
Abstract
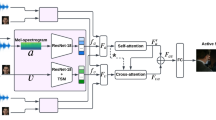
Meetings are a common activity in professional contexts, and it remains challenging to endow vocal assistants with advanced functionalities to facilitate meeting management. In this context, a task like active speaker detection can provide useful insights to model interaction between meeting participants. Detection of the active speaker can be performed using only video based on the movements of the participants of a meeting. Depending on the assistant design and each participant position regarding the device, active speaker detection can benefit from information coming from visual and audio modalities. Motivated by our application context related to advanced meeting assistant, we want to combine audio and visual information to achieve the best possible performance. In this paper, we propose two different types of fusion (naive fusion and attention-based fusion) for the detection of the active speaker, combining two visual modalities and an audio modality through neural networks. In addition, the audio modality is mainly processed using neural networks. For comparison purpose, classical unsupervised approaches for audio feature extraction are also used. We expect visual data centered on the face of each participant to be very appropriate for detecting voice activity, based on the detection of lip and facial gestures. Thus, our baseline system uses visual data (video) and we chose a 3D Convolutional Neural Network (CNN) architecture, which is effective for simultaneously encoding appearance and movement. To improve this system, we supplemented the visual information by processing the audio stream with a CNN or an unsupervised speaker diarization system. We have further improved this system by adding visual modality information using motion through optical flow. We evaluated our proposal with a public and state-of-the-art benchmark: the AMI corpus. We analysed the contribution of each system to the merger carried out in order to determine if a given participant is currently speaking. We also discussed the results we obtained. Besides, we have shown that, for our application context, adding motion information greatly improves performance. Finally, we have shown that attention-based fusion improves performance while reducing the standard deviation.






Similar content being viewed by others


References
Afouras T, Chung JS, Senior A, Vinyals O, Zisserman A (2019) Deep audio-visual speech recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI). https://doi.org/10.1109/tpami.2018.2889052https://doi.org/10.1109/tpami.2018.2889052
Bahdanau D, Cho K, Bengio Y (2015) Neural machine translation by jointly learning to align and translate. In: 3rd International conference on learning representations, ICLR. San Diego, USA. 1409.0473
Bonastre JF, Anguera X, Sierra GH, Bousquet PM (2011) Speaker modeling using local binary decisions. In: Proc. Conference of the international speech communication association, Interspeech, pp 13–16. Florence. http://www.isca-speech.org/archive/interspeech_2011/i11_0013.html
Borghi G, Venturelli M, Vezzani R, Cucchiara R (2017) POSEidon: face-from-depth for driver pose estimation. In: Proc. IEEE Conference on computer vision and pattern recognition CVPR. https://doi.org/10.1109/cvpr.2017.583, Honolulu, pp 5494–5503
Bost X, Linarés G, Gueye S (2015) Audiovisual speaker diarization of TV series. In: Proc. IEEE International conference on acoustics, speech and signal processing, ICASSP. https://doi.org/10.1109/ICASSP.2015.7178882, South Brisbane, pp 4799–4803
Bradley AP (1997) The use of the area under the roc curve in the evaluation of machine learning algorithms. Pattern Recogn 30(7):1145–1159. https://doi.org/10.1016/S0031-3203(96)00142-2
Carletta J (2007) Unleashing the killer corpus: experiences in creating the multi-everything ami meeting corpus. Lang Resour Eval 41(2):181–190. https://doi.org/10.1007/s10579-007-9040-x
Chakravarty P, Zegers J, Tuytelaars T, Van hamme H (2016) Active speaker detection with audio-visual co-training. In: Proc. 18th ACM international conference on multimodal interaction, ICMI. https://doi.org/10.1145/2993148.2993172, Tokyo, pp 312–316
Cho K, van Merriënboer B, Gulcehre C, Bougares F, Schwenk H, Bengio Y (2014) Learning phrase representations using RNN encoder-decoder for statistical machine translation. In: Proc. ACL Conference on empirical methods in natural language processing, EMNLP. https://doi.org/10.3115/v1/d14-1179, Doha, pp 1724–1734
Chung JS, Lee BJ, Han I (2019) Who said that?: audio-visual speaker diarisation of real-world meetings. In: Proc. Conference of the international speech communication association, Interspeech, pp 371–375. Graz. https://doi.org/10.21437/Interspeech.2019-3116, https://www.isca-speech.org/archive/pdfs/interspeech_2019/chung19b_interspeech.pdf
Das A, Bhattacharjee U, Mitra DK (2017) One-decade survey on speaker diarization for telephone and meeting speech. International Journal of Scientific Research in Computer Science Engineering and Information Technology IJSRCSEIT 2(5)
Dubey H, Sangwan A, Hansen JH (2019) Transfer learning using raw waveform sincnet for robust speaker diarization. In: Proc. IEEE International conference on acoustics, speech and signal processing, ICASSP. IEEE, Brighton, pp 6296–6300. https://doi.org/10.1109/ICASSP.2019.8683023
el Khoury E, Sénac C, Joly P (2014) Audiovisual diarization of people in video content. Multimedia Tools and Applications MTAP 68(3):747–775. https://doi.org/10.1007/s11042-012-1080-6
Everingham MR, Sivic J, Zisserman A (2006) Hello! my name is... buffy” – automatic naming of characters in TV video. In: Proc. of the British machine vision conference, BMVC. British Machine Vision Association, Edinburgh, pp 899–908. https://doi.org/10.5244/c.20.92
Haider F, Campbell N, Luz S (2016) Active speaker detection in human machine multiparty dialogue using visual prosody information. In: Proc. IEEE Global conference on signal and information processing, GlobalSIP. IEEE, Washington, pp 1207–1211. https://doi.org/10.1109/globalsip.2016.7906033
Hanley JA, McNeil BJ (1982) The meaning and use of the area under a receiver operating characteristic (roc) curve. Radiology 143(1):29–36. https://doi.org/10.1148/radiology.143.1.7063747
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proc. IEEE Conference on computer vision and pattern recognition, CVPR. IEEE, Las Vegas, pp 770–778. https://doi.org/10.1109/cvpr.2016.90
He W, Motlicek P, Odobez JM (2018) Deep neural networks for multiple speaker detection and localization. In: Proc. IEEE International conference on robotics and automation, ICRA, Brisbane, pp 74–79. https://doi.org/10.1109/icra.2018.8461267
Hong X, Yao H, Wan Y, Chen R (2006) A PCA based visual DCT feature extraction method for lip-reading. In: Proc. IEEE International conference on intelligent information hiding and multimedia signal processing, IIH-MSP, Pasadena, pp 321–326. https://doi.org/10.1109/iih-msp.2006.265008
Hruz M, Zajic Z (2017) Convolutional neural network for speaker change detection in telephone speaker diarization system. In: Proc. IEEE International conference on acoustics, speech and signal processing, ICASSP, New Orleans, pp 4945–4949. https://doi.org/10.1109/icassp.2017.7953097
Kingma DP, Ba J (2015) Adam: a method for stochastic optimization. In: Bengio Y, LeCun Y (eds) 3rd International conference on learning representations, ICLR. San Diego, USA. 1412.6980
Korshunov P, Halstead M, Castan D, Graciarena M, McLaren M, Burns B, Lawson A, Marcel S (2019) Tampered speaker inconsistency detection with phonetically aware audio-visual features. In: Proc. International conference on machine learning, ICML. Long Beach, USA
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: Advances in neural information processing systems, NIPS, Lake Tahoe, pp 1097– 1105
Le N, Odobez JM (2016) Learning multimodal temporal representation for dubbing detection in broadcast media. In: Proc. ACM on multimedia conference, MM. ACM Press, Amsterdam, pp 202–206. https://doi.org/10.1145/2964284.2967211
Li S, Zou C, Li Y, Zhao X, Gao Y (2020) Attention-based multi-modal fusion network for semantic scene completion. In: AAAI
Madrigal F, Lerasle F, Pibre L, Ferrané I (2021) Audio-video detection of the active speaker in meetings. In: IEEE International conference on pattern recognition, ICPR, Milan, pp 2536– 2543
Miró XA, Bozonnet S, Evans NWD, Fredouille C, Friedland G, Vinyals O (2012) Speaker diarization: a review of recent research. IEEE Transactions on Audio, Speech, and Language Processing TASLP 20 (2):356–370. https://doi.org/10.1109/TASL.2011.2125954
Nagrani A, Chung JS, Xie W, Zisserman A (2020) Voxceleb: large-scale speaker verification in the wild. Comput Speech Lang 60:101027. https://doi.org/10.1016/j.csl.2019.101027
Patino J, Delgado H, Evans N (2018) The EURECOM submission to the first DIHARD challenge. In: Proc. Conference of the international speech communication association, Interspeech. ISCA, Hyderabad, pp 2813–2817. https://doi.org/10.21437/interspeech.2018-2172
Petridis S, Shen J, Cetin D, Pantic M (2018) Visual-only recognition of normal, whispered and silent speech. In: Proc. IEEE International conference on acoustics, speech and signal processing, ICASSP, Calgary, pp 6219–6223. https://doi.org/10.1109/icassp.2018.8461596
Ren J, Hu Y, Tai YW, Wang C, Xu L, Sun W, Yan Q (2016) Look, listen and learn — a multimodal lstm for speaker identification. In: Proc. Thirtieth AAAI conference on artificial intelligence, Phoenix, pp 3581–3587. http://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/view/12386
Roth J, Chaudhuri S, Klejch O, Marvin R, Gallagher A, Kaver L, Ramaswamy S, Stopczynski A, Schmid C, Xi Z, Pantofaru C (2019) Supplementary material: AVA-ActiveSpeaker: an audio-visual dataset for active speaker detection. In: 2019 IEEE/CVF International conference on computer vision workshop, ICCVW, Seoul, pp 3718–3722. https://doi.org/10.1109/iccvw.2019.00460
Sarkar A, Dasgupta S, Naskar SK, Bandyopadhyay S (2018) Says who? deep learning models for joint speech recognition, segmentation and diarization. In: Proc. IEEE International conference on acoustics, speech and signal processing, ICASSP. https://doi.org/10.1109/icassp.2018.8462375https://doi.org/10.1109/icassp.2018.8462375, Calgary, pp 5229–5233
Stefanov K, Beskow J, Salvi G (2017) Vision-based active speaker detection in multiparty interaction. In: International workshop on grounding language understanding, GLU. Stockholm. https://doi.org/10.21437/GLU.2017-10, https://www.isca-speech.org/archive/pdfs/glu_2017/stefanov17_glu.pdf
Tao F, Busso C (2019) End-to-end audiovisual speech activity detection with bimodal recurrent neural models. Speech Comm 113:25–35. https://doi.org/10.1016/j.specom.2019.07.003
Tran D, Bourdev L, Fergus R, Torresani L, Paluri M (2015) Learning spatiotemporal features with 3d convolutional networks. In: Proc. IEEE International conference on computer vision, ICCV, Santiago, pp 4489–4497. https://doi.org/10.1109/iccv.2015.510
Tran D, Wang H, Torresani L, Ray J, LeCun Y, Paluri M (2018) A closer look at spatiotemporal convolutions for action recognition. In: Proc. IEEE Conference on computer vision and pattern recognition, CVPR, Salt Lake City, pp 1874–1883. https://doi.org/10.1109/cvpr.2018.00675
Vestman V, Gowda D, Sahidullah M, Alku P, Kinnunen T (2018) Speaker recognition from whispered speech: a tutorial survey and an application of time-varying linear prediction. Speech Comm 99:62–79. https://doi.org/10.1016/j.specom.2018.02.009
Wang Q, Downey C, Wan L, Mansfield PA, Moreno IL (2018) Speaker diarization with LSTM. In: Proc. IEEE International conference on acoustics, speech and signal processing, ICASSP, Calgary, pp 5239–5243. https://doi.org/10.1109/icassp.2018.8462628
Wu JD, Tsai YJ (2011) Speaker identification system using empirical mode decomposition and an artificial neural network. Expert Syst Appl 38 (5):6112–6117. https://doi.org/10.1016/j.eswa.2010.11.013
Xie W, Nagrani A, Chung JS, Zisserman A (2019) Utterance-level aggregation for speaker recognition in the wild. In: Proc. IEEE International conference on acoustics, speech and signal processing, ICASSP. IEEE, Brighton, pp 5791–5795. https://doi.org/10.1109/icassp.2019.8683120
Yasir M, Nababan MN, Laia Y, Purba W, Gea A, et al. (2019) Web-based automation speech-to-text application using audio recording for meeting speech. In: Journal of physics: conference series, vol 1230, p 012081. IOP Publishing. https://doi.org/10.1088/1742-6596/1230/1/012081
Zhong Y, Arandjelović R, Zisserman A (2018) Ghostvlad for set-based face recognition. In: Proc. Asian conference on computer vision, ACCV, pp 35–50. Springer, Perth. https://doi.org/10.1007/978-3-030-20890-5_3
Zhou Z, Zhao G, Hong X, Pietikäinen M (2014) A review of recent advances in visual speech decoding. Image Vis Comput 32(9):590–605. https://doi.org/10.1016/j.imavis.2014.06.004
Funding
This work was supported by the LinTO project (2018-2021) P169201-2658717// DOS0069247, funded by Bpi France, as part of the French project “PIA3: Programme d’Investissements d’Avenir 3”.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Pibre, L., Madrigal, F., Equoy, C. et al. Audio-video fusion strategies for active speaker detection in meetings. Multimed Tools Appl 82, 13667–13688 (2023). https://doi.org/10.1007/s11042-022-13746-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-022-13746-7