
Abstract
Asthma, a common chronic respiratory disease among children and adults, affects more than 200 million people worldwide and causes about 450,000 deaths each year. Machine learning is increasingly applied in healthcare to assist health practitioners in decision-making. In asthma management, machine learning excels in performing well-defined tasks, such as diagnosis, prediction, medication, and management. However, there remain uncertainties about how machine learning can be applied to predict asthma exacerbation. This study aimed to systematically review recent applications of machine learning techniques in predicting the risk of asthma attacks to assist asthma control and management. A total of 860 studies were initially identified from five databases. After the screening and full-text review, 20 studies were selected for inclusion in this review. The review considered recent studies published from January 2010 to February 2023. The 20 studies used machine learning techniques to support future asthma risk prediction by using various data sources such as clinical, medical, biological, and socio-demographic data sources, as well as environmental and meteorological data. While some studies considered prediction as a category, other studies predicted the probability of exacerbation. Only a group of studies applied prediction windows. The paper proposes a conceptual model to summarise how machine learning and available data sources can be leveraged to produce effective models for the early detection of asthma attacks. The review also generated a list of data sources that other researchers may use in similar work. Furthermore, we present opportunities for further research and the limitations of the preceding studies.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Asthma, a common long-term lung condition, is caused by inflammation in the airways of the respiratory system. Asthma affected 262 million people in 2019, and it causes an average of 461,000 deaths each year [1]. Often beginning in childhood, asthma affects all ages [2]. A diagnosis of asthma considers clinical signs and symptoms, including wheezing, breathlessness, chest tightening, and coughing [3]. Asthma exacerbations could arise in patients due to multiple factors, including genetic, clinical, and environmental factors. For instance, if asthma patients are exposed to atmospheric changes such as dust, fumes, and pollen, their asthma can worsen, and it can lead to asthma attacks.
The reasons for asthma exacerbations are multifactorial, and worsening of asthma control may go unnoticed in patients if their symptoms are mild. However, asthma can worsen rapidly, leading to hospitalisation or death [4]. The National Review of Asthma Deaths (NRAD), conducted in the UK, found that 58% of patients with asthma who died were diagnosed as having mild or moderately severe asthma, with almost half having had no asthma review in the previous 12 months [5]. This highlights the need for innovative approaches to managing asthma and responding to attacks to ensure that care is delivered promptly. Another study [6] found that hospitalisation due to COVID-19 has increased among children (5-17 years) with poorly controlled asthma, as compared to children with well-controlled or without asthma. This highlights the increased risk that asthma patients face and emphasises the need for regular medical review, treatment, and proper management. This is important since asthma control can be affected by other factors, including environmental and meteorological conditions [7,8,9], workplace conditions, and severe adverse life events [10]. Therefore, early detection of asthma symptoms or exacerbations is essential to ensure rapid mitigation.
Even so, asthma prediction is challenging and complex due to its heterogeneous nature and the diverse multifactorial triggers unique to individuals [11, 12]. Patients with asthma are at a high risk of needing unscheduled medical care, which could be prolonged and costly to the health system. Any approach to predict asthma attacks will enhance asthma management and will reduce costs while increasing the quality of life. Whilst there has been a range of approaches to predicting the risk for asthma attacks that have been investigated in prior literature [13], the recent development of novel artificial intelligence techniques has seen a rapid rise in efforts to predict asthma exacerbations. However, the clinical relevance of these techniques and the potential to improve the accuracy and reliability of risk prediction is not yet known. There is a need to synthesise the available machine learning models that have been developed to a) identify the performance of these models in risk prediction and b) determine the range of clinical factors that have been included in these models. Understanding these factors is key if these models are to be used in routine practice for triaging patients based on their level of attack risk, or informing changes in their treatment based on their changing risk as part of clinical decision-making.
Machine learning (ML) techniques that have emerged to manage and treat various diseases are increasingly being applied, particularly in terms of risk prediction. ML is developed based on mathematics, logic, probability, neuroscience, and decision theory. Using these concepts, different algorithms are constructed that can store important information from data elements via continuous training sessions. Consequently, the models built upon these algorithms have the ability to identify patterns and generate outcomes from complex data without any human-generated explicit programming code [14]. These computer methodologies have been found to perform better than traditional statistical approaches that can facilitate personalised medicine by addressing individual patient characteristics while processing vast amounts of data [15, 16]. Previous studies have shown that ML models can support asthma monitoring, prediction, diagnosis, and control in children and adults. These techniques complement clinicians if expertise or resources are limited [17], preventing or mitigating tragic circumstances. This may be particularly true for exacerbation prediction as it will be difficult for health practitioners to consider a variety of factors, other than medical and clinical, in determining future attacks. Computer-based assistance can help predict impending attacks by considering a range of factors, and it will assist clinicians in making the appropriate decisions for the patient. The existence of a risk prediction model will be helpful for physicians to monitor disease control. It can also help patients as they will be made aware of any possible upcoming attacks.
There are three categories of ML algorithms: supervised, unsupervised and reinforcement. Supervised algorithms are used to solve classification and regression problems. Typical applications of these algorithms are seen in spam filters, fraud detection systems, recommendation engines, image recognition systems, and so on. Figure 1 shows some of the commonly used ML algorithms for making predictions.

Commonly used machine learning algorithms for making a prediction
This systematic review explores the application of ML techniques to predict the risk of asthma attacks. The review question was "How do machine learning techniques perform in predicting asthma attacks?". Specifically, we identify the ML techniques used, categorise the predictive models based on the outcome, and identify the suitability of ML approaches as they relate to the scenarios we analysed. We also identify the best-performing ML algorithms and provide prospective research directions.
The subsequent sections of this paper are organised as follows. Section “Methodology” explains the methodology employed in this investigation, while “Results” section articulates the findings derived from the study. Section “Discussion” provides an in-depth discussion of these findings. Section “Conclusion” summarises the study and suggests potential avenues for future research.
Methodology
This review adopted the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) methodology [18]. The protocol has been registered with the PROSPERO International Prospective Register of Systematic Reviews (PROSPERO CRD42023402178).
Inclusion Criteria
This study included primary studies of ML-based solutions for asthma in adults and children published in English from January 2010 to February 2023. No limitations were placed on the study design, setting, or minimum follow-up, but studies were limited to the English language due to the language capabilities of the research team.
Exclusion Criteria
Studies focusing on the diagnosis/prediction of asthma itself (as a condition), rather than asthma exacerbations, were excluded from the current study. Any studies that have followed a non-machine learning approach were excluded. Additionally, studies focusing on predicting asthma symptoms/control/severity level, peak expiratory flow rate (PEFR) and emergency department (ED) visits due to other diseases were eliminated from the study pool. Further, we excluded research work published as reviews, systematic reviews, editorials, letters, comments to the editor, book chapters, abstracts, conceptual papers, opinions, unavailable sources, protocols, commentary, and unpublished full-text documents.
Data Sources and Search Strategy
We searched the databases Medline (via PubMed), Cochrane (via Wiley), Embase, IEEE Xplore, and Google Scholar using the search terms Asthma AND (attack* OR exacerbat* OR control* OR symptom*) AND (detect* OR predict* OR diagnos* OR manag*) AND ("artificial intelligence" OR AI OR "machine learning" OR "deep learning" OR "neural network" OR computer-based OR "computer based" OR computer-assisted OR "computer assisted" OR "computer technology" OR technology).
Selection Process
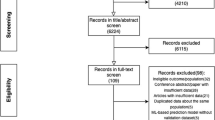
The database search identified 860 eligible records. We used the tool RAYYAN for the study selection process [19]. After removing 122 duplicates, the titles and the abstracts of the remaining studies were screened. At the end of this step, we eliminated 667 records, and the rest of the studies were sent through full-text screening, which resulted in the selection of 20 studies to be included in our review. These were blindly reviewed by two different researchers. This study selection process is illustrated in Fig. 2.

Study inclusion process via PRISMA
Data Extraction
A data extraction table was created to record the specific data extracted from the selected studies. The design of the table structure was informed by previous research [20, 21]. We extracted the year, country, title, aim, data source/s, sample size, research techniques, findings, evaluation metrics, model performance, and the limitations and strengths of each study.
Risk of Bias Assessment
A risk of bias assessment of the selected studies was conducted using the Critical Appraisal Skills Programme (CASP) for Clinical Prediction Rule [22]. The CASP checklist was completed for each study independently by two authors. Any disagreements were resolved by consensus discussion. An additional file shows the quality of each study (see Supplementary file S1).
Results
Characteristics of Included Studies
Characteristics of the 20 studies included in this review are elaborated in Fig. 3. The included studies were conducted in a range of different countries, represented in Fig. 3a. (A study [23] that used an international data set from multiple countries is not included in the figure.) Importantly, as can be seen from Fig. 3a, the USA is the main country of origin for many of these studies predicting asthma attack risk using ML techniques. As shown in Fig. 3b, 75% of the studies were published as journal articles and the rest as conference papers. Figure 3c shows the distribution of the studies by year of publication. The majority of the studies have been published after 2020. The data sets employed in these studies have different sample sizes according to the number of participants or records (data instances). These details are presented in Table 1, showing the absolute values and percentages. Table 1 highlights the distribution of the two classes of the target variable: asthma attacks, both absent and present, as well as the portions of data used for training and testing the prediction models.
In this review, we identify the data sources that the previous studies incorporated to predict the risk of asthma attacks. Table 2 shows the different data domains including biological, clinical, environmental and meteorological, hospital and medical, and socio-demographic that have been used to develop the asthma risk prediction models. Clinical data may include asthma symptoms, PEFR, and inhalations while prescribed medications and treatments come under medical data. Hospital data consists of hospital admissions, previous attacks, comorbidities, ED visits, etc.

Characteristics of the included studies
ML Models
The 20 studies used different ML techniques to predict the risk of asthma attacks. The outcome, asthma exacerbation, was considered either as a categorical variable or as a continuous variable in the form of a probability. Therefore, the studies can be categorised into 2 groups: 1) studies that predict the risk of asthma attacks as a classification (n=18) and 2) studies that predict the risk of asthma attacks as a probability (n=2). The classification group was further divided into 2 groups: studies with (n=11) and without (n=7) a prediction window. The studies with a prediction window can again be subdivided based on the window size: less than (n=6) and more than (n=5) a month. This categorisation of the studies is illustrated in Fig. 4.

Presentation of the results of the review
In the literature, many studies predicted the risk of asthma exacerbations without considering the temporal effect. For instance, the impact of weather data from the previous day or a few days ago that might have triggered the symptoms of asthma patients. Therefore, it is critical to consider the impact of the different factors from previous days (lags) in forecasting the risk of asthma attacks. Further, instead of just making a prediction, a group of studies constructed models to predict asthma attacks for a specific time (prediction window), such as the coming 3 days, 7 days, 3 months, 1 year, and so on. Details about these models are presented in the following sections.
Among the ML algorithms employed in these studies, logistic regression (LR), decision trees (DT), random forest (RF), gradient boosting machines (GBM), extreme gradient boost (XGB), support vector machines (SVM), and neural network (NN) algorithms were used most often. Most of the studies exercised the k-fold cross-validation technique to validate the model on the training data. Different studies chose different k values such as 3 [38], 4 [27, 28], 5 [16, 23, 24, 32, 34] and 10 [30, 33, 35].
Hyperparameter Tuning
Hyperparameters in ML models are external configuration settings that are not learned from the data but are set prior to the training process. They influence the overall behaviour of the model and affect its performance. Hyperparameters can be optimised using different techniques. Among the studies included in this review, only a very few [24, 34, 38, 40] conducted hyperparameter tuning. The grid search technique was applied in two of these studies [24, 34] while the randomised search technique was applied in another one [38]. (There are not enough details regarding the hyperparameter tuning process in [40].) Table 3 presents the details of the hyperparameter tuning conducted by past studies. It shows the various hyperparameters tuned with different values and techniques.
Model Performance
The studies used different evaluation metrics to evaluate and compare the performance of the models, as shown in Table 4. These metrics were predominantly accuracy, area under the receiver operating curve (AUC-ROC), specificity, sensitivity, positive predictive value (PPV), and negative predictive value (NPV). Accuracy is the ratio of correctly predicted outcomes and the total number of samples, simply the overall correctness of the model. The AUC-ROC value represents the capability of the model to distinguish between the classes. Sensitivity, also called recall, measures the completeness of positive predictions, while specificity measures the completeness of negative predictions. PPV, also called precision, is the accuracy of positive predictions, while NPV is the accuracy of negative predictions.
Predicting Risk of Asthma Attacks As a Classification
Nineteen of the previous studies predicted the risk of an asthma attack as a binary classification, and one study [37] considered asthma attacks as a multi-class classification problem. Most studies in the binary category predicted the presence or absence of an asthma attack, while others considered different levels of asthma attack, such as mild, moderate, or severe. This section discusses the studies that predicted the risk of asthma exacerbation as a category. Furthermore, imminent attacks could be predicted for a future time frame, for instance, the possibility of an attack in the next 3 days. While some studies constructed models by taking prediction windows into account, others did not. The following sub-section describes these groups.
Predicting Risk of Asthma Attacks With a Prediction Window of Less Than a Month
In the literature, many studies predicted the risk of asthma exacerbations without considering the temporal effect. For instance, the impact of weather data from the previous day or a few days ago might have triggered the symptoms of asthma patients. Therefore, it is critical to consider the impact of the different factors from previous days (lags) in forecasting the risk of asthma attacks. Further, instead of just making a prediction, a group of studies constructed models to predict asthma attacks for a specific time (prediction window), such as the coming 3 days, 7 days, 3 months, 1 year and so on. Figure 5 depicts the association between prediction window size and the model’s performance. The figure highlights that the shorter the prediction window, the higher the model’s performance. The following section discusses those studies. We synthesised these studies into two categories according to the size of the prediction window as follows. This section represents the studies that classified the risk of asthma attacks using prediction windows for less than a one-month period. Table 5 in the Appendix shows a summary of the studies that developed ML models to predict asthma risk as a category using the prediction window concept.

Association between prediction window size and model performance
Six studies [23,24,25,26,27,28] developed models for short-term prediction of severe asthma exacerbations. Five studies [23,24,25,26, 28] kept the prediction window at less than a week while one study [27] used more than 2 weeks (15 days) for the prediction window. In training the ML models, the authors used data from several previous days, which they defined as a lookback window. Four of the studies [24,25,26,27] applied the lookback window concept with the size of the lookback window ranging from 5 to 365 days for near-term prediction. However, [27] included inputs such as count of events for multiple lookback windows sizes - 10, 30, 60, 90, and 365 days. With the aim of exploring telemonitoring data for asthma risk prediction, and using the minimum description length (MDL) principle, [26] found that the telemonitoring alert (out of four zones) on day 7 has higher importance in predicting the asthma risk on day 8. Comorbidity burden and previous exacerbations were important predictors, identified through collinearity [27]. Even though they have implemented principal component analysis (PCA) and recursive feature elimination techniques to identify important features, those are not clearly stated in the article. Most works used tree-based algorithms such as DT [23], RF [27, 28], XGB [24, 27, 28], and CART [25]. Studies also developed models using LR [23, 24, 27, 28], SVM [24, 26], and NN [23, 27] algorithms. Only two studies applied data imbalance handling techniques- random under-sampling [23, 27], random over-sampling [23], and synthetic minority oversampling technique (SMOTE) [23]. There is no clear data available for data imbalance handling in other works.
Predicting Risk of Asthma Attacks with a Prediction Window of More Than a Month
A set of studies defined their prediction window size as greater than or equal to a one-month period. One study [29] used a 1-month period while [30] used 6-months period as the prediction window size. All of the other studies [31,32,33] kept the prediction window size to 1 year. While [29, 30, 32] considered lookback windows similar in size to prediction windows, no clear details of lookback windows are provided in [31, 33]. One study [29] identified clinical factors such as obesity, atopy, medication, asthma controller plan and patient service utilisation history as important asthma risk predictors. Asthma medication also played an important role in the research by [33]. Further, previous asthma exacerbations and length of treatment with biologics were key predictors of asthma risk in [30]. Meanwhile, age, hospital stay, blight prevalence, and neighbourhood inequality are important predictors, according to another study [32]. In developing prediction models, the most common ML algorithms utilised by these studies are LR [29, 30, 33], RF [29, 30, 32, 33], and XGB [29, 31, 33]. Only one study [32] in this category applied random undersampling to handle data imbalance.
Predicting Risk of Asthma Attacks Without a Prediction Window
This section focuses on the studies that developed ML models to predict the risk of asthma attacks without considering a prediction window. Table 6 represents the study summary for these studies. Seven studies [34,35,36,37,38,39,40] are included in this category and six of them considered this to be a binary classification problem. The seventh study [37] defined three target classes for risk as low, medium and high. A few studies specifically chose hospitalisations [38, 40] or ED visits [40], due to asthma attack being the target variable. Only two studies exercised feature selection. While [34] used the LASSO regression technique, [39] did feature selection with RF. With the aim of utilising environmental triggers and bio-signals for asthma risk prediction, one study [34] identified temperature, wind speed, relative humidity, air quality index (AQI), smoking status, allergies, normal PEFR and daily readings, asthma symptoms of the last 4 weeks, and number of asthma attacks for the last 4 weeks as important predictors. Incorporating other data with community viral load, [38] determined the key predictors as patient vital signs, acuity, age, weight, socio-economic status, dry bulb temperature, wind speed, and station pressure. Another work [40] mentioned the key features as age, long-acting beta-agonist, high dose inhaled glucocorticoid or chronic oral glucocorticoid therapy, FEV1, and FEV1 to FVC ratio. For developing the prediction models, commonly used ML algorithms were, DT [34, 35, 38], RF [34, 38,39,40], GBM variations [34, 38, 40], LR [34, 38, 40], and SVM [34, 35, 37]. Additionally, some authors experimented with Naive Bayes (NB) [35] and NN extensions [36, 37]. Only one of the studies [35] did not possess a high imbalance data set. However, all the other works had highly imbalanced data sets and they have not tried to handle it, other than [34], who applied SMOTE with SVM technique to handle data imbalance.
Predicting Risk of Asthma Attacks as a Probability
Most of the previous studies on predicting the risk of asthma attacks addressed this risk as a binary or multi-class classification scenario. However, a prediction generated as a probability gives more meaning to the output. Rather than saying yes or no, a probability indicates the likelihood of something happening. Furthermore, a prediction presented as a risk score will help the medical practitioner better understand the status of the asthma patient. Accordingly, in the current review, we identified a few studies that used a probability or a score as the prediction outcome, which is clarified in this section. Table 7 summarises the studies that predict the risk of asthma attacks as a probability.
One study [41] presents a Deep Q-learning Network (DQN) framework to predict asthma attacks using the Q-learning method and LSTM to consider the personal risk scores of triggers. The authors calculated a relative risk score as the probability of an event in the exposed group divided by the probability of an event in the not-exposed group. The authors used this separately with vital signs and environmental time series data and they updated each record with a calculated personalised relative risk, presented as a numeric value. The deep learning algorithm, LSTM, was employed to predict the relative risk of asthma patients, which is then utilised in the Q-learning algorithm. Similarly, another study [16] was conducted to predict the risk of asthma exacerbations while exploring the potential risk factors using LSTM. They proposed a time-sensitive attentive neural network (TSANN) by applying an attention mechanism on both code-level and visit-level variables, which eased the model’s interpretability. They also added elapsed time embeddings into the model to indicate the relative time interval between each visit date and the prediction date. They identified gender, race, a few diagnoses and medications as important predictors of asthma attacks [16].
Discussion
Data for Predicting Risk of Asthma Attacks
A conceptual model for predicting the risk of asthma attacks using machine learning techniques is presented in Fig. 6. As asthma is a health condition affected by many factors, data from heterogeneous domains have been integrated to predict the risk of asthma exacerbations listed in Table 2. Asthma is affected by socio-demographic factors, including age, sex, education level, socio-economic status, and marital status [42]. Socio-demographic features including age, gender, race, insurance type, and area of residence [16, 29, 30, 32, 33, 36, 39, 40] have been used with clinical factors such as asthma symptoms, PEFR, reliever medications, and inhalations [24, 25, 28, 34, 40]. Diagnoses, BMI, smoking status, previous asthma attacks, dispensed medications, Charlson Comorbidity Index, comorbidities, ED visits, and hospital visits [27, 29, 30, 33,34,35, 41] were embedded as hospital and medical factors.
Environmental and meteorological data can be used for health forecasting with respect to respiratory diseases [43]. Meteorological data, such as temperature, humidity, air pressure, and wind speed have impacts on asthma [7, 8]. Air pollutants can have chronic effects on humans and thereby pose a greater risk to a larger population. These factors are useful for predicting asthma since they could lead to a high number of asthma-related hospital admissions. Asthma triggers including temperature, relative humidity, wind speed, AQI, air pressure, PM\(_{2.5}\), pollen and gasses like CO, \(NO_2\), \(SO_2\) were the environmental and meteorological factors investigated in the predictor list by [29, 34, 36,37,38, 41]. Additionally, we found one study using the biological factor SNP [39].

Conceptual overview for asthma risk prediction using ML
Among several factors collected from multiple domains, previous studies have found that smoking status [34], normal PEFR and daily readings, previous asthma attacks, asthma symptoms, medication usage [16, 27,28,29, 33, 34], comorbidities [27,28,29], and hospital stays [32] are important predictors of future asthma attacks. Socio-economic factors, including SES [38], age [32, 38, 40], gender, and race [16], have shown to be important in predicting asthma attacks. Weather changes highly affect the control level of asthma patients, and accordingly, past studies show that temperature, wind speed, relative humidity,[34, 38], and AQI [34] have strong predictive power.
These results show the importance of including multiple factors from different domains (see Fig. 6). However, only a few studies have utilised predictors from more than three of the above heterogeneous domains. It seems important to incorporate different factors from multiple domains to forecast impending asthma attacks, as previous works have identified important predictors from each domain. Further, with the vast development of technology, smart devices such as smart peak flow meters and smart inhalers are in the hands of asthma patients. Utilising data from these devices will be more accurate than using data from daily diaries because manually entered data is prone to human errors and recall bias. Finally, social media usage has become a popular place where participants share their feelings and opinions. Therefore, it is worth investigating the use of social media data streams in asthma risk prediction.
Handling Data Imbalance
In real-world data, especially health data, the existence of positive cases is very low compared to the negatives. For instance, the proportion of asthma patients who are admitted to hospitals due to asthma attacks is very low compared to the number of patients who are not admitted to hospitals. This kind of research aims to identify the minority class over the majority. Hence, class imbalance needs to be carefully addressed when applying ML models that highly depend on data. Otherwise, the model will not be able to learn the patterns of positive cases and thereby produce a lower performance for the minority class.
There are several ways to handle data imbalance. The most commonly used techniques are random under-sampling [23, 27, 32] and random over-sampling [23]. In random under-sampling, the number of records in the majority class will be reduced to match with the minority class, and it is vice versa for random over-sampling. Additionally, SMOTE is a more advanced technique that is used to handle data imbalance. An alternative to the random over-sampling technique mentioned above, SMOTE uses a more robust approach to generate new points based on the existing data. Further, the edited nearest neighbours (ENN) and Tomek link are under-sampling techniques that can be used for down-sampling data.
Data imbalance should be handled; otherwise, classifiers would be biased or generate misleading results [7, 27, 44]. However, applying a data balancing technique is not necessary, provided that the data set has considerable balance among target values. It should be noted that these data balancing techniques need to be applied only on the training set; otherwise, a data leakage issue arises. These techniques may improve the predictions in some cases by artificially eliminating or simplifying the records in the data set. The prediction model using the random under-sampling technique showed the best performance with higher specificity and sensitivity values compared to the other models (see Table 3). This highlights the importance of addressing data imbalance prior to developing the ML models.
ML Techniques in Asthma Risk Prediction
Clinical practices are mostly dependent on the professional skills that individuals acquire with practice and experience. However, the human brain has limited abilities to identify longitudinal patterns from massive amounts of data [14]. ML-based models can assist in analysing the growing amount of patient data, achieving patient-oriented decisions [45]. ML techniques can discover undisclosed patterns and find new information from the data. Costs incurred in healthcare could be reduced with the support of ML. Even though the knowledge and experience of a physician are irreplaceable, computer-aided support could increase the efficiency and accuracy of the diagnostic process. Therefore, ML could play a significant role in diagnosing and predicting asthma.
There are several machine learning algorithms that previous studies have used to predict imminent asthma attacks, as mentioned in Tables 5 and 6. In terms of classifying a patient to have or not have an asthma attack in the future, XGB, RF, and LR algorithms have achieved the best performance compared to other classifiers, regardless of the presence of a prediction window or not (see Table 4). On the other hand, both studies that predict the risk probability have used extensions of NN. In contrast to predicting the risk of asthma attacks as a category (yes or no), the probability of having an asthma attack will deliver more information to the health practitioner. The limited number of studies in this review that utilised probability prediction (see Table 7) emphasise that further research is required to understand the applicability of ML techniques in predicting the risk of asthma attacks as a probability.
Prediction and Lookback Window
When anticipating the risk of attacks, it is more useful if the prediction can be made within a specified time window. As presented in the “Results” section, researchers set the prediction window from 1 day [25, 26] to 1 year [31,32,33]. However, none of the studies mentioned a specific reason for choosing the window size. They used either a random value or chose the window size according to the nature of the dataset. From the analysis of the results of those models, we identified that short-term predictions achieved better performance compared to long-term predictions (refer to Fig. 5). In parallel, the researchers fed the past data into the prediction models within a lookback window, which is also called lag (i.e. past data for a given period of time). Incorporating historical data is crucial, especially when considering more common triggers, such as weather factors. While most of the studies have considered lookback windows, there is no clear information in defining the window size. Also, it seems that they have defined the window size according to the availability of data. There is a lack of knowledge about the optimum size of the lookback and prediction windows in predicting the risk of asthma attacks. Hence, it is important to explore and determine these windows for an accurate prediction.
Generating an Explainable Risk Score
Different clinical tools have been developed for monitoring and managing asthma. Global Initiative for Asthma (GINA) guidelines have been formulated based on the level of symptoms in the last four weeks to differentiate between controlled, partially controlled, and poorly controlled asthma. The Asthma Control Test (ACT) [46] and Asthma Control Questionnaire (ACQ) are the most common clinical scores used for asthma control. A study [47] predicted the Pediatric Asthma Risk Score (PARS) with a logistic regression model by assigning weights to the predictors using the rounded odds ratios. Many studies [48,49,50] have used multivariate logistic regression to develop a risk score. Accordingly, past models have considered a linear relationship between the predictors in generating the risk score or used the manually calculated scores as the target outcome of ML models. However, when the number of features becomes high, it is unreasonable to assume that they always have linear relationships. Therefore, developing a new asthma risk score requires more advanced technologies, such as machine learning, which can handle non-linearity among the predictors. While using these techniques, the prediction should be explainable to the clinicians in order for them to trust the score. This transparency is essential in the healthcare industry. The existing asthma risk scores are derived mainly from demographic and clinical factors. Instead of considering only the subjective factors, such as the prevalence of symptoms for a period, it is important to examine objective factors, such as peak flow and inhaler data, in deriving a control score. Asthma is a multi-factorial disease; it triggers patients’ disease levels based on individual factors. Therefore, a more objective continuous score is necessary to predict the asthma control level. Further, rather than keeping the model a “black box”, adding the reason behind the generated value would add more value and transparency to the prediction. It adds interpretability to the model which will be clinically important.
Hyperparameter Tuning
Machine learning algorithms comprise diverse parameters assigned varying values to optimise performance. Among these, model parameters, internal in nature, undergo configuration during the learning process as the model adapts to data provided to it. A prime example is the weights of a neural network, acquired during the training phase. Conversely, hyperparameters, external in nature, necessitate the assignment of values before the training stage. Identification of hyperparameter values, termed hyperparameter optimisation or tuning, precedes model training. For instance, determining the optimal learning rate for a neural network is pivotal for achieving peak model performance. In practice, iterative fine-tuning of hyperparameters involves training multiple models with diverse parameter combinations, evaluating performance, and selecting the most optimal model. This procedure can be executed by utilising the default values for the algorithm, manually configuring them based on past examples or experiments, or seeking assistance from experts to define these parameters [51]. Random searching [52] is one of the strategies for hyperparameter tuning that will consider a pool of values and choose different combinations randomly to find the best set of hyperparameter values. On the other hand, in the grid search technique, all the combinations of the specified set of values will be tried to determine the best combination which gives the highest model performance. A study compared the grid search and random search techniques to predict chronic kidney failure using XGB [53]. The best results came from the grid search technique. There are other hyperparameter optimisation techniques such as Bayesian optimisation [54, 55], genetic algorithm, etc. Experimental outcomes were comparable; nevertheless, the genetic algorithm outperformed the grid search technique and the Bayesian algorithm to predict customer transactions using NN [56]. However, except for a few works, the studies we reviewed lacked this important step. The ultimate goal of constructing these ML models for risk prediction is to gain the highest performance for the given problem. Therefore, conducting hyperparameter optimisation is crucial in developing ML models as it can improve the models’ performance. Researchers must delve into suitable techniques for tuning hyperparameters in the machine learning models they construct.
Conclusion
With growing ML applications in healthcare, several studies have employed these advanced computer-based techniques for predicting impending asthma attacks using heterogeneous data sources. In this review, firstly, we have presented a conceptual overview of the landscape of this research so that researchers can engage in future research in a similar context (see Fig. 4). Secondly, this review has generated a list of data sources available for researchers, which is available in Table 2. Thirdly, for each branch of the review, we presented lists of studies predicting the risk of an asthma attack as a classification with and without a prediction window (Tables 5 and 6) and prediction as a probability (Table 7).
The findings of this review confirm the importance of using different predictors from multiple data sources for predicting asthma attacks. The analysis shows the applicability of ML algorithms and their ability to perform on asthma patient data, including other factors. For classifying future attacks, ensemble methods based on decision trees have given better performance, while extended neural networks have achieved acceptable results on probability prediction. Further, the summary of the past studies confirmed that having a shorter prediction window improves the prediction outcome. For future research in ML applications in asthma prediction, hyperparameter tuning and data imbalance handling need to be carefully followed to integrate data from multiple sources. Additionally, optimal lookback and prediction windows for asthma risk prediction require further investigation. Moreover, deriving an explainable asthma risk score with the integration of multiple data sources using ML techniques needs to be explored which will assist health practitioners.
Availability of Data and Materials
Not applicable.
References
World Health Organization (2021) Asthma. https://www.who.int/news-room/fact-sheets/detail/asthma, accessed: 2021-09-15
National Health Service (2021) Asthma. https://www.nhs.uk/conditions/asthma/, accessed: 2021-09-18
Global Initiative for Asthma (2021) Global strategy for asthma management and prevention. Tech. rep., Global Initiative for Asthma, https://ginasthma.org/
Tsang KCH, Pinnock H, Wilson AM, et al (2020) Application of machine learning to support self-management of asthma with mhealth. Annual International Conference of the IEEE Engineering in Medicine and Biology Society IEEE Engineering in Medicine and Biology Society Annual International Conference 2020:5673–5677. https://doi.org/10.1109/EMBC44109.2020.9175679
Levy ML, Winter R (2015) Asthma deaths: what now? Thorax 70(3):209–210. https://doi.org/10.1136/thoraxjnl-2015-206800, https://thorax.bmj.com/content/70/3/209
Shi T, Pan J, Katikireddi SV, et al (2022) Risk of covid-19 hospital admission among children aged 5-17 years with asthma in scotland: a national incident cohort study. The Lancet Respiratory Medicine 10(2):191–198. https://doi.org/10.1016/S2213-2600(21)00491-4
Khatri KL, Tamil LS (2018) Early detection of peak demand days of chronic respiratory diseases emergency department visits using artificial neural networks. IEEE Journal of Biomedical and Health Informatics 22(1):285–290. https://doi.org/10.1109/JBHI.2017.2698418
Kim MS, Lee JH, Jang YJ, et al (2020) Hybrid deep learning algorithm with open innovation perspective: a prediction model of asthmatic occurrence. Sustainability 12(15):6143. https://doi.org/10.3390/su12156143
Maung TZ, Bishop JE, Holt E, et al (2022) Indoor air pollution and the health of vulnerable groups: A systematic review focused on particulate matter (pm), volatile organic compounds (vocs) and their effects on children and people with pre-existing lung disease. International journal of environmental research and public health 19(14). https://doi.org/10.3390/ijerph19148752
Sandberg S, Paton JY, Ahola S, et al (2000) The role of acute and chronic stress in asthma attacks in children. The Lancet 356(9234):982–987. https://doi.org/10.1016/S0140-6736(00)02715-X
Gaudillo J, Rodriguez JJR, Nazareno A, et al (2019) Machine learning approach to single nucleotide polymorphism-based asthma prediction. PLOS One 14(12):1–12. https://doi.org/10.1371/journal.pone.0225574
Patel D, Hall GL, Broadhurst D, et al (2021) Does machine learning have a role in the prediction of asthma in children? Paediatric Respiratory Reviews https://doi.org/10.1016/j.prrv.2021.06.002
Loymans RJ, Debray TP, Honkoop PJ, et al (2018) Exacerbations in adults with asthma: a systematic review and external validation of prediction models. The Journal of Allergy and Clinical Immunology: In Practice 6(6):1942–1952
Messinger AI, Luo G, Deterding RR (2020) The doctor will see you now: How machine learning and artificial intelligence can extend our understanding and treatment of asthma. Journal of Allergy and Clinical Immunology 145(2):476–478. https://doi.org/10.1016/j.jaci.2019.12.898
Lovrić M, Banić I, Lacić E, et al (2021) Predicting treatment outcomes using explainable machine learning in children with asthma. Children 8(5):376. https://doi.org/10.3390/children8050376
Xiang Y, Ji H, Zhou Y, et al (2019) Asthma exacerbation prediction and interpretation based on time-sensitive attentive neural network: A retrospective cohort study. medRxiv p 19012161. https://doi.org/10.1101/19012161
Kaplan A, Cao H, FitzGerald JM, et al (2021) Artificial intelligence/machine learning in respiratory medicine and potential role in asthma and copd diagnosis. The Journal of Allergy and Clinical Immunology: In Practice 9(6):2255–2261. https://doi.org/10.1016/j.jaip.2021.02.014
Page MJ, McKenzie JE, Bossuyt PM, et al (2021) The prisma 2020 statement: an updated guideline for reporting systematic reviews. Systematic Reviews 10(1):89. https://doi.org/10.1136/bmj.n71
Ouzzani M, Hammady H, Fedorowicz Z, et al (2016) Rayyan—a web and mobile app for systematic reviews. Systematic Reviews 5(1):210. https://doi.org/10.1186/s13643-016-0384-4
Aggarwal S, Cepalo T, Gill S, et al (2023) Factors associated with future hospitalization among children with asthma: a systematic review. Journal of Asthma 60(3):425–445. https://doi.org/10.1080/02770903.2022.2070762
Alharbi ET, Nadeem F, Cherif A (2021) Predictive models for personalized asthma attacks based on patient’s biosignals and environmental factors: a systematic review. BMC Medical Informatics and Decision Making 21(1):1–13. https://doi.org/10.1186/s12911-021-01704-6
Critical Appraisal Skills Programme (2022) Casp (clinical prediction rule checklist). https://casp-uk.net/
Zhang O, Minku LL, Gonem S (2021) Detecting asthma exacerbations using daily home monitoring and machine learning. Journal of Asthma 58(11):1518–1527. https://doi.org/10.1080/02770903.2020.1802746
De Hond AAH, Kant IMJ, Honkoop PJ, et al (2022) Machine learning did not beat logistic regression in time series prediction for severe asthma exacerbations. Sci Rep 12(1):20363. https://doi.org/10.1038/s41598-022-24909-9
Finkelstein J, Jeong IC (2016) Using cart for advanced prediction of asthma attacks based on telemonitoring data. In: 2016 IEEE 7th Annual Ubiquitous Computing, Electronics and Mobile Communication Conference (UEMCON), pp 1–5, https://doi.org/10.1109/UEMCON.2016.7777890
Finkelstein J, Jeong IC (2017) Machine learning approaches to personalize early prediction of asthma exacerbations. Annals of the New York Academy of Sciences 1387(1):153–165. https://doi.org/10.1111/nyas.13218
Lisspers K, Ställberg B, Larsson K, et al (2021) Developing a short-term prediction model for asthma exacerbations from swedish primary care patients’ data using machine learning - based on the arctic study. Respiratory Medicine 185:106483. https://doi.org/10.1016/j.rmed.2021.106483
Lugogo NL, DePietro M, Reich M, et al (2022) A predictive machine learning tool for asthma exacerbations: Results from a 12-week, open-label study using an electronic multi-dose dry powder inhaler with integrated sensors. J Asthma Allergy 15:1623–1637. https://doi.org/10.2147/jaa.S377631
Hurst JH, Zhao C, Hostetler HP, et al (2022) Environmental and clinical data utility in pediatric asthma exacerbation risk prediction models. BMC Medical Informatics and Decision Making 22(1). https://doi.org/10.1186/s12911-022-01847-0
Inselman JW, Jeffery MM, Maddux JT, et al (2023) A prediction model for asthma exacerbations after stopping asthma biologics. Ann Allergy Asthma Immunol 130(3):305–311. https://doi.org/10.1016/j.anai.2022.11.025
Luo G, Johnson MD, Nkoy FL, et al (2020) Automatically explaining machine learning prediction results on asthma hospital visits in patients with asthma: Secondary analysis. JMIR Med Inform 8(12):e21965. https://doi.org/10.2196/21965
Shin EK, Mahajan R, Akbilgic O, et al (2018) Sociomarkers and biomarkers: predictive modeling in identifying pediatric asthma patients at risk of hospital revisits. NPJ Digit Med 1:50. https://doi.org/10.1038/s41746-018-0056-y
Jiao T, Schnitzer ME, Forget A, et al (2022) Identifying asthma patients at high risk of exacerbation in a routine visit: A machine learning model. Respir Med 198:106866. https://doi.org/10.1016/j.rmed.2022.106866
Alharbi E, Cherif A, Nadeem F, et al (2022) Machine learning models for early prediction of asthma attacks based on bio-signals and environmental triggers. In: 2022 IEEE/ACS 19th International Conference on Computer Systems and Applications (AICCSA), pp 1–7, https://doi.org/10.1109/AICCSA56895.2022.10017305
Farion KJ, Wilk S, Michalowski W, et al (2013) Comparing predictions made by a prediction model, clinical score, and physicians: Pediatric asthma exacerbations in the emergency department. Appl Clin Informatics 4(3):376–391. https://doi.org/10.4338/ACI-2013-04-RA-0029
Haque R, Ho SB, Chai I, et al (2021) Intelligent asthma self-management system for personalised weather-based healthcare using machine learning. In: Advances and Trends in Artificial Intelligence. Artificial Intelligence Practices. Springer International Publishing, pp 297–308, https://doi.org/10.1007/978-3-030-79457-6_26
Priya CK, Sudhakar M, Lingampalli J, et al (2021) An advanced fog based health care system using ann for the prediction of asthma. In: 2021 5th International Conference on Computing Methodologies and Communication (ICCMC), pp 1138–1145, https://doi.org/10.1109/ICCMC51019.2021.9418248
Patel SJ, Chamberlain DB, Chamberlain JM (2018) A machine learning approach to predicting need for hospitalization for pediatric asthma exacerbation at the time of emergency department triage. Acad Emerg Med 25(12):1463–1470. https://doi.org/10.1111/acem.13655
Xu M, Tantisira KG, Wu A, et al (2011) Genome wide association study to predict severe asthma exacerbations in children using random forests classifiers. BMC Med Genet 12. https://doi.org/10.1186/1471-2350-12-90
Zein JG, Wu CP, Attaway AH, et al (2021) Novel machine learning can predict acute asthma exacerbation. Chest 159(5):1747–1757. https://doi.org/10.1016/j.chest.2020.12.051
Do Q, Tran S, Doig A (2019) Reinforcement learning framework to identify cause of diseases - predicting asthma attack case. In: 2019 IEEE International Conference on Big Data (Big Data), pp 4829–4838, https://doi.org/10.1109/BigData47090.2019.9006407
Eisner MD, Katz PP, Yelin EH, et al (2000) Risk factors for hospitalization among adults with asthma: the influence of sociodemographic factors and asthma severity. Respiratory research 2(1):1–8. https://doi.org/10.1186/rr37
Soyiri IN, Reidpath DD (2012) Evolving forecasting classifications and applications in health forecasting. International journal of general medicine 5:381. https://doi.org/10.2147/IJGM.S31079
Bose S, Kenyon CC, Masino AJ (2021) Personalized prediction of early childhood asthma persistence: A machine learning approach. PLOS ONE 16(3):1–17. https://doi.org/10.1371/journal.pone.0247784
Mariani S, Lahr MM, Metting E, et al (2021) Developing an ml pipeline for asthma and copd: The case of a dutch primary care service. International Journal of Intelligent Systems 36(11):6763–6790. https://doi.org/10.1002/int.22568
Myers JMB, Schauberger E, He H, et al (2019) A pediatric asthma risk score to better predict asthma development in young children. Journal of Allergy and Clinical Immunology 143(5):1803–1810
Jones CA, Bender BG, Haselkorn T, et al (2009) Predicting asthma control using patient attitudes toward medical care: the react score. Annals of Allergy, Asthma & Immunology 102(5):385–392
Boer S, Sont JK, Loijmans RJ, et al (2019) Development and validation of personalized prediction to estimate future risk of severe exacerbations and uncontrolled asthma in patients with asthma, using clinical parameters and early treatment response. The Journal of Allergy and Clinical Immunology: In Practice 7(1):175–182
Chan L, Nadkarni GN, Fleming F, et al (2021) Derivation and validation of a machine learning risk score using biomarker and electronic patient data to predict progression of diabetic kidney disease. Diabetologia 64:1504–1515
Xie F, Chakraborty B, Ong MEH, et al (2020) Autoscore: a machine learning–based automatic clinical score generator and its application to mortality prediction using electronic health records. JMIR medical informatics 8(10):e21798
Luo G (2016) A review of automatic selection methods for machine learning algorithms and hyper-parameter values. Network Modeling Analysis in Health Informatics and Bioinformatics 5:1–16
Bergstra J, Bengio Y (2012) Random search for hyper-parameter optimization. Journal of machine learning research 13(2)
Anggoro DA, Mukti SS (2021) Performance comparison of grid search and random search methods for hyperparameter tuning in extreme gradient boosting algorithm to predict chronic kidney failure. International Journal of Intelligent Engineering & Systems 14(6)
Hutter F, Hoos HH, Leyton-Brown K (2011) Sequential model-based optimization for general algorithm configuration. In: Learning and Intelligent Optimization: 5th International Conference, LION 5, Rome, Italy, January 17-21, 2011. Selected Papers 5, Springer, pp 507–523
Snoek J, Larochelle H, Adams RP (2012) Practical bayesian optimization of machine learning algorithms. Advances in neural information processing systems 25
Alibrahim H, Ludwig SA (2021) Hyperparameter optimization: Comparing genetic algorithm against grid search and bayesian optimization. In: 2021 IEEE Congress on Evolutionary Computation (CEC), IEEE, pp 1551–1559
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions No funding was received for conducting this study
Author information
Authors and Affiliations
Contributions
WJ searched the databases and conducted the initial article selection. The studies included in the study were blindly selected by WJ, FM and AC and finalised through a discussion. WJ performed the data extraction. WJ, FM and AC blindly conducted risk of bias assessments to check the quality of the studies and discussed them. WJ was a major contributor to writing the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics Approval and Consent to Participate
Not applicable.
Consent for Publication
Not applicable.
Competing Interest
AC is the recipient of the Auckland Medical Research Foundation senior research fellowship, which investigates asthma attack prediction models. She has also received funding from the Health Research Council for research into asthma. AC also sits on the board of Asthma New Zealand, is affiliated with Asthma UK Centre of Applied Research, member of the Respiratory Effectiveness Group and is part of the European Respiratory Society CONNECT Clinical Research Collaboration. The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Appendix
Appendix
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Darsha Jayamini, W.K., Mirza, F., Asif Naeem, M. et al. Investigating Machine Learning Techniques for Predicting Risk of Asthma Exacerbations: A Systematic Review. J Med Syst 48, 49 (2024). https://doi.org/10.1007/s10916-024-02061-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10916-024-02061-3