
Abstract
A new approach to derive Pareto front approximations with evolutionary computations is proposed here.
At present, evolutionary multiobjective optimization algorithms derive a discrete approximation of the Pareto front (the set of objective maps of efficient solutions) by selecting feasible solutions such that their objective maps are close to the Pareto front. However, accuracy of such approximations is known only if the Pareto front is known, which makes their usefulness questionable.
Here we propose to exploit also elements outside feasible sets to derive pairs of such Pareto front approximations that for each approximation pair the corresponding Pareto front lies, in a certain sense, in-between. Accuracies of Pareto front approximations by such pairs can be measured and controlled with respect to distance between elements of a pair.
A rudimentary algorithm to derive pairs of Pareto front approximations is presented and the viability of the idea is verified on a limited number of test problems.
Similar content being viewed by others


1 Introduction
Evolutionary multiobjective optimization (EMO) algorithms [1–3] derive finite approximations of Pareto fronts (i.e. sets of efficient solutions, as defined below). They can be regarded, conventionally, as lower approximations (we assume that all objectives are to be maximized), because all their elements are feasible solutions. Yet, with the exception of test problems, Pareto fronts are generally not known. Hence the exact accuracy of such approximations is not known either.
To rectify this, we propose to work with elements outside the feasible solution set (infeasible solutions), with the objective to provide upper approximations of Pareto fronts. A pair consisting of a lower and an upper approximation forms an approximation of the Pareto front, whose accuracy can be controlled by distance between the lower and the upper approximation. Thus, the approach proposed herein effectuates the idea of two-sided Pareto front approximations, which is as yet absent from the literature on EMO. Exploiting explicitly infeasible solutions to provide two-sided approximations of Pareto fronts offers a new turn in research in the field.
Our research has been motivated by the absence, to our best knowledge, of papers pertaining to EMO or multiobjective optimization, in which active use of infeasible elements would be harnessed to approximate the Pareto front. The only exception is perhaps paper [4]; however, in that work, infeasible solutions were not generated intentionally, as it is done in our work.
The outline of the paper is as follows. In Sect. 2, necessary definitions are provided; in particular; lower and upper shells, which yield specific lower and upper approximations of Pareto fronts, are defined. In Sect. 3, an approximation accuracy measure is set, and a relaxation of the definition of upper shell is proposed with the purpose to have a construct more suitable for computations than upper shell itself.
In Sect. 4, a rudimentary evolutionary algorithm for approximating Pareto fronts within given accuracy is presented. The algorithm has been run on five test problems taken from literature and the results are reported in Sect. 5. Directions for further research are proposed in Sect. 6, whereas Sect. 7 contains the concluding remarks.
2 Definitions and Notation
Multicriteria Optimization (MO) problem is formulated as
where \(f: \mathbb{R}^{n} \rightarrow \mathbb{R}^{k}; \ f=(f_{1},\ldots ,f_{k}), \ f_{i}: \mathbb{R}^{n} \rightarrow \mathbb{R}, \ i=1, \ldots,k, \ k \geq2\), are objective (criteria) functions; max denotes the operator of deriving all efficient elements (see the definition below). We assume that X 0 has an interior.
The dominance relation ≺ is defined on \(\mathbb{R}^{n}\) as
where ≪ denotes f i (x′)≤f i (x), i=1,…,k, and f i (x′)<f i (x) for at least one i.
If x≺x′ then x is dominated by x′ and x′ is dominating x.
An element x of X 0 is called efficient iff
We denote the set of efficient elements by N and the set f(N) (the Pareto front) by P, P⊆f(X 0).
Lower shell is a finite nonempty set S L ⊆X 0, elements of which satisfy
(thus no element of S L is dominated by another element of S L ).
We define the nadir point y nad as
Upper shell is a finite nonempty set \(S_{U} \subseteq \mathbb{R}^{n} \setminus X_{0}\), elements of which satisfyFootnote 1
3 Approximations of P
We aim at constructing numerically viable two-sided approximations of P.
To derive S L for which f(S L ) is “close” to P, any EMO algorithm can be used (cf. [1, 2, 6–9]).
Since the definition of an upper shell involves N, this construct is not a suitable approximation of N. A more suitable construct, referring to S L instead of N, namely an upper approximation A U , is obtained by replacing:
condition (3) by
condition (4) by
condition (5) by
where y nad(S L ) denotes an element of \(\mathbb{R}^{k}\) such that
(y nad(S L ) varies with S L ).
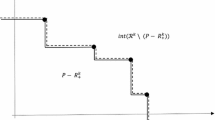
By definition, an upper approximation A U can contain elements which are dominated by some elements of N, as shown in Fig. 1, and certainly such elements are undesirable for the purpose. Condition (8) is meant to limit the domain for such elements. However, as S L gets “closer” to N and y nad(S L ) gets “closer” to y nad, the chance for such elements being included in A U decreases.

An example when an element x, dominated by some element of N, belongs to A U
With S L and A U derived, the accuracy of the approximation of P by f(S L ) and f(A U ) can be measured as
or
where ∥⋅∥ is a norm and |⋅| is cardinality of a set. In numerical experiments and applications, a form of normalization of \(\overline{\mathit{acc}}_{P}\) and acc P with respect to ranges of values of objective functions over e.g. S L is advisable (cf. Sect. 5).
Those two indices measure only “closeness” of f(S L ), f(A U ). “Goodness” or “fairness” of the approximation of P by such constructs has to be ensured by standard EMO mechanisms.
In next section, we propose an algorithm for deriving two-sided approximations of P.
4 An Algorithm for Two-sided Approximations of P
The algorithm we propose below derives two-sided approximations of P, thus providing a way for approximation accuracy monitoring.
Let α P denote the desired value of acc P .
We limit the domain of searching in \(\mathbb{R}^{n} \setminus X_{0}\) to some set
By assumption, X 0 has an interior, hence elements of X DEC, generated randomly, belong to X 0 with positive probability.
Algorithm EMO-APPROX
-
1.
\(j :=0, \ S^{j}_{L} := \emptyset, \ A^{j}_{U} := \emptyset\).
-
2.
Select randomly η elements of X 0 and derive \(S^{j}_{L}\).
-
3.
Select randomly an element x of \(S^{j}_{L}\) and:
-
3.1.
derive an element x′∈X DEC such that x′⊀x,
-
3.2.
if x′∈X 0 then update \(S_{L}^{j}\) and \(A_{U}^{j}\) with \(S' = S_{L}^{j} \cup\{ x' \}\), go to 3.4,
-
3.3.
update \(A_{U}^{j}\) with \(A' = A_{U}^{j} \cup\{ x' \}\),
-
3.4.
if acc P ≤α P or j=j max then STOP,
-
3.5.
j:=j+1, go to 3.
-
3.1.
In step 2, η is a parameter and derivation of S L means that selected elements which do not satisfy condition (2) are to be removed.
In substep 3.1, to derive an element x′ of the required properties, components of x are mutated until x∈X DEC and x′⊀x holds. Mutations can increase or decrease with probability 0.5 the value of a randomly selected component. The range of mutations decreases with the increasing j. If a mutation increases the ith component of x, then the value of this component after mutation is
and if this mutation decreases the component, then the value of this component after mutation is
Function rnd(0,1) returns a random number from the range [0,1] with uniform probability. The presented method of mutation and the strategy of decreasing mutation range have been taken from the literature (cf. e.g. [6]).
In substep 3.2, the update of \(S^{j}_{L}\) means that elements of \(S' = S^{j}_{L} \cup\{ x' \}\) which do not satisfy condition (2) are to be removed from S′, and only then \(S^{j}_{L} := S'\). The update of \(A^{j}_{U}\) means that elements of \(A^{j}_{U}\) which do not satisfy condition (7) with respect to updated \(S^{j}_{L}\) are to be removed.
In substep 3.3, the update of \(A^{j}_{U}\) means that elements of \(A'= A^{j}_{U} \cup\{ x' \}\) which do not satisfy conditions (6), (7) and (8) are to be removed from A′, and only then \(A^{j}_{U} := A'\).
In substep 3.4, j max is the maximal number of iterations in the algorithm.
There is no guarantee that the approximation accuracy monotonously improves by each iteration of EMO-APPROX (i.e. on (i+1)-th iteration acc P takes a smaller value than on iteration i). The phenomenon is illustrated in Fig. 2. Indeed, suppose that S L ={a,b}, A U ={c,d}. Clearly, \(\mathit{acc}_{P}^{1} = \max\{ \|f(a) - f(c)\|, \|f(b) - f(d)\| \} \) (the superscript indicates the iteration). Including e into S L causes b to be eliminated from S L (for e dominates b—condition (2)). Now we have \(\mathit{acc}_{P}^{2} = \max\{ \|f(a) - f(c)\|, \|f(e) - f(d)\| \} \) and clearly \(\mathit{acc}_{P}^{2} \geq \mathit{acc}_{P}^{1}\), which means that the approximation accuracy has deteriorated. However, it can be expected that in successive iterations mutations of e or d can recover this local loss of accuracy.

Possible non-monotonous behavior of the algorithm
As the algorithm is founded on genetic-type heuristics, no formal proof is offered that in general the algorithm is able to derive a two-sided approximation of P within a given accuracy. However, by means of two-sided approximations at least the behavior of such heuristics is put under control.
5 Numerical Experiments
We illustrate the behavior of EMO-APPROX on four test problems taken from [8], denoted DTLZ2a, DTLZ4a, DTLZ7a, Selri, and one taken from [10, 11], denoted Kita.
We normalized the accuracies \(\overline{\mathit{acc}}_{P}\) and acc P as follows:
where \(s^{f}_{i} := \max_{x \in S_{L}} f_{i}(x) - \min_{x \in S_{L}} f_{i}(x), \ i = 1,\ldots,k\) (the normalization factor varies with S L ).
We ran EMO-APPROX on the test problems with j max=9000, η=100 in each case, taking three shots of the algorithm behavior and the results it provided at j=3000, j=6000 and finally at j=9000. Since it was not certain what values of the parameter α P should be used, we set it to zero and we stopped the algorithm after the iteration count reached j max. In each case, X DEC was assumed to be [−0.2,1.2]×[−0.2,1.2]×…×[−0.2,1.2] for all four DTLZ problems and [−2.0,9.0]×[−2.0,9.0] for the Kita problem.
Table 1 Footnote 2 shows the values of \(\overline{\mathit{acc}}_{P}\) and acc P for each problem and shot, where n, m, b and k are, respectively, the number of variables, the number of general constraints, the number of box constraints and the number of criteria; #f is the number of function f evaluations; ∥A U ∥, ∥S L ∥ and ∥A U ∥+∥S L ∥ are the cardinality of, respectively, A U , S L and A U ∪S L .
Figures 3 and 4 present, respectively, the elements of S L , A U and f(S L ), f(A U ) for the Kita problem.

Elements of S L and A U for the Kita problem

Elements of f(S L ) and f(A U ) for the Kita problem
These test results constitute a rather limited base for drawing general conclusions. It is, nevertheless, possible to point to some regularities, which seem to be in line with the expected behavior of the algorithm.
Both accuracies improve monotonously for 3000, 6000 and 9000 iterations only in two instances (DTLZ7a and Kita), whereas for other problems improvements are not monotonous due to a phenomenon explained in previous section. In the remaining instances, there was no significant gain in increasing the number of iterations from 6000 to 9000, for at 9000 the accuracies are either worse or only slightly better.
In all instances, S L has more elements then A U . This is caused by the order in which the algorithm attempts to produce new elements of those sets—first in S L and then in A U . By interchanging this order, more balanced sets can be produced.
For the Kita, DTLZ2a and DTLZ4a problems, for which analytic forms of N are known, we have generated a number of elements of N (1852 elements for Kita, 2001 elements for DTLZ2a and DTLZ4a). In none of those problems is an element of A U dominated by a generated element of N, which could be attributed to the strength of condition (8) (we have inspected only A U derived in 9000 iterations).
6 Further Directions
To demonstrate the potential in further fine tuning of the approach, we have coupled EMO-APPROX with the algorithm NSGA-II ([7]); the latter has proved itself a very effective in producing well distributed and accurate lower approximations (S L ) of P. In this experiment, NSGA-II has been instructed to derive, for each problem considered, a lower approximation of P with 200 elements in 200 generations (’generation’ is NSGA-II parlance) to serve as a starting S L for EMO-APPROX.
Next, EMO-APPROX has been run for each problem with the respective S L . Because EMO-APPROX has been building successive S L and A U not from scratch, but from the results provided by NSGA-II, we have decreased j max to 3000. And as we did not know how to account in EMO-APPROX for NSGA-II impact on mutating factor \((1-\mathrm{rnd}(0,1)^{2(1-\frac{j}{j^{\max}})})\), for each problem we run the tandem NSGA-II + EMO–APPROX with four different scalings of the starting mutating factor values, namely with 1.0,0.1,0.01,0.001.
For each problem, at least one scaling produced lower or equal acc P than algorithm EMO-APPROX run alone for 9000 iterations. From all such cases, we have selected those with the highest ∥S L ∥+∥A U ∥. Results for runs selected in that manner are presented in Table 2.Footnote 3
Comparing Tables 1 and 2, it is evident that EMO-APPROX, producing two-sided approximations of the Pareto front, has benefited significantly from the preprocessing provided by NSGA-II—the tandem NSGA-II + EMO-APPROX has produced results comparable to, and in some cases distinctly better than those produced by EMO-APPROX alone, within three times less iterations. This strengthens our claim that, in the future, embedding the full range of EMO mechanisms into EMO-APPROX is worthwhile.
7 Conclusions
In this work, we limited ourselves to showing the viability of the idea to approximate Pareto fronts by pairs of lower and upper approximations. We also demonstrated how to improve interactively “closeness” between them. “Goodness” or “fairness” of approximations of P by such constructs constitutes the topic for further research. Another further topic is to provide means to derive pairs of S L and S U -like (A U -like) constructs for cases where S U does not exist. Some preliminary results pertaining to that issue have been already obtained and are reported in [5].
In the future experiments, to ensure even more uniform layouts of pairs f(A U ), f(S L ) along P, other genetic operators should be also exploited, whereas here we have confined ourselves only to the operator of mutation. We have done this deliberately to ensure clarity of the presentation and to demonstrate the viability of the concept of two-sided approximations of P.
The problem of providing accurate two-sided approximations with uniform layouts along Pareto fronts, being of interest in itself, has an immediate application in Multiple Criteria Decision Making, where a decision process can be enhanced if it is started with a not necessarily very accurate but uniform two-sided approximation of the Pareto set to roughly represent it. Next, in the course of the decision process, such approximations can be improved locally as directed by the decision maker’s preferences [12, 13].
Notes
Pairs of sets S L ,A U and f(S L ),f(A U ) for all five problems at j equal to 3000,6000,9000 can be obtained from the Authors on request.
Actually, for problem DTLZ2a, NSGA-II + EMO-APPROX in its best run produced slightly higher acc P than EMO-APPROX, 0.608 versus 0.603, but considering the spread in the iteration count, such a difference can be regarded as nil.
References
Deb, K.: Multi-Objective Optimization Using Evolutionary Algorithms. Wiley, Chichester (2001)
Coello Coello, C.A., Van Veldhuizen, D.A., Lamont, G.B.: Evolutionary Algorithms for Solving Multi-Objective Problems. Kluwer Academic, New York (2002)
Talbi, E.: Metaheuristics: From Design to Implementation. Wiley, New York (2009)
Legriel, J., Le Guernic, C., Cotton, S., Maler, O.: Approximating the Pareto front of multi-criteria optimization problems. In: International Conference on Tools and Algorithms for the Construction and Analysis of Systems, TACAS, pp. 69–83 (2010)
Kaliszewski, I., Miroforidis, J.: Real and virtual Pareto set upper approximations. In: Trzaskalik, T., Wachowicz, T. (eds.) Multiple Criteria Decision Making ’11. The Publisher of University of Economics in Katowice, vol. 121 (2012)
Michalewicz, Z.: Genetic Algorithms + Data Structures = Evolution Programs. Springer, Berlin (1996)
Deb, K., Pratap, A., Agarwal, S., Meyariva, T.: A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 6(2) (2002)
Knowles, J.: ParEGO: a hybrid algorithm with on-line landscape approximation for expensive multiobjective optimization problems. IEEE Trans. Evol. Comput. 10, 50–66 (2005)
Hanne, T.: A multiobjective evolutionary algorithm for approximating the efficient set. Eur. J. Oper. Res. 176, 1723–1734 (2007)
Kita, H., Yabumoto, Y., Mori, N., Nishikawa, Y.: Multi-objective optimization by means of the thermodynamical genetic algorithm. In: Voigt, H.-M., Ebeling, W., Rechenberg, I., Schwefel, H.-P. (eds.) Parallel Problem Solving from Nature–PPSN IV. Lecture Notes in Computer Science, pp. 504–512. Springer, Berlin (1996)
Kita test problem: http://delta.cs.cinvestav.mx/~ccoello/EMOO/testfuncs/, downloaded August 22, 2012
Kaliszewski, I., Miroforidis, J., Podkopayev, D.: Interactive multiple criteria decision making based on preference driven evolutionary multiobjective optimization with controllable accuracy—the case of ρ-efficiency. Systems Research Institute Report, RB/1/2011 (2011)
Kaliszewski, I., Miroforidis, J., Podkopayev, D.: Interactive multiple criteria decision making based on preference driven evolutionary multiobjective optimization with controllable accuracy. Eur. J. Oper. Res. 216, 188–199 (2012)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Kaliszewski, I., Miroforidis, J. Two-Sided Pareto Front Approximations. J Optim Theory Appl 162, 845–855 (2014). https://doi.org/10.1007/s10957-013-0498-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10957-013-0498-y