) [43]. The RNN-like neural networks are prone to the problems of gradient disappearance and gradient explosion when dealing with the NER task. In contrast, the Spiking neural P systems have inherent distributed and powerful numerical computing capabilities. The proper combination of RNN-like structures and the SNP system mechanisms are recognized as potential solutions to the NER problems in all the neural network studies reviewed here. The idea for the proposed solution comes from recognizing that current RNN-like architectures cannot explicitly identify the syntactic relationships between words in a sentence. Conversely, the SNPs can construct syntactic relationships between words in a sentence by combining the SNP mechanisms in a neural network model.
2.4 Large Language Models with NER
Introduction to Large Language Models (LLMs) in Named Entity Recognition (NER) Research. The progress of Large Language Models (LLMs) marks a pivotal moment in the field of natural language processing (NLP) [25, 26, 44,45,46,47], significantly influencing various NLP tasks. This overview distills essential insights from three key research papers focusing on the intersection of LLMs and Named Entity Recognition (NER).
Commencing our exploration with GPT-NER [44], the introduction of LLMs, especially the groundbreaking GPT model, has initiated a revolution in NLP through the paradigm of in-context learning. GPT-NER illustrates this adaptability by redefining NER as a text-generation model, achieving performance levels comparable to supervised baselines. Notably, implementing a self-verification strategy addresses inherent limitations in LLMs, marking a significant stride in enhancing the effectiveness of real-world NER applications.
Shifting focus to GPT-RE [45], the paper delves into challenges associated with Relation Extraction (RE) despite the capabilities of LLMs. It introduces nuanced in-context learning for RE, proposing innovative approaches such as task-aware retrieval and gold label-induced reasoning. GPT-RE’s state-of-the-art performance underscores the untapped potential of LLMs in tasks demanding a deep understanding of language relationships, representing a notable leap forward in leveraging LLMs for intricate linguistic tasks.
The evolutionary trajectory takes a strategic turn with UniversalNER [46], emphasizing targeted distillation for open Named Entity Recognition (NER). Acknowledging the prohibitive costs involved, the paper explores mission-focused instruction tuning to distill LLMs into cost-efficient student models. UniversalNER, trained in collaboration with ChatGPT, not only demonstrates remarkable generalizability but also surpasses the NER accuracy of ChatGPT. This approach signals the immense potential of targeted distillation in producing highly efficient models with a reduced parameter footprint.
In summary, the development of LLMs has shifted from in-context learning to addressing task-specific challenges [25, 26], particularly in the domains of NER and RE. The paradigm shift represented by targeted distillation, as exemplified by UniversalNER, provides valuable insights into the future landscape of utilizing LLMs for a myriad of applications in NLP, ranging from diverse to complex and resource-intensive scenarios.
3 Problem Formalization
Named entity recognition (NER) is a task that is performed to identify and classify named entities within the text. The NER research pertains to NLP and information retrieval (IR). This study refers notation \(\Delta \) to a set of labels such as persons, organizations, locations, products, etc. Let set \({\mathbb {S}}=\left\{ S_1,S_2,..., S_n\right\} \) denote the training set of sentences. For any element \({S_i}\in {\mathbb {S}}\), \(S_i=\left\{ x_1,x_2,...,x_h\right\} \) represents an sentence (instance) with length h, i.e., h words (tokens). Any word \(x_t\in S_i\) will be assigned a label \(\varepsilon \in \Delta \). NER systems are designed to take a text sequence \(S_i\), output a set of entities, and predict their labels. We address the NER problem by constructing a mapping model that takes a text sequence \({S_i}\in {\mathbb {S}}\) as input and predicts the labels of the resulting set of entities. As an example, when given the sentence, “John Wilson is a professor of XXX University”, a NER system based on either rule-based, machine learning, or deep learning algorithms could accurately assign the entity labels “John Wilson” (person) and “XXX University” (organization). In particular, the label for a word will be the category of the entity if that word is indeed an element of a named entity. Otherwise, this word falls outside the scope of named entities.
To be specific, we assume that the dataset \({\mathbb {S}}=\left\{ S_1,S_2,..., S_n\right\} \) has n sentences, each sentence \(S_i=\left\{ x_1,x_2,...,x_h\right\} \) has h words, and each word \(x_t=\left\{ c_{1},c_{2},...,c_{l}\right\} \) has l characters. The dataset should be processed according to Algorithm 1. The time complexity of the Algorithm 1 is \(O(h\cdot l)\), where h is the number of words in the sentence, and l is the average number of characters per word.

NER data pre-processing
4 CLSTM-SNP Model Specification
4.1 Overview
This work presents a novel neural network model, namely CLSTM-SNP, to address named entity recognition (NER) issues. The proposed model combines convolutional neural networks (CNNs) and LSTM-SNP modules to obtain improved accuracy and efficiency, allowing for syntactic and semantic information integration in the NER task. The CLSTM-SNP model is an effective sequence analysis tool consisting of two components: multi-feature embeddings and an LSTM-SNP module processor. The multi-feature embeddings provide a way to represent sequence features of characters, word semantics, and word capitalization. Some classical methods are effectively combined to extract the above three features. The CNN module is responsible for extracting character-level features of entities from the input text. The Glove [23] module provides an exceptional way to learn vector representations of the input sequence that accurately capture the semantic features of words. We assess Collobert’s [48] approach to identify word capitalization characteristics.
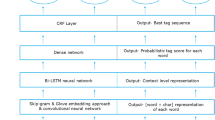
The LSTM-SNP module processor then uses this information to analyze the text sequence, fed with the text representations created by combining the embedding of the three features (character-level, word semantic, and word capitalization). The LSTM-SNP module processor allows CLSTM-SNP to be used for a variety of sequence analysis tasks, especially for NER issues. Finally, the model has produced the sequence of entity labels predicted. Figure 1 illustrates the overall structure of the CLSTM-SNP model.

Overview of the CLTSM-SNP model
4.2 Multi-feature Embeddings
In this section, the multi-feature embeddings are discussed in detail. These representations allow the encoding of multiple features in a single representation, which can be used for solving NER issues. Section 4.2.1 depicts the workflow of collecting the character-level features. Sections 4.2.2 and 4.2.3 indicate the mechanisms of word semantic features and word capitalization features, respectively.
4.2.1 Character-Level Features Embedding
The architecture of the convolutional neural networks (CNNs) developed by LeCun et al. [24] are widely recognized as one of the most influential neural network designs in deep learning. By utilizing convolutional and pooling layers, CNNs can learn the hierarchical representation of visual data, making them very suitable for image recognition and other computer vision tasks. Furthermore, CNNs have been successfully applied to natural language processing, audio processing, and other domains. The experimental setup in this paper utilizes a CNN module to extract character-level features from English text data pertaining to named entities. English words consist of very fine-grained letters with hidden features such as prefixes and suffixes. The CNN module is trained on a labeled dataset and can learn the complex relationship between the letters and the associated named entity. The extracted features are then used to classify the entity. This technique is advantageous compared to traditional methods, as it can capture the contextual information surrounding the entity, leading to improved accuracy in entity recognition. In the execution details, we set random character vectors for different characters to distinguish between characters and character types (letters, numbers, punctuation, and special symbols). For example, uppercase ‘A’ and lowercase ‘a’ correspond to two different sets of character vectors. The illustration in Fig. 2 provides an example of how the CNN module extracts the character-level features of an individual word.

Overview of the CNN module used in text data
Let \({c_k} \in {{\mathbb {R}}^d}\) be the d-dimensional character vector corresponding to the kth character in a word \(x_t\). A character vector \(c_k\) is formed by querying the character lookup table T (Collobert et al. [48]). A word of length l is represented as
where operation ‘\(\oplus \)’ indicates the concatenation. Accordingly, character vector matrix \(C_t\) (\({C_t} \in {{\mathbb {R}}^{d \times l}}\)) of the word \(x_t\) is generated, where d represents the dimension of a character vector \(c_k\) and l signifies the length of the word \(x_t\). The problem of uneven word lengths in the character vector matrix is addressed by adding extra placeholders to the left and right sides of the words in the sequence, achieving the same word length based on the longest word. In general, let \(c_{k:k+j}\) refer to the concatenation of characters \(c_k,c_{k+1},...,c_{k+j}\). The CLSTM-SNP model employs one convolutional layer to obtain character-level feature vectors in the convolutional process. The convolutional layer also helps to reduce the complexity of the model and speed up the process of feature extraction. The convolution process involves taking a filter \(w\in {{\mathbb {R}}^{d \times m}}\) and applying it to a span of m characters to generate a fresh feature. For instance, a feature \(F_k\) is generated from a window of characters \(c_{k:k+m-1}\) by
where, \(b\in {\mathbb {R}}\) is a bias term and f is a non-linear function such as the hyperbolic tangent or relu. This filter is used for each possible window of characters in the word \(\left\{ c_{1:m}, c_{2:m+1},..., c_{l-m+1:l}\right\} \) to obtain a feature map
with \({F} \in {{\mathbb {R}}^{l-m+1}}\). Afterward, we utilize the max pooling operation on the feature map and pick the maximum value \({\hat{F}} = \max \{ F\} \) as the feature linked to the particular filter. The primary goal is to acquire the most significant feature by choosing the highest value from each feature map. We describe the process of extracting one feature from a filter. The CLSTM-SNP model utilizes various filters (each with a distinct window size) to create multiple feature maps, thus allowing for a better understanding of the underlying text information.
Finally, we construct a representation of word \(x_t\) by connecting all the feature maps.
where \({\hat{F}}_{word}\) is a character-level features embedding by a convolution neural network, ‘\(\oplus \)’ is the concatenation operator, and n specifies the quantity number of filter.
The CLSTM-SNP model has incorporated the CNN module for character-level feature embedding processing. This module is based on the Keras framework of TensorFlow technology, providing an effective way to extract and encode features from characters. The specific process can be found in Algorithm 2. The time complexity of Algorithm 2 is characterized by two main components: text data initialization and iterative CNN module execution. Text data initialization is denoted as O(f(n)), where f(n) represents the complexity related to text data. The iterative execution of the CNN module, controlled by total_iterations, contributes O(g(m)), where g(m) signifies the complexity related to the CNN module, and m is associated with the input size. In summary, the overall time complexity is succinctly expressed as \(O(f(n) + total\_iterations \cdot \mathrm{{g(m))}}\), with n and m representing the scale of text data and the input size of the CNN module, respectively.

Character-Level Data Processing with CNN Module Construction
4.2.2 Word Semantic Features Embedding
Word embeddings can be employed to convey the semantic implications of words in a fashion analogous to the way humans conceptualize words. In recent years, NLP has seen significant advancements in the field of NER. Several powerful theoretical tools, such as word2vec [49, 50] and Glove [23], have been developed and widely adopted to facilitate the extraction of entities from text. These tools are designed to analyze and understand the context of words and phrases in order to identify and classify entities accurately. We conducted experiments with the CLSTM-SNP model by utilizing a set of published embeddings, specifically Stanford’s GloVe embedding, which was trained with 6 billion words from Wikipedia and Web text. By using global matrix decomposition and a local context window technique, GloVe embedding produces a vector space with a meaningful substructure and lower dimensions compared to one-hot representations with more sparse structures. The specifics and inner workings of the GloVe embedding will be discussed below.
The GloVe module primarily draws from the latent semantic analysis (LSA) approach proposed by Hofmann [51] and the word2vec technique of singular value decomposition. The LSA algorithm splits the individual elements of the term-document matrix (each one represented as a TF-IDF) to create vector representations for the terms and documents. This TF-IDF is mainly utilized to obtain the terms’ global statistical characteristics. Word2vec algorithms, first introduced by Mikolov et al. [49, 50], are used to generate vector representations of words, known as word embeddings. These algorithms can be divided into two main categories: skip-gram and continuous bag of words (CBOW) [49]. Skip-gram focuses on predicting a target word given the context words, while CBOW focuses on predicting the context words given the target word [49]. These two techniques (skip-gram, CBOW) rely on a local sliding window approach for determining the context. Word2vec algorithms are used for various NLP tasks, such as sentiment analysis and text classification.
LSA and word2vec are the representatives of two kinds of word embedding techniques. One method of matrix decomposition relies on global features, whereas the other takes into account the local context. The GloVe module merges two characteristics: the general data feature of the corpus and the nearby context feature (for instance, a sliding window) to generate semantic features. The GloVe module introduces the co-occurrence probabilities matrix. We present the co-occurrence matrix of word-word.
The quantity \(Y_{ab}\) refers to the total occurrences of word b when it is in the vicinity of word a across all corpus. Alternatively, the total number of occurrences of all words (except for a) in conjunction with word a is denoted by \({Y_a}\):
The possibility \(P_{ab}\) of word b appears in the context of word a can be calculated by:
A simple example of the co-occurrence matrix [23] is shown in Table 1. The first entry of the co-occurrence matrix is the probability of the word ‘solid’ appearing when the word ‘ice’ is present. Similarly, the probability of the word ‘gas’ appearing when ‘ice’ is present is recorded in the second entry.
The ratio of \(P_{ac}\) and \(P_{bc}\) is denoted by:
It is used to measure the relative size of the two probabilities. The ratio value displayed in the co-occurrence matrix is in accordance with the rules outlined in Table 2.
The ratio can be used to gauge the relationship between words. Thus the GloVe module takes advantage of this metric to generate vector representations of each word. When we obtained the word vectors \(w_a\), \(w_b\), and \(w_c\) of word a, b, and c, respectively, according to the work [23], the rhythm represented by the three vectors in the module GloVe through the action of a function F is consistent with the \({ratio} = \frac{{{P_{ac}}}}{{{P_{bc}}}}\). Essentially, the word vectors encapsulate the data found in the co-occurrence matrix. The anonymous function is as follows:
The ratio of \({P_{ac}}\) to \({P_{bc}}\) can be determined using the statistical analysis provided in Eq. 7, which considered the relationship of three words a, b, and c. In the GloVe module, we initially consider two words a and b. The similarity of words a and b could be captured in the subtraction of two vectors \(w_a\) and \(w_b\). The form of F can be altered to the format presented in Eq. 9.
The ratio of \(P_{ac}\) to \(P_{bc}\) is a scalar quantity, whereas the function F is a vector quantity. Hence, the inner product is naturally taken into account, and the form of F can be altered to match Eq. 10.
The GloVe module establishes a connection (Eq. 11) between the divergence on the left and the ratio on the right by employing the exp function as the F function.
If the left and right sides of the equation have the same numerators and denominators, we can theoretically find the vector representation of words. In the actual experiment, the GloVe module must ensure that the vector exchange between \({w_a}^T{w_c}\) and \({w_c}^T{w_a}\) is balanced. The cost function J is designed to optimize the word vector, as the two sides of Eq. 11 only need to be close in proximity. Further information on obtaining word vectors through optimization of a loss function can be found in the available literature [23].
4.2.3 Word Capitalization Features Embedding
The CLSTM-SNP model applies the method reported by Collobert et al. [48] to obtain the capitalization information during word embeddings. The idea behind this method is to attach a special capitalization option (numeric, allLower, allUpper, initialUpper, other, mainly_numeric, contains_digit, Padding_token) included in a lookup table C to each letter of a word during the word embedding process, indicating whether the letter is uppercase or lowercase. Each capitalization option corresponds to an index number as Table 3 presented. These indexes allow the model to learn the capitalization information for each letter during the word embedding process.
After using the lookup table C with the length \(l'\), we can obtain a capitalization features embedding \(emb\_cap\), which has dimensions of \({{\mathbb {R}}^{l' \times l'}}\). Our method unifies the embeddings of character-level features, word semantic features, and capitalization features to produce a complete representation of a word, which can effectively capture the semantic relationship between words while preserving the unique information of the three features. An example of capitalization information embeddings of a sentence can be seen in Fig. 3. All the words in the sentence “Only France and Britain backed the 199 proposal (Padding_token)” are capitalized according to specific rules. We utilize various colors for the seven distinct kinds of case categories in the diagram depicted in Fig. 3. The capitalization of each word can be maintained when performing word embeddings.

An example of capitalization information embeddings
4.3 LSTM-SNP Module Processor
In recent years, the field of NLP has benefited dramatically from the development of recurrent neural networks (RNNs). In many applications, RNNs have become the preferred model for processing sequence data and have achieved significant results in tasks such as text classification, machine translation, and speech recognition. The advantage of RNNs is that they can remember the information from previous steps in the sequence and automatically learn long-term dependencies through their recurrent structure. This allows RNNs to handle natural language data better and improve the accuracy of their predictions. However, the gradient calculation of the RNNs is limited by the length of the time sequence. When the sequence length is large, the gradient calculation will disappear or explode, resulting in the RNNs module being unable to learn correctly.
Long short-term memory networks (LSTMs), a variation of RNNs, are more successful at distinguishing between information that has been disregarded and retained than RNNs. An LSTM introduces hidden states that refer to the information stored internally by the LSTM network at the current time step. The three gates (forget gate, input gate, output gate) of an LSTM act as regulators of neural information transmission. A neuron in an SNP system characterized by spikes has an internal state and two modes of spike evolution (spike consumption and spike generation). Liu and Peng [21] introduce a parameterized nonlinear SNP system, the LSTM-SNPs, inspired by the state and mechanisms of the SNP systems and LSTMs.

Model neuron cell structure of the LSTM-SNP module
LSTM-SNPs [21] have redesigned the gate mechanisms, state equations, and input–output equations in the LSTMs by using SNP nonlinear gate functions and SNP-based membrane computation rules. Figure 4 represents the novel gate mechanisms: reset gate \(r_t\), consumption gate \(c_t\), and generation gate \(o_t\). The reset gate considers the current input, the previous state, and a bias to determine the number of the preceding state to be reset. We fed the series \(S_i=\left\{ x_1,x_2,...,x_h\right\} \) that has been processed with CNNs and word embeddings modules into the LSTM-SNP module. We have utilized the reset gate \(r_t\) in order to select the identified information within the scope of named entity recognition. The formalization of the reset gate \(r_t\) is represented as follows:
where \(x_t\) is the data input at time step t. \(u_{t-1}\) is the hidden state at time step \(t-1\). \(g_r()\) describes the inner relationship between \(x_t\) and \(u_{t-1}\) through the weight matrices to redundant information.
We rely on the consumption gate \(c_t\) to decide how much of the previous state will be consumed based on the present input, the previous state, and the bias.
where, function \(g_c()\) describes the consumption mechanism between \(x_t\) and \(u_{t-1}\) through the weight matrixes to previous information. In named entity recognition, the consumption gate \(c_t\) is employed to handle abnormal circumstances in conjunction with neurons, thereby creating new cases.
The generation gate \(o_t\) is a gating mechanism that determines the number of generated spikes to be output depending on the current input, the previous state, and the bias. The gate \(o_t\) is typically implemented as a hyperbolic tangent (tanh) function, where \(g_o(\dot{)}\) calculates and returns the relationship between \(x_t\) and \(u_{t-1}\) through the weight matrices to influence output.
Neuron \(\sigma \) generates spikes as follows:
Using the three nonlinear gates and the spikes they produced, the state and output of neuron \(\sigma \) at time t can be determined as follows:
where ‘\( \odot \)’ denotes the inner product of two vectors. The quantity \(h_t\) represents the output of either an LSTM-SNP module or an LSTM-SNP layer belonging to a combined model, representing the contextual information of an NLP task.
The diagram shown in Fig. 4 and the formulas for LSTM-SNPs describe the activity of individual neurons. Numerous LSTM-SNP neurons are connected together to form an LSTM-SNP neural network module, allowing for complex calculations to be performed. The overall flow of the CLSTM-SNP model can be seen in Algorithm 3. The time complexity of the CLSTM-SNP model construction algorithm is characterized by two main components: text data initialization (O(f(n))), where f(n) eflects the complexity related to text data, and the construction of the CNN module, involving various layers and parameters. The overall time complexity is expressed as \(O(f(n) + L \cdot h + l \cdot h + k \cdot f \cdot h + L \cdot h + h + total\_iterations \cdot g(m))\), where n is the scale of text data, h is the number of words, l is the average characters per word, L is the sentence length, and m is linked to the input size of the CNN module.

CLSTM-SNP Model Construction
5 Experiment Analysis
5.1 Datasets
This study preferred two classical NER datasets CoNLL-2003Footnote 2 and OntoNotes 5.0Footnote 3 to evaluate the performance of the proposed model CLTSM-SNP. All the datasets are publicly available online. These datasets have been extensively used in the field of NER and thus offer an appropriate evaluation setting for the proposed model. The details of the datasets are represented as follows.
-
CoNLL-2003 [52]: The dataset was designed for the CoNLL-2003 shared task, focusing on language-independent named entity recognition. This newswire corpus is composed of data that has been labeled with four distinct categories: location, organization, person, and miscellaneous. Since the data was limited, we performed hyperparameter optimization on the development set and then trained the model using both the training and development sets.
-
OntoNotes 5.0 [53]: The dataset is established for the CoNLL-2012 shared task and describes a standard train/dev/test split. We followed the example of Durrett and Klein [54] and applied our model to the part of the dataset which had been given named entity annotations of the highest quality. A portion of the New Testament was excluded due to the lack of gold-standard annotations. This dataset contains more information than CoNLL-2003 and text from various sources, including broadcast conversations, news, newswires, magazines, telephone conversations, and web posts.
The statistics of two datasets can be visualized in Table 4. It includes the total number (All) of sentences, the average sentence length (Avg.Len), and the setting of the training (Train), development (Dev), and test (Test) sets. This table reveals that the dataset OntoNotes 5.0 has more sentences and a slightly longer average sentence length than the dataset CoNLL-2003. This comparison highlights the differences between the two datasets and provides valuable insight into their respective structures. Table 5 provides an illustration of the entities contained in the CoNLL-2003 dataset. There are four distinct groups: location, organization, person, and miscellaneous. We take the first sentence “The television also said Netanyahu had sent messages to reassure Syria via Cairo, the United States and Moscow.” as an illustration, which contains four location entities that are described as City or Country. We utilized the CoNLL-2003 dataset in our experiments to demonstrate the validity of the CLSTM-SNP model.
5.2 Performance Metrics
This study thoroughly assessed the CLSTM-SNP model and LSTM-SNP module for addressing NER challenges, using standard metrics like precision, recall, and macro F1. The results suggest that both models hold promise as valuable tools for Natural Language Processing applications. Test samples are classified into actual and predicted entities.
The calculations of precision (P), recall (R), F1-score (F1), and accuracy (Acc) are represented as follows.
Precision gauges the ratio of true positives to all positive predictions, while recall gauges the ratio of true positives to all actual positive cases. F1-score signifies the model’s equilibrium between precision and recall. Accuracy quantifies the proportion of correct predictions among all predictions. These metrics offer a holistic view of the model’s performance.
NER problem is a typical multi-classification task. Therefore, we also utilize macro F1 as a measure of our performance, which is determined by the harmonic mean of precision and recall:
Macro F1 provides a more informative measure of the model’s performance than accuracy, as it considers false positives and false negatives. This metric is especially valuable in addressing imbalanced datasets, revealing the model’s capacity to accurately identify both majority and minority classes.
5.3 Parameter Configuration
In our experiments, we utilized the CLSTM-SNP model to analyze the NER issue. We were pleased with the results of our implementation and are confident that this model will continue to be a valuable asset for our research. Parameter configuration is a critical component of any learning model. Proper configuration of the parameters can have a significant impact on the performance of the model. The information regarding the LSTM-SNP module hyperparameters can be found in Table 6. The kernel size, filter, etc., specified in Table 7 are also hyperparameters utilized by the convolutional neural network module.
CLSTM-SNP is effective if certain parameters are specified, such as the word embedding size, iteration count, dropout rate, CNN module hyperparameters, the number of neurons in the LSTM-SNP module, and the length of the sentence, which needs to be learned. The experimental result of parameter configuration is evaluated based on the evaluation script for the Conference on Computional Natural Language Learning (CoNLL) 2003 shared task [52].
5.3.1 Hyperparameter Settings for Word Embeddings
We first use the data set CoNLL-2003 as an example to illustrate the hyperparameter configuration and the evaluation process. The parameter setup for OntoNotes 5.0 follows a similar approach to that of CoNLL-2003. We provide a range of optimal parameters. The capability of GloVe word vectors to extract various features has been demonstrated by many studies and downstream applications. It has been pre-trained to generate a multi-dimensional (50, 100, 200, or 300 dimensions) model in response to different requirements. In the group using CoNLL-2003, we set the number of iterations as 80, dropout as 0.5, the number of LSTM-SNP neurons as 256, sentence length as 60, kernel size as 3, filter as 20, and strides as 1. All trial runs are conducted using the hyperparameters mentioned above. In our model, we keep the others the same when we change one variable. A Glove module with a x billion-scale corpus and y dimensions can be labeled as the form Glove.xb.yd. The CLSTM-SNP model was tested on the GloVe.6B.50d, GloVe.6B.100d, and GloVe.6B.200d models, and the respective macro F1 scores achieved were 86.23 \(\%\), 88.2\(\%\), and 88.36\(\%\), respectively. Experimental results have shown that the macro F1 scores of the 100 and 200-dimensional models exceed that of the 50-dimensional model. We decide to use GloVe.6B.100d as the word embeddings for the CLSTM-SNP model because the 100 and 200-dimensional models produce similar macro F1 scores, and the 100-dimensional model has a faster computing speed and utilizes fewer computing resources. The experimental results are recorded in Table 8, and the visualization of the results is shown in Fig. 5.

Performance details of precision, recall, and macro F1 about GloVe embeddings dimensions
5.3.2 Hyperparameter Settings for Iterations, Dropout, and Sentence Length
A CLSTM-SNP model is developed based on the dataset to determine the iterations, dropout, and sentence length hyperparameters. We set dataset CoNLL-2003 as an instance and employ the technique of controlling variables too. This approach enables us to consider the impact of variables that are not the main focus of our inquiry but may still have an effect on the outcomes. Adjusting our research parameters will give us a more accurate understanding of the outcomes and give us a clearer picture of the results. The analysis above has determined that the word embeddings of GloVe.6B.100d is applied. The testing results can be seen in the diagram shown in Fig. 6. We will provide an in-depth analysis of how three hyperparameters affect the entire model below.
-
Hyperparameter setting for iterations
We evaluated the performance of the CLSTM-SNP model for various iterations settings, including 60, 70, 80, 85, 90, etc. Through a comparative analysis of the results, we were able to gain insights into how varying iteration settings affect the performance of the model. The results from the experiment are portrayed in Table 9 and Fig. 6a, which exhibit the scores of four entity types (Location, Miscellaneous, Organization, and Person) as well as the overall entity classifications.
The overall macro F1 remains relatively unchanged when the number of iterations is between 60 and 70, with a value of 87\(\%\). The macro F1 score increased to 88.21\(\%\) when 80 iterations were set. However, the macro F1 is progressively reduced as the number of iterations increases. When the number of iterations reaches 80 and 90, the performance of the CLSTM-SNP model is roughly the same. We carefully evaluated the computing resources available. We chose 80 iterations based on this assessment. This decision was made in order to ensure that we could complete our task in a reasonable amount of time while still achieving the desired results.
-
Hyperparameter setting for dropout
We are assessing the performance (macro F1) of the CLSTM-SNP model under varying dropout settings and analyzing the results. We consider the performance of the CLSTM-SNP model with different dropout settings. Five macro F1 results are presented in Table 10 and Fig. 6b while considering the dropout rates 0, 0.15, 0.4, 0.6, and 0.65, respectively. The overall macro F1 reaches 88.83\(\%\) when dropout is set to 0.15, which is 0.72 \(\%\) higher than the macro F1 scores without dropout. The CLTM-SNP model’s performance is significantly weaker when the dropout rate is 0.4, 0.6, and 0.65, respectively. After considering the above data, we have determined that a dropout value of 0.15 is the most advantageous.
-
Hyperparameter setting for sentence length
The sentence length of an input to a convolutional neural network or padding algorithm is an important hyperparameter that directly influences the model’s accuracy and the training process’s speed. Furthermore, it plays a significant role in the success of the application of the algorithm. If the sentence length is inadequate, the model may struggle to identify the key characteristics of the data that are necessary to make reliable predictions. Alternatively, if the sentence is excessively lengthy, the model may become overwhelmed with too much information, thus causing a decrease in macro F1 scores. We analyze the impacts of sentence length on macro F1 scores by five categories near the mean, which are 50, 52, 53, 60, and 67. From the experimental results, changing the input length of sentences has little effect on the model’s overall performance. The overall macro F1 reaching a peak of 89.2 \(\%\) at length 53 is the most successful. Hence, we set the sentence length as 53. The details can be seen in Table 11 and Fig. 6c.

The influence of iterations, dropout and sentence length on the CLSTM-SNP model is reflected by macro F1
5.3.3 Hyperparameter Settings for LSTM-SNP Neurons
The number of neurons in the LSTM-SNP module put forward by Liu et al. [21] corresponds to the time step used for processing time problems. LSTM-SNP neurons can recognize and process long-term dependencies between adjacent and nonadjacent words, allowing for a more accurate determination of entity boundaries. We evaluate the influence of the number of LSTM-SNP neurons on the CLSTM-SNP model by utilizing five distinct parameter configurations 50, 200, 256, 275, and 300. We selected three sets of data that seemed to show distinct variances and presented them in Table 12 and Fig. 7, as suggested by the experimental results. The macro F1 of the overall entities is 87.83 \(\%\) when the number of LSTM-SNP neurons is set to 50. We decided to use 256 LSTM-SNP neurons due to the impressive macro F1 score of 88.80 \(\%\), which is the highest among the three groups.

The influence of the number of LSTM-SNP neurons on the CLSTM-SNP model
5.3.4 Hyperparameter Settings for CNN Module
The one-dimensional convolution layer Conv1D is added to the CLSTM-SNP model. The convolution core has a width of 1 when it is used to process sequential sequence data in one-dimensional convolution. The size of the Conv1D convolution layer is determined by the hyperparameter kernel size. We changed the value of the kernel size by 2 each time we experimented. The data from the experiment reveals that the model with a kernel size of 3 yields the best performance. The filter is the size of the kernel, which is also the same as the output dimension of the CNN module.
The filter is an integral component of the kernel, which is the primary unit of the CNN module. The filter determines the output dimension of the CNN module, thereby influencing the model’s performance and accuracy. By adjusting the filter’s size, the model can be tailored to provide the most accurate and reliable results. We establish the influence on the CLSTM-SNP model by adjusting the number of filters to 15, 20, 53, and 60, respectively, when the shape of the kernel remains constant. Using Table 13 and Fig. 8 as our parameter selection guide, we pick a kernel size of 3 and filter of 53, resulting in a macro F1 score of 88.80\(\%\).

Influence of CNN module parameters kernel size and filter on CLTM-SNP model
5.4 Experimental Results and Discussion
The data presented in Table 14 and Fig. 9 reveals the performance of the proposed CLSTM-SNP model in recognizing named entities. The results demonstrate the effectiveness of the model, providing further evidence of its potential to become a general model of the underlying natural language processing model. The FFNN model proposed by Collobert et al. [48] is taken as a baseline for comparison. The results shown in Table 14 suggest that although FFNN does well on the CoNLL-2003 dataset, it is unsuitable for OntoNotes 5.0, which has seven different domains. Our CLTM-SNP model outperformed the FFNN baseline model, achieving a macro F1 score of 89.2 \(\%\) on the CoNLL-2003 dataset. Moreover, the CLSTM-SNP model has a macro F1 score of 9.11 \(\%\) higher than the model proposed by Li and Du et al. [29] on CoNLL-2003, which uses active learning to address the NER problem.
The CoNLL-2003 English corpus generally performs better than the OntoNotes 5.0 dataset in sequence-to-sequence models due to the four types of named entities in CoNLL-2003 and the eighteen fine-grained named entity categories in OntoNotes 5.0. Similar performance differences can be found in the case system proposed by Chiu and Nichols [55] and Strubell et al. [56]. The CLSTM-SNP model demonstrated an impressive macro F1 score of 75.5 \(\%\) when evaluated on OntoNotes 5.0. The CLSTM-SNP model yielded a less satisfactory outcome than the models listed in Table 14. The CLSTM-SNP model’s macro F1 score decreased by 13.7\(\%\) when tested on the OntoNotes 5.0 dataset, demonstrating its sensitivity to a variety of domains and entity types compared to the CoNLL-2003 dataset.
In contrast to the prevailing approach of employing large language models for named entity recognition, the performance of CLSTM-SNP seems to be suboptimal across both datasets. This discrepancy may be attributed to the inherent advantages of large language models. These models, through extensive training on vast datasets and parameters, attain a profound and comprehensive understanding of language, showcasing robust generality and adaptability.
The CLSTM-SNP model excels in resource efficiency, surpassing GPT-3 and LLaMA in key aspects in Table 15. With a compact size of 13.52M, it ensures efficient storage and optimized memory utilization, crucial for overall performance enhancement. The pre-training data scale, ranging from 20,000 to 80,000 tokens, is notably lighter than GPT-3’s 300 billion tokens and LLaMA’s 14 trillion tokens, streamlining the model architecture and reducing reliance on extensive datasets. In terms of hardware, CLSTM-SNP’s practical advantage lies in requiring only a 12 g 2080ti GPU, compared to LLaMA’s need for a more specialized and expensive 2048 80 G A100, making it a cost-effective option. Additionally, CLSTM-SNP’s training time, ranging from 0.5 to 3 h, significantly outpaces LLaMA’s 21 days, emphasizing its efficiency and responsiveness to applications with time constraints. In summary, CLSTM-SNP’s resource-efficient profile makes it an optimal choice for applications constrained by considerations of model size, data scale, and training time.
The objective of evaluating the performance of the CLSTM-SNP model against other existing models (Collobert et al. [48], Chiu and Nichols [55], and Li and Du et al. [29]) is not to demonstrate that CLSTM-SNP is superior to the already prominent neural-like models, but to suggest that CLSTM-SNP can be employed in named entity recognition with satisfactory performance when compared to these other neural-like computing models. The findings of this study may lead to potential uses or ideas to address real-world issues in certain circumstances through SNP systems or in collaboration with other models.
5.4.1 Influence of the LSTM-SNP Module
Relevant ablation experiments have been conducted with the same parameter settings to understand each component’s impact on the overall performance of the CLSTM-SNP model. The results of these experiments are used to inform design decisions and further improve the system. The settings of the particular parameter can be viewed in Table 16. The LSTM-SNP worked well in the CoNLL-2003 dataset when performing NER tasks, which achieved a macro F1 score of 71\(\%\). The unsatisfactory performance of LSTM-SNP in the OntoNotes 5.0 dataset indicates that the model is quite sensitive to multiple domain knowledge.
The LSTM-SNP model has demonstrated its efficacy in performing named entity recognition tasks with fewer classifications through its performance on the two datasets. The LSTM-SNP module is essential for extracting word relationships. The component of the CLSTM-SNP model plays the most significant role in achieving a high macro F1 score when performing NER.
5.4.2 Influence of the Word Embeddings
Word embeddings are an important component of the CLSTM-SNP model, allowing the model to capture semantic meaning from text and better understand the context of words. All indicators are significantly improved at data set CoNLL-2003 When the 100-dimensional GloVe word vectors are added to the LSTM-SNP model, with 13.2 \(\%\) increase in accuracy, 14.1 \(\%\) increase in recall, and 13.9 \(\%\) increase in macro F1. The OntoNotes 5.0 dataset shows similarly improved performance, with a 39.2 \(\%\) rise in precision, 30.3 \(\%\) increase in recall, and 34.5 \(\%\) enhancement in macro F1. This experiment demonstrates the GloVe word vector’s capability to improve the CLTSM-SNP model’s performance.
5.4.3 Influence of the CNN Module and the Capitalization Features
Convolutional neural networks are commonly employed to identify character-level characteristics in identifying named entities. The impact of GloVe embeddings on the overall model is relatively small. The recall of the CLSTM-SNP model on the CoNLL-2003 dataset increased by 7.5 \(\%\), and its macro F1 score rose by 3.9 \(\%\) following the incorporation of the CNN module. In the data set OntoNotes 5.0, the precision decreased by 4.9 \(\%\), and the recall and macro F1 increased by 6.8 \(\%\) and 1.2 \(\%\) separately. In general, the addition of the CNN module plays a positive role in the whole model, especially in the dataset with fewer entity categories to be identified.
We assess the influence of incorporating capital information features into the CLSTM-SNP model by comparing CLSTM-SNP with a combination of LSTM-SNP, GloVe embeddings, and CNN modules. It has been discovered that the inclusion of capital information features did not have a visible effect, and the macro F1 of the two data sets was enhanced by approximately 0.4 \(\%\) or 0.5 \(\%\).

Precision, recall, and macro F1 of CLSTM-SNP with different feature sets
6 Conclusion and Future work
This paper presents a CLSTM-SNP model (a variant of LSTM-SNPs), which is a combination of LSTM-SNPs, GloVe word vectors, and convolutional neural networks. The CLSTM-SNP model and its LSTM-SNP module demonstrate remarkable feature extraction abilities and offer a promising solution for dealing with sequential text, for example, in named entity recognition tasks. The CLTSM-SNP model achieved the macro F1 score of 89.2 \(\%\) in CoNLL-2003 and 75.5 \(\%\) in OntoNotes 5.0, signifying the first successful attempt to tackle the named entity recognition problem in the field of SNP systems. The CLSTM-SNP model offers a potential solution to the issue of sparse NER data through the application of membrane computing.
In contrast, the LSTM-SNP module is the initial effort to combine long short-term memory networks with the SNP system through deep learning. The research work using the LSTM-SNP model to tackle some practical problems is relatively lacking. Therefore, we assess the effectiveness of the LSTM-SNP module and enhance its feature representation capacity through GloVe and CNN modules when performing the NER task. The experimental results indicate that LSTM-SNP acts great application potential in named entity tasks based on delicate data preprocessing.
In this paper, we have employed the CLSTM-SNP model and the LSTM-SNP module to resolve the issue of NER, thereby broadening the application of SNP systems to address practical problems. The conversion of a unidirectional LSTM-SNP module in the CLSTM-SNP model to a bidirectional LSTM-SNP could result in improved performance since adjacent words could be captured both forward and backward. Exploring ways to effectively utilize CLSTM-SNP and other SNP models to address NLP issues, such as text sentiment classification, is a highly sought-after area of research.
References
Păun G (2000) Computing with membranes. J Comput Syst Sci 61(1):108–143
Bagchi S (2012) Self-adaptive and reconfigurable distributed computing systems. Appl Soft Comput 12(9):3023–3033
Bernardini F, Gheorghe M (2005) Cell communication in tissue p systems: universality results. Soft Comput 9(9):640–649
Krishna SN (2007) Universality results for p systems based on brane calculi operations. Theor Comput Sci 371(1–2):83–105
Manca V, Bianco L (2008) Biological networks in metabolic p systems. Biosystems 91(3):489–498
Frisco P, Gheorghe M, Perez-Jimenez MJ (2013) Applications of membrane computing in systems and synthetic biology. Emerg Complex Comput 7(09):624
Graciani C (2005) Applications of membrane computing. Theor Comput Sci 287(1):73–100
Wang X, Zhang G, Gou X, Paul P, Neri F, Rong H, Yang Q, Zhang H (2021) Multi-behaviors coordination controller design with enzymatic numerical p systems for robots. Integrat Comput-Aid Eng 28(2):119–140
Li B, Peng H, Wang J (2021) A novel fusion method based on dynamic threshold neural p systems and nonsubsampled contourlet transform for multi-modality medical images. Signal Process 178:107793
Wang T, Zhang G, Zhao J, He Z, Wang J, Pérez-Jiménez MJ (2014) Fault diagnosis of electric power systems based on fuzzy reasoning spiking neural p systems. IEEE Trans Power Syst 30(3):1182–1194
Zhu M, Yang Q, Dong J, Zhang G, Gou X, Rong H, Paul P, Neri F (2021) An adaptive optimization spiking neural p system for binary problems. Int J Neural Syst 31(01):2050054
Wu T, Pan L, Yu Q, Tan KC (2020) Numerical spiking neural p systems. IEEE Trans Neural Netw Learn Syst 32(6):2443–2457
Song T, Pan L, Wu T, Zheng P, Wong MD, Rodríguez-Patón A (2019) Spiking neural p systems with learning functions. IEEE Trans Nanobiosci 18(2):176–190
Song X, Valencia-Cabrera L, Peng H, Wang J, Pérez-Jiménez MJ (2021) Spiking neural p systems with delay on synapses. Int J Neural Syst 31(01):2050042
Peng H, Wang J, Pérez-Jiménez MJ, Riscos-Núñez A (2019) Dynamic threshold neural p systems. Knowl-Based Syst 163:875–884
Peng H, Wang J (2018) Coupled neural p systems. IEEE Trans Neural Netw Learn Syst 30(6):1672–1682
Peng H, Li B, Wang J, Song X, Wang T, Valencia-Cabrera L, Pérez-Hurtado I, Riscos-Núñez A, Pérez-Jiménez MJ (2020) Spiking neural p systems with inhibitory rules. Knowl-Based Syst 188:105064
Wu T, Bîlbîe F-D, Păun A, Pan L, Neri F (2018) Simplified and yet turing universal spiking neural p systems with communication on request. Int J Neural Syst 28(08):1850013
Peng H, Lv Z, Li B, Luo X, Wang J, Song X, Wang T, Pérez-Jiménez MJ, Riscos-Núñez A (2020) Nonlinear spiking neural p systems. Int J Neural Syst 30(10):2050008
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780
Liu Q, Long L, Yang Q, Peng H, Wang J, Luo X (2022) Lstm-snp: a long short-term memory model inspired from spiking neural p systems. Knowl-Based Syst 235:107656
Ma F, Chitta R, Zhou J, You Q, Sun T, Gao J (2017) Dipole: Diagnosis prediction in healthcare via attention-based bidirectional recurrent neural networks. In: Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp 1903–1911
Pennington J, Socher R, Manning CD (2014) Glove: Global vectors for word representation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp 1532–1543
LeCun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324
Kojima T, Gu SS, Reid M, Matsuo Y, Iwasawa Y (2022) Large language models are zero-shot reasoners. arXiv:2205.11916
Zhang S, Roller S, Goyal N, Artetxe M, Chen M, Chen S, Dewan C, Diab M, Li X, Lin XV, et al (2022) Opt: Open pre-trained transformer language models. arXiv:2205.01068
Vilar D, Freitag M, Cherry C, Luo J, Ratnakar V, Foster G (2022) Prompting palm for translation: Assessing strategies and performance. arXiv:2211.09102
Li J, Fei H, Liu J, Wu S, Zhang M, Teng C, Ji D, Li F (2022) Unified named entity recognition as word-word relation classification. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol 36, pp 10965–10973
Li W, Du Y, Li X, Chen X, Xie C, Li H, Li X (2022) Ud_bbc: Named entity recognition in social network combined bert-bilstm-crf with active learning. Eng Appl Artif Intell 116:105460
Cao P, Chen Y, Kang L, Zhao J, Liu S (2018) Adversarial transfer learning for chinese named entity recognition with self-attention mechanism. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing
Lai J, Qiang L, Yi L (2010) Web information extraction based on hidden Markov model. In: International Conference on Computer Supported Cooperative Work in Design
Lafferty J, Mccallum A, Pereira F (2002) Conditional random fields: Probabilistic models for segmenting and labeling sequence data. proceedings of icml
Etzioni O, Cafarella M, Downey D, Popescu A-M, Shaked T, Soderland S, Weld DS, Yates A (2005) Unsupervised named-entity extraction from the web: an experimental study. Artif Intell 165(1):91–134
Wang Z, Li J, Wang Z, Li S, Li M, Zhang D, Shi Y, Liu Y, Zhang P, Tang J (2013) Xlore: a large-scale English-Chinese bilingual knowledge graph. In: ISWC (Posters & Demos), pp 121–124
Ratnaparkhi A (2002) A maximum entropy model for part-of-speech tagging
Ekbal A, Bandyopadhyay S (2010) Named entity recognition using support vector machine: a language independent approach. Int J Comput Syst Eng 2:155
Makino T, Ohta Y, Tsujii J, et al (2002) Tuning support vector machines for biomedical named entity recognition. In: Proceedings of the ACL-02 Workshop on Natural Language Processing in the Biomedical Domain, pp 1–8
Krishnan V, Manning CD (2006) An effective two-stage model for exploiting non-local dependencies in named entity recognition. In: Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, pp 1121–1128
Luo L, Yang Z, Yang P, Zhang Y, Wang L, Lin H, Wang J (2018) An attention-based bilstm-crf approach to document-level chemical named entity recognition. Bioinformatics 34(8):1381–1388
Li L, Guo Y (2018) Biomedical named entity recognition with cnn-blstm-crf. J Chin Inform Process 32(1):116–122
Devlin J, Chang M-W, Lee K, Toutanova K (2018) Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805
Yang Z, Dai Z, Yang Y, Carbonell J, Salakhutdinov RR, Le QV (2019) Xlnet: Generalized autoregressive pretraining for language understanding. Advances in neural information processing systems, 32
Dey R, Salem FM (2017) Gate-variants of gated recurrent unit (gru) neural networks. In: 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS). IEEE, pp 1597–1600
Wang S, Sun X, Li X, Ouyang R, Wu F, Zhang T, Li J, Wang G (2023) Gpt-ner: Named entity recognition via large language models. arXiv:2304.10428
Wan Z, Cheng F, Mao Z, Liu Q, Song H, Li J, Kurohashi S (2023) Gpt-re: In-context learning for relation extraction using large language models. arXiv:2305.02105
Zhou W, Zhang S, Gu Y, Chen M, Poon H (2023) Universalner: Targeted distillation from large language models for open named entity recognition. arXiv:2308.03279
Li J, Zhang Z, Zhao H (2022) Self-prompting large language models for open-domain qa. arXiv:2212.08635
Collobert R, Weston J, Bottou L, Karlen M, Kavukcuoglu K, Kuksa P (2011) Natural language processing (almost) from scratch. Journal of machine learning research 12(ARTICLE), 2493–2537
Mikolov T, Chen K, Corrado G, Dean J (2013) Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781
Mikolov T, Sutskever I, Chen K, Corrado GS, Dean J (2013) Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems, 26
Hofmann T (1999) Probabilistic latent semantic indexing. In: Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 50–57
Sang EF, De Meulder F (2003) Introduction to the conll-2003 shared task: Language-independent named entity recognition. arXiv preprint cs/0306050
Pradhan S, Moschitti A, Xue N, Ng HT, Björkelund A, Uryupina O, Zhang Y, Zhong Z (2013) Towards robust linguistic analysis using ontonotes. In: Proceedings of the Seventeenth Conference on Computational Natural Language Learning, pp. 143–152
Durrett G, Klein D (2014) A joint model for entity analysis: Coreference, typing, and linking. Transactions of the association for computational linguistics 2:477–490
Chiu JP, Nichols E (2016) Named entity recognition with bidirectional lstm-cnns. Transactions of the association for computational linguistics 4:357–370
Strubell E, Verga P, Belanger D, McCallum A (2017) Fast and accurate entity recognition with iterated dilated convolutions. arXiv preprint arXiv:1702.02098
Fisher J, Vlachos A (2019) Merge and label: A novel neural network architecture for nested ner. arXiv preprint arXiv:1907.00464
Brown T, Mann B, Ryder N, Subbiah M, Kaplan J, Dhariwal P, Neelakantan A, Shyam P, Sastry G, Askell A, et al (2020) Language models are few-shot learners.[cs]. In: Proceedings Of
Touvron H, Lavril T, Izacard G, Martinet X, Lachaux M-A, Lacroix T, Rozière B, Goyal N, Hambro E, Azhar F, et al (2023) Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971
Acknowledgements
The authors would like to express their sincere thanks to the Editor and anonymous reviewers for their helpful comments and suggestions. This work was supported in part by the Science and Technology Program of Sichuan Province (no. 2023YFS0424); in part by the Yibin Science and Technology Program (No. 2023SF004); in part by the National Natural Science Foundation (Nos. 61902324, 11426179, and 61872298).
Author information
Authors and Affiliations
Contributions
QD, Conceptualization; QD and ZYY, Data curation; QD, Formal analysis; XLC and YJD, Funding acquisition; QD, Investigation; XLC, Methodology; XLC, Project administration; XYL, Resources; QD, Software; XLC, Supervision; XYL, Validation; QD, Visualization; QD/Writing—original draft; XLC/Writing—review and editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Deng, Q., Chen, X., Yang, Z. et al. CLSTM-SNP: Convolutional Neural Network to Enhance Spiking Neural P Systems for Named Entity Recognition Based on Long Short-Term Memory Network. Neural Process Lett 56, 109 (2024). https://doi.org/10.1007/s11063-024-11576-2
Accepted:
Published:
DOI: https://doi.org/10.1007/s11063-024-11576-2