
Abstract
We study a two-player nonzero-sum stochastic differential game, where one player controls the state variable via additive impulses, while the other player can stop the game at any time. The main goal of this work is to characterize Nash equilibria through a verification theorem, which identifies a new system of quasivariational inequalities, whose solution gives equilibrium payoffs with the correspondent strategies. Moreover, we apply the verification theorem to a game with a one-dimensional state variable, evolving as a scaled Brownian motion, and with linear payoff and costs for both players. Two types of Nash equilibrium are fully characterized, i.e. semi-explicit expressions for the equilibrium strategies and associated payoffs are provided. Both equilibria are of threshold type: in one equilibrium players’ intervention are not simultaneous, while in the other one the first player induces her competitor to stop the game. Finally, we provide some numerical results describing the qualitative properties of both types of equilibrium.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Controller–stopper games are two-player stochastic dynamic games, whose payoffs depend on the evolution over time of some state variable, one player can control its dynamics, while the other player can stop the game. The study of these games started with Maitra and Sudderth’s work [1] on a zero-sum discrete time setting. Later on, many authors investigated such games in continuous time, especially in the zero-sum case, while very little has been done in the nonzero-sum. Indeed, apart from Karatzas and Sudderth [2] and Karatzas and Li [3], all the other articles focus on the zero-sum case and in all of them the controller uses regular controls, i.e. absolutely continuous for the Lebesgue measure. Here, we mention Karatzas and Sudderth [4], who derived the explicit solution for a game with a one-dimensional diffusion with absorption at the endpoints of a bounded interval as a state process; Karatzas and Zamfirescu [5, 6] developed a martingale approach to a general class of controller–stopper games, while Bayraktar and Huang [7] showed that the value functions of such games are the unique viscosity solution to an appropriate Hamilton–Jacobi–Bellman equation. Moreover, Hernandez-Hernandez et al. [8] have analysed the case when the controller plays singular controls and derived a set of variational inequalities characterizing the games value functions. On the whole, this class of games is motivated by a variety of applications in finance, insurance and economics. In view of this, we quote Bayraktar et al. [9] on convex risk measures, Nutz and Zhang [10] on sub-hedging of American options under volatility uncertainty, Bayraktar and Young [11] on minimization of lifetime ruin probability and Karatzas and Wang [12] on pricing and hedging of American contingent claims among others.
Here, we consider the case of a controller facing fixed and proportional costs every time he moves the state variable, so that intervening continuously over time is clearly not feasible for him. In this context, the controller will make use of impulse controls, which are sequences of interventions times and corresponding intervention sizes, describing when and by how much will the controlled process be shifted. This kind of controls look like the natural choice in many concrete applications, from finance to energy markets and to real options. For this reason, they have been experiencing a comeback due to a demand for more realistic financial models (e.g. fixed transaction costs and liquidity risk), see for instance [13,14,15,16,17,18,19].
Impulse controls have been studied in stochastic differential games as well, and as in the controller–stopper case, most of the research has been done in the zero-sum framework. For this reason, it is worth mentioning the work by Aïd et al. [20], who developed a general model for nonzero sum impulse games implementing a verification theorem which provides an appropriate system of quasivariational inequalities for the equilibrium payoffs and related strategies of the two players. Thereafter, Ferrari and Koch [21] produced a model of pollution control where the two players, the regulator and the energy producer, are assumed to face proportional and fixed costs and, as such, play an impulse nonzero-sum game which admits an equilibrium under some suitable conditions. Lastly, Basei et al. [22] studied the mean field game version of the nonzero-sum impulse game in [20] and proved the existence of \(\epsilon \)-Nash equilibrium for the corresponding N-player game. Regarding the zero-sum case, here we quote Cosso [23], who examined a finite time horizon two-player game where both players act via impulse control strategies and showed that such games have a value which is the unique viscosity solution of the double-obstacle quasivariational inequality. Furthermore, Azimzadeh [24] considered an asymmetric setting with one participant playing a regular control, while the opponent is playing an impulse control with precommitment, meaning that at the beginning of the game the maximum number of impulses is declared, and proved that such a game has a value in the viscosity sense.
This paper is at the crossroad of the two streams of research we have discussed above: stopper–controller games and impulse games. Indeed, we study an impulse controller–stopper nonzero-sum game, focusing on the mathematical properties of Nash equilibria, while application to economics and finance are postponed to future research. Turning to the game’s description, we consider a nonzero-sum stochastic differential game between two players, P1 and P2, where P1 can use impulse controls to affect a continuous-time stochastic process X, while P2 can stop the game at any time. When P1 does not intervene, we assume X to diffuse according to a time homogeneous multidimensional diffusion process. Both players want to maximize their expected payoffs which are defined for every initial state \(x \in {\mathbb {R}}^d\) and every couple \((u, \, \eta )\) featuring, P1’s intervention cost (gain for P2), running and terminal payoffs.
We will adopt a PDE-based approach to characterize the Nash equilibria of this game, identifying a suitable system of quasivariational inequalities (QVI’s, for short) whose solution will give equilibrium payoffs. One of the main contributions of this paper consists in Verification Theorem 2.1 establishing that if two functions \(V_1\) and \(V_2\) are regular enough and they are solution to the system of QVI’s, then they coincide with some equilibrium payoff functions of the game and a characterization of the related equilibrium strategies is possible.
Furthermore, building on the verification theorem, we present an example of solvable impulse controller and stopper game. More in detail, we consider a game with a one-dimensional state variable X, modelled as a real-valued (scaled) Brownian motion. Both players have linear running payoffs. When P1 intervenes, he faces a penalty, while P2 faces a gain, both characterized by a fixed and a variable part, proportional to the size of the impulse. Moreover, when P2 stops the game, he may suffer a loss proportional to the state variable, while P1 might gain something proportional to X as well. Some preliminary heuristics on the QVIs above leads us to consider two pairs of candidates for the functions \(V_i\). Then, a careful application of the verification theorem shows that such candidates actually coincide with some equilibrium payoff functions. In particular, we are able to identify two kinds of Nash equilibria, both of threshold type, that can be shortly described as follows:
-
(i)
in the first type of equilibrium, P1 intervenes when the state X is smaller than some threshold \({\bar{x}}_1\) and moves the process to some endogenously determined target \(x_1^*\), while P2 terminates the game when the state X is bigger than some \({\bar{x}}_2\); in this kind of equilibrium the optimal target of P1, \(x_1 ^*\), is strictly smaller than \({\bar{x}}_2\), so the two players intervene separately.
-
(ii)
In the second type, P1 intervenes when the state X is smaller than some (possibly different) threshold \({\bar{x}}_1\) and moves the state variable to the intervention region of P2, who is then forced by P1 to end the game. In this case, players’ interventions are simultaneous.
We provide quasiexplicit expressions for the value functions and for the thresholds \({\bar{x}}_i\), \(x_1^*\) for both equilibria. Finally, we perform some numerical experiments providing several cases when one of the two equilibria emerges. The question if there are cases when the two types of equilibria can coexist is still open.
The paper is organized as follows. Section 2 gives the general formulation of impulse controller and stopper game, in particular the notion of admissible strategies, and more importantly we state and prove a verification theorem giving sufficient condition in terms of the system of QVIs for a given couple of payoffs to be a Nash equilibrium. In Sect. 3, we consider the one-dimensional example with linear payoffs and provide quasiexplicitly characterizations for the two types of Nash equilibria sketched above. Finally, some numerical experiments illustrate the qualitative behaviour of such equilibria.
2 Description of the Game
In this section, we have gathered all main theoretical results on a general class of nonzero-sum impulse controller and stopper games. We start with a detailed description of the game, together with all technical assumptions and the definition of admissible strategies.
Let \(( \varOmega , {\mathbb {F}}, {\mathbb {P}})\) be a probability space equipped with a complete and right-continuous filtration \({\mathbb {F}} = ({\mathcal {F}}_t)_{t \ge 0}\). On this space, we consider the uncontrolled state variable \(X\equiv X^x\) defined as solution of the following time-homogeneous SDE:
where \((W_t)_{t\ge 0}\) is an \({\mathbb {F}}\)-Brownian motion and the coefficients \(b: {\mathbb {R}}^d \rightarrow {\mathbb {R}}^d\) and \(\sigma : {\mathbb {R}}^d \rightarrow {\mathbb {R}}^{d\times m}\) are assumed to be globally Lipschitz continuous, i.e. there exists a constant \(C>0\) such that for all \(x_1, \, x_2 \in {\mathbb {R}}^d\) we have:
so that existence of a unique strong solution is granted and X is well-defined.
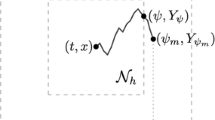
We consider two players that we call P1 and P2. Equation (1) describes the evolution of the state process in case of no intervention from both players. Let Z be a given subset of \({\mathbb {R}}^d\). During the game, P1 can affect X’s dynamics applying some impulse \(\delta \in Z\) in an additive fashion, moving the state variable from its left limit at \(\tau \), \(X_{\tau ^-}\), to its new value \(X_{\tau } = X_{\tau ^-} + \delta \), where \(\tau \) denotes the intervention time. The controlled state variable will be denoted by \(X^{x,u}\):
On the other hand, P2 can stop the game by choosing any stopping time \(\eta \) with values in \([0,\infty ]\). We, now, give a proper definition of such strategies.
Definition 2.1
P1’s strategy is any sequence \(u=(\tau _n, \delta _n)_{n \ge 0}\), where \((\tau _n)_{n \ge 0}\) is a sequence of stopping times such that \(0 = \tau _0< \tau _1< \tau _2<\ldots <\tau _n \uparrow \infty \) and \(\delta _n \in L^0({\mathcal {F}}_{\tau _n})\) with values in Z. P2’s strategy is any stopping time \(\eta \in {\mathcal {T}}\), where \({\mathcal {T}}\) is the set of all \([0,\infty ]\)-valued \({\mathbb {F}}\)-stopping times.
Remark 2.1
We observe that simultaneous interventions are possible in this game. This is in contrast with games where both players intervene with impulses, where simultaneous interventions are usually not allowed since they would be very difficult to handle with from a modelling perspective (cf. [20]). On the other hand here, due to the different nature of the strategies for the two players, one can safely allow for simultaneous actions. This has an interesting consequence on our analysis, as we will see in the linear game of the next section that at least two types of Nash equilibria are possible and in one of them P1 induces P2 to stop instantaneously.
The players want to maximize their respective objectives, featuring each of them three discounted terms: a running payoff, P1’s intervention cost/gain and a terminal payoff. The players’ discount factors can be different of each other. More precisely, for each \(i=1,2\), \(r_i > 0\) denotes the discount rate of player i, \(f,g: {\mathbb {R}}^d \rightarrow {\mathbb {R}}\) are their running payoffs, \(h,k: {\mathbb {R}}^d \rightarrow {\mathbb {R}}\) their terminal payoffs and \(\phi , \psi :{\mathbb {R}}^d \times Z \rightarrow {\mathbb {R}}\) are the intervention cost and gain, respectively. Throughout the whole paper, we will work under the assumption that all these functions are continuous. Hence, we can define the payoffs as follows.
Definition 2.2
Let \(x \in {\mathbb {R}}^d\), and let \((u, \eta )\) be a pair of strategies. Provided that the right-hand sides exist and are finite, we set:
where the subscript in the expectation denotes the conditioning with respect to the starting point.
In order for \(J_1\) and \(J_2\) to be well defined, we now introduce the set of admissible strategies.
Definition 2.3
Let \(x \in {\mathbb {R}}^d\) be some initial state, and let \((u ,\eta )\) be some strategy profile. We say that the pair \((u, \eta )\) is x-admissible if:
-
(i)
the following random variables are all in \(L^1(\varOmega )\):
$$\begin{aligned}&\int _0^\infty e^{- r_1 t} {|}f(X_t^{x, u}){|} \mathrm{d}t, \int _0^\infty e^{- r_2 t} {|}g(X_t^{x, u}){|} \mathrm{d}t,\\&e^{- r_1\eta } {|}h(X_{\eta }^{x, u}){|}, e^{- r_2\eta } {|}k(X_{\eta }^{x, u}){|}, \\&\sum _{k: \tau _k \le \infty } e^{- r_1\tau _k} {|}\phi (X_{\tau _k^-}^{x,u}, \delta _k){|}, \sum _{k: \tau _k \le \infty } e^{- r_2\tau _k} {|}\psi (X_{\tau _k^-}^{x, u}, \delta _k){|}; \end{aligned}$$ -
(ii)
for each \(p \in {\mathbb {N}}\), the random variable \({\Vert }X^{x, u}{\Vert }_\infty = \sup _{t \ge 0} {|}X_t^{x, u}{|}\) is in \(L^p(\varOmega )\).
We denote by \({\mathcal {A}}_x\) the set of all x-admissible pairs.
Remark 2.2
Notice that, as it is formulated above, admissibility is a joint condition on the strategies of both players. Under condition (ii) above and if all functions f, g, h, k, \(\phi \) and \(\psi \) have at most polynomial growth in their respective variables, the set of all jointly admissible strategies can be expressed as \({\mathcal {A}}_x^1 \times {\mathcal {A}}_x^2 = {\mathcal {A}}_x\), where \({\mathcal {A}}_x^i\) denotes Pi’s set of (individually) admissible strategies for \(i=1,2\), and is defined as follows: \({\mathcal {A}}_x ^1\) is the set of all P1’s strategies \(u=(\tau _n, \delta _n)_{n \ge 0}\) such that \(\sum _{n \ge 0} |\delta _n| \in L^p (\varOmega )\) for all \(p \ge 1\), while \({\mathcal {A}}_x ^2\) is the set of all \([0,\infty ]\)-values stopping times.
Indeed, for P1’s strategies for instance, using classical a-priori \(L^p\)-estimates of the (uncontrolled) state variable, there exists a constant \(c>0\) such that
Moreover, similar estimates can be performed for the other expectations in Definition 2.3(i).
We conclude this section with the classical definition of Nash equilibrium and the corresponding equilibrium payoffs.
Definition 2.4
(Nash Equilibrium) Given \(x \in {\mathbb {R}}^d\), we say that \((u^*, \eta ^*) \in {\mathcal {A}}_x\) is a Nash equilibrium if
Finally, the equilibrium payoffs of any Nash equilibrium \((u^*, \eta ^*) \in {\mathcal {A}}_x\) are defined as
2.1 The System of Quasivariational Inequalities
Now, we introduce the differential problem that will be satisfied by the equilibrium payoff functions of our game. Let \(V_1, V_2 : {\mathbb {R}}^d \rightarrow {\mathbb {R}}\) be two measurable functions such that
for some measurable function \(\delta : {\mathbb {R}}^d \rightarrow Z\). Moreover, we define the following two intervention operators:
for each \(x \in {\mathbb {R}}^d\).
The expressions in (2), (3) and (4) have the following natural interpretation:
-
Equation (2) let x be the current state of the process, if P1 intervenes immediately with impulse \(\delta (x)\), P1’s payoff after intervention changes to \(V_1(x+\delta (x)) - \phi (x, \delta (x))\), given by the payoff in the new state minus the intervention cost. Therefore, \(\delta (x)\) in (2) is the optimal impulse that P1 would apply in case of intervention.
-
Equation (3) \({\mathcal {M}}V_1(x)\) represents P1’s payoff just after her intervention.
-
Equation (4) similarly, \({\mathcal {H}}V_2(x)\) represents P2’s payoff following P1’s intervention.
Moreover, for any functions V regular enough (specific assumptions will be given later) we can consider the infinitesimal generator of the uncontrolled state variable X:
where \(b, \sigma \) are as in (1), \(\sigma ^t\) denotes the transposed of \(\sigma \), \(\nabla V\) and \(D^2 V\) are the gradient and the Hessian matrix of V, respectively. We are interested in the following quasivariational inequalities (QVI’s, for short) for \(V_1, V_2\):
Each part of the QVI’s system above can be interpreted in the following way:
-
Equation (5) it means that it is not always optimal for P1 to intervene, and it is a standard condition in impulse control theory [15, 25];
-
Equation (6) if the current state is x and P2 chooses to stop the game, i.e. \(\eta = 0\), he gains k(x), and since this is a suboptimal strategy, we have \(V_2(x) \ge k(x)\) for all \(x \in {\mathbb {R}}^d\);
-
Equation (7) by definition of Nash equilibrium we expect that P2 does not lose anything when P1 intervenes as in [20]; otherwise, P2 would like to deviate, by contradicting the notion of equilibrium;
-
Equation (9) before P2 stops the game, P1 plays as in a classic impulse control problem (e.g. [15]);
-
Equation (10) similarly as above, when P1 does not intervene, P2 solves his own optimal stopping problem (e.g. [26]).
After all this preparation, we are ready to move to our main result, which is a verification theorem linking Nash equilibria and solutions to the QVI system above.
2.2 The Verification Theorem
In this subsection, we state and prove our main verification theorem. This result will be key in order to compute Nash equilibria in specific examples.
Theorem 2.1
Let \(V_1, V_2 : {\mathbb {R}}^d \rightarrow {\mathbb {R}}\) be two given functions. Assume that (2) holds and set
with \({\mathcal {M}}V_1\) as in (3). Moreover, assume that:
-
\(V_1\) and \(V_2\) are solutions of the system of QVIs;
-
\(V_i \in C^2({\mathcal {C}}_j \setminus \partial {\mathcal {C}}_i) \cap C^1({\mathcal {C}}_j) \cap C({\mathbb {R}}^d)\), for \(i \ne j\), and both functions have at most polynomial growth;
-
\(\partial {\mathcal {C}}_i\) is a Lipschitz surface, i.e. it is locally the graph of a Lipschitz function, and \(V_i\)’s second-order derivatives are locally bounded near \(\partial {\mathcal {C}}_i\) for \(i=1,2\).
Finally, let \(x \in {\mathbb {R}}^d\) and assume that \((u^*, \eta ^*) \in {\mathcal {A}}_x\), where \(u^*=(\tau _n, \delta _n)_{n \ge 1}\) is given by
and
with the convention \(\tau _0 =0\). Then, \((u^*, \eta ^*)\) is a Nash equilibrium and \(V_i = J_i(x; u^*, \eta ^*)\) for \(i =1, 2\).
Remark 2.3
First, we stress that, unlike usual control problems, the candidates \(V_1,V_2\) are not required to be twice differentiable everywhere, but only in \( \{ V_2 > k \}\) and \(\{ {\mathcal {M}}V_1 - V_1 < 0 \}\), respectively. Moreover, we observe that for the equilibrium strategies in the theorem above the right continuity of \((X_t^{x; u})_{t \ge 0}\) implies the following:
for every strategies u and \(\eta \) such that both \((u^*, \eta )\), \((u, \eta ^*)\) belong to \({\mathcal {A}}_x\), for every \(s \in [0, \eta [\) and every \(\tau _k < \infty \).
Proof
Let \(V_i(x) = J_i(x; u^*, \eta ^*)\) for \(i=1,2\). By definition of Nash equilibrium we have to prove that \(V_1(x) \ge J_1(x; u, \eta ^*)\) and \(V_2(x) \ge J_2(x; u^*, \eta )\) for every \((u, \eta )\) such that both \((u^*, \eta )\), \((u, \eta ^*)\) belong to \({\mathcal {A}}_x\). The proof is performed in three steps.
Step 1: We show that \(V_1(x) \ge J_1(x; u, \eta ^*)\). Let u be a strategy such that \((u, \eta ^*) \in {\mathcal {A}}_x\). Thanks to the regularity assumptions and by approximation arguments of Theorem 2.1 in [27] (for more details see the proof of Theorem 3.3 in [20]), we can assume without loss of generality that \(V_1 \in C^2({\mathcal {C}}_2) \cap C({\mathbb {R}}^d)\). For each \(r > 0\) and \(n \in {\mathbb {N}}\), we set
with \(\tau _r := \inf \{s >0 : X_s \not \in B(x,r)\}\), where B(x, r) is an open ball with radius r and centre in x. As usual, we adopt the convention \( \inf \emptyset = + \infty \). Applying Itô’s formula to \(e^{-r_1s}V_1(X_s)\) between time zero and \(\tau _{r,n}\) and taking conditional expectations on both sides give
From (10) it follows that
for all \(s \in [0, \eta ^*[\). Moreover, using (5) we also have:
Therefore,
Observe that by admissibility we have
for some constants \(C>0\) and \(p \in {\mathbb {N}}\). Thus, we can use dominated convergence theorem and pass to the limit, first as \(r \rightarrow \infty \) and then for \(n \rightarrow \infty \). Finally, because of (8), we obtain
Step 2: We show that \(V_2(x) \ge J_2(x; u^*, \eta )\). Let \(\eta \) be a \([0,\infty ]\)-valued stopping time such that \((u^*, \eta ) \in {\mathcal {A}}_x\). Thanks to regularity assumptions and by the same approximation argument as before, we can assume again without loss of generality that \(V_2 \in C^2({\mathcal {C}}_1) \cap C({\mathbb {R}}^d)\). Arguing exactly as in Step 1 we obtain
for the localizing sequence \(\tau _{r,n} := \tau _r \wedge n \wedge \eta \) (\(r > 0\), \(n \in {\mathbb {N}}\)), where \(\tau _r := \inf \{s >0 : X_s \not \in B(x,r)\}\). From (9) it follows that
for all \(s \in [0, \eta [\). Moreover, due to (7) and (13) we obtain
Then,
and as before we can use dominated convergence theorem and pass to the limit so that using (8) we obtain
Step 3: Let \(V_1(x) = J_1(x; u^*, \eta ^*)\). We argue as in Step 1, with equalities instead of inequalities by the property of \(u^*\). Similarly for P2 with \(V_2(x) = J_2(x; u^*, \eta ^*)\). \(\square \)
3 An Impulse Controller–Stopper Game with Linear Payoffs
In next Sects. 3.1–3.4, we provide an application of the verification theorem, Theorem 2.1, to an impulse game with a one-dimensional state variable evolving essentially as a Brownian motion, which can be shifted by P1’s impulses and stopped by P2, and where both players want to maximize linear payoffs. We find two types of Nash equilibria for this game, depending on whether P1 finds it convenient or not to force P2 to stop the game. For both types, we provide quasiexplicit expressions for the equilibrium payoff functions and related strategies. Our findings will be illustrated by some numerical examples.
3.1 Setting
We are in a more specific setting than before. This time, the state variable is one-dimensional, while the players have the following linear payoffs for \(x \in {\mathbb {R}}\):
with \(s, \, c,\, \lambda , \, a, \, q, \, d, \, \gamma , \, b\) positive constants fulfilling
Hence, given an initial state x and an impulse strategy \(u= (\tau _n, \delta _n)_{n\ge 1}\), we define the controlled process \( X_t^{x;u}\) as
where W is a standard one-dimensional Brownian motion and \( \sigma >0 \) is a fixed parameter. Moreover, we assume that the two players have the same discount factor \(r_1 = r_2 = r\) such that
The players’ payoff functions are given by
Therefore, in this game P1 can shift the state variable X by intervening with impulses in order to keep it high enough, while paying some costs at each intervention time, until the end of the game, which is decided by P2. In addition to that, P2, who want to keep X low, might gain something each time P1 intervenes. At the end of the game, P1 (resp. P2) receives (resp. loses) some amount proportional to X. Hence, depending on whether her terminal payoff is high enough, P1 might want to end the game soon, by forcing P2 to do that.
Our goal is to find some Nash equilibrium by solving the QVI problem in (5)–(10). More specifically, a heuristic analysis of the QVI system will help us finding a couple of quasiexplicit candidates \(W_1, \, W_2\) for the equilibrium payoff functions of the game \(V_1, \, V_2\). We recall the optimal impulse size and the intervention operators in this setting
together with the infinitesimal generator of the uncontrolled state variable
Before giving the QVI system in this case, let us introduce the continuation regions for both players
so that the respective intervention regions are given by \({\mathcal {C}}_i ^c\) for \(i=1,2\). Now, the QVIs system becomes
A first look at the system suggests the following representation for \(W_1\) and \(W_2\):
where \(\varphi _1\) and \(\varphi _2\) are solution to the ODEs
Hence, for each \( x \in {\mathbb {R}}\), we have:
where \(C_{11}, \, C_{12}, \, C_{21}, \, C_{22}\) are real parameters and \(\displaystyle {\theta := \sqrt{2r / \sigma ^2}}\).
3.2 An Equilibrium with No Simultaneous Interventions
In this subsection, we push our heuristics further by focusing on a first type of Nash equilibrium, where simultaneous interventions are not allowed. By this we mean that we are looking for an equilibrium of threshold type, where P1 intervenes each time X falls below a certain level, say \({\bar{x}}_1\), in which case P1 applies an impulse moving the state variable towards an optimal level \(x_1 ^*\) belonging to the continuation region of both players. On the other hand, P2 waits until X is too high for him, i.e. until X crosses some upper level, say \({\bar{x}}_2\), at which point P2 decides to stop the game. The heuristics will lead us to propose candidates for the equilibrium payoffs and related strategies, which will be then checked to be the correct ones subject to some additional conditions. Such additional conditions will be checked in some numerical examples.
Heuristics Loosely speaking, since P1 is happy when X is high, while P2 prefers it to be low, we make the following ansatz about the continuation regions:
Hence, we can rewrite (18)–(19) as
Let us find more explicit expressions for the operators \({\mathcal {M}}W_1\) and \({\mathcal {H}}W_2\). In this example, it is natural to restrict the analysis to \(\delta \ge 0\) since P1 prefers high values of \(X^{x,u}\). Hence, whenever he intervenes he will always move the process X to the right, so that
Here, we focus on the case where the maximum point belongs to \(]{\bar{x}}_1, {\bar{x}}_2[\); in other words, P1 does not force P2 to stop. In particular, we have \(W_1(x_1^*) = \varphi (x_1^*)\) and
Therefore, we obtain
The parameters appearing in the expressions for \(W_1\) and \(W_2\) must be chosen so as to satisfy the regularity assumptions in the verification theorem, i.e.
We can summarize the description of our candidates for equilibrium payoffs in the following
Ansatz 3.1
Let \(W_1\) and \(W_2\) be as in (22)–(23) where the parameters involved
satisfy the order condition
and the following equations
Reparametrization We will conveniently reparametrize the equations above in order to reduce their complexity. Using the expressions in (21) we can rewrite (25) as follows
So, subtracting (26b) to (26a) we obtain
Then, adding (26c) to (26g) we find
Hence, by substitution, we are reduced to solving the following sub-system
Now, the change of variable \(z = e^{\theta (x_1^* - {\bar{x}}_1)}\) turns Eq. (28a) into the following
which has a unique solution \({\tilde{z}} > 1\). Indeed, let \(F(z) := \ln z - 2 (\frac{z - 1}{z + 1} ) - \frac{c r \theta }{1 - \lambda r}\) and observe that it satisfies \(F'(z) > 0\) for all \(z>1\). Moreover \(z = e^{\theta (x_1^* - {\bar{x}}_1)} > 1\) due to order condition (24), \(F(1) < 0\) and \(\lim _{z \rightarrow +\infty } F(z) = +\infty \). Therefore, there is only one value \({\tilde{z}}\) such that \(F({\tilde{z}}) = 0\), which can be easily computed numerically.
Now, in order to solve (28b) and (28c) we perform a second change of variable, \(w = e^{\theta ({\bar{x}}_2 - {\bar{x}}_1)}\), leading to the following equations
Notice that (30a) is linear in \({\bar{x}}_2\), hence it can be easily solved in terms of \({\tilde{z}}\) and w, to get
Regarding (30b), it can be rewritten as
The equation for w above is a quartic equation for which explicit formulae for its roots are available. However, since they are quite cumbersome and not easy to use, we will solve it numerically, leaving the analysis for later. Once the two new parameters \({\tilde{z}}\) and \({\tilde{w}}\) are found, by solving numerically the respective equations above, the thresholds \({\bar{x}}_1, {\bar{x}}_2\) and the optimal level for P1, \(x_1 ^*\), can be deduced automatically. It remains to check under which additional conditions such thresholds correspond to a Nash equilibrium of our original linear game. This will be done in the next paragraph.
Characterization of the Equilibrium and Verification The next proposition summarizes our findings and establishes the link between the solutions \({\tilde{z}}\) and \({\tilde{w}}\) to the equations above with the Nash equilibrium of threshold type we are looking for, provided some additional inequalities are fulfilled.
Proposition 3.1
Assume that there exists a solution \(({\tilde{z}}, \, {\tilde{w}})\) to (29)–(32) such that \(1< {\tilde{z}} < {\tilde{w}}\) and additionally
Then, a Nash equilibrium for the game in Sect. 3 exists and it is given by the pair \((u^*, \eta ^*)\), where \(u^* = (\tau _n, \, \delta _n)_{n \ge 1}\) is defined by
and
where the thresholds \({\bar{x}}_1, \, x_1^*\) and \({\bar{x}}_2\) satisfy
Moreover, the functions \(W_1, \, W_2\) in Ansatz 3.1 coincide with the equilibrium payoff functions \(V_1, \, V_2\), i.e.
Proof
The proof consists in checking all the conditions needed to apply Verification Theorem (2.1). First, notice that by construction the functions \(W_1\) and \(W_2\) satisfy all required regularity properties, i.e. \(W_1\) and \(W_2\) have polynomial growth and
Moreover, Lemmas A.1 and A.2 in “Appendix” grant the optimality of the impulse \(\delta (x)\), i.e.
together with the properties
Next, we show that for all \(x \in \{ {\mathcal {M}} W_1 - W_1 = 0 \} =\; ] -\infty , \, {\bar{x}}_1]\), and we have \(W_2(x) = {\mathcal {H}} W_2(x)\). Indeed, by definition of \({\mathcal {H}}W_2\) we have:
Now, let \(x \in \{{\mathcal {M}} W_1 - W_1 < 0\}\). We have to prove that
Since \(\{{\mathcal {M}} W_1 - W_1 < 0\} = \; ]{\bar{x}}_1, \, \infty [\), we can consider two separate cases. In \(]{\bar{x}}_1, \, {\bar{x}}_2[\) we have \({-bx - W_2(x) <0}\) and
since \(\varphi _2\) is solution to ODE (20). On the other hand, in \([{\bar{x}}_2, \, \infty [\) we know that \(-bx = W_2(x)\); then, we have to check that \({\mathcal {A}}W_2(x) - rW_2(x) + q - x \le 0\) for all \(x \in [{\bar{x}}_2, \, \infty [\). First, notice that \(W_2(x) = - bx\) and \({\mathcal {A}}W_2(x) = 0\). Hence, we are reduced to checking the inequality
Since by assumption \(1 - br > 0\), the function \(x \mapsto q - ( 1 - br) x\) is decreasing, so we just need to check whether the inequality holds in \({\bar{x}}_2\), i.e. \((1 - br){\bar{x}}_2 - q\ge 0 \) which is satisfied by (33).
To conclude our verification that the candidate equilibrium payoffs satisfy the QVI system, we are left with checking that \(-bx - W_2(x) = 0\) implies \(W_1(x) = ax\), and that, on the other side, \(-bx - W_2(x) < 0\) implies
Now, the first implication holds by definition, while the second one boils down to proving
For \(x \in \; ]{\bar{x}}_1, \, {\bar{x}}_2[\) we have \({\mathcal {M}} W_1(x) - W_1(x) < 0\) and, as before,
as \(\varphi _1\) is solution to ODE (20). For \(x \in \; ]-\infty , {\bar{x}}_1]\), we know that \( {\mathcal {M}}W_1(x) - W_1(x) = 0\) and therefore we have to check that
To do that, recall first that \(W_1(x) = \varphi _1(x_1^*) - c - \lambda (x_1^* - x)\) and \({\mathcal {A}}W_1(x) = 0\), which gives
since \( \varphi _1({\bar{x}}_1) = \varphi _1(x_1^*) - c - \lambda (x_1^* - {\bar{x}}_1) \). Notice that, since by assumption \( 1 - \lambda r > 0\), the function \(x \mapsto - r \varphi _1({\bar{x}}_1) - r \lambda (x - {\bar{x}}_1) + x -s \) is increasing in x. As a result, we only need to prove that the desired inequality holds for \( x = {\bar{x}}_1\), i.e.
which is verified since \({\mathcal {A}}\varphi _1({\bar{x}}_1) - r \varphi _1({\bar{x}}_1) + {\bar{x}}_1 - s = 0\) and \({\mathcal {A}} \varphi _1({\bar{x}}_1) = r \varphi _1({\bar{x}}_1) - {\bar{x}}_1 + s \ge 0\), due to \(\varphi _1''({\bar{x}}_1) \ge 0\).
To finish the proof, we check that equilibrium strategies are x-admissible for every \(x \in {\mathbb {R}}\). By construction, the controlled process never exits from \(]{\bar{x}}_1, \, {\bar{x}}_2[ \,\cup \,\{ x \}\), so that \(\sup _{t \ge 0} {|}X_t{|} \in L^p(\varOmega )\) holds. It is easy to check that all the other conditions are satisfied provided we show the following:
To start, let us assume that the initial state x is \(x_1^*\). The idea is to write \(\tau _k\) as a sum of independent and identically distributed copies of some exit time (as in the proof of Proposition 4.7 in [20]). Denote by \(\mu \) the exit time of the process \(x_1^* + \sigma W\) from \(]{\bar{x}}_1, \, {\bar{x}}_2[\) where W is a one-dimensional Brownian motion. Then each time \(\tau _k\) can be decomposed as \(\tau _k =\sum _{l \ge 1}^k \zeta _l\) where \(\zeta _l\) are i.i.d. random variables with the same law as \(\mu \). We can now show (36). As \( \delta _k = \delta _1 = x_1^* - {\bar{x}}_1 \) for all \(k \ge 1\), we have
and, by the Fubini–Tonelli theorem and the independence of \((\zeta _l)_{l\ge 1}\), we get
which is a convergent geometric series, since \(\mu > 0\). Then, for any \(x \in \;]{\bar{x}}_1, \, {\bar{x}}_2[\) same arguments hold, whereas, when \(x \in [{\bar{x}}_2, \, +\infty [\), P2 stops as soon as the game starts and, as a consequence, P1 cannot apply any impulse, hence, the condition is satisfied. Finally, if \(x \in \;]-\infty , \, {\bar{x}}_1]\) we have
since \(\sup _{t \ge 0} {|}X_t{|} \in L^p(\varOmega )\). \(\square \)
3.3 An Equilibrium where the Controller Activates the Stopper
We turn now to another kind of Nash equilibrium, where P1 behaves similarly as in the previous type with the main difference that this time when the state variable X falls below a given threshold, he will intervene and send X directly to the stopping region of P2, hence forcing him to stop the game instantaneously. In particular, this would be an equilibrium in which the two players act at the same time. The approach we use to characterize such an equilibrium follows the same steps as in the previous subsection.
Heuristics We start with some heuristics leading us to formulate a conjecture on the equations the thresholds characterizing this equilibrium should reasonably satisfy. Arguing as before, we expect the candidates for equilibrium payoffs to be of following type (18)–(19) as
for suitable thresholds \({\bar{x}}_i\), \(i=1,2\).
Now, according to the type of equilibrium we want to identify, we investigate the case in which the maximum point of the function \(y \mapsto W_1(y) - \lambda y \) belongs to \( [ {\bar{x}}_2, \, \infty [ \), meaning that when P1 intervenes he is applying an optimal impulse moving the state variable to the stopping region of her competitor. Thus, in this case we have
Therefore, we have the following scenarios:
-
if \( a > \lambda \, \Rightarrow \, x_1^* \rightarrow \infty \);
-
if \( a = \lambda \, \Rightarrow \, x_1^* \) could be any \(x \ge {\bar{x}}_2\);
-
if \( a < \lambda \, \Rightarrow \, x_1^* = {\bar{x}}_2\).
Clearly, the only interesting case is \( a < \lambda \), so that \(x_1^* = {\bar{x}}_2\). As a consequence, this type of equilibrium will be characterized only by two thresholds. Similarly as in the previous subsection, we characterize the parameters \(( C_{11}, C_{12}, C_{21}, C_{22})\) and the thresholds \(]{\bar{x}}_1, {\bar{x}}_2 [\) by exploiting the smooth pasting conditions coming from the regularity assumptions postulated in Theorem 2.1. By doing so, we obtain
together with the order condition \( {\bar{x}}_1 < {\bar{x}}_2 \).
Reparametrization We first rewrite (39) as
Then, dividing (40a) by \(\theta \) and adding it to (40d), we can solve the equation for \(C_{11}\) and consequently find \(C_{12}\) as in the previous case, (27). A similar manipulation of equations (40b) and (40e) yields \(C_{21}\) and \(C_{22}\). At this point, plugging \(C_{11}\) and \(C_{12}\) in (40c) we obtain
which, noting that \({\bar{x}}_1 = {\bar{x}}_2 - \frac{\ln w}{\theta }\) and applying the change of variable \(w = e^{\theta ( {\bar{x}}_2 - {\bar{x}}_1)}\), can be rewritten as
This is a linear equation in \({\bar{x}}_2\), yielding
Proceeding analogously with (40f), we obtain the following alternative expression for \({\bar{x}}_2\)
Then, by equating (41) to (42), we obtain an equation in w:
which has at least a solution, say \({\widehat{w}} > 1\), due to \(\lim _{w \rightarrow + \infty } G(w) = + \infty \) and \(\lim _{w \rightarrow 1} G(w) = - \infty \). The first limit follows from the highest order term, \(w^2\ln w\), being multiplied by \(\frac{1 - \lambda r}{1 - ar} > 0\) (cf. (17)). On the other hand, the second limit follows from (16):
Characterization of the Equilibrium and Verification The next proposition summarizes our characterization of this Nash equilibrium in terms of only one parameter, \({\widehat{w}}\), provided some further conditions, that will be checked numerically in the next subsection.
Proposition 3.2
Assume that there exists \({\widehat{w}}\) solution to (43) such that
Then, a Nash equilibrium for the game in Sect. 3 exists and it is given by the strategies \((u^*, \eta ^*)\), with \(u^* = (\tau _n, \delta _n)_{n \ge 1}\) defined by
and
where the thresholds satisfy
Moreover, the functions \(W_1, \, W_2\) in Ansatz 3.1 coincide with the equilibrium payoff functions \(V_1, \, V_2\), i.e.
Proof
We proceed as for the previous equilibrium, by checking all the conditions necessary to apply the verification theorem. First of all, the functions \(W_1,W_2\) satisfy by construction all required regularity properties, i.e.
and both have at most polynomial growth.
together with
for all \(x \in {\mathbb {R}}\). Let \(x \in \{ {\mathcal {M}} W_1 - W_1 = 0 \} = \;] -\infty , \, {\bar{x}}_1]\). By definition of \({\mathcal {H}}W_2\) we have:
Now, in order to prove that
we consider two separate cases as for the previous equilibrium. First, for \(x \in \;]{\bar{x}}_1, \, {\bar{x}}_2[\), we have \(-bx - W_2(x) <0\) and
since \(\varphi _2\) is solution to ODE (20), so the maximum between the two terms is zero. Second, we know that \(-bx = W_2(x)\) for \(x \in [{\bar{x}}_2, \, \infty [\), then we have to check that \({\mathcal {A}}W_2(x) - rW_2(x) + q - x \le 0\) for any \(x \in [{\bar{x}}_2, \, \infty [\). Since \({\mathcal {A}}W_2(x) = 0\), we are reduced to verify the inequality
Given that \(x \mapsto q - ( 1 - br) x\) is decreasing due to \(1 - br > 0\), it suffices to show the inequality above at the point \({\bar{x}}_2\), i.e. \((1 - br){\bar{x}}_2 - q\ge 0 \), which is implied by (45).
To complete the verification that \(W_1,W_2\) are solutions to the QVI system, we show that in \({-bx - W_2(x) = 0}\) implies \( W_1(x) = ax\) and that \({-bx - W_2(x) < 0}\) yields
The first implication holds by definition. For the second one, we have to prove
For \(x \in \;]{\bar{x}}_1, \, {\bar{x}}_2[\) we have \({\mathcal {M}} W_1(x) - W_1(x) < 0\) and as before
as \(\varphi _1\) is solution to ODE (20). For any \(x \in \;]-\infty , {\bar{x}}_1]\) we know that \( {\mathcal {M}}W_1(x) - W_1(x) = 0\); hence, we have to check that
To do so, we notice that the function \({x \mapsto (1 - \lambda r)x + cr - s - (a - \lambda )r{\bar{x}}_2}\) is increasing in x by assumption \( 1 - \lambda r > 0\). Therefore, we only need to prove that the desired inequality for \( x = {\bar{x}}_1\), i.e.
which is given by Lemma A.3. Finally, the optimal strategies are x-admissible for every \(x \in {\mathbb {R}}\). Indeed, by construction, the controlled process never exits from \(]{\bar{x}}_1, {\bar{x}}_2[ \;\cup \, \{ x \}\), and, as a consequence, \({\sup _{t \ge 0} {|}X_t{|} \in L^p(\varOmega )}\) holds for all \(p \ge 1\). It is easy to check that all the other conditions are satisfied as in the first type of equilibrium. \(\square \)
3.4 Numerical Experiments
In this section, we will give some numerical illustrations of the equilibrium payoff functions and a selection of comparative statics regarding the two types of Nash equilibria identified in the previous subsections (the numerical results in this section were obtained using R, rootSolve package). It is useful to remember that in order for the solutions to the QVI system to be Nash equilibria of one of the two types, they have to satisfy either (33)–(34) or (44)–(45). Before we start, let us recall the meaning of the parameters involved:
-
s and q might be interpreted as exogenous costs and gains, respectively. Note that P1’s running payoff \(f(x) = x -s\); hence, in order to make profit P1 needs x to be greater than s, which can fairly be considered as P1’s expense, an analogous reasoning applies for P2, but in the opposite direction since \(g(x) = q - x\);
-
a and b can be considered as terminal payoff sensitivity to the underlying process, \(X_t\), as we have \(h(x) = ax\) and \(k(x) = -bx\), respectively;
-
at each intervention time P1 faces a fixed cost, c, while P2 receives a fixed gain, d;
-
moreover, \(\lambda \) is P1’s proportional cost parameter, while \(\gamma \) is P2’s proportional gain parameter;
-
finally, r is the discount rate, the same for both players, and \(\sigma \) is the volatility of the state variable.
Equilibrium 1: No Simultaneous Interventions In order to fulfil (33)–(34), we can observe that both inequalities are satisfied for high enough values of \({\tilde{w}}\). It is possible to show via graphical analysis that \({\tilde{w}}\), solution to (32), is decreasing in a, b, s and increasing in \(c, d, q, \lambda \) and \(\gamma \). Therefore, we have chosen small values of a, b and s to obtain the first equilibrium, Scenario A, whereas for Scenario B we have looked for higher values and increased q and d in order to find an equilibrium. The table provides the exact parameter settings, with \({\bar{x}}_1\), \(x_1^*\) and \({\bar{x}}_2\), are as in Proposition 3.1:
r | \(\sigma \) | c | d | \(\lambda \) | \(\gamma \) | a | b | s | q | \({\bar{x}}_1\) | \(x_1^*\) | \({\bar{x}}_2\) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Scenario A | 0.01 | 5 | 500 | 100 | 20 | 40 | 0 | 0 | 1 | 5 | − 31.11 | 16.95 | 34.84 |
Scenario B | 0.01 | 1.5 | 50 | 150 | 10 | 15 | 2 | 8 | 10 | 10 | 4.95 | 14.26 | 18.18. |

Type I equilibria
Figure 1(i)–(ii) shows how the equilibrium payoff functions behave in the selected scenarios, with the dashed lines showing the smooth pasting of the three components of the payoff in (22) and (23). From Fig. 1(i)–(ii) we can see how a reduction in the volatility seems to shrink the continuation region; hence, the players become more cautious, reducing their intervention regions when there is more uncertainty. Another interesting fact to note is how the relative distance between \({\bar{x}}_1\) and \({\bar{x}}_2\) becomes smaller. This can be due to the increase in P2’s terminal payoff sensitivity, b, and the increase in P1’s exogenous cost, s. In one direction, P2 is losing more money when she decides to terminate the game; therefore, she will not stop when the state process value is too high; hence, she reduces her threshold \( {\bar{x}}_2\). In the other, since P1 is facing higher exogenous costs, she pushes the target, \(x_1^*\), as far as she can, making sure the state process is not going too low, rising the barrier \({\bar{x}}_1\).
Figure 1(iii)–(vi) represents some comparative statics of the thresholds \({\bar{x}}_1, \, x_1^*\) and \({\bar{x}}_2\) for Scenario B. Similar graphs hold for Scenario A as well; therefore, they are omitted. First, in Fig. 1(iii) we can observe how an increase in P1’s fixed cost expands the gap between \({\bar{x}}_1\) and \(x_1^*\). The more P1 has to pay at any intervention time, the less often she will intervene, lowering the threshold, \({\bar{x}}_1\), and increasing the target, \(x_1^*\). This allows P2, who does not like high values of x, to slightly lower her threshold, \({\bar{x}}_2\), so as to pay less when she will stop the game. In Fig. 1(iv) the behaviour with respect to the proportional cost is quite different. P1 will reduce the interventions for higher \(\lambda \), with the distance between \({\bar{x}}_1\) and \(x_1^*\) left nearly unchanged, while P2 keeps the barrier at a constant level \({\bar{x}}_2\). In particular, P1 tends to never intervening when the proportional cost reaches its maximum, set by the condition \(1 - \lambda r >0\). This behaviour shows how P1 is quite indifferent to changes in the proportional cost when this is not too big, while she is really sensitive once it gets high. Finally, in Fig. 1(v)–(vi) we can see that, when P2’s gains more each time P1 intervenes increases, P2 is happy playing for longer, heightening the threshold \({\bar{x}}_2\), since she is receiving more money.
Equilibrium 2: P1 Induces P2 to Stop To satisfy (44)–(45), we want \({\widehat{w}}\) to be neither too high nor too low; in particular, high \(\lambda \) should help in (44) as high \({\widehat{w}}\) in (45). As before, via graphical analysis it is possible to show that \({\widehat{w}}\), solution to (43), is decreasing in a, b, s and increasing in \(c, d, q, \lambda \) and \(\gamma \). Therefore, the first instance of Nash equilibrium, Scenario B, has been selected to have high \(\lambda \) and \({\widehat{w}}\), choosing high values of c, d, q and \(\gamma \) and low values of b and s, whereas for Scenario A we have looked for lower values of \(\lambda \) and adapted the others. The table shows the selected parameter settings, with \({\bar{x}}_1\) and \({\bar{x}}_2\) are as in Proposition 3.2:
r | \(\sigma \) | c | d | \(\lambda \) | \(\gamma \) | a | b | s | q | \({\bar{x}}_1\) | \({\bar{x}}_2\) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
Scenario A | 0.01 | 5 | 100 | 100 | 25 | 10 | 24 | 9 | 45 | 0 | 22.56 | 32.68 |
Scenario B | 0.01 | 1.5 | 150 | 125 | 80 | 25 | 70 | 15 | 10 | 15 | 14.27 | 25.72. |

Type II equilibria
As before, Fig. 2(i)–(ii) represents the equilibrium payoff functions in the selected examples. First, we can observe that the continuation region in Scenario A is shifted to the right with respect to the one in Scenario B and we can observe that its width has not changed much from one case to the other. Furthermore, we can notice that Scenario B is more profitable for P2 and less profitable for P1. These two facts might be explained by the following changes from Scenario B to Scenario A: P1’s exogenous cost, s, increases, so P1 cannot tolerate low levels of x, increasing her threshold \({\bar{x}}_1\). Moreover, although P2’s gains, q, d and \(\gamma \), decrease, we do not see her threshold scale down as it would be expected as the game is now less profitable. This is probably due to b’s reduction, which leads P2 to stop for higher values of \({\bar{x}}_2\) since she is going to lose less when she decides to stop.
Now, let us spend some words on the comparative statics in Fig. 2(iii)–(vi). When P1’s costs, c and \(\lambda \), increase, Fig. 2(iii)–(iv), P1 would intervene for lower values of x and the distance \({\bar{x}}_2 - {\bar{x}}_1\) will increase, even though \({\bar{x}}_2\) gets lower as well. This can be explained as follows, with the costs increasing, P1 is less willing to intervene, reducing \({\bar{x}}_1\), even though this shift allows P2 to lower her threshold, \({\bar{x}}_2\), since she likes low values of x. When the fixed gain, d, rises, Fig. 2(v), P2 can afford the game to run for longer, increasing \({\bar{x}}_2\), as she will gain more when P1 will make her stop. Moreover, this makes P1 heighten \({\bar{x}}_1\) in order to limit the proportional costs increment. Lastly, we have a similar behaviour to the one described above for the proportional gain, \(\gamma \), Fig. 2(vi). The main difference is the speed with which the distance between the thresholds increases, higher for proportional gain increments. This happens because, in case of proportional gain increments, P2 is more incentivized to push \({\bar{x}}_2\) far away since the bigger the impulse the more the revenue, whereas an analogous behaviour in case of fixed gain increments would lead to a loss in the terminal payoff outrunning the additional profit due to the fact that the gain, d, does not depend on the intensity of the impulse P1 is playing, while the losses are increasing, since they depend on P2’s threshold, \(-b{\bar{x}}_2\).
Comparison Between the Two Equilibria We conclude with a short discussion on the reasons why P1 would play aggressively, forcing P2 to stop. To do so we compare first the two Scenarios A and B in both equilibria. So, going from Type I to Type II we see a reduction in the proportional gain, \(\gamma \), an increase in P1 terminal payoff sensitivity, b, and a reduction in P2’s exogenous gain, q, making P2 lower her threshold, \({\bar{x}}_2\), to reduce the losses at the end of the game. Then, P1’s exogenous cost, s, increases making P1 rise both the threshold and the target, \({\bar{x}}_1\) and \(x_1^*\), respectively. Furthermore, P1 terminal payoff sensitivity, a, increases and, intuitively incentivize P1 to let P2 end the game sooner so to receive the terminal payoff. More specifically, since \({\tilde{w}}\) is decreasing in a, its increase makes \(\ln {\tilde{w}} = \theta ({\bar{x}}_2 - {\bar{x}}_1)\) decrease; hence, since the distance between the two thresholds is now smaller, P1’s target, \(x_1^*\), is closer to P2’s barrier up to the point they coincide, \(x_1^*\equiv {\bar{x}}_2\).
Regarding Scenario B, again from Type I to Type II, we observe increments in the terminal payoff sensitivity of the two players, a and b, in particular P1’s sensitivity rises much more than in the first scenario, hence, P1 is more incentivized to let P2 end the game. Another important change regards the proportional cost, \(\lambda \), which is very high in case P1 induces P2 to stop. As we have seen before in the comparative statics in Fig. 1(iv), P1 intervenes less and less when the proportional cost becomes higher and higher, so it is more convenient to intervene only once, inducing P2 to stop.
We finally observe that while we have managed to find numerical values for which only one of the two types of Nash equilibria emerges at a time, the problem of whether the two equilibria can coexist remains open.
4 Conclusions
In this paper, we have introduced a general class of impulse controller vs stopper games whose state variable evolves according to a multi-dimensional Brownian motion-driven diffusion. Moreover, we have provided a verification theorem giving sufficient conditions under which the solution of the suitable system of quasivariational inequalities we implemented coincides with the two players’ equilibrium payoff functions of the game. To show how the verification theorem and the system of quasivariational inequalities are meant to be used, we have solved the game in a specific setting with linear payoffs and a one-dimensional scaled Brownian motion as a state variable, discovering the existence of two different types of equilibria which we have fully characterized. In particular, the one where player 1 forces player 2 to end the game could be considered as a limit case of the other equilibrium and further research in this direction might be interesting given that we did not prove if the two equilibria are alternative and we were not able to find any setting under which they could coexist.
References
Maitra, A.P., Sudderth, W.D.: The gambler and the stopper. Lect. Notes Monogr. Ser. 30, 191–208 (1996)
Karatzas, I., Sudderth, W.: Stochastic games of control and stopping for a linear diffusion. In: Hsiung, A.C., Ying, Z., Zhang, C.-H. (eds.) Random Walk, Sequential Analysis And Related Topics: A Festschrift in Honor of Yuan-Shih Chow, pp. 100–117. World Scientific, Singapore (2006)
Karatzas, I., Li, Q.: Bsde approach to non-zero-sum stochastic differential games of control and stopping. In: Cohen, S.N., Madan, D., Siu, T.K., Yang, H. (eds.) Stochastic Processes, Finance and Control: A Festschrift in Honor of Robert J Elliott, pp. 105–153. World Scientific, Singapore (2012)
Karatzas, I., Sudderth, W.D.: The controller-and-stopper game for a linear diffusion. Ann. Probab. 29(3), 1111–1127 (2001)
Karatzas, I., Zamfirescu, I.M.: Martingale approach to stochastic control with discretionary stopping. Appl. Math. Optim. 53(2), 163–184 (2006)
Karatzas, I., Zamfirescu, I.M.: Martingale approach to stochastic differential games of control and stopping. Ann. Probab. 36(4), 1495–1527 (2008)
Bayraktar, E., Huang, Y.J.: On the multidimensional controller-and-stopper games. SIAM J. Control Optim. 51(2), 1263–1297 (2013)
Hernandez-Hernandez, D., Simon, R.S., Zervos, M.: A zero-sum game between a singular stochastic controller and a discretionary stopper. Ann. Appl. Probab. 25(1), 46–80 (2015). https://doi.org/10.1214/13-AAP986
Bayraktar, E., Karatzas, I., Yao, S.: Optimal stopping for dynamic convex risk measures. Ill. J. Math. 54(3), 1025–1067 (2010)
Nutz, M., Zhang, J.: Optimal stopping under adverse nonlinear expectation and related games. Ann. Appl. Probab. 25(5), 2503–2534 (2015)
Bayraktar, E., Young, V.: Proving regularity of the minimal probability of ruin via a game of stopping and control. Finance Stoch. 15(4), 785–818 (2011)
Karatzas, I., Wang, H.: A barrier option of american type. Appl. Math. Optim. 42(3), 259–279 (2000)
Basei, M.: Optimal price management in retail energy markets: an impulse control problem with asymptotic estimates. Preprint arXiv:1803.08166 (2018)
Bruder, B., Pham, H.: Impulse control problem on finite horizon with execution delay. Stoch. Processes Their Appl. 119(5), 1436–1469 (2009). https://doi.org/10.1016/j.spa.2008.07.007
Cadenillas, A., Zapatero, F.: Optimal central bank intervention in the foreign exchange market. J. Econ. Theory 87(1), 218–242 (1999)
Chen, Y.S.A., Guo, X.: Impulse control of multidimensional jump diffusions in finite time horizon. SIAM J. Control Optim. 51(3), 2638–2663 (2013). https://doi.org/10.1137/110854205
Chevalier, E., Ly Vath, V., Scotti, S., Roch, A.: Optimal execution cost for liquidation through a limit order market. Int. J. Theor. Appl. Finance 19(1), 1650,004 (2016). https://doi.org/10.1142/S0219024916500047
Ly Vath, V., Mnif, M., Pham, H.: A model of optimal portfolio selection under liquidity risk and price impact. Finance Stoch. 11(1), 51–90 (2007). https://doi.org/10.1007/s00780-006-0025-1
Belak, C., Christensen, S.: Utility maximisation in a factor model with constant and proportional transaction costs. Finance Stoch. 23(1), 29–96 (2019)
Aïd, R., Basei, M., Callegaro, G., Campi, L., Vargiolu, T.: Nonzero-sum stochastic differential games with impulse controls: a verification theorem with applications. Math. Oper. Res. 45, 205–232 (2019). (forthcoming)
Ferrari, G., Koch, T.: On a strategic model of pollution control. Ann. Oper. Res. (2017). https://doi.org/10.1007/s10479-018-2935-7
Basei, M., Cao, H., Guo, X.: Nonzero-sum stochastic games with imulse controls. Preprint arXiv:1901.08085 (2019)
Cosso, A.: Stochastic differential games involving impulse controls and double-obstacle quasi-variational inequalities. SIAM J. Control Optim. 51(3), 2102–2131 (2013)
Azimzadeh, P.: A zero-sum stochastic differential game with impulses, precommitment, and unrestricted cost functions. Appl. Math. Optim. (2017). https://doi.org/10.1007/s00245-017-9445-x
Bertola, G., Runggaldier, W.J., Yasuda, K.: On classical and restricted impulse stochastic control for the exchange rate. Appl. Math. Optim. 74(2), 423–454 (2016)
Chen, N., Dai, M., Wan, X.: A nonzero-sum game approach to convertible bonds: tax benefit, bankruptcy cost, and early/late calls. Math. Finance 23(1), 57–93 (2013)
Øksendal, B.K., Sulem, A.: Applied Stochastic Control of Jump Diffusions, vol. 498. Springer, Berlin (2005)
Acknowledgements
Open access funding provided by Università degli Studi di Milano within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
In this appendix, we have gathered some technical results used in the verification parts of Sect. 3 for both types of Nash equilibrium. We start with two lemmas on the continuations regions in the equilibrium where simultaneous actions are not allowed.
Lemma A.1
Let \(W_1\) be as in (22). Then we have
Moreover
Proof
By a simple change of variable we obtain
Let \(\varGamma (y) := W_1(y) - \lambda y\). By definition of \(W_1\) we have \(\varGamma '({\bar{x}}_1) = \varGamma '( x_1^*) = 0 \). Moreover, the following properties are satisfied:
-
(i)
\(\varGamma '(x) = 0\) in \(]-\infty , \, {\bar{x}}_1]\);
-
(ii)
\(\varGamma '(x) = a - \lambda < 0\) in \([{\bar{x}}_2, \, \infty [\);
-
(iii)
\(\varGamma '(x) > 0\) (resp. \(<0\)) in \(] {\bar{x}}_1, \, x_1^*[\) (resp. in \(] x_1^*, \, {\bar{x}}_2[\)).
Properties (i) and (ii) are easily checked. Regarding (iii), recall that
To study its sign, notice that \(\varGamma ''(x) = \theta ^2 C_{11} e^{\theta x} + \theta ^2 C_{12} e^{- \theta x} >0\) for all \(x \in \; ]{\bar{x}}_1, {\tilde{x}}[\),
where \({\tilde{x}}\) is such that \(e^{\theta {\tilde{x}}} = \sqrt{ -C_{12}/C_{11}} = e^{\frac{\theta }{2}(x_1^* + {\bar{x}}_1)}\). Moreover, since \({\tilde{x}} < x_1^*\) we have \(\varGamma ''(x_1^*)<0\). Hence, it follows that \(\varGamma '(x) > 0\) in \(] {\bar{x}}_1, \, x_1^*[\), while \(\varGamma '(x) < 0\) in \(] x_1^*, \, {\bar{x}}_2[\).
As a consequence, \(\varGamma \) has a unique global maximum in \( x_1^*\), so that
which gives
This implies the first part of our statement, i.e. \(\delta (x) = (x_1^* - x){\mathbf {1}}_{] -\infty , x_1^*]}(x)\). Now, to show (47), notice first that
where we set
Now, we prove that \(\zeta >0\). By \(C^0\)-pasting in \({\bar{x}}_1\) we have \( \varphi _1( {\bar{x}}_1) = \varphi ( x_1^*) - c - \lambda (x_1^* - {\bar{x}}_1)\), therefore
which is strictly positive since \(\varGamma \) is increasing in \(]{\bar{x}}_1, \, x_1^*]\). Hence, \(\zeta \) is strictly positive and we have
\(\square \)
Lemma A.2
Let \(W_2\) be as in (23). Assume there exists a solution \(({\tilde{z}}, \, {\tilde{w}})\) to (29)–(32) such that \(1< {\tilde{z}} < {\tilde{w}}\) and
Then, we have
Proof
First, we recall that
where
We want to prove that \(\varphi _2(x) > - bx \) in \(]{\bar{x}}_1, \, {\bar{x}}_2[\) and \( {\mathcal {H}} W_2(x) > -bx \) in \(]- \infty , \, {\bar{x}}_1]\). For the first inequality we are interested in the conditions such that, for all \(x \in \;]{\bar{x}}_1, \, {\bar{x}}_2[\), we have
or, equivalently,
Now, applying the change of variable \(e^{\theta ({\bar{x}}_2 - x)} = z > 1\) to the inequality above yields
Since \(\ln z >0\) and \(1-br>0\) by assumption, the left side above is bigger than
which is quadratic in z and it can be factorized as
We show that our assumptions grant that the expression above is positive, which in turn will imply (48). Hence, the second factor is positive if the following holds:
Then, using (31), the two inequalities above can be rewritten as
which is true by assumption.
For showing the second inequality, i.e. \( {\mathcal {H}} W_2(x) > -bx \) in \(]- \infty , \, {\bar{x}}_1]\), we observe first that
From the \(C^0\)-pasting condition in \({\bar{x}}_1\) we have that \(\varphi _2({\bar{x}}_1) = \varphi _2(x_1^*) + d + \gamma ( x_1^* - {\bar{x}}_1)\); therefore, we can rewrite (49) as
Since \( b < \gamma \) we only need to check that \(F({\bar{x}}_1)>0\):
Now, using again the change of variable \(w=e^{\theta ({\bar{x}}_2 - {\bar{x}}_1)}\), we have \({\bar{x}}_1 = {\bar{x}}_2 - \frac{\ln w}{\theta }\) and so \(F({\bar{x}}_1)e^{\theta ({\bar{x}}_2 - {\bar{x}}_1)}\) can be re-expressed as
which, using (31), can be rewritten as
which is positive by assumption. \(\square \)
We conclude appendix with two more lemmas on similar results for the other kind of equilibrium, where P1 forces P2 to stop the game.
Lemma A.3
Let \(W_1\) be as in (22). Assume there exists a solution \({\widehat{w}} \) to (43) such that
Then we have
Moreover, we have
Proof
First, observe that
Let us denote \(\varGamma (y) := W_1(y) - \lambda y\). By definition of \(W_1\) we have \(\varGamma '({\bar{x}}_1) = 0 \). Moreover, the following properties hold true:
-
(i)
\(\varGamma '(x) = 0\) in \(]-\infty , \, {\bar{x}}_1]\);
-
(ii)
\(\varGamma '(x) = a - \lambda < 0\) in \([{\bar{x}}_2, \, \infty [\);
-
(iii)
\(\varGamma '(x)>0\) in \(]{\bar{x}}_1, {\bar{x}}_2[\).
As properties (i) and (ii) can be easily checked, we turn to showing (iii). Observe that, for all \(x \in \;]{\bar{x}}_1, {\bar{x}}_2[\), one has \(\varGamma '(x) = \varphi _1'(x) - \lambda = \theta C_{11} e^{\theta x} - \theta C_{12} e^{- \theta x} + \frac{1}{r} - \lambda \), hence
Using the fact that \({\bar{x}}_1 = {\bar{x}}_2 - \frac{\ln {\widehat{w}}}{\theta }\) and setting \(z=e^{\theta (x - {\bar{x}}_1)}\) we can rewrite it as
which can be factorized as
which is true whenever \(\frac{1 - \lambda r}{\theta }(\ln {\widehat{w}} - 1) - (1 - ar){\bar{x}}_2 - cr + s > 0\). Therefore, recalling (41), after some algebraic manipulation, we obtain the equivalent condition
Hence property (iii) is fulfilled. As a consequence, \(\varGamma \) has a unique global maximum point in \({\bar{x}}_2\), and the rest of the proof follows the same lines as for Lemma A.1. Hence, the details are omitted. \(\square \)
Lemma A.4
Let \(W_2\) be as in (23). For every \( x \in {\mathbb {R}} \), assume there exists a solution \({\widehat{w}}\) to (43) such that:
Then, we have
Proof
First, recall that
where
Hence, we want to prove that \(\varphi _2(x) > - bx \) in \(]{\bar{x}}_1, \, {\bar{x}}_2[\) and \( {\mathcal {H}} W_2(x) > -bx \) in \(]- \infty , \, {\bar{x}}_1]\). For the first inequality we are interested in the conditions granting
or equivalently
Letting \(z=e^{\theta ({\bar{x}}_2 - x)}\), the above inequality holds whenever
Since \(\ln z >0\) and \(1-br>0\) by assumption, the left side above is bigger than
which can be factorized as in the proof of Lemma A.2 in
We show that our assumptions grant that the expression above is positive. We proceed as in the proof of Lemma A.2: the second factor above is positive if the following holds
which, using (42), can be rewritten as
which is true by assumption.
For the second inequality we have
Since \(\gamma > b\), the inequality holds whenever \( (\gamma - b) ({\bar{x}}_2 - {\bar{x}}_1) + d > 0\), which is always true since \({\bar{x}}_2 > {\bar{x}}_1\) by the ordering condition. \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Campi, L., De Santis, D. Nonzero-Sum Stochastic Differential Games Between an Impulse Controller and a Stopper. J Optim Theory Appl 186, 688–724 (2020). https://doi.org/10.1007/s10957-020-01718-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10957-020-01718-6
Keywords
- Controller–stopper games
- Stochastic differential games
- Impulse controls
- Quasivariational inequalities
- Nash equilibrium