
Abstract
Handling the depth estimation of low-texture regions using photometric error loss is a challenge due to the difficulty of achieving convergence due to the presence of multiple local minima for pixels in low-texture regions (or even no-texture regions). In this paper, based on the photometric loss, we also introduce texture feature metric loss as a constraint and combine the coordinate attention mechanism to improve the depth map's texture quality and edge detail. This paper uses a simple yet compact network structure, a unique loss function, and a relatively flexible embedded attention module, which is more effective and easier to arrange in robotic platforms with weak arithmetic power. The tests show that our network structure not only shows high quality and state-of-the-art results on the KITTI dataset, but the same training results also perform well on the cityscapes and Make3D datasets.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Monocular depth estimation is currently a research focus in computer vision tasks and has a wide range of applications in intelligent driving, robot motion, and 3D cognition. Traditional algorithms such as SFM are more difficult to implement in many tasks [1,2,3], and as deep learning is becoming the current mainstream algorithm [4,5,6,7,8], it is increasingly effective to accomplish using monocular cameras and also has the advantages of cost savings and small size.
Learning-based methods are divided into two main categories: supervised learning and self-supervised learning. Supervised learning requires a large variety of datasets and paired real ground depth labels as input [9,10,11,12]. The task of acquiring data is relatively difficult and the equipment used, such as LiDAR, is expensive. Self-supervised learning is relatively much easier in acquiring depth and poses, usually using monocular camera image sequences [8] as input and employing a corresponding network architecture that unifies the two tasks of depth mapping and poses estimation into a single framework, where the supervised information is mainly derived from view synthesis [8, 13,14,15,16].
However, the self-supervised method is still inferior to the supervised method in terms of the effectiveness of the current implementation. The main reason is that when using photometric error loss as the supervised signal, the features cannot be extracted effectively in some places with high light intensity or weak texture. To address this situation this paper proposes texture feature loss to enhance feature extraction [17], which can enhance the depth map generation in low-texture parts as in Fig. 1. At present, the edge part of many depth maps is often characterized by unclear boundaries and weak textures, etc. To address this problem, this paper introduces coordinate attention [18] to enhance the feature extraction of channels and spatial locations.

Compared with the existing methods, the method in this paper performs well for the low-texture part and edge detail part, and the street light pole in the figure has an obvious effect
In summary, our contributions are summarized in three areas:
-
(1)
We introduce coordinate attention, enhance channel and position attention, and improve boundary features.
-
(2)
We introduce texture feature loss on top of photometric error loss to enhance the effect of depth estimation in the absence of texture or weak texture.
-
(3)
We achieve good results in different data domains. This experiment is based on the KITTI dataset training, but it performs well on KITTI, Cityscapes and Maker3D datasets.
2 Related Work
In this section, we review related work on monocular depth estimation, and related strategies for attention.
2.1 Supervised Depth Estimation
The problem of estimating depth from a single image exists that can be projected to multiple reasonable depths, which suffers from non-uniqueness. To address this problem, various approaches have been explored from a deep learning perspective, such as combining end-to-end supervised learning [9, 10, 19], local prediction [12, 20], etc.
Supervised learning requires knowledge of the true distance in the scene during training, but it is very difficult to obtain the true depth in a realistic environment. Therefore, much of the current work makes use of weakly supervised training data, e.g., in the form of supervised appearance matching terms [21, 22], unpaired synthetic depth data [23,24,25], but additional depth still needs to be collected. Synthetic training data is an alternative [26], but generating large amounts of synthetic data is also not an easy task.
Eigen et al. [9] first introduced deep learning techniques using multiscale networks to combine global coarse depth maps with local fine depths. Laina et al. [19] proposed to improve the training using a new upsampling module and inverse Huber loss. Fu et al. [10], on the other hand, used multiscale networks to enhance the training. Their method obtained higher accuracy and faster convergence.
2.2 Self-supervised Depth Estimation
Monocular depth estimation and egomotion. SfMLearner first introduced this study [8], where the geometric estimation of depth nets and PoseNet is supervised by photometric losses, mainly assuming camera motion in a relatively stationary environment. To address moving objects that break the static scene assumption, optical flow estimation is used to compensate for these moving pixels [13, 25, 27, 28], and the segmentation mask provided by the pre-trained segmentation model is also used to handle potentially moving objects individually [4, 29, 30].
Monodepth2 [16] used automatic masking loss to reject objects moving at similar speeds, and proposed minimum reprojection loss to deal with occlusion, and proposed a multiscale sampling method to enhance sampling to reduce visual artifacts. lite-Mono [31] proposed a continuous extended convolution (CDC) module to extract rich multiscale local features and local global feature interaction ( LGFI) module to encode remote global information into features. R-MSFM [32] proposed recursive multiscale feature modulation to extract per-pixel features, construct a multiscale feature modulation module, and iteratively update the inverse depth at a fixed resolution through a parameter sharing decoder. Featdepth [17] introduced the FeatureNet network architecture for single-view reconstruction based on the cross-view reconstruction networks DepthNet and PosNet. Feature losses generated by FeatureNet are used to constrain the overall network depth map reconstruction, but the additional feature reconstruction network increases the computational burden of the system. Geometric priors are introduced in [7, 14, 33], which consider the 3D consistency between point clouds back-projected from adjacent views.
In addition, depth feature reconstruction [22] proposes to use depth features from a pre-trained model to define the reconstruction loss. Our approach has the same thinking and further explicitly learns depth features from image features.
2.3 Attention Studies
The most popular attention mechanism for mobile networks is still Squeeze and Stimulate (SE) attention, which computes channel attention with the help of 2D global pooling and significantly improves performance gains. However, SE attention focuses only on inter-channel information and not on the importance of location information, which is detrimental for monocular cameras to acquire object structures in the scene [34]. Architectures such as CBAM [34] attempt to obtain location information by reducing the channel dimension of the input tensor and then using convolution to compute spatial attention. However, convolution can only capture local relations and cannot obtain stable channel space effects.
In this paper, we introduce an efficient coordinate attention mechanism [18] that guides the computational network to be able to engage on a large scale by embedding location information into the channel attention and can attenuate the computational burden of the system. To alleviate the loss of location information due to 2D global pooling, we use two 1D global pooling operations to aggregate the input features in vertical and horizontal directions into two independent direction-aware feature maps and encode them into two attention maps. Each attention graph captures the long-distance dependence of the input feature maps on the x and y coordinate axes.
Our coordinate attention mechanism provides the following advantages, first, it can capture not only cross-channel information but also orientation-aware and position-sensitive information, which helps the model to locate and identify objects of interest more accurately.
3 Method
In this section we first introduce our network architecture and the associated coordinate attention mechanism, then introduce photometric error loss and texture feature loss to train depth map and poses estimation training, and finally introduce the details related to the overall network training.
3.1 Network Structure
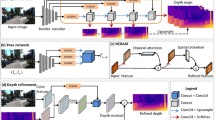
The whole network consists of a depth network and a bit-pose network, and the network structure is shown in Fig. 2. The depth network adopts the U-net network structure, in which the Encoder adopts the Resnet18 [35] network, introduces the coordinate attention at the output and connects to the Decoder network. The entire network structure is designed with a multi-scale structure, which can extract photometric features at different scales to solve problems such as "artifacts". To effectively improve the compactness of the overall network structure, the Encoder part of the pose network also adopts the resnet18 network, and the relative pose relationship between three consecutive frames is output at the output of the pose network decoder.

Network structure
In the whole network structure, the input image sources \(I_{s} \in \left\{ {I_{t - 1} ,I_{t} ,I_{t + 1} } \right\}\) are three adjacent image frames, where \(I_{t}\) is the target image. It is input to the depth network DepthNet, and the corresponding depth map \(D_{t}\) is output. It is input to the PoseNet, and the corresponding pose data is output, where \(I_{t - 1}\) and \(I_{t + 1}\) are used for \(I_{t}\) compute the pose estimation [8] notated as \(T_{t \to t^{\prime}} .\)
3.2 Image Reconstruction Model
The idea of image reconstruction is to convert a 2D pixel point \(I_{t} \left( p \right)\) in one frame from the image coordinate system to a point in the corresponding camera coordinate system, and then convert this 3D point into a 2D pixel point \(I_{s} \left( {\hat{p}} \right)\) in another frame by combining the pose relationship between the two frames, and take various optimization measures to achieve the best reconstruction value according to the feature error between the two-pixel points.
To generate an effective depth map, this paper uses the output depth map \(D_{t}\) of DepthNet, the relative bit pose \(T_{t \to t^{\prime}}\) generated by the PoseNet network, and the internal reference K of the camera to generate the corresponding reconstructed image \(I_{s} \left( {\hat{p}} \right)\) relative to the target frame \(I_{t} \left( p \right)\). The image reconstruction model is as in Eq. (1):
The target frame It is reconstructed from the source frame Is, and the reconstruction result is denoted by \(I_{s} \left( {\hat{p}} \right)\), where \(\hat{p}\) denotes the reconstructed pixel, proj denotes the projection relationship between 2 and 3D, and < > is the sampling operator.
3.3 Improved Feature Metric Loss
Photometric error loss is more common in in-depth estimation but performs poorly for low-texture regions. In this paper, texture feature metric loss is introduced to increase the feature extraction in low-texture regions.
Photometric feature loss. The reconstruction model theory is based on conditions such as camera motion and absence of moving objects. If there are no occlusions and moving objects in both views, \(I_{s} \left( {\hat{p}} \right)\) and \(I_{s} \left( {\hat{p}} \right)\) should be similar in photometric feature criteria. The photometric error loss in the network structure is illustrated in Fig. 3.

Flow chart of photometric feature loss calculation
\( I_{t} \left( p \right)\) is input to the dispNet network as the target image (Target), which finally generates the depth map Disp. the Poses output from the joint pose network are reconstructed by Disp, and the reconstructed image pred is generated after sampling, that is, \( I_{s}\)(p ̂). The corresponding photometric error loss is calculated for \( I_{t} \left( p \right)\) and \( I_{s}\)(p ̂):
where l(,) is the measurement of the photometric difference loss for each pixel.
Texture feature metric loss. In the case of normal depth estimation and pose motion, the photometric error loss can serve well, but corresponding to low-texture or even no-texture regions, if the photometric differences are similar or equal then it cannot serve as a good supervision. According to Eqs. (3) and (4), the gradient of depth D(p) and self-motion M in the photometric error loss can be further analyzed as follows:
The gradients of depth and pose depend on the image gradient \(\frac{{I_{s} \left( {\hat{p}} \right)}}{{\partial \hat{p}}}\) as can be seen from the above equations. The gradient of the image in the texture-free region can be seen as zero, which leads to the result of Eqs. (3) and (4) as zero. It can be seen that the multi-view reconstruction cannot be adequately performed by the photometric error alone, and the texture feature gradient \(\frac{{\partial \emptyset_{s} \left( {\hat{p}} \right)}}{{\partial \hat{p}}}\) is introduced into Eq. (2).
where \(\phi_{s} \left( {\hat{p}} \right)\) denotes the reconstructed texture features and \( \phi_{t} \left( p \right)\) denotes the texture features of the target image, and the schematic diagram is shown in Fig. 4.

Schematic diagram of texture feature loss generation
The target map (\(I_{t}\)) is passed through Encoder to generate the feature map tgt_f, and then the depth map (disp) output by Decoder. The image is reconstructed to generate \(I_{t}{\prime}\), and then it is fed into Encoder to generate the feature map Src_f. Bringing the target feature map tgt_f and the source feature map Src_f to Eq. (5), we get the Texture feature loss function:
The losses and gaps are further narrowed by comparing the losses of both feature maps.
Inspired by articles such as Monodepth2 [8, 15, 36], we follow the sampling minimization projection error strategy to resolve the effect of moving objects in the scene while sampling multiple scales [36,37,38] for computing the resolution of parallax and color images for photometric reprojection errors and texture feature loss. The low-resolution depth map is up-sampled to the input image resolution, then reprojected and resampled, and the error at that higher input resolution is calculated.
3.4 Coordinate Attention
The coordinate attention module can be a computational unit that improves the expression of the network learning features. It can take as input any intermediate feature tensor.
\({\text{X}} = { }\left[ {x_{1} ,x_{2} , \cdots ,x_{c} } \right] \in R^{C \times H \times W}\) and output an augmented matrix \({\text{Y}} = { }\left[ {y_{1} ,y_{2} , \cdots ,y_{c} } \right]\) that is all the same size as X. The coordinate attention structure is shown in Fig. 5, where given the input X, two spatial ranges (H,1) or (1,W) of the kernel are pooled using the X and Y directions to encode each channel along the horizontal and vertical coordinates, respectively, and the final output Y is of the same size C × H × W.

Coordinate attention schematic
The output equation for the cth channel at height h can be translated as,
Similarly, the output equation for the cth channel at a broadband of w is similarly,
The above two transformations aggregate features along two spatial directions, respectively, to produce a pair of direction-aware feature maps. After X avg pool and Y avg pool processing, they are connected, and then the 1 × 1 convolutional transform that they send is performed to obtain an intermediate feature map with spatial information encoded in the horizontal and vertical directions. We decompose the feature maps into two independent tensors along the spatial dimension for separate processing and finally obtain the output of equal dimensionality with spatial and channel attention features.
3.5 Loss Function
According to Eq, (5), the texture feature metric loss can be obtained as:
Our overall use of L1 and SSIM [39] follows [15, 40] to generate the photometric error \(L_{phRec}\):
take α = 0.85. At the same time we can solve for the parallax smoothing loss for the generated depth map:
We combine the per-pixel smoothness, photometric feature loss,and texture feature loss into an overall loss function:
3.6 Implementation Rules
For DispNet, ResNet18 with fully connected layers removed is used as the encoder, where the deepest feature map goes through five downsampling stages and the resolution of the input image is reduced to 1/32. The decoder contains five 3 × 3 convolutional layers, each followed by a bilinear upsampling layer. The multi-scale feature maps of the decoder convolution layers are used to generate multi-scale reconstructed images, where each scale feature map is further reconstructed by 3 × 3 convolution and sigmoid function for image reconstruction.
PoseNet is a pose estimator with an Encoder structure of ResNet18, modified to receive cascaded image pairs and predict the relative poses within them. Here the axis angle is chosen to represent the 3D rotation.
This experiment uses a 1-chip NVIDIA 2080 super GPU platform with 8G memory. The model uses Pytorch, 20 epochs are used, the batch size is 4, the numworkers is 12, and Adam is used for optimization. The image size is 640 × 192, the KITTI dataset is used for training, in which 39,810 frames of training image and 4242 frames of test image are used, and Monocular(M) training is mainly used for training comparison.
4 Experiment
In this section, we present a fair comparison of the KITTI 2015 dataset [41] with existing techniques for the single-view depth estimation task. A detailed ablation study of our approach is also performed to demonstrate the effectiveness of feature metric loss and coordinate attention.
4.1 Kitti Split Eigen
We used the data segmentation of Eigen et al. [42]. In addition to the ablation experiments, for training using monocular sequences, we followed the preprocessing of Zhou et al. [8] to remove static frames. 39,810 monocular three-image sequences were used for training and 4424 for validation. During the evaluation, we limited the depth to 80m according to standard practice [15].
We compare the training results of our model, and our monocular approach outperforms all existing state-of-the-art self-supervised methods, referring to Table 1 for specific experimental results, and Figs. 6, 7, and 8 for testing on different datasets, respectively.

Comparison of the two models in this paper and several models such as monodepth2, Lite-mono, R_MSFM, etc. in the KITTI dataset. We have better results in the details and edges of low-texture areas, especially in the more strongly illuminated areas, such as indicator poles, fences, trees, etc. And the distance is more in line with the actual distance, such as the distance of the cyclist is more in line with the actual distance effect

In the comparison of the effect of the two models in this paper with the other three models in the Cityscapes dataset, this paper performs better at the edges and details of the depth map, especially the details of trees in the distance. It is also friendly to the distant poles, trees, and sky parts, other methods are showing black holes

The two models in this paper, especially ours (coor + feat), show outstanding textures in detail, especially the leaves and the grass on the ground where the light is strong
4.2 Estimation Results for Different Datasets
4.2.1 The KITTI Dataset
The evaluation in this paper samples 640 × 192 images and uses monocular sequential images (M) for comparison. Also in order to compare with classical algorithms such as monodepth2 to verify the effectiveness of texture features and attention, the same number of epochs is used for training. However, this experiment uses a single GPU and only 8G of memory, and the batch size is reduced to 4 for the experiment, which has a significant loss in the final metrics. monodepth2 uses the same parameters for training and finally obtains an Abs Rel of 0.120. The final results show that the model still performs relatively well for evaluation even under the conditions of limited computational resources.
Figure 6 shows the effect of KITTI data testing, using the comparison effect of the classical algorithm Monodepth2, but also the latest results Lite-mono and R_MSFM and other methods, as well as this paper uses only the method of texture features ours(Feat) and texture attention combined with ours(coor + Feat) two methods. From the results ours(coor + Feat) method performs better at low texture details, as shown in (a) the outline of trees in the column map is relatively clear, (b) the thickness and size of the logo poles and even the reflective logo in the columns are clearly expressed, (c) the treatment of the columns in the strongly illuminated corners, and (d) the treatment of the sunlit shrubs as well as the railings in the columns. The inconsistency of photometric error often leads to inconsistency of the actual distance of the object near the camera in the depth map, which cannot reflect the prepared distance from the object to the camera in the depth map, specifically referring to the cyclist in column (b), our method can specifically reflect the actual distance.
4.2.2 The Cityscape Dataset
The KITTI data are static scenes taken by moving cameras, lacking moving targets, but there are many vehicles and pedestrians on the road in the actual real-world environment. Unlike the KITTI dataset, the Cityscapes dataset has a large number of pedestrians and moving vehicles. Here, the models trained in the KITTI dataset are used to test the Cityscapes dataset to verify the effectiveness of our models in different datasets.
In the Fig. 7 test, the input part of the distant street light poles, the shape details of trees, and the pedestrian recognition become the basis for our algorithm to identify the strengths and weaknesses. In column (a) our algorithm can clearly show the distant street light poles, in column (b) the surrounding street light poles are clearly shown, while in column (c) the tree texture details are only clearer to us, while in column (d) we can show the surrounding street light poles and the distant sky. You can see that the effect of using our method in Fig. 7 is better in comparison, the effect is obvious.
4.2.3 The Make3D Dataset
The models we trained in KITTI were tested against the Make3D dataset for comparison. Among the three methods compared, Monodepth2 performs the best but only reflects the general outline of the image, and the details are blurred, especially the grass on the ground, which is barely reflected due to the strong lighting. Our method, as shown in Fig. 8, performs better in the details of the depth map, especially the outline, and details of the houses and trees are better reflected in the more strongly illuminated areas.
4.3 Ablation Experiment
To better understand how the components of our model affect the overall performance of monocular training, in Table 2, we conducted an ablation study by varying the attention module and texture feature content of the model. The baseline approach is the same as monodepth2, BaseLine + Coor is an attention module-only model, BaseLine + Feat is a model with only feature metric loss, and Baseline + Coor + Feat is a model that incorporates coordinate attention and texture feature metric loss.
We find that the baseline model performs the worst without any contribution, each module and baseline combined improves somewhat, and our model brings the best performance when all are combined.
4.4 Shortcomings
There are also certain shortcomings in the experimental process, the depth of two objects in relative proximity can not be expressed, such as in Fig. 9(a) the signage and trees are close together, several methods listed in the figure can not achieve the corresponding separation effect, the signage and trees fused in one object, although our method is clearer in texture, still did not achieve the separation effect.

In (a) the trees and traffic signs are close together and cannot be distinguished by several methods. In (a), it can be seen that the trees and traffic signs are very close, and are imaged as a whole in (b), (c), and (d). However, our algorithm in this paper (e) and (f), although imaged as a whole, can still display traffic signs
4.5 Comparison of Different Attention Levels
For different types of attention, coordinate attention has better detail convergence compared to CBMA attention, as shown in Fig. 10. (c) better reflects the details of trees compared to (e). The vehicle driving towards the distance in (d) has a better effect than in (f).

The second row uses a coordinate attention depth map, while the third row uses a CBMA attention depth map
5 Conclusion
We propose a general model for self-supervised monocular depth estimation, which achieves state-of-the-art depth prediction that better reflects the texture details and edge cues at the texture, especially at strong illumination. We present three contributions: (i) a coordinate attention mechanism is introduced to achieve depth map detail at edges, (ii) feature metric loss improves feature extraction in low-texture parts and enhances the depth map effect, and (iii) it can be adapted to different datasets with good results. We show a depth estimation model with a good network structure supervision effect, which can be trained using KITTI monocular video data the model can adapt to different datasets for use.
References
Engel J, Koltun V, Cremers D (2013) Direct sparse odometry. arXiv e-prints,.
Mur-Artal R, Montiel JMM, Tardos JD (2015) ORB-SLAM: a versatile and accurate monocular SLAM system. IEEE Trans Rob 31(5):1147–1163
Pire T, Fischer T, Castro G, Cristóforis P, Civera J, Berlles JJ (2017) S-PTAM: stereo parallel tracking and mapping. Robotics and Autonomous Systems, 2017.
Casser V, Pirk S, Mahjourian R, Angelova A (2018) Depth prediction without the sensors: leveraging structure for unsupervised learning from monocular videos.
Li R, Wang S, Long Z, Gu D (2017) UnDeepVO: monocular visual odometry through unsupervised deep learning.
Andraghetti L, Myriokefalitakis P, Dovesi PL, Luque B, Mattoccia S (2019) Enhancing self-supervised monocular depth estimationwith traditional visual odometry. IEEE, New York.
Bian JW et al (2019) Unsupervised scale-consistent depth and ego-motion learning from monocular video.
Zhou T, Brown M, Snavely N, Lowe DG (2017) nsupervised learning of depth and ego-motion from video. In: 2017 IEEE conference on computer vision and pattern recognition (CVPR), 2017.
Eigen D, Puhrsch C, Fergus R (2014) Depth map prediction from a single image using a multi-scale deep network. MIT Press, Cambridge
Fu H, Gong M, Wang C, Batmanghelich K, Tao D (2018) Deep ordinal regression network for monocular depth estimation. In: 2018 IEEE/CVF conference on computer vision and pattern recognition, 2018.
Lee JH, Han MK, Ko DW, Suh IH (2019) From Big to small: multi-scale local planar guidance for monocular depth estimation.
Saxena A, Min S, Ng AY (2008) Make3D: Learning 3D Scene structure from a single still image. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008.
Yin Z, Shi J (2018) GeoNet: unsupervised learning of dense depth, optical flow and camera pose. In: 2018 IEEE/CVF conference on computer vision and pattern recognition (CVPR)
Mahjourian R, Wicke W, Angelova A (2018) Unsupervised learning of depth and ego-motion from monocular video using 3D geometric constraints. IEEE, New York.
Godard C, Aodha OM, Brostow GJ (2017) Unsupervised monocular depth estimation with left-right consistency. In: Computer Vision & Pattern Recognition, 2017.
Godard C, Aodha OM, Firman M, Brostow G (2018) Digging into self-supervised monocular depth estimation, 2018.
Shu C, Yu K, Duan Z, Yang K (2020) Feature-metric loss for self-supervised learning of depth and egomotion, 2020.
Hou Q, Zhou D, Feng J (2021) Coordinate attention for efficient mobile network design, 2021.
Laina I, Rupprecht C, Belagiannis V, Tombari F, Navab N (2016) Deeper depth prediction with fully convolutional residual networks. IEEE, New York.
Hoiem D, Efros AA, Hebert M (2005) Automatic photo pop-up. Acm Trans Graphics 24(3):577
Žbontar J, Lecun Y (2016) Stereo matching by training a convolutional neural network to compare image patches, ed: JMLR.orgPUB6573, 2016.
Zhan H, Garg R, Weerasekera CS, Li K, Agarwal H, Reid I (2018) Unsupervised learning of monocular depth estimation and visual odometry with deep feature reconstruction. IEEE, New York.
Kundu JN, Uppala PK, Pahuja A, Babu RV (2018) AdaDepth: unsupervised content congruent adaptation for depth estimation. IEEE, New York.
Atapour-Abarghouei A (2018) Real-time monocular depth estimation using synthetic data with domain adaptation. In: IEEE/CVF conference on computer vision & pattern recognition, 2018.
Zou Y, Luo Z, Huang JB (2018) DF-Net: unsupervised joint learning of depth and flow using cross-task consistency, 2018.
Mayer N et al (2018) What makes good synthetic training data for learning disparity and optical flow estimation? Int J Comput Vis126(9):942–960
Yang Z, Wang P, Wang Y, Xu W, Nevatia R (2018) Every pixel counts: unsupervised geometry learning with holistic 3D motion understanding. Springer, Cham
Luo C, Yang Z, Wang P, Wang Y, Yuille A (2018) Every Pixel Counts ++: Joint Learning of Geometry and Motion with 3D Holistic Understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018.
Meng Y et al (2020) SIGNet: semantic instance aided unsupervised 3D geometry perception. In: 2019 IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2020.
Gordon A, Li H, Jonschkowski R, Angelova A (2019) Depth from videos in the wild: unsupervised monocular depth learning from unknown cameras, 2019.
Zhang N, Nex F, Vosselman G, Kerle N (2022) Lite-mono: a lightweight CNN and transformer architecture for self-supervised monocular depth estimation, 2022.
Zhou Z, Fan X, Shi P, Xin Y (2021) R-MSFM: recurrent multi-scale feature modulation for monocular depth estimating. In: International Conference on Computer Vision, 2021.
Chen Y, Schmid C, Sminchisescu C (2020) Self-supervised learning with geometric constraints in monocular video: connecting flow, depth, and camera. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2020.
Sanghyun W, Jongchan P, Joon-Young L, In SK (2018) Cbam: Convolutional block attention module. In: Proceedings of the European conference on computer vi-sion (ECCV), pages 3–19, 2018.
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. IEEE, New York.
Leibe B, Matas J, Sebe N, Welling M (2016) "[Lecture Notes in Computer Science] Computer Vision – ECCV 2016 Volume 9912 || Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue," 2016.
Jaderberg M, Simonyan K, Zisserman A, Kavukcuoglu K (2015) Spatial transformer networks. MIT Press, Cambridge
Kendall A, Martirosyan H, Dasgupta S, Henry P, Bry A (2017) End-to-end learning of geometry and context for deep stereo regression. IEEE, New York
Zhou W, Bovik AC, Sheikh HR, Simoncelli EP (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process 13(4).
Zhao H, Gallo O, Frosio I, Kautz J (2017) Loss functions for image restoration with neural networks. IEEE Transactions on Computational Imaging, 2017.
Geiger A, Lenz P, Urtasun R (2012) Are we ready for autonomous driving? The KITTI vision benchmark suite. In: IEEE Conference on Computer Vision & Pattern Recognition, 2012.
Eigen D, Fergus R (2014) Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. IEEE, New York.
Yang Z, Wang P, Xu W, Zhao L, Nevatia R (2017) Unsupervised learning of geometry with edge-aware depth-normal consistency, 2017.
Wang C, Buenaposada JM, Rui Z, Lucey S (2018) Learning depth from monocular videos using direct methods. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018.
Acknowledgements
Thanks to Godard and his team who shared their results.
Funding
This work was supported by the National Natural Science Foundation of China (NSFC Grant No. 61903124).
Author information
Authors and Affiliations
Contributions
The overall article was written and experimented by FW , discussed by JZ, and guided and reviewed by JS and HW.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wei, F., Zhu, J., Wang, H. et al. CFDepthNet: Monocular Depth Estimation Introducing Coordinate Attention and Texture Features. Neural Process Lett 56, 154 (2024). https://doi.org/10.1007/s11063-024-11477-4
Accepted:
Published:
DOI: https://doi.org/10.1007/s11063-024-11477-4