
Abstract
Text mining methods usually use statistical information to solve text and language-independent procedures. Text mining methods such as polarity detection based on stochastic patterns and rules need many samples to train. On the other hand, deterministic and non-probabilistic methods are easy to solve and faster than other methods but are not efficient in NLP data. In this article, a fast and efficient deterministic method for solving the problems is proposed. In the proposed method firstly we transform text and labels into a set of equations. In the second step, a mathematical solution of ill-posed equations known as Tikhonov regularization was used as a deterministic and non-probabilistic way including additional assumptions, such as smoothness of solution to assign a weight that can reflect the semantic information of each sentimental word. We confirmed the efficiency of the proposed method in the SemEval-2013 competition, ESWC Database and Taboada database as three different cases. We observed improvement of our method over negative polarity due to our proposed mathematical step. Moreover, we demonstrated the effectiveness of our proposed method over the most common and traditional machine learning, stochastic and fuzzy methods.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Opinion mining is a general framework for processing emotions, criticisms, suggestions and comments in different inputs such as text, video, voice, etc. Social networks such as Twitter, Facebook, or any other platforms process textual information and then categorize them using opinion mining methods [5, 14, 44].
A large number of political [81], social [34], economic [29], health [17, 50], educational [82], and military groups are interested in obtaining the opinion of customers to modify or improve their services. For example, the information obtained from opinion mining helps financial companies to identify the risks related to new investments [59]. Furthermore, politicians are interested in becoming aware of their voter’s satisfaction or dissatisfaction using their comments [31]. Governments tend to know their policies consequences through domestic and foreign media [23]. Sentiment analysis leads to a better and faster understanding of challenges and shortcomings during e-learning and enables providers to solve problems [56]. Physicians can evaluate and improve their treatments by opinion mining. Some managers use sentiment analysis (SA) to invest in new products or change company strategies [42].
Sentiment analysis contains various processes such as subjectivity and polarity detection [4, 77], emotion estimation [79], answering to the emotional questions [53], detecting spam comments [75], question answering [70], crime detection [38], sarcasm/irony detection [43], summarizing opinions [44] and many other subjects. Much research are currently conducting to extract user’s comments from documents [15], sentences [57], or aspect-based [55]. Different methods of analyzing sentiments can be classified into three categories [73]. The first are the ones that determine the sentiment polarity through opinion words, known as dictionary-based analysis methods [1, 52].
Pattern classification is a usual method in text categorization (TC) and SA for training a classifier with a set of examples from different classes. In the first step, these methods should extract useful features from documents or phrases. Therefore, the performance of classifier is highly dependent on the extracted features. As a result, newly developed techniques will inevitably generate large amounts of features and select useful ones for classification operations. The main purpose of sentiment analysis and polarity detection is to extract information from a large volume of unstructured texts to find a structured concept of sentiment. One of the advantages of polarity detection is providing a classification of unlabeled comments that specify the semantic bias of comments. Based on the above explanations, finding an algebraic method to solve the subjective concept of sentiment in a phrase or document is interesting.
The contributions of our work are summarized as follows.
-
Proposing an approach that transforms text and labels into a set of equations.
-
Proposing a deterministic mathematical approach to solve ill-posed equation of polarity detection problem.
2 Literature of opinion mining
The first documented work on opinion mining was made in 1979 at Yale University in the United States by designing a computer model of human mental understanding following the work of Carbonell [14]. It automatically determined the political views of the people of the United States and Russia. Subsequently, with the development of general computer systems, in the early work in 2002, Pang and his colleagues [44] conducted an automated survey using machine learning techniques in which they converted the textual data of movies into various forms, including single words and then used Bayesian, Maximum Entropy, and Support Vector Machines to classify the textual data prepared in the preprocessing stage. The best performance was obtained by using the backing vector classification of single-word and two word data sets. They manually tagged 2,000 different comments on the films for training purpose [14].
Furthermore, Pang and co-workers investigated machine learning and observation techniques [45, 46]. They presented a survey on Social Network Data Observation Using the Cloud Bags Approach. The database used in this research consists of comments on Twitter using a specific set of keywords. The simulations were performed in three main parts. In the first step, Naive Bayes was performed on the bag of words and 71% accuracy was achieved. Secondly, the simple Bayesian algorithm on the word bag was used without stop words, which obtained 72% accuracy. In the final step, the information interest was figured out by selecting the most-informative features using the quadratic probability density function which obtained the best accuracy. The Naive Bayes algorithm yielded an accuracy of about 89% by applying the data quadratic accuracy criterion using this method.
Long Short-term memory networks (LSTM) have performed well in emotion analysis tasks. The general way to use LSTM is to combine embedded words to display text. However, embedding words carry more semantic information rather than emotions. It is only the use of word expressions to represent words in false emotion analysis tasks. To solve this issue, a vocabulary enhanced LSTM model was proposed that used emotion vocabulary as additional information before teaching a classification and then emotion words incorporated into words, including words that are not available in the vocabulary. The combination of embedded emotion and embedded words can train the system to be more accurate. The results of the tests on the English and Chinese datasets show that the presented models have equivalent results as the existing models [25].
Other researchers have described the effectiveness of various emotion classification techniques ranging from simple rule-based and vocabulary-based approaches to more sophisticated machine learning systems. Vocabulary based approaches suffer from a lack of vocabulary, on the other hand, machine learning approaches usually show lower accuracy than vocabulary based approaches. Iqbal and his team [19] presented an integrated framework that bridges the gaps between vocabulary-machine learning approaches for achieving accuracy and scalability. To solve the scalability problem created by increasing the set features, a new genetic algorithm (GA) is suggested using a feature reduction method. Using this hybrid method, we can reduce the feature dimensions up to 42% without compromising accuracy. Based on delayed semantic analysis, feature reduction techniques showed 15.4% and 40.2% accuracy increments compare to Principal Component Analysis (PCA) and Latent Semantic Analysis (LSA) techniques respectively [30].
The text-based emotion analysis method of emotion dictionary often has problems. For example, the emotion dictionary contains inadequate emotion words and does not eliminate some emotion words in the field. Besides, due to the presence of some positive, negative, and neutral polysemic emotional words, the polarity of the words cannot be accurately expressed, thus reducing the accuracy of emotion analysis of the text. In 2019, a vast emotional vocabulary is constructed, and to improve the accuracy of emotion analysis, extensive emotion dictionaries containing the main emotion words, contextual emotion words, and multimedia emotion words were introduced. The Bayesian classification is utilized to designate the text field where the word is polysemic. Therefore, the value of the word emotion comes from polysemic feelings in this context. Using emotion-based vocabulary and designed scoring rules, the text emotion is achieved. The empirical results prove a promising ability and accuracy of the proposed emotion analysis method based on the emotion dictionary [72].
Due to the rich morphology of the Arabic language and the informal nature of the language on Twitter, on the other hand, the emotional analysis of Arabic tweets is a complex task. Previous research on SA from tweets focused mainly on manual extraction of text features. Recently, embedded neural words have been used as powerful displays for manual feature engineering. Many of these keywords model the syntactic information of the words while ignoring the emotional text. To solve this problem, a feature set model of surface and Deep-Neural-Network-based (DNN-based) features is proposed. Surface features are extracted manually (hand-crafted), and DNN-based features containing embedding of general words and special words. Experimental results reveal that: 1) the best model used a set of surface-based and DNN based features and 2) the approach achieved state-of-the-art results on several benchmarking datasets [3].
The widespread availability of online comments and posts on social media provides valuable information for businesses to make better decisions on guiding their marketing strategies toward their interests and preferences of users. Therefore, evaluating emotions is necessary to determine public opinion about a particular subject, product, or service. Traditionally, emotion analysis was done on a single data source, for example, online product reviews or tweets. However, the need for more accurate and comprehensive results has led to the move to conduct emotion analysis across multiple data sources. Using multiple data sources for a particular domain of interest can increase the number of datasets needed for emotion classification training. So far, the problem of insufficient data sets for classifier training has only been addressed by multi-domain emotion analysis [2].
Many researchers have suggested using machine learning algorithms to accurately analyze tweets based on regression. The proposed method includes pre-processing tweets and using a feature extraction method to create an efficient feature set. Then, under several classes, these features are scored and balanced. Multivariate logistic regression (Soft Max), support vector regression (SVR), decision tree (DTs), and random forest (RF) algorithms are used to classify sentiments within the proposed framework. Experimental findings showed that these approaches can detect regular regression using machine learning techniques with acceptable accuracy. Besides, the results proved that the decision tree achieves the best results over the other algorithms [58].
Recently, many works used hierarchical structures to obtain specific emotional information which may, in turn, lead to emotion mismatches in some specific aspects by extracting irrelative words. To solve this problem, a collaborative extraction hierarchical attention network is proposed consisting of two hierarchical units. One-unit extracts attribute and use them to capture specific information about the other layer. Experiments show that the proposed approach performed better than recent methods that only use aspect features [26]. Emotional vocabulary is an important source of thought extraction. Lately, many of the best works of art used deep learning techniques to build emotional vocabulary. Generally, they learned the word embedding by including emotional awareness first and then used it as features to build an emotional vocabulary. However, these methods do not take the importance of each word in distinguishing the polarities of attribution emotions into account. As we know, most of the words in a document do not help to understand the meaning or feelings of the entire document. For example, in the tweet, It’s a good day, but I can’t feel it. I’m really unhappy. The words “unhappy”, “feel” and “can’t” much more important than the words “good”, “day” in predicting the polarity of this twitter emotion. Meanwhile, many words, such as “this”, “it” and “I am” are ignored. At Sparse self-attention LSTM (SSALSTM), a new self-awareness mechanism is used to emphasize the importance of each word in identifying the pole of emotions. When we learn a word using conscious and efficient emotions, we train a classifier that uses the word conscious feeling as a characteristic to predict the polarity of the words’emotions. Extensive experiments on four publicly available datasets, SemEval 2013-2016, show that the sentimental vocabulary produced by the SSALSTM model achieves optimal performance in both the supervised and unsupervised emotion classification tasks [20].
Word embedding, which provides low dimensional vector representations of words, have been widely used for various natural language processing tasks. However, text-based word embedding such as Word2vec and Glove typically failed to capture enough emotional information, which may lead to words with similar representation vector having a polarity of conflicting emotions (e.g., good and bad). Thus, the performance of emotion analysis may reduce. To address this problem, recent studies have suggested learning to combine empathy information (positive and negative) from labeled corpora [28]. This study adopts another strategy for learning emotional embodiments. Instead of creating a new word embedded by labeled companies, it proposes a word vector refinement model to refine existing pre-prepared word vectors using the actual emotion intensity scores provided by the emotional vocabulary. The idea behind the refinement model is to improve each word vector in a way that it can be used in terms of both semantic and emotional words (i.e., those with the same severity scores) and beyond the different emotional words (e.g. those with no difference). A significant advantage of the proposed method is the capability of applying to any pre-embedded variant. Besides, intensity scores can provide accurate sensory information (real value) compare to the binary polarity label to guide the refinement process [78].
In one of the recent methods Pre-training of language, models have been shown to provide large improvements for a range of language understanding tasks [21, 47, 49, 54]. The main part is training a large generative model in big data and using the result on tasks whit limited amounts of labeled data. Sequence Pre-training models have been previously investigated for text classifying [16] but not for text generation. In neural machine translation, there has been work on transferring representations from high resource language pairs to low-resource settings [83]. Nemes et al. [41] used Recurrent Neural Network (RNN) to classify emotions on tweets. They created an emotion dataset using Twitter API and after some simple preprocessing steps, applied it to RNN.
2.1 Grammatical structures (Language limited)
In 2013, Kim proposed a supervised vector machine-based learning approach using a hierarchical sense recognition structure [32]. In this method, first of all, a tree is built in which, each node has two levels. The first level defines the word position in the sentence in terms of importance and the second level polarizes the sentence in terms of the emotion given by the users.
In 2014, Vinodini and coworkers proposed a hybrid machine learning method that attempts to classify users’comments as positive or negative, using several classifiers. This method combines both Bayesian boosting and bagging models with the PCA method to reduce feature dimensions. This article also examines the impact of different types of features such as one, two, and three-part. The classifications used include SVM methods and logistic regression. Finally, it was found that the best performance was observed when the combination of the three sets is used namely, unigrams, bi-grams and, tri-grams [71].
In 2015, Tewari and his team proposed a system of E-learning recommendations called A3. The system uses feature-based research that studies the details of individual student reviews of a topic [18].
Thus far, several methods have been introduced to analyze emotions and opinions from social media on SA and opinion mining [45, 46] as there is a special interest in sharing opinions on social networks like Facebook [71], Twitter [18], and TripAdvisor [69], regarding many topics. These data are analyzed using two main methods: ML methods and lexicon-based methods. ML methods such as the support vector machine (SVM), Naive Bayes (NB), logistic regression, and multilayer perceptron (MLP) need a training dataset to learn the model from corpus data, and a testing dataset to verify the built model [25, 27, 35, 36, 62]. The lexicon-based method is based on a dictionary of words and phrases with positive and negative values.
Grammatical structures are limited to language and text. One of the disadvantages of statistical methods is their uncertainty and language dependence, so we seek to propose an algorithmic algebraic equation that solves these problems in a deterministic and non-probabilistic method while maintaining the advantage of language independence.
2.2 Statistical structure (Uncertainty)
SentiWordNet is the most widely used lexicon in the field of sentiment analysis [19, 40]. However, due to the different senses of words, this approach may not obtain a good result in some domains. To overcome this problem, domain dependent lexicons are presented for the proposed system. In the field of text mining, the extraction of relevant information from social media is a challenging task. Many approaches have been proposed for information extraction and sentiment analysis, in the literature, including lexical knowledge, deep learning, neural word embedding, and fuzzy logic [11, 67, 76].
Statistical structures are used in many text mining methods. Mahmoudi et al. [37] analyzed tweets for finding behavior of tweet writers in COVID-19 conditions. The proposed scheme was based on statistical and mathematical operations about user sentiment changes in COVID-19 conditions. Sharma et al. [61] analyzed textual entries posted by college students in a four year period and found that Education topics were less important than health issues during Covid-19 growth. Some other research worked on SA in COVID-19 [50].
Although they are independent of the text or language and are therefore common, as mentioned, these methods are not deterministic.
2.3 N-gram properties
One of the most important phases of the process of analyzing emotions is the text modeling using the attributes that are capable of expressing attributes of documents by focusing on N-gram properties. N-gram attributes are divided into two categories:
-
Fixed N-gram: An exact sequence at the character or vocabulary level. Such as 1-gram or 2-gram;
-
Variable N-grams: Templates for extracting information from text. Such as noun + adjective.
Variable N-gram attributes are capable of expressing more complex linguistic concepts [71]. Besides, N-POS features, which are N combinations of speech utensils, are used in emotion analysis [18]. The N-POS Word, which is a combination of N words, along with their speech tags, has not been used extensively. Since POS-Tag features along with the word itself can reduce word ambiguity, thus improving the accuracy of evaluating and classifying texts if the problems of dispersion and redundancy can be managed [62].
2.4 Machine-based learning methods
Classifiers such as Maximum Entropy, Naive Bayes, and Support Vector Machines are some of the methods that should be taught appropriately with a learning set. In the case of a specific subject like hotel reviews, the dataset and the learning set should be selected from the same type while the use of inappropriate educational data has caused a severe loss of accuracy in classification and this indicates the importance of appropriate educational data.
Blankers and his colleagues [7] used the chi-square method to select the feature. They achieved their best results by employing SVM classification and maximum entropy in combination. To improve the classification, presenting a correct model of documentation is crucial. Simultaneous uses of several classification algorithms do not necessarily increase classification accuracy but may increase complexity over time. Using a combination of several classification algorithms for a dataset cannot be a solution to improve the speed and accuracy of text classification. Instead of using multiple classifiers, we can use some feature selection filters or look for a more suitable model for document modeling. Univariate methods have been utilized in many investigations due to their less time complexity compare to multivariate methods.
2.5 Semantic-lexical methods
Advanced lexical dictionaries are used in the developed methods for text analysis. These dictionaries include WordNet, which is built for language processing research. It emphasizes the meaning of the words, clustering all the English words, and each of these clusters can have a relation like contradiction or proportionality to the other clusters [39].
For example, a simple lexical approach examines the text using a glossary, in which all words in the domain are rated as positive or negative. This method is rarely used despite its simplicity due to the complexity of the linguistic structure. A sentence can have lots of negative words but it may entail a positive meaning. Another problem is the inability to recognize metaphors. This problem can be partially solved by having a separate glossary for common metaphors and similarity recognition methods. But in this case, vocabulary alone is not enough and other methods such as the grammar tree should be used [67].
Considering advantages and shortcomings in the previous researches, our focus in this research is on the detection of content on fully automated methods and features based on mathematical analysis, solving equations in sparse (thin) space.
3 Prerequisites
Given the background of literature analysis in gaining perspective or emotion in sentences and weaknesses of previously employed methods in this field, we attempt a mathematical weight allocation method to enhance the accuracy of polarity detection in texts. This study is expected to overcome the disadvantages of available statistical methods such as the lack of attention to the mathematical possibilities and shortcomings of the text processing when different combinations are used. It should be noted that the processing required for the mathematical investigation of weight allocation to vocabulary in different databases is the main factor in adding the complexity of the task. This section introduces the existing databases and dictionaries, followed by the approach.
3.1 Amazon
The Amazon site is one of the first successful examples of its kind in the world as an American E-commerce company. This site was first launched in 1994 by Jeff Bezos in Seattle, USA. The company’s core business began in 1995 as a book store online, following legal and regulatory processes in the United States. ESWC Semantic Sentiment Analysis 2016 consisted of some challenges. Fine-Grained Sentiment analysis as one of these challenges was divided into five subtasks related to classification and quantification of the polarity of sentiment according to a two or five-point scale in Amazon reviews. We tested our method on a two-scale polarity detection task.
3.2 Taboada database
The Taboada database is a collection of eight different domains and has fifty positive and negative comments in each domain [66]. This database was collected and labelled by Stanford University in 2004. Because of the variety of vocabulary, this database is commonly used as a benchmark for comparison between different methods.
3.3 Dictionary
In the proposed method, we needed a list of sentimental words and the sign of their scores. GI dictionary [64], WordNet dictionary [39], ANEW dictionary [9] and SentiWordNet dictionary [6] have been considered as usual sentiment dictionaries in our work. The SentiWordNet 3.0 [6] dictionary is the main dictionary that has been used. The SentiWordNet 3.0 is an improved version of SentiWordNet 1.0. This dictionary is a lexical resource that was made by automatically annotating WordNet.
4 Proposed method
4.1 Pre-processing
The steps are used for preprocessing are consistent with many other articles that have been implemented with the following procedure:
- Word bag conversion::
-
A common way to learn text categorization is to parse the documents into their constituent words. In this case, we have transformed the document into a constant-length vector of existing lists by creating our dictionary of several words.
- Lowercase::
-
It will be used to identify a single word with two uppercase and lowercase letters.
- Token::
-
At this point, we remove all dots and signs and replace spaces with non-text characters into a space character, and as a result, our text becomes a set of words.
- Length::
-
Based on the existing document, the number of useful lengths of words is identified, and finally, by removing unnecessary length words, we clean the collection of redundant words.
- Stop words::
-
A list of words that have no semantic directions and will be deleted in processing.
- Remove unnecessary parts::
-
A list of words that have no semantic directions, have different forms of representation, or have a specific representation pattern, will be deleted in the process.
- Root extraction::
-
Extracting the root of words and removing some words together can be eliminated.
4.2 Proposed algorithm
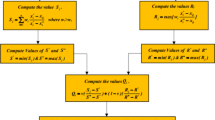
The proposed system (shown in Fig. 1) gets the total inputs, such as database labelled texts, dictionaries, intensifiers, negators, etc., and breaks the labelled texts into unigrams and bigrams (Match & Extract) that include sentimental words or intensifiers and negators.

Proposed system block diagram
A bigram is deleted even if one of the two components is out of range. We convert each unigram, and bigram to an equivalent numeric code. Assuming that for every unigram, bigram is a variable and we have a sum of m variables and n labelled expressions, the problem arose for solving an n equation with m unknowns.
The above steps are given in the example below for a sample negative text from the BOOK section of the Taboada database.
Original text:
“I have read all of Grisham’s books and this was by far the most boring one! The story is about a lawyer who gives up his high paying job to help the homeless in an office staffed by 2 other people. There is no mystery to the story. Grisham’s books are normally mysterious, can’t wait to finish it, a “who done it” style. This book does not have any surprises, its dull. I expected a book like other books (f.i. Pelican Brief etc) he has written. It definitely was not! I would definitely not recommend it to anybody”
This phrase has 98 words, and only nine of them include boring, definitely, help, high, homeless, like, normally and recommend, are in the sentiment dictionary.
This routine is done for all phrases and an equation is made for each phrase. In this equation system, each sentimental word is a variable and the coefficients of variables are the number of sentimental word repetitions in the phrase. The answer of the equation is set to + 1 for positive and − 1 for negative documents. The following (1–4) are four samples of 2 positive and 2 negative documents.
Since the number of equations and unknowns is not balanced, in a large database we solve the sparse ill-posed equations using the Tikhonov method. In a normal database such as Taboada, we can use classical numerical methods such as Cholesky’s decomposition, LU decomposition, QR decomposition, least-squares method, etc (In this article, we used LU decomposition).
4.3 Tikhonov method
The main problem with discrete position problems such as our system is the lack of numerical order of the unknown coefficient matrix and the indefiniteness of the problem due to the small single values of the coefficient matrix. Therefore, to stabilize the problem, it is necessary to add information about the systems of position equations mentioned in the form “Answer method” to the problem. One of the methods to solve these equations is “Tikhonov” which is the most common method in stabilizing discrete position problems, especially solving inverse problems. The idea of this method was proposed almost simultaneously, but independently, by Philips and Tikhonov. From a statistical point of view, this method is considered inverse methods of solving inverse problems and is used when the initial information or assumption of unknowns is available.
In the Tikhonov method, as in the least square’s method, the assumption is that the observational error is random and that the probability distribution function of the errors is normal and that their mathematical expectation is zero. Therefore, in this method, like the least square method, we are looking for an answer with the least number of residuals. But it was also not possible to obtain an answer only with the least-squares condition in the devices of discrete position equations due to the bad conditions of the operator, so in Tikhonov’s method, while minimizing the residuals vector, by minimizing a feature of unknowns, the infinity of the answer is prevented. Tikhonov has many applications in various research fields belong to computer science, simulations and engineering such as load identification [51], radiation problem [60], Thermal-Conductivity problem [8], Hemivariational Inequality problems [68], Time-fractional diffusion equation [74] and Singular value decomposition [12].
The responses, in the ill-posed equations are sensitive to the input data error, meaning a small disturbance in the input data leads to a fundamental disturbance in the response. On the other hand, in practical applications, data always contains errors such as measurement errors, approximation errors, rounding errors, and so on that greatly affect the solution of the problem. In regularization methods, they add more information about the answer to the problem to obtain a sustainable answer.
By introducing this constraint, they seek to provide an appropriate balance between the constraint minimization and the residual ∥Ax − b∥2 minimization [13].
In Tikhonov method, the ordered solution is defined as the minimum of the residual norm weight combination and the constraint.
In Tikhonov’s method, the systematic solution to the system of linear equations, Ax = b which A is a maladaptive matrix, is defined as follows.
Where the parameter λ > 0 is regularization and must be carefully selected. A large λ (equivalent to a large amount of regularization) results in norm shrinkage, and enlarges in contrast to the remaining norm, while a small λ (equivalent to a small amount of regularization) has the opposite effect.
According to the matrix SVD analysis, Tikhonov’s ordered solution is expressed as follows.
Where \(f_{i}=\frac {{\sigma _{i}^{2}}}{{\sigma _{i}^{2}}+\lambda ^{2}},i=1,2,{\dots } ,n\) the coefficients are the filter, and we have
If λ = 0, all filter coefficients will be one, and we will have the xi answer given by relation 8, and in return \(\lambda =\infty ,x_{reg}=0\), is obtained.
Formula (6) can be simply used by the Tikhonov function achieved.
By calculating the soft and deriving from (9) we have the minimum to calculate.
The following ATA,ATb can be expressed using the right singularity vectors.
Substituting in (10) results in (11).
According to the expression \(\frac {{u_{i}^{T}}b}{\sigma _{i}}\) in (8), it is clear that the rate of velocity that \({u_{i}^{T}}b\) and σi tends to zero to each other plays an important role in the behavior of the bad condition. Intuitively, we expect that when the coefficients \(\vert {u_{i}^{T}}b\vert \) tend to be zero at a much slower rate of σi Tikhonov’s regularization and other methods that filter out small singular values cannot provide a well-ordered systematic answer. This causes the softening of a large regularization error. The error in the regularization methods for which filter coefficients are defined is expressed in (12).
To calculate the orderly answer that approximates the exact answer to the problem well, the right xexact should apply to the discrete Picard’s condition criterion.
The discrete Picard condition applies if the Fourier coefficients \(\vert {u_{i}^{T}}b_{exact}\vert \) (at least on average) tend to zero when I increasing, faster than singular values σi [63].
5 Result
The important details of the training step are as follows:
-
In making equations, the positive polarity answer has been assumed 1 and negative polarity -1.
-
The list and sign of sentimental words have been made using SentiWordNet 3.0 [6].
-
The list of intensifiers has been made using the list of general intensifiers [10, 25]. The negators are selected based on Kiritchenko and Saif research [35, 75].
The proposed dictionary has 14072 negative and 15023 positive sentimental words (a totally of 29095 words), 15 negators and 176 general intensifiers.
We calculated scores in two different datasets.
-
First: The train and test set were selected from Taboada database. Since the number of equations is lower than unknowns in Taboada database, we used LU decomposition for solving equation system. The sentimental words, intensifiers and negators which do not exist in train samples are removed from the sentimental words, intensifiers and negators list.
-
Second: The train set was 70% (700000 samples) of randomly selected samples from the Amazon dataset, and the calculated scores were tested on the remaining samples. Since the number of equations is so higher than unknowns, in this case, we solved the sparse ill-posed equation system using the Tikhonov method.
All implementations have been done using Matlab 2021a.
For comparison of the proposed method versus other states of the art methods, True Positives (TP), True Negatives (TN), False Positives (FP) and False Negatives (FN) were calculated and using these values, precision, recall, F-measure, and accuracy were obtained.
5.1 Taboada dataset
To validate our method in normal database we compared our method with Zargari et al. [80] and Senti-N-Gram dictionary [22] an equation system was made based on the 350 sample (equivalent to 70% of the Taboada dataset) and then the results on the all samples show the efficiency of our method. The Other conditions are selected similar to Zargari et al.’s research. Due to two different methods being proposed in Zargari et al. [80], we compared our method with the best-reported result. The Taboada database, including 500 positive and 500 negative samples, has been used as the train and test set in this case.
Due to Table 1 results, our method enhances scoring efficiency by increasing accuracy in negative polarity. Obviously, this increase in negative polarity decreases positive polarity detection accuracy, but the overall result shows that our system detects polarity better than the state of the art methods.
In fact, scoring sentimental words based on mathematical solutions is more accurate than statistical or ML approach. ML methods have many challenges in scoring negative sentimental words but our analytic approach found scores in negative and positive cases more accurate without any problem.
5.2 Amazon dataset
In this case, we compared our method with Sygkounas et al. [65], Di Rosa & Durante [24] and Petrucci & Dragoni [48]. The evaluation conditions are selected similar to these researches. Since the number of equations is so higher than unknowns, in this case, we solved the sparse ill-posed equation system using the Tikhonov method. Table 2, shows the result on the Amazon test set. In this test set, the number of positive samples, similar to negative samples, is equal to 150000. In our method, to eliminate the effect of random training and testing data, the training scheme, run 10 times, and the reported result is the median of obtained answers.
Based on simulation results, our method’s overall accuracy, Precision, Recall, and F measure is better than other methods in this case. In fact, the proposed scheme enhances the efficiency of scoring. Similar to Taboada, our method enhances scoring efficiency by increasing accuracy in negative polarity. Obviously, this increase in negative polarity decreases positive polarity detection accuracy, but the overall result shows that our system detects polarity better than the state of the art methods. In fact, Tikhonov method (as an analytic approach) is more accurate than other methods in finding the score of sentimental words.
6 Conclusion
This research contributes to presenting an application of Tikhonov method to solve unbalanced, complex semi linear algebraic equation systems. The suggested method uses Tikhonov method to solve an NLP scoring scheme in a polarity detection method. The simulation results showed the proposed method’s efficiency compared to other machine learning, fuzzy or stochastic methods.
The proposed method was tested on two different cases. On Taboada dataset and ESWC (Amazon) databases. In both cases, our method surpassed the state of the art methods. The ESWC Database is a very large, balanced database from Amazon. We observed improvement of our method over negative polarity due to our proposed mathematical scheme. Moreover, we demonstrated the effectiveness of our proposed method over the most common and traditional machine learning, stochastic and fuzzy methods.
Data Availability
Experiments are performed using the SemEval-2013 dataset Tweets from: https:\paperswithcode.com/dataset/semeval-2013 and taboada dataset from: https:\www.sfu.ca/~mtaboada/SFU_Review_Corpus.html
References
Abdi A, Shamsuddin SM, Hasan S, Piran J (2018) Machine learning-based multi-documents sentiment-oriented summarization using linguistic treatment. Expert Syst Appl 109:66–85
Abdullah NA, Feizollah A, Sulaiman A, Anuar NB (2019) Challenges and recommended solutions in multi-source and multi-domain sentiment analysis. IEEE Access 7:144957–144971
Al-Twairesh N, Al-Negheimish H (2019) Surface and deep features ensemble for sentiment analysis of arabic tweets. IEEE Access 7:84122–84131
Amini I, Karimi S, Shakery A (2019) Cross-lingual subjectivity detection for resource lean languages. In: Proceedings of the 10th workshop on computational approaches to subjectivity, sentiment and social media analysis, pp 81–90
Araque O, Zhu G, Iglesias CA (2019) A semantic similarity-based perspective of affect lexicons for sentiment analysis. Knowl-Based Syst 165:346–359
Baccianella S, Esuli A, Sebastiani F (2010) Sentiwordnet 3.0: an enhanced lexical resource for sentiment analysis and opinion mining. Lrec 10 (2010):2200–2204
Blankers M, van der Gouwe D, van Laar M (2019) 4-Fluoramphetamine in the Netherlands: text-mining and sentiment analysis of internet forums. Int J Drug Policy 64:34–39
Borshchev NO, Sorokin AE, Belyavskii AE (2020) Determination of the thermal-conductivity tensor by Tikhonov regularization in spherical coordinates. Russ Eng Res 40(7):593–595
Bradley MM, Lang PJ (1999) Affective norms for English words (ANEW): instruction manual and affective ratings, 30(1), technical report C-1, the center for research in psychophysiology, University of Florida
Brooke J (2009) A semantic approach to automated text sentiment analysis, PhD diss., Dept. of Linguistics-Simon Fraser University
Brown D, Huntley C, Spillane AA (1989) Parallel genetic heuristic for the quadratic assignment problem. In: Proceedings of the 3rd international conference on genetic algorithms J. Scha® Ed. Morgan Kaufmann, pp 406–415
Buccini A, Pasha M, Reichel L (2020) Generalized singular value decomposition with iterated Tikhonov regularization. J Comput Appl Math 373:112276
Bulirsch R, Stoer J, Stoer J (2002) Introduction to numerical analysis, vol 3. Springer, Heidelberg
Carbonell JG (1979) Subjective understanding: computer models of belief systems. Yale University
Chatterjee N, Aggarwal T, Analysis RMS, Maheshwari R (2020) Sarcasm detection using deep learning-based techniques. In: Deep learning-based approaches for sentiment analysis. Springer, Singapore, pp 237–258
Dai AM, Le QV (2015) Semi-supervised sequence learning. arXiv:1511.01432
Dangi D, Dixit DK, Bhagat A (2022) Sentiment analysis of COVID-19 social media data through machine learning. Multimed Tools Appl:1–23
Dave K, Lawrence S, Pennock DM (2003, May) Mining the peanut gallery: opinion extraction and semantic classification of product reviews. In: Proceedings of the 12th international conference on World Wide Web, pp 519–528
Delibasis K, Asvestas PA, Matsopoulos GK (2010) Multimodal genetic algorithms-based algorithm for automatic point correspondence. Pattern Recognit 43(12):4011–4027
Deng D, Jing L, Yu J, Sun S (2019) Sparse self-attention LSTM for sentiment lexicon construction. IEEE/ACM transactions on audio, speech, and language processing 27(11):1777–1790
Devlin J, Chang MW, Lee K, Toutanova K (2018) Bert: pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805
Dey A, Jenamani M, Thakkar JJ (2018) Senti-N-Gram: an n-gram lexicon for sentiment analysis. Expert Syst Appl 103:92–105
de Vries G (2020) Public communication as a tool to implement environmental policies. Social Issues Policy Rev 14(1):244–272
Di Rosa E, Durante A (2016) App2check extension for sentiment analysis of amazon products reviews. In: Semantic Web evaluation challenge. Springer, Cham, pp 95–107
Fu X, Yang J, Li J, Fang M, Wang H (2018) Lexicon-enhanced LSTM with attention for general sentiment analysis. Proc IEEE Access 6:71884–71891. https://doi.org/10.3906/elk-1612-279.11
Gao Y, Liu J, Li P, Zhou D (2019) CE-HEAT: an aspect-level sentiment classification approach with collaborative extraction hierarchical attention network. IEEE Access 7:168548–168556
Haddadi A, Sahebi MR, Mansourian A (2011) Polarimetric SAR feature selection using a genetic algorithm. Canadian J Remote Sens 37(1):27–36
Haoran XIE (2019) Erratum: segment-level joint topic-sentiment model for online review analysis. IEEE Intell Syst 34:43–50
Hogenboom A, Hogenboom F, Frasincar F, Schouten K, Van Der Meer O (2013) Semantics-based information extraction for detecting economic events. Multimed Tools Appl 64(1):27–52
Iqbal F, Hashmi JM, Fung BC, Batool R, Khattak AM, Aleem S, Hung PC (2019) A hybrid framework for sentiment analysis using genetic algorithm based feature reduction. IEEE Access 7:14637–14652
Jazyah YH, Hussien IO (2018) Multimodal sentiment analysis: a comparison study. J Comput Sci 14(6):804–818
Kim S, Zhang J, Chen Z, Oh A, Liu S (2013) A hierarchical aspect-sentiment model for online reviews. Proc. Twenty-Seventh AAAI Conference on Artificial Intelligence 27(1):526–533
Kiritchenko S, Mohammad SM (2017) The effect of negators, modals, and degree adverbs on sentiment composition. arXiv:1712.01794
Kumar A, Garg G (2020) Systematic literature review on context-based sentiment analysis in social multimedia. Multimed Tools Appl 79(21):15349–15380
Lu C, Zhu Z, Gu X (2014) An intelligent system for lung cancer diagnosis using a new genetic algorithm based feature selection method. J Med Syst:1–9. https://doi.org/10.1007/s10916-014-0097-y
Maghsoudi Y, Collins MJ, Leckie DG (2013) Radarsat-2 polarimetric SAR data for boreal forest classification using SVM and a wrapper feature selector. IEEE J Sel Topics Appl Earth Obs Remote Sens 6(3):1531–1538
Mahmoudi A, Yeung VW, See-To EW (2021) User behavior discovery in the COVID-19 era through the sentiment analysis of user tweet texts. arXiv:2104.08867
Mihaylova T, Karadjov G, Atanasova P, Baly R, Mohtarami M, Nakov P (2019) SemEval-2019 task 8: fact checking in community question answering forums. arXiv:1906.01727
Miller GA (1995) Wordnet: a lexical database for English. Commun ACM 38(11):39–41
Nemati S, Basiri ME, Ghasem-Aghayee N, Aghdam MH (2009) A novel ACO-GA hybrid algorithm for feature selection in protein function prediction. J Expert Syst Appl 36:12086–12094
Nemes L, Attila K (2021) Social media sentiment analysis based on COVID-19. J Inf Telecommun 5(1):1–15
Ngo VTT (2020) Estimating the effect of paywalls in media economics: an application of empirical IO, machine learning and NLP methods (Doctoral dissertation, Rice University)
Osorio J, Beltran A (2020) Enhancing the detection of criminal organizations in Mexico using ML and NLP. In: 2020 International joint conference on neural networks (IJCNN). IEEE, pp 1–7
Pang B, Lee L, Vaithyanathan SH (2002) Thumbs up? sentiment classification using machine learning techniques. In: Proceedings of the ACL-02 conference empirical methods in natural language processing association for computational linguistics, vol 10, pp 79–86
Pang B, Lee L (2004) A sentiment education: sentiment analysis using subjectivity summarization based on minimum cuts. In: Proceedings of the 42nd annual meeting on association for computational linguistics, pp 271–278
Pang B, Lee L (2005) Seeing stars: exploiting class relationships for sentiment categorization concerning rating scales. In: Proceedings of the 43rd annual meeting on association for computational linguistics ACL’05, pp 115–124
Peters ME, Neumann M, Iyyer M, Gardner M, Clark C, Lee K, Zettlemoyer L (2018) Deep contextualized word representations. arXiv:1802.05365
Petrucci G, Dragoni M (2016) The IRMUDOSA system at ESWC-2016 challenge on semantic sentiment analysis. In: Semantic Web evaluation challenge. Springer, Cham, pp 126–140
Phang J, Févry T, Bowman SR (2018) Sentence encoders on stilts: supplementary training on intermediate labeled-data tasks. arXiv:1811.01088
Priyadarshini I, Mohanty P, Kumar R, Sharma R, Vikram Puri V, Singh PK (2022) A study on the sentiments and psychology of twitter users during COVID-19 lockdown period. Multimed Tools Appl 81(19):27009–27031
Qiao G, Rahmatalla S (2020) Moving load identification on Euler-Bernoulli beams with viscoelastic boundary conditions by Tikhonov regularization. Inverse Probl Sci Eng:1–38
Qiu Q, Xie Z, Wu L, Tao L (2020) Dictionary-based automated information extraction from geological documents using a deep learning algorithm. Earth Space Sci 7(3):e2019EA000993
Qureshi SA, Dias G, Hasanuzzaman M, Saha S (2020) Improving depression level estimation by concurrently learning emotion intensity. IEEE Comput Intell Mag 15(3):47–59
Radford A, Narasimhan K (2018) Improving language understanding by generative pre-training, Sutskever I
Raju k V, Sridhar M (2020) Based sentiment prediction of rating using natural language processing sentence-level sentiment analysis with bag-of-words approach. In: First international conference on sustainable technologies for computational intelligence. Springer, Singapore, pp 807–821
Ray A, Bala PK, Dwivedi YK (2020) Exploring barriers affecting eLearning usage intentions: an NLP-based multi-method approach. Behav Inf Technol:1–17
Ruseti S, Sirbu MD, Calin MA, Dascalu M, Trausan-Matu S, Militaru G (2020) Comprehensive exploration of game reviews extraction and opinion mining using NLP techniques. In: 4th International congress on information and communication technology. Springer, Singapore, pp 323–331
Saad SE, Yang J (2019) Twitter sentiment analysis based on ordinal regression. IEEE Access 7:163677–163685
Sánchez-Núñez P, Cobo MJ, De Las Heras-Pedrosa C, Peláez JI, Herrera-Viedma E (2020) Opinion mining, sentiment analysis and emotion understanding in advertising: a bibliometric analysis. IEEE Access 8:134563–134576
Santos TM, Tavares CA, Lemes NH, dos Santos JP, Braga JP (2020) Improving a Tikhonov regularization method with a fractional-order differential operator for the inverse black body radiation problem. Inverse Probl Sci Eng 28 (11):1513–1527
Sharma R, Sri Divya P, Pratool B, Sriram C, Trine S, Raj G (2020) Assessing COVID-19 impacts on college students via automated processing of free-form text. arXiv:2012.09369
Snyder B, Barzilay R (2007) Multiple aspect ranking using the good grief algorithm. In: Proceedings of the joint human language technology/North American chapter of the ACL conference (HLT-NAACL), pp 300–307
Stoer J, Bulirsch R (2013) Introduction to Numerical Analysis, 2nd edn. Springer, Berlin
Stone PJ, Dunphy DC (1966) The general inquirer: a computer approach to content analysis
Sygkounas E, Rizzo G, Troncy R (2016) Sentiment polarity detection from amazon reviews: an experimental study. In: Semantic web evaluation challenge. Springer, Cham, pp 108–120
Taboada M, Grieve J (2004) Analyzing appraisal automatically. In: Proceedings of the AAAI spring symposium on exploring attitude and affect in text (AAAI technical report SS-04-07). Stanford, pp 158–161
Taboada M, Brooke J, Tofiloski M, Voll K, Stede M (2011) Lexicon-based methods for sentiment analysis. In: Proceedings of the computational linguistics, vol 37, pp 267–307
Tang GJ, Wan Z, Wang X (2020) On the existence of solutions and tikhonov regularization of hemivariational inequality problems. Vietnam J Math 48 (2):221–236
Tewari AS, Saroj A, Barman AG (2015) E-learning recommender system for teachers using opinion mining. In: Information Science and Applications. Springer, Berlin, pp 1021–1029
Upadhya BA, Udupa S, Kamath SS (2019) Deep neural network models for question classification in community question-answering forums. In: 2019 10th International conference on computing, communication and networking technologies. ICCCNT, pp 1–6
Vinodhini G, Chandrasekaran RM (2014) Opinion mining using principal component analysis based ensemble model for E-Commerce application. Trans CSI Trans ICT 2:169–179
Xu G, Yu Z, Yao H, Li F, Meng Y, Wu X (2019) Chinese text sentiment analysis based on extended sentiment dictionary. IEEE Access 7:43749–43762
Yang C, Zhang H, Jiang B, Li K (2019) Aspect-based sentiment analysis with alternating coattention networks. Inf Process Manag 56(3):463–478
Yang F, Pu Q, Li XX (2020) The fractional Tikhonov regularization methods for identifying the initial value problem for a time-fractional diffusion equation. J Comput Appl Math 380:112998
Ye Q, Misra K, Devarapalli H, Rayz JT (2019) A sentiment based non-factoid question-answering framework. In: 2019 IEEE international conference on systems, man and cybernetics (SMC). IEEE, pp 372–377
Yi J, Nasukawa T, Bunescu R, Niblack W (2003) Sentiment analyzer: extracting sentiments about a given topic using natural language processing techniques. In: Proceedings of the 3rd IEEE Int’l conference data mining, pp 427–434
You L, Peng Q, Xiong Z, He D, Qiu M, Zhang X (2020) Integrating aspect analysis and local outlier factor for intelligent review spam detection. Futur Gener Comput Syst 102:163–172
Yu LC, Wang J, Lai KR, Zhang X (2017) Refining word embeddings using intensity scores for sentiment analysis. IEEE/ACM transactions on audio, speech, and language processing 26(3):671–681
Yurtalan G, Koyuncu M, Turhan Ç (2019) A polarity calculation approach for lexicon-based Turkish sentiment analysis. Turkish J Electric Eng Comput Sci 27(2):1325–1339
Zargari H, Zahedi M, Rahimi M GINS: a global intensifier-based n-gram sentiment dictionary. J Intell Fuzzy Syst Preprint:1–14
Zhao Y, Qin B, Liu T, Tang D (2016) Social sentiment sensor: a visualization system for topic detection and topic sentiment analysis on microblog. Multimed Tools Appl 75(15):8843–8860
Zhou J, Ye J (2020) Sentiment analysis in education research: a review of journal publications. Interactive Learn Environ:1–13
Zoph B, Yuret D, May J, Knight K (2016) Transfer learning for low-resource neural machine translation. arXiv:1604.02201
Acknowledgements
The authors wish to thank members of the Human Language Technology research laboratory at the Shahrood University of Technology.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interests
The authors did not receive support from any organization for the submitted work.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Jalali, M., Zahedi, M. & Basiri, A. Deterministic solution of algebraic equations in sentiment analysis. Multimed Tools Appl 82, 35457–35474 (2023). https://doi.org/10.1007/s11042-023-15140-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-15140-3