
Abstract
Text plagiarism has greatly spread in the recent years, it becomes a common problem in several fields such as research manuscripts, textbooks, patents, academic circles, etc. There are many sentence similarity features were used to detect plagiarism, but each of them is not discriminative to differentiate the similarity cases. This causes the discovery of lexical, syntactic and semantic text plagiarism types to be a challenging problem. Therefore, a new plagiarism detection system is proposed to extract the most effective sentence similarity features and construct hyperplane equation of the selected features to distinguish the similarity cases with the highest accuracy. It consists of three phases; the first phase is used to preprocess the documents. The second phase is depended on two paths, the first path is based on traditional paragraph level comparison, and the second path is based on the computed hyperplane equation using Support Vector Machine (SVM) and Chi-square techniques. The third phase is used to extract the best plagiarized segment. The proposed system is evaluated on several benchmark datasets. The experimental results showed that the proposed system obtained a significant superiority in the performance compared to the systems with a higher ranking in the recent years. The proposed system achieved the best values 89.12% and 92.91% of the Plagdet scores, 89.34% and 92.95% of the F-measure scores on the complete test corpus of PAN 2013 and PAN 2014 datasets, respectively.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
There is a huge amount of data available on the Internet, and it is also easily accessible, which has led to the emergence of text plagiarism. IEEE defines text plagiarism as “The reuse of someone else’s prior ideas, processes, results, or words without explicitly acknowledging the original author and source” [8]. In general, plagiarism can occur in any form of data such as text, music, images, videos, and codes. Several studies of digital plagiarism have found that 79.5 % of the authors are implicated in digital plagiarism [22]. It is a serious problem for scientific publications and the academic community. Therefore, automated plagiarism detection systems are needed.
Plagiarism detection systems mainly deal with three types of changes used to convert the original text into the plagiarized text: lexical, syntactic, and semantic changes. The lexical changes are accomplished by adding and removing words from the text and using synonyms or concepts with similar meanings as a replacement of words. The syntactic changes are carried out by altering the syntax of sentences such as sentence restructuring, active-passive transformations, etc. Finally, semantic changes are a mixture between lexical strategy and syntactic strategy, which is the most difficult strategy for researchers nowadays. Therefore, semantic knowledge databases are developed in English language such as WordNet [34], Gene Ontology [18], and Transfer Standard [43]; in order to integrated with plagiarism detection systems for determining conceptual similarity without the need of human interaction. There are two types of the plagiarism detection systems: intrinsic and extrinsic [10]. In the intrinsic plagiarism detection system, the suspected documents are compared basing on the stylometric features, which were included within the documents. But in the extrinsic plagiarism detection system, the suspected document is compared with external source documents.
Recently, plagiarism detection systems have attempted to come up with an approach that can handle different types of the text plagiarism [23,24,25, 28, 51, 54, 58] by extracting lexical, syntactic and semantic characteristics. These approaches represent the extracted characteristics into vectors, and apply similarity measurements as cosine criterion, jaccard criterion, dice criterion, match criterion, etc. Afterward in the recent researches [2, 3, 13, 33, 52, 57, 64, 65, 67, 68], some researches proposed new equations for measuring the similarity of sentences, these equations depended on the integration of two criteria to calculate the resemblance of sentences and words, and the others relied on the integration of three or four sentence similarity features. Each similarity feature within the proposed equations in the previous researches is multiplied by a weighting coefficient. To find the appropriate value of the weighted coefficient in the previous researches, a lot of experiments were done to compare the results to find the best values of the criteria weights. The purposed systems that relied on two, three or four criteria instead of relying on one criterion have been developed to achieve a high level of accuracy for detecting the text plagiarism, and discover the different images of the lexical, syntactic, and semantic plagiarisms.
Natural Language Processing (NLP) is a field of computer science, linguistics and artificial intelligence dealing with computer-human interactions (natural). The processing of different human languages by computer systems is the aim of NLP. In many fields, NLP plays a significant role including computer-assisted language acquisition, search engine optimization, and biological data extraction [48]. In this paper, NLP approaches including feature selection and classification techniques are utilized to detect the different types of text plagiarism with the highest accuracy.
The previous research [2, 3, 23,24,25, 28, 39, 51, 54, 58] depended on 2, 3 or 4 sentence similarity features instead of depending on only one feature to enhance the text plagiarism detection. There is a challenge to depend on few numbers of sentence similarity features, because these features are not discriminative of the different types of text plagiarism cases. Therefore, the proposed system takes into consideration all the different plagiarism types by creating a supervised dataset of 34 sentence similarity features to train SVM classification algorithm. The proposed system is also interested to extract the most effective sentence similarity features that have the ability to differentiate the suspicious cases with the highest accuracy. Therefore, it is depended on filter feature selection approach using Chi-square algorithm to rank the 34 features and extract the most discriminative features of the different types of lexical, syntactic, and semantic text plagiarisms. The proposed system is also based on constructing the hyperplane equation of selected features using SVM classification algorithm, rather than conducting extensive experiments to find the best weighting coefficient values for incorporating the selected features.
The main contribution of this paper can be summarized as:
-
Proposing a new plagiarism detection system that deals with all the different types of lexical, syntactic, and semantic plagiarisms.
-
Negative Non-plagiarized” and positive “Plagiarized” cases are extracted from the documents of benchmark datasets that have different plagiarism types.
-
Thirty-four values to the sentence similarity features of each extracted case are computed and recorded aggregating with the class label to build supervised training database.
-
Chi-square algorithm is used to rank the thirty-four features of the created training database and extract the most discriminative features that achieve the highest detect accuracy.
-
SVM classification algorithm is used to construct the hyperplane equation of selected features, which has the ability to add new dimensionality to distinguish the overlapping between the training cases of different classes.
The proposed system is implemented through three phases: preprocessing, seeding, and post-processing. In the preprocessing phase, preprocessing techniques such as sentence segmentation, paragraph composition, tokenization, lower casing, removing stop-words, punctuation removal and removed all tokens that did not start with a letter, part of speech tagging, and lemmatization are applied. Secondly, seeding process is utilized to extract the set of possible plagiarized cases, compute the lexical, syntactic, and semantic features, select the most effective features, create the training database, and construct the support vector machine model. It is based on two paths to detect the sentences similarity cases, the first path is based on traditional paragraph‑level comparison, and the second path is based on the hyperplane equation of the constructed SVM classifier. The final phase is based on filter seeds, merging adjacent detected seeds, adaptive behavior, and filter segments techniques to extract the best-plagiarized segment between suspicious and source documents.
The performance of the proposed system was evaluated basing on three benchmark datasets from the PAN Workshop series: PAN 2012 [44], PAN 2013 [45], and PAN 2014 [47]. The performance is measured using five standard metrics of PAN series; Recall, Precision, F- measure, Granularity, and Plagdet. The proposed system achieved the highest F- measure and Plagdet scores comparing with the recent related systems on the complete test corpus of PAN 2013 and PAN 2014. The rest of the paper is structured as follows. Section 2 shed light on the previous related work. In Section 3, the details of the proposed system stages will be explained. In Section 4, the details of the experimental setup and the experimental results will be described. This research will be concluded in Section 5.
2 Related work
The recent plagiarism detection systems are explained in this section of the paper. The researchers work on different techniques such as n-gram based, semantic-syntactic, etc. most of the following researches consist of four levels to detect plagiarism: preprocessing, seeding, extension and filter. In this section, recent plagiarism detection systems are concluded, it developed to facilitate the comparison between plagiarism detection techniques. In addition, the limitations of each approach is discussed.
Kong et al. [23, 24, 28] presented a technique of plagiarism detection based on vector space model to capture semantic similarity. Mainly is divided into four stages: preprocessing, seeding, extension and filtering. The first stage prepared the documents by special characters elimination, stop words elimination, lower case conversion, and stemming. The second stage was interested in extracting plagiarized sentences and their corresponding source sentences. Therefore, the overlap similarity model is applied in passage level and sentence level. In the next stage, Bilateral Alternating Sorting between the detection pairs was applied for getting large plagiarized passages by merging adjacent pairs. In the final stage, passages whose words overlap under a modified Jaccard coefficient and less than a certain threshold, are eliminated. The main limitation is to find the appropriate thresholds and build an extension algorithm that can adapt with the different types of plagiarism. Rodríguez Torrejón and Martín Ramos [51] designed a model dependent on context n-grams and context skip n-grams. There are four steps in this model. Firstly, basic preprocessing techniques are performed in documents. Secondly, the suspected document is compared with the source document by using context 3-grams and skips context n-grams where n is between 1 and 3. In the third step, simultaneously nearby detections are joined if the gap is less than 4000 characters. Finally, small passages with a length of fewer than 190 characters are discarded. However, the model is not concerned with the semantic side in the analysis.
Shrestha and Solorio [58] proposed an approach that used n-grams having different characteristics, to deal with different plagiarism levels from copy-paste to high-level plagiarism. This approach compares documents upon stop words 8-grams, context 5-grams, and entity 5-grams to extract plagiarized cases. Afterward, adjacent catch plagiarized cases are extended, when the gap between these is less than 8 words. Finally, short passages are filtered out. The shortcoming in this approach is to find a way for mixing n-grams characteristics to improve the overall performance. Palkovskii and Belov [39] introduced a system for plagiarism detection based on context 5-grams for comparison between suspicious and the source documents. Then, the system used clustering by Euclidean distance for the extension of detected seeds. Finally, passes with a length less than 190 characters are deleted. The results of this system show that it failed to detect summary plagiarism types.
Küppers and Conrad [25] proposed an algorithm that based on the following steps: preprocessing text by Tokenization, Stop words removal, collapsing whitespace. The next processing step is to chunk documents with a semi-fixed window size of 250 characters. Then, it compared each suspicious chunk with all the source chunks by using Dice’s coefficient. Afterward, the detected plagiarisms cases are joined together if the gap is less than 500 characters. However, the algorithm is failed on highly obfuscated plagiarism. Sanchez-Perez et al [54] presented an adaptive algorithm consist of 4 phases: preprocessing, seeding, extension and filter. In the first phase, preprocessing natural language techniques such as sentence segmentation and tokenizing, special characters removal, converting all letters to lowercase, and stemming are applied. In the seeding phase, each sentence is represented in the VSM of tf-idf weights. Then, it applied Dice coefficient and cosine measure. In the extension phase, it used clustering and validation between fragments of the source document and corresponding fragments of the suspicious document. In the filter phase, overlapping cases are resolved and small cases with length 150 characters are removed. The main limitation of their method is neglecting the semantic aspects.
Altheneyan et al [3] proposed an automatic plagiarism detection system divided into four steps: paragraph level comparison, sentence-level comparison, SVM classifier, post-processing. In the first step, all documents are converted into paragraphs with length 500 characters, and a comparison between each suspicious paragraph is occurred with all source paragraphs according to unigram and bigram. In the second step, the retrieved pairs of suspicious paragraphs and their corresponding source paragraphs are split into sentences, and are compared using the common unigrams and Meteor score. The SVM classifier step is used to verify the decision using lexical, syntactic, and semantic features. In the post-processing step, the detected pairs with a gap less than 900 characters are merged, and short passages less than 150 characters are discard.
Lovepreet Ahuja et al [2] introduced a plagiarism detection method in which semantic and syntactical knowledge between documents was extracted to detect the plagiarized segment from the text. This approach was applied in three phases: preprocessing, detailed analysis, filtering. In the preprocessing phase, Text segmentation, stop words removal, and lemmatization processes are used to prepare both suspicious and source documents. In the detailed comparison phase, a unique joint vector was formed by using suspected sentences and source sentences. Then, syntactic and semantic scores are calculated upon assigned different weights to linguistic characteristics: inverse path length characteristic and depth estimation characteristic. Afterward, the overall similarity is computed by combine syntactical and semantic scores with various weights. In the filtering phase, the non-plagiarized sentences that do not meet the conditions are removed. The system unable to detect complicated instances of plagiarism and determine the method that provides the best weights. Table 1 shows a summary of the stages that used to detect plagiarism in related researches.
Chia-Yang et al [7] concerned in plagiarism detection for documents retrieval and text alignment, it is focused on embedding Word2Vec word. After that, the embedding is grouped into semantic concepts, which are represented at several granularity levels. Word2vec is used to convert words into word vectors that contain semantic relations between the words. Spherical K-means is also used to cluster the words into semantic concepts. This method has major limitations, the terms used are single words, and the semantic meaning of the sentences remains unknown. Faisal Alvi et al [5] is proposed an approach to identify two important types of obfuscation: changes in sentence structure and synonym substitution. This is accomplished by proposing a three-step methodology: pre-processing, identification of word reordering, and identification of synonymous substitutions. In these steps, permutations of identical textual segments and paraphrase patterns of the reordered words have been used. In addition, the embedding word of ConceptNet Numberbatch and the Smith-Waterman algorithm are used to detect synonym substitution. The shortcoming of this approach is that it does not deal with the other types of obfuscation, such as deletion and addition.
Bilal Ghanem et al [12] introduced a hybrid arabic plagiarism detection system, it is called (HYPLAG) that deals with all different types of plagiarism such as copy-and-paste, paraphrasing, and synonym substitution. The system is architecture-based on Arabic WordNet in order to extract all the synonyms. HYPLAG consists of three steps: sentence ranking, Td-Idf terms weighting, and feature based semantic similarity. In the first process, sentence ranking is based on the structure of the search engine. In the second process, the similarity measure is calculated based on the Td-Idf weights for retrieved sentences with cosine similarity. The feature based semantic similarity process is based on the calculation of Tversky sentences measurement. The main limitation is the selection of the threshold values. Asif Ekbal et al [11] proposed an approach for external plagiarism detection. This approach consists of four stages: pre-processing, subset selection, passage selection, and filtering of false detections. In the sub-selection stage, the document retrieval task is achieved by using a vector space model (VSM). This model is based on converting all documents into vectors, where each cell in the vector is assigned by term-frequency and inverse document frequency (TF-IDF). Then, the similarity measure between vectors is calculated by cosine similarity. Their approach has many limitations such as the semantic aspect is not considered in the analysis and the failure to detect cases of high obfuscation.
3 Proposed system
The proposed system aims to detect the text plagiarism with the highest possible accuracy. Therefore, it takes into consideration all the different types of lexical, syntactic and semantic similarity features. All previous researches of the text plagiarism depended on 1, 2, 3 or 4 sentence similarity features for detecting the text similarity [2, 3, 23,24,25, 28, 39, 51, 54, 58], they also carried out extensive experiments to find the best weighting coefficient values for incorporating their selected similarity features. On the other side, the proposed system is based on 34 features that reflect all the different types of the text similarity. Increasing the number of text similarity features, makes the proposed method more robust in differentiating the confusion similarities that have a difficulty to detect their plagiarism, and detecting the different variations of text plagiarism with more accuracy. The proposed system also takes into consideration the determination of most effective features that have the ability to discriminate the suspicious cases with the highest accuracy. Therefore, it is depended on filter feature selection approach using Chi-square algorithm to rank the 34 features and extract the most discriminative features for the different types of lexical, syntactic and semantic text plagiarisms. The proposed system is also depended on constructing the hyperplane equation of 34 features using SVM classification algorithm, rather than conducting extensive experiments to find the best weighting coefficient values for incorporating the 34 features.
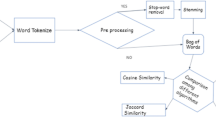
The proposed system is constructed basing on three main phases: preprocessing, seeding and post-processing. The general workflow of the proposed system is described in Fig. 1. The first phase is used to preprocess the suspicious and source documents. The second phase “Seeding” is depended on two paths to detect the sentences similarity, the first path is based on traditional paragraph‑level comparison, and the second path is based on the hyperplane equation of the constructed SVM classifier. The third phase “Post-processing” is used to extract the best-plagiarized segment between the suspicious and source documents.

General workflow of the proposed system
3.1 Preprocessing
The inputs of proposed system are suspicious and source documents. The proposed system analyzes these inputs through three phases as shown in Fig. 1 to detect the text plagiarism. The first phase of the proposed system is used to preprocess the suspicious and source documents, it depends on several processes: sentence segmentation, paragraph composition, tokenization, lowercasing, removing all tokens that do not start with a letter, stop words removal, punctuation removal, part of speech tagging, remain valuable class (noun, verb, adjective, adverb) and lemmatization.
-
Sentence segmentation: it splits the document into sentences by using sentence delimiters symbols such as “.”, “?” and “!”.
-
Paragraph composition: each document is paraphrased into the form of paragraphs. In the English language, the average of paragraph length is 100 words [32] and the average of word length is 5.1 characters [6]. Therefore, 500 characters for each paragraph length is chosen, and the adjacent sentences are grouped until the required length of characters “500” is achieved. During the clustering process of the sentences to paragraphs, each sentence is grouped with all of its words without cutting to preserve the context of the sentences. Therefore, each extracted paragraph will contain number of characters around 500.
-
Tokenization: it divides the text into smaller parts called tokens using unigrams and bigrams techniques.
-
Lowercasing: it converts all the tokens into a lowercasing form.
-
Removing stop-words: there are common terms that appearing in the text, they comprise around 40% to 50% of the words in plain text [62]. Therefore, these words will be removed from the text to reduce the computation time of the proposed system and improve its efficiency and accuracy. The proposed system removes the stop words basing on the NLTK stop word list, it contains around 160 stop-words including is, i, am, are, will, we, my, etc.
-
Punctuation and all tokens that do not start with a letter are also removed.
-
Part of speech tagging: it gives each word in the text its equivalent word-class basing on its definition and context. The word-classes contains noun, verb, adjective, adverb, conjunction, preposition, articles, pronouns, prepositions and determiners class labels. The proposed system eliminates all the classes except noun, verb, adjective and adverb classes, because these classes have a significant role in the semantics of a sentence.
-
Lemmatization: it is an operation of converting words into a dictionary base form.
3.2 Seeding
Each case of the text plagiarism is fragments of the source and suspicious documents, which are consistent in the context and meaning. The goal of the proposed system is to detect the text plagiarism cases with the highest possible accuracy. Therefore, it doesn’t only depend on the traditional techniques for the sentences comparison, but it is also based on the artificial intelligent approaches to achieve the desired goal. One of the recommended important phases of the proposed system is the seeding phase, it aims to extract a set of the possible plagiarized cases calling seeds. The seeding phase is based on two paths to detect the sentences similarity cases, the first path is based on traditional paragraph‑level comparison using two levels; paragraph‑level comparison and sentence‑level comparison. The second path is based on the hyperplane equation of the constructed SVM classifier.
3.2.1 First path of the seeding phase
The first path of the seeding phase is based on traditional paragraph‑level to detect the plagiarized cases, it consists of two levels; paragraph‑level comparison and sentence‑level comparison.
Paragraph‑level comparison: this level aims to extract the most similar paragraphs between the suspicious and source documents. It compares each paragraph of the suspicious document with all the paragraphs of the source document based on n-gram approach where n=1 and 2 [31]. The operational work of this step is described in algorithm 1 as shown in Fig. 2. It consists of three processes. Firstly, the common unigram between each suspicious paragraph hz and all source paragraphs are computed. Then, the N source paragraphs that have the maximum value of common unigrams are selected, the previous and next paragraphs for the selected paragraph are also chosen. Additionally, the shared bigrams between each suspicious paragraph hz and all source paragraphs are calculated. Then, the N source paragraphs that have the maximum value of shared bigrams are selected, the previous and next paragraphs for the selected paragraph are also chosen. Finally, in the case of selection the same source paragraph in unigram and bigram, unique source paragraph is selected.

Pseudo code of algorithm 1 for the paragraph-level comparison

Paragraph-level comparison
Sentence-level comparison: after extracting the suspicious paragraphs hz and their paired source paragraphs in the previous level, the preprocessed steps that explained in Section 3.1 are applied to these paragraphs. Subsequently, each suspicious sentence Cz is compared with all the source sentences. Then, the source sentence will be extracted, if it has the maximum value of the common unigrams comparing with Cz. The operational work of this step is described in algorithm 2 as shown in Fig. 3. There are three different decisions for comparing the pair of sentences. These decisions are based on two threshold m and t comparing to the value of Meteor score between the pair of sentences. If a value exceeds or is equal to a threshold m, it is considered as “Plagiarized case”. Else if a Meteor score value is less than a threshold t, it is considered a “Non-plagiarized case”. Otherwise, the pair of sentences will be analyzed using SVM classifier.

Pseudo code of algorithm 2 for the sentence-level comparison

Sentence-level comparison
3.2.2 Second path of the seeding phase
Seeding phase of the proposed system depends on two paths to detect the sentences similarity. The first path is based on traditional paragraph‑level comparison as described in the previous section, and the second path is based on SVM classifier as shown in Fig. 1. The second path of seeding phase is used, if the first path “Paragraph‑level comparison” didn’t able to discover the text similarity, it is based on constructing SVM classifier that has the ability to detect all the different types of lexical, syntactic, and semantic plagiarism cases. The construction process of SVM classifier is described in Fig. 4, it consists of four stages; negative and positive instances extraction, features computation, features selection, and classifier construction. In the first stage, negative “Non-plagiarized” and positive “Plagiarized” cases are extracted from the training documents to build a supervised training database. In the second stage, 34 values of the sentences similarity features are computed and recorded aggregating with the class label for each extracted case of the first stage, which can reflect all the different types of lexical, syntactic and semantic text similarities.

Construction process of SVM classifier
This phase of the proposed system also takes into consideration the determination of most effective features that have the ability to discriminate the suspicious cases and differentiate the variations of the text similarities with the highest accuracy. Therefore, in the third stage, it is depended on the filter feature selection approach using Chi-square algorithm to rank the 34 features, and extracted the most discriminative features for detecting the text plagiarism including the different types of lexical, syntactic and semantic text plagiarisms. The proposed system is also depended on constructing the hyperplane equation of 34 features using SVM classification algorithm in the fourth stage, rather than conducting extensive experiments to find the best weighting coefficient values for incorporating the 34 features.
Negative and positive instances extraction
In this stage, negative “Non-plagiarized” and positive “Plagiarized” cases are extracted from the training documents to build a supervised training database. The paragraphs of suspicious documents dz and source documents do are extracted from the training documents and converted into sentences. The extracted sentences are preprocessed using the preprocessing steps that described in Section 3.1. Then, each suspicious sentence will be compared with all the source sentences to compute meteor score and shared unigrams using algorithm 3 and 4 as shown in Figs. 5 and 6. The sentences are selected as a negative instance “Non-plagiarized case”, if the shared unigrams of the non-plagiarized paragraphs are more than 1. The sentences are selected as a positive instance “Plagiarized case”, if the pair of sentences have maximum meteor score and shared unigrams of the plagiarized paragraphs.

Pseudo code of algorithm 3 to extract the features of the positive instance cases

Pseudo code of algorithm 4 to extract the features of the negative instance cases.

Feature extraction from positive instances

Feature extraction from negative instances
Features computation
This stage aims to construct the training database of the SVM algorithm, it will be consisted by all the different similarity features that have the ability to detect the different types of the text plagiarism. Therefore, 34 values of the sentences similarity features are computed and recorded aggregating with the class label for each extracted case of the first stage. The computed sentence similarity features is based on similarity feature [17], hybrid syntactic and semantic similarity features [2], and 32 features have been calculated basing on four different criteria of the sentence similarity; cosine measure [70], dice measure [66], Jaccard measure [19] and Syntactic measure [29]. Each one of the sentence similarity is computed eight times basing on a different word similarity feature. The proposed system takes into consideration all the different features of the word similarities including path similarity [42], depth estimation similarity [53], combined word similarity [2], lch similarity [26], wup similarity [69], res similarity [49], lin similarity [30], and jcn similarity [21].
Word similarity features
WordNet [34] lexical database was created to provide resemblance in the meaning between the words, it consists of the alternative synonyms and concepts for each word. These alternative concepts and synonyms are related to each other in relationships and structured in a tree called “Lexical tree”.
-
Path similarity metric (PSM) [42]: it is based on the shortest path length between two concepts in the lexical tree. The range of PSM values is between 0 to 1. If the two concepts are identical, “1” value is returned.
$$PSM\left({c}_{z},{c}_{o}\right)= \frac{1}{distance+1}$$(1)
where \({c}_{z}\) and \({c}_{o}\) are word concepts, and distance is shortest path between \(\left({c}_{z},{c}_{o}\right).\)
-
Depth estimation similarity metric (DESM) [53]: it is based on the depth and least common subsume (LCS) values.
$$DESM\left({c}_{z}, {c}_{o}\right)= {e}^{-(depth\left({c}_{z}\right)+depth\left({c}_{o}\right)-2 * depth(lcs\left({c}_{z},{c}_{o}\right)))}$$(2)
Where depth (cx) is the maximum depth of the concept cx and LCS (\({c}_{z},{c}_{o}\)) is the least common subsumer of the concept-pair.
-
Leacock-Chodorow similarity metric (LCHSM) [26]: it uses the length of the shortest path between two concepts, and the maximum depth of the WordNet structure.
$$\mathrm{LCHSM}\left({c}_{z}, {c}_{o}\right)=-\mathrm{log}\frac{distance+1}{2*depth({c}_{z}, {c}_{o})}$$(3) -
Wu and Palmer similarity metric (WUPSM) [69]: it is based on the depth of each concept and the depth of the nearest ancestor shared by both concepts, also known as the least common subsume (LCS).
$$WUPSM({c}_{z},{c}_{o})=\frac{2*depth(LCS({c}_{z},{c}_{o}))}{depth\left({c}_{z}\right)+depth({c}_{o})}$$(4) -
Resnik similarity metric (RESSM) [49]: it uses the Information Content (IC) of LCS. IC metric assesses a concept's specificity. It is based on the word frequency in a corpus, where each occurrence of the word affects the counts of all to its WordNet taxonomic ancestors.
$$RESSM\;\left({c}_{z}, {c}_{o}\right)=IC(LCS({c}_{z}, {c}_{o}))$$(5)$$IC\left(c\right)=\mathrm{log}\frac{1}{P(c)}$$(6)$$P\left(c\right)=\frac{\sum_{t\in T(c)}appearances(t)}{V}$$(7)
Where P(c) probability of the concept c in corpus,\(T(c)\) is the set of terms in the corpus that can be inferred by c and v is the total number of corpus terms.
-
Lin similarity metric (LINSM) [30]: it is based on Information Content (IC) metric.
$$LINSM\left({c}_{z}, {c}_{o}\right)=\frac{2* IC(LCS({c}_{z}, {c}_{o}))}{IC\left({c}_{z}\right)+ IC\left({c}_{o}\right)}$$(8) -
Jiang and Conrath similarity metric (JCNSM) [21]: it is based on IC and LCS metrics.
$$JCNSM\left({c}_{z}, {c}_{o}\right)=\frac{1}{IC\left({c}_{z}\right)+ IC\left({c}_{o}\right)-2*IC(LCS({c}_{z}, {c}_{o}))}$$(9)
Sentence similarity features: these features were focused on two types of sentence similarity: semantic similarity [17, 19, 70] and syntactic similarity [29]. These features were computed based on four steps. The first step is to construct a joint matrix, given two preprocessed sentences CPz and CPo, “joint matrix” was constructed using unique words of the sentences. Let JM = {W1, W2, ···Wd } indicates a joint matrix, where d is the number of unique words in the joint matrix.
The second step constructs the semantic matrices by using semantic similarity between the words, it started by calculating the semantic similarity between the words using 7-WordNet similarity metrics [34]. The dimension of the semantic matrix equals the number of words in the joint matrix, which each cell corresponds to a word in the joint matrix. The semantic matrix's cells are weighted based on the estimated semantic similarity between the words in the joint matrix and the corresponding sentence. As an example, If the word W of the joint matrix exists in the sentence CPz, the semantic matrix's weight of the word is assigned to 1. Otherwise, the weight of W in the semantic matrix is assigned to 0, if there is no similarity value between W and all of the words in the sentence CPz.
The third step computes the semantic similarity measurements. The proposed system is based on three measures of semantic similarity: cosine measure Eq. (10), dice measure Eq. (11), and Jaccard measure Eq. (12), to measure the similarity degree between CPz and CPo using the semantic matrix.
where CMz = (R11, R12, R13,…R1v) and CMo= (R21, R22, R23,…,R2v) are semantic matrices of the suspicious and source sentences, respectively, Rzi is the suspicious semantic matrix's weight, Roi is the source semantic matrix's weight, and v is the number of words.
The fourth step computes Word-order similarity measurements, it is utilized syntactic-matrix technique [29] to calculate the word-order similarity. The syntactic matrix is created from the joint matrix and corresponding sentence. For each W word in the joint matrix. The cell in the syntactic matrix is assigned to the index position of the corresponding word in the sentence CPz, if the W appeared in the sentence CPz. If the word W does not exist in sentence CPz, a semantic similarity measure is computed between the W and each word in sentence CPz. The cell's value is assigned to the index position of the word with the highest similarity measure in the sentence CPz.
where Jz = (J11, J12, J13, …, J1v) and Jo = (J21, J22, J23, …, J2v) are syntactic matrices of the suspicious and source sentences, respectively. ||Jz − Jo|| and ||Jz + Jo|| are computed as follows:
Hybrid syntactic and semantic features: it is based on syntactic and semantic features, which used a cooperation coefficient \(\alpha\) to weight the path and depth similarity metrics, it is estimation as shown in Eq. (16), where \(\alpha\) between 0 and 1, \(PSM\left({c}_{z},{c}_{o}\right)\) is the path similarity metric, and \(DESM\left({c}_{z},{c}_{o}\right)\) is the depth estimation similarity metric.
Then, syntactic similarity is calculated by using Eq. (13), and semantic similarities are calculated through Eqs. (10), (11), and (12). Afterwards, semantic similarity is computed using Eq. (17), where 0≤β ≤1 is used to determine the weights of semantic and syntactic.
Fuzzy similarity feature: the semantic similarity between the preprocessed suspicious sentence Cpz and source sentence Cpo is computed as shown in Eq. (18). Firstly, for each suspicious-source pair of words (Wz, Wo), synsets are selected using WordNet lexical database. A synset is a synonym ring of the words that are semantically similar [3]. Secondly, the synset lists of Wz and Wo “Wzsyn and Wosyn” are created. Then, the semantic similarity between each pair of synsets (wzsyn, wosyn) is calculated using wup_similarity metric [69] Eq. (4) based on the fuzzy function Fz,o as shown in Eq. (20). This function adapts the semantic value using heuristic boundary conditions, and selects the maximum value of the synset pairs.
where µz,o is the word-to-sentence correlation factor for each word Wz in CPz and CPo, n is the total number of words in CPz, Fz,o is the fuzzy-semantic similarity between Wz and Wo, and p is the output of fuzzy-semantic similarity.
Features selection
After computing the 34 features that described in the previous stage, the feature selection stage of this phase aims to extract the most discriminative features for detecting the text plagiarism with the highest classification accuracy. Chi-square algorithm [41] is used to rank the features, which depends on the calculation of Chi-square value between each feature and the class labels. Then, the proposed system computes the classification accuracy for each subset of the ranked features. The operational work of this step is described in algorithm 5 as shown in Fig. 7. It starts with the first feature in the list of the ranked features as a first subset, it will continue generating new subsets of the ranked features to arrive to the last subset that have all the features, where each subset of the ranked features consists of the features of previous subset plus the next feature in the list of the ranked features. The subset of the ranked features that achieved the highest classification accuracy during the repetition process is selected to be the best subset of the features that have the ability to discover the different types of lexical, syntactic and semantic plagiarisms.

Pseudo code of algorithm 5 for the feature selection stage.

Feature selection
Construction process of SVM classifier
After selecting the most effective subset of the computed features, the proposed system is based on SVM classification algorithm to fit the values of the selected features, and find the hyperplane equation of the selected features that have the ability to detect the plagiarism cases, rather than conducting extensive experiments to find the best weighting coefficient values for incorporating the selected subset of features. SVM classification algorithm is more effective in high dimensional structured datasets compared with the other classification algorithms, which has the ability to add new dimensionality to distinguish the overlapping between the training cases of different classes.
3.3 Post processing
Post processing phase of the proposed system aims to extract the best-plagiarized segment between the suspicious and source documents using filter seeds, merging adjacent detected seeds, adaptive behavior, and filter segments techniques. This phase helps to improve precision accuracy value by removing some “bad” plagiarism cases using filtering techniques. It also improves recall and granularity accuracy values using extension technique.
-
Seeding phase of the proposed system may detect the plagiarized case with multiple source sentences. Therefore, filter seed technique is used to select the source sentence that having the highest Meteor score value.
-
The proposed system is also based on filter segments, which removed small cases by rejecting the plagiarized the small segments; if either suspicions or source segments have a length less than 145 characters as a threshold of the suspicious segment, and 250 characters as a threshold for source segment, the case is discarded, else the case is saved.
-
Extension technique is also used to merge adjacent detected seeds that are similar between the suspicious and source documents, to form larger text segments. The work flow of this technique is described in algorithm 6 as shown in Fig. 8. It depends on recursive algorithm used by Sanchez-Perez et al. [54]. The extension step is divided into two processes: clustering and validation. In the clustering process, seeds that are not separated by a gap will be grouped. But to avoid adding a noise in the clustering process, the extension technique uses a validating process, which bases on a similarity threshold (thsimilarity) between the text segments.

Pseudo code of algorithm 6 for extension technique

Extension algorithm
Pan workshop series [44, 45, 47] is an international competition interested in the plagiarism detection, each of them consists of different plagiarism types. Pan 2013 consists of no-obfuscation, random obfuscation, translation obfuscation, and summary obfuscation types. Pan 2014 includes no-obfuscation and random obfuscation types. The parameters that achieved the best result in each plagiarism type are different from another type. Therefore, the proposed system has the ability to adapt its behavior depending on the adaptive extension technique, it is based on an extension algorithm using two different gap values of the sentences: maxgap_summary and maxgap. Maxgap_summary is the best observed gap value between the sentences of the summary obfuscation type, and maxgap is the best observed gap value between the sentences of other types.
4 Experimental evaluation
The proposed system was implemented by using python programming language on an Intel®Core™i5-4210U CPU @ 1.70 GHz-2.40 GHz and computer with a 4.00 GB RAM.
4.1 Datasets used for experiments
Experiments were conducted on three datasets from the PAN Workshop series: PAN 2012 [44], PAN 2013 [45] and PAN 2014 [47]. Each of them contains suspicious and source documents. Authors applied many obfuscation strategies on different length paragraphs of the source documents and incorporated into the suspicious documents. Number of document for each obfuscation strategy in the training and testing corpus of PAN 2012, PAN 2013 and PAN 2014 are described in Table 2. PAN 2012 used the books available at Project Gutenberg to extract its suspicious and source documents, it consists of training and testing sets. The training set contained 1804 suspicious and 4210 source documents, while the test set contained 3000 suspicious and 3500 source documents. PAN 2013 depended on ClueWeb 2009 corpus to extract its suspicious and source documents, it comprises of 3653 suspicious documents and 4774 source documents. PAN 2014 was also depended on ClueWeb 2009 corpus as PAN 2013, it has the same training corpus of PAN 2013 but introduced an additional test set.
4.2 Evaluation metrics
The proposed system performance is evaluated according to plagdet score, which was proposed by Potthast et al. [46] to rank the various proposed systems of the plagiarism detection depending on PAN competitions. There are other evaluation metrics also used to rank the various proposed systems including the overall score of precision, recall, F-measure, and granularity metrics.
where the F-measure is the harmonic mean of recall and precision scores, it is determined using the following equation:
where
where w indicates a detected plagiarism case, W indicates the set of all detected plagiarism cases provided that w ∈ W, q indicates an actual plagiarism case, and Q indicates the set of all plagiarism cases provided that q ∈ Q. Precision metric is the proportion of properly matched characters in the given documents to the total number of characters retrieved as shown in Eq. (23). Recall metric is the proportion of properly matched characters between the given documents to the number of actual plagiarized characters as shown in Eq. (24). Neither precision nor recall introduces interpretation, if the plagiarism detectors may indicate overlapping or multiple detections for a single plagiarism case. Therefore, in order to overcome this limitation, the granularity of a detector is also measured as follows:
where QW ⊆ Q are the cases detected in W and WQ ⊆ W are all the detections of case q.
4.3 Results and discussion
The proposed system depends on two paths to detect the text plagiarism. The first path is based on traditional paragraph‑level comparison, and the second path is based on SVM classifier. The second path is used, if the first path didn’t able to discover the text similarity, it is based on constructing SVM classifier that has the ability to detect all the different types of lexical, syntactic, and semantic plagiarism cases. The proposed system depends on building a supervised training database to train SVM algorithm. Therefore, Negative “Non-plagiarized” and positive “Plagiarized” cases are extracted from PAN 2012 and PAN 2013 documents as explained in Section 3.2.3. Thirty-four values of the sentences similarity features are computed and recorded aggregating with the class label for each extracted case to build the supervised training database of SVM algorithm.
Two supervised training datasets are created. The first dataset is contained by the extracted positive and negative cases from the documents of PAN 2012. The second dataset is created by the extracted cases from the documents of PAN 2012 and PAN 2013. Two experiments are conducted to evaluate the created datasets. In the first experiment, the proposed system is constructed depending on the first dataset. The second experiment, SVM of the proposed system is trained on the second dataset. The purpose of the second experiment is to train the proposed system on more different cases of the text plagiarism and show their effectiveness. Tables 3, 4 and 5 show the performance results of the two experiments using test documents of random obfuscation PAN 2013 sub-corpora, complete PAN 2013 corpus, and complete PAN 2014. The results show that the proposed system that trained on the second dataset achieved the highest classification accuracy comparing with the constructed model that trained on the first dataset. This indicates that the second dataset creating by the extracted cases from the documents of PAN 2012 and PAN 2013 is more effective to train SVM, which make it more accurate to discover the different types of the text plagiarism.
The statistical analysis of the constructed training database of SVM algorithm is developed and shown in Table 6 to explain the importance of each created feature. The range of values for all sentence similarity features of the constructed training database is between 1 and 0. If the feature value is closer to 1, this indicates that the two sentences are similar, and if the feature value is closer to 0, this indicates that the two sentences are dissimilar. The discriminative sentence similarity feature that has the ability to differentiate the positive and negative cases with high accuracy, is the feature that contains high intra similarity and low inter similarity values of the class labels. Therefore, metrics of the mean, standard deviation and 95% confidence limits are calculated for each sentence similarity feature. Whenever the feature mean values of the positive and negative cases are closer, and 95% confidence limits values of positive cases are also closer to the mean value of negative cases, this indicates that relying on this feature alone will cause a confusion in the decision. As shown in Table 6, most of the sentence similarity features have closer positive and negative mean values, and 95% confidence limits values of the positive cases are far from the one value and closer to the positive and negative mean values. Therefore, the previous researches [2, 3, 26, 53, 67, 69] depended on 2, 3 or 4 sentence similarity features instead of depending on one feature to enhance the text plagiarism detection. There is also a challenge to depend on 2, 3 or 4 sentence similarity features, because these features are not discriminative as shown in Table 6. Therefore, the proposed system takes into consideration all the different types of the sentence similarity features by creating the supervised dataset to train SVM classification algorithm, which has the ability to compute the hyperplane equation of the 34 features to distinguish the two classes, rather than conducting extensive experiments as the previous researches to find the best weighting coefficient values for incorporating features.
The proposed system also takes into consideration the determination of most effective features that have the ability to discriminate the suspicious cases and differentiate the variations of the text similarities with the highest accuracy. As shown in Table 6, there is a challenge to find the best subset of the features that discriminate the similarity cases. The proposed system is based on the filter feature selection approach using Chi-square algorithm to rank the 34 features, and generate 34 subset of features. The first subset is included with the first feature of the ranked features, and each subset of the ranked features consists of the features of previous subset plus the next feature in the list of the ranked features. The classification accuracy value was calculated for each generated subset, the subset of the ranked features that achieved the highest classification accuracy is extracted to be the most discriminative subset of the features.
Two experiments were developed to rank and select the most effective sentences similarity features. The first experiment was conducted on the documents of PAN 2013 test set, and the second experiment was developed on the documents of PAN 2014 test set to verify the results. As shown in Figs. 9 and 10, the subset No. 32 that includes all the ranked features except the last two features, achieved the highest classification accuracy in the two experiments. Therefore, it was selected to be the best subset of the sentences similarity features.

Classification accuracy of the different subsets of the ranked features on PAN 2013 test set by chi-square

Classification accuracy of the different subsets of the ranked features on PAN 2014 test set by chi-square.
Three experiments were also conducted to evaluate the proposed system comparing with the recent approaches. These experiments were implemented using the documents of PAN 2013 and PAN 2014. Tables 7, 8 and 9 show the performance results of the proposed system. The results show that the proposed system achieved the best recall score and the second score for f-measure and plagdet values in the random obfuscation sub-corpora of PAN 2013. The performance results also show that the proposed system outperformed all the other state-of-the-art systems on the all documents of PAN 2013 and PAN 2014 corpus.
From the results shown in Tables 8 and 9, it can be seen that the most of the previous systems achieved a varied rank into the different datasets, this change depends on the structure of the dataset and the types of its plagiarism. On the other hand, the proposed system maintained its rank and superiority in the performance with the different datasets. So based on these results, the proposed system achieves the efficiency and robustness to detect the different forms of the text plagiarism. These also indicate the ability of the support vector machine algorithm to find the hyperplane equation of the selected 32 features to detect the different types of text similarities. Additionally, the utilization of the recursive extension algorithm led to improve the recall and granularity scores without the false impact of precision. The adaptive behavior of the proposed system is also affected on improving Plagdet score in the summary sub-corpus without negative influence of the recall value in the no-obfuscation sub-corpus.
5 Conclusions and future work
In this paper, a new system is proposed to detect all the different types of text plagiarism including the lexical, syntactic, and semantic cases. It is based on two paths to detect the sentences similarity cases, the first path is based on traditional paragraph‑level comparison, and the second path is based on the hyperplane equation of the constructed SVM classifier. Training database of SVM algorithm is created including 34 sentence similarity features. Statistical analysis of the constructed training database is developed, which indicated that the 34 sentence similarity features have closer positive and negative mean values, and values of 95% confidence limits of the positive cases are closer to the positive and negative mean values, which indicted that each feature is not discriminative to distinguish the similarity cases. Two experiments were developed to rank the sentences similarity features and select the most effective subset of these features. The first experiment was conducted on the documents of PAN 2013 test set, and the second experiment was developed on the documents of PAN 2014 test set to verify the results. The results showed that all the ranked features except the last two features, achieved the highest classification accuracy in the two experiments. Therefore, the ranked 32 features were selected to be the best subset of the sentences similarity features. SVM classification algorithm was used to fit the training dataset values, which has the ability to compute the hyperplane equation of the selected 32 features and add new dimensionality to distinguish the overlapping between the training cases of different classes.
Three experiments were also conducted to evaluate the proposed system comparing with the recent approaches. The results showed that the proposed system achieved the best scores 88.42%, 89.12% and 92.91% of Plagdet metric and 88.48%, 89.34% and 92.95% of F-measure metric on the test documents of random obfuscation in PAN 2013 dataset, and all documents of the different plagiarism types in PAN 2013 and PAN 2013 datasets, respectively. These results indicated that the proposed system outperformed all the other state-of-the-art systems.
In the future work, we plan to create a training database that containing a variation in the level of lexical, syntactic and semantic similarity cases. The constructed SVM classifier can be more accurate and robust, if it will be trained on cases with confusion similarities that have a difficulty to detect their plagiarism, rather than the extracted cases from PAN 2012 and PAN 2013 databases using meteor score and shared unigrams. We also plan to use Meta-heuristic algorithms to detect the best values of the threshold m and t parameters that used in the path of sentence level comparison of the seeding phase. The proposed system cannot be able to detect the text plagiarism between the documents that have different languages, so we plan to modify it by adding an extra phase to translate the documents into English language to detect the text plagiarism between the documents that written by different languages. Moreover, we also plan to apply audio recognize phase to convert it into sentences. After extracting the sentences from the audio, the proposed system can be applied using the recognized sentences to detect the audio plagiarism in videos.
References
Abnar S, Dehghani M, Zamani H, Shakery A (2014) Expanded N-Grams for Semantic Text Alignment. In: CLEF (working notes) 1180:928-938. Available: http://ceur-ws.org/Vol-1180/CLEF2014wn-Pan-AbnarEt2014.pdf
Ahuja V, Gupta R. Kumar (2020) A New Hybrid Technique for Detection of Plagiarism from Text Documents. Arab J Scie Eng 45(12):9939–9952. https://doi.org/10.1007/s13369-020-04565-9
Altheneyan AS, El BachirMenai M (2020) Automatic plagiarism detection in obfuscated text. Pattern Anal Applic 23(4):1627–1650. https://doi.org/10.1007/s10044-020-00882-9
Alvi F, Stevenson M, Clough P (2014) Hashing and Merging Heuristics for Text Reuse Detection. In: CLEF (working notes) 1180:939-946. Available: http://ceur-ws.org/Vol-1180/CLEF2014wn-Pan-AlviEt2014.pdf
Alvi Faisal, Stevenson Mark, Clough Paul (2021) Paraphrase type identification for plagiarism detection using contexts and word embeddings. Int J Educ Technol Higher Educ 18(1):1–25. https://doi.org/10.1186/s41239-021-00277-8
Bochkarev VV, Shevlyakova AV, Solovyev VD (2015) The average word length dynamics as an indicator of cultural changes in society. Soc Evol Hist 14(2):153–175
Chang Chia-Yang et al (2021) Using word semantic concepts for plagiarism detection in text documents. Inform Retrieval J 24(4):298–321. https://doi.org/10.1007/s10791-021-09394-4
Craig Causer (2011) The Way Ahead. IEEE Potentials 30(4):3–3. https://doi.org/10.1109/MPOT.2011.942130
Daud A, Khan JA, Nasir JA, Abbasi RA, Aljohani NR, Alowibdi JS (2018) Latent dirichlet allocation and POS tags based method for external plagiarism detection: LDA and POS tags based plagiarism detection. Int J Semantic Web Inform Syst 14(3):53–69. https://doi.org/10.4018/IJSWIS.2018070103
Eissen SMZ, Stein B (2006) Intrinsic plagiarism detection. In: Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 3936:565-569.https://doi.org/10.1007/11735106_66
Ekbal A, Saha S, Choudhary G (2012) Plagiarism detection in text using vector space model. In: 2012 12th international conference on hybrid intelligent systems (HIS) IEEE, pp. 366-371.https://doi.org/10.1109/HIS.2012.6421362
Ghanem Bilal et al (2018) HYPLAG Hybrid Arabic text plagiarism detection system. International conference on applications of natural language to information systems. Springer, Cham, pp 315–323. https://doi.org/10.1007/978-3-319-91947-8_33
Gharavi E, Veisi H, Rosso P (2020) Scalable and language-independent embedding-based approach for plagiarism detection considering obfuscation type: no training phase. Neural Comput Applic 32(14):10593–10607. https://doi.org/10.1007/s00521-019-04594-y
Gillam L, Notley S (2014) Evaluating robustness for ‘IPCRESS’: Surrey’s text alignment for plagiarism detection. In: CLEF (working notes) 1180:951-957. Available: http://ceur-ws.org/Vol-1180/CLEF2014wn-Pan-GillamEt2014.pdf
Glinos DG (2014) A hybrid architecture for plagiarism detection. In: CLEF (working notes) 1180:958-965. Available: http://ceur-ws.org/Vol-1180/CLEF2014wn-Pan-Glinos2014.pdf
Gross P, Modaresi P (2014) Plagiarism alignment detection by merging context seeds. In: CLEF (working notes) 1182:966-972. Available: https://pan.webis.de/downloads/publications/papers/gross_2014.pdf
Gupta D, Vani K, Singh CK (2014) Using Natural Language Processing techniques and fuzzy-semantic similarity for automatic external plagiarism detection. In: 2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI), pp 2694-2699. https://doi.org/10.1109/ICACCI.2014.6968314
Harris MA et al (2004) The Gene Ontology (GO) database and informatics resource. Nucl Acids Res 32:258–261. https://doi.org/10.1093/nar/gkh036
Jaccard P (1912) THE distribution of the flora in the alpine zone. New Phytologist 11(2):37–50. https://doi.org/10.1111/j.1469-8137.1912.tb05611.x
Jayapal A, Goswami B (2013) Vector Space Model and Overlap Metric for Author Identification. In: CLEF (working notes). Available: http://ceur-ws.org/Vol-1179/CLEF2013wn-PAN-JayapalEt2013.pdf
JJiang JJ, Conrath DW (1997) Semantic similarity based on corpus statistics and lexical taxonomy. In: Proceedings of the 10th Research on Computational Linguistics International Conference, pp 19-33
Kauffman Yashu, Young Michael F (2015) Digital plagiarism: An experimental study of the effect of instructional goals and copy-and-paste affordance. Comput Educ 83:44–56. https://doi.org/10.1016/j.compedu.2014.12.016
Kong L, Qi H, Wang S, Du C, Wang S and Han Y (2012) Approaches for candidate document retrieval and detailed comparison of plagiarism detection. CLEF (working notes). Available: http://ceur-ws.org/Vol-1178/CLEF2012wn-PAN-LeileiEt2012.pdf
Kong L, Han Y, Han Z, Yu H, Wang Q, Zhang T, Qi H (2014) Source Retrieval Based on Learning to Rank and Text Alignment Based on Plagiarism Type Recognition for Plagiarism Detection. CLEF (working notes) 1180: 973-976. Available: http://ceur-ws.org/Vol-1180/CLEF2014wn-Pan-KongEt2014.pdf
Küppers R, Conrad S (2012) A set-based approach to plagiarism detection. CLEF (working notes). Available: http://ceur-ws.org/Vol-1178/CLEF2012wn-PAN-KuppersEt2012.pdf
Leacock C, Chodorow M (1998) Combining Local Context and WordNet Similarity for Word Sense Identification. In: WordNet: An electronic lexical database 49(2):265-283. https://doi.org/10.7551/mitpress/7287.003.0018
Lee G (2013) Guess again and see if they line up: Surrey’s runs at plagiarism detection. In: CLEF (working notes) 1179. Available: http://ceur-ws.org/Vol-1179/CLEF2013wn-PAN-Gillam2013.pdf
Leilei K, Haoliang Q, Cuixia D, Mingxing W, Han Z (2013) Approaches for source retrieval and text alignment of plagiarism detection. conference and labs of the evaluation forum and workshop (CLEF’13). Available: http://ceur-ws.org/Vol-1179/CLEF2013wn-PAN-LeileiEt2013.pdf
Li Y, McLean D, Bandar ZA, O’Shea JD, Crockett K (2006) Sentence similarity based on semantic nets and corpus statistics. IEEE Trans Knowl Data Eng 18(8):1138–1150. https://doi.org/10.1109/TKDE.2006.130
Lin, D (1998) An information-theoretic definition of similarity. In: Icml 98(1998):296-304
Lyon C, Malcolm J, Dickerson B (2001) Detecting short passages of similar text in large document collections. In: Proceedings of the 2001 Conference on Empirical Methods in Natural Language Processing (EMNLP 2001), pp. 118-125
Larock Margaret, Jacob Tressler, and Claude Lewis (1980) Mastering effective English. Copp Clark Pitman, Mississauga
Mariani J, Francopoulo G, Paroubek P (2018) Reuse and plagiarism in Speech and Natural Language Processing publications. Int J Digital Libr 19:2–3. https://doi.org/10.1007/s00799-017-0211-0
Miller George A (1995) WordNet: a lexical database for English. Commun ACM 38:39–41. https://doi.org/10.1145/219717.219748
Nourian A (2013) Submission to the 5th international competition on plagiarism detection. Available: http://www.uni-weimar.de/medien/webis /events/pan-13
Oberreuter G, Eiselt A (2014) Submission to the 6th international competition on plagiarism detection. Available: https://www.uni-weimar.de/medien/webis/events/pan-14/pan14-web/
Oberreuter G, Carrillo-Cisneros D, Scherson I, Velásquez J (2012) Submission to the 4th international competition on plagiarism detection. Available: http://www.uni-weima r.de/medie n/webis /event s/pan- 12
Palkovskii Y, Belov A (2012) Applying specific clusterization and fingerprint density distribution with genetic algorithm overall tuning in external plagiarism detection. In: CLEF (working notes). Available: http://ceur-ws.org/Vol-1178/CLEF2012wn-PAN-PalkovskiiEt2012.pdf
Palkovskii Y, Belov A (2013) Using hybrid similarity methods for plagiarism detection. CLEF (working notes). Available: http://ceur-ws.org/Vol-1179/CLEF2013wn-PAN-PalkovskiiEt2013.pdf
Palkovskii Y, Belov A (2014) Developing high-resolution universal multi-type n-gram plagiarism detector. In: Conference and Labs of the Evaluation Forum and Workshop (CLEF’14) 1180:984-989. Available: http://ceur-ws.org/Vol-1180/CLEF2014wn-Pan-PalkovskiiEt2014.pdf
Pearson K (1900) X. On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling. London, Edinburgh, Dublin Philos Mag J Sci 50(302):157–175. https://doi.org/10.1080/14786440009463897
Pedersen T, Patwardhan S, Michelizzi J (2004) WordNet: Similarity - Measuring the relatedness of concepts. AAAI 4:25–29
Phyllis A (2016) Spatial Data Transfer Standard (SDTS). In: Encyclopedia of GIS, pp 1-11. https://doi.org/10.1007/978-3-319-23519-6_1259-2
Potthast M, Gollub T, Hagen M, Graßegger J, Kiesel J, Michel M, Oberländer A, Tippmann M, Barrón-Cedeño A, Gupta P, Rosso P, Stein B (2012) Overview of the 4th international competition on plagiarism detection
Potthast M, Gollub T, Hagen M, Tippmann M, Kiesel J, Rosso P, Stamatatos E, Stein B (2013) Overview of the 5th international competition on plagiarism detection. In: Forner P, Navigli R, Tufs D (eds) Working notes papers of the CLEF 2013 evaluation labs, pp. 301–33
Potthast M, Stein B, Barrón-Cedeño A, Rosso P (2010) An evaluation framework for plagiarism detection. In Coling 2010: Posters, pp 997-1005
Potthast M, Hagen M, Beyer A, Busse M, Tippmann M, Rosso P, Stein B (2014) Overview of the 6th international competition on plagiarism detection. In: Cappellato L, Ferro N, Halvey M, Kraaij W (eds) Working notes papers of the CLEF 2014 evaluation labs, CLEF and CEUR-WS.org, CEUR workshop proceedings, pp 845–876
Reshamwala A, Mishra D, Pawar P (2013) Review on natural language processing. IRACST Eng Sci Technol: An Int J (ESTIJ) 3(1):113–116
Resnik P (1995) Using information content to evaluate semantic similarity in a taxonomy. In: Proceedings of the 14th International Joint Conference on Artificial Intelligence, Montreal 1:448-453
Rodríguez Torrejón D, Martín Ramos J (2014) CoReMo 2.3 Plagiarism Detector Text Alignment Module. In: CLEF (working notes) 1180:997-1003. Available: http://ceur-ws.org/Vol-1180/CLEF2014wn-Pan-RodriguezTorrejonEt2014.pdf
Rodríguez Torrejón DA, Ramos JMM (2013) Text Alignment Module in CoReMo 2.1 Plagiarism Detector. CLEF (working notes). Available: http://ceur-ws.org/Vol-1179/CLEF2013wn-PAN-RodriguezTorrejonEt2013.pdf
Roostaee M, Fakhrahmad SM, Sadreddini MH (2020) Cross-language text alignment: A proposed two-level matching scheme for plagiarism detection. Expert Syst Applic 160:113718. https://doi.org/10.1016/j.eswa.2020.113718
Sahi M, Gupta V (2017) A Novel Technique for Detecting Plagiarism in Documents Exploiting Information Sources. Cogn Comput 9(6):852–867. https://doi.org/10.1007/s12559-017-9502-4
Sanchez-Perez M, Sidorov G, Gelbukh A (2014) A winning approach to text alignment for text reuse detection at PAN 2014– notebook for PAN at CLEF. In: Cappellato L, Ferro N, Halvey M, Kraaij W (eds) CLEF 2014 evaluation labs and workshop-working notes papers, 15–18 September, CEUR-WS.org, Shefeld, 1180:1004–1011. http://ceur-ws.org/Vol-1180/CLEF2014wn-Pan-SanchezPerezEt2014.pdf
Sánchez-Vega F, Montes-y-Gómez M, Pineda LV(2012) Optimized fuzzy text alignment for plagiarism detection In: CLEF (working notes). Available: http://ceur-ws.org/Vol-1178/CLEF2012wn-PAN-SanchezVegaEt2012.pdf
Saremi M, Yaghmaee F (2013) Submission to the 5th international competition on plagiarism detection. Available: http://www.uni-weima r.de/medie n/webis /event s/pan-13
Shahmohammadi H, Dezfoulian MH, Mansoorizadeh M (2021) Paraphrase detection using LSTM networks and handcrafted features. Multimedia Tools Applic 80(4):6479–6492. https://doi.org/10.1007/s11042-020-09996-y
Shrestha P, Solorio T (2013) Using a variety of n-grams for the detection of different kinds of plagiarism. CLEF (working notes). Available: http://ceur-ws.org/Vol-1179/CLEF2013wn-PAN-ShresthaEt2013.pdf
Shrestha P, Maharjan S, Solorio T (2014) Machine translation evaluation metric for text alignment: Notebook for PAN at CLEF 2014. In: CEUR Workshop Proceedings 1180:1012-1016. Available: https://pan.webis.de/downloads/publications/papers/shrestha_2014.pdf
Suchomel Š, Kasprzak J, Brandejs M (2013) Diverse queries and feature type selection for plagiarism discovery. In: CLEF (working notes). Available: http://ceur-ws.org/Vol-1179/CLEF2013wn-PAN-SuchomelEt2013.pdf
Suchomel Š, Kasprzak J, Brandejs M (2012) Three way search engine queries with multi-feature document comparison for plagiarism detection. In: CLEF (working notes). Available: http://ceur-ws.org/Vol-1178/CLEF2012wn-PAN-SuchomelEt2012.pdf
Tomasic A, Garcia-Molina H (1993) Query processing and inverted indices in shared-nothing text document information retrieval systems. VLDB J 2(3):243–275. https://doi.org/10.1007/BF01228671
Torrejón DA, Ramos JMM (2012) Detailed Comparison Module In CoReMo 1.9 Plagiarism Detector. In: CLEF (working notes). Available: http://ceur-ws.org/Vol-1178/CLEF2012wn-PAN-RodriguezTorrejonEt2012.pdf
Ullah F, Wang J, Farhan M, Jabbar S, Wu Z, Khalid S (2020) Plagiarism detection in students’ programming assignments based on semantics: multimedia e-learning based smart assessment methodology. Multimedia Tools Applic 79(13):8581–8598. https://doi.org/10.1007/s11042-018-5827-6
Vani K, Gupta D (2015) Investigating the impact of combined similarity metrics and POS tagging in extrinsic text plagiarism detection system. In: 2015 international conference on advances in computing, communications and informatics (ICACCI), pp 1578-1584. https://doi.org/10.1109/ICACCI.2015.7275838.
Vani K, Gupta D (2014) Using K-means cluster based techniques in external plagiarism detection. In: 2014 international conference on contemporary computing and informatics (IC3I), pp 1268-1273. https://doi.org/10.1109/IC3I.2014.7019659
Vani K, Gupta D (2017) Detection of idea plagiarism using syntax–Semantic concept extractions with genetic algorithm. Expert Syst Applic 73:11–26. https://doi.org/10.1016/j.eswa.2016.12.022
Vani K, Gupta D (2018) Unmasking text plagiarism using syntactic-semantic based natural language processing techniques: Comparisons, analysis and challenges. Inform Process Manag 54(3):408–432. https://doi.org/10.1016/j.ipm.2018.01.008
Wu Z, Palmer M (1994) Verbs semantics and lexical selection. In: Proceedings of the 32nd Annual Meeting on Association for Computational Linguistics, pp 33-38. https://doi.org/10.3115/981732.981751
Zobel J, Moffat A (1998) Exploring the similarity space. In: Acm Sigir Forum, New York 32(1):18-34. https://doi.org/10.1145/281250.281256
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no affiliation with any organization with a direct or indirect financial interest in the subject matter discussed in the manuscript.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
El-Rashidy, M.A., Mohamed, R.G., El-Fishawy, N.A. et al. An effective text plagiarism detection system based on feature selection and SVM techniques. Multimed Tools Appl 83, 2609–2646 (2024). https://doi.org/10.1007/s11042-023-15703-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-15703-4