
Abstract
COVID-19 disease is a major health calamity in twentieth century, in which the infection is spreading at the global level. Developing countries like Bangladesh, India, and others are still facing a delay in recognizing COVID-19 cases. Hence, there is a need for immediate recognition with perfect identification of infection. This clear visualization helps to save the life of suspected COVID-19 patients. With the help of traditional RT-PCR testing, the combination of medical images and deep learning classifiers delivers more hopeful results with high accuracy in the prediction and recognition of COVID-19 cases. COVID-19 disease is recently researched through sample chest X-ray images, which have already proven its efficiency in lung diseases. To emphasize corona virus testing methods and to control the community spreading, the automatic detection process of COVID-19 is processed through the detailed medication reports from medical images. Although there are numerous challenges in the manual understanding of traces in COVID-19 infection from X-ray, the subtle differences among normal and infected X-rays can be traced by the data patterns of Convolutional Neural Network (CNN). To improve the detection performance of CNN, this paper plans to develop an Ensemble Learning with CNN-based Deep Features (EL-CNN-DF). In the initial phase, image scaling and median filtering perform the pre-processing of the chest X-ray images gathered from the benchmark source. The second phase is lung segmentation, which is the significant step for COVID detection. It is accomplished by the Adaptive Activation Function-based U-Net (AAF-U-Net). Once the lungs are segmented, it is subjected to novel EL-CNN-DF, in which the deep features are extracted from the pooling layer of CNN, and the fully connected layer of CNN are replaced with the three classifiers termed “Support Vector Machine (SVM), Autoencoder, Naive Bayes (NB)”. The final detection of COVID-19 is done by these classifiers, in which high ranking strategy is utilized. As a modification, a Self Adaptive-Tunicate Swarm Algorithm (SA-TSA) is adopted as a boosting algorithm to enhance the performance of segmentation and detection. The overall analysis has shown that the precision of the enhanced CNN by using SA-TSA was 1.02%, 4.63%, 3.38%, 1.62%, 1.51% and 1.04% better than SVM, autoencoder, NB, Ensemble, RNN and LSTM respectively. The comparative performance analysis on existing model proves that the proposed algorithm is better than other algorithms in terms of segmentation and classification of COVID-19 detection.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The Severe acute respiratory syndrome Corona virus 2(Sars-Cov-2), which is also called as Corona Virus Disease-19 (COVID-19) virus comes from the corona virus family [10]. This virus induces illness starting from communicable diseases like fever, common cold to severe respiratory diseases, which leads to difficulty in breathing [26]. In December 2019, this novel corona virus is initially reported in Wuhan, China that is now started to spreading in other countries around world-wide. The World Health Organization (WHO) officially declared the Corona virus explosion a pandemic on March 11, 2020. Due to this COVID-19 virus, people's lifestyle and healthcare [25] sectors are tremendously affected around the world. The latest reports have portrayed that the global death record has exceeded over 578 K. Among them, the US is the most affected country with confirmed cases of 3.48 M (as of July 2020), and significantly there were 7.37 M of the people relieved from the disease [34]. Due to this difficult pandemic situation, most of the countries have announced a whole lockdown to stop the virus from spreading across the people. The people are affected by COVID-19, including both asymptomatic and symptomatic cases [39]. So, it is important to test the people who have the infection and also the people who have contact with affected people [2].
The COVID-19 infection easily spreads among humans by its aerosols kind of nature, especially by means of the sneeze, cough, or any other kind of physical contact [19]. Even though this virus affects people regardless of age group, most of the elderly aged people and the people who are already affected with cardiovascular diseases, cancer, diabetes, and respiratory diseases are targeted easily. The COVID-19 infection has some common symptoms such as fever, dry cough, exhaustion, and body pain [31]. Still, sometimes these mild symptoms start to grow around 5 to 6 days with severe symptoms such as high fever and breathing difficulty after being affected by the virus. Even though specific drugs, possible vaccines, and plasma-therapy treatment are being examined and implemented on sample subjects [14], there are no clinically proven medicines against this disease up-to-date. The rehabilitation of this disease is mainly based on the immunity power of the people who are all affected [13]. Moreover, precaution is better than cure, so the WHO advises taking necessary preventive options such as basic personal hygienic measures and social distancing [37]. It also recommends real-time Polymerase Chain Reaction (PCR) testing that identifies the presence of antigen from the respiratory samples for COVID-19 detection [40]. The test results are usually acquired in a few hours to two days, which is considered as a critical phase according to the treatment rules. Rapid Diagnostic Test (RPT) is another diagnostic testing method to identify the presence of viral proteins which in respiratory samples.
The disease is rapidly diagnosed by many kinds of automatic detection that reduce the work pressure of doctors and also useful for treating the patients at the appropriate time and reduces the dead counts [1]. The X-Ray images develop the observation and identification of automatic detection with various computational approaches based on machine learning. It is a combination of methods essentially focused on classifying and automatically extracting the images. Deep learning is experienced in the fields of segmentation, classification, and medical image recognition [38]. In the last five years, deep learning applications have enhanced and empower experimenters to analyze X-Ray scans [30]. Deep learning is based on machine learning, and it offers automatic learning of realistic features from new data sets [15]. CNN is a technique that provides a major contribution in the medical field to develop deep learning techniques, such as “Deep Boltzmann Machine (DBM), Stacked Auto-Encoder (SAE), and Deep Belief Network (DBN)” [27]. The emergence of deep learning in the medical field helps researchers to focus on automatic detection models [17].
The main contribution of the lung segmentation and classification model of the proposed COVID-19 detection model is given here.
-
To propose a new COVID-19 detection model by innovative approaches like AAF-U-Net segmentation with EN-CNN-DL based classification through SA-TSA algorithm for improving the accuracy of outcomes.
-
To develop an enhanced lung segmentation method using AAF-U-Net with developed SA-TSA algorithm by optimizing the activation functions of U-Net with the aim of maximizing the accuracy and precision rate of segmented images.
-
To establish a novel SA-TSA algorithm for developing a new lung segmentation and classification techniques by optimizing the activation functions of U-Net and through optimizing the hidden neurons of CNN, kernel of SVM, Gaussian function in NB and hidden neurons in auto encoder.
-
To examine the efficiency of segmentation and classification phases on COVID-19 model by estimating with various performance metrics through comparing with the existing algorithms and classifiers.
The rest of the sections of this paper are given here. Section II discusses the existing methodologies, their advantages, and their challenges. Section III briefly reviews the enhanced lung segmentation and classification process using X-ray images for COVID-19 detection model. Section IV presents the lung segmentation by the proposed AAF-U-Net model. Section V elaborates the ensemble learning with CNN-based deep features for COVID-19 detection. Section VI analyzes the performance of the COVID-19 classification model. Section VII concludes the COVID-19 detection model.
2 Literature survey
2.1 Related works
In 2020, Karthik et al. [21] have developed a unique CNN architecture, which has convolutional filter patterns that would return only a specific COVID-19 class by prohibiting some filters in the convolutional layer. The CNN architecture has included various types of convolutional methods to obtain a better framework for increasing gradient flow and learning robust features between layers. The specific pneumonia classes were identified using deep learning, which acquired custom filters inside one convolutional layer. The proposed work has compared several methods for COVID-19 through X-ray images with improved accuracy.
In 2021, Sheykhivand et al. [33] have developed a new method for the automatic detection of COVID-19 using a deep neural network. The X-ray images were classified into 4 classes such as bacterial, viral, COVID-19, and healthy classes.“The Generative Adversarial Networks (GANs) and Long Short Term Memory (LSTM) networks” were used together with a combination of the deep transfer learning that doesn't include the feature extraction to diagnosis pneumonia. The deep transfer learning networks such as “Inception V4, MobileNet, Inception-ResNet V2 and Inception V4” were compared with the deep proposed network, and the results generated over the developed model were improved on the basis of precision, specificity, sensitivity, and accuracy. The proposed method has been used in the real time treatment based on its high performance.
In 2020, Panwar et al. [28] have proposed an algorithm on the basis of deep transfer learning that has enhanced the recognition of COVID-19. The proposed algorithm has used X-ray images and CT-Scan of chest. Later, the primary screening of these images has delivered the proper information in the identification of assumed COVID-19 cases. There were 3 datasets used for this method namely “Chest X-ray images (Pneumonia), COVID-chest X-ray and SARS-COV-2 CT-scan”. The results have revealed that the developed model has recognised the positive cases in less than two seconds, which was earlier when compared to existing RT-PCR screening. Grad-CAM was another approach, which was implemented based on colour visualization method to create a typical pattern between COVID-19 and Pneumonia radiology images for future use.
In 2021, Ismael and Sengur [18] have suggested a new end-to-end training model based on CNN. The superior classification accuracy of this experimental study was attained on “two hundred healthy and one hundred and eighty COVID-19 datasets”. The profound features have obtained from the SVM classifier, and ResNwt50 model with the input Linear Kernel function attained 94.7% accuracy. The success of the tuned end-to-end training model was found to be 91.6% and ResNet50 produced 92.6% result. The deep approaches were compared with SVM classifiers and different types of local texture descriptors and the obtained results has shown that the performance of deep approaches was high when compared to existing models in the recognition of COVID-19 through chest X-ray images.
In 2021, Hussain et al. [16] have proposed a CoroDet based novel CNN model for automatic recognition of COVID-19 through chest X-rays and CT scan images. The proposed model has produced the accurate diagnosis with 2 class (Normal and COVID), 3 class classifications (non-COVID pneumonia, COVID and Normal) and 4 class classifications (Normal, non-COVID pneumonia, non-COVID viral pneumonia and COVID). The developed model was compared with 10 existing models to calculate the accuracy for achieving better performance. In 2020, Rajaraman et al. [29] have established a pruned deep learning model for identifying pulmonary symptoms of COVID-19 through X-ray images. A pre-trained Image-Net models and a novel CNN were accomplished at patient-level on widely available chest X-Ray image collections to examine the modality-specific representations. This model has studied fine-tuned information and increased the performance in classifying the X-Ray images as normal, COVID-19 and bacterial pneumonia defects. The finest models were continuously pruned and compared with different ensemble models to improve classification performance, memory efficiency and to reduce complexity. The iterative pruning model, ensemble learning and modality-specific information transfer have used in this model, which has resulted in improved forecasts. This method was expected to implement in COVID-19 tests with chest radiographs.
In 2020, Julian et al. [3] have demonstrated a deep neural network models to improve an automatic detection of COVID-19 with chest X-ray images to differentiate between pneumonia and COVID-19 and groups. There were three pre-processing models used to test the developed model, which has also estimated how the pre-processed data have impact on the results. Similarly, the serious enquiry of different inconsistency problems was performed, and 5% of the results have shown that it has attained 87.4% accuracy and 91.5% average recall for classification.
In 2020, De et al. [8] have proposed a unique automatic method for the detection of chest X-ray images developed by handy device into two various clinical categories such as pathological and normal. There were three deep learning methods based on densely CNN architecture. The combined response of all these methods have permitted to improve the variation between patients affected with COVID-19 and patients with other diseases. Even with the low quality of X-Ray images, the developed model has provided high performance, which has promoted to improve the medical decision-making progression.
In 2021, Chen et al. [6] have developed a structured model pruning library for TensorFlow2 to modify the models instead of combining the mask layers. The accuracy-efficiency trade-off was measured for various structured model pruning methods and datasets (CIFAR-10 and ImageNet) on Tensor Processing Units (TPUs). It has shown that the structured model pruning could improve model memory usage and speed on TPUs without losing accuracy, especially for small datasets. The results were suggested that structured model pruning was a promising approach to improve the efficiency of CNNs on TPUs.
In 2021, Kaur et al. [22] have proposed an expert model on the basis of deep features, and Parameter Free BAT (PF-BAT) optimized Fuzzy K-nearest neighbor (PF-FKNN) classifier to diagnose novel corona virus. The features were extracted from the fully connected layer of transfer learned MobileNetv2 by the FKNN training. The PF-BAT was fine-tuned by the hyperparameters of FKNN. Then, the proposed model has been extensively validated on publicly available CT scan image datasets. The analyses on the datasets have revealed that with the scheme of hyper-parameter optimization, an increase in the validation accuracy was obtained.
In 2021, Wang and Quan [7] have proposed a deep supervised autoencoder (DSAE) framework to automatically identify COVID-19 using multi-view features extracted from CT images. It was designed to encode valuable information from different frequency features and has constructed a compact class structure for separability. Here, a multi-task loss function has consisted of a supervised loss and a reconstruction loss. This method has demonstrated that it has achieved better diagnostic performance and has potential clinical application for the diagnosis of COVID-19.
2.2 Problem statement
COVID-19 is a deadly pandemic that resulted in important threats to human lives. The automatic COVID-19 detection can be done through control community outbreak, exact medication, and reinforcing corona virus testing techniques. Various challenges exist in the manual tracing of this infection from the X-ray images. Table 1 reveals the features and challenges of the traditional COVID-19 detection methods. CNN decreases the model complexity, prediction variance, and enhanced generalization, performance and faster inference and also exactly localizes the salient ROI by the pruned methods. Yet, it is limited by the computational resources, inherent variability, and dataset size. Deep learning permits a reliable and robust analysis for supporting the clinical decision-making process. Still, it does not attain the datasets from the portable equipment. Hence, novel deep learning methods must be established for diagnosing the COVID-19 pandemic from the X-Ray images in a more reliable and appropriate manner.
3 Enhanced lung segmentation and classification for COVID-19 detection using X-ray images
3.1 Covid-19 detection using proposed model
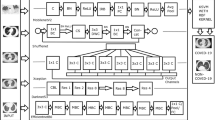
In recent years, COVID-19 spreads rapidly, and so the diagnosis and detection of COVID-19 is significant and considered as a major challenge in the world. X-rays and Computed Tomography (CT) are used to detect COVID-19. The benefits offered by using X-rays over CT scans are safer, quicker, and less harmful during diagnosis. However, the manual evaluation of these methods is time-consuming. Therefore instead of RT-PCR test, X-rays and CT scans tests are used, and it is easy for the medical professionals to see the results immediately while the process is going on, whereas the conventional RT–PCR only provides results when the process is at the end-stage. However, it is required to re-examine the high volume of infected people to know the seriousness of the disease. Therefore, the performance of X-rays and CT scans has to be improved by increasing the diagnosis speed. The performance of detection is improved by Artificial Intelligence (AI), which is a technique used for diagnosis. AI algorithm needs to associate with exposure history, laboratory tests and chest imaging with clinical symptoms of COVID-19 detection. The detection performance of COVID-19 is further improved by deep learning approaches which leads to train AI to predict outputs with given dataset that produce high accuracies. Although deep learning algorithm provides detection enhancement in COVID-19, the major drawback is the over-fitting problem. Therefore, the performance and success ratio of COVID-19 detection can be enhanced by developing a new deep learning model, depicted in Fig. 1.

Proposed COVID-19 diagnosis model using EL-CNN-DF
The proposed COVID-19 detection has different processes like, "(1) Pre-processing, (2) Lung segmentation, (3) Deep feature extraction, and (4) Ensemble learning-based detection", which has been followed in both training and testing stages. Initially, the gathered X-ray images are given as input for the pre-processing phase, which is done by image scaling and image filtering approaches. The image scaling resizes the input images, and the image filtering enhances the input images, including smoothening, sharpening, and edge enhancement of input images. In the filtering, a median filter is used, which reduces blurriness or noise from the images. The pre-processed images are forwarded to the lung segmentation process, which is done by using ADL-U-Net. It is a medical segmentation tool that acts as a binary segmentor to discriminate the infected and healthy lung tissues, also learns the infection type on the lung images by acting as the multi-class segmentors. The improved UNET [41] termed AAF-U-Net is intended to maximize the multi-objective function concerning accuracy and precision for attaining the accurate segmented results, in which the activation function of U-Net is optimized using SA-TSA. Then, the segmented images are processed to the deep feature extraction phase, which is done by the CNN model. In this phase, the features are extracted from the pooling layer of CNN, where the hidden neurons are optimized using SA-TSA. Further, the COVID-19 diagnosis is processed by the Ensemble learning-based detection model named EL-CNN-DF, which employs three models, namely SVM, Auto-encoder, and Naive-Bayes classifiers, in which the image is classified efficiently using SA-TSA. As the major contribution of this developed diagnosis model, the detection accuracy is maximized for efficient COVID-19 diagnosis.
3.2 Description of datasets for COVID-19 detection
The proposed COVID-19 detection model gathers the input images from “https://github.com/ieee8023/covid-chestxray-dataset”: Access date: 2021–05-21″. The datasets consist of X-ray images of lungs with COVID-19 and other viral pneumonia diseases. The sample X-ray images consist of two parts such as (i) Pneumonia or other virus affected lung images and (ii) COVID-19 affected lung images, which are depicted in Fig. 2.

taken from the datasets
Sample images are
The gathered input X-ray images are termed as Yn, where \(n = 1,2, \cdots ,N\) and N represent the total number of images present in the dataset.
3.3 Pre-processing of X-ray images
The developed COVID-19 diagnosis involves pre-processing phase to improve the quality of input image. The pre-processing method is used to enhance some features and suppress the undesired distortions in the input images. The pre-processing phase improves the input images by reducing the noise or blurriness in the images. The preprocessing phase consists of two techniques, namely (1) Image scaling, (2) Median filtering. These techniques are described here:
-
(a) Image scaling [36]: The image scaling is efficient in resizing the input X-ray images. There are two types of scaling such as scaling down and scaling up, which make the images into smaller and larger images. The images should not loss its quality during the process. Image scaling describes the homogenous map between the image pixels, which is formulated in Eq. (1).
$$Y_n^{RS} = imresize\left( {{Y_n},scale} \right)$$(1)
Here, the input image is termed as Yn, the resize factor is denoted as scale that is a numerical scalar and the resized image is considered as \(Y_n^{RS}\). If \(Y_n^{RS} > {Y_n}\), then scale > 1. After the scaling process, the original images are resized into 128 × 128 respectively. The resized images \(Y_n^{RS}\) are given to the filtering process.
-
(2) Median filtering [44]: It is used to provide a noiseless image which is done by the nonlinear filter, where the median is used to retain the sharpness of image edges while filtering. The median value is replaced in the place of noise value by considering the ranking of gray levels. The median filtering output is formulated in Eq. (2).
$$Y_n^M\left( {a,b} \right) = med\{ Y_n^{RS}\left( {a - i,b - j} \right),i,j \in T\}$$(2)
Here, the input image is termed as \(Y_n^{RS}\left( {a,b} \right)\), and the output image is represented as \(Y_n^M\left( {a,b} \right)\), T is the two-dimensional mask.
4 Lung segmentation by proposed AAF-U-Net model
4.1 U-Net-based lung segmentation
The proposed COVID-19 diagnosis involves the segmentation phase for efficient and faster diagnosis. This model has used AFF-U-Net [12] based lung segmentation to obtain more precise segments. U-Net is classified into two parts: The first part is based on typical CNN, which is the contracting path. In this path, each block comprises of two consecutive 3 × 3 convolutions carried by a max-pooling layer and ReLU activation unit. This method is repeated many times. In the expansive path of U-Net, the feature map is unsampled based on 2 × 2 up-convolutions in each stage. Then, the feature map in the contracting path and the unsampled feature map is cropped and connected, which is followed by ReLU activation and two successive 3 × 3 convolutions. Finally, the segmented image is produced by an additional 1 × 1 convolution, which is employed to minimize the channels counts in the feature map. In this method, cropping is a significant part of discarding the small amount of contextual information in the edges of pixel features. This implements a U-shape network and significantly leads to pass the contextual information from large overlapping areas across the networks. Therefore, U-Net uses very limited trading samples and provides highly detailed segmentation feature maps in our proposed COVID-19 detection lung segmentation phase.
4.2 Proposed AAF-U-Net-based lung segmentation
In our proposed COVID-19 detection model, U-Net provides a better segmentation process with detailed feature maps. However, this architecture provides less performance while extracting the deep feature representations. In middle layers, the hidden neurons of deeper or complex models are present in UNet. As a modification to the conventional UNet model, the activation functions are optimized by the SA-TSA, so-called as AAF-U-Net for increasing the segmentation accuracy in COVID-19 detection. Here, the COVID-19 detection model takes the input as the pre-processed images \(Y_n^M\). The activation functions used in UNet are explained here, which are (1) Linear, (2) Sigmoid, (3) Soft-max, (4) Tanh, and (5) ReLU. In the network architecture, the biases and weights of the neurons are restructured based on the error at the output, and it is known as the back-propagation process. Activation functions allow the process to update the biases and weights by providing the gradients and the error. Unfortunately, the neuron does not study with just a linear function. So the proposed model has to use some non-linear functions such as Sigmoid, Soft-max, ReLU, and Tanh.
(1) Linear activation function
It is a simple form of the linear function. “It takes the inputs, multiplied by the weights for each neuron, and creates an output signal proportional to the input”.
(2) Sigmoid activation function
This function is very simple, which takes “a real value as input and gives probability always between 0 and 1”. The main advantage is that, it provides good performance for classification. However, it raises a problem of “vanishing gradients” because of the non-zero centered output that makes the gradient updates to extreme in different directions. If the output is considered as 0 < output < 1, then it results in harder optimization. However, it suffers from the computational time in hidden layer.
(3) Soft-max activation function
This function is used usually at the final layer of neural network. It computes “the probability distribution of the event above ‘n’ different events”. The benefit of the function is its ability to handle multiple classes. However, this function produces interrelated outputs.
(4) Tanh activation function
This function is used to solve the non-zero centered problem, which is the drawback of the sigmoid function. However, it can’t eradicate the vanishing gradient problem.
(5) ReLU activation function
This is the most common activation function in the U-Net model. It is used in the hidden layer of neural networks. It is not a linear function, but it provides the same benefits as a sigmoid function with improved performance. The main advantage of this function is that it solves the problem of gradient vanishing and is less expensive in computation when compared to tanh and sigmoid. However, it creates dead neurons due to the fragileness of some gradients.
Therefore, in the proposed model, the above activation functions are optimized or tuned using the SA-TSA algorithm to achieve the optimal results of lung segmentation for an efficient COVID-19 detection model. The optimization pattern of AAF-U-Net model using SA-TSA algorithm is represented in Fig. 3.

Solution encoding of the proposed segmentation model
Here, the activation functions like Linear, Sigmoid, Soft-max, Tanh and ReLU are represented as Lr, Sd, Sm, Th and Ru respectively, which are in the range of 0 to 4, respectively. The proposed AAF-U-Net-based lung segmentation considers the multi-objective function concerning with maximization of accuracy (accr) and precision (pcn).
Accuracy accr is referred as “the nearness of the measurements to a specific value. The low accuracy creates the difference between a result and a "true" value”. The high accuracy needs both high trueness and high precision. The accuracy is the number of correct forecasts (both true negatives and true positives) between the total cases tested. It is formulated in Eq. (4).
Here, term tp is denoted as true positives, fp is denoted as false positives, tn is denoted as true negatives and fn is denoted as false negatives.
Precision pcn is referred as the points that are stated to be positive; especially, it is used to declare what percentage of the points is truly positive.
Finally, the AAF-U-Net-based segmented images are represented as \(Y_n^{AAF - Unet}\).
The proposed AAF-U-Net using SA-TSA algorithm for the COVID-19 detection model is depicted in Fig. 4. The pre-processed images of the chest X-ray images are done by image scaling and median filtering. The second phase is lung segmentation, which is accomplished by the AAF-U-Net. As a modification, a Self SA-TSA is developed as a boosting algorithm to increase the performance of segmentation and detection. The multi-objective functions concerning with accuracy and precision to achieve the accurate segmented results, in which the activation function of U-Net is optimized using SA-TSA.

Proposed AAF-U-Net-based lung segmentation model using SA-TSA
5 Ensemble learning with CNN-based deep features for COVID-19 detection
5.1 CNN-based deep features
In the proposed COVID-19 detection model, the CNN model is used to extract the spatial dependencies from the segmented input image. The CNN has achieved significant performance in image classification by extracting the features from the given input image efficiently. In general, the CNN layer consists of four layers such as convolution layer, pooling layer, fully-connected layer and non-linearity layers. The proposed model use (i) convolution layer and (ii) pooling layer for the extraction of deep features, which improves the detection efficiency. It considers the input as AAF-U-Net-based segmented images \(Y_n^{AAF - Unet}\) to get deep features.
-
(i)
Convolution layer: The convolution layers provide output as extracted features through input images. The feature map consists of neurons, and each neuron has its own field which is connected to adjacent neurons in the previous layer. A set of learned weights connects the neurons. The inputs are given to the convolution layer with trained weights in order to produce a new feature map. The performance of the convolution layer is improved by hidden neurons optimization in the feature map using SA-TSA.
The feature map extraction is formulated in Eq. (6).
Here, the input image is termed as \(Y_n^{AAF - Unet}\), Et is represented as output feature image, YFt is termed as tth output feature map in the convolutional layer, * symbol denotes two dimensional convolutional operators which calculates the inner features of the input image at each location and g(.) is termed as non-linear activation function.
-
(ii)
Pooling layer: The feature maps which are extracted from the convolution layer are given to the pooling layer. This layer decreases the spatial resolution of the input feature map images and transmits the maximum value to the next layer inside the field. The pooling layer chooses the leading element inside each receptive field, and it is formulated in Eq. (7).
$${E_{tjk}} = \mathop {\max }\limits_{(u,v) \in {L_{jk}}} {\left( {Y_n^{AAF - Unet}} \right)_{ntuv}}$$(7)
Here the outcome of the pooling process is termed as Etjk, related with the tth feature map. The location of the element \(Y_n^{AAF - Unet}\) is termed as (u,v) enclosed by the pooling area Ljk, which represents a receptive field near the position (j,k).
Further, the extracted deep features Edf from the pooling layer are used for ensemble-based detection process, where \(df = 1,2, \cdots ,DF\) and DF denotes the total number of deep features extracted from the pooling layer of CNN. The number of epochs and the convergence of CNN network are shown in Fig. 5.

Number of epochs and the convergence of CNN network
5.2 Developed EL-CNN-DF-based detection
The ensemble learning methods are used to improve the results of deep learning by combining several models, which gives an improved prediction. The proposed COVID-19 detection use ensemble classification techniques, which improve the accuracy of detection with enhanced performance. In recent studies, ensemble learning shows the better prediction with the most significant outcomes, and thus, the proposed model suggests a new EL-CNN-DF to get more suitable results for COVID-19 diagnosis. There are three classifiers used in the EL-CNN-DF based detection, namely (a) SVM, (b) Autoencoder, and (c) NB, in which the ranking strategy is used to get the efficient result in the final decision regarding the detection of COVID-19 by taking the input as the extracted deep features Edf from the pooling layer of CNN.
-
(a) SVM [11]: The proposed model uses the SVM classifier to achieve improved efficiency. It is used to reduce the unseen errors or generalization errors caused by machine learning data. SVM uses a function namely kernel function, which is a set of mathematical functions. The input data Edf is given to the kernel function that is transformed into the required form of data. Therefore, SVM classifier takes the input from the CNN deep features, and it clearly classifies the features to show the relevancy among the features with COVID-19 diseases or other Pneumonia viral diseases. The process of SVM classifier is formulated in Eq. (8).
$${g_{SVM}}\left( y \right) = {V_t}\varphi \left( y \right) + b$$(8)Here, Vt is denoted as weight vector, ϕ denotes the mapping function of input and the dimensional space that makes the classification process as an easy one. The output gSVM(y) uses the trained image values, and this value is used to classify the test images clearly. The kernel function κ is used to convert the input data into the required form which is optimized using the SA-TSA algorithm.
-
(b) Autoencoder [43]: The proposed COVID-19 model uses an autoencoder to get the distortion-less feature classes by mapping the features, where the hidden neurons are optimized using SA-TSA. The optimization of hidden neurons has been done by adjusting the values among 10 to 50.The mapping is done by transferring the data into encoder, which converts the high-dimensional data into low-dimensional data and finally getting back the high-dimensional data using decoder. At last, the classified outcomes are attained accurately that reveals the features between classes. It reduces the dimensionality of the data used. It can extract the features easily. Due to these advantages, the autoencoder has been chosen as a classifier.
-
(c) NB [5]: It is capable among many learning algorithms, which is mainly used for data mining processes based on machine learning. It is generally a simple classifier with the traditional statistical theory named “Bayes theorem”, which has a strong hypothesis. The extracted features should not be dependent on each other concerning the class. The advantages of NB algorithm are high efficiency in computation, provides new training data quickly, capable of handling the distortion and missing values in the dataset. Thus it is selected for ensemble learning. The probability distribution of each class for the predictive attributes with the given vector values is formulated in Eq. (9).
$$P\left( {{X_j}|{E_{df}}} \right) = \frac{{P\left( {X_j} \right)P\left( {{E_{df}}|{X_j}} \right)}}{{\sum\limits_{i = 1}^c {P\left( {X_i} \right)} P\left( {{E_{df}}|{X_i}} \right)}},j = 1,2,.....,L$$(9)
Here Edf denotes the vector of random variables, which are the observed attribute values as given as \({E_{df}} = \left[ {{E_1},{E_2},....,{E_{DF}}} \right]\) in the training set to certain class label L, P(Xj) denotes the prior probability of class Xj and \(P\left( {{X_j}|{E_{df}}} \right)\) refers to class conditional probabilitydensity functions. The estimation of test cases from training datasets is formulated in Eq. (10).
Here \({E_{df}}_i\) denotes the ith attributes values in Edf and a is the number of attributes. The calculated probability distribution P(Edf) over the set of features is formulated in the Eq. (11).
Here c denotes the number of classes and Li denotes the ith class. However, the assumption of feature independence is a major challenge for NB algorithm. Therefore, the proposed model uses the Gaussian function along with NB algorithm.
The Gaussian function is also called as a probability density function, which gives the estimation for the probability of new input value. The Gaussian predictions give more accuracy rate by substituting the new values to the input parameters. The normal distribution is computed using the mean and variance of Z is formulated in Eq. 12.
Here, μ and σ is the mean and variance of the continuous variable Edf calculated for a given class L of X. This Gaussian function is optimized using the SA-TSA algorithm.
EL-CNN-DF
The developed COVID-19 detection model use ensemble classification techniques with deep features for effective classification. The three ensemble classification techniques are SVM, Autoencoder and NB classifiers The features Edf extracted from the pooling layer of CNN are processed through these classifiers to obtain the better-classified results. The kernel function κ in SVM is optimized to solve the unseen errors in the extracted feature images. The autoencoder classifier is used to get the distortion-less classes, where the hidden neurons Ah are also optimized using the SA-TSA algorithm. NB classifier is used to attain the accurate prediction value by using the Gaussian function Gfun, which is done by substituting new input parameter values. The Gaussian function of NB is optimized using the SA-TSA algorithm. Finally, the highest ranking of classes from three classifiers is taken as the final outcomes, which are considered as the most accurate results. Therefore, the proposed model improves a new optimized EL-CNN-DF model using the SA-TSA algorithm. The main objective of this algorithm is considered as the maximization of accuracy concerned with classified outcomes.
Here, OF2 denotes the second objective function of the SA-TSA algorithm. The accuracy accr denotes the accuracy, which is formulated in Eq. (4). The proposed COVID-19 diagnosis model use ensemble learning techniques for improving classification accuracy. The optimization of classified outcomes using the SA-TSA algorithm is represented in Fig. 6.

Solution encoding of the proposed EL-CNN-DF
The EN-CNN-DF model uses SVM, in which the kernel function κ is ranging from 0 to 3, the hidden neurons optimized in autoencoder has the bounding limit from 10 to 50 and the Gaussian function of NB lies among 8 to 32. At last, the classified outputs are attained using the SA-TSA algorithm, which is diagrammatically represented in Fig. 7.

Proposed EL-CNN-DF-based Covid-19 diagnosis
5.3 Proposed SA-TSA algorithm
The proposed COVID-19 detection model proposes a new algorithm SA-TSA for improving the efficiency of outcomes. As a primary objective of the proposed model, the designed SA-TSA optimizes the activation function of U-Net-based lung segmentation, in which Linear Lr, Sigmoid Sd, Soft-max Sm, Tanh Th, and ReLU Ru functions are optimized for getting the enhanced segmented images. The deep features extracted from the CNN are further classified by using ensemble learning techniques, in which the kernel function k in SVM, hidden neurons in autoencoder, and Gaussian function in NB are optimized using the SA-TSA algorithm. This optimization improves the outcomes of the ensemble model of COVID-19 detection. SA-TSA produces the better optimal solutions when compared with the other competitive algorithms and it is capable of solving real case studies having unknown search spaces. An agent-based model is the computational model for simulating the actions and interactions of autonomous agents for understanding the behavior of a system and what governs its outcomes.
TSA [32] is a meta-heuristic optimization algorithm, which optimizes non-linear constrained problems in recent studies. The advantages of TSA are efficient in solving real-world optimizations, giving the best standard deviation and mean–variance values for search agents, and providing better optimal designs. However, the major drawbacks of TSA are deflation in the searching process and a low convergence rate. Therefore, an enhanced TSA is developed, namely SA-TSA, which is used to improve searching behavior efficiency and improve the convergence rate. In the conventional TSA, the solutions are updated based on the random number mand, which is in the range,[0,1] whereas the proposed SA-TSA uses a new fitness-based parameter for updating the solutions. It offers better search efficiency and convergence rate.
TSA is a meta-heuristic optimization algorithm that reproduces the swarm behaviors and jet propulsion during searching and navigation. TSA is a special class of algorithm among many bio-inspired algorithms, which is developed by swarm behavior. TSA has the capability of solving many optimization problems in reality. Tunicates are considered as insect in the ocean, which are bio-luminescent and bright to see from many kilometers away by producing pale green–blue light. Tunicates are capable of finding the food source location in the sea without having any idea about the search space in which the food source is available. The behaviors such as swarm intelligence and jet propulsion are used to find the food source. This process is known as optimization. It includes fluid jet-like propulsion, which is used for the migration of tunicates to the depth of the ocean in the vertical direction. Therefore, the idea of swarm behavior and jet propulsion are the major facts used in the proposed model to achieve improved optimization.
Tunicate should satisfy three conditions to implement the mathematical modeling of jet propulsion behavior such as movement towards the position of best search agent, closer movement to the best search agent and avoid the conflicts between search agents. On the other hand, the swarm behavior gives the best optimal solution by updating the locations of search agents. The conflicts between the other tunicates should be avoided to calculate the position of new search agent. A vector \(\vec E\) is applied and the computation is formulated in Eq. (14).
Here, term \(\vec W\) denotes the water flow direction in ocean and \(\vec F\) denotes the gravity force. The variables d1,d2 and d3 denote the random numbers, which lies in the range [0,1]. The vector \(\vec S\) refers to the social force among search agents and it is formulated in Eq. (17).
Here, terms Qmax and Qmin refers to the subordinate and initial speeds to create social interaction, respectively. The range of Qmax and Qmin is considered as 4 and 1, respectively.
After the process of avoiding conflicts among tunicates, the next step is for search agents, which move towards the location of the best neighbor. This process is formulated in Eq. (18).
In the above equation, \(\vec SF\) refers to the position of food source, z denotes the current iteration, \({T_q}\left( {\vec z} \right)\) denotes the position of search agents and mand refers to the random number which lies in the range[0,1].
The tunicate keeps moving towards the position where the best search agents with the food source.
The vector \({\vec T_q}\left( {z^{\prime}} \right)\) refers to the position of food source \(\vec SF\) concerned with new position of tunicate.
The mathematical simulation of the swarm behavior is done by two optimal solutions such as update and save the positions of tunicates to the position of best or near search agents accordingly. The swarm behavior of tunicate is formulated in Eq. (20).
Therefore, the improved updating of swarm behavior and jet propulsion of TSA algorithm is used in SA-TSA for the enhancement of proposed model. The following procedures are used to get the improved algorithm of TSA as follows.
-
The random variable mand is new formulated based on the current fitness value and the previous fitness value of search agents.
-
Both the fitness values of search agents are intended to find the best search agent.
-
Then, the position of the best search agent is updated and adjusted to the given space without including the boundary beyond the search space.
A new formula for mand is derived in Eq. (21).
Here, \(\vec SF\left( {z - 1} \right)\) denotes the fitness of previous iteration \(\vec SF\left( z \right)\) denotes the fitness of current iteration. The pseudo code of the developed SA-TSA algorithm is represented in Algorithm 1.

The developed SA-TSA algorithm is used in the proposed COVID-19 detection model to provide optimal outcomes. The SA-TSA algorithm improves the performance of search agents by solving the search deflation issues and it offers better performance by increasing the rate of convergence. In the proposed COVID-19 detection model, the developed SA-TSA algorithm improves the performance of segmentation and detection. The flowchart of the developed SA-TSA algorithm is represented in Fig. 8.

Flowchart of the developed SA-TSA algorithm
6 Results and discussions
6.1 Experimental setup
In the proposed COVID-19 detection model, the experimental study has done by X-ray images and it was developed in Python. The assessment has been done among the existing model and proposed model based on meat-heuristic algorithms and classifiers in terms of “Accuracy, Sensitivity, Specificity, Precision, False Positive Rate (FPR), False Negative Rate (FNR), Negative Predicted Value (NPV), False Discovery Rate (FDR), F1-score and Matthews’s correlation coefficient (MCC)”. If the 75% of the dataset used for training purposes, then the remaining 25% is used for testing purposes. The COVID-19 detection analysis was conducted based on 10 numbers of population and 25 maximum numbers of iterations. The proposed meta-heuristic algorithm was examined with additional algorithms like “Particle Swarm Optimization (PSO) [20], Grey Wolf Optimizer (GWO) [9], Whale Optimization Algorithm (WOA) [35], TSA [32], classifiers such as Support Vector Machine (SVM) [11], Auto encoder [43], Naive Bayes [5], Ensemble learning [24], RNN [42], LSTM [23] and SA-TSA”.
6.2 Performance measures
Different performance measures [4] considered for evaluating the performance that are given below.
-
(a) Sensitivity: It refers “to the true positive rate and measures the ratio of positives that are properly recognized”.
$$Sensitivity = \frac{{t_p}}{{\left( {{t_p} + {f_n}} \right)}}$$(22) -
(b) Specificity: It refers “to the true negative rate and it measures the amount of negatives that are suitably identified”.
$$Specificity = \frac{{t_n}}{{\left( {{t_n} + {f_p}} \right)}}$$(23) -
(c) FPR: It is “the probability of falsely eliminating the null premise for a particular test”.
$$FPR = \frac{{f_p}}{{t_n}}$$(24) -
(d) FNR: It is “the proportion of positive values which return negative test results with the test”.
$$FNR = \frac{{f_n}}{{t_p}}$$(25) -
(e) NPV: It “denotes the negative predicted value. If the value of NPV is 1 (100%), then it returns no false negatives. If the value of the NPV is 0, then it returns no true negatives”.
$$NPV = \frac{{t_n}}{{\left( {{t_n} + {f_n}} \right)}}$$(26) -
(f) FDR: It is a “process of abstracting the rate of type I errors in null premise testing when conducting various evaluations”.
$$FDR = \frac{{f_p}}{{\left( {{t_p} + {f_p}} \right)}}$$(27) -
(g) F1-Score: It is used “to calculate the test accuracy. It is referred as a weighted average of the recall and precision. While F1 score is 1, it is considered as best and on 0, it is considered as worst”.
$$F1 = \frac{{2{t_p}}}{{\left( {2({t_p} + {f_p} + {f_n}} \right)}}$$(28) -
(h) MCC: It is used “to calculate the quality of two-class binary classifications. It produced a correlation coefficient among the predicted and observed binary classifications and it yields a value among − 1 and + 1”.
$$MCC = \frac{{\left( {{t_p} \times {t_n}} \right) - \left( {{f_p} - {f_n}} \right)}}{{\sqrt {\left( {{t_p} + {f_p}} \right)\left( {{t_p} + {f_n}} \right)\left( {{t_n} + {f_p}} \right)\left( {{t_n} + {f_n}} \right)} }}$$(29)
6.3 Segmented results
The segmented results using AAF-U-Net model with SA-TSA algorithm is given in Fig. 9.

Segmented lung images by proposed AAF-U-Net
6.4 Segmentation analysis
The segmentation process by developing AAF-U-Net using the SA-TSA algorithm is analyzed with other optimization algorithms are given in Table 2. The accuracy of the proposed segmentation using SA-TSA-U-Net is 1.71%, 2.53%, 1.13%, and 2.76%, superior to PSO-U-Net, GWO-U-Net, WOA-U-Net, and TSA-U-Net, respectively. It clearly reveals that the SA-TSA algorithm is improved than other algorithms in terms of accuracy. The precision of the proposed segmentation using SA-TSA-U-Net is 1.51%, 1.003%, 1.30%, 1.20% improved than PSO-U-Net, GWO-UNet, WOA-U-Net, and TSA-U-Net, respectively. The values clearly show that the SA-TSA-U-Net gives a better precision value than other algorithms. The FDR of the proposed segmentation using SA-TSA-U-Net is 46.96%, 37.13%, 43.33%, 41.32% progressed than PSO-U-Net, GWO-U-Net, WOA-U-Net, and TSA-U-Net, respectively. Hence, the results show that the proposed AAF-U-Net with the SA-TSA algorithm provides better performance for segmentation than the other algorithms.
6.5 Performance analaysis on meta-heuristic-based algorithms
The proposed COVID-19 detection model is validated with other algorithms with different performance measures by changing the learning percentages as given in Fig. 10. The accuracy for the corresponding learning percentage 55, the SA-TSA-EL-CNN-DF attains 2.11%, 2.10%, 3.19%, and 1.04% greater than TSA-EL-CNN-DF, WOA-CNN-DF, GWO-CNN-DF, and PSO-CNN-DF, respectively. In terms of sensitivity, for the corresponding learning percentage 65, the SA-TSA-EL-CNN-DF attains 2.08%, 3.16%, 2.08%, and 2.08% larger than TSA-EL-CNN-DF, WOA-CNN-DF, GWO-CNN-DF, and PSO-CNN-DF, respectively. In terms of specificity, for the corresponding learning percentage 35, the SA-TSA-EL-CNN-DF attains 1.03%, 2.08%, 2.08%, and 3.16% better than TSA-EL-CNN-DF, WOA-CNN-DF, GWO-CNN-DF, and PSO-CNN-DF, respectively. In terms of precision, for the corresponding learning percentage 75, the SA-TSA-EL-CNN-DF attains 1.042%, 1.042%, 1.05%, and 1.05% greater than TSA-EL-CNN-DF, WOA-CNN-DF, GWO-CNN-DF, and PSO-CNN-DF, respectively. In terms of FPR, for the corresponding learning percentage 65, the SA-TSA-EL-CNN-DF attains 82.14%, 80%, 68.75%, and 78.26% larger than TSA-EL-CNN-DF, WOA-CNN-DF, GWO-CNN-DF, and PSO-CNN-DF, respectively. In terms of FNR, for the corresponding learning percentage 85, the SA-TSA-EL-CNN-DF attains 35.29%, 21.43%, 19.12%, and 15.38% better than TSA-EL-CNN-DF, WOA-CNN-DF, GWO-CNN-DF, and PSO-CNN-DF, respectively. In terms of NPV, for the corresponding learning percentage 35, the SA-TSA-EL-CNN-DF attains 2.08%, 4.26%, 4.26%, and 3.16% increased than TSA-EL-CNN-DF, WOA-CNN-DF, GWO-CNN-DF, and PSO-CNN-DF, respectively. In terms of FDR, for the corresponding learning percentage 55, the SA-TSA-EL-CNN-DF attains 52.17%, 51.75%, 64.52%, and 69.44% increased than TSA-EL-CNN-DF, WOA-CNN-DF, GWO-CNN-DF, and PSO-CNN-DF, respectively. In terms of F1-Score, for the corresponding learning percentage 65, the SA-TSA-EL-CNN-DF attains 52.17%, 51.75%, 64.52%, and 69.44%, better than TSA-EL-CNN-DF, WOA-CNN-DF, GWO-CNN-DF, and PSO-CNN-DF, respectively. In terms of MCC, for the corresponding learning percentage 75, the SA-TSA-EL-CNN-DF attains 8.24%, 9.52%, 8.24%, and 4.55% greater than TSA-EL-CNN-DF, WOA-CNN-DF, GWO-CNN-DF, and PSO-CNN-DF, respectively. Hence, the graphical representation results shows that the proposed SA-TSA-EL-CNN-DF based classification provides better performance than the other algorithms.


Performance ananlysis of the proposed COVID-19 detection model with different optimization functions in terms of “(a)Accuracy, (b)Sensitivity, (c)Specificity, (d)Precision, (e)FPR, (f)FNR, (g)NPV, (h)FDR, (i)F1-score, (j) MCC”
6.6 Performance analaysis on meta-heuristic-based algorithms
The proposed classification technique of developed COVID-19 detection model is validated with other classifiers with various performance measures and learning percentages as given in Fig. 11. In terms of accuracy, for the corresponding learning percentage 35, the SA-TSA reaches 24.05%, 22.50%, 18.07%, 15.29%, 12.64%, and 16.67% better than SVM, autoencoder, NB, ensemble, RNN and LSTM respectively. In terms of sensitivity, for the corresponding learning percentage 55, the SA-TSA gets 45.45%, 37.14%, 23.08%, 15.66%, 20% and 31.51% improved than SVM, autoencoder, NB, ensemble, RNN and LSTM respectively. In terms of specificity, for the corresponding learning percentage 65, the SA-TSA reaches 1.03%, 6.52%, 4.26%, 4.26%, 2.08% and 3.16% increased than SVM, autoencoder, NB, ensemble, RNN and LSTM respectively. In terms of precision, for the corresponding learning percentage 75, the SA-TSA attains 1.03%, 7.69%, 6.52%, 4.26%, 5.38% and 3.16% improved than SVM, autoencoder, NB, ensemble, RNN and LSTM respectively. In terms of FPR, for the corresponding learning percentage 35, the SA-TSA attains 72.22%, 91.53%, 89.58%, 82.14%, 80%, and 80% higher than SVM, autoencoder, NB, ensemble, RNN, and LSTM, respectively. In terms of FNR, for the corresponding learning percentage 55, the SA-TSA reaches 85.29%, 83.33%, 77.27%, 72.22%, 75% and 79.17% superior than SVM, autoencoder, NB, ensemble, RNN and LSTM respectively. In terms of NPV, for the corresponding learning percentage 65, the SA-TSA achieves 1.03%, 3.16%, 3.16%, 2.08%, 2.08%, and 1.03 better than SVM, autoencoder, NB, ensemble, RNN, and LSTM respectively. In terms of FDR, for the corresponding learning percentage 55, the SA-TSA gets 72.22%, 89.58%, 87.50%, 77.27%, 78.26%, and 73.68% better than SVM, autoencoder, NB, ensemble, RNN, and LSTM, respectively. In terms of F1-Score, for the corresponding learning percentage 35, the SA-TSA reaches 25.64%, 22.50%, 16.67%, 15.29%, 12.64%, and 18.07%, improved than SVM, autoencoder, NB, ensemble, RNN and LSTM, respectively. In terms of MCC, for the corresponding learning percentage 65, the SA-TSA 58.06%, 53.13%, 25.64%, 22.50%, 27.27%, and 30.67% superior than SVM, autoencoder, NB, ensemble, RNN, and LSTM, respectively. Therefore, the results of graphical representation show that the proposed SA-TSA algorithm-based classification model provides better performance than the other classifiers.


Performance analysis of the proposed COVID-19 detection model with different machine learning algorithms in terms of “(a)Accuracy, (b)Sensitivity, (c)Specificity, (d)Precision, (e)FPR, (f)FNR, (g)NPV, (h)FDR, (i)F1-score, (j)MCC”
6.7 Overall performance analysis
The overall comparative analysis on the proposed COVID-19 detection is depicted in Table 3 and Table 4. The accuracy of the proposed SA-TSA-EL-CNN-DF is 1.92%, 3.08%, 3.56% and 3.20% greater than PSO-EL-CNN-DF, GWO-EL-CNN-DF, WOA-EL-CNN-DF, and TSA-EL-CNN-DF respectively. The precision of the proposed using SA-TSA-EL-CNN-DF is 1.89%, 3.85%, 5.48% and 4.86% improved than PSO-EL-CNN-DF, GWO-EL-CNN-DF, WOA-EL-CNN-DF, and TSA-EL-CNN-DF respectively. The FDR of the proposed using SA-TSA-EL-CNN-DF is 70.17%, 70.72%, 52.31% and 52.03 better than PSO-EL-CNN-DF, GWO-EL-CNN-DF, WOA-EL-CNN-DF, and TSA-EL-CNN-DF, respectively. The accuracy of the developed SA-TSA is 21.89%, 20.59%, 15.79%, 10.95%, 14.18% and 13.46 improved than SVM, autoencoder, NB, ensemble, RNN and LSTM respectively. The sensitivity of the proposed SA-TSA is 41.84%, 33.75%, 25.35%, 17.94%, 24.48% and 23.62 better than SVM, autoencoder, NB, ensemble, RNN and LSTM respectively. The FDR of the proposed SA-TSA is 64.39%, 88.82%, 85.46%, 74.15%, 72.82% and 64.97% greater than SVM, autoencoder, NB, ensemble, RNN and LSTM respectively. Hence, the overall analysis shows that the proposed SA-TSA algorithm of COVID-19 detection model provides better performance than the existing algorithms.
6.8 Comparison on the existing methods
The comparison of the proposed SA-TSA with the existing methods is shown in the Fig. 12. At learning percentage 55, the accuracy of the proposed SA-TSA performs 10.52%, and 12.63% better than DNN and Grad-CAM. Thus, the performance of the proposed method is better in all the performance measures. Therefore, the proposed SA-TSA algorithm of COVID-19 detection model provides better performance than the existing algorithms.

Comparative analysis of the proposed COVID-19 detection model with existing methods in terms of “(a)Accuracy, (b)Sensitivity, (c)Specificity, (d)Precision, (e)FPR, (f)FNR, and (g) F1-score”
7 Conclusion
In this work, a novel algorithm has been proposed to detect the COVID-19 disease effectively. The proposed COVID-19 model has improved the process of segmentation and classification of images. The input X-Ray images were pre-processed through image scaling and filtering. The lung segmentation was improved by the performed by the novel AFF-U-Net. Then, the segmented images were processed through CNN, in which the deep features were extracted from the pooling layer. The CNN model was also enhanced by the proposed algorithm SA-TSA, so called as EL-CNN-DF by optimizing the hidden neurons in convolution layer. The optimized outcomes from CNN were processed through three classifiers which were also enhanced by the proposed SA-TSA algorithm and thus the efficient results were attained. The overall analysis has shown that the precision of the enhanced CNN by using SA-TSA was 1.02%, 4.63%, 3.38%, 1.62%, 1.51% and 1.04% better than SVM, autoencoder, NB, Ensemble, RNN and LSTM respectively. Finally, the overall experimental analysis have revealed that the proposed algorithm SA-TSA has given comparatively enhanced results in the phases of segmentation and classification over the existing algorithms. The collection of non-COVID cough samples can be performed in future to make cough detection model that is more robust against incorrectly classifying non COVID coughs as COVID coughs, which can be performed by adopting intelligent approaches.
References
Ai T, Yang Z, Hou H, Zhan C, Chen C, Lv W, Tao Q, Sun Z, Xia L (2020) Correlation of chest CT and RT-PCR testing in coronavirus disease 2019 (COVID-19) in China: a report of 1014 cases. Radiology 296(2)
Apostolopoulos ID, Mpesiana TA (2020) Covid-19: automatic detection from x-ray images utilizing transfer learning with convolutional neural networks. Phys Eng Sci Med
Arias-Londoño JD, Gómez-García JA, Moro-Velázquez L, Godino-Llorente JI (2020) Artificial intelligence applied to chest X-Ray images for the automatic detection of COVID-19. A thoughtful evaluation approach. IEEE Access 8:226811–226827
Atila U, Ucar M, Akyol K, Ucar E (2021) Plant leaf disease classification using EfficientNet deep learning model. Ecol Inform 61
Bilgin S, Güzeler AC (2015) Naive Bayes classification of neurodegenerative diseases by using discrete wavelet transform. 19th National Biomedical Engineering Meeting, pp 1–4
Chen K, Franko K, Sang R (2021) Structured Model Pruning of Convolutional Networks on Tensor Processing Units. arXiv preprint arXiv
Cheng J, Zhao W, Liu J, Xie X, Wu S, Liu L, Yue H, Li J, Wang J, Liu J (2021) Automated diagnosis of covid-19 using deep supervised autoencoder with multi-view features from CT images. IEEE/ACM Transactions on Computational Biology and Bioinformatics
De Moura J, García LR, Vidal PFL, Cruz M, Lopez LA (2020) Deep Convolutional Approaches for the Analysis of COVID-19 Using Chest X-Ray Images From Portable Devices. IEEE Access 8:195594–195607
Devanathan K, Ganapathy N, Swaminathan R (2019) Binary Grey Wolf Optimizer based Feature Selection for Nucleolar and Centromere Staining Pattern Classification in Indirect Immunofluorescence Images," 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), pp 7040–7043
Esposito A, Palmisano A, ScottiGM, Morelli MJ, Vignale D, De CobelliF, Tonon G, Tacchetti C (2020) Why is chest CT important for early diagnosis of COVID-19?” Prevalence matters. medRxiv
Geweid GGN, Abdallah MA (2019) A New Automatic Identification Method of Heart Failure Using Improved Support Vector Machine Based on Duality Optimization Technique. IEEE Access 7:149595–149611
Hambarde P, Talbar S, Mahajan A, Chavan S, Thakur M, Sable N (2020) Prostate lesion segmentation in MR images using radiomics based deeply supervised U-Net. Biocybernetics Biomed Eng 40(4):1421–2143
Harrison X. Bai, Ben Hsieh, Zeng Xiong, Kasey Halsey, Ji Whae Choi, Thi My Linh Tran, Ian Pan, Lin-Bo Shi, Dong-Cui Wang, Ji Mei, Xiao-Long Jiang, Qiu-Hua Zeng, Thomas K. Egglin, Ping-Feng Hu, Saurabh Agarwal, Fang-Fang Xie, Sha Li, Terrance Healey, Michael K. Atalay, Wei-Hua Liao, “Performance of radiologists in differentiating COVID-19 from viral pneumonia on chest CT”, Radiology, pp. 200823, 2020.
Horry MJ et al (2020) COVID-19 detection through transfer learning using multimodal imaging. Data IEEE Access 8
Hosseiny M, Kooraki S, Gholamrezanezhad A, Reddy S, Myers L (2020) Radiology perspective of coronavirus disease 2019 (COVID-19): Lessons from severe acute respiratory syndrome and middle east respiratory syndrome. Am J Roentgenol 215(5):1–5
Hussain E, Hasan M, Rahman MA, Lee I, Tamanna T, Parvez MZ (2021) CoroDet: A deep learning based classification for COVID-19 detection using chest X-ray images. Chaos, Solitons Fractals 142
Islam MdZ, Islam M, Asraf A (2020) A combined deep CNN-LSTM network for the detection of novel coronavirus (COVID-19) using X-ray images. Inf Med Unlocked 20
Ismael AM, Şengür A (2021) Deep learning approaches for COVID-19 detection based on chest X-ray images. Expert Syst Appl 164
Jaiswal A, Gianchandani N, Singh D, Kumar V, Kaur M (2020) Classification of the COVID-19 infected patients using DenseNet201 based deep transfer learning. J Biomol Struct Dyn 1–8
Jiang H, Zou L (2011) Improved PSO-SVM based disease detection in medical images processing. 6th International Conference on Computer Sciences and Convergence Information Technology (ICCIT), pp 922–927
Karthik TR, Menaka R, Hariharan M (2020) Learning distinctive filters for COVID-19 detection from chest X-ray using shuffled residual CNN. Appl Soft Comput 99
Kaur T, Gandhi TK, Panigrahi BK (2021) Automated diagnosis of COVID-19 using deep features and parameter free BAT optimization. IEEE J Transl Eng Health Med 9:1–9
Li P, Tang H, Yu J, Song W (2020) LSTM and multiple CNNs based event image classification. Multimed Tools Appl
Livieris IE, Kanavos A, Tampakas V, Pintelas P (2018) Article An Ensemble SSL Algorithm for Efficient Chest X-Ray Image Classification. J Imaging
Manne R, Kantheti SC (2021) Application of artificial intelligence in healthcare: chances and challenges. Curr J Appl Sci Technol 78–89
Nour M, Cömert Z, Polat K (2020) A Novel Medical Diagnosis model for COVID-19 infection detection based on Deep Features and Bayesian Optimization. Appl Soft Comput 97(part A):106580
Pan F, Ye T, Sun P, Gui S, Liang Bo, Li L, Zheng D, Wang J, Hesketh RL, Yang L, Zheng C (2020) Chest computed tomography in children with COVID-19 respiratory infection. Pediatr Radiol 50(6):796–799
Panwar H, Gupta PK, Siddiqui MK, Morales-Menendez R, Bhardwaj P, Singh V (2020) A deep learning and grad-CAM based color visualization approach for fast detection of COVID-19 cases using chest X-ray and CT-Scan images. Chaos, Solitons Fractals 140
Rajaraman S, Siegelman J, Alderson PO, Folio LS, Folio LR, Antani SK (2020) Iteratively pruned deep learning ensembles for COVID-19 detection in chest X-Rays. IEEE Access 8:115041–115050
Rothan HA, Byrareddy SN (2020) The epidemiology and pathogenesis of coronavirus disease (COVID-19) outbreak. J Autoimmun 109
Rubin GD, Ryerson CJ, Haramati LB, Sverzellati N, Kanne JP, Raoof S, Schluger NW, Volpi A, Yim J-J, Martin IBK, Anderson DJ, Kong C, Altes T, Bush A, Desai SR, Goldin O, Goo JM, Humbert M, Inoue Y, Kauczor H-U, Luo F, Mazzone PJ, Prokop M, Remy-Jardin M, Richeldi L, Schaefer-Prokop CM, Tomiyama N, Wells AU, Leung AN (2020) The role of chest imaging in patient management during the COVID-19 pandemic: a multinational consensus statement from the fleischner society. Radiology 201365
SatnamKaur LKA, Sangal AL, GauravDhiman (2020) Tunicate Swarm Algorithm: A new bio-inspired based metaheuristic paradigm for global optimization. Eng Appl Artif Intell 90
Sheykhivand S, Mousavi Z, Mojtahedi S, Rezaii TY, Farzamnia A, Meshgini S, Saad I (2021) Developing an efficient deep neural network for automatic detection of COVID-19 using chest X-ray images. Alexandria Eng J 60(3):2885–2903
Sibylle BS, Patrick R, Yassoungo S, Alexandra M, Christine C, Anne S, Matthieu M, Laure M, Mathieu N, Clément B, Estelle Y, Sylvie B, Sophie I, Duc N, Denis M, Xavier LF, Scarlett G, Clément L, Anouk T, Morgane S, Vincent E, Bruno C, Daniel L-B (2020) First cases of coronavirus disease 2019 (COVID-19) in France: surveillance, investigations and control measures. Eurosurveillance 25(6):2000094
Singh I, Bansal R, Gupta A, Singh A (2020) A Hybrid Grey Wolf-Whale Optimization Algorithm for Optimizing SVM in Breast Cancer Diagnosis. 2020 Sixth International Conference on Parallel, Distributed and Grid Computing (PDGC), pp 286–290
Stojnev D, Ilic AS (2020) Pre-processing image data for deep learning. International Scientific Conference On Information Technology And Data Related Research
Ucar F, Korkmaz D (2020) COVIDiagnosis-Net: Deep Bayes-SqueezeNet based diagnosis of the coronavirus disease 2019 (COVID-19) from X-ray images. Med Hypotheses 10
Wang L, Lin ZQ, Wong A (2020) COVID-Net: A tailored deep convolutional neural network design for detection of COVID-19 cases from chest X-ray images, Front Med 10(1)
Yan G, Lee CK, Lam LTM, Yan B, Chua YX, Lim AYN, Phang KF, Kew GS, Teng H, Ngai CH, Lin L, Foo RM, Pada S, Ng LC, Tambyah PA (2020) Covert COVID-19 and false-positive dengue serology in Singapore. Lancet Infect Dis
Yan L, Zhang H-T, Xiao Y, Wang M, Guo Y, Sun C, Tang X, Jing L, Li S, Zhang M, Xiao Y, Cao H, Chen Y, Ren T, Jin J, Wang F, Xiao Y, Huang S, Tan X, Huang N, Jiao B, Zhang Y, Luo A, Cao Z, Xu H, Yuan Y (2020) Prediction of criticality in patients with severe Covid-19 infection using three clinical features: a machine learning-based prognostic model with clinical data in Wuhan. medRxiv
Yang Y, Feng C, Wang R (2020) Automatic segmentation model combining U-Net and level set method for medical images. Expert Syst Appl 153:113419
Yanming Guo Yu, Liu EM, Bakker YG, Lew MS (2018) CNN-RNN: a large-scale hierarchical image classification framework. Multimed Tools Appl 77:10251–10271
Zhou Q, Yong B, Lv Q, Shen J, Wang X (2020) Deep autoencoder for mass spectrometry feature learning and cancer detection. IEEE Access 8:45156–45166
Zhu Y, Huang C (2012) An Improved Median Filtering Algorithm for Image NoiseReduction. Phys Procedia 25:609–616
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Das, A. Adaptive UNet-based Lung Segmentation and Ensemble Learning with CNN-based Deep Features for Automated COVID-19 Diagnosis. Multimed Tools Appl 81, 5407–5441 (2022). https://doi.org/10.1007/s11042-021-11787-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-021-11787-y