
Abstract
Road detection on aerial and remote sensing vague images is a hard task. In this paper, an automatic road detection method for the vague images is proposed. The method firstly uses an improved MSR algorithm to enhance image, and it automatically takes different scales in different image regions, based on the image depths obtained by the dark channel prior algorithm. Then the enhanced image is roughly segmented on the principle of the local gray scale consistency, in that, an eight-neighborhood template is considered as a processing unit in which a threshold is utilized for all the neighboring pixels of the detecting pixel. Finally, the Dempster-Shafer (D-S) evidence for road features is applied to finalize road tracing in the binary image, where, the road features include length, width, aspect ratio and fullness rate, all the parameters are obtained in the least external rectangle of a road segment, and then the detected roads are regulated. In experiments, 300 vague road images were selected for testing, by comparing to several traditional algorithms and recent semantic methods, the testing results show that the new method is satisfactory, and the detection accuracy is up to 89%.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
It is important to retrieve the earth surface information from aerial images. High spatial resolution aerial and remote sensing images provide the more accurate information, which offers the advantages over urban planning, geometrics, military monitoring, object extraction, changes monitoring and GIS data updating. The fast and accurate useful information extraction from the images has become a hot research topic, and the road detection in vague aerial and remote sensing images is one of the hardest tasks in this research field.
In the past three decades, a lot of efforts have been made for developing road detection algorithms. As our literature review [20, 38], many researchers have done a lot of research work in this area, and the research content includes the traditional image segmentation algorithms and the recent semantic segmentation methods, such as Fractional differential and Graph based image segmentation algorithms [38], and Neural network and Deep learning semantic segmentation methods [20]. No matter what kind of algorithms and methods are applied, the automatic road detection is still difficult for vague aerial and remote sensing images due to the poor image quality.
There are many similar applications related to road detection in a vague image. Since a road is a linear object which is similar to the pavement crack in the road construction, the pavement surface is rough and the illumination on an image is uneven in most cases, the studied algorithms for crack detection are similar to that for road detection. For the road construction, there are a lot of new algorithms, such as the algorithms based on Level set, Hydrodynamics and the methods by using Deep learning [12, 36, 39, 40, 42], but until now, there is still no standard for road detection. Therefore, the algorithms and methods need to be continually studied and improved.
In general, the surface of the road is uniform with similar colors in a certain length of road segment, which is good for road detection if a road image is not vague. As the traditional classification, the road extraction algorithms can be divided into two types: semi-automatic algorithms and full-automatic ones. At present, there is no breakthrough with the full-automatic algorithms for vague aerial and remote sensing images, but some successes on the semi-automatic ones have been achieved [34, 45]. For automatic ones, in 2010, reference [24] presented an algorithm based on the particular combination of EKF and PF as a road-tracing approach, it is valuable for normal road detection, but it might fail to the vague images. After then, many algorithms for road extraction are studied based on spectral or textures [8, 30, 37, 47], such as the algorithm for image segmentation based on a multi-resolution application of a wavelets transform and feature distribution [18], and a number of the recent road detection algorithms based on color information [13].
Currently, the semantic segmentation methods in theory and practice have been applied into different applications, such as Network for scene segmentation [7], Network for RGBD semantic segmentation [16], the semantic segmentation for remote sensing images [5] and Scale channel attention network for image segmentation [3], U-net: convolutional networks for biomedical image segmentation [43], and SegNet for image segmentation [21], etc. There are many researchers have applied the those semantic segmentation methods into the road extraction, e.g., Xin et al. (2019) made the road extraction in high-resolution remote sensing images by DenseUNet [31]; and Liu (2021) studied road extracting network in high resolution remote sensing images [1].
But most of the previous algorithms/methods are not for the images under extreme weather that make image vague much. Hence, there are a lot of researchers made contributions for image dehazing/defogging and image enhancement, such as Non-local method [27], Linear depth model [33], Multi-scale deep residual learning algorithm [44], and Color attenuation prior model [25]. Although there are some research work on vague road image processing, most of them are only for special situations, there is no standard for vague aerial and remote sensing road image processing. In addition to the vague image processing, some algorithms were studied by combining the road shape features and environment characteristics, e.g., the algorithm in reference [6] preliminarily applies the road shape features and other road features to detect roads, which is good for the binary images in some cases, but it is lacking of versatility.
For a vague aerial and remote sensing image, before road detection, an image should be enhanced for sharpening roads and smoothing away noise [10, 11, 28], which is needed in the first step [17, 22]. One of examples for road detection in a vague aerial image is to utilize Fractional differential to sharpen the road edges [41, 46], which is useful for the image with many textures in a blur image, but the algorithms might not be effective for very dark and vague road images. So, the new method/algorithm study for automatic road detection in a vaguer image is still significant.
To detect roads automatically and accurately in a vague aerial and remote sensing image, and to overcome the deficiencies of the previous algorithms/methods for vaguer aerial images, a new method is proposed in this paper. For a vague image, it firstly does image enhancement based on the combination of Multiple scale Retinex (MSR) and Dark channel prior, then makes road detection roughly on the principle of the local gray scale consistency, finally, accurately finalizes roads by applying the road shape features with D-S evidence [4]. The method mainly includes three parts: (1) Image enhancement on MSR with variable scale; (2) Image segmentation on gray scale image; (3) Road tracing and regulating by using road features with D-S evidence.
2 Image enhancement on improved MSR algorithm
2.1 Introduction of Retinex
When there are either spatial or spectral variations caused by bad weather condition, aerial and remote sensing images suffer from significant losses in visual quality compared to the direct observation by human vision. The visibility of colors and details in shadows is quite poor for recorded images, and a spectral shift in illumination either toward to the blue color or to the red color reduces the overall visibility of scene details and colors. These lighting defects are quite common. Likewise for scenes with some white surfaces (clouds or snow, for example), the visibility of colors and details in the non -white zones of the image is poor. Therefore, a general purpose for automatic computation is needed to routinely improve those aerial and remote sensing images. In some cases, some traditional algorithms might be applied for making image enhancement, and they may only be applicable in some special cases, but not available for many cases. As enhancement algorithm study and test in our Lab., the Retinex based method is one of more valuable algorithms than others in vague aerial and remote sensing road images.
The Retinex algorithm was introduced in 1971 by Edwin, who formulated “Retinex theory” to explain it. Many researchers demonstrated the great dynamic range compression, increased sharpness and colors and accurate scene rendition, which are produced by the Multiscale Retinex with color restoration, specifically in aerial images under smoke/haze conditions [29]. Overall, Retinex performs automatically and consistently superior to any of the other methods. While the other methods might work well on occasion cooperative images, it is easy to find images where they perform poorly. The Retinex performs well on the cases where the other methods are clearly not appropriate. In order to use Retinex algorithms into the studied vague aerial and remote sensing images, a single scale Retinex algorithm is extended into a multiple scale Retinex algorithm by referring previous research work [49].
The simple description of a single scale Retinex algorithm (SSR) can be expressed as:
Where, Ii(x, y)is the image in the ith spectral band; Ri(x, y)is Retinex output in the ith spectral band; Gaussian function: \( F\left(x,y\right)={Ke}^{-\left({x}^2+{y}^2\right)/{\sigma}^2} \); and K is determined by ∬F(x, y)dxdy = 1; and σ is the Gaussian surround space constant.
Because of the trade off between dynamic range compression and color rendition, one has to choose a good scale in the eq. F(x, y) in SSR. If one does not want to sacrifice either dynamic range compression or color rendition, the multiscale Retinex algorithm, which is a combination of weighted different scales of SSR, called MSR, is a good solution,
Where, N is the number of scales, Rni is the ith component of the nth scale, and ωn is the ith component’s weight. The obvious question about MSR is the number of scales, scale values, and weight values. Experiments showed that three scales are enough for most of images, and weights can be equal to each other. Generally the fixed scales of 15, 80 and 250 are used, or the scales of the fixed portion can be utilized. But these are more experimental than theoretical, because the scale of an image is unknown to the real scenes. The weights can be adjusted to weigh more on dynamic range compression or color rendition.
2.2 Improved Retinex
Hence in our enhancement algorithm, the scale in the Retinex algorithm is not a constant value for an image. It takes different values in different regions, and the scale values are determined by the image depths [9]. First of all, we get a dark channel image [9] using a 15 × 15 mask, and calculate the transmission map t(x, y). The value of t(x, y) is between 0 to 1, and which represents a region how far away from the camera. In the transmission map, the dark region is far away from the camera and the bright region is opposite. In our algorithm, it is doing the small scale transformation where far from the camera, and doing the large scale transformation where near the camera. We assume that it has a linear relationship between the scale parameter c(x, y) and the transmission map t(x, y).
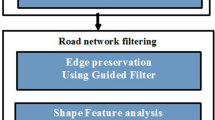
Where, max(t(x, y)) and min(t(x, y)) are the maximum and minimum values of t(x, y). Thus, we obtain the scale c(x, y), and its range is in 10 to 110, from a small scale to a large scale. According to the scale parameters obtained, we do a Gauss filter to a haze image, and then calculate Retinex results. The algorithm flow chart is illustrated in Fig. 1.

Flow chart of vagueness removal procedure
For the above transmission map t(x, y), the reference [9] has the detailed description, the brief explanation can be presented as the follows. The dark primary color of an image can be defined as [9]:
Where, Jc is the cth color channel of Image J, Ω (x) represents the block centered on pixel x. Through a large number of statistical experiments, for a clear image:
Assuming that in a local block, the propagation graph t(x) is constant, according to the imaging model of blurred image, make dark primary color transformation on both sides of Eq.(5) to obtain:
According to the theory of dark primary color, the first term on the right of the equal sign of Eq.(7) is about 0, so Eq.(7) is equivalent to:
According to the dark primary color defogging algorithm, the restoration formula of scene light intensity J is as follows:
Eq. (9) can be transformed into the following form. Note that max(t(x), t0) is less than 1.
In the above equations, I refers to the observed image, i.e. haze image, J refers to the intensity of scene light, and A refers to atmospheric light; t is called propagation diagram, which is used to describe the part of light that is not scattered when it is transmitted to the camera through the medium. The goal of removing haze is to recover J, A and t from I.
3 Road detection on gray scale consistency
Based on the surveys of various roads and the analyses of the actual situations, the road characteristics can be described as:
-
1)
Generally, a road is a belt, the width of the same road has the small variable values at a certain length range, therefore the road width varies slowly.
-
2)
The gray scales of a road differ much from that of the background (non-road areas).
-
3)
Roads in an image have obvious edges that can be easily detected by a normal edge detector.
-
4)
Each road has certain of length and it is a linear object, which differs from other objects that are not elongated much.
-
5)
A road can be divided into different segments according to its curvature, such as line segments and curved segments. The curvatures of the curved segments are quite different each other.
-
6)
There is connectivity among the roads in a road network.
-
7)
There might be disruptions in a retrieved road image because of the local disturbances of cars, lane lines, trees etc.
According to the road characteristics above, this paper proposes a new algorithm for road detection roughly in a gray scale image. Figure 2 shows the flow chart of the algorithm procedure. The details of image segmentation are discussed in the following.

Flowchart of road extraction procedure
A traditional gray scale based image segmentation algorithm is studied mainly based on edge detection and/or regional similarity. An edge detection algorithm is greatly dependent on the object boundary information and is often sensitive to noise. There exists a number of irregular objects in an aerial or remote sensing image, and the quality of a processed image is uncertain (such as image distortion, spectral differences etc.), therefore, the edge based segmentation algorithms will breed too many partitions of lines as well as difficulties to form a full target region in a vague image.
In a regional similarity based image segmentation algorithm, an image is divided into internal connected and external unconnected regions, according to the similarity and uniformity of objects. The segmented regions are suitable for the subsequent feature extraction. For a simple image segmentation algorithm [15, 19, 26, 35], such as Otsu thresholding [19, 26] and iterative thresholding [38], it is often to extract “background” and “targets” separately to make image binarization, the more recent algorithm is that Hu et al. used neutrosophic cross-entropy thresholding for object tracking [15]. However, it is not possible for the complex vague images. Another way is that different segments/regions can be retrieved through a K-means clustering method [35, 38], which is easy to perform the subsequent operations for road characteristic extraction, but the outcome depends on the initial number of classes. In addition to these, in some cases, the different objects in an image can be split/merged into a connected region based on split and merge rules, which might make image segmentation or road extraction not accurate and it is difficult to adapt for the post-processing for road segment detection further.
Roads, houses and artificial target surfaces in an aerial or remote sensing image have their own higher gray scale consistency, so this study improves a global threshold algorithm for road extraction based on the gray scale consistency on the road surfaces, by combining the gray-scale mutation of the road edges.
In the algorithm, an eight-neighborhood template is considered as a processing unit in which a threshold is utilized for all the neighboring pixels, rather than for the entire image. In this procedure, a large target with a uniform gray scale will be well extracted into a target region. While the edge information, which does not meet the similarity of the road due to the gray scale mutation, is considered as the background information. To achieve the better segmentation result, an image processing filter (i.e. eight-neighborhood kernel median filter) is needed to make image smooth. The specific segmentation algorithm using an eight-neighborhood template comprises the following steps.
Step 1
For a pixel f(x, y) in an image, retrieve its neighborhood pixels f(x + Δx, y + Δy), where Δx and Δy∈(−1,0,1). The gray scales of the pixels f(x + Δx, y + Δy) are denoted as Gf (Δx,Δy).
Step 2
Obtain RGB difference between Gf (Δx, Δy) and Gf (x, y), which is denoted as Mfi (Δx, Δy) = abslute value (Gf (Δx, Δy) and Gf (x, y)), where i = R, G, B. If Mfi (Δx, Δy) < T0, then set flagfi = 1, else flagfi = 0, where T0 is a threshold. The value of T0 depends on the human visual capability for the gray scale variation. Generally, the human visual capability is valuable to a gray scale range between 6%–10% of the average gray scale value of the image, hence, in our case, based on a number of image testing, T0 is given in (12, 22) to obtain the visual effect. Do Step 2 until all the neighborhood pixels of f(x, y) are handled.
Step 3
Compute each flagf of the neighborhood pixels and the center pixel.
Step 4
Calculate the gray scale of the pixel f(x, y) by using its neighboring pixels’ flags.
Step 5
Do step 1 to step 4, until all the pixels in the processed gray scale image are handled, then a binary image is obtained.
Figure 3a shows an aerial road image that is vague, and the roads cannot be seen clearly. Figure 3b presents the gray scale histogram equalization result; and the enhancement effect is not satisfactory. Figure 3c illustrates the improved Retinex algorithm enhancement result, where, the roads are enhanced clearly, and other objects are enhanced too. Figure 3d presents the image segmentation result after image enhancement, where, T0 = 10, the main road is obviously shown up, although the result includes noise, the result can be enhanced after the operations of erosion and thinning, so on.

Original aerial road image and its Retinex enhancement and segmentation results. a Original image b Histogram equalization c Improved Retinex d Segmentation on c
The single central line of a road may be retrieved by a thinning processing step, before which, the morphological closing and opening operations are applied to eliminate the small holes and spot noises.
4 Road finalizing in binary image
The theory of Dempster-Shafer (D-S) Evidence was firstly brought up by Dempster [32], was extended to form the theory by Shafer [23], and the current art status of the theory study and application development are described in [23, 32, 50]. The theory of D-S Evidence can grasp the uncertainty problems better than traditional probability theories. In the D-S evidence theory, let Θ be the universal set: the set of all states under consideration. The power set 2Θ is the set of all subsets of Θ, including the empty set Φ. The theory of evidence assigns a belief mass to each element of the power set. Formally, a function m: 2Θ → [0, 1] is called a basic belief assignment (BBA), when it has the two properties. Firstly, the mass of the empty set is zero: m(Φ) = 0. Secondly, the masses of the remaining members of the power set are added up to 1 totally:
Where, A is a given member set of the power set.
The D-S evidence theory defines a belief function called Bel and a plausibility function called Pls to express the problem of uncertainty, which can be represented as:
In the case of multiple evidences, the Dempster combination rule can be used to synthesize multiple BPAF, that is:
Where, \( K=\sum \limits_{\cap {A}_i\ne \Phi}\prod \limits_{1<i<n}{m}_i\left({A}_i\right) \).
The D-S evidence theory is of a great value in data fusion. In the case of multiple characteristics, each characteristic threshold selection is determined based on image classification, resulting in a lack of interoperability in practical applications. Through the integration of D-S theory, the versatility of the shape features in road extraction can be improved. In accordance with the road model and D-S theory, the framework of road identification is constructed: Θ = {Y, N}, where, Y represents the roads and N is for the non-roads. Let TL, TW, TR, TF represent the basic thresholds for which the road must meet. Respectively, they are the thresholds of length, width, aspect ratio and fullness rate. Their definitions and calculations are based on the least circumscribed (external) rectangle for a road segment, as follows:
The main idea of the algorithm procedure for the least external rectangle of an object is:
-
(1)
First, a simple circumscribed rectangle is a circumscribed rectangle whose edges are parallel to the X or Y axis in a XY coordinate system.
-
(2)
The algorithm of rotating a certain angle around a fixed point on a plane is realized. The mathematical basis is that if the point (x, y) on the plane rotates counterclockwise around another point (x0, y0) and the point after the angle α is (x2, y2), then
When clockwise, α can be changed to - α.
-
(1)
It rotates the original object (0°-90°, set the start angle α0 = 1° and the angle spacing αstep), find the simple circumscribed rectangle of the object after each degree of rotation, and record the area of the simple circumscribed rectangle, vertex coordinates and the degree of rotation at this time.
-
(2)
By comparing all the simple circumscribed rectangles of the object obtained by the rotation process, the simple circumscribed rectangle with the smallest area are got, and the vertex coordinates (x3, y3) and rotation angle β of the simple circumscribed rectangle are obtained.
-
(3)
It rotates the angle β of the minimum rectangle and the object in the opposite direction, then, the minimum circumscribed rectangle is got.
After the rectangle is taken for each of road segments, we set up the road parameters as the follows.
-
(a)
Object size S: The smaller interfering targets can be filtered out by using this feature, which can reduce the execution time for the subsequent processes. Ts is the threshold value of this feature and is selected according to the image spatial resolution and the object size, i.e., the circle equivalent diameter of the object is less than the average road width in the image (for our images in this study, Ts = 30).
-
(b)
Length L and Width W of the rectangle: A road has certain of length and width, which cannot be too short. The longer the length is, the greater possibility of the road is. The width feature also plays an important role for filtering out objects, the wider an objects is, the smaller possibility of the road. The probability distribution function of length L is defined:
Similarly, the probability distribution function of width W is defined as:
-
(c)
Aspect ratio (object elongation) R:
Where, MERL is the minimum length of the exterior rectangle; MERW is the minimum width of the exterior rectangle. If R < 1, and the less R is, the greater possibility the road is. The probability distribution function of R is defined as:
-
(d)
Fullness rate F:
Where, S is the object area and SMER is the area of the smallest circumscribed rectangle.
The following is the probability distribution function:
Where, ɑ1, ɑ2, ɑ3, ɑ4 are the input parameters of attribute weights. According to several hundreds of road testing in our images, the thresholds for all the characteristics are set as: TL = 30, TW = 4, TR = 0.2, and TF = 0.3 (in pixels).
References [6] adopt the shape features in object extraction, but the shape features summarized are simple, resulting in the low detecting probability and the difficulties in adapting to the specific roads.
For the two different models above, the aspect ratio and the fullness rate perform differently. With the aspect ratio feature, a road line can be detected well. The fullness rate feature is more suitable for a curved road than for a line road. Therefore, it must be handled separately. Finally, an improved scheme combining a road line with a curved road is presented, which makes a great improvement for the comprehensiveness and accuracy of the road extraction. The process procedure is shown in Fig. 4.

Separating and merging procedure
Feature fusion process steps: (1) Fuse road length, width and aspect ratio by the Dempster combination rule, through which one can get the information of a line-liked road; (2) Fuse road length, fullness rate to obtain the information of a curved road or a road network; and (3) Merge the two kinds of the fusion results above to do the final road extraction. For the road segment connection, firstly, some seed pixels are selected in the road segment that has been extracted. This paper treats all the border pixels as the seed points. And then the region growing operation is carried out to connect the road segments. As local excessive growth might occur, it is necessary to do the further regulative processing operations. The region-growing algorithm includes: search for the four-neighborhood pixels for each seed pixel, and use centroid-based region growing for each seed pixel. If the region growing encounters a pixel that satisfies the consistency, the pixel is marked as a road pixel (the growing region pixel) candidate, then the algorithm starts from the pixel to continually search until no road pixel can be found out. This function can achieve the maximum similarity region merging and road segment connecting. After region-growing, the following steps are applied.
-
1)
Regulation processing on edge information
It is often that the region-growing might lead to some excessive region growing; therefore, the post-processing is quite necessary. In the post processing, the edge detection information (including edge gradient magnitude and direction information) is important for the region boundary judgment. In this step, the region-growing results are checked and repaired based on the edge detection information and the results from the morphological operations, which can detect the over-growing regions and then make the corrections for the over-growing regions. In this study, the traditional derivative operator Sobel (edge detector) is applied:
Where, TD is the gradient magnitude threshold, and D(x, y) refers to the gradient magnitude at the pixel f(x, y) of the gradient magnitude image.
-
2)
Road center structure
The road information which has been extracted can be operated by a morphological thinning operation so as to obtain the road centerline. If there is a hole in the extracted road, to some extent, there will be a closed cycle. This can be solved by utilizing morphological closing and opening operations simply. Firstly the hole filling operation is carried out, and then the filled hole is refined further, so that the extraction of the road centerline cannot be affected by holes. In this procedure, all the lines and/or the curves are detected and measured, and the short lines/curves are elliminated after the thinning operation is carried out. Fig. 5 shows the example of road tracing on Fig. 3f.

Post processing result after thinning operation on the image in Fig. 3d. a Filling road gaps b Deleting noise (L<10) c Irregular object removal d Final road tracing result
5 Experiments and analyses
The data source in experiment comes from the vaguer aerial images taken by the authors. All the algorithms or operators mentioned above are coded under the VC++ (version 6 or above) environment of Windows (version 8 and above) in a PC computer, and the hardware name and parameters are: DELL, CPU Intel Core i7–10,700, Ram 8GB. In this kind of environment, for a gray scale image of 1600 × 1200 pixels, the algorithm spends about 0.5 s. In this study, we choose 200 aerial images captured from airplane (about 8000 m height from ground), and 100 public remote sensing images from the dataset referencing [31, 43].
According to more 300 image testing and theoretical analysis, we set different thresholds in this study; the threshold value in the image thresholding segmentation algorithm is set to T0 = 10, and the threshold in the region-growing is TR = 12 (for all the images in this study). And the other four parameters based on a number of image testing are set as ɑ1 = 0.55, ɑ2 = 0.5, ɑ3 = 0.8, and ɑ4 = 0.7 respectively, according to road parameter statistical analysis.
In general, after image segmentation on gray scale, we have to remove non-road objects, identify the main roads for road tracing. To do the two kinds of the work, our procedure includes a number of functions such as thinning, endpoint detection, small line or curve removal, road gap linking, and other morphological operations. Most of the functions are performed according to the above rules of D-S evidence in this study.
In Fig. 6, the original image (a) is a gray scale image with uneven illumination, the illumination difference between horizontal middle parts and other parts are large, including two roads and different noises, the whole image is very vague. After image enhancement by the improved Retinex algorithm in this study, the image contrast is increased, and the roads are much sharper than before, as shown in (b). Since the image illumination is uneven, when Otus thresholding [19, 26] is applied on the image in (b), the result (c) is not satisfied, where, since a large black area appears in the middle of the image, the roads cannot be extracted. In addition to the similarity algorithms, the discontinuity based algorithms [2, 48] still cannot make image segmentation well, as shown in (d) and (e). If the image in (b) is operated by the new image segmentation algorithms in this study (gray scale consistency with D-S evidence), the road extraction results are satisfactory as shown in (g) and (h).

Road extraction on vague and uneven illumination gray scale aerial road image by different algorithms. a Original image b Enhancement c Otus d Laplacian e Canny f Gray scale consistency g D-S evidence h Final result
The original image in Fig. 7a is a color road image, comparing to the original image in Fig. 6a, the illumination difference between left part and right part is large, as shown in (c). Anyhow, after image enhancement by the improved Retinex algorithm (b), the road extraction is good by using our new algorithm, as shown in (f-h).

Road extraction on vague and uneven illumination color aerial road image by our algorithms. a Original image b Enhancement c Otus d Gray scale consistency e D-S evidence f Final result
It is much different to the both original images in Figs. 6a and 7a, the original image in Fig. 8a is a heavy hazed aerial image, the roads almost are invisible. After image enhancement and image segmentation by applying the algorithms in this study, the results are satisfied except for lost some small roads, as presented in (b-d).

Road extraction on heavy hazed vague color aerial road image by our algorithms. a Original image b Enhancement c Gray scale consistency d Final result
The original image in Fig. 9a is a fog aerial road image, the image is blur, the several roads cannot be fully visible. When we use Clustering analysis algorithm to process this image, the image is separated into two large areas with some short segments, the boundary between the two areas might be a road, and three short segments are the parts of roads, but the whole result is not satisfied as shown in (b). If we use Fuzzy C-Means algorithm (FCM) [17, 38] on the image, the result (c) is still not satisfied except for more regions than (b). By using studied algorithms in this paper, after image enhancement, the image contrast is increased a lot and the roads are much sharper then before (d). The gray scale consistency operation result shows that the most road segments are detected, but there are many noise spots and gaps on roads (e). When we use the operation on D-S evidence on (e), the most of noise are removed and all the gaps are filled, as shown in (h).

Complex road extraction on fog color aerial road image by different algorithms. a Original image b Clustering c FCM d Enhancement e Gray scale consistency f D-S evidence
In Fig. 10, the original image is a more complicated and the vague aerial image including a main road and other small roads in Fig. 10a. If an edge detector [2, 50] is utilized, the most edges can be detected, but a lot of them belong to spurious edges, and it is difficult to identify the main road (b). If a similarity based algorithm [15, 19, 26, 35] is applied, the result image is presented (c), where, a large bright region appears in the middle part of the image because of uneven illumination and non-road object effects. In order to overcome the problem, FCM [35], Clustering analysis and Minimum Spanning Tree (MST) algorithms [35, 38] are operated respectively, but all the results are not good (d, e, f). When the original image is processed by the improved Retinext algorithm, the main road (in the diagonal direction) can be enhanced well, as shown in Fig. 10g. Then, when the new image segmentation algorithm based on gray scale consistency plus D-S evidence is performed, the processing result is very good, in which, the main road is clearly detected with the light color.

Single road tracing on a complicated fuzzy aerial image by different algorithms. a Original image b Canny c Otsu d FCM e Clustering f MST g Improved Retinex h Tracing result on g
For the multiple roads tracing, Fig. 11 shows an example. Where, the original image in Fig. 11a is a vague aerial image, because the illumination is uneven and clouds and fog are included, the road network is unclear. The image involves a road network which consists of seven roads as shown in (b). The image in (b) is the manual segmentation result (Ground truth), where, four vertical road lines (1, 2, 3, 4) are marked by the green color digits, and three horizontal road lines (5, 6, 7) are marked by the blue color digits. The road lines cut the network area into 13 blocks, which are marked by the red colors. In order to compare the different algorithms for road extraction in details in Fig. 11, Table 1 lists the detection results by using the percentages of roads’ lengths and the number of blocks in the images (Fig. 11). The more percentage is for a road line, it means that the road line detection by the corresponding algorithm is better, and the more blocks are, the detection result is better for the road network.

Multiple road tracing by different algorithms. a Original image b Manual c Otsu d Canny e Dynamic f FCM g Clustering h MST i Improved Retinex on (a) j Segmentation on (i) k Pre-D-S on (j) l Final result on (k)
As shown in Table 1, the simple similarity based algorithm Otsu thresholding [19, 26] separates the whole image into three main areas, the white color area is almost fitting block No.1; the black color area covers blocks No. 4,5,6,7,10,13 partly, without line shown up distinctly; and the blue color area includes six full blocks and distinct six road lines, since the result includes three large areas, there are only two lines are detected completely, and the other lines are just partly detected in the blue color area. The typical discontinuous algorithm Canny [2, 48] is not affected by uneven illumination, but the noise is too much in the result image (c), the road lines cannot be sown up clearly, e.g. some lines are shown up only 30–70% roughly, the more complicated post processing might be needed for road line/curve extraction completely.
When Dynamic thresholding [38], FCM, Clustering analysis and Minimum Spanning Tree algorithms [35, 38] are applied on the image respectively, Dynamic thresholding makes the segmentation result worst; FCM and Clustering analysis only extract two road lines which is not better that that by Otsu [19, 26], that means no matter if the algorithm is complicated or not, it is not available to this kind of vague images, and they cannot perform well as shown in Table 1, which might be affected by the image vague degree, which means that the more vague the image is, the road lines are harder detected. On contrast to the above algorithms, if the new image segmentation method performs on the vague road image, the processing results in the middle steps and the final step are satisfactory as shown in Fig. 11i-l and Table 1, even the length of road line 7 is shorter than that in manual segmentation result (b), which makes block number less than the real number, but this does not affect road line extraction much.
The original image in Fig. 12a is taken from public dataset [43], the images in (c) and (d) are the results of two Deep learning methods [21, 43]. Comparing to the ground truth in (b), the result image has the extra three segments at the image bottom, and the right part of the top road is missing; and in the result image in (c), from top to bottom, there is an extra section at the intersection of the second horizontal road and the vertical road. So, the results by Unet [43] and Liu’ s method [21] are not satisfactory. The algorithm in this study can achieve the satisfactory result, in the result image (e), a part of vertical road is missing at the bottom, and the reason is that in the original image, there is no that part which may be created by manual drawing.

In Fig. 13, the original image is taken from a public dataset [31], and it is processed by the semantic segmentation methods U-Net [31] and SegNet [1]. Comparing to ground truth, the result images in (c-d) have some parts missing. The result by the new algorithm has no missing part road, but has an extra short road at the top horizontal long road, which may be caused by tree noise at the roads.

In order to illustrate the extraction result better, a comprehensive evaluation routine is set up by counting correct road pixels, detected road pixels, error-detected road pixels and by utilizing artificial interpretation to determine the reference images. The reference images are as follows:
The detection rate can be set as PD = (correct detected road length/reference road length); the error-detected rate PF = (error detected road length/reference road length) and the test quality θ = (correct detected road length / (detected road length + non-detected road length)), which is referred to [14].
Judging from the preliminary test results, the approach in this paper can extract most of the roads in high-resolution aerial vague images and the results are satisfactory, and the detection accuracy (quality) is up to 89%. For the normal aerial image (non-vague), the detection rate is relatively high on average (over 92%), but the false alarm rate is also high, resulting in the decrease of the accuracy (quality) in some parts.
6 Conclusion
Based on the analyses and classification of the road features in vague aerial and remote sensing images, this paper proposes a new method (including several algorithms) for road detection. The first step is to combine the MSR algorithm and the Dark channel prior algorithm, then the dynamic scales in MSR for different image regions are obtained, and in this way the vague image can be enhanced well. The second step is to segment the enhanced image with two procedures: the segmentation based on the principle of the local gray scale consistency and shape feature fusion on the D-S evidence. In the new enhancement algorithm, the scale is not constant in the enhancing image, it takes different values in different regions, and the scale values are determined by the image depths obtained by using the algorithm of the Dark channel prior. For the image segmentation on local gray scale consistency, an eight-neighborhood template is considered as a processing unit in which a threshold is utilized for all the neighboring pixels. After roughly gray scale image segmentation, in the binary image, the road features are used based on D-S evidence theory, and the road feature parameters are determined according to the least external rectangle of a road segment. For the algorithm testing, the three hundreds of the typical vague aerial and remote sensing road images were selected, and the new method is compared to a number of traditional algorithms and recent semantic methods, and the experimental results show that the new method is satisfactory and much better than other exiting algorithms, and the road detection accuracy can be up to 89%.
In the near future, the multi-spectral and color image analyses will be studied to improve the quality and accuracy of the road detection results for more vague and complicated images. Besides, for the more complex vague images even with different resolutions, the thresholds for road detection in the algorithms in this study should be systematically and mathematically setup based on image quality and resolution, the accurate and quick road segment gap filling will be further studied.
References
Badrinarayanan V, Kendall A, Cipolla R (2017) SegNet: a deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans Pattern Anal Mach Intell 39(12):2481–2495. https://doi.org/10.1109/tpami.2016.2644615
Canny J (1986) A computational approach to edge detection. IEEE Trans Pattern Anal Mach Intell 8(6):679–698. https://doi.org/10.1109/TPAMI.1986.4767851
Chen JJ, Tian YL, Ma W, Mao Z, Hu Y (2020) Scale channel attention network for image segmentation. Multimed Tools Appl 80(6):1–17. https://doi.org/10.1007/s11042-020-08921-7
Dempster AP (1967) Upper and lower probabilities induced by a multivalued mapping. Ann Math Stat 38(2):325–339. https://doi.org/10.1214/AOMS/1177698950
Ding L, Tang H, Bruzzone L (2020) LANet: local attention embedding to improve the semantic segmentation of remote sensing images. IEEE Trans Geosci Remote Sens 59(1):426–435. https://doi.org/10.1109/TGRS.2020.2994150
Fan LX, Fan E, Yuan CG, Hu KL (2016) Weighted fuzzy track association method based on Dempster-Shafer theory in distributed sensor networks. Int J Distrib Sens Netw 12(7):15–21. https://doi.org/10.1177/1550147716658599
Fu J, Liu J, Tian HJ, Fang ZW, Lu HQ (2019) Scene segmentation with dual relation-aware attention network. IEEE Trans Neural Netw Learn Syst 32(6):2547–2560. https://doi.org/10.1109/TNNLS.2020.3006524
Gray M (1988) Collection of classic machine vision papers: Readings in computer vision Fischler, M A and Firschein, O Morgan Kaufmann (1987) 800 pp 18.95. Comput Aided Des 20(2):109–109. https://doi.org/10.1016/0010-4485(88)90060-7
He KM, Sun J, Tang XO (2011) Single image haze removal using dark channel prior. IEEE Trans Pattern Anal Mach Intell 33(12):2341–2353. https://doi.org/10.1109/TPAMI.2010.168
He ZW, Cao YP, Du L et al (2020) MRFN: multi-receptive-field network for fast and accurate single image super-resolution. IEEE Trans Multimedia 22(4):1042–1054. https://doi.org/10.1109/TMM.2019.2937688
He R, Guan M, Wen C (2021) SCENS: simultaneous contrast enhancement and noise suppression for low-light images. IEEE Trans Ind Electron 68(9):8687–8697. https://doi.org/10.1109/TIE.2020.3013783
Hong Z, Ming D, Zhou K et al (2018) Road extraction from a high spatial resolution remote sensing image based on richer convolutional features. IEEE Access, 2018, PP:1-1 6:46988–47000. https://doi.org/10.1109/ACCESS.2018.2867210
Hong GS, Kim BG, Dogra DP, Roy PP (2018) A survey of real-time road detection techniques using visual color sensor. J Multimed Inf Syst 5(1):9–14. https://doi.org/10.9717/JMIS.2018.5.1.9
Hu J, Razdan A, John C et al (2007) Road network extraction and intersection detection form aerial images by tracking road footprints. IEEE Trans Geosci Remote 45:4144–4157. https://doi.org/10.1109/TGRS.2007.906107
Hu KL, Ye J, Fan E, Shen S, Huang L, Pi J (2017) A novel object tracking algorithm by fusing color and depth information based on single valued neutrosophic cross-entropy. J Intell Fuzzy Syst 32(3):1775–1786. https://doi.org/10.3233/jifs-152381
Hu XX, Yang KL, Fei L et al (2019) ACNet: attention based network to exploit complementary features for RGBD semantic segmentation. IEEE international conference on image processing (ICIP) 1440-1444. https://doi.org/10.1109/ICIP.2019.8803025
Jaouen V, Bert J, Boussion N, Fayad H, Hatt M, Visvikis D (2019) Image Enhancement with PDEs and Nonconservative Advection Flow Fields. IEEE Trans Image Process 28(6):3075–3088. https://doi.org/10.1109/TIP.2018.2881838
Kim BG, Shim JI, Park DJ (2003) Fast image segmentation based on multi-resolution analysis and wavelets. Pattern Recogn Lett 24(16):2995–3006. https://doi.org/10.1016/S0167-8655(03)00160-0
Lamphar H (2020) Spatio-temporal association of light pollution and urban sprawl using remote sensing imagery and GIS: a simple method based in Otsu's algorithm. J Quant Spectrosc Radiat Transf 253:107068. https://doi.org/10.1016/j.jqsrt.2020.107068
Lian RB, Wang WX, Mustafa N, Huang L (2020) Road extraction methods in high-resolution remote sensing images: a comprehensive review. IEEE J Sel Top Appl Earth Observations and Remote Sensing 13:5489–5507. https://doi.org/10.1109/JSTARS.2020.3023549
Liu K (2021) Research on road network extraction algorithm in high resolution remote sensing images. Master thesis, Chang’an University in China
Liu S, Rahman MA, Lin CF, Wong CY, Jiang G, Liu SC, Kwok N, Shi H (2017) Image contrast enhancement based on intensity expansion-compression. J Vis Commun Image Represent 48:169–181. https://doi.org/10.1016/j.jvcir.2017.05.011
Mcclean S (2006) Evidence, dempster–Shafer theory of. John Wiley & Sons, New Jersey https://doi.org/10.1002/0471667196.ess1039.pub2
Movaghati S, Moghaddamjoo A, Tavakoli A (2010) Road extraction from satellite images using particle filtering and extended kalman filtering. IEEE Trans Geosci Remote Sens 48(7):1–11. https://doi.org/10.1109/TGRS.2010.2041783
Ngo D, Lee GD, Kang B (2019) Improved Color Attenuation Prior for Single-Image Haze Removal. Appl Sci 9(19):4011. https://doi.org/10.3390/app9194011
Otsu N (1979) A threshold selection method from gray-level histograms. IEEE Trans on System Man Cybernetics 9(1):62–66. https://doi.org/10.1109/tsmc.1979.4310076
Pal NS, Lal S, Shinghal K (2018) Visibility enhancement of images degraded by hazy weather conditions using modified non-local approach. Optik 163:99–113. https://doi.org/10.1016/j.ijleo.2018.02.067
Pandian SK, Poruran S (2021) An efficient approach for removing haze from single image using Gaussian pyramidal decomposition. Concurr Comput Pract Exp 33:e6279. https://doi.org/10.1002/cpe.6279
Parthasarathy S, Sankaran P (2012) An automated multi scale retinex with color restoration for image enhancement. In 2012 National Conference on Communications (NCC), February 3–5, 2012, Kharagpur, India, 1–5. https://doi.org/10.1109/NCC.2012.6176791
Prahara A, Akbar SA, Azhari A (2021) Texton based segmentation for road defect detection from aerial imagery. Int J Artif Intell Res 4(2):107. https://doi.org/10.29099/ijair.v4i2.179
Ronneberger O, Fischer P, Brox T (2015) U-net: convolutional networks for biomedical image segmentation. Medical image computing and computer-assisted intervention: 234-241. https://doi.org/10.1007/978-3-319-24574-4_28
Shafer G (2020) A mathematical theory of evidence. Princeton University Press, London
Suresh C (Nov. 2017) Raikwar and Shashikala Tapaswi (2018) an improved linear depth model for single image fog removal. Multimed Tools Appl 77:19719–19744. https://doi.org/10.1007/s11042-017-5398-y
Udomhunsakul S, Kozaitis SP, Sritheeravirojana U (2004) Semi-automatic road extraction from aerial images. SPIE Remote Sensing 5239:26–32. https://doi.org/10.1117/12.508365
Wang WX (2011) Colony image acquisition system and segmentation algorithms. Opt Eng 50(12):123001. https://doi.org/10.1117/1.3662398
Wang J (2021) Efficient occluded road extraction from high-resolution remote sensing imagery. Remote Sens 13:4974. https://doi.org/10.3390/rs13244974
Wang WX, Li HX (2020) Pavement crack detection on geodesic shadow removal with local oriented filter on LOF and improved level set. Constr Build Mater 237:117750. https://doi.org/10.1016/j.conbuildmat.2019.117750
Wang WX, Yang N, Zhang Y, Wang F, Cao T, Eklund P (2016) A review of road extraction from remote sensing images. J Traffic Transp Eng (Engl Ed) 3(3):271–282. https://doi.org/10.1016/j.jtte.2016.05.005
Wang WX, Wang MF, Li H, Zhao H, Wang K, He C, Wang J, Zheng S, Chen J (2019) Pavement crack image acquisition methods and crack extraction algorithms: a review. J Traffic Transp Eng (Engl Ed) 6(6):535–556. https://doi.org/10.1016/j.jtte.2019.10.001
Wang WX, Chen WW et al (2020) Extraction of tunnel center line and cross sections on fractional calculus and 3D invariant moments and best-fit ellipse. Opt Laser Technol 128:106220. https://doi.org/10.1016/j.optlastec.2020.106220
Wang WX, Li RQ, Wang K, Lang F, Chen W, Zhao B (2020) Crack and fracture central line delineation on Steger and hydrodynamics with improved fractional deferential. Int J Wavelets Multiresolution Inf Process 18(5):197–205. https://doi.org/10.1142/S021969132050037X
Wang WX, Li L, Han Y (2021) Crack detection in shadowed images on gray level deviations in a moving window and distance deviations between connected components. Constr Build Mater 271:121885. https://doi.org/10.1016/J.CONBUILDMAT.2020.121885
Xin J, Zhang XC, Zhang ZQ, Fang W (2019) Road extraction of high-resolution remote sensing images derived from dense U-net. Remote Sens 11(21):2499. https://doi.org/10.3390/rs11212499
Yeh C, Huang C, Kang L (2019) Multi-scale deep residual learning-based single image haze removal via image decomposition. IEEE Trans Image Process 29 (Dec. 2019):3153–3167. https://doi.org/10.1109/TIP.2019.2957929
Yoon T, Park W, Kim T (2002) Semi-automatic road extraction from IKONOS satellite image. Proceedings of SPIE - the International Society for Optical Engineering 4545. https://doi.org/10.1117/12.453690
Zhang SY, Wang WX, Liu S, Zhang X (2014) Image enhancement on fractional differential for road traffic and aerial images under bad weather and complicated situations. Transp Lett: the International Journal of Transportation Research 6(4):197–205. https://doi.org/10.1179/1942787514Y.0000000025
Zhao Q, Wu Y, Wang H, Li Y (2020) Road extraction from remote sensing image based on marked point process with a structure mark library. Int J Remote Sens 41(16):6183–6208. https://doi.org/10.1080/01431161.2020.1736731
Zhou L, Zhou Z, Ning H (2021) Road detection based on edge feature with GAC model in aerial image. Int J Pattern Recognit Artif Intell 35(14):2154032. https://doi.org/10.1142/S021800142154032X
Zhuang P, Li C, Wu J (2021) Bayesian retinex underwater image enhancement. Eng Appl Artif Intell 101:104171. https://doi.org/10.1016/j.engappai.2021.104171
Иванов ВК, Виноградова НВ, Палюх БВ, Сотников АН (2018) Современные направления развития и области приложения теории Демпстера-Шафера (обзор). Искусственный Интеллект и Принятие Решений 4:32-42. https://doi.org/10.14357/20718594180403
Acknowledgements
This research is financially supported by the National Natural Science Fund in China (grant no. 61170147) and the National Natural Science Key Fund in China (grant no. U1401252), and Zhejiang Provincial Natural Science Foundation of China (Grant No. LTY22F020003).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest disclosures
Authors in this paper declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Weixing, W., Limin, L. & Zhen, Z. Road extraction in vague images on gray scale consistency and improved MSR and D-S evidence. Multimed Tools Appl 81, 43657–43678 (2022). https://doi.org/10.1007/s11042-022-12994-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-022-12994-x