
Abstract
Due to the increasing demand for virtual avatars, there has been a recent growth in the research and development of frameworks for realistic digital humans, which create a demand for realistic and adaptable facial motion capture systems. Most frameworks belong to private companies or represent high investments, which is why the creation of democratized solutions is relevant for the growth of digital human content creation. This research work proposes a facial motion capture framework for digital humans with the use of machine learning for facial codification intensity regression. The main focus is to use coded face movement intensities to generate realistic expressions on a digital human. The ablation studies performed on the regression models show that Neural Networks, using Histogram of Oriented Gradients as features, and with person-specific normalization, present overall better performance against other methods in the literature. With an RMSE of 0.052, the proposed framework offers reliable results that can be rendered in the face of a MetaHuman.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Modeling the motion of a human face is a challenging task in computer animation for at least two reasons. First, the face is a complex structure composed of several layers with different characteristics, such as flexible skin, cushioned fat, solid bones, and elastic muscles. The interaction of these layers produces facial movement, making it challenging to specify the motion of such a complex structure [1]. Secondly, faces are very familiar to us, and we have a well-developed sense of what expressions and motions are natural for a face. Therefore, any small deviation from our concept of how a face should appear is easily noticeable [2] and may fall into the uncanny valley, a concept created by Masahiro Mori in 1970, where the emotional response to a human-like entity would abruptly transition from empathy to revulsion as it approaches, but does not quite achieve, a truly lifelike appearance [3].
Computer facial animation has experienced continuous and rapid growth since the groundbreaking work of Parke [2], who described the foundations of the representation, animation, and data collection techniques that had been used to produce realistic computer-generated animated sequences of a human face. The recent growth in research and development of realistic human representations is partly due to the increasing demand for virtual characters or avatars in the field of gaming, filming, human-computer interaction, and human-machine communication. According to Deng and Noh [4], the fundamental goal in facial modeling and animation research is to develop a system that is easily adapted to any individual face, capable of realistic real-time animation, and decreases the manual handling process [5].

An overall view of the proposed facial motion capture framework, the blue rectangle encloses the main contribution of this research work
There are several solutions for facial motion capture such as Masquerade [6], Faceware [7], or Avatary [8]; however, some of those solutions belong to private companies, so the possibility of using some of the required technology is not easily accessible. Moreover, the high cost associated with implementing such solutions presents a significant financial barrier that precludes many individuals from accessing them. The continuous growth of virtual environments and digital humans drives the research for democratized solutions to make empathic digital humans a more viable option for a wider public. The focus of this paper is to present the implementation of a method that applies machine learning for facial codification regression as part of a facial motion capture framework. This is inspired by the methodological approach that facial coding offers to analyzing and interpreting facial expressions. Figure 1 summarizes the proposed framework at a high level. An input frame from a live feed of an actor’s facial performance is passed to a face detection model, followed by a facial landmarks estimation model. Based on the landmarks, distance features are extracted and the face goes through an alignment and masking process. After that, the masked face is used to extract appearance features, which then go through a dimensionality reduction process. After the person-specific normalization of the features, a facial coding regression model is applied. The resulting expression intensities are solved into a rendering engine, where the data is translated into the facial movement of a digital human. This framework utilizes Unreal Engine 4.27, MetaHumans, and state-of-the-art Artificial Intelligence (AI) facial performance capture methods to imbue virtual characters with realistic expressions.
The purpose of using facial coding regression in this research is to achieve a systematic examination of facial movements that display emotional states and communication cues. A prominent facial coding framework is the Facial Action Coding System, which categorizes facial expressions into specific Action Units with a scale of intensity, that represents muscle movements responsible for various facial expressions [2]. By identifying and quantifying these Action Units, the goal is to generate emotionally resonant facial expressions rather than solely accurate movement portrayals of the face, understanding that each face is unique, and direct mapping of movements may lead to expressions that fall into the uncanny valley. Furthermore, this is, to the best of our knowledge, the first work that attempts to use the intensity of Action Units for real-time facial animation of digital humans.
The remainder of the paper is structured as follows. Section 2 introduces the related literature, including an introduction to facial coding, a survey on current facial capture solutions and expression intensity regression, and presents Unreal Engine and its tools for digital humans. The proposed method is presented in Section 3 with a detailed description of each step of the proposed framework. The experimental evaluation is described in Section 4, including the data preparation, the implementation details, the ablation studies, and the baseline results. A functional interface prototype is presented and evaluated in Section 5. Then, Section 6 includes a discussion of the results, along with future work. Finally, Section 7 describes the conclusions of the research work.

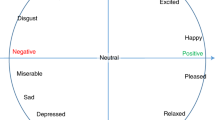
Action Units illustrated by iMotions [10]
2 Related work
2.1 Facial codification
To synthesize facial expressions for their replication through computer graphics, different schemes have been explored. One prominent scheme is the Facial Action Coding System (FACS) [9], originally designed in 1978 as a theory to observe, study, and analyze how facial expressions describe emotions and intentions in the field of psychology. The FACS describes all the visually distinguishable facial activity using 44 unique Action Units (AUs), in addition to several categories of head and eye positions and movements. Each AU is labeled with an arbitrary numeric code and is scored on a 5-point intensity scale, for the timing of facial actions and the coding of facial expressions in terms of events. These events are the AU-based description of each facial configuration, which may consist of one or more AUs contracted as a single display [9]. Figure 2 shows some examples of these Action Units.
The FACS model has been used for Digital Human experiments and animation as early as 1995 [11], with industry leaders in facial performance capture, like 3Lateral, still using it for real-time applications [12]. Due to this and to the availability of FACS-based data to train Machine Learning models, the solution presented in this paper focuses mainly on the use of FACS AUs.
2.2 Facial motion capture
Facial motion capture converts the movements and expressions of the face into data that is simple to process by solving and rendering engines. To make this possible multiple external sensors are used, such as video or infrared cameras, however, the main capture strategy can be classified into two general methodologies, the marker-based and the markerless-based, which are discussed in the subsections below.
2.2.1 Marker-based
The average marker-based system uses approximately 112 markers applied to the face of the performer to track their movement. The position, velocity, and displacement information of the markers are determined in the three dimensions by capturing the light reflected or emitted by them and using triangulation [13]. An example of a marker-based system is Masquerade [6], which is a modular and expandable in-house facial capture system built by Digital Domain. The different modules of Masquerade identify, accurately predict, and track the facial markers used during the performance. Based on the marker data and deformation gradients, the bending and deformation of the face surface, relative to the rest of the facial pose, is extracted.
This kind of approach allows adaptability of the marker model, bringing focus and accurate tracking to the areas of interest; however, because of the setup time, the artifacts from skin movement, and the accidental marker displacement during a performance, the process becomes cumbersome and repeatability becomes complex.
2.2.2 Markerless-based
Markerless systems use the visual features of the face for tracking, such as the corners of the lips, eyes, eyebrows, or jaw. This approach is mainly based on computer vision through the use of principal component analysis [14], eigen tracking [15], histogram of oriented gradients [16], active appearance models [17], deformable surface models [18], among other techniques to track the desired facial features per frame.
The technology for markerless face tracking is heavily related to facial recognition research. The process usually consists of face detection, facial landmark estimation, and expression recognition. For example, in the work of Somepalli et al. [19], the implementation of a single-camera markerless facial motion capture system is proposed, where face detection and facial landmark estimation play an important part. The landmarks are used along morph targets, which are duplicates of the original mesh with translations, rotations, or scale transformations that represent each expression.
This morph targets avoid unnatural positions of the virtual character that could be created by purely following the landmark movements. To capture a certain expression, the distance between a referential landmark with minimal movement and the driving landmark determines the influence of the corresponding morph target. This morph target is then blended back into the original mesh using a linear transformation model, known as a blendshape, to generate the final facial animation [19].
In general, the use of computer vision technology makes the process of facial tracking less cumbersome, however, it is limited by resolution and framerate, as well as being heavily dependent on the data available for the development of the tracking models. Furthermore, errors are much harder to fix during a real-time performance.
2.3 Face detection
Face detection is a problem in the computer vision field that involves finding the regions of an image that contains a face. It is also the initial step for various facial-related research, such as face modeling, head pose tracking, or facial expression recognition [20], and its performance has a direct impact on the effectiveness of those tasks [21]. Recent developments in computational technologies have also brought improvements to face detection research. Some recent methods were explored for the proposed framework and Table 1 offers a summary of the performance of each model based on the WIDER FACE Detection Benchmark [22] in terms of the output’s Frames Per Second (FPS) and mean Average Precision (mAP), which represents the mean over all classes of the average maximum precision calculated at different recall values.
2.4 Facial landmarks
Among the different necessary tasks to achieve many of the present-day facial analysis processes, one of the key fundamentals is to define, identify, and classify specific facial landmarks [27]. These landmarks allow, for example, to align facial images to mean face shapes or to locate the corners of an eye, mouth, nose, or eyebrow.
Some traditional algorithms are the Holistic, Constrained Local Model (CLM), and regression-based methods. In recent times, deep learning methods gained prominence over traditional ones and thereby became the most common approach to detecting facial landmarks. Several deep learning models were explored and Table 2 provides a summary of the performance of each method in terms of the output’s FPS, number of landmarks, and Normalized Mean Error (NME) on the 300 Faces In-the-Wild Challenge (300-W) [28], which represents the mean over the L2 distance between ground-truth points and model prediction results divided it by a normalized factor.
2.5 Action unit intensity estimation
Facial Action Unit intensity estimation is often regarded as a multi-class or a regression problem. Recently, novel models have tried to exploit the semantic meaning of Action Units by using global representations or spatial locations. An approach to Action Unit intensity estimation, proposed by Sánchez-Lozano et al.[35], is the use of heatmap regression to identify the location and intensity of a given Action Unit. The proposed approach uses facial landmarks and 2D Gaussians to generate the ground-truth heatmaps for a target AU using the BP4D dataset, where the amplitude and size of the Gaussian determine the intensity of the AU. A single hourglass network is used for regression by training it to learn a pixel-wise regression function that returns a score per AU, which indicates an AU intensity at a given spatial location.
A similar research work that extracts AU intensity and location is the work of Fan et al. [36], where they introduce a semantic correspondence convolution module that dynamically computes the correspondences from deep and low-resolution feature maps in a deep CNN framework to jointly predict AU intensities and their occurrence region. Furthermore, a non-maximum intensity suppression model is proposed for refining the prediction results at inference time. Both of these joint prediction approaches do not require face detection and alignment pre-processing steps, however, that also makes them not as robust to certain face poses with head rotations.
Another approach that uses alignment, proposed by J. Ma et al. [37], is the use of facial features constructed from facial landmarks. In the cited work, the three-dimensional coordinates of 68 facial landmarks are obtained based on a convolutional experts-constrained local model (CE-CLM), which enables the construction of dynamic facial features. These features go through dimension reduction with a principal components analysis (PCA), and a radial basis function neural network uses the reduced features to estimate the action unity intensity values.
2.6 Unreal engine and MetaHumans
The real-time display of a digital human can improve the emphatic response of the emotions it evokes since the notion of interactivity is incorporated into the interaction [38]. To achieve this, the industry has several options for real-time rendering engines, with characteristics favorable for digital humans, with the most notable one being Unreal Engine by Epic Games.
This real-time 3D creation tool for photo-real visuals and immersive experiences can be coupled with MetaHuman Creator [39], an Epic Games free cloud-based app that enables the creation of fully rigged photo-realistic digital humans in a few simple steps. Furthermore, another Epic Games product known as Live Link, provides a common interface for streaming and consuming animation data from external sources into Unreal Engine, allowing the solving of the facial capture data into a digital human face. Taking into consideration all of these characteristics, Unreal Engine can be considered one of the best options to democratize the use of highly realistic human characters for any kind of project.
3 Methods
Following the survey done on the state-of-the-art models for face detection and facial landmarks, and based on the different techniques for markerless motion capture systems and Action Unit intensity estimation models, this work proposes a facial motion capture framework, summarized in Fig. 1, that uses the regression of AU intensities as values for the facial blendshapes of a MetaHuman.
The proposed framework receives as input the frames captured from a video stream of an actor, which is then processed for face detection. The detected face region of the frame is used to estimate facial landmarks, which in turn are used to align the actor’s face and mask the image to keep only the face data of the image. The aligned and masked image is then used to extract appearance features and the facial landmarks are further used to extract distance features. After a dimensionality reduction and person-specific normalization of the appearance and distance features, a regression model is used to calculate the intensity of each AU. Next, with the estimated values for the expressions, a solving method is used to send the information into Unreal Engine and finally animate a digital human model. Further details of each step in the proposed pipeline are explained in the following subsections.
3.1 Face detection and facial landmarks
A face detection algorithm is considered necessary for the first steps of the framework, however, when a Head-Mounted Camera (HMC) system is included, the face detection step can become optional, since the face is distributed in the whole frame. The results obtained with Faceboxes [25], compared to the other methods listed in Table 1, show superior performance on both speed and accuracy, and the bounding boxes did not present much jittering, being the most consistent of the explored models. It is also important to note that FaceBoxes [25] achieves a bounding box that covers the whole face when the other methods fail to predict a robust bounding box, such as when the actor is performing extreme facial expressions like widely opening the mouth. Thus, this model is the one used in the framework.
Once the facial region of interest is defined, a facial landmark algorithm is considered necessary for the second step of the proposed framework, since it aids in the alignment and masking of the face, while also bringing to light distance data related to the facial features. The PIPNet model [34] from the explored methods mentioned in Section 2.4 is used for this step since it showed the best results on accuracy and obtained the second-best frames per second speed.
3.2 Facial expression tracking
The proposed facial expression tracking is done by calculating the AU intensities from the face. This process uses two different types of features: appearance features and geometric features. To extract those features, the input frames go through some pre-processing, which consists of the alignment and masking of the face using the facial landmarks previously detected. After obtaining and merging the features, a person-specific normalization is applied by subtracting the features of a neutral expression from the current feature vector. Having normalized the features, the data is used to train a Regression model for each AU.
3.2.1 Alignment and masking
To better analyze the texture of the face and extract significant features, it is necessary to map the face to a common reference frame and to remove changes due to scaling and in-plane rotation. The goal is to warp and transform the image to an output coordinate space, given the input coordinates of the facial landmarks. In this output coordinate space, the face should be centered in the image, rotated so that the eyes align horizontally, and scaled to maintain a consistent facial size across all input images. After aligning the image the framework also aligns the facial landmarks, to have the points in the new coordinate space.
To remove non-facial information, the image requires masking. This is performed using a convex hull surrounding the aligned landmark points. To capture the wrinkling of the forehead, the eyebrow landmarks are transformed slightly to the top of the frame. Figure 3 offers a visualization of the alignment and masking process.

The process of aligning and masking the face
3.2.2 Appearance features
The appearance features are based on Histogram of Oriented Gradients (HOGs) features [40], which is a feature descriptor used in computer vision and image processing for object detection problems [41]. This algorithm counts the occurrences of gradient orientation in the localized portion of an image, thus focusing on the structure or the shape of an object.
For the framework, once the face is aligned and masked, the image is resized to a \(112 \times 112\) image and used for implementation of the HOGs algorithm as proposed by Felzenszwalb et al. [41]. The algorithm uses cells of \(8 \times 8\) pixels and blocks of \(2 \times 2\), leading to \(14 \times 14\) blocks of 36-dimensional histograms. This results in a feature vector of 6084 dimensions to describe the face characteristics. Figure 4 offers a visualization of the extraction of HOG features. In order to reduce the dimensionality of the HOG feature vector, a Principal Component Analysis (PCA) is applied. By applying PCA to the data, the models are trained with 99% of explained variance

The process of extracting HOG features
3.2.3 Landmark-based features
After obtaining the coordinates of 68 facial landmarks, the framework creates the facial geometric features using them as information. Points in space can greatly differ due to their differences in the origin and direction of movement for each axis in a coordinate system. Therefore, constructing the features based on the relationship between the points in space may lead to adequate features for the model prediction. For the model, the distances between points are calculated in a similar way as J. Ma et al. [37], but using the specific regions for each AU group proposed by C. Ma, Chen, and Yong [42].
Different ways to construct information between points in a coordinate system are shown in Fig. 5. The framework uses only the euclidean distance between points because of two reasons: 1) the angles between facial landmark points vary in a small range, and 2) the perpendicular distance is equivalent to the euclidean distance and the computation complexity of calculating the perpendicular distance between a point and a line is greater than calculating the euclidean distance. Constructing the facial features from 68 landmarks leads to a feature vector with 2278 dimensions which represents the full distances graph and therefore the complete facial information.
Although these geometric features could be used as input for the model, they can still be optimized by using expert prior knowledge through the region definitions proposed by Ma, Chen, and Yong [42], given the co-occurrence of certain AUs in the same facial sections. The AUs are divided into 8 groups based on AU-related muscles defined in the FACS and the co-occurrence statistics of several databases.
Using these AU regions, a graph for each group can be constructed with the nodes being the landmark points and the edges being the connections between nodes. The implemented region partition rule uses the 68 facial landmark points provided by PIPNet [34] and 15 additional landmarks estimated through the average of relevant pair points where AUs tend to occur. Figure 6 shows all the landmarks and edges considered for partitioning the face into specific regions.

Different methods to construct landmark-based geometric features

All the facial landmarks used for the region partition. Blue points are the original 68 landmarks given by PIPNet [34]. Green points are the additional 15 landmarks calculated using the average of relevant pair points
The edges have the value of the euclidean distance between each pair of points. Each group will have a different number of nodes thus a different feature vector size. Table 3 summarizes the partition rules with the number of nodes and edges for each group, and Fig. 7 shows the region masks of each group.
3.2.4 Person-specific normalization
People’s faces can be very different from each other. While some people can appear more smiley, others can appear more sad or angry, even if their faces are at rest. Therefore, to determine correctly a facial expression, it is important to calibrate the data for each person by correcting it with a neutral expression. The framework uses a method proposed by Baltrušaitis, Mahmoud and Robinson [43], which estimates the neutral expression descriptors in a video sequence of a person. It is assumed that, for real-life situations, a neutral face is displayed most of the time. Thus, the median value of the feature vector is computed to obtain the neutral expression.

Action Unit regions by group
The difference between the feature vectors of facial images with and without expressions, can be calculated by subtracting the neutral expression from the feature descriptor. This leads to a person-specific normalized feature, which can be defined by:
For HOG features, the normalized feature from a person can be directly subtracted. For the landmark-based features, the formula can be defined as:
where \(d_{i,j}\) is the euclidean distance between landmarks i and j, and \(\Delta d_{i,j}\) is the normalized feature.
3.2.5 Action unit intensity regression
For the problem of Action Unit intensity estimation, two different approaches were used, Support Vector Regression (SVR) and Neural Network (NN) Regression. The models are trained for each AU, to apply the expert prior knowledge introduced in Section 3.2.3. The SVR model was tested with Radial Basis Function (RBF) and linear kernels to understand the trade-off between performance and speed. The model was trained using 5-fold cross-validation to tune the gamma parameter of the RBF kernel, the epsilon parameter for the linear kernel, and the C parameter for both kernels.
The NN model has 2 hidden layers and a sigmoid activation. The number of nodes in each layer was tested using 5-fold cross-validation with 0, 256, 512, and 1024 as options, where a value of 0 indicates no hidden layer. The cross-validation showed that a hidden layer with 256 nodes provided the best performance. Finally, a Root Mean Squared Error (RMSE) function is used as loss. RMSE is a signal fidelity measure that describes the degree of similarity or the level of error between signals by providing a quantitative score. The RMSE between two finite-length and discrete signals, x and y is defined as:
where N is the number of signal samples and \(x_i\) and \(y_i\) are the values of the ith samples in each signal [44].
3.3 Solving
The objective of the solving process is to translate information from the facial components into a common and easy-to-interpret language for a 3D engine. For the framework, the facial information is composed of the AU intensity values that need to be delivered as deformer blendshape values. For this implementation, a MetaHuman is prepared with a blendshape per AU, so that the intensities can be sent to Unreal Engine and mapped directly. The framework uses the Open Sound Control (OSC) communication protocol to send messages through an application and display them on a MetaHuman in Unreal Engine.
4 Experimental evaluation
This section presents the steps implemented for the experimental evaluation of the facial expression tracking capabilities of the framework. These steps include data preparation, implementation details, baseline calculations, and ablation studies, which are further explored in the next subsections.
4.1 Data preparation
The AU intensity models are trained on the Denver Intensity of Spontaneous Facial Action (DISFA) [45] database. This data set consists of one video for each of the 27 subjects (12 women and 15 men) with an age range of 18-50 years old. The subjects vary in heritage but the majority are Euro-American. Each video consists of 4845 annotated frames with 12 AU intensities from spontaneous expressions. The intensities are on a 0-5 scale with integer numbers, which are normalized to a 0-1 scale for the proposed framework.
The first step for data preparation is to balance the data. The original dataset is highly unbalanced with much more 0 intensities than other intensities, therefore a downsample strategy is used to reduce the 0 intensity for each AU. Depending on the number of samples with other intensities, a new sample size with 0 intensities is decided. For example, in the case of AU1, the number of samples for each intensity is as follows, 0: 122036, 1: 2272, 2: 1749, 3: 2809, 4: 1393, and 5: 555. Based on these numbers, the instances with 0 intensity are downsampled to 2500.
The second step of data preparation is to clean the data. Some frames contain samples where the face is occluded or incomplete, and since useful information cannot be obtained from such frames, they are removed. Such faulty frames are detected by applying the face detection and facial landmark prediction algorithms to each frame of the balanced data, if either model failed to characterize the face, that frame was removed, resulting in a total of 439 frames deleted.
4.2 Implementation details
All experiments were conducted using Colab Pro for cloud computing with Python-based Jupyter notebooks. The virtual environments utilized had 26 GB of RAM, along with Tesla T4 and P100 GPUs. The implementation of the deep learning tasks was done with Pytorch, which includes face detection, facial landmarks estimation, and Neural Network regression. RAPIDS is used to train the models, which is an open GPU data science library that allowed faster training.
4.3 Ablation studies and baseline results
For the ablation studies, the behavior of the models is compared by using different features and including or excluding person-specific normalization. This is done to explore the contribution of each component in the proposed pipeline, and how the performance changes by combining and tuning each part of the model. Table 4 RMSE obtained from experiments conducted as part of the ablation studies, analyzing various approaches to AU intensity regression. It can be observed that, overall, the best results were obtained from a NN regression model that only uses HOGs as features and applies person-specific normalization, with an RMSE of 0.052.
Finally, to evaluate the overall performance of the AU intensity estimation of the framework, the work presented by Fan et al. [36] and the research by J. Ma et al. [37], also mentioned in Section 2.5, was used as a baseline. Table 5 summarizes the results of the baseline and the proposed approach based on the results of the ablation studies and in terms of RMSE. The results indicate that the proposed approach outperforms both of the aforementioned models.
5 Implementation and performance
To implement the framework, an easy-to-use Graphical User Interface (GUI) was developed, which can monitor the facial expressions and the performance of all the steps in the pipeline. The desktop application was developed using PySide 6, as displayed in Fig. 8.

Screen capture of the GUI developed for the proposed framework, along with an example of the process of solving into a MetaHuman in Unreal Engine 4.27
The GUI shows a visualization of the facial detection and facial landmarks models on the live video sequence. The performance information is shown on the top right of the window, with the FPS and execution time in milliseconds of the different steps. The AU intensity predictions are displayed in a horizontal bar graph below the performance information. The application offers visualizations for the alignment and HOG calculations. A widget is included to rotate the video feed, since some Head Mounted Camera rigs stream the frames vertically, as well as another widget to input information necessary to stream the data through OSC, for it to be received on Unreal Engine 4.27 and solved into a MetaHuman. The performance of the application was evaluated in terms of mean computation times for each task, as summarized in Table 6.
Additionally, using a 30 FPS camera with a resolution of 640x480 pixels, the AU intensity data could be streamed at speeds of up to 20 FPS, with an average data streaming performance of 10.75 FPS using a single GPU, for it to be received by Unreal Engine 4.27 and solved into a MetaHuman while maintaining a frame rate of 30 FPS in real-time rendering using an Nvidia 1650 GPU. The inference time and processing speed during a 5-minute performance of 12 AUs are compared against approximate implementations of the work presented by Fan et al. [36] and the research by J. Ma et al. [37], previously mentioned in Section 2.5, using the same hardware setup. The results are summarized in Table 7.
6 Discussion
The pipeline presented in this manuscript was built on the investigation done regarding facial coding, facial detection, facial landmarks, and AU intensity regression. The proposed framework receives as input the frames captured from a video stream, which are then processed for different tasks:
-
1.
Facial detection.
-
2.
Facial landmarks.
-
3.
Appearance feature extraction.
-
4.
Distance feature extraction.
-
5.
AU intensity regression.
-
6.
Person-specific normalization.
-
7.
Solving.
The framework pipeline used the best models of the explored literature based on the performance and precision results of the algorithms. The best models were Faceboxes [25] for face detection and PIPNet [34] for facial landmark estimation. Different experiments and ablation studies were performed to find the best AU intensity regression method and to observe how the different feature extraction and normalization processes contribute to the pipeline. It was concluded that NN regression models outperformed SVR models and, within the SVR models, using an RBF kernel gives better performance, but a linear kernel offers a faster inference. Furthermore, person-specific normalization can be observed to improve the performance of the AU intensity models in most cases.
The NN model that only used HOGs as features obtained the same results as the NN model that uses HOGs and landmark distances as features. The models that used the same features, but additionally performed person-specific normalization, obtained better results by a margin of \(0.001 - 0.002\). Combining the appearance and distance features turned out to be too expensive for the SVR models, so the overall framework could choose to use the NN model with only HOGs as features if computational resources are limited. For the overall best result, the NN model with HOGs as a feature and person-specific normalization is recommended. In the end, the best-performing model obtained from the ablation studies outperformed other state-of-the-art research that was mostly based on facial landmarks, proving the relevance of appearance features in the estimation of AU intensities.
7 Conclusions and future work
In the last decade, digital humans have become a relevant and consolidated subject of research as a new form of embodied conversational agents. An interesting approach to constructing facial expressions for digital humans involves recreating all that the human face does when expressing emotions, which can be achieved through facial coding. FACS provides a direct correspondence between facial muscles and expressions through AUs, so this manuscript introduces a framework that uses the intensity of AUs to display realistic emotions in a digital human face.
Based on the results of the ablation study, the best regression approach was with the use of a NN, using HOGs features and person-specific normalization. This proposed approach outperforms other solutions from the literature on the 12 AUs from the DISFA dataset. Furthermore, the AU intensity values were shown to be successfully solved into a MetaHuman through the use of blendshapes. As future work, the regions used on the landmark-based features can be applied for HOGs features so that the model focuses on the specific locations of the face where each AU can occur. Additionally, optimizations on the HOGs model can be implemented to improve the performance of this task, since it also displayed the highest mean computation time in the whole pipeline, being the main bottleneck to achieve real-time performance of 30 FPS. On the other hand, the current face alignment algorithm is very basic, so the implementation of a more robust algorithm could improve the results of the model.
For future testing, the AU intensity regression model could be trained with a cross-dataset approach using several other samples to achieve better generalization. Then, for a more complete facial capture solution, different eye-tracking and head pose state-of-the-art models can be explored and implemented into the proposed framework. A lip-syncing module can also be included by using a viseme detection model that takes in audio or video. Finally, several improvements can be done to the user interface of the application, since it is currently only used by researchers to debug each component of the pipeline. For the general public, a redesign of the GUI and an executable of the application could help in its ease of use and configuration.
Availability of data
Data from the Denver Intensity of Spontaneous Facial Action (DISFA) [45] database is used in this paper. The database is available for distribution for research purposes. The full data set, documentation, and requirements to request DISFA can be found at http://mohammadmahoor.com/disfa/
Code availability
Code for the implementation of the proposed framework will be available at https://github.com/EugeniaResearch.
References
Krumhuber EG, Tamarit L, Roesch EB, Scherer KR (2012) Facsgen 2.0 animation software: Generating three-dimensional facs-valid facial expressions for emotion research. Emotion 12(2):351
Parke FI (1972) Computer generated animation of faces. In: Proceedings of the ACM annual conference - vol 1. ACM ’72, pp 451–457. Association for Computing Machinery, New York, NY, USA. https://doi.org/10.1145/800193.569955
Mori M, MacDorman KF, Kageki N (2012) The uncanny valley [from the field]. IEEE Robot Autom Mag 19(2):98–100
Deng Z, Noh J (2008) In: Deng Z, Neumann U (eds) Computer facial animation: a survey, pp 1–28. Springer, London. https://doi.org/10.1007/978-1-84628-907-1_1
Ping HY, Abdullah LN, Sulaiman PS, Halin AA (2013) Computer facial animation: A review. Int J Comput Theory Eng 658–662. https://doi.org/10.7763/ijcte.2013.v5.770
Moser L, Hendler D, Roble D (2017) Masquerade: fine-scale details for head-mounted camera motion capture data. In: ACM SIGGRAPH 2017 Talks, pp 1–2. ACM, Los Angeles California. https://doi.org/10.1145/3084363.3085086
Faceware Technologies I (2023) Faceware Website. https://facewaretech.com Accessed 22 May 2023
FACEGOOD Co.,Ltd (2023) Avatary by Facegood. https://www.facegood.cc Accessed 22 May 2023
Rosenberg EL, Ekman P (2020) What the Face Reveals: Basic and Applied Studies of Spontaneous Expression Using the Facial Action Coding System (FACS), 3rd edn. Series in Affective Science. Oxford University Press, Oxford
Farnsworth B (2019) Facial Action Coding System (FACS) – A Visual Guidebook. https://imotions.com/blog/facial-action-coding-system/ Accessed 22 May 2023
Terzopoulos D (1995) Modeling living systems for computer vision. In: Proceedings of the 14th international joint conference on artificial intelligence - vol 1. IJCAI’95, pp 1003–1013. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA
Lumsden B (2019) Digital humans: 3Lateral cracks the code for real-time facial performance. https://www.unrealengine.com/en-US/blog/digital-humans-3lateral-cracks-the-code-for-real-time-facial-performance Accessed 22 May 2023
Dagnes N, Marcolin F, Vezzetti E, Sarhan F-R, Dakpé S, Marin F, Nonis F, Ben Mansour K (2019) Optimal marker set assessment for motion capture of 3d mimic facial movements. J Biomech 93:86–93. https://doi.org/10.1016/j.jbiomech.2019.06.012
Peng P, Portugal I, Alencar P, Cowan D (2021) A face recognition software framework based on principal component analysis. PLOS ONE 16(7):1–46. https://doi.org/10.1371/journal.pone.0254965
De A, Saha A, Pal MC (2015) A human facial expression recognition model based on eigen face approach. Procedia Comput Sci 45: 282–289. https://doi.org/10.1016/j.procs.2015.03.142. International Conference on Advanced Computing Technologies and Applications (ICACTA)
Nazir M, Jan Z, Sajjad M (2018) Facial expression recognition using histogram of oriented gradients based transformed features. Cluster Computing 21. https://doi.org/10.1007/s10586-017-0921-5
Ravikumar S (2019) Lightweight markerless monocular face capture with 3d spatial priors. CoRR arXiv:1901.05355
Goenetxea J, Unzueta L, Dornaika F, Otaegui O (2020) Efficient deformable 3d face model tracking with limited hardware resources. Multimed Tools App 79:12373–12400
Somepalli MR, Charan MDS, Shruthi S, Palaniswamy S (2021) Implementation of single camera markerless facial motion capture using blendshapes. In: 2021 IEEE International conference on computation system and information technology for sustainable solutions (CSITSS), pp 1–6. https://doi.org/10.1109/CSITSS54238.2021.9683460
Hasan MK, Ahsan MS, Abdullah-Al-Mamun, Newaz SHS, Lee GM (2021) Human face detection techniques: A comprehensive review and future research directions. Electronics 10(19). https://doi.org/10.3390/electronics10192354
Minaee S, Luo P, Lin Z, Bowyer K (2021) Going deeper into face detection: A survey. arXiv:2103.14983 [cs.CV]
Yang S, Luo P, Loy CC, Tang X (2015) WIDER FACE: A face detection benchmark. CoRR arXiv:1511.06523
Anand S (2023) Face Recognition with OpenCV. https://docs.opencv.org/3.4/da/d60/tutorial_face_main.html Accessed 22 May 2023
Deng J, Guo J, Zhou Y, Yu J, Kotsia I, Zafeiriou S (2019) Retinaface: Single-stage dense face localisation in the wild. ArXiv arXiv:1905.00641
Zhang S, Zhu X, Lei Z, Shi H, Wang X, Li SZ (2017) Faceboxes: A CPU real-time face detector with high accuracy. arXiv arXiv:1708.05234
NVIDIA NGC Catalog (2023) FaceDetect. https://catalog.ngc.nvidia.com/orgs/nvidia/teams/tao/models/facenet Accessed 22 May 2023
Bätz A, De A, Palacio M, Mishra G, Rodrıguez I, Pranti M, Satorre Mulet P, Supervisor P, Shahriar MH, Lippert C (2021) Facial Landmarks Detection : A Brief Chronological Survey & Practical Implementation. https://doi.org/10.13140/RG.2.2.36199.98722
Sagonas C, Tzimiropoulos G, Zafeiriou S, Pantic M (2013) 300 faces in-the-wild challenge: The first facial landmark localization challenge. In: 2013 IEEE International conference on computer vision workshops, pp 397–403. https://doi.org/10.1109/ICCVW.2013.59
Mallick S (2018) Facemark : Facial Landmark Detection using OpenCV. https://learnopencv.com/facemark-facial-landmark-detection-using-opencv/ Accessed 22 May 2023
NVIDIA NGC Catalog (2023) Facial Landmark Estimator (FPENet) Model Card. https://catalog.ngc.nvidia.com/orgs/nvidia/teams/tao/models/fpenet Accessed 22 May 2023
Guo J, Zhu X, Yang Y, Yang F, Lei Z, Li SZ (2020) Towards fast, accurate and stable 3d dense face alignment. CoRR arXiv:2009.09960
OpenMMLab project (2023) MMPose. GitHub
Grishchenko I, Bazarevsky V (2020) MediaPipe Holistic — Simultaneous Face, Hand and Pose Prediction, on Device. https://ai.googleblog.com/2020/12/mediapipe-holistic-simultaneous-face.html Accessed 10 Dec 2020
Jin H, Liao S, Shao L (2020) Pixel-in-pixel net: Towards efficient facial landmark detection in the wild. CoRR arXiv:2003.03771
Sánchez-Lozano E, Tzimiropoulos G, Valstar MF (2018) Joint action unit localisation and intensity estimation through heatmap regression. CoRR arXiv:1805.03487
Fan Y, Shen J, Cheng H, Tian F (2020) Joint facial action unit intensity prediction and region localisation. In: 2020 IEEE International conference on multimedia and expo (ICME), pp 1–6. https://doi.org/10.1109/ICME46284.2020.9102833
Ma J, Li X, Ren Y, Yang R, Zhao Q (2021) Landmark-based facial feature construction and action unit intensity prediction. Mathematical Problems in Engineering 2021
Aneja D, McDuff D, Shah S (2019) A high-fidelity open embodied avatar with lip syncing and expression capabilities. In: 2019 International conference on multimodal interaction, pp 69–73
International Epic Games (2023) Epic Games MetaHuman Creator. https://metahuman.unrealengine.com/
Dalal N, Triggs B (2005) Histograms of oriented gradients for human detection. In: 2005 IEEE Computer society conference on computer vision and pattern recognition (CVPR’05), vol 1, pp 886–893. Ieee
Felzenszwalb PF, Girshick RB, McAllester D, Ramanan D (2010) Object detection with discriminatively trained part-based models. IEEE Trans Pattern Anal Mach Intell 32(9):1627–1645
Ma C, Chen L, Yong J (2019) Au r-cnn: Encoding expert prior knowledge into r-cnn for action unit detection. neurocomputing 355:35–47
Baltrušaitis T, Mahmoud M, Robinson P (2015) Cross-dataset learning and person-specific normalisation for automatic action unit detection. In: 2015 11th IEEE International conference and workshops on automatic face and gesture recognition (FG), vol 6, pp 1–6. IEEE
Wang Z, Bovik AC (2009) Mean squared error: Love it or leave it? a new look at signal fidelity measures. IEEE Signal Process Mag 26(1):98–117. https://doi.org/10.1109/MSP.2008.930649
Mavadati SM, Mahoor MH, Bartlett K, Trinh P, Cohn JF (2013) Disfa: A spontaneous facial action intensity database. IEEE Trans Affect Comput 4(2):151–160
Funding
For the research leading to these results, author Carlos Vilchis has received funding in the form of a scholarship from the Mexican National Council of Humanities, Science, and Technology (CONAHCYT) and from Tecnologico de Monterrey. Author Mauricio Mendez-Ruiz and Carmina Perez-Guerrero receive a salary from Eugenia Virtual Humans S.A. de C.V., a start-up that is supported by the Epic MegaGrants program under Grant FACS DEEP LEARNING TOOL. Author Carlos Vilchis is CTO and Co-Founder of Eugenia Virtual Humans S.A. de C.V.
Author information
Authors and Affiliations
Contributions
Carlos Vilchis, Mauricio Mendez-Ruiz, and Carmina Perez-Guerrero made substantial and equivalent contributions to this research project. Their collaborative efforts encompassed conceptualization, data curation, formal analysis, investigation, methodology development, software implementation, supervision, validation, visualization, and the creation of the original draft of the manuscript. They were also actively involved in the review and editing process, collectively shaping the project’s outcomes. Miguel Gonzalez-Mendoza played a critical role in data curation, formal analysis, investigation, supervision, validation, and contributed to the review and editing of the manuscript. While his focus was more specialized, his contributions were integral to the project’s success.
Corresponding author
Ethics declarations
Ethics approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Vilchis, C., Mendez-Ruiz, M., Perez-Guerrero, C. et al. Action unit intensity regression for facial MoCap aimed towards digital humans. Multimed Tools Appl (2024). https://doi.org/10.1007/s11042-024-19400-8
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11042-024-19400-8