
Abstract
This abstract proposes an algorithm for human head detection in elevator cabins that addresses the challenges of improving detection accuracy, reducing detection speed, and decreasing the number of parameters. The algorithm is based on GhostNet-SSD and includes several improvements, such as an efficient coordinate attention mechanism to replace the Squeeze-and-Excitation attention mechanism, optimization of auxiliary convolutional layer with large parameter weight, and adjustment of anchor ratio based on the statistical results of human head labeling frame. In addition, data normalization and convolutional fusion methods are used for inference acceleration. The algorithm was tested on JETSON XAVIER NX development board and achieved a new state-of-the-art 97.91% AP at 61FPS, outperforming other detectors with similar inference speed. The effectiveness of each component was validated through careful experimentation.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Real-time object detection is a fundamental task in computer vision that involves identifying and localizing objects of interest within an image or video. It is a crucial area of study in computer vision as it is an essential component in many computer vision systems. It has a wide range of applications, such as autonomous driving [1, 2], robotics [3, 4], and video surveillance [5]. One important subtype of object detection is head detection, which focuses on detecting human heads in images or videos.
Head detection plays a crucial role in various applications, especially in video surveillance where it can provide essential information for tracking and recognizing individuals. In scenarios such as elevator cabins where occlusions between individuals are common, head detection becomes even more critical. It has become increasingly important for crowd counting [6], lift scheduling [7], lift safety [8, 9], maintenance, and repair. Effective head detection can significantly improve lift scheduling efficiency, prevent safety incidents, and provide a solid foundation for crowd management.
However, head detection is a challenging task due to the complexity and variability of the human head's appearance and shape, as well as the presence of occlusions and varying lighting conditions.
Therefore, developing effective and efficient head detection methods is an active area of research in computer vision, with many approaches proposed in recent years.
The Improvements of SSD model has been extensively explored in research scholars, resulting in the development of lightweight versions of the network specifically designed for object detection on low-power devices, such as CPUs. Although researchers have studied SSD optimization for optimal performance on embedded devices, most of the work has focused on optimizing the backbone network by incorporating lighter backbone networks such as MobileNet, ShuffleNet, or GhostNet.
But there exists a strong need for further optimization of the SSD model, specifically in (1) improving the SSD structure to enhance its lightweight capabilities, (2) enhancing detection accuracy through attention mechanisms and other approaches, and (3) selecting optimal anchor ratios for generating higher quality anchor boxes.
In this paper, we aim to optimize GhostNet-SSD [10] for head detection tasks (1) an analysis of the parameters and computational complexity of each layer in the network model is conducted. The auxiliary convolutional layer with a high parameter weight is then optimized to reduce the overall computational cost of the network; (2) An efficient coordinated attention(ECoA) mechanism is proposed that combines the advantages of both the coordinate attention mechanism and the efficient channel attention mechanism, in order to enhance the region of interest using fewer parameters and computational resources; (3) Incorporating the statistical results of the human head labeling frame, the anchor ratio is adjusted, taking into consideration the concentrated characteristics of the human head's width-to-height ratio; (4) An approach for inference acceleration is proposed to improve the inference speed, which is achieved through the use of data normalization and convolutional fusion methods.
The remainder of this paper is organized as follows.The previous research related to head detection is summarized in the related work section. The shortcomings of GhostNet-SSD and the improvements made to it are outlined in the Methods section. Details on the dataset and experiments are provided in the experiment and results section, and the effectiveness of the optimized algorithm for head detection is demonstrated from multiple perspectives. The experimental results are summarized and future work is suggested in the conclusion section.
2 Related Work
The past decade has witnessed significant advancements and remarkable achievements in the field of computer vision across diverse domains. Computer vision, as a subfield of artificial intelligence and computer science, is dedicated to empowering machines with the ability to interpret and comprehend visual information from the world, akin to human perception. In this review, we conduct a comprehensive examination of pertinent literature related to generic object detection, and head detection.
2.1 Object Detection
Object detection is a crucial element in computer vision with far-reaching importance. It allows computers to understand image and video content [11], aiding in autonomous driving [12, 13], robot navigation [14], security [15], and more. It's used in medical image analysis, retail for product recognition, and in agriculture and environmental monitoring. Additionally, it plays a role in biometrics for identity verification and document analysis. In essence, object detection enhances efficiency, security, and innovation across various domains, making it an essential aspect of computer vision.
2.2 Head Detection
Head detection constitutes a subtype of object detection, specifically designed for the localization of human heads within an image. Head detection has a broad range of applications across different domains. It is commonly used in video surveillance [16] and security systems to identify potential threats and intruders. In large public events, it assists in crowd management [17, 18] by counting people and analyzing crowd density. Head detection is also vital for intelligent transportation systems, enhancing road safety by detecting pedestrians [19, 20] and cyclists. In the medical field, it supports the analysis of medical images like CT scans and MRIs by locating patients' heads. Additionally, head detection plays a crucial role in virtual reality and augmented reality applications, allowing for head tracking. It is utilized in video games [21], social media for photo tagging, education for monitoring student engagement, and computer-human interaction through gesture and gaze tracking. In summary, head detection is a versatile technology with applications in security, healthcare, entertainment, and various other domains.
Various neural network techniques have been proposed in recent years to tackle the problem of head detection. For instance, Jiang et al. [22] presented TEDNet, which achieved promising results in crowd detection through multi-path coding. Zhang et al. [23] improved the accuracy of the DLA-34 network to 91% with a speed of 61.5 FPS on the SCUT-HEAD dataset. Weijun et al. [24] proposed MKYOLOv3-tiny, which uses multi-scale fusion of low-level head features and achieved better results on the Brainwash dense head detection dataset. In addition, Pengju et al. [25] improved the accuracy of head detection by 4% through anchor clustering based on FaceBoxes.
However, existing head detection algorithms also encounter challenges. On one hand, some high-performance detectors can achieve extremely accurate results, but they are often too computationally expensive and resource-intensive for practical applications. On the other hand, some lightweight detectors are more feasible to deploy, but they may struggle to achieve high levels of precision in detection.
3 Methodology
3.1 Disadvantages of GhostNet-SSD
GhostNet [26] is a lightweight convolutional neural network constructed by stacking Ghost Bottlenecks, which are comprised of Ghost modules. Compared to other lightweight network models, such as the MobileNet family [27, 28] and the ShuffleNet family [29, 30], GhostNet has been shown to exhibit higher accuracy and is capable of characterizing more features with fewer calculations. Ghost modules and Ghost Bottlenecks are structured as shown in Figs. 1 and 2, respectively.

The Ghost module

Ghost bottleneck. Left: Ghost bottleneck with stride = 1; right: Ghost bottleneck with stride = 2. The first Ghost module needs to perform dimensionality expansion, so its output channel is the expansion size. The second Ghost module is designed to reduce the number of channels back to the input channel size, in order to match the shortcut branch
While the Squeeze-and-Excitation attention mechanism (SE) module in GhostNet performs well for classification tasks, it only focuses on re-weighting each channel by assigning significance, and ignores location information, which is crucial for constructing spatially selective attention maps. Additionally, the SE module increases the total number of parameters and computing effort of the network. Although the fully connected layer used in GhostNet is not more computationally costly than the convolutional layer, the number of parameters also grows significantly.
Numerous researchers have developed lighter networks to replace the SSD backbone, in order to improve the performance of SSD networks and minimize the number of network parameters. GhostNet has been used to replace the SSD backbone to enhance network performance. However, the auxiliary convolutional layer in the SSD structure still requires a significant number of parameters and processing resources.
3.2 SSD Architecture Optimization
Compared with the original SSD, GhostNet-SSD achieves significant improvements in both speed and accuracy. However, in practical applications, there still exist problems with large model parameters and suboptimal detection speed. To investigate the reasons for the slow parameter detection and large number of model parameters, this paper statistically analyzes the main parameters (Params) and multiply-accumulate operations (MAdd) of the GhostNet-SSD model using a model analysis tool. The analysis results are presented in Fig. 3.

Analysis of parameter and computational complexity in GhostNet-SSD network. The parameter and computational complexity are mainly concentrated in the auxiliary convolutional layers
Based on the successful experience of SqueezeNext, which employs deep convolution and point-by-point convolution to reduce the number of parameters and computations, this paper replaces the original convolution in the auxiliary convolution layer with deep convolution and point-by-point convolution, resulting in the architecture shown in Fig. 4.

Schematic comparison of the new Auxiliary Layer (a) to the old Auxiliary Layer (b)
The network was analyzed using the model analysis tool before and after optimization, and the results are presented in Table 1.
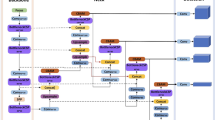
This study utilizes Optimized GhostNet-SSD, with 300 × 300 RGB images as direct input. The original SE attention mechanism is replaced with the ECoA module, and a new auxiliary convolution layer is introduced to replace the original one. Table 2 shows the network parameters, and Fig. 5 shows the optimized network structure.

Network architecture
3.3 Attention Mechanism Optimization
The attention mechanism, which focuses on the most salient parts of an image and disregards the unimportant parts, has been widely used in various computer vision tasks, including image classification, object detection, and pose estimation, and has shown remarkable success [31,32,33,34,35,36,37,38]. However, current attention mechanisms employed in lightweight networks mainly rely on the channel attention (SE) mechanism [39], which compresses each 2D feature map to build interdependencies across channels. Although many networks, such as GhostNet, have used SE modules to enhance model recognition ability, SE does not consider the value of location information, leading to suboptimal performance in downstream visual tasks.
To address this issue, Hou et al. proposed a coordinate attention (CA) mechanism [40] that incorporates positional information into channel attention to accurately locate target objects. The structure of the CA mechanism is illustrated in Fig. 6a. While both CA and SE mechanisms compress the number of channels to lower model complexity, this method cannot directly describe the relationship between the weight vector and input characteristics, which may impact the output quality. To overcome this limitation, Wang et al. introduced the efficient channel attention (ECA) method [41], which analyzes the direct interaction between each channel and its k nearest neighbors instead of performing dimensionality reduction. The structure of the ECA mechanism is illustrated in Fig. 6b. The ECA method allows for the precise selection of relevant features by incorporating global information into the feature maps. In addition, it introduces a negligible number of parameters and computation, making it an efficient and effective method for enhancing the performance of lightweight models.

Schematic comparison of the coordinate attention block (a) to efficient channel attention block (b)
To further improve the detection performance of the GhostNet-SSD model, this paper proposes an improved attention mechanism that combines the ECA and CA mechanisms. The proposed mechanism is called the efficient coordinate attention (ECoA) mechanism, which first employs the CA method to compress feature maps and then applies the ECA mechanism to selectively emphasize the most informative positions in the compressed feature maps. Experimental results demonstrate that the proposed ECoA mechanism improves the detection performance of the GhostNet-SSD model while maintaining its efficiency and lightweight design. The structure of the ECoA mechanism is illustrated in Fig. 7.

efficient coordinate attention block
The ECoA mechanism works as follows: Firstly, each channel is encoded horizontally and vertically by a 2D Pool and the output is stitched into a 2D tensor with height \({\text{C}}\) and width (\(W + H\)). Then, the convolution is performed using the convolution kernel of the \(1 \times k\) channels so that each channel interacts directly with its k neighboring channels, and finally, the resulting tensor is split into two separate tensors to produce an attention vector with the same number of channels, acting on the horizontal and vertical coordinates of the input X. i.e.
where \(GAP^{h}\) and \(GAP^{w}\) represent the average pooling in the vertical and horizontal directions, and the convolution kernel size may be chosen adaptively by
where \(\gamma\) and \(b\) are hyperparameters, denotes the odd number to which \(\left| x \right|_{odd}\) and \(x\) are closest.
3.4 Anchor Scale Optimization
Traditional SSD networks employ anchors with varying aspect ratios to effectively detect objects of different sizes. However, for head detection tasks, which are essentially single-target detection tasks, the original anchor point settings are meaningless. To validate this claim, a dataset of 10,000 images was randomly sampled, with 70,219 head detection frames manually labeled, and the aspect ratios of the labeled frames were analyzed to visualize the anchor ratio in the original SSD with the labeled frames. The original anchor and labeled frame visualization results were then compared. The statistical analysis revealed that the distribution of human head-labeled boxes closely resembled a normal distribution with μ = 1.03 and σ = 0.201. As a result, the anchor ratios were adjusted to 0.6, 0.8, 1, 1.2, and 1.4 based on the distribution of the human head label box (Figs. 8, 9 and 10).

The resulting visualization of the original anchors and labeled boxes. The scatter is mostly concentrated around y = x, with little scatter on the other scale. This showed the original anchor gauge is not properly set

Histogram of the proportional distribution of human head width and height labeling. The distribution of the human head-labeled boxes is close to a normal distribution with μ = 1.03 and σ = 0.201

Improved Anchor with annotation box visualization results graph. Improved Anchor is more reasonable compared to the original Anchor settings
3.5 Reasoning Acceleration
When utilizing deep learning for image classification or target detection, data pretreatment of the image is required. Firstly, and the typical way is image normalization, and the operation of normalizing the image not only takes a longer time but also requires more CPU resources. In order to tackle this challenge, this research provides a way to merge the data normalization procedure with convolution. The image normalization formula and the convolution formula can be expressed as follows.
Fusing Eq 7 with Eq 8 yields the following,
\(X_{std}\) is the feature map data after normalizing the training data, \(value_{mean}\) and \(value_{std}\) denote the mean value and the standard deviation, \(Y\) indicates the feature map data output from the convolution layer, \(W\) and \(B\) express the weight parameter and the bias parameter corresponding to the convolution layer, and \(X\) stand for the feature map data input from the convolution layer. Equation 10 is obtained by decomposing and combining Eq. 9.
where, \(\frac{W}{{value_{std} }}\) and \(- W * \frac{{value_{mean} }}{{value_{std} }}\) indicate the fused weight parameter and the intermediate matrix. The global average pooling of the intermediate matrix and the initial bias parameters are added together to obtain the bias parameters after fusion. The fused weights \(W_{merged}\) and bias parameters \(B_{merged}\) can be expressed as
The new model is created by fusing the parameters of the data normalization with those of the convolutional layer, and the new model does not require further data normalization of the input picture data in the inference process, therefore it is faster and less CPU-intensive than the original model. After extensive experiments, the operation of merging normalization into convolution does not affect the detection accuracy while enhancing the network inference time.
4 Experiments and Results
4.1 Dataset
The dataset used in this paper consists of the SCUT-HEAD [42], CrowdHuman [43], and Self-picked elevator headcount datasets. SCUT-HEAD dataset consists of two parts, Part A contains 2000 images taken from surveillance videos of university auditoriums and annotated with 67,321 avatars. Part B contains 2405 images extracted from the Internet and annotated with 43,930 avatars. CrowdHuman dataset with a total of 470,000 human instances from the training and validation subsets, 22.6 persons per image, with various types of occlusions in the dataset. Self-picked elevator headcount dataset, 25,268 elevator car head images are labeled and marked, with homemade samples from different cities, different buildings and different elevator cars, with a total of 96,735 head frames marked.
4.2 Evaluation Metrics
For target detection tasks, traditional evaluation metrics include precision, recall and average precision (mAP); Since the human head detection task is a single target detection task, this paper selects the Precision (P) with IoU at 0.5, Speed, main parameters (Params) and multiply-accumulate operations (MAdd) for the evaluation of the model. Precision (P) can be expressed as follows:
where TP, FP denote true positive and false positive.
4.3 Implementation Details
The environment configuration of our work is based on the Caffe framework and CUDA 8.0 and CUDNN 7.0. The models are trained on NVIDIA RTX 3080 (10GB) and Intel(R) Core (TM) i5-10600KF CPU. In the training phase, we employ the SGD optimizer with an initial learning rate of 0.01 with the weight decay as 5E−3. Furthermore, we use three warm-up epochs with a momentum of 0.8. Each experiment is trained for 200 epochs with a batch size of 32. The algorithm in this paper prefers practical application scenarios such as elevator car environments, so the procedure is modified so that each batch (32) contains at least six random samples from the homemade sample set, thus increasing the weight contribution of real environment data to the whole network and enhancing the robustness of the model. Different loss ratios are used at different stages of the network training process. At the early stage of training, the network focuses more on the detection task and uses a ratio of 100:1 to set the detection loss and regression loss; after the detection accuracy leveled off, the loss was adjusted to 1:500; after the regression loss dropped to about 0.005, the ratio was adjusted to 50:1 to improve the detection accuracy.
4.4 Comparative Results with Other Models
In this subsection, we compare the performance of the proposed model with the other seven state-of-the-art models used for head detection. The seven models, namely the baseline from GhostNet-SSD, MobileNet V3_Small-SSD, MobileNet V3_Large-SSD, YOLOv5-N(r6.1), YOLO-X-S [44] and YOLOv7-tiny-SiLU [45]; The comparison results are shown in Table 3.
The comparative results demonstrate that the proposed model achieves the best performance in terms of Params, MAdd, P and is only slightly inferior to YOLOv7-tiny-SiLU in terms of speed. Compared with the baseline model, the proposed model increases the Params, MAdd, P and Speed by 53.59%, 37.31%, 3.54% and 90.62%, respectively, which is a qualitative leap. The smaller amount of computation makes this network require less computing power, which enables it to be deployed to edge devices with insufficient computing power and enables the network to move better to applications.
4.5 Ablation Study
To demonstrate the effectiveness of the proposed modifi-cations based on GhostNet-SSD, in this subsection we perform the ablation studies on ECoA, New Auxiliary Layer, New anchor and reasoning acceleration on the dataset with GhostNet-SSD as a baseline. Precision and FPS are used as evaluation metrics. The experiment results are summarized in Table 4.
ECoA block By replacing the original SE attention block of GhostNet-SSD with ECoA attention, not only increased the accuracy of GhostNet-SSD by 2.7 percentage points but also increased the speed by 15.62%. This indicates that the ECoA block may be able to better extract features and focus on useful information.
New Auxiliary Layer Replacing the original auxiliary convolutional layer with an optimized auxiliary convolutional layer, resulting in a speedup of 56.25%, although with a 0.17 percentage point reduction. The results indicate that using New Auxiliary Layer is more likely to be applied in practice and deployed on relevant equipment.
New anchor Anchor's adjustment Improved by 1.31 percentage points, speed by 18.75%, It can make bounding boxes regress better and obtain higher quality anchors.
Acceleration The combination of convolution and normalization improves the speed by 6.25% without loss of accuracy. The results show that using this approach allows our network to be better deployed on devices with low computing power.
4.6 Effect of Sigma (σ) on Anchor Scale
In our anchor scale parameterization, denoted as sigma, which quantifies the degree of discreteness in anchor scales, we assess its impact on anchor scale selection. We validate the effectiveness of our parameter settings by training and testing the model on the dataset with different sigma values, specifically, 0.1, 0.2, 0.5, 1.0, and 1.5. The results are presented in the Table 5.
From σ value 0.1 to 0.5, there is a significant improvement in precision (P), increasing from 91.27 to 95.86%. This suggests that excessively low discreteness leads to inference boxes that are too small to capture some larger objects. Between σ values of 0.5 and 1.0, precision (P) remains relatively stable, fluctuating between 95.86% and 95.83%. This indicates that within this range, the choice of σ value has minimal impact on precision. From σ value 1.0 to 1.5, precision (P) declines, decreasing from 95.83 to 91.41%. Excessive discreteness, although capable of covering larger objects, may result in smaller objects being encompassed within other inference boxes. With an increase in σ value, inference speed (FPS) gradually decreases. It drops from 40 FPS at σ value 0.1 to 30 FPS at σ value 1.5. This is because larger σ values typically require more computational resources, thereby reducing inference speed. Overall, a σ value of 0.5 provides relatively high precision (95.86%) while maintaining reasonable speed (35 FPS).
4.7 Migration Verification
For deploying model-embedded devices, this paper chose the JETSON XAVIER NX from NVIDIA, which is a good small AI computer that offers strong performance at an affordable price. It runs multiple neural networks in parallel, can process data from multiple high-resolution sensors at the same time, and also provides powerful hardware codecs. The program was deployed to the JETSON XAVIER NX development board and tested using 4 RTSP video streams in H264 as the input source of the program. The running results are shown in Fig. 11.

Running results. The left side shows the detection results of 4 RTSP video streams, the upper right part shows the GPU usage, and the lower right part shows the rate of each detection. It can be seen that the inference speed of the network model can reach 16 FPS on average in the case of 4 video streams, which can meet the requirements of real-time detection
5 Conclusion
In this paper, based on the requirements of high accuracy and speed of modern industrial detection, a head detection algorithm based on a strengthened coordinate attention mechanism is proposed in the Caffe framework which is both fast and lightweight, for solving the problems of difficult deployment and slow recognition of head detection models in elevator cabs. The model has an excellent performance in terms of parameters, FLOPs, MAdd and model size. And the model performs well on embedded devices with limited computational resources, with fast inference and actual detection Precision of 97.91%. The average inference speed can reach 16FPS under the simultaneous processing of 4 RTSP video streams, which meets the head detection requirements in elevator cabs. However, there are still some false detections for heads generated by elevator billboards and mirror reflections, and further optimization of the algorithm is needed in the next work to reduce the occurrence of false detections caused by environmental factors. In the subsequent research work, we will further improve the operation efficiency of the algorithm and the recognition accuracy of difficult samples.
Data Availability
Data will be made available upon reasonable request to the first author and subject to copyright permissions (email: houhongtao@ mail.gufe.edu.cn).
References
Feng D, Haase-Schütz C, Rosenbaum L et al (2020) Deep multi-modal object detection and semantic segmentation for autonomous driving: datasets, methods, and challenges. IEEE Trans Intell Transp Syst 22(3):1341–1360
Li B, Ouyang W, Sheng L et al (2019) Gs3d: an efficient 3d object detection framework for autonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 1019–1028
Karaoguz H, Jensfelt P (2019) Object detection approach for robot grasp detection. In: 2019 International conference on robotics and automation (ICRA). IEEE, pp 4953–4959
Paul SK (2020) Object detection and pose estimation from rgb and depth data for real-time, adaptive robotic grasping. University of Nevada, Reno, p 1
Chen J, Li K, Deng Q et al (2019) Distributed deep learning model for intelligent video surveillance systems with edge computing. IEEE Trans Ind Inform, 1
Zhao J, Yan G (2019) Passenger flow monitoring of elevator video based on computer vision. In: 2019 Chinese control and decision conference (CCDC), pp 2089–2094
Beamurgia M, Basagoiti R, Rodríguez I et al (2022) Improving waiting time and energy consumption performance of a bi-objective genetic algorithm embedded in an elevator group control system through passenger flow estimation. Soft Comput 26(24):13673–13692
Lan S, Gao Y, Jiang S (2021) Computer vision for system protection of elevators. In: Journal of Physics: Conference Series, pp 012156
Liu P, Wang C (2021) Statistical analysis of elevator failures and safety. In: International conference on intelligent equipment and special robots (ICIESR 2021), pp 706–710
Liu J, Cong W, Li H (2020) Vehicle detection method based on GhostNet-SSD. In: 2020 International conference on virtual reality and intelligent systems (ICVRIS), pp 200–203
Peng S, Genova K, Jiang C et al (2023) Openscene: 3d scene understanding with open vocabularies. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 815–824
Alaba SY, Ball JE (2022) A survey on deep-learning-based lidar 3d object detection for autonomous driving. Sensors 22(24):9577
Wang K, Zhou T, Li X et al (2022) Performance and challenges of 3D object detection methods in complex scenes for autonomous driving. IEEE Trans Intell Veh 8(2):1699–1716
Astua C, Barber R, Crespo J et al (2014) Object detection techniques applied on mobile robot semantic navigation. Sensors 14(4):6734–6757
Cheng L, Ji Y, Li C et al (2022) Improved SSD network for fast concealed object detection and recognition in passive terahertz security images. Sci Rep 12(1):12082
Tomar A, Kumar S, Pant B (2022) Crowd analysis in video surveillance: a review. In: 2022 International conference on decision aid sciences and applications (DASA). IEEE, pp 162–168
Castellano G, Mencar C, Sette G et al (2022) Crowd flow detection from drones with fully convolutional networks and clustering. In: 2022 International joint conference on neural networks (IJCNN). IEEE, pp 1–8
Teoh SK, Yap V, Nisar H (2023) Computer vision and machine learning approaches on crowd density estimation: a review. In: AIP conference proceedings, vol 2654, no 1. AIP Publishing
Qi Z, Zhou M, Zhu G et al (2022) Multiple pedestrian tracking in dense crowds combined with head tracking. Appl Sci 13(1):440
Li F, Li X, Liu Q et al (2022) Occlusion handling and multi-scale pedestrian detection based on deep learning: a review. IEEE Access 10:19937–19957
Matviienko A, Lehé M, Heller F et al (2023) QuantiBike: quantifying perceived cyclists' safety via head movements in virtual reality and outdoors. In: Proceedings of the 2023 ACM symposium on spatial user interaction, pp 1–12
Jiang X, Xiao Z, Zhang B et al (2019) Crowd counting and density estimation by trellis encoder-decoder networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 6133–6142
Zhang Y, Zhou D, Chen S et al (2016) Single-image crowd counting via multi-column convolutional neural network. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 589–597
Weijun G, Yang S, Jie Y (2020) An improved lightweight head detection method. Comput Eng Appl, 1–9
Pengju Z, Peimin Y, Qiuyu Z (2021) Head detection algorithm based on improved FaceBoxes. Microelectron Comput 38(1):33–37
Han K, Wang Y, Tian Q et al (2020) Ghostnet: more features from cheap operations. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 1580–1589
Howard A, Sandler M, Chu G et al (2019) Searching for mobilenetv3. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 1314–1324
Sandler M, Howard A, Zhu M et al (2018) Mobilenetv2: inverted residuals and linear bottlenecks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4510–4520
Ma N, Zhang X, Zheng H-T et al (2018) Shufflenet v2: practical guidelines for efficient CNN architecture design. In: Proceedings of the European conference on computer vision (ECCV), pp 116–131
Zhang X, Zhou X, Lin M et al (2018) Shufflenet: an extremely efficient convolutional neural network for mobile devices. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 6848–6856
Yang X (2020) An overview of the attention mechanisms in computer vision. In: Journal of Physics: Conference Series, pp 012173
Guo M-H, Xu T-X, Liu J-J et al (2022) Attention mechanisms in computer vision: a survey. Comput Vis Media, 1–38
Gao Z, Xie J, Wang Q et al (2019) Global second-order pooling convolutional networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 3024–3033
Cheng S, Wang L, Du A (2021) Asymmetric coordinate attention spectral-spatial feature fusion network for hyperspectral image classification. Sci Rep 11(1):1–17
Qin Z, Zhang P, Wu F et al (2021) Fcanet: frequency channel attention networks. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 783–792
Dai J, Qi H, Xiong Y et al (2017) Deformable convolutional networks. In: Proceedings of the IEEE international conference on computer vision, pp 764–773
Carion N, Massa F, Synnaeve G et al (2020) End-to-end object detection with transformers. In: European conference on computer vision, pp 213–229
Chu X, Yang W, Ouyang W et al (2017) Multi-context attention for human pose estimation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1831–1840
Hu J, Shen L, Sun G (2018) Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 7132–7141
Hou Q, Zhou D, Feng J (2021) Coordinate attention for efficient mobile network design. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 13713–13722
Wang Q, Wu B, Zhu P et al (2020) Supplementary material for ‘ECA-Net: efficient channel attention for deep convolutional neural networks. In: Proceedings of the 2020 IEEE/CVF conference on computer vision and pattern recognition, IEEE, Seattle, WA, USA, pp 13–19
Peng D, Sun Z, Chen Z et al (2018) Detecting heads using feature refine net and cascaded multi-scale architecture. In: 2018 24th International conference on pattern recognition (ICPR), pp 2528–2533
Shao S, Zhao Z, Li B et al (2018) Crowdhuman: A benchmark for detecting human in a crowd. arXiv preprint arXiv:1805.00123
Ge Z, Liu S, Wang F et al (2021) Yolox: exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430
Wang C-Y, Bochkovskiy A, Liao H-YM (2022) YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv preprint arXiv:2207.02696
Funding
This research is supported by National Natural Science Foundation of China (No. 11664005); Science Research Project for students of Guizhou University of Finance and Economics (No. 2021ZXSY113); Innovative exploration and academic seedling project of Guizhou University of Finance and Economics (No. 2022XSXMB03); Doctoral research initiation project of ShunDe Polytechnic (No:KYQD019).
Author information
Authors and Affiliations
Contributions
HH was mainly responsible for the design of the work, MG was mainly responsible for data collection, WW was mainly responsible for drafting the paper, KL was mainly responsible for making important changes to the paper, and ZL was mainly responsible for approving the final version of the paper.
Corresponding authors
Ethics declarations
Conflict of interest
The author(s) declare(s) that there is no conflict of interest regarding the publication of this paper.
Ethical Approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hou, H., Guo, M., Wang, W. et al. Improved Lightweight Head Detection Based on GhostNet-SSD. Neural Process Lett 56, 126 (2024). https://doi.org/10.1007/s11063-024-11563-7
Accepted:
Published:
DOI: https://doi.org/10.1007/s11063-024-11563-7