
Abstract
Hearing loss is one of the most prevalent chronic health problems worldwide and a common intervention is the wearing of hearing aids. However, the tedious fitting procedures and limited hearing experts pose restrictions for the popularity of hearing aids. This paper introduced a hearing loss classification method based on the insertion gain of hearing aids, which aims to simplify the fitting procedure and achieve a fitting-free effect of the hearing aid, in line with current research trends in key algorithms for fitting-free hearing aids. The proposed method innovatively combines the insertion gain of hearing aids with the covariates of patient’s gender, age, wearing history to form a new set of hearing loss vectors, and then classifies the hearing loss into six categories by unsupervised cluster analysis method. Each category of representative parameters characterizes a typical type of hearing loss, which can be used as the initial parameter to improve the efficiency of hearing aid fitting. Compared with the traditional audiogram classification method AMCLASS (Automated Audiogram Classification System), the proposed classification method reflect the actual hearing loss of hearing impaired patients better. Moreover, the effectiveness of the new classification method was verified by the comparison between the obtained six sets of representative insertion gains and the inferred hearing personalization information.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The WHO defines hearing loss as a “silent epidemic” because more than 1.5 billion people worldwide suffer from varying degrees of hearing loss [9]. According to the latest WHO hearing report in 2021, nearly 2.5 billion people are expected to have different degrees of hearing loss and at least 700 million will need hearing rehabilitation by 2050 [34]. A host of adverse effects of hearing loss can be mitigated through early detection and intervention. Among them, wearing hearing aids is one of the most effective means of hearing rehabilitation, and the main way to improve the daily communication impairment of hearing-impaired patients [27]. However, the hearing aid fitting usually requires audiological expertise to participate in the entire process that has cumbersome procedures. Hearing-impaired patients, especially the elderly, are difficult to tolerate the procedure, which will seriously affect the fitting efficiency. In addition, the fitting effect of hearing aids is also directly related to professional knowledge and techniques. In some underdeveloped communities, the extreme lack of audiological experts results in low utilization of hearing aids.
To improve this situation, on October 19, 2021 the FDA released a proposal to create a new category of hearing aids aimed at developing an OTC hearing aid so that tens of millions of Americans with hearing loss can more easily access hearing aid products to improve communication and their lives. The main difference between OTC and traditional hearing aids is whether it is necessary to select hearing aids under the guidance of professionals [33]. Nowadays, fitting-free and self-fitting hearing aids have attracted the attention of many experts and scholars in the field of audiology [17, 28]. It is the research focus to enable hearing-impaired patients to obtain a better hearing experience without fitting. One research idea is to classify hearing-impaired patients and set a series of hearing aid parameters for each type of user. Then, these parameters can be optimized by means of interaction with patients. An effective classification method can help ordinary patients with hearing loss find a more reasonable initial parameter for fitting, thus simplifying the hearing aid fitting process and increasing the user satisfaction with hearing aids [30].
The audiogram classification process is not only a valid method for modeling individual hearing loss but can also be used to study the prevalence of different types of hearing loss [12, 16, 35]. Generally, the degree of hearing loss of patients is represented by an audiogram. An audiogram shows a person’s ability to hear at different frequencies and preserves valuable information related to the underlying causes of hearing impairment [14, 24]. Therefore, it is a technical means worth investigating to classify patients according to audiograms to apply fitting-free hearing aids. Raymond Carhart who proposed the first standardized audiogram classification system [8] highlighted the importance of hearing loss research as early as 1945. In recent years, various classification systems have been proposed, which are mainly divided into two categories: rule-based classification and deep learning-based classification [15, 23, 25].
Most rule-based classification systems rely on manual rules that relate to the common description of hearing loss. The configuration of the audiogram, the symmetry of the binaural hearing loss, and the severity are currently the common terms used to describe the hearing loss shown in the pure tone audiogram, and they can provide information for audiological diagnosis. Margolis and Saly developed a sophisticated rule-based system, AMCLASS, specifically for classifying audiograms generated by automated audiometers [25]. Rules within the system are derived by audiologists and can automatically generate standardized descriptors of the shape, severity, symmetry, and type of lesion (sensorineural, conductive, or mixed) of hearing loss. AMCLASS system consists of more than 160 manually derived and refined rules, which can maximize the consistency between the ruleset and five audiologists’ annotations to audiograms. The purpose of AMCLASS was to determine whether there was a standardized definition of different types of hearing loss. However, it was found that even with the standardized descriptors, experts still had significant bifurcation on how to best summarize hearing loss. For example, an audiogram may appear flat to one audiologist but skewed to another; the current classification system does not consider this fact. Second, the existing methods have not considered factors such as the age and gender of the subjects. These factors have been confirmed to affect the compensation effect in many classical fitting formulas, such as NAL2 or DSL. Finally, when more data arrives, rule-based systems are not flexible enough to learn and adapt to the new data [11].
In the era of big data, the application of machine learning algorithms is becoming more and more widespread [1,2,3,4]. Data-driven methods are equally applicable to the classification of hearing loss, as they can learn rules directly from the data [6, 22, 26]. An audiogram classification approach [10] is based on a decision tree to classify audiograms which are labeled in detail by experts. However, this method requires experts to label various audiogram data, which is resource-intensive and the classification result is easily affected by the professional level and subjective preference of experts. Additionally, unsupervised clustering algorithms can be used to derive standard audiogram configuration classification [5, 7]. Unlike supervised learning, unsupervised clustering methods can divide a dataset into different categories or clusters according to a certain criterion (such as distance) for data with unknown labels. An unsupervised clustering method suggested by Anwar was applied in the processing of audiology medical records by using the k-means algorithm to classify the audiograms of hearing-impaired patients. The classification results were then combined with textual information about the relevant diagnosis or hearing aid type using the Self-Organizing Map (SOM) statistical method. A method utilizing vector quantization was also proposed to derive standard audiograms and obtain classifications of different types by exploiting the idea of unsupervised learning [7]. Compared to rule-based methods, the cluster-based method is quantitative which introduces the concept of similarity (or distance) between audiograms. The clustering-based methods are more flexible than traditional rule-based methods and can mine more information from the audiogram, but the existing classification methods have certain limitations. On the one hand, the methods employ the hearing threshold vector marked on the audiogram as a classification feature. It can partly reflect the hearing level of the patients with hearing loss, but cannot reflect the required compensation in actual hearing loss. On the other hand, the existing methods do not consider factors that have a significant impact on hearing loss, such as the subjects’ age, gender, and other factors. Moreover, it is likely to exert an influence on the users, such as primary care physicians to understand the hearing loss. Therefore, selecting an effective feature is a feasible idea to improve the performance of the hearing loss classification system.
In the fitting process of hearing aid, the actual effect on the signal is the hearing aid insertion gain. Insertion gain refers to the gain value obtained when the sound pressure near the eardrum of the external auditory canal changes after wearing the hearing aid. The compensation effect of the insert gain is directly applied to the human ear which reflects the compensation performance of the hearing aids [13]. The value of the insertion gain is not only related to the audiogram, but also affected by other objective factors. As many experiments have shown, objective factors that affect the compensation performance of hearing aids include age, gender, wearing experience, and tone of language [18,19,20, 31]. It can be seen that the final compensation effect of hearing aids is affected by multiple factors. Consequently, it is difficult to fully describe the hearing loss of patients only from the perspective of the audiogram.
To address the challenges that the existing classification models cannot comprehensively consider the information of hearing loss patients, a novel hearing loss classification algorithm is proposed in this contribution, which covers the individualized information of the hearing-impaired people in the fitting process of hearing aids from a new perspective. The method takes the insertion gain of the hearing aid as a feature, which includes the relevant information of patients as covariates in the model. Then, the proposed method employed unsupervised cluster analysis to classify hearing loss into six categories, and a set of representative insertion gains can be obtained for different categories. According to different representative gain vectors, the personalized information of the patient was obtained by calculating the shortest distance. The information was used as the category information of fitting-free hearing aids, and the corresponding parameters can be the initial point in the next fitting process. The new approach can assist hearing-impaired patients to obtain a better hearing experience without fitting.
The main contributions of this paper were as follows:
-
1.
The insertion gain was innovatively used as a feature to classify hearing-impaired patients, which could better reflect the hearing loss difference among patients.
-
2.
The effects of different factors on classification results were analyzed, including age, wearing experience, and tone of language.
-
3.
Unsupervised clustering algorithm was applied to classify the hearing loss, and classification results were compared with those of the AMCLASS system. The rationality of the classification algorithm was thus verified.
-
4.
The personalized parameters that represented the characteristics of different types of hearing-impaired users were studied which reflected the design idea of fitting-free hearing aids.
2 Principle of algorithm
2.1 Audiogram and loudness compensation
Generally, the patient’s hearing condition is represented by an audiogram. The audiogram depicts the patient’s hearing loss(or hearing threshold) as a function of frequency and is obtained by a hearing test performed on the patient by a physician or audiologist. In early, hearing aid fitting is the process of adjusting the gain parameters of a hearing aid according to hearing level of the hearing-impaired patients, so that the hearing aid can provide the appropriate loudness compensation for the wearer. The block diagram of loudness compensation in hearing aid is shown in Fig. 1. The prescription formula is based on the pure tone audiogram, combined with the spectrum of speech and the patient’s auditory loudness information, and developed some regular parameters, whose function is to calculate the target gain at different frequencies according to the patient’s audiogram. The commonly used prescription formulas for fitting are NAL-NL2, DSL and FIG6 [19, 21, 31].

The block diagram of loudness compensation in hearing aid
Unlike Fig6, NAL-NL2 and DSL take into account more personalized information beyond the audiogram, such as age, gender, etc. Keidser and Dillon analyzed the actual insertion gain value of 187 adults under the input sound pressure level of 65dB. The objective factors that affected the compensation performance of hearing aids include age, gender, wearing experience, and tone of language [18]. Regardless of the degree of hearing loss or the hearing aid wearing experience, female hearing aid wearers require less gain than male wearers and such difference has been statistically significant [31]. From the analysis of widely used NAL-NL2 and DSL, these fitting formulas also take these factors into account. The same data set showed [32] that there was no difference in overall gain preference between new hearing aid users and experienced hearing aid users when the degree of hearing loss is mild. However, new users preferred less gain than experienced users when the hearing loss is above the intermediate. level. Related research revealed that young people prefer higher gains than adults [29]. In addition, the gain at the low frequency of tonal language is usually higher than that of non-tone language, because the tonal language has sufficient gain at low frequency to help improve speech intelligibility [18].
2.2 K-means clustering algorithm
The unsupervised learning method is an important branch of machine learning. In recent years, there has been an increasing number of studies on hearing loss classification by using unsupervised clustering algorithm methods.
K-means is a common unsupervised algorithm in machine learning, which can divide the data with unknown labels into different groups according to their characteristics. Each group of data is called a “cluster” and the center of the corresponding cluster is called the “centroid”. The number of sub-clusters can be determined by calculating the relevant quantitative metrics. The clustering algorithm can use its own advantages to process the data and obtain statistically significant clustering results. The process of classification using K-means is as follows:
-
1)
Arbitrarily select K initial centers of centroids (which may not be sample points), find the nearest centroid for each sample point, and classify the sample points and centroids into the same cluster, thus generating K clusters.
-
2)
When all sample points are divided, for each cluster, the new centroid (the average coordinate value of all points in the same cluster) is recalculated
-
3)
Keep iterating until the position of the centroids does not change or the maximum number of iterations is reached.
The above classification process can make the relatively close sample points divided into the same group and form one class cluster so that the similarity of sample points in the same class and the difference of sample points not in the same class is as large as possible.
2.3 Hearing loss classification based on insertion gain
This paper proposes a hearing loss classification method that takes the insertion gain of hearing aids as input and implicitly considers the patient’s personalized information, which intends to explore the research idea of a fitting-free hearing aid. The main classification steps are as follows.
Firstly, based on the audiograms and personal information of N hearing-impaired patients, the corresponding insertion gain is calculated using the prescription formula, such as NAL-NL2. Then, the insertion gain of the hearing aid and the covariates of the patient information are combined into a new vector, denoted as the association gain, which can be expressed as
where Gi denotes the association gain vector corresponding to the i - th audiogram, and {g1,g2,...,gM} is the M-dimensions insertion gain. Four covariates are introduced, namely, gender, age, hearing aid wearing experience, and whether it is a tonal or non-tonal language. Gender represents gender, and takes values in 0 and 1, with 0 indicating male and 1 indicating female; Age represents age, and has 8 values, corresponding to 8 age groups, including 10-20, 20-30, 30-40, 40-50, 50-60, 60-70, 70-80; Experience represents whether or not the patient has experience with hearing aids, taking a value between 0 and 1, with 0 indicating no experience and 1 indicating a history of wearing a hearing aid. Language represents whether the patient’s language is tonal or not, and the values are 0 and 1, with 0 indicating non-tonal language and 1 indicating tonal language. This shows that there are 64 combinations of covariates. After obtaining the above association gains, the k-means algorithm is applied to conduct the classification, and the set of association gain vectors is noted as
Assuming that hearing loss is classified into k categories, an association gain is randomly selected from the set of association gains as the first cluster center μ1. For each association gain sample Gi, calculate its minimum distance Di from the selected cluster center
where r represents the number of clustering centers that have been selected. Then, the point with the largest Di is selected as the new cluster center μr+ 1. The distance from each association gain Gi to center vector of each cluster μj(j = 1,2,⋯,k) is calculate in the next step:
The Gi is classified into the category cj corresponding to the smallest dij. For all samples in category cj, the mean value is calculated as the new cluster center μj. Repeat this step, if all k cluster center vectors μj do not change or reach the maximum number of iterations, then the current classification is completed and k cluster centers are selected.
The average of the association gain of hearing aids under different categories is calculated to characterize each type of individual hearing loss. Each category of hearing loss corresponds to a set of hearing aid fitting parameters. When a new patient arrives, the hearing-impaired patient performs audiometry from the k types configuration and selects one of the most satisfying parameters as the initial parameter, thus simplifying the fitting process.
3 Results and discussion
3.1 Dataset preprocessing
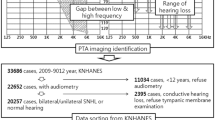
The data for the experiment were obtained from the National Health and Nutrition Examination Survey (NHANES), which works in part to assess the hearing status of subjects through pure-tone audiometry, and therefore the NHANES dataset contains many pure-tone audiograms. The audiograms were obtained according to pure-tone audiometric standard and contained air conduction thresholds at seven test frequencies: 500 Hz, 1,000 Hz, 2,000 Hz, 3,000 Hz, 4,000 Hz, 6,000 Hz, and 8,000 Hz for participants aged 12 to 85 years (mean: 39 ± 21 years).
For a better assessment of the effects, we preprocessed the data: 1) removing incomplete audiograms with at least one threshold missing and 2) removing audiograms where hearing was clearly within the normal range in both ears. According to the American Speech-Language-Hearing Association (ASHA) guidelines on hearing loss [19], all audiograms with thresholds less than or equal to 20 dB and 15 dB are considered to indicate normal hearing for adults and children, respectively, and there is essentially no need for hearing aids in these populations.
A representative audiogram dataset was screened out by preprocessing the original audiograms. A total of 300 audiograms were selected in this experiment, including 110 for mild hearing loss, 120 for moderate hearing loss, and 70 for severe hearing loss. The covariate information of the four patients was gender, age, hearing aid wearing experience, and tone of language. The association gain values were calculated using the NAL-NL2 prescription formula under different combinations of covariates. The 133 dimensions of the NAL-NL2 insertion gain were calculated at 19 frequency points 125, 160, 200, 250, 315, 400, 500, 630, 800, 1000, 1250, 1600, 2000, 2500, 3150, 4000, 5000, 6300, 8000 Hz under 50, 55, 60, 65, 70, 80 and 90 dB SPL input sound pressure level.
3.2 Selection of the number of categories
It is crucial for unsupervised clustering algorithms to evaluate the performance of clustering. In this section, the average silhouette coefficient is taken as an indicator to figure out the number of natural clusters of the association gain [29]. Assuming that all sets of the association gain samples are classified according to the proposed algorithm, each well-classified subset is denoted as CGm, and the number of samples within the corresponding subset is nm, the silhouette coefficients are:
where the silhouette coefficient of the gain sample Gi is
where ai represents the average distance between Gi and samples of the same category and bi represents the average distance between Gi and all samples in the category closest to it. The range of values for the silhouette coefficient is generally [-1,1], and the larger value means the inter-cluster distance is farther and the intra-cluster distance is more compact. Figure 2 shows the variation of the silhouette coefficient with the number of clusters, and the number of clusters takes a range from 4 to 30. It can be observed that the value of the silhouette coefficient is optimal when the number of clusters is 6. Therefore, this paper divides hearing loss into six categories.

Silhouette index as a function of the number of clusters
3.3 Comparison with AMCLASS
To compare the effectiveness of the proposed method with the classical classification algorithm, we first classified the audiograms into six categories according to the AMCLASS system, and the six types are sloping, flat, rising, peaked, trough-shaped, and other. The association gains obtained from 300 audiograms under the effect of different covariates were different, and the experiments were performed to classify 64 groups of association gains, corresponding to 64 different groups of classification results, as shown in Fig. 3. The horizontal axis corresponds to 64 different sets of covariate combinations, and the vertical axis is the silhouette coefficient of the corresponding classification. The classification labels of AMCLASS can be obtained in advance using the official online classification tool, and the labels of the proposed method are obtained by the k-means algorithm. The experimental results show that the silhouette coefficients of the classification method introduced in this contribution are much higher than those of the AMCLASS, which verifies the rationality and effectiveness of the proposed method for classification. The main reason is that AMCLASS only utilizes the audiogram without considering the influence of patient information, and the role of covariates cannot be reflected in the classification results, so the silhouette coefficients are lower.

Comparison of silhouette coefficients
3.4 Effect of different covariates on classification
The experiments in this section compared the effects of different covariates on the classification results, including gender, age, the experience of wearing hearing aids, and whether it is a tonal language. All experiments used the same 300 audiograms as input. In each group of experiments, one covariate was selected as the control variable, and other covariates were kept unchanged. Then, the association gains under various conditions were calculated and classified by a clustering algorithm. Figures 4–7 show the different classification results with the four covariates as control variables, respectively.

Classification results with different gender

Classification results with different age

Classification results with different wearing experience

Classification results with different language
Each graph represents the classification results under a set of control variables. In the figure, the red and blue plots indicate the two classification labels for a set of covariates taking different values with the other covariates unchanged, respectively. And the black label means that the two labels for that point are the same. As can be distinctly seen from the figures, there are no overlapping items between Figs. 4 and 5, which shows that the association gain of hearing aids varies greatly with different ages or gender. Figure 6 demonstrates the difference in association gain between patients with hearing aids experience and those without wearing history. There is a small amount of overlap between the two types of association gain in Category 1, and the number of overlap samples is 14. Therefore, it can be inferred that wearing experience has a certain influence on the association gain. Figure 7 compares the influence of the language on classification results. It can be observed that there are many overlapping parts and the number of overlapping samples is 179. Consequently, whether tonal language also influences hearing classification results, but is relatively slight. In summary, the experimental results are consistent with the conclusions in Section 2.1, that is, the four covariates have a certain impact on the hearing aid insertion gain. Such a conclusion also verifies the limitation of relying solely on audiograms for hearing loss classification.
3.5 Acquisition of representative hearing loss
In this section, we first obtained the 300 audiograms introduced in the previous section and corresponding patient information. Next, the corresponding 300 association gains were calculated according to the NAL-NL2 prescription formula. The gain set was then classified by using the classification algorithm described in Section 2.3. When the number of clusters is set to six, the clustering results of association gains are shown in Fig. 8.

Distribution of cluster sizes
After obtaining six types of gain sets, the average values of the association gains under different categories are calculated, respectively, and the average gain can be used to characterize the hearing loss of each category. Figure 9 demonstrates six groups of corresponding representative vectors for different hearing loss.

Six sets of representative gain vectors
As shown in Fig. 9, the gain vector of hearing loss 1 corresponds to the hearing loss of the whole frequency band, with approximately the same gain value obtained in the 0-6000 Hz band range and less gain required in the 6000-8000 Hz range. The gain vector in hearing loss 2 indicates a better hearing situation in the lower frequencies, while compensation is required in the frequency band above 1000 Hz. Hearing loss 3 represents the light degree of hearing loss and the gain required in the whole frequency band is low, which only needs to be provided in the frequency band around 1000 Hz. Compared to type 3, hearing loss 4 is obviously the case of severe hearing loss. Thus, the frequency band between 0 and 6000 Hz requires a gain of more than 30 dB. The curve trends of hearing loss 5 and 6 are similar to those of 1 and 2, but more gains are needed.
The representative gain vectors are the average association gain of hearing aids in different categories. The distance between the representation vectors and the gain vectors acquired under 64 combinations of covariates are calculated after obtaining the representative vectors of each group. The audiogram and covariate within the nearest gain vector were finally selected as the representation information of each type of hearing loss. Figure 10 shows the audiograms corresponding to the six groups of gain representation vectors.

Audiograms corresponding to six representative gain vectors
In Fig. 10, audiogram 1 is from patients with moderate and full-frequency hearing loss. Audiogram 2 and 3 are both case of mild hearing loss. The patients in audiogram 2 have normal hearing at low frequency, and it is difficult for them to identify the middle and high frequency components in speech. While the patients in audiogram 3 possess normal hearing at middle and high frequency but have hearing loss at low frequency. Audiogram 4 indicates the case of severe hearing loss and the hearing threshold is above 80dB, especially at low frequency. Audiograms 5 and 6 both correspond to moderate hearing loss, but the trend of the hearing threshold curve is different. Finally, the covariate information corresponding to each audiogram are as follows: (a) 50 years old, female, with wearing experience; (b) 50 years old, male, with wearing experience; (c) 50 years old, male, with wearing experience; (d) 20 years old, female, without wearing experience; (e) 20 years old, male, with wearing experience; (f) 60 years old, female, with wearing experience. According to the previous discussion, the language has an extremely slight impact on the final gain, so the covariate information listed includes age, gender, and wearing experience.
The insertion gain reflects the true effect that the hearing aid finally imposes on the input signal. By observing the audiograms derived from the representative gain vectors, it is found that similar audiograms correspond to different gains in the presence of covariates. As shown in Fig. 10, the audiograms are obviously different between audiograms 1 and 5 as well as audiograms 2 and 6, but the curve trend of the gain vector is very similar. This also indirectly confirmed the unreasonableness of classifying hearing loss only based on audiograms. The method proposed in this paper takes factors such as gender, age, and hearing aid wearing experience into account. The hearing loss is classified based on the association gain of hearing aids, and the average association gains under different categories are calculated to characterize various types of individual hearing loss. This approach can effectively describe the hearing loss of patients and is more in line with the actual compensation effect of hearing-impaired patients.
4 Conclusion
In order to improve the low prevalence of hearing aids, fitting-free technology is currently the attractive focus in the field of hearing aid fitting. The technology can help hearing-impaired patients obtain a better hearing experience without fitting. It is a common method to classify patients according to audiograms to achieve the fitting-free aim. However, there exists the problem of low accuracy by classifying hearing loss solely based on audiograms. Based on this, a personalized hearing loss classification method based on the insertion gain of hearing aids is proposed in this paper. The method chooses the insertion gain of hearing aids as the feature and takes the information of patients’ gender, age, and wearing history as covariates in the input of the model. Then, an unsupervised cluster analysis method is applied to classify and obtain a representative set of insertion gains. Finally, according to different representation gains, a set of feature information of different categories of patients was obtained as the initial parameters of hearing aid fitting. Compared with the traditional audiogram classification method, the novel method based on insertion gain has a higher quantitative evaluation index and is more suitable for the representation of hearing loss. Future research will focus on expanding the dataset to optimize the performance of the algorithm. Another possible research direction is to explore multiple fitting formulas and analyze the impact of more covariates on actual gain.
References
Ali A, Zhu Y, Zakarya M (2021) Exploiting dynamic spatio-temporal correlations for citywide traffic flow prediction using attention based neural networks. Inf Sci 577:852–870
Ali A, Zhu Y, Zakarya M (2021) A data aggregation based approach to exploit dynamic spatio-temporal correlations for citywide crowd flows prediction in fog computing. Multimed Tools Appl 80(20):31401–31433
Ali A, Zhu Y, Zakarya M (2022) Exploiting dynamic spatio-temporal graph convolutional neural networks for citywide traffic flows prediction. Neural Netw 145:233–247
Ali A, Zhu Y, Chen Q, Yu J, Cai H (2019) Leveraging spatio-temporal patterns for predicting citywide traffic crowd flows using deep hybrid neural networks. In: 2019 IEEE 25th international conference on parallel and distributed systems, pp 125–132
Anwar MN, Oakes MP, Wermter S, Heinrich S (2010) Clustering audiology data. In: 19th Annual Belgian-Dutch conference on machine learning, pp 1–6
Bhat GS, Shankar N, Panahi IMS (2020) Automated machine learning based speech classification for hearing aid applications and its real-time implementation on smartphone. In: 2020 42nd Annual international conference of the IEEE engineering in medicine and biology society, pp 956–959
Bisgaard N, Vlaming MS, Dahlquist M (2010) Standard audiograms for the IEC 60118-15 measurement procedure. Trends Amplification 14(2):113–120
Carhart R (1945) An improved method for classifying audiograms. Laryngoscope 55(11):640–662
Chadha S, Lopez L, Agarwal P, Ambett R (2017) Global costs of unaddressed hearing loss and costs-effectiveness of interventions. A WHO report. WHO Offset Publication
Charih F, Bromwich M, Mark AE, Lefrancois R, Green JR (2020) Data-driven audiogram classification for mobile audiometry. Sci Rep 10 (1):1–13
Charih F, Bromwich M, Lefrancois R, Mark AE, Green JR (2018) Mining audiograms to improve the interpretability of automated audiometry measurements. In: 13th IEEE international symposium on medical measurements and applications, pp 1029–1034
Demeester K, Wieringen AV, Hendrickx JJ, Topsakal V, Heyning P (2007) Prevalence of tinnitus and audiometric shape. B-ENT 3:37–49
Dillon H (1993) Hearing aid evaluation: predicting speech gain from insertion gain. J Speech Lang Hear Res 36(3):621–633
Elkhouly A, Rahim HA, Abdulaziz N, Abd Malek MF (2020) Modelling audiograms for people with dementia who experience hearing loss using multiple linear regression method. In: International conference on communications, computing. cybersecurity, and informatics (2020), pp 1–4
Hannula S, Bloigu R, Majamaa K, Sorri M, Maki-Torkko E (2011) Audiogram configurations among older adults: prevalence and relation to self-reported hearing problems. Int J Audiol 50(11):793–801
Isaac MJ, Mcbroom DH, Nguyen SA, Halstead LA (2017) Prevalence of hearing loss in teachers of singing and voice students. J Voice 31(3):379.e21–379.e32
Keidser G, Convery E (2016) Self-fitting hearing aids: status quo and future predictions. Trends Hear 20:1–15
Keidser G, Dillon H (2006) What’s new in prescriptive fittings down under. Hear Care Adults 133–142
Keidser G, Dillon HR, Flax M, Ching T, Brewer SJAR (2011) The NAL-NL2 prescription procedure. Audiol Res 1(1):88–90
Keidser G, O’Brien A, Carter L, Mclelland M, Yeend I (2008) Variation in preferred gain with experience for hearing-aid users. Int J Audiol 47 (10):621–635
Killion MC (1995) Loudness-data basis for “FIG6” hearing-aid fitting targets. J Acoust Soc Am 98(5):2927–2927
Koyama H, Mori A, Nagatomi D, Fujita T, Saito K, Osaki Y, Yamasoba T, Doi K (2021) Machine learning technique reveals prognostic factors of vibrant soundbridge for conductive or mixed hearing loss patients. Otol Neurotol 42(9):e1286–e1292
Lee CY Hwang, Hou SJ, Liu TC (2010) Using cluster analysis to classify audiogram shapes. Int J Audiol 49(9):628–633
Maclennan-Smith F, Swanepoel DW, Hall Iii JW (2013) Validity of diagnostic pure-tone audiometry without a sound-treated environment in older adults. Int J Audiol 52(2):66–73
Margolis RH, Saly GL (2007) Toward a standard description of hearing loss. Int J Audiol 46(12):746–758
Rajkomar A, Dean J, Kohane I (2019) Machine learning in medicine. N Engl J Med 380(14):1347–1358
Rasetshwane DM, Gorga MP, Neely ST (2013) Signal-processing strategy for restoration of cross-channel suppression in hearing-impaired listeners. IEEE Trans Biomed Eng 61(1):64–75
Ruiyu L, Ruxue G, Ji X, Yue X, Li Z (2017) Self-Fitting algorithm for digital hearing aid based on interactive evolutionary computation and expert system. Appl Sci 7(3):272
Rousseeuw PJ (1987) Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J Comput Appl Math 20:53–65
Sanchez Lopez R, Bianchi F, Fereczkowski M, Santurette S, Dau T (2018) Data-driven approach for auditory profiling and characterization of individual hearing loss. Trends Hear 22:1–12
Scollie S (2005) The desired sensation level multistage input/output algorithm. Trends Amplif 9(4):159–197
Scollie S, Ching TYC, Seewald R, Dillon H, Britton L, Steinberg J, Corcoran J (2010) Evaluation of the NAL-NL1 and DSL v4.1 prescriptions for children: preference in real world use. Int J Audiol 49(sup1):S49–S63
Warren E, Chuck G (2017) Over-the-counter hearing aids: the path forward. JAMA Intern Med 177(5):609–610
World Health Organization (2021) World report on hearing
Yuen K, Mcpherson B (2002) Audiometric configurations of hearing impaired children in Hong Kong: implications for amplification. Disabil Rehabil 24 (17):904–913
Acknowledgements
This work was supported in part by the National Key Research and Development Program of China under grant No. 2020YFC2004002 and 2020YFC2004003.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interests
The authors declare that they have no conflicts of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Ruiyu Liang, Qingyun Wang and Cairong Zou are contributed equally to this work.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Guo, R., Liang, R., Wang, Q. et al. Hearing loss classification algorithm based on the insertion gain of hearing aid. Multimed Tools Appl 82, 41225–41239 (2023). https://doi.org/10.1007/s11042-023-14886-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-14886-0