
Abstract
A novel approach for the stabilization of the Discontinuous Galerkin method based on the Dafermos entropy rate crition is presented. First, estimates for the maximal possible entropy dissipation rate of a weak solution are derived. Second, families of conservative Hilbert–Schmidt operators are identified to dissipate entropy. Steering these operators using the bounds on the entropy dissipation results in high-order accurate shock-capturing DG schemes for the one-dimensional Euler equations, satisfying the entropy rate criterion and an entropy inequality. Other testcases include the one-dimensional Buckley–Leverett equation.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Discontinuous Galerkin methods [8] are a popular tool to design numerical schemes for hyperbolic systems of conservation laws [12]
An intriguing feature of DG methods is their ability to transfer the definition of a weak solution to a hyperbolic conservation law [22]
to the semidiscrete level [2, 3, 7]. Using a method of lines approach this leads to the set of equations
for every cell \(Z \in \mathscr {Z}\) of a subdivision \(\mathscr {Z}\) of the domain. Here, the inner products
stand in for the volume and surface integrals of the semidiscrete weak form. Consult also Table 1 for a complete overview of the notation used in this work. The solution u(x, t) is approximated in every cell by
out of a finite dimensional space of ansatz functions \(V^Z\). No continuity between cells is assumed, hence the name Discontinuous Galerkin method. The inner products can be represented on these finite-dimensional spaces via the Gramian matrices
If we select \(p + 1\) nodes in every cell Z and the functions \(\varphi _k^Z\) are a nodal basis of the space \(V^Z\) then the resulting matrices are also approximations to these inner products when the functions do not stem from the space \(V^Z\). Evaluating these approximations is equivalent to interpolating the point values of the function u in the space \(V^Z\) as \({{\,\mathrm{\mathbb {I}}\,}}_{V^Z} u\) and evaluating \(\left\langle {{{\,\mathrm{\mathbb {I}}\,}}_{V^Z} u}, {{{\,\mathrm{\mathbb {I}}\,}}_{V^Z} v} \right\rangle _Z\). Using this approximation of the inner products by point evaluations results in the matrix vector form
This scheme can be evaluated by multiplying with the inverse of the mass matrix \(M^Z\). In equation (3) several flux values are marked with an asterisk because they lie on the boundary of the cell Z. Discontinuities in the ansatz functions imply the possibility of discontinuities in the fluxes between different cells. Conservation of our conserved quantities is only ensured if the outflow flux of one cell is equal to the inflow of the adjacent cell. A sufficient condition for this is that the fluxes at the adjacent edges match, and we therefore swap the evaluation of flux function at the Ansatz polynomial for numerical fluxes
when flux values at the cell edges are needed. In our case the family of HLL fluxes [14, 15, 26, 58, 59] will be used for this purpose. Sadly, the constructed schemes lack robustness and stability in the high order case and some stabilization measures and robustness enhancements are needed. Popular are overintegration, flux-differencing, modal filtering, sub-cells and (W)ENO recoveries [3, 19, 21, 40, 44, 51, 62]. In this publication the procedure first presented in [30] will be refined, connections to some other stabilization techniques will be shown, and the technique will be tested on a catalog of problems including the Buckley–Leverett equation and the Euler system of conservation laws. Additional admissibility conditions are needed as weak solutions in the sense of (2) are non-unique. An entropy [35] is a convex functional \(U:\mathbb {R}^m \rightarrow \mathbb {R}\) satisfying
in conjunction with an entropy flux function \(F:\mathbb {R}^m \rightarrow \mathbb {R}\). Assume the solution u is the strong \(\textrm{L}^p\) limit of solutions \(u_\varepsilon \) satisfying a viscosity regularization
of the system of conservation laws (1). Such a solution u is called a vanishing viscosity solution [35]. One can show that for a vanishing viscosity solution u and any entropy pair (F, U) holds
in the sense of distributions [35]. If the solution is smooth one can even show
Apart from the hope that the numerical counterparts of entropy admissibility criteria will enforce convergence to a physically relevant solution a numerical entropy inequality will also increase robustness [45]. Counterexamples for the hoped uniqueness of such an entropy solution exist for the multidimensional isentropic [4,5,6] and full Euler equations [18]. The method in [30] is based on the entropy rate admissibility criterion [9, 10, 17]. This criterion states that the total entropy
of the selected weak solution u should reduce faster than the entropy of any other existing weak solution \({\tilde{u}}\) with the same initial data
Usage of this criterion can be motivated from direct examples, the fact that it implies the classical entropy inequality for self similar solutions to Riemann initial data of small amplitude [9] and for piecewise smooth solutions of scalar conservation laws [10]. One can show for Lagrangean gas dynamics under assumptions on the value of the adiabatic exponent \(\gamma \) that it is not always equivalent to the entropy inequality [27]. Our hope is that at least the physical entropy combined with the entropy rate criterion singles out physically relevant weak solutions for the (multidimensional) Euler equations. A numerical approximation of the total entropy can be defined as
via a (positive) quadrature rule \(\omega ^Z_k\) on each cell \(Z \in \mathscr {Z}\). The numerical enforcement of the criterion with respect to such a definition of the discrete entropy happened in [30] in three steps:
-
Calculate the time derivative of the ansatz function \({\frac{ \textrm{d}{\tilde{u}}^Z }{ \textrm{d}t}}\) using a DG scheme.
-
Calculate an error prediction \(\delta ^Z\) for \({\frac{ \textrm{d}{\tilde{u}}^Z }{ \textrm{d}t}}\) on Z, i.e. \(\left| \left| {\frac{ \textrm{d}{\tilde{u}}^Z }{ \textrm{d}t}} - {\frac{\partial {u} }{\partial {t}}}\right| \right| _Z \le \delta ^Z\).
-
Correct the time derivative into the direction of the steepest entropy descent
$$\begin{aligned} {\frac{ \textrm{d}u^Z }{ \textrm{d}t}} = {\frac{ \textrm{d}{\tilde{u}}^Z }{ \textrm{d}t}} + \frac{\delta ^Z}{\left| \left| h^Z\right| \right| _Z} h^Z, \end{aligned}$$where h shall be the steepest descent direction that does not change the average value in cell Z.
While the approach above is successful for scalar conservation laws [30] significant improvements can be made by introducing two refinements. The first one concerns the usage of an error indicator to estimate the entropy correction needed. We will instead show that it is possible to directly give bounds on how dissipative a weak solution can be. This will eliminate the need for the error indicator while allowing a faster convergence, because the derived bounds converge to zero significantly faster in the smooth case. A second refinement concerns the direction used for the entropy correction. DG methods can make use of modal filtering to remove unwanted high frequency modes from the solution [44]. These filters can be sometimes expressed as viscosity. We will devise correction directions that at the same time dissipate entropy and filter the solution from unwanted oscillations and thereby combine the dissipation and filtering.
Our schemes will therefore follow the slightly different general layout of:
-
Calculate a time derivative for the ansatz function \({\frac{ \textrm{d}{\tilde{u}}^Z }{ \textrm{d}t}}\) using a DG scheme.
-
Estimate the highest possible entropy dissipation speed \(\sigma ^Z\) in cell Z.
-
Calculate the correction direction \(\upsilon ^Z\).
-
Calculate the size \(\lambda ^Z\) of the correction needed to achieve that
$$\begin{aligned} {\frac{\partial {u^Z} }{\partial {t}}} = {\frac{\partial {{\tilde{u}}^Z} }{\partial {t}}} + \lambda ^Z \upsilon ^{Z} \end{aligned}$$satisfies
$$\begin{aligned} {\frac{ \textrm{d}E_{u, Z} }{ \textrm{d}t}} = \left\langle {{\frac{ \textrm{d}U }{ \textrm{d}u}}}, {{\frac{\partial {{\tilde{u}}^Z} }{\partial {t}}} + \lambda ^Z \upsilon ^Z} \right\rangle _Z \le \sigma ^Z + F^*_l - F^*_r \end{aligned}$$(7)with the dissipation \(\sigma ^Z\) mandated by the estimate. \(F^*\) shall be a numerical entropy flux [52,53,54].
The procedure makes only use of the fact that in our cells there exist local ansatz functions. It is therefore also applicable to similar schemes like the spectral volume (SV) method [60]. The only difference would lie in the evaluation of a different scheme for the uncorrected derivative \({\frac{ \textrm{d}{\tilde{u}} }{ \textrm{d}t}}\). One complication is brought in by the fact that entropy dissipation implies the non-smoothness of the solution, as otherwise the entropy equality applies. Therefore, dissipation cannot happen in cells in the continuous setting, as polynomials are smooth. Instead, dissipation is a process taking place at the cell edges were our different ansatz functions transition. As we are not correcting the numerical fluxes used between cells, dissipation will be centered in cells and not at cell edges, and we will show in Sect. 3.1 how to work around this problem.
2 Entropy Inequality Predictors
2.1 Bounds for Entropy and Entropy Dissipation
Our main tool to approximate the most dissipative weak solution using a DG method will be a bound on the derivative of the total entropy. We will derive a lower bound for the entropy dissipation
Here \(\theta \subset \varOmega \) shall be an arbitrary open subdomain of the complete domain. This value has to be smaller than zero for a solution that is admissible with respect to the classical entropy inequality (5). Further, we are interested in the entropy dissipation speed
If \(s^\theta _u\) and \(\sigma ^\theta _u\) are known one can estimate the total entropy \(E_u(t)\) and the time derivative of the total entropy \({\frac{ \textrm{d}E_u }{ \textrm{d}t}}\) as
when \(\varTheta = \{ \theta _1, \theta _2, \theta _3, \dots , \theta _L\}\) is overlapping \(\varOmega \) in the sense of
Please note that the inflow into and outflow of entropy can influence the total amount of entropy, but we are only interested in infinite domains without boundaries or finite domains with periodic boundary conditions for the theoretical part of this publication. Otherwise the entropy inflow and outflow would influence equation (8). Inflow and outflow do not influence \(s^\theta _u\) as it only accounts for entropy dissipation.
To achieve our goal of estimating \(s^\theta \) we will view the problem in the setting of classical Finite-Volume schemes [50] and go over to the limit \(\varDelta x \rightarrow 0\). In [11] it was shown that for scalar conservation laws the flux f of the solution to the Riemann problem \(u_\text {R}(u_l, u_r; x/t)\) at \(x/t = 0\) is given by
i.e. by entering the value of u from the convex hull
into f that when entered into the flux yields the fastest entropy dissipation. This identity is in general wrong for systems as the existence of a counterexample shows [42, Theorem 9.8]. In [31] it was shown that some approximate Riemann solvers, for example the local Lax-Friedrichs flux, can be also interpreted as approximate solutions to such variational descriptions of two-point fluxes. While the aforementioned results hold for semidiscrete schemes the new results below are fully discrete and aim at three point first order Finite-Difference/Finite-Volume schemes for systems of conservation laws. As one assumes piecewise constant functions in those first order methods any quadrature exact for constants will yield the same result in equation (6). As we only look at discrete time values in this part of the publication we will write \(E^n_u = E_u(t_n)\) for the discrete total entropy at time level n.
Lemma 1
Let a system of hyperbolic conservation laws in conservation form and a strictly convex entropy pair (U, F) be given that is approximated by an explicit Finite-Volume scheme with grid constant \(\lambda = \frac{\varDelta t}{\varDelta x}\). Assume there exists a conservative consistent three-point scheme with minimal (most negative) entropy rate for the discrete entropy
Then this scheme has to be the original Lax-Friedrichs scheme.
Proof
Assume \(f(u_k, u_{k+1})\) is a consistent numerical two-point-flux minimizing the total entropy with maximal rate and let \(u_l, u_r\) be arbitrary in the domain of admissible values for the conserved variables. We apply a scheme using this flux to a Riemann problem, i.e. the initial data
to query the flux value \(f(u_l, u_r) = f(u_0, u_1) = f_{\frac{1}{2}}\) by analyzing the solution. As the flux is consistent it holds
The scheme
therefore implies that \(u^1_k = u^0_k\) for all \(k \not \in \{0, 1\}\). The total entropy
is minimized by \(u^1_0 = u^1_1\), as U is strictly convex. Assume \(u^1_0 \ne u^1_1\) holds. In this case the strict form of Jensen’s inequality
would imply that the total entropy could be reduced by setting \(u_0^1 = u_1^1\) using averaging. Entering this into the scheme’s definition with \(u^0_0 = u_l\) and \(u^0_1 = u_r\) implies
Rearranging for \(f(u_l, u_r)\) shows
and this is the classical Lax-Friedrichs flux. \(\square \)
This result shows that the classical LF scheme is the most direct realisation of a scheme satisfying Dafermos’ entropy rate criterion and therefore justifies the use of the LF scheme in [29] as the most dissipative explicit three-point scheme possible for systems of conservation laws for fixed grid constant \(\lambda = \frac{\varDelta t}{\varDelta x}\). Similar results are also known for scalar conservation laws. Tadmor showed in [52, 53] that every monotonicity preserving scheme, that can be written in averaging form and satisfies classical numerical entropy inequalities, has a viscosity coefficient less or equal to that of his modified Lax-Friedrichs (MLF) scheme, and higher or equal than the viscosity coefficient of Godunov’s scheme. The LF scheme was modified in that case
to be in an averaging form, i.e. can be written as
This scheme can be devised from the Lax-Friedrichs scheme by applying it to a grid with half the cell size, and averaging after each timestep two adjacent cells. In a more general form we will speak of schemes in averaging form if the cell update can be written in a two-step process—first the calculation of subcell values at the next time layer
As a second step the averaging of these two states into the next time-layer
A suitable total entropy for the intermediate subgrid states would be
This total entropy is obviously dissipated by the primary grid averaging of equation (12). We can use this reformulation to state the following result.
Lemma 2
The modified Lax-Friedrichs scheme is the most dissipative scheme with respect to the total entropy (13) that is also conservative, consistent, three point and can be written in averaging form.
Proof
Let \(u^n\) be an arbitrary initial condition. Then the total entropy \(E^{n+1}\) before averaging takes place can be written as
where the terms \(E_{k + \frac{1}{2}}\) are determined by the fluxes \(f_{k + \frac{1}{2}}\). The minimum is achieved for \(u^{n+1}_{k + \frac{1}{4}} = u^{n+1}_{k + \frac{3}{4}}\) and rearranging yields, as in the proof of lemma 1 above,
\(\square \)
Our result can be seen as a generalization of the MLF part of Tadmors result to systems of conservation laws, as it states that the MLF flux is the most dissipative flux for a selected time-step size concerning the sub-cell entropy.
Using the scheme above one can derive estimates for the highest possible entropy dissipation in a time-step. The difference quotient of this result and the time step size approximates the lowest possible derivative of the total entropy with respect to time.
Corollary 1
The biggest possible entropy dissipation during a discrete time-step of a Finite-Volume scheme with grid constant \(\lambda = \frac{\varDelta t}{\varDelta x}\) is given by the difference
and an approximation to the total entropy’s minimal derivative by
The second estimate above degenerates for \(\lambda \rightarrow 0\) as the difference in entropy is in general finite between cells \(u_{k-1}, u_k, u_{k +1}\). Similar problems exist for first generation central schemes and the LF scheme can be interpreted as a central scheme using piecewise constant recovery [34]. As the estimate above is only a lower bound this divergence for \(\lambda \rightarrow 0\) is not a paradox if one can find a sharper bound from below. A second, more refined, estimate is given by the following lemma based on the ideas from [26] and does not have these deficiencies.
Lemma 3
Given bounds on the fastest signal speed to the left \(a_l\) and the highest signal speed to the right \(a_r\) let \(R \ge \max (\left| a_l\right| , \left| a_r\right| )\). The maximum entropy dissipation of a Riemann problem solution on the interval \(\theta = (-R, R)\) is bounded from below by
with
The rate is bounded from below by
The entropy dissipation is bounded by
and its rate by
Proof
The entropy of the initial condition in the interval \([-R, R]\) is given by
for any \(R > 0\). Integrating over the triangle \(T = {{\,\textrm{ch}\,}}\{(0, 0), (a_l, 1), (a_r, 1)\}\) in spacetime and using the conservation law yields
in conjunction with the Gauß divergence theorem, cf. Fig. 1. Here \(u_{lr}\) shall denote the mean value of u(x, 1) on \([a_l, a_r]\) and is
as apparent from the calculation above. Jensen’s inequality implies
Therefore it follows
for the entropy dissipation between \(t=0\) and \(t=1\) and using the invariance under transformations \((x, t) \mapsto (\mu x, \mu t)\) for \(\mu > 0\) yields
for the rate. To calculate the entropy dissipation \(s^\theta \) and its speed \(\sigma ^\theta \) we just have to account for the entropy flowing in and out of the intervall \(\theta \) using the entropy flux F. This is possible as u is constant to the left of \((ta_l, t)\) and to the right of \((t a_r, t)\). \(\square \)

Layout of the integration areas in the proof (blue). As originally used in [26]. To the left and right of the lines \({\frac{ \textrm{d}x }{ \textrm{d}t}} = a_l\) and \({\frac{ \textrm{d}x }{ \textrm{d}t}} = a_r\) the initial condition is unaltered
The estimate above does not depend on any grid constant, and reduces to the previous one for \(-a_l = c_\text {max} = a_r\), \(\lambda c_\text {max} = 1\), and this is the CFL condition for the classical Lax-Friedrichs scheme, i.e. both estimates are compatible.
A Godunov type scheme using the HLL approximate Riemann solver is also compatible with the estimate above. The discrete total entropy after one time-step is still less or equal than the bound given above.

A set of noninteracting HLL approximate Riemann solutions
Let \(\lambda c_{\text {max}} \le \frac{1}{2}\) hold implying that the Riemann problems do not interact and \(u^\textrm{HLL}(x, t_{n+1})\) be the picewise constant solution of the HLL solver as in Fig. 2, but not averaged over the cells, while \(u^{n+1}_k\) shall be the corresponding cell averages. In this case the total discrete entropy at the next time-step is given by
Therefore, the discrete entropy of the approximate solution is lower than the entropy of any exact weak solution. The next subsection will move beyond first order schemes by generalizing this lower bound to one that also allows smooth solutions instead of piecewise constant ones. To complete our predictor we need formulas for the speeds \(a_l\) and \(a_r\). A big set of literature exists concerning these speeds and the first ones to our knowledge are the formulas given by Einfeld [15] and Davis [14]. The second formula given by Davis for the Euler equations is
Here v should be the particle speed and c the speed of sound. In our implementation a \(\ll \) numerical sound speed\(\gg \) \(c = \sqrt{\frac{3 p }{\rho }}\) is used in the speed calculations to circumvent the sonic point glitch present in HLL type solvers [56]. While its simplicity is intriguing it was shown that these formulas are in general no upper bounds [58]. Still, this formula is easily generalized to other systems as it only needs the eigenvalues of the Jacobians of the flux on the left and right side. The generalizations in the next chapter are not as formal as before and we therefore do not see the Davis estimates as a fundamental weakness.
2.2 Asymptotic Analysis Based Entropy Inequality Predictor

Construction and application of the generalized HLL dissipation estimate
The entropy inequality predictor in this section will be based on an asymptotic analysis of the problem described in Fig. 3a, i.e. two smooth solutions splined together at an interface. An obstacle lies in the missing self-similarity. This is a difference to the previous part where the self-similarity of the initial condition and assumed self-similarity of the solution induced the existence of a self-similar, i.e. constant, speed of the entropy dissipation. We will therefore try to approximate
for reasonably small \(\left| t_2 - t_1\right| \) and the discontinuity at the interface in the interior of \(\theta \). The schemes in which we will use these entropy inequality predictors should converge with high orders for smooth solutions, necessitating a convergence of the predictor to zero with a high order for smooth solutions. This convergence is also dictated by the entropy equality for smooth solutions. If \(u_l(x)\) and \(u_r(x)\) are piecewise constant this problem is already solved by the methods described in the last subsection. We will therefore now reiterate through the proof of lemma 3 assuming that \(u_l(x)\) and \(u_r(x)\) are smooth functions. The missing self-similarity of Generalized Riemann problems [1], cf. Fig. 3b, defies the existence of the speed estimates \(a_l\) and \(a_r\), and we therefore just assume that these speed estimates exist for small times. Further we assume that for small times the solutions left of \((ta_l, t)\) and right of \((ta_r, t)\) remain smooth, as no waves from the interaction arrive there and \(u_l(x), u_r(x)\) have bounded derivatives.
The average value \(u_{lr}\) shall be determined by applying the conservation law to the triangle \(T = {{\,\textrm{ch}\,}}\{(0, 0), (t a_l, t), (t a_r, t)\}\)
Dividing this equation by t and going over to the limit \(t \rightarrow 0\) results in
using the continuity of the integrands and the mean value theorem of integration [37]. Therefore it follows
for vanishing t. Equation (16) stays also valid in the case of piecewise polynomial functions as initial conditions and for small \(t > 0\). We can therefore conclude that a generalization of equation (17) holds in the form
Accounting for the entropy flowing in and out of \([-R, R]\) yields
Applying the entropy equality to the subdomains \([-R, ta_l] \times [0, t]\) and \([ta_r, R] \times [0, t]\)
that holds for small \(t > 0\) because the solution stays smooth in the subdomains, allows us to restate this as
Dividing by t and going over to the limit, using the limit of \(u_{lr}\) and once more the mean value theorem, shows in this case also
A significant problem of the derivation above lies in the fact that one can only estimate the entropy dissipation speed in the interval \(\theta = (-R, R)\), but not in \((-R, 0)\) as the true dissipation can be located anywhere in the cone \([ta_l, ta_r]\). As the cells
in our numerical tests will be layed out as in Fig. 3d a suitable set of overlapping open intervals is
We are therefore left with the problem of how to split this dissipation onto the two neighboring cells that have overlap with \(\theta _{k + \frac{1}{2}}\). This problem will be handled below in Sect. 3.1.
2.3 Accounting for Aliasing Errors
In [30] one of the findings in the numerical tests section was that the entropy dissipation of the numerical solutions started already shortly before a real entropy dissipating discontinuity formed. This was attributed to the fact that while the entropy of the exact solution is still constant as long as the solution is smooth this exact solution will in general not be representable in our ansatz space. It is therefore wise to dissipate entropy to arrive at a function that still lies in our space, and certainly better than selecting an ansatz function that has more entropy than the true solution.

The effect of \(\textrm{L}^2\) projection on jump recovery. A function u, jumping from 0 to 1 at \(\frac{1}{100}\) was \(\textrm{L}^2\) projected onto an Ansatzspace consisting of 4 cells with polynomials with degrees between 4 and 7. The dotted line of the function \(\textrm{P}_7u\), the projection of the jump onto polynomials of degree less or equal 7, underpredicts the jump. Lower order projections deliver significantly better approximations of the jump
A similar issue could be the fact that in the \(\textrm{L}^p\) norms, for \(p < \infty \), near each piecewise continuous solution \(u^T\) lies a \(\mathscr {C}^\infty \) function that can be constructed via mollification. Therefore an infinitely small perturbation of \(u^T\) in the usual norms leads to a vanishing entropy dissipation. Or, put differently, the dissipation bound as a functional is discontinuous in the \(L^p\) spaces. While unsatisfactory, let us remark that the functional is better behaved with respect to the BV semi norms. The discontinuity of the entropy dissipation bound is problematic with under-resolved solutions where a lucky, or in this case better to be considered unlucky, too smooth approximation of the solution in our piecewise polynomial spaces induces wrong, i.e. too conservative entropy dissipation predictions. One such situation is depicted in Fig. 4. There, a discontinuous u with a jump at \(x = \frac{1}{100}\) was projected on the ansatzpolynomials of 4 cells. The polynomial order was varied between 4 and 7. The jump predicted by the lower order expansions is significantly bigger than the jump between the Ansatz polynomials of higher order. Therefore an entropy inequality predictor using the high-order expansion will deliver a slower dissipation speed than one that only uses the first 5 orthogonal basis functions, i.e. the first 4 Legendre polynomials in the cell.
We are therefore interested in allowing our entropy inequality predictor to be also greedy, or one could say pessimistic, with respect to an under-resolved solution. The key to this strengthening is the following lemma.
Lemma 4
(Order of the entropy dissipation bound) The maximal entropy dissipation prediction (20) of a Riemann problem for a smooth flux function with smooth entropy-entropy flux pair vanishes quadratically with the jump of u at the interface
Proof
As the entropy inequality holds it is clear that the entropy dissipation is non-positive in the sense of distributions. As we only allow entropy dissipative solutions the entropy dissipation on \(\theta \) is a non-positive constant for a fixed jump. On the contrary (20) has to be zero for \(u_l = u_r\) and is smooth, implying that the line \(u_l = u_r\) consists of local maxima. Therefore, a power expansion of (20) around \(u_l\) in \(u_r\) has to be of the form
with a negative semi-definite Hessian \(H \in \mathbb {R}^{m \times m}\). This shows the claim. \(\square \)
We are therefore in the relaxing position that even if our approximations of \(u_l, u_r\) only satisfy \(\left| \left| u_l - u_r\right| \right| \in {{\,\mathrm{\mathscr {O}}\,}}((\varDelta x)^p)\) the corresponding estimate will converge significantly faster with \(\sigma ^\theta (u_l, u_r) \in {{\,\mathrm{\mathscr {O}}\,}}((\varDelta x)^{2p})\). Our basic DG method predicts values for our solution \(u^Z\) in a Hilbertspace that is spanned by polynomials on every cell. In this case a suitable orthonormal basis is spanned by Legendre polynomials and the limits of these basis representations are \(\textrm{L}^2\) functions. But as explained before our functional is not continuous on \(\textrm{L}^2\) and our ansatz \(u^Z\) is only an approximation of a projection of the true solution onto our ansatz space. We can therefore try to exploit different projections of our ansatz, especially projections that assume less regularity of \(u^Z\), and estimate our entropy dissipation with the strongest one encountered in all of these different approximations of \(u_l\) and \(u_r\). A natural choice for projections on spaces assuming less regularity are projections on lower order polynomials. As the Legendre polynomials on each cell, when truncated up to polynomial p, are an orthogonal basis of the polynomials with degree less than or equal to p, the orthogonal projection onto these spaces is given by discarding the higher order coefficients in the Legendre expansion of \(u^Z\). We can truncate down to order \(p-1\) by discarding the highest coefficient and still achieve a convergence order of at least \(q = 2p-2 > p\) of our entropy inequality predictor for \(p>2\). This can be summed up in the following procedure used above order \(p = 2\).
-
Assign \(\sigma ^{\theta _{k + \frac{1}{2}}}_p = \sigma ^{\theta _{k + \frac{1}{2}}}_{u(x, t)}\).
-
Project the ansatz \(u^Z\) in every cell onto \(V^{Z, p-1}\) using an orthonormal projection
$$\begin{aligned} u^{Z, p-1} = {{\,\mathrm{\mathbb {P}}\,}}_{V^{Z, p-1}} u(\cdot , t). \end{aligned}$$ -
Assign \(\sigma ^{\theta _{k + \frac{1}{2}}}_{p-1} = \sigma ^{\theta _{k + \frac{1}{2}}} _{ u^{p-1}(\cdot , t) }\).
-
Use
$$\begin{aligned} \sigma ^{\theta _{k + \frac{1}{2}}} = \min \left( \sigma ^{\theta _{k + \frac{1}{2}}}_p,\sigma ^{\theta _{k + \frac{1}{2}}}_{p-1}\right) \end{aligned}$$(21)as entropy inequality prediction.
The kind of aliasing errors described above were not observed for low order DG schemes (\(p = 1, 2\)). We therefore do not see the limitation \(p > 2\) for the method above as an obstacle (Fig. 5).
3 Suitable Dissipation Directions and Filtering

Use of alternative dissipation directions. The direction \(-{\frac{\partial {f} }{\partial {x}}}\) shall denote the \(\textrm{L}^2\) projection of the exact solutions’ derivative \({\frac{\partial {u} }{\partial {t}}}\) onto V. Our approximation \({\frac{ \textrm{d}u^Z }{ \textrm{d}t}}\) is not entropy dissipative in this example and should be corrected into the entropy dissipative half-space characterized by the normal \(-{\frac{ \textrm{d}U }{ \textrm{d}u}}\). The direction \(\nabla ^2 u\) that stems from a discretization of the heat kernel is suitable for this correction and has additional benefits compared to \(-{\frac{ \textrm{d}U }{ \textrm{d}u}}\). While the diffusion also has a smoothing effect the addition of \(-{\frac{ \textrm{d}U }{ \textrm{d}u}}\) can even result in a sharpening effect. Higher even derivatives like \(\nabla ^8 u\) will smooth the solution but will not result in a dissipation for all entropies
After deriving approximations for the entropy dissipation needed we will now determine how to correct the time derivative of the DG scheme to dissipate the amount of entropy needed. At the same time the resulting scheme is hopefully still high order accurate for entropy conservative solutions. In the scalar case the direction of the steepest descent of the entropy, corrected for conservation, was used for this purpose. This approach incurs several problems:
-
The direction of steepest entropy descent has in general no smoothing/filtering effect.
-
It was proved in the previous publication that a correction in the steepest descent direction with the length taken from an error indicator results in an entropy inequality. This resulted in highly technical arguments and the arguments are coupled to the error indicator and the steepest descend direction [30].
-
Dissipation stems from the viscous and parabolic history of hyperbolic conservation laws. Let us define a viscous flux
$$\begin{aligned} f_{\varepsilon }\left( u, {\frac{\partial {u} }{\partial {x}}}\right) = f(u) - \varepsilon {\frac{\partial {u} }{\partial {x}}} \end{aligned}$$associated with a viscous regularization of a hyperbolic conservation law. The viscous part of this flux is proportional to the gradient of the solution for fixed viscosity. If we fix a particular solution gradient \({\frac{\partial {u} }{\partial {x}}}\) the regularizing change to the flux will be proportional to the viscosity \(\varepsilon \). If a component of u is smooth with a low magnitude of the first and second derivative the viscous flux of this component will also only differ from the hyperbolic flux by a small margin. If our scheme is corrected with the steepest entropy descent direction one can ask if this correction can be expressed using some viscosity distribution \(\varepsilon (x)\) in the domain. This will be false in general. Even worse, the steepest gradient descent of the entropy cannot be bounded using the first derivative of the respective component of the vector valued function u(x, t), incurring an infinitely large viscosity.
All of the above reasons motivate us to devise alternative directions for the entropy correction. These alternative directions should have the following properties
-
The dissipation direction should have a filtering effect. When the direction is used as \({\frac{\partial {u} }{\partial {t}}} = \upsilon (u)\) the high order modes of u should be dissipated.
-
The direction should be one of entropy decay, even if not that of steepest decay.
-
The dissipation should stem from a viscosity added to the hyperbolic flux.
Our new correction directions will be based on the construction of filters, i.e. operators that can regularize a solution u. A filter will in our case be a special Hilbert–Schmidt operator K [36].
Definition 1
(Filter) An operator \(K: \textrm{L}^2(\varOmega ) \rightarrow \textrm{L}^2(\varOmega )\) is said to be a filter if it is an integral operator whose pointwise evaluation results in a weighted average, i.e.
is satisfied and the kernel k is of bounded Hilbert–Schmidt norm.
We are especially interested in conservative filters as they do not destroy the conservation of our basic schemes when they are applied on a per cell basis.
Lemma 5
(Conservative filter) A filter \(K: \textrm{L}^2(\varOmega ) \mapsto \textrm{L}^2(\varOmega )\) is conservative
if it can be written as an integral operator with a kernel with mass one, i.e.
Proof
Using Fubini’s theorem shows
in this case. \(\square \)
Please note that the weighted average property is stated using the integration w.r.t. the second variable while the conservation results from the unit measure in the first variable. Obviously a convolution with a convolution kernel satisfying
satisfies both as \(k(x, y) = k(x -y)\) holds in this case, but not every operator satisfying these properties is a convolution. Especially when one is interested in bounded domains, convolutions are not an option, but there still exist suitable smoothing operators.
Theorem 1
(Universally dissipative filters) A conservative filter K is dissipative for all convex entropies U,
if it can be written as a conservative filter with a positive kernel, i.e.
with \(\forall x, y: k (x, y) \ge 0\).
Proof
Using Jensen’s inequality [46], the positivity and conservation of the filter allows us to show
\(\square \)
This theorem shows that the first and second bullet above can be satisfied by an integral operator with a suitable kernel. An example of a dissipation that can be identified with a positive conservative filter is the filtering by the time evolution of
on the entire domain as the assorted filter has the heat kernel as kernel function [16],
Further, this filtering obviously stems from viscosity and has therefore a direct physical interpretation. It is known that while a positive conservative filter always dissipates entropy, a high order finite-difference implementation of a second derivative will not dissipate all entropies [43] and similar theorems hold for higher even derivatives even in the analytic case. We will therefore outline how to construct a filter that is dissipative in the semidiscrete and fully discrete setting and can therefore be used as a descent direction. We begin by stating some discrete equivalents of the theorems above and will analyze if usual dissipations/filters satisfy this property. We will assume that \(\omega _k \ge 0\) is a positive quadrature rule on the cell Z for the rest of the chapter and all notions of conservation for our filters will be centered around being conservative with respect to this quadrature rule. For a general DG method with dense mass matrix a quadrature can be calculated via \(\sum _l M_{lk} = \omega _k\), i.e. by entering the constant one into the discretised inner product, but positivity is not guaranteed in general. A general view of our plan could be to not discretise the second derivative, but its action as the generator of a Hilbert–Schmidt operator. We will therefore, when given a discrete filter, consider also its (discrete) generator.
Definition 2
(Conservative and positive filter generator) Let \(G \in \mathbb {R}^{(p+1) \times (p+1)}\) be a square matrix. We call this matrix a filter generator if
holds. It will be conservative if
is satisfied. Further, we call it positive, if
holds.
Definition 3
(Discrete conservative and positive filter) We call a matrix \(\varUpsilon \in \mathbb {R}^{(p+1) \times (p+1)}\) a filter, if
holds. It is termed conservative, if
is satisfied. Further, we call it positive, if
Obviously, the definition of the conservative positive discrete filter mirrors the definition of such a filter in the continuous case using the quadrature rule. The definition of the averaging property on the other hand is not based on the quadrature rule, as this rule is not used when applying the filter pointwise
Forward Euler steps connect the generators defined above with the filters, as we will see in the lemma below.
Lemma 6
(Connecting generators and filters) It holds
Let further \(\varDelta t \max _l \left| G_{ll}\right| \le 1\). Then it follows
Proof
We begin by showing the conservativity and filter property. It holds
As the identity is conservative follows
The positivity follows, as for non-diagonal elements,
is satisfied for any positive time step size, while the given restriction is needed to enforce
\(\square \)
It is clear that a discrete filter that is positive and conservative is also dissipative by reiterating through the arguments given above for the continuous case. Sadly, it is also true that while in the continuous case the filter which is generated by the second derivative, i.e. the heat kernel, is positive, the second derivative discretised in our DG method is not a positive generator and also does not induce a positive filter directly. We will therefore show how to design a generator that is an approximation of the heat kernel for forward Euler steps, thereby even allowing to prove the dissipativity of the correction operator for finite time steps. The basis will be the heat equation with varying heat conductivity \(\alpha (x)\) [28]
on the (reference) element in conjunction with Neumann boundary conditions. The Neumann boundary conditions enforce the conservation of the resulting solution operator as any change of the cell mean values must happen through the numerical flux of the basic DG method. We discretize this problem with the nodal basis of our DG method [28]
This is a continuous Galerkin discretization, as we consider only a single element. In general there exists no \(\varDelta t > 0\) where \({{\,\mathrm{\textrm{I}}\,}}+ \varDelta t (-M^{-1} Q)\) is a positive operator because the negative elements in \((-M^{-1} Q)\) prohibit it from being a positive generator. Yet the following theorem shows that the exact ODE solution to this problem for a \(t > 0\) big enough is in fact eligible as a filter.
Theorem 2
If the quadrature \(\omega \) is exact on \(V^Z\), the solution of (22) for a positive initial condition \(u_0 \in \mathbb {R}^{p+1}\) satisfies for all \(t > 0\)
-
\(\sum _{k = 1}^{p+1} \omega _k u_k(t) = \sum _{k=1}^{p+1} \omega _k u_k(0)\) (conservation),
-
\(u_k(t) = C_{kl} (t) u_l(0)\) with \(\forall k\in \{ 1, \dots , p+1\}: \quad \sum _{l = 1}^{p+1} C_{kl} = 1\) (averaging property).
Further, for a \(t > 0\) big enough it follows \(\forall k \in \{ 1, \dots , p+1\}: \quad u_k(t) \ge 0\).
Proof
Entering \(v = 1\) into the weak form results in
As the quadrature is exact for the basis functions the same follows for the discretisation, and this shows the conservation. The matrix C used to describe the solution has the explicit form [36, sec. 34]
Multiplying this matrix with the vector \(v \in V\) representing the function 1 from the right reveals
This already shows the second result as the nodal representation of C(t) must have unit row sum. The matrix \(-Q\) is negative semi-definite, the v vector is in its null space. If another linearly independent \(u \in V\) would be in its null space it would follow
and this is a contradiction to \({\frac{\partial {u} }{\partial {x}}} \ne 0\), as u was assumed non-constant. Therefore, there exists an orthonormal eigenvalue decomposition of the discretisation whose eigenvalues, apart from the constant eigenfunction \(\psi _1 = v\) with eigenvalue \(\lambda _1 = 0\), are bounded away from zero,
We assume that the eigenvectors are sorted by increasing absolute value of the corresponding eigenvalues,
The solution
therefore converges to the average of u(0), as
holds. Because a positive initial condition has a positive average the solution will converge to this positive average. \(\square \)
Using the theorem above we can construct filters \(\varUpsilon \) simply by calculating the matrix \(C(t) = G\) used in the proof above. This matrix, which maps an initial state onto the solution at time t, is always a conservative filter, and when t is large enough also positive. In the implementation the suitable t was found using a bisection algorithm. Using \(\varUpsilon = (C(t) - {{\,\mathrm{\textrm{I}}\,}})/t\) the corresponding generator can be found. We note in passing that numerous other possibilites exist to define a positive conservative filter as defined above, but that the method given above defines a filter than can be associated with viscosity.
Lemma 7
Assume that the null space of G consists only of constants. Then for a non-constant u and a strictly convex entropy U it holds
If U is just convex only \(>> \le <<\) applies in the equation above.
Proof
The discrete dissipativity
follows from the positive conservative filter property of G for \(\lambda \varDelta t > 0\) small enough as in lemma 6 in conjunction with the strict convexity and Jensen’s inequality in the strict sense. Let now \(\varDelta t\) be fixed and small enough for all \(\lambda \in [0, 1]\), and denote by \(\varepsilon = E^Z(u + \varDelta t G u) - E^Z(u) < 0\) the entropy dissipation for \(\lambda = 1\). The convexity of U implies with \( u + \lambda \varDelta t Gu = (1-\lambda ) u + \lambda (u + \varDelta t Gu)\)
Entering this into the definition of the derivative of \(E^Z\) with respect to \(\lambda \) shows
and therefore
If U is not strictly convex the case \(\varepsilon = 0\) is possible, reducing the result to \(>>\le <<\). \(\square \)
The result above is not only of theoretical value. The equations (23), (24) show
We can therefore refrain from evaluating the effectivity of the correction direction \(\upsilon = Gu\) via the direct computation of \(\partial _{\lambda }{E^Z(u + \lambda \varDelta t Gu)}\). Instead it suffices to enter u and \(u + \varDelta t Gu\) into the definition of the total entropy and use a finite-difference approximation of the derivative. This approximation will predict a smaller effectivity, i.e. a not so negative value. The last step consists of selecting a suitable viscosity distribution \(\alpha \). We choose \(\alpha (x) = 1\) for simplicity. Please note that this viscosity is not zero at the boundary \(\partial Z\). The derivation of the weak form above assumes zero flux over the surface of the cell \(\partial Z\). Therefore the discrete weak form is not equivalent to the discrete strong form via summation by parts - the boundary terms are missing. We are therefore sure that this is not equivalent to adding a parabolic term discretised using continuous FE. The matrix G is not a suitable discretisation of a second derivative. Any high order discretisation of a second derivative would employ negative weights in its difference matrix on non-diagonal positions [43]. This is a direct contradiction to the positivity of G. Experiments of the author with dissipation matrices constructed from subcells showed that these are also suitable. Still it was felt that the presented process is the most natural one for DG, while subcells are the natural construction procedure for spectral volume methods.
3.1 Stable Computation of the Correction Size Required and Timestep Restrictions
After we have calculated the entropy dissipation needed and a suitable direction \(\upsilon = G u^Z\) one would guess we only have to calculate \(\lambda \) as in equation (7) via
with \(\sigma ^Z\) from equation (21). It turns out that this process is significantly more intricate than one would expect as this computation has to be stable with respect to roundoff errors. Further, our entropy inequality predictors can only estimate the entropy dissipation that can take place at the interface between two adjacent cells, but are not able to give information on how this dissipation is split between the two cells. Our method of calculating suitable values of \(\lambda ^Z\) therefore consists of two steps. First,
is calculated to enforce the per cell entropy dissipativity
In a second step a correction to enforce an entropy rate high enough
is determined for all \(\theta \in \varTheta \). Both corrections are then added together
for all cells \(Z \in \mathscr {Z}\). Round-off errors tend to influence the calculation out of two reasons. The division by \(\left\langle {{\frac{ \textrm{d}U }{ \textrm{d}u}}}, { \upsilon } \right\rangle \) in equation (26) and (27) can approach a division by zero for a solution that is nearly constant in the cell, as \(\upsilon \rightarrow 0\) follows in this case. Further, we saw in lemma (1) that the entropy inequality predictor can vanish with a high order for smooth solutions, and an accurate DG scheme will also have an entropy error that tends to zero with a high order. The difference of these two values, i.e. the denominator of the fraction above, will in general not vanish that fast because round-off in the difference becomes important. Therefore \(\lambda \) will, for highly resolved smooth solutions, be to big because round-off errors propagate into the calculation. Our solution to this problem is to calculate
every time a \(\lambda \) is calculated by a division in the procedure above. Here, a shall be the nominator, b shall be the denominator and c shall be a suitable bound on the round-off error, a constant small with respect to a, b but large with respect to the machine precision. In our implementation this is selected as \(c = \sqrt{10^{-16}}\), i.e. the square root of the machine precision for a solution scaled to be of unit magnitude. The addition of c can be seen as the one-dimensional version of Tikhonov regularization [33]. Clipping the calculation of \(\lambda \) at 0 ensures that if a or b become negative from rounding errors \(\lambda \) will not become negative, i.e. \(\lambda \upsilon \) will not be antidissipative. In a last step,
the upper limit \(\lambda _{\text {max}}\) is introduced for stability reasons as we want to enforce stability of
If a Runge–Kutta time integration method can be written as convex combination of forward Euler steps, i.e. is Strong Stability Preserving (SSP) [23, 47, 48] and the time-steps satisfy \(\varDelta t \lambda \le 1\) during every Euler step, the lemma 6 allows us to show that the solution is also entropy dissipative in the discrete case. If the time integration method used is just a conditionally stable Runge–Kutta method [13, 61] we are interested in limiting the operator norm of \(\varDelta t \left| \left| \lambda G\right| \right| \le R\) in order to at least avoid a linear instability. The exact size depends on the time integration methods’ stability region as we would like to fit the half-circle
into the stability region of the method.
4 Numerical Tests
4.1 Final Algorithm
The last sections described our (refined) methods to estimate the maximal entropy dissipation possible and our refined dissipation directions. These are combined with the orthogonal projection approach to define a stable entropy dissipation functional and our round-off hardened \(\lambda \) calculation procedure. We will now describe the final algorithm, as all of these pieces have to be plugged together to form the final scheme. First, a startup has to be carried out:
-
1.
Calculate the reference element mass matrix M.
-
2.
Determine the reference element first derivative stiffness matrix S.
-
3.
Find the dissipation generator G:
-
Calculate the laplacian stiffness matrix Q for the reference element in conjunction with the heat conductivity \(\alpha (x)\).
-
Solve \({\frac{ \textrm{d}v }{ \textrm{d}t}} = -M^{-1}Q v\) forward in time with \(v(0) = {{\,\mathrm{\textrm{I}}\,}}\) the identity matrix as initial condition.
-
Determine a value for t using bisection that is minimal (to floating point accuracy) but also satisfies \((v(t))_{kl} \ge 0\) elementwise.
-
Set the dissipation operator to \(G = (v(t) - {{\,\mathrm{\textrm{I}}\,}})/t.\)
-
-
4.
Initialize the grid.
-
5.
\(\textrm{L}^2\)-Project the initial condition onto the ansatz polynomials in every cell.
One evaluation of the scheme in semidiscrete form for \(p > 2\) is done using the following enumerated steps:
-
1.
Calculate the time derivative of the coefficients using a standard DG method as in equation (3).
-
2.
Estimate the maximal possible entropy dissipation per cell edge:
-
(a)
Evaluate the entropy inequality predictor on the values at the cell edges as in equation (20).
-
(b)
\(\textrm{L}^2\) Project the ansatz polynomial to a polynomial of one degree lower as in Sect. 2.3.
-
(c)
Evaluate the entropy inequality predictor on the values at the cell edges of the projected polynomials as in equation (20).
-
(d)
Take the minimal value of both (the fastest dissipation) as prediction as in Sect. 2.3.
-
(a)
-
3.
Determine the correction direction and size:
-
(a)
Calculate a dissipation direction for every cell via the application of G to u as \(\upsilon = Gu\).
-
(b)
Determine the effectivity of the dissipation direction \(\upsilon \) per cell, i.e. the denominator in equation (26) or approximate using equation (25).
-
(c)
Find the total application of the dissipation direction needed from equations (26) and (27).
-
(a)
-
4
Apply the correction \({\frac{ \textrm{d}u }{ \textrm{d}t}} = {\frac{ \textrm{d}u }{ \textrm{d}t}} + \lambda \upsilon \).
In case of \(p=1, 2\) points 2(b) through 2(d) are left out. Nearly all tests that follow need boundary conditions while the theoretical parts of this publication was restricted to periodic boundary conditions. The shock-tube tests below add a ghost cell to the left and right of the domain that is kept constant during the computation to allow us to only use a finite number of cells for our computations. A third publication in this series is in preparation dealing with two-dimensional tests and real boundary conditions. Time integration will be carried out using the SSPRK(4, 3) method for most solutions [32, 41], while the convergence analysis for \(p = 7\) below will use the Hairer-Wanner DOPRI8 method, to achieve the needed convergence speed of the time integration [24]. In all images below the ansatz functions of all cells are shown without any post-processing. The used reference solvers and flux functions are given in Table 2.
4.2 Comparison with Part I for Burgers’ Equation

Solutions to the testcases from [30] using the new method but the old parameters. Initial condition \(u_1(x, 0) = \sin (\pi x)\) is a sine that develops a shock at around \(t=0.3\) while \(u_2(x, 0)\) depicts the ability of the scheme to handle rarefactions
The results are printed in Fig. 6. The values
were used as wave speed estimates. As before the shock disturbs only two cells that are connected to it. Sadly the chaos in these two cells is significantly higher than with the old method. This is not necessarily a problem as the resolution of the new method is higher in case of the rarefaction. Further, as we will see in the numerical tests section for the Euler equations, the new method converges with a higher order for smooth problems. If one accepts the less clean cells around the shock the new scheme is superior for scalar problems.
4.3 Buckley–Leverett Equation
The Buckley–Leverett equation is given by the flux function
It is used to predict two-phase flow in a porous medium [39]. A solution to a Riemann problem for this scalar conservation law can involve a rarefaction and a shock wave at the same time. We use
as entropy flux pair. Our implementation calculates the entropy flux using numerical quadrature. \(N_{quad} = 30\) Gauß-Lobatto points are used in the interval [0, u] for this numerical quadrature and this was found to be exact up to machine precision. The speed estimates for the non-convex flux of the Buckley–Leverett equation were calculated by splitting the domain of the flux into two zones. For \(u \in [0, \frac{1}{2}]\) is \({\frac{ \textrm{d}f }{ \textrm{d}u}}\) increasing, while it is decreasing for \(u \in [\frac{1}{2}, 1]\). The extrema have to be at the ends of the intersections between these intervalls and the values \(u_l\) and \(u_r\). The HLL flux dissipates all entropies [26] and was therefore used in a first order FV solver to calculate reference solutions with \(N = 3\cdot 10^4\) cells.

Solution to Riemann initial data for the Buckley–Leverett equation. The domain is periodic and polynomials of degree 3 and 7 were used. The solutions are shown at \(t = 0.6\) and the reference solution was calculated using a first order FV scheme using a HLL approximate Riemann solver
The results for the Riemann problem
can be seen in Fig. 7. The DG solver converges to the same solution as the HLL-FV solver. Several examples of non-convex conservation laws exist where solvers do not converge to the same solution as a robust first order scheme while they are entropy dissipative at the same time [38]. One can conjecture that the good behavior of our DG method is due to a numerical enforcement of the entropy rate criterion.
4.4 Tests for the Euler Equations
The next tests will be carried out for the Euler equations of gas dynamics in conservation form [25]
in conjunction with the physical entropy [25, 55]
The tests below will focus on the cases \(p = 3\) and \(p = 7\) as the latter are popular in applications because they amount to 4 and 8 nodes, suitable for SIMD processor instructions. Results for values in between are essentially interpolatory to the ones reported for \(p = 3\) and \(p = 7\) and the source code is available to carry out tests for all values \(p > 0\). Equation (19) will be used as wave speed estimate for the Euler equations.
4.4.1 Shock Tube Tests
First, a series of shock tube tests was done to highlight the effectivity of the entropy correction in shock calculations as this is the primary aim of this publication. The first initial condition is the problem of Sod [Problem 6a] [48, 49]
This problem is one of the most well known shock tube tests in the literature. A slight variation of this problem is given in [59, Problem I, Section 4.3.3]
This variation can show entropy violations of the classical entropy inequality as a left sonic rarefaction wave is part of the solution.
Our third shock tube is the time-evolution of the following Riemann problem [48, Problem 6b])
More severe shocks can be expected from the following three initial conditions that originaly served as testcases 3,4 and 5 in [59] and will be our initial conditions 4, 5 and 6:

Shock tube 1 at \(t = 1.8\) with 25 cells corresponding to 100 degrees of freedom and 100 cells corresponding to 400 degrees of freedom (\(p=3\))

Shock tube 1 at \(t = 1.8\) with 13 cells corresponding to 104 degrees of freedom and 100 cells corresponding to 800 degrees of freedom (\(p=7\))

Shock tube 2 at \(t = 1.8\) with 25 cells corresponding to 100 degrees of freedom and 100 cells corresponding to 400 degrees of freedom (\(p=3\))

Shock tube 2 at \(t = 1.8\) with 13 cells corresponding to 104 degrees of freedom and 100 cells corresponding to 800 degrees of freedom (\(p=7\))

Shock tube 3 at \(t = 1.2\) with 25 cells corresponding to 100 degrees of freedom and 100 cells corresponding to 400 degrees of freedom (\(p=3\))

Shock tube 3 at \(t = 1.2\) with 13 cells corresponding to 108 degrees of freedom and 100 cells corresponding to 400 degrees of freedom (\(p=7\))

Shock tube 4 at \(t = 1.8\) with 25 cells corresponding to 100 degrees of freedom and 100 cells corresponding to 400 degrees of freedom (\(p=3\))

Shock tube 4 at \(t = 1.8\) with 13 cells corresponding to 104 degrees of freedom and 100 cells corresponding to 800 degrees of freedom (\(p=7\))

Shock tube 5 at \(t = 1.8\) with 25 cells corresponding to 100 degrees of freedom and 100 cells corresponding to 400 degrees of freedom (\(p=3\))

Shock tube 5 at \(t = 1.8\) with 13 cells corresponding to 104 degrees of freedom and 100 cells corresponding to 800 degrees of freedom (\(p=7\))

Shock tube 6 at \(t = 1.8\) with 25 cells corresponding to 100 degrees of freedom and 100 cells corresponding to 400 degrees of freedom (\(p=3\))

Shock tube 6 at \(t = 1.8\) with 13 cells corresponding to 104 degrees of freedom and 100 cells corresponding to 800 degrees of freedom (\(p=7\))
The shock tube tests were carried out for two different numbers of cells. First for \(N = N_{\text {typ}}/(p +1)\) cells, where \(N_{typ} = 100\) is the usual number of cells used in comparisons for Finite-Volume methods. This was done so that the same number of degrees of freedom has to be saved. The results are satisfactory and highlight the effectivity of the method in Figs. 8, 9, 12, 13. All shocks are sharp and concentrated to less than one cell width. Yet, only slight overshoots and oscillations are visible directly around the shocks. These distortions are confined to the cell directly next to the shock. Contact discontinuities are slightly smeared over one cell, but after they have been smeared to this width no additional smearing takes place. The computational complexity per timestep is still low as no recovery stencil selection has to be carried out and only \(1/(p + 1)\) times the number of two-point fluxes need to be evaluated. Because some other publications use 100 cells also for DG methods we carried out the tests once more for \(N = 100\) cells, amounting to 400 and 800 degrees of freedom for orders \(p=3\) and \(p=7\) (Figs. 10, 11, 12, 13, 14, 15, 16, 17, 18, 19).
4.4.2 Numerical Validation of the Entropy Rate Criterion
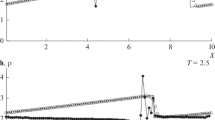
To verify the entropy rate criterion the total entropy of the solution to the first shock tube above was compared to the solution calculated by a modified Lax-Friedrichs scheme with \(3\cdot 10^4\) cells. Similar comparisons were carried out in [29,30,31]. This is supported by our findings in lemma 1, lemma 2 and corollary 1 as a (modified) Lax-Friedrichs solution therefore has to comply with the entropy rate criterion. A scheme should in these comparisons have the same entropy dissipation rate (in the limit) as the Lax-Friedrichs scheme in the limit. Comparisons for orders \(p=3\) and \(p=7\) in Fig. 20 show that this seems to be the case. The DG scheme always has an entropy that lies below the entropy of the LF scheme. As the entropy inequality for vanishing viscosity solutions is also desirable it was also verified on a per-cell basis. We just note that the small positive violations in Fig. 20 are of the same magnitude as the precision achievable during the calculation of \(\lambda \) using our procedure with double precision floats (Fig. 21).

Entropy tests for the first shock tube
4.4.3 Shu–Osher Test
To showcase a combination of shocks and smooth areas the well established shock-sine interaction problem from [48, Problem 8] was tested. The initial conditions are given by
The parameter \(\varepsilon \) was set to the canonical value of \(\varepsilon = 0.2\).

Shu-Osher test for 50, 100 and 200 cells and order \(p = 3\) and \(p = 7\) and therefore 200, 400, 800 and 1600 degrees of freedom at \(t = 1.8\)
The results look satisfactory already when only \(N = 100\) cells are used in the calculation. Yet, we note that this already corresponds to 400 and 800 degrees of freedom for the selected orders. When \(N=200\) cells are used the solution is nearly indistinguishable from the reference solution.
4.4.4 Convergence Analysis
While the main aim of our modification was to devise a new DG scheme usable for shock-capturing calculations the scheme also converges with high order of accuracy for smooth solutions in our experiments. As an example the solution of
with
and periodic boundary conditions was calculated using our modified DG method. The analytical solution for this test problem is
with suitable periodic boundary conditions.

Convergence analysis for \(p = 3\) and \(p = 7\). The error of the baseline DG scheme is shown next to the error of the modified scheme. The error of the modified scheme is higher, and for small cell numbers dominates the error of the additional dissipation. The entropy inequality predictors vanish with a higher order than the base scheme, and therefore vanishes the difference between both schemes under grid refinement
After the solution was calculated for \(N = \{10, 15, 20, 25, 30, 40, 50, 60, 70, 80, 90, 100\}\) cells for \(p = 3\) and with the same stepping up to 50 cells for \(p = 7\) up to \(t = 5\) the \(\textrm{L}^1\) and \(\textrm{L}^2\) errors were calculated. The convergence in Fig. 22 seems to take place with too high an order for the ansatz polynomials used. The reason for this could be that the accuracy of the basic scheme is significantly higher for these solutions than the accuracy of the corrected scheme, because the entropy dissipation estimate still falsely reports high amounts of entropy dissipation. When the grid is refined the entropy dissipation estimate converges with a higher speed than the basic scheme following lemma 4, and because the error introduced to enforce the dissipation dominates a higher convergence speed than expected is observed.
4.4.5 Timestep Analysis
An important result of any modification to a basic scheme can be an impact on the allowed timestep size. In the first part of this publication [30] this influence was tested by measuring the maximal timestep possible before a blow-up occurs. This was done once more.

Maximal timestep sizes for \(p = 3\) and \(p = 7\) and the shock tube 1
The maximal timestep possible for the first shock tube for orders \(p = 3\) and \(p=7\) is shown in Fig. 23. Obviously this timestep is acceptable and when corrected for the larger maximal wave speed of the Riemann problem used for testing, larger than the timestep reported in the previous part, highlighting the superiority of the new dissipation direction.
5 Conclusion
The method described in [30] to enforce an entropy rate criterion for DG methods was improved. By using a direct indicator for the entropy dissipation the error indicator used before could be replaced, resulting in a lower dissipation in situations like contact discontinuities. For smooth solutions this new method to quantify the amount of dissipation needed converges significantly faster to zero than the error estimate used before, and therefore allows us to recover the convergence speed of the basic DG scheme that was reduced by one degree before. Further, the direct quantification of the entropy dissipation needed allows us to consider different dissipation directions, especially combining smoothing and dissipation and therefore bridging into the field of modal filtering. The effectivity of the refined method was demonstrated for the Buckley–Leverett equation and the Euler system of gas dynamics. The method is not only high order accurate but also able to handle shocks, contact discontinuities, and rarefaction waves. The next logical steps can be the application to two-dimensional problems, the application of the designed entropy inequality predictors to other schemes like continuous Galerkin and Spectral Volume schemes, where several adjustments will be needed, and revisiting the splitting into a fully discrete scheme already explored in [30]. The presented method to estimate the entropy dissipation needed could also be used with artificial viscosity shock-capturing as for example described in [20].
Data Availability
The commented implementation of the schemes is available under https://github.com/simonius/dgdafermos.
References
Ben-Artzi, M., Falcovitz, J.: Generalized Riemann problems in computational fluid dynamics., volume 11 of Camb. Monogr. Appl. Comput. Math. Cambridge: Cambridge University Press, reprint of the 2003 hardback ed. edition (2011). https://doi.org/10.1017/CBO9780511546785
Chavent, G., Cockburn, B.: The local projection \(P^ 0-P^ 1\)-discontinuous-Galerkin finite element method for scalar conservation laws. RAIRO, Modélisation Math. Anal. Numér., 23(4), 565–592 (1989). https://doi.org/10.1051/m2an/1989230405651
Chen, T., Shu, C.-W.: Entropy stable high order discontinuous Galerkin methods with suitable quadrature rules for hyperbolic conservation laws. J. Comput. Phys., 345, 427–461 (2017) https://doi.org/10.1016/j.jcp.2017.05.025
Chiodaroli, E., Kreml, O.: Non-uniqueness of admissible weak solutions to the Riemann problem for isentropic Euler equations. Nonlinearity 31(4), 1441–1460 (2018). https://doi.org/10.1088/1361-6544/aaa10d
Chiodaroli, E., De Lellis, C., Kreml, O.: Global ill-posedness of the isentropic system of gas dynamics. Commun. Pure Appl. Math. 68(7), 1157–1190 (2015). https://doi.org/10.1002/cpa.21537
Chiodaroli, E., Kreml, O., Mácha, V., Schwarzacher, S.: Non-uniqueness of admissible weak solutions to the compressible Euler equations with smooth initial data. Trans. Am. Math. Soc. 374(4), 2269–2295 (2021). https://doi.org/10.1090/tran/8129
Cockburn, B., Shu, C.-W.: TVB Runge–Kutta local projection discontinuous Galerkin finite element method for conservation laws. II: General framework. Math. Comput., 52(186), 411–435 (1989). https://doi.org/10.2307/2008474
Cockburn, B.: Shu, C.-W.: Runge-Kutta discontinuous Galerkin methods for convection-dominated problems. J. Sci. Comput. 16(3), 173–261 (2001). https://doi.org/10.1023/A:1012873910884
Dafermos, C.M.: Maximal dissipation in equations of evolution. J. Differ. Equ. 252(1), 567–587 (2012). https://doi.org/10.1016/j.jde.2011.08.006
Dafermos, C.M.: The entropy rate admissibility criterion for solutions of hyperbolic conservation laws. J. Differ. Equ., 202–212 (1972)
Dafermos, C.M.: A variational approach to the Riemann problem for hyperbolic conservation laws. Discrete Contin. Dyn. Syst. 23(1–2), 185–195 (2009). https://doi.org/10.3934/dcds.2009.23.185
Dafermos, C.M.: Hyperbolic Conservation Laws in Continuum Physics, vol. 325. Springer, Berlin (2016)
Dahlquist, G.G.: A special stability problem for linear multistep methods. BIT, Nord. Tidskr. Inf.-behandl., 3, 27–43 (1963) https://doi.org/10.1007/BF01963532
Davis, S.F.: Simplified second-order Godunov-type methods. SIAM J. Sci. Stat. Comput. 9(3), 445–473 (1988). https://doi.org/10.1137/0909030
Einfeldt, B.: On Godunov-type methods for gas dynamics. SIAM J. Numer. Anal. 25(2), 294–318 (1988). https://doi.org/10.1137/0725021
Evans, L.C.: Partial differential equations, volume 19 of Graduate Studies in Mathematics Providence, RI: American Mathematical Society (AMS), 2nd ed. edition (2010)
Feireisl, E.: Maximal dissipation and well-posedness for the compressible Euler system. J. Math. Fluid Mech. 16(3), 447–461 (2014). https://doi.org/10.1007/s00021-014-0163-8
Feireisl, E., Klingenberg, C., Kreml, O., Markfelder, S.: On oscillatory solutions to the complete Euler system. J. Differ. Equ. 269(2), 1521–1543 (2020). https://doi.org/10.1016/j.jde.2020.01.018
Gassner, G.J.: A skew-symmetric discontinuous Galerkin spectral element discretization and its relation to SBP-SAT finite difference methods. SIAM J. Sci. Comput. 35(3), a1233–a1253 (2013). https://doi.org/10.1137/120890144
Glaubitz, J., Nogueira, A.C., Almeida, J.L.S., Cantão, R.F., Silva, C.A.C.: Smooth and compactly supported viscous sub-cell shock capturing for discontinuous Galerkin methods. J. Sci. Comput., 79(1): 249–272 (2019) https://doi.org/10.1007/s10915-018-0850-3
Glaubitz, J., Öffner, P., Sonar, T.: Application of modal filtering to a spectral difference method. Math. Comput. 87(309), 175–207 (2018). https://doi.org/10.1090/mcom/3257
Godlewski, E., Raviart, P.-A.: Hyperbolic Sytems of Conservation Laws. Ellipses (1991)
Gottlieb, S., Shu, C.-W., Tadmor, E.: Strong stability-preserving high-order time discretization methods. SIAM Rev. 43, 05 (2001). https://doi.org/10.1137/S003614450036757X
Hairer, E., Nørsett, S.P., Wanner, G.: Solving ordinary differential equations. I: Nonstiff problems., volume 8 of Springer Ser. Comput. Math. Berlin: Springer, 2nd revised ed., 3rd corrected printing edition (2010)
Harten, A.: On the symmetric form of systems of conservation laws with entropy. J. Comput. Phys. 49, 151–164 (1983)
Harten, A., Lax, P.D., van Leer, B.: On upstream differencing and Godunov-type schemes for hyperbolic conservation laws. SIAM Rev. 25, 35–61 (1983). https://doi.org/10.1137/1025002
Hsiao, L.: The entropy rate admissibility criterion in gas dynamics. J. Differ. Equ. 38, 226–238 (1980). https://doi.org/10.1016/0022-0396(80)90006-6
Johnson, C.: Numerical solution of partial differential equations by finite element method. Mineola, NY: Dover Publications, reprint of the 1987 English ed. edition (2009)
Klein, S.-C.: Using the Dafermos entropy rate criterion in numerical schemes. BIT 62(4), 1673–1701 (2022). https://doi.org/10.1007/s10543-022-00927-x
Klein, S.-C.: Stabilizing discontinuous Galerkin methods using Dafermos’ entropy rate criterion: i-one-dimensional conservation laws. J. Sci. Comput. 95(2), 55 (2023)
Klein, S.-C., Sonar, T.: Entropy-aware non-oscillatory high-order finite volume methods using the Dafermos entropy rate criterion arXiv:2302.08971 (2023)
Kraaijevanger, J.F.B.M.: Contractivity of Runge–Kutta methods. BIT 31(3), 482–528 (1991). https://doi.org/10.1007/BF01933264
Kress, R.: Ill-Conditioned Linear Systems, pp. 77–92. Springer New York, New York, NY (1998) https://doi.org/10.1007/978-1-4612-0599-9_5
Kurganov, A., Tadmor, E.: New high-resolution central schemes for nonlinear conservation laws and convection–diffusion equations. J. Comput. Phys. 160(1), 241–282 (2000). https://doi.org/10.1006/jcph.2000.6459
Lax, P.D.: Shock Waves and Entropy. Contributions to Nonlinear Functional Analysis, pp. 603–634 (1971)
Lax, P.D.: Functional Analysis. Wiley Interscience (2002)
Lax, P.D., Burstein, S., Lax, A.: Calculus with applications and computing. Vol. I. Undergraduate Texts Math. Springer, Cham (1976)
LeFloch, P.G., Ranocha, H.: Kinetic functions for nonclassical shocks, entropy stability, and discrete summation by parts. J. Sci. Comput. 87(2), 38 (2021). https://doi.org/10.1007/s10915-021-01463-6
LeVeque, R.J.: Birkhäuser Verlag, Numerical methods for conservation laws. Basel etc. (1990)
Luo, H., Baum, J.D., Löhner, R.: A hermite WENO-based limiter for discontinuous Galerkin method on unstructured grids. J. Comput. Phys. 225(1), 686–713 (2007). https://doi.org/10.1016/j.jcp.2006.12.017. (https://www.sciencedirect.com/science/article/pii/S0021999106006164)
Rackauckas, C., Nie, Q.: Differentialequations.jl—a performant and feature-rich ecosystem for solving differential equations in Julia. J. Open Res. Softw. 5(1), 15 (2017)
Ranocha, H.: Generalised Summation-by-Parts Operators and Entropy Stability of Numerical Methods for Hyperbolic Balance Laws. Ph.D. thesis, TU Braunschweig, 02 (2018)
Ranocha, H.: Mimetic properties of difference operators: product and chain rules as for functions of bounded variation and entropy stability of second derivatives. BIT Numer. Math. 59(2), 547–563 (2019). https://doi.org/10.1007/s10543-018-0736-7
Ranocha, H., Glaubitz, J., Öffner, P., Sonar, T.: Stability of artificial dissipation and modal filtering for flux reconstruction schemes using summation-by-parts operators. Appl. Numer. Math. 128, 1–23 (2018). https://doi.org/10.1016/j.apnum.2018.01.019
Rojas, D., Boukharfane, R., Dalcin, L., Del Rey, D.C., Fernández, H.R., Keyes, D.E., Parsani, M.: On the robustness and performance of entropy stable collocated discontinuous Galerkin methods. J. Comput. Phys. 426, 17 (2021). https://doi.org/10.1016/j.jcp.2020.109891. (Id/No 109891)
Rudin, W.: Real and complex analysis. McGraw-Hill Series in Higher Mathematics. New York etc.: McGraw-Hill Book Company. xi, 412 p. (1966)
Shu, C.-W., Osher, S.: Efficient implementation of essentially non-oscillatory shock-capturing schemes. J. Comput. Phys. 77, 439–471 (1988)
Shu, C.-W., Osher, S.: Efficient implementation of essentially non-oscillatory shock-capturing schemes II. J. Comput. Phys. 83, 439–471 (1989)
Sod, G.A.: A survey of several finite difference methods for systems of nonlinear hyperbolic conservation laws. J. Comput. Phys. 27, 1–31 (1978). https://doi.org/10.1016/0021-9991(78)90023-2
Sonar, T.: Chapter 3—classical finite volume methods. In: Rémi, A., Chi-Wang, S., (eds), Handbook of Numerical Methods for Hyperbolic Problems, volume 17 of Handbook of Numerical Analysis, pp. 55–76. Elsevier (2016). https://doi.org/10.1016/bs.hna.2016.09.005
Sonntag, M., Munz, C.-D.: Shock capturing for discontinuous Galerkin methods using finite volume subcells. In: Jürgen, F., Mario, O., Christian, R. (eds), Finite Volumes for Complex Applications VII-Elliptic, Parabolic and Hyperbolic Problems, pp. 945–953, Cham. Springer International Publishing (2014)
Tadmor, E.: The large-time behavior of the scalar, genuinely nonlinear Lax–Friedrichs scheme. Math. Comput. 43, 353–368 (1984). https://doi.org/10.2307/2008281
Tadmor, E.: Numerical viscosity and the entropy condition for conservative difference schemes. Math. Comput. 43, 369–381 (1984). https://doi.org/10.2307/2008282
Tadmor, E.: The numerical viscosity of entropy stable schemes for systems of conservation laws. Math. Comput. 49, 91–103 (1987)
Tadmor, E.: Entropy stability theory for difference approximations of nonlinear conservation laws and related time dependent problems. Acta Numerica, 451–512 (2003)
Tang, H.: On the sonic point glitch. J. Comput. Phys. 202: 507–532 (2005). https://doi.org/10.1016/j.jcp.2004.07.013
Toro, E.F.: A fast Riemann solver with constant covolume applied to the random choice method. Int. J. Numer. Methods Fluids 9(9), 1145–1164 (1989). https://doi.org/10.1002/fld.1650090908
Toro, E.F., Müller, L.O., Siviglia, A.: Bounds for wave speeds in the Riemann problem: direct theoretical estimates. Comput. Fluids 209, 18 (2020). https://doi.org/10.1016/j.compfluid.2020.104640
Toro, E.F.: Riemann solvers and numerical methods for fluid dynamics. A practical introduction. Berlin: Springer (2009). https://doi.org/10.1007/b79761
Wang, Z.J.: Spectral (finite) volume method for conservation laws on unstructured grids. Basic formulation. J. Comput. Phys. 178(1), 210–251 (2002). https://doi.org/10.1006/jcph.2002.7041
Wanner, G., Hairer, E., Nørsett, S.P.: Order stars and stability theorems. BIT, Nord. Tidskr. Inf.-behandl., 18: 475–489 (1978) https://doi.org/10.1007/BF01932026
Zhu, J., Qiu, J.: Local DG method using WENO type limiters for convection–diffusion problems. J. Comput. Phys., 230(11): 4353–4375 (2011) https://doi.org/10.1016/j.jcp.2010.03.023. Special issue High Order Methods for CFD Problems
Funding
Open Access funding enabled and organized by Projekt DEAL. The authors have not disclosed any funding.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author has no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A: Per Cell Entropy Inequality for the Three State HLL Flux
Appendix A: Per Cell Entropy Inequality for the Three State HLL Flux
In this appendix we give the derivation of the per cell entropy inequality for the HLL numerical interface flux, originally presented in [26]. This also includes the special case \(-a_l = c_{\textrm{max}} = a_r\) that reduces to the local Lax-Friedrichs scheme.
Lemma 8
(Per-cell entropy inequality for the HLL flux) Assume there exist speed estimates \(a_l(u_l, u_r)\) and \(a_r(u_l,u_r)\) that bound the fastest signal velocities to the left and right in an entropy solution to the Riemann problem of a hyperbolic system of conservation laws. Then the HLL flux using these speed estimates satisfies a per cell entropy inequality with the numerical entropy flux
Here, \(\lambda \in [0, 1]\) is an arbitrary constant and the extreme points of the set of possible entropy fluxes for the transsonic case are
Proof
The approximate solution of the HLL flux is constructed out of the exact solution by averaging in three areas. The first from \(-R\) to \(a_l\), the second from \(a_l\) to \(a_r\) for \(u_{lr}\) and the third from \(a_r\) to R. As explained in Sect. 2, this averaging implies that the entropy of the approximate solution is lower than the entropy of the exact solution that was averaged. One therefore concludes
This entropy inequality has the same structure as the conservation property of the approximate solution in the derivation of the state \(u_{lr}\). The flux \(f^{\textrm{HLL}}\) was constructed by asserting that this flux yields the correct average for the integration domain \([-R, 0]\). We will use the same argument to devise an entropy flux \(F^*\) that respects the inequality above in the sense
In the derivation of \(f^*\) this determined the flux completely, and satisfying one of the equalities for the interval \([-R, 0]\) or [0, R] also implied the other. We are dealing with inequalities in this case, and we will therefore have some freedom in our choice. The case \(0 < a_l\) is determined as in this case the solution is constant and equal to \(u_l\) at all times in \([-R, 0]\). Therefore holds equality in the inequality in (30), defining \(F(u_l)\). The case \(a_r < 0\) follows vice-versa. In case \(a_l< 0 < a_r\) holds the aforementioned freedom of choice occurs. We can choose the extreme by setting \(F^{*}\) to enforce equality in the left equation
The other extreme would be the numerical entropy flux
that produces equality in the right equation. Both imply the other inequality when selected and we can therefore conclude that a suitable numerical entropy flux in the transsonic case is
for every \(\lambda \in [0, 1]\) fixed. \(\square \)
Our implementation uses \(\lambda = \frac{1}{2}\) for symmetry.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Klein, SC. Stabilizing Discontinuous Galerkin Methods Using Dafermos’ Entropy Rate Criterion: II—Systems of Conservation Laws and Entropy Inequality Predictors. J Sci Comput 100, 42 (2024). https://doi.org/10.1007/s10915-024-02595-1
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10915-024-02595-1
Keywords
- Discontinuous Galerkin methods
- Entropy stability
- High-order methods
- Finite-volume methods
- Entropy rate criterion