
Abstract
In this paper, we propose a novel and effective approximation method for finding the value function for general utility maximization with closed convex control constraints and partial information. Using the separation principle and the weak duality relation, we transform the stochastic maximum principle of the fully observable dual control problem into an equivalent error minimization stochastic control problem and find the tight lower and upper bounds of the value function and its approximate value. Numerical examples show the goodness and usefulness of the proposed method.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
There has been extensive research in utility maximization for continuous-time stochastic models, see Pham [19] for expositions. If all model parameters are known or can be observed, then one only needs to solve the optimization problem. However, if some model parameters are not observable, as in many financial applications, then one needs to extract the information of unknown parameters as well as to solve the optimization problem. Thanks to the separation principle and the filtering theory, the unobservable model may be first transformed into an equivalent fully observable model which is then solved using the known optimization methods, see Björk et al. [4] for an excellent introduction of the topic.
For utility maximization with incomplete market information, the traded risky asset is usually assumed to have observable volatility but unobservable growth rate, see Karatzas and Xue [13]. To uncover the unknown growth rate, one may compute its conditional expectation (the filter) with updated market information (the filtration generated by traded assets). It is in general difficult to compute the filter as one needs to solve a stochastic partial differential equation (SPDE), but there are three important special cases where the filtering equations can be expressed in finite-dimensional closed form. These filters are consequently easily implemented in practice and are found in a wide range of applications. They are Kalman–Bucy filter for linear diffusion, Wonham filter for finite state Markov chain, and Bayesian filter for random variable. Each of them has been widely studied in portfolio optimization, see, for example, Lakner [15] and Papanicolaou [18] for the linear diffusion model, Sass and Haussmann [21] and Eksi and Ku [7] for the continuous-time finite state Markov chain model, Ekstrom and Vaicenavicius [8] and Bismuth et al. [3] for the random variable model. All the aforementioned papers deal with only specific (power or logarithmic) utility without control constraints.
To solve a stochastic optimal control problem, one may use the dynamic programming principle (DPP) to derive the HJB equation (a nonlinear partial differential equation (PDE)) for the value function in the Markovian case, or the convex duality and the martingale representation for the optimal terminal state and the replicating control strategy in the convex case, or the stochastic maximum principle (SMP) to derive the fully coupled forward and backward stochastic differential equation (FBSDE) for the optimal state and adjoint processes, see Fleming and Soner [9], Karatzas and Shreve [12], and Yong and Zhou [23] for these methodologies. For utility maximization with closed convex control constraints, one may also use the dual control approach to solving the problem, see Li and Zheng [16], which is particularly effective when there is only one state variable for wealth process and the control constraint set is a cone, then the dual HJB equation is a linear PDE and the dual value function has a Feynman–Kac representation, see Bian et al. [1].
It is considerably more difficult to solve utility maximization with partial information, even if the filtering equation has a finite-dimensional closed form. The key reason is that the model has at least two state variables, one for the wealth process and one for the correlated filter process. Both the primal HJB equation and the dual HJB equation are fully nonlinear PDEs, which is in sharp contrast with utility maximization of one state variable as in [1]. One may also view the model having one state variable (wealth) satisfying a stochastic differential equation (SDE) with random coefficients (filters) and use the SMP to get the fully coupled nonlinear controlled FBSDE with the control satisfying the Hamiltonian condition, which is again highly difficult to solve. More discussions on portfolio optimization with partial information can be found in the literature, for example, Fouque et al. [10] perform perturbation analysis, Brennan [5] analyzes the effect of uncertainty about the mean return of the risky asset on investors’ optimal strategies by comparing the myopic and “full information” allocations, Bichuch and Guasoni [2] discuss the price-divide ratio and interest rate equilibrium over time.
In this paper, for utility maximization with general utility functions, closed convex control constraints and partial information, instead of trying to find the value function and optimal control exactly, a highly difficult task as discussed above, we suggest a novel and effective computational method for finding tight lower and upper bounds of the value functions. The idea is to transform the SMP of the equivalent fully observable dual control problem, which is difficult to solve as it is a system of constrained FBSDEs, into an equivalent form in forward controlled SDEs and then further into an error minimization problem, which is relatively easy to solve as it is a combined scalar minimization and optimal stochastic control problem. It opens a way of finding a good approximate optimal solution, a feature not yet available for solving the constrained FBSDE from the SMP in the literature, and, thanks to the weak duality relation, the tight lower and upper bounds for the value function and its approximate value.
The rest of the paper is organized as follows. In Sect. 2 we introduce general utility maximization with partial information and then use the separation principle and the innovation process to transform the problem into an equivalent fully observable problem. We also give three examples of finite-dimensional filters. In Sect. 3 we review three well known methods for solving the filtered utility maximization, including the primal and dual HJB equations, and SMP, and illustrate these methods with an example which has a closed-form solution. In Sect. 4 we propose an effective approximation method for finding the lower and upper bounds of the value function. In Sect. 5 we do some numerical tests for power utility and discuss the relevant information values. Section 6 concludes the paper. Appendix includes some equations and formulas used in the paper.
2 Model and Equivalent Filtered Problem
In this section we introduce the market models that will be employed and the optimal choice of investors with partial information under a closed convex constraint. As the setup in Björk et al. [4], we consider the stochastic basis \((\Omega ,{\mathbb {F}},{\mathcal {F}},{\mathbb {P}})\) for financial markets, where the filtration \({\mathcal {F}}=\{{\mathbb {F}}_t\}_{0\le t\le T}\) satisfies the usual conditions. In what follows, we consider a market consisting of \(N+1\) securities, among them one is the risk-free bond account whose price is denoted by \(S_0(t)\):
and others are risky securities with prices \(\{S_n(t)\}_{n=1}^N\):
where \(\{W(t),t\in [0,T]\}\) is a \({\mathbb {R}}^N\)-valued standard Brownian motion, \(S(t)=(S_1(t),\ldots ,S_N(t))^\mathrm{T}\), \(\mu (t)=(\mu _1(t),\ldots ,\mu _N(t))^\mathrm{T}\quad (a^\mathrm{T} \text { is the transpose of }a)\) and \(\sigma (t)=(\sigma _{nm}(t))_{n,m=1}^N\). Denote the filtration generated by the asset price processes \(S_1,\dots , S_N\) as \({\mathcal {F}}^S\). The interest rate \(\{r(t)\}\) and the volatility rates \(\sigma (t)\) are assumed to be uniformly bounded \({\mathcal {F}}_t^S\)-progressively measurable processes on \(\Omega \times [0,T]\). We also assume that there exists \(k\in {\mathbb {R}}^+\) such that
for all \((z,w,t)\in {\mathbb {R}}^N\times \Omega \times [0,T]\). This ensures the matrices \(\sigma (t),\sigma ^\mathrm{T}(t)\) are invertible and uniformly bounded by Xu and Shreve [22]. The drift processes of the return, \(\mu (t)\), are assumed to be \({\mathcal {F}}\)-adapted processes.
Remark 1
Throughout the paper different information sets are assumed to be available for various market participants. The full information is given by the filtration \({\mathcal {F}}\), while the observable information is given by the filtration \({\mathcal {F}}^S\), generated by the evolution of asset price processes S and we have \( {\mathcal {F}}^S\subset {\mathcal {F}}\). The completely observable case is obtained by assuming \({\mathcal {F}}={\mathcal {F}}^S\).
Remark 2
The assumption that r is \({\mathcal {F}}^S\)-adapted (cf. [13]) implies that the interest rates can be known by observing the stock prices only, and \({\mathcal {F}}^{r,S}={\mathcal {F}}^{S}\).
Define a self-financing trading strategy as \(\pi =(\pi (t))_{t\in [0,T]}\), which is an N-dimensional \({\mathcal {F}}^S\)-progressively measurable process and \(\pi _i(t)\) denotes the fraction of the wealth invested in the stock i for \(i=1,\ldots ,N\) at time \(t\in [0,T]\). Additionally, the set of admissible portfolio strategies is given by
where \(K\subseteq {\mathbb {R}}^N\) is a closed convex set containing 0, and
Some examples of K are discussed in Sass [20], which shows the generality of this assumption and some common situations are included, such as short selling prohibited, limited funds and so on. Given any \({\mathcal {F}^S}\)-measurable \(\pi \in {\mathcal {A}}\), the dynamics of the investor’s total wealth \(X^{\pi }\) is given as
where \(x>0\) and \(\mathbf{1} \in {\mathbb {R}}^N\) has all unit entries. A pair \((X^{\pi },\pi )\) is said to be admissible if \({\mathcal {F}}^S\)-measurable \(\pi \in {\mathcal {A}}\) and \(X^{\pi }\) satisfies (2). The utility function \(U:(0,\infty )\rightarrow {\mathbb {R}}\) considered here is continuous, increasing, concave and \(U(0)=0\).
Define the value of the expected utility maximization problem as
We assume that \(-\infty<V<+\infty \) to avoid trivialities and as the available information is only the securities’ dynamics, we actually are facing a stochastic control problem with partial information. Any \(\pi ^*\in \mathcal {A}\) satisfying \(E[U(X^{\pi ^*}(T))]=V\) is called the optimal control, and the corresponding \(X^*=X^{\pi ^*}\) is called the optimal state process.
The above partially observable problem can be reduced to an equivalent problem under full information, as in [4]. Here we define the innovation process \(\hat{V}=(\hat{V}(t))_{t\in [0,T]}\) as
where \(\hat{\mu }(t)=E[\mu (t)|{\mathcal {F}}_t^S]\) is the filter for \(\mu (t)\). The following result holds:
Theorem 1
(Fujisaki et al. [11]) Assume that \((\sigma ^{-1}(t))_{t\in [0,T]}\) is uniformly bounded and \(E\left[ \int _0^T\Vert \sigma ^{-1}(t)\mu (t)\Vert ^2\hbox {d}t\right] <\infty \). Then \(\hat{V}\) is a \({\mathcal {F}}^S\)-Brownian motion under \({\mathbb {P}}\).
From the definition of \(\hat{V}\) in (4) we have the following representatives:
The corresponding wealth process would be
Under this transformation, the original partially observed problem has been transformed to a related problem as in the full information. After solving the reformulated completely observed problem, the partially observable case would be discussed by embedding the filtering equations for unobservable processes. As discussed in [4], for general hidden Markov models, the infinite dimensional state space problem of the Kolmogorov backward equation would make it impossible to give explicit solutions of optimal control. We next give three examples of special but important filters, they are the Kalman–Bucy filter, the Wonham filter and the Bayesian filter.
Example 1
Linear stochastic differential equation Suppose that \(\mu (t)=H(t)\) in (1), where H satisfies the following SDE:
where \(\bar{H}\in {\mathbb {R}}^N\) and \(\lambda , \sigma _H\in {\mathbb {R}}^{N\times N}\) are constant vector and matrices, \(\rho \in [-1,1]\), \(W_H\) is an N-dimensional Brownian motion independent of W, and the initial condition H(0) of process H is independent of \(W,W_H\). By Liptser and Shiryayev [17], let the conditional density of H(t) given \({{\mathcal {F}}}^S\) be Gaussian, then \(\hat{H}(t)=E[H(t)|{\mathcal {F}}_t^S]\), called the Kalman–Bucy filter, satisfies the following SDE:
where \(\hat{\Sigma }_R(t):=\sigma ^{-1}(t)\Sigma (t)+\rho \sigma _H^T\), \(\Sigma (t):=\mathrm{Var}(H(t)|{\mathcal {F}}_t^S)= E[(H(t)-\hat{H}(t))(H(t)-\hat{H}(t))^T|{\mathcal {F}}_t^S]\) and
subject to \( \hat{H}(0)=E[H(0)], \Sigma (0)=\mathrm{Var}(H(0)). \) Under specific cases, \(\hat{H}(t)\) can be solved explicitly in terms of \(\Sigma (t)\), see Appendix A [15]. Note that the above process H is not necessarily mean-revering. If \(\lambda \) is a diagonal matrix with positive diagonal entries, then H is an N-dimensional mean-reverting Ornstein-Uhlenbeck (OU) process [15].
Example 2
Continuous time finite state Markov chain process Suppose that \(\mu (t)=M H(t)\) in (1), where H(t) is a stationary, irreducible, continuous time Markov chain, independent of W, with state space \(\{\mathbf {e}_1,\dots ,\mathbf {e}_d\}\), \(\mathbf{e} _k\) is the kth unit vector in \({\mathbb {R}}^d\), and generating matrix \(Q=(q_{ij})\in {\mathbb {R}}^{d\times d}\), matrix \(M\in {\mathbb {R}}^{N\times d}\) with column k representing the drift when \(H(t)=\mathbf{e} _k\). By [20], \(\hat{H}(t)=E[H(t)|{\mathcal {F}}_t^S]\), called the Wonham filter, satisfies the following SDE:
subject to \( \hat{H}(0)=E[H(0)], \) see Appendix B for details.
Example 3
Unobservable random variable Suppose that \(\mu (t)=B\) in (1), where B is an unobservable random vector with distribution m, independent of W, and \(E[B^2]<\infty \). The prior law m represents the subjective beliefs of the investor about the likelihood of the different values that B might take. The volatility matrix \(\sigma \) is assumed to be constant. The knowledge of B is updated with new observable information. By [6], \(\hat{\mu }(t):=E[B|{\mathcal {F}}_t^S]\), called the Bayesian filter, satisfies the following SDE:
where \(\psi \) is a matrix-valued function determined by m. In particular, if \(B\sim N(b_0, \Sigma _0)\), a multivariate normal distribution with mean \(b_0\) and covariance matrix \(\Sigma _0\), then \(\psi (t,b)\) is independent of b and given by \(\psi (t,b)=(\Sigma _0^{-1}+\Sigma ^{-1}t)^{-1}(\sigma ^{-1})^T\), where \(\Sigma =\sigma \sigma ^T\), and the filtered process \(\hat{\mu }\) is a Gaussian process measurable with respect to \({\mathcal {F}}^S\), see [6] for details.
Using the innovation process \({\hat{V}}\) in (4), we can transform a partially observed problem into a fully observed problem (3) with the wealth process X satisfying the SDE (5), where \(\hat{\mu }(t)\) is a filtered drift process. We assume from now on that \(\hat{\mu }(t)=\mu ({\hat{H}}(t))\) for some deterministic function \(\mu \) and \({\hat{H}}\) satisfies the following SDE:
For the Kalman and Bayesian filters, we have \(\mu (h)=h\) and for the Wonham filter, we have \(\mu (h)=M h\) with \(d=N\). The corresponding value function is defined by, for \(0\le t\le T\),
where \(E_{t,x,h}[\cdot ]=E[\cdot |X^{\pi }(t)=x, \hat{H}(t)=h]\), the conditional expectation operator at time t. Since \(\hat{H}(t)=E[H(t)|{\mathcal {F}}_t^S]\), h is the conditional expectation value of H(t), not the value of H(t) which is \({\mathcal {F}}_t\) measurable but not \({\mathcal {F}}^S_t\) measurable, in other words, H(t) is a constant given \({\mathcal {F}}_t\) (full informaton) but a random variable given \({\mathcal F}^S_t\) (partial information). Such a distinction is important when we discuss the information value of H(t) and that of \({\hat{H}}(t)\), see Sect. 5.3.
3 Optimality Conditions
To solve the filtered utility maximization problem (11), we may use one of the following three methods: stochastic control, convex duality and stochastic maximum principle. We next give a brief discussion of these methods.
3.1 HJB Equation
After filtering, the stochastic control approach applies, and the value function satisfies the following HJB equation
with the terminal condition \(J(T,x,h)=U(x)\). Equation (12) is a nonlinear PDE with control constraint, which is in general difficult to solve, even numerically. There is one important special case in which the nonlinear PDE (12) can be simplified into a semilinear PDE, and the solution may have a representation in terms of the solution of a BSDE. For the case \(U(x)=(1/\beta )x^{\beta }, 0<\beta <1\), we have an ansatz solution form \(J(t,x,h)=U(x)f(t,h)\), substituting into (12), we have
with \(f(T,h)=1\), where
Example 4
Suppose the utility function \(U(x)=(1/\beta )x^\beta \) (power utility) with \(K={\mathbb {R}}^N\) and \({\hat{H}}\) satisfies SDE (7) , then we have an ansatz for J:
and the optimal control \(\pi ^*\) is given by
where A(t) is a \(N\times N\) symmetric matrix, B(t) a \({\mathbb {R}}^N\) vector, C(t) a scalar, and the detailed ODEs for A, B, C are given in Appendix C. Since \({\hat{H}}(t)=h\), \(\pi ^*(t)\) depends on the conditional expectation value of H(t), given \({\mathcal F}^S_t\), but not the value of H(t) itself.
3.2 Dual HJB Equation
Define the dual function of U as
We have that \(\tilde{U}\) is a continuous, decreasing and convex function on \((0,\infty )\). The dual process is given by, for \(0\le t\le T\),
where \({\hat{H}}\) satisfies SDE (10), \(\delta _K\) is the support function of the set \(-K\), defined by \( \delta _K(z)\triangleq \sup _{\pi \in K}\{-\pi ^\mathrm{T}z\},z\in {\mathbb {R}}^N, \) and v is the dual control process defined in the set
The dual problem is the following:
Any \((y^*,v^*)\in (0,\infty )\times \mathcal {D}\) satisfying \(xy^*+E_{t,y,h}[\tilde{U}(Y^{(y^*,v^*)}(T))]=\tilde{V}(t,x,h)\) is called the optimal dual control and the corresponding \(Y^{(y^*,v^*)}\) the optimal dual process. Fix y, the dual value function is defined by
Suppose K is a closed convex cone, which gives \(\delta _K(v)=0\) for \(v\in {\tilde{K}}\) and \(\infty \) otherwise, where \({\tilde{K}}=\{v: v^\intercal \pi \ge 0, \, \forall \pi \in K\}\) is the positive polar cone of K. The dual value function \(\tilde{J}\) satisfies the following dual HJB equation:
and \(\tilde{J}(T,y,h)=\tilde{U}(y)\). After giving optimal dual control y, v by (15) and strong duality, the primal value function J(t, x, h) and the primal optimal control can be derived using the dual value function. This is also a nonlinear PDE with control constraint, which is also impossible to give explicit solutions. Instead we focus on the following specific case.
Example 5
Assume the same setting as Example 4. Then \(\tilde{K}=\{0\}\), which gives the dual control \(v(t)=0\) and the dual value function \(\tilde{J}(t,y,h)= E_{t,y,h}[\tilde{U}(Y^{(y,0)}(T))]\). We have an ansatz for \(\tilde{J}\):
where \(\hat{A}(t)\) is a \(N\times N\) symmetric matrix, \(\hat{B}(t)\) a \({\mathbb {R}}^N\) vector, \({\hat{C}}(t)\) a scalar, and \({\hat{A}},\hat{B},{\hat{C}}\) satisfy some ODEs, see Appendix D for these equations. Solving (15), we have
with the minimum point \(y^*(t,x,h)=x^{\beta -1}\exp \Bigg ((1-\beta )\Bigg [h^\mathrm{T}\hat{A}(t)h+\hat{B}^\mathrm{T}(t)h+\hat{C}(t)\Bigg ]\Bigg )\). From the primal-dual relation \(J(t,x,h)=\tilde{V}(t,x,h)\), combining (13) and (17), we have \((1-\beta )\hat{A}(t)=A(t), (1-\beta )\hat{B}(t)=B(t)\) and \((1-\beta ){\hat{C}}(t)=C(t)\). The optimal control is given by
which is exactly (14).
3.3 Stochastic Maximum Principle
For constrained utility maximization, one may also use the SMP to solve it. There is extensive literature on this. Here we only cite the results from [16] and the reader can find more references and discussions there. [16] gives the necessary and sufficient optimality conditions for both primal and dual problems in terms of constrained controlled FBSDEs and characterizes their dynamic relations of the optimal control, the state process, and the adjoint process. Under some regularity and integrablility assumptions on utility function and stochastic processes, we have the following result.
Theorem 2
([16], Theorems 3.9 and 3.10) Let \((\tilde{y},\tilde{v})\in (0,\infty )\times \mathcal {D}\). Then \((\tilde{y},\tilde{v})\) is optimal for the dual problem if and only if the solution \((Y^{(\tilde{y},\tilde{v})},\hat{P},\hat{Q})\) of FBSDE
satisfies the following conditions
The optimal control for the primal problem with initial wealth \(x_0\) is given by
We give an example to illustrate its use.
Example 6
Assume the same setting as Example 4, then \(\tilde{v}(t)=0\). Solving the BSDE in (18), we have
where \(\phi (t)=E_{t,y,h}[-Y^{\hat{y}}(T)\tilde{U}'(Y^{\hat{y}}(T))]=E_{t,y,h}[Y(T)^{\frac{\beta }{\beta -1}}] \), \(\hat{\theta }(t):=\sigma ^{-1}(t)[\mu )(\hat{H}(t)-r(t)\mathbf{1} ]\) and \(\phi (t)=\phi (T)-\int _t^\mathrm{T}\varphi ^\mathrm{T}(s)\hbox {d}\hat{V}(s)\). By Theorem 3.10 of [16], the optimal strategy is given by
Since \(\phi (t)=\frac{\beta }{1-\beta }\tilde{J}(t,y,h)\) and \(\tilde{J}\) has an ansatz (16), using It\(\hat{o}\)’s formula and the Feynman–Kac formula, we have
which indicates that \(\varphi (t)=\phi (t)\left\{ \frac{\beta }{1-\beta }\hat{\theta }(t)+\hat{\Sigma }_R(t)[2\hat{A}(t)h+\hat{B}(t)]\right\} \). Substituting into (20), we get
We have recovered the optimal control. In general, it is difficult to give \(\varphi (t)\) as this is from the martingale representation theorem.
4 Effective Approximation Method
For general utilities with closed convex constraint case, one can write the HJB equation but it is not possible to find an ansatz solution even for power utility due to control constraint. For the same reason one cannot apply the martingale representation theorem to construct a control (replicating portfolio which may be negative) and therefore the standard martingale method cannot be used to solve the problem. The primal and dual value functions satisfy the following weak duality relation:
The inequalities show that the dual formulation gives an upper bound for the primal value function. Instead of focusing on the exact controls, we explore the tight lower and upper bounds of the value function for general cases. We show it is possible to achieve this with the dual FBSDE. Assume (y, v) is a feasible dual control. By Theorem (2), (y, v) is an optimal dual control if and only if \((Y^{(y,v)}, \hat{P}, \hat{Q})\) satisfying (18) and (19). Denote by \(\pi (t):=\hat{P}^{-1}(t) [\sigma ^\mathrm{T}(t)]^{-1} \hat{Q}(t)\), (19) can be rewritten as
The dual FBSDE system (18) and (19) is equivalent to, also noting (10) for \({\hat{H}}\),
and
where \(w\in (0,1)\) is a given constant. Here we have used the fact that \(\delta _K\) is the support function of \(-K\), so \(\delta _K(v(t))+\pi (t) v(t)\ge 0\) for all \(\pi (t)\in K\).
Consider the following optimal control problem:
Note that (21) is a forward controlled SDE system with state variables \(Y,{\hat{P}}, {\hat{H}}\) and control variables \(\pi ,v\), and (22) is a standard control problem with an additional decision variable \(y>0\). If we can manage to find \((y,\pi ,v)\) that makes the objective function zero, then we have solved (18) and (19). The key advantage of (22) over the dual FBSDE system (18) and (19) is that (22) is an optimal control problem and the known optimization techniques can be used to solve it, which is in sharp contrast to the dual FBSDE system (18) and (19) that is a pure equation system and difficult to find its solution.
In general, we may only be able to find \((y,\pi ,v)\) that makes the objective function close to zero, but not exactly zero, then \((y,\pi ,v)\) is not a solution to the dual FBSDE system (18) and (19), that is, not the optimal solution to the dual problem. However, \((y,\pi ,v)\) and \((Y,\hat{P})\) still provide useful information about the value function, that is, we can get the lower and upper bounds as
If the difference of LB and UB is small, we may approximate the value function J in (11) by a simple average \((\text {LB}+\text {UB})/2\) with \(\pi \) a good approximate feasible control corresponding to the lower bound. This shows the usefulness of solving the control problem (22), that is, one may find a good approximate solution with (22), which is essentially impossible if one tries to achieve the same with the dual FBSDE system (18) and (19).
To find the approximate optimal solution of (22), we may proceed as follows: Divide the interval [0, T] into n subintervals with grid points \(t_i=ih\), \(i=0,1,\ldots ,n\), and step size \(h=T/n\). On each interval \([t_i,t_{i+1})\), \(i=0,1,\ldots ,n-1\), choose constant controls \(\pi _i\) and \(v_i\) that are \({\mathcal F}_{t_{i}}\) measurable. Discretize (21) to get a discrete time controlled system with \(Y_i\) denoting \(Y(t_i)\), etc.
where \(\hat{V}_{i+1}-\hat{V}_i\), \(i=0,1,\ldots ,n-1\), are independent N(0, h) random variables. The discrete version of problem (22) is given by
The lower bound is given by \(\text {LB}=E[U(\hat{P}_n)]\) and the upper bound by \(\text {UB}=x_0y + E[\tilde{U}(Y_n)]\). With the specific information of the structure of the model, we can then try to solve the discrete time optimal control problem (25) as shown in the numerical examples in the next section.
Remark 3
if the control constraint set K is a closed convex cone, then \(\delta _K(v)=0\) for \(v\in \tilde{K}\) and \(\infty \) otherwise. (24) becomes
and (25) becomes
In particular, if K is the whole space, then \(\tilde{K}=\{0\}\) and \(v_i=0\) for all i.
5 Numerical Examples
In this section we use the above method to compute the lower and upper bounds under Kalman filtering case. For simplicity, we assume the market has riskless asset and one risky asset and \(r, \sigma \) are constants, and utility function is power utility \(U(x)=(1/\beta )x^{\beta }\) with \(0<\beta <1\). We consider two cases: one is \(K={\mathbb {R}}\) and the other \(K={\mathbb {R}}^+\), the former gives \(\tilde{K}=\{0\}\) and the latter \(\tilde{K}={\mathbb {R}}^+\). We need to solve the discrete time control problem (27).
5.1 Unconstrained Case
The optimal value at time 0 is given by (13), that is,
where \(X(0)=x_0\) and \({\hat{H}}(0)=E[H(0)|{\mathcal F}^S_0] = E[H(0)]=h_0\). (28) provides benchmark values for testing the efficiency of the lower and upper bounds computed with (23) and (27). Since \(K={\mathbb {R}}\) and \(\pi _i\) is \({\mathcal F}_{t_i}^S\) measurable and \({\hat{H}}_i\) is exogenous, we have \(v_i=0\) for all i and we consider controls \(\pi _i\) in the following form: \( \pi _i=a_i+b_i\hat{H}_i\) which incorporates the OU process \(\hat{H}\) in controls, where \(a_i,b_i\) are constants to be determined, and denote by \(a=(a_0,\ldots ,a_{n-1})^\mathrm{T}\in {\mathbb {R}}^n\) and \(b=(b_0,\ldots ,b_{n-1})^\mathrm{T}\in {\mathbb {R}}^n\). We can now write out the discrete version of (21), together with SDE for \(\hat{H}\): for \(i=0,1,\ldots , n-1\),
The discrete version of problem (29) is given by
We still need to compute the expectation to get function f, which can be achieved by taking the sample average. Specifically, for fixed y, a, b, generate n independent standard normal random variables \(Z_{i+1}\), \(i=0,\ldots , n-1\), and compute \(Y_{i+1},\hat{P}_{i+1},\hat{H}_{i+1}\) by replacing \(\hat{V}_{i+1}-\hat{V}_i\) with \(\sqrt{h} Z_{i+1}\), which generates a sample path of \(Y,\hat{P},\hat{H}\). We can repeat this procedure M times and take the average of M copies of \( |\hat{P}_n + \tilde{U}'(yY_n)|^2 \), which gives an approximate value for f(y, a, b). The problem now is to find (y, a, b), with a total of \(2n+1\) variables, such that the objective function f(y, a, b) is minimized. This is a finite dimensional nonlinear minimization problem.
For numerical results, we try two forms for control \(\pi \), one is \(\pi _i=a+b\hat{H}_i\) with a, b being constants (Form I), the other is \(\pi _i=a_i+b\hat{H}_i\) with \(a_i, b\) being constants (Form II). For illustration, the parameters are given as \(r=0.05, \sigma =0.8,\beta =0.5,x_0=10,h_0=0.1,\bar{H}=0.1,\sigma _H=0.5,\lambda =1,\rho =0,\sigma _0=0.2,h=0.1,T=1\) and the time step here is \(N=T/h=10\). Since H(0) is a normal random variable with mean \(h_0\) and variance \(\sigma _0\), by varying these parameters, we can compute the corresponding benchmark values in (28) and the lower and upper bounds. Tables 1 and 2 list these results and their comparisons. The shorthand notations BC, LB, UB and OB denote benchmark values, lower bounds, upper bounds and objective function values, respectively, and MV \(=\) (LB \(+\) UB)/2 is the approximate optimal value, rel-diff-1 \((\%)=(\text {UB}-\text {LB)/LB}\times 100\) the relative error of lower and upper bounds, and rel-diff-2\((\%)=|\text {(MV}-\text {BC)/BC}|\times 100\) the relative error of approximate optimal value and benchmark value. The corresponding A(t), B(t) and C(t) are given by using equations in Appendix C and the fourth-order Runge–Kutta method with \(N=10\). Tables 1 and 2 show that the considered two formulas for controls give good approximate values MV with relative errors less than one percent compared with the benchmark values, although relative errors between LB and UB are slightly bigger in comparison, which is expected in estimating bounds. Tables 1 and 2 also show that the optimal values are similar for different combinations of \(h_0\) and \(\sigma _0\), two parameters for the initial distribution of H(0), which indicates the optimal value is less sensitive to the initial estimate of these parameters. The results show that by using dual method, we can always give a range for the value function and generate tight lower and upper bounds. Additionally, the estimated controls for both primal and dual problems can be derived clearly. Moreover, the results show that the mean values are quite close to the benchmark results for most cases.
5.2 Constrained Case
Since \(K={\mathbb {R}}^+\), there is no closed form solution. From \(\tilde{K}={\mathbb {R}}^+\), we let \(\pi _i=(a_i+b_i\hat{H}_i)^+, v_i=(\tilde{a}_i+\tilde{b}_i\hat{H}_i)^+\), where \(x^+=\max (x,0)\). In the numerical tests, we in particular discuss two forms: \(\pi _i=(a+b\hat{H}_i)^+, v_i=(\tilde{a}+\tilde{b}\hat{H}_i)^+\) with \(a,b,\tilde{a},\tilde{b}\) being constants (Form I), \(\pi _i=(a_i+b\hat{H}_i)^+, v_i=(\tilde{a}_i+\tilde{b}\hat{H}_i)^+\) with \(a_i,\tilde{a}_i, b,\tilde{b}\) being constants (Form II). Here we use the same parameter settings as in the unconstrained case.
By solving the above minimization problem (27), the optimal results of two forms are given below (\(w=0.5\)). In Form I, the optimal parameters are \(a=0.04682, b=-0.1281, \tilde{a}=-0.0019 , \tilde{b}=-0.1958\), and \(y=0.3172\). In Form II, the optimal parameters are \(b=-0.1060, \tilde{b}=-0.0572, y=0.3196\) and the estimation of \(a(t),\tilde{a}(t)\) is given in Table 3. Under one sample path of \(\hat{H}\), the controls \(\pi , v\) estimated by two forms are given in Table 3. The lower and upper bounds for primal value function obtains accordingly. The parameter w is added to control the weight put on different objectives, to show the sensitivity of the results with it, the results are listed in Table 4. In the following tables, the shorthand notations LB, UB and OB denote lower bound, upper bound and estimated values of the corresponding objective functions respectively,and rel-diff\((\%)=\text {(UB}-\text {LB)/LB}\times 100\). The results illustrate that when \(w=0.9\), the relative difference and the value of the objective function are the best among all the choices.
In the considered OU case, we suppose some known assumptions for initial state of hidden sequence \(\hat{H}\), whose first and second moments(\(h_0,\sigma _0\)) are given in advance. Tables 5 and 6 give the results by varying the initial assumptions. These tables show that the method always generate good bounds for different assumptions of the initial sates. More specifically, under almost all cases, Form I would give better estimations. Additionally, as \(\sigma _0\) get bigger, that is, we are less confident in the assumption, in this circumstance the bounds would be wider.
Remark 4
For simplicity, in the above numerical cases, we only focus on the 1-dimensional cases, that is only one risky asset considered. Our method can be easily generalized to d-dimensional problems with polynomial growth of computation. In our numerical examples, if the constraint set \(K={\mathbb {R}}^d\) (\(d>1\)), then the corresponding considered controls are \(\pi (t)=a+b{\hat{H}}(t)\) for some \(a\in {\mathbb {R}}^d, b\in {\mathbb {R}}^{d\times d}\), the total number of parameters to be determined is \(d+d^2\). If the constraint set \(K={\mathbb {R}}^d_+\), similarly we may choose \(\pi (t)=(a+b\hat{H}(t))^+\), the number of parameters is \(d+d^2\), not \(2^d\). Even we use piecewise constant controls with n subintervals, then the number of parameters is \(n(d+d^2)\). Therefore, in our setting, the number of parameters would grow polynomially with respect to the number of traded assets and subintervals, not exponentially. For example, if we set \(d=2\), then the considered format for the control would be
For fixed parameters \(a_i,b_j\), controls \(\pi (t)\) are determined once \({\hat{H}}(t)\) are known. In other words, there is no exponential explosion \(2^d\) as we do not need to check possible combinations of \(\pi _1(t)\) and \(\pi _2(t)\) being positive or zero, they are determined naturally by \(a_i,b_j, {\hat{H}}(t)\) and \(a_i,b_j\) can be found by a continuous variable minimization in a finite dimension space. We emphasize that \(\pi (t)=(a+b{\hat{H}}(t))^+\) when \(K={\mathbb {R}}^d_+\) is a feasible control, but NOT an optimal control for problem (27), which is in general difficult to find. There are many ways of choosing feasible controls, for example, we may also set \(\pi (t)=(a+b{\hat{H}}(t)+ {\hat{H}}(t)^\mathrm{T} c {\hat{H}}(t))^+\), where \({\hat{H}}(t)^\mathrm{T} c {\hat{H}}(t)\in {\mathbb {R}}^d\) with the ith component given by \({\hat{H}}(t)^\mathrm{T} c_i {\hat{H}}(t)\) and \(c_i\in {\mathbb {R}}^{d\times d}\) for \(i=1,\ldots ,d\), and then determine a, b, c by solving a minimization problem with \(d+d^2+d^3\) variables. The numerical examples for \(d=1\) show that the choice of control \(\pi (t)=(a+b{\hat{H}}(t))^+\) provides a good compromise in the sense that it is easy to compute while gives tight lower and upper bounds. These control forms still provide lower and upper bounds for \(d>1\), but other forms may exist to give tighter bounds. It is still an open question on the best parametric form of feasible controls for lower and upper bounds in multidimensional case.
Remark 5
The dual FBSDE method is applicable for general constrained optimal portfolio selection problems, including general utilities and other filtering cases of hidden processes. The CIR case given in [18] can be discussed similarly.
5.3 Information Value of Learning
We may call the problem (3) subject to (5) the utility maximization with learning, in which the admissible control \(\pi \) is \({\mathcal F}^S\) measurable. If \(\mu \) and W can be observed and the admissible control \(\pi \) is \({\mathcal F}\) measurable, we may call the corresponding problem (3) subject to (2) the utility maximization with full information. In other words, we focus on the following cases: (P1) we can fully observe H process and use it to find the value function and optimal control, (P2) we cannot observe H process and use the Kalman–Bucy filter to learn the process H. Intuitively the investors with full information would gain more than those with partial information, as the full information investors master the market better. To gain some insight into the magnitude of the effect of information sets, we assume \(U(x)=(1/\beta )x^\beta \) with \(0<\beta <1\) and \(N=1, K={\mathbb {R}}\). For the full information case (P1), the value function is given by
where \(A^f,B^f,C^f\) satisfy some ODEs, see Appendix E Both H(t) and \(J^f(t,x,h)\) are \({\mathcal F}_t\) measurable but not \({\mathcal F}^S_t\) measurable. On the other hand, for the partial information case (P2), both \(\hat{H}(t))\) and the value function \(J(t,x,\hat{H}(t))\), see (13) and Appendix C, are \({\mathcal F}^S_t\) measurable. We cannot directly compare \(J^f(t,x,H(t))\) and \(J(t,x,\hat{H}(t))\) as the former is a random variable in \({\mathcal F}^S_t\) while the latter a constant in \({\mathcal F}^S_t\). However, we can compute the conditional expectation of \(J^f(t,x,H(t))\) given \({\mathcal F}^S_t\) and then compare its value with \(J(t,x,\hat{H}(t))\). The difference of the two,
is the so called information premium or the loss in utility due to partial information. Papanicolaou [18, Proposition 3.15] shows that the information premium is always nonnegative. This is from the average value point of view, if we draw samples of \(J^f(t,x,H(t))\) and \(J(t,x,\hat{H}(t))\), they do not necessarily have that relationship. We next illustrate numerically the point with the optimal value at time 0 and draw some sample paths.
The full information value function at time 0 is given by \(J^f(0,x_0,H(0))\), where H(0) is an observed value under the full information setting and is a sample from the normal distribution with mean \(h_0\) and variance \(\sigma _0\).
For the no information with learning case (P2), the value function at time 0 is given by \(J(0,x_0,h_0)\).
Table 7 lists the numerical results of information values at time 0, where the column \(E[J^f]\) denotes \(E[J^f(0,x,H(0))]\), which is calculated as
and \(f(Z)=A(0)\sigma _0z^2+(2A^f(0)h_0+B^f(0))\sqrt{\sigma _0 }Z\) with Z being a standard normal random variable. The expectation \(E[\exp (f(Z))]\) can be easily computed with simulation. The parameters are chosen as those in Sect. 5.1 with \(r=0.05, \sigma =0.8,\beta =0.5,x_0=10,\bar{H}=0.1,\sigma _H=0.5,\lambda =1,h=0.01,T=1\). By varying \(h_0\), the initial state, from 0.1 to 0.9 with state step 0.2, the results of \(E[J^f(0,x,H(0))]\) for full information case (\(E[J^f](P1)\)) and \(J(0,x,h_0)\) for partial information case (J(P2)) are shown in Table 7. We give four comparing results under \(\rho =0, \rho =0.5\) and \(\sigma _0=0.2, \sigma _0=0.4\) separately.
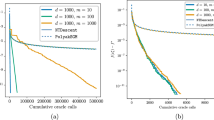
It is observed that the value of investors with full information is greater than those with partial information, which verifies the comparing relation (31) numerically. Figures 1, 2, 3 and 4 plot the sample paths of H and G. In Figs. 1 and 3, H is simulated using (6) and \(\hat{H}\) is simulated using (7). In Figs. 2 and 4, \(G^f(t)=A^f(t)H^2(t)+B^f(t)H(t)+C^f(t)\), \(G^p(t)=A(t)\hat{H}^2(t)+B(t)\hat{H}(t)+C(t)\) and \(\Delta (t)=G^f(t)-G^p(t)\). The results indicate that although \(E[G^f(t,H(t))|{\mathcal {F}}_t^S]\ge G^p(t)\), \(G^f(t,H(t))\) could be less than \(G^p(t)\) at some times depending on sample paths. We have used the step size 0.01 and the number of time steps 100 over the time interval [0, 1].

Drift processes with \(\rho =0\)

G-processes with \(\rho =0\)

Drift processes with \(\rho =0.5\)

G-processes with \(\rho =0.5\)
6 Conclusions
In this paper we propose a novel and effective approximation method to find the value function for general utility maximization with closed convex control constraints and uncertain drift coefficients of the stock. Using separation principle and the dual FBSDE, we transform the utility maximization with partial information into an equivalent, fully observable, error minimization stochastic control problem and, using the weak duality relation, find the tight lower and upper bounds of the value function. The numerical results indicate that our proposed method can provide good approximation. There remain many open questions, for example, convergence and error analysis of discrete-time stochastic optimization problem (24) and (25) to its continuous-time counterpart (21) and (22), theoretical estimation of the difference between the lower and upper bounds (23), the best parametric form of feasible controls for lower and upper bounds in multidimensional case. We leave these and other questions for future research.
Data Availability Statement
Data sharing not applicable—no new data generated, as the article describes entirely theoretical research.
References
Bian, B., Miao, S., Zheng, H.: Smooth value functions for a class of nonsmooth utility maximization problems. SIAM J. Financ. Math. 2, 727–747 (2011)
Bichuch, M., Guasoni, P.: The learning premium. Math. Financ. Econ. 14, 175–205 (2020)
Bismuth, A., Gueant, O., Pu, J.: Portfolio choice, portfolio liquidation, and portfolio transition under drift uncertainty. Math. Financ. Econ. 13, 661–719 (2019)
Björk, T., Davis, M.H.A., Landén, C.: Optimal investment under partial information. Math. Methods Oper. Res. 71, 371–399 (2010)
Brennan, M.J.: The role of learning in dynamic portfolio decisions. Rev. Finance 1, 295–306 (1998)
De Franco, C., Nicolle, J., Pham, H.: Bayesian learning for the Markowitz portfolio selection problem. Int. J. Theor. Appl. Finance 22, 1950037 (2019)
Eksi, Z., Ku, H.: Portfolio optimization for a large investor under partial information and price impact. Math. Methods Oper. Res. 86, 601–623 (2017)
Ekstrom, E., Vaicenavicius, J.: Optimal liquidation of an asset under drift uncertainty. SIAM J. Financ. Math. 7, 357–381 (2016)
Fleming, W., Soner, M.: Controlled Markov Processes and Viscosity Solutions. Springer, Berlin (1993)
Fouque, J.P., Papanicolaou, A., Sircar, R.: Perturbation analysis for investment portfolios under partial information with expert opinions. SIAM J. Control Optim. 55, 1534–1566 (2017)
Fujisaki, M., Kallianpur, G., Kunita, H.: Stochastic differential equations for the nonlinear filtering problem. Osaka J. Math. 9, 19–40 (1972)
Karatzas, I., Shreve, S.E.: Methods of Mathematical Finance. Springer, Berlin (2001)
Karatzas, I., Xue, X.: A note on utility maximization under partial observations. Math. Finance 1, 57–70 (1991)
Kim, T.S., Omberg, E.: Dynamic nonmyopic portfolio behavior. Rev. Financ. Stud. 9, 141–161 (1996)
Lakner, P.: Optimal trading strategy for an investor: the case of partial information. Stoch. Process. Appl. 76, 77–97 (1998)
Li, Y., Zheng, H.: Dynamic convex duality in constrained utility maximization. Stochastics 90, 1145–1169 (2018)
Liptser, R., Shiryayev, A.: Statistics of Random Processes. Springer, Berlin (2004)
Papanicolaou, A.: Backward SDEs for control with partial information. Math. Finance 29, 208–248 (2019)
Pham, H.: Continuous-Time Stochastic Control and Optimization with Financial Applications. Springer, Berlin (2009)
Sass, J.: Utility maximization with convex constraints and partial information. Acta Appl. Math. 97, 221–238 (2007)
Sass, J., Haussmann, U.G.: Optimizing the terminal wealth under partial information: the drift process as a continuous time Markov chain. Finance Stoch. 8, 553–577 (2004)
Xu, G.L., Shreve, S.E.: A duality method for optimal consumption and investment under short-selling prohibition. I. General market coefficients. Ann. Appl. Probab. 2, 87–112 (1992)
Yong, J., Zhou, X.Y.: Stochastic Controls: Hamiltonian Systems and HJB Equations. Springer, Berlin (1999)
Acknowledgements
The authors are very grateful to two anonymous reviewers whose constructive comments and suggestions have helped to improve the paper of the previous two versions.
Open Access
This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Negash G. Medhin.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Dongmei Zhu: Supported in part by the NSF (China) Grants (72091213 and 71831004). Harry Zheng: Supported in part by the EPSRC (UK) Grant (EP/V008331/1).
Appendices
Appendix A: The specific case of (8)
Under the case \(N=1\), the Riccati equation (8) has an explicit solution with \(\sigma ,\sigma _H\) being constants. The equation becomes
with \(\Sigma (0)=\sigma _0\), which has the solution:
where \(G=\left( \lambda \sigma +\rho \sigma _H\right) ^2+\sigma _H^2(1-\rho ^2)\), \(G_1=\sqrt{G}\sigma +\left( \lambda \sigma +\rho \sigma _H\right) \sigma +\sigma _0\), and \(G_2=-\sqrt{G}\sigma +\left( \lambda \sigma +\rho \sigma _H\right) \sigma +\sigma _0\).
Appendix B: Derivation of \(\hat{H}\) in (9)
To derive finite-dimensional filters and smoothers, define the reference measure \(\bar{{\mathbb {P}}}\) as
and
By Girsanov’s theorem,
is a \(\bar{{\mathbb {P}}}\)-Brownian motion.
To determine the filter \(\hat{H}(t)=E[H(t)|{\mathcal {F}}_t^S]\), we first introduce the unnormalized filter \(\xi (t)\) and the conditional density \(\zeta (t)\) as follows
Then the unnormalized filter \(\xi \) is given by
Furthermore,
By Bayes’ formula
By the product rule:
where \(\hat{V}(t)\) is the innovation process given in (4).
Appendix C: Equations for A, B, C in (13)
The functions A(t), B(t) and C(t) satisfy the following equations on the interval [0, T]:
with the terminal condition \(A(T)=0\). This is a Riccati-type ODE.
with the terminal condition \(B(T)=0\). This is a linear ODE once A is known and can be easily solved.
with the terminal condition \(C(T)=0\). This is a linear ODE once A, B are known and can be easily solved.
The above equations depend on \(\Sigma (t)\) of (8) and \(\hat{\Sigma }_R(t)\), we have to solve them numerically. For this purpose, we solve \(\Sigma (t)\) first and then substitute into the equations to derive the numerical results.
In our numerical example, under the parameter setting \(r=0.05, \sigma =0.8,\beta =0.5,x_0=10,h_0=0.1,\bar{H}=0.1,\sigma _H=0.5,\lambda =1,\rho =0,\sigma _0=0.2,h=0.1,T=1\) and the time step \(N=T/h=10\), the fourth order Runge–Kutta method is used to solve A, B, C and the results are given in Table 8.
If we set the initial variance of the Kalman filter to be its equilibrium value, that is, \(\sigma _0=\sqrt{G}\sigma -(\lambda \sigma +\rho \sigma _H)\sigma \), then \(\Sigma (t)=\sigma _0\) and \(\hat{\Sigma }_R(t)=\sqrt{G}-\lambda \sigma \) for all \(t\ge 0\), in this case, the Riccati for A(t) is solvable with a closed form formula. The analytical results of A(t) and the estimated results from the fourth order Runge–Kutta method are given in Table 9. Similar results can be obtained for B(t). Table 9 shows that their numerical results are the same to the first four decimal places.
Appendix D: Equations for \(\hat{A},\hat{B},\hat{C}\) in (16)
The functions \(\hat{A}(t),\hat{B}(t)\) and \(\hat{C}(t)\) satisfy the following equations on the interval [0, T]:
with the terminal condition \(\hat{A}(T)=0\). This is a Riccati-type ODE.
with the terminal condition \(\hat{B}(T)=0\). This is a linear ODE once \(\hat{A}\) is known.
with the terminal condition \(\hat{C}(T)=0\). This is a linear ODE once \(\hat{A}, \hat{B}\) are known.
Appendix E: Equations for \(A^f,B^f,C^f\) in (30)
The HJB equation for V has the form:
with the terminal condition \(J^f(T,x,h) = (1/\beta ) x^{\beta }\). Assume the ansatz
Substituting V into the HJB equation, canceling the common factor U(x), using the optimal control \(\pi ^*=-\frac{(h-r)g+\rho \sigma \sigma _H g_h}{\sigma ^2(\beta -1)g}\), and setting the coefficients of power of h to be zero, we have the equations for \(A^f,B^f,C^f\):
with the terminal condition \(A^f(T)=B^f(T)=C^f(T)= 0\). The solutions of \(A^f, B^f\) and \(C^f\) can be given similarly as in [14].
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhu, D., Zheng, H. Effective Approximation Methods for Constrained Utility Maximization with Drift Uncertainty. J Optim Theory Appl 194, 191–219 (2022). https://doi.org/10.1007/s10957-022-02015-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10957-022-02015-0
Keywords
- Constrained utility maximization
- Drift uncertainty
- Stochastic maximum principle
- Effective approximation method
- Lower and upper bounds of value function