
Abstract
We present here the first experimental science (consensus)-based mineral prospectivity mapping (MPM) method and its validation results in the form of national prospectivity maps and datasets for PGE–Ni–Cu–Cr and Witwatersrand-type Au deposits in South Africa. The research objectives were: (1) to develop the method toward applicative uses; (2) to the extent possible, validate the effectiveness of the method; and (3) to provide national MPM products. The MPM method was validated by targeting mega-deposits within the world’s largest and best exploited geological systems and mining districts—the Bushveld Complex and the Witwatersrand Basin. Their incomparable knowledge and mega-deposit status make them the most useful for validating MPM methods, serving as “certified reference targets”. Our MPM method is built using scientific consensus via deep ensemble construction, using workflow experimentation that propagates uncertainty of subjective workflow choices by mimicking the outcome of an ensemble of data scientists. The consensus models are a data-driven equivalent to expert aggregation, increasing confidence in our MPM products. By capturing workflow-induced uncertainty, the study produced MPM products that not only highlight potential exploration targets but also offer a spatial consensus level for each, de-risking downstream exploration. Our MPM results agree qualitatively with exploration and geological knowledge. In particular, our method identified areas of high prospectivity in known exploration regions and geologically and geospatially corresponding to the known extents of both mineral systems. The convergence rate of the ensemble demonstrated a high level of statistical durability of our MPM products, suggesting that they can guide exploration at a national scale until significant new data emerge. Potential new exploration targets for PGE–Ni–Cu–Cr are located northwest of the Bushveld Complex; for Au, promising areas are west of the Witwatersrand Basin. The broader implications of this work for the mineral industry are profound. As exploration becomes more data-driven, the question of trust in MPM products must be addressed; it can be done using the proposed scientific method.
Graphical Abstract

Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Mineral prospectivity mapping (MPM) is a form of mineral reconnaissance (Mihalasky, 1998; Paganelli et al., 2002). It has the potential to lower exploration cost and expedite mineral discovery (Carranza & Hale 2000, 2002; Carranza et al., 2005, 2008; Carranza & Laborte, 2015; Yousefi et al., 2021; Zhang et al., 2021), through the integrated analysis of multidisciplinary geodata (Agterberg, 1989; Agterberg et al., 1993; Harris, 2001; Agterberg & Cheng, 2002; Porwal & Hale, 2003; Partington, 2010; Zhang et al., 2014). Geodata used in MPM can include geographical, geophysical, geological, and geochemical types (Dentith et al., 1994; Sabins, 1999; Milsom, 2006; Carranza, 2008, 2017; Sundararajan, 2012; Rajan Girija & Mayappan, 2019; Okada, 2021). Recently, MPM has shifted from largely relying on geographic information systems (GIS) to generalized data modeling methods (Zuo et al., 2023). In particular, the integration of data science methods, particularly machine learning (ML), into MPM marks a fundamental shift toward more data-driven methodologies, creating a philosophical counterpart to knowledge-based approaches (Li et al., 2023). This is because information contained in geodata has drastically increased in the variable domain (aspatial data attributes or variables), as geodata have become higher dimensional and bigger (Zuo et al., 2023). Therefore, ML suits MPM because it is intended for generalized data analysis and mining, and automation (Hastie et al., 2009; Hazzan & Mike, 2023).
In mining-mature and economically developed countries such as Australia, Canada and the USA, the advent of ML-aided MPM at the national scale is recent, with the first products published within the last decade (Harris et al., 2015; Lawley et al., 2021, 2022; Parsa et al., 2024). Data-driven MPM is technically demanding because it necessitates both breadth and depth of knowledge across the geosciences, geodata science and GIS (Yousefi et al., 2019; Gonzalez-Alvarez et al., 2020). There are outstanding problems in data-driven MPM, some of which are major and impact the trustworthiness of MPM products (Zhang et al., 2024b): (1) intra-practitioner differences creating equiprobable “best” models, promoted by an incomplete geodata science framework; (2) despite the use of big data analysis methods, there is a lack of “just-in-time” validation methods; and (3) an absence of negative-outcome publications (e.g., mismatched predictions and outcomes). South Africa’s unique mega-deposits and longevity of mineral extraction and research (Frost-Killian et al., 2016) favor MPM method development and validation. The mining sector’s contribution to the country’s economy is in decline, affecting the nation’s economy and prospects. Part of the issue stems from an exhaustion of existing deposits, which actually is an unprecedented opportunity for MPM method development and validation because the spatial extent of mineralization is best known after significant extraction has occurred. Consequently, systems that are both spatially extensive and becoming exhausted, especially of a mega-deposit type, have the potential to become “certified reference targets” of MPM methods.
Resource exhaustion also means that South Africa needs rejuvenated exploration efforts, but it has yet to develop national MPM products to attract investment. This can be attributed to the considerable skills and knowledge gap in key disciplines. A concerted national and international effort is needed to cultivate expertise in transdisciplinary disciplines (e.g., data science, which is applicative in other fields), exchange best practices and solve outstanding problems. South African MPM products could help to focus future exploration efforts and contribute to sustainable and environmentally conscious mining practices (Joly et al., 2015). A modern pathway could be for South Africa to leverage MPM to capitalize on the global demand for critical raw minerals (Castillo et al., 2023) because it is well endowed in platinum group elements (PGEs), iron (Fe), manganese (Mn), copper (Cu), lead (Pb), zinc (Zn), gold (Au), and chromium (Cr), among others (Frost-Killian et al., 2016).
Among South Africa's most prized mining and geological terranes are the Bushveld Complex (BC) and the Witwatersrand Basin (WB) (Frost-Killian et al., 2016). The BC is known for its abundant resources of PGEs (the world’s largest reserves; Schulte, 2024), Ni, Cu and Cr, aside from its status as the host of the world’s largest ultramafic–mafic layered intrusion (e.g., Eales & Cawthorn, 1996; Cawthorn, 2010), while the WB has been a significant source of Au for over a century (e.g., Frimmel, 2014; Frimmel & Nwaila, 2020). These terranes are well explored but are still under active exploration, which makes MPM in these terranes a meaningful challenge. The available knowledge of the BC and WB also permits geoscientists to substantiate the realism of MPM outcomes at a large scale, which is critical in the adoption of MPM methodology and products. A lack of validation, especially for new methods, leads to investor apathy. The value of MPM products is ultimately determined by its adoption in the mining industry. The BC and WB were thus selected as “certified reference targets” for four reasons:
-
1)
Geological validation potential: The BC is the world's largest layered ultramafic–mafic intrusions and is rich in PGEs and other metals, making it a prime example of such deposits. Similarly, the WB is known for its vast auriferous deposits. The geology and metallogenesis of these deposits are exceptionally well studied, with known documentations of the spatial extent of both systems and their internal structures.
-
2)
Economic validation potential: The mineral deposits for which the BC and WB are known have considerable economic value due to their rich metal content. Understanding and improving the accuracy of MPM in these areas is important to the South African economy. Validation of MPM products should extend beyond geology and include economic feasibility. Therefore, known exploration efforts in predicted positive prospectivity regions are important to build economic trust in MPM products.
-
3)
There is sufficient data for data-driven MPM for the mineral deposits of interest in the BC and WB due to their long history of exploration, study and mining.
-
4)
Diversity of deposits: This diversity allows for a more comprehensive assessment of the consensus approach in different geological contexts.
Therefore, we aimed to develop, implement and validate an experimental science-based MPM method, which explicitly propagates workflow-induced uncertainty in typical geodata science-based MPM. We attempted to validate the MPM outcomes using knowledge and well-studied mega-deposits, and therefore demonstrate the effectiveness of scientific consensus as applied to MPM workflows. We provided the first national-scale maps of prospectivity for PGE–Ni–Cu–Cr and Witwatersrand-type Au, with explicit depictions of the level of consensus.
Mineral Prospectivity Mapping and Associated Uncertainties
MPM practitioners generally follow established frameworks (e.g., Alozie, 2019; Yousefi et al., 2021) that range from knowledge—to data-driven (Bonham-Carter, 1994; Skabar, 2005; Senanayake et al., 2023). Knowledge-driven methods leverage geological knowledge to map target areas (Harris et al., 2015) and can suffer from incomplete knowledge, heuristic methodology and subjective or biased application, potentially overlooking atypical mineralization patterns (Ford et al., 2019). Data-driven methods can be more objective, but suffer from data quality issues (Burkin et al., 2019) and methodology problems, such as framework limitations (Zhang et al., 2024b). Data typically required in MPM include evidence layers that capture proxies of mineralization and deposit labels. However, spatial relationships between mineralization proxies and deposits may not be local (Zuo, 2016).
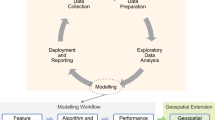
The procedures for data-driven MPM adhere to the geodata science framework (Zuo, 2020) and are mainly formulated as ML tasks (e.g., Wang et al., 2020). The geodata science framework consists of two major components (Zuo, 2020; Zhang et al., 2024b): (1) a data science framework; and (2) a geospatial extension. Data science techniques excel at handling non-spatial relationships in data (Hazzan & Mike, 2023), and are therefore intended for modeling data primarily in the variable domain (e.g., without using spatial coordinates). Data science workflows commonly contain a cyclical set of components: (1) data collection; (2) data preparation; (3) exploratory data analysis; (4) data modeling; and (5) deployment and reporting. The geospatial component handles spatial analyses of data models, such as spatial visualization (e.g., mapping) and performance assessment of models in the spatial domain (measurement of spatial characteristics, such as areal reductions).
Construction of geodata science workflows depends on the objective of the task. For MPM tasks, the objective is to minimize the search area for mineral resources (the spatial objective) while attaining the highest model performance (the variable domain objective). The data science portion of the workflow is steered by ML task formulation. For example, supervised methods require data labels and a supervised workflow design. For binary class labels, which is the equivalent to grid cells being labeled “prospective” or “not” (positive or negative, respectively), the most natural ML task is binary classification. The objective of the ML task is therefore abstracted to become: given training data, predict grid cells as positive (prospective) or negative (Zhou & Liu, 2006; Seiffert et al., 2010). This task formulation is necessary but insufficient. The spatial objective of MPM imparts additional model constraints. Therefore, the geodata science task is more complex than merely a ML task. To ensure an optimal and unique solution, both objectives must be maximized jointly.
There are three known classes of uncertainties in data-driven MPM (Zhang et al., 2024b): (1) data-related (aleatoric); (2) model-related (epistemic); and (3) workflow-induced. Aleatoric uncertainty is the result of non-perfect quality, resolution and completeness of data (An et al., 1991, 1994; Brown et al., 2000; Cai & Zhu, 2015; Burkin et al., 2019; Parsa & Carranza, 2021), which affect the realism of MPM products. Epistemic uncertainty is introduced by model limitations (Hüllermeier & Waegeman, 2021). Consistent with the intention of the data science framework, workflow components are plug-and-play, whose selection is subject to metric-driven experimentation. Therefore, algorithms can be simple (e.g., logistic regression) or complex (e.g., ensemble-based algorithms or neural networks) (Ma et al., 2020; Sun et al., 2020; Daviran et al., 2022; Yin & Li, 2022). Workflow-induced uncertainty is a newer discovery, which captures the effects of a decoupling of the spatial objective from the data science framework. It results in an inability to build a model deterministically, whose area of predicted sites meets a spatial objective.
Workflow-induced uncertainty is a result of two geodata science conditions (Zhang et al., 2024b): (1) unlimited component choices in the data science workflow (e.g., ML algorithm); and (2) a unidirectional geospatial extension of the data science framework, which prevents a joint optimization of model performance in both domains. Data science workflows are technically experiments, whose design is steered by model performance. A better workflow is assumed to result in a better model. This assumption is upheld for typical data science products because models typically have only variable domain objectives (e.g., performance benchmarks). However, for MPM because modeling uses mainly aspatial covariates (data in the variable domain), and spatial evaluations are made after model construction due to the unidirectional geospatial extension, optimization is aspatial. It was observed that spatial characteristics are only weakly dependent on model performance statistically (Zhang et al., 2024b). In particular, the biggest source of workflow-induced uncertainty is the selection of ML algorithm, followed by feature space dimensionality and the hyperparameter tuning metric (Zhang et al., 2024b). Solely building models using the data science framework results in spatially equiprobable models, which create a type of uncertainty that is unquantifiable in singleton workflows.
Due to workflow-induced uncertainty, inter-practitioner differences in data-driven MPM can create substantial targeting differences, especially in greenfield areas. From the perspective of the mining industry, a key question is: how reliable are individual MPM products? A scientific answer requires an adherence to experimental science practices, particularly the ascribing of value of experimental findings using scientific consensus (Zhang et al., 2024b). A scientific solution to workflow-induced uncertainty was proposed by explicitly propagating inter-practitioner differences as a form of uncertainty to the final MPM product. This solution also avoids manually scrutinizing models based on their perceived spatial characteristics, which is subjective and implicitly knowledge-driven.
Methodology, Data Engineering and Geodata Science
Workflow Design—Background of the Consensus-based MPM Workflow
This study advances the workflow introduced by Zhang et al. (2024b), which was designed to propagate workflow-induced uncertainty. Development focused on engineering the workflow from pure research to applicative purposes by: (1) propagating uncertainty of negative label selection, which is a known type of uncertainty in data engineering (Zuo et al., 2021); (2) creating a model merging metric; and (3) creating a model acceptance criterion that is generally useful. For the purpose of uncertainty propagation, workflow modulation controls the extent of epistemic and aleatoric uncertainties. Our workflow contained two portions: (1) a data science workflow; and (2) a post-hoc geodata science extension. The data science workflow handles feature extraction and dimensionality reduction, predictive modeling and variable domain performance assessment. The geodata science extension handles the spatial evaluation of models. Uncertainty propagation occurs by: (1) creating a deep ensemble using de-correlated workflows, with de-correlation occurring by modulating workflow component choices; (2) merging models using a metric, by treating each optimized model as an experimental outcome; and (3) mapping the consensus and dissent of the ensemble. Decomposing prospectivity into ensemble dissent and consensus adheres to best practices in metrology, which improves the usability of MPM products. This is because as per definition of scientific dissent, targeting areas of high dissent in the ensemble is risky but can give rise to new discoveries (Solomon, 1994). Similarly, high consensus areas are less risky but are also less rewarding because they are more likely to be brownfield (Laudan, 1984).
Data Engineering—Spatial Indexing and Grid Construction
The complete data compilation is presented in Supplementary Material 1, including the prediction results from this study. Datasets were sourced from various published material (mostly from the Council for Geosciences [CGS]). The two types of data in the variable domain were: (1) evidence layers or ML covariates; and (2) data labels of the presence of mineral deposits. Covariates are intended to capture proxies of mineral presence, such as rock alteration zones, cratonic and mobile belt signatures, geochemical anomalies, and distinctive geophysical signatures (Agterberg, 1992). Compared to other countries, such as Australia, USA and Canada (Lawley et al., 2021, 2022), South Africa’s national geodata availability and coverage are less complete and some data types are unavailable (e.g., national geochemical surveys are insufficient in coverage for large-scale MPM). There are other unique issues associated with the South African data as well, including the usefulness of geophysical proxies to the lithosphere-to-asthenosphere boundary (discussed below). Consequently, covariates available for this study were sourced to be as complete and general as possible to facilitate data reuse. In total, there were 38 covariates in the compilation.
Covariates were integrated using QGIS (version 3.34.3). The first step was data management and engineering, which entailed importing and standardizing various vector (e.g., spatial boundaries, geology and geochronology) and raster (e.g., geophysical and proximity analysis layers) datasets into a unified coordinate reference system (EPSG4326). The datasets were rasterized into hexagonal blocks with distinct H3 addresses using the H3 Discrete Global Grid System (DGGS), an open-source framework developed by Uber Technologies Inc. under an Apache 2 license (Uber Technologies Inc., 2020) (Fig. 1). The H3 address is therefore a unique key of the database. The H3 DGGS is hierarchical and (nearly entirely) hexagonal. Hexagonal tessellation features equal-distance neighbors, which favor the depiction of isotropic and continuous spatial objects, such as roads, faults and lithological boundaries. It offers a complete coverage across multiple resolutions globally.

Illustration of spatial indexing process showing: (a) conversion of raster and vector datasets to a coordinate reference system for zonal statistics and spatial indexing with the H3 Discrete Global Grid System; and (b) joining of indexed data through unique H3 addresses
The integration and spatial indexing of both raster and vector data were performed at the seventh resolution level of the H3 DGGS, which contains over 98 million unique H3 addresses globally, with hexagons averaging an area of 5.16 km2 and edge lengths of roughly 1.22 km. The “H3 Toolkit” plugin for QGIS was employed for spatial indexing (https://plugins.qgis.org/plugins/h3_toolkit/). Block-to-block rasterization (re-polygonization) was carried out using super-sampling, followed by vectorization into the H3 grid (e.g., for resampling geophysical datasets) using the method described in Nwaila et al. (2024). The spatially indexed datasets were then stored in a relational database, a data structure also known as a 'datacube' (Lu et al., 2018). Point vector interpolation was performed using either Gaussian processes, quadratic-inverse distance weighting, kernel density, or triangulated irregular network depending on the properties of the layer (https://docs.qgis.org/3.28/en/docs/gentle_gis_introduction/spatial_analysis_interpolation.html). For example, for derived maps such as fault proximity, buffered regions based on kernel density approximations were used.
Data Engineering—Geological Data
Datasets such as stratigraphy, geochronology, bedrock composition, and structural data were acquired from the CGS digital database (https://maps.geoscience.org.za/portal/apps/sites/#/council-for-geoscience-interactive-web-map-1). Gaps in the data due to the use of provincial geological maps were supplemented with data from the seamless national geology database, scaled at 1:1 million. For MPM, rock sub-types were aggregated into 13 broader groups (rock classes), preserving the nomenclature as published by the CGS (Fig. 2). These classifications were subsequently consolidated into four overarching categories: (1) sedimentary, (2) igneous, (3) metamorphic, and (4) other. Chronological data were collated from CGS compilations and integrated, also adhering to the age designations from the CGS. While the original map data were preserved, geological periods were simplified into parental categories where possible. Fault data were compiled from both the CGS database and various mining sites, with no de-duplication conducted. Minor discrepancies between fault traces from separate sources are not expected to significantly influence national-scale prospectivity outcomes because grid distances to faults are typically much larger than potentially duplicated faults.

Geological dataset used in the study. Rock types are shown at the highest-level classification. Three classes (sedimentary, metamorphic and igneous) are sufficiently visible at this scale. The fourth class (other) is not visible. Positive data labels for PGE–Cr–Ni–Cu (n = 593) and Witwatersrand-type Au (n = 1073) deposits are overlaid on the map
Data Engineering—Geophysical Data
Geophysical datasets were chosen based on their coverage, relevance to the targeted mineral systems, and their ability to image subsurface structures from hundreds of meters to kilometers deep. These datasets are not exhaustive inputs for MPM, but they include common potential-field, radiometric and seismic datasets, which plausibly capture useful physical properties (e.g., density and acoustic velocity) at various depths. Seismic datasets from legacy passive teleseismic surveys were used. Depth estimates for the seismogenic Moho were derived from peer-reviewed sources and regional models specific to southern Africa. A radiometric (gamma ray) dataset was sourced from Andreoli et al. (2006). Gravity datasets were collected from various sources, including satellites, airborne surveys, and ground-based measurements. Free-air gravity was sourced from a combination of satellites (Akinrinade et al., 2021). The regional Bouguer gravity data across South Africa have an approximate station spacing of 14 km (Venter et al., 1999). These data were drift- and latitude-corrected (theoretical gravity based on IGSN71 and IGF67), free-air and Bouguer corrected with a reduction density of 2670 kg/m3.
In the 1990s, a passive teleseismic experiment (the South African Seismic Experiment) was carried out to understand the deeper crustal and mantle structure below South Africa (James et al., 2001). During the experiment, broadband seismometers were deployed in a swath across South Africa. Results showed a Mohorovičić discontinuity (Moho) that is deeper below the Proterozoic mobile belts (around 45 km) as compared to the Archean Kaapvaal Craton, where the Moho thins to around 35 km (Nguuri et al., 2001). The only exception is below the BC and Limpopo Belt to the northeast, where Moho depths increase to 45–50 km (Kgaswane et al., 2012). These Moho depths were in contradiction to prior expectation based on regional Bouguer gravity data. These data show a gravity low over the Kaapvaal Craton, which typically indicates a deeper Moho beneath the craton compared to the surrounding Proterozoic belts. Gravity modeling by Webb (2009) offered an alternative explanation—that the gravity low below the craton is instead due to changes in mantle composition below the craton, rather than changes in Moho depths. This possibility means that for MPM tasks, a combination of mantle composition and Moho depths are proxies to mineralization. Therefore, Moho and other datasets (e.g., gravity) still suit our task because: (1) relationships between evidence layers and targets were only modeled inferentially in this study; and (2) only extracted features were used, which are nonlinear transformations of the evidence layers. Derivative products of gravity included: (1) analytical signal; (2) horizontal gradient magnitude (HGM); (3) the first vertical derivative (1VD); and (4) tilt derivative (TD).
Regional magnetic data were collected over South Africa from the 1980s to the late 1990s (Stettler et al., 2000). The surveys were conducted in blocks and flight lines were every 1 km, with a flight height between 100 and 150 m. Tie lines were flown every 10 km at ninety degrees to the survey lines. The grids were stitched together by CGS (Ledwaba et al., 2009). The magnetic data were first reduced to pole using an average survey date of 1990/01/01. This filter acts to shift the magnetic anomaly directly over the body. There are several limitations to this filter, including that the data were collected over approximately 20 years and over a larger region, and several of the rock units will have strong remanent magnetization. Magnetic anomalies were transformed to align with the magnetic north pole using the differential method for reduction to pole (RTP) as outlined by Arkani-Hamed (2007). Other derivative outputs from the RTP-adjusted grids include: (1) analytic signal, (2) HGM, (3) 1VD, and (4) TD.
The derived potential datasets generally included derivatives to enhance the edges of bodies, and the TD to highlight the orientation of linear tectonic fabrics. For example, 1VD data facilitate the identification and delineation of magnetic variances within the upper crustal layers. HGM data permit the delineation of shallow magnetic sources, which serve to enhance the visibility of contours proximal to the HGM peaks. The limitation of these derived datasets is that they contain accentuated noise. In particular, for spatially joined datasets, the derived data can highlight flight lines and edges between the stitched blocks. As our MPM study is targeting larger, regional features, these shorter-wavelength features should not affect the realism of the outcome.
Seismic velocities in the upper mantle and teleseismic-based lithosphere-asthenosphere boundary estimations were sourced from White-Gaynor et al. (2020), Akinrinade et al. (2021), Xue & Olugboji (2021), and Olugboji et al. (2024). In general, regions with high seismic velocities (approximately 0.3–0.8% higher than the average for P-wave velocity and 0.5–1.3% higher for S-wave velocity, White-Gaynor et al., 2020) are typically associated with older, colder, and melt-depleted cratonic lithosphere found within continental interiors. This contrasts with areas where lithospheric regions have been influenced by younger asthenospheric melts, exhibiting relatively slower seismic velocities (approximately 0.3–1.0% lower than the average P-wave velocity and a 0.5–1.0% lower for S-wave velocity, White-Gaynor et al., 2020). These abrupt variations in seismic velocities, coupled with rapid changes in lithospheric thickness, are proxies for tectonic plate morphologies and deeper pathways of melts or fluids within the lithosphere. The focusing of mantle-derived fluids and melts into the overlying crust is also evident through rapid changes in crustal thickness, specifically the Moho depth.
Data Engineering—Mineral Deposits Data
Positive data labels are generally a combination of deposits and occurrences. Positive labels in this study were assembled from various sources including contributions from mining companies, pre-existing scholarly compilations, records of the Department of Mineral Resources and Energy in South Africa as well as from the U.S. Geological Survey (Padilla et al., 2021). The data encompassed a range of operational statuses: from active and historic mining sites to sites identified as promising through advanced-stage exploration activities. These were categorized as ‘deposits’ within the scope of this research, which were manually verified (e.g., using information about lithologies and mineralization), and if possible, using published geospatial boundaries depicting the extent of the deposit, as proxied by mining leases. This permitted the rasterization of positive labels using approximately the footprint of a deposit, rather than treating it as a point geometric object. A caveat of this type of rasterization is that it can cause sample clustering, which can increase model overfitting. However, our method is purposefully designed to reject overfitted models using spatial detection methods (discussed below).
The term ‘occurrences’ describes less definitive signs of mineral presence, such as geological prospects, surface indications, and notable drill interceptions that suggest but does not confirm the existence of a mineral deposit (e.g., Lawley et al., 2022). The context of the MPM product controls the composition of the positive labels. For example, more speculative targets can be derived using mineral occurrences as labels. Because a main intent of this study was method development and validation, it was important to utilize data labels that are more definitive of mineralization. We were able to accumulate sufficient positive labels using solely deposits because both the BC and the WB are extensively mined. This permitted us to directly compare our MPM products with knowledge of the target systems, with the caveat of a decreased novelty for targeting solely greenfield areas. Our MPM products can serve as a baseline for future applicative studies that integrate mineral occurrences data to target for more greenfield areas. We created two types of target labels: PGE–Cr–Ni–Cu deposits of the BC, and Witwatersrand-type Au deposits (Fig. 2). Post-hoc quality control was performed on the data labels to remove unclassifiable labels due to insufficient information or economic value. Additionally, we de-duplicated positive labels using a cross-referencing of names and geographical coordinates.
Comprehensive drilling data are generally sparse across the world, which would have provided a clear delineation of areas without mineralization, or ‘true negatives’. In the absence of such data, we adopted a statistical approach. A sufficiently large population of unlabeled cells in the dataset should statistically resemble negative labels because of the rarity of mineral deposits in general. Therefore, unlabeled cells were treated as proxies for true negatives, following Lawley et al. (2021). The selection of negative labels follows the data science workflow as a part of data engineering. Its variability introduces uncertainty (e.g., Zuo & Wang, 2020). For the purpose of data modeling, this type of labeling introduces uncertainty through noise injection into the negative labels (e.g., where a positive label is accidentally picked as a negative), which we propagated using multiple random sets of negative labels.
Data Modeling—Feature Extraction and Predictive Modeling
Feature extraction is performed in the most general manner possible to support modulation of ML algorithms downstream, through the use of autoencoders. Here, we provide a brief description; for full details in MPM context, see Zhang et al. (2024b). Autoencoders are a form of feed-forward artificial neural network (ANN) that exhibit a tapered architecture with a bottleneck (the coding layer). Given the bottleneck, autoencoders attempt to maximize the similarity of the input and output data. Consequently, some information, progressing generally from noise to useful information (Zhang et al., 2024a), is variably discarded in a manner similar to truncating the number of components in principal components analysis. For dimensionality reduction, autoencoders are a generalization of principal components analysis because they make no assumption on the types of relationship in data (Kramer, 1991). Autoencoders extract features with the property that they are information-dense, maximally compact, de-correlated (linearly and nonlinearly) and unspecific to downstream algorithms. Consequently, modulation of feature space dimensionality is maximally productive and the broadest range of modeling algorithms could be used with extracted features.
To modulate the feature space dimensionality, we chose a range of coding layer sizes to: (1) explore a range of feature space density to incorporate the effects of the curse of dimensionality (Márquez, 2022), which affects model outcome in an algorithm-dependent manner (Zhang et al., 2024b); and (2) capture the range of dimensions that MPM practitioners may practically choose. For (2), it is important to generate a range of feature space dimensions, such that they cover likely outcomes of elbow-based selection heuristics, which are not ideal but about the only objective criterion available (Ketchen et al., 1996). Therefore, the range should be sized to visibly cover a data reconstruction performance curve, such that concavity is clearly visible. This ensures that most practical choices of the number of dimensions around the elbow region of the curve are represented in the modulation of feature space dimensionality.
For the predictive modeling phase of the workflow, modulation must encompass a set of algorithms that could be used by MPM practitioners to mimic inter-practitioner variability. This is impossible to accomplish empirically. Firstly, published MPM literature only captures a few successful candidates and not all choices, especially unsatisfactory ones (a positive outcome bias in MPM literature that is not explicitly recognized in geodata science but is in other domains; Mlinarić et al., 2017). Consequently, MPM literature cannot be generally used to perform a meta-analysis of algorithmic feasibility, particularly as it is context dependent (e.g., data used). Secondly, there is no limit to the diversity of feasible algorithms because, in addition to development of new algorithms, existing ones are often modified. Algorithmic diversity for MPM is plausibly the largest source of workflow variability because the novelty of many MPM publications focused on algorithmic success (Zhang et al., 2024b). Consequently, it is impossible to rank-order all algorithms that could be used for MPM in terms of their success rate. First principles indicate that it is feasible to capture the effects of change in ML algorithm because algorithmic variability affects the number of degrees of freedom in the resulting models, which control their epistemic characteristics. Simpler algorithms typically result in less degrees of freedom (e.g., linear regression) as compared with more complex models (e.g., tree-based methods) and universal functional approximators with unlimited complexity (e.g., ANNs). Therefore, it is practical to adopt a range of algorithms that can modulate model complexity, which facilitates a range of “fitted-ness” (relatively overfit or underfit).
We adopted the same set of algorithms as Zhang et al. (2024b), which included: (1) simple algorithms—k-nearest neighbors (kNN; Tikhonov, 1943; Fix & Hodges, 1951; Cover & Hart, 1967) and logistic regression (LR; Cramer, 2002); (2) moderately complex algorithms—Gaussian process (GP; Rasmussen & Williams, 2006; Kotsiantis, 2007) and support vector machines (SVM; Vapnik, 1998); and (3) high complexity algorithms—ANN (Curry, 1944; Rosenblatt, 1961; Rumelhart et al., 1985; Hastie et al., 2009; Lemaréchal, 2012), random forest (RF), adaptive boosting of decision trees (AB; Ho, 1995; Breiman, 1996a, b; Freund & Schapire, 1997; Breiman, 2001; Kotsiantis, 2014; Sagi & Rokach, 2018); and extremely randomized or extra trees (ET; Geurts et al., 2006). Similar to that in Zhang et al. (2024b), ANN is used for both shallow and deep learning (autoencoder coupled with predictive modeling). These algorithms and their hyperparameters are described in Zhang et al. (2024b). Here, we forwent a full description of these algorithms and their hyperparameters, but highlight that the effect of the hyperparameters is mainly to control model complexity by modulating the complexity of the decision boundaries in feature space. For the hyperparameters, see Table 1. We withheld 25% of training data for testing and employed a four-fold cross-validation for model construction, guided by either the F1 score or the area under the curve of the receiver-operating-curve (AUC–ROC) (Fawcett, 2006). These two metrics are intended to measure either model discriminatory power (AUC–ROC) or quality of predictions (F1 score). To modulate the choice of negative labels, we randomly sampled five different sets of negative labels. The size of negative labels was chosen to achieve class balance. In summary, there were 13 feature dimensions, 8 algorithms, 2 model selection metrics, and 5 sets of negative labels, resulting in 1040 unique workflows per target.
Geospatial Component—Geospatial and Model Consensus Analysis
In the geodata science extension, the spatial domain performance can be assessed through a mathematical formulation of the goal of MPM, which is to reduce the search area for mineral deposits. To measure area, we adopted the spatial selectivity (\(SS\)) metric that was used by Zhang et al. (2024b). It is assessed as the site fraction that is prospective and is an aspatial generalization of the occupied area metric, which is technically a spatial metric that measures areal ratios (Mihalasky & Bonham-Carter, 2001). Compared to the areal formulation of the occupied area metric, \(SS\) has an advantage for aspatial modeling methods because: (1) aspatial and even spatial algorithms do not consider areas (only grid-cell connectivity or notions of neighborhood); and (2) at large spatial scales, it is impossible to create equal-cell-area grids. Therefore, \(SS\) provides a similar result as occupied area, but does not incur gridding-induced areal distortion.
For joint analysis of spatial and variable domain performance, we used the variable-spatial metric (\(VS\)). It was introduced in its fractional form by Zhang et al. (2024b) because it was a generalization of the normalized density metric (Mihalasky & Bonham-Carter, 2001). Fractional formulation is better for developmental purposes because it intentionally reveals relationships of model behavior between the spatial and variable domains. For model merging, this metric is not useful because although its domain is 0 to 1 for both numerator and denominators, its range is unbounded. Hence, we created a range-limited version of this metric, which is the product of: (1) a data science metric; and (2) one minus \(SS\). For example, using the F1 metric, \(VS = (F1 score)\cdot (1-SS)\). This metric’s range is bounded between 0 to 1 and, besides, it is equally sensitive to both variable and spatial domains. For example, for all models with the same F1 score, \(VS\) increases if \(SS\) decreases, and vice versa at the same rate. A better MPM model across both domains features a higher \(VS\) score, unless it is extremely overfitted.
A diversity of models produced through modulated workflows naturally ranges from relatively underfitted (e.g., using simple algorithms) to overfitted (e.g., using complex algorithms), which controls the information content of the models. Model usability depends on context. For large ensembles, underfitted models are desirable because they function similarly to weak learners in ensemble ML algorithms (e.g., RF), which means that their average is statistically robust and meaningful. Spatially, they identify prospective areas beyond training data with variable dissent, which means that users of MPM products are well informed in terms of exploration risk. In contrast, extremely overfitted models do not add new information to the ensemble and are useless because they mostly predict the training data as prospective. Such models are not always detectable within the data science workflow using out-of-sample testing, especially where data labels are clustered (which is probable for solely using mine footprints as positive labels), which means detection is more robust in the spatial domain (Zhang et al., 2024b).
Extremely overfitted models result from two conditions for MPM tasks (Zhang et al., 2024b): (1) an enabling geoscientific condition—finite feature diversity of positive labels, resulting from a lack of lithodiversity of mineral deposits or occurrences, relative to the diversity of negative labels; and (2) the absence of a constraint in spatial optimization—there is no lower-bound to the minimum search space. If positive labels capture a small subset of all lithodiversity, then negative labels represent a far larger volume of the feature space, which enables decision boundaries to become tightly bound to positive labels. Consequently, out-of-sample testing is ineffective to detect overfitting because the out-of-sample and in-sample labels are substantially similar. This effect is enhanced by high feature space dimensionality (Zhang et al., 2024b). The enabling condition should be addressed through data engineering (e.g., surveys to discover new positive labels) and cannot be addressed within the current geodata science framework because no data augmentation method can add synthetic diversity to positive labels in the manner of greenfield discoveries. This implies that models fitted using augmented data are further biased toward brownfield discoveries because exploration data are already biased (Porwal et al., 2015; Yousefi et al., 2021).
The lack of a constraint is a general problem caused by low velocity geodata because high data velocity enables “just-in-time” or post-deployment validation (which is exceedingly rare, if at all for MPM). This is exacerbated by the mostly academic nature of, and a positive outcome bias in, MPM, which creates perpetual challenges with product validation. The constraint problem can be solved within the geodata science framework by reframing the best practice of model acceptance criteria from applicative data science-domains to MPM (e.g., Shearer, 2000; Hazzan & Mike, 2023). Minimum acceptable performance is specified by users of data science models. However, MPM products are almost entirely published without identifiable clients (despite the mineral industry being a primary MPM product user), which implies that there are no user-specified constraints. Moreover, the usability of MPM products should never be solely evaluated by their creators because of a conflict of interest. To remediate this weakness, where MPM products (and similar geodata products) do not directly serve end-users, we engineered a spatial constraint using minimum spatial selectivity as a model acceptance criterion. It is based on the distinction between deposit scale exploration and mineral reconnaissance. We considered areas that are at least one order of magnitude greater than the summary area of positive labels as acceptable, which is implied by the distinction that reconnaissance must occur at a scale that is much larger than deposit scale exploration. This permits us to complete model acceptance during model deployment using geospatial analysis after predictive modeling. A summary for the entire workflow is shown in Figure 3.

Summary of the geodata science workflow used for consensus-based MPM in this study. All modulations of components are indicated below each component in curly brackets
Geological Context
PGE–Cr–Ni–Cu Deposits of the Bushveld Complex
The Paleoproterozoic BC (2.060–2.055 Ga; Walraven et al., 1990; Scoates & Wall, 2015; Zeh et al., 2015; Mungall et al., 2016) sits in the northeastern portion of the Kaapvaal Craton in South Africa. It is world-renown for its chromitite reef deposits. Its physical extent and its resources are well known. Notably, it has been divided into the: (1) Rooiberg Group, (2) Rustenburg Layered Suite (RLS), (3) Rashoop Granophyre Suite, and (4) Lebowa Granite Suite (SACS, 1980). Spatially, it is divided into five lobes, the: (1) eastern, (2) western, (3) northern, (4) southeastern, and (5) far-western lobes (Fig. 4). In addition, it has a number of satellite intrusions, notably the Barneveld, Helvetia, Losberg, Mashaneng, Moloto, Mooifontein, Rhenosterhoekspruit, and Uikomst intrusions, as well as the Molopo Farms Complex (Cawthorn, 1987; Cawthorn et al., 2006).

Location of (inset, top left) and simplified geological map of the Bushveld Complex (modified from Bourdeau et al., 2020)
Of particular importance to this study is the RLS, which constitutes the world’s largest layered ultramafic–mafic intrusion, with a coverage of 40,000 km2 and thickness of ≤ 8 km (Eales & Cawthorn, 1996; Cawthorn et al., 2015). The RLS intruded at shallow crustal levels (<12 km; Zeh et al., 2015) between the Neoarchean–Paleoproterozoic Transvaal Supergroup sediments (floor) and the Rooiberg Group rocks (roof; Fig. 4). Based on major isotopic and mineralogical changes, the suite is divided into five stratigraphic zones (from bottom to top): Marginal, Lower, Critical, Main, and Upper zones (SACS, 1980; Kruger, 1994). Overall, rocks of the RLS grade from poorly-layered norites (Marginal Zone), to layered dunite, harzburgite and pyroxenite (Lower Zone), layered pyroxenite–norite–anorthosite–chromitite (Critical Zone), poorly-layered gabbronorite (Main Zone), and ferrogabbro–anorthosite–magnetitite and apatite-bearing diorite (Upper Zone) (Eales & Cawthorn, 1996; Cawthorn et al., 2015).
The BC hosts the world’s largest resources and reserves of PGEs. Notably, 191 metric tons of PGEs (i.e., Pt and Pd) were mined from the BC in 2023, accounting for 49% of world production (Schulte, 2024). In addition, it was estimated that 88% (63,000 metric tons) of the world’s PGE reserves are found within the complex (Schulte, 2024). Interestingly, every chromitite-rich layer of the BC contains some PGEs (Cawthorn, 2010). In addition to PGEs, Cr, Ni and Cu are also extracted from the ore. All significant PGE ore deposits are hosted within the Critical Zone of the RLS and include the Merensky Reef, UG2 Chromitite and Platreef. Economical chromitite layers contain abundant chromite (≤ 43.3% Cr2O3), pyrrhotite, pentlandite and pyrite, can reach measure up to 1 m in thickness and contain up to 3 g/ton PGE, often with high proportions of Rhodium (Rh) and lesser amounts of Iridium (Ir) and Ruthenium (Ru) (Cawthorn, 2010).
Witwatersrand-type Au Deposits
The Mesoarchean WB is located at the center of the Kaapvaal Craton (Fig. 5) and it is the largest known accumulation and source of gold globally (Frimmel, 2019). Apart from hosting gold, the WB also hosts one of the world’s major uranium (U) resources (>200,000 metric tons; Frimmel, 2019). It is defined by a set of overlapping cratonic successor basins, altogether resting on Paleo- to Mesoarchean granitoid–greenstone terranes belonging to the Kaapvaal Craton. Altogether, the WB extends for ~ 350 km in a northeasterly direction and ~ 200 km in a northwesterly direction, and it reaches a thickness of 7 km (Frimmel, 2019). At the base of the WB are the Dominion Group rocks (3.086–3.087 Ga; Armstrong et al., 1991; Robb et al., 1992) consisting of a thin siliciclastic basal unit overlain by a bimodal volcanic sequence. Overlying the Dominion Group is the Witwatersrand Supergroup, which is further divided into the West and Central Rand groups. The West Rand Group is composed of quartzite and shale, with minor conglomerate beds in the upper part of the group, altogether deposited in a marine shelf environment (Eriksson et al., 1981; Frimmel, 2019). Paleocurrent data indicate that the sediment source was to the north–northeast (Frimmel & Minter, 2002). The Central Rand Group (upper age limit of 2.790 Ga; Gumsley et al., 2018) was deposited following a 10 m.y. sedimentation hiatus (Minter, 2006; Frimmel & Nwaila, 2020). This group is dominated by fluvial and fluvio–deltaic sandstones and conglomerates, separated by erosional unconformities, deposited in a retro-arc foreland basin environment (Catuneanu, 2001).

Location of (inset, top left) and simplified geological map of the Witwatersrand Basin (modified after Frimmel et al., 2005). Note that the younger sequences (Ventersdorp and Transvaal supergroups) covering the basin are omitted
Following the deposition of the Witwatersrand Supergroup, the WB was peneplaned after the stabilization of the Kaapvaal Craton. The supergroup was then overlain by the predominantly volcanic Ventersdorp Supergroup (~3 km thick) and subsequently by the Transvaal Supergroup sediments (~15 km thick) (Burger and Coertze, 1975; Poujol et al., 2005). The burial, dewatering, crustal thickening, and emplacement of the BC, followed by the Vredefort meteorite impact (2.023 Ga; Kamo et al., 1996; also see Vredefort Dome in Fig. 5), resulted in widespread low-grade metamorphism (except near the impact crater) and post-depositional hydrothermal alteration of Witwatersrand rocks (Frimmel et al., 2005).
Goldfields are predominantly found along the northern and western edges of the WB (Fig. 5). To date, the Witwatersrand goldfields have produced about 53,000 metric tons of gold, or approximately one-third of all gold mined in history, and account for 30% of global known resources (Frimmel, 2014, 2019). For decades, exploration of gold in the WB has been motivated by the possibility of gold-rich outlying remnants. The historic discovery of the Evander Basin in the early 1950s, facilitated by pioneering airborne aeromagnetic surveys, significantly motivated further exploration. This event led to extensive regional gravity and magnetic surveys across the entire craton. Gold deposits in the WB primarily occur in coarse-grained siliciclastic rocks (e.g., conglomerates) and are often locally referred to as ‘reefs’, with sharp lower and upper contacts but are laterally extensive. Gold concentrations within these reefs can range attain up to 25 g/ton Au (AngloGold Ashanti, 2014). Notably, gold has been extracted from over 30 different reefs, with majority of them (95% of production) located in the Central Rand Group (Robb & Robb, 1998). Cross-cutting features such as faults and veins in the WB also host minor amounts of gold, with such features being more auriferous near or within mineralized reefs (Frimmel et al., 2005). The subsequent peneplanation of the Witwatersrand Supergroup also resulted in the re-mobilization of gold into younger sequences, notably in the Ventersdorp Contact Reef (Ventersdorp Supergroup) and the Black Reef Formation (Transvaal Supergroup), which has since produced 40 metric tons of gold (Frimmel, 2018; Frimmel & Nwaila, 2020).
Results
Feature Extraction
Modulation of feature space dimensionality resulted in 13 sets of features, with their dimensionality spanning from 5 to 17. The autoencoder’s data reconstruction performance varied from about 0.95 to 0.77, as averaged over 25 trials per coding layer size, using randomized network weights. The loss in performance was generally gradual over this range, but with a steeper loss below a coding layer size of 9 and a slower loss above 13 (Fig. 6). The performance of the autoencoder as a function of coding layer size showed a concave curvature and steeper losses at the lowest coding layer sizes and a saturation in performance at highest sizes. Concavity is indicative of an elbow structure. However, the location of the elbow was ambiguous, whose exact value is unimportant for this study, but is likely to be around 11 nodes. It is important to appreciate that these sets of features cover a sufficient span of feature space dimensions around the probable elbow portion of the performance curve.

Autoencoder’s reconstruction performance as measured using the coefficient of determination (CoD) as a function of the coding layer size
PGE–Ni–Cu–Cr Deposits
In total, 1025 models met the spatial acceptance criterion and were used for subsequent analyses. The relationship between model performance in the spatial and variable domains was noisy, poor or non-existent (Fig. 7). Our results corroborated the findings of Zhang et al. (2024b) that the spatial selectivity of tree-based methods was insensitive or ambiguous to model performance in the variable domain (Fig. 7). On average, the AUC–ROC scores of models were systematically higher than the F1 (weighted) scores (Fig. 8a). Moreover, the spatial outcome of models was more strongly affected by tuning using the F1 (weighted) metric than the AUC–ROC metric (Fig. 8b). Tuning models using the AUC–ROC metric produced less spatially discriminating models, despite high AUC–ROC scores (the slopes are substantially different, Fig. 8). The joint spatial-variable domain performance of the ensemble was distributed with bias toward higher values (between 0.90 and 0.95) (Fig. 9a).

Performance assessments of the variable and spatial domains of all models tuned using the weighted F1 metric, categorized by algorithm. kNN = k-nearest neighbors, SVM = support vector machines, RF = random forest, ET = extremely randomized or extra trees, AB = adaptive boosting of decision trees, LR = logistic regression, ANN = artificial neural network, and GP = Gaussian process

(a) Performance distribution of models in the variable domain. (b) Aggregate analysis of all models that are tuned using the F1 (weighted) or AUC–ROC metrics. kNN = k-nearest neighbors, SVM = support vector machines, RF = random forest, ET = extremely randomized or extra trees, AB = adaptive boosting of decision trees, LR = logistic regression, ANN = artificial neural network, and GP = Gaussian process

(a) Performance distribution of models in both the spatial and variable domains using the \(VS\) metric. (b) Convergence of random subsamples (number of trials is inversely proportional to sample size, such that at the lowest sample size of 20 samples, there is a total of 100 trials) of the ensemble to the consensus model, using the \(VS\) metric. CoD = coefficient of determination
To assess the ensemble’s rate of convergence, we analyzed the similarity between random subsets of models and the full consensus model (Fig. 9b). It can be seen that convergence was relatively rapid and an elbow was reached by 200 models. It is impossible to present visualizations of all models independently due to the ensemble’s size. Therefore, to assist readers with visualizing the ensemble of models and the convergence process, an animated video is provided in Supplementary Material 2. In terms of the modulated components of the data science workflow, the absolute impact on the spatial selectivity score was: ML algorithm (7.7%); feature space dimensionality (4.4%); hyperparameter tuning metric (0.7%); and negative labels (0.6%). Therefore, sensitivity can be calculated as the absolute impact divided by the number of choices per component, which resulted in a sensitivity ranking: ML algorithm (1%); hyperparameter tuning metric (0.4%); feature space dimensionality (0.3%); and negative labels (0.1%).
The consensus model was merged using all acceptable models (Fig. 10). The consensus was strong for positive prospectivity around the BC, roughly corresponding to the location of the RLS (Fig. 5). These areas are expected findings because the training data contained positive labels there (Fig. 2). However, a strong positive consensus was found over the Waterberg plateau (blue arrow in Fig. 10, also see Fig. 4). This finding is a surprise (and greenfield in the sense of data used) because there are no positive labels there. Notably, an abundance of literature accepts that the Vila Nora and northern lobe segments are connected at depth (e.g., Huthmann et al., 2016). However, its PGE potential remains unexplored. A lesser degree of consensus was found in the sedimentary successions of the Transvaal Supergroup, notably from Pretoria (externally surrounding the BC) and Postmasburg (near the center of South Africa) groups. Notably, the Transvaal Supergroup is known to host a number of Fe, Mn, Mississippi Valley-type, and structurally-controlled gold deposits (Eriksson et al., 2006 and references therein). While it is possible that the diminished consensus was influenced by known and extensive iron deposits within the supergroup, it is worthwhile to note that the supergroup has yet to be evaluated for PGEs, Ni, Cu, and Cr. The patchwork of dissent toward the north and northwest presents another possibility. This area consists of variable lithologies associated with the Kaapvaal Craton (granite–greenstone terranes) and Limpopo Belt (which joins the Kaapvaal Craton with the Zimbabwe Craton to the north). However, similar to the sequences of the Transvaal Supergroup, the area is underexplored. In terms of data-driven discoveries, these aforementioned areas were not covered by the training data (Fig. 2) and are therefore novel discoveries made possible by MPM. The findings confirm that the consensus-based method is effective because known exploration regions are predicted to exhibit a high degree of consensus, and lowered consensus or some level of dissent is observed in regions that are plausible given knowledge of the BC.

The consensus model for PGE–Ni–Cu–Cr (of 1025 individual models). The color bar depicts the degree of consensus to dissent. Values closer to either 1 or 0 mean high consensus of either prospective or non-prospective sites. Values near 0.5 mean strong dissent. The outline of the Rustenburg Layered Suite which contains known and notable PGE deposits is in green. The blue arrow highlights the continuation of the RLS beneath the Waterberg plateau
Witwatersrand-type Gold Deposits
In total, 773 models met the spatial acceptance criterion. The relationship between model performance in the spatial and variable domains was noisy, poor or non-existent (Fig. 11). The spatial selectivity of tree-based methods was insensitive to model performance in the variable domain (Fig. 11). This is consistent with the trend observed thus far and by Zhang et al. (2024b). On average, the AUC–ROC scores of all models were higher than the F1 (weighted) scores (Fig. 12a). For Au, the pattern was similar to that for PGE–Ni–Cu–Cr – the spatial outcome of models was more strongly affected by tuning using the F1 (weighted) metric than the AUC–ROC metric (Fig. 12b). The joint spatial-variable domain performance of the ensemble was clustered, for example, between 0.85 and 0.95, with a smaller population from 0.85 to 0.75 (Fig. 13a). The ensemble’s rate of convergence was qualitatively similar to that of PGE–Ni–Cu–Cr (Fig. 13b). It can be seen that convergence was relatively rapid and an elbow was reached by 200 random models. To assist readers with visualizing the large ensemble of models and the convergence-to-consensus process, an animated video is provided in Supplementary Material 3. In terms of the modulated components in the data science workflow, the absolute impact on the spatial selectivity score was: feature space dimensionality (13.7%); ML algorithm (12.3%); hyperparameter tuning metric (1.0%); and negative labels (0.5%). The sensitivity ranking was: ML algorithm (1.5%); feature space dimensionality (1.1%); hyperparameter tuning metric (0.5%); and negative labels (0.1%).

Performance assessments of the variable and spatial domains of all models tuned using the weighted F1 metric, categorized by algorithm. kNN = k-nearest neighbors, SVM = support vector machines, RF = random forest, ET = extremely randomized or extra trees, AB = adaptive boosting of decision trees, LR = logistic regression, ANN = artificial neural network, and GP = Gaussian process

(a) Performance distribution of models in the variable domain. (b) Aggregate analysis of all models that are tuned using the F1 (weighted) or AUC–ROC metrics. kNN = k-nearest neighbors, SVM = support vector machines, RF = random forest, ET = extremely randomized or extra trees, AB = adaptive boosting of decision trees, LR = logistic regression, ANN = artificial neural network, and GP = Gaussian process

(a) Performance distribution of models in both the spatial and variable domains using the \(VS\) metric. (b) Convergence of random subsamples (number of trials is inversely proportional to sample size, such that at the lowest sample size of 20 samples, there is a total of 100 trials) of the ensemble to the consensus model, using the \(VS\) metric. CoD = coefficient of determination
The consensus model strongly supports the positive prospectivity of the WB, with internal variability (Fig. 14). This variability was expected, given that most of the lithologies belonging to the WB are covered by younger sequences, notably by the Ventersdorp and Transvaal supergroups. This model highlights a pronounced consensus for high prospectivity particularly in the northern and western portions of the WB, areas that now stand as focal points for potential exploration and development (Fig. 14). However, the model also identifies areas of strong dissent, most notably to the southwest and north of the WB (Fig. 14). This dissent increases radially outward from high positive consensus regions, specifically from the western portion of the WB, suggesting a riskier exploration landscape.

The consensus model for the Witwatersrand-type Au (of 773 individual models). The color bar depicts the degree of consensus to dissent. Values closer to 1 or 0 mean high consensus of either prospective or non-prospective sites. Values at 0.5 mean strong dissent. The outline of the Witwatersrand Basin, which contains known and notable Au deposits, is in green. The outline of the Transvaal Supergroup is in white, and the inferred extent (southern portion overlain by younger Karoo Supergroup rocks) of the Ventersdorp Supergroup is in blue. The inferred outline of the Ventersdorp Supergroup is from Humbert et al. (2019)
The areas of strong dissent are associated with known re-mobilized WB Au deposits into the Ventersdorp (Ventersdorp Contact Reef) and Transvaal (Black Reef Formation) supergroups (Frimmel, 2018; Frimmel & Nwaila, 2020). Previously undocumented is the extent of the Ventersdorp lithologies beneath the younger sequences of the Karoo Supergroup. The extent of these is denoted in Figure 14. Thus, adding to the understanding of the WB's prospectivity, our results uncovered additional potential for Witwatersrand-type Au mineralization along the peripheral margins of the known basin. Combined with our data-driven findings, there exists a broader and underexplored area of potential for new discoveries beyond the traditional boundaries of the WB (Fig. 5). The rich potential within the established boundaries of the WB lends validity to our consensus model. The findings confirm that the consensus-based method is effective also for Witwatersrand-type Au because known exploration regions were predicted to exhibit a high degree of consensus for positive prospectivity, and some level of dissent is observed in regions that are plausible given knowledge of the WB.
Implications for Exploration
The main sources of known inter-practitioner variability in MPM were propagated as uncertainty into our MPM products. For our models, the biggest source of variability was the choice of ML algorithm, which is at least one order of magnitude more significant than the variability introduced by the selection of negative labels (the smallest source). This finding builds scientific consensus upon the much larger scale study conducted by Zhang et al. (2024b) (multiple continents, more data). The deep ensembles converged rapidly, which implies that: (1) the diversity of workflows was sufficient to produce consensus; and (2) a small amount of additional unexplored workflows is unlikely to significantly perturb the predictions. Therefore, we are reasonably confident that our consensus model is statistically robust. However, we cannot preclude the possibility that differences in data engineering, such as the resolution and variety of evidence layers may produce an appreciable impact. Although we have employed evidence layers that are the best available to our knowledge, it is still possible to add evidence layers but it would be difficult to replace all of them. The fastest timescales of variability are within the data usage portion of the data pipeline, as data science is optimized for big data analysis and workflow automation. Changes in evidence layers occur much more slowly (e.g., new national-scale surveys) on the timescales of data generation, which is not generally automatable and produces low velocity data (Bourdeau et al., 2024). We therefore expect our MPM products to be durable, at least until substantial new national-scale data have accumulated to warrant a re-investigation. Consequently, because of our explicit design for robustness and durability, our MPM products are much more suitable than singleton MPM products to guide the slower and riskier task of mineral exploration.
For MPM, consensus maps and (deep) workflow ensembles represent a significant methodology advancement, akin to the formulation of a data-driven version of expert opinion-aggregation. Because this method mitigates the key weakness of a poor coupling between spatial and variable domain outcomes in the geodata science framework, it improves stakeholder trust in MPM products. The level of consensus and dissent directly captures spatial targeting changes that can occur between different MPM practitioners tackling the same challenge. A large ensemble means that the statistical nature of the ensemble is more relevant than individual models, and as such, there are two main benefits: (1) no single model (or MPM practitioner) is solely relied upon; and (2) there is a spatial depiction of a probable range of targets without losing the extreme values (e.g., less probable targets in areas of high dissent). Therefore, our MPM products are substantially more reliable than singleton models. An improved methodology is important to the mineral industry because committing a higher level of effort in the reconnaissance stage results in MPM products that better match the timescales and risks of mineral exploration and are more likely to attract investment.
Our analysis revealed a qualitatively significant spatial conformity of our MPM products to geoscientific knowledge of well-explored regions for both the BC and WB. In particular, the delineation of high-confidence positive areas was generally sharp for the BC and variable for the WB. This was expected given the igneous and modified-sedimentary natures of the BC and the WB, respectively. Additional regions with promising exploration potential were also identified. For PGE–Ni–Cu–Cr, the continuation of the northern lobe beneath the Waterberg plateau is a high-confidence target (Fig. 10). This area's known geological context, combined with our model's insights, underscores its potential for mineral exploration. Moreover, the vast and underexplored regions toward the northern tip of South Africa present variably interesting areas for these commodities, each with unique geological characteristics that could hint at untapped mineral wealth. The underexplored nature of these regions highlights the need for targeted research and exploration to assess their potential economic viability. For Au, the extension of the WB to the southwest is a large and potentially fruitful area (Fig. 14). This region, large and relatively underexplored in the context of its gold potential, could bear extensions of the mineralization patterns known within the WB. Beyond that, and to a lesser degree of consensus, areas to the north of the WB could also be considered, but are riskier.
Benefits to the Mineral Industry and Conclusion
Mineral exploration is at an all-time-high because of demand, market competition and resource contention. These factors will continue to drive changes in the mineral industry. A shift from knowledge- to data-driven exploration methods continues, enabled by an accumulation of data, new instruments, computer power and big-data-suitable algorithms. A key question that we have witnessed from the mineral industry is: how trustworthy are individual mineral prospectivity maps? This is a difficult question to answer because of an unbounded diversity of MPM workflows, whose spatial impacts are not trivial on prospectivity maps, and an inability of the geodata science framework to accept spatial constraints. The question aligns with the scientific expectation that singleton experimental outcomes are not reliable without consensus. This is a thorny issue for MPM because MPM products and methods are of value mainly to the industry but are seldom validated and mainly academic in origin. Ideally, MPM as a geodata science product should a-priori take as a constraint—user requirements, which for MPM is the extent of area that is feasible to explore, then produce the best product meeting that constraint. The only way to deterministically reduce the search area given a weakly unidirectionally-coupled framework is to create a deep ensemble of models and select a spatial extent based on the level of consensus (or dissent). Where low-risk exploration is desirable, areas of positive prospectivity at a high level of consensus can be targeted. Where truly greenfield and often black swan discoveries are desirable, areas of significant dissent can be targeted, with the obvious caveat that such areas are risky.
South Africa has had a long history of mining. Although no one knows for sure, there may still be appreciable economic resources. Historically, both the BC and WB were opportunistic, black swan discoveries, the likes of which, there are no comparable entities elsewhere. Therefore, discovering smaller ore deposits using modern methods could seem to be a much less daunting challenge in comparison. However, exploration is faced with the increasingly brownfield nature of the world. Within this setting, there lies opportunity—the accumulation of data. The timing is ripe for South Africa to envision a future on the labor of the past—legacy data and exploration knowledge, to make a renewed effort to rejuvenate its mineral industry and therefore, its economy and job prospects for the youth. In this context, this study serves both the global MPM and South African communities by providing: an applicative version of a scientific consensus-based MPM method, and to the extent possible, its validation; a comprehensive datacube that could be used for other targets and MPM method validation (by serving as “certified reference materials”); and hope for South Africans.
References
Agterberg, F. P. (1989). Computer programs for mineral exploration. Science, 245, 76–81.
Agterberg, F. P. (1992). Combining indicator patterns in weights of evidence modeling for resource evaluation. Nonrenewable Resources, 1(1), 39–50.
Agterberg, F. P., & Cheng, Q. (2002). Conditional independence test for weights-of-evidence modeling. Natural Resources Research, 11, 249–255.
Agterberg, F. P., Bonham-Carter, G. F., Cheng, Q., & Wright, D. F. (1993). Weights of evidence modeling and weighted logistic regression in mineral potential mapping. In J. C. Davis & U. C. Herzfeld (Eds.), Computers in Geology (pp. 13–32). Oxford University Press.
Akinrinade, O. J., Li, C.-F., & Afelumo, A. J. (2021). Geodynamic processes inferred from Moho and Curie depths in Central and Southern African Archean Cratons. Tectonophysics, 815, 228993.
Alozie A C (2019) Sustainable management of mineral resource active regions: a participatory framework for the application of systems thinking. Ph.D. thesis, Imperial College London
An, P., Moon, W. M., & Rencz, A. (1991). Application of fuzzy set theory to integrated mineral exploration. Canadian Journal of Exploration Geophysics, 27, 1–11.
An, P., Moon, W. M., & Bonham-Carter, G. F. (1994). Uncertainty management in integration of exploration data using the belief function. Nonrenewable Resources, 3(1), 60–71.
Andreoli, M. A., Hart, R. J., Ashwal, L. D., & Coetzee, H. (2006). Correlations between U, Th content and metamorphic grade in the western Namaqualand Belt, South Africa, with implications for radioactive heating of the crust. Journal of Petrology, 47(6), 1095–1118.
Arkani-Hamed, J. (2007). Differential reduction to the pole: Revisited. Geophysics, 72(1), L13–L20. https://doi.org/10.1190/1.2399370
Armstrong, R. A., Compston, W., Retief, E. A., Williams, I. S., & Welke, H. (1991). Zircon ion microprobe studies bearing on the age and evolution of the Witwatersrand Triad. Precambrian Research, 53, 243–266.
Ashanti, AngloGold. (2014). Mineral resource and ore reserve report (p. 194). AngloGold Ashanti Ltd.
Bonham-Carter, G. F. (1994). Geographic information systems for geoscientists: Modelling with GIS (p. 398). Pergamon Press.
Bourdeau, J. E., Zhang, S. E., Hayes, B., & Logue, A. (2020). Field, petrographical and geochemical characterization of a layered anorthosite sequence in the upper main zone of the bushveld complex. South African Journal of Geology, 123(3), 277–296.
Bourdeau, J. E., Zhang, S. E., Nwaila, G. T., & Ghorbani, Y. (2024). Data generation for exploration geochemistry: Past, present and future. Applied Geochemistry. https://doi.org/10.1016/j.apgeochem.2024.106124
Breiman, L. (1996a). Bagging predictors. Machine Learning, 24(2), 123–140.
Breiman, L. (1996b). Stacked regressions. Machine Learning, 24(1), 49–64.
Breiman, L. (2001). Random forests. Machine Learning, 45, 5–32.
Brown, W. M., Gedeon, T. D., Groves, D. I., & Barnes, R. G. (2000). Artificial neural networks: a new method for mineral prospectivity mapping. Australian Journal of Earth Sciences, 47(4), 757–770.
Burger, A. J., & Coertze, F. J. (1975). Age determinations—April 1972 to march 1974, technical report. Annals of the Geological Survey of South Africa, 11, 317–321.
Burkin, J. N., Lindsay, M. D., Occhipinti, S. A., & Holden, E. J. (2019). Incorporating conceptual and interpretation uncertainty to mineral prospectivity modeling. Geoscience Frontiers, 10(4), 1383–1396.
Cai, L., & Zhu, Y. (2015). The challenges of data quality and data quality assessment in the big data era. Data Science Journal, 14, 1–10.
Carranza, E. J. M. (2017). Natural resources research publications on geochemical anomaly and mineral potential mapping, and introduction to the special issue of papers in these fields. Natural Resources Research, 26, 379–410.
Carranza, E. J. M., & Hale, M. (2000). Spatial association of mineral occurrences and curvilinear geological features. Mathematical Geology, 34, 199–217.
Carranza, E. J. M., & Hale, M. (2002). Geologically constrained probabilistic mapping of gold potential, Baguio District, Philippines. Natural Resources Research, 9, 237–253.
Carranza, E. J. M., & Laborte, A. G. (2015). Random forest predictive modeling of mineral prospectivity with small number of prospects and data with missing values in Abra (Philippines). Computers & Geosciences, 74, 60–70.
Carranza, E. J. M., Woldai, T., & Chikambwe, E. M. (2005). Application of data-driven evidential belief functions to prospectivity mapping for aquamarine-bearing pegmatites, Lundazi district, Zambia. Natural Resources Research, 14, 47–63.
Carranza, E. J. M., Hale, M., & Faassen, C. (2008). Selection of coherent deposit-type locations and their application in data-driven mineral prospectivity mapping. Ore Geology Reviews, 33, 536–558.
Carranza, E. J. M. (2008). Geochemical anomaly and mineral prospectivity mapping in GIS: Amsterdam. In M. Hale (Eds.), Handbook of exploration and environmental geochemistry (vol. 11, p. 351). Amsterdam: Elsevier.
Castillo, E., del Real, I., & Roa, C. (2023). Critical minerals versus major minerals: a comparative study of exploration budgets. Mineral Economics, 1-12.
Catuneanu, O. (2001). Flexural partitioning of the late Archaean Witwatersrand foreland system, South Africa. Sedimentary Geology, 141, 95–112.
Cawthorn, R. G. (1987). Extensions to the platinum resources of the Bushveld Complex. South African Journal of Science, 83(2), 69–71.
Cawthorn, R. G. (2010). The platinum group element deposits of the Bushveld Complex in South Africa. Platinum Metals Review, 54(4), 205–215.
Cawthorn, R. G. (2015). The Bushveld Complex, South Africa. In B. Charlier, O. Namur, R. Latypov, & C. Tegner (Eds.), Layered Intrusions (pp. 517–587). Springer.
Cawthorn, R. G., Eales, H. V., Uken, R., & Watkeys, M. K. (2006). The Bushveld Complex. In M. R. Johnson, C. R. Anhaeusser, & R. J. Thomas (Eds.), The Geology of South Africa (pp. 261–281). South African Council for Geosciences and the Geological Society of South Africa.
Cover, T., & Hart, P. (1967). Nearest neighbor pattern classification. IEEE Transactions in Information Theory, 13(1), 21–27.
Cramer, J. S., (2002). The origins of logistic regression. Tinbergen Institute Working Paper No. 2002-119/4, pp. 16. https://doi.org/10.2139/ssrn.360300
Curry, H. B. (1944). The method of steepest descent for non-linear minimisation problems. Quarterly of Applied Mathematics, 2, 258–261.
Daviran, M., Parsa, M., Maghsoudi, A., & Ghezelbash, R. (2022). Quantifying uncertainties linked to the diversity of mathematical frameworks in knowledge-driven mineral prospectivity mapping. Natural Resources Research, 31(5), 2271–2287.
Dentith, M. C., Frankcombe, K. F., & Trench, A. (1994). Geophysical signatures of Western Australian mineral deposits: an overview. Exploration Geophysics, 25(3), 103–160.
Eales, H. V., & Cawthorn, R. G. (1996). The Bushveld Complex. In R. G. Cawthorn (Eds.), Layered Intrusions (pp. 181–229). Developments in Petrology, 15. Elsevier.
Eriksson, K. A., Turner, B. R., & Vos, R. G. (1981). Evidence of tidal processes from the lower part of the Witwatersrand Supergroup, South Africa. Sedimentary Geology, 29, 309–325.
Eriksson, P. G., Altermann, W., & Hartzer, F. J. (2006). The Transvaal Supergroup. In M. R. Johnson, C. R. Anhaeusser, & R. J. Thomas (Eds.), The Geology of South Africa (pp. 237–260f). South African Council for Geosciences and the Geological Society of South Africa.
Fawcett, T. (2006). An introduction to ROC analysis. Pattern Recognition Letters, 27(8), 861–874.
Fix, E., & Hodges, J. L. (1951). An important contribution to nonparametric discriminant analysis and density estimation. International Statistical Review, 57(3), 233–238.
Ford, A., Peters, K. J., Partington, G. A., Blevin, P. L., Downes, P. M., Fitzherbert, J. A., & Greenfield, J. E. (2019). Translating expressions of intrusion-related mineral systems into mappable spatial proxies for mineral potential mapping: Case studies from the Southern New England Orogen. Australia Ore Geology Reviews, 111, 102943.
Freund, Y., & Schapire, R. E. (1997). A decision-theoretic generalization of on-line learning and an application to boosting. Journal of Computer and System Sciences, 55(1), 119–139.
Frimmel, H. E. (2005). Archaean atmospheric evolution: Evidence from the Witwatersrand gold fields, South Africa. Earth-Science Reviews, 70, 1–46.
Frimmel, H. E. (2014). A giant Mesoarchaean crustal gold-enrichment episode: Possible causes and consequences for exploration. Society of Economic Geologists, Special Publication, 18, 209–234.
Frimmel, H. E. (2018). Episodic concentration of gold to ore grade through Earth’s history. Earth-Science Reviews, 180, 148–158.
Frimmel, H. E. (2019). The Witwatersrand basin and its gold deposits. In A. Kröner & A. Hofmann (Eds.), The Archaean geology of the Kaapvaal craton, Southern Africa (pp. 255–275). Springer.
Frimmel, H. E., & Minter, W. E. L. (2002). Recent developments concerning the geological history and genesis of the Witwatersrand gold deposits, South Africa. Society of Economic Geologists, Special Publication, 9, 17–45.
Frimmel, H. E., & Nwaila, G. T. (2020). Geologic evidence of syngenetic gold in the Witwatersrand gold fields, South Africa. In R. H. Sillitoe, R. J. Goldfarb, F. Robert, & S. F. Simmons (Eds.), Geology of the world’s major gold deposits and provinces. Society of Economic Geologists, Special Publication, 23. https://doi.org/10.5382/SP.23.31.
Frost-Killian, S., Master, S., Viljoen, R. P., & Wilson, M. G. (2016). The great mineral fields of Africa introduction. Episodes Journal of International Geoscience, 39(2), 85–103.
Geurts, P., Ernst, D., & Wehenkel, L. (2006). Extremely randomized trees. Machine Learning, 63, 3–42.
Gonzalez-Alvarez, I., Goncalves, M. A., & Carranza, E. J. M. (2020). Introduction to the special issue challenges for mineral exploration in the 21st century: Targeting mineral deposits under cover. Ore Geology Reviews, 126, 103785.
Gumsley, A., Stamsnijder, J., Larsson, E., Söderlund, U., Naeraa, T., de Kock, M. O., & Ernst, R. (2018). The 2789–2782 Ma Klipriviersberg large igneous province: Implications for the chronostratigraphy of the Ventersdorp Supergroup and the timing of Witwatersrand gold deposition. In GeoCongress 2018, Geological Society of South Africa (p. 133). University of Johannesburg, South Africa, July 18–20, 2018, Proceedings.
Harris, J., Wilkinson, L., Heather, K., Fumerton, S., Bernier, M., Ayer, J., & Dahn, R. (2001). Application of GIS processing techniques for producing mineral prospectivity maps—a case study: mesothermal Au in the Swayze Greenstone Belt, Ontario. Canada. Natural Resources Research, 10(2), 91–124.
Harris, J. R., Grunsky, E., Behnia, P., & Corrigan, D. (2015). Data-and knowledge-driven mineral prospectivity maps for Canada’s North. Ore Geology Reviews, 71, 788–803s.
Hastie, T., Tibshirani, R., Friedman, J. H., & Friedman, J. H. (2009). The elements of statistical learning: data mining, inference, and prediction. Springer.
Hazzan, O., & Mike, K. (2023). The data science workflow in guide to teaching data science. Springer.
Ho, T. K. (1995). Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition (pp. 278–282). Montréal, Canada. https://doi.org/10.1109/ICDAR.1995.598994.
Hüllermeier, E., & Waegeman, W. (2021). Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods. Machine learning, 110(3), 457–506.
Humbert, F., de Kock, M., Lenhardt, N., & Altermann, W. (2019). Neoarchean to Early Proterozoic within-plate volcanism of the Kaapvaal Craton: Comparing the Ventersdorp Supergroup and the Ongeluk and Hekpoort formations (Transvaal Supergroup). In A. Kröner & A. Hofmann (Eds.), The Archaean geology of the Kaapvaal craton, Southern Africa (pp. 277–302). Springer.
Huthmann, F. M., Yudovskaya, M. A., Frei, D., & Kinnaird, J. A. (2016). Geochronological evidence for an extension of the northern lobe of the Bushveld Complex, Limpopo province, South Africa. Precambrian Research, 280, 61–75.
James, D. E., Fouch, M. J., VanDecar, J. C., van der Lee, S., & Group, K. S. (2001). Tectospheric structure beneath southern Africa. Geophysical Research Letters, 28(13), 2485–2488.
Joly, A., Porwal, A., McCuaig, T. C., Chudasama, B., Dentith, M. C., & Aitken, A. R. (2015). Mineral systems approach applied to GIS-based 2D-prospectivity modelling of geological regions: Insights from Western Australia. Ore Geology Reviews, 71, 673–702.
Kamo, S. L., Reimold, W. U., Krogh, T. E., & Colliston, W. P. (1996). A 2.023 Ga age for the Vredefort impact event and a report of shock metamorphosed zircons in pseudotachylitic breccias and granophyre. Earth and Planetary Science Letters, 144, 369–387.
Ketchen, D. J., & Shook, C. L. (1996). The application of cluster analysis in strategic management research: An analysis and critique. Strategic management journal, 17(6), 441–458.
Kgaswane, E. M., Nyblade, A. A., Durrheim, R. J., Julià, J., Dirks, P. H., & Webb, S. J. (2012). Shear wave velocity structure of the Bushveld Complex, South Africa. Tectonophysics, 554, 83–104.
Kotsiantis, S. B. (2014). Bagging and boosting variants for handling classifications problems: a survey. The Knowledge Engineering Review, 29(1), 78–100.
Kotsiantis, S. B., Zaharakis, I., & Pintelas, P. (2007). Supervised machine learning: A review of classification techniques. Emerging Artificial Intelligence Applications in Computer Engineering, 160(1), 3–24.
Kramer, M. A. (1991). Nonlinear principal component analysis using autoassociative neural networks. AIChE journal, 37(2), 233–243.
Kruger, F. J. (1994). The Sr-isotopic stratigraphy of the western Bushveld Complex. South African Journal of Geology, 97, 393–398.
Laudan, L. (1984). Science and Values: The Aims of Science and Their Role in Scientific Debate. University of California Press.
Lawley, C. J., Tschirhart, V., Smith, J. W., Pehrsson, S. J., Schetselaar, E. M., Schaeffer, A. J., Houlé, M. G., & Eglington, B. M. (2021). Prospectivity modelling of Canadian magmatic Ni (±Cu±Co±PGE) sulphide mineral systems. Ore Geology Reviews, 132, 103985.
Lawley, C. J., McCafferty, A. E., Graham, G. E., Huston, D. L., Kelley, K. D., Czarnota, K., Paradis, S., Peter, J. M., Hayward, N., Barlow, M., Emsbo, P., Coyan, J., San, J. C., & A., & Gadd, M. G. (2022). Data–driven prospectivity modelling of sediment–hosted Zn–Pb mineral systems and their critical raw materials. Ore Geology Reviews, 141, 104635.
Ledwaba, L., Dingoko, O., Cole, P., & Havenga, M. (2009). Compilation of survey specifications for all the old regional airborne geophysical surveys conducted over South Africa. Council for Geoscience.
Lemaréchal, C. (2012). Cauchy and the gradient method. Doc Math Extra, 251(254), 10.
Li, Q., Chen, G., & Luo, L. (2023). Mineral prospectivity mapping using attention–based convolutional neural network. Ore Geology Reviews, 156, 105381.
Lu, M., Appel, M., & Pebesma, E. (2018). Multidimensional arrays for analysing geoscientific data. ISPRS International Journal of Geo-Information, 7(8), 313.
Ma, Y., Zhao, J., Sui, Y., Liao, S., & Zhang, Z. (2020). Application of knowledge-driven methods for mineral prospectivity mapping of polymetallic sulfide deposits in the southwest Indian ridge between 46° and 52° E. Minerals, 10(11), 970.
Márquez, A. C. (2022). The curse of dimensionality. In: Digital Maintenance Management. Springer Series in Reliability Engineering (pp. 67-86). Springer. https://doi.org/10.1007/978-3-030-97660-6_7.
Mihalasky, M. J., & Bonham-Carter, G. F. (2001). Lithodiversity and its spatial association with metallic mineral sites, Great Basin of Nevada. Natural Resources Research, 10, 209–226.
Mihalasky, M. J. (1998). Mineral potential mapping of gold and silver mineralization in Nevada Great basin, a GIS Based analysis using weights of evidence. PhD thesis, University of Ottawa.
Milsom, J. (2006). Geophysical methods. Introduction to Mineral Exploration, 127.
Minter, W. E. L. (2006). The sedimentary setting of Witwatersrand placer mineral deposits in an Archean atmosphere. Memoir of the Geological Society of America, 198, 105–119.
Mlinarić, A., Horvat, M., & Šupak Smolčić, V. (2017). Dealing with the positive publication bias: Why you should really publish your negative results. Biochemia medica, 27(3), 447–452.
Mungall, J. E., Kamo, S. L., & McQuade, S. (2016). U-Pb-geochronology documents out-of-sequence emplacement of ultramafic layers in the Bushveld Igneous Complex of South Africa. Nature Communications, 7, 1–13.
Nguuri, T. K., Gore, J., James, D. E., Webb, S. J., Wright, C., Zengeni, T. G., Gwavava, O., Snoke, J. A., & Group, K. S. (2001). Crustal structure beneath southern Africa and its implications for the formation and evolution of the Kaapvaal and Zimbabwe cratons. Geophysical Research Letters, 28(13), 2501–2504.
Nwaila, G. T., Zhang, S. E., Bourdeau, J. E., Frimmel, H. E., & Ghorbani, Y. (2024). Spatial interpolation using machine learning: from patterns and regularities to block models. Natural Resources Research, 33(1), 129–161.
Okada, K. (2021). A historical overview of the past three decades of mineral exploration technology. Natural Resources Research, 30, 2839–2860.
Olugboji, T., Xue, S., & Jean-Joel Legre, Yuri Tamama,. (2024). Africa’s crustal architecture inferred from probabilistic and perturbational inversion of ambient noise: ADAMA. Geochemistry, Geophysics, Geosystems. https://doi.org/10.1029/2023GC011086
Padilla, A. J., Otarod, D., Deloach-Overton, S. W., Kemna, R. F., Freeman, P. A., Wolfe, E. R., Bird, L. R., Gulley, A. L., Trippi, M. H., Dicken, C. L., Hammarstrom, J. M., & Brioche, A. S. (2021). Compilation of geospatial data (GIS) for the mineral industries and related infrastructure of Africa. U.S. Geological Survey Data Release. https://doi.org/10.5066/P97EQWXP.
Paganelli, F., Richards, J. P., & Grunsky, E. C. (2002). Integration of structural, gravity, and magnetic data using the weights of evidence method as a tool for kimberlites exploration in the Buffalo Head Hills, Northern Central Alberta. Canada Natural Resources Canada, 11(3), 219–236.
Parsa, M., & Carranza, E. J. M. (2021). Modulating the impacts of stochastic uncertainties linked to deposit locations in data-driven predictive mapping of mineral prospectivity. Natural Resources Research, 30, 3081–3097.
Parsa, M., Lawley, C. J. M., Cumani, R., Schetselaar, E., Harris, J., Lentz, D. R., Zhang, S. E., & Bourdeau, J. E. (2024). Predictive Modeling of Canadian Carbonatite-Hosted REE+/− Nb Deposits. Natural Resources Research. https://doi.org/10.1007/s11053-024-10369-7
Partington, G. (2010). Developing models using GIS to assess geological and economic risk: An example from VMS copper gold mineral exploration in Oman. Ore Geology Reviews, 38(3), 197–207.
Porwal, C., & Hale, M. (2003). Extended weights-of-evidence modelling for predictive mapping of base-metal deposit potential in Aravalli Province, western India. Exploration and Mining Geology, 10(4), 155–163.
Porwal, A., Deb Das, R., Chaudhary, B., Gonzalez-Alvarez, I., & Kreuzer, O. (2015). Fuzzy inference systems for prospectivity modeling of mineral systems and a case-study for prospectivity mapping of surficial Uranium in Yeelirrie Area, Western Australia. Ore Geology Reviews, 71, 839–852.
Poujol, M., Kiefer, R., Robb, L. J., Anhaeusser, C. R., & Armstrong, R. A. (2005). New U-Pb data on zircons from the Amalia greenstone belt Southern Africa: Insights into the Neoarchaean evolution of the Kaapvaal craton. South African Journal of Geology, 108(3), 317–332.
Rajan Girija, R., & Mayappan, S. (2019). Mapping of mineral resources and lithological units: A review of remote sensing techniques. International Journal of Image and Data Fusion, 10(2), 79–106.
Rasmussen, C. E., & Williams, C. K. (2006). Gaussian processes for machine learning (vol. 1). Cambridge, MIT press.
Robb, L. J., Davis, D., Kamo, S. L., & Mayer, F. M. (1992). Ages of altered granites adjoining the Witwatersrand basin with implications for the origin of gold and uranium. Nature, 357(6380), 677–680.
Robb, L. J., & Robb, V. M. (1998). Gold in the Witwatersrand Basin. In M. G. C. Wilson & C. R. Anhaeusser (Eds.), The mineral resources of South Africa (pp. 294-349). Pretoria: Council for Geoscience.
Rosenblatt, F. (1961). Principles of neurodynamics: perceptrons and the theory of brain mechanisms. Spartan Books, Washington DC. https://doi.org/10.1007/978-3-642-70911-1_20
Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1985). Learning internal representations by error propagation. Institute for Cognitive Science, University of California, San Diego, Ics Report, 8506, 49.
Sabins, F. F. (1999). Remote sensing for mineral exploration. Ore Geology Reviews, 14(3–4), 157–183.
SACS (1980). Lithostratigraphy of the Republic of South Africa, South West Africa/Namibia and the Republics of Bophuthatswana, Transkei and Venda. Geological Survey of South Africa, Handbook 8, Part 1.
Sagi, O., & Rokach, L. (2018). Ensemble learning: A survey. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 8(4), e1249.
Schulte, R. F. (2024). Platinum-group metals. In Mineral Commodity Summaries 2024. U.S. Geological Survey. https://doi.org/10.3133/mcs2024.
Scoates, J. A., & Wall, C. J. (2015). Geochronology of layered intrusions. In B. Charlier, O. Namur, R. Latypov, & C. Tegner (Eds.), Layered Intrusions (pp. 3–74). Springer.
Seiffert, C., Khoshgoftaar, T. M., Van Hulse, J., & Napolitano, A. (2010). RUSBoost: A hybrid approach to alleviating class imbalance. IEEE Transactions on Systems Management and Cybernetics-Part A Systems & Humans, 40, 185–197.
Senanayake, I. P., Kiem, A. S., Hancock, G. R., Metelka, V., Folkes, C. B., Blevin, P. L., & Budd, A. R. (2023). A spatial data-driven approach for mineral prospectivity mapping. Remote Sensing, 15(16), 4074.
Shearer, C. (2000). The CRISP-DM model: the new blueprint for data mining. Journal of data Warehousing, 5(4), 13–22.
Skabar, A. A. (2005). Mapping mineralization probabilities using multilayer perceptrons. Natural Resources Research, 14, 109–123.
Solomon, M. (1994). Social empiricism. Noûs, 28(3), 325–343.
Stettler, E. H., Fourie, C. J. S., & Cole, P. (2000). Total magnetic field intensity map of the Republic of South Africa (in 4 panels). Council for Geoscience, Pretoria.
Sun, T., Li, H., Wu, K., Chen, F., Zhu, Z., & Hu, Z. (2020). Data-driven predictive modelling of mineral prospectivity using machine learning and deep learning methods: a case study from southern Jiangxi Province. China Minerals, 10(2), 102.
Sundararajan, N. (2012). A general perspective on geophysical methods in mineral exploration In On a Sustainable Future of the Earth’s Natural Resources. Springer.
Tikhonov, A. N. (1943). On the stability of inverse problems. In Proceedings of the USSR Academy of Sciences, (vol. 39, pp. 195-198).
Uber Technologies Inc. (2020) H3: A hexagonal hierarchical geospatial indexing system. Retrieved on 01 March 2023 from https://github.com/uber/h3.
Vapnik, V. N. (1998). Statistical learning theory. Wiley.
Venter, C. P., du Plessis, J. G., Stettler, R. H., Potgieter, T. D., Kleywegt, R. J., Hattingh, E., Fourie, C. J. S., Wolmarans, L. G., Cloete, A. J., & Maré, L. P. (1999). Gravity, South African Geophysical Atlas. Council for Geoscience, South Africa, 77, 4.
Walraven, F., Armstrong, R. A., & Kruger, F. J. (1990). A chronostratigraphic framework of the northcentral Kaapvaal Craton, the Bushveld Complex and the Vredefort structure. Tectonophysics, 171, 23–48.
Wang, J., Zuo, R., & Xiong, Y. (2020). Mapping mineral prospectivity via semi–supervised random forest. Natural Resources Research, 29, 189–202.
Webb, S. J. (2009). The use of potential field and seismological data to analyze the structure of the lithosphere beneath southern Africa. School of Geoscience University of the Witwatersrand, Johannesburg, 377.
White-Gaynor, A. L., Nyblade, A. A., Durrheim, R., Raveloson, R., van der Meijde, M., Fadel, I., Paulssen, H., Kwadiba, M., Ntibinyane, O., Titus, N., & Sitali, M. (2020). Lithospheric boundaries and upper mantle structure beneath southern Africa imaged by P and S wave velocity models. Geochemistry, Geophysics, Geosystems, 21(10), e2020GC008925.
Xue, S., & Olugboji, T. (2021). UR Seismology, ACE_ADAMA. Retrieved February 22, 2024, from https://github.com/URseismology/ACE_ADAMA/tree/V2.
Yin, J., & Li, N. (2022). Ensemble learning models with a Bayesian optimization algorithm for mineral prospectivity mapping. Ore Geology Reviews, 145, 104916.
Yousefi, M., Kreuzer, O. P., Nykänen, V., & Hronsky, J. M. (2019). Exploration information systems–A proposal for the future use of GIS in mineral exploration targeting. Ore Geology Reviews, 111, 103005.
Yousefi, M., Carranza, E. J. M., Kreuzer, O. P., Nykänen, V., Hronsky, J. M., & Mihalasky, M. J. (2021). Data analysis methods for prospectivity modelling as applied to mineral exploration targeting: State-of-the-art and outlook. Journal of Geochemical Exploration, 229, 106839.
Zeh, A., Ovtcharova, M., Wilson, A. H., & Schaltegger, U. (2015). The Bushveld Complex was emplaced and cooled in less than one million years - results of zirconology, and geotectonic implications. Earth and Planetary Science Letters, 418, 103–114.
Zhang, D., Cheng, Q., Agterberg, F. P., & Zuo, R. (2014). A comparison of modified fuzzy weights of evidence, fuzzy weights of evidence, and logistic regression for mapping mineral prospectivity. Mathematical Geosciences, 46, 869–885.
Zhang, S., Carranza, E. J. M., Xiao, K., Chen, Z., Li, N., Wei, H., Xiang, J., Sun, L., & Xu, Y. (2021). Geochemically constrained prospectivity mapping aided by unsupervised cluster analysis. Natural Resources Research, 30, 1955–1975.
Zhang, S. E., Bourdeau, J. E., Nwaila, G. T., Parsa, M., & Gorbani, Y. (2024a). Denoising of geochemical data using deep learning – implications for regional surveys. Natural Resources Research, 33, 495–520.
Zhang, S. E., Lawley, C. J. M., Bourdeau, J. E., Nwaila, G. T., & Ghorbani, Y. (2024b). Workflow-induced uncertainty in data-driven mineral prospectivity mapping. Natural Resources Research, 33, 995–1023.
Zhou, Z., & Liu, X. (2006). Training cost-sensitive neural networks with methods addressing the class imbalance problem. IEEE Transactions on Knowledge and Data Engineering, 18, 63–77.
Zuo, R. (2016). A nonlinear controlling function of geological features on magmatic–hydrothermal mineralization. Scientific Reports, 6(1), 27127.
Zuo, R. (2020). Geodata science-based mineral prospectivity mapping: A review. Natural Resources Research, 29(6), 3415–3424.
Zuo, R., & Wang, Z. (2020). Effects of random negative training samples on mineral prospectivity mapping. Natural Resources Research, 29, 3443–3455.
Zuo, R., Kreuzer, O. P., Wang, J., Xiong, Y., Zhang, Z., & Wang, Z. (2021). Uncertainties in GIS-based mineral prospectivity mapping: Key types, potential impacts and possible solutions. Natural Resources Research, 30, 3059–3079.
Zuo, R., Xiong, Y., Wang, Z., Wang, J., & Kreuzer, O. P. (2023). A new generation of artificial intelligence algorithms for mineral prospectivity mapping. Natural Resources Research, 32(5), 1859–1869.
Acknowledgments
The authors would like to thank Dr. George Henry (Wits Mining Institute, University of the Witwatersrand) for constructive feedback, which have improved this manuscript. We would like to acknowledge Prof. Raymond Durrheim (School of Geosciences, University of the Witwatersrand) for his gracious assistance with data sourcing, which had improved the quality of our evidence layers. We also thank Dr. Christopher J.M. Lawley (Geological Survey of Canada) for data management ideas. Two anonymous reviewers are thanked for their constructive comments, which helped us improve this paper. We also thank an Associate Editor for editorial handling.
Funding
Open access funding provided by University of the Witwatersrand. No funds, grants, or other support was received.
Author information
Authors and Affiliations
Contributions
Glen T. Nwaila contributed to conceptualization, investigation, data curation methodology, analysis and writing. Steven E. Zhang contributed to conceptualization, methodology, formal analysis and writing. Julie E. Bourdeau contributed to data curation, validation, visualisation and writing. Emmanuel John M. Carranza contributed to validation and writing. Stephanie Enslin and Musa S.D. Manzi contributed to data curation, data analysis and writing. Fenitra Andriampenomanana contributed to data curation and visualisation. Yousef Ghorbani contributed to writing.
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Supplementary Information
Below is the link to the electronic supplementary materials. All supplementary materials are embedded in a single portable document format (PDF) file for convenience. To access individual supplementary materials, click to open each link in the PDF file. Supplementary Material 1. Datasets to support prospectivity modeling of South Africa including PGE–Ni–Cu–Cr and Witwatersrand-type Au occurrences and deposits. Supplementary Material 2. Video: Convergence to consensus of models for PGE–Ni–Cu–Cr ore deposits. Supplementary Material 3. Video: Convergence to consensus of models for the Witwatersrand-type Au deposits.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nwaila, G.T., Zhang, S.E., Bourdeau, J.E. et al. Mineral Reconnaissance Through Scientific Consensus: First National Prospectivity Maps for PGE–Ni–Cu–Cr and Witwatersrand-type Au Deposits in South Africa. Nat Resour Res (2024). https://doi.org/10.1007/s11053-024-10390-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11053-024-10390-w