
Abstract
Cosplay has grown from its origins at fan conventions into a billion-dollar global dress phenomenon. To facilitate the imagination and reinterpretation of animated images as real garments, this paper presents an automatic costume-image generation method based on image-to-image translation. Cosplay items can be significantly diverse in their styles and shapes, and conventional methods cannot be directly applied to the wide variety of clothing images that are the focus of this study. To solve this problem, our method starts by collecting and preprocessing web images to prepare a cleaned, paired dataset of the anime and real domains. Then, we present a novel architecture for generative adversarial networks (GANs) to facilitate high-quality cosplay image generation. Our GAN consists of several effective techniques to bridge the two domains and improve both the global and local consistency of generated images. Experiments demonstrated that, with quantitative evaluation metrics, the proposed GAN performs better and produces more realistic images than conventional methods. Our codes and pretrained model are available on the web.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Costume play (cosplay) is a performance art in which people wear clothes to represent specific fictional characters from their favorite sources, such as manga (Japanese comics) and anime (cartoon animation). The popularity of cosplay has spanned the globe; for example, the World Cosplay Summit, which is an annual international cosplay event, attracted approximately 300,000 people from 40 countries in 2019 [38]. There are also astonishingly many domestic and regional cosplay contests and conventions involving diverse creative activities. To succeed at these events, it is crucial for cosplayers to wear attractive, unique, expressive cosplay looks. However, designing elaborate cosplay clothes requires imagining and reinterpreting animated images as real garments. This motivated us to devise a new system for supporting costume creation, which we call automatic costume image generation.
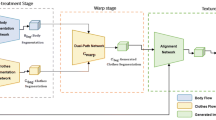
As shown in Fig. 1, our aim is to generate cosplay clothing item images from anime images. This task is a subtopic of image-to-image translation, which learns a mapping that can convert an image from a source domain to a target domain. Image-to-image translation has attracted much research attention, for which several generative adversarial networks (GANs) [7] have been presented. In the literature of fashion image translation, Yoo et al. [41] trained a network that converted an image of a dressed person’s clothing to a fashion product image using multiple discriminators. For the same task, Kwon et al. [16] introduced a coarse-to-fine scheme to reduce the visual artifacts produced by a GAN. These conventional methods were trained using a dataset of images collected from online fashion shopping malls. Specifically, the images were manually associated so that each pair consisted of a clothing product image and its fashion model correlate. This dataset is high-quality and less diverse because all the product images were taken in the same position and the dressed person usually stood up straight. However, our task of cosplay clothing synthesis presents a different hurdle to preparing such training images: the images are not be in consistent positions and cosplay items vary wildly in style and shape (e.g., dresses, kimonos, suits, sportswear, and school uniforms), so conventional methods cannot be directly applied.

Outline of the proposed system, the aim of which is to generate a real clothing image for a given anime character image. (Image: Natsu, Fairy Tail)
To solve this problem, this paper proposes a novel approach to cleaning a paired dataset constructed for the specific task of cosplay costume generation. In addition, we present a novel GAN for translating anime character images to clothing images. Our GAN architecture uses pix2pix [11] as the baseline model, to which we introduce additional discriminators and losses that have shown effectiveness in conventional work [37, 41]. To improve the quality of image generation, we present a novel loss, which we call input consistency loss, to fill the gap between the source domain (i.e., anime images) and the target domain (i.e., real clothing images). The results of experiments conducted using 35,633 image pairs demonstrated that our method performed better than the conventional methods in terms of three quantitative evaluation measures. Our new system will be useful not only for facilitating cosplay costume creation but also for other tasks, such as illustration-based fashion image retrieval. Figure 2 shows examples of the results produced by the proposed method. Our codes and the pretrained model that produced these images are available on the web.Footnote 1

Examples of images generated by our method. Ours represent the proposed method’s translated results. (Input images are: Gilgamesh, Fate/Grand Order; Imai Risa, BanG Dream!; Dekomori Sanae, Love, Chunibyo & Other Delusions; Nagakura Shinpachi, Hakuoki Shinsengumi Kitan; and Rengoku Kyojuro, Kimetsu no Yaiba)
The remainder of this paper is organized as follows: Section 2 describes related work. Section 3 presents a dataset-construction method for this specific task, which is one of the main novelties of this research. Section 4 presents a GAN-based anime-to-real translation method for generating cosplay costume images. Section 5 presents the results of the experiments conducted with a novel dataset constructed using the proposed method. Finally, in Section 6, we summarize the paper and recommend directions for future work.
2 Related work
GANs [7] have achieved remarkable results in many computer vision tasks, including with photograph editing, super resolution, image-to-text (and text-to-image) translation, and image-to-image translation. A GAN-based conditional generation approach (conditional GAN) [23] has been proposed to assign textual tags to an input image, followed by several applications. Examples of applying conditional GANs to the anime domain include anime colorization [4], anime face generation [12], and full body generation [8]. GANs have also been used to synthesize realistic-looking images [3]. A typical example of a fashion-synthesis application is a virtual try-on [9, 40, 44], which is closely related to our task. Virtual try-on methods generally translate between real clothes within images; specifically, clothes are deformed to fit body shapes and poses. However, our goal is to generate imaginary but realistic clothes given an anime image, requiring learning a mapping between different domains (i.e., real and anime).
In image-to-image translation, determining how to prepare a dataset for training models is a crucial problem. Conventional datasets can be divided into two types: paired and unpaired image datasets. A paired dataset consists of an image in a source domain and its corresponding image in a target domain, while an unpaired dataset does not associate images between the source and target domains. One of the most famous image-to-image translation models is pix2pix [11], which requires a paired dataset for supervised learning of the conditional GAN. Yoo et al. [41] used pix2pix to convert dressed person images to fashion product images. They presented a domain discriminator that judged whether an input pair was actually associated, which is used in addition to the conventional real/fake discriminator. To generate higher-resolution images, pix2pix has been improved with a novel adversarial loss, a multi-scale generator, and discriminator architectures; this advanced version is called pix2pixHD[37]. Collecting images paired across source and target domains is usually time-consuming, so unpaired image-to-image translation frameworks have also been studied [28, 34, 39]. Nonetheless, current methods still require images within a single domain to be consistent; for example, to transfer face images across different styles, both domains’ images should be taken in frontal views with a white background because a generator cannot directly learn the correspondence of shapes and colors across two domains. Thus, to achieve our goal, we used the paired dataset based framework and present a useful dataset-construction approach.
To improve the quality of generated images, various GAN techniques have been proposed, such as spectral normalization [24], coarse-to-fine schemes [13], and useful tips for training [10, 29]. The design of our architecture was inspired by these successful improvements. In particular, although our framework is based on a paired dataset, images within a source or target domain are highly diverse compared to conventional problems because anime characters often wear costumes that are much more elaborate than our daily clothing. To tackle this difficulty, we introduced a calibration strategy that aligns the position of cosplay costumes in images into the dataset construction. In addition, our GAN architecture is equipped with a novel loss that can make the features of input and output images similar.
3 Dataset construction by collecting web images
Our approach requires a dataset that consists of pairs of anime characters and their corresponding cosplay clothes. To the best of our knowledge, no public datasets comprising pairs of anime characters and clothing images is currently available online. Therefore, in this study, we focused on online cosplay shopping websites that have uploaded paired images (Fig. 3). To collect these images, we first selected our query keywords using a set of anime titles listed in existing datasets for anime recommendation [1, 5]. The query phrases used were “cosplay costumeA B,” in which A and B stood for one of the anime titles and one of 40 cosplay costume shop names, respectively. We downloaded the images returned by the search engine, the total size of which reached approximately 1 TB, including irrelevant and noisy images. To discard images that did not correspond to cosplay clothes or anime characters, we preprocessed all the images as follows: As shown in Fig. 4, we first removed unpaired images using an active learning framework (see Section 3.1). We then cropped image regions using an object detector and removed duplicate images (see Section 3.2). Finally, we calibrated the positions of the clothing images for effective GAN training (see Section 3.3).

Examples of web images we collected. ((a) Lucy, Elfen Lied (b) Ichigaya Arisa, BanG Dream! (c) Sophie, Howl’s Moving Castle, (d) Aqua, KonoSuba)

Dataset construction workflow. (Images: Eugeo, Sword Art Online; Monika, Doki Doki Literature Club!)
3.1 Removing unpaired images based on active learning
Image search results are often noisy and contain irrelevant images. To efficiently detect images that were unpaired or did not contain any clothes, this study used an active learning strategy [36], which requires manually inspecting a few samples to train the detector. Specifically, we first manually assigned binary labels to hundreds of images so that each label indicated whether or not the corresponding image contained a character–clothes pair. The labeled images were divided into a set of 2,760 training images and a set of 109 validation images, which we used to fine-tune the VGG-16 model that had been pretrained on ImageNet [32] to classify the desired pairs. We applied the detector to additional images and manually re-labeled false classification results produced by the model, producing a larger training set for the detector. Using the refined set of 3,052 training images and 215 validation images, we fine-tuned the model again to improve the performance of the detector. We applied the final detector to the whole dataset and removed images that were judged as negative. The resulting dataset was further checked, as described below.
3.2 Cropping image regions and detecting duplicates
For translation model training in this study, it was desirable for each anime character and its costume to be horizontally aligned within an image (Fig. 3 (a)–(c)). However, we found that some pairs did not have this layout, such as the one in Fig. 3 (d), which required realigning the images. To crop the characters and clothing from the images, we used a single-shot detector (SSD) [18] for object detection. Specifically, for the 1,059 images, we manually depicted the bounding boxes of anime characters and their clothing and used those for SSD training. The resulting model was used to detect the regions of anime characters and clothing for all images.
Because the dataset was constructed on the basis of web crawling, it contained sets of identical images. Such duplicate images in training and testing sets usually make the performance evaluation unfair. Therefore, to reduce the number of duplicate images, we used DupFileEliminator [26], a GUI-based application that can detect highly similar images in terms of color, brightness, and contrast. We set each similarity threshold to 90% and removed all images whose character regions were regarded as identical. The resulting dataset consisted of 35,633 pairs of anime characters and their cosplay clothing images.
3.3 Calibrating the clothing positions
Finally, we adjusted the positions of the training images to reduce the difficulty of GAN training. Figure 5 shows the workflow of our image calibration. Given a cropped image such as the one in Fig. 5 (a), we applied a super-resolution method provided by [20] to improve the image quality. The upper and lower figures in Fig. 5 (b) show the images before and after super-resolution, respectively. We further applied mirror padding and Gaussian blur to both sides of the target figure as shown in Fig. 5 (c). In the expanded image, to detect the clothing region, we applied a fashion key point detector [17] based on the cascaded pyramid network [2], which was pretrained using the Fashion AI Dataset[45]. The center position of the clothing was calculated using the detected keypoints (Fig. 5 (d)), and we obtained images where the center positions corresponded to those of clothing regions via cropping the image width (Fig. 5 (e)). Table 1 summarizes the resulting dataset.

The workflow for calibrating the position of clothing images
4 Translating anime character images into clothing images
In this section, we propose a method for translating an anime character image into a cosplay clothing image. The conventional pix2pix [11] is not suitable for translations that involve great changes in the shapes of target objects and would therefore have difficulty in translating an anime character image into a cosplay image, as Section 4.1 explains. Our GAN architecture used pix2pix [11] as a backbone, and we introduced a novel loss with useful techniques, which Section 4.2 presents.
4.1 The pix2pix baseline
The pix2pix framework consists of a generator G and domain discriminator Dd. A paired dataset of training images is denoted by {(x,y)}, where x is an anime character image and y is a cosplay clothing image. The aim was to make the input image closer to the target image by employing the following minimax game:
where λ controls the importance of the two terms, and the objective function \({\mathscr{L}}_{GAN_{domain}}(G,D_{d})\) and the L1 loss function \({\mathscr{L}}_{L_{1}} (G)\) are defined as
The pix2pix framework adopts the U-Net [27] as G and a patch-based, fully convolutional network [21] as Dd. The U-Net has a contracting path between the encoder and the decoder of the conventional auto encoder, which contributes to high-quality image generation. The discriminator judges whether local image patches are real or fake, which improves the detail of the generated images.
As seen in (1), pix2pix combines adversarial learning and the L1 loss. Minimizing the L1 loss allows learning the correspondence of shapes and colors between two image domains whose visual compositions are closely related (e.g., building images and their semantic segmentation images [6]). However, in the case of translating from an anime character image to a cosplay clothing image, the shapes of objects do not correspond and so cannot be captured well by the L1 loss. Furthermore, adversarial learning that focuses on local image patches lacks the ability to improve the global quality of generated images.
4.2 The proposed GAN architecture
To solve the above problems with applying the conventional pix2pix framework in our task, we present a novel GAN architecture with an improved domain discriminator (see Section 4.2.1). To boost the generation quality, our GAN has additional functions: a real/fake discriminator (see Section 4.2.2) and feature-matching loss (see Section 4.2.3). We propose a novel loss that maintains consistency between input and output images (see Section 4.2.4). The final objective function for training our GAN is described in Section 4.2.5. Figure 6 shows the overall architecture of our GANs, and Fig. 7 shows the architectures of our discriminators.

Overview of the proposed GAN architecture

Structures of our model’s discriminators
4.2.1 Improved domain discriminator
For effective anime-to-real translation, two techniques were used to improve the domain discriminator Dd. First, to stabilize high-quality image generation from coarse to fine levels, we extended the discriminator to a multi-scale architecture [37], as shown in Fig. 7 (a). Specifically, using three discriminators (D1, D2, and D3) with identical network structures but different image scales, the objective is modified as a multi-task learning of
Solving this problem guides the generator G to generate globally consistent images, keeping fine details. We applied spectral normalization [24] to each discriminator to satisfy the Lipschitz constraint.
Second, we designed a modified supervision of the domain discriminator. The original pix2pix’s domain discriminator determines whether an input image and a generated image are paired; specifically, given an input image, it regards its real ground truth (GT) image and any synthesized image as true and false, respectively. However, this supervision is too weak to capture the relationship between the anime and real domains. Inspired by related work [41], we added new False judgments: for each input image, we gave other images false labels when they were real clothes but did not correspond to the input image’s truly associated image. This new associated/unassociated supervision can facilitate the transfer of an anime character image into a more realistic, relevant clothing image.
4.2.2 Real/fake discriminator
Using the domain discriminator alone, it is difficult to generate images with substantial shape changes, such as a translation from anime characters to clothing images. This is because the domain discriminator only determines whether the two input images are associated or unassociated and does not specialize in the quality of the generated image. To improve the image quality, we needed to use a discriminator that checked the quality of the generated image, which is called a real/fake discriminator [41]. Hereafter, the real/fake discriminator is denoted as Dr.
Like the improved domain discriminator, this real/fake discriminator should also contribute to high-quality image generation. Here, to maintain local consistency, we propose a multi-scale patch discriminator similar to the structure reported in [30]. As shown in Fig. 7 (b), our multi-scale patch discriminator outputs three different patches: 1 × 1, 13 × 13, and 61 × 61 feature maps. These different discriminators are denoted as \(D_{r_{1}}\), \(D_{r_{2}}\), and \(D_{r_{3}}\), respectively. Using multiple patch sizes allows for capturing both fine-grained details and coarse structures in the image. The GAN generates images via the following minimax game:
where the objective function \({\mathscr{L}}_{GAN_{real/fake}}(G,D_{r})\) is given by
We also applied spectral normalization to each discriminator.
4.2.3 Feature matching loss
The feature matching loss was originally presented by [37] to generate an image closer to a corresponding real one. For a given pair of real and synthesized images, it is computed as the L1 loss between the outputs of the intermediate layer of a discriminator. We designated D(i) as the i-th layer of the discriminator. In the proposed method, the feature matching loss based on the domain discriminator and the feature matching loss based on the real/fake discriminator are defined as follows:
where T is the total number of layers, and Ni denotes the number of elements in each layer [37].

Overview of calculating the input consistency loss, which is based on the L1 loss of the matrix extracted from the intermediate layers of the discriminator
4.2.4 Input consistency loss
In our task, the generator had to generate real clothing images that retained the detailed shape and color information of their original anime character images. To maintain consistency between the input images and their corresponding output images, we propose a method to minimize the differences between them called input consistency loss. Figure 8 shows our calculation overview. As shown, we computed the L1 loss over all the intermediate layers as follows:

The structure of our U-Net generator. (Image: Sakai Wakana, TARI TARI)
4.2.5 Training
Finally, using the U-Net as the generator whose structure is shown in Fig. 9, our full objective was calculated based on the combination of the GAN objectives, the feature matching loss, and the input consistency loss as follows.
Training GANs based on high-resolution images often results in the gradient problem and takes a lot of computation time. To alleviate this problem, we used a coarse-to-fine scheme to train the GAN [13]. This scheme progressively grows both the generator and discriminator: starting with low-resolution images, we added new layers that introduced higher-resolution details as the training progressed. The effectiveness of this coarse-to-fine scheme was also investigated in the experiments.
5 Experimental evaluation
5.1 Implementation details
We divided the dataset into 32,608 training images and 3,025 testing images. All the networks were trained using the Adam optimizer [14] with an initial learning rate α = 0.0002 and momentum parameters β1 = 0.5 and β2 = 0.99 on two NVIDIA RTX 2080Ti GPUs. After 70 epochs, the learning rate α was linearly decayed over the next 30 epochs. The initial weights were sampled from the normal distribution with a mean of zero and a standard deviation of 0.02. To avoid overfitting, we applied the following data-augmentation techniques [31] to the input anime images: three-degree random rotations, a random crop, and a hue and saturation jitter of 0.05. We also applied random horizontal flips to the clothing images. For the adversarial loss of the GANs, we used the squared difference, as proposed for LSGANs [22]. Throughout all the experiments, we used λ = 10 in Eq. (10) and N1 = 5, N2,3,4 = 1.5, and N5 = 1 in Eqs. (7) and (8).
5.2 Evaluation metrics
The performance of a paired image-to-image translation system should be evaluated from two points of view: image-based similarities and distribution-based similarities. First, because every source image of a system has a corresponding target image, the generated and target images should be similar. Second, images generated in the same domain can reasonably be assumed to be sampled from an identical probability distribution, so the probability distributions followed by the sets of generated and target images should be similar. The first and second points were measured using learned perceptual image patch similarity (LPIPS) [42] and the Fréchet inception distance (FID) [10], respectively.
Learned perceptual image patch similarity (LPIPS) [42] : LPIPS quantifies how similar two images are using feature vectors extracted from the intermediate layer of the AlexNet [15]. A lower LPIPS value means that the generated image is perceptually more like the actual image.Footnote 2
Fréchet inception distance (FID) [10]: Assuming that images in the same domain are sampled from an identical probability distribution, the FID measures the divergence between the two probability distributions followed by the sets of generated and target images, respectively. Specifically, the FID computes the Wasserstein-2 distance between distributions approximated with the Gaussian, which were estimated using the vectors extracted from the intermediate layer of the inception networks [33] when inputting the generated and target images. The FID score should decline as an image synthesis system improves. Our experiments prepared two Inception v3 models for FID calculation: a public model that was pretrained using ImageNet and another that was fine-tuned for a fashion domain. Specifically, the latter was trained using 289,222 images from the DeepFashion database [19] so that it could recognize 50 fine-grained clothes categories in the Category and Attribute Prediction Benchmark.Footnote 3 The domain-transferred model can evaluate the differences between images focusing on clothing-specific visual features. The scores calculated using the former and latter models are denoted by FID and FIDFashion, respectively.
5.3 Comparing different configurations of the proposed method

Results of image generation with different configurations (a)–(i), which correspond to the rows of Table 2. GT stands for “ground truth”. (Input images are: Tsurumaru Kuninaga, Touken Ranbu; Sakai Wakana, TARI TARI; Sakurauchi Riko, Love Live! Sunshine!!; Gamagori Ira, Kill la Kill; Ginko, Mushishi; Yona, Akatsuki no Yona; Kitashirakawa Tamako, Tamako Market; and Tateyama Ayano, Kagerou Project)
To evaluate the effectiveness of the techniques described in Section 4.2, we experimented with several configurations of the proposed method. Table 2 shows the quantitative evaluation results. The baseline (a) used the conventional pix2pix [11], as explained in Section 4.1. In (b), we added the coarse-to-fine scheme, where we changed the size of the discriminator’s feature maps from 70 × 70 to 1 × 1.Footnote 4 In (c), we calibrated the positions of all the clothing images to validate the effectiveness of our dataset-construction approach. In (d), we added the real/fake discriminator [41]. This discriminator significantly improved the two types of FID scores compared with (c). It enabled the generator to output images similar to the GT images. In (e), we added unassociated pairs with False labels to the domain discriminator’s training. In (f), we applied spectral normalization to each discriminator, which made the training stable and significantly improved the two types of FID scores. In (g), we used the multi-scale discriminator Dd. In (h), we used the multi-scale patch discriminator Dr, improving the FID scores. In (i), we added the feature-matching losses \({\mathscr{L}}_{FM_{domain}} (G,D_{d})\) and \({\mathscr{L}}_{FM_{real/fake}} (G,D_{r})\). These contributed to generating images that captured global and local consistency, improving all performance measures, compared with (h). Finally, in (j), we added the input consistency loss, completing the proposed method. Our method achieved the best FID and FIDfashion scores as well as a better LPIPS score than the baseline. Figure 10 shows the clothing image-generation results of each configuration for eight testing images. We observed in Fig. 10 that adding each technique to the architecture effectively improved image quality. In particular, as shown in Fig. 10 (h) and Fig. 10 (j), the multi-scale patch discriminator Dr and the input consistency loss contributed to describing the textures in detail.
5.4 Comparing the proposed method with conventional methods
Using the dataset constructed with our approach outlined in Section 3, we compared our method with the following conventional methods:
-
CycleGAN [43]: The CycleGAN is a typical unpaired image-to-image translation method. We trained it by regarding our dataset as unpaired and following its official implementation with a batch size of 1.
-
Pixel-level domain transfer (PLDT) [41]: PLDT was trained with a batch size of 128. Because the resolution of PLDT’s outputs was originally 64 × 64, it was enlarged to 256 × 256 using the bicubic interpolation based on 4 × 4 pixels.
-
Pix2pix [11]: The pix2pix was trained with the batch size of 1, using its official implementation.
-
pix2pixHD [37]: The pix2pixHD was trained with a batch size of 16 and a resolution of 256 × 256, using its official implementation.
-
SPADE [25]: SPADE is a state-of-the art image-to-image translation method with conditional normalization layers. For a fair comparison, we modified it to work, not with semantic segmentation maps, but our input images. It was trained with a batch size of 1 using its official implementation.
All the GANs were trained using the same data augmentation as ours. Table 3 shows a comparison with the conventional image-to-image translation methods in terms of FID, FIDfashion, LPIPS, and the number of parameters used in each model’s generator. Note that the difference between the baseline in Table 2 (a) and pix2pix in Table 3 is whether or not the proposed dataset calibration approach was used. As shown, our method performed better on all measures. PLDT had no L1 loss, and its training was unstable. Although pix2pixHD is an advanced version of pix2pix, it suffered from overfitting and failed to generate high-quality images. SPADE is based on the instance normalization and needs to learn 92.06 million parameters of its generator, which requires a huge amount of training time in our computation environment. We also found from the FIDfashion scores that the images generated by SPADE were less consistent with their GT images in terms of fashion-related visual features than the images generated by our method, implying the need of constructing domain-transfer strategies to use SPADE in our task.

Comparisons with the conventional image-to-image translation methods. GT stands for “ground truth”. (Input images are: Asaka Karin, Love Live! School Idol Festival; Jin, Samurai Champloo; Shirakiin Ririchiyo, Inu×Boku SS; Sonoda Umi, Love Live! Sunshine!!; and Kirito, Sword Art Online)
Figure 11 shows the clothing image-generation results obtained by the proposed method and the conventional methods for five testing images. Characters in these testing images wore diverse, complex costumes. CycleGAN failed to generate real clothing images, indicating the difficulty of treating our task as an unpaired one and confirming the usefulness of our automatic approach to constructing a paired dataset. We also found that conventional methods tended to paint images with smooth textures and did not reflect the detailed shapes of input anime clothes. Their discriminators had difficulty finding the correspondences between input anime images and output clothing images because these two domains are significantly different in terms of body balances, poses, and shapes. However, the proposed method effectively produced more realistic, fine-grained images than conventional methods. Our input consistency loss found the correspondences between paired images via feature matching at intermediate layers, which made the shapes of the generated clothes similar to their corresponding anime clothes. Our pretrained model, which is available on the web, thus demonstrated that it could produce such clothing images for any anime character image. Note that the proposed method not only accepts multi-channel images, such as RGB color images, but also grayscale images. Our preliminary experiments, the detailed results of which are not shown due to space limitations, confirmed that the proposed method performed better than the conventional methods, even when converting all images in the dataset to grayscale.
6 Conclusion and further work
This paper proposed a novel method for translating anime character images into clothing images to facilitate cosplay costume creation. We first described an approach to constructing a clean, paired dataset for our task. Then, we presented a novel GAN architecture equipped with several techniques to bridge anime and real clothing and improve the generated image quality. The experiments conducted using our dataset demonstrated that the proposed GAN performed better than several existing methods in terms of both FID, fashion-focused FID, and LPIPS. We also showed that the images generated by the proposed method were more realistic than those generated by conventional methods using five testing images. In particular, we found that an unpaired image-to-image translation method failed to generate target cosplay clothing images, validating the importance of constructing a paired dataset to bridge two different domains.
Our method still has room for improvement. Although our dataset calibration was effective for GAN training, outliers may exist in the noisy images. The proposed input consistency loss was calculated based on the L1 loss between an input anime character and its synthesized clothes image, assuming the body proportions of the characters to be relatively constant over all the training images. If the face or head of a character in the input image is significantly larger than its clothes (e.g., Hello KittyFootnote 5), the current generator might fail to output a relevant clothing image: the clothes’ colors and shapes are affected by the face or head. We plan to develop a more sophisticated approach that considers the pixel-level correspondence between inputs and outputs, and we plan to investigate how to transform an input character’s body shape to be consistent throughout the dataset.
Notes
Please note that this metric name is “similarity,” but the smaller it is, the more similar it is.
http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/AttributePrediction.html
References
Azathoth (2018) MyAnimeList Dataset: contains 300k users, 14k anime metadata, and 80mil. ratings from MyAnimeList.net. https://www.kaggle.com/azathoth42/myanimelist. Accessed 19 Aug 2020
Chen Y, Wang Z, Peng Y, Zhang Z, Yu G, Sun J (2018) Cascaded Pyramid Network for Multi-Person Pose Estimation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 7103–7112
Cheng W-H, Song S, Chen C-Y, Hidayati SC, Liu J (2020) Fashion Meets Computer Vision: A Survey. arXiv:2003.13988
Ci Y, Ma X, Wang Z, Li H, Luo Z (2018) User-guided deep anime line art colorization with conditional adversarial networks. In: Proceedings of the 26th ACM international conference on multimedia, pp 1536–1544
CooperUnion (2016) Anime Recommendations Database: Recommendation data from 76,000 users at myanimelist.net. https://www.kaggle.com/CooperUnion/anime-recommendations-database. Accessed 19 Aug 2020
Cordts M, Omran M, Ramos S, Rehfeld T, Enzweiler M, Benenson R, Franke U, Roth S, Schiele B (2016) The Cityscapes Dataset for Semantic Urban Scene Understanding. In: Proceedings of the IEEE Conferene on Computer Vision and Pattern Recognition, pp 3213–3223
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative Adversarial Nets. In: Advances in Neural Information Processing Systems, pp 2672–2680
Hamada K, Tachibana K, Li T, Honda H, Uchida Y (2018) Full-Body High-Resolution Anime Generation with Progressive Structure-Conditional Generative Adversarial Networks. In: European Conference on Computer Vision. Springer, pp 67–74
Han X, Wu Z, Wu Z, Yu R, Davis L S (2018) Viton: An Image-based Virtual Try-on Network. In: Proceedings of the IEEE Conferene on Computer Vision and Pattern Recognition, pp 7543–7552
Heusel M, Ramsauer H, Unterthiner T, Nessler B, Hochreiter S (2017) GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In: Advances in Neural Information Processing Systems, pp 6626–6637
Isola P, Zhu J-Y, Zhou T, Efros A A (2017) Image-to-Image Translation with Conditional Adversarial Networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 1125–1134
Jin Y, Zhang J, Li M, Tian Y, Zhu H, Fang Z (2017) Towards the Automatic Anime Characters Creation with Generative Adversarial Networks. arXiv:1708.05509
Karras T, Aila T, Laine S, Lehtinen J (2017) Progressive Growing of GANs for Improved Quality, Stability, and Variation. arXiv:1710.10196
Kingma DP, Ba J (2014) Adam: A Method for Stochastic Optimization. arXiv:1412.6980
Krizhevsky A, Sutskever I, Hinton G E (2012) ImageNet Classification with Deep Convolutional Neural Networks. In: Advances in Neural Information Processing Systems, pp 1097–1105
Kwon Y, Kim S, Yoo D, Yoon S-E (2019) Coarse-to-Fine Clothing Image Generation with Progressively Constructed Conditional GAN. In: 14th International Conference on Computer Vision Theory and Applications, SCITEPRESS-Science and Technology Publications, pp 83–90
Li V (2018) FashionAI KeyPoint Detection Challenge Keras. https://github.com/yuanyuanli85/FashionAI_KeyPoint_Detection_Challenge_Keras. Accessed 19 Aug 2020
Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C-Y, Berg AC (2016) SSD: Single Shot Multibox Detector. In: European Conference on Computer Vision. Springer, pp 21–37
Liu Z, Luo P, Qiu S, X, Tang X (2016) DeepFashion: Powering robust clothes recognition and retrieval with rich annotations. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp 1096–1104
lltcggie (2018) Waifu2x-Caffe. https://github.com/lltcggie/waifu2x-caffe. (Last accessed: 19/08/2020)
Long J, Shelhamer E, Darrell T (2015) Fully Convolutional Networks for Semantic Segmentation. In: Proceedings of the IEEE Conferene on Computer Vision and Pattern Recognition, pp 3431–3440
Mao X, Li Q, Xie H, Lau RY, Wang Z, Paul Smolley S (2017) Least Squares Generative Adversarial Networks. In: Proceedings of the IEEE International Conference on Computer Vision, pp 2794–2802
Mirza M, Osindero S (2014) Conditional Generative Adversarial Nets. arXiv:1411.1784
Miyato T, Kataoka T, Koyama M, Yoshida Y (2018) Spectral Normalization for Generative Adversarial Networks. arXiv:1802.05957
Park T, Liu M-Y, T-C, Zhu J-Y (2019) Semantic Image Synthesis with Spatially-Adaptive Normalization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 2337–2346
ripobi-tan (2016) DupFileEliminator. https://www.vector.co.jp/soft/winnt/util/se492140.html. Accessed 19 Aug 2020
Ronneberger O, Fischer P, Brox T (2015) U-Net: Convolutional Networks for Biomedical Image Segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, pp 234–241
Royer A, Bousmalis K, Gouws S, Bertsch F, Mosseri I, Cole F, Murphy K (2020) XGAN: Unsupervised Image-to-Image Translation for Many-to-Many Mappings. In: Domain Adaptation for Visual Understanding. Springer, pp 33–49
Salimans T, Goodfellow I, Zaremba W, Cheung V, Radford A, Chen X (2016) Improved Techniques for Training GANs. In: Advances in Neural Information Processing Systems, pp 2234–2242
Shocher A, Bagon S, Isola P, Irani M (2018) InGAN: Capturing and Remapping the ``DNA” of a Natural Image. arXiv:1812.00231
Shorten C, Khoshgoftaar TM (2019) A Survey on Image Data Augmentation for Deep Learning. J Big Data 6(1):60
Simonyan K, Zisserman A (2014) Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv:1409.1556
Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z (2016) Rethinking the Inception Architecture for Computer Vision. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 2818–2826
Tang H, Xu D, Sebe N, Yan Y (2019) Attention-Guided Generative Adversarial Networks for Unsupervised Image-to-Image Translation. arXiv:1903.12296
Ulyanov D, Vedaldi A, Lempitsky V (2017) Improved Texture Networks: Maximizing Quality and Diversity in Feed-forward Stylization and Texture Synthesis. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 6924–6932
Vijayanarasimhan S, Grauman K (2011) Cost-Sensitive Active Visual Category Learning. Int J Comput Vis 91(1):24–44
Wang T-C, Liu M-Y, Zhu J-Y, Tao A, Kautz J, Catanzaro B (2018) High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 8798–8807
WCS Inc. (2019) What’s WCS?. https://en.worldcosplaysummit.jp/championship2019-about. 24 May 2020
Wu W, Cao K, Li C, Qian C, Loy CC (2019) Transgaga: Geometry-Aware Unsupervised Image-to-Image Translation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 8012–8021
Wu Z, Lin G, Tao Q, Cai J (2019) M2E-Try On Net: Fashion from Model to Everyone. In: Proceedings of the 27th ACM International Conference on Multimedia, pp 293–301
Yoo D, Kim N, Park S, Paek AS, Kweon IS (2016) Pixel-Level Domain Transfer. In: European Conference on Computer Vision. Springer, pp 517–532
Zhang R, Isola P, Efros AA, Shechtman E, Wang O (2018) The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 586–595
Zhu J-Y, Park T, Isola P, Efros AA (2017) Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In: Proceedings of the IEEE International Conference on Computer Vision, pp 2223–2232
Zhu S, Urtasun R, Fidler S, Lin D, Change Loy C (2017) Be Your Own Prada: Fashion Synthesis with Structural Coherence. In: Proceedings of the IEEE International Conference on Computer Vision, pp 1680–1688
Zou X, Kong X, Wong W, Wang C, Liu Y, Cao Y (2019) FashionAI: A Hierarchical Dataset for Fashion Understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp 296–304
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Koya Tango and Marie Katsurai contributed equally.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tango, K., Katsurai, M., Maki, H. et al. Anime-to-real clothing: Cosplay costume generation via image-to-image translation. Multimed Tools Appl 81, 29505–29523 (2022). https://doi.org/10.1007/s11042-022-12576-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-022-12576-x