
Abstract
For human beings, neck movement will be degraded due to aging, trauma, musculoskeletal disorders, or degenerative diseases. Cervical range of motion (CROM) measurement is one of the popular quantitative neck examinations. Despite radiography is considered as the gold standard, it suffers from invasiveness, radiation exposure, and expensiveness. Recently, vision-based methods have been applied for CROM measurement but achieve large errors and require depth camera. On the other hand, deep neural networks provide good performances on head pose estimation (HPE) from a single image, thus promising for medical CROM measurement. We propose to use CNN networks to extract pyramidal or multi-level image features, which are passed to cross-level attention modules for feature fusion and then to a modified ASPP module and a multi-bin classification/regression module for spatial-channel attention and Euler angle conversion/prediction, respectively. The proposed technique was evaluated on public datasets, such as 300W_LP, AFLW2000, and BIWI, to verify its superior performances (with mean MAE = 3.50°, 3.40°, and 2.31° for different experimental protocols) than state-of-the-art methods. Our pre-trained model was also evaluated with our own collected dataset from hospital for CROM measurement. It also achieved the lowest MAE of 4.58° among other methods and conformed with a medical standard of 5 degrees except the pitch angle (which has a MAE of 5.70°, larger than the standard and the yaw (MAE = 3.60°) and roll angles (MAE = 4.44°)). In general, HPE technique is feasible for CROM measurement and shows its advantages of speed, non-invasiveness, free of anatomical landmark and low cost of operation.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The neck movement is required and often in our daily life. However, the movement functionality might be decreasing due to factors such as aging, trauma, pain, muscle fatigue, abnormal posture, migraine, and cervical spine degenerative diseases such as cervical spondylotic myelopathy (CSM), cervical herniated disc, and cervical foraminal stenosis [1]. These lead to decreasing functional activity and quality of life. The most popular physical examination method for functional neck movement to assess severity and prognosis and to determine treatment progress and effectiveness is cervical range of motion (CROM) [2] measurement. CROM measurement is to evaluate the maximum angles of neck movement in six directions: flexion, extension, left lateral bending, right lateral bending, left rotation, and right rotation.
The neck direction can be described by Euler angles (i.e., yaw, pitch, and roll) referring to the Frankfort plane, which is determined by two centers of the external auditory meatus and the inferior margin of each orbit [3]. The yaw angle, which is related to the left and right rotation, measures the rotation around the axis-1 perpendicular to the Frankfort plane. The pitch angle, which is related to the flexion and extension, measures the rotation around the axis-2 parallel to a line passing through the two external auditory meatus. The roll angle, related to the left and right lateral bending, measures the rotation around the axis orthogonal to both axis-1 and axis-2.
The gold standard procedure of CROM measurement is in radiography. The measurement is applied by taking radiographs in two different head positions: neutral position and flexion and extension. This technique provides the most validity and accuracy in CROM measurement. However, it is not practical due to invasiveness, radiation exposure and high cost of operation [4].
Non-invasive CROM measurement methods consist of visual inspection, goniometer, cervical range of motion device (CROM device), ultrasonography, and electromagnetic devices. Some of them are not practical for clinical usage due to the requirement of finding anatomical landmarks, long time usage, high cost, and high technical expertise. Moreover, some of them have large measurement errors. Recently, there is a development of vision-based CROM measurement methods by using Microsoft Kinect or Cambridge Face Tracker [5]. They are more portable, affordable, and convenient because of marker-less requirement [4]. However, Kinect results in large CROM measurement errors and is difficult to be used in uncontrolled environments [4, 6]. Cambridge Face Tracker needs to be integrated with a facial landmark detection module (like Constrained Local Neural Fields (CLNF) [5]) and is only applicable to limited head pose ranges. The problematic issues for medical CROM measurement are summarized in Table 1.
To overcome the above drawbacks, this study employs head pose estimation (HPE) technique for CROM measurements. HPE is a computer vision technique used to estimate head orientation with respect to the observing camera from a single digital imagery, where the orientation is described in terms of three Euler angles: yaw, pitch, and roll. HPE has several other applications: driver attention detection [7], human–computer interaction, best frame selection, and face frontalization [8]. The challenge in head pose estimation comes from the robustness and invariance to a variety of variations in illumination, geometry, facial appearance, facial expression, and facial accessories like glasses and hats. In recent years, HPE is progressed by the development of modern deep neural networks to compete with other kinds of methods and becomes a benchmark performance.
To the best of our knowledge, no research applies deep-learning-based HPE algorithms for CROM measurement. Herein, our work aims to propose an end-to-end HPE algorithm featured of multi-level feature extraction and cross-level attention and fusion to estimate the head pose (or, their associated Euler angles) accurately. The proposed method will be evaluated in two different scenarios. The first scenario is to train and test three public datasets (300W_LP [9], AFLW2000 [9], and BIWI [10]) and the second scenario is to use the pre-trained model for evaluation in our private dataset for medical CROM measurement, which collected RGB images from 15 healthy subjects with the ground truth angles measured with a goniometer [11]).
There are three main contributions in this paper:
-
1.
This study proposed a novel landmark-free HPE algorithm, characterized of multi-level feature extraction and cross-level attention and fusion, to estimate the head pose from a single image. Our design aggregates multi-scale (i.e., pyramid structured) semantic information, focuses on spatial and channel attention to selectively emphasize informative features, thus improving the pose estimation accuracy.
-
2.
The proposed technique was evaluated in two common protocols and compared with state-of-the-art (SOTA) methods. Our accuracy is comparable to the benchmark performance.
-
3.
Our HPE design has a novel application to medical CROM measurement and shows its practical feasibility after comparison with goniometer measurement (as ground truth) conducted by rehabilitation doctors.
2 Related works
Head pose estimation (HPE) is the process of estimating head orientation (in terms of Euler angles) from digital imagery. HPE algorithms can be classified into two categories: landmark-based and landmark-free.
2.1 Landmark-based techniques
Landmark-based HPE algorithms commonly estimate head orientation in three steps. This kind of algorithms first detects 2D facial landmarks [12,13,14,15,16] (referring to the projections of a set of feature points on a 3D face model) from the input image, establishes the correspondences between the 2D landmarks and their 3D counterparts on the face model and finally utilizes the Perspective-n-Point (PnP) algorithm [17] to estimate pose parameters.
Werner et al. [18] proposed a simple method of learning the head pose estimator (HPEL) on top of a facial landmark detector via Support Vector Regression (SVR). This study can be easily combined with any facial landmark detector such as OpenFace [19] and IntraFace [20]. However, sometimes facial landmark algorithms suffer from failures to track faces in extreme poses. Bullat and Tzimiropoulos [21] proposed Face Alignment Network (FAN) by using four stacked hourglasses network to estimate heatmaps of 2D facial landmarks. In the sequel, they proposed a 2D-to-3D FAN to generate 3D facial landmarks. This FAN [21] technique however suffered from sensitivity to very low facial image resolution, and no optimal number of landmarks for accurate head poses estimation. Due to the above reasons, FAN is famous for its 2D/3D facial landmark detection, but not for HPE.
Zhu et al. [9] proposed a 3D Dense Face Alignment (3DDFA) algorithm. It is based on cascaded convolutional neural networks to convert a 2D facial image into dense vertices on a 3D facial model via 3D morphable model (3DMM) [22] fitting. The primary result of 3DDFA is to output 3D facial landmarks, with a by-product 3DMM, which can be transformed into Euler angles of the corresponding head pose. This technique can estimate in full head pose range to eliminate inaccurate facial landmarks for semi-profile and profile faces which present self-occlusions.
Wu et al. [22] proposed SynergyNet, a CNN which reversely regresses 3DMM parameters from 3D facial landmarks and establishes representations between 3DMM and 3D landmarks iteratively. As a result, 3DMM and 3D landmarks are used to learn 3D facial geometry better in a collaborative manner. This leads to better head orientation estimation and also finer facial landmarks, at an expense of more time in iterations. Xia et al. [23] proposed an HPE method to use detected facial landmarks for affine transformation of the facial image. The warped facial image is stacked with the landmark heatmap as an input to the CNN to estimate head angles. This technique can be considered as a hybrid method which is based on landmarks and RGB image features.
Lie et al. [24] considered the facial landmarks as a graph and proposed a two-stream architecture where Adaptive Graph Convolutional Network (AGCN) is adopted to process the 2D and 3D facial landmarks extracted from FAN [21]. The teacher-student training policy was also used to distillate knowledge from the teacher network (3D) to the student network (2D) so that the pose estimation accuracy after late fusion of the two-streams output can be enhanced. This technique strengthens some drawbacks of the landmark-based algorithms by knowledge distillation and multi-stream fusion, but at an expense of a larger model size.
2.2 Landmark-free methods
Landmark-free HPE techniques directly estimate features and convert them into head pose parameters from 2D digital images without using 2D/3D facial landmarks as the media.
Albiero et al. [25] proposed Img2pose network, a Faster R-CNN-based [26] technique with ResNet-18 as the backbone to detect faces and estimate head poses in 6 degrees of freedom (6DoF) such as three rotational and three translational parameters. However, this technique requires manual annotations of the bounding box labels for the training dataset. Ruiz et al. [17] proposed to use ResNet-50 as the backbone which is integrated with multiple fully connected layers to estimate the yaw, pitch, and roll angles (in a range between -99 and 99 degrees). This technique was further developed by Li et al. [6] to rectify the input image so as to align the subject’s head to a virtual optical center and tackle the perspective distortion. As a result, it achieved good accuracy at a very lightweight model size of 0.88 MB. However, camera intrinsic parameters were required and a limitation on the angular range of the head orientation exists.
To obtain Euler angles of the head pose, there are two possible ways. The first one uses direct regression [27] and the second one adopts bin or heatmap classification [6, 17]. FSA-Net [27] proposed by Yang et al. used a compact SSR-Net-based model with a soft-stage-wise regression scheme and a feature aggregation module to directly output the Euler angles. On the other hand, Hsu et al. [28] proposed QuatNet, a GoogLeNet-based architecture, to independently regress each of the 4 quaternion parameters. It can be better learned to disentangle the shared features and provide less computing complexity than predicting the 9 rotation matrix elements. Cao et al. [29] proposed TriNet, a ResNet-50 architecture with feature mapping and prediction modules based on FSA-Net Capsule network, to regress the 3 × 3 rotation matrix (or, 3 rotation vectors). Moreover, some studies introduced an orthogonality loss [29] or geodesic loss [12] to measure the orthogonal relationship between each pair of the 3 predicted vectors and guaranteed the correctness of the predicted 3-vectors. This achieved full-range head poses with higher accuracies than the priors.
Actually, the representation of 3 × 3 rotational matrix is capable of solving the so-called gimbal lock problem on Euler angles (in case the angle is near -90 or 90 degrees [28]) and the antipodal problem on quaternion (q and -q confusingly correspond to the same rotation [29]). Hampel’s work on RepVGG [12] was also thinking to reduce the rotation representation to 2-vectors (or, 6 elements) via Gram-Schmidt conversion to drop the prediction of the 3rd vector. Even so, Euler angles are the most common one in head pose estimation due to its more robust implementation via bin classification or heatmap estimation.
Landmark-based and landmark-free methods have their own advantages and downsides. Landmark-based methods output accurate head poses with resistance to occlusions, illumination, and extreme pose angles. However, they are susceptible to low image resolution, and require accurate landmark predictions as a premise. Landmark-free methods extract features from the raw images, aggregate them, and regress the head angles without facial landmark dependency. In general, this category of methods gets higher accuracy than the landmark-based techniques, except [23] which is a hybrid one (stacking the warped image and the landmark heatmap together as the input to the network for prediction).
3 Our proposed method
The design of our architecture, being in the landmark-free category, aims to build a pyramidal architecture to extract image features at multiple levels of details and then aggregate them to synergize advantages of multi-scale semantic information (e.g., edges and corners in the bottom layers and abstract features for classification in the top layers [30, 31]). Moreover, our architecture also aims to emphasize the attention in spatial and channel levels to focus on where and what to pay attention to each aggregated feature map [32]. Thus, our design is capable of improving the performance of head pose classification and regression.
3.1 Pyramid backbone for multi-level feature extraction
A pyramid structure is designed to extract multi-level image features (or, multi-scales of details) after multiple layers of convolution blocks, where the lower pyramidal levels produce larger feature maps to reveal detailed edges or corners information, while the higher levels output smaller feature maps to reflect abstract characteristics. All of the pyramid outputs are combined based on gradual aggregations from cross-level fusions (i.e., between two adjacent pyramidal levels) to synergize for HPE improvement.
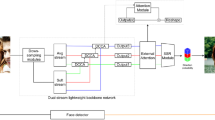
To have a balanced architecture scaling on network, the scalable CNN backbone, EfficientNet-Lite4 [33], is used with the first six layers being the mobile inverted bottleneck convolutions (MBConv) [34], as shown in Fig. 1 to acquire the RGB image with the resolution of 224 × 224 pixels. MBConv [34] consists of a point-wise expansion layer and a depth-wise convolution layer to widen the number of channels, and a final 1 × 1 convolution layer to project the inner layers to the output. Batch normalization and ReLU6 follow the expansion and depth-wise convolution layers. A shortcut connects the input of the expansion layer and the output of the final 1 × 1 convolution layer to carry necessary information for assisting the backpropagation. This increases prediction performance while keeping low computational complexity [34].

The overall architecture of the proposed HPE technique
To comply with the pyramid structure, the output of each MBConv, except for the first one, is passed as the input to Multiple Attention Modules (MAMs). The outputs from the 2nd and 3rd pyramid levels are input to the 1st MAM module. Each MAM module will aggregate the output from the prior MAM module with the output of the topper pyramid level of the EfficientNet-Lite4. Notice that our feature aggregations by MAMs, in contrast to the popular UNet, ResUNet [35], or other pyramid network [36], are to collect and fuse attention information at the smallest resolution (i.e., 7 × 7 × 272) so as to reduce the overall model size and speedup subsequent processing.
3.2 Multiple attention modules (MAM) for feature fusion
In Fig. 1, MAMs are used to acquire and fuse attention features from different levels, where multiple cross-level attention modules are used to process adjacent hierarchical features which have different semantic meanings. As shown in Fig. 2 for each MAM module, it first builds attention masks by fusing cross-level features which are then used as the weight map for local feature enhancement by multiplication. Moreover, each MAM module is benefited from the pyramidal structure to better fuse semantic context information from the lower (2H × 2W resolution) to higher (H × W resolution) levels by two parts.

The structure of each cross-level attention module
The first part is an Attention Unit. Both inputs are first passed to conv blocks (shown as blue ones in Fig. 2). The processed output from the lower level (2H × 2W resolution) is passed through 2 × 2 Max pooling. Then, both outputs are combined together. Among the MAM #1-#4 in Fig. 1, the 3rd MAM does not have the max pooling due to the same feature size from two adjacent levels. Next, the input from a higher level (H × W resolution) is passed through another conv block to let the output been multiplied to the prior combined output. The second part is an Addition Unit. It is built as a shortcut connection to transfer features from the higher level (H × W resolution) to the output and prevent vanishing gradients in network backpropagation.
3.3 Modified atrous spatial pyramid pooling (Modified ASPP)
A modified ASPP module after the MAMs, as shown in Fig. 1, is used for channel attention purpose, which is detailed in Fig. 3. This part acquires the output of MAMs to process via the Atrous convolutions [37] and the ECA (Effective Channel Attention) [32] modules.

The two-paths structure of the modified ASPP module for channel attention
Atrous or dilated convolution is one kind of 2D convolution layer which calculates the convolutions via the down-sampled or dilated kernel elements to increase the receptive fields without increasing the real kernel size and without resizing the feature maps. However, the dilation rates need to fit the feature maps to prevent degenerating feature extraction from a 3 × 3 convolution to a simple 1 × 1 filter [37]. To prevent this problem, the image-level features are employed as a globally semantic information by using a 2D global average pooling (GAP) and a 1 × 1 convolution to average the features of the whole image. This makes the network more robust with a small amount of additional training and inference time. As a result, this study employs Atrous convolutions with the dilation rates of 1 and 2 to fit the output from MAMs (7 × 7 × 272).
After Atrous convolutions, precise and important pixel-level semantic information can be acquired via channel attention mechanisms. This will re-calibrate the channel weights to moderate the channel interdependencies, selectively emphasize informative features, and suppress the less useful ones. We modify ASPP by applying Effective Channel Attention (ECA) [32] module after Atrous convolutions to aggregate features by GAP without dimensionality reduction and perform 1 × 1 convolution with a sigmoid activation function to learn channel attention. This ECA module is capable of effectively enhancing the channel-wise features, and hence the prediction performance. After combining ECA outputs and the image-level features by concatenation, the result is passed to 1 × 1 and 3 × 3 convolution modules and get a final output of 7 × 7 × 256 for multi-bin classification and regression.
3.4 Multi-bin classification and regression heads
Multi-bin classification and regression heads are used to convert the aggregated image features (7 × 7 × 256) into Euler angles. To prevent a large model size in FC (Fully Connected) implementation, a 1 × 1 GAP layer is applied first (see Fig. 1) before entering into 3 sets of FC layers. The output of each FC block contains 66 bins, each of which represents a quantized angle value so that our regression problem becomes a classification problem into 66 categories with each bin representing a 3-degrees interval to keep the range of each Euler angle (yaw, pitch, or roll) between -99° ~ 99°. This multi-bin classification method, accompanying with the Arg_softmax function [45] that follows, has the advantages of easy convergence as most of the classification problems and easy measurement of errors for regression problems. The centroid of the probability distribution in multi-bins can be identified via Eq. (1) which is known as Arg_softmax function [38] to obtain a fine-grained Euler angle:
The calculation of this function by Eq. (1) is done first by the softmax function for each i-th bin via normalization by the sum of exponential functions of all the predictions \({x}_{c}\) in bin c. Next, the results of the softmax in a total of N = 66 bins are calculated to find expectation (i.e., centroid). Then, the centroid position is multiplied by 3 and minus 99 to output the predicted angle (\({\theta }_{Pred}\)) in the range of -99° ⁓ 99°. The predicted angle \({\theta }_{Pred}\) can then be compared with its ground truth value to solve the regression problem (see loss functions below).
3.5 Loss function
Our loss function (\({L}_{total}\)) in yaw, pitch, and roll is composed of the classification sub-loss (\({L}_{cls}\)) and the regression sub-loss (\({L}_{reg}\)), which are expressed in Eq. (2) and (3), respectively. The cross-entropy loss is adopted for \({L}_{cls}\) and the wrapped loss [39] is for \({L}_{reg}\).
where \(\{{p}_{i}\}\) are the predicted bin outputs, \(\{{y}_{i}\}\) are the bin-label ground truths (converted from the Euler angle ground truth \({\theta }_{true}\)), N = 66, and \({\theta }_{pred}\) is calculated from Eq. (1). The wrapped loss will reduce large angular errors, especially the yaw angle. It will be converged smoothly during training, compared to the traditional mean square error loss, and thus provide lower head pose estimation error.
4 Experiments
4.1 Datasets and configurations for experiments
Three popular datasets, 300W_LP [9], AFLW2000 [9], and BIWI [10], are used for HPE evaluation. 300W_LP [9] is a synthetic dataset created by expanding several images via 3DMM fitting [22] to 2D images for accurate ground truth head poses. It was collected from four different sub-datasets, thus amounting to a total of 61,225 images. All images were flipped to increase the number of images to 122,450. AFLW2000 [9] is a challenging real-world dataset, composed of a variety of personal identities, illuminations, and occlusions. It contains 2,000 in-the-wild images which are then re-annotated with 68 3D facial landmarks. BIWI dataset [10] is gathered in a laboratory environment by recording 20 subjects (6 females and 14 males) across different head poses from a frontal position via the Microsoft Kinect V2 sensor. The depth annotation was applied for the creation of head pose labels represented as rotation matrices. It possesses 15,678 images. The head pose range of BIWI is -75 ~ 75 degrees for yaw, -60 ~ 60 degrees for pitch, and -50 ~ 50 degrees for roll.
For fair comparison, this study follows common protocols: (1) Protocol 1: use 300W_LP as the training set and AFLW2000 and BIWI as the test sets, (2) Protocol 2 [8]: use 70% of BIWI as the training set and 30% of BIWI as the test set, (3) keep only samples whose Euler angles are in the range of -99 ~ 99 degrees.
As is well-known, increasing the number of training samples is generally helpful to increase the deep neural network performance. This study hence proposes to augment the data via geometric and pixel-level transformations [40]. Geometric transformations include: (1) horizontal flipping, (2) shifting of the ROI (Region of Interest) within 10% of the image width, (3) image scaling between 1.0 ~ 1.25. On the other hand, pixel-level transformations include: (1) Gaussian noise, (2) brightness and contrast alteration, and (3) Gaussian blurring. This data augmentation was conducted under the guidance of 50% of samples for unaltered images and the other 50% for equally random selection out of the above 6 transformations.
This study trains the proposed network with 160 epochs using AdamW optimization with a learning rate of 0.00001, and with \({\beta }_{1}\) = 0.9, \({\beta }_{2}\) = 0.999, and \(\epsilon\) = \({10}^{-8}\) [41]. Image data are also z-score-normalized before training based on the mean and standard deviation. Moreover, the platform for this study was Core i9 CPU equipped with NVIDIA RTX 3080 GPU.
4.2 Ablation study
This study adds/removes some modules (e.g., Modified ASPP (Mod ASPP) and MAMs) to see their individual impacts on our HPE performances. Moreover, this study also tries to remove the addition (see Fig. 2) inside each attention module (denoted as MAM-w/o-Add), which is shown in Fig. 4a. And this study also tries to remove the attention unit (see Fig. 2) inside each attention module by replacing it with a 2 × 2 convolution layer (denoted as MAM-w/o-Att), which is shown in Fig. 4b. The evaluation metric is MAE (mean absolute error) [27, 42] shown in Eq. (5):
where \({\widetilde{y}}_{n}\) is the predicted angle, \({y}_{n}\) is the ground truth angle, and \(N\) represents the number of images in the dataset. Table 2 shows the results of the ablation analysis. It shows that the use of MAMs, Mod ASPP, and data augmentation is really capable of enhancing the overall performance in MAE metric.

a The MAM module without addition (MAM-w/o-Add) and b the MAM module without attention unit (replaced with a 2 × 2 convolution layer) (MAM-w/o-Att)
Removing each part (MAMs, Mod ASPP, and data augmentation) degrades HPE performance due to three reasons such as: no pyramidal structure compliance via multi-level semantic information acquisition from hierarchical features with cross-level attention, no receptive field enhancement and channel attention mechanism, and no increased number of training samples for enhancing the robustness of our HPE performance. Moreover, when removing the addition or attention unit inside each MAM, the performances will be degraded accordingly due to no cross-level spatial feature enhancement from adjacent-level outputs in the pyramid structure, and no shortcut connection for assisting the backpropagation.
4.3 Comparison with state-of-the-art (SOTA) methods
Here we make comparison in terms of MAE metric with other methods for Protocol 1 and 2 in Tables 3 and 4, respectively. Our proposed technique outperforms SOTA methods in both Protocols 1 & 2, except the lightweight CNN [6] for the Protocol 1 test on BIWI.
The results show the robustness of our proposed method in different datasets. Thanks to the pyramid structure in multi-level feature extraction, multiple spatial attention modules in fusing them, and modified ASPP module in channel attention. Our technique is free from facial landmarks, a 3D head model, and a 2D-3D correspondence process.
Among the prior works listed in Tables 3 and 4, FSA-Net [27] and Lightweight CNN [6], have much inferior performances than ours, but consuming smaller hardware resources (see Sect. 4.4). Though Lightweight CNN [6] is more comparable to ours, it needs to extra rectify the input image for pre-alignment purpose and the camera intrinsic parameters need to be provided. This will prevent its practical applications. TriNet [29] and 6DRepNet [12] are based on 3- or 2-vectors for rotation matrix, respectively, to represent the output poses. This shows that classification-based (e.g., on Euler angles) methods like ours are able to achieve higher accuracies than regression-based (e.g., on rotation matrix) methods [12, 29], but at a tradeoff of possible gimbal lock situation [28]. The Img2pose [25], based on a Faster R-CNN [26] and ResNet-18 as the backbone, achieves slightly inferior performance than ours, but requires manual annotations of the bounding box labels for training and much larger computations and time in inference (see Sect. 4.4). The performance of WHENet [39], not only inferior than ours in dataset test, but also shows less robustness in realistic medical CROM measurement (Table 5 in Sect. 4.4).
It is observed from Tables 3 and 4 that larger estimation errors on the pitch angle, compared to the yaw and roll angles, seem to be a common characteristic for most of the methods. The reason is the lack of extreme pitch ground truth samples in the datasets for training. A possible solution may be to augment the training dataset via synthesis by using 3D head model [17].
4.4 Applications of HPE to medical CROM measurement
To the best of our knowledge, this work may be the first study to apply deep-learning-based HPE algorithm to measure medical CROM. This application has the advantages of fast, non-invasive, free of radiation exposure, low cost of operation, and anatomical landmark free, compared to the use of traditional standard medical instrument like a goniometer [11]. Our dataset collected data from 15 subjects in the medical examination room (department of rehabilitation medicine, Ramathibodi Hospital, Thailand). The measurements were approved by the institutional review board of the same hospital with the certificate of approval (COA) number MURA2021/73. Consents were obtained for all subjects. The inclusion criteria include:
-
1.
persons with the age between 18 and 80 years old,
-
2.
no relationship with the research team,
-
3.
no neck movement disorder, and
-
4.
no history of cervical surgeries or trauma.
During video recording, the subject was asked to sit in front of a recording camera (Fig. 5). Calibration of the head pose was first conducted by asking the subject to move in six head directions such as flexion, extension, left and right lateral bending, and left and right rotation (e.g., Fig. 6b, c) for two sessions. In each session, the measurement for each movement was conducted two times by using a goniometer. The maximum movement in each direction was captured by the webcam and saved as an image file. The number of files thus amounts to 360 (15 persons × 6 directions × 2 sessions × 2 times). The ranges for pitch, yaw, and roll angles were [-70, 68], [-87, 88], and [-57, 52], respectively.

Arrangement of a webcam in front of the subject

Pose calibration: a front position, b left rotation, and c right rotation
The camera was configured with an image resolution of 800 × 600 pixels at 30 fps (frame per second) and a bit rate of 2.5Mbps. The rationale of setting the bitrate considers factors of bandwidth, hardware, and software in video network transmission for telemedicine [43]. Compressed videos without significant quality degradation are required for medical diagnosis.
The pre-processing of the collected video data consists of four steps and visualized in Fig. 7 accordingly: (1) face bounding box detected with RetinaFace [44], (2) facial landmarks detected with Face alignment network (FAN) [18], (3) face ROI adjusted based on the detected landmarks to expand the bounding box with an additional 20% to make a loose cropping of the face to cover the rest of the head (this follows a common pre-processing process in [17, 27]), and (4) cropped and resized face ROI based on the expanded face ROI to 224 × 224 pixels.

Visualization of the results of pre-processing
The pre-trained model based on 300W_LP dataset was used to measure the CROM vector in each direction of head movement and compared with the CROM vector in the frontal view position to get the relative CROM angle, which reveals the maximum angle by which the subject can rotate. The results will be compared to the ground truths measured by two rehabilitation doctors by using a goniometer. Table 4 compares the results by various HPE methods (codes executed by us).
It is observed that the proposed technique achieves the lowest MAE of 4.58 degrees, compared to other SOTA methods with a statistical significance. Our MAE, less than 5 degrees, is acceptable according to the error threshold defined on the research of Cambridge Face Tracker [5]. However, in Table 5, compared to the yaw and the roll angles, the pitch angles provide the larger CROM estimation errors. The reason is the same as in the previous section.
Figure 8 shows the statistics between the estimated angles and their corresponding ground truths (measured by the goniometer) for the all 360 images. A linear model is regressed and shown in Fig. 8, revealing a high goodness- of-fit of \({R}^{2}\) equal to 0.90. This means that our HPE model can estimate the angles faithfully.

Assessing goodness-of-fit for the linear regression model established between the estimated angles and their corresponding ground truths measured by the goniometer. The solid line shows a linear regression between two measures, which is via the formula \(y=0.9204x+4.305\) with \({R}^{2}\) value of 0.90
Figure 9 plots the MAE distribution of HPE for the yaw, pitch, and roll angles on our dataset for CROM measurements. It is observed that our proposed technique achieves a MAE lower than 5 degrees in the range of [-90°, 79°] for yaw angles, a smaller range of [-60°, 59°] for pitch angles and a least range of [-50°, 49°] for roll angles. The three ranges we achieved actually all cover the specified CROM ranges of [-70°, 70°], [-55°, 55°], and [-40°, 40°] on yaw, pitch, and roll angles defined in [45]. Capability of measuring CROM within specified ranges is mandatory in rehabilitation. This experiment shows the feasibility of our HPE technique in rehabilitation via CROM measurement.

The MAEs at different ground truth angles (-99° ~ 99°) for test on our dataset for CROM measurement
We also conducted a performance study of the SOTA methods on the CROM measurement. This study evaluated the performances in terms of number of parameters, computational complexity (in units of Giga floating-point operations (GFLOPS), and the inference speed per image (in millisecond). Table 6 provides the results, with all models being pre-trained based on the 300W_LP dataset.
For medical CROM measurement application, accuracy and speed are two main concerns. In view of this, our technique outperforms 3DDFA [9], FSA [27], Img2Pose [25], TriNet [29], and 6DRepNet [12] by a faster speed and accuracy. Though HopeNet [17], WHENet [38], and Lightweight CNN [6] have a better speed than ours, HopeNet [17] has a larger model size and GFLOPS, while WHENet [38] and Lightweight CNN [6] have inferior accuracy performance than ours (see Tables 3, 4, and 5). This benefits from the use of EfficientNet-Lite [33] to have balanced scaling of neural network architecture in terms of channel size, network depth, and input image resolution to effectively optimize between FLOPS and accuracy.
In overall considerations, our proposed method is much more suitable for realistic CROM measurement application.
5 Conclusion
In this paper, a deep-learning-based HPE algorithm based on EfficientNet-Lite4, multiple attention modules and modified ASPP was proposed. Compared to the SOTA methods, our proposed technique has been verified to achieve the lowest MAE on two public datasets AFLW2000 and BIWI. Moreover, this study is the first to evaluate deep-learning-based HPE techniques in the medical aspect on CROM measurements. Via real tests on our own collected dataset, the results also show our better accuracy and robustness for medical CROM measurements than SOTA methods. Our error analysis also shows the conformity with medical standards and is thus acceptable in real applications.
This work still has some remaining challenges. Better CROM measurement instruments like CROM device [2] and 3D motion analysis technique [4], or even gold standard like radiography [1], will be preferred, instead of a goniometer, for measuring the ground truths. Moreover, this study evaluates the proposed technique for healthy subjects, preferably other subject groups like CROM-limited patients who have aging, trauma, pain, musculoskeletal problems, and cervical spine degenerative diseases.
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Janjua MB, Zhou PL, Vasquez-Montes D, Moskovich R (2020) Photogrammetric analysis: An objective measure to assess the craniocervical range of motion after cervical laminoplasty surgeries. J Clin Neurosci 71:76–83. https://doi.org/10.1016/j.jocn.2019.10.012
Thoomes-de Graaf M, Thoomes E, Fernández-de-las-Peñas C, Plaza-Manzano GA, Cleland J (2020) Normative values of cervical range of motion for both children and adults: A systematic review. Musculoskelet Sci Pract 49:102182. https://doi.org/10.1016/j.msksp.2020.102182
Pittayapat P, Jacobs R, Bornstein MM, Odri GA, Lambrichts I, Willems G et al (2018) Three-dimensional Frankfort horizontal plane for 3D cephalometry: a comparative assessment of conventional versus novel landmarks and horizontal planes. Eur J Orthod 40:239–248. https://doi.org/10.1093/ejo/cjx066
Song YS, Yang KY, Youn K, Yoon C, Yeom J, Hwang H et al (2016) Validation of attitude and heading reference system and microsoft kinect for continuous measurement of cervical range of motion compared to the optical motion capture system. Arm 40:568–574. https://doi.org/10.5535/arm.2016.40.4.568
Thomas PBM, Baltrušaitis T, Robinson P, Vivian AJ (2016) The Cambridge face tracker: accurate, low cost measurement of head posture using computer vision and face recognition software. Transl Vis Sci Technol 5:8. https://doi.org/10.1167/tvst.5.5.8
Li X, Zhang D, Li M, Lee D-J (2023) Accurate head pose estimation using image rectification and a lightweight convolutional neural network. IEEE Trans Multimed 25:2239–2251. https://doi.org/10.1109/TMM.2022.3144893
Pandey NN, Muppalaneni NB (2022) A survey on visual and non-visual features in Driver’s drowsiness detection. Multimed Tools Appl 81:38175–38215. https://doi.org/10.1007/s11042-022-13150-1
Abate AF, Bisogni C, Castiglione A, Nappi M (2022) Head pose estimation: An extensive survey on recent techniques and applications. Pattern Recogn 127:108591. https://doi.org/10.1016/j.patcog.2022.108591
Zhu X, Lei Z, Liu X, Shi H, Li S-Z (2016) Face alignment across large poses: a 3D solution. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, pp 146–155. https://doi.org/10.1109/CVPR.2016.23
Fanelli G, Gall J, Gool L Van (2011) Real time head pose estimation with random regression forests. In: CVPR 2011. IEEE, pp 617–624. https://doi.org/10.1109/CVPR.2011.5995458
Bible JE, Biswas D, Miller CP, Whang PG, Grauer JN (2010) Normal functional range of motion of the cervical spine during 15 activities of daily living. J Spinal Disord Tech 23:15–21. https://doi.org/10.1097/BSD.0b013e3181981632
Hempel T, Abdelrahman AA, Al-Hamadi A (2022) 6d rotation representation for unconstrained head pose estimation. In: 2022 IEEE International Conference on Image Processing (ICIP). IEEE, pp 2496–2500. https://doi.org/10.1109/ICIP46576.2022.9897219
Jabberi M, Wali A, Chaudhuri BB, Alimi AM (2023) 68 landmarks are efficient for 3D face alignment: what about more? Multimed Tools Appl 82:41435–41469. https://doi.org/10.1007/s11042-023-14770-x
Wang W, Yang J, Xiao J, Li S, Zhou D (2015) Face recognition based on deep learning. In: Zu Q, Hu B, Gu N, Seng S (eds) HCC 2014: Human Centered Computing. Springer, Cham, pp 812–820. https://doi.org/10.1007/978-3-319-15554-8_73
Ayeche F, Alti A (2021) Facial expressions recognition based on Delaunay triangulation of landmark and machine learning. Traitement Signal 38:1575–1586. https://doi.org/10.18280/ts.380602
Noothout JMH, Vos BDD, Wolterink JM, Postma EM, Smeets PAM, Takx RAP et al (2020) Deep learning-based regression and classification for automatic landmark localization in medical images. IEEE Trans Med Imaging 39:4011–4022. https://doi.org/10.1109/TMI.2020.3009002
Ruiz N, Chong E, Rehg JM (2018) Fine-grained head pose estimation without keypoints. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, pp 2155–2164. https://doi.org/10.1109/CVPRW.2018.00281
Werner P, Saxen F, Al-Hamadi A (2017) Landmark based head pose estimation benchmark and method. In: 2017 IEEE International Conference on Image Processing (ICIP). IEEE, pp 3909–3913. https://doi.org/10.1109/ICIP.2017.8297015
Baltrusaitis T, Robinson P, Morency L-P (2016) OpenFace: An open source facial behavior analysis toolkit. In: 2016 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, pp 1–10. https://doi.org/10.1109/WACV.2016.7477553
De la Torre F, Chu W-S, Xiong X, Vincente F, Ding X, Cohn J (2015) IntraFace. In: 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG). pp 1–8. https://doi.org/10.1109/FG.2015.7163082
Bulat A, Tzimiropoulos G (2017) How far are we from solving the 2D &; 3D face alignment problem? (and a Dataset of 230,000 3D Facial Landmarks). In: 2017 IEEE International Conference on Computer Vision (ICCV). IEEE, pp 1021–1030. https://doi.org/10.1109/ICCV.2017.116
Wu C-Y, Xu Q, Neumann U (2021) Synergy between 3DMM and 3D landmarks for accurate 3D facial geometry. In: 2021 International Conference on 3D Vision (3DV). IEEE, pp 453–463. https://doi.org/10.1109/3DV53792.2021.00055
Xia J, Cao L, Zhang G, Liao J (2019) Head pose estimation in the wild assisted by facial landmarks based on convolutional neural networks. IEEE Access 7:48470–48483. https://doi.org/10.1109/ACCESS.2019.2909327
Lie W-N, Yim M, Aing L, Chiang J-C (2022) 3D Head pose estimation based on graph convolutional network from a single RGB image. In: 2022 IEEE International Conference on Image Processing (ICIP). IEEE, pp 3963–3967. https://doi.org/10.1109/ICIP46576.2022.9897519
Albiero V, Chen X, Yin X, Pang G, Hassner T (2021) img2pose: face alignment and detection via 6DoF, face pose estimation. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, pp 7613–7623. https://doi.org/10.1109/CVPR46437.2021.00753
Ren S, He K, Girshick R, Sun J (2017) Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell 39:1137–1149. https://doi.org/10.1109/TPAMI.2016.2577031
Yang T-Y, Chen Y-T, Lin Y-Y, Chuang Y-Y (2019) FSA-Net: learning fine-grained structure aggregation for head pose estimation from a single image. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, pp 1087–1096. https://doi.org/10.1109/CVPR.2019.00118
Hsu H-W, Wu T-Y, Wan S, Wong WH, Lee C-Y (2019) QuatNet: quaternion-based head pose estimation with multiregression loss. IEEE Trans Multimed 21:1035–1046. https://doi.org/10.1109/TMM.2018.2866770
Cao Z, Chu Z, Liu D, Chen Y (2021) A vector-based representation to enhance head pose estimation. In: 2021 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, pp 1187–1196. https://doi.org/10.1109/WACV48630.2021.00123
Zhang J, Yan Y, Cheng Z, Wang W (2020) Lightweight attention pyramid network for object detection and instance segmentation. Appl Sci 10:883. https://doi.org/10.3390/app10030883
Liu W, Liu X, Luo X, Wang M, Han G, Zhao X et al (2023) A pyramid input augmented multi-scale CNN for GGO detection in 3D lung CT images. Pattern Recogn 136:109261. https://doi.org/10.1016/j.patcog.2022.109261
Wang Q, Wu B, Zhu P, Li P, Zuo W, Hu Q (2020) ECA-Net: efficient channel attention for deep convolutional neural networks. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, pp 11531–11539. https://doi.org/10.1109/CVPR42600.2020.01155
Tan M, Le Q (2019) EfficientNet: rethinking model scaling for convolutional neural networks. In: Proceedings of the 36th International Conference on Machine Learning. PMLR, pp 6105–6114. https://doi.org/10.48550/arXiv.1905.11946
Sandler M, Howard A, Zhu M, Zhmoginov A, Chen L-C (2018) MobileNetV2: inverted residuals and linear bottlenecks. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, pp 4510–4520. https://doi.org/10.1109/CVPR.2018.00474
Jha D, Smedsrud PH, Riegler MA, Johansen D, Lange TD, Halvorsen P, et al (2019) ResUNet++: an advanced architecture for medical image segmentation. In: 2019 IEEE International Symposium on Multimedia (ISM). IEEE, pp 225–2255. https://doi.org/10.1109/ISM46123.2019.00049
Li H, Xiong P, An J, Wang L (2018) Pyramid attention network for semantic segmentation. In: British Machine Vision Conference 2018 (BMVC 2018). British Machine Vision Association (BMVA), pp 1–13. https://doi.org/10.48550/arXiv.1805.10180
Chen L-C, Papandreou G, Kokkinos I, Murphy K, Yuille AL (2018) DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans Pattern Anal Mach Intell 40:834–848. https://doi.org/10.1109/TPAMI.2017.2699184
Sun X, Xiao B, Wei F, Liang S, and Wei Y (2018) Integral human pose regression. In: 2018 European Conference on Computer Vision (ECCV). https://doi.org/10.48550/arXiv.1711.09229.
Zhou Y, Gregson J (2020) Whenet: Real-time fine-grained estimation for wide range head pose. In: 31st British Machine Vision Conference 2020. British Machine Vision Association (BMVA). https://doi.org/10.48550/arXiv.2005.10353
Zhao H, Li H, Cheng L (2022) Chapter 14 - Data augmentation for medical image analysis. In: Burgos N, Svoboda D (eds) Biomedical Image Synthesis and Simulation. Academic Press, pp 279–302
Ilya L, Frank H (2017) Decoupled weight decay regularization. arXiv preprint. https://doi.org/10.48550/arXiv.1711.05101
Ayeche F, Alti A (2021) HDG and HDGG: an extensible feature extraction descriptor for effective face and facial expressions recognition. Pattern Anal Applic 24:1095–1110. https://doi.org/10.1007/s10044-021-00972-2
Chaabouni A, Gaudeau Y, Lambert J, Moureaux J-M, Gallet P (2016) H.264 medical video compression for telemedicine: A performance analysis. IRBM 37:40–48. https://doi.org/10.1016/j.irbm.2015.09.007
Deng J, Guo J, Ververas E, Kotsia I, Zafeiriou S (2020) RetinaFace: single-shot multi-level face localisation in the wild. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, pp 5202–5211. https://doi.org/10.1109/CVPR42600.2020.00525
Mostoufi SA (2020) Cervical radiculopathy. In: Essentials of Physical Medicine and Rehabilitation. Elsevier, pp 22–28
Acknowledgements
This research project is supported by Mahidol University (Basic Research Fund: fiscal year 2022) (FRB650007/0185) (Contract No BRF1-056/2565).
Funding
Open access funding provided by Mahidol University
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All authors certify that they have no affiliations with or involvement in any organization or entity with any financial interest or non-financial interest in the subject matter or materials discussed in this manuscript.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ritthipravat, P., Chotikkakamthorn, K., Lie, WN. et al. Deep-learning-based head pose estimation from a single RGB image and its application to medical CROM measurement. Multimed Tools Appl (2024). https://doi.org/10.1007/s11042-024-18612-2
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11042-024-18612-2