
Abstract
Early diagnosis of psychological disorders is very important for patients to regain their health. Research shows that many patients do not realize that they have a psychological disorder or apply to different departments for treatment. The detection of hidden psychological disorders in patients will both increase the quality of life of patients and reduce the traffic of patients who apply to the wrong department. This study aimed to determine whether patients who consult a physician for any reason need psychological treatment. For this purpose, the relationships, and similarities between the sentences of previous psychiatric patients and the sentences of newly arrived patients were analyzed. Domain-based trained ELECTRA language model was used to detect sentence similarities semantically. In the study, the dialogues of patients with physicians in 92 different specialties were analyzed using the MedDialog dataset, which consists of online physician applications, and the DAIC-WOZ dataset. As a result of the experiments, 90.49% success was achieved for the MedDialog dataset and 89.36% for the DAIC-WOZ dataset. With the proposed model, patients in need of psychological treatment were identified and the medical departments where psychological problems were revealed the most were determined. These divisions are Neurology, Sexology, Cardiology, and Plastic Surgery, respectively. With the findings obtained, complications caused by psychological problems and types of diseases that are precursors to psychological disorders were determined. To the best of our knowledge, this article is the first study that aims to analyze all psychological illness instead of focusing on any of the psychological problems (depression, OCD, schizophrenia, etc.) and validated by electronic health records.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Psychological disorders are very important problems that affect a person's health and quality of life. As with other health problems, early diagnosis is important, and precautions should be taken before it causes more serious consequences. However, unlike most other health problems, it may be more difficult for people with psychological disorders to realize or accept this situation. Studies have been carried out to raise awareness on this issue. Studies show that awareness of this issue has increased in recent years [1]. In addition, the number of patients with mental problems has been increasing due to various factors such as changing living standards, social problems, and pandemic in recent years [2]. As of 2020, 26% of adults in the USA are exposed to at least one different mental health problem each year. In larger-scale studies, the rate of receiving psychological treatment at least once exceeded 56% of the population. In the USA, the number of patients admitted to the hospital due to any mental illness (AMI) problem in 2020 is over 24.3 million [3]. Recent studies show that the need for psychological treatment has increased in many countries due to the Covid-19 pandemic [4]. Based on these studies, it is expected that the need for mental health treatment is much higher than in previous years.
Eliminating the need for psychological treatment is an important factor that will reduce other health problems of people. Because when the pre-diseases that cause the most chronic diseases were investigated, it was seen that psychological disorders took the second place [5]. It has been observed that the tendency to develop heart diseases and diabetes is increased in chronic psychiatric patients [6, 7]. Apart from these diseases, psychological problems that cause many physical disorders are also seen as the primary reason in suicide cases [8]. All these reasons show that the need for psychological treatment should be well-identified and treated. An important problem encountered at this stage is the determination of whether people have a mental illness or not. Many studies in the literature have focused on predicting possible symptoms of psychological illness based on people's behaviors or social media posts [9,10,11,12,13]. Most of these studies, which are shared in detail in the next section, produce predictions by making use of Machine Learning and Deep Learning methods. With the developments in data science, medical prediction, and detection studies, based on both texts and images, continue increasingly in the field of Psychology.
1.1 Research objectives and contributions
This study, unlike other similar studies in the literature, focused on identifying the psychological disorders of patients who applied to a different polyclinic. It is aimed to make inferences about possible mental disorders of patients who are not aware of a psychological disorder. In particular, it will be possible to detect hidden psychological disorders of patients who apply to physicians via telemedicine and to direct these patients to psychological treatment if the physician deems it necessary. To the best of the authors' knowledge, this is the first study aiming at detecting psychological disorders from real patient records in different branches (cardiology, internal medicine, aesthetics, etc.).
In the vast majority of studies in this area, possible patient data obtained from social media users or psychology clinics are used. In Chapter 2, these studies are discussed in detail. The reasons such as the character limitations in the shares of social media users, the possibility of the shares not reflecting the truth, and the focus of the posts on different subjects are important difficulties in revealing psychological disorders. In order to avoid these disadvantages, in this study, real patient records were used, predicting that the patient's dialogue with the physician would provide more realistic data and that these data would be medically oriented.
The main contributions presented in the study are as follows:
-
A predictive model was developed to determine whether patients presenting for a different illness need psychological treatment.
-
With the results of the experiments, it became possible to detect the complications of psychological disorders and to identify some diseases that cause these disorders as side effects.
-
It was determined that the patients who applied to which department most often experienced psychological disorders. Thus, a physician recommendation system was developed to ensure the psychological health of patients coming to these departments (such as Sexology, Cardiology, and Plastic Surgery).
-
A comparison of the success of popular language models (BERT, SBERT, RoBERTa, BioBERT, XLNet and ELECTRA) on medical texts was made and success analyzes were interpreted.
With the early detection of chronic psychological disorders, a successful model is being developed for the development of clinical decision systems. Realizing that the primary problem is psychological while waiting for treatment from a different clinic or determining the need for psychological treatment in addition to the current treatment will be a very important gain for the patient's health. A physician recommendation system is presented in this study to refer patients to psychiatry as a complement to their treatment. In addition, it is possible to use systems similar to the current study in telemedicine platforms that are frequently used today. The fact that patients use written texts directly on these platforms is a factor that will increase the usability of the study.
2 Related works
In past studies, inference methods from data have been used frequently to detect psychological disorders. Thanks to the storable keeping of electronic health records (EHR) and the creation of technological opportunities that reveal people's emotional states (social media, sharing blogs on the internet, etc.), it has become easier to access data to make medical inferences. By courtesy to these tools, Natural Language Processing, Image Processing, Machine Learning and Deep Learning methods are frequently used to make medical inferences [14, 15]. While visual data is needed for the detection of some diseases or anomalies according to the field of study, text-oriented inferences are mostly used for the detection of mental problems. In this area, it is mostly possible to diagnose after people express their thoughts and express their experiences verbally or in writing. It is known that in the real hospital environment, physicians mostly focus on verbal expressions to reach the result, and they do not need an additional visual examination (ultrasound, MRI, etc.) to a large extent. Due to the nature of the problem, language processing models and Machine Learning models for inference are used extensively in the literature for the solution.
It has been observed that the literature mostly focuses on social media posts to detect mental disorders of people [9, 10, 16,17,18]. In these studies, posts of people on social media platforms such as Twitter, Instagram etc. or comments made on longer content blogs such as Reddit are taken into account [19]. Outputs such as estimation of depression, estimation of anxiety and obsessive disorders, estimation of schizophrenia are produced based on these comments. When the studies are examined, it is seen that Support Vector Machine (SVM), Neural Network and Random Forest algorithms are the most preferred methods [20, 21]. It is seen that the results obtained from the studies vary between 54 and 95% in conditions with strong symptoms such as schizophrenia, and the prediction success can be increased in tasks such as depression prediction and bipolar disorder prediction [7, 22,23,24].
It is seen that popular language representation models are used in current studies for the early detection of mental health problems [25, 26]. It is seen that more successful inferences are made with vector representation models, which are known to be more successful than traditional machine learning and deep learning methods. These studies have been used to learn about the psychology of the general society, along with the psychological effects of current social events [13, 27, 28]. However, as mentioned before, the majority of the studies were conducted with data originating from social media. Therefore, the adequacy of data length for a general psychological analysis can be seen as the most important limitation of these studies [11, 12].
When past studies are examined, it is seen that there is a concentration on detection systems that focus on one or more of the psychological disorders. These studies mostly focus on tasks such as perceiving major depression or obsessive–compulsive disorders or determining the level of anxiety [29,30,31,32]. In this paper, it was examined whether the person needed psychological treatment for any reason, focusing on the whole of psychological disorders. Unlike most of the previous studies, text analysis and inference studies were carried out on the records obtained from the interviews of the patients with the doctors, not the social media posts. Thus, it will be possible to make inferences that a patient should receive psychological treatment in addition to his current illness, that he has a psychological disorder as the main cause of the current illness, or that the main problem can be resolved with psychological treatment. To achieve these goals, preliminary experiments were carried out in the semantic sentence similarity task with 6 different language representation models. The ELECTRA model, which gave the most successful results, was used in the continuation of the study. The operation and advantages of the model used are explained in detail in the next section.
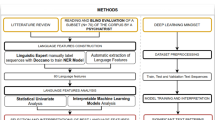
3 Material and methods
The data set required for the realization of the study, the text mining performed on the data and the algorithms used are explained in sub-titles in this section.
3.1 Data
Two different data sets were used in the study. Experiments were conducted with text data from patients with psychological disorders from the MedDialog and DAIC-WOZ datasets. The patient-doctor dialogs used in the study were obtained from the MedDialog dataset prepared by Zeng et al. [33]. In this dataset, there are patient-doctor interviews obtained from Chinese and English online clinical services (telemedicine) websites. The English records in the data set include 257,332 patient records in 92 categories. In these systems, more than 20 thousand doctors and telemedicine services are provided to 6 million individual users in total.
The DAIC-WOZ dataset includes video, audio, and text-converted data from 3 different data formats obtained from psychological rehabilitation interviews [34, 35]. In this study, the text part of the data set was used, and experiments were conducted with the text recordings of the interviews held in 189 different sessions. This data set has been used in many studies in the past, such as the detection of depression and the detection of image-text relationships of psychological disorders [36, 37]. The main information for the combined test dataset prepared for the present study is shown in Table 1.
As seen in Table 1, the study collected data on 3372 different cases to determine whether a patient had mental problems or not. 2201 of these cases described their situation in less than 7 sentences. In 1171 cases, there were longer narratives, so these cases were categorized as long texts. In the following sections, the prediction models for both short texts and long texts are explained in detail.
3.2 Preprocessing of data in dataset
Since the MedDialog-EN dataset to be used in the study includes dialogues from many medical departments, only the dialogues of the psychiatry department were taken from the dataset. This section will be used later in the study to analyze the sentences of patients who actually need psychological treatment. The important part of the study consists of patients who did not apply to the psychiatry department but were referred to psychiatry by the doctors of the other department. The data of these patients will be used in the testing phase of the study and presented to the developed prediction model. For this reason, suitable templates in the data set were sought to identify patients referred to psychiatry. At this stage, referral links to psychiatrists from different departments were used. With the help of these links, referrals to the psychiatry department were determined among physician responses. The data formats collected in this way are illustrated in the following examples. Table 2 shows the narratives of the patients who applied to cardiology and neurology and the answers of the doctors.
As seen in the examples, some patients were directed to the system's online psychiatrists or psychologists via 'icliniq'. Thanks to these referral links, the conversations of 556 patients who were referred to psychological treatment from other departments were collected. In the Healthcaremagic system, routing links were not used as in the icliniq data. For this reason, 1007 patient data were collected by manual selection among physician discourses in the first stage. Then, a semantic similarity study was conducted by using the sentences such as "please consult a psychiatrist", "you need to consult a psychologist" or "you should not receive psychological treatment", which are frequently used by physicians when referring them. At the stage of finding semantic similarity, the SBERT model was used to identify sentences with more than 75% similarity to the sentences of the physicians who referred the patient to psychiatry. 123 more records, which are close to the sentences given in the example but written with different expressions, were added to the data set. The features and working principle of the model used in this step are clearly shared in next chapters. With these cases, a test data set consisting of a total of 1686 case dialogs to be used for testing was prepared. After this stage, the data to be used for the pre-training, testing and validation stages of the study are categorically ready.
In the DAIC-WOZ dataset, which is the other data set in the study, the records of 107 patients are available as training dataset and 47 patient records with labels are ready for use as test datasets. Longer texts were obtained compared to the data obtained by the telemedicine method since the interview durations lasted an average of 16 min. In this way, it will be possible to test the success of the proposed model by conducting separate experiments on both short texts and long texts.
3.3 Proposed method
In the study, sentence similarities between a patient and real patients will be measured to estimate the likelihood of a patient experiencing psychological problems. As a result of these measurements, the higher the similarities between the patients, the higher the likelihood that the current case will have a psychological disorder. ELECTRA language model will be used to detect the similarity between sentences. For the success of the research, first of all, the sentences of patients receiving psychological treatment must be well represented. Because patients convey their current situation and discomfort to the physician with these sentences. Why the ELECTRA model was chosen in the study and its prominent advantages over other language models are explained in detail in Section 3.5. At what stage the similarity between two patients is accepted and its mathematical principles are explained in detail in Section 3.3. The method we propose is to first build the language model on a related dataset.
If the vector equivalents of sentences are meaningful enough, these vectors will include word patterns that will require psychological treatment. Thus, the assumption can be made that a new person who later uses expressions similar to these sentences also needs psychological treatment. For this purpose, as the first step of the study, the preliminary training of the ELECTRA model was carried out with the MedDialog-En and DAIC-WOZ datasets. In order to better represent the expressions frequently used by patients and doctors, training was conducted on medical data. It is expected that medical terms will be better represented, thanks to medical data in the same format and with similar content as the data to be used in the next test phase.
In the next step, the statements of the patients who applied to the psychiatrist or psychologist from the categories in the MedDialog-En dataset were divided into sentences. Similarly, patient discourses directed to psychological treatment from different departments are also divided into sentences. These sentences will be given as inputs to the ELECTRA model and a similarity score will be generated for each pair of sentences out of cosine similarity. Since ELECTRA architecture provides vectorial output, cosine similarity metric was preferred to determine the relationship between two vectors. In this metric, measurement is made according to the cosine value of the angle between the vectors. When the cosine value approaches 0, it means that the similarity of the vector representations will increase. Thus, it becomes possible to detect semantic similarities. In the next stage, the patient's need for psychological treatment will be decided based on these similarity scores. The similarity detection architecture used in the study is shown in Fig. 1.

Architecture of detection of text similarity in the proposed method
The ELECTRA model seen in Fig. 1 generates token embedding with a pair of sentence inputs. With the subsequent pooling process, a 768-dimensional vector is created and cosine similarity is measured between these vectors. The results obtained will have a value between -1 and 1. As this value gets closer to 1, the similarity of the sentences increases. The 'Mean Squared Error' is used as the objective function to eliminate negative values from the results. Thus, the results obtained will be in the range of 0 to 1.
Two different sentence groups are sent as input to the language model. In this process, the sentences of a patient who is actually undergoing psychological treatment and the sentences of a new patient used as test data are converted into vectors with the help of transformers. In this process, the length of the vectorized sentences is not an important factor. The compound vector formed based on semantic word vectors represents the sentence. A sentence consisting of 5 words and a sentence consisting of 10 words are created in the same format (300-digit numerical vector). In this way, sometimes an expression that can be expressed in 3 words can produce a similar vector when expressed in a single word. Thanks to this method, the similarity between sentences of different lengths is achieved with a completely semantic approach, independent of the number of words. The major difficulty of the current experiment was not the difference in the length of the sentences, but rather the large differences in the number of sentences uttered by the patients. It becomes difficult to detect the similarity between a patient who has a similar illness but tells it in 3 sentences without giving details, and a patient who makes 15 sentences. In the study, each test case is compared with all past patients in the data set, one by one. As a result of this comparison, we obtain semantic text similarity scores for each of the new case and past patients. If there is even one past patient with greater than 75% similarity to the new case, we propose to create a psychological treatment recommendation for the new case. As a result of this experiment, it becomes possible to detect case similarities between the new patient and the previous patients. An example of semantic similarity detection performed on a sentence basis is shared in Fig. 2.

Single case similarities between a new patient and existing psychological treatment patients
Figure 3 shows an example of how similar the new patient, who has not yet been diagnosed psychologically, and each patient who received psychological treatment in the past. Each sentence of the new patient was compared with the sentences of the previous patients. At this stage, the highest similarity ratios between sentence pairs are marked regardless of the order. The highest similarity rates are kept for each sentence made by the new patient, and the approximate closeness between the average of these rates and the discourses of the cases is determined. If the average similarity value is above 75%, a suggestion is made that the new patient can also receive psychological treatment based on the similarity of these sentences. The algorithm of the method used in Fig. 2 is shown in Algorithm 1 step by step.

Multiple case similarities between a new patient and existing psychological treatment patients (yellow colors are sentences similar to patient number n, blue colors are sentences similar to patient number m)

Pseudocode of finding the average similarity between cases
The sentences of two different patients are presented as lists to the algorithm. The first list consists of the sentences of the test case and the second list consists of the sentences of a patient with a positive label in the data set. Each sentence in the lists is expressed as x and y. Starting from the first sentence of the test case, x1, for each sentence, similarity rates are found with all sentences in the y1 – yn range. The similarity between the sentences previously translated into semantic vectors with the ELECTRA model is found by the Cosine Similarity method. In this way, a similarity matrix is created between all the sentences of the new patient and all the sentences of the previous patient. Then, for each xi sentence, the similarity of the yj sentence with the highest similarity is taken and the average similarity value is obtained. If the average similarity value obtained is above 75%, a psychological treatment recommendation is created for this patient. If this value is below 75%, similarity experiments are repeated sequentially with all other positive label patient records in the dataset.
If a similarity higher than 75% is not found between the new case and any of the previous patients, the multiple similarity finding phase will be started. In some cases, the sentences of the new patient may be similar to the sentences of more than one previous patient. For example, the first 5 sentences of a patient describing his illness in 9 sentences are very similar to a case in the ship, but the last 4 sentences may be very similar to a different case. In a single case similarity measurement, this patient will have less than 75% similarity to two cases with which he has been similar in the past. In such cases, it would be logical to offer psychological treatment to the new patient. In order to detect such hidden similarities, a multiple case similarity measurement is performed for the patients who pass the first stage negatively. When measuring multiple similarity, each sentence of the new patient is compared with sentences from different patients in the past. Since psychological disorders can show very different and many symptoms, it is possible to make a sentence-based evaluation, not patient-based, by collecting the sentences of all patients in a common pool. While one sentence of a new patient may be similar to a sentence of patient n, another sentence of him/her may be similar to patient m’s. In this way, although there is no exact similarity between the cases, it will be possible to detect the sentences of the new patient pointing to psychological treatment. The multiple similarity measurement is illustrated in Fig. 3 with sample similarity values.
Figure 3 shows the similar sentences of a new patient with two different patients who received psychological treatment in the past. The new patient here does not have more than 75% similarity to any previous case according to the one-to-one case similarity. However, almost all the sentences of this patient are similar to the sentences of the two previous patients. As in this example, it is possible to detect one-to-many similarities when the sentences of the new patient are compared with all sentences in the dataset. Thus, it is possible to detect hidden similarities with a wider search than individual case similarities. In the multiple case similarity measurement, the similarity measurements between the new patient and the combination of previous patients are evaluated. How to determine the past patients selected for similarity measurement constitutes the important processing load at this stage. First, when measuring individual case similarity, the top 10 patients with the highest similarity are determined. All sentences of these patients that are most similar to the present case are listed sequentially. If the total similarity with the patient sentences selected from this cluster is above the 75% threshold, the patient is offered psychological treatment.
3.4 Measurements and verification results for the threshold values determined in the proposed model
The threshold value of 75% determined during the result labeling was decided as a result of repeated experiments. At this stage, validation experiments were carried out with different threshold values. The similarities between the cases randomly selected from different departments in the same number and the patients referred for psychological treatment were measured, and the obtained values are shared in Fig. 4.

Single case similarities between new patient and existing psychological treatment patients
As seen in the graph in Fig. 4, the similarities between the sentences of past psychiatric patients were measured with two different test data sets. It is necessary to set a threshold value in order to distinguish whether a case in the test data needs or does not need psychological treatment. For this reason, decision measurements were made with different threshold values on 1686 patients who were actually referred to a psychiatrist and on 1686 patients collected from all departments except psychiatry. When the similarity threshold was accepted as 50%, it was concluded that 59% of the patients who had nothing to do with psychological disorders should be referred to psychiatry. This ratio shows that the threshold value should be higher and more distinctive. At each step, the threshold value was increased by 5% and the trials continued up to the 95% level. The biggest breakout in this experiment is experienced at the 75% level. For patients referred to psychiatry, the predictive success of the model drops from 89 to 65% when the threshold value rises from 75 to 80%. At the same threshold, the need for psychological treatment was recommended for 17% of non-psychiatric patients. When these data are examined together, it has been observed that the proposed model is at the most successful level between 70 and 75%. Therefore, in the proposed model, the similarity value of 75% was accepted as the threshold value when deciding on the patient's condition.
3.5 Data augmentation on expand the text data
In many studies in the literature, data augmentation methods are used due to the lack of data or the goal of increasing the prediction success on a larger cluster. In this research, the test set of the DAIC-WOZ data set, which contains especially long data, consists of a limited number of data (47 records). For this reason, the records in the data set were increased with the SMOTE [38] method both in order to increase the test data and to test the effect of language models on the prediction success.
In the experiments conducted to find the semantic similarity between sentences, new records derived from a sentence are used as separate inputs. The SMOTE method is a very useful method for homogeneously increasing the data of classes with low amount of data in classification problems. In the current study, since classification is based on sentence similarity, it is difficult to determine the similarity between short sentences and long sentences. Therefore, in order to convert short sentences between patient narratives into sentences consisting of 7 words on average, the SMOTE percentage was accepted as 200. Thus, it was possible to reach the average sentence size in sentences consisting of 3 and 4 words and to eliminate data imbalance. In the experiments of the study, firstly, experimental results will be obtained using the original data set. Then the same experiments will be repeated with augmented data and the effect of this process on the results will be discussed. Since some of the synthetic sentences produced increase the semantic similarity rate, a new experimental study will be made in which synthetic data is added in the experiments section of the study. Thus, it is aimed to help the proposed model to detect semantic similarities more precisely.
3.6 Choosing the appropriate model for sentence embeddings
In the current study, it is important to represent all meaningful parts in the text, as predictions will be produced through medical dialogues. Semantic text similarity determination will be made to find similarities between patient discourses. At this stage, it is possible to measure similarity between parts by dividing the text into words, sentences or larger parts. In the past studies, these options have been examined and it has been seen those sentences or expressions consisting of multiple words are represented with higher success by vectors [39, 40]. For this reason, measurements based on sentence similarity were preferred in the study. In order to determine the model to be used in the proposed method, proven models were determined to find similarities between health-oriented texts [41, 42]. These models are BERT [39], SBERT [43], RoBERTa [44], BioBERT [45], ELECTRA [46] and XLNet [47], models. All these models, which have been used most frequently in the literature in recent years, have distinct advantages and disadvantages. The language model suitable for the data set to be used in the study and the desired tasks will be selected and the next experiments will continue with this model.
In order to determine the representation model to be used in the rest of the study, preliminary experiments were carried out on the test data using the 'base' modes of all models. In these experiments, sentences from 1686 test cases were compared with sentences from past patients. When making a one-to-one case comparison, the average similarity calculation was made for the sentences of the test case. Cases that exceeded the 75% similarity rate for all models were labeled as ‘same result as physician' and were deemed successful. The success rates obtained as a result of the preliminary experiments are presented in Table 3.
According to Table 3, the ELECTRA model detects text similarity more successfully than other. In addition, it has been observed in the experiments that the ELECTRA and SBERT models works much faster than other models. Because of these advantages, it was decided to use ELECTRA architecture for sentence representation in the proposed method. While only one-to-one case similarity is used in preliminary experiments, one-to-many similarity measurements will also be made in the proposed method. In addition, the success of the ELECTRA model reaches 90.49%, as can be seen in Table 4, together with the method improvements explained in detail in the next chapter.
4 Results and discussion
In this section, the experimental results are shared, and the results obtained from these experiments are evaluated. fivefold cross-validation was used in all experiments in the study. In addition, both positive and negative samples were prepared in equal numbers in order to reach similar results with the physician in the determination of psychological disorders, which is the main goal of the article. In order to create a negative sample, a total of 1752 patient records from all medical departments except psychology were selected randomly and in equal numbers and used in the experiments. Since the text length is longer in the DAIC-WOZ dataset than in the MedDialog dataset, care has been taken to use longer patient records for experiments with this dataset. Thus, within the scope of the study, the disadvantage of over-learning a model that trains only on positive examples has been removed. In the experiments, the accuracy of the prediction models was measured by their agreement with the actual physician decisions. Since there are real physician decisions in the data sets, this estimate is considered correct if the prediction of the proposed model is the same as the physician's decision. Otherwise, it is accepted that the system makes an incorrect prediction. Experiments and results for the different contributions of the study are evaluated under sub-headings.
4.1 Identifying patients who need to be referred for psychological treatment
After the experiments conducted in the study, patients referred to psychological treatment by real physicians were presented as input to the proposed model. The similarity scores were measured by comparing the sentences of these patients with the sentences of the patients who received psychological treatment in the past. By making use of these results, the success percentages were obtained by comparing the outputs suggested by the system with the decisions of the physicians. The results obtained from two different data sets are shared in Table 4.
The results in Table 4 show the success achieved with two different data sets. For both data sets, it is seen that data augmentation positively affects the success while measuring sentence similarity in the estimation phase. The records in the MedDialog-En dataset consist of substantially shorter texts than in the DAIC-WOZ dataset. Since there are more sentences in long texts, more similarity was achieved with data augmentation, which led to a higher increase. In order to see the success of the study in both short and long texts, separate experiments were conducted for the two data sets. The MedDialog-En dataset contains 3372 test data that are considered labeled. Half of these records consist of patients who were offered treatment by psychiatrists in telemedicine systems. The other half consists of 1686 randomly selected patients from outside the fields of psychiatry and neurology. Thus, balanced positive and negative labeled records were obtained in the test data. The labeled test data of the DAIC-WOZ dataset consists of 47 patients. The proposed method produced 90.49% successful predictions on short data. In 3051 cases, the same opinion with the physicians was produced while the proposed system was wrong in 321 cases. In the DAIC-WOZ dataset with long texts, the system's estimates and physician labels were matched for 42 of the 47 labeled samples. It is seen that the system produces different estimates from physicians for only 6 patients. The success of the proposed method in long texts decreased by approximately 4% to 89.36%. Our guess as the reason for this situation is that there are patient expressions that are specialized in a way that reduces the sentence-based similarity rate as the texts get longer. Especially since the DAIC-WOZ dataset contains answers to physician questions, the number of sentences in which the patient does not use symptoms or words that will provide important inferences is increasing. According to the results obtained from the experiments, there is a tendency to decrease in the success of the proposed system as the patient expressions are longer than 15 sentences. The representation of the findings obtained from the test results with the confusion matrix is presented in Fig. 5.

Display of test results with confusion matrix
According to Fig. 5, success rates of 0.901 and 0.903 were obtained in short texts according to Accuracy and F1 metrics, respectively. Precision and Recall metrics, which are more frequently used in medical studies, have scores of 0.882 and 0.925, respectively. Based on these metrics, it is seen that True-Positive results are detected more successfully in the experiments conducted for both short texts and long texts. It is observed that the success of the proposed method decreases in False-Positive predictions. It is thought that there are two important factors causing this situation. Firstly, it is known that there are more symptoms and well-represented data in sentences made by patients in need of psychological treatment. It is thought that the language model better represents these words with the training of the developed method on texts containing psychological treatment. The second reason is the possibility of the intense presence of symptoms that are likely to be seen similar to psychological disorders in the sentences of patients with negative labels. As explained in detail in the next sub-section, psychological diseases are frequently seen among the side effects of other disorders. In particular, the majority of the patients of the Neurology, Sexology and Cardiology departments are likely to experience the effects of psychological disorders. In this case, symptoms pointing to a different department may be perceived as psychological discomfort symptoms.
It was observed that the sensitivity of the proposed model decreased slightly with increasing text length. In addition, while the rate of False-Positive predictions is 16.67% in the DAIC-WOZ dataset with a high text length, the same rate drops to 12.34% in the MedDialog dataset. The results show that the proposed model is generally 3% to 4% more successful on short data.
Since sentence similarities are used in the decision mechanism of the proposed model, the results obtained in all cases are not of equal weight. For example, while 78% of a case's sentences result in referral to psychological treatment, in another case this rate may be over 90%. It can be thought that the higher the sentence similarity averages, the stronger the prediction. For this reason, the distribution of cases with positive labels (sentence similarity greater than 75%) between 75 and 100% is shared in Table 5. Thus, when a different threshold value is selected, it will be possible to see how the success of the system will be affected and how strong the system recommendations are.
When the results in Table 5 are examined, it is seen that the majority of the test cases have sentence similarities between 75 and 85% with the previous cases. This data shows that most of the sentences made by patients in need of psychological treatment play an important role for diagnosis.
According to another finding obtained from the study, the average number of sentences made by patients in need of psychological treatment was calculated as 6.83 in MedDialog dataset. The highest similarity scores among these sentences are obtained from the first sentences. Based on this data, when the first sentences were examined, it was observed that the patients introduced themselves in the first sentence and especially stated their age and gender. The data on the patient's general complaints were concentrated from the second sentence and it was concluded that the similarities to be obtained after this stage may be more important. If these findings are examined in the light of the data in Table 3, it is expected that the patient will describe his problem in approximately 7 sentences and will give information about his psychological disorders in at least 4 sentences except the first sentence. Since MedDialog data is obtained by telemedicine method, the fact that patients use fewer sentences in a real hospital environment or use more sentences due to mutual dialogue with the physician will be an important factor that will affect the success of the estimation. In the DAIC-WOZ data set, on the other hand, the number of sentences formed by the patients can be much higher than the data obtained in the form of mutual questions and answers. Since the conversations were in the form of a dialogue, no consistent difference was found between the first sentences and the next sentences.
4.2 Detecting complications or precursors of psychological disorders
Since the MedDialog dataset used in the study includes patients referred from different departments, it contains important findings that can be detected. One of them is the answer to the question 'From which departments are patients referred for psychological treatment the most?'. While seeking an answer to this question, the physicians who directed the patients in the test data set were divided according to their departments. In the next step, how many patients from which department were referred for psychological treatment and the percentage similarities in the sentences of these patients were calculated. The data obtained as a result of the calculation are shared in Table 6.
When the values in the table are examined, it is seen that ' Neurology ' is the field that most frequently directs patients to psychological treatment among 92 different departments. Various conclusions can be drawn from this data. These are briefly outlined below.
-
Patients experiencing confusion between neurological disorders and psychological disorders,
-
Experiencing neurological complications due to psychological disorders in patients,
-
Suggesting additional psychological treatment by the physician to facilitate neurological treatment.
Another remarkable result in Table 6 is the rate of referral to psychological treatment of patients who applied to the online system for sexual treatment. A total of 368 patients were referred for psychological support from departments such as Sexology, Andrology and Urology where sexual problems were treated. It is possible that some patients received psychological support to solve their sexual problems or were directed to seek psychological treatment to normalize the issues they saw as problems. The following departments are Cardiology, Plastic Surgery – Reconstructive and Cosmetic. In studies in the literature, it is known that psychological problems cause many heart diseases as a complication [48, 49]. In addition, it is a known problem that many people feel needy for aesthetic operations because they feel unwell due to their appearance, or they are exposed to various bullying [50]. For this reason, it is possible that the patients who applied to these departments were directed to psychological treatment to decide on a healthier. Since the evaluation of the findings obtained in this section requires medical expertise, only the findings based on the literature and the first reasons that come to mind from the patient’s point of view are shared. Many different reasons can be determined by medical professionals to refer patients to psychological treatment.
The 'Average Sentence Similarity Rate' column shared in Table 6 shows the average sentence similarity of the referred patients as in Table 5. In this way, the similarity rate between the patients who applied to the departments listed and the patients who received psychological treatment in the past can be seen. With these rates, it is possible to reach the conclusion that the patient applied to the wrong department or that he/she should receive psychological support as an additional treatment despite applying to the right department. For this, it is necessary to make an examination of the sentences that reduce the total similarity among the sentences of the patient. For example, if a patient applied to the Cardiology department with an average sentence similarity of over 95%, this patient is more likely to choose the wrong department. However, if she/he applied to the Cardiology department with an average sentence similarity of 76%, the relevance of the sentences that lowered the average to the Cardiology department should be questioned. While these sentences describe a heart condition, if the remaining sentences are similar to patients who receive strong psychological treatment, it can be thought that this patient applied to the Cardiology department as a result of various complications. These findings are shared in Fig. 6 with numerical values and more descriptively through a sample case.

Examining the difference between the case study and the recommendation for additional treatment or directly referral
While evaluating the example case shared in Fig. 6, the focus was on the second and fifth sentences that lowered the average. While these sentences are not very similar to the cases receiving psychological treatment, they are seen closer to the Cardiology section, which is the main reference. In this case, it can be assumed that the patient has heart problems in the continuation of her/his psychological problems. Another possibility is that existing heart conditions may trigger psychological disturbances in the patient. In such cases, the possibility of attending physicians supporting the current treatment with psychological treatment will increase. In addition, with the detection of possible secondary diseases, it will be possible to recommend a more comprehensive treatment to the patient. Being aware of secondary diseases while treating the current disease provides important contributions such as preventing adverse drug reactions [51]. With such methods, more comprehensive and complementary treatments can increase the possibility of the patient's recovery.
5 Conclusions
The study aimed to determine whether the patients who applied to a physician due to any complaint needed psychological treatment. Thus, it will be possible to solve the main causes of the patients' current ailments or eliminate the psychological damage they experience due to their current ailments. Another goal is to correct the erroneous search for treatment, which occurs as a result of the patient's going to a doctor in a different department without being aware of his/her psychological disorder. For these purposes, experiments based on sentence similarity were prepared with the two datasets, which consists of patient-physician dialogues. To select the language representation model to be used throughout the study, preliminary experiments were made with BERT, SBERT, RoBERTa, BioBERT, ELECTRA, and XLNet models, and performance comparisons were shared. For similarity measurement, the ELECTRA model, which uses sentence converters and showed higher success than other models in preliminary experiments, was used. The sentences formed by the patients belonging to the psychiatry department in the data set and the sentences of the patients referred to psychiatry were extracted from the data set and vectorized. The language model was trained with the corpus formed from the sentences of the patients of the psychiatry department, and the expressions used by these patients were represented semantically. The sentences of the patients referred to psychiatry were similarly digitized and used for testing purposes in the proposed system. To increase the success of the proposed system and expand the test data, the experiments are repeated with the increased data by increasing the data with the SMOTE method. The obtained results showed that the proposed model produced more successful results after data augmentation.
In the experiments conducted with the proposed method, the same opinion with the physicians was obtained for 1561 patients out of the test data set consisting of 1686 patients. 90.49% of patients referred to psychiatry in real life were labeled as 'psychological treatment is recommended' in the proposed model. In the DAIC-WOZ dataset, which consists of longer data, the predictions of the proposed model agree with the physicians at a rate of 89.36%. In this way, it is seen that the proposed system successfully predicts the need for psychological treatment. Another important finding obtained from the study; is to determine the departments that refer their patients to psychological treatment the most. In the experiments conducted it is seen that Neurology, Sexology, Cardiology and Plastic Surgery – Reconstructive and Cosmetic have the highest number of referrals to psychiatry. These departments have been determined as the departments with the complications caused by psychological problems are seen most frequently or where the diseases that show psychological disorders as a side effect are also experienced. With the results obtained, a method has been proposed that will facilitate the determination of the psychological treatment needs that the patient needs without being aware of it, through a physician. It is planned to develop a patient referral recommendation model to be used in other medical departments along with similar models in future studies.
Data availability
The datasets used in our experiments are available from from the MedDialog and DAIC-WOZ datasets, URL links: https://doi.org/https://doi.org/10.48550/arxiv.2004.03329, https://dcapswoz.ict.usc.edu/, and http://www.biopac.com. Accessed 2 April 2023.
The datasets used or analysed during the current study are available from the corresponding author on reasonable request.
References
Henderson C, Evans-Lacko S, Thornicroft G (2013) Mental Illness Stigma, Help Seeking, and Public Health Programs. Am J Public Health 103(5):777. https://doi.org/10.2105/AJPH.2012.301056
Inchausti F, MacBeth A, Hasson-Ohayon I, Dimaggio G (2020) Psychological Intervention and COVID-19: What We Know So Far and What We Can Do. J Contemp Psychother 50(4):243–250. https://doi.org/10.1007/S10879-020-09460-W
‘Key Substance Use and Mental Health Indicators in the United States’. [Online]. Available: https://www.samhsa.gov/data/sites/default/files/reports/rpt35325/NSDUHFFRPDFWHTMLFiles2020/2020NSDUHFFR1PDFW102121.pdf. Accessed 17 May 2022
Wang M et al (2021) Prevalence of psychological disorders in the COVID-19 epidemic in China: A real world cross-sectional study. J Affect Disord 281:312–320. https://doi.org/10.1016/J.JAD.2020.11.118
Otte C et al (2016) Major depressive disorder. Nat Rev Dis Prime 2(1):1–20. https://doi.org/10.1038/nrdp.2016.65
Eylül D, Hemşirelik Ü, Dergisi YE (2013) ‘DEUHYO ED 6(3) 159–164. Psikiyatri hastaları ve fiziksel sağlık 160’, Accessed: Mar. 24, 2022. [Online]. Available: http://www.deuhyoedergi.org
Zulfiker MdS, Kabir N, Biswas AA, Nazneen T, Uddin MS (2021) An in-depth analysis of machine learning approaches to predict depression. Curr Res Behav Sci 2:100044. https://doi.org/10.1016/J.CRBEHA.2021.100044
Brådvik L (2018) Suicide Risk and Mental Disorders. Int J Environ Res Public Health 15(9):2028. https://doi.org/10.3390/IJERPH15092028
Lin C, et al. (2020) ‘SenseMood: Depression detection on social media’, ICMR 2020 - Proceedings of the 2020 International Conference on Multimedia Retrieval, pp. 407–411. https://doi.org/10.1145/3372278.3391932.
Tadisetty S, Ghazinour K (2021) Anonymous Prediction of Mental Illness in Social Media. 2021 IEEE 11th Annual Computing and Communication Workshop and Conference. CCWC 2021:954–960. https://doi.org/10.1109/CCWC51732.2021.9376140
Maulana AT et al (2023) Analyze Mental Health Disorders from Social Media: A Review. Lecture Notes Networks Syst 597:65–74. https://doi.org/10.1007/978-3-031-21438-7_5/COVER
Zhang T, Yang K, Ji S, Ananiadou S (2023) Emotion fusion for mental illness detection from social media: A survey. Information Fusion 92:231–246. https://doi.org/10.1016/J.INFFUS.2022.11.031
Ríssola EA, Aliannejadi M, Crestani F (2022) Mental disorders on online social media through the lens of language and behaviour: Analysis and visualisation. Inf Process Manag 59(3):102890. https://doi.org/10.1016/J.IPM.2022.102890
Aygun I, Kaya B, Kaya M (2021) Aspect Based Twitter Sentiment Analysis on Vaccination and Vaccine Types in COVID-19 Pandemic with Deep Learning. IEEE J Biomed Health Inform. https://doi.org/10.1109/JBHI.2021.3133103
Jackson RG et al (2017) Natural language processing to extract symptoms of severe mental illness from clinical text: the Clinical Record Interactive Search Comprehensive Data Extraction (CRIS-CODE) project. BMJ Open 7(1):e012012. https://doi.org/10.1136/BMJOPEN-2016-012012
Al Asad N, Mahmud Pranto MA, Afreen S, Islam MM (2019) ‘Depression Detection by Analyzing Social Media Posts of User’. 2019 IEEE International Conference on Signal Processing, Information, Communication and Systems, SPICSCON 2019, pp. 13–17. https://doi.org/10.1109/SPICSCON48833.2019.9065101
Burdisso SG, Errecalde M, Montes-y-Gómez M (2019) A text classification framework for simple and effective early depression detection over social media streams. Expert Syst Appl 133:182–197. https://doi.org/10.1016/J.ESWA.2019.05.023
Mustafa RU, Ashraf N, Ahmed FS, Ferzund J, Shahzad B, Gelbukh A (2020) A Multiclass Depression Detection in Social Media Based on Sentiment Analysis. Adv Intell Syst Comput 1134:659–662. https://doi.org/10.1007/978-3-030-43020-7_89
Tadesse MM, Lin H, Xu B, Yang L (2019) Detection of depression-related posts in reddit social media forum. IEEE Access 7:44883–44893. https://doi.org/10.1109/ACCESS.2019.2909180
Bracher-Smith M, Crawford K, Escott-Price V (2020) Machine learning for genetic prediction of psychiatric disorders: a systematic review. Molec Psychiatry 26(1):70–79. https://doi.org/10.1038/s41380-020-0825-2
Priya A, Garg S, Tigga NP (2020) Predicting Anxiety, Depression and Stress in Modern Life using Machine Learning Algorithms. Procedia Comput Sci 167:1258–1267. https://doi.org/10.1016/J.PROCS.2020.03.442
S. Graham et al. (2019) Artificial Intelligence for Mental Health and Mental Illnesses: an Overview. Curr Psychiatry Rep 21(11). Current Medicine Group LLC 1. https://doi.org/10.1007/s11920-019-1094-0
Milintsevich K, Sirts K, Dias G (2023) Towards automatic text-based estimation of depression through symptom prediction. Brain Inform 10(1):1–14. https://doi.org/10.1186/S40708-023-00185-9/FIGURES/4
Uddin MZ, Dysthe KK, Følstad A, Brandtzaeg PB (2022) Deep learning for prediction of depressive symptoms in a large textual dataset. Neural Comput Appl 34(1):721–744. https://doi.org/10.1007/s00521-021-06426-4
Swati S, Kumar M, Namasudra S (2022) Early prediction of cognitive impairments using physiological signal for enhanced socioeconomic status. Inf Process Manag 59(2):102845. https://doi.org/10.1016/J.IPM.2021.102845
Zhang T, Schoene AM, Ji S, Ananiadou S (2022) Natural language processing applied to mental illness detection: a narrative review. Npj Digital Med 5(1):1–13. https://doi.org/10.1038/s41746-022-00589-7
Blanco G, Lourenço A (2022) Optimism and pessimism analysis using deep learning on COVID-19 related twitter conversations. Inf Process Manag 59(3):102918. https://doi.org/10.1016/J.IPM.2022.102918
Soroya SH, Farooq A, Mahmood K, Isoaho J, Zara SE (2021) From information seeking to information avoidance: Understanding the health information behavior during a global health crisis. Inf Process Manag 58(2):102440. https://doi.org/10.1016/J.IPM.2020.102440
Cong Q, Feng Z, Li F, Xiang Y, Rao G, Tao C (2019) ‘X-A-BiLSTM: A Deep Learning Approach for Depression Detection in Imbalanced Data’. Proceedings - 2018 IEEE International Conference on Bioinformatics and Biomedicine, BIBM 2018, pp. 1624–1627. https://doi.org/10.1109/BIBM.2018.8621230
Kim S-HK et al (2023) A Review of Machine Learning and Deep Learning Approaches on Mental Health Diagnosis. Healthcare 11(3):285. https://doi.org/10.3390/HEALTHCARE11030285
Mumtaz W, Qayyum A (2019) A deep learning framework for automatic diagnosis of unipolar depression. Int J Med Inform 132:103983. https://doi.org/10.1016/J.IJMEDINF.2019.103983
Thakre TP, Kulkarni H, Adams KS, Mischel R, Hayes R, Pandurangi A (2022) Polysomnographic identification of anxiety and depression using deep learning. J Psychiatr Res 150:54–63. https://doi.org/10.1016/J.JPSYCHIRES.2022.03.027
G. Zeng et al. (2020) MedDialog: Two Large-scale Medical Dialogue Datasets. EMNLP 2020 - 2020 Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference, pp. 9241–9250. https://doi.org/10.48550/arxiv.2004.03329
Gratch J, et al. The Distress Analysis Interview Corpus of human and computer interviews. Accessed: Apr. 02, 2023. [Online]. Available: http://www.biopac.com
Ringeval F, et al. (2019) AVEC 2019 workshop and challenge: State-of-mind, detecting depression with ai, and cross-cultural affect recognition. AVEC 2019 - Proceedings of the 9th International Audio/Visual Emotion Challenge and Workshop, co-located with MM 2019, pp. 3–12. https://doi.org/10.1145/3347320.3357688
Du M et al (2023) Depression recognition using a proposed speech chain model fusing speech production and perception features. J Affect Disord 323:299–308. https://doi.org/10.1016/J.JAD.2022.11.060
Tian H, Zhu Z, Jing X (2023) Deep learning for Depression Recognition from Speech. Mobile Networks Applic, pp. 1–16. https://doi.org/10.1007/S11036-022-02086-3/FIGURES/13
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP (2002) SMOTE: Synthetic Minority Over-sampling Technique. J Artificial Intell Res 16:321–357. https://doi.org/10.1613/JAIR.953
Devlin J, Chang MW, Lee K, Toutanova K (2018) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL HLT 2019 - 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies - Proceedings of the Conference, vol. 1, pp. 4171–4186. https://doi.org/10.48550/arxiv.1810.04805
Tenney I et al. (2019) What do you learn from context? Probing for sentence structure in contextualized word representations. 7th International Conference on Learning Representations, ICLR 2019. https://doi.org/10.48550/arxiv.1905.06316
Chen Q, Rankine A, Peng Y, Aghaarabi E, Lu Z (2021) Benchmarking Effectiveness and Efficiency of Deep Learning Models for Semantic Textual Similarity in the Clinical Domain: Validation Study. JMIR Med Inform 9(12):e27386. https://doi.org/10.2196/27386. (https://medinform.jmir.org/2021/12/e27386)
Yang X, He X, Zhang H, Ma Y, Bian J, Wu Y (2020) Measurement of Semantic Textual Similarity in Clinical Texts: Comparison of Transformer-Based Models. JMIR Med Inform 8(11):e19735. https://doi.org/10.2196/19735 (https://medinform.jmir.org/2020/11/e19735)
Reimers N, Gurevych I (2019) Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. EMNLP-IJCNLP 2019 - 2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Proceedings of the Conference, pp. 3982–3992. https://doi.org/10.48550/arxiv.1908.10084
Liu Y, et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach. 2019, Accessed: May 17, 2022. [Online]. Available: https://github.com/pytorch/fairseq
Lee J et al (2020) BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 36(4):1234–1240. https://doi.org/10.1093/BIOINFORMATICS/BTZ682
Clark K, Luong M-T, Le QV, Manning CD (2020) ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. https://doi.org/10.48550/arxiv.2003.10555
Yang Z, Dai Z, Yang Y, Carbonell J, Salakhutdinov RR, Le QV (2019) XLNet: Generalized Autoregressive Pretraining for Language Understanding. Adv Neural Inf Process Syst 32. [Online]. Available: https://github.com/zihangdai/xlnet. Accessed 30 Dec 2022
Contrada RJ, Goyal TM, Cather C, Rafalson L, Idler EL, Krause TJ (2004) Psychosocial Factors in Outcomes of Heart Surgery: The Impact of Religious Involvement and Depressive Symptoms. Health Psychol 23(3):227–238. https://doi.org/10.1037/0278-6133.23.3.227
Contrada RJ et al (2008) Psychosocial Factors in Heart Surgery: Presurgical Vulnerability and Postsurgical Recovery. Health Psychol 27(3):309–319. https://doi.org/10.1037/0278-6133.27.3.309
Lee K, Guy A, Dale J, Wolke D (2017) Adolescent desire for cosmetic surgery: Associations with bullying and psychological functioning. Plast Reconstr Surg 139(5):1109–1118. https://doi.org/10.1097/PRS.0000000000003252
Aygün İ, Kaya M, Alhajj R (2020) Identifying side effects of commonly used drugs in the treatment of Covid 19. Sci Reports 10(1):1–14. https://doi.org/10.1038/s41598-020-78697-1
Acknowledgements
This research was supported by the Scientific and Technological Research Council of Turkey (TUBITAK) under Grant No 122E437.
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All authors have no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Aygün, İ., Kaya, B. & Kaya, M. Identifying patients in need of psychological treatment with language representation models. Multimed Tools Appl (2024). https://doi.org/10.1007/s11042-024-18992-5
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11042-024-18992-5