
Abstract
We consider the optimization problem of minimizing an objective functional, which admits a variational form and is defined over probability distributions on a constrained domain, which poses challenges to both theoretical analysis and algorithmic design. We propose Mirror Variational Transport (mirrorVT), which uses a set of samples, or particles, to represent the approximating distribution and deterministically updates the particles to optimize the functional. To deal with the constrained domain, in each iteration, mirrorVT maps the particles to an unconstrained dual domain, induced by a mirror map, and then approximately performs Wasserstein Gradient Descent on the manifold of distributions defined over the dual space to update each particle by a specified direction. At the end of each iteration, particles are mapped back to the original constrained domain. Through experiments on synthetic and real world data sets, we demonstrate the effectiveness of mirrorVT for the distributional optimization on the constrained domain. We also analyze its theoretical properties and characterize its convergence to the global minimum of the objective functional.







Similar content being viewed by others
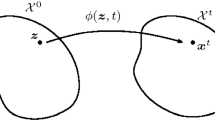

Code availability
The simulated data and source code for experiments can be accessed through https://github.com/haidnguyen0909/mirrorVT after the acceptance of the paper.
Notes
1-Wasserstein is defined as: \(\mathscr {W}_{1}(p, q)= \inf _{\pi \in \Pi (p,q)} \int _{\mathscr {X}\times \mathscr {X}} \Vert {\textbf {x}} - {\textbf {x}}^\prime \Vert _{2}\textrm{d}\pi ({\textbf {x}},{\textbf {x}}^\prime )\)
We use [N] to indicate the list \(\left[ 1,2,\ldots ,N\right]\) throughout the rest of the paper.
For any \({\textbf {x}}{}, {\textbf {x}}^\prime \in \mathscr {X}\) and \({\textbf {y}}=\nabla \varphi ({\textbf {x}}),{\textbf {y}}^\prime =\nabla \varphi ({\textbf {x}}^\prime )\), we have: \(\Vert \nabla g^{*}_{t}({\textbf {y}})-\nabla g^{*}_{t}({\textbf {y}}^\prime ) \Vert _{2} = \Vert \nabla ^{2} \varphi ({\textbf {x}})^{-1}\nabla f^{*}_{t}({\textbf {x}})-\nabla ^{2} \varphi ({\textbf {x}}^\prime )^{-1}\nabla f^{*}_{t}({\textbf {x}}^\prime )\Vert _{2} \le h \Vert {\textbf {x}}-{\textbf {x}}^{\prime } \Vert _{2} = h \Vert \nabla \varphi ^{*}({\textbf {y}})-\nabla \varphi ^{*}({\textbf {y}}^\prime ) \Vert _{2} \le h/\alpha \Vert {\textbf {y}}-{\textbf {y}}^\prime \Vert _{2}\), where the last inequality holds as \(\varphi ^{*}\) is \(1/\alpha\)-smooth.
References
Ahn, K., & Chewi, S. (2021). Efficient constrained sampling via the mirror-Langevin algorithm. Advances in Neural Information Processing Systems, 34, 28405–28418.
Arjovsky, M., Chintala, S., & Bottou, L. (2017). Wasserstein generative adversarial networks. In International conference on machine learning (pp. 214–223). PMLR.
Beck, A., & Teboulle, M. (2003). Mirror descent and nonlinear projected subgradient methods for convex optimization. Operations Research Letters, 31(3), 167–175.
Bowman, S. R., Vilnis, L., Vinyals, O., Dai, A. M., Jozefowicz, R., & Bengio, S. (2015). Generating sentences from a continuous space. arXiv preprint arXiv:1511.06349
Cheng, X., & Bartlett, P. (2018). Convergence of Langevin MCMC in KL-divergence. In Algorithmic learning theory (pp. 186–211). PMLR.
Cuturi, M. (2013). Sinkhorn distances: Lightspeed computation of optimal transport. Advances in Neural Information Processing Systems, 26.
Duchi, J., Shalev-Shwartz, S., Singer, Y., & Chandra, T. (2008). Efficient projections onto the l 1-ball for learning in high dimensions. In Proceedings of the 25th international conference on Machine learning (pp. 272–279).
Gretton, A., Borgwardt, K. M., Rasch, M. J., Schölkopf, B., & Smola, A. (2012). A kernel two-sample test. The Journal of Machine Learning Research, 13(1), 723–773.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780.
Hsieh, Y.-P., Kavis, A., Rolland, P., & Cevher, V. (2018). Mirrored Langevin dynamics. Advances in Neural Information Processing Systems, 31.
Joo, W., Lee, W., Park, S., & Moon, I.-C. (2020). Dirichlet variational autoencoder. Pattern Recognition, 107, 107514.
Kingma, D. P., & Welling, M. (2013) Auto-encoding variational Bayes. arXiv preprint arXiv:1312.6114
Koziel, S., & Michalewicz, Z. (1998). A decoder-based evolutionary algorithm for constrained parameter optimization problems. In Parallel problem solving from nature-PPSN V: 5th International conference Amsterdam, 1998 Proceedings (Vol. 5, pp. 231–240). Springer.
Liu, L., Zhang, Y., Yang, Z., Babanezhad, R., & Wang, Z. (2021). Infinite-dimensional optimization for zero-sum games via variational transport. In International conference on machine learning (pp. 7033–7044). PMLR.
Liu, Q., & Wang, D. (2016). Stein variational gradient descent: A general purpose Bayesian inference algorithm. Advances in Neural Information Processing Systems, 29.
Ma, Y.-A., Chen, T., & Fox, E. (2015). A complete recipe for stochastic gradient MCMC. Advances in Neural Information Processing Systems, 28.
Michalewicz, Z., & Schoenauer, M. (1996). Evolutionary algorithms for constrained parameter optimization problems. Evolutionary Computation, 4(1), 1–32.
Nguyen, D. H., Nguyen, C. H., & Mamitsuka, H. (2021). Learning subtree pattern importance for Weisfeiler–Lehman based graph kernels. Machine Learning, 110, 1585–1607.
Nguyen, D. H., & Tsuda, K. (2023). On a linear fused Gromov–Wasserstein distance for graph structured data. Pattern Recognition (p. 109351).
Rosasco, L., Belkin, M., & De Vito, E. (2009). A note on learning with integral operators. In COLT. Citeseer.
Santambrogio, F. (2017). \(\{\)Euclidean, metric, and Wasserstein\(\}\) gradient flows: An overview. Bulletin of Mathematical Sciences, 7(1), 87–154.
Shi, J., Liu, C., & Mackey, L. (2021). Sampling with mirrored stein operators. arXiv preprint arXiv:2106.12506
Villani, C. et al. (2009). Optimal transport: Old and new (Vol. 338). Springer.
Welling, M., & Teh, Y. W. (2011). Bayesian learning via stochastic gradient Langevin dynamics. In Proceedings of the 28th international conference on machine learning (ICML-11) (pp. 681–688).
Wibisono, A. (2018). Sampling as optimization in the space of measures: The Langevin dynamics as a composite optimization problem. In Conference on learning theory (pp. 2093–3027). PMLR.
Xu, P., Chen, J., Zou, D., & Gu, Q. (2018). Global convergence of Langevin dynamics based algorithms for nonconvex optimization. Advances in Neural Information Processing Systems, 31.
Zhang, H., & Sra, S. (2016). First-order methods for geodesically convex optimization. In Conference on learning theory (pp. 1617–1638). PMLR.
Funding
D. H. N. was supported by the Japan Society for the Promotion of Science (JSPS) KAKENHI Grant Number 23K16939. T. S. was supported by the New Energy and Industrial Technology Development Organization (NEDO) Grant Number JPNP18010 and Japan Science and Technology Agency (JST) Grant Number JPMJPF2017.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Editors: Fabio Vitale, Tania Cerquitelli, Marcello Restelli, and Charalampos Tsourakakis.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix 1
Appendix 1
1.1 Appendix 1.1: Proof of Theorem 2
Proof
We have assumed \(F(p)=\text {KL}(p||p^{*})\) for \(p,p^{*}\in \mathscr {P}_{2}(\mathscr {X})\), so \(G(q)=\text {KL}(q||q^{*})\), for \(q,q^{*}\in \mathscr {P}_{2}(\mathscr {Y})\). By the definition of the first variation of a functional, we have:
We can compute the left-hand side as follows:
which indicates that \(\partial G/\partial q= \log q - \log q^{*}\). For t-th iteration, the update direction \(v_{t}\) is given by:
for all \({\textbf {x}}\in \mathscr {X}, {\textbf {y}}=\nabla \varphi ({\textbf {x}})\in \mathscr {Y}\). By applying the integral operator \(\mathscr {L}_{k, p_{t}}\) (see Definition 1) to \(v_{t}\), we obtain:
The first equality is obtained by the definition of the integral operator (see Definition 1), the second equality is obtained by using (30) and the forth equality is obtained by applying the integration by parts to the first term. The proof is completed. \(\square\)
1.2 Appendix 1.2: Proof of Theorem 3
Proof
We analyze the performance of one step of mirrorVT. Under the Assumption 1.1 (\(L_{2}\)-smoothness of G), for any \(t\ge 0\), we have:
where \(\eta _{t}\in \left( 0, \alpha /h\right]\) (see (11)) and \(\tilde{\delta }_{t}=-\texttt {div}(q_{t}(\nabla \tilde{g_{t}^{*}}-\nabla g^{*}_{t}))\) is the difference between the true 2-Wasserstein gradient at \(q_{t}\) given by \(\texttt {grad}G(q_{t})=-\texttt {div}(q_{t}\nabla g^{*}_{t})\) and its estimate given by \(-\texttt {div}(q_{t}\nabla \tilde{g_{t}^{*}})\). The corresponding expected gradient error for G is defined as:
Also since \(0 \prec \alpha {\textbf {I}}\preceq \nabla ^{2}\varphi ({\textbf {x}})\) for all \({\textbf {x}}\in \mathscr {X}\), we have
By applying the basic inequality: \(\langle \texttt {grad}G(q_{t}), \tilde{\delta }_{t}\rangle \le \frac{1}{2}\langle \texttt {grad}G(q_{t}), \texttt {grad}G(q_{t})\rangle + \frac{1}{2} \langle \tilde{\delta }_{t}, \tilde{\delta }_{t}\rangle\) and combining with (34), we have:
By the definition of the inner product on the tangent space and the assumption of \(\mu\)-strong convexity of F, we obtain the following inequality:
where the first inequality is obtained by \(\nabla ^{2}\varphi ({\textbf {x}})\preceq \beta {\textbf {I}}\) for all \({\textbf {x}}\in \mathscr {X}\) and the second inequality is obtained by Assumption 1.3 (see 26). Thus combining (35) and use the identity: \(F(p_{t})=G(q_{t})\), we have:
By setting \(\eta _{t} =\eta \le \min \left\{ \frac{1}{2L_{2}},\frac{1}{\mu \beta ^{2}}\right\}\), we have:
In the sequel, we define \(\rho = 1-\frac{\mu \eta }{2\beta ^{2}}\in \left[ 0,1 \right]\), we have:
By forming a telescoping sequence and combining the upper bound of \(\epsilon _{t}\) given in Liu et al. (2021), we have:
Finally, by taking the expectation over the initial particle set, we complete the proof. \(\square\)
1.3 Appendix 1.3: Details of the mirror maps
In this section, we describe more details of the mirror maps used in our simulated experiments.
1.3.1 Appendix 1.3.1: Mirror map on the unit ball
For the mirror map defined in (28), we can easily shown that:
Hence the Hessian matrix can be written as: \(\nabla ^{2}\varphi ({\textbf {x}})=\frac{1}{1-\Vert {\textbf {x}} \Vert _{2}}{} {\textbf {I}}+\frac{1}{\Vert {\textbf {x}} \Vert _{2} \left( 1- \Vert {\textbf {x}} \Vert _{2}\right) ^{2}}{} {\textbf {x}} {\textbf {x}}^\top\), where \({\textbf {I}}\) is the identity matrix. In order to obtain the inversion of Hessian matrix, we apply the celebrated Woodbury matrix identity and show that
1.3.2 Appendix 1.3.2: Mirror map on the simplex
For the entropic mirror map (see Beck & Teboulle 2003), we can consider \({\textbf {x}}=\left[ {\textbf {x}}_{1},\ldots ,{\textbf {x}}_{d-1}\right] \in \mathbb {R}^{d-1}\) by discarding the last entry \({\textbf {x}}_{d}=1 - \sum _{i=1}^{d-1}{} {\textbf {x}}_{i}\) and easily show that:
Hence the Hessian matrix can be written as: \(\nabla ^{2}\varphi ({\textbf {x}})=\texttt {diag}(1/{\textbf {x}}_{1},1/{\textbf {x}}_{2},\ldots ,1/{\textbf {x}}_{d-1})+1/{\textbf {x}}_{d} {\textbf {1}}{} {\textbf {1}}^\top\). By applying the Sherman-Morrison formula, we obtain the inverse Hessian matrix of the following form:
1.4 Appendix 1.4: Details of network architectures
We present the neural network architectures of DirVAE on the image data set MNIST in Table 4 and on the text data set in Table 5.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Nguyen, D.H., Sakurai, T. Mirror variational transport: a particle-based algorithm for distributional optimization on constrained domains. Mach Learn 112, 2845–2869 (2023). https://doi.org/10.1007/s10994-023-06350-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10994-023-06350-9