
Abstract
We consider general classes of gradient models on regular trees with spin values in a countable Abelian group S such as \({\mathbb {Z}}\) or \({\mathbb {Z}}_q\). This includes unbounded spin models like the p-SOS model and finite-alphabet clock models. Under a strong coupling (low temperature) condition on the interaction, we prove the existence of families of distinct homogeneous tree-indexed Markov chain Gibbs states \(\mu _A\) whose single-site marginals concentrate on a given finite subset \(A\subset S\) of spin values. The existence of such states is a new and robust phenomenon which is of particular relevance for infinite spin models. These states are extremal in the set of homogeneous Gibbs states, and in particular cannot be decomposed into homogeneous Markov-chain Gibbs states with a single-valued concentration center. Whether they are also extremal in the set of all Gibbs states remains an open, challenging question. As a further application of the method we obtain the existence of new types of gradient Gibbs states with \({\mathbb {Z}}\)-valued spins, whose single-site marginals do not localize, but whose correlation structure depends on the finite set A, where we provide explicit expressions for the correlation between the height-increments along disjoint edges.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
1.1 Gradient Models on Lattices and Trees
Statistical mechanics models for \({\mathbb {Z}}\)- or \({\mathbb {R}}\)-valued height variables with gradient interactions have been studied in a number of variations. For homogeneous models with different types of base spaces (such as lattices and trees) and different interaction potentials, see [5, 8, 10, 11, 20, 24, 26, 29]. For disordered models with quenched randomness in the interaction, see [4, 6, 7, 9, 27].
In this paper we study S-valued gradient models on d-regular trees, whose interactions are defined by transfer operators given by an symmetric function \(Q:S \rightarrow (0,\infty )\). Here, S is assumed to be a countable Abelian group which we think of as the local state space of the system. In particular, if \(S \subset {\mathbb {R}}\) is infinite, then the local state space can be viewed as the height-dimension of the system. In concrete applications in statistical mechanics, we often encounter the case \(S={\mathbb {Z}}\) and the transfer operator is given by \(Q(i)=\exp (-\beta U(|i|))\), where \(U:S\rightarrow {\mathbb {R}}\) is a potential function prescribing the energetic cost of a spin configuration to make an increment of size |i| along an edge of the tree, or more generally an edge of the supporting graph.
Important special cases for the choice of the potential are the p-SOS model with \(U(|i|)=|i|^p\), for which exponents \(p\in (0,\infty )\) are allowed. The most popular choices are \(p=1\) which corresponds to the classical SOS model, and \(p=2\) which gives the discrete Gaussian (see [2, 3] for an analysis on the lattice). In our present approach besides positivity and evenness of Q, however, we will make no assumption on monotonicity or convexity in the interaction, and treat the function Q as an infinite-dimensional parameter of the model.
The main interest of the study is in the construction and description of infinite-volume Gibbs measures (GM) given by the DLR-consistency equation, as well as in gradient Gibbs measures (GGM) in the case of non-compact local spin space S (for general background see [11, 14, 26]). GGMs are relevant as generalizations of the concept of GMs since they are suited to describe infinite-volume states which do not localize in any bounded region \(A\subset S\). By contrast to our work, Lammers and Toninelli [25] provide a full description of localization and delocalization properties of gradient Gibbs measures for two specific instances of gradient models on the tree whose underlying potential function is strictly convex. These two instances are the uniform graph homomorphism model, allowing for height increments of size \(\{\pm 1\}\), and uniform monotone models on directed rooted graph, which allow only configurations whose spin-values are non-increasing when going over from the parent to a child. For the uniform graph homomorphism model Lammers and Toninelli are able to employ martingale-based methods from [26] established for studying gradient models on the lattice \({\mathbb {Z}}^d\), where for the uniform monotone model they provide a classification of extremal Gibbs states by means of flows, which is possible by a suitable comparison to the geometric distribution. To the best of our knowledge, our more general set-up does not allow for this reasoning and hence our proof is based on the tree-specific boundary law formalism of Zachary [30]. In our present work we will only consider homogeneous (tree-automorphism invariant) measures. For some results on non-homogeneous measures on trees with homogeneous interactions we refer to [1, 6, 12, 13, 16].
1.2 Main New Result: Localization on Arbitrary Finite Sets
In a previous paper [15] two of us considered the case \(S={\mathbb {Z}}\) and proved the existence of localized Gibbs measures under a strong coupling condition formulated for Q, namely boundedness of \((d+1)/2\)-norm and small deviation of Q from \(1_{\{0\}}\) in terms of the \(d+1\)-norm. We showed that there are homogeneous states \(\mu _i\) whose single-site marginals are concentrated around single fixed heights \(i \in {\mathbb {Z}}\).
In the present paper we will extend this type of result to the case of arbitrary finite localization sets \(A\subset S\), for the height variables, under appropriate strong coupling conditions. The strong-coupling states with non-singleton concentration sets are of a new type in the setup of unbounded spin models, and to our best knowledge have not been discussed before. To appreciate the result it is important to note that these new tree-indexed Markov chain Gibbs measures \(\mu _A\) constructed in our present work are not convex combinations of each other, and in particular not of the spatially homogeneous measures \(\mu _i\) with single-height concentration which were constructed in [15].
The existence result of Theorem 3.1 holds under an N-dependent strong-coupling condition on Q which provides existence of measures \(\mu _A\) which concentrate on localization sets A of size \(|A|\le N\). It is particularly remarkable that under this condition the localization sets in these families can be arbitrarily spread out.
This existence result may look surprising but can be made plausible by seeing it as an infinite-dimensional generalization of a simpler phenomenon which is known to appear in the q-state Potts model on the tree. The homogeneous Markov chain states of the Potts model can described via explicit computations [23], due to the full invariance of the interaction under permutation in local spin-space. For results on the extremality and non-extremality of the Potts states, see [21]. In this way, the low temperature Potts model is the simplest illustrating example of our existence theorem for finite spins. Conversely it is also motivation to search for natural classes of interactions for which such A-localized states exist, which lead us to our theory. In the more difficult case of integer-valued spins, the results are new and the simplest interesting example of our theory could be seen to be the classical SOS-model for which we obtain: Any choice of a subset A of heights (the concentration set) comes with a transition temperature below which an infinite-volume Gibbs state \(\mu _A\) exists which concentrates on A. Much different from the Potts model, there is no simplification from the concrete form of the interaction. Therefore we choose to formulate our theorem in the natural general framework, from which one can then easily derive properties for special models, see Appendix A. Note that our framework includes for instance also the interesting case of \({\mathbb {Z}}^d\)-valued spins, and it suggests to formulate low-temperature conditions in terms of smallness of p-norms of transition operators. This use of p-norms is really for convenience; as the p-norms can be easily computed in given models, this easily transfers into explicit applications down to concrete numbers, see again Appendix A.
Our proof in the case of spins with values in an arbitrary countable Abelian group S is based on the boundary law description of Gibbs measures going back to Zachary [30]. This leads to a non-linear fixed point equation in the space \(\ell ^{d+1}(S)\) of \(d+1\)-summable functions \(u: S \rightarrow {\mathbb {R}}\). In general explicit solutions are out of question, and for our proof we will develop a fixed point method, adapted to the type of A-dependent states we are hoping to find, see Sect. 5.2.
Our approach to study the infinite-dimensional fixed point problem is to break the problem into two parts: on the given finite concentration set A where we expect to find the large components, and a conditional problem away from it where we expect to find the small components. For the latter we devise a suitable (conditional) map on sequence space which we show to be a contraction, for the former we employ the Brouwer fixed point theorem, see (42). This leads us to quite explicit quantitative thresholds for the system parameters of given models for which we can prove existence of A-concentrated states, see Proposition 5.6. On the level of system parameters, the strong coupling condition on \(Q=\exp (-\beta U)\) translates into the fact that the parameter \(\beta \)—which as usual should be interpreted as the inverse temperature—should be large enough, see Appendix A for a discussion along two concrete examples. For a discussion of uniqueness, see the Remarks 5.8 and 5.9.
1.3 Harvesting New Families of Delocalized Gradient Gibbs Measures
In the case \(S={\mathbb {Z}}\), next to proper Gibbs measures, another class of consistent measures, namely the gradient Gibbs measures (GGM) have received much attention, see [11, 17, 20, 26]. Gradient Gibbs measures (as opposed to Gibbs measures) are measures which are only defined on \({\mathbb {Z}}^V/{\mathbb {Z}}\), which is the space of infinite-volume height configurations modulo a joint height shift (as opposed to the state space of absolute heights \({\mathbb {Z}}^V\) itself). Their defining property is the validity of the DLR consistency equation, but read only modulo joint height-shift, for details see Subsect. 4.1. As a consequence of the first part of our work we also obtain new families of gradient Gibbs measures \(\nu ^{q}_{A}\), where \(q\ge 2\) is an integer and \(A\subset {\mathbb {Z}}^q\). They have the delocalization property (see Theorem 4.5), and hence do not stem from homogeneous Markov chain GMs, which are localized as irreducible, aperiodic and positive recurrent Markov processes (see e.g. [15, Theorem 4]). Therefore they are completely different in character from the localized GMs.
We construct these states \(\nu ^{q}_{A}\) as follows. The idea is to relate a GGM \(\nu \) to the Gibbs measures \(\mu ^q_A\) in an associated q-state clock model on \({\mathbb {Z}}_q\) with an interaction \(Q^q\) built from the original interaction Q on \({\mathbb {Z}}^V\). This is done via an edge-wise resampling procedure, see Subsect. 4.2. The concentration properties of the clock-measures \(\mu ^q_A\) we constructed in our first main Theorem 3.1, then carries over to an interesting A-dependent correlation structure for the gradient measures \(\nu ^{q}_{A}\), see Corollary 4.7 and the discussion below.
The remainder of the paper is organized as follows: In Sect. 2 we define our models. Section 3 then contains our main results regarding Gibbs measures for arbitrary finite concentration sets \(A \subset S\). Section 4 discusses existence of delocalized gradient states with A-dependent correlation structure. Finally, Sect. 5 contains the proofs.
2 Definitions
In this section, we review some definitions and known facts which are necessary in order to formulate our main result.
2.1 Spin Configurations on the Cayley Tree
Let \(\Gamma ^d=(V,E)\) denote the d-regular tree or Cayley tree of order \(d \ge 2\), where V is the countably infinite set of vertices and \(E \subset V \times V\) is the set of (unoriented) edges. The term d-regular tree means that the graph \(\Gamma ^d\) is connected without cycles and each vertex \(x \in V\) has exactly \(d+1\) nearest neighbors, i.e., vertices which are connected to x by an edge.
A path connecting two vertices \(x,y \in V\) is an ordered list of n edges
where any two consecutive edges share a common vertex. The length of the unique shortest path from x to y defines the graph distance \(\text {d}(x,y)\).
Besides the set of unoriented edges E, we also consider the set \(\vec {E}\) of oriented edges, which consists of the ordered pairs (x, y) of vertices such that \(\{x,y\} \in E\).
For any subset \(\Lambda \subset V\), we denote by \(\Lambda ^c\) the complement of \(\Lambda \) in V and by
the outer boundary of \(\Lambda \). By \(\Lambda \Subset V\) we indicate that \(\Lambda \) is a finite subset of V.
We set
and note that the pair \((\Lambda ,E_\Lambda )\) is a subgraph of \(\Gamma ^d\), which is a subtree if and only if it is connected.
Let \((S,+)\) be a countable Abelian group, which we think of as the local state space of our system. Important particular cases are given by the lattices \(S={\mathbb {Z}}^k\), \(k\in {\mathbb {N}}\), and by the finite cyclic groups \(S={\mathbb {Z}}_q\), \(q\in {\mathbb {N}}\). We see S as a discrete group and endow it with the measurable structure given by the whole power set \({\mathcal {P}}(S)\).
By \(\ell ^p(S)\), \(1\le p \le \infty \), we denote the space of p-summable real valued functions on S, which is a Banach space with the norm
We recall that
When the group S is finite, the spaces \(\ell ^p(S)\) are of course independent of p, as they all coincide with \({\mathbb {R}}^S\), but the p-norms on them are different. Convolution on S is denoted by
A spin configuration \(\omega =(\omega _x)_{x \in V}\) is a map from the set of vertices V to the local state space S, and the set of all spin configurations is denoted by \(\Omega :=S^V\). For any subset \(\Lambda \subset V\) and any \(\omega \in \Omega \), we set \(\Omega _\Lambda :=S^\Lambda \) and denote by \(\omega _{\Lambda }\in \Omega _\Lambda \) the restriction of \(\omega \) to \(\Lambda \).
We endow each \(\Omega _\Lambda \) with the product \(\sigma \)-algebra \({\mathcal {F}}_\Lambda \) generated by the spin projections \(\sigma _y: \Omega _\Lambda \rightarrow S, \ \sigma _y(\omega )=\omega _y\), where \(y \in \Lambda \), and denote by \({\mathcal {F}}:={\mathcal {F}}_V\) the product \(\sigma \)-algebra on \(\Omega \).
The set of all probability measures on the space \((\Omega ,{\mathcal {F}})\) is denoted by \({\mathcal {M}}_1(\Omega ,{\mathcal {F}})\). We call a probability measure \(\mu \in {\mathcal {M}}_1(\Omega , {\mathcal {F}})\) (spatially) homogeneous if it is invariant under all automorphisms \(\varphi : V \rightarrow V\) of the tree, i.e., \(\mu = \mu \circ \varphi _*^{-1}\), where \(\varphi _*: {\mathcal {F}} \rightarrow {\mathcal {F}}\) is the map \(\varphi _*(A):=\{\omega \circ \varphi ^{-1} \mid \omega \in A\}\).
Given a spatially homogeneous probability measure \(\mu \), we denote by
the single state marginal and the transition matrix induced by \(\mu \). Here, \(x\in V\) is any vertex and \(\{x,y\}\in E\) is any edge, but the above objects do not depend on these choices because the measure \(\mu \) is assumed to be spatially homogeneous.
2.2 Tree-Indexed Markov Chains
The notion of a tree-indexed Markov chain as given in Chap. 12 of [14] is based on the definition of the past of an oriented edge. Given any vertex \(v \in V\) we write
for the oriented edges pointing away from v. The past of an oriented edge \((x,y) \in \vec {E}\) is then defined by
In other words, it consists of those vertices \(v \in V\) for which the shortest path from v to y contains x. A probability measure \(\mu \) on \((\Omega ,{\mathcal {F}})\) is then called a tree-indexed Markov chain (or simply a Markov chain) if for all oriented edges \((x,y) \in \vec {E}\) and all \(i \in S\) we have
2.3 Transfer Operators and Gibbs Measures
In this paper, by a transfer operator on \((\Gamma ^d,S)\) we mean a function
which is symmetric (i.e., \(Q(-i) = Q(i)\) for every \(i\in S\)) and belongs to \(\ell ^{\frac{d+1}{2}}(S)\). A more precise name for such an object would be spatially homogeneous positive symmetric transfer operator. Often, transfer operators are given in terms of a suitable symmetric interaction function \(U : S \rightarrow [0,+\infty )\) as
where \(\beta >0\) should be interpreted as the inverse of a temperature.
A transfer operator Q induces the Markovian gradient specification
by the assignment
for every \(\Lambda \Subset V\), \({{\tilde{\omega }}}\in \Omega _{\Lambda }\) and \(\omega \in \Omega \). Here, the partition function \(Z_{\Lambda }\) gives for every \(\omega \in \Omega \) the normalization constant \(Z_{\Lambda }(\omega ) = Z_{\Lambda }(\omega _{\partial \Lambda })\) turning \(\gamma _{\Lambda }(\cdot \mid \omega )\) into a probability measure on \((\Omega ,{\mathcal {F}})\). The assumptions \(Q>0\) and \(Q\in \ell ^{\frac{d+1}{2}}(S)\) guarantee that such a partition function does exist. See Lemma 1 in [15] (here the case \(S={\mathbb {Z}}^k\) is considered, but the proof immediately generalizes to the case of an arbitrary countable group S). The quantities \(Q({\tilde{\omega }}_x-{\tilde{\omega }}_y)\) and \(Q({\tilde{\omega }}_x-\omega _y)\) are well defined for \(\{x,y\}\in E\) because Q is assumed to be symmetric.
Remark 2.1
-
(a)
Note that if \({\tilde{Q}}=c\,Q\) for some \(c >0\), then the Markovian gradient specifications which are induced by Q and \({\tilde{Q}}\) coincide. We shall often find it useful to normalize Q by requiring \(Q(0)=1\).
-
(b)
The notion gradient refers to the fact that the specification \(\gamma \) is measurable with respect to the field of height increments (gradients). We will elaborate on the details in Sect. 4.1 below.
A Gibbs measure for a specification \(\gamma \) (a transfer operator Q, respectively) is by definition a probability measure \(\mu \) on \((\Omega ,{\mathcal {F}})\), such that for all \(\Lambda \Subset V\) and all \(A \in {\mathcal {F}}\) the Dobrushin–Lanford–Ruelle (DLR) equation
holds true.
We denote the (possibly empty) convex set of Gibbs measures on \((\Omega , {\mathcal {F}})\) for a specification \(\gamma \) by \({\mathcal {G}}(\gamma )\). If \({\mathcal {G}}(\gamma )\) is not empty, then each of its elements can be written in a unique way as a convex combination of extremal elements (see e.g. Thm. 7.26 in [14]). On the tree, each extremal Gibbs measure for a Markovian specification is a tree-indexed Markov chain (e.g. Thm. 12.6 in [14] for this statement in the case in which S is finite; the proof generalizes to countable local state spaces). Writing \(\text {ex} \,C\) for the set of extremal points of a convex set C and \(\mathcal{M}\mathcal{G}(\gamma )\) for the set of Gibbs measures for \(\gamma \) which are Markov chains, the above statement reads
A homogeneous Markov chain Gibbs measure \(\mu \) for a Markovian gradient specification \(\gamma \) induced by a transfer operator Q has the transition matrix
Here, the function \(u: S \rightarrow (0,\infty )\) is a boundary law, i.e., satisfying the fixed-point equation (5.1) that uniquely characterizes \(\mu \). For the understanding of our main result, Theorem 3.1 below, it is not necessary to know about boundary laws, hence we will give a brief introduction to boundary laws not earlier than in Sect. 5.1 below to prepare the proof of Theorem 3.1.
Remark 2.2
Assume that the transfer operator Q on the discrete Abelian group S is normalized by \(Q(0)=1\) and satisfies \(Q(i)<1\) for every \(i\in S\setminus \{0\}\). Then Q induces the translation invariant “distance function”
where the quotes refer to the fact that the function \(\textrm{dist}_Q(i,j)\) is symmetric, non-negative, zero if and only if \(i=j\), but in general does not satisfy the triangle inequality. It is a genuine distance function if Q satisfies the \(\log \)-superadditivity condition \(Q(i+j)\ge Q(i)Q(j)\). If we write \(Q=e^{-U}\), where U is a non-negative symmetric function on S vanishing only at zero, then this is equivalent to the subadditivity of U. This condition is indeed fulfilled by many models, including the SOS-model and the Log-model which are analysed in Appendix A below, while it is not satisfied, e.g., for the p-SOS model with potential \(U(i) = \vert i \vert ^p\) when \(p>1\).
3 Main Result
In this section, we present the main result of this paper regarding the existence of Markov-chain Gibbs measures on the regular Cayley d-tree with a countable Abelian group S as local state space. The Gibbs measures we find localize on an arbitrary finite subset of S. We also discuss some of its immediate implications and applications.
3.1 Existence of Gibbs Measures Localizing on Finite Sets
In order to formulate the main existence result, we need to introduce some functions of the order d of the Cayley tree and of the cardinality n of the subsets of S on which our Gibbs measure will localize. We denote by \(\rho =\rho (d,n)\) the unique positive number such that
and we set
Note that \(\rho \) belongs to the interval (0, 1), so \(\eta (d,n)\) is a positive number. We actually have the bounds \(\rho (d,n) < d^{-\frac{1}{d-1}}\) and
as shown in Lemma B.1 in Appendix B below. We can now state the main existence result of the paper:
Theorem 3.1
Let \(d\ge 2\) and \(N\ge 1\) be integers. Assume that the transfer operator \(Q\in \ell ^{\frac{d+1}{2}}(S)\) is normalized by \(Q(0)=1\) and satisfies the condition
Then for every \(A\subset S\) with \(1\le |A|\le N\) the Markovian gradient specification which is induced by Q on the regular d-tree with local state space S admits a spatially homogeneous Markov-chain Gibbs measure \(\mu \) such that, denoting by
the functions giving the single-site marginals of \(\mu \) and the diagonal elements of the transition matrix \(P_{\mu }\), we have:
Moreover, setting \(\epsilon := \Vert Q-\mathbbm {1}_{\{0\}}\Vert _{\frac{d+1}{2}}\) and \(n:=|A|\), the following estimates hold:
-
(i)
\(\Vert \Delta |_{A^c}\Vert _{\frac{d+1}{d-1}} \le c_1\, \epsilon ^{d-1}\), where \(c_1 = c_1(d,n) := \frac{\rho (d,n)^{d-1}}{\eta (d,n)^{d-1}}\).
-
(ii)
\({\min _A \Delta } > 1 - c_2\, \epsilon \), where \(c_2 = c_2(d,n) := (d^{\frac{d}{d-1}} - d)(1+n)^{\frac{d}{d+1}}\).
-
(iii)
\({\sum _{i\in A^c} \pi _{\mu }(i) } \le c_3\, \epsilon ^{d+1}\), where \(c_3 = c_3(d,n) := \frac{d^{\frac{d+1}{d-1}} \rho (d,n)^{d+1}}{n \, \eta (d,n)^{d+1}} \).
-
(iv)
\((1-c_5 \, \epsilon ) \frac{1}{|A|} \le \pi _{\mu }|_A \le (1-c_4 \, \epsilon )^{-1} \frac{1}{|A|}\), where \(c_4 = c_4(d,n) := \frac{d+1}{d-1} c_2(d,n)\) and \(c_5 = c_5(d,n) := c_4(d,n) + \frac{\rho (d,n)^{d+1}}{n \, \eta (d,n)^{d+1}}\).
-
(v)
\(\pi _{\mu }(i) \ge \frac{1}{|A|} (1-c_6 \,\epsilon ) \left( \sum _{j\in A} Q(i-j) \right) ^{d+1}\) for every \(i\in A^c\), where \(c_6=c_6(d,n):=d\, c_4(d,n) + \frac{\rho (d,n)^{d+1}}{n \, \eta (d,n)^{d+1}}\).
Some comments are in order. First of all notice that the Assumption (5) constrains the cardinality of A but involves neither the specific choice of the Abelian group S nor the way in which A sits in S. Thanks to (4), (5) implies that \(Q(i)<1\) for every \(i \in S\setminus \{0\}\).
Property (6) tells us that the spin values in A are preferred by the Gibbs measure \(\mu \): the probability that a given vertex is not in A is smaller than the probability that it is in the least likely of the spin values of A. The bounds (iii) and (iv) control how the probability distribution \(\pi _{\mu }\) giving us the single state marginals converges to the equidistribution on A as the \(\frac{d+1}{2}\)-norm of \(Q - \mathbbm {1}_{\{0\}}\) tends to zero.
Property (7) and its asymptotic Q-dependent refinements (i) and (ii) tell us that A is the “lazy” set of the Gibbs measure \(\mu \). Indeed, in the case \(d=2\) (7) says that if a vertex is in a state i belonging to the set A, then its neighbouring vertices will prefer to remain in i with probability larger than \(\frac{1}{2}\); otherwise, they will prefer to change their state with probability larger than \(\frac{1}{2}\). When the order d increases, the probability threshold has the smaller value \(\frac{1}{d}\): if the number \(d+1\) of vertices that influence the state at a given vertex gets larger, then a change of state becomes more probable for states in \(A^c\), but possibly also for those in A.
The asymptotic bounds (i) and (ii) moreover quantify how the “laziness” of A gets stronger and stronger as the \(\frac{d+1}{2}\)-norm of \(Q - \mathbbm {1}_{\{0\}}\) tends to zero. In the typical case of a function Q of the form (1), this corresponds to the low temperature asymptotic \(\beta \rightarrow +\infty \). Both the probability of changing state if i is not in A and the probability of keeping the same state for i in A tend to one.
Given any state i, the probability to go from i to some state in \(A^c\) along some edge also tends to zero as \(\epsilon := \Vert Q - \mathbbm {1}_{\{0\}} \Vert _{\frac{d+1}{2}}\) tends to zero. By (ii), this is clear for states i in A. For states i in \(A^c\) it can be shown as follows. Thanks to the formula
which is discussed in Remark 5.5 below, the Hölder inequality and the bound (iii) imply for each \(i \in S\)
where \(c_7:= c_3^{\frac{d}{d+1}}\). This already implies our claim for any fixed \(i\in S\). Together with the lower bound (v), for \(i\in A^c\) we obtain the further estimate
Recalling that \(\textrm{dist}_Q\) denotes the “distance function” discussed in Remark 2.2, we find
Therefore, (9) implies that for every \(i\in A^c\) we have the estimate
which tells us that as \(\epsilon \) tends to zero \(P_{\mu }(i,A^c)\) converges to zero uniformly for i in any subset of \(A^c\) whose elements have uniformly bounded distance from A.
A graphical illustration of the above discussion is given in Fig. 1.

The pictures show a part of the set \(S={\mathbb {Z}}\) with the bars in picture (i) marking the distribution of single-site marginals of the Gibbs measure \(\mu \) from Theorem 3.1. Here, the red coloured (dark, if you are looking at a black and white version of this picture) circles with long bars belong to \(A \Subset S\). If the chain is in a state in A, then it prefers to stay in this state, see (ii). On the other hand, being in a state which does not belong to A, the chain prefers jumps into states in A, with weights as indicated by the arrows in (iii). Under suitable decaying conditions on Q, (8) implies that shortest jumps are more likely (Color figure online)
Remark 3.2
For \(|A|=1\) and \(S={\mathbb {Z}}\), the existence of a Gibbs measure as in the above theorem has been proven in [15] under similar but not exactly equivalent assumptions on Q.
Remark 3.3
(Uniqueness) If \(|A|=1\) and \(\Vert Q-\mathbbm {1}_{\{0\}}\Vert _{\frac{d+1}{2}} \le \eta (d,1)\), then we can further show that the spatially homogeneous Markov-chain Gibbs measure \(\mu \) satisfying (7) is unique. See Remark 5.10 below. For larger sets A, we do not know whether the Gibbs measure \(\mu \) satisfying (7) is necessarily unique under the assumption \(\Vert Q-\mathbbm {1}_{\{0\}}\Vert _{\frac{d+1}{2}} \le \eta (d,|A|)\). By strengthening this assumption, we could get the following uniqueness statement: There exist positive numbers \(\eta '(d,n)\) and \(\delta (d,n)\) such that if A is a finite subset of S and \(\Vert Q- \mathbbm {1}_{\{0\}} \Vert _{\frac{d+1}{2}} \le \eta '(d,|A|)\) then the Markovian gradient specification which is induced by Q on the regular d-tree with local state space S has a unique spatially homogeneous Markov-chain Gibbs measure \(\mu \) whose single-site marginal probability distribution \(\pi _{\mu }\) satisfies
See Remark 5.9 below.
Remark 3.4
(Affine independence) Assuming that \(\Vert Q-\mathbbm {1}_{\{0\}}\Vert \le \eta (d,N)\) holds, the above theorem gives us a family of Gibbs measures \(\{\mu _A\}_{A\in {\mathcal {A}}_N}\), where \({\mathcal {A}}_N\) denotes the set of all subsets A of S with \(1\le |A|\le N\). Condition (7) implies that these measures are pairwise distinct. More is actually true: none of the measures in the above family is a convex combination of the other ones, so each \(\mu _A\) should be though as irreducible. Indeed, this is a direct consequence of the fact that a non-trivial convex combination of spatially homogeneous Markov-chain Gibbs measures is never a Markov-chain Gibbs measure. In the case of a finite local state space S, this follows from Corollary 12.18 in [14], but the proof directly generalizes to the case of a countably infinite state space, as all occurring sums are finite by the normalizability assumption on our boundary laws and all terms are strictly positive by the assumption of positivity of Q. In particular, we obtain that when S is an infinite Abelian group and \(\Vert Q-\mathbbm {1}_{\{0\}}\Vert \le \eta (d,2)\) holds, then the convex set of all Gibbs measures \({\mathcal {G}}(\gamma )\) of the Gibbs specification induced by Q is infinite dimensional also after modding out the action on it which is given by translations on S.
The proof of Theorem 3.1 is based on an existence result for positive solutions \(u\in \ell ^{\frac{d+1}{d}}(S)\) of the normalized boundary law equation
which are suitably concentrated near the finite subset A. Boundary laws are discussed in Sect. 5.1 and the proof of the existence result, which is based on a combined use of the contraction mapping theorem and Brouwer’s fixed point theorem, is discussed in Sect. 5.2 and Appendix B. How to derive Theorem 3.1 from this result is explained in Sect. 5.3.
The next two examples show how the Assumption (5) translates for some concrete models.
Example 3.5
(SOS model) Consider the case \(S={\mathbb {Z}}\) and \(Q(i)=e^{-\beta |i|}\), where \(\beta \) is a positive parameter modelling the inverse temperature. Assumption (5) is fulfilled whenever
where b is a suitable positive number. See Example A.1 in Appendix A for the computations leading to this and for more precise results. Note that for any fixed \(N\ge 1\) the lower threshold for \(\beta \) has size of the order \(\log N\) for \(d\rightarrow \infty \). When \(N=1\), this threshold converges to zero and is asymptotic to \(\frac{\log d}{d}\) for \(d\rightarrow \infty \).
Example 3.6
(Log potential) Consider the case \(S={\mathbb {Z}}\) and \(Q(i)=\frac{1}{(1+|i|)^{\beta }}\). One can check that (5) is fulfilled whenever
where b is a suitable positive number. See Example A.2 in Appendix A for details. Up to the multiplication by the factor \(\frac{1}{\log 2}\), the asymptotic of this threshold is analogous to the one we found in Example 3.5 for the SOS model.
4 An Application to the Existence of Delocalized Gradient Gibbs Measures
In this section, we show how Theorem 3.1 implies the existence of suitable gradient Gibbs measures with height-dimension \({\mathbb {Z}}\). The sets A which appear as a discrete parameter of the measures and which played the role of localization sets for the Gibbs measures of the previous section will now acquire a different role. Indeed, for the delocalized gradient Gibbs measures we discuss in this section, there is no invariant single-site probability distribution in which the height variables would localize. Instead, the sets A will govern the structure of most probable increments along the edges, in a way that we will describe now. We first review the necessary definitions.
4.1 Gradient Gibbs Measures
The notion of a gradient Gibbs measure for lattice models has been established in [11] and further exploited in [26]. In this subsection we present an adaption to the situation on the tree, which is based on [15, 22]. Consider the case \(S = {\mathbb {Z}}\), in which we interpret a spin configuration \(\omega \in \Omega \) as a height configuration and denote the local state space \({\mathbb {Z}}\) as the height-dimension of the model.
Define the gradient projection \(\nabla : \Omega \rightarrow {\mathbb {Z}}^{\vec {E}}; (\omega _x)_{x \in V} \mapsto (\omega _y-\omega _x)_{(x,y) \in \vec {E}}\). Then
is the set of all gradient configurations. For any oriented edge \(b=(x,y) \in \vec {E}\) let \(\eta _b: \Omega ^\nabla \rightarrow S,\, \eta _b(\zeta ):=\zeta _{b}\) denote the gradient spin projection along b. By construction, \(\eta _{(x,y)} \equiv -\eta _{(y,x)}\) whenever \((x,y) \in \vec {E}\). We endow \(\Omega ^\nabla \) with the product \(\sigma \)-algebra \({\mathcal {F}}^\nabla \) generated by all gradient spin projections, i.e., \({\mathcal {F}}^\nabla =\sigma (\eta _b \mid b \in \vec {E})\).
Let \(x_0 \in V\) be any fixed vertex. By connectedness of the tree and absence of cycles, prescription of any fixed height \(s \in {\mathbb {Z}}\) at \(x_0\) gives rise to a well-defined injective map
A gradient configuration on the tree can be thus considered as a relative height configuration where two height configurations are equivalent iff one is obtained from the other one by a joint height shift \(\theta _i(j):= j+i\). Hence we have the identification
Similar to the situation on the lattice [26], we may think of \({\mathcal {F}}^\nabla \) (or more precisely the \(\sigma \)-algebra on \(\Omega \) generated by \(\nabla \)) as the set of all events in \({\mathcal {F}}\) which are invariant under all joint height shifts \(\theta _i\).
To let the Markovian gradient specification \(\gamma \) for height configurations act on gradient configurations one has to consider that due to the absence of cycles on the tree the complement of any finite subtree \((\Lambda ,E_\Lambda )\) decomposes into disjoint subtrees. This means that
does not determine the relative heights at the boundary as an element of \({\mathbb {Z}}^{\partial \Lambda } /{\mathbb {Z}}\), i.e., up to a joint height shift at the boundary.
Thus, the appropriate outer gradient \(\sigma \)-algebra \({\mathcal {T}}^\nabla _\Lambda \) has to implement both the information on the gradient spin variables outside \(\Lambda \) and the information on the relative heights at the boundary. As the relative heights of the boundary are uniquely determined by the gradients inside \(\Lambda \cup \partial \Lambda \) (each two vertices at the boundary are connected by a unique path in \(\Lambda \cup \partial \Lambda \)), these relative heights at the boundary can be expressed in terms of an \({\mathcal {F}}^\nabla \) measurable function \([\cdot ]_{\partial \Lambda }: \Omega ^\nabla \rightarrow {\mathbb {Z}}^{\partial \Lambda } / {\mathbb {Z}}\). Hence
Definition 4.1
(Definition 2.3 in [22]) The gradient-\(\sigma \)-algebra outside \(\Lambda \) is defined as
With that framework given, let us now make precise in which way a Markovian gradient specification \(\gamma \) acts on the gradients.
Remark 4.2
(cp. Definition 2.4 in [22]) A Markovian gradient specification \(\gamma \) can be regarded as a stochastic kernel \((\gamma _\Lambda )_{\Lambda \Subset V}\) from \((\Omega ^\nabla , {\mathcal {T}}_\Lambda ^\nabla )\) to \((\Omega ^\nabla , {\mathcal {F}}^\nabla )\) by means of
for all bounded \({\mathcal {F}}^{\nabla }\)-measurable functions F, where \(\omega \in \Omega \) is any height configuration with \(\nabla \omega = \zeta \).
To ease readability, in the following we will write \(\gamma '\) instead of \(\gamma \) when we let the Markovian gradient specification \(\gamma \) act on the gradients. Also, we will use the notion gradient Gibbs specification to make precise that we let \(\gamma \) act on the gradients.
Finally, the DLR-equation for gradient measures on the tree reads:
Definition 4.3
(Definition 2.5 in [22]) A measure \(\eta \in {\mathcal {M}}_1(\Omega ^\nabla )\) is called a gradient Gibbs measure (GGM) if it satisfies the DLR equation
for every finite subtree \((\Lambda ,L_\Lambda )\) and for all bounded continuous functions F on \(\Omega ^\nabla \).
4.2 From Gibbs-Measures for Clock-Models to Integer-Valued Gradient Gibbs Measures
Consider the case \(S={\mathbb {Z}}\) and let \(q \ge 2\) be an integer. Assume that \(Q \in \ell ^1({\mathbb {Z}})\). Then
is a well defined function on the Abelian group \({\mathbb {Z}}_q:= {\mathbb {Z}}/q{\mathbb {Z}}\), which we think of as a “fuzzy” transfer operator on \({\mathbb {Z}}_q\). Then the Gibbsian specification \(\gamma ^q\) on \(({\mathbb {Z}}_q)^V\) associated with \(Q_q\) via (2) describes a clock model. As shown in [15, 16, 22], any Gibbs measure on \(({\mathbb {Z}}_q)^V\) for \(Q_q\) can be assigned an (integer-valued) gradient Gibbs measure on \(\Omega ^\nabla \). In this subsection we briefly summarize the construction as described in [16].
For any \({\bar{i}} \in {\mathbb {Z}}_q\) define a conditional distribution \(\rho _Q^q(\cdot \mid {\bar{i}})\) on \({\mathbb {Z}}\) equipped with the power set \({\mathcal {P}}({\mathbb {Z}})\) by
Then we can define a map \(T_Q^q: {\mathcal {M}}_1({\mathbb {Z}}_q^V, {\mathcal {P}}({\mathbb {Z}}_q)^{\otimes {V}}) \rightarrow {\mathcal {M}}_1(\Omega ^\nabla , {\mathcal {F}}^\nabla )\) from q-spin measures on vertices to integer-valued gradient measures in terms of the following two-step procedure:
where \(\Lambda \subset V\) is any finite connected set and \(w \in V\) is an arbitrary fixed vertex.
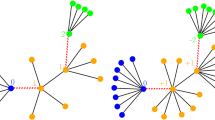
The assignment (14) describes a two-step procedure, where in the first step \({\mathbb {Z}}_q\)-valued configurations are drawn from \(\mu \) and in the second step integer-valued gradients are edge-wise independently sampled conditioned on the \({\mathbb {Z}}_q\)-valued increment along the respective edge. See also Fig. 2.
Then the following holds true without any assumption on spatial homogeneity:
Theorem 4.4
(Theorem 4.1 in [22], Theorem 2 in [16]) \(T^q_Q\) maps Gibbs measures on \({\mathbb {Z}}_q^V\) for the fuzzy specification \(\gamma ^q\) to gradient Gibbs measures on \(\Omega ^\nabla \) for the gradient Gibbs specification \(\gamma '\) (11).
The fact that Gibbs measures are mapped to gradient Gibbs measures as described in Theorem [18] is a rare example for the preservation of the quasilocal Gibbs property, as it occurs throughout the whole phase diagram. In general, local maps tend to destroy the Gibbs property in strong coupling regions, see e.g., [18, 28].

Construction of the measure \(T_Q^q(\mu ^q)\): In the first step, a \({\mathbb {Z}}_q\)-valued configuration \({\bar{\omega }}\) is drawn from \(\mu ^q\). Conditional on the \({\mathbb {Z}}_q\)-valued increment along the respective edge, the integer-valued gradient \(\eta \) is then distributed with respect to \(\rho _Q^q\) (13)
The map \(T_Q^q\) as defined in (14) has two important properties: First, as we will see below, any integer-valued gradient Gibbs measure \(\eta \in T_Q^q({\mathcal {G}}(\gamma ^q))\) is delocalized.
Second, for any gradient Gibbs measure \(\nu ^q\) which is given as the image of a homogeneous Markov-chain Gibbs measure \(\mu ^q\) on \({\mathbb {Z}}_q\) we can identify both the period q and the distribution of the underlying Markov chain \(\mu \) from \(\nu ^q\) up to certain symmetries. This motivates to call such a gradient Gibbs measure \(\nu ^q\) a delocalized gradient Gibbs measure of height-period q.
The general delocalization statement of Theorem 4.5 below directly follows from Proposition 1 in [16] for the specific case of \(\nu \) being constructed from a Markov-chain Gibbs measure in combination with extremal decomposition in \({\mathcal {G}}(\gamma ^q)\). It crucially employs the nature of \(\nu \) restricted to a branch of the tree being a random walk in a random environment. The less general identifiability result has already been proved in [15].
Theorem 4.5
Let \(q \ge 2\) be an integer. Then any \(\nu \) in \(T_Q^q({\mathcal {G}}(\gamma ^q)) \subset {\mathcal {G}}(\gamma ')\) delocalizes in the sense that \(\nu (W_n=k) {\mathop {\rightarrow }\limits ^{n \rightarrow \infty }} 0\) for any total increment \(W_n\) along a path of length n and any \(k \in {\mathbb {Z}}\).
Note that Theorem 4.5 holds without the assumption of homogeneity, while for the identifiability result below we have to restrict to homogeneous measures.
Theorem 4.6
(Theorem 5 and Corollary 1 in [15]) Let \(q\ge 2\) be an integer. Let \(\nu ^q \in T_Q^q({\mathcal {G}}(\gamma ^q))\) be such that \(\nu ^q=T_Q^q(\mu ^q)\) for some homogeneous Markov-chain Gibbs measure \(\mu ^q\) on \({\mathbb {Z}}_q^V\). Then the period q is uniquely determined by \(\nu \) up to integer-valued multiples. Moreover, the distribution of \(\mu ^q\) is uniquely determined by \(\nu ^q\) up to a joint height shift \(\theta _i\) on \({\mathbb {Z}}_q\).
Proof of Theorem 4.5
By Proposition 1 in [16], we already know that for any (not necessarily homogeneous) q-state Markov-chain Gibbs measure \(\mu ^q \in {\mathcal {G}}(\gamma ^q)\) the associated integer-valued gradient Gibbs measure \(T_Q^q(\mu ^q)\) delocalizes in the sense of \(T_Q^q(\mu ^q)(W_n=k) {\mathop {\rightarrow }\limits ^{n \rightarrow \infty }} 0\) for any fixed \(k \in {\mathbb {Z}}\).
Now let \(\mu \in {\mathcal {G}}(\gamma ^q)\) be any Gibbs measure on \(({\mathbb {Z}}_q)^V\). By extremal decomposition, we have a unique probability measure \(w_\mu \) on \((\text {ex}\,{\mathcal {G}}(\gamma ^q), \text {ev}\,\text {ex} \, {\mathcal {G}}(\gamma ^q))\), such that
Here, \(\text {ev}\,\text {ex} \, {\mathcal {G}}(\gamma )\) denotes the evaluation \(\sigma \)-algebra on \(\text {ex} \, {\mathcal {G}}(\gamma )\) generated by the evaluations of the form \(\pi _A: {\tilde{\mu }} \mapsto {\tilde{\mu }}(A)\), where \(A \in {\mathcal {P}}({\mathbb {Z}}_q)^{V}\) is a fixed event.
Recalling the definition of \(T_Q^q\) in (14), linearity of the integral gives
by Proposition 1 in [15] and dominated convergence (e.g., Corollary 6.26 in [19]) with integrable majorant \(g({\tilde{\mu }}) =1\). \(\square \)
4.3 Existence of Height-Periodic Gradient Gibbs Measures
The existence result for localized Gibbs measures of Theorem 3.1 above implies an existence criterion for an associated family of height-periodic gradient Gibbs measures:
Corollary 4.7
Consider the d-regular tree with \(d \ge 2\). Let the integer \(q \ge 2\) be a fixed height-period and let \(Q \in \ell ^1({\mathbb {Z}})\) be a spatially homogeneous positive transfer operator normalized by \(Q(0)=1\). Let \(N \in \{1, \ldots , q-1\}\) and assume that the normalized fuzzy transfer operator \(Q_q\) on \({\mathbb {Z}}_q\) satisfies
Then for every \(A\subset {\mathbb {Z}}_q\) with \(1\le |A|\le N\) there exists a spatially homogeneous q-periodic delocalized gradient Gibbs measure \(\nu ^q_A\) of the form
where \(\mu _A\) is the homogeneous Markov-chain Gibbs measure on \({\mathbb {Z}}_q\) with lazy set A given by Theorem 3.1.
Remark 4.8
The similar statement can be proved for the q-Potts model in zero external field by explicit computations, as they can be reduced to one-dimensional equations in that case. This relies on the very special property that in the Potts model we necessarily have
which follows from the boundary law equation using permutation symmetry, see [23]. This does not hold true anymore for more general clock models, and the equations become truly q-dimensional.
An illustration of the construction of such a gradient Gibbs measure \(\nu \) in the case \(q=5\) is given in Fig. 3.

The gradient Gibbs measure \({\nu _A^5}\) associated to the subset \(A:=\{0,1\} \subset {\mathbb {Z}}_5\): two main transitions of the fuzzy chain \(\mu \) with a lighter and a darker colour saturation and the distribution of single-site marginals \(\pi _{\mu }\) of \(\mu \) concentrated on \(\{0,1\}\). The lighter coloured jump from 4 to 1 of the chain \(\mu \) allows jumps of height \(-3+5{\mathbb {Z}}\) for \(\nu \), whose conditional distribution is according to \(\rho ^5_Q(\cdot \mid {\bar{2}})\) (see (13)). Three of these possible jumps are marked by the dashed black arrows
How do the period q and the concrete choice of the lazy set \(A \subset {\mathbb {Z}}_q\) affect the associated gradient Gibbs measure \(\nu _A^q\)? The answer lies in (the proof of) Theorem 4.6 above: Considering the sequence of empirical distributions of increments along a branch of the tree gives in particular the sequence of empirical distributions of increments of the homogeneous fuzzy chain \(\mu _A^q\). By the ergodic Theorem for Markov chains this sequence converges. The knowledge of the limit is equivalent to the knowledge of the stationary distribution on \({\mathbb {Z}}_q\) modulo cyclic shift, from which the set A can be read off. In particular, also the period q can be recovered. For more details, see also the proof of Corollary 1 in [16].
More can be said in the present case. Consider the joint empirical distribution along a branch of the tree \(x_1,x_2,\dots \) for fuzzy spin values and integer-valued increments of the form
which is a random measure on \({\mathbb {Z}}_q\times {\mathbb {Z}}\). It is important in the case of delocalized gradient Gibbs measures to consider fuzzy spins \({\bar{\sigma }}_{x_i}\) in the first entry, as the empirical measures for spins \(\sigma _{x_i}\) would not converge.
We claim that there is the \(\nu _A^q\)-a.s. convergence
Before we prove this statement, let us discuss what it tells us about the correlation structure of the gradient state. First note that jump probabilities of increment size c, for fixed mod q fuzzy classes \({\bar{a}},{\bar{c}}\) depend only on the multiplicative factor Q(c), which strongly suppresses large jumps. On the other hand, recall that by the concentration bounds of Theorem 3.1 the mod q fuzzy measure \(\pi _{\mu ^q_A}\) concentrates strongly on the set \(A\subset {\mathbb {Z}}_q\) where it equals up to small errors the equidistribution. So, (18) means that the delocalized measure \(\nu _A^q\) inherits a structure from the underlying measure \(\mu _A^q\), in which fuzzy jumps occur mostly from A to A, while arbitrarily large jumps in \({\mathbb {Z}}\) occur, but are suppressed and modulated via the summable Q. An example is discussed in Fig. 3.
Finally, to prove the a.s. convergence (18) for a fixed pair \(({{\bar{a}}}, c)\), denote by \({{\bar{c}}}\) for the mod-q class of c and use the hidden Markov model structure (14) of the gradient measure to write the l.h.s. of (18) in the product form
where \(\Lambda _n({{\bar{a}}}, {{\bar{c}}})=\{1\le i \le n, ({{\bar{\sigma }}}_i, {{\bar{\sigma }}}_{i+1}-{{\bar{\sigma }}}_i)=({{\bar{a}}},{{\bar{c}}})\}\). Here the variables \(Y_i(c)\) are independent Bernoulli with success probability \(\rho _Q^q(c \mid {\bar{c}})=Q(c)/Q^q({{\bar{c}}})\).
By the Birkhoff a.s. ergodic theorem applied to the first factor in (19) which we recognize as the pair empirical distribution of the irreducible hidden Markov chain \(\mu _A^q\), there is a set of full measure for \(\mu _A^q\) (and hence for \(\nu _A^q\)) such that the first term in the product converges to its expectation. On this full measure set, in particular \(|\Lambda _n({{\bar{a}}}, {{\bar{c}}})|\uparrow \infty \) by positivity of \(Q^q\), and conditionally on that we can apply the SLLN for the independent variables \(Y_j(c)\) to see that also the second term converges to its expectation \(\frac{Q(c)}{Q^q({\bar{c}})}\). Plugging in these expectations the claimed a.s. limit of (18) follows.
As suggested by a referee, besides the considerations on the empirical distributions, we also provide an expression similar to (18) to describe the covariance between two gradient spin variables \(\eta _{(x,y)}\) and \(\eta _{(u,v)}\) at disjoint edges (x, y) and (u, v). We will restrict to the case where (x, y) and (u, v) point in the opposite direction in that \(n+1=d(x,v)=d(x,u)+1\), where the other case can be treated similarly. Note that by construction the measure \(\nu ^q_A\) has a zero tilt, i.e., \(\nu (\eta _{(x,y)})=0=\nu (\eta _{(u,v)})\). Let \(({\bar{\sigma }}_w)_{w \in V}\) denote the \({\mathbb {Z}}_q\)-valued spin variables of the internal fuzzy Markov chain \(\mu _A\) with transition matrix \(P_\mu \). Then conditioning on the spin value at site x gives:
This shows explicitly how the localization property of the single-site marginal, and the exponential decorrelation of the fuzzy chain along a branch, enter into the correlation structure of the full gradients.
5 Proof of Theorem 3.1
5.1 Boundary Laws and Gibbs Measures
As established in [30], tree-indexed Markov-chain Gibbs measures for nearest-neighbour interactions and a countable local state space can be described in terms of the solutions to a recursive system of boundary law equations on the tree. In this subsection, we briefly outline this formalism for the specific case of spatially homogeneous Gibbs measures for gradient interactions on the d-regular tree.
Definition 5.1
A spatially homogeneous boundary law for a transfer operator Q is a positive function \(u\in \ell ^{\frac{d+1}{d}}(S)\) such that
for some \(c>0\).
Remark 5.2
If (u, c) is a solution of (20) and a is any positive number, then \(v:=au\) satisfies
with \(c'=a^{1-d}c\), and hence v is also a boundary law. Boundary laws differing by a multiplicative constant are considered to be equivalent. By multiplying u by a suitable constant, we can always assume that \(c=1\) in (20).
Now, the relation between boundary laws and tree-indexed Markov chains reads:
Theorem 5.3
(See Theorem 3.2 in [30]) Let Q be a transfer operator. Then for the Markov specification \(\gamma \) associated to Q we have:
-
(i)
Each spatially homogeneous boundary law u for Q defines a unique spatially homogeneous tree-indexed Markov-chain Gibbs measure \(\mu \in \mathcal{M}\mathcal{G}(\gamma )\) with marginals
$$\begin{aligned} \mu (\sigma _{\Lambda \cup \partial \Lambda }=\omega ) = \frac{1}{Z_\Lambda } \prod _{y \in \partial \Lambda } u (\omega _y) \prod _{\begin{array}{c} {\{x,y\} \in L}\\ {\{x,y\} \cap \Lambda \ne \emptyset } \end{array}} Q(\omega _y-\omega _x), \end{aligned}$$(21)for any connected set \(\Lambda \Subset V\) and \(\omega \in S^{\Lambda \cup \partial \Lambda }\), where \(Z_{\Lambda }\) is the normalization constant which turns \(\mu \) into a probability measure.
-
(ii)
Conversely, every spatially homogeneous tree-indexed Markov-chain Gibbs measure \(\mu \in \mathcal{M}\mathcal{G}(\gamma )\) admits a representation of the form (21) in terms of a spatially homogeneous boundary law u which is unique up to a constant positive factor.
We note that the boundary law equation guarantees that (21) describes a projective family of finite-volume marginals, whereas the summability condition \(u\in \ell ^{\frac{d+1}{d}}(S)\) gives us the finiteness of these finite-volume marginals.
From (21) and (20), we can easily determine the single-site marginals and the transition matrices of the spatially homogeneous Gibbs measure that is determined by a boundary law:
Proposition 5.4
Let u be a spatially homogeneous boundary law for the transfer operator Q and let \(\mu \) be the corresponding spatially homogeneous tree-indexed Markov-chain Gibbs measure. Then
for every \(i,j\in S\).
Remark 5.5
From the identities of Proposition 5.4 we deduce the formula
which we used in (8).
5.2 Existence of Solutions of the Boundary Law Equation
Let \(d\ge 2\) be a positive integer and \(Q\in \ell ^{\frac{d+1}{2}}(S)\) be a positive function, which we normalize by assuming that \(Q(0)=1\). In this section, we wish to discuss the existence of positive solutions \(u\in \ell ^{\frac{d+1}{d}}(S)\) of the normalized boundary law equation
More precisely, given a finite subset \(A\subset S\) we wish to find a solution \(u\in \ell ^{\frac{d+1}{d}}(S)\) close to \(\mathbbm {1}_A\) provided that \(\Vert Q-\mathbbm {1}_{\{0\}} \Vert _{\frac{d+1}{2}}\) is small enough. The existence and uniqueness of such a solution could be deduced from the implicit mapping theorem starting from the fact that for \(Q=\mathbbm {1}_{\{0\}}\) the function \(u=\mathbbm {1}_A\) is indeed a solution. See Remark 5.9 below for more details. However, a naive application of this argument would require a very strong smallness assumption on \(Q-\mathbbm {1}_{\{0\}}\) and would not give the precise information on \(u-\mathbbm {1}_A\) that we need for proving Theorem 3.1. In order to obtain a better quantitative result we argue as follows.
First, it is convenient to set \(u=x^d\) and rewrite the Eq. (22) as
where x is a positive element of \(\ell ^{d+1}(S)\). We split Q as
and rewrite (23) as
The reformulation (24) shows that every positive solution x takes values in the interval (0, 1).
We fix a finite subset \(A\subset S\) and look for solutions \(x\in \ell ^{d+1}(S)\) of (24) which are close to 1 on A and close to 0 on its complement \(A^c\). More precisely, we denote by
the point at which the function
achieves its maximum and look for solutions \(x\in \ell ^{d+1}(S)\) of (24) such that
Our strategy for finding a solution of (24) satisfying (26) will be to split the fixed point equation (23) into two coupled fixed point equations for functions on \(A^c\) and on A. The first fixed point equation will have a unique solution by the contraction mapping theorem, whereas the fixed point of the second equation will be found by the Brouwer fixed point theorem, using the fact that A is a finite set. A drawback of this strategy is that in the latter step we do not get uniqueness, but the advantage will be that the smallness assumption for q will be rather weak.
In order to describe this assumption, recall that in Sect. 3.1 we defined \(\rho =\rho (d,n)\) to be the unique positive number such that
and \(\eta =\eta (d,n)\in (0,1)\) to be the number
Here is our existence result for solutions of (23) satisfying the conditions (26).
Proposition 5.6
Let \(Q\in \ell ^{\frac{d+1}{2}}(S)\) be a positive function with \(Q(0)=1\) and set \(q := Q - \mathbbm {1}_{\{0\}}\). Assume that
for some integers \(d\ge 2\) and \(n\ge 1\). Then for every subset \(A\subset S\) with \(|A|=n\) there exists a positive function \({\overline{x}} \in \ell ^{d+1}(S)\) such that
Moreover:
-
(i)
\(\Vert {\overline{x}}|_{A^c}\Vert _{d+1} \le \frac{\rho (d,n)}{\eta (d,n)} \Vert q\Vert _{\frac{d+1}{2}}\);
-
(ii)
\(0< 1 - {\overline{x}}|_A \le \frac{d^{\frac{d}{d-1}}-d}{d-1} (1+n)^{\frac{d}{d+1}} \Vert q\Vert _{\frac{d+1}{2}}\).
-
(iii)
\({\overline{x}}(i) \ge (1- \frac{d}{d-1} (d^{\frac{d}{d-1}}-d) (1+n)^{\frac{d}{d+1}} \epsilon ) \sum _{j\in A} Q(i-j)\) for every \(i\in A^c\).
Proof
Given functions \(x_0:A^c \rightarrow {\mathbb {R}}\) and \(x_1: A \rightarrow {\mathbb {R}}\), we denote by
the function mapping \(i\in A^c\) to \(x_0(i)\) and \(i\in A\) to \(x_1(i)\). We start by fixing an arbitrary \(x_1\in [\lambda _d,1]^A\) and look for functions x of the form \(x=x_0\sqcup x_1\) which solve (23) on \(A^c\), i.e.
Equivalently, we are looking for the fixed points of the map
which is well defined because of the Young inequality
Given \(r>0\), set
We now check which condition on r guarantees that \(F_{x_1}\) maps \(X_r\) to itself. If \(x_0\) is in \(X_r\) then \(F_{x_1}(x_0)\ge 0\) and using again the Young inequality we find
where we have also used the inequality \(|x_1|\le 1\) and the following consequence of the monotonicity of the \(\ell ^p\) norms: \(\Vert x_0\Vert _{d(d+1)} \le \Vert x_0\Vert _{d+1}\). Therefore, \(F_{x_1}\) maps \(X_r\) to itself provided that
This condition can be equivalently rewritten as
where \(f_{d,n}:[0,+\infty ) \rightarrow {\mathbb {R}}\) is the function
Next note that
where \(0_{A^c}\) denote the zero function on \(A^c\). The map \(F_0\) is the composition of the maps
and
By the mean value theorem, the first map has Lipschitz constant \(dr^{d-1}\) on the r-ball of \(\ell ^{d+1}(A^c)\). The second map is linear with operator norm not exceeding
Therefore, the restriction of the map \(F_{x_1}\) to \(X_r\) is a contraction if r satisfies (32) and
This condition forces r to belong to the interval \((0,\lambda _d)\) and can be equivalently rewritten as
where \(g_d: (0,\lambda _d] \rightarrow {\mathbb {R}}\) is the function
The next lemma describes some useful properties of the functions \(f_{d,n}\) and \(g_d\). See also Fig. 4 for an illustration.

An illustration of the set-up and statement of Lemma 5.7: Plot (a) shows the graphs of the functions \(f_{d,n}\) and \(g_d\) in the case \(d=n=2\), i.e., \(\lambda _2=0.5\). Plot (b) is a zoomed-in version of plot (a), in which the graph of \(f_{2,2}\) is supplemented with two marks. The left (triangular shaped) mark indicates the unique maximum of \(f_{2,2}\), obtained at \(\rho \approx 0.473\). Hence, \(\eta (2,2)=f_{2,2}(\rho ) \approx 0.152\). The right (star shaped) mark is at the unique point of intersection of the two graphs, which happens at \(r_* \approx 0.481\). We see that the number \(\rho \), where \(f_{2,2}\) achieves its maximum, is smaller than the number \(r_*\) at which \(f_{2,2}\) and \(g_2\) coincide
Lemma 5.7
Let \(\rho =\rho (d,n)\) be the unique positive solution of the Eq. (27). Then \(\rho \) belongs to the interval \((0,\lambda _d)\) (see (25)). The function \(f_{d,n}\) defined in (33) is strictly increasing on the interval \([0,\rho ]\), strictly decreasing on \([\rho ,+\infty )\) and strictly concave on [0, 1]. Its maximum is the number
which is introduced in (28). The function \(g_d\), defined in (36), is strictly decreasing on \((0,\lambda _d]\) and there exists a number \(r_* \in (\rho ,\lambda _d)\) such that
The proof of this Lemma is elementary but rather delicate. The interested reader can find the details in Appendix B. We now proceed with the proof of Proposition 5.6. By the above lemma and our Assumption (29), we can find a number \(r_q\in [0,\rho ]\) such that
Then the equality holds in (32) with \(r=r_q\) and hence \(F_{x_1}\) maps \(X_{r_q}\) to itself. Since \(r_q\) belongs to \([0,\rho ]\), the above lemma implies that
so \(r=r_q\) satisfies (35). We conclude that \(F_{x_1}\) is a contraction on \(X_{r_q}\) and hence has a unique fixed point \(\xi _0(x_1)\) in \(X_{r_q}\). In particular, we have
so \(x_0=\xi _0(x_1)\) takes values in \([0,\rho (d,n))\) and is a solution of (31).
Note that by (34)
where the map \(\textrm{id} - F_0\) is a homeomorphism from \(X_{r_q}\) to its image thanks to the fact that \(F_0\) has Lipschitz constant less than 1 on \(X_{r_q}\). From the above identity we deduce that the map
is continuous.
Let \(x_1\in [\lambda _d,1]^A\). The function \(x=\xi _0(x_1)\sqcup x_1\) is a solution of (23) if and only if \(x_1\) satisfies the equation
which can be rewritten as
We set
and claim that
for every \(x_1\in [\lambda _d,1]^A\). The first inequality is clear. In order to prove the second one, we use the upper bound
By the bound \(\Vert q\Vert _{d+1}\le \Vert q\Vert _{\frac{d+1}{2}}\) and our choice of \(r_q\) we have
as claimed in (40). Thanks to (40), we can rewrite (38) as
where \(\psi : [0,\mu _d] \rightarrow [\lambda _d,1]\) is the inverse of the restriction of \(\varphi _d\) to the interval \([\lambda _d,1]\), on which \(\varphi _d\) is strictly decreasing. Therefore, \(x_1\in [\lambda _d,1]^A\) satisfies (37) if and only if it is a fixed point of the continuous map
By Brouwer’s fixed point theorem, G has a fixed point \({\overline{x}}_1\) on the n-dimensional cube \([\lambda _d,1]^A\). Setting \({\overline{x}}_0:= \xi _0({\overline{x}}_1)\), we obtain that \({\overline{x}}:= {\overline{x}}_0\sqcup {\overline{x}}_1\) is a positive solution of (23) and as such takes values in (0, 1).
By the strict upper bound in (40) and by the properties of \(\psi \), we have \({\overline{x}}_1 > \lambda _d\). Since \({\overline{x}}_0\) belongs to \(X_{r_q}\) with \(r_q< \rho (d,n)\), we have
We conclude that \({\overline{x}}\in \ell ^{d+1}(S)\) is a positive solution of (30).
There remains to prove the bounds (i), (ii) and (iii). By construction,
Since \(f_{d,n}\) is strictly increasing and concave on \([0,\rho ]\), its restriction to \([0,\rho ]\) has an inverse which is strictly increasing and convex on \([0,\eta (d,n)]\). The convexity of this inverse implies the inequality
so (i) follows from (43).
Since the restriction of \(\varphi _d\) to \([\lambda _d,1]\) is strictly decreasing and concave, its inverse \(\psi _d\) is strictly decreasing and concave on \([0,\mu _d]\). The concavity of \(\psi _d\) implies
By the first inequality in (41), we have
Together with the fact that \(\psi _d\) is decreasing and satisfies the concavity inequality (44), the above upper bound implies
proving (ii).
The map \(F_{{\overline{x}}_1}\) is monotonically increasing on the subset of non-negative functions in \(\ell ^{d+1}(A^c)\), with respect to the standard partial order of functions. Since the fixed point \({\overline{x}}_0\) of \(F_{{\overline{x}}_1}\) satisfies \({\overline{x}}_0\ge 0\), we have
By evaluating at \(i\in A^c\) and using (ii), we obtain the lower bound
where in the last step we have used the Bernoulli inequality \((1+x)^d\ge 1 + dx\) for every \(x\ge -1\) and \(d\ge 1\). This proves (iii) and concludes the proof of Proposition 5.6. \(\square \)
Remark 5.8
(Uniqueness for \(|A|=1\)) Consider the standard partial order on the space of real valued functions. It is easy to show that the map \(G:[\lambda _d,1]^A \rightarrow [\lambda _d,1]^A\) is monotonically decreasing. Indeed, the fact that the map \((x_0,x_1) \mapsto F_{x_1}(x_0)\) is monotonically increasing implies that if \(x_1\le x_1'\) then \(F_{x_1}^n(x_0) \le F_{x_1'}^n(x_0)\) for every \(n\in {\mathbb {N}}\) and every \(x_0\). Taking the limit in n, we deduce that the map \(\xi _0\) which associates to every \(x_1\in [\lambda _d,1]^A\) the unique fixed point of \(F_{x_1}\) is also monotonically increasing, and so is the map \(x_1 \mapsto (q*(\xi _0(x_1) \sqcup x_1^d))|_A \in [0,\mu _d]^A\). From the fact that the function \(\psi _d\) is montonically decreasing on \([0,\mu _d]\), we deduce that G is monotonically decreasing, as claimed. When \(|A|=1\), this implies that G has a unique fixed point . In this case, the solution \({\overline{x}}\) of (30) is unique.
Remark 5.9
(Uniqueness for \(|A|>1\)) If \(n=|A|>1\), we do not know whether the solution of (30) is unique under the assumption \(\Vert q\Vert _{\frac{d+1}{2}} \le \eta (d,n)\). By assuming a stronger smallness assumption on \(\Vert q\Vert _{\frac{d+1}{2}}\), we surely have existence and uniqueness of a solution \(x\in \ell ^{d+1}(S)\) of the equation \(x=Q*x^d\) which is sufficiently close to \(\mathbbm {1}_A\) in the \((d+1)\)-norm. This follows from the implicit mapping theorem applied to the continuously differentiable map
Indeed, \(H(\mathbbm {1}_{\{0\}}, \mathbbm {1}_A) = 0\) and the differential of H with respect to the second variable at \((\mathbbm {1}_{\{0\}}, \mathbbm {1}_A)\) is the linear operator
which is an isomorphism on \(\ell ^{d+1}(S)\) because \(d\ne 1\). From Theorem 5.3 and the first identity in Proposition 5.4, we then deduce that there exists positive numbers \(\eta '(d,n)\) and \(\delta (d,n)\) such that if \(\Vert q\Vert _{\frac{d+1}{2}} \le \eta '(d,n)\) and \(A\subset S\) has n elements, then the Markovian gradient specification which is induced by Q on the regular d-tree with local state space S has a unique spatially homogeneous Markov-chain Gibbs measure \(\mu \) whose single-site marginal probability distribution \(\pi _{\mu }\) satisfies
as claimed in Remark 3.2. The bounds \(\eta '\) and \(\delta \) which one gets from standard quantitative versions of the implicit function theorem are much worse than the ones appearing in Theorem 3.1. In order to obtain better bounds, one can look for a solution \(x\in \ell ^{d+1}(S)\) of the equation \(x=Q*x^d\) which is close to \(\mathbbm {1}_A\) by considering the fixed point of the map
which can be shown to be a contraction on a suitable closed subset of \(\ell ^{d+1}(A^c) \times \ell ^{\infty }(A)\) if \(\Vert q\Vert _{\frac{d+1}{2}}\) is small enough. In this way, one gets an existence and uniqueness statement as above but with bounds which are not too much worse than those in Theorem 3.1.
5.3 Proof of Theorem 3.1
Building on Theorem 5.3 and Proposition 5.4, we now show how Theorem 3.1 follows from Proposition 5.6. We assume that
and we fix a subset A with \(1\le n:=|A| \le N\). Let \({\overline{x}}\in \ell ^{d+1}(S)\) be a solution of (30), whose existence is guaranteed by Proposition 5.6. Let \( u = {\overline{x}}^d \in \ell ^{\frac{d+1}{d}}(S)\) be the corresponding solution of the boundary law equation (20) with \(c=1\). By Theorem 5.3 and Proposition 5.4, the boundary law u induces a spatially homogeneous Markov-chain Gibbs measure \(\mu \in \mathcal{M}\mathcal{G}(\gamma )\) whose single-site marginal distribution \(\pi _{\mu }\) and transition matrix \(P_{\mu }\) are given by
From the identities \(u={\overline{x}}^d\) and \({\overline{x}} = Q * {\overline{x}}^d\), we find
Then (30) implies, setting \(\theta := \theta (d,n) := (\frac{\rho (d,n)}{\lambda _d})^{d+1}\),
proving (6) in Theorem 3.1. By (45), the diagonal elements \(\Delta (i)=P_{\mu }(i,i)\) of the transition matrix are given by
The bounds
from (30) translate into
Remark 5.10
As shown in Remark 5.8, if \(|A|=1\) then the solution \({\overline{x}}\in \ell ^{d+1}(S)\) of (30) is unique. Together with the uniqueness of the boundary law which is determined by a Gibbs measure (see again Theorem 5.3), this implies that in the case \(|A|=1\) the above \(\mu \) is the unique spatially homogeneous Markov-chain Gibbs measure \(\mu \) whose transition matrix \(P_{\mu }\) satisfies (7).
In the following proof of statements (i)–(v) of Theorem 3.1, we use the abbreviations
By statement (i) in Proposition 5.6 we have
proving assertion (i) in Theorem 3.1. By statement (ii) in Proposition 5.6 we have, using the Bernoulli inequality,
which proves statement (ii) in Theorem 3.1.
There remains to prove the bounds (iii), (iv) and (v) on the single-site marginal distribution \(\pi _{\mu }\). By (46), the \((d+1)\)-norm of \({\overline{x}}\) has the lower bound
By statement (i) in Proposition 5.6 we have
which proves assertion (iii) in Theorem 3.1. From statement (ii) in Proposition 5.6 we obtain, using the Bernoulli inequality,
and hence
which proves the right-hand side inequality in statement (iv) of Theorem 3.1. On the other hand, using statement (i) in Proposition 5.6 we have
and hence, using also the inequality \(\epsilon \le \eta (d,N) \le 1\) (see (62)),
Using again statement (ii) in Proposition 5.6 and the Bernoulli inequality we obtain
This proves the left-hand inequality in statement (iv) of Theorem 3.1. By (47), statement (iii) in Proposition 5.6 and a last application of the Bernoulli inequality, we obtain for every \(i\in A^c\) the lower bound
This proves statement (v) of Theorem 3.1 and concludes the proof of Theorem 3.1.
References
Akin, H., Rozikov, U.A., Temir, S.: A new set of limiting Gibbs measures for the Ising model on a Cayley tree. J. Stat. Phys. 142(2), 314–321 (2011). https://doi.org/10.1007/s10955-010-0106-6
Bauerschmidt, R., Park, J., Rodriguez, P.-F.: The discrete Gaussian model, II. Infinite-volume scaling limit at high temperature. Preprint. arXiv:2202.02287 (2022)
Bauerschmidt, R., Park, J., Rodriguez, P.-F.: The discrete Gaussian model, I. Renormalization group flow at high temperature. Preprint. arXiv:2202.02286 (2022)
Bovier, A., Külske, C.: A rigorous renormalization group method for interfaces in random media. Rev. Math. Phys. 6(3), 413–496 (1994). https://doi.org/10.1142/S0129055X94000171
Caputo, P., Lubetzky, E., Martinelli, F., Sly, A., Toninelli, F.L.: Dynamics of \((2+1)\)-dimensional SOS surfaces above a wall: slow mixing induced by entropic repulsion. Ann. Probab. 42(4), 1516–1589 (2014)
Coquille, L., Külske, C., Le Ny, A.: Extremal inhomogeneous Gibbs states for SOS-models and finite-spin models on trees. J. Stat. Phys. 190(4), Paper No. 71, 26 (2023). ISSN: 0022-4715,1572-9613. https://doi.org/10.1007/s10955-023-03081-y
Cotar, C., Külske, C.: Uniqueness of gradient Gibbs measures with disorder. Probab. Theory Relat. Fields 162(3), 587–635 (2015). https://doi.org/10.1007/s00440-014-0580-x
Cotar, C., Deuschel, J.-D., Müller, S.: Strict convexity of the free energy for a class of non-convex gradient models. Commun. Math. Phys. 286(1), 359–376 (2009)
Dario, P., Harel, M., Peled, R.: Random-field random surfaces. Probab. Theory Relat. Fields 186(1–2), 91–158 (2023). ISSN: 0178-8051,1432-2064. https://doi.org/10.1007/s00440-022-01179-0
Deuschel, J.-D., Giacomin, G., Ioffe, D.: Large deviations and concentration properties for \(\nabla \phi \) interface models. Probab. Theory Relat. Fields 117(1), 49–111 (2000). https://doi.org/10.1007/s004400050266
Funaki, T., Spohn, H.: Motion by mean curvature from the Ginzburg-Landau interface model. Commun. Math. Phys. 185(1), 1–36 (1997). https://doi.org/10.1007/s002200050080
Gandolfo, D., Ruiz, J., Shlosman, S.: A manifold of pure Gibbs states of the Ising model on a Cayley tree. J. Stat. Phys. 148(6), 999–1005 (2012). https://doi.org/10.1007/s10955-012-0574-y
Gandolfo, D., Maes, C., Ruiz, J., Shlosman, S.: Glassy states: the free Ising model on a tree. J. Stat. Phys. 180(1–6), 227–237 (2020)
Georgii, H.-O.: Gibbs Measures and Phase Transitions (de Gruyter Studies in Mathematics), 2nd edn., vol. 9, pp. xiv+545. Walter de Gruyter & Co., Berlin (2011). https://doi.org/10.1515/9783110250329
Henning, F., Külske, C.: Coexistence of localized Gibbs measures and delocalized gradient Gibbs measures on trees. Ann. Appl. Probab. 31(5), 2284–2310 (2021)
Henning, F., Külske, C.: Existence of gradient Gibbs measures on regular trees which are not translation invariant. Ann. Appl. Probab. 33(4), 3010–3038 (2023). ISSN: 1050-5164,2168-8737. https://doi.org/10.1214/22-aap1883
Henning, F., Külske, C., Le Ny, A., Rozikov, U.A.: Gradient Gibbs measures for the SOS-model with countable values on a Cayley tree. Electron. J. Probab. 24 (2019). https://doi.org/10.1214/19-EJP364
Henning, F., Kraaij, R.C., Külske, C.: Gibbs-non-Gibbs transitions in the fuzzy Potts model with a Kac-type interaction: closing the Ising gap. Bernoulli 25(3), 2051–2074 (2019)
Klenke, A.: Probability theory (Universitext), 2nd edn., pp. xii+638. Springer, London (2014). https://doi.org/10.1007/978-1-4471-5361-0
Kotecký, R., Luckhaus, S.: Nonlinear elastic free energies and gradient Young-Gibbs measures. Commun. Math. Phys. 326(3), 887–917 (2014)
Külske, C., Rozikov, U.A.: Fuzzy transformations and extremality of Gibbs measures for the Potts model on a Cayley tree. Random Struct. Algorithms 50(4), 636–678 (2017). ISSN: 1042-9832. https://doi.org/10.1002/rsa.20671
Külske, C., Schriever, P.: Gradient Gibbs measures and fuzzy transformations on trees. Markov Process. Relat. Fields 23(4), 553–590 (2017). [Online]. https://www.ruhr-uni-bochum.de/imperia/md/content/mathematik/kuelske/grad-gibbs-fuzzy-transf-tree.pdf
Külske, C., Rozikov, U.A., Khakimov, R.M.: Description of the translation-invariant splitting Gibbs measures for the Potts model on a Cayley tree. J. Stat. Phys. 156(1), 189–200 (2014). https://doi.org/10.1007/s10955-014-0986-y
Lammers, P., Ott, S.: Delocalization and absolute-value-FKG in the solid-on-solid model. Probab. Theory Relat. Fields (2023). https://doi.org/10.1007/s00440-023-01202-y
Lammers, P., Toninelli, F.: Height function localisation on trees. Comb. Probab. Comput. (2023). https://doi.org/10.1017/S0963548323000329
Sheffield, S.: Random Surfaces (Astérisque 304). Société mathématique de France (2005). http://www.numdam.org/item/AST_2005__304__R1_0
van Enter, A.C.D., Külske, C.: Nonexistence of random gradient Gibbs measures in continuous interface models in d = 2. Ann. Appl. Probab. 18(1), 109–119 (2008). https://doi.org/10.1214/07-AAP446
van Enter, A., Fernández, R., den Hollander, F., Redig, F.: Possible loss and recovery of Gibbsianness during the stochastic evolution of Gibbs measures. Commun. Math. Phys. 226, 101–130 (2002). https://doi.org/10.1007/s002200200605
Velenik, Y.: Localization and delocalization of random interfaces. Probab. Surv. 3, 112–169 (2006). https://doi.org/10.1214/154957806000000050
Zachary, S.: Countable state space Markov random fields and Markov chains on trees. Ann. Probab. 11(4), 894–903 (1983). https://doi.org/10.1214/aop/1176993439
Acknowledgements
We thank the anonymous referees for insightful comments and suggestions.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Communicated by Cristina Toninelli.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix: Examples
In this Appendix, we study how the Assumption (5) of Theorem 3.1 translates for the concrete models of Examples 3.5 and 3.6. In the study of these models, we shall make use of the fact that the function \(\eta \) which is defined at the beginning of Sect. 3.1 satisfies the bounds
for suitable positive numbers \(\underline{c}\) and \({\overline{c}}\), as proven in Lemma B.1 in Appendix B.
Example A.1
(SOS model) Consider the case \(S={\mathbb {Z}}\) and \(Q(i)=e^{-\beta |i|}\), where \(\beta \) is a positive parameter modelling the inverse temperature. Then
and the Assumption (5) reads
Table 1 lists some approximate values of the threshold \(\underline{\beta }\).
The asymptotic behaviour of this threshold for d and/or n tending to infinity can be determined as follows. By (48), \(\underline{\beta }\) has the bounds
By the inequalities
we obtain the bounds
and hence
for suitable positive numbers a and b.
Example A.2
(Log potential) Consider the case \(S={\mathbb {Z}}\) and \(Q(i)=\frac{1}{(1+|i|)^{\beta }}\). Then
where \(\zeta \) denotes the Riemann zeta function. The Assumption (5) now becomes
where \(\zeta ^{-1}:(1,+\infty ) \rightarrow (1,+\infty )\) denotes the inverse of the restriction of the Riemann zeta function to the interval \((1,+\infty )\), on which this function is strictly monotonically decreasing with image \((1,+\infty )\). Table 2 lists some approximate values of the threshold \(\underline{\beta }\).
We now determine the asymptotics of \(\underline{\beta }(d,n)\) for d and/or n tending to infinity. On the interval \((1,+\infty )\), the Riemann zeta functions satisfies the bounds
If \({\overline{s}}\) is the unique number in \((1,+\infty )\) such that \(\zeta ({\overline{s}}) = \frac{3}{2}\), we have
where \(c:= 1 + \frac{2}{{\overline{s}}-1}\). From the lower bound in (50) we deduce the bound
Similarly, the upper bound (51) implies
By (49), (52) and (48) we find
for a suitable positive number a. Similarly, (49), (53), (48) and the bound \(\frac{1}{2} \eta (d,n)^{\frac{d+1}{2}}< \frac{1}{2}\) imply
for a suitable number \(b>0\). We conclude that the threshold \(\underline{\beta }\) satisfies the lower and upper bounds
for every \(d\ge 2\) and \(n\ge 1\).
Appendix: Proof of Lemma 5.7 and of the Bounds on \(\eta \)
For the sake of simplicity, we omit subindices and use the abbreviations \(f=f_{d,n}\), \(g=g_d\), \(\varphi =\varphi _d\), \(\lambda =\lambda _d\) throughout this section.
Proof of Lemma 5.7
The identity
shows that f is strictly increasing on the interval \([0,\rho ]\) and strictly decreasing on the interval \([\rho ,+\infty )\), where \(\rho =\rho (d,n)\) is the unique positive solution of (27). Since
is negative, the number \(\rho \) at which f achieves its global maximum belongs to the interval \((0,\lambda )\).
From the identity
and the Decartes rule of signs, we deduce that \(f''\) changes sign exactly once on \((0,+\infty )\), so the fact that the number
is negative implies that f is strictly concave on [0, 1].
The function g is positive on \((0,\lambda )\), where it strictly decreases from \(+\infty \) to \(g(\lambda )=0\). Since \(f(0)=0\) and \(f(\lambda )>0\), there exist solutions \(r_*\in (0,\lambda )\) of the equation \(f(r_*)=g(r_*)\). Since g is strictly convex on \((0,\lambda ]\) and f is strictly concave on this interval, the solution \(r_*\) is unique and we have
There remains to prove that \(r_*\) is larger than \(\rho \). Thanks to (54), it sufficies to find a number \(\sigma \in [\rho ,\lambda )\) such that \(f(\sigma )<g(\sigma )\).
We set \(\rho =\lambda (1-\theta )\), where \(\theta \) belongs to the interval (0, 1), and rewrite (27) as
From the Bernoulli inequality
we deduce the bound
which can be reformulated as
We conclude that \(\rho \le \sigma \) where
In the remaining part of the proof, we show that \(f(\sigma ) < g(\sigma )\). Using again the Bernoulli inequality we find
so it is enough to prove the inequality
We first deal with the case \(d=2\), in which \(\lambda \) and \(\sigma \) have the values
Since
(55) will be proven if we can show that
By raising both sides to the power 3, the above inequality is easily seen to be equivalent to
Since
(56) is implied by the inequality
which is indeed true for every \(n\ge 1\), being equivalent to
This proves (55) in the case \(d=2\). The case \(d\ge 3\) can be dealt with by starting from the weaker bound
By the above upper bound on \(f(\sigma )\), (55) holds true if we can prove the inequality
Using the identity \(\lambda =d^{-\frac{1}{d-1}}\) and the Bernoulli inequality, the right-hand side of (57) can be estimated in the following way:
Therefore, (57) is implied by
A simple algebraic manipulation shows that (58) is equivalent to
where
We shall prove that \(p_{d,n}(x)> 0\) for every \(x\ge 3\), \(d\ge 3\) and \(n\ge 1\), which implies (59) and by the above discussion (55) for every \(d\ge 3\). By the Decartes rule of signs, the polynomial \(p_{d,n}\) has precisely one positive real root \(\alpha \), and
Therefore, it is enough to prove
Using the inequalities \(n\ge 1\) and \(d\ge 3\), we find
From the fact that the sequence \(\lambda _d = d^{-\frac{1}{d-1}}\) is monotonically increasing and converges to 1 we deduce
Therefore, (61) implies
as we wished to prove. \(\square \)
We conclude this Appendix by proving the bounds (4) and (48) for the quantity \(\eta (d,n)\).
Lemma B.1
For every pair of integers \(d\ge 2\) and \(n\ge 1\) the quantity \(\eta (d,n)\) satisfies the bounds
for suitable positive numbers \(\underline{c}\) and \({\overline{c}}\).
Proof
By (39), the function \(\varphi (r)=r-r^d\) achieves its maximum at \(\lambda =d^{-\frac{1}{d-1}}\), where it has the value \(\lambda (1-\frac{1}{d})\). From this fact, we obtain the bound
which gives us the right-hand side estimate in (62). From the fact that \(\eta (d,n)\) is the maximum of the function f and that \(\lambda \) is smaller than one, we obtain also the lower bound
which is the left-hand side estimate in (62).
The sequence
is increasing from the value \(\frac{1}{2}\) it takes for \(d=2\) towards the value 1 of its limit for \(d\rightarrow \infty \). From this fact and the identity
we deduce that
where we have used also the fact that the sequence \(\left( 1- \frac{1}{d} \right) ^{d+1}\) is increasing from the value \(\frac{1}{8}\) it takes for \(d=2\) to the value \(\frac{1}{e}\) of its limit. Moreover, we have
where we have used the fact that the sequence \(\left( 1+ \frac{1}{d} \right) ^{d}\) is increasing and converges to e. Since \(\eta (d,n)\) is the maximum of f, (64) and (65) imply
On the other hand, since \(\lambda \) maximizes the function \(\varphi \), we have by (64)
The bounds (66) and (67) imply that (63) holds with \(\underline{c}=e\) and \({\overline{c}}=32e\). \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Abbondandolo, A., Henning, F., Külske, C. et al. Infinite-Volume States with Irreducible Localization Sets for Gradient Models on Trees. J Stat Phys 191, 63 (2024). https://doi.org/10.1007/s10955-024-03278-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10955-024-03278-9