
Abstract
Measuring geotechnical and natural hazard engineering features, along with pattern recognition algorithms, allows us to categorize the stability of slopes into two main classes of interest: stable or at risk of collapse. The problem of slope stability can be further generalized to that of assessing landslide susceptibility. Many different methods have been applied to these problems, ranging from simple to complex, and often with a scarcity of available data. Simple classification methods are preferred for the sake of both parsimony and interpretability, as well as to avoid drawbacks such as overtraining. In this paper, an experimental comparison was carried out for three simple but powerful existing variants of the well-known nearest neighbor rule for classifying slope/landslide data. One of the variants enhances the representational capacity of the data using so-called feature line segments, while all three consider the concept of a territorial hypersphere per prototype feature point. Additionally, this experimental comparison is entirely reproducible, as Python implementations are provided for all the methods and the main simulation, and the experiments are performed using three publicly available datasets: two related to slope stability and one for landslide susceptibility. Results show that the three variants are very competitive and easily applicable.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Growing interest has emerged in recent years for data-driven techniques supported by pattern recognition (PR) and statistical/machine learning (ML) approaches applied to slope stability and landslide prediction (Achour and Pourghasemi 2020; Ma et al. 2021), due to their ability to deal with different uncertainty sources commonly found in geotechnical and natural hazard engineering (Phoon 2020). Probabilistic analysis of slopes using surrogate models (Li et al. 2016), reliability-based design optimization (Pandit and Babu 2018), location of the critical slip in soil slopes (Li et al. 2020), statistical dependence of critical factors on debris flow (Tang et al. 2018), landslide susceptibility (Korup and Stolle 2014), and data-driven safety analysis of slopes (Samui 2013) are among the problems for which solutions have been proposed using PR/ML approaches. However, the uncertainty due to scarcity of available geotechnical data is still a challenge when a data-driven approach using real-world information is adopted (Phoon et al. 2021). Such is the case with slope stability prediction and landslide susceptibility, which have limited data and features per site/experiment, typically cohesion (c), friction angle (\(\varphi \)), unit weight (\(\gamma \)), and geometric properties in the first case or geological/topographic factors (land coverage, hydrology conditions, among others) for the latter.
In this direction, many computational learning methods have been proposed for data-driven slope/landslide classification using real-world datasets. Advanced classifiers for slope stability based on gradient boosting machines (Zhou et al. 2019), ensemble machine learning (Qi and Tang 2018), and extreme learning (Hoang and Bui 2017) have been reported in the literature. Similarly, in landslide susceptibility, logistic regression (Lee et al. 2015), random forest, and adaptive boosting (AdaBoost) methods for feature engineering (Micheletti et al. 2014), support vector classifiers (Huang and Zhao 2018), comparison/ensemble between ML methods (Chen et al. 2017b, a), and deep learning algorithms (Huang et al. 2020), among other methods (Reichenbach et al. 2018), have been applied. Nevertheless, any engineering application of PR/ML should ideally have as few parameters as possible (Mohri et al. 2018, p. 23), that is, the lower the number of parameters to tune, the less complex and more effective explanatory models that can be obtained for real-world problems under adaptive environments (Murdoch et al. 2019). In this regard, Fernández-Delgado et al. (2014, p. 3134) noted that “A researcher may not be able to use classifiers arising from areas in which he/she is not an expert (e.g., to develop [a proper] parameter tuning)...” These issues have also been highlighted in geotechnical and natural hazard engineering by Pourghasemi and Rahmati (2018) and Ospina-Dávila and Orozco-Alzate (2020), who suggested an incremental analysis of parsimony for PR systems applied to slope stability problems.
In a practical context, nonparametric classification rules such as the nearest neighbor rule (Cover and Hart 1967) could be simple enough to support this parameter-free or parameterless ML approach (Keogh et al. 2004; Bicego and Orozco-Alzate 2021). Furthermore, this nearest neighbor approach can provide the basis for more advanced methods which can address complex pattern classification problems while maintaining a simple decision scheme without a complicated (hyper)parameter tuning process. Such is the case with the nearest feature line (NFL) classifier (Li and Lu 1999) and its segmented and rectified version, the rectified nearest feature line segment (RNFLS) (Du and Chen 2007), as well as with adaptive (non)metric distance learning strategies, such as the hypersphere classifier (HC) (Lopes and Ribeiro 2015) or the adaptive nearest neighbor (ANN) classifier (Wang et al. 2007), which are powerful methods that enhance the representational capacity for small datasets and improve the classification performance in overlapping situations, without having to rely on tricky (hyper)parameter tuning tasks, which in some situations are large and very often impose inappropriate assumptions (Keogh et al. 2007).
Therefore, this paper empirically shows the appropriateness of this kind of method for slope/landslide data classification when uncertainty plays a key role due to data scarcity, keeping as few parameters as possible in striving for parsimony and interpretability, when a PR viewpoint is adopted. In addition, this experimental setup and results are established under a very reproducible framework (Keogh 2007; Vandewalle et al. 2009). For this purpose, three publicly available datasets—namely Taiwan (Cheng and Hoang 2015), Multinational (Hoang and Pham 2016), and Yongxin (Fang et al. 2020)—are utilized; the first two relate to slope stability and the last to landslide susceptibility. The computational procedures using source code snippets in Python language are also presented.
The rest of the paper is organized as follows. Section 3 introduces the methods from PR/ML that motivate the present work. In Sects. 4 and 5, the experimental setup and the results, discussed under the premise of letting the data themselves speak to us in a data-driven slope/landslide prediction approach, are described in detail. Finally, Sect. 6 presents a discussion regarding the importance of a parameterless and reproducible research perspective in this particular problem.
2 Description of Available Data
The main properties of the three datasets used for the experiments are summarized in Table 1. The positive class in Taiwan and Multinational corresponds to examples of collapsing slopes and, similarly, the positive class in Yongxin refers to landslide cases.
The first two belong to the slope stability problem and are available as tables in the corresponding papers of Cheng and Hoang (2015, Table 2) and Hoang and Pham (2016, Appendix). Tables 2 and 3 summarize the main properties of each dataset. A graphical representation of this kind of problems is given in Fig. 1.

Representation of geotechnical/geometric properties in the slope stability problem
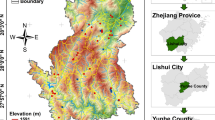
The Yongxin dataset is released on a companion repository [see the URL in Ref. Fang et al. (2020)] related to a landslide susceptibility problem located at the western part of Jiangxi Province, China (see Fig. 2). This dataset includes 16 factors, whose graphical distribution over the Yongxin area can be seen in Figs. 3 and 4, among which are the normalized difference vegetation index (NDVI), sediment transport index (STI), stream power index (SPI), and topographic wetness index (TWI); for further explanation and details, see (Fang et al. 2020).

Yongxin area: location of landslides. Source (Fang et al. 2020) (permission granted by Elsevier Ltd. by order number 5333851293554)
3 Methods
One of the most representative classification rules is the nearest neighbor (1-NN) classifier (Cover and Hart 1967), which is nonparametric and is known for its clear geometric interpretation. Moreover, the 1-NN classifier in Euclidean space has at most twice the Bayes error rate,Footnote 1 in an asymptotic sense (Pȩkalska and Duin 2008). However, its performance is strongly dependent on (1) the representational capacity of the dataset, that is, a potential loss in its performance when the training set is small (Pȩkalska and Duin 2002), and (2) the choice of a proper dissimilarity measure, especially when facing complex PR problems (Duin et al. 2014). To counteract these disadvantages, which are also present in data-driven geotechnical and natural hazard engineering problems (see Sect. 1), three simple but powerful variants of the 1-NN classifier are considered in the present study, namely the RNFLS classifier, which enriches the feature space via a linear interpolation between two prototype feature pointsFootnote 2 (Du and Chen 2007), and two methods—ANN (Wang et al. 2007) and HC (Lopes and Ribeiro 2015)—that use a (non)metric distance learning strategy based on the concept of territorial hyperspheres. In fact, the RNFLS classifier also defines territorial hyperspheres as sample territories in its learning scheme. A formal description of these three classifiers, as well as their key concepts, will be introduced in the following subsections.

Yongxin area: landslide factors. Source (Fang et al. 2020) (permission granted by Elsevier Ltd. by order number 5333851293554)
3.1 Territorial Hyperspheres
The three enriched/enhanced nearest feature classifiers compared in this paper for slope/landslide data classification are supported by the common idea of a region of influence, which is based on the concept of so-called territorial hyperspheres.
Let \({\varvec{x}} \in {\mathbb {R}}^{d}\) be a query point and \({\varvec{x}}_{i}^{c} \in {\mathbb {R}}^{d}\) be the ith prototype feature point with an associated class label \(c \in \{ 1, \ldots , C\}\). The territorial hypersphere of the prototype \({\varvec{x}}_{i}^{c}\) is centered at it and has a radius defined by
where n is the number of prototype feature points in the class r, \(\left\| \cdot \right\| \) is assumed to be the Euclidean norm, and the radius is computed as the minimum distance from the prototype \({\varvec{x}}_{i}^{c}\) to the nearest prototype belonging to a different class, \({\varvec{x}}_{j}^{r}\), that is, with \(c\ne r\).

Yongxin area: landslide factors (continuation). Source (Fang et al. 2020) (permission granted by Elsevier Ltd. by order number 5333851293554)
For the case of RNFLS, the hypersphere associated with \({\varvec{x}}_{i}^{c}\) is called the sample territory, which determines the class territory for all the prototype feature points belonging to the same class. The class territory is used to eliminate the interpolation inaccuracy of the original NFL classifier. On the other hand, for HC and ANN rules, these hyperspheres constitute an important part of the so-called adaptive procedure: HC subtracts \(\rho _{{\varvec{x}}_i^c}\) from \(\left\| {\varvec{x}} - {\varvec{x}}_{i}^{c} \right\| \) and ANN divides \(\left\| {\varvec{x}} - {\varvec{x}}_{i}^{c} \right\| \) by \(\rho _{{\varvec{x}}_i^c}\) such that for both cases, the query point \({\varvec{x}}\) is no longer classified according to its nearest prototype feature point, \({\varvec{x}}_{i}^{c}\)—in the conventional sense—but to the class of the \({\varvec{x}}_{i}^{c}\) that becomes the closest after scaling the distance by the radius of its nearest region of influence.
The first procedure for the three classifiers under comparison is computing the territorial hyperspheres; see Listing 1, which shows the code that returns the radii of the training vectors. Here, a vector saves the information provided by a prototype feature point; similarly, a collection of these vectors are saved as arrays or matrices. All vectors and matrices are stored as NumPy arrays (Harris et al. 2020). The radius for each training vector is equal to the distance to its closest neighbor belonging to a different class. Note that the diagonal of this matrix is initialized with Inf values instead of zeros; this is for convenience when characterizing a vector according to the classes of its closest neighbors, in particular to avoid the case in which a point is considered the closest neighbor to itself when sorting the distances. Note also that only the upper triangular part of the distance matrix is explicitly computed, and it is then copied to the lower part, taking advantage of the symmetric property of the matrix in order to avoid unnecessary computations.

3.2 Feature Lines
A feature line is a linear interpolation (and also extrapolation) between two prototype feature points of the same class. The so-called NFL classifier (Li and Lu 1999) is a nearest feature method which uses the additional information provided by these feature lines in order to enrich and generalize the representativeness of the original set of prototype feature points. Its effectiveness has been tested on several problems with small datasets, for instance in machine perception (Li and Lu 2013).
The NFL classifier generalizes each pair of prototype feature points, \(\left\{ {\varvec{x}}_{i}^{c}, {\varvec{x}}_{j}^{c} \right\} \), in the same class by a feature line subspace, \(L_{ij}^c\) (see Fig. 5). A query point \({\varvec{x}}\) is then projected onto \(L_{ij}^c\) as follows
where \(\mu \) is the position parameter given by \(\mu = ( {\varvec{x}} - {\varvec{x}}_{i}^{c} )\cdot ( {\varvec{x}}_{j}^{c} - {\varvec{x}}_{i}^{c} ) / \Vert {\varvec{x}}_{j}^{c} - {\varvec{x}}_{i}^{c} \Vert \in {\mathbb {R}}\).

Three query points, \({\varvec{x}}, {\varvec{x}}_1, {\varvec{x}}_2\), and their distances \(d(\cdot ,L_{ij}^{c})\) to the feature line \(L_{ij}^{c}\)
The classification of \({\varvec{x}}\) is performed by assigning the class label \({\hat{c}}\) to it, according to the nearest feature line
where
Figure 5 shows three query points to classify, denoted by \({\varvec{x}}, {\varvec{x}}_1\), and \({\varvec{x}}_2\). The projected point for the first one lies in the interpolating part, and the projections of the last two lie in the extrapolating part of \(L_{ij}^{c}\). In all cases, the distance \(d(\cdot ,L_{ij}^{c})\) is computed by means of the projected point.

3.3 The Rectified Nearest Feature Line Segment Classifier
In the NFL classifier, the interpolating and/or extrapolating part of some feature lines could involve two trespass errors: the extrapolation inaccuracy pointed out by Zheng et al. (2004) and the interpolation inaccuracy considered by Du and Chen (2007). Several refined NFL approaches for handling these issues have been reported in the literature. One rule that addresses both types of trespassing issues of NFL is the RNFLS classifier (Du and Chen 2007), which overcomes them in a two-stage procedure, building at the end an RNFLS subspace.

The two-stage procedure of the RNFLS classifier
First, and in contrast to the NFL classifier, when the projection of the query lies in the extrapolation part, only a segment (denoted by \(\widetilde{L_{ij}^{c}}\)) of the feature line subspace is used, where \(d({\varvec{x}},\widetilde{L_{ij}^{c}})\) is assumed as the distance from the query, \({\varvec{x}}\), to the closest point of the feature line segment, \({\varvec{z}} \in \widetilde{L_{ij}^{c}}\). In Fig. 6a, \({\varvec{z}}\) might correspond to any point along the line but between \({\varvec{x}}_{i}^c\) and \({\varvec{x}}_{j}^c\). Thus, this distance is obtained by reformulating Eqs. (3) and (4) in terms of \(\widetilde{L_{ij}^{c}}\), such that Eq. (4) becomes
Note that in this case, the distance obtained in Eq. (5)—called distance2line in Listing 2—depends on whether the position parameter takes a value less than zero or greater than 1 when computing the closest point. This position parameter, \(\mu \), is computed and saved in the variable mu; the extremes of the feature line segment subspace, \({\varvec{x}}_{i}^c\) or \({\varvec{x}}_{j}^c\), are also defined by the variables pointLeft and pointRight. Then the closest point, called p, is assigned.
Subsequently, if the projection of the query lies on the interpolation part, hyperspheres are used to examine the territories of each class and determine whether the feature line segment trespasses a territory which belongs to another class; if so, that feature line segment would be removed. Here, the sample territory, \(T_{{\varvec{x}}_{i}^{c}} \subseteq {\mathbb {R}}^{n}\), is expressed as
where \(\rho _{{\varvec{x}}_{i}^{c}}\) is defined by Eq. (1), and the union of the sample territories belonging to the same class leads to the class territory \({\mathcal {T}}_{c} = \underset{c}{\bigcup }\ T_{{\varvec{x}}_{i}^{c}}\). When a feature line segment from a different class r trespasses the c-class territory, then it is rejected, or vice versa. In this case, \(\mu \) takes a value between zero and 1 such that the projected point, \(\tilde{{\varvec{x}}}_{ij}^c\), is computed in the variable p which corresponds to Eq. (2). The distance to the projected point is then computed in the distance2line variable.
Figure 6b shows an example of a feature line segment from \({\varvec{x}}_{1}^{c}\) to \({\varvec{x}}_{3}^{c}\), belonging to c-class, that is rejected because it trespasses the r-class territory, composed of three circles. The implementation of this trespass verification is shown in Listing 3 for a given query point and two prototype feature points from the same class, which in turn is derived from Listing 4 in order to compute all accepted/rectified feature line segments for each class.


3.4 Hypersphere-Based Scaling
As mentioned above, the HC and ANN classifiers make use of the territorial hypersphere concept in order to obtain a (non)metric learning version of the 1-NN method where these methods essentially attempt to weigh distances to prototype feature points which are well inside their class (Orozco-Alzate et al. 2019), meaning that the larger the hypersphere, the more influential its center for the assignment of the class labels.
HC (Lopes and Ribeiro 2015) defines the region of influence of a given prototype feature point \({\varvec{x}}_{i}^{c} \in {\mathbb {R}}^{d}\) as \(\eta _i = \rho _i \mathbin {/} 2\), where \(\rho _i\) is its radius computed by Eq. (1). Thus, the distance from \({\varvec{x}}\) to \({\varvec{x}}_{i}^{c}\) for HC is given by
where g is the parameter that controls the overlapping between hyperspheres from different classes. The original version of the HC method proposes a value of \(g=2\), resulting in
On the other hand, according to the ANN classifier (Wang et al. 2007), the distance is scaled as
This hypersphere-based scaling was recently applied with successful results in a problem of seismic-volcanic signal classification by Bicego et al. (2022).
4 Experimental Setup
First, even though the Yongxin dataset was originally provided in separate parts for training and test, it was decided to fuse them into a single one (the so-called design set) which was then conveniently split into training and test according to the k-fold cross-validation protocol.
Commonly in PR tasks, a normalization preprocessing of data is required when the values are very different, especially when the Euclidean distance is used in a distance-based classifier such as 1-NN or support vector machine (SVM) classifiers; Listing 5 shows this procedure when the training and test sets have been defined beforehand.

As suggested by Bramer (2016, p. 185), a common means of finding the best classifier for a particular problem is using the receiver operating characteristic (ROC) graph and measuring the distances from the point (FP rate, TP rate) of each classifier to the (0,1) point, which corresponds to a perfect classification. The ROC graph is a plot which shows the trade-off between costs (FP rate) and benefits (TP rate) (Fawcett 2006), where FP is the false positive rate of a classifier and is estimated by
and where TP is the true positive rate, which is estimated by
This approach was adopted in order to find the best classifier for each dataset. The performance estimation is shown in Listing 6, where a counter of FP, TP, and “successes” (hits) of the results of a given classifier are saved.

Note that the Multinational and Yongxin datasets have a balanced number of positive and negative examples; in contrast, for the Taiwan dataset, the number of negative examples is more than 2.5 times the number of positive ones. The imbalance is an important factor to take into account when analyzing the reported classification accuracy.
Part of the Multinational dataset originally comes from Zhou and Chen (2009). In that part, the label of a specific sample from the Multinational dataset does not match the originally assigned label. After checking the Multinational dataset, rows 43 and 60 were found to have the same feature values but different labels, so it was assumed that the correct label was the one given originally in Zhou and Chen (2009), namely label 1.
In order to obtain reliable but computationally feasible performance estimations, the approach suggested in Japkowicz and Shah (2011, p. 203) is adopted, namely the leave-one-out estimate for small datasets and the k-fold cross-validation for moderate-sized ones. Accordingly, leave-one-out was used for experiments with the Taiwan and Multinational datasets, and fivefold cross-validation for the Yongxin dataset. Recall that leave-one-out is a particular case of k-fold cross-validation, where k is equal to the number of instances in the dataset (Bramer 2016, p. 83); moreover, since there is no randomness involved in leave-one-out, the same performance figures are obtained when the experiment is repeated. This cross-validation procedure, based on the Scikit-learn Python package, is coded in Listing 7.

5 Results and Discussion
For the three datasets used in this paper, a comparative evaluation is performed considering the test phase scheme proposed in Listing 8 for the 1-NN, ANN, and HC methods, and in Listing 9 for the RNFLS method, according to the description given in Sect. 4.


The performance rates were computed as shown in Listing 10, whose results for classification accuracy are presented in Table 4. First, note that very sound accuracy was obtained with 1-NN—the baseline method in the present paper—for the slope stability (Taiwan and Multinational) datasets; moreover, this also applies to the RNFLS classifier, which shows the highest accuracy highlighted in boldface. Note that the RNFLS classifier boosts the discriminant capacity of the 1-NN classifier, suitably addressing the imbalance condition of the Taiwan dataset. Apart from that, the ANN and HC methods show very similar performance for all three datasets.
Competitive results for classification accuracy were also obtained for the landslide Yongxin dataset, in particular with the RNFLS classifier. This would suggest that if a landslide dataset had a greater number of prototypes, that is, an enriched feature space, higher classification accuracy could be achieved. On the other hand, enhanced descriptions of key features, such as rainfall infiltration analysis (Tang et al. 2018), could be an important factor when designing a PR classifier.
In addition, it should be highlighted that for all datasets, the performance of the RNFLS classifier is consistently the best. This is also consistent with the ROC graphs, which are shown in Fig. 7, and the corresponding distances to the best classifier which are reported in Table 5. It suggests that “non-exotic” shapes dominate the data distribution in the feature space; thus, a linear subspace of synthetic prototype feature point generation may be a potential choice for classifying slope/landslide condition as stable or at risk of collapse. With that in mind, geometric classifiers could be evaluated, all based on simple but powerful geometric rules whose main advantage is supported by the enrichment of the feature space, such as affine/convex hulls (Cheema et al. 2015). Table 5 shows, highlighted in boldface, the results for the RNFLS classifier.


ROC graphs for Taiwan, Multinational, and Yongxin datasets considering 1-NN, ANN, HC, and RNFLS
6 Conclusion
Because of the frequent scarcity of available data on slope stability and landslide susceptibility when dealing with real-world information, the use of simple but powerful enrichment/enhancement of existing PR techniques was evaluated in this paper. These techniques derive from the fields of machine perception and computer vision, and until now have been unexplored for this type of geotechnical and natural hazard problem.
The experimental comparison offers sound results under a well-established step-by-step design cycle of a PR system, and provides meaningful insights when a data-driven focus is used. A parameter-free or parameterless classification framework based on the RNFLS, ANN, and hypersphere classifiers supports this inference, where the cornerstone is the powerful concept of territorial hyperspheres. Furthermore, the RNFLS classifier showed the best performance, thus indicating that it is more important to enrich the representational capacity of the prototype feature set for data-driven slope/landslide prediction problems. Also, the experimental comparison enables reproducible results, as (1) only publicly available datasets were used, (2) the entire actual code was presented using source snippets in a free general-purpose programming language such as Python, and (3) the classifiers employed in this paper do not require any previous knowledge in order to tune a (hyper)parameter set.
Finally, an interesting direction in which this paper may be extended is the use or ensemble of advanced geometric classifiers, mentioned in the final part of Sect. 4. In particular, a geometric extension of the NFL, the so-called nearest feature plane (NFP), may be suitable for data-driven slope/landslide prediction.
Notes
This refers to the lowest possible test error rate in classification tasks, according to the Bayes classifier, which is defined by \(1-E\left( \max _{j} \Pr \left( Y=j\mid X\right) \right) \), where X represents the data and j the labels of the classes (James et al. 2021).
Prototype feature points are also commonly called sample points, training examples, training vectors/points, or simply prototypes.
References
Achour Y, Pourghasemi HR (2020) How do machine learning techniques help in increasing accuracy of landslide susceptibility maps? Geosci Front 11(3):871–883. https://doi.org/10.1016/j.gsf.2019.10.001
Bicego M, Orozco-Alzate M (2021) PowerHC: non linear normalization of distances for advanced nearest neighbor classification. In: 25th International conference on pattern recognition (ICPR), pp 1205–1211. https://doi.org/10.1109/ICPR48806.2021.9413210
Bicego M, Rossetto A, Olivieri M, Londoño-Bonilla JM, Orozco-Alzate M (2022) Advanced KNN approaches for explainable seismic-volcanic signal classification. Math Geosci (in press). https://doi.org/10.1007/s11004-022-10026-w
Bramer M (2016) Principles of data mining, 3rd edn. Undergraduate Topics in Computer Science, Springer, Berlin. https://doi.org/10.1007/978-1-4471-7307-6
Cheema MS, Eweiwi A, Bauckhage C (2015) High dimensional low sample size activity recognition using geometric classifiers. Digital Signal Process 42:61–69. https://doi.org/10.1016/j.dsp.2015.03.019
Chen W, Pourghasemi HR, Kornejady A, Zhang N (2017) Landslide spatial modeling: introducing new ensembles of ANN, MaxEnt, and SVM machine learning techniques. Geoderma 305:314–327. https://doi.org/10.1016/j.geoderma.2017.06.020
Chen W, Pourghasemi HR, Panahi M, Kornejady A, Wang J, Xie X, Cao S (2017) Spatial prediction of landslide susceptibility using an adaptive neuro-fuzzy inference system combined with frequency ratio, generalized additive model, and support vector machine techniques. Geomorphology 297:69–85. https://doi.org/10.1016/j.geomorph.2017.09.007
Cheng MY, Hoang ND (2015) Typhoon-induced slope collapse assessment using a novel bee colony optimized support vector classifier. Nat Hazards 78:1961–1978. https://doi.org/10.1007/s11069-015-1813-8
Cover T, Hart P (1967) Nearest neighbor pattern classification. IEEE Trans Inf Theory 13:21–27. https://doi.org/10.1109/TIT.1967.1053964
Du H, Chen YQ (2007) Rectified nearest feature line segment for pattern classification. Pattern Recognit 40(5):1486–1497. https://doi.org/10.1016/j.patcog.2006.10.021
Duin RP, Bicego M, Orozco-Alzate M, Kim SW, Loog M (2014) Metric learning in dissimilarity space for improved nearest neighbor performance. In: Fränti P, Brown G, Loog M, et al (eds) Structural, syntactic, and statistical pattern recognition. Springer, Berlin, pp 183–192. https://doi.org/10.1007/978-3-662-44415-3_19
Fang Z, Wang Y, Peng L, Hong H (2020) Integration of convolutional neural network and conventional machine learning classifiers for landslide susceptibility mapping. Comput Geosci 139(104):470. https://doi.org/10.1016/j.cageo.2020.104470
Fawcett T (2006) An introduction to ROC analysis. Pattern Recognit Lett 27(8):861–874. https://doi.org/10.1016/j.patrec.2005.10.010
Fernández-Delgado M, Cernadas E, Barro S, Amorim D (2014) Do we need hundreds of classifiers to solve real world classification problems? J Mach Learn Res 15(90):3133–3181
Harris CR, Millman KJ, Van Der Walt SJ, Gommers R, Virtanen P, Cournapeau D, Wieser E, Taylor J, Berg S, Smith NJ, Kern R (2020) Array programming with NumPy. Nature 585(7825):357–362. https://doi.org/10.1038/s41586-020-2649-2
Hoang ND, Bui DT (2017) Chapter 18: Slope stability evaluation using radial basis function neural network, least squares support vector machines, and extreme learning machine. In: Samui P, Sekhar S, Balas VE (eds) Handbook of neural computation. Academic Press, pp 333–344, https://doi.org/10.1016/B978-0-12-811318-9.00018-1
Hoang ND, Pham AD (2016) Hybrid artificial intelligence approach based on metaheuristic and machine learning for slope stability assessment: a multinational data analysis. Expert Syst Appl 46:60–68. https://doi.org/10.1016/j.eswa.2015.10.020
Huang F, Zhang J, Zhou C, Wang Y, Huang J, Zhu L (2020) A deep learning algorithm using a fully connected sparse autoencoder neural network for landslide susceptibility prediction. Landslides 17(1):217–229. https://doi.org/10.1007/s10346-019-01274-9
Huang Y, Zhao L (2018) Review on landslide susceptibility mapping using support vector machines. CATENA 165:520–529. https://doi.org/10.1016/j.catena.2018.03.003
James G, Witten D, Hastie T, Tibshirani R, James G, Witten D, Hastie T, Tibshirani R (2021) Statistical learning. Springer, US, pp 15–57. https://doi.org/10.1007/978-1-0716-1418-1_2
Japkowicz N, Shah M (2011) Evaluating learning algorithms: a classification perspective. Cambridge University Press, New York. https://doi.org/10.1017/CBO9780511921803
Keogh E (2007) Why the lack of reproducibility is crippling research in data mining and what you can do about it. In: Proceedings of the 8th international workshop on multimedia data mining: (Associated with the ACM SIGKDD 2007). Association for Computing Machinery, New York, NY, USA, MDM ’07, https://doi.org/10.1145/1341920.1341922
Keogh E, Lonardi S, Ratanamahatana CA (2004) Towards parameter-free data mining. In: Proceedings of the tenth ACM SIGKDD international conference on knowledge discovery and data mining. association for computing machinery, New York, NY, USA, KDD ’04, pp 206–215, https://doi.org/10.1145/1014052.1014077
Keogh E, Lonardi S, Ratanamahatana CA, Wei L, Lee SH, Handley J (2007) Compression-based data mining of sequential data. Data Min Knowl Disc 14:99–129. https://doi.org/10.1007/s10618-006-0049-3
Korup O, Stolle A (2014) Landslide prediction from machine learning. Geol Today 30(1):26–33. https://doi.org/10.1111/gto.12034
Lee S, Won JS, Jeon SW, Park I, Lee MJ (2015) Spatial landslide hazard prediction using rainfall probability and a logistic regression model. Math Geosci 47(5):565–589. https://doi.org/10.1007/s11004-014-9560-z
Li DQ, Zheng D, Cao ZJ, Tang XS, Phoon KK (2016) Response surface methods for slope reliability analysis: review and comparison. Eng Geol 203:3–14. https://doi.org/10.1016/j.enggeo.2015.09.003
Li J, Lu CY (2013) A new decision rule for sparse representation based classification for face recognition. Neurocomputing 116:265–271. https://doi.org/10.1016/j.neucom.2012.04.034
Li S, Wu L, Luo X (2020) A novel method for locating the critical slip surface of a soil slope. Eng Appl Artif Intell 94(103):733. https://doi.org/10.1016/j.engappai.2020.103733
Li SZ, Lu J (1999) Face recognition using the nearest feature line method. IEEE Trans Neural Netw 10(2):439–443. https://doi.org/10.1109/72.750575
Lopes N, Ribeiro B (2015) Incremental hypersphere classifier (IHC). In: Machine learning for adaptive many-core machines: a practical approach, studies in big data, vol. 7. Springer, Cham, chap 6, pp 107–123. https://doi.org/10.1007/978-3-319-06938-8_6
Ma Z, Mei G, Piccialli F (2021) Machine learning for landslides prevention: a survey. Neural Comput Appl 33(17):10881–10907. https://doi.org/10.1007/s00521-020-05529-8
Micheletti N, Foresti L, Robert S, Leuenberger M, Pedrazzini A, Jaboyedoff M, Kanevski M (2014) Machine learning feature selection methods for landslide susceptibility mapping. Math Geosci 46(1):33–57. https://doi.org/10.1007/s11004-013-9511-0
Mohri M, Rostamizadeh A, Talwalkar A (2018) Foundations of machine learning, 2nd edn. MIT Press, Cambridge
Murdoch WJ, Singh C, Kumbier K, Abbasi-Asl R, Yu B (2019) Definitions, methods, and applications in interpretable machine learning. Proc Natl Acad Sci 116(44):22071–22080. https://doi.org/10.1073/pnas.1900654116
Orozco-Alzate M, Baldo S, Bicego M (2019) Relation, transition and comparison between the adaptive nearest neighbor rule and the hypersphere classifier. In: Ricci E, Rota Bulò S, Snoek C, et al (eds) Image analysis and processing – ICIAP 2019. Springer, Cham, pp 141–151. https://doi.org/10.1007/978-3-030-30642-7_13
Ospina-Dávila YM, Orozco-Alzate M (2020) Parsimonious design of pattern recognition systems for slope stability analysis. Earth Sci Inf 13(2):523–536. https://doi.org/10.1007/s12145-019-00429-5
Pandit B, Babu GLS (2018) Reliability-based robust design for reinforcement of jointed rock slope. Georisk: Assessment Manag Risk Eng Syst Geohazards 12(2):152–168. https://doi.org/10.1080/17499518.2017.1407800
Pȩkalska E, Duin RP (2002) Dissimilarity representations allow for building good classifiers. Pattern Recognit Lett 23(8):943–956. https://doi.org/10.1016/S0167-8655(02)00024-7
Pȩkalska E, Duin RPW (2008) Beyond traditional kernels: classification in two dissimilarity-based representation spaces. IEEE Trans Syst Man Cybernet Part C (Applications and Reviews) 38(6):729–744. https://doi.org/10.1109/TSMCC.2008.2001687
Phoon KK (2020) The story of statistics in geotechnical engineering. Georisk: Assessment Manag Risk Eng Syst Geohazards 14(1):3–25. https://doi.org/10.1080/17499518.2019.1700423
Phoon KK, Ching J, Shuku T (2021) Challenges in data-driven site characterization. Georisk: Assessment Manag Risk Eng Syst Geohazards 1–13. https://doi.org/10.1080/17499518.2021.1896005
Pourghasemi HR, Rahmati O (2018) Prediction of the landslide susceptibility: which algorithm, which precision? CATENA 162:177–192. https://doi.org/10.1016/j.catena.2017.11.022
Qi C, Tang X (2018) A hybrid ensemble method for improved prediction of slope stability. Int J Numer Anal Meth Geomech 42(15):1823–1839. https://doi.org/10.1002/nag.2834
Reichenbach P, Rossi M, Malamud BD, Mihir M, Guzzetti F (2018) A review of statistically-based landslide susceptibility models. Earth Sci Rev 180:60–91. https://doi.org/10.1016/j.earscirev.2018.03.001
Samui P (2013) Support vector classifier analysis of slope. Geomat Nat Haz Risk 4(1):1–12. https://doi.org/10.1080/19475705.2012.684725
Tang G, Huang J, Sheng D, Sloan SW (2018) Stability analysis of unsaturated soil slopes under random rainfall patterns. Eng Geol 245:322–332. https://doi.org/10.1016/j.enggeo.2018.09.013
Tang XS, Wang JP, Yang W, Li DQ (2018) Joint probability modeling for two debris-flow variables: copula approach. Nat Hazard Rev 19(2):05018004. https://doi.org/10.1061/(ASCE)NH.1527-6996.0000286
Vandewalle P, Kovacevic J, Vetterli M (2009) Reproducible research in signal processing. IEEE Signal Process Mag 26(3):37–47. https://doi.org/10.1109/msp.2009.932122
Wang J, Neskovic P, Cooper LN (2007) Improving nearest neighbor rule with a simple adaptive distance measure. Pattern Recognit Lett 28(2):207–213. https://doi.org/10.1016/j.patrec.2006.07.002
Zheng W, Zhao L, Zou C (2004) Locally nearest neighbor classifiers for pattern classification. Pattern Recognit 37(6):1307–1309. https://doi.org/10.1016/j.patcog.2003.11.004
Zhou J, Li E, Yang S, Wang M, Shi X, Yao S, Mitri HS (2019) Slope stability prediction for circular mode failure using gradient boosting machine approach based on an updated database of case histories. Saf Sci 118:505–518. https://doi.org/10.1016/j.ssci.2019.05.046
Zhou KP, Chen ZQ (2009) Stability prediction of tailing dam slope based on neural network pattern recognition. In: 2009 Second international conference on environmental and computer science, pp 380–383. https://doi.org/10.1109/icecs.2009.55
Acknowledgements
The second author acknowledges support from Universidad Nacional de Colombia - Sede Manizales. The anonymous reviewers are also acknowledged for their useful comments to improve the manuscript.
Funding
Open Access funding provided by Colombia Consortium
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ospina-Dávila, Y.M., Orozco-Alzate, M. Enriching Representation and Enhancing Nearest Neighbor Classification of Slope/Landslide Data Using Rectified Feature Line Segments and Hypersphere-Based Scaling: A Reproducible Experimental Comparison. Math Geosci 55, 1125–1145 (2023). https://doi.org/10.1007/s11004-023-10044-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11004-023-10044-2