
Abstract
We study a block spin mean-field Ising model, i.e. a model of spins in which the vertices are divided into a finite number of blocks with each block having a fixed proportion of vertices, and where pair interactions are given according to their blocks. For the vector of block magnetizations we prove Large Deviation Principles and Central Limit Theorems under general assumptions for the block interaction matrix. Using the exchangeable pair approach of Stein’s method we establish a rate of convergence in the Central Limit Theorem for the block magnetization vector in the high temperature regime.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Mean-field block models were introduced as an approximation of a lattice model of a meta-magnet, see e.g. formula (4.1) in [24]. Furthermore, they can arise in disordered systems with random pair interactions, studied for example in [9, 31, 32]. Later, they were rediscovered as interesting models for statistical mechanics systems, see [8, 17, 19, 25, 27], as well as models for social interactions between several groups, e.g. in [1, 20, 29]. This latter approach follows very much the social re-interpretation for one group of the Curie—Weiss model in [6] or of the Hopfield model in [10] or [26]. A third source of interest in mean-field spin block models is a statistical point of view. In [3], the authors gave another analysis of the bipartite mean-field Ising block model with equal block sizes, and asked the question whether one can recover the blocks from several observations from this model, and if so, how many observations are needed. In this aspect, the block spin models are related to the stochastic block models from random graph theory. These have been in the center of interest in statistics and probability theory over the past couple of years (see, e.g. [2, 21]). The statistical interest in them arises from their relation to graphical models. In this framework a major question is always how to reconstruct the block structure under sparsity assumptions (see e.g. [4, 5, 28]).
Our starting point is [27]. There, the fluctuations of an order parameter for a two-groups block model with equal block sizes were analyzed on the level of large deviations principles (LDPs, for short) and central limit theorems (CLTs). Starting from these results, there are several natural questions. First: Can these results be also proven for systems with not necessarily identical block sizes? Second: Can we generalize our results to the situation of more than two groups? And third: Can we give a speed of convergence for the CLT? The main goal of the current note is to (partially) answer these questions. To this end, we will present a new approach to mean-field block spin models, via the corresponding block interaction matrix. Moreover, to obtain a speed of convergence in the CLT, we will employ Stein’s method as in [7, 14] for the standard mean-field Ising, or Curie–Weiss model.
The rest of this note is organized in the following way. In the remaining part of this introduction, we define our model in a way that makes it accessible to our techniques in Sects. 2 and 3, and state our main results. Section 2 is devoted to the proof of the LDP results. Afterwards, we analyze the critical points of the rate function and obtain the mean field equations, showing that in the high temperature case the only maximum is 0, whereas in the low temperature case there are nonzero maximizers, and we obtain a solution for a special class of block interaction matrices. In Sect. 3 we prove the CLT for the order parameter of the model in two ways. One uses the classical Hubbard–Stratonovich transformation. This was already used for proving the CLT for the magnetization in the Curie–Weiss model in [16], and also is the core technique for the CLT in [27]. The second proof uses a multivariate version of the exchangeable pair approach in Stein’s method, developed in [30]. Lastly, Sect. 4 contains a discussion of some of the results and further open questions.
1.1 The Model
The block spin Ising model will be characterized by two quantities, a number \(k \in {{\,\mathrm{\mathbb {N}}\,}}\)—number of blocks—and a symmetric, positive definite matrix \(A \in {{\,\mathrm{\mathbb {R}}\,}}^{k \times k}\), which is the block interaction matrix. \(A_{ij}\) will determine the strength of interaction between two particles in block i and j respectively. Here, \({{\,\mathrm{\mathbb {R}}\,}}^{r_1 \times r_2}\) is the set of all \(r_1\) by \(r_2\) matrices with real entries.
Let N(n) be a strictly increasing subsequence of \({{\,\mathrm{\mathbb {N}}\,}}\). For a system of size \(N=N(n)\) let \(B_1^{(n)}, \ldots , B_k^{(n)} \subset \{1,\ldots , N\}\) be a partition of \(\{1,\ldots , N\}\) into k blocks. Without loss of generality, we assume that the indices in the blocks are ordered, i.e. if \(i_0 \in B_{i}^{(n)}\) and \(j_0 \in B_{j}^{(n)} \) and \(i<j\), it follows \(i_0 <j_0\). We call \(| B_i^{(n)}|\) the block size of the ith block. Note that, in particular, we have a system of size N, where for \(n \in {\mathbb {N}}\)
Define for each \(n \in {{\,\mathrm{\mathbb {N}}\,}}\) the matrix of the relative block sizes
We assume that for each \(i = 1,\ldots , k\) the limit
exists, so that the matrix of asymptotic relative block sizes
is invertible. If the k partition blocks are asymptotically of the same size, i.e.
we call this the uniform case. The block spin Ising model with k blocks of sizes \(|{B^{(n)}_1} |, \ldots , |{B^{(n)}_k} |\) and block interaction matrix A is defined as the Ising model with interaction matrix
where \(O(m,n) \in {{\,\mathrm{\mathbb {R}}\,}}^{m \times n}\) is the matrix with all entries equal to 1. We denote this model by \(\mu _{J_n}\). More precisely, \(\mu _{J_n}\) is the probability measure on \(\{-1,+1\}^N, N = N(n),\) defined by
Here, of course, \(Z_n\) is the partition function
Note that, contrary to the usual convention, we do not require the diagonal of \(J_n\) to be zero for technical convenience. However, since \(x_i^2 = 1\), both \(J_n\) and its “dediagonalized” version \({\widetilde{J}}_n = J_n - {{\,\mathrm{diag}\,}}(J_{ii})\) give rise to the same Ising model. Here and in the sequel, \({{\,\mathrm{diag}\,}}(\lambda _1, \ldots , \lambda _l)\) is a diagonal \(l \times l\) matrix with values \(\lambda _1, \ldots , \lambda _l\) on its diagonal. Lastly, for any \(p, q \in [1,\infty ]\) and any matrix \(A \in {{\,\mathrm{\mathbb {R}}\,}}^{k \times k}\) we define the operator norm
1.2 Main Results
We prove results on the fluctuations of the block magnetization vector on different scales. In what follows, we use the non-normalized and normalized versions of the block magnetization vector defined as
Note that this allows us to rewrite the Hamiltonian \(H_n\) of \(\mu _{J_n}\) as
which we use tacitly.
We begin by presenting the large deviation results. The first result is a generalization of [27, Theorem 2.1]. In that paper, an LDP for \({\widetilde{m}}^{(n)}\) was proved in the situation of \(k=2\) blocks of equal size. Here we analyze the general case.
Theorem 1
Let \(k \in {{\,\mathrm{\mathbb {N}}\,}}\) and A be a block interaction matrix. The sequence \(({\widetilde{m}}^{(n)})_{n \in {{\,\mathrm{\mathbb {N}}\,}}}\) satisfies an LDP under \((\mu _{J_n})_{n \in {{\,\mathrm{\mathbb {N}}\,}}}\) with speed N and rate function
where
and \(L^*\) denotes the convex conjugate of \(\log \cosh \), i.e.
More precisely, in the notion of large deviations, the sequence of push-forwards \(({\widetilde{m}}^{(n)} \circ \mu _{J_n})_{n \in {{\,\mathrm{\mathbb {N}}\,}}}\) satisfies an LDP with speed N and the rate function I.
In the special case of asymptotically uniform block sizes the function I is related to the matrix A in an even more straightforward way, since in this case
We show that the rate function I has a unique minimum at 0 in the case \(\Vert {\varGamma _\infty ^2 A \varGamma _\infty ^2} \Vert _{2 \rightarrow 2} \le 1\), which yields the following corollary.
Corollary 1
Under the general assumptions, if \(\Vert {\varGamma _\infty A \varGamma _\infty } \Vert _{2 \rightarrow 2} \le 1\), the normalized vector of magnetizations \({\widetilde{m}}^{(n)}\) converges to 0 exponentially fast in \(\mu _{J_n}\)-probability. By this we mean more precisely, for each \(\varepsilon >0\) there is a constant \(I_\varepsilon \) such that
Let us discuss the large deviation results. In the classical Curie–Weiss model, i.e. the case \(k=1\), there is a phase transition: The limiting behavior of \({{\widetilde{m}}}^{(n)}\) changes, depending on whether \(A_{11} \le 1\) (the high temperature regime), or \(A_{11} > 1\) (the low temperature regime) (see [15] for an extensive treatment of this model). A corresponding phase transition can be observed in our model. This is stated in [18] for the bipartite model. In [25] the authors prove the existence of such a phase transition using the method of moments. Of course, with that method one cannot obtain an exponential speed of convergence as in Corollary 1. In accordance with the notion in the classical Curie–Weiss model, we will call these different parameter regimes the \(\textit{high temperature}\) and \(\textit{low temperature}\) regime, respectively. Here, the high temperature regime corresponds to \(\Vert {\varGamma _\infty A \varGamma _\infty } \Vert _{2 \rightarrow 2} \le 1\) and the low temperature regime to \(\Vert {\varGamma _\infty A \varGamma _\infty } \Vert _{2 \rightarrow 2} > 1\). In the special case of asymptotically uniform block sizes (i.e. \(\varGamma _\infty = \frac{1}{\sqrt{k}} {{\,\mathrm{Id}\,}}\)) these conditions reduce to \(\Vert {A} \Vert _{2 \rightarrow 2} \le k\) and \(\Vert {A} \Vert _{2 \rightarrow 2} > k\) respectively.
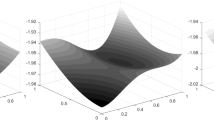
Next, we consider the scaled block magnetization vector \({\widehat{m}}^{(n)}\). Again, in the classical (i.e. one-dimensional) case it is known that the magnetization satisfies a central limit theorem with variance \(\sigma ^2 = (1-A_{11})^{-1}\) whenever \(A_{11} < 1\). The following theorem is a generalization of this phenomenon (Fig. 1).
Theorem 2
Let \(k \in {{\,\mathrm{\mathbb {N}}\,}}\) and A be a block interaction matrix. In the high temperature regime we have
Consequently, in the uniform case

A visualization of the block magnetization vector \({\widehat{m}}^{(n)}\) (left) for \(n = 500\), using the Glauber dynamic for sampling, and a heat map for the limiting normal distribution. Here, we choose \(k = 2\), \(A = \begin{pmatrix} 1.1 &{} 0.6 \\ 0.6 &{} 1.1 \end{pmatrix}\) and the uniform case
Note that \(\varSigma _{\infty }\) exists, and it can be expanded into a Neumann series. Moreover, if \(\varGamma _\infty A \varGamma _\infty = V^T \varLambda V\) is an orthogonal decomposition, then \(\varSigma _\infty = V^T {{\,\mathrm{diag}\,}}((1 - \lambda _i)^{-1}) V\). Again, a similar statement is derived in [25] using the method of moments.
Furthermore, we can treat the critical case. In the Curie–Weiss model, for \(\beta = 1\), the quantity \(N^{-3/4} \sum _{i = 1}^N \sigma _i\) converges weakly to a measure with Lebesgue-density \(g_1(x) :=Z^{-1} \exp \left( - \frac{x^4}{12} \right) \) (see e.g. [15, Theorem V.9.5]). As proven in [27] and [18] a similar statement holds true for the vector of magnetizations in the case of \(k=2\) blocks. The next theorem gives a further generalization of this fact in the case \(k \ge 2\). Moreover, it shows that statistics associated to the orthogonal decomposition of the block interaction matrix give rise to k asymptotically independent random variables with either a Gaussian distribution or a distribution with a Lebesgue-density \(g_1\).
In the multidimensional critical case \(\Vert {\varGamma _\infty A \varGamma _\infty } \Vert _{2 \rightarrow 2} = 1\) we restrict to the uniform case with a simple eigenvalue \(\lambda _k = k\), i.e. we have \(A = V^T {{\,\mathrm{diag}\,}}(\lambda _1, \ldots , \lambda _{k-1}, k) V\). Let \( \varGamma _n A \varGamma _n = V^T_n \varLambda _n V_n,\) be the orthogonal decomposition, where \(V_n\) is a unitary \(k \times k\)-matrix and \(\varLambda _n\) a diagonal \(k\times k\)-matrix. If we define the normalized vector
and the matrix
we have the following result.
Theorem 3
Under the above assumptions let \(Y_n \sim {\mathcal {N}}(0, {\hat{C}}_N^{-1})\) and \(X_n \sim \mu _{J_n}\) be independent random variables, defined on a common probability space. Then \(w'_n(X_n) + Y_n\) converges in distribution to a probability measure with density
for a suitable normalization \({{\widetilde{Z}}}\) that makes the expression (1) a probability density.
Thus, the vector \((w_n'(X_n)_j)_{j = 1,\ldots , k-1}\) converges to a normal distribution with covariance matrix \(\varSigma = {{\,\mathrm{diag}\,}}\left( (k-\lambda _j)^{-1}\right) \) and the random variable \(w_n'(X_n)_k\) converges to a distribution with Lebesgue-density \(Z^{-1} \exp \left( - (\frac{k^3}{12} \sum _{i = 1}^k V_{ki}^4) x^4 \right) dx\).
We believe it is possible to extend Theorem 3 to the case where the eigenvalue k has multiplicity greater than 1, by appropriately rescaling all the eigenvectors which belong to the eigenvalue k.
Note that the parameter \(\sigma ^2 :=k^3/12 \sum _{i = 1}^k V_{ki}^4\) is directly related to the variance of a random variable with that distribution; indeed, a short calculation shows that for \(X \sim \exp (-\sigma ^2 x^4) dx\) we have \({\mathrm {Var}}(X) = c \sigma ^{-1}\), where c is an absolute constant. Moreover, \(\sum _{i = 1}^k V_{ki}^4 = \Vert {v_k} \Vert _4^4\), where \(v_k\) is the eigenvector belonging to the eigenvalue k.
In a final step, we establish convergence rates in the CLT in the high temperature case for a special class of functions. We use the exchangeable pair approach of Stein’s method, that was also used in [14] and [7] in the case of the Curie–Weiss model. The proof of the next result will rely on a multivariate version of Stein’s method proven in [30]. To this end, define the function class
of all three times differentiable functions with all partial derivatives (up to order three) bounded.
Theorem 4
Assume that \(\Vert {\varGamma _\infty A \varGamma _\infty } \Vert _{2 \rightarrow 2} < 1\) and for each \(n \in {{\,\mathrm{\mathbb {N}}\,}}\) let \(\varSigma _n:={{\,\mathrm{\mathbb {E}}\,}}{\hat{m}}^{(n)} ({\hat{m}}^{(n)})^T\). For \(Z \sim {\mathcal {N}}(0,{{\,\mathrm{Id}\,}})\), we have
2 Proofs of the Large Deviation Results and the Mean-Field Equations
Let us start off by proving the LDP result for the rescaled block magnetization vector \({\widetilde{m}}^{(n)}\). Recall the notion of an LDP (for which we also refer to [13] and [12]): If \({\mathcal {X}}\) is a Polish space and \((a_n)_{n \in {{\,\mathrm{\mathbb {N}}\,}}}\) is an increasing sequence of non-negative real numbers, we say that a sequence of probability measures \((\nu _n)_n\) on \({\mathcal {X}}\) satisfies a large deviation principle with speed \(a_n\) and rate function \(I: {\mathcal {X}} \rightarrow {{\,\mathrm{\mathbb {R}}\,}}\) (i.e. a lower semi-continuous function with compact level sets \(\{x: I(x) \le L\}\) for all \(L>0\)), if for all Borel sets \(B \in {\mathcal {B}}({\mathcal {X}})\) we have
where \({\mathrm {int}}(B)\) and \({\mathrm {cl}}(B)\) denote the topological interior and closure of a set B, respectively.
We say that a sequence of random variables \(X_n: \varOmega \rightarrow {\mathcal {X}}\) satisfies an LDP with speed \(a_n\) and rate function \(I: {\mathcal {X}} \rightarrow {{\,\mathrm{\mathbb {R}}\,}}\) under a sequence of measures \(\mu _n\) if the push-forward sequence \(\nu _n :=\mu _n \circ X_n\) satisfies an LDP with speed \(a_n\) and rate function I.
To prove Theorem 1, we will need the following lemma.
Lemma 1
Let \({\mathcal {X}}\) be a Polish space and assume that a sequence of measures \((\mu _n)_{n \in {{\,\mathrm{\mathbb {N}}\,}}}\) on \({\mathcal {X}}\) satisfies an LDP with speed n and rate function I. Let \(F: {\mathcal {X}} \rightarrow {{\,\mathrm{\mathbb {R}}\,}}\) be a continuous function which is bounded from above and \(\eta _n: {\mathcal {X}} \rightarrow {{\,\mathrm{\mathbb {R}}\,}}\) a sequence of functions such that \(\Vert {\eta _n} \Vert _{L^\infty (\mu _n)} \rightarrow 0\). Then the sequence of measures
satisfies an LDP with speed n and rate function
Proof
Note that this is a slight modification of the tilted LDP, which is an immediate consequence of Varadhan’s Lemma ( [13, Theorem III.17]). Indeed, according to this tilted LDP, the sequence of measures \((\nu _n)_n\) with \(\mu _n\)-density \(\exp (nF)\) satisfies an LDP with speed n and rate function J. Since for any \(n \in {{\,\mathrm{\mathbb {N}}\,}}\) and any \(B \in {\mathcal {B}}({\mathcal {X}})\) the inequalities
hold, this easily implies an LDP for \(({\widetilde{\mu }}_n)_n\) with speed n and the same rate function J due to \(\Vert {\eta _n} \Vert _{L^\infty (\mu _n)} \rightarrow 0\). \(\square \)
Proof of Theorem 1
First, note that under the uniform measure \(\mu _0\) (i.e. \(A \equiv 0\)) we have
so that
By the Gärtner-Ellis Theorem ([12, Theorem 2.3.6]), \({\widetilde{m}}^{(n)}\) satisfies an LDP under \(\mu _0\) with speed N and rate function
where \(L^*(x)\) is the convex conjugate of \(\log \cosh \). Next, it is easy to see that we can rewrite the \(\mu _0\)-density of \(\mu _{J_n}\) as
where
Note that we artificially inserted the truncation in F to emphasize the boundedness of \(F({\widetilde{m}}^{(n)})\). This does not affect the quadratic form, as
Moreover, F is obviously continuous and \(\eta _n\) satisfies
on the support of \(\mu _0 \circ {\widetilde{m}} = [-1,1]^k\), so that the assertion follows from Lemma 1. \(\square \)
2.1 The Mean-Field Equations
Theorem 1 states that the function \(I(x) = \frac{1}{2} \left\langle {x, \varGamma _\infty ^2 A \varGamma _\infty ^2 x} \right\rangle - \sum _{i = 1}^k \gamma _i^2 L^*(x_i)\) determines the asymptotic behavior of the magnetization, and thus the critical points of I are of utter importance. These satisfy the so-called mean-field equations
For example, in the well-studied case \(k = 2\), choosing
for a positive definite matrix A and \(\gamma \in (0,1)\) Eq. (2) reduce to
Whereas for the two-dimensional fixed point problem the existence of a solution can be shown by monotonicity arguments, the existence of a solution to (2) for general k is more involved. First off, we show that in the high temperature regime the only critical point of I is 0. This will immediately yield Corollary 1.
Proof of Corollary 1
In the sense of the formulation in Corollary 1, \({\widetilde{m}}^{(n)}\) concentrates exponentially fast in the minima of the function J. However, under the condition \(\Vert {\varGamma _\infty A \varGamma _\infty } \Vert _{2 \rightarrow 2} \le 1\) there is only one minimum, which is zero. To see this, note that any local minimum satisfies
Here, \({{\,\mathrm{artanh}\,}}(x)\) is understood componentwise. Clearly, 0 is a solution, and due to
this is a local minimum. Assume there is some \(y \ne 0\) solving (3), and observe that
Here the first inequality follows from the general fact that the spectrum of the matrices BC and CB agree, applied to \(B = \varGamma _\infty \) and \(C = \varGamma _\infty A\). The last inequality follows from \({{\,\mathrm{artanh}\,}}(x)x \ge x^2\) for all \(x \in (-1,1)\), with equality for \(x = 0\) only. This means that for any solution y we have equality in (5). However, equality can only hold if \(y_i = 0\) whenever \(\gamma _i \ne 0\). Due to our assumption \(\gamma _i \in (0,1)\), this proves the claim. \(\square \)
In contrast, in the low temperature regime, there are other solutions to the mean-field equations (2). Let us start with the following proposition showing the connection of the k-dimensional mean-field equations to the one-dimensional equations of the Curie–Weiss model. It provides an explicit formula for the solution of the k-dimensional problem in terms of the solution of the Curie–Weiss equation.
Proposition 1
Let \(k \in {{\,\mathrm{\mathbb {N}}\,}}\), \(\varGamma _\infty = \frac{1}{\sqrt{k}} {{\,\mathrm{Id}\,}}\) and A be a positive semidefinite, symmetric matrix with \(\Vert {A} \Vert _{2 \rightarrow 2} > k\). If the eigenvector \(v_k\) belonging to the largest eigenvalue \(\lambda _k\) can be rescaled to satisfy \(v_k \in \{-1,0,1\}^k\), then there exists a solution \(x \ne 0\) to the mean-field equations (2) and it is given by \(x = m^* v_k\), where \(m^*\) is the positive one-dimensional solution of the Curie–Weiss model with temperature \(\beta = \lambda _k k^{-1} > 1\).
Proof
Let \(m^* > 0\) be the unique positive solution of the Curie–Weiss equation \(\tanh (\frac{\lambda _k}{k} x) = x\) for \(\beta :=\frac{\lambda _k}{k} > 1\) and define \(v :=m^* v_k\). We have
where in the second-to-last step we have used explicitly that \(v_k \in \{ -1,0,1 \}^k\), and so v is a critical point of I. Moreover, in this case it is easily seen that
is negative definite. Indeed, from
we obtain
\(\square \)
Example 1
Even though the assumptions in the previous proposition seem to be tailor-made for its proof (and the conclusion also holds true more generally), there are interesting non-trivial examples of a matrix satisfying the conditions of Proposition 1. One of them is the family of \(k \times k\) matrices (\(k \in {{\,\mathrm{\mathbb {N}}\,}}\)) of the form
for any parameters \((\alpha , \beta )\) satisfying
This corresponds to k groups with an interaction parameter \(\beta \) within the group and \(\alpha \) between the groups. For example, the condition (6) is satisfied whenever \(\beta> \alpha > 1\).
In the general case, the conclusion of Proposition 1 holds as well. In this case the proof relies on the fact that the continuous function I has a global maximum on its (compact) domain \([-1,1]^k\), and the next lemma excludes maxima on the boundary. Hence there is always at least one solution \(y \ne 0\) (since 0 is either an inflection point or a minimum) to (2).
Lemma 2
Let I be the large deviation rate function from Theorem 1, i.e.
and \(L^*\) denotes the convex conjugate of \(\log \cosh \).
- 1.
I has no global maxima on the boundary of \([-1,1]^k\).
- 2.
If \(x \in [-1,1]^k\) satisfies the mean-field equations, we have
$$\begin{aligned} I(x) = \frac{1}{2} \sum _{i = 1}^k \gamma _i^2 \left( x_i {{\,\mathrm{artanh}\,}}(x_i) + \log (1-x_i^2) \right) . \end{aligned}$$(7) - 3.
The set of all global maximisers has a positive distance from the boundary.
Proof
(1): Assume that x is a global maximum of I on the boundary. Then there is at least one index \(j \in \{1,\ldots ,k\}\) such that \(x_j = 1\) (if \(x_j = -1\), switch to \(-x\) since \(I(-x) = I(x)\)). Rewriting the fact that x is a maximum of I, we have for any \(y_j \in [-1,1]\) and \(C :=\varGamma _\infty ^2 A \varGamma _\infty ^2\)
where \({\overline{x}}_j\in {\mathbb {R}}^{k-1}\) is the vector obtained from x by deleting the jth component. If we divide both sides by \(1-y\) and let \(\limsup _{y \rightarrow 1}\), the left hand side is finite, as \(\frac{1}{2} \left\langle {x,Cx} \right\rangle \in C^\infty ({{\,\mathrm{\mathbb {R}}\,}}^k)\), and the right hand side tends to \(\infty \) by l’Hospital’s rule. This proves statement (1).
(2): Clearly, x can only satisfy the mean-field equations if \(x \in (-1,+1)^k\). For any \(i = 1,\ldots ,k\) we have \({{\,\mathrm{artanh}\,}}(x_i) = \sum _{j = 1}^k A_{ij} \gamma _j^2 x_j = (A \varGamma _\infty ^2 x)_i.\) Inserting this into the function I gives
(3): The function I is bounded in \([-1,1]^k\), as
On the other hand, if there exists a sequence of maximisers approaching the boundary, i.e. for at least one i we have \(x_i \rightarrow 1\), this gives \(R(x_i) \rightarrow \infty \). \(\square \)
In the case of two blocks, i.e. \(k=2\), equal block sizes and the same interaction within a group, the set of maximisers of the rate function is explicitly known. Indeed, in [3, Proposition 2.1] and [27, Theorem 2.1] the authors show that for
satisfying \(\beta \ge \alpha \ge 0\) and \(\beta + \alpha > 2\) (the low temperature case) the distribution of \({\widetilde{m}}^{(n)}\) concentrates in the two points \(x = (m^+((\beta +\alpha )/2), m^+((\beta +\alpha )/2)\), and \(-x\). In the case \(\alpha < 0\) the limit points for \({\widetilde{m}}^{(n)}\) become \(x = (m^+((\beta +\alpha )/2), -m^+((\beta +\alpha )/2))\), and \(-x\). Here \(m^+(b)\) is the largest solution to
If \(\beta + |{\alpha } | \le 2\), the distribution of \({\widetilde{m}}^{(n)}\) concentrates in the origin. For \(k=2\), we can extend this result to arbitrary block sizes.
Proposition 2
Let \(k = 2\), \(A = \begin{pmatrix} \beta &{} \alpha \\ \alpha &{} \beta \end{pmatrix}\) be a block interaction matrix and \(\gamma _1^2=\gamma \), \(\gamma _2^2 =(1-\gamma )\) for some \(0<\gamma < \frac{1}{2}\). In the low temperature case, if the groups are not interacting (i.e. \(\alpha = 0\)) there exists either two or four global maxima of I; for \(\alpha \ne 0\), there are always two global maxima of I.
Note that we have to restrict to \(|{\alpha } | < \beta \) and \(\beta > 0\) in order for A to be positive definite. Moreover, the characterization of the high temperature phase \(\varGamma _\infty A \varGamma _\infty \preceq {\mathrm {Id}}\) (where \(\preceq \) is the Loewner partial ordering) can be reduced to \(\left\langle {({\mathrm {Id}} - \varGamma _\infty A \varGamma _\infty )e_1, e_1} \right\rangle > 0\) and \(\det ({\mathrm {Id}} - \varGamma _\infty A \varGamma _\infty ) > 0\). Thus we are in the high temperature regime if and only if
Proof
The case \(\alpha = 0\) is an easy consequence of the statements for the one-dimensional Curie–Weiss model, since \(I(x_1,x_2) = I_1(x_1) + I_2(x_2)\) and \(\varGamma _\infty ^2 A \varGamma _\infty ^2 = {\mathrm {diag}}(\beta \gamma ^2, \beta (1-\gamma ^2))\).
We treat the case \(\alpha > 0\) only—the case \(\alpha < 0\) follows immediately from the equality \(I_{\alpha ,\beta }(x,y) = I_{-\alpha ,\beta }(x,-y)\) (with the appropriate modifications, e.g. the maximum will be in the second quadrant instead of the first).
Due to (7) the maximum of the rate function is non-negative, let us call this maximum \(\eta \). Then, \(I(x,y)=\eta = 0\) implies \((x,y) = 0\), which is a contradiction to the low temperature case (recall the Hessian of I in 0 given in Eq. (4)), so that \(\eta > 0\). Moreover, every global maximum (and thus local maximum, as it is not attained on the boundary) satisfies the mean-field equations, and so the value of I at any maximum is given by equation (7). As a consequence, all global maxima lie on a contour line \(C_\eta :=\{ x \in [-1,1]^2 : \gamma R(x_1) + (1- \gamma ) R(x_2) = 2\eta \}\), where \(R(x) = x {{\,\mathrm{artanh}\,}}(x) + \log (1-x^2)\) was defined in the previous lemma.
Firstly, let us show that in the first quadrant there can only be one such point. Due to symmetry, the global maximum will also be present in the third quadrant. For \(x_1 > 0\) the points on the contour line \(C_{\eta }\) can be described by a function \(x_2 = g(x_1)\), and due to the monotonicity of R the function g is non-increasing. Moreover, the solutions of the mean-field equations can be described by the functions
via \(x_2=f_1(x_1) \text { and } x_1= f_2(x_2).\) The function \(f_1\) can behave in two ways, depending on the parameter \(\gamma \beta \): For \(\gamma \beta \le 1\) it increases monotonically. For \(\gamma \beta > 1\) it decreases first and then increases. More precisely, in the latter case, \(f_1(t)=0\) if and only if \(t \in \{0, \pm m_{\gamma \beta }\}\) for some \(m_{\gamma \beta } > 0\) and \(f_1\) is strictly increasing for \(t \ge m_{\gamma \beta }\). Moreover, the curve \((x, f_1(x))\) is only in the first quadrant if \(m_{\gamma \beta } <x \le 1\). In either case, there is only one intersection point of g and \(f_1\) in the first quadrant.
Secondly, the maximum cannot be in the second quadrant. Assume that there are solutions to the mean field equations both in the first and in the second quadrant. If we denote by \(m_c\) the zeros of \(\phi _c(t) :={{\,\mathrm{artanh}\,}}(x) - cx\), for the solution in the second quadrant, we easily see that \(-m_c<x <0\) and \(0\le y \le m_{\beta (1- \gamma )}.\) Hence
If there is also a solution in the first quadrant with coordinates \((x^*, y^*)\), we obtain analogously
This yields that the maximum must lie in the first quadrant \(\square \)
Furthermore, we can treat the case \(k > 2\) for uniform block sizes and special matrices. The proof is motivated by [3, Proposition 2.1].
Lemma 3
Let \(k \ge 2\) and A be a block interaction matrix with positive entries such that we have for any \(i = 1,\ldots , k\) for two constants \(c_1, c_2 > 0\)\(A_{ii} = c_1\) and \(\sum _{j \ne i} A_{ij} = c_2\).
In the uniform case, there are exactly two maximisers of the rate function I and they satisfy \(x = m^* (1,\ldots , 1)\) for \(m^*\) solving the Curie–Weiss equation \(\frac{c_1 + c_2}{k} x = {{\,\mathrm{artanh}\,}}(x)\).
Proof
Using the equality \(xy = -\frac{1}{2} (x-y)^2 + \frac{1}{2} x^2 + \frac{1}{2} y^2\) we can rewrite the rate function as
where equality only holds in the case \(x_i = x_j\) for all i, j. Thus, we search for maximisers of I on the generalized diagonal \(\{ x \in [-1,1]^k : x_i = x_j\;\forall i,j \}\). On this set we have
i.e it reduces to the Curie–Weiss equations in one dimension. For \(c_1 + c_2 > k\) it has a unique nonzero solution \(m^*\), and \(x = m^* (1,\ldots , 1)\) solves the k-dimensional maximization problem. \(\square \)
Unfortunately, the proof cannot be modified in a straightforward way to deal with non-equal block sizes, not even in the case \(k = 2\). The reason is that the inequality used in the proof does not give any information on the actual maximiser in this setting (i.e. I is not maximized on any type of (weighted) diagonal). As such, we cannot reduce this to the one-dimensional setting.
Example 2
For example, Lemma 3 can be used to prove that given three positive parameters \(\alpha ,\beta ,\gamma \) with \(\beta > \alpha \) and \(\beta + \alpha > 2 \gamma \), the rate function corresponding to
only has two maximisers in the uniform case. The conditions on \(\alpha , \beta , \gamma \) ensure that A is positive definite, and it is clear that \(c_1 = \beta \) and \(c_2 = \alpha + 2 \gamma \).
As a concluding remark let us note that the previous results imply that there is indeed a phase transition in our block spin model. However, if \(k>2\) or the block sizes are not equal, it seems hard to give a similarly explicit formula for the limit points. Nevertheless, the above observations show that there is a phase transition in a very general class of block spin models with an arbitrary number of blocks and general class of block sizes. In particular, they also justify the names “high temperature regime” and “low temperature regime”.
3 Proofs of the Limit Theorems
In this section we prove (standard and non-standard) Central Limit Theorems for the vector \({\widehat{m}}^{(n)}\). In the first subsection we will treat the high temperature regime. Here we derive a standard CLT using the Hubbard–Stratonovich transform. This is in spirit similar to the third section in [27] and technically related to [22]. The result can also be derived from [17], where similar techniques are used. However, the subsection also prepares nicely for Sect. 3.2, where we treat the critical case and show a non standard CLT. This generalizes results from [18] and [27]. Finally, in Sect. 3.3 we will use Stein’s method, an alternative approach to prove the CLT for \({\widehat{m}}^{(n)}\). This is not only interesting in its own right, but also has the advantage of providing a speed of convergence, which is missing in the case of a proof via the Hubbard–Stratonovich transform.
3.1 Central Limit Theorem: Hubbard–Stratonovich Approach
For the proof we shall use the transformed block magnetization vectors
where \(\varGamma _n A \varGamma _n = V_n^T \varLambda _n V_n\) is the orthogonal decomposition. It is easy to see that
Proof of Theorem 2
As in [27] or [17] (both papers are inspired by [16]), we use the Hubbard–Stratonovich transform (i.e. a convolution with an independent normal distribution). For each \(n \in {{\,\mathrm{\mathbb {N}}\,}}\),
Our first step is to prove that \({\widehat{w}}^n\) converges weakly to a normal distribution. Let \(Y_n \sim {\mathcal {N}}(0, \varLambda _n^{-1})\) be an independent sequence, which is moreover independent of \(({\widehat{w}}^n)_{n \in {{\,\mathrm{\mathbb {N}}\,}}}\). We have for any \(B \in {\mathcal {B}}({{\,\mathrm{\mathbb {R}}\,}}^k)\)
where we have defined
Since \(\log \cosh (x) = \frac{1}{2} x^2 + O(x^4)\), we obtain
For parameters \(r, R > 0\) let \(B_{0,r,R} :=\{ x \in {{\,\mathrm{\mathbb {R}}\,}}^k : r \le \Vert {x} \Vert _2^2 \le R \}\) and decompose
Since \(\varLambda _n \rightarrow \varLambda _\infty \) (which is a consequence of the continuity of the eigenvalues) we have for any \(R > 0\)
Next, we will estimate (8) from below in order to obtain an upper bound for \(I_2\). If we define \(C_{2,4} :=\Vert {{{\,\mathrm{Id}\,}}} \Vert _{2 \rightarrow 4}\), it follows that
Here, we have used the convergence of \(\varGamma _n\) to \(\varGamma _\infty \) to bound \(\Vert {\varGamma _n^{-1/2}} \Vert _{4 \rightarrow 4}\) and the fact that \(C(r)r^2 \rightarrow 0\) as \(r \rightarrow 0\), so that the right hand side is positive definite for r small enough, uniformly in n. Thus, after taking the limit \(n \rightarrow \infty \), \(I_2\) will vanish in the limit \(R \rightarrow \infty \).
Lastly, we need to show that \(I_3\) vanishes as well. To this end, we show that we can choose \(r > 0\) small enough to ensure that \(\varPhi _n(x) \ge \exp (-N c)\) uniformly for \(x \in B_{r\sqrt{N}}(0)^c\) and for n large enough. Since \(\Vert {\varLambda _n - \varLambda _\infty } \Vert _{2 \rightarrow 2} \rightarrow 0\) and \(\Vert {\varLambda _\infty } \Vert _{2 \rightarrow 2} < 1\), choose n large enough so that \(\Vert {\varLambda _n} \Vert _{2 \rightarrow 2} < 1\) uniformly. Again, as before, it can be seen that 0 is the only minimum for n chosen that way. Indeed, after some manipulations any critical point satisfies \(\varGamma _n A \varGamma _n \tanh (y) = y\), and since \(\Vert {\tanh (y)} \Vert _2 \le \Vert {y} \Vert _2\) and \(\Vert {\varGamma _n A \varGamma _n} \Vert _{2 \rightarrow 2} < 1\), this is only possible for \(y = 0\). As a consequence, for any \(r > 0\) there is a constant c such that uniformly \({\widetilde{\varPhi }}_n(x) \ge c\), i.e.
Lastly, choose \(r > 0\) so small that \(\varLambda _n - \varLambda _n^2 - C(r)r^2 C\) is uniformly positive definite, and observe that we obtain
From here, it remains to undo the convolution (e.g. by using the characteristic function), giving
With the help of Slutsky’s theorem and the definition \({\widehat{m}}^n = V^T_n {\widehat{w}}^n\) this implies
as claimed. \(\square \)
Example 3
Consider the case \(k = 2\) and
\(A_2\) is positive definite if \(\beta \ge 0\) and \((\beta - \alpha )(\beta + \alpha ) \ge 0\), i.e. if \(|{\alpha } | \le \beta \). We have the diagonalization
and \(w = V^T m = \frac{1}{\sqrt{2}} \begin{pmatrix} 1 &{} 1 \\ 1 &{} -1 \end{pmatrix}m\) corresponds to the transformation performed in [27, Theorem 1.2] (up to a factor of \(\sqrt{2}\)). In this case
which is exactly the covariance matrix in [27] (again up to a factor of 2). Note that similar results have been derived in [25].
Remark 1
If \(A \in M_k({{\,\mathrm{\mathbb {R}}\,}})\) is symmetric and positive semidefinite, then a variant of the proof shows that if we let \(A = V^T \varLambda V\) with \(\varLambda = {{\,\mathrm{diag}\,}}(\lambda _1, \ldots , \lambda _l, 0, \ldots , 0)\) for \(l < k\), \(((V{\widetilde{m}})_i)_{i \le l}\) converges to an l-dimensional normal distribution with covariance matrix \(\varSigma _l :=({{\,\mathrm{Id}\,}}- \varLambda _l)^{-1}, \varLambda _l = {{\,\mathrm{diag}\,}}(\lambda _1, \ldots , \lambda _l)\). This can be applied to the matrix \(A_2\) above with \(\alpha = \beta \), resulting in a CLT for the magnetization in a Curie–Weiss model, which of course can also be obtained by choosing \(k = 1\) and \(0< \beta < 1\).
3.2 Non-central Limit Theorem
Recall the situation of Theorem 3: The block interaction matrix has eigenvalues \(0< \lambda _1 \le \ldots \le \lambda _{k-1} < \lambda _k = k\) and we consider the uniform case, i.e. \(\varGamma _\infty ^2 = k^{-1}\). Moreover, we use the definitions
so that
Proof of Theorem 3
Let \(Y_n \sim {\mathcal {N}}(0, {\hat{C}}_N^{-1})\) and \(X_n \sim \mu _{J_n}\) be independent random variables, defined on a common probability space. We have for any Borel set \(B \in {\mathcal {B}}({{\,\mathrm{\mathbb {R}}\,}}^k)\)
where we used
Now the proof is along the same lines as the proof of the CLT in the high temperature phase, with the slight modification that we use the expansion of \(\log \cosh \) to fourth order
We again split \({{\,\mathrm{\mathbb {R}}\,}}^k\) into three regions, namely the inner region \(I_1 = B_R(0)\) for an arbitrary \(R > 0\), the intermediate region \(I_2 = K_r \backslash B_R(0)\) for some arbitrary \(r > 0\), where
and the outer region \(I_3 :=K_r^c\). Also define the rescaled vector
Firstly, in the inner region we rewrite
and since the convergence of the error terms is uniform on any compact subset of \({{\,\mathrm{\mathbb {R}}\,}}^k\), for any fixed \(R > 0\) this yields
Secondly, we show that the outer region does not contribute to the limit \(N \rightarrow \infty \). It can be seen by elementary tools that \({\widetilde{\varPhi }}_N\) has a unique minimum 0 in 0, and so for any \(r > 0\) we have \(\inf _{x \in I_3} {\widetilde{\varPhi }}(x) > 0\). Using the monotone convergence theorem, we obtain
Lastly, we will estimate the contribution of the intermediate region from above by a quantity which vanishes as \(R \rightarrow \infty \). To this end, we will bound the function \(\varPhi _N\) from below. Recall that
and since \(\Vert {V^T \widetilde{x_i}} \Vert _4^4 \ge C \Vert {{\widetilde{x}}_i} \Vert ^4_4\) for \(C = \Vert {V} \Vert _{4 \rightarrow 4}^{-4}\) this yields
Now, as in the case of the central limit theorem, we can estimate from below the error term in such a way that there is a positive constant c and a positive definite matrix C such that
from which we obtain an upper bound, i.e.
and the right hand side vanishes as \(R \rightarrow \infty \) by dominated convergence. As a result, the limit \(n \rightarrow \infty \) exists and is equal to
The convergence results for the non-convoluted vector follow easily by considering the characteristic functions. We have for any \(t \in {{\,\mathrm{\mathbb {R}}\,}}^k\)
where \({\widetilde{\varSigma }} = {{\,\mathrm{diag}\,}}\left( \lambda _i^{-1} + (k-\lambda _i)^{-1} \right) \) and \(\phi \) is the characteristic function of a random variable with distribution \(\exp \left( -x_k^4 k^3/12 \sum _{i = 1}^k V_{ki}^4 \right) \). Using the independence of \(X_n\) and \(Y_n\), the results follow by simple calculations. \(\square \)
3.3 Central Limit Theorem: Stein’s Method
Lastly, we will prove Theorem 4 using Stein’s method of exchangeable pairs. For brevity’s sake, for the rest of this section we fix \(n \in {{\,\mathrm{\mathbb {N}}\,}}\) and we will drop all sub- and superscripts (e.g. we write \(B_i\) instead of \(B_i^{(n)}\), \({\hat{m}}\) instead of \({\hat{m}}^{(n)}\), J instead of \(J_n\) et cetera). It is more convenient to formulate this approach in terms of random variables. Let X be a random vector with distribution \(\mu _J\) and I be an independent random variable uniformly distributed on \(\{1,\ldots , N\}\). First, denote by \((X, {\widetilde{X}})\) the exchangeable pair which is given by taking a step in the Glauber chain for \(\mu _J\), i.e. \({\widetilde{X}}\) is the vector after replacing \(X_I\) by an independent \({\widetilde{X}}_I\) with distribution \({\widetilde{X}}_I \sim \mu _J( \cdot \mid {\overline{X}}_I)\) (the exchangeability follows from the reversibility of the Glauber dynamics). Consequently, \(({\hat{m}}, {\hat{m}}') = ({\hat{m}}(X), {\hat{m}}({\widetilde{X}}))\) is also exchangeable. More precisely, with the standard basis vectors \((e_i)_{i = 1,\ldots ,k}\) of \({{\,\mathrm{\mathbb {R}}\,}}^k\) we have
We need the following lemma to identify the conditional expectation of \({\widetilde{X}}_i\). Here, we write \(h: \{1,\ldots , N\} \rightarrow \{1,\ldots ,k\}\) for the function that assigns to each position its block, i.e. \(h(j) = k \Longleftrightarrow j \in B_k\).
Lemma 4
Let \({\mathcal {F}} = \sigma (X)\) and \((X, {\widetilde{X}})\) be defined as above. Then for each fixed \(i \in \{1, \ldots , N\}\)
Proof
For any Ising model \(\mu = \mu _J\) the conditional distribution of \({\widetilde{X}}_i\) is given by \(\mu (\cdot \mid {\overline{X}}_i)\) and so
where we recall the notation \(J^{(d)}\) for the matrix without its diagonal, i.e. \(J^{(d)} = J - {{\,\mathrm{diag}\,}}(J_{ii})\). In the case that \(J = J_n\) is the block model matrix, this yields
\(\square \)
Since the conditional expectation will be of importance, we define
so that \({{\,\mathrm{\mathbb {E}}\,}}({\widetilde{X}}_i \mid {\mathcal {F}}) = \tanh (g_i(X))\). Note that \(g_i\) actually does not depend on \(X_i\), the latter term is added for convenience to rewrite the first term. Thus we have \(g_i(X) = {{\,\mathrm{\mathbb {E}}\,}}({\widetilde{X}}_i \mid {\overline{X}}_i)\).
Lemma 5
We have
with
Proof
From Eq. (9) and Lemma 4 we obtain
\(\square \)
For n large enough, the matrix \(\varLambda :=N^{-1}({{\,\mathrm{Id}\,}}- \varGamma A \varGamma )\) satisfies \(\Vert {\varLambda } \Vert _{2 \rightarrow 2} < \frac{1}{N}\) and is thus invertible, with inverse \(\varLambda ^{-1} = N \sum _{l = 0}^\infty (\varGamma A \varGamma )^l\). Moreover, we also have \(\Vert {\varLambda ^{-1}} \Vert _{2 \rightarrow 2} \le N (1-\Vert {\varGamma A \varGamma } \Vert _{2 \rightarrow 2})^{-1}\).
We will need the following approximation theorem for random vectors.
Theorem 5
([30, Theorem 2.1]) Assume that \((W,W')\) is an exchangeable pair of \({{\,\mathrm{\mathbb {R}}\,}}^d\)-valued random vectors such that
with \(\varSigma \in {{\,\mathrm{\mathbb {R}}\,}}^{d\times d}\) symmetric and positive definite. Suppose further that
is satisfied for an invertible matrix \(\varLambda \) and a \(\sigma (W)\)-measurable random vector R. Then, if Z has d-dimensional standard normal distribution, we have for every three times differentiable function
where, with \(\lambda {(i)} :=\sum _{m = 1}^d |{\left( \varLambda ^{-1} \right) _{m,i}} |\), we define the three error terms
Here, \(|{h} |_j\) denotes the supremum of the partial derivatives of up to order j.
Note that in the proof the choice of \(\sigma (W)\) for the conditional expectation is arbitrary; it suffices to take any \(\sigma \)-algebra \({\mathcal {F}}\) with respect to which W is measurable. Clearly, the value \(E_1\) has to be adjusted accordingly.
Corollary 2
Let \({\hat{m}}\) be the block magnetization vector and \({\hat{m}}'\) as above, define \(\varSigma :={{\,\mathrm{\mathbb {E}}\,}}{\hat{m}}{\hat{m}}^T\) and let \(Z \sim {\mathcal {N}}(0, \varSigma )\). For any function \(h \in {\mathcal {F}}_3\)
with the three error terms
Finally, the following lemma shows that all error terms \(E_i\) can be bounded by a term of order \(N^{-3/2}\).
Lemma 6
In the situation of Corollary 2 we have
Before we prove this lemma (and consequently Theorem 4), we will state concentration of measure results in the block spin Ising models. These will be necessary to bound \(E_1, E_2, E_3\). The first step is the existence of a logarithmic Sobolev inequality for the Ising model \(\mu _{J_n}\) with a constant that is uniform in n.
Proposition 3
Under the general assumptions, if \(\Vert {\varGamma _\infty A \varGamma _\infty } \Vert _{2 \rightarrow 2} < 1\), then for n large enough the Ising model \(\mu _{J_n}\) satisfies a logarithmic Sobolev inequality with a constant \(\sigma ^2 = \sigma ^2(\Vert {\varGamma _\infty A \varGamma _\infty } \Vert _{2 \rightarrow 2})\), i.e. for any function \(f: \{-1,+1\}^N \rightarrow {{\,\mathrm{\mathbb {R}}\,}}\) we have
where \({{\,\mathrm{Ent}\,}}\) is the entropy functional and \(T_i(\sigma ) = (\sigma _1,\ldots , \sigma _{i-1}, -\sigma _i, \sigma _{i+1}, \ldots , \sigma _N)\) the sign flip operator.
This follows immediately from [23, Proposition 1.1], since \(\varGamma _n A \varGamma _n \rightarrow \varGamma _\infty A \varGamma _\infty \), which implies the convergence of the norms, i.e. for n large enough we have \(\Vert {\varGamma _n A \varGamma _n} \Vert _{2 \rightarrow 2} < 1\). Although the condition in [23] is \(\Vert {J} \Vert _{1 \rightarrow 1} < 1\), this was merely for applications’ sake and \(\Vert {J} \Vert _{2 \rightarrow 2} < 1\) is sufficient to establish the logarithmic Sobolev inequality.
For any function \(f: \{-1,+1\}^N \rightarrow {{\,\mathrm{\mathbb {R}}\,}}\) and any \(r \in \{1,\ldots ,N\}\) we write
so that (10) becomes
Moreover, it is known that (10) implies a Poincaré inequality
Proof of Lemma 6
Error term\(\mathbf{E }_\mathbf{1 }\): To treat the term \(E_1\), fix \(i \in \{1,\ldots , k\}\) and observe that
Thus, if we define
we see that
and we need to show that \({{\,\mathrm{Var}\,}}(f_i(X)) = O(1)\). Using the Poincaré inequality (11) it suffices to prove that \({\mathfrak {h}}_r f_i(X)^2 \le C |{B_i^{(n)}} |^{-1}\).
Let \(r \in \{1,\ldots , N\}\) be arbitrary and define \(h_i(X) :=N^{-1} \sum _{l = 1}^k A_{il} m_l(X) - N^{-1} A_{ii} X_i\). The first case is that \(r \in B_i^{(n)}\), for which
The second case \(r \notin B_i^{(n)}\) follows by similar reasoning.
Error term\(\mathbf{E }_\mathbf{2 }\): The second term \(E_2\) is much easier to estimate, as
Error term\(\mathbf{E }_\mathbf{3 }\): To estimate the variance of the remainder term R we first split it into two sums. For any \(i = 1, \ldots , k\) write
Clearly \(\Vert {R_i - {{\,\mathrm{\mathbb {E}}\,}}R_i} \Vert _2 \le \Vert {R_i^{(1)} - {{\,\mathrm{\mathbb {E}}\,}}R_i^{(1)}} \Vert _2 + \Vert {R_i^{(2)} - {{\,\mathrm{\mathbb {E}}\,}}R_i^{(2)}} \Vert _2\) and we estimate these terms separately. It is obvious that the \(L^2\) norm of the second term is of order \(O(N^{-2})\). To estimate \(R^{(1)}_i\), we use \(\tanh (x) - x = O(x^3)\) to obtain
In the last line we have used the fact that \(\Vert {(A \varGamma {\hat{m}})_i^3} \Vert _2 = \Vert {A \varGamma {\hat{m}}_i} \Vert _6^3\) and for all \(p \ge 2\)
which evaluated at \(p = 6\) gives \(\Vert {(A\varGamma {\hat{m}})_i} \Vert _6^3 = O(1)\). For the details see [23]. The constant depends on a norm of \(A \varGamma \), which by convergence to \(A \varGamma _\infty \) can again be chosen independently of n. \(\square \)
Proof of Theorem 4
The theorem follows immediately from Corollary 2 and Lemma 6. \(\square \)
4 Discussion and Open Questions
Although the questions raised in the introduction have been answered to a certain degree, there are still open questions that we were not yet able to answer.
The first question concerns the maxima of the rate function I. Firstly, note that by [11, Theorem A.1] the global maxima of I are related to the global minima of the so-called pressure functional, which can for example be found in [17, equation (14)]. Using the compactness of \([-1,1]^k\) and the continuity of I, the existence of a maximiser easily follows, but the number of maximisers is still obscure. From real-analyticity of I, we can infer that the set of maximisers is a \(\lambda ^k\) null set, but it could in principle contain infinitely many points. However, Lemmas 2 and 3 as well as numerics suggest that for positive interactions and \(k \ge 2\), the number of local minima is twice the number of independent systems - see Figures 2 for the \(k = 3\) and 3 for the \(k = 2\) case below.
However, we believe that the case of negative interactions between groups might drastically change the picture. Indeed, consider a model with three blocks and positive interaction \(\beta \) within the blocks and negative interaction \(\alpha \) between the blocks. Then, if \(\beta \) is large enough, the points within the blocks will tend to be aligned. However, as \(\alpha \) is negative, the magnetizations of block one and two will try to have different signs, but so do the magnetizations of blocks two and three, and three and one. Hence, frustration occurs. In this respect, a model with positive and negative interactions carries features of a spin glass.

A scatterplot of the normalized block magnetization \({\widetilde{m}}\) in the uniform case with \(k = 3\) blocks and \(n = 500\), sampled using the Glauber dynamics—note that it is not rapidly mixing!

A heatmap (left) and a histogram (right) of the block magnetization vector \(m = (m^1, m^2)\) in the uniform, low temperature case. The block interaction matrix is given by \(A = \begin{pmatrix} 1.8 &{} 0.8 \\ 0.8 &{} 1.8 \end{pmatrix}\)
Another question is the relationship of Theorems 2 and 4. In Theorem 4 we consider the distance to a normal distribution with covariance matrix \(\varSigma _n :={{\,\mathrm{\mathbb {E}}\,}}{\hat{m}}^{(n)} ({\hat{m}}^{(n)})^T\) and not to \(\varSigma _{\infty } :=({{\,\mathrm{Id}\,}}- \varGamma _\infty A \varGamma _\infty )^{-1}\), which is the covariance matrix of the limiting distribution. Testing against functions \(h \in {\mathcal {C}}_c^\infty ({{\,\mathrm{\mathbb {R}}\,}}^k)\), we see that \(\varSigma _\infty \) is the limit of the matrices \(\varSigma _n\). It is an interesting task to provide suitable bounds of \(\Vert {\varSigma _n - \varSigma _{\infty }} \Vert \) in any matrix norm, since [30, Proposition 2.8] provides bounds of \(|{{{\,\mathrm{\mathbb {E}}\,}}h(X) - {{\,\mathrm{\mathbb {E}}\,}}h(Y)} |\) for two random vectors with \(X \sim {\mathcal {N}}(0,\varSigma _0)\) and \(Y \sim {\mathcal {N}}(0, \varSigma _1)\) in terms of the 1-distance of \(\varSigma _0\) and \(\varSigma _1\).
Thirdly, it remains an open problem to quantify the distance to a normal distribution with the “limiting” covariance matrix \(\varSigma _\infty \). The central limit theorem in the one-dimensional Curie–Weiss model has been solved for example in [14, Corollary 2.9]. Therein one can see that the limiting covariance is \((1-\beta )^{-1}\) by considering the approximate linear regression condition. A similar condition is true in the multidimensional case. For example, in Lemma 5 we have proven
where \(\lambda = N^{-1}\) and \(\varLambda = ({{\,\mathrm{Id}\,}}- \varGamma _n A \varGamma _n)^{-1}\). Thus, in the case \(\varGamma _n \equiv \varGamma _\infty \) (e.g. consider a subsequence along which this holds) \(\varLambda \) is the covariance matrix of the limit distribution. However, we have been unable to find a suitable modification of [30, Theorem 2.1] that enables one to compare the distribution of the random vector \({\hat{m}}^{(n)}\) with \({\mathcal {N}}(0, \varLambda )\).
References
Agliari, E., Burioni, R., Contucci, P.: A diffusive strategic dynamics for social systems. J. Stat. Phys. 139(3), 478–491 (2010). https://doi.org/10.1007/s10955-010-9948-1
Amini, A.A., Levina, E.: On semidefinite relaxations for the block model. Ann. Stat. 46(1), 149–179 (2018). https://doi.org/10.1214/17-AOS1545
Berthet, Q., Rigollet, P., Srivastava, P.: Exact recovery in the Ising blockmodel. Ann. Stat. 47(4), 1805–1834 (2019). https://doi.org/10.1214/17-AOS1620
Bresler, G.: Efficiently learning Ising models on arbitrary graphs [extended abstract]. In: STOC’15—Proceedings of the 2015 ACM Symposium on Theory of Computing, pp. 771–782. ACM, New York (2015)
Bresler, G., Mossel, E., Sly, A.: Reconstruction of Markov random fields from samples: some observations and algorithms. SIAM J. Comput. 42(2), 563–578 (2013). https://doi.org/10.1137/100796029
Brock, W.A., Durlauf, S.N.: Discrete choice with social interactions. Rev. Econom. Stud. 68(2), 235–260 (2001). https://doi.org/10.1111/1467-937X.00168
Chatterjee, S., Shao, Q.M.: Nonnormal approximation by Stein’s method of exchangeable pairs with application to the Curie–Weiss model. Ann. Appl. Probab. 21(2), 464–483 (2011). https://doi.org/10.1214/10-AAP712
Collet, F.: Macroscopic limit of a bipartite Curie–Weiss model: a dynamical approach. J. Stat. Phys. 157(6), 1301–1319 (2014). https://doi.org/10.1007/s10955-014-1105-9
Comets, F.: Large deviation estimates for a conditional probability distribution. Applications to random interaction Gibbs measures. Probab. Theory Relat. Fields 80(3), 407–432 (1989). https://doi.org/10.1007/BF01794432
Cont, R., Löwe, M.: Social distance, heterogeneity and social interactions. J. Math. Econom. 46(4), 572–590 (2010). https://doi.org/10.1016/j.jmateco.2010.03.009
Costeniuc, M., Ellis, R.S., Touchette, H.: Complete analysis of phase transitions and ensemble equivalence for the Curie–Weiss–Potts model. J. Math. Phys. 46(6), 063301 (2005). https://doi.org/10.1063/1.1904507
Dembo, A., Zeitouni, O.: Large Deviations Techniques and Applications. Stochastic Modelling and Applied Probability, vol. 38. Springer, Berlin (2010)
den Hollander, F.: Large Deviations, Fields Institute Monographs, vol. 14. American Mathematical Society, Providence (2000)
Eichelsbacher, P., Löwe, M.: Stein’s method for dependent random variables occurring in statistical mechanics. Electron. J. Probab. 15(30), 962–988 (2010). https://doi.org/10.1214/EJP.v15-777
Ellis, R.S.: Entropy, Large Deviations, and Statistical Mechanics. Classics in Mathematics. Springer, Berlin (2006)
Ellis, R.S., Newman, C.M.: Limit theorems for sums of dependent random variables occurring in statistical mechanics. Z. Wahrsch. Verw. Gebiete 44(2), 117–139 (1978). https://doi.org/10.1007/BF00533049
Fedele, M., Contucci, P.: Scaling limits for multi-species statistical mechanics mean-field models. J. Stat. Phys. 144(6), 1186–1205 (2011). https://doi.org/10.1007/s10955-011-0334-4
Fedele, M., Unguendoli, F.: Rigorous results on the bipartite mean-field model. J. Phys. A 45(38), 385001, 18 (2012). https://doi.org/10.1088/1751-8113/45/38/385001
Gallo, I., Contucci, P.: Bipartite mean field spin systems. Existence and solution. Math. Phys. Electron. J. 14, 1, 21 (2008)
Gallo, I., Barra, A., Contucci, P.: Parameter evaluation of a simple mean-field model of social interaction. Math. Models Methods Appl. Sci. 19(suppl.), 1427–1439 (2009). https://doi.org/10.1142/S0218202509003863
Gao, C., Ma, Z., Zhang, A.Y., Zhou, H.H.: Achieving optimal misclassification proportion in stochastic block models. J. Mach. Learn. Res. 18, 60, 45 (2017)
Gentz, B., Löwe, M.: The fluctuations of the overlap in the Hopfield model with finitely many patterns at the critical temperature. Probab. Theory Relat. Fields 115(3), 357–381 (1999). https://doi.org/10.1007/s004400050241
Götze, F., Sambale, H., Sinulis, A.: Higher order concentration for functions of weakly dependent random variables. Electron. J. Probab. 24(85), 19 (2019). https://doi.org/10.1214/19-EJP338
Kincaid, J.M., Cohen, E.G.D.: Phase diagrams of liquid helium mixtures and metamagnets: experiment and mean field theory. Phys. Rep. 22(2), 57–143 (1975). https://doi.org/10.1016/0370-1573(75)90005-8
Kirsch, W., Toth, G.: Two groups in a Curie-Weiss model with heterogeneous coupling. J. Theor. Probab. (2019). https://doi.org/10.1007/s10959-019-00933-w
Knöpfel, H., Löwe, M.: Zur Meinungsbildung in einer heterogenen Bevölkerung–ein neuer Zugang zum Hopfield Modell. Math. Semesterber. 56(1), 15–38 (2009). https://doi.org/10.1007/s00591-008-0049-z
Löwe, M., Schubert, K.: Fluctuations for block spin Ising models. Electron. Commun. Probab. 23, 53, 12 (2018). https://doi.org/10.1214/18-ECP161
Mossel, E., Neeman, J., Sly, A.: Belief propagation, robust reconstruction and optimal recovery of block models. Ann. Appl. Probab. 26(4), 2211–2256 (2016). https://doi.org/10.1214/15-AAP1145
Opoku, A.A., Owusu Edusei, K., Ansah, R.K.: A conditional Curie–Weiss model for stylized multi-group binary choice with social interaction. J. Stat. Phys. 171(1), 106–126 (2018). https://doi.org/10.1007/s10955-018-1988-y
Reinert, G., Röllin, A.: Multivariate normal approximation with stein’s method of exchangeable pairs under a general linearity condition. Ann. Probab. 37(6), 2150–2173 (2009). https://doi.org/10.1214/09-AOP467
van Hemmen, J.L., van Enter, A.C.D., Canisius, J.: On a classical spin glass model. Z. Phys. B 50(4), 311–336 (1983). https://doi.org/10.1007/BF01470043
van Hemmen, J.L., Grensing, D., Huber, A., Kühn, R.: Elementary solution of classical spin-glass models. Z. Phys. B 65(1), 53–63 (1986). https://doi.org/10.1007/BF01308399
Acknowledgements
Open access funding provided by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Hal Tasaki.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Knöpfel, H., Löwe, M., Schubert, K. et al. Fluctuation Results for General Block Spin Ising Models. J Stat Phys 178, 1175–1200 (2020). https://doi.org/10.1007/s10955-020-02489-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10955-020-02489-0