
Abstract
Generalized Zero-Shot Learning (GZSL) learns from only labeled seen classes during training but discriminates both seen and unseen classes during testing. In GZSL tasks, most of the existing methods commonly utilize visual and semantic features for training. Due to the lack of visual features for unseen classes, recent works generate real-like visual features by using semantic features. However, the synthesized features in the original feature space lack discriminative information. It is important that the synthesized visual features should be similar to the ones in the same class, but different from the other classes. One way to solve this problem is to introduce the embedding space after generating visual features. Following this situation, the embedded features from the embedding space can be inconsistent with the original semantic features. For another way, some recent methods constrain the representation by reconstructing the semantic features using the original visual features and the synthesized visual features. In this paper, we propose a hybrid GZSL model, named feature Contrastive optimization for GZSL (Co-GZSL), to reconstruct the semantic features from the embedded features, which ensures that the embedded features are close to the original semantic features indirectly by comparing reconstructed semantic features with original semantic features. In addition, to settle the problem that the synthesized features lack discrimination and semantic consistency, we introduce a Feature Contrastive Optimization Module (FCOM) and jointly utilize contrastive and semantic cycle-consistency losses in the FCOM to strengthen the intra-class compactness and the inter-class separability and to encourage the model to generate semantically consistent and discriminative visual features. By combining the generative module, the embedding module, and the FCOM, we achieve Co-GZSL. We evaluate the proposed Co-GZSL model on four benchmarks, and the experimental results indicate that our model is superior over current methods. Code is available at: https://github.com/zhanzhuxi/Co-GZSL.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Image classification has achieved great success by taking the advantage of deep learning, but its great performance is based on massive labeled samples from seen classes for training. However, realistic samples usually follow the long-tailed distribution, where a small number of classes possess abundant training samples, while the great majority of the other classes only possess a few or no training samples available. When we classify those classes with few or no training samples, conventional methods are no longer applicable. A feasible solution to the above problem is provided by Zero-Shot Learning (ZSL) for classifying unseen classes by using seen classes. In conventional ZSL tasks, there is no class intersection between the training set and test set, which leads to the application of these tasks being unsuitable for practice. Instead, our work focuses on Generalized Zero-Shot Learning (GZSL) that includes not only unseen classes but also partially seen classes in the test set, which is more suitable for real-world scenarios.
At present, there are mainly two categories available for ZSL methods. The first one is based on the spatial embedding [2, 21, 25], which usually maps visual or semantic features as embedded features to learn projection functions by using deep-learning networks, such as the Semantic AutoEncoder (SAE) [21]. However, these methods tend to recognize unseen classes as seen classes in the context of lacking training samples on unseen classes in GZSL tasks, which results in low accuracy during testing. Therefore, recent works propose generative-based models, such as the Generative Dual Adversarial Network (GDAN) [16], the GZSL via Synthesized Examples (SE-GZSL) [32], Inference guided Feature Generation (Inf-FG) [13], Cross-Modal ConsistencyGAN (CMC-GAN) [38], a Generative Adversarial Network (GAN) named f-CLSWGAN [36], center-VAE with discriminative and semantic-relevant fine-tuning features for generalized zero-shot learning (CvDSF) [40], and Dual-Focus Transfer Network (DFTN) [17], to synthesize the sufficient number of samples for the unseen classes. Semantic features are usually mapped as synthesized visual features in generative models to tackle the problem that the unseen classes lack enough training samples. On the basis of the Variational Auto-Encoder [20] (VAE) and GAN [8], numerous generative models are designed recently, such as the Leveraging invariant side GAN (LisGAN) [23], a Multi-modal reconstruction Variational Autoencoder (GAN-MVAE) [28], and Cross-Modal Propagation Network (CMPN) [31]. Specially, DAA-GZSL builds a semantic generator leveraging a pre-trained semantic mapper to augment category semantics. Utilizing these augmented category semantics for visual feature generation enhances the compatibility of the generated visual features with the distribution of real features. Benefiting from the generative-based methods, the GZSL task is transferred into traditional supervised learning. In this paper, we choose the GAN as a basic skeleton to generate synthesized visual features for unseen classes.
However, the synthesized features in the original feature space lack discriminative information and are sub-optimal for the subsequent GZSL classification. The Simple framework for Contrastive Learning of visual Representations (SimCLR) [4] maps the visual features extracted by the feature extractor into the latent space via a non-linear projection, where the contrastive loss is utilized to maximize agreement among different augmented views of the same example. SimCLR significantly improves the learned representations. The CE-GZSL [12] and SCE-GZSL [14] combine the generation model with the embedding model as a hybrid model, performing the constraint operations in the embedding space, as shown in Fig. 1a. However, considering that imposing too many constraints directly on the embedded features in the embedding space may be overly restrictive. It could also lead to a situation where the learned features diverge from the original semantic features. Therefore, we decide not to directly intervene too much in learning of the embedded features. CE-GZSL demonstrates that the semantic space may not be the optimal choice for embedding. Therefore, we train the classifier in the embedding space for offering more representative features. But the difference lies in the operation that we reconstruct semantic features from embedded features, rather than concatenating together, to not directly intervene too much in the training of the embedded features. Although CE-GZSL compares the embedding features with the semantic descriptor for class-level contrastive embedding, the instance-level contrastive embedded features utilize no semantic descriptor for following operation. We assume it is significant for instance-level contrastive embedded features to be close to the original semantic features. Therefore, we reconstruct semantic features with the embedded features at the instance level.

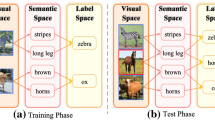
Comparison between previous methods and our Co-GZSL. a, b present existing methods, and c presents our proposed Co-GZSL. a Some of recent methods improves the learned representations in the embedding space, b some reconstruct the original semantic feature a to the reconstructed semantic feature \(\hat{a}\) by using the original visual features and the synthesized visual features. Different from these existing methods, our method Co-GZSL generates the reconstructed semantic feature \(\hat{a}\) in the embedding space, which extracts the advantages of above two types of methods
Due to the semantic bias between seen and unseen classes, the visual features experience quality deviation when transferred to GZSL Tasks, which leads to low recognition performance. Therefore, some works try to reconstruct the semantic features with the original visual features and the synthesized visual features, as shown in Fig. 1b, such as FREE [3]. Specially, a recent method TF-VAEGAN [26] rebuilds the semantic features with a cycle-consistency loss for generating semantically consistent features from the generator. Moreover, a Salient Attributes Learning Network (SALN) [39] produces distinctive and meaningful semantic representations, which is achieved under the guidance of visual features supervision. However, these methods perform the reconstruction operation in the original feature space, where discriminative information is lacking. In this paper, we utilize the hybrid model and reconstruct semantic features in the embedding space, as shown in Fig. 1c, which extracts the advantages of above two methods. We reconstruct the semantic features by utilizing the embedded features and indirectly perform subsequent constraint operations for the reconstructed semantic features. Therefore, the problem of inconsistency between the embedded features and the original semantic features can be solved.
Specifically, we introduce a hybrid GZSL model, named feature Contrastive optimization for GZSL (Co-GZSL), which combines the generative method with the embedding method. The proposed Co-GZSL maps the real samples and the synthesized samples to an embedding space, where GZSL classification is performed. In order to optimize the visual features, we propose the Feature Contrastive Optimization Module (FCOM) for strengthening the intra-class compactness and the inter-class separability with the contrastive loss and encouraging the model to generate more semantically consistent and discriminative visual features. Within this module, the embedded features from the embedding space are mapped as the reconstructed semantic features. In general, the proposed model reconstructs the semantic features by using the embedded features, similar to the Sandwich Theorem, optimizing the embedded features by squeezing from two sides of the original semantic features and the reconstructed semantic features.
Our contributions lie in three parts: (1) We propose a hybrid GZSL model, named Co-GZSL, which combines a Feature-Generating Module (FGM), an Embedding Module (EmM), and an FCOM. (2) We enhance the correlations between the original semantic features and the synthesized visual features, and strengthen the intra-class compactness and the inter-class separability by reconstructing the semantic features from the embedded features in FCOM, which ends up semantically consistent and discriminative visual features. (3) We perform extensive experiments that provide superior performance over current methods on four benchmark datasets.
2 Methods
2.1 Problem Definition
We denote the seen class as \({\mathcal {C}}^s\) and the unseen class as \({\mathcal {C}}^u\), respectively. Noted that \({\mathcal {C}}^{s} \cap {\mathcal {C}}^{u}=\phi \). \({\mathcal {D}}_{tr}=\bigcup _{i=1}^{M}\left( x_{i}, c_{i}\right) \) represents the training set with M samples from seen classes, where \(x_i\) represents one single sample and \(c_i\) represents its corresponding class label. Meanwhile, \({\mathcal {D}}_{t e}=\bigcup _{i=1}^{N} x_{i}\) are N samples that are unlabeled and provided for testing. In conventional ZSL tasks, \({\mathcal {D}}_{te}\) only consists of unseen classes. Nevertheless, in GZSL tasks, \({\mathcal {D}}_{te}\) comes from both seen and unseen classes. Each class, whether it is a seen or unseen class, has its corresponding semantic feature \(a_i\in {\mathcal {A}}\), where \({\mathcal {A}}=\bigcup _{i=1}^{{\mathcal {C}}^s+{\mathcal {C}}^{u}} a_{i}\). The GZSL tasks aim to learn a map \(\psi _{GZSL}:X\rightarrow {\mathcal {C}}^s \cup {\mathcal {C}}^{u}\).

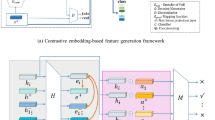
Overview of Co-GZSL. It contains a Feature-Generating Module (FGM), an Embedding Module (EmM), and a Feature Contrastive Optimization Module (FCOM). There are two networks in FGM including a generator network G and a discriminator network D. First, the Gaussian noise \(\epsilon \) and semantic features a are concatenated into the generator network G to produce synthesized visual features \(x^+\). Then, real visual features x and synthesized visual features \(x^+\) are transformed into the real embedded features h and synthesized embedded features \(h^+\) at the embedding module, respectively. FCOM is trained to synthesize semantic features \(\hat{a}\). In FCOM, the semantic cycle-consistency loss \({\mathcal {L}}_{cyc}\) is used to ensure that the reconstructed semantic vectors \(\hat{a}\) are close to the original real semantic features and enhance the semantic relevance, while the contrastive loss \({\mathcal {L}}_{con}\) is utilized to constrain the reconstructed semantic features so as to indirectly optimize the embedded features and encourage the intra-class compactness and the inter-class separability. Finally, the real embedded features h and synthesized embedded features \(h^+\) are used for training a softmax classifier CLS
2.2 Co-GZSL
As shown in Fig. 2, our model Co-GZSL contains three modules, including an FGM, an EmM, and an FCOM. FGM combines the generator network G with the discriminator network D for synthesizing visual features by concatenating the original semantic features a with the Gaussian noise \(\epsilon \sim {\mathcal {N}}(0, 1)\). Real visual features x and synthesized visual features \(x^+\) are transformed into the embedded features h and \(h^+\) at the embedding module, respectively. FCOM is trained to synthesize semantic features \(\hat{a}\) by utilizing the embedded features in the new embedding space. The above modules are jointly trained for semantically consistent and discriminative visual features by adopting the semantic cycle-consistency loss \({\mathcal {L}}_{cyc}\) and the contrastive loss \({\mathcal {L}}_{con}\). Finally, we utilize the embedded features to train a softmax classifier CLS for classification tasks. During the training stage, we train the classifier CLS by optimizing the FGM, EmM, and FCOM modules. During the test stage, we utilize the trained CLS to classify unseen classes and seen classes, in which embedded features are mapped with synthesized visual features generated by the G.
2.2.1 Feature Generation Module
As mentioned in Sect. 1, some feature generative methods [16, 32, 36] have been proposed to compensate for those missing visual features from semantic features on unseen classes. Likewise, FGM is conditioned on semantic features. As shown in Fig. 2, the Gaussian noise \(\epsilon \) and real semantic features a are concatenated into the conditional generator network G to generate synthesized visual features \(x^+\). Meanwhile, the visual features, whether they are real or synthesized, are concatenated with their corresponding semantic features. Then, the joint feature pairs (x, a) and \((x^+, a)\) are sent into the discriminator D, which is trained to differentiate synthesized features from real features. G learns together with D.
In this module, the generator G seeks to generate visual features that are hardly distinguished by the discriminator D so that the synthesized visual features own the same distributions as the original visual features. Due to the instability of the original GAN, the gradient vanishing problem and the gradient exploding problem are common issues that can occur during training. Instead, we adopt the improved Wasserstein GAN [9] as the base backbone to address these issues. The FGM can be optimized by:
where x is the original feature, \(x^{+}=G\left( \epsilon , a\right) \) represents the synthesized visual features generated by the generator G, and \(\epsilon \sim {\mathcal {N}}(0, 1)\) is the Gaussian noise. \(\tilde{x}=\eta x+(1-\eta )x^{+}\), and \(\eta \sim U(0, 1)\). \(\rho \) is the gradient penalty, and \(\mathbb {E}\) denotes the expected value. With respect to D, we minimize the \(\mathcal L_{WGAN}\). And for G, we maximize the \(\mathbb {E}[D(x^{+}, a)]\).
2.2.2 Feature Embedding and Contrastive Optimization Module
All visual features, whether real or synthesized, are mapped into the embedding space at EmM. After mapping into the embedding space, real embedded features h and synthesized embedded features \(h^+\) are transferred by two FC layers into a vector that has a dimension that is twice of a. Then, the Gaussian distribution is introduced to generate the synthesized semantic features \(\hat{a}\) by using the re-parameterization trick [20]. The hidden vector that is the output from the second FC layer is divided into two parts and used as the input for the re-parameterization trick to get the reconstructed semantic features. The hidden vector plays the role of messenger that conveys the information of the synthesized features for the process of reconstruction. The final reconstructed semantic features \(\hat{a}\) is computed as:
where \(\mathbf {\mu }\) and \(\mathbf {\sigma }\) are from two parts of the hidden vector that is twice the dimensions of a, and \(\epsilon \) is generated by the standard normal distribution. \(FC_2(\cdot )\) denotes the hidden vector output by the second full connected layer. \(\mathbf {\mu }\) and \(\mathbf {\sigma }\) are generated after dividing the hidden vector into two parts. Finally, FCOM achieves the reconstructed semantic features \(\hat{a}\) that have the same dimensions as a. In this module, the semantic cycle-consistency loss \({\mathcal {L}}_{cyc}\) is utilized to reduce the differences between the synthesized semantic vectors \(\hat{a}\) and the original real semantic features a. We develop the semantic cycle-consistency loss function by adopting L1-loss that is defined as:
where \(\hat{a}_{real}\) is the semantic features reconstructed from the embedded features h, and \(\hat{a}_{syn}\) is the semantic features reconstructed from the embedded features \(h^+\). Meanwhile, \(\hat{a}=\hat{a}_{real} \cup \hat{a}_{syn}\).
Under the inspiration of contrastive learning, we utilize the contrastive loss function to strengthen the intra-class compactness and the inter-class separability. We select a positive sample and K negative samples to contrast with the anchor sample. The anchor sample and a selected sample are paired together to form a sample pair. Positive sample pairs are formed from samples belonging to the same class, while negative sample pairs are formed from samples belonging to different classes. We aim to define the objectives to strengthen intra-class compactness and inter-class separability of the paired samples. However, different datasets may have different levels of sensitivity to these objectives. To address this problem, the temperature parameter \(\tau \) is adopted to adapt different datasets automatically. Concretely, the contrastive loss for one sample \(\hat{a}_{i}\) is formulated as:
where \(\tau >0\) is the temperature parameter, K is the number of negative samples, \(\hat{a}^+\) are the positive samples and \(\hat{a}^-\) are the negative samples. \(\hat{a}_{i}^{T}\) denotes the transposition of \(\hat{a}_{i}\).
Therefore, the expected loss for all samples is as follows:
2.3 Total Loss and Classification
In the proposed hybrid GZSL method, adversarial and contrastive methods are used to train our model. Thus, the total loss of the Co-GSZL model is formulated by:
where \(\lambda \) denotes the balance parameter, which controls the intensity of \({\mathcal {L}}_{cyc}\) and \({\mathcal {L}}_{con}\).
For classification, the learned generator G is used to generate synthesized visual features, which are then mapped as embedded features in the embedding space. Finally, we train a classifier by adopting the embedded features and use this classifier to perform testing.
3 Experiments
3.1 Datasets and Evaluation Metrics
We conduct evaluation experiments of the proposed Co-GZSL on four benchmarks, including the Animals with Attributes 1 (AWA1) dataset [22], the Animals with Attributes 2 (AWA2) dataset [34], the Oxford Flowers (FLO) dataset [27], and the Caltech-UCSD Birds-200-2011 (CUB) dataset [33]. Both AWA datasets consist of 50 coarse-grained animal categories labeled with 85 attributes. The CUB and FLO datasets are both fine-grained. The CUB and FLO datasets are both fine-grained. The former consists of 200 categories annotated with 312-dimensional attributes, and the latter contains 102 categories annotated with 1024-dimensional attributes. The numbers of images in the above datasets are 30475, 5882, 1746, and 5631 in the order of AWA1, AWA2, CUB, and FLO datasets, respectively. We adopt the Top-1 accuracy to measure the performance of the proposed model on unseen classes for ZSL, and the evaluation strategy of the harmonic mean [35] for GZSL. The top-1 accuracy for both seen classes and unseen classes are represented as S and U, respectively. The harmonic mean H is formulated as follows:
3.2 Implementation Details
The original visual features with 2048 dimensions are generated by ResNet-101 [15], which is pre-trained on ImageNet. Synthetic visual features are set to the same dimension as real visual features. The generator G and discriminator D are MultiLayer Perceptrons (MLPs) activated by the ReLU function with 4096 hidden units. The EmM is a non-linear projection activated by the ReLU function, and the dimension of all features in this embedding space is set to 4096. The FCOM contains two hidden layers. The first one has 4096 hidden units, and the second one has a variable size denoted by \(2\times |a|\). The output features, with the same dimension as a, are generated by using the re-parameterization trick [20] after the second hidden layer in the FCOM. We train the model by using mini-batch data, which randomly samples P classes and then randomly samples K images from each class, thus a batch of \(P\times K\) images is obtained, forming a training batch. Any sample in the training batch can serve as an anchor, corresponding positive and negative samples are selected from the same class and the different classes of the anchor in the training batch, respectively. The size of the random mini-batch is 2048 for the AWA1, AWA2, and CUB datasets, and 3072 for the FLO dataset, respectively. The learning rate is set to 0.0001. We set the temperature parameter \(\tau \) to 0.4 for the AWA1 dataset, 0.2 for the AWA2 and FLO datasets, and 0.02 for the CUB dataset, respectively. As for the balance parameter \(\lambda \), we set it to 0.001 for the AWA1, AWA2, and FLO datasets, and 0.01 for the CUB dataset, respectively. The number of synthesized samples generated by G is set to 1800, 2400, 300, and 200 for the AWA1, AWA2, CUB, and FLO datasets, respectively. We choose the Adam optimizator and set \(\beta _1\)=0.5, \(\beta _2\)=0.99 as the same in [19] for a fair comparison.
3.3 Comparison with State-of-the-Arts (SOTAs)
As shown in Table 1, we compare the Co-GZSL model with advanced GZSL models. The results demonstrate that Co-GZSL outperforms other models under the top-1 accuracy. Overall, Co-GZSL achieves the best H value on three benchmarks, i.e., 65.6% on the CUB dataset, 69.1% on the AWA1 dataset, and 70.7% on the AWA2 dataset. Meanwhile, Co-GZSL achieves the second-best result on the FLO dataset.
In the context of lacking samples of unseen classes, some models tend to sort unseen classes as seen classes. Therefore, their results show that the value of S is quite higher than U, which results in a low H value, such as Simple Zero-Shot Learning (ESZSL) [29] and SAE [21]. Generating synthesized visual features alleviates the classification bias to a certain extent, but there still exist gaps among synthesized features and high-quality features, such as Redundancy-Free Feature-based Generalized Zero-Shot Learning (RFF-GZSL) [11], TF-VAEGAN [26], SE-GZSL [18], and FREE [3]. Besides, in comparison with the recent TDCSS [6], CMPN [10], DFTN [17], CvDSF [40], CMC-GAN [38], and SALN [39], Co-GZSL still achieves excellent improvements on the performance. Moreover, although the results of CE-GZSL [12] are close to our model, it exists a gap between them. CE-GZSL refines the visual features in both instance-level and class-level supervision, and shows the significance of the instance-level supervision. However, we conduct our method just in instance-lavel. We strengthen the correlations between the original semantic features and the synthesized visual features by reconstructing the semantic features.
Co-GZSL develops the contrastive and semantic cycle-consistency loss to offset the shortage of discriminative synthesized features, which contributes to the outstanding performance of the model by strengthening intra-class compactness and inter-class separability and encouraging the model to generate more semantically consistent and discriminative visual features. Considering that the AWA1 and AWA2 datasets are coarse-grained, and the CUB and FLO datasets are fine-grained, the results demonstrate the robustness and high generalization of Co-GZSL.
Besides the GZSL tasks that we focus on, we also provide the comparisons of our model with current methods in Conventional ZSL (CZSL) tasks as shown in Table 2, where four of them are based on the embedding methods, while the other ones utilize the generating methods. For the CZSL tasks, our model still achieves competitive performance. The proposed method excels in GZSL while underperforming in CZSL. We can address this problem in two aspects. First, the evaluation metrics of GZSL and CZSL are not consistent. For GZSL, we use the Harmonic mean as the evaluation metrics, and for CZSL, we only use the classification accuracy of unseen classes as the evaluation metrics. Second, our method performs more stable compared with other methods, such as CMPN, which performs the best in CZSL, while the results in GZSL are not competitive. During the test, CZSL only contains classes that are never seen at the training stage, while GZSL also contains some seen classes. Therefore, performance varies along with setting changes. CE-GZSL’s performance also declines on FLO datasets when transferred from GZSL to CZSL. Meanwhile, our model performs better on CUB datasets. Due to the setting differences, results changes are common. On the other hand, according to Fig. 4, the number of synthesized samples also has an important effect on unseen classes. There exist differences when performing CZSL with the same settings to GZSL, which may lead to performance varying.
3.4 Ablation Studies
In order to make a further understanding of Co-GZSL, we perform ablation studies on the FLO dataset. We compare the effect of the FCOM and different loss functions in the proposed Co-GZSL model.
As shown in Table 3, we study the effect of the FCOM in our framework. In comparison with our integrated framework, the model without the FCOM has a much lower accuracy on unseen classes, which leads to a bad performance on the H value with a gap of 8.7 points compared to Co-GZSL. Similar to the results without FCOM, the accuracy of the model without EmM also drops significantly by 7.8 decreases on the H value.
Furthermore, as shown in Table 3, we compare the impact of different loss functions in FCOM. When only using the \(\mathcal L_{cyc}\) loss, the accuracy of the model drops extremely, which demonstrates the tight association between the new-added loss \({\mathcal {L}}_{con}\) and the Co-GZSL model. In contrast, when only using the loss \({\mathcal {L}}_{con}\), the accuracy of the model drops moderately, but it is still lower than the Co-GZSL model. These results indicate that the combination of \({\mathcal {L}}_{con}\) and \({\mathcal {L}}_{cyc}\) benefits our proposed hybrid GZSL model. The contrastive loss encourages similarity among reconstructed semantic features within the same class while increasing the distances between different classes, where all the features are reconstructed. Meanwhile, the semantic cycle-consistency loss compares the synthesized semantic features with the original semantic features within the same class, establishing a correlation between the reconstructed and original semantic features. Thus, these two losses indirectly optimize the visual features. Moreover, the semantic cycle-consistency loss, employed in the process of semantic feature reconstruction, serves to minimize the discrepancy between reconstructed semantic features and the original ones. It indirectly restricts the embedded features to be more correlated with the original semantic features. Without this loss, it might result in a bias between the embedded features and the original semantic features, but lead the model to lean towards the seen classes during training. Therefore, upon removing this loss function, the model achieves slightly better performance on seen classes, while experiencing a decline in performance on unseen classes.

The results for GZSL on four benchmark datasets with different temperature parameters \(\tau \)
3.5 Hyper-Parameter Analysis
3.5.1 Temperature Parameter \(\tau \)
We assess the impact of the temperature parameter \(\tau \) on the contrastive loss in FCOM on four benchmark datasets as shown in Fig. 3. Different datasets have different sensitivity to the \(\tau \) value. CUB demonstrates a higher sensitivity to \(\tau \) compared to other datasets, resulting in fluctuations in accuracy. However, the remaining datasets exhibit gradual variations. Overall, the proposed model shows no significant increase or decrease in performance across different datasets about multiple \(\tau \) values, which indicates the robustness of the proposed model.
3.5.2 Dimension of the Embedded Feature h
Furthermore, we present the impact of different dimensions of the embedded feature h on four benchmark datasets as shown in Table 4. We experiment with dimensions of 1024, 2048, and 4096 for h, respectively. As the dimension of h increases, the performance of our Co-GZSL method improves accordingly. However, considering the computational cost, we select 4096 as the dimension for h by default.

The results for GZSL on four benchmark datasets with different numbers of synthesized samples generated by the generator G
3.5.3 Number of Synthesized Samples Generated by G
We illustrate the impact of the number of synthesized samples generated by the generator G for each unseen class as shown in Fig. 4. As the number of synthesized samples increases, the performance on four datasets improves accordingly, which indicates a relief in the problem of lacking visual features for unseen classes. For optimal performance, we set the number of synthesized samples as 1800, 2400, 300, and 200 for the AWA1, AWA2, CUB, and FLO datasets, respectively.
3.5.4 Balance Parameter \(\lambda \)
We conduct experiments with different values of the balance parameter \(\lambda \) to assess its effectiveness as presented in Table 5. Despite weak variations in the data, there is still an optimal value for the balance parameter that needs to be determined. For the optimal results, we set \(\lambda \) as 0.001 for the AWA1, AWA2, and FLO datasets, and 0.01 for the CUB dataset, respectively.

t-SNE visualization for the AWA2 dataset. Different classes are marked with different colors
3.6 Visualization
In order to visualize our model, we plot the t-SNE as shown in Fig. 5, where different colors represent different classes. In this figure, (a) presents the distribution of real visual features, (b) shows the distribution of synthesized visual features generated by the generator G with semantic features, and (c) displays the distribution of embedded features mapped by the EmM in the embedding space by using the same features as (b). Compared to the original features, the synthesized and embedded features are more suitable for training the classifier due to more discriminative features, which indicates that our Co-GZSL optimizes the synthesized features. It should be noted that although the boundaries between classes are explicit, the synthesized features appear to be more clustered compared to the embedded features, which is adverse to model training. Since synthesized visual features are generated with semantic features and Gaussian noise, highly clustered synthesized visual features need precise semantic information, placing high demands on dataset annotation or leading to significant error. Therefore, the embedded features are more suitable for strengthening the robustness of our model and reducing identification errors.
3.7 Computational Cost Analysis
We conduct our experiments with Pytorch on an NVIDIA RTX 3060. The total number of parameters is 60.02 M, and the total number of Flops is 8.59 G.
4 Conclusions
We proposed a hybrid GZSL model, named feature Contrastive optimization for GZSL (Co-GZSL), to synthesize semantically consistent and discriminative visual features by reconstructing the semantic features in the embedding space. The Co-GZSL model derived advantages from both the embedding method and the reconstruction method. That is, features in the embedding space contain more discriminative information than the original features. Moreover, the reconstruction method constrains the embedded features to be consistent with the original semantic features indirectly by squeezing from two sides of the original and reconstructed semantic features. Comparison among reconstructed semantic features strengthens the intra-class compactness and the inter-class separability. Experimental results showed that the proposed Co-GZSL achieved impressive improvements in top-1 accuracy on four benchmark datasets. In GZSL tasks, semantic information plays a crucial role in bridging the gap between the training and testing data. While the synthesized visual features are optimized for semantic consistency, the semantic information used in our model is typically represented by attribute features that are pre-designed manually. However, the pre-designed attributes may not capture the full semantic information of the data. To overcome this limitation, future work can focus on improving the representation of semantic information. One potential approach is to incorporate text description embedding, which can provide a richer representation of semantic information.
References
Akata Z, Perronnin F, Harchaoui Z et al (2015) Label-embedding for image classification. IEEE Trans Pattern Anal Mach Intell 38(7):1425–1438
Akata Z, Reed S, Walter D, et al (2015b) Evaluation of output embeddings for fine-grained image classification. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2927–2936
Chen S, Wang W, Xia B, et al (2021) Free: feature refinement for generalized zero-shot learning. In: Proceedings of the IEEE international conference on computer vision, pp 122–131
Chen T, Kornblith S, Norouzi M, et al (2020) A simple framework for contrastive learning of visual representations. In: Proceedings of the international conference on machine learning, pp 1597–1607
Felix R, Reid I, Carneiro G, et al (2018) Multi-modal cycle-consistent generalized zero-shot learning. In: Proceedings of the European conference on computer vision (ECCV), pp 21–37
Feng Y, Huang X, Yang P, et al (2022) Non-generative generalized zero-shot learning via task-correlated disentanglement and controllable samples synthesis. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 9346–9355
Frome A, Corrado G, Shlens J, et al (2013) A deep visual-semantic embedding model. In: Proceedings of the advances in neural information processing systems, pp 2121–2129
Goodfellow IJ, Pouget-Abadie J, Mirza M, et al (2014) Generative adversarial nets. In: Proceedings of the annual conference on neural information processing systems, pp 2672–2680
Gulrajani I, Ahmed F, Arjovsky M, et al (2017) Improved training of wasserstein gans. In: Proceedings of the advances in neural information processing systems, pp 5767–5777
Guo T, Liang J, Liang J et al (2022) Cross-modal propagation network for generalized zero-shot learning. Pattern Recognit Lett 159(7):125–131
Han Z, Fu Z, Yang J (2020) Learning the redundancy-free features for generalized zero-shot object recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 12865–12874
Han Z, Fu Z, Chen S, et al (2021a) Contrastive embedding for generalized zero-shot learning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2371–2381
Han Z, Fu Z, Li G et al (2021) Inference guided feature generation for generalized zero-shot learning. Neurocomputing 430:150–158
Han Z, Fu Z, Chen S et al (2022) Semantic contrastive embedding for generalized zero-shot learning. Int J Comput Vis 130(11):2606–2622
He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778
Huang H, Wang C, Yu PS, et al (2019) Generative dual adversarial network for generalized zero-shot learning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 801–810
Jia Z, Zhang Z, Shan C et al (2023) Dual-focus transfer network for zero-shot learning. Neurocomputing 541(1):126264
Kim J, Shim K, Shim B (2022) Semantic feature extraction for generalized zero-shot learning. In: Proceedings of the AAAI conference on artificial intelligence, pp 1166–1173
Kingma DP, Ba J (2015) Adam: A method for stochastic optimization. In: Proceedings of the international conference on learning representations, pp 1–15
Kingma DP, Welling M (2014) Auto-encoding variational Bayes. In: Proceedings of the international conference on learning representations, pp 1–14
Kodirov E, Xiang T, Gong S (2017) Semantic autoencoder for zero-shot learning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3174–3183
Lampert CH, Nickisch H, Harmeling S (2009) Learning to detect unseen object classes by between-class attribute transfer. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 951–958
Li J, Jing M, Lu K, et al (2019) Leveraging the invariant side of generative zero-shot learning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 7402–7411
Liu Y, Guo J, Cai D, et al (2019) Attribute attention for semantic disambiguation in zero-shot learning. In: Proceedings of the IEEE international conference on computer vision, pp 6698–6707
Long Y, Liu L, Shao L, et al (2017) From zero-shot learning to conventional supervised classification: Unseen visual data synthesis. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1627–1636
Narayan S, Gupta A, Khan FS, et al (2020) Latent embedding feedback and discriminative features for zero-shot classification. In: Proceedings of the European conference on computer vision, pp 479–495
Nilsback ME, Zisserman A (2008) Automated flower classification over a large number of classes. In: Proceedings of the Indian conference on computer vision, graphics & image processing, pp 722–729
Peirong M, Hong L, Bohong Y et al (2022) GAN-MVAE: a discriminative latent feature generation framework for generalized zero-shot learning. Pattern Recognit Lett 155(3):77–83
Romera-Paredes B, Torr P (2015) An embarrassingly simple approach to zero-shot learning. In: Proceedings of the international conference on machine learning, pp 2152–2161
Schonfeld E, Ebrahimi S, Sinha S, et al (2019) Generalized zero-and few-shot learning via aligned variational autoencoders. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 8247–8255
Ting G, Jianqing L, Jiye L et al (2022) Cross-modal propagation network for generalized zero-shot learning. Pattern Recognit Lett 159(7):125–131
Verma VK, Arora G, Mishra A, et al (2018) Generalized zero-shot learning via synthesized examples. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4281–4289
Wah C, Branson S, Welinder P, et al (2011) The Caltech-UCSD birds-200-2011 dataset. https://www.visioncaltechedu/datasets/cub_200_2011/
Xian Y, Schiele B, Akata Z (2017) Zero-shot learning-the good, the bad and the ugly. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4582–4591
Xian Y, Lampert CH, Schiele B et al (2018) Zero-shot learning—a comprehensive evaluation of the good, the bad and the ugly. IEEE Trans Pattern Anal Mach Intell 41(9):2251–2265
Xian Y, Lorenz T, Schiele B, et al (2018b) Feature generating networks for zero-shot learning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5542–5551
Xian Y, Sharma S, Schiele B, et al (2019) f-vaegan-d2: a feature generating framework for any-shot learning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 10275–10284
Yang FE, Lee YH, Lin CC et al (2023) Semantics-guided intra-category knowledge transfer for generalized zero-shot learning. Int J Comput Vis 131(6):1331–1345
Yun Y, Wang S, Hou M et al (2022) Attributes learning network for generalized zero-shot learning. Neural Netw 150(1):112–118
Zhai Z, Li X, Chang Z (2023) Center-VAE with discriminative and semantic-relevant fine-tuning features for generalized zero-shot learning. Signal Process Image Commun 111(1):116897
Acknowledgements
This work was partially supported by the National Natural Science Foundation of China under Grant No. 62276143 and No. 61906099, Natural Science Foundation of Jiangsu Province under Grant No. BK20231287.
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, Q., Zhan, Z., Shen, Y. et al. Co-GZSL: Feature Contrastive Optimization for Generalized Zero-Shot Learning. Neural Process Lett 56, 99 (2024). https://doi.org/10.1007/s11063-024-11557-5
Accepted:
Published:
DOI: https://doi.org/10.1007/s11063-024-11557-5