
Abstract
This paper argues that semelfactive and degree achievement verbs are morphosyntactically distinct, despite the fact that the morphemes they are made of are often syncretic even in languages with synthetic verb morphology like Czech or Polish. We use the mechanisms of Nanosyntax, a theory of the architecture of grammar in which the lexicon stores entire syntactic subtrees, to show that there is a structural containment between semelfactives and degree achievements such that semelfactives include more syntactic structure than degree achievements. In this respect, the relative structure of these two verb classes contributes to Bobaljik’s (2012) general claim that syncretism anchors structural containment as well as to the ongoing discussion about the form of spell out in syntax. The resulting picture supports the view whereby the semantics of lexical items is determined by their fine-grained internal syntax.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction and synopsis
Languages like English do not exhibit a morphological distinction between verb stems that belong to different structural or aspectual classes. That is, a stative transitive verb love and an activity intransitive verb walk both have monomorphemic stems and their argument structure properties cannot be predicted on the basis of their morphology. Moreover, verbs of different aspectual classes are sometimes homonymous with each other, for example, a semelfactive wink denotes a single-stage event in a sentence John winked at ten o’clock and is homonymous with an activity as in John winked furiously for several minutes till he got our attention. On the other hand, languages which exhibit a considerable degree of morphological compositionality in the formation of verb stems, like for instance Slavic languages, may not show a morphological distinction between two or more aspectual verb classes, either. This is the case with the Czech suffix NU, as well as its equivalent in Polish and some other Slavic languages, which creates either semelfactives in (1) or degree achievements in (2).
-
(1)


-
(2)


Despite the fact that semelfactives and degree achievements are morphologically indistinguishable, we argue that they are structurally different. Namely, there is a syntactic containment relation between these two types of stems such that semelfactives are structurally bigger than degree achievements.
We argue for the existence of structural inclusion of degree achievement structure inside the semelfactive syntactic structure on the basis of four new empirical discoveries about the NU-stems together with three motivated assumptions about syntactic containment.
-
(3)


These empirical findings are going to be coupled with the following assumptions about the following containment relations in syntax (where > stands for inclusion based on dominance):
-
(4)


The paper proceeds as follows. Before we discuss the properties of the Slavic NU morpheme and the way it provides the insight into the syntactic structure of semelfactives and degree achievements, we outline the mechanisms of Nanosyntax in Sect. 2. Nanosyntax is a theory of the syntax-lexicon interface whose major premise is that the lexicon stores entire syntactic subtrees and that spell out targets subconstituents of fine-grained syntactic representations rather than terminal nodes. The way Nanosyntax explains syncretic morphology is going to be essential in the analysis of NU.
In Sect. 3 we discuss the properties of NU in the context of other Slavic theme vowels. We show that degree achievement stems result from the merger of NU with adjectival roots and semelfactive stems result from the merger of NU with nominal roots. We also identify challenges in treating the NU sequence as a theme vowel and, instead, we propose that NU is not a singleton morpheme but two separate morphemes of which only U is a thematic suffix and N spells out the light verb.
Section 4 puts forward the light verb theory of the N morpheme, where it is argued that N incorporates the sequence ‘GIVE > GET’. We then use the containment theory of lexical categories, whereby nouns and verbs are bigger than adjectives to observe that semelfactive stems are syntactically bigger than degree achievement stems in two ways: they include bigger roots and the light verb GIVE present in the structure of semelfactives is bigger than the light verb GET in degree achievements.
In Sect. 5, we discuss the other morpheme of the split NU sequence, the thematic suffix U, which is responsible for the argument structure properties of verb stems. The discussion of the properties of the U-theme allows us to observe a third difference between the two aspectual classes of the NU-stems: semelfactive stems spell out the argument structure of a larger size than degree achievements do. This explains why Czech and Polish degree achievement verbs based on NU-stems are exclusively unaccusative, while semelfactive verbs are either transitive/accusative or unergative.
In Sect. 6 we show how the selectional restrictions between lexical categories of roots, the size of the light verb N, and the size of the U-theme become spelled out together into an attested morpheme order.
A brief Sect. 7 depicts the relations between the three zones of functional sequence discussed in the previous sections.
Section 8 is a short excursus on a thematic suffix EJ, which can also form degree achievement, but not semelfactive, verb stems.
Before we proceed to discuss the syntax of NU—a morpheme which builds both semelfactive and degree achievement stems in Czech and Polish—in a greater detail, consider first how syncretism has been used to explain the morpheme–phrasal syntax connection in Nanosyntax and its consequences to structure and interpretation of grammatical representations.
2 Nanosyntax: What syncretism teaches us about representation and lexicalization of syntactic structures
Nanosyntax is a new and developing theory of the syntax–lexicon interface, whereby the lexicon stores entire syntactic subtrees. The major tenet of Nanosyntax stems from the observation that terminal nodes of syntactic representations are smaller than morphemes, that is, syntactic structures can be submorphemic (Starke 2006, 2009, 2014). A scenario in which morphemes often relate to more than one, and often several, syntactic projections emerges from the expanding work on the structuralization of lexical semantics (see especially Ramchand 2008, among many others) and is consonant with what has often been called the strong cartographic thesis, namely that each grammatical feature heads its own syntactic projection (see, for instance, Cinque and Rizzi 2008:50).
The major advantage of Nanosyntax is the way it explains syncretism and morphosyntactic derivation of syncretic forms. The explanation based on mechanisms of spell out offered by this approach leads to the view that syncretism anchors the structural containment of grammatical representations, the conclusion reached also in Bobaljik (2012) on independent grounds.Footnote 1
2.1 Linear contiguity as structural containment
On the basis of a wide cross-linguistic study into suppletive forms of adjectival comparative and superlative morphology, Bobaljik (2012) argues that adjectival root forms are morphosyntactically contained in the structure of comparative forms, which are in turn contained in the structure of superlative forms, as in (5).
-
(5)
[[[ root ] comparative ] superlative ]
This claim is based on the observation that in nested structures (paradigms), a more complex structure and a less complex structure are not spelled out as an exponent A, if structures that are in between them in terms of complexity are spelled out as an exponent B (‘the *ABA’). In the domain of comparative and superlative suppletive morphology, this constraint can be illustrated by the following patterns.
-
(6)
root
comp
superl
pattern
English
smart
smart-er
smart-est
AAA
English
good
bett-er
be-st
ABB
Polish
dobry
lep-szy
naj-lep-szy
ABB
Latin
bon-us
mel-ior
opt-imus
ABC
Welsh
da
gwell
gor-au
ABC
unattested
*ABA
Bobaljik’s conclusion that superlatives morphologically include comparatives entails a bigger picture: elements that form a paradigm are in a containment relation.
The same view emerges from what we observe in the domain of case in Caha’s (2009, 2013) work, which shows that case involves a containment of universally ordered privative features Kn merged on top of the NP, as in (7), and individual cases such as ‘accusative’ or ‘dative’ result as a spell out of cumulatively ordered features Kn, as in (8).Footnote 2
-
(7)


-
(8)
nom ⇔ [ K1]
gen ⇔ [ K3 [ K2 [ K1]]]
loc ⇔ [ K4 [ K3 [ K2 [ K1]]]]
dat ⇔ [ K5 [ K4 [ K3 [ K2 [ K1]]]]]
inst ⇔ [ K6 [ K5 [ K4 [ K3 [ K2 [ K1]]]]]]
Such a representation explains the *ABA found in case paradigms, with the difference that they comprise more paradigmatic cells than comparative morphology, as in the examples from Polish, which morphologically distinguishes 6 cases.
-
(9)
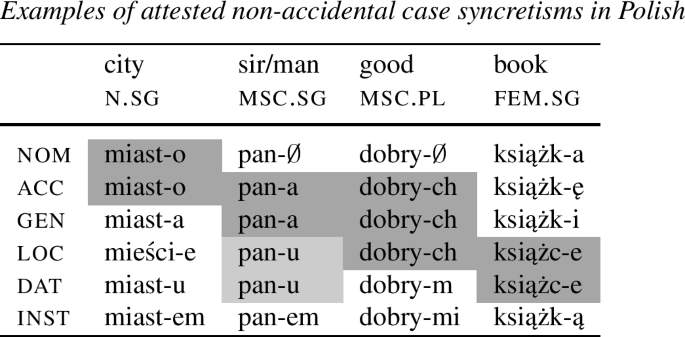

Adopting the containment theory of case, the *ABA can be explained structurally in the following way: syncretic spans are restricted only to contiguous regions of (7).Footnote 3
2.2 Spell-out
The restriction of syncretic spans to adjacent cells follows from the two major claims of Nanosyntax, namely that (i) lexical insertion targets phrasal nodes and (ii) it is regulated by the Superset Principle.
-
(10)
The Superset Principle
A phonological exponent of a lexical item is inserted into a syntactic node if its lexical entry has a (sub-)constituent which matches that node. Where several items meet the conditions for insertion, the item containing fewer features unspecified in the node must be chosen (Starke 2009).
This principle can be broken into two ingredients: the Superset clause and the Elsewhere Condition. The Superset clause explains the one-to-many relation between exponence and meaning, since it allows an exponent of a single lexical item to realize more than one syntactic representation. The Elsewhere Condition makes sure that if there is more than one possible lexical item to match a syntactic representation, it is the most specific item which wins the competition for insertion.
For example, there is a lexical item made of three features A, B, C, whose phonological exponent is α as in (11).
-
(11)
Lexical entry:


-
(12)
Syntactic representations:
-
a.

-
b.

-
c.

-
a.



According to the Superset statement of (10), the representations in (12a) and (12b) are both spelled out as α since they constitute a superset, in (12b), and proper subset, in (12a), of α. In other words, the syntactic structure in (12a) is spelled out as α just like (12b) is, due to the fact that it is contained in the lexical entry of α.
In contrast, α is not inserted into (12c). This structure does not match the lexical entry of (11). As a result, only (12a) and (12b) come out as syncretic. (12c) can only become lexicalized if there is another lexical item β, such that it includes also (at least) feature D in its specification, like in (13).
-
(13)
Lexical entry:


While the presence of a lexical item β in a language allows all the syntactic representations listed in (12) to be spelled out, we now face a problem of competition for lexical insertion: (12b) can spell out both as (a perfect constituent of) α and as (a proper subconstituent of) β. This competition is resolved by the Elsewhere clause of (10), a condition well-established in the work on morpho-phonology since at least Kiparsky (1973). The Elsewhere Condition makes sure that (12b) spells out as α, which is a more specific match than β.Footnote 4
Note that once feature D is merged with the existing structure CBA, the previous spell out of CBA as α is superseded by β, which lexicalizes the bigger tree.
-
(14)


This principle is called Cyclic Override, as an attempt to spell out takes place after each merge. The result is that a lexical entry matching a bigger tree will always override the smaller matches.
With these basic lexicalization principles in place, let us consider how a case paradigm of pan ‘man, sir’ in (9) with two syncretic pairs, acc=gen-a and loc=dat-u, becomes spelled out. Given (7), the complete set of the case entires is as follows.
-
(15)
Lexical entries for cases for pan ‘man, sir’(msc.sg)
-
a.
/∅/ ⇔ [ K1]
-
b.
/a/ ⇔ [ K3 [ K2 [ K1]]]
-
c.
/u/ ⇔ [ K5 [ K4 [ K3 [ K2 [ K1]]]]]
-
d.
/em/ ⇔ [ K6 [ K5 [ K4 [ K3 [ K2 [ K1]]]]]]
While the sets of features to the right of the exponents above correspond to the cases in the paradigm of pan, these sets do not form constituents of the case fseq in (7) and, hence, cannot be spelled out. In order to facilitate spell out, (7) must be changed into a representation with the relevant K-features in lexicalizable constituents.Footnote 5 This is achieved by the so-called spell out driven movement, which takes the form of successive-cyclic movement of the NP in (16), to the effect that phrasal constituents such as NomP, AccP, etc. come out as suffixes on the NP.
-
(16)
Spell-out driven NP-movement


Two final observations are to be made about this derivation. The first is that we have naturally achieved a scenario in which the entire phrasal constituents rather than terminal nodes get spelled out.Footnote 6 In such a system, each application of Merge is followed by lexical access from PF, which consists of exponents available to insertion at a given syntactic node, which we see in (16) where the size of the case suffix gets bigger and bigger with each merger of the NP upward in the case fseq.Footnote 7
The second is that what moves in a spell-out driven movement in the case fseq is only (and always) a constituent which contains the head noun, which is in concert with the restrictive theory of NP-internal movements of Cinque (2005).
2.3 Peeling
Apart from a successive-cyclic (spec-to-spec) movement in (16), movement can involve stranding, in which case only the bottom layers of an fseq are extracted, as in the so-called peeling derivation outlined in (17).
-
(17)


It is important to consider peeling from the perspective of the fate of the fseq layers stranded by extraction. That is, if the syntactic tree (18a) with A at the bottom is lexicalized as α (as it matches the entry (11)), then the constituent in (18b) with C at the bottom derived by extraction clearly is not (as it does not constitute a proper subconstituent of (11)).
-
(18)


Such a derivational scenario is not abstract—Caha (2009)/(2013) argues that in the domain of case, peeling movement changes structurally bigger cases into smaller cases, e.g. K2P into K1P. This is exhibited by the fact that the higher the position of the NP in the clause is, the smaller the case in the hierarchy in (7) this NP bears.Footnote 8 For example, in (19), the NP base-generated together with case projections on top is attracted by a licensing head in the NP-external domain.
-
(19)


The movement of K2P is triggered by checking its features against the head Y. In turn, the movement of K1P is triggered by checking its features against the higher head X, which is subextracted from K2P.Footnote 9
The aspect of peeling that is going to be most relevant in the discussion of semelfactives and degree achievements is what happens to case layers stranded by extraction. That is, if (20a) with K1 at the bottom spells out as accusative case morphology, then what does (20b) spell out as?
-
(20)


In Caha (2009) and Taraldsen Medová and Wiland (2018), case peels are argued to constitute parts of lexical entires of other morphemes. In what follows, we will extend this reasoning to argue specifically that peels stranded by NomP-extraction as in (20b) are spelled out as part of unergative verb stems in Czech and Polish. What is even more essential, however, is that peeling is a general property of Nanosyntax and is not limited to the domain of case. We will argue that it also applies in the domain of verbs.
Since Czech and Polish semelfactive and degree achievement stems are derived by the syncretic morpheme NU, we will apply the same logic and methodology as just outlined in the analysis of their syntactic structure. The resulting picture is going to be consonant with the view that syncretism anchors structural containment of morphosyntactic representations.
3 Slavic themes and the problem of the NU morpheme
Most Slavic verbs have a clear morphological make-up. Verbs with the NU morpheme stand out in two ways: they form two different aspectual classes (semelfactives and degree achievements) and they differ morpho-phonologically from the rest of the verbs. Before we discuss the properties of the verbs with the NU morpheme and observe what they indicate, let us first review the structure of the Slavic verb.
3.1 Verbs and theme vowels
3.1.1 Verb morphology
The format of a Slavic verb is to a considerable degree templatic (cf. Jakobson 1948; Laskowski 1975; Townsend and Janda 1996), as shown in the example from Czech in (21).Footnote 10
-
(21)
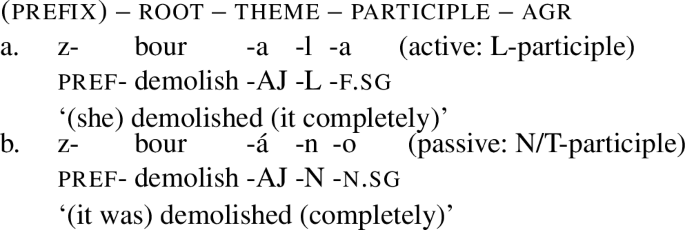
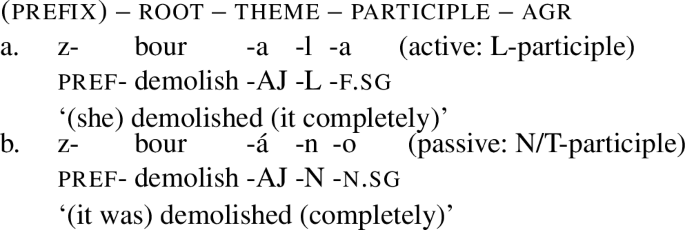
The root is optionally preceded by a prefix that introduces various aspectual and aktionsart properties, it is followed by a thematic suffix (the so-called theme vowel), which contributes to the argument structure properties of the verb stem, as we illustrate it below.
The theme is followed by a participial suffix: either active (non-present) L or passive N/T, as in (21a) and (21b), respectively. The ending (marked as ‘AGR’ in (21)) indicates subject agreement in gender and number. Neither the form of the participle nor the AGR suffix contribute to the aspectual properties of verb stems (i.e., a semelfactive verb stem remains semelfactive irrespective of whether it is suffixed with an active or passive participle). By and large, we are not concerned with prefixes, participles or agreement in this work and we concentrate exclusively on the verb stem, that is a combination of the root with the thematic suffix.
There are six themes in Czech and Polish: E, AJ, OVA, I, EJ, and NU. There is a long tradition in Slavic phonology of analyzing theme vowels as cyclic morphemes, that is, morphemes subject to phonological rules sensitive to morpheme boundary. In other words, there is abundant evidence from the work on Slavic phonology for the existence of a morphological boundary before and after a theme vowel, as indicated in (21) (see Rubach 1984, among many others).
The morphemes whose phonological exponents are theme vowels encode the verbal argument structure together with the root they merge with. This picture, however, is not fully clear since the root–theme combination has been a location for various phonological changes throughout the historical development of Slavic languages, an example of which is the existence of an obscure theme vowel whose phonetic exponent is Ø,Footnote 11 as in (22).
-
(22)


We tend to find the Ø-theme in verb stems belonging to different verb classes; there are activity verbs as in (22a), reflexive anticausative verbs like in (22b) and also some unaccusatives, e.g. Polish umrzeć ‘die’ or paść ‘fall’.
Furthermore, there are relatively infrequent verbs with the theme E. This theme builds stative verbs and a group of verbs related to perception or production of sounds (e.g. Polish jęcz-e-ć ‘moan’):
-
(23)


In turn, AJ, OVA and I themes derive activity verbs. In this group, the I theme is a typical ingredient of causative verbs (cf. ‘make X do Y’).Footnote 12
-
(24)


-
(25)


-
(26)


With an exception of EJ-stems, which we go back to later, we leave other verb stems out in our discussion and instead we focus on degree achievement and semelfactive stems.
Degree achievement stems are derived in Czech and Polish either by the theme EJ, as in (27),Footnote 13 or NU, as in (28). The term ‘degree achievement’ comes from Dowty (1979) and like Hay et al. (1999) and many others, we will keep using it for expository purposes (despite the fact that we, just like many others, do not share the intuition that such verbs actually denote achievements).
-
(27)


-
(28)


The Czech and Polish degree achievements are best rendered by the English gloss ‘get’ or ‘become,’ cf. ‘get/become grey, rusty, stupid,’ to indicate the meaning of examples (27) and (28). Whether a verb selects the theme EJ or NU is a question we leave unanswered for the most part of what follows. Nevertheless, quite clearly, in contemporary Czech and Polish, the choice is lexicalized. In other words, the degree achievement stems are formed by either NU or EJ, never both.Footnote 14 The theme NU can also—when merged with roots other than those which form degree achievements—create semelfactives, roughly defined as one-time events. In the case of these Slavic verbs, the native speakers instinctively also add that they denote events very short in duration.
-
(29)


In the rest of this section, we show that the theme NU is rather specific among the Slavic themes: not only does it create two aspectually distinct types of verbs, it is also the only Slavic theme that has a consonant in the onset. Before we go on to focus on the morphosyntax and semantics of NU, let us first briefly mention a phonological rule of Glide Truncation, which explains why certain theme vowels in inflected verb forms are sometimes difficult to recognize.
3.1.2 Verb phonology: Glide Truncation
The themes AJ and EJ surface as /a/ and /e/, respectively, whenever they are followed by a non-present active L- or passive N- or T-participle suffix, exactly as we observe it in (21). The glide becomes deleted by a phonological rule of Glide Truncation, whereby glides are deleted before a consonant in Slavic (Jakobson 1948):
-
(30)
j, w ⇒ ∅ / _ C0
This cyclic rule deletes morpheme final glides in AJ and EJ themes also in other contexts, including a boundary with the infinitival suffix -t in Czech or -ć in Polish. This is observed in infinitives like, for instance, in Polish łysi-e-ć ‘lose hair’ (not *łysi-ej-ć). The underlying shape of the theme vowel is preserved in surface forms of non-past tense inflection, for instance 1.plłysi-ej-e-my or in the imperative łysi-ej. The truncation rule operates on cyclic morphemes (by and large, the suffixes) and does not apply to non-cyclic domains, which results in glides being preserved at the prefix-stem boundaries, as in the Polish adjective naj-większy ‘biggest’ (not *na-większy).
3.2 Properties of NU
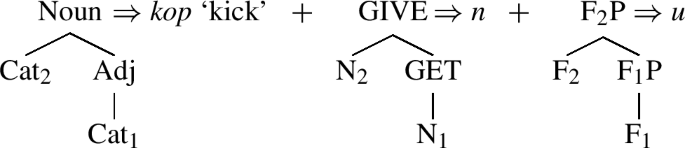
The combination of a root and the NU-theme builds either semelfactive (in (31)) or degree achievement (in (32)) stems, never both, in the sense that it is never ambiguous between degree achievement and semelfactive.Footnote 15’Footnote 16
-
(31)
semelfactive stems
-
a.
kop-nou-t ‘kick once’ (Cz) kous-nou-t ‘bite exactly once’
couv-nou-t ‘go back one step’
-
b.
kop-ną-ć ‘kick once’ (Pol)
umk-ną-ć ‘escape once’
dotk-ną-ć ‘touch once’
-
a.
-
(32)
degree achievement stems
-
a.
mrz-nou-t ‘become frozen’Footnote 17 (Cz)
slep-nou-t ‘become blind’
bled-nou-t ‘become pale’
-
b.
marz-ną-ć ‘become frozen’ (Pol)
sch-ną-ć ‘become dry’
chud-ną-ć ‘become slim’
-
a.
While the two readings are exclusive in both Czech and Polish, NU is productive only for semelfactives, not for degree achievement, which we see on the examples of borrowings:
-
(33)


In Czech, NU-based degree achievements and semelfactives have exactly the same morphological behavior: the allomorphs of the NU morpheme, -nou-, -nu-, and -n-, appear in exactly the same environments, like imperative forms of degree achievement bled-nou-t – bled-n-i! ‘get pale’ or semelfactive kop-nou-t – kop-n-i! ‘give a kick’ or, in the case of the -nu- allomorph, in past masculine gerunds forms like vy-bled-nu-v ‘having gotten pale’ or vy-kop-nu-v ‘having kicked’. It is perhaps worth mentioning that according to Caha and Scheer (2008), the infinitival allomorph -nou- surfaces as a result of templatic lengthening, a phonological process dependent on the morphosyntactic structure of Czech infinitives.
The phonological shape of the Polish equivalent of the Czech -nu- is - -. This exponent has been claimed to be either an underlying -non-, which undergoes the nasalization process involving a vowel followed by a nasal consonant in a coda (Gussmann 1980; Rubach 1984), or alternatively, a nasal diphthong consisting of a vowel and a nasal glide (Czaykowska-Higgins 1988). Throughout the paper, we refer to the thematic suffix which builds degree achievements and semelfactives as NU both for Czech and Polish.
-. This exponent has been claimed to be either an underlying -non-, which undergoes the nasalization process involving a vowel followed by a nasal consonant in a coda (Gussmann 1980; Rubach 1984), or alternatively, a nasal diphthong consisting of a vowel and a nasal glide (Czaykowska-Higgins 1988). Throughout the paper, we refer to the thematic suffix which builds degree achievements and semelfactives as NU both for Czech and Polish.
Another property of NU in both degree achievements and semelfactives is that it disappears in certain forms of participles (both in Czech and Polish). In L-participles (cf. (21a)), the NU tends to appear only in the masculine singular form, but in other singular and plural forms, it tends to disappear. There is a certain degree of variation among speakers of Czech and Polish with respect to which inflected forms retain or delete NU, as for instance in the following examples from Czech.
-
(34)


-
(35)
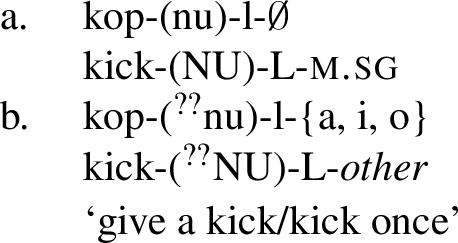
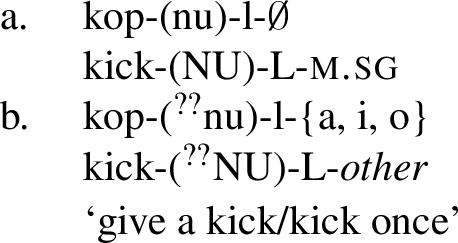
3.3 Degree achievement vs. semelfactive stems
The most telling difference between degree achievement and semelfactive stems with the NU-theme in both Czech and Polish is that degree achievement stems have adjectival roots while semelfactive stems have nominal roots.
3.3.1 Degree achievement roots are adjectival
Some examples of adjectival roots (which form adjectives when suffixed with an adjectival inflection -ý in Czech, as in (36), and -y/-i in Polish, as in (37)) in degree achievement stems are as follows:
-
(36)
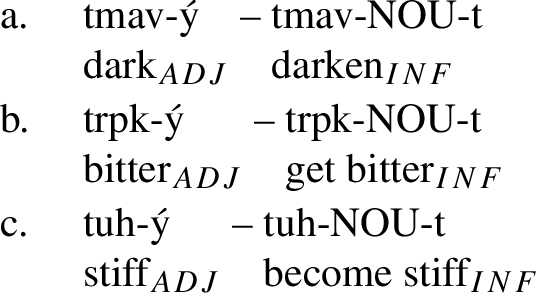
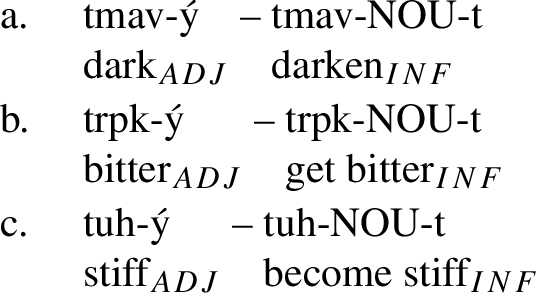
-
(37)


The format of a degree achievement stem is, thus, ‘an adjectival root + NU.’Footnote 18
3.3.2 Semelfactive roots are nominal
The roots of semelfactive stems are nominal in both Czech and Polish (as in (38)–(39), respectively), rendering the format of a semelfactive stems as ‘a nominal root + NU’.
-
(38)


-
(39)


The picture of semelfactive stems comprising a nominal root and NU is rather clear except, perhaps, two observations.Footnote 19
First, the directionality of the noun—semelfactive stem relation is not always crystal clear, as nominal roots can also merge with certain other themes, as in (40) for instance (we return to this fact later).
-
(40)


Second, there are a few NU-stems that are clearly not semelfactives, but activities. Importantly, all these activity stems have verbal rather than nominal roots (in both Czech and Polish).
-
(41)
-
a.
ply-nou-t ‘flow, follow’ (Cz)
-
b.
vi-nou-t ‘wind, wrap’
-
c.
ž-nou-t ‘mow, cut’
-
d.
tisk-nou-t ‘print once/print’
-
a.
-
(42)
-
a.
ciąg-ną-ć ‘pull, drag’ (Pol)
-
b.
pło-ną-ć ‘burn’
-
c.
pach-ną-ć ‘smell nice’
-
d.
pły-ną-ć ‘swim’
-
a.
It is significant to note that the roots in (41)–(42) form verb stems only, that is, these roots will not form adjectival or nominal stems (except for nominalizations and deverbal nouns, the forms which are derived from the entire verb stem, not the bare root, as they contain the N part of the theme vowel, as in Polish ciąg-n-ik ‘tractor’ or s-pło-n-ka ‘combustible detonator’). This is also manifested by the fact that they merge with typically verbal prefixes such as za-, as in za-vinout ‘swaddle’, za-ciągnąć ‘pull onto’, or prze-płynąć lit. ‘manage to complete a certain distance swimming’, where an excessive prefix prze- can be added only to stems based on verbs. The situation in which the property of a stem is determined by the combination of a particular category of root and a morpheme it directly merges with is a scenario which challenges an often adopted hypothesis that roots are acategorial. We observe such a situation in (41)–(42), where a rather exceptional merger of typically verbal roots and NU results with the formation of activity stems. This adds up to the pattern in which the merger of NU with an adjectival root produces a degree achievement stem and its merger with a nominal root produces a semelfactive stem.Footnote 20
It is important to note at this point that there are also a few verbs with the NU theme that are neither degree achievement nor semelfactive—and which are still different from those listed in (41)–(42). Historically, these verbs belong to the NU conjugation because their roots end in n (or m, as for instance in vez-m-u ‘take.1.sg’). These verbs share the conjugation type with degree achievements and semelfactives but without having the degree achievement or semelfactive semantics. According to Šmilauer (1972:241), in contemporary Czech there is a rather odd-looking group of 7 roots (sometimes referred to as the začít ‘start’ type in traditional Czech grammatical description) whose present-stem forms look exactly as any NU-verb (e.g. za-č-n-u ‘start-1.sg’ is exactly as za-kop-n-u ‘stumble-1.sg’) whereas their past-stem forms lack the N-morpheme completely but in a way different from the disappearing NU in the past forms discussed in (34)–(35), namely za-č-a-l ‘start-m.sg’ vs.za-kop-(nu)-l ‘stumble-m.sg.’ Three of these verbs even have roots that end in m and even they were attracted to the black hole of the N-based conjugation introduced in Late Common Slavic (e.g. vez-m-u ‘take.1.sg.pres’ – vz-a-l ‘took-m.sg.past’ – vzí-t ‘take.inf’). The NU-lization of these verbs is still in progress, as shown by the colloquial version of the infinitive: instead of the expected začít ‘start-inf’ a new NU-based infinitive form zač-nou-t is occasionally used. Thus, it appears that the root ending in n is a reason for verbs that are not semantically degree achievement or semelfactive to still follow the NU conjugation paradigm.Footnote 21
3.4 NU is inexplicable as a theme vowel
We have seen that Czech and Polish theme ‘vowels’ include Ø, E, EJ, NU, AJ, OVA, and I. Given that Slavic roots are typically CVC-clusters, themes make sense as vowels which complement the CVCV pattern typical for Slavic phonology. In this respect, NU stands out as odd with a consonant in the onset (not to mention the fact that it is hard to call NU a ‘vowel,’ similarly to OVA).
There are, however, morpho-semantic reasons which indicate that both Czech NU and its Polish equivalent NĄ are not themes but rather constitute sequences of two morphemes, whose exponents are /n/ and /u/ in Czech and /õ/ (spelled as -ą-) in Polish. The latter are the real theme vowels and N is a morpheme that lexicalizes the light verb which comprises the sequence ‘GIVE > GET’. In particular, we submit that the morpheme N in semelfactive stems spells out the GIVE layer, while in degree achievement stems N spells out the GET layer of the light verb. This is mirrored by the fact that semelfactives have GIVE-readings, as in (43), while degree achievements have GET-readings, as in (44):
-
(43)
-
a.
kop ‘a kick’ – kop-nou-t ‘give a kick’ (Cz)
-
b.
dotyk ‘a touch’ – dotk-ną-ć ‘give a touch’ (Pol)
-
c.
krzyk ‘a shout’ – krzyk-ną-ć ‘give a shout’ (Pol)
-
a.
-
(44)
-
a.
bledý ‘pale’ – bled-nou-t ‘get pale’ (Cz)
-
b.
slepý ‘blind’ – slep-nou-t ‘get blind’ (Cz)
-
c.
chudy ‘slim’ – chud-ną-ć ‘get slim’ (Pol)
-
a.
An argument for breaking the NU sequence into two separate morphemes comes also from the fact that the N appears without the U in environments other than semelfactive and degree achievement verbs. For example, we find the N morpheme with other theme vowels than U in passive participles in Polish (e.g. kop-N-ię-T-y ‘kicked’) and in nominalizations (e.g. kup-owa-N-ie ‘buying’, kop-a-N-ie ‘kicking’, Pol.).Footnote 22 Another context where we find the N morpheme without the U-theme is the Czech imperative, e.g. bled-n-ěte! ‘become pale!’.
4 N as a light verb
Before we discuss the light verb property of N in semelfactives and degree achievements, let us first point out the fact that both these categories have been occasionally argued to include the ingredient of the same semantic type. Notably, Rothstein (2004) proposed that the semantic element common for them is a natural atomic function. While from this perspective, the N morpheme can be hypothesized to spell out the natural atomic function, there are reasons to reject such a view in favor of the light verb theory of N. Consider the following.
4.1 Semelfactives and degree achievements in Rothstein (2004)
4.1.1 Natural subevents are necessary for semelfactives
There is an essential morphological difference between activity and semelfactive verbs that are created from the same roots in languages like English and Czech or Polish such that while English verb stems are structurally ambiguous between activity and semelfactivity, Czech or Polish verb stems are each created by a different theme: activity verbs include AJ, semelfactives NU. Consider the following examples with English wink and its Czech equivalent mrk-a-t.Footnote 23
-
(45)


-
(46)


Semantically speaking, the difference between activities like walk and semelfactives like wink concerns their natural subevents. Essentially, even if semelfactive verbs are used as activities as in (45a), there are easily identifiable single occurrences of subevents of wink while there are no such single occurrences of walk. In Dowty’s (1979) terms, these single occurrences are themselves the smallest events of the predicate P to the effect that an activity event has minimal parts (\(=P_{min}\)), which are the smallest events in P which count as events of P. Thus, events like winking comprise natural minimal events (single winks) but events like walking do not comprise such minimal events.
Assuming Dowty’s analysis, Rothstein (2004, 2008) distinguishes between semelfactives and activities on the basis of natural atomicity. A naturally atomic entity is the one which comes with a perceptually salient unit structure (marked by natural beginning and end points) given by the world (this includes the denotation of countable nominals like wink, kick, or jump) and the natural atomic function (NAF) is the function which picks out the set of minimal parts \(P_{min}\) of the predicate P, as defined in (47).
-
(47)
Natural Atomic Function (NAF)
“An activity predicate P will denote a set of events P, and will contain a subset \(P_{min}\), which is the set of minimal events in its denotation. If a predicate has a semelfactive use, then there will be a natural atomic function which picks out the set \(P_{min}\), and \(P_{min}\) will be an atomic set” (Rothstein 2004:186).
In other words, Rothstein submits that naturally atomic subevents are recognizable and referrable for semelfactives, but not for activities. The former ones denote events with natural beginning and end points, while the latter do not.
4.1.2 Scale is necessary for degree achievements
Rothstein observes that while natural subevents are necessary for semelfactives, degree achievements must comprise a scale.
We have observed in Sect. 3.3 that Czech and Polish degree achievement are derived from adjectival roots. Since the denotation of adjectives makes reference to scales, understood as ordered sets of degrees, the scalar structure is present in the denotation of degree achievements, as specifically argued for in Hay et al. (1999).
Consider the following examples with degree achievements in English from Rothstein (2004).
-
(48)
-
a.
The soup cooled for some hours.
-
b.
The sky darkened between 2 pm and 4 pm.
-
a.
Despite the fact that cool and darken have properties that make them similar to activities, for these sentences to be true, there must have existed intervals during which the single occurrences of cooling and darkening took place. In particular, Rothstein (2004:189) argues that the sky darkened does not denote a change from the state ‘not being dark’ to the state ‘being dark,’ rather, the darkening denotes changes of degrees on a scale of darkness such that the endpoint of one change is the starting point of the next change. A similar series of changes of a degree of coolness is a part of denotation of the soup cooled.
Assuming the denotation depends on changes of a degree along a scale, Rothstein draws a parallel between degree achievements and semelfactives based on natural atomicity. While NAF defines minimal parts of a predicate which have a beginning and an endpoint in semelfactives, in the case of scales, NAF defines the minimal degree of a change on that scale. This is in essence what seems to be a common ingredient in Czech and Polish semelfactive stems, which are all based on nominal roots, and degree achievement stems, which are all based on adjectival roots.
4.1.3 Challenges to the NAF analysis of N
Since semelfactive and degree achievement stems include different roots but stems of both categories include the morpheme N, it is tempting to suggest that N simply spells out NAF. Such a hypothesis would quite naturally hold that in the structure of semelfactive stems the morpheme N picks out the atomic event from the denotation of a nominal root, e.g. kop- ‘kick’, which is the single occurrence of the event \(P_{min}\). In the case of degree achievements, it could be hypothesized that the denotation of a minimal degree of a change on a scale is conditioned by the presence of the N morpheme in combination with the adjectival root.
Such an approach, however, is not free from problems. First, it remains unclear if the natural atomicity is really a grammatical feature lexicalized by the N morpheme (that is, NAF is part of the morphosyntactic representation) or the function in the denotation of the entire stem (as it is in the case of English semelfactives and degree achievements). Second, if N is supposed to spell out NAF, it is unclear what NAF picks out from typically verbal roots that also merge with N in examples listed in (41)–(42). The existence of such forms in fact rules out the NAF hypothesis of N, as the resulting stems in these two examples are clearly activities. If Rothstein’s natural atomicity remains the function in the denotation of the entire category rather than part of the morphosyntactic representation, the problem of what N spells out remains.
4.2 The light verb theory of N
Instead, we argue below that N is a light verb, whose grammatical ingredients are responsible for GIVE and GET readings of semelfactive and degree achievement stems, respectively.
4.2.1 Layers of the light verb structure
We submit that N is a light verb which includes abstract GET and GIVE such that GET is contained in the structure of GIVE, as in the following:Footnote 24
-
(49)


The light verb structure of the N morpheme in Czech and Polish is genuinely similar to the decomposition of the light GIVE in English into ‘GIVE > GET > possessive HAVE’, which is manifested in the fact that both lexical get and give integrate a possessive functor, which is indicated in English by the restatements with have:
-
(50)
-
a.
John gave Mary the book. → John caused Mary to have the book.
-
b.
Mary got the book. → Mary came to have the book.
-
a.
A frequently cited argument (e.g. Ross 1976; Dowty 1979; Beavers et al. 2009) in favor of an underlying possessive HAVE state in lexical give and get in English is that it can be modified by durative for-adverbials:
-
(51)
-
a.
John gave Mary the book for two weeks. → have the book for two weeks.
-
b.
Mary got the book for two weeks. → have the book for two weeks
-
a.
A particularly interesting argument in favor of the decomposition of the lexical give as comprising both light GET and possessive HAVE comes from Richards (2001), who shows that there are idioms which consist of an object and a part of a lexical verb give in which case it has the GET-reading.Footnote 25 Richards (2001) adopts Harley’s (1997, 2003) structure of the lexical verb give as in (52), which incorporates HAVE.
-
(52)
[x CAUSE y [HAVE DP]]
-
a.
John gave Mary the book.
-
b.
John CAUSE Mary [HAVE the book].
-
a.
In Harley’s analysis, sentences like in (52a) differ from to-dative sentences like John gave the book to Mary in that the latter do not incorporate the possessive HAVE.Footnote 26 On this basis, Richards (2001) observes that there is a class of give idioms which obligatorily involve the structure in (52), as the idiom is broken when the double object form is not used:
-
(53)
-
a.
The Count gives Mary the creeps.
-
b.
*The Count gives the creeps to Mary.
-
a.
-
(54)
-
a.
Mary gave John the sack.
-
b.
*Mary gave the sack to John.
-
a.
-
(55)
-
a.
Mary gave Susan the boot.
-
b.
*Mary gave the boot to Susan.
-
a.
This contrast signals that double object sentences do not inevitably involve a separate predicate HAVE but rather the meaning of a possessive HAVE is part of a ditransitive predicate. Importantly, Richards points out that the idiomatic part is smaller than give DP, since it is preserved with get:
-
(56)
-
a.
Mary got the creeps.
-
b.
John got the sack.
-
c.
Susan got the boot.
-
a.
This leads Richards to conclude that the idiomatic part is only [HAVE DP] which is lexicalized as part of a monotransitive get DP or a ditransitive give DP in English. Since the GET-reading is part of the GIVE-reading there exists a containment relation between GIVE and GET and GET and possessive HAVE.
As indicated in (43)–(44), the merger of N+U with the root produces a stem which has a GIVE-reading or a GET-reading. Since the theme vowel U turns the structure into a verb stem—just like all the other themes do—and together with the root it merges with is responsible for the argument structure properties of the stem (including its case), it is the morpheme N that appears to be the locus of the light GIVE and GET readings. The fact that degree achievements stems have GET-readings suggests that their adjectival roots merge with the light verb of the following size, a subset of (49):
-
(57)
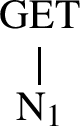
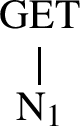
In turn, the fact that semelfactive stems have GIVE-readings, suggests that their nominal roots merge with a light verb with an additional layer of structure, a superset of (49). Under such an analysis of the N morpheme, its lexical entry is as follows:
-
(58)
N: /n/ ⇔ [\(_{GIVE}\) N2 [\(_{GET}\) N1]]
Recall that due to the Superset Principle in (10), both representations in (49) and (57) are spelled out as N. We have, thus, identified the first contrast in the sizes of morphemes forming degree achievement and semelfactive verb stems: the lexical entry for the light N morpheme in a degree achievement stem includes a subset of the syntactic structure of the lexical entry for the light N in a semelfactive stem.
It must be noted that the fact that the English light “give DP” (give a kick) and “get Adj” (darken, get dumber) have the form of “nominal root + N” (kop-N-ou-t) and “Adj + N” (hloup-N-ou-t) in Czech and Polish is not by itself the argument for the existence of the light verb N. The argument is the valency identity between these forms. That is, while English “give DP” is causative, so is the Czech and Polish “nominal root + N”. This is well visible below, where a nominal root with the light N in (60) corresponds to a direct object of the lexical dać ‘give’ in the Polish example (59).
-
(59)


-
(60)


The same is true about light verbs like darken or periphrastic get dumber and “Adj + N” mergers in Czech and Polish: both are exclusively unaccusative, which we return to shortly.
4.2.2 Light GIVE and GET in Persian
An argument supporting the analysis of the facts discovered to hold inside Czech and Polish NU-stems comes from Persian, where a formation of a semelfactive stem involves a merger of a nominal preverb with a light verb dadæn ‘give’.Footnote 27
In Persian, the majority of verbal predicates are built by merging a non-verbal part, the so-called preverb, with a light verb (which includes verbs like kærdæn ‘do’, shodæn ‘become/get’, amædæn ‘come’). The preverbs can belong to different categories: nouns, adjectives, adverbs, prepositions, or PPs. However, a few light verbs merge with preverbs of only a particular lexical category. Such a category restriction holds in the case of the light verb dadæn ‘give’, which builds semelfactives and accomplishments, and which merges only with nominal preverbs and occasionally with prepositions (cf. Folli et al. 2005; Pantcheva 2009). Whether a semelfactive or an accomplishment verb is produced depends on the type of noun dadæn merges with. For instance, in the examples from Family (2014:109), three nouns denoting rotation—twist, turn, and roll, produce semelfactives when merged with dadæn:
-
(61)


Here, again, just like in Slavic NU-stems or English semelfactives of the form ‘give a kick’, the semelfactive involving dadæn ‘give’ is always causative, as in:
-
(62)


There are two non-causative variants of dadæn ‘give’: light verbs gereftæn ‘get’ and shodæn, literally ‘become/get’ (Pantcheva (2009) classifies them as resultative versions of dadæn ‘give’, which both lack an initiator of an event in Ramchand’s (2008) decomposition of the event structure). While gereftæn ‘get’ corresponds to English change-of-possession get, as in (63) below, it is shodæn ‘become/get’ which corresponds to a change-of-state get in degree achievements like get dumber, or Czech hloup-N-ou-t.
-
(63)


Unlike dadæn ‘give’, it can merge with adjectival preverbs, as in (64) (where the possibility to modify the “gradable adjective + shodæn” complex by both for- and in-adverbials indicates that it forms a degree achievement, given the claim in Ramchand (2008) about the telic/atelic status of such stems):
-
(64)


This is exactly the scenario that we find to hold inside the semelfactive stems in Czech and Polish.
4.2.3 Change-of-possession and change-of-state light GET
Putting the Persian facts aside, it could be hypothesized that in English, the ‘GIVE > GET’ inclusion is restricted only to the change-of-possession relation and does not show up in the change-of-state GET. Such a supposition, however, must be rejected. Richards’ (2001) observation about English idioms which consist of an object and a part of a lexical give, in which case it has the GET-reading, quite clearly reveals that both change-of-state and change-of-possession GETs are related by comprising a possessive HAVE. This is illustrated by a subset of change-of-possession GIVE/GET idioms that are retained with a change-of-state GET, e.g.:
-
(65)
-
a.
John gave Mary a sack.
-
b.
Mary got a sack.
-
c.
Mary got sacked.
-
a.
-
(66)
-
a.
Susan gave Mary a boot.
-
b.
Mary got a boot.
-
c.
Mary got booted.
-
a.
-
(67)
-
a.
John gave Mary an evil eye.
-
b.
Mary got an evil eye (from John).
-
c.
Mary got evil eyed (by John).
-
a.
It is, thus, quite clear that the core of the GET-reading is the change itself, namely
-
(i)
change-of-possession as part of the lexical get or give, and
-
(ii)
change-of-state as part of only the lexical get, not give.
In degree achievements, we never have a change-of-possession, only the change-of-state reading of GET (based on the adjectival root) in the following format:
-
(68)


Semelfactive stems in Czech and Polish have a clear GIVE-reading (i.e., GET plus more). But in this case, this GET requires a possession, not a state. So, starting with a possessed object like kop- ‘a kick-’, it is not enough to merge it with the light GET only, as such a structure does not correspond to any attested stem:
-
(69)


Instead, in the case of semelfactives, the light verb structure must be bigger and it has to grow all the way to GIVE-layer, that is the bigger N-suffix of (49).
4.3 Slavic ‘GIVE > GET’ without HAVE
In Czech and Polish, nothing suggests that there is HAVE lower than GET. Instead, the ‘resultant state’ of degree achievements is expressed with an adjective with a separate auxiliary verb BE, not HAVE, as illustrated on the example of Czech in:Footnote 28
-
(70)


The light N in degree achievement does not have the HAVE-reading, not even in the exceptional degree achievement stem mrzout ‘get cold’ (discussed in fn. 17), which can get a stative reading, as shown in (71).
-
(71)


For the purposes of describing the light verb properties of the N morpheme, it is sufficient to observe that it has GIVE- and GET-readings, while it lacks possessive HAVE-readings. For this reason, the HAVE-layer is absent from the structural representation of the N-morpheme in (49).Footnote 29
4.4 Light GIVE, GET, and root selection
The situation in which the GIVE-readings and the GET-readings of N-stems are restricted by the category of the root indicates that the merger of the N morpheme with the root is regulated by selection whereby a bigger N\(_{GIVE}\) merges with nominal roots and a smaller N\(_{GET}\) merges with adjectival roots. It, thus, appears that the size of the morpheme N—in particular, the presence of the top GIVE layer in the structure of the light verb—depends on the category of the root it merges with. It must be observed that the relation between the size of the N morpheme and the category of the root can be reduced to a general size-to-size selectional relation under a containment theory of lexical categories put forward in Starke (2009).
According to the containment theory, detailed in Lundquist’s (2008) analysis of the structure of Swedish participles, lexical categories are not primitive but structurally complex such that adjectives are smaller than nouns which are, in turn, smaller than verbs, as simplified in (72).Footnote 30
-
(72)


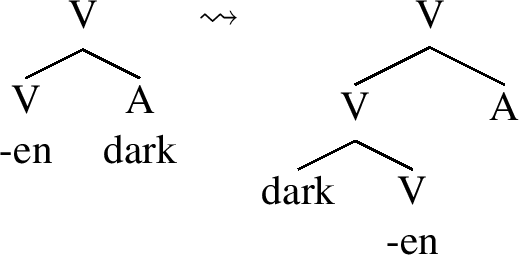
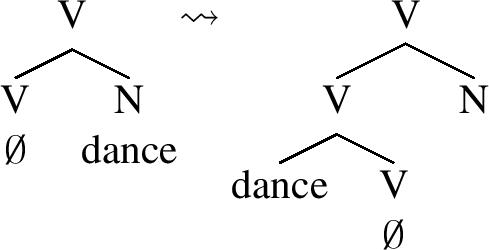
As discussed at length in Lundquist (2008), the idea that verbs structurally contain nouns and adjectives is not new and has been based on an observation that the more functional structure that participles and nominalizations contain, the more verbal syntactic properties they exhibit. Likewise, participles and nominalizations behave like non-derived adjectives and nouns if they contain a smaller functional structure. This general observation constitutes the basis of Hale and Keyser’s (2002) theory of the formation of deadjectival (e.g. darken) and denominal (e.g. dance) verbs. These classes of verbs are argued to be derived by conflation, that is, the merger of an adjectival or a nominal root with a verbal head in the lexical representation, as outlined below:Footnote 31
-
(73)

-
(74)

Similarly, verbs are analyzed as categories bigger than adjectives in Baker (2003). Apart from analyzing verbs as categories composed of adjectives merged with the Predication head in syntax, Baker also observes that the internal argument of verbs usually corresponds to the external argument of adjectives:
-
(75)
-
a.
John hungers.
-
b.
John is hungry.
-
a.
-
(76)
-
a.
John likes mushrooms.
-
b.
John is fond of mushrooms.
-
a.
Assuming the Universal Thematic Hierarchy (UTAH), Baker concludes that this fact makes the argument structure of a verb derived from a smaller argument structure of an adjective.
The idea that verbs are bigger than nouns and adjectives has been supported more substantially than the idea that nouns are bigger than adjectives. Though, apart from Lundquist (2008), Baker’s (2005) theory of lexical categories lists adjectives as the most basic category devoid of both nominal structure (“the referential index”) and the verbal structure (“a specifier”).
If the avenue of the lexical containment between nouns and adjectives as in (72) is on the right track, then we must state that the syntactic structure of the root in degree achievements is a subset of the syntactic structure of the root in semelfactives. This constitutes the second difference in syntactic sizes of morphemes in these stems after the contrast in the size of the light N morpheme giving the emerging picture as follows: semelfactives are formed by a nominal root and the light N\(_{GIVE}\), while degree achievements are formed by their subsets, the adjectival root and the light N\(_{GET}\).
The merger between the varying sizes of the light N morpheme and different lexical categories of roots does not appear to be accidental but rather an instance of a size-relative selection. We have observed that a smaller N\(_{GET}\) selects for adjectival roots, while a bigger N\(_{GIVE}\) selects only for nominal roots, which are bigger than adjectives in the lexical containment theory, as outlined in (77). (Since the spans of syntactic projections indicated in the diagrams below do not constitute morphemes at this early derivational stage when selection takes place, we are referring to them simply as ‘zones’ rather than ‘morphemes’).
-
(77)


We will observe another instance of the size-to-size selectional restriction taking place in the Slavic verb stem in Sect. 5.2 when we discuss the properties of the thematic suffix U, which completes the morphological make up of NU-stems.
4.5 Spelling out the light N zone
In the model of phrasal spell out, the insertion of a lexical material at a phrasal node requires that the representation to be lexicalized forms a constituent. The representations in (77) do not match the lexical entry in (58). The lexicalization of these structures is obtained by spell out driven movement of the root zone, in the same way the lexicalization of the case fseq is obtained by the movement of the NP outlined in Sect. 2.2.
Following the logic in Starke (2009) and Caha (2011b), it is the shape of a lexical entry that triggers movement. In particular, in a model in which each application of external merge is followed by lexical access, it is the lexical access that determines the way the syntactic derivation proceeds. Consider the partial derivations of a Czech and Polish noun-based stem kop-N- as in a semelfactive kopnout ‘give a kick’ and an adjective-based stem slep-N- as in a degree achievement slepnout ‘get blind’ at a stage before the thematic morpheme U is merged.
-
(78)
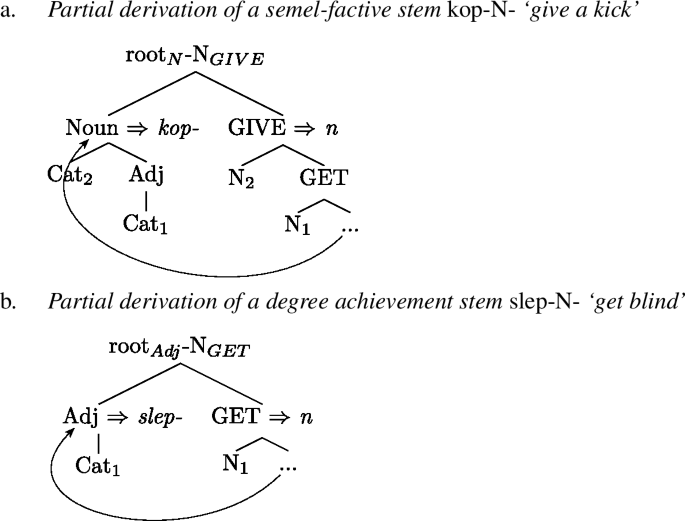

The evacuation movement that targets a sister to node N1 in (78a) derives a constituent that matches the lexical entry for /n/ in (58). The height of the evacuation movement in (78b) is delimited by the node GET, which results in the formation of a constituent like in (57). Due to the Superset Principle, this constituent also spells out as /n/. In principle, there is nothing that prohibits the moved constituent to include other layers of structure than the ones in (78). However, the lexical entry for /n/ has N1 at the bottom, so any movement that does not create a constituent with N1 at the foot will not spell out as /n/.Footnote 32
Once an evacuation movement of the root zone takes place and a constituent that matches a lexical entry is formed, the structures become input to further external merge. In the case at hand, the fseq that forms the theme U zone, the other part of the split N+U sequence, becomes merged. We discuss the U theme in the next section.
To sum up, the partial structure of both types of stems discussed so far looks, thus, as follows:
-
(79)
-
a.
semelfactive: [[ N-root] \(\mathrm{N}_{\mathit{GIVE}>\mathit{GET}}\)]
-
b.
degree achievement: [[ Adj-root] \(\mathrm{N}_{\mathit{GET}}\)]
-
a.
In what follows, we show that both these types of stems have different syntactic properties, which reflects the different amounts of syntactic structure spelled out by the theme vowel U.
5 U theme and argument structure properties of NU-stems
Splitting the NU part of the stem into separate morphemes N and U makes it possible to link the internal syntax of semelfactive and degree achievement stems with their argument structure properties. The major observation behind this premise is that while both semelfactive and degree achievement stems have the same morphological makeup comprising the root, the N morpheme and the theme vowel U, they display different argument structure properties. Since, as argued above, the N morpheme has the properties of a light verb, the morpheme which determines, though indirectly, the argument structure properties of NU-stems is the thematic suffix U. In other words, the theme U is responsible for argument structure properties just like the other themes are.
5.1 Unaccusative degree achievements, accusative or unergative semelfactives
The corpus analysis of Czech and Polish semelfactive and degree achievement verbs based on NU-stems leads to the generalization that while degree achievement stems are all unaccusative, semelfactive stems are either transitive/accusative or unergative.Footnote 33 Some examples of Czech and Polish unaccusative degree achievements are given in (80)–(81).
-
(80)


-
(81)


Unlike degree achievements, semelfactive NU-verbs are either transitive/accusative or unergative. Examples of transitive/accusative semelfactives are given in (82)–(83).
-
(82)


-
(83)


Finally, examples of unergative semelfactives are given in (84)–(85).Footnote 34
-
(84)


-
(85)


5.2 Theme vowel U
Descriptively speaking, theme vowels are verbalizing morphemes, which participate in encoding the argument structure properties of verb stems. This is perhaps best illustrated by those themes which can merge with a single root, in which case we observe the causative-inchoative alternations as in (86).
-
(86)
Examples of causative-inchoative alternations
unaccusative N+U
accusative I
marz-ną-ć
‘get cold’
mroz-i-ć
‘freeze (something)’
(Pol)
mięk-ną-ć
‘get soft’
mięk-cz-y-ć
‘make (something) soft’
(Pol)
mok-nou-t
‘get wet’
moč-i-t
‘soak (something)’
(Cz)
chlad-nou-t
‘get cold’
chlad-i-t
‘make (something) cold’
(Cz)
For instance, a root marz- ‘cold’ builds an unaccusative (degree achievement) stem by merging with N+U, as in Wszyscy marz-ną ‘Everybody is getting cold’, but when merged with a causative theme vowel I, it builds an accusative stem, as in Jan mroz-i piwo ‘Jan is cooling the beer’. Essentially, the causative I-stem is always accusative and the NU∼I alternation is rather common in both languages.Footnote 35
The syntactic properties of Polish thematic suffixes have been detailed in Jabłońska (2007), where it is argued convincingly that they spell out layers of a fine-grained vP/VP structure.Footnote 36 The thematic structure properties of the thematic suffixes in contemporary Czech and Polish are summed up in the following table. Starting at the bottom, there are two rather exceptional classes: the Ø thematic suffix (a result of historical changes in morphophonology) and the theme -OVA- (apart from N+U, the only thematic suffix productive in contemporary Czech and Polish).Footnote 37
-
(87)
Summary of argument structure properties of Czech and Polish themes
semantic class
theme vowel
argument structure
verb class
example
gloss
causative
I
Ag+Th
acc
top-i-t
‘drown sb’
iterative/habit.
AJ
Ag+Th
acc
klek-a-t
‘kneel (iter.)’
semel#1
(N-)U
Ag(+Th)
unerg
klek-nou-t
‘kneel’
semel#2
(N-)U
Ag+Th
acc
kop-nou-t
‘kick sb’
become#1
(N-)U
Th
unacc
bled-ną-ć
‘get pale’
become#2
EJ
Th
unacc
plan-ej-t
‘get wild’
stative
E
Th/Exp
unacc
kleč-e-t
‘kneel’ (stative)
causative/all
OVA
Ag+Th
acc
stud-ova-t
‘study’
causative/all
Ø
Ag+Th
acc
nés-Ø-t
‘carry’
While the general approach to thematic suffixes in what follows and in Jabłońska’s work is similar, for space reasons, we are restricting the discussion of argument structure properties of Slavic theme vowels to a minimum necessary to understand the general similarity of the U theme with other themes like I or AJ, which are clearly responsible for the syntactic properties of the verb stems they build.
Suffice it to say, Czech and Polish themes do not simply encode bare argument structure but rather the structural properties that are a part of the aspectual event structure. That is, while the theme vowel I is an exponent of a suffix that builds causative stems, another theme vowel AJ builds activity stems (iteratives and habituals), which are both unergative and/or transitive, just like semelfactive NU-stems. Many roots which build either unergative or accusative NU-semelfactive stems can instead merge with the AJ-theme, as in (88). Such a combination creates an activity stem with unergative syntax. Also this alternation is common in both Polish and Czech.
-
(88)
Examples of semelfactives and activities alternations
unergative or accusative N+U
unergative AJ
liz-ną-ć
‘lick once’
liz-a-ć
‘lick’
(Pol)
kop-ną-ć
‘give a kick’
kop-a-ć
‘keep kicking’
(Pol)
štěk-nou-t
‘give a short bark’
štěk-a-t
‘bark’
(Cz)
klik-nou-t
‘click once’
klik-a-t
‘keep clicking’
(Cz)
On the proviso that a separate morpheme N spells out the structure responsible for GIVE/GET readings, the morpheme which lexicalizes the syntactic structure that comes out unaccusative, accusative, and unergative in NU-stems is the theme U. In a system in which spell out targets subconstituents rather than terminal nodes, this indicates that the syntactic representation of the U theme spans across several layers of the syntactic event (or “VP”) structure. While the ongoing work on the VP structure, usually couched within the variants of the “accusative little vP” > “unaccusative VP” split approach based on Hale and Keyser (2002) and Kratzer (1996), differs with respect to what heads the articulate VP is made of, it has been established that an unaccusative VP is structurally smaller than an accusative VP (at the very least in the way that it includes a layer of structure that contains an accusative object).
In turn, the fact that external arguments are merged higher than accusative objects indicates that they are introduced by another higher head in the eventive verbal structure. For this reason, unergatives have been argued to be structurally similar to accusatives rather than unaccusatives (see for instance Levin and Rappaport Hovav (1995) or Ramchand (2008), who argue that both unergatives and accusatives differ from unaccusatives in that they include the layer of structure with event initiators as arguments). An often reported structural proximity between unergatives and accusatives is also manifested by the fact that certain NU semelfactives are either unergative or accusative. Oftentimes, such an alternating verb will receive a non-literal reading as in (89), where the unergative semelfactive ‘whistle’ in (89a) has a non-literal meaning ‘steal’ if it is an accusative semelfactive, as in (89b).
-
(89)


The situation in which a singleton morpheme U lexicalizes a syntactic representation which includes projections bigger than unaccusative constitutes an argument in favor of the phrasal spell out of a (part of) the eventive verb structure in the same way as a single case morpheme lexicalizing representation that contains other cases does. For the case at hand, the theme U spells out the lowest unaccusative projection as part of degree achievement stems and bigger accusative and unergative projections as part of semelfactive stems as in the following representation in (90), which captures the ‘unergative > accusative > unaccusative’ distinction:Footnote 38
-
(90)


The lexical span of U stretches further up to at least one layer, F3P in (90), atop the accusative structure and excludes higher layers of the unergative structure. This correctly captures the observation that not only does U spell out as unaccusative, accusative and unergative but also that there is (at least) one other morpheme which spells out as unergative, namely the AJ theme, which builds activity stems (cf. (88)). In other words, U is syncretic for unaccusatives, accusatives and (lower) unergatives and the lexical entry for the unergative AJ theme is bigger than the lexical entry for U.
Note that the fact that U spells out unaccusative, accusative, and unergative while AJ spells out only unergative structure is in concert with the *ABA constraint. Recall from Sect. 2.1 that the *ABA states that in nested structures, a more complex structure and a less complex structure are not spelled out as an exponent A, if structures that are in between them in terms of complexity are spelled out as an exponent B. Thus, the hypothetical *ABA scenario for the ‘unergative > accusative > unaccusative’ hierarchy of structural complexity would be that the AJ theme spells out accusatives and the U theme spells out unergatives and unaccusatives, counter fact. The representation of the argument structure hierarchy as the syntactic tree allows us to explain why such a scenario is unattested, namely the syncretic span of the U theme is restricted only to a contiguous region of (90).
The lexical entry for the thematic morpheme U, whose exponent is /u/ in Czech and /ą/ in Polish, is given in (91), and the syntactic constituents which on the strength of the Superset Principle can spell out as U in (92).
-
(91)
Lexical entry for U
U: /u/ (Cz), /ą/ (Pol) ⇔ [ F3[ AccP peel [ F2[ F1]]]]]
-
(92)
Constituents spelled out as the thematic suffix U in Czech and Polish
-
a.
U: /u/ (Cz), /ą/ (Pol) ⇔ [ F3[ AccP peel [ F2[ F1]]]]]
-
b.
U: /u/ (Cz), /ą/ (Pol) ⇔ [ F2 [ F1]]
-
c.
U: /u/ (Cz), /ą/ (Pol) ⇔ [ F1]
-
a.
The lexical entry for U in (91) includes an AccP peel, that is the AccP stranded by the extraction of a lower NomP, a scenario discussed in Sect. 2.3. The extraction of the NomP subconstituent strands the AccP layer of the case fseq as part of the tree representation which is spelled out as the thematic suffix U, the issue we return to shortly. The subconstituents in (92b) and (92c) are also spelled out as U due to the Superset Principle in (10).Footnote 39
Despite the fact that the theme vowel U spells out part of the fseq of the eventive verbal structure, it is imprecise to state that it is solely responsible for the argument structure properties of NU-stems. Otherwise, we would expect any kind of a NU-stem, that is both degree achievements or semelfactives, to come out as unaccusative, accusative or unergative, contrary to fact. Instead, the relation between how much argument structure U spells out is dependent on the syntactic size of the root and the light N morpheme. Namely, a small root zone (descriptively speaking, an adjectival root) and a small N zone (the light GET) as in (77b) merge with a small thematic U zone, while a bigger root zone (a nominal root) and a bigger N zone (the light GIVE) as in (77a) merge with bigger U zones. Assuming the hierarchical ‘unergative > accusative > unaccusative’ VP structure, we observe a size-relative selection between the U theme and the root+N constituent, the type of selection which we earlier observed to hold between the light N and the root, a situation which we will return to shortly.
To sum up, together with the U-theme, the structure of both types of semelfactive (unergative and accusative) and unaccusative degree achievement stems look as follows:
-
(93)
-
a.
semelfactive #1: [[[ N-root] \(\mathrm{N}_{\mathit{GIVE}>\mathit{GET}}\)] \(\mathrm{U}_{\mathit{unerg}>\mathit{acc}>\mathit{unacc}}\) ]
-
b.
semelfactive #2: [[[ N-root] \(\mathrm{N}_{\mathit{GIVE}>\mathit{GET}}\)] \(\mathrm{U}_{\mathit{acc}>\mathit{unacc}}\) ]
-
c.
degree achievement: [[[ Adj-root] \(\mathrm{N}_{\mathit{GET}}\)] \(\mathrm{U}_{\mathit{unacc}}\) ]
-
a.
6 Spelling out NU-stems
With the selectional restriction and the shape of the lexical entry for the U-theme in (91) in place, it remains to be explained how the attested morpheme order and argument structure properties of degree achievement and semelfactive stems become derived. Let us first work with the smallest stem, the unaccusative degree achievement, before we move on to bigger semelfactive stems.
6.1 Unaccusative degree achievements
The smallest part of the syntactic structure that spells out as U comprises only the bottom projection of the U-zone, that is F1P of (90)/(92c). Its merger with an adjectival root and a small light N\(_{GET}\) as in (78b) derives a sequence of projections as in (94) (with the root and the light N zones already forming constituents that spell out slep-N- in a degree achievement stem ‘get blind’).
-
(94)
Lexicalization of an unaccusative degree achievement stem
e.g. Karel slep-n-u-l. ‘Karel was getting blind.’ (Cz)
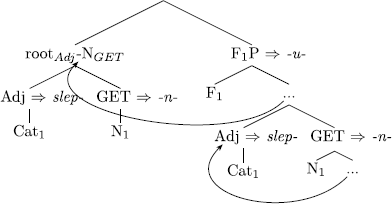

While (78b) matches the lexical entries, the sequence with F1P merged on top of it does not match any. Since each merge is followed by an immediate lexical access, the slep-N- constituent moves up and remerges as the sister to the node where the lexical entry which triggers its evacuation is to be inserted. The derived constituent F1P is spelled out as /u/ in Czech (as in Karel slep-n-u-l, ‘Karel was getting blind’) or as /ą/ in Polish (as in Karol ślep-n-ą-ł), in concert with (92). Since only the smallest layer of the fseq making up the theme U zone is projected on top of a small light N\(_{GET}\), /u/ in degree achievement stems comes out as unaccusative.
6.2 Accusative semelfactives
In line with the observation that there is a size-relative selectional restriction, the U zone of a size comprising (at least) one more layer of its fseq, that is F2P on top of F1P, merges with a bigger nominal root and a bigger light N\(_{GIVE}\) as in (78a), as for instance kop-N- in a semelfactive stem ‘give a kick’ in (95). Such a representation with F2P on top and the root at the bottom, again, does not match any lexical entry and a spell out driven movement of an already spelled out constituent takes place. The evacuated constituent remerges as the sister to the node where the lexical entry which triggers its movement is to be inserted.
-
(95)
Lexicalization of an accusative semelfactive stem e.g. Petr kop-n-u-l psa. ‘Petr kicked the dog (once).’ (Cz)
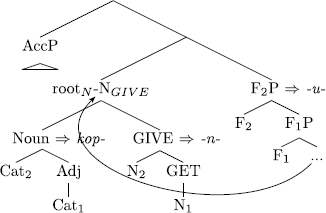

Since every application of merge is followed by lexical access, the derived constituent [ F2[ F1]] becomes spelled out as /u/ in line with (92b). This bigger span of the U-theme zone comes out as accusative. According to Caha’s theory of case, the presence of an accusative NP as part of a syntactic structure of a certain size indicates that a selection of an AccP takes place at that level. In line with case representation outlined in Sect. 2, the AccP is an internally complex phrase which dominates NomP on top of the NP.Footnote 40
Perhaps the most robust prediction of the relation between the syntactic size of the thematic U morpheme and the size of the N morpheme is that NU-stems with GET-readings are only unaccusative, while NU-stems with GIVE-readings are either accusative or unergative. We have not found an exception to this generalization in Czech or Polish.
6.3 Unergative semelfactives
The derivation of the unergative semelfactive proceeds exactly like in (95) but it is then further extended by the merger of another layer of the thematic structure, F3P as for instance in Czech syk-N- in a semelfactive stem ‘hiss (once)’ in (96).
-
(96)
The merger of F 3 P layer on top of an accusative stem
e.g. Karel syk-n-u-l. ‘Karel hissed (once).’ (Cz)
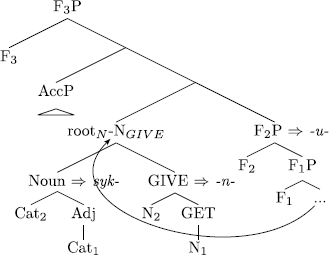

The newly added feature F3P is followed by lexical access but, again, the tree as in (96) does not match any existing lexical entry.
In order to spell F3 out, two evacuation movements must take place: the second movement of syk-N- to a sister position of F3P (i.e. a node which triggers this evacuation movement) and the subextraction of the NomP from the AccP, as shown below:
-
(97)
Lexicalization of an unergative semelfactive stem
e.g. Karel syk-n-u-l. ‘Karel hissed (once).’ (Cz)
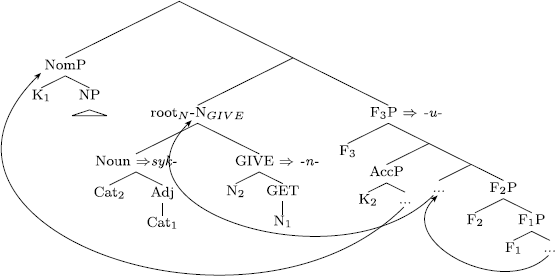

The subextraction of the NomP leaves the AccP-layer in its base position, in which it becomes spelled out as part of the lexical entry for the U theme in (91).Footnote 41
Note that the shape of the lexical entry for the U-theme which includes the peel of the accusative case-shell directly implies that the NP-argument of an unergative predicate starts low as an internal argument and is remerged as an external argument only later in the derivation. Such an analysis of unergatives is advanced in Taraldsen (2010b), who observes that Norwegian sentences with unergative participles have agentive get-passive readings. For space reasons, we leave this issue at this point.Footnote 42
6.4 Argument realization in an unergative superstructure
Let us bring up the issue of the relation between the unergative superstructure in the hierarchy in (90) and argument realization. More specifically, we need to address the following question: if, by our assumption, the unergative structure contains both the unaccusative and accusative structures, how does the accusative argument ‘go away’ in the unergative structure?
A possibility that comes up naturally in the domain we are looking at is that an argument which is a part of the unaccusative structure does not ‘go away’ at all but is preserved in the form of the nominal root of the unergative verb—in the way predicted by Hale and Keyser’s (2002) analysis of English unergatives.
Let us recall one more time that the roots of both accusative and unergative semelfactive verbs are nominal. As outlined earlier in (74), Hale and Keyser’s (2002) theory of the formation of unergative verbs submits that nouns like dance, run, talk first merge with and then undergo conflation with an abstract transitive V-head to form verbal predicates dance, run, talk. This effectively yields unergative structures which comprise a transitive V and a nominal root, a constituent that is further (minimally) extended by an external argument.Footnote 43
The view that unergative VPs include a transitive V-head and its nominal complement is particularly transparent in those Slavic semelfactives which alternate between unergative N+U stems and periphrastic monotransitive ‘give NP’ structures, as shown below (where dać is a lexical verb ‘give’):
-
(98)


-
(99)


In (98), we see a semelfactive verb stem which comprises a nominal root sus ‘leap’, the light GIVE suffix N, and the unergative theme vowel U. In (99), which can be described as a periphrastic semelfactive construction, we see the same root with the accusative case suffix sus-a ‘leap-acc’ appearing as the object of the lexical transitive verb dać ‘give’. In other words, such unergative–accusative pairs inform us about the relation between the argument of an accusative semelfactive and the unergative semelfactive verb in a similar way as the valency identity between a double transitive verb ‘give’ and its accusative argument kop ‘kick’ as in (100) informs us about the presence of the light GIVE applied to kop ‘kick’ in (101):
-
(100)


-
(101)


7 Selectional restrictions between the three fseq zones
Let us return to the observation that there is a size-to-size selectional restriction which holds (i) between the light N zone and the root zone and (ii) between the theme zone and the light N zone.
We have seen that degree achievement stems comprise the smallest subsets of all three fseqs of the morphemes they are made of: the adjectival root, the light GET, and the unaccusative U-theme, as in the Czech (uninflected) stem slep-n-u- ‘get blind’:
-
(102)


In turn, we have seen that semelfactive stems comprise the supersets of the morphemes they are made of: the nominal root and the light GIVE and either the bigger subset of the accusative U-theme, as in the Czech (uninflected) stem kop-n-u- ‘give a kick’ and synk-n-u- ‘hiss once’, respectively:
-
(103)

-
(104)


7.1 Chinese menu
At the first glance, such a selectional restriction appears to be based on isomorphism between the merged fseqs such that a selecting tree can only merge with a tree not bigger than its own size (let us refer informally to this restriction as ‘the Chinese menu’, since it resembles the restriction on selecting menu items in some Chinese restaurants where one can compose their order only from menu items that belong to the same price category).Footnote 44 This kind of restriction has been argued to be a universal property of constituent embedding in Williams (2003) and much of the subsequent work on the Representation Theory (Chaps. 4–7 of Williams 2011).
Williams’s (2003) theory holds that different fseqs in a clause are independent trees that are built in parallel in the derivational workspace. The essential ingredient of the Representation Theory is the Level Embedding Conjecture (LEC), which states that selected syntactic objects are built up only to the size permitted by the matching size of the selector. Only such trees can merge and then project (i.e. grow syntactically) together.Footnote 45
Williams’s theory, thus, correctly predicts all attested selections in (102)–(104), including the essential difference between (103) and (104), where the theme and the light GIVE are of the same syntactic size in (103) but not in (104), where the theme tree is bigger. Recall from (95) and (96) that the selection of the light GIVE by the theme is identical in both kinds of semelfactives and takes places at F2P: the theme [ F2[ F1]] selects the light GIVE [ N2[ N1]] in both accusative and unergative semelfactives. LEC predicts that after selection has taken place, both trees can be extended together. This is exactly what we observe in both (95) and (96), where the derived constituent [ noun [ N2[ N1[ F2[ F1]]]]] is further extended by the merger of the accusative argument (in both types of semelfactive stems) and F3 (in unergative semelfactives only).
7.2 Overgeneration problem
However, while LEC correctly predicts the attested mergers in (102)–(104), it fails to rule out the unattested mergers. LEC states that selected syntactic objects are build up to the size of its selector, which means they can also be smaller in size than their selectors. But this makes the wrong prediction that adjectival roots can be selected by the light GIVE (as in (105a)) and that light GET can be selected by the transitive/accusative theme (as in (105b)).
-
(105)
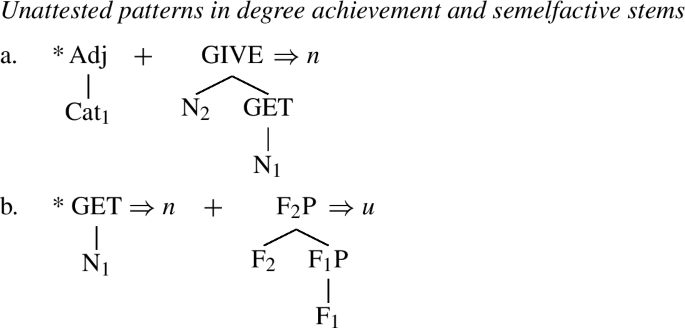
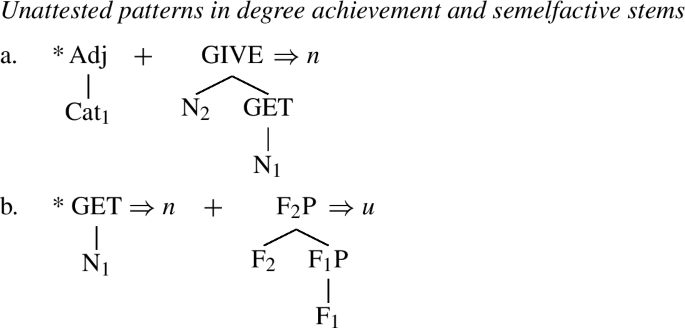
Meantime, neither adjectival stems with GIVE-readings nor transitive/accusative stems with GET-readings are attested among Czech and Polish stems, as detailed in Sect. 3. This indicates that in the domain that we are looking at, the selection á la Chinese menu leads to overgeneration. The unattested mergers in (105) can be eliminated by restricting selection between fseq zones to trees of exactly the same size, rather than to trees ‘up to the same size’ as in Williams’s work.
It must be pointed out that although such a restriction gives the desired result, there is currently no technology from which it follows. While it is tempting to derive it by restricting spell-out driven movement such that a constituent that needs to be spelled out triggers the evacuation of a tree of its own size, such a solution creates a problem for the cyclicity of spell-out, whereby spell-out is attempted after each application of Merge (cf. Sect. 2.2).Footnote 46 We leave this issue unresolved at this point.
7.3 Alternative: The light verb zone and the theme zone as a singleton fseq
The selection problem is less pertinent if the light verb zone and the theme zone are not two separate fseqs that are in a selection relation but instead form a singleton monotonically growing fseq, which is simply realized as morphology by two separate lexical items: N and U.Footnote 47
An advantage of such a scenario is that it allows us to integrate argument licensing and the event structure into one sequence. That argumenthood and event decomposition structures are in lockstep has been argued for in Ramchand (2008) and is in fact the only option if—as suggested in Sect. 6.4—the nominal objects of unaccusative semelfactives form a root for the verb stems of unergative semelfactives.
However, if we have one fseq which is realized by two morphemes, then we need to account for the existence of subset structures in a different way than in the case of two separate fseqs. All we need to say about the subset structures in the latter case is that certain features can be missing from the top of the light N fseq and the theme fseq, as shown in (102)–(103), while the bottom layers of both fseqs are preserved. Such an explanation is unavailable for a singleton fseq as in (106), since now the GIVE-forming feature N2, which is absent in degree achievement stems, is in the middle of a sequence.Footnote 48
-
(106)
Singleton fseq lexicalized by the light N morpheme and the theme vowels U and AJ Footnote 49


This problem is resolved if the GIVE-forming feature N2 is skippable, that is it can be missing from the sequence (as in degree achievements) but once present, it must be ordered in a specific place in the sequence, on top of the GET-forming feature N1. In fact, as Starke (2001) argues, we can observe the existence of skippable layers of structure more transparently on the example of sentential negation: Neg can be missing from the sequence of clausal heads but if present, it is rigidly ordered with respect to other heads, as in John will (not) kiss Mary.
To sum up, controlling for the subset GET structure appearing in the middle of a sequence allows us to dispense with postulating two separate fseqs, which captures the observation than the argument licensing is in lock-step together with light GIVE>GET and the theme U.
8 Excursus on EJ-based degree achievements
One final note about degree achievement stems is in order. Recall that it was indicated in Sect. 3.1.1 that degree achievements can also be formed with the EJ-theme (cf. (27)). EJ merges with adjectives, derived or not. For instance, in both Czech and Polish, EJ merges with derived stems as in (107), where it suffixes onto an adjective-forming morpheme IV or the theme OVA (cf. (25)).
-
(107)


The fact that EJ merges with adjectives is particularly transparent in (107b), where brąz ‘brown color’ is a noun hence *brąz-ej is correctly predicted to be ill-formed. In turn, the (inflected) adjective brąz-ow-y ‘brown-OVA-agr’ includes a derived adjectival stem brąz-OVA-, which EJ can merge with resulting in the (inflected) brąz-owi-ej-e ‘it’s getting brown’.
The light verb zone, which is spelled out as a separate N morpheme in degree achievement stems with N+U, appears to be included in the structure lexicalized as the EJ-theme, since it is the EJ-theme that has the light GET-reading, not the IV morpheme or the OVA-theme of (107). We can see this on the basis of what constitutes the major difference between degree achievements in Czech and Polish: in Polish, the EJ-theme can merge directly with certain adjectival roots, unlike in Czech, where EJ is present only in derived stems.
-
(108)


Several historically related adjectival roots that in Czech build degree achievements by merging with the light N and the U-theme are instead derived by merging with the EJ-theme in Polish, as in (109). Recall from the Sect. 3.1.2 that the EJ-theme surfaces as -e- in front of a consonantal infinitival suffix -ć in Polish due to a phonological rule of Glide Truncation. We are indicating the truncated glide in the second column in (109) in brackets for the ease of exposition.
-
(109)
Examples of adjectival roots that form degree achievement NU-stems in Czech and EJ-stems in Polish
Czech N+U-stems
Polish EJ-stems
hloup-nou-t
głupi-e(j)-ć
‘get stupid’
šed-nou-t
szarz-e(j)-ć
‘turn gray’
mlád-nou-t
młodni-e(j)-ć
‘get younger’
rud-nou-t
rudzi-e(j)-ć
‘get red (about hair)’
All these forms are unaccusative and we have not found differences in other syntactic properties of the same roots that form degree achievements by merging with N and U in Czech and EJ in Polish.
More work on the internal syntax of the EJ-theme is necessary before the source of difference in its distribution in Czech and Polish degree achievements can be established.
9 Conclusion
Two distinct aspectual classes of stems, semelfactives and the degree achievements, have the same morphological make-up in Czech and Polish, yet they turn out to be structurally distinct once their submorphemic representations are considered. Using the mechanisms of Nanosyntax, we have argued that the morphemes forming degree achievement stems are syntactically contained in morphemes forming semelfactive stems in these languages. The size distinctions between them are three-fold:
-
(1)
Semelfactive stems have nominal roots, which are bigger than the adjectival roots of degree achievements (on the proviso that lexical categories are lexically contained).
-
(2)
Semelfactives spell out the light morpheme GIVE, which is bigger than the light GET present in degree achievement stems.
-
(3)
The fseq which makes up the eventive verbal structure is bigger in semelfactives than in degree achievement, which is mirrored by the fact that the first are accusative or unergative, while the second are unaccusative (under the assumption that the argument structure involves the hierarchy ‘unergative > accusative > unaccusative’).
These findings contribute to the growing evidence about structural containment of grammatical categories, made explicit in Bobaljik (2012). In the case of Slavic verbs with synthetic verb morphology, we observe syntactic containment within more than one morpheme in the structure of semelfactive and degree achievement verb stems.
Notes
Bobaljik’s work on syncretism anchoring structural containment has been done in the Distributed Morphology framework. While this paper shares the same rationale about syncretism, we will make a case for an analysis of syncretism in the domain of verbs based on the mechanisms of Nanosyntax. While there are a few essential differences between DM and Nanosyntax, including the basic building blocks of grammar (feature bundles in a pre-syntactic lexicon vs. feature structures build in narrow syntax), the existence of a separate morphology module (present in DM, absent in Nanosyntax), and the structure of spell out (terminal node vs. phrasal spell out), the scope of the paper and space limit the possibility to investigate them on the material detailed in the remainder of this paper. For a discussion of the differences between DM and Nanosyntax and their predictions see Caha (2018).
Note that the content of K is not relevant for the fseq in (7). What is essential, instead, is the form of the decomposition of cases which includes features Kn that make up contiguous levels of embedding. Though see Caha (2013:1030–1032) for a suggestion about the content of individual K-heads that form structural cases (nom-acc), stative cases (loc-gen), the goal case (dat) and source cases (abl-inst).
Further support for the syntactic decomposition of case as in Caha’s work comes from Smith et al. (2016), who investigate suppletive patterns in case and number in pronouns.
The Elsewhere clause sometimes goes by the name ‘minimize junk principle’ in the literature on Nanosyntax, as it effectively means that it is always a lexical item with the least number of superfluous features that wins a competition for insertion into a syntactic node.
Recall that the formulation of the Superset Principle as in (10) does not simply state that an exponent of a lexical item is inserted into a node if the item contains all or a superset of features contained in the node. Rather, it specifies that the entry of this lexical item must have a (sub-)constituent matching that syntactic node, in which way it effectively includes a clause on constituent lexicalization and does not predict that a span of features or feature bundle is going to get spelled out.
The fact that lexical access happens cyclically can be reminiscent of a general idea behind the phase theory (Chomsky 2008). Unlike in the phase theory, however, in Nanosyntax lexical access is triggered by each application of merge and not by the presence of any special heads (phase heads) in the representation. Though, as pointed out by a reviewer, a strictly cyclic lexical access is similar to those conceptions of phase theory in which each phrase is a phase (e.g. Epstein and Seely 2002).
The extraction of K1P out of K2P violates the Freezing Condition, whereby a constituent becomes an island for extraction when it has undergone movement. However, there is a bulk of work against freezing understood in such a way, which includes extraction out of fronted wh-phrases in Spanish (Torrego 1985), combien de split in French (Starke 2001), topicalization from subject phrases in German (Abels 2007), left-branch extraction out of fronted WhPs (Wiland 2009, 2010), or object extraction out of fronted constituents leading to OVS order in Polish (Wiland 2016), among others. Instead, as noted in Caha (2009:146–147), peeling is in line with Rizzi’s (2007) Criterial Freezing, whereby a constituent which is moved into its criterial (checking) position becomes frozen for subsequent movements. The K2P layer is frozen once it remerges above the head Y and what moves further is its subconstituent K1P, a movement which not only is in line with Criterial Freezing, but which can serve as an argument in its favor, given the fact than NP-movement into a case position is terminated when the nominative position is reached. In the peeling analysis of case derivation, no further NP-movement to a case position is possible since nominative is the smallest case-layer (K1P) in the case fseq (7).
Throughout the paper, we use Townsend and Janda’s (1996) one-stem-system notation. (The original proposal comes from Jakobson 1948.) The system uses the stem that is visibly more telling for the verbal inflection in Russian and, in fact, it uses present stem for some verbal classes and past stem for other classes. Most notably, for the verbs based on AJ and EJ stems, the present tense stems are used as default for the one-stem-system: this is clearly shown by the 3rd person plural present forms such as Czech sáz-ej-í ‘they plant’ and děl-aj-í ‘they do’. In the past tense of the same verbs, the shape of the stem is different: sáz-e-l and děl-a-l ‘he planted’ and ‘he did’, respectively, which has to do with the phonological truncation rule, that we mention at a relevant point later in the paper. However, following the standard notation of one-stem-system, we would (also for the past) note the stem-internal (thematic) morpheme as ‘EJ’ and ‘AJ’, respectively, despite the fact that the glide does not surface in this morphophonological environment.
Some work on Slavic phonology has classified stems with Ø theme as C-stems, as they end with a consonant instead of a vowel (Rubach 1984, a.o.).
It is important to note that we speak of (strong) tendencies rather than absolute generalizations with respect to the classification of verb stems into aspectual classes on the basis of theme vowels. For example, as pointed out by a reviewer, the verb koch-a(j)-ć ‘love’ (Pol) is more likely a stative predicate than an activity despite the fact that it is based on an AJ-theme. Also, an OVA-stem like in chor-owa-ć ‘be sick’ (Pol) is a state rather than an activity. Though, in contemporary Czech and Polish, the OVA theme is the (only, together with NU-type, exemplified in (33)) productive theme, which appears in all (other than semelfactive) borrowings, such as e.g. skyp-owa-ć ‘to Skype’ (Pol), or forward-ova-t ‘to forward’ (Cz).
Glide Truncation (see Sect. 3.1.2) makes the past tense forms in (23a) and (27a) look identical; however, other verb forms show the difference clearly: sed-í ‘they sit’ vs. šed-iv-ěj-í ‘they are getting grey’.
It is not clear that there ever was a meaning difference in these two verbalizers, at least no historical grammars of the Slavic languages seem to indicate so. From our survey, it follows that Polish has more EJ verbs than Czech. We briefly discuss it in Sect. 8.
The Czech verb blb-nou-t can be either semelfactive, as in Karel blb-nu-l a spadl ze schodů ‘Karel was acting stupid and fell down the stairs’, or degree achievement, as in Karel stár-nu-l, slep-nu-l a blb-nu-l ‘Karel was getting old, blind and stupid’. This behavior is consistent with the observation we make in the next subsection, namely that degree achievement stems are built from adjectival roots and semelfactive stems are built from nominal roots. There is both an adjective blb-ý (which serves a base for a degree achievement stem) as well as a noun blb (which serves as a base for a semelfactive stem).
There are other ways of building semelfactivity, which includes inherently semelfactive verbs, like skočit (Cz) ‘jump (once)’ or adding a perfectivizing inceptive prefix like za- to a stem as in za-wiązać (Pol) ‘wind, bind’ (cf. Dickey and Janda (2009) for a discussion of a semelfactive function of a perfectivizing prefix in Russian, Bacz (2012) for Polish, and Biskup (2012) for Czech). One should also note that Markman (2008) offers an interesting analysis of NU, whereby the Russian NU and the secondary imperfective suffix IV are related in that both can lexicalize the little v in syntax, depending on its featural composition.
This degree achievement verb can get a stative reading in a sentence like Mrznu ‘I’m freezing’ (Cz), as pointed out by a reviewer. A possible source of this exceptional reading appears to be in the root mrz- itself, since it is rather unusual: all other roots that combine with the theme NU to create degree achievements are moraically heavier, cf. sláb-nou-t ‘be getting weak’, mlád-nou-t ‘be getting young(er)’, houst-nou-t ‘be getting thick’, žlout-nou-t ‘be getting yellow’, etc. with respect to their corresponding adjectives: slab-ý ‘weak’, mlad-ý ‘young’, hust-ý ‘thick’, žlut-ý ‘yellow’ (or the degree achievement roots are the same as the corresponding adjectival ones). The root mrz- is, from this perspective, irregular: why is it this root—and not the moraically heavier root used in a causative mraz-i-t ‘to freeze something’—that is used in the degree achievement, especially given the fact that is also a root used in an adjective mraz-iv-ý ‘frosty’. Notice that there is no corresponding adjective based on the root mrz-.
This picture is almost perfect, except for the fact that not all roots have a corresponding adjective, at least not in present day Czech or Polish (we have found a couple of such roots, some are the same in both languages, as for instance (i) below). They do, however, form adjectival L-participles with an adjectival inflection, as in the right column below:
-
(i)

-
(i)
Following Kiparsky (1997), a contrast in the acceptability of instrumental phrases with an entity not directly named in the event of a denominal verb as in (a) vs. (b) below has often been taken to show that a denominal verb is based either on a noun (as with tape) or a category-neutral root (hammer).
-
(i)
-
a.
tape it to the wall (*with nails)
-
b.
hammer nails in the wall (✓with shoes)
-
a.
However, apart from some other problems with the reliability of this test for English outlined in McIntyre (2015), the nominal roots of semelfactive stems in Slavic are mostly abstract nouns and are associated with a sound (e.g. lick, bark, as in (38)–(39)) while Kiparsky’s contrast is mostly (if not exclusively) based on nouns that are tangible objects (e.g. hammer, tape). Moreover, Kiparsky’s test includes non-eventive nouns (e.g. *the hammering(s) of X by Y), which contrasts, again, with the nouns in semelfactive stems in Slavic. These nouns are by and large eventive, as they can build nominalizations with an agentive by-phrase (e.g. liznięcie przez psa, po-lizanie przez psa ‘licking by the dog’). All in all, recognizing a nominal root and a category-neutral root in denominal verbs like tape or hammer is not applicable to Slavic.
-
(i)
The fact that a lexical category of a Slavic root is essential in determining its possibility to form larger grammatical categories upon merger with functional affixes goes of course beyond the example of adjectival, nominal, and verbal roots forming semantically different types of stems upon the merger with NU. Sensitivity to the lexical category of roots in Slavic (and the literature that reports the same phenomenon from other languages, e.g. Julien 2003, 2007 on Northern Saami) is a reason why we reject the idea that roots are acategorial.
The few non-canonical activity NU-verbs—those that are semantically odd in that they are neither degree achievement nor semelfactives—show an interesting twist when it comes to the formation of the N/T-participle, which may suggest that they try to assimilate to the actual activity verbs in that category. These verbs form N/T participles in the typical way expected of NU-stems, that is with the T-allomorph (e.g. při-stih-nu-T ‘caught.m.sg’), but most of them can also form an N-based participle (e.g. při-stiž-eN ‘caught.m.sg’). This en-based participle brings them very close to canonical activity verbs. Again, according to Šmilauer (1972:213), there are 13 roots in Czech that form the N/T-participle (alongside with the t allomorph, as well-behaved NU semelfactives) also using the en allomorph, which is typical to the transitive activity I-stems (e.g. slad-i-t ‘sweeten-inf’ – slaz-en-ý ‘sweetened-m.sg’). For at least some of these roots, there is a semantic distinction between the t- and en-based participle: the en-participle is more likely to be used when there is an implied external argument, as in:
-
(i)

-
(ii)

Thus, it seems that the verbs that semantically do not fit the NU conjugation paradigm somehow migrate, at least in some categories, to the semantically more fitting conjugation paradigms.
-
(i)
These morphological environments must not be confused with the occurrence of N without U in phonological environments like the present tense participles (e.g. kop-N-iesz ‘you (will) kick’), as in this case the exponent of the U morpheme most likely gets deleted due to a phonological rule of vowel deletion, since the present tense suffix is also a vowel (either -i- or -e-, depending on the class of the present tense stem).
Recall the Glide Truncation rule (30), which explains why the surface form with the theme vowel is here mrk-a-t and not *mrk-aj-t.
In the same way as in Sect. 2, the terminals N1 and N2 in (49) indicate the levels of embedding and, besides stating their ordering in the light verb sequence, we are not making any claims about their feature content. Nevertheless, there is literature (e.g., Harley 2003) which argues for a particular compositional structure of GET and GIVE on the basis of the content of syntactic heads that merge with the possessive part of the light verb.
Thanks to Pavel Caha (p.c.) for bringing Richards (2001) to our attention in the context of the N morpheme.
Instead of possessive HAVE, they incorporate LOCATION in Harley’s analysis.
We are grateful to Pavel Caha (p.c.) for bringing these facts to our attention.
Following Szabolcsi (1983) and Kayne (1993), we can analyze the auxiliary verb HAVE as ‘BE plus something else’. In Kayne (1993), this extra piece of structure is a preposition while in Taraldsen and Taraldsen Medová (2016) this extra piece on top of BE is stranded case layers (in an approach to case decomposition as in Caha’s (2009) work outlined in Sect. 2.2).
If we go back and consider the few activity verbs listed in (41)–(42), we can hypothesize that they might turn out to have the roots combined with yet a bigger N (bigger than ‘GIVE > GET’) the HAVE-layer, as the following paraphrases would suggest: tisk-nou-t → mít tisk ‘to print’ is ‘to have a print’; vlád-nou-t → mít vládu ‘to rule (lit. power)’ is ‘to have power’, etc. Such a scenario would constitute a welcome extension of the analysis that we have drawn so far to cover those non-canonical NU-verbs too. Not all verbs, however, allow for such a paraphrase, hence, it is difficult to argue for their uniform analysis. We leave this issue open at this point.
See also Ross (1972) for category squish, an idea similar in spirit to the one adopted in (72). There are two differences between the hierarchy in Ross (1972) and (72). The first one is that Ross’s work finds adjectives to share some of the properties with verbs and nouns, which results in locating adjectives in the hierarchy of lexical categories between (top) verbs and (bottom) nouns. The other difference is that Ross’s hierarchy includes also present, perfect, and passive participles, the categories that have been since argued to constitute different hierarchies (see especially Starke (2006) for the functional sequence of participles). That participles form a distinct hierarchy of syntactic positions in Slavic, where the participle is a separate morpheme (either an active L or a passive N/T morpheme as indicated in (21)). We discuss the internal syntax of Slavic participles in certain detail in Taraldsen Medová and Wiland (2018).
According to Hale and Keyser’s (2002), conflation is a process whereby the complement of the governing V nucleus, affixal as in (73) or empty as in (74), is inserted into this V position, which results with the verb bearing the adjectival or nominal properties of its V-complement. The process is, thus, distinct from head movement (⇝ stands here for ‘leads to’).
This follows from the Superset Principle in (10), which makes reference to syntactic constituency, not to any given spans of heads.
The Czech data were last obtained in Fall 2012 from SYN2010, a synchronic representative corpus of written Czech comprising 101 million tokens, available at http://ucnk.ff.cuni.cz/english/syn2010.php. The total of 1493 NU-infinitives were found and manually sorted as semelfactives, degree achievements, and a few examples of entries more difficult to classify initially as either semelfactives and degree achievements, e.g. couvnout ‘back up a little’. The Polish data were last obtained in August 2013 from the IPI PAN Corpus, a morphosyntactically annotated corpus of written Polish comprising over 250 million segments, available at korpus.pl. 200 NĄ-infinitives were manually annotated into semelfactives, degree achievements, as well as a few activity verbs reported in Sect. 3.3.2. The attested examples of forms with NU in Czech and its equivalent NĄ in Polish that were neither unaccusative degree achievements based on adjectival roots nor accusative or unergative semelfactives based on nominal roots were a few activity verbs with typically verbal roots listed in (41)–(42). Moreover, the relatively few degree achievement stems based on roots which cannot be unambiguously classified as adjectival since they do not have a corresponding adjective in present day Czech or Polish, such as the ones listed in fn. 18, are also clearly unaccusative. This can be tested by the fact that they build L-passives (instead of N/T-passives), e.g. Czech chřad-nou-t – z-chřad-l-ý ‘get withered away’, jih-nou-t – z-jih-l-ý ‘get sentimental’, žluk-nou-t – (ze-)žluk-l-ý ‘get rancid’ or Polish gas-ną-ć – z-gas-ł-y ‘be dying away’, więd-ną-ć – z-więd-ł-y ‘wither’.
Adjectival passives constitute a reliable test for unaccusative vs. unergative distinction in Czech and Polish: unaccusatives form adjectival L-participles, while unergatives and transitives do not (they may only form N/T-participles) (see Cetnarowska 2002a, 2002b for Polish). Examples of well-formed L-participles will include: vy-hub-l-ý ‘skeletal’, z-vlh-l-ý ‘wet’, ze-stár-l-ý ‘grown.old’, po-blad-ł-y ‘pale’, z-gas-ł-y ‘extinguished’, z-mięk-ł-y ‘softened’ (cf. (80)–(81)), but not *syk-l-ý, *dup-l-ý, *máv-l-ý, *křik-l-ý, *hvízd-l-ý, *kich-ł-y, *ziew-ł-y, *wark-ł-y (cf. (84)–(85)).
Again, we stress that the I-based verbs are by and large transitives, and by and large causatives. However, there are some transitive I-stems that are activities, both in Polish mów-i-ć ‘tell/speak’ and in Czech pros-i-t ‘ask for something’ or even states, lub-i-ć ‘like’ (Pol). Even these exceptions share certain common properties with causative I-stems: all of them take an external argument.
More precisely, Jabłońska (2007) argues for a radical decomposition of not only a VP—taken to comprise the BECOME and RESULT components in her analysis—but also of the vP on top of it. In Jabłońska’s theory, particular theme vowels spell out different spans of a sequence of little v0 heads on top of the VP. While there are differences with respect to both the form of spell out (Jabłońska’s work allows for lexicalization of non-constituent spans of heads), insertion of roots, and the properties of N+U, we share with her the general idea of thematic suffixes as pieces of a syntactic tree responsible of argument structure properties of Slavic verb stems.
We leave aside secondary imperfectives.
The presence of the accusative-marked object indicates that there is an accusative selector in the VP fseq. The selection of an accusative-marked object is morphosyntactically a merger of an entire AccP, which embeds the NomP and the NP in its internal structure.
While in (90) the span F3P > F2P > F1P forms a proper subset of the sequence F4P > F3P > F2P > F1P, the latter does not become lexicalized as U, only as AJ, since U surfaces only if the syntactic structure is not bigger than its lexical entry in (91). The merger of F4P forms a structure that is spelled out as AJ, which overrides the earlier spell out of the sequence F3P > F2P > F1P as U. Overriding is a consequence of bigger constituents being spelled out later than their subconstituents and has been informally referred to as the ‘biggest wins theorem’ in the literature on Nanosyntax (e.g. in Starke 2009 and in Taraldsen 2010a).
There is a positional argument in favor of the merger of the AccP as the sister to the node derived by the movement of kop-N-—that is as the sister to kop-N-U- in (95)—rather than the merger of the AccP directly on top of F2P and before the evacuation of kop-N-. Since lexical access in Nanosyntax takes place after every merge operation, the spell out driven movement of kop-N- takes place immediately after F2P is merged on top of F1P as the resulting [ F2[ F1[ kop-N-]]] sequence does not match any lexical entry. Such a movement allows for the spell out of (92b) as a suffix on kop-N-U. Suppose that lexical access is delayed so that the evacuating movement of the kop-N- takes place only after AccP is selected as sister to F2P, as below.
-
(i)
*[[kop-N-]i[ AccP \([\underbrace{ \mathrm{F}_{2} \ [ \mathrm{F}_{1} \ \mathrm{t}_{i} ]}_{\text{-}u\text{-}}]\) ]]
In such a scenario, the U-theme zone can be lexicalized in line with (92b) but it will not surface as the suffix on kop-N- as long as the AccP separates it from the stem. Note that a subsequent movement of the intervening accusative NP to a higher position is not a solution in a system in which case layers undergo peeling, as discussed in Sect. 2.3. A subsequent subextraction of NomP embedded inside AccP would mean that the object surfaces with nominative case, contrary to fact.
-
(i)
The subextraction of the AccP in (97), just like any case peeling movement, is not an instance of a derivational look-ahead. Despite the fact that lexical access takes place after each application of merge, the shape of syntactic representations changes throughout the derivation. The subextraction of the NomP takes place only once there is a nominative selector present higher in the structure (such as the ‘traditional EPP’ trigger).
Of course, with phrasal spell-out, there is no need to assume Hale and Keyser’s (2002) ‘conflation’ to account for the morphological realization of nominal roots such as the English dance, run, or talk as verbs that show syncretism with these roots. All we need to say is that the noun dance is a syncretic subset of the unergative verb stem dance.
Lucie Taraldsen Medová heard the Chinese menu metaphor used by a linguist about a similar selection problem—and while the general idea remained, neither the similar selection problem, nor the name of the linguist stuck with her. Thus, thanks to the unascertained linguist.
For example, according to Williams’s LEC, bare verbs select for bare nouns, but not for combinations of a noun together with other elements of the extended projection of the NP. That is, verbs do not select for a noun with a particular demonstrative pronoun. In turn, verbs embedded inside clauses select for entire clauses but not for particular ingredients of subordinated clauses, etc.
Interestingly, the idea that a constituent to be spelled out triggers the movement of an isomorphic tree holds for unergatives as in (97)/(104) on the assumption that after its own evacuation in the first cycle, the root zone is remerged as a (non-projecting) specifier to the light N zone, not as a third “complex N3 head”, which is a standard assumption about movement (made explicit in Caha’s (2009), (2011a) formulation of spell-out driven movement). If we follow the derivation leading to spell-out in (97), we can observe that the first leg of movement of a span of previously spelled out features N2+N1 facilitates the spell-out of an isomorphic span F2+F1 (as an accusative theme vowel -u- in (95)). The second leg of movement of the span N2+N1 facilitates the spell-out of F3+K2 (as an unergative theme vowel -u-).
In other words, using the terminology from Taraldsen Medová and Wiland (2018), morphemes spelling out as N and U form two ‘fseq zones’ of a singleton sequence of heads. Under such view, the presence of multiple morphemes is merely a consequence of spell-out (the shape of lexical items), not of syntactic partitioning into distinct fseqs.
The same problem will apply to features F\(_{n>1}\) if the extension of the representation in (106) continues the same fseq.



References
Abels, Klaus. 2007. Towards a restrictive theory of (remnant) movement. Linguistic Variation Yearbook 7: 53–120.
Bacz, Barbara. 2012. Reflections on semelfactivity in Polish. Studies in Polish Linguistics 7: 107–128.
Baker, Mark. 2003. Lexical categories: Verbs, nouns and adjectives. Cambridge: Cambridge University Press.
Baker, Mark. 2005. On gerunds and the theory of categories. Ms., Rutgers University.
Beavers, John, Elias Ponvert, and Stephen Wechsler. 2009. Possession of a controlled substantive: Light ‘have’ and other verbs of possession. In Semantics and Linguistic Theory (SALT) 18, eds. Tova Friedman and Satoshi Ito, 108–125. Ithaca: CLC Publications.
Biskup, Petr. 2012. Slavic prefixes and adjectival participles. In Slavic languages in formal grammar FDSL 8.5, Brno 2010, eds. Markéta Ziková and Mojmír Dočekal, 271–289. Frankfurt am Main: Peter Lang.
Bobaljik, Jonathan. 2012. Universals in comparative morphology. Cambridge: MIT Press.
Caha, Pavel. 2009. The nanosyntax of case. PhD diss., CASTL/University of Tromsø. http://ling.auf.net/lingbuzz/000956.
Caha, Pavel. 2011a. Case in adpositional phrases. Ms., CASTL/University of Tromsø.
Caha, Pavel. 2011b. The parameters of case marking and spell out driven movement. Linguistic Variation Yearbook 10: 32–77.
Caha, Pavel. 2013. Explaining the structure of case paradigms by the mechanisms of Nanosyntax: The classical Armenian nominal declension. Natural Language and Linguistic Theory 31 (4): 1015–1066.
Caha, Pavel. 2018. Notes on insertion in Distributed Morphology and Nanosyntax. In Exploring Nanosyntax, eds. Lena Baunaz, Karen De Clercq, Liliane Haegeman, and Eric Lander, 57–87. New York: Oxford University Press.
Caha, Pavel, and Tobias Scheer. 2008. The syntax and phonology of Czech templatic morphology. In Annual workshop on formal approaches to Slavic linguistics. The Stony Brook meeting 2007, eds. Christina Bethin, Andrei Antoneko, and John Bailyn, 68–83. Ann Arbor: Michigan Slavic Publications.
Cetnarowska, Bożena. 2002a. Adjectival past-participle formation as an unaccusativity diagnostic in English and in Polish. In Morphology 2000: Selected papers from the 9th morphology meeting, Vienna, 24–28 February 2000, eds. Sabrina Bendjaballah, Wolfgang U. Dressler, Oskar E. Pfeiffer, and Maria D. Voeikova, 59–72. Amsterdam: Benjamins.
Cetnarowska, Bożena. 2002b. Unaccusativity mismatches and unaccusativity diagnostics from derivational morphology. In Many morphologies, ed. Paul Boucher, 48–81. Somerville: Cascadilla Press.
Chomsky, Noam. 2008. On phases. In Foundational issues in linguistic theory: Essays in honor of Jean-Roger Vergnaud, eds. Carlos P. Otero, Robert Freidin and Maria Luisa Zubizaretta, 133–166. Cambridge: MIT Press.
Cinque, Guglielmo. 2005. Deriving Greenberg’s Universal 20 and its exceptions. Linguistic Inquiry 36: 315–332.
Cinque, Guglielmo, and Luigi Rizzi. 2008. The cartography of syntactic structures. CISCL Working Papers, Studies in Linguistics Vol. 2: 42–58.
Czaykowska-Higgins, Ewa. 1988. Investigations into Polish morphology and phonology. PhD diss., MIT.
Dickey, Stephan, and Laura Janda. 2009. Hohotnul, shitril: The relationship between semelfactives formed with -nu- and s- in Russian. Russian Linguistics 33: 229–248.
Dowty, David. 1979. Word meaning and Montague Grammar. Dordrecht: Kluwer.
Epstein, Samuel, and T. Daniel Seely. 2002. Rule applications as cycles in a level-free syntax. In Derivation and explanation in the Minimalist Program, eds. Samuel Epstein and T. Daniel Seely, 65–89. Oxford: Blackwell.
Family, Neiloufar. 2014. Semantic spaces of Persian light verbs: A constructionist account. Leiden: Brill.
Folli, Rafaella, Heidi Harley, and Simin Karimi. 2005. Determinants of event type in Persian complex predicates. Lingua 115 (10): 1365–1401.
Gussmann, Edmund. 1980. Studies in abstract phonology. Cambridge: MIT Press.
Hale, Kenneth, and Samuel J. Keyser. 2002. Prolegomenon to a theory of argument structure. Cambridge: MIT Press.
Harley, Heidi. 1997. If you have you can give. In West Coast Conference on Linguistics (WCCFL) 15, eds. Brian Agbayani and Sze-Wing Tang, 193–207. Stanford: CSLI Publications.
Harley, Heidi. 2003. Possession and the double object construction. In Linguistic variation yearbook, eds. Pierre Pica and Johan Rooryck, Vol. 2, 31–70. Amsterdam: Benjamins.
Hay, Jennifer, Christopher Kennedy, and Beth Levin. 1999. Scalar structure underlies telicity in ‘Degree achievements’. In Semantic and Linguistic Theory (SALT) 9, eds. Tanya Matthews and Devon Strolovitch, 127–144. Ithaca: CLC Publications.
Jabłońska, Patrycja. 2007. Radical decomposition and argument structure. PhD diss., CASTL/University of Tromsø.
Jabłońska, Patrycja. 2008. Silverstein’s Hierarchy and Polish argument structure. In Scales, eds. Marc Richards and Andrej Malchukov. Linguistische Arbeits Berichte 86, 221–245.
Jakobson, Roman. 1948. Russian conjugation. Word 4: 155–167.
Julien, Marit. 2003. Nominal and adjectival roots in North Saami verbs. In Berkeley Linguistics Society (BLS) 29, General Session and Parasession on Phonetic Sources of Phonological Patterns: Synchronic and Diachronic Explanations, eds. Paweł M. Nowak, Corey Yoquelet, and David Mortensen, 221–231.
Julien, Marit. 2007. Roots and verbs in North Saami. In Saami linguistics, eds. Ida Toivonen and Diane Nelson, 137–166. Amsterdam: Benjamins.
Kayne, Richard S. 1993. Toward a modular theory of auxiliary selection. Studia Linguistica 47 (1): 3–31.
Kiparsky, Paul. 1973. Elsewhere in phonology. In A Festschrift for Morris Halle, eds. Paul Kiparsky and Stephen R. Anderson, 93–106. New York: Holt, Rienhart and Winston.
Kiparsky, Paul. 1997. Remarks on denominal verbs. In Complex predicates, eds. Alex Alsina, Joan Bresnan, and Peter Sells, 473–499. Stanford: CSLI.
Kratzer, Angelika. 1996. Severing the external argument from its verb. In Phrase structure and the lexicon, eds. Johan Rooryck and Laurie Zaring, 109–138. Dordrecht: Kluwer.
Laskowski, Roman. 1975. Studia nad morfonologią współczesnego języka polskiego. Wrocław: Zakład Narodowy imenia Ossolińskich.
Levin, Beth, and Malka Rappaport Hovav. 1995. Unaccusativity: At the syntax-semantics interface. Cambridge: MIT Press.
Lundquist, Björn. 2008. Nominalizations and participles in Swedish. PhD diss., University of Tromsø. http://ling.auf.net/lingbuzz/000887.
Markman, Vita G. 2008. On Slavic semelfactives and secondary imperfectives: Implications for the split ‘AspP’. In Annual Penn Linguistics Colloquium (PLC) 31. Vol. 14 of University of Pennsylvania Working Papers in Linguistics, 255–268.
McCawley, James. 1968. The role of semantics in a grammar. In Universals in linguistic theory, eds. Emmon Bach and Robert Harms, 124–169. New York: Holt, Rinehart and Winston.
McIntyre, Andrew. 2015. Denominal verbs. In Word-formation: An international hanbook of the languages of Europe, eds. Peter Müller, Ingeborg Ohnheiser, Susan Olsen, and Franz Rainer, Vol. 2, 434–450. Berlin: de Gruyter.
Medová, Lucie. 2009. Reflexive clitics in Slavic and Romance. PhD diss., Princeton University. http://ling.auf.net/lingbuzz/001028.
Neeleman, Ad, and Krista Szendröi. 2007. Radical pro-drop and the morphology of pronouns. Linguistic Inquiry 38: 671–714.
Pantcheva, Marina. 2009. First phase syntax of Persian complex predicates: Argument structure and telicity. Journal of South Asian Linguistics 2 (1): 53–72.
Ramchand, Gillian. 2008. Verb meaning and the lexicon: A first phase syntax. Cambridge: Cambridge University Press.
Richards, Norvin. 2001. An idiomatic argument for lexical decomposition. Linguistic Inquiry 32: 183–192.
Rizzi, Luigi. 2007. On some properties of Criterial Freezing. In CISCL working papers on language and cognition, ed. Vincenzo Moscati, 145–158. Siena: Universitá degli studi di Siena.
Ross, John Robert. 1972. Endstation hauptwort: The category squish. In Chicago Linguistic Society (CLS) 8, eds. Judith N. Levi, Paul M. Peranteau, and Gloria C. Phares, 316–328. Chicago: University of Chicago.
Ross, John Robert. 1976. To have ‘have’ and not to have ‘have’. In Linguistics and literary studies in honor of Archibald A. Hill, eds. Mohammad A. Jazayery, Edgar C. Polomé, and Werner Winter, 263–270. The Hague: Mouton.
Rothstein, Susan. 2004. Structuring events: A study in the semantics of lexical aspect. Explorations in semantics. Oxford: Blackwell.
Rothstein, Susan. 2008. Two puzzles for the theory of lexical aspect: Semelfactives and degree achievements. In Event structures in linguistic form and interpretation, eds. Johannes Döling, Tatjana Heyde-Zybatow, and Martin Shaefer, 175–198. Berlin: de Gruyter.
Rubach, Jerzy. 1984. Cyclic and lexical phonology: The structure of Polish. Dordrecht: Foris.
Smith, Peter W., Beata Moska, Ting Xu, Jungmin Kang, and Jonathan Bobaljik. 2016. Case and number suppletion in pronouns. Ms., Goethe Universität, Queens College, University of Connecticut. http://ling.auf.net/lingbuzz/003110.
Starke, Michal. 2001. Move dissolves into Merge: A theory of locality. PhD diss., University of Geneva. http://ling.auf.net/lingbuzz/000002.
Starke, Michal. 2006. The nanosyntax of participles. Lectures at the 13th EGG summer school, Olomouc.
Starke, Michal. 2009. Nanosyntax: A short primer to a new approach to language. Nordlyd 36: 1–6.
Starke, Michal. 2014. Towards elegant parameters: Language variation reduces to the size of lexically stored trees. In Linguistic variation in the Minimalist framework, ed. M. Carme Picallo, 140–152. New York: Oxford University Press.
Szabolcsi, Anna. 1983. The possessor that ran away from home. The Linguistic Review 3 (1): 89–102.
Šmilauer, Vladimír. 1972. Nauka o českém jazyku. Prague: SPN.
Taraldsen, Tarald. 2010a. The nanosyntax of Nguni noun class prefixes and concords. Lingua 120: 1522–1548.
Taraldsen, Tarald. 2010b. Unintentionally out of control. In Argument structure and syntactic relations: A cross-linguistic perspective, eds. Maia Duguine, Susana Huidobro, and Nerea Madariaga, 283–302. Amsterdam: Benjamins.
Taraldsen, Tarald, and Lucie Taraldsen Medová. 2016. Oblique arguments raised. Linguistica Brunensia: A special issue dedicated to Petr Karlík 64 (1): 131–142.
Taraldsen Medová, Lucie, and Bartosz Wiland. 2018. Functional sequence zones and Slavic L>T>N participles. In Exploring Nanosyntax, eds. Lena Baunaz, Karen De Clercq, Liliane Haegeman, and Eric Lander, 305–328. New York: Oxford University Press.
Torrego, Esther. 1985. On empty categories in nominals. University of Massachusetts, Boston.
Townsend, Charles E., and Laura A. Janda. 1996. Common and comparative Slavic: Phonology and inflection. Bloomington: Slavica Publishers.
Weerman, Fred, and Jacqueline Evers-Vermeul. 2002. Pronouns and case. Lingua 112: 301–338.
Wiland, Bartosz. 2009. Aspects of order preservation in Polish and English. PhD diss., Adam Mickiewicz University in Poznań. http://ling.auf.net/lingbuzz/000906.
Wiland, Bartosz. 2010. Overt evidence from left-branch extraction in Polish for punctuated paths. Linguistic Inquiry 41 (2): 335–347.
Wiland, Bartosz. 2016. Le charme discret of remnant movement: Crossing and nesting in Polish OVS sentences. Studies in Polish Linguistics 11 (3): 133–165.
Wiland, Bartosz. 2018. Spell-out driven extraction. Colloquium talk at University of Wuppertal.
Williams, Edwin. 2003. Representation theory. Cambridge: MIT Press.
Williams, Edwin. 2011. Regimes of derivation in syntax and morphology. New York: Routledge.
Acknowledgements
This work started in the Fall 2012 as a project for Michal Starke’s (Skype) seminar. We want to thank Michal Starke both for the impulse to work on this issue as well as for his comments and suggestions. Thanks also to Pavel Caha, Mojmír Dočekal, and Tarald Taraldsen for discussions at various stages of this work as well as the audiences of conferences where pieces of this work were presented (FASL 23 at UC Berkeley in May 2014, SLE 47 in Poznań in September 2014, and the workshop on Current Exploits in the Morphosyntax of Slavic Languages held at A. Mickiewicz University in Poznań in April 2015). We are equally grateful to four anonymous reviewers and to Gillian Ramchand, the handling editor, whose excellent comments helped us bring this paper to its final shape. Needless to say, we are solely responsible for the statements made in this paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Taraldsen Medová, L., Wiland, B. Semelfactives are bigger than degree achievements. Nat Lang Linguist Theory 37, 1463–1513 (2019). https://doi.org/10.1007/s11049-018-9434-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11049-018-9434-z