
Abstract
Supervised deep learning requires a huge amount of reference data, which is often difficult and expensive to obtain. Domain adaptation helps with this problem—labelled data from one dataset should help in learning on another unlabelled or scarcely labelled dataset. In remote sensing, where a variety of sensors produce images of different modalities and with different numbers of channels, it would be very beneficial to develop heterogeneous domain adaptation methods that are able to work between domains that come from different input spaces. However, this challenging problem is rarely addressed, the majority of existing heterogeneous domain adaptation work does not use raw image-data, or they rely on translation from one domain to the other, therefore ignoring domain-invariant feature extraction approaches. This article proposes novel approaches for heterogeneous image domain adaptation for both the semi-supervised and unsupervised settings. These are based on extracting domain invariant features using deep adversarial learning. For the unsupervised domain adaptation case, the impact of pseudo-labelling is also investigated. We evaluate on two heterogeneous remote sensing datasets, one being RGB, and the other multispectral, for the task of land-cover patch classification, and also on a standard computer vision benchmark of RGB-depth map object classification. The results show that the proposed domain invariant approach consistently outperforms the competing methods based on image-to-image/feature translation, in both remote sensing and in a standard computer vision problem.












Similar content being viewed by others


Availability of data and materials
Publicly available datasets were used for this work.
Code availability
The experimental code is publicly available online.
Notes
It is not clear in the original article (Voreiter et al., 2020) if the method was evaluated on the same or on the different numbers of channels
References
Arjovsky, M., et al. (2017). Wasserstein generative adversarial networks. In ICML (pp. 214–223).
Benjdira, B., et al. (2019). Unsupervised domain adaptation using generative adversarial networks for semantic segmentation of aerial images. Remote Sensing, 11(11), 1369.
Benjdira, B., Ammar, A., Koubaa, A., & Ouni, K. (2020). Data-efficient domain adaptation for semantic segmentation of aerial imagery using generative adversarial networks. Applied Sciences, 10(3), 1092.
Bousmalis, K., et al. (2016). Domain separation networks. In NIPS (pp. 343–351).
Chen, W.-Y., et al. (2016). Transfer neural trees for heterogeneous domain adaptation. In ECCV (pp. 399–414).
Cheng, G., et al. (2017). Remote sensing image scene classification: Benchmark and state of the art. Proceedings of IEEE, 105(10), 1865–1883.
Courty, N., et al. (2014). Domain adaptation with regularized optimal transport. In ECML/PKDD (pp. 274–289).
Courty, N., et al. (2017). Joint distribution optimal transportation for domain adaptation. In NIPS (Vol. 30).
Damodaran, B., et al. (2018). DeepJDOT: Deep joint distribution optimal transport for unsupervised domain adaptation. In ECCV (pp. 447–463).
Duan, L., et al. (2012). Learning with augmented features for heterogeneous domain adaptation. In ICML (pp. 667–674)
Fuentes, M., et al. (2019). SAR-to-optical image translation based on conditional generative adversarial networks-optimization, opportunities and limits. Remote Sensing, 11(17), 2067.
Ganin, Y., & Lempitsky, V. (2015). Unsupervised domain adaptation by backpropagation. In ICML (pp. 1180–1189).
Ganin, Y., et al. (2016). Domain-adversarial training of neural networks. JMLR, 17(1), 2096–2030.
Gómez, P., & Meoni, G. (2021). MSMatch: Semisupervised multispectral scene classification with few labels. IEEE JSTARS, 14, 11643–11654.
Goodfellow, I., et al. (2014). Generative adversarial nets. In NIPS (pp. 2672–2680).
Gulrajani, I., et al. (2017). Improved training of Wasserstein GANs. In NIPS (Vol. 30).
Gupta, S., et al. (2014). Learning rich features from RGB-D images for object detection and segmentation. In ECCV (pp. 345–360).
Helber, P., et al. (2019). EuroSAT: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE JSTARS, 12(7), 2217–2226.
Hoffman, J., et al. (2018). CyCADA: Cycle-consistent adversarial domain adaptation. In ICML (pp. 1989–1998).
Ledig, C., et al. (2017). Photo-realistic single image super-resolution using a generative adversarial network. In CVPR (pp. 4681–4690).
Ley, A., et al. (2018). Exploiting GAN-based SAR to optical image transcoding for improved classification via deep learning. In EUSAR (pp. 1–6).
Li, J., et al. (2018). Heterogeneous domain adaptation through progressive alignment. IEEE Transactions on Neural Networks and Learning Systems, 30(5), 1381–1391.
Li, H., et al. (2020). RSI-CB: A large-scale remote sensing image classification benchmark using crowdsourced data. Sensors, 20(6), 1594.
Mordan, T., et al. (2018). Revisiting multi-task learning with ROCK: a deep residual auxiliary block for visual detection. In NeurIPS.
Neumann, M., et al. (2020). Training general representations for remote sensing using in-domain knowledge. In IGARSS (pp. 6730–6733).
Rudner, T., et al. (2019). Multi3Net: Segmenting flooded buildings via fusion of multiresolution, multisensor, and multitemporal satellite imagery. In AAAI (pp. 702–709).
Saha, S., et al. (2020). Building change detection in VHR SAR images via unsupervised deep transcoding. In IEEE TGRS.
Saito, K., et al. (2019). Semi-supervised domain adaptation via minimax entropy. In ICCV (pp. 8050–8058).
Sebag, A., et al. (2019). Multi-domain adversarial learning. In ICLR.
Shen, J., et al. (2018). Wasserstein distance guided representation learning for domain adaptation. In AAAI (pp. 4058–4065).
Shu, X., et al. (2015). Weakly-shared deep transfer networks for heterogeneous-domain knowledge propagation. In ACM Multimedia (pp. 35–44).
Silberman, N., et al. (2012). Indoor segmentation and support inference from RGBD images. In ECCV.
Simonyan, K., & Zisserman, A. (2015). Very deep convolutional networks for large-scale image recognition. In ICLR (pp. 1–14).
Sumbul, G., et al. (2019). BigEarthNet: A large-scale benchmark archive for remote sensing image understanding. In IGARSS (pp. 5901–5904).
Tasar, O., et al. (2020). SemI2I: Semantically consistent image-to-image translation for domain adaptation of remote sensing data. In IGARSS (pp. 1837–1840).
Titouan, V., et al. (2020). CO-optimal transport. NeurIPS, 33, 17559–17570.
Tzeng, E., et al. (2017). Adversarial discriminative domain adaptation. In CVPR (pp. 7167–7176).
Voreiter, C., et al. (2020). A Cycle GAN approach for heterogeneous domain adaptation in land use classification. In IGARSS (pp. 1961–1964).
Wang, X., et al. (2018). Heterogeneous domain adaptation network based on autoencoder. The Journal of Parallel and Distributed Computing, 117, 281–291.
Yan, Y., et al. (2018). Semi-Supervised optimal transport for heterogeneous domain adaptation. IJCAI, 7, 2969–2975.
Yi, Z., et al. (2017). DualGAN: Unsupervised dual learning for image-to-image translation. In ICCV (pp. 2849–2857).
Zhu, J.-Y., et al. (2017). Unpaired image-to-image translation using cycle-consistent adversarial networks. In ICCV (pp. 2223–2232).
Acknowledgements
This work was granted access to the HPC resources of IDRIS under the allocation 2021-A0111011872 made by GENCI. We thank Nvidia Corporation and the Centre de Calcul de l’Université de Strasbourg for access to GPUs. Supported by the French Government through co-tutelle PhD funding and ICube’s internal project funding (RL4MD).
Funding
This work was supported by the French Government through co-tutelle PhD funding.
Author information
Authors and Affiliations
Contributions
MO: methodology, experiments, coding, writing; TL: conceptualisation, experimental design, writing, supervision; PG: supervision, reviewing; MI: supervision, reviewing.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevantconflicting/competing interests to disclose.
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Editors: Fabio Vitale, Tania Cerquitelli, Marcello Restelli, Charalampos Tsourakakis.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Implementation details
1.1 A.1 Remote sensing
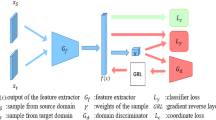
Unlike WDGRL, whose components are fully connected neural networks, SS-HIDA and UPL-HIDA are convolutional architectures (see Fig. 3 for details). The feature extractor for RESISC45 consists of two convolutional layers with 16 and 32 filters respectively. Each conv. layer is followed by \(4\times 4\) max-pooling. The feature extractor for EuroSAT is the same, except that it has \(2\times 2\) max-pooling after every conv. layer. The shared invariant feature extractor has two convolutional layers with 32 and 64 filters respectively, and one fully-connected (FC) layer of 100 nodes. All of the kernels have size \(5\times 5\). The class discriminator has one FC layer with softmax activation. The domain critic (DC) is identical to that in WDGRL—it has an FC layer with 100 nodes followed by an FC layer with 1 node.
In each training step, the DC is trained for 10 iterations with a learning rate of \(10^{-3}\), the DC is then frozen and the rest of the model is trained for 1 iteration with a learning rate of \(10^{-4}\). The DC loss’ weight \(\lambda\) is 0.1. The Adam optimiser is used.
The input data is standardised per channel so that each channel has mean 0 and standard deviation 1. The following augmentation transformations are used: flipping with a probability of 0.45, rotation with a probability of 0.75 for \(90^{\circ }\), \(180^{\circ }\), or \(270^{\circ }\), changing contrast with the probability of 0.33 by multiplying the values of the pixels with the coefficient ranging between 0.5 and 1.5, changing brightness with the probability of 0.33 by adding the coefficient ranging between \(-0.3\) and 0.3 scaled by the mean of pixel values per channel before standardisation, blurring with the probability of 0.33 with Gaussian filter with \(\sigma\) parameter values ranging from 1.5 to 1.8, and finally adding Gaussian noise with mean 0 and standard deviation between 10 and 15 with the probability of 0.33. The batch size is 32, and in each iteration, half of the training batch (16) comes from the source, and the other half from the target domain. The model is trained for 40 epochs.
1.2 A.2 RGB-depth
At the first phase of training, the convolutional part of the network is frozen, and only the FC layers are trained with the learning rate \(10^{-4}\). Then the whole network is fine-tuned with a smaller learning rate of \(10^{-5}\). We present the results of two variants of our unsupervised method:
-
UPL-HIDA—uses the CycleGAN (ResNet generator) to obtain pseudo-labels (trained for 50 epochs) with a source classifer initialised with a VGG-16 backbone (FC layers trained for 40 epochs, then finetuned for 40 additional epochs), the most confident 10 images per class (where available) are used for pseudo-labelling; UPL-HIDA (VGG-16 backbone) FC layers are trained for 1 epoch, then the whole network is finetuned for 5 epochs.
-
U-HIDA—(VGG-16 backbone) FC layers trained for 40 epochs, then finetuned for 30 epochs.
The domain critic has a similar architecture to ADDA’s domain classifier: a fully connected NN having 3 layers (1024 nodes, 2048 nodes, and 1 node). The rest of the training process is as described in the RS experiments.
The data is preprocessed as is required for the pretrained VGG network—all the patches are resized to \(224 \times 224\) pixels, and all the channels are zero-centered without scaling. Data augmentation is not used here to be fair in comparison to ADDA which also does not use it. The batch size used is 256, 128 samples per domain. Note that VGG can be easily replaced with any other architecture, e.g. ResNet.
Appendix B: Remote sensing unsupervised ablation study
In order to asses the impact of using different thresholds for pseudo-labelling, we show the results of UPL-HIDA on different amounts of pseudo-labelled target data, ranging from \(100\%\) (whole dataset) to \(1.25\%\) (the most confident 5 images per class are pseudo-labelled). The results without using any pseudo-labels (\(0\%\)) are also included. The performance of CycleGAN for HDA is given as a horizontal line. The comparison is shown in Fig. 13. These results are obtained using the RGB version of EuroSAT. As CycleGAN for HDA does not translate very well between RGB and multispectral data, the potential of UPL-HIDA using pseudo-labels given by CycleGAN is better seen on RGB-only data. N.B. These results are not comparable to those above as the ablation study is performed on the validation set of the target domain (rather than the test set).

Accuracy of the unsupervised pseudo-labelled solution with varying thresholds for choosing the most confident pseudo labels. Horizontal dashed line shows the performance of CycleGAN for HDA. The numbers are expressed in percentages of labelled images
When RESISC45 is source and EuroSAT is target domain, starting with \(1.25\%\), the accuracy grows as more pseudo-labelled data is added, outperforming CycleGAN for HDA from \(2.5\%\), and reaching its peak with a threshold of \(12.5\%\). Afterwards, additional pseudo-labels become less reliable and harm performance, but the accuracy remains higher than that of CycleGAN for HDA.
The situation is not as clear when adapting in the opposite direction, when EuroSAT is source and RESISC45 is target. As stated before, the RESISC45 dataset is more difficult to solve than EuroSAT, so the quality of pseudo-labels given by CycleGAN is not very high to begin with. Regardless, the model without using any pseudo-labels (\(0\%\)) already outperforms CycleGAN for HDA, and remains higher in all the cases. As can be seen, better performances could have been obtained using threshold values different than \(12.5\%\) (notably \(2.5\%\)), however optimising this parameter would require using a certain amount of additionally labelled target data, so it was not done for these experiments.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Obrenović, M., Lampert, T., Ivanović, M. et al. Learning domain invariant representations of heterogeneous image data. Mach Learn 112, 3659–3684 (2023). https://doi.org/10.1007/s10994-023-06374-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10994-023-06374-1