
Abstract
In this paper, we first study the projections onto the set of unit dual quaternions, and the set of dual quaternion vectors with unit norms. Then we propose a power method for computing the dominant eigenvalue of a dual quaternion Hermitian matrix. For a strict dominant eigenvalue, we show the sequence generated by the power method converges to the dominant eigenvalue and its corresponding eigenvector linearly. For a general dominant eigenvalue, we establish linear convergence of the standard part of the dominant eigenvalue. Based upon these, we reformulate the simultaneous localization and mapping problem as a rank-one dual quaternion completion problem. A two-block coordinate descent method is proposed to solve this problem. One block has a closed-form solution and the other block is the best rank-one approximation problem of a dual quaternion Hermitian matrix, which can be computed by the power method. Numerical experiments are presented to show the efficiency of our proposed power method.
Similar content being viewed by others
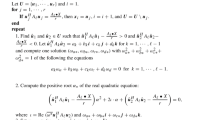

Avoid common mistakes on your manuscript.
1 Introduction
Dual quaternion numbers and dual quaternion matrices are important in robotic research, i.e., the hand-eye calibration problem [7], the simultaneous localization and mapping (SLAM) problem [1,2,3, 5, 23, 25], and the kinematic modeling and control [20]. In [19], Qi and Luo studied right and left eigenvalues of square dual quaternion matrices. If a right eigenvalue is a dual number, then it is also a left eigenvalue. In this case, this dual number is called an eigenvalue of that dual quaternion matrix. They showed that the right eigenvalues of a dual quaternion Hermitian matrix are dual numbers. Thus, they are eigenvalues. An n-by-n dual quaternion Hermitian matrix was shown to have exactly n eigenvalues. It is positive semidefinite, or positive definite, if and only if all of its eigenvalues are nonnegative, or positive and appreciable, dual numbers, respectively. A unitary decomposition for a dual quaternion Hermitian matrix was also proposed. In [20], it was shown that the eigenvalue theory of dual quaternion Hermitian matrices plays an important role in the multi-agent formation control. However, the numerical methods for computing the eigenvalues of a dual quaternion Hermitian matrix is blank.
The power method is one of the state of the art numerical approaches for computing eigenvalues, such as matrix eigenvalues [11], matrix sparse eigenvalues [27], tensor eigenvalues [12], nonnegative tensor eigenvalues [17], and quaternion matrix eigenvalues [15]. In this paper, we propose a power method for computing the dominant eigenvalue of a dual quaternion Hermitian matrix. We first study the projections onto the set of unit dual quaternions and the set of dual quaternion vectors with unit norms. Then we propose a power method for computing the dual quaternion Hermitian matrix eigenvalues. This fills the blank of dual quaternion matrix computation. We also define the convergence of a dual number sequence and study the convergence properties of the power method we proposed.
Dual quaternion is a powerful tool for solving the SLAM problem. The SLAM problem aims to build a map of the environment and to simultaneously localize within this map, which is an essential skill for mobile robots navigating in unknown environments in absence of external referencing systems such as GPS. An intuitive way to solve the SLAM problem is via graph-based formulation [10]. One line of work reformulates SLAM as a nonlinear least square and solves it by the Gauss-Newton method [13]. However, as this problem is nonconvex and Gauss-Newton may be trapped in local minimal points, a good initialization is important [5]. Several methods have been proposed to address the issue of global convergence, including the majorization minimization [9] and the Lagrangian duality [4]. In this paper, we reformulate SLAM as a rank-one dual quaternion completion problem and propose a two-block coordinate descent method to solve it. One block subproblem has a closed form solution and the other block subproblem can be solved by the dominant eigenpair. This connects the dual quaternion matrix theory with the SLAM problem.
The distribution of the remainder of this paper is as follows. In the next section, we review some basic properties of dual quaternions and dual quaternion matrices. We also define the convergence of a dual number sequence there. In Sect. 3, we show the projections onto the set of unit dual quaternions, and the projection onto the set of dual quaternion vectors with unit norms, can be obtained by normalization for appreciable numbers and vectors, respectively. In Sect. 4, we show that the sequence generated by the power method converges linearly to a strict dominant eigenvalue and eigenvector of a dual quaternion Hermitian matrix. For a general dominant eigenvalue, we show the convergence and the linear convergence rate of the standard part of the sequence to the standard part of the dominant eigenvalue. In Sect. 5, we present numerical experiment results on computing the eigenvalues of Laplacian matrices. In Sect. 6, we reformulate SLAM as a rank-one approximation model and present a block coordinate descent method for solving it. Some final remarks are made in Sect. 7.
2 Dual Quaternions and Dual Quaternion Matrices
2.1 Dual Quaternions
The sets of real numbers, dual numbers, quaternion, unit quaternion, dual quaternion, and unit dual quaternion are denoted as \(\mathbb {R}\), \(\mathbb {D}\), \(\mathbb {Q}\), \(\mathbb {U}\), \(\hat{\mathbb {Q}}\), and \(\hat{\mathbb {U}}\), respectively. Denote \(\mathbb {R}^3\) as \(\mathbb {V}\).
A quaternion \({\tilde{q}} = [q_0, q_1, q_2, q_3]\) is a real four-dimensional vector. We use a tilde symbol to distinguish a quaternion. We may also write \({\tilde{q}} = [q_0, \textbf{q}]\), where \(\textbf{q}= [q_1, q_2, q_3] \in \mathbb {V}\). See [6, 7, 22]. If \(q_0 = 0\), then \({\tilde{q}} = [0, \textbf{q}]\) is called a vector quaternion. Suppose that we have two quaternions
\({\tilde{p}} = [p_0, \textbf{p}], {\tilde{q}} = [q_0, \textbf{q}] \in \mathbb {Q}\), where \(p = [p_1, p_2, p_3], q = [q_1, q_2, q_3] \in \mathbb {V}\). The addition of \({\tilde{p}}\) and \({\tilde{q}}\) is defined as \({\tilde{p}} + {\tilde{q}} = [p_0+q_0, \textbf{p}+\textbf{q}].\) Denote the zero element of \(\mathbb {Q}\) as \({\tilde{0}}:= [0, 0, 0, 0] \in \mathbb Q\). The multiplication of \({\tilde{p}}\) and \({\tilde{q}}\) is defined by
where \(\textbf{p}\cdot \textbf{q}\) is the dot product, i.e., the inner product of \(\textbf{p}\) and \(\textbf{q}\), with
and \(\textbf{p}\times \textbf{q}\) is the cross product of \(\textbf{p}\) and \(\textbf{q}\), with
Thus, in general, \({\tilde{p}} {\tilde{q}} \not = {\tilde{q}} {\tilde{p}}\), and we have \({\tilde{p}}{\tilde{q}} = {\tilde{q}}{\tilde{p}}\) if and only if \(\textbf{p}\times \textbf{q}= \textbf{0}\), i.e., either \(\textbf{p}= \textbf{0}\) or \(\textbf{q}= \textbf{0}\), or \(\textbf{p}= \alpha \textbf{q}\) for some real number \(\alpha \). We can also represent the product of \({\tilde{p}}\) and \({\tilde{q}}\) as the product of a matrix and a vector, i.e.,
Furthermore, let \(\tilde{\textbf{p}}=[\tilde{p}_1, \dots , \tilde{p}_n]^\top \in \mathbb Q^n\) and \(\tilde{\textbf{q}}=[\tilde{q}_1, \dots , \tilde{q}_n]^\top \in \mathbb {Q}^n\) be two quaternion vectors, and \(\tilde{P} = [\tilde{\textbf{p}}_1, \dots , \tilde{\textbf{p}}_n] \in \mathbb {Q}^{n\times n}\) be a quaternion matrix. Then there is
where \({\mathcal {M}}(\tilde{\textbf{p}}^\top ) = [{\mathcal {M}}(\tilde{p}_1), \ldots , {\mathcal {M}}(\tilde{p}_n)]\in \mathbb {R}^{4\times 4n}\), \({\mathcal {R}}(\tilde{\textbf{p}}) = [{\mathcal {R}}(\tilde{p}_1)^\top , \ldots , {\mathcal {R}}(\tilde{p}_n)^\top ]^\top \in \mathbb {R}^{4n\times 1}\), and \({\mathcal {M}}(\tilde{P})=({\mathcal {M}}(\tilde{p}_{ij})) \in \mathbb R^{4n\times 4n}\).
The conjugate of a quaternion \({\tilde{q}} = [q_0, q_1, q_2, q_3] \in \mathbb {Q}\) is defined as \({\tilde{q}}^* = [q_0, -q_1, -q_2, -q_3]\). Let \({\tilde{1}}:= [1, 0, 0, 0] \in \mathbb {Q}\). Then for any \({\tilde{q}} \in \mathbb {Q}\), we have \({\tilde{q}}{\tilde{1}} = {\tilde{1}}{\tilde{q}} = {\tilde{q}}\), i.e., \({\tilde{1}}\) is the identity element of \(\mathbb {Q}\). For any \({\tilde{p}}, {\tilde{q}} \in \mathbb {Q}\), we have \(({\tilde{p}}{\tilde{q}})^* = {\tilde{q}}^*{\tilde{p}}^*.\) Suppose that \({\tilde{p}}, {\tilde{q}} \in \mathbb {Q}\), \({\tilde{p}} {\tilde{q}} = {\tilde{q}} {\tilde{p}} = {\tilde{1}}\). Then we say that \({\tilde{p}}\) is invertible and its inverse is \({\tilde{p}}^{-1} = {\tilde{q}}\).
For a quaternion \({\tilde{q}} = [q_0, q_1, q_2, q_3]\in \mathbb {Q}\), its magnitude is defined by
If \(|{\tilde{q}}|=1\), then it is called a unit quaternion. If \({\tilde{p}}, {\tilde{q}} \in \mathbb {U}\), then \({\tilde{p}}{\tilde{q}} \in \mathbb {U}\). For any \({\tilde{q}} \in \mathbb {U}\), we have \({\tilde{q}}{\tilde{q}}^* = {\tilde{q}}^* {\tilde{q}} = {\tilde{1}},\) i.e., \({\tilde{q}}\) is invertible and \({\tilde{q}}^{-1} = {\tilde{q}}^*\). Furthermore, we have \(|\tilde{q}|=\Vert {\mathcal {R}}(\tilde{q})\Vert \). For a quaternion vector \(\tilde{\textbf{q}}=[\tilde{q}_1, \dots , \tilde{q}_n]^\top \in \mathbb {Q}^n\), we then have \(\Vert \tilde{\textbf{q}}\Vert =\Vert {\mathcal {R}}(\tilde{\textbf{q}})\Vert \).
A dual number \(a = a_{\textrm{st}}+a_{\mathcal {I}}\epsilon \) consists of the standard part \(a_{\textrm{st}} \in \mathbb {R}\) and the dual part \(a_{\mathcal {I}} \in \mathbb {R}\). The symbol \(\epsilon \) is the infinitesimal unit. It satisfies \(\epsilon \ne 0\) and \(\epsilon ^2 = 0\). If \(a_{\textrm{st}}\ne 0\), then a is appreciable, otherwise, a is infinitesimal [18].
For \(a = a_{\textrm{st}}+a_{\mathcal {I}}\epsilon , b = b_{\textrm{st}}+b_{\mathcal {I}}\epsilon \in \mathbb {D}\), the addition of a and b is defined as
the multiplication of a and b is defined as
and the division of a and b, when \(a_{\textrm{st}}\ne 0\), or \(a_{\textrm{st}}= 0\) and \(b_{\textrm{st}}=0\) is defined as
where \(c\in \mathbb {R}\) is an arbitrary real number. One may show that the division of dual numbers is the inverse operation of the multiplication of dual numbers.
The zero element of \(\mathbb {D}\) is \(0_D:= 0+0\epsilon \). The identity element of \(\mathbb {D}\) is \(1_D = 1+0\epsilon \). The absolute value of \(a\in \mathbb {D}\) is defined in [18] as
When \(a\ne 0_D\), we have \(\frac{a}{|a|}=\text {sgn}(a_{\textrm{st}})\) if \( a_{\textrm{st}}\ne 0\), and \(\frac{a}{|a|}=\text {sgn}(a_{\mathcal {I}})+c\epsilon \) for any \(c\in \mathbb {R}\) if \( a_{\textrm{st}}=0\).
The total order of dual numbers was defined in [18]: we say that \(a>b\) if \(a_{\textrm{st}}>b_{\textrm{st}}\), or \(a_{\textrm{st}}=b_{\textrm{st}}\) and \(a_{\mathcal {I}}>b_{\mathcal {I}}\). Let \(a>0_D\) be a nonnegative dual number. Then the square root of a is defined by [18]
Let \(\{a_k = a_{k, \textrm{st}}+ a_{k, \mathcal {I}}\epsilon : k = 1, 2, \ldots \}\) be a dual number sequence. We say that this sequence is convergent and has a limit \(a = a_{\textrm{st}} + a_{\mathcal {I}}\epsilon \) if both its standard part sequence \(\{ a_{k, st}: k = 1, 2, \ldots \}\) and its dual part sequence \(\{ a_{k, \mathcal {I}}: k = 1, 2, \ldots \}\) are convergent and have limits \(a_{\textrm{st}}\) and \(a_{\mathcal {I}}\) respectively.
Given a dual number sequence \(\{ a_k: k = 1, 2, \ldots \} \subset \mathbb {D}\) and a real number sequence \(\{ c_k: k = 1, 2, \ldots \} \subset \mathbb {R}\), we introduce a big \(O_D\) notation as follows,
Clearly, in this case, if the real number sequence \(\{c_k: k = 1, 2, \ldots \}\) is convergent, then the dual number sequence \(\{ a_k: k = 1, 2, \ldots \}\) is also convergent. Furthermore, if \(c_k=O(c^k h(k))\) for a real positive number \(c<1\) and a polynomial h(k), then we denote \(c_k=\tilde{O}(c^k)\). Similarly, we denote
A dual quaternion \({\hat{q}} = {\tilde{q}}_{\textrm{st}}+ {\tilde{q}}_{\mathcal {I}}\epsilon \) consists of two quaternions \({\tilde{q}}_{\textrm{st}}\), the standard part of \({\hat{q}}\), and \({\tilde{q}}_{\mathcal {I}} \), the dual part of \({\hat{q}}\). We use a hat symbol to distinguish a dual quaternion. If \(\tilde{q}_{\textrm{st}}\ne \tilde{0}\), then \(\hat{q}\) is appreciable, otherwise, \(\hat{q}\) is infinitesimal [18].
Let \({\hat{p}} = {\tilde{p}}_{\textrm{st}}+{\tilde{p}}_{\mathcal {I}} \epsilon , {\hat{q}} = {\tilde{q}}_{\textrm{st}}+{\tilde{q}}_{\mathcal {I}}\epsilon \in \hat{\mathbb {Q}}\). Then the sum of \({\hat{p}}\) and \({\hat{q}}\) is
and the product of \({\hat{p}}\) and \({\hat{q}}\) is
Again, in general, \({\hat{p}} {\hat{q}} \not = {\hat{q}}{\hat{p}}\). The conjugate of \({\hat{p}} = {\tilde{p}}_{\textrm{st}}+ {\tilde{p}}_{\mathcal {I}}\epsilon \) is \({\hat{p}}^* = {\tilde{p}}_{\textrm{st}}^*+ {\tilde{p}}_{\mathcal {I}}^*\epsilon \). Denote \({\hat{0}} = {\tilde{0}} + {\tilde{0}}\epsilon \) and \({\hat{1}} = {\tilde{1}} + {\tilde{0}}\epsilon \).
A dual quaternion \({\hat{q}} = {\tilde{q}}_{\textrm{st}}+{\tilde{q}}_{\mathcal {I}}\epsilon \) is called a unit dual quaternion if
The magnitude of a dual quaternion \({\hat{q}}\in \hat{\mathbb {Q}}\) is [18]
Here, \(sc({\tilde{q}})=\frac{1}{2} ({\tilde{q}}+{\tilde{q}}^*)\) is the scalar part of \({\tilde{q}}\).
For any dual quaternion number \(\hat{q}=\tilde{q}_{\textrm{st}}+\tilde{q}_{\mathcal {I}}\epsilon \) and dual number \(a=a_{\textrm{st}}+a_{\mathcal {I}}\epsilon \) with \(a_{\textrm{st}}\ne 0\), or \(a_{\textrm{st}}= 0\) and \(\tilde{q}_{\textrm{st}}=\tilde{0}\), there is
where \({\tilde{c}}\in \mathbb {Q}\) is an arbitrary quaternion number.
2.2 Dual Quaternion Matrices
We denote the set of m-by-n real, quaternion, unit quaternion, dual quaternion, and unit dual quaternion matrices as \(\mathbb R^{m\times n}\), \(\mathbb {Q}^{m\times n}\), \(\mathbb {U}^{m\times n}\), \(\hat{\mathbb {Q}}^{m\times n}\), and \(\hat{\mathbb {U}}^{m\times n}\), respectively. We use \(\tilde{\textbf{O}}_{m\times n}\) and \(\hat{\textbf{O}}_{m\times n}\) to denote the m-by-n zero quaternion and zero dual quaternion matrices, and \(\tilde{\textbf{I}}_{m\times m}\) and \(\hat{\textbf{I}}_{m\times m}\) to denote the m-by-m identity quaternion and identity dual quaternion matrices, respectively. Given \(\hat{\textbf{Q}}\in \hat{\mathbb {Q}}^{m\times n}\), if \(\tilde{\textbf{Q}}_{\textrm{st}}\ne \tilde{\textbf{O}}_{m\times n}\), then \(\hat{\textbf{Q}}\) is appreciable, otherwise, \(\hat{\textbf{Q}}\) is infinitesimal.
The 2-norm of a dual quaternion vector \(\hat{{\textbf{x}}}=({\hat{x}}_{i})\in \hat{\mathbb {Q}}^{n\times 1}\) is
A vector \(\hat{{\textbf{x}}}=({\hat{x}}_{i}) \in \hat{\mathbb U}^{n\times 1}\) is called a unit dual quaternion vector if each element in \(\hat{{\textbf{x}}}\) is a unit dual quaternion number. The set of \(n \times 1\) quaternion vectors with unit 2-norms is denoted by \(\mathbb {Q}^{n \times 1}_2\). A matrix \(\hat{{\textbf{Q}}}=({\hat{q}}_{i,j}) \in \hat{\mathbb {U}}^{m\times n}\) is called a unit dual quaternion matrix if each element in \(\hat{{\textbf{Q}}}\) is a unit dual quaternion number.
Given a matrix \(\hat{{\textbf{Q}}}=(\hat{q}_{i,j}) \in \hat{\mathbb {Q}}^{m\times n}\), the transpose of \(\hat{{\textbf{Q}}}\) is \(\hat{{\textbf{Q}}}^\top =(\hat{q}_{j,i}) \in {\hat{\mathbb Q}}^{n\times m}\), and the conjugate transpose of \(\hat{{\textbf{Q}}}\) is \(\hat{{\textbf{Q}}}^*=(\hat{q}^*_{j,i}) \in \hat{\mathbb {Q}}^{n\times m}\). If \(\hat{{\textbf{Q}}}=\hat{{\textbf{Q}}}^*\), then it is a dual quaternion Hermitian matrix, and both its standard part and infinitesimal part are quaternion Hermitian matrices.
The F-norm of a dual quaternion matrix \(\hat{{\textbf{Q}}}=({\hat{Q}}_{ij})\in \hat{\mathbb {Q}}^{m\times n}\) is
and the \(F^*\)-norm is
For convenience in the numerical experiments, we define the \(2^R\)-norm of a dual quaternion vector \(\hat{{\textbf{x}}}=({\hat{x}}_{i}) \in \hat{\mathbb {Q}}^{n\times 1}\) as
and the \(F^R\)-norm of a dual quaternion matrix \(\hat{\textbf{Q}}=(\hat{q}_{ij}) \in \hat{\mathbb {Q}}^{m\times n}\) as
respectively. The \(2^R\)-norm and \(F^R\)-norm here are not norms since they do not satisfy the scaling condition of norms. For instance, let \(\alpha =1+\epsilon \), then \(\Vert \alpha \Vert _{2^R}=\sqrt{2}\), and
We only use the \(2^R\)-norm and \(F^R\)-norm to present the numerical results since they are real numbers, while the 2-norm and F-norm are dual numbers that are more complicated.
Let \(A \in \hat{\mathbb {Q}}^{n \times n}\), \(\textbf{x}\in \hat{\mathbb {Q}}^n\) be appreciable, and \(\lambda \in \hat{\mathbb {Q}}\). If
then \(\lambda \) is called a right eigenvalue of A, with \(\textbf{x}\) as its corresponding right eigenvector. If
then \(\lambda \) is called a left eigenvalue of A, with a left eigenvector \(\textbf{x}\). It was proved in [19] that all the right eigenvalues of a dual quaternion Hermitian matrix A are dual numbers. As dual numbers are commutative with dual quaternions, they are also left eigenvalues. Thus, we may simply call them eigenvalues of A. Note that A may still have other left eigenvalues, which are not dual numbers. See an example of a quaternion matrix in [28].
3 Projection Onto the Set of Dual Quaternions with Unit Norms
Given a quaternion number \(\tilde{q}\ne \tilde{0}\) and a quaternion vector \(\tilde{\textbf{q}}\ne \tilde{\textbf{O}}_{n\times 1}\), we have
Here, \(\mathbb {Q}^{n \times 1}_2\) is the set of n dimensional quaternion vectors with unit 2-norms. In the following, we will show that for the dual quaternion number and the dual quaternion vector, the projection has a similar formulation.
Theorem 1
Given a dual quaternion number \(\hat{q}=\tilde{q}_{\textrm{st}}+\tilde{q}_{\mathcal {I}}\epsilon \in \hat{\mathbb {Q}}\), we have the following conclusions.
-
(i)
If \(\tilde{q}_{\textrm{st}}\ne \tilde{0}\), the normalization of \(\hat{q}\) is the projection of \(\hat{q}\) onto the unit dual quaternion set. Namely,
$$\begin{aligned} \hat{u} = \frac{\hat{q}}{|\hat{q}|} \text { with } \tilde{u}_{\textrm{st}}=\frac{\tilde{q}_{\textrm{st}}}{|\tilde{q}_{\textrm{st}}|},\ \tilde{u}_{\mathcal {I}}= \frac{\tilde{q}_{\mathcal {I}}}{|\tilde{q}_{\textrm{st}}|}-\frac{\tilde{q}_{\textrm{st}}}{|\tilde{q}_{\textrm{st}}|}sc\left( \frac{\tilde{q}_{\textrm{st}}^*}{|\tilde{q}_{\textrm{st}}|}\frac{\tilde{q}_{\mathcal {I}}}{|\tilde{q}_{\textrm{st}}|}\right) \end{aligned}$$(6)is a unit dual quaternion number and
$$\begin{aligned} \hat{u}\in \mathop {\arg \min }_{\hat{v}\in \hat{\mathbb {U}}}\quad |\hat{v}-\hat{q}|^2. \end{aligned}$$(7) -
(ii)
If \(\tilde{q}_{\textrm{st}}= \tilde{0}\) and \(\tilde{q}_{\mathcal {I}}\ne \tilde{0}\), then the projection of \(\hat{q}\) onto the unit dual quaternion set is \(\hat{u} = \tilde{u}_{\textrm{st}} + \tilde{u}_{\mathcal {I}} \epsilon \), where
$$\begin{aligned} \tilde{u}_{\textrm{st}}=\frac{\tilde{q}_{\mathcal {I}}}{|\tilde{q}_{\mathcal {I}}|}, \ \tilde{u}_{\mathcal {I}} \text { is any quaternion number satisfying } {sc(\tilde{q}_{\mathcal {I}}^*\tilde{u}_{\mathcal {I}})=0}. \end{aligned}$$(8)
Proof
(i) The normalization formula in equation (6) follows from
By direct computations, we have \(\tilde{u}_{\textrm{st}}^*\tilde{u}_{\textrm{st}}=\tilde{1}\) and \(\tilde{u}_{\textrm{st}}^*\tilde{u}_{\mathcal {I}}+\tilde{u}_{\mathcal {I}}^*\tilde{u}_{\textrm{st}}=0\). Furthermore, by
and the definition of the total order of dual numbers, we have
Moreover, we have \(sc((\tilde{u}_{\textrm{st}}-\tilde{q}_{\textrm{st}})^*(\tilde{v}_{\mathcal {I}}-\tilde{q}_{\mathcal {I}}))=-sc((\tilde{u}_{\textrm{st}}-\tilde{q}_{\textrm{st}})^*\tilde{q}_{\mathcal {I}})\) for all \(\tilde{v}_{\mathcal {I}}\) satisfying \(sc(\tilde{q}_{\textrm{st}}^*\tilde{v}_{\mathcal {I}})=0\). In other words, any \(\hat{u}\) with the standard part \(\tilde{u}_{\textrm{st}}=\frac{\tilde{q}_{\textrm{st}}}{|\tilde{q}_{\textrm{st}}|}\) and the infinitesimal part satisfying \(sc(\tilde{q}_{\textrm{st}}^*\tilde{u}_{\mathcal {I}})=0\) is an optimal solution. Hence, we conclude that \(\hat{u}\) in (6) is an optimal solution of (7).
(ii) When \(\tilde{q}_{\textrm{st}}=0\), we have
for any \(\hat{v}\in \hat{\mathbb {U}}\). By the definition of the total order of dual numbers, there is
Hence, \({\tilde{u}}_{\textrm{st}}=\frac{\tilde{q}_{\mathcal {I}}}{|\tilde{q}_{\mathcal {I}}|}\). As the objective function is independent of \(\tilde{v}_{\mathcal {I}}\), the infinitesimal part of \(\hat{u}\) can be any quaternion number satisfying \(sc(\tilde{q}_{\mathcal {I}}^*\tilde{u}_{\mathcal {I}})=0\). This completes the proof. \(\square \)
For problem (7), any \(\tilde{u}_{\mathcal {I}}\) satisfying \(sc(\tilde{q}_{\textrm{st}}^*\tilde{u}_{\mathcal {I}})=0\) is an optimal solution. However, the choice of \(\tilde{u}_{\mathcal {I}}\) in (6) is geometric meaningful, as shown in the following proposition.
Proposition 2
Suppose \(\tilde{q}_{\textrm{st}}\ne \tilde{0}\). Then \(\tilde{u}_{\mathcal {I}}\) defined by (6) is a solution to the following optimization problem,
Furthermore, \(\hat{u} = \frac{\hat{q}}{|\hat{q}|}\) is the optimal solution to the following problem
Proof
Problem (10) is a convex quaternion optimization problem [21] since the objective function is convex and the constraint is linear. Then it follows from the first-order optimality conditions given in Theorem 4.3 of [21], there is a Lagrange multiplier \(\lambda \in \mathbb {R}\) such that
By multiplying \(\tilde{q}_{\textrm{st}}^*\) at the both sides of the first equation, there is \(\lambda = \frac{sc(\tilde{q}_{\textrm{st}}^*\tilde{q}_{\mathcal {I}})}{|\tilde{q}_{\textrm{st}}|^3}\). Consequently, we have
This completes the proof.
\(\square \)
Similarly, we can show the projection onto the set of dual quaternion vectors with unit norms also have closed-form solutions.
Theorem 3
Given a dual quaternion vector \(\hat{\textbf{q}}\in \hat{\mathbb {Q}}^{n\times 1}\), we have
-
(i)
If \(\tilde{\textbf{q}}_{\textrm{st}}\ne \tilde{\textbf{O}}_{n\times 1}\), the normalization of \(\hat{\textbf{q}}\) is the projection of \(\hat{\textbf{q}}\) onto the set of dual quaternion vectors with unit norms. Namely,
$$\begin{aligned} \hat{\textbf{u}}=\frac{\hat{\textbf{q}}}{\Vert \hat{\textbf{q}}\Vert _2} \text { with } \tilde{\textbf{u}}_{\textrm{st}}=\frac{\tilde{\textbf{q}}_{\textrm{st}}}{\Vert \tilde{\textbf{q}}_{\textrm{st}}\Vert _2},\ \tilde{\textbf{u}}_{\mathcal {I}}=\frac{\tilde{\textbf{q}}_{\mathcal {I}}}{\Vert \tilde{\textbf{q}}_{\textrm{st}}\Vert _2}-\frac{\tilde{\textbf{q}}_{\textrm{st}}}{\Vert \tilde{\textbf{q}}_{\textrm{st}}\Vert _2}sc\left( \frac{\tilde{\textbf{q}}_{\textrm{st}}^*}{\Vert \tilde{\textbf{q}}_{\textrm{st}}\Vert _2}\frac{\tilde{\textbf{q}}_{\mathcal {I}}}{\Vert \tilde{\textbf{q}}_{\textrm{st}}\Vert _2}\right) \end{aligned}$$(11)is a dual quaternion vector with unit norm and
$$\begin{aligned} \hat{\textbf{u}} \in \mathop {\arg \min }_{\hat{\textbf{v}}\in {\hat{\mathbb {Q}}}_2^{n\times 1}}\quad \Vert \hat{\textbf{v}}-\hat{\textbf{q}}\Vert _2^2. \end{aligned}$$ -
(ii)
If \(\tilde{\textbf{q}}_{\textrm{st}}= \tilde{\textbf{O}}_{n\times 1}\), the projection of \(\hat{\textbf{q}}\) onto the set of dual quaternion vectors with unit norms is \(\hat{\textbf{u}}=\tilde{\textbf{u}}_{\textrm{st}}+\tilde{\textbf{u}}_{\mathcal {I}}\epsilon \) satisfying
$$\begin{aligned} \tilde{\textbf{u}}_{\textrm{st}}=\frac{\tilde{\textbf{q}}_{\mathcal {I}}}{\Vert \tilde{\textbf{q}}_{\mathcal {I}}\Vert _2}, \ \tilde{\textbf{u}}_{\mathcal {I}} \text { is any quaternion satisfying } sc(\tilde{\textbf{q}}_{\mathcal {I}}^*\tilde{\textbf{u}}_{\mathcal {I}})=0. \end{aligned}$$
Proof
The proof of this theorem is similar to the proof of Theorem 1. We do not repeat it here. \(\square \)
Similar to Proposition 2, we have the following result.
Proposition 4
If \(\tilde{\textbf{q}}_{\textrm{st}}\ne \tilde{\textbf{O}}_{n\times 1}\), \(\tilde{\textbf{u}}_{\mathcal {I}}\) in (11) is a solution to the following optimization problem,
Furthermore, \(\hat{\textbf{u}} = \frac{\hat{\textbf{q}}}{\Vert \hat{\textbf{q}}\Vert _2}\) is the optimal solution to the following problem
Proof
The proof is similar to that of Proposition 2 and we omit it here. \(\square \)
4 The Power Method for Computing the Dominant Eigenvalue of a Dual Quaternion Hermitian Matrix
For a quaternion matrix \(\tilde{\textbf{Q}}\), the power method can return the eigenvalue with the maximum absolute value and its associated eigenvector [15]. We now study the power method for dual quaternion Hermitian matrices.
4.1 The Dominant Eigenvalues of Dual Quaternion Hermitian Matrices
Based on Theorem 4.2 in [19], a dual quaternion Hermitian matrix \(\hat{\textbf{Q}}\in \hat{\mathbb {Q}}^{n\times n}\) has exactly n eigenvalues, which are dual numbers. It also has n eigenvectors \(\hat{\textbf{u}}_1,\dots ,\hat{\textbf{u}}_n\), which are orthonormal vectors, i.e.,
Furthermore, \(\{ \hat{\textbf{u}}_i: i = 1, \dots , n \}\) forms an orthonormal basis of \(\hat{\mathbb {Q}}^{n\times 1}\).
For any unit dual quaternion numbers \(\hat{q}_i\in \hat{\mathbb {U}}\), \(i=1,\dots ,n\), if we multiply \(\hat{q}_i\) on the right of \(\hat{\textbf{u}}_i\), there is
where the second equality follows from that a dual number is commutative with a dual quaternion matrix. Hence, for a dual quaternion Hermitian matrix,
the unit norm eigenvectors \(\{\hat{\textbf{u}}_i\}_{i=1}^n\), which form an orthonormal basis of \(\hat{\mathbb {Q}}^{n\times 1}\), are not unique.
Suppose that we have a dual quaternion Hermitian matrix \(\hat{\textbf{Q}}\in \hat{\mathbb {Q}}^{n\times n}\). We say that an eigenvalue \(\lambda _1\) of \(\hat{\textbf{Q}}\) is a dominant eigenvalue of \(\hat{\textbf{Q}}\), and an eigenvector corresponding to \(\lambda _1\) a dominant eigenvector, if for any eigenvalue \(\lambda _j \) of \(\hat{\textbf{Q}}\), we have
We say that an eigenvalue \(\lambda _1\) of \(\hat{\textbf{Q}}\) is a strict dominant eigenvalue of \(\hat{\textbf{Q}}\), with multiplicity l, if \(\hat{\textbf{Q}}\) has eigenvalues \(\lambda _j\) for \(j = 1, \ldots , n\), and they satisfy
Assumption A The standard parts of the dominant eigenvalues have the same sign.
If \(\hat{\textbf{Q}}\) has a strict dominant eigenvalue, then \(\hat{\textbf{Q}}\) satisfies Assumption A. On the other hand, if \(\hat{\textbf{Q}}\) does not satisfy Assumption A. Let \(\hat{\textbf{P}} = \hat{\textbf{Q}} + \alpha \hat{\textbf{I}}_{n\times n}\), where \(\alpha \) is a nonzero real number. Then \(\hat{P}\) must satisfy Assumption A, and \(\lambda \) is an eigenvalue of \(\hat{\textbf{Q}}\) if and only if \(\lambda + \alpha \) is an eigenvalue of \(\hat{\textbf{P}}\). Thus, it is adequate that we may assume that \(\hat{\textbf{Q}}\) satisfies Assumption A.
Given any initial dual quaternion vector \(\hat{\textbf{v}}^{(0)}\) with unit norm, the power method computes
iteratively. This process is repeated until convergent or the maximal iteration number is reached.

The power method for computing the dominant eigenvalues of a dual quaternion Hermitian matrix
4.2 Computing the Strict Dominant Eigenvalues by the Power Method
Similar to the power method for the real matrices and quaternion matrices, we show \(\hat{\textbf{v}}^{(k)}\) converges to the eigenvector corresponding to a strict dominant eigenvalue linearly.
Theorem 5
Given a dual quaternion Hermitian matrix \(\hat{\textbf{Q}}\in \hat{\mathbb {Q}}^{n\times n}\) and a dual quaternion vector \(\hat{\textbf{v}}^{(0)}=\sum _{j=1}^n\hat{\textbf{u}}_j\hat{\alpha }_j\) with unit norm, where \(\hat{\textbf{u}}_1,\dots ,\hat{\textbf{u}}_n\) are orthonormal eigenvectors of \(\hat{\textbf{Q}}\). Suppose \(\sum _{j=1}^l|\tilde{\alpha }_{j,\textrm{st}}| \ne 0\), \(\tilde{\textbf{Q}}_{\textrm{st}}\ne \tilde{\textbf{O}}_{n\times n}\), and \(\hat{\textbf{Q}}\) has a strict dominant eigenvalue with multiplicity l that satisfies (13). Then the sequence generated by the power method (14) satisfies
where \(s=sgn(\lambda _{1,\textrm{st}})\), \(\hat{\gamma }_j=\frac{\hat{\alpha }_j}{\sqrt{\sum _{i=1}^l |\hat{\alpha }_i|^2}}\), and
In other words, the sequence \(\hat{\textbf{v}}^{(k)}s^k\) converges to a strict dominant eigenvector \(\sum _{j=1}^l\hat{\textbf{u}}_j \hat{\gamma }_j\) at a rate of \({\tilde{O}}_D\left( \left| \frac{\lambda _{l+1,\textrm{st}}}{\lambda _{1,\textrm{st}}}\right| ^{k}\right) \) and the sequence \(\lambda ^{(k)}\) converges to the strict dominant eigenvalue \(\lambda _1\) at a rate of \({\tilde{O}}_D\left( \left| \frac{\lambda _{l+1,\textrm{st}}}{\lambda _{1,\textrm{st}}}\right| ^{2k}\right) \).
Proof
Let \(\hat{\textbf{v}}^{(0)}\) be a dual quaternion vector with unit norm and \(\hat{\textbf{v}}^{(0)}=\sum _{j=1}^n \hat{\textbf{u}}_j\hat{\alpha }_j\), where \(\hat{\alpha }_j,j=1,\dots ,n\) are dual quaternion numbers, \(\sum _{j=1}^n \hat{\alpha }_j^*\hat{\alpha }_j=\hat{1}\), and \(\sum _{j=1}^l|\tilde{\alpha }_{j,\textrm{st}}|\ne \tilde{0}\). Combing this with (14), we have
By direct derivations, we have \(|\lambda _j^k\hat{\alpha }_j| = |\lambda _j^k||\hat{\alpha }_j|\).
Furthermore, there is
where \(\beta _j=\lambda _{j,\textrm{st}}^{-1}\lambda _{j,\mathcal {I}}\).
When k goes to infinity, we have
where \(O_D(\cdot )\) is defined by (2). Hence,
If \(j\in \{1,\dots ,l\}\), it holds that
Here, \(\hat{\gamma }_j=\frac{\hat{\alpha }_j}{\sqrt{\sum _{i=1}^l |\hat{\alpha }_i|^2}}\),
and the second equality follows from \(\frac{\lambda _1^k}{|\lambda _1|^k}=s^k\). Furthermore, if \(j\ge l+1\), we have
Consequently, (15) holds true and \(\hat{\textbf{v}}^{(k)}s^k\) converges to \(\sum _{j=1}^l\hat{\textbf{u}}_j \hat{\gamma }_j\). Since
and
we have that \(\sum _{j=1}^l\hat{\textbf{u}}_j \hat{\gamma }_j\) is also an eigenvector corresponding to \(\lambda _1\). Furthermore,
This completes the proof. \(\square \)
4.3 General Dominant Eigenvalues
In general, we may assume that \(\hat{\textbf{Q}}\) satisfies Assumption A.
Then we show the convergence of the standard part of the dominant eigenvalue.
Lemma 6
Given a dual quaternion Hermitian matrix \(\hat{\textbf{Q}}\in \hat{\mathbb {Q}}^{n\times n}\) and a dual quaternion vector \(\hat{\textbf{v}}^{(0)}=\sum _{j=1}^n\hat{\textbf{u}}_j\hat{\alpha }_j\) with unit norm, where \(\hat{\textbf{u}}_1,\dots ,\hat{\textbf{u}}_n\) are orthonormal eigenvectors of \(\hat{\textbf{Q}}\). Suppose \(\tilde{\textbf{Q}}_{\textrm{st}}\ne \tilde{\textbf{O}}_{n\times n}\), \(\sum _{j=1}^l |\tilde{\alpha }_{j,\textrm{st}}|^2\ne 0\), and (12) holds.
Then for the sequence generated by the power method (14), we have
where \(s=sgn(\lambda _{1,\textrm{st}})\), \(\tilde{\gamma }_{j,\textrm{st}}=\frac{\tilde{\alpha }_{j,\textrm{st}}}{\sqrt{\sum _{i=1}^l |\tilde{\alpha }_{i,\textrm{st}}|^2}}\), and
In other words, the sequence \(\tilde{\textbf{v}}_{\textrm{st}}^{(k)}s^k\) converges to \(\sum _{j=1}^l\tilde{\textbf{u}}_{j,\textrm{st}} \tilde{\gamma }_{j,\textrm{st}}\) at a rate of \(O\left( \left| \frac{\lambda _{l+1,\textrm{st}}}{\lambda _{1,\textrm{st}}}\right| ^{k}\right) \), and the sequence \(\lambda _{\textrm{st}}^{(k)}\) converges to \(\lambda _{1,\textrm{st}}\) at a rate of \(O\left( \left| \frac{\lambda _{l+1,\textrm{st}}}{\lambda _{1,\textrm{st}}}\right| ^{2k}\right) \).
Proof
For the standard part of the coefficient of \(\hat{\textbf{u}}_j\) in the sequence \(\hat{\textbf{v}}^{(k)}\) presented in (16), we have
If \(j\in \{1,\dots ,l\}\), it holds that
Here, \(\tilde{\gamma }_{j,\textrm{st}}=\frac{\tilde{\alpha }_{j,\textrm{st}}}{\sqrt{\sum _{i=1}^l |\tilde{\alpha }_{i,\textrm{st}}|^2}}\). If \(j\ge l+1\), we have
Consequently, (17) holds true and \(\tilde{\textbf{v}}_{\textrm{st}}^{(k)}s^k\) converges to \(\sum _{j=1}^l\tilde{\textbf{u}}_{j,\textrm{st}} \tilde{\gamma }_{j,\textrm{st}}\). Since
and
we have \(\sum _{j=1}^l\tilde{\textbf{u}}_{j,\textrm{st}} \tilde{\gamma }_{j,\textrm{st}}\) is also an eigenvector of \(\tilde{\textbf{Q}}_{\textrm{st}}\) corresponding to \(\lambda _{1,\textrm{st}}\). Furthermore, \(\lambda _{\textrm{st}}^{(k)}=(\tilde{\textbf{v}}_{\textrm{st}}^{(k)})^*\tilde{\textbf{Q}}_{\textrm{st}}\tilde{\textbf{v}}_{\textrm{st}}^{(k)}\) converges to \(\lambda _{1,\textrm{st}}\). This completes the proof. \(\square \)
In the general case, the dual parts of \(\hat{\textbf{v}}^{(k)}\) may not converge. We now give an example to illustrate this phenomenon.
Example 4.1 Let \({\hat{A}}=A_{\textrm{st}}+A_{\mathcal {I}}\epsilon \), where
Then \({\hat{A}}\) is a dual number Hermitian matrix.
By the power method, if \(\hat{\textbf{v}}^{(0)}=[1,0]^\top \), then there is \(\hat{\textbf{v}}^{(k)}=[1,k \epsilon ]^\top \), \(\lambda ^{(k)}=1\); if \(\hat{\textbf{v}}^{(0)}=[0,1]^\top \), then there is \(\hat{\textbf{v}}^{(k)}=[k \epsilon ,1]^\top \), \(\lambda ^{(k)}=1\). In the both cases, \(\tilde{\textbf{v}}_{\mathcal {I}}^{(k)}\) does not converge.
If the dual part of the sequence generated by the power method does not converge, Algorithm 1 can still return the standard part of the dominant eigenvalue \(\lambda _{\textrm{st}}\) successfully. Then we may compute \(\lambda _{\mathcal {I}}\), \(\tilde{\textbf{u}}_{\textrm{st}}\), and \(\tilde{\textbf{u}}_{\mathcal {I}}\) via the definition [19], i.e.,
Here, the last equation is applied to guarantee that \(\hat{\textbf{u}}\) is appreciable. This is a quaternion nonlinear system, and may not be easy to solve. Fortunately, \(\lambda _{\mathcal {I}}\) is a real number. By (1), we can reformulate (19) into
Equation (20) is a real nonlinear system, and may be solved by many numerical algorithms such as the Levenberg–Marquardt (LM) method [8]. It should be noted that \(\lambda _{\textrm{st}}\) is already known as the standard part of the dominant eigenvalue by our power method, hence the LM method may return a dominant eigenpair of \(\hat{\textbf{Q}}\). Otherwise, the LM method may return any eigenpair of \(\hat{\textbf{Q}}\).
For Example 4.1, by the LM method, we may obtain the eigenpairs \(\lambda _1=1+\epsilon ,\ \hat{\textbf{u}}_1=\left[ \frac{\sqrt{2}}{2}, \frac{\sqrt{2}}{2}\right] ^\top +\tilde{\textbf{u}}_{1,\mathcal {I}}\epsilon ,\) and \(\lambda _2=1-\epsilon , \ \hat{\textbf{u}}_2=\left[ \frac{\sqrt{2}}{2}, -\frac{\sqrt{2}}{2}\right] ^\top +\tilde{\textbf{u}}_{2,\mathcal {I}}\epsilon ,\) where \(\tilde{\textbf{u}}_{1,\mathcal {I}}\) and \(\tilde{\textbf{u}}_{2,\mathcal {I}}\) are arbitrary quaternion vectors.
4.4 All Appreciable Eigenvalues of a Dual Quaternion Hermitian Matrix
By Theorem 7.1 in [16], the Eckart–Young-like theorem holds for dual quaternion matrices. If \(\hat{\textbf{Q}}\in \hat{\mathbb {Q}}^{n\times n}\) is a dual quaternion Hermitian matrix, then by Theorem 4.1 in [19], \(\hat{\textbf{Q}}\) can be rewritten as
where \(\hat{\textbf{U}}=[\hat{\textbf{u}}_1,\dots ,\hat{\textbf{u}}_n]\in \hat{\mathbb {Q}}^{n\times n}\) is a unitary matrix, \( \mathbf \Sigma =\text {diag}(\lambda _1,\dots ,\lambda _n)\in \mathbb {D}^{n\times n}\) is a diagonal dual matrix, and \(\lambda _i, i=1,\dots ,n\) are in the descending order.
Denote \(\hat{\textbf{Q}}_{k}=\hat{\textbf{Q}}-\sum _{i=1}^{k-1}\lambda _i \hat{\textbf{u}}_i\hat{\textbf{u}}_i^*\). Then \(\lambda _k,\hat{\textbf{u}}_k\) is a dominant eigenpair of \(\hat{\textbf{Q}}_{k}\). If \(\lambda _{k,\textrm{st}}\ne 0\), \(\lambda _k,\hat{\textbf{u}}_k\) can be computed by implementing the power method on \(\hat{\textbf{Q}}_k\). By repeating this process from \(k=1\) to n, we get all appreciable eigenvalues and their corresponding eigenvectors.
The process is summarized in Algorithm 2.

Computing all appreciable eigenvalues of a dual quaternion Hermitian matrix
Lemma 7
Given a dual quaternion Hermitian matrix \(\hat{\textbf{Q}}\in \hat{\mathbb {Q}}^{n\times n}\). Suppose that all appreciable eigenvalues \(\lambda _i\) either equal each other or have distinct standard parts. Then Algorithm 2 can return all appreciable eigenvalues and their corresponding eigenvectors.
Proof
This lemma follows directly from (21) and Theorem 5. \(\square \)
4.5 Relationship with the Best Rank-One Approximation
Lemma 8
Given an appreciable dual quaternion Hermitian matrix \(\hat{\textbf{Q}}\in \hat{\mathbb {Q}}^{n\times n}\). The dominant eigenvalue and eigenvector formulate the best rank-one approximation of \(\hat{\textbf{Q}}\) under the square of the F-norm, i.e.,
Proof
By the ordering of the eigenvalues, there is
Furthermore, by
\(\tilde{\textbf{Q}}_{\textrm{st}}\tilde{\textbf{u}}_{1,\textrm{st}}= \lambda _{1,\textrm{st}} \tilde{\textbf{u}}_{1,\textrm{st}}\), \(\tilde{\textbf{u}}_{1,\textrm{st}}^*\tilde{\textbf{u}}_{1,\textrm{st}}=\tilde{1}\), and \(sc(\tilde{\textbf{u}}_{1,\textrm{st}}^*\tilde{\textbf{u}}_{\mathcal {I}})= 0\), we have
which is invariant of \(\tilde{\textbf{u}}_{\mathcal {I}}\).
Hence, \(\lambda _1\) and \(\hat{\textbf{u}}_1\) is an optimal solution of (22). This completes the proof. \(\square \)
5 Numerical Experiments for Computing Eigenvalues
In this section, we first show the numerical experiments for computing all appreciable eigenvalues of the Laplacian matrices of circles and random graphs.
5.1 Eigenvalues of Laplacian Matrices of Circles
In the multi-agent formation control, the Laplacian matrix of the mutual visibility graph plays a key role [20]. Given a vector \(\hat{\textbf{q}}\in \hat{\mathbb {U}}^{n\times 1}\) and a graph \(G=(V,E)\) with n vertices and m edges, the Laplacian matrix of G is defined as follows,
where \( {\textbf{D}}\) is a diagonal real matrix where the i-th diagonal element is equal to the degree of the i-th vertex, and \(\hat{\textbf{A}}=(\hat{a}_{ij})\),
In the multi-agent formation control, \(\hat{q}_i\in \hat{\mathbb {U}}\) is the configurations of the i-th rigid body, \(\hat{a}_{ij}\in \hat{\mathbb {U}}\) is the relative configuration of the rigid bodies i and j, and \(\hat{\textbf{A}}\) is the relative configuration adjacency matrix.

The illustration of a five-point circle
Consider a five-point circle as shown in Fig. 1. Suppose \(\hat{\textbf{q}}\) is a random unit dual quaternion vector as follows,
We now compute all appreciable eigenvalues of \(\hat{\textbf{L}}\) by Algorithm 2. After 23, 25, 1, and 1 iterations respectively, we get four eigenvalues 3.618, 3.618, 1.382, and 1.382. Then Algorithm 2 is stopped since the stopping criterion \(\Vert \tilde{\textbf{L}}_{5,\textrm{st}}\Vert _F\le 10^{-6}\times \Vert \tilde{\textbf{L}}_{\textrm{st}}\Vert _F\) is satisfied and \(\tilde{\textbf{L}}_{5,\mathcal {I}}\) is also close to a zero matrix. Here, \(\hat{\textbf{L}}_5=\hat{\textbf{L}}-\sum _{k=1}^4\lambda _k\hat{\textbf{u}}_k\hat{\textbf{u}}_k^*\). Hence, all five eigenvalues of \(\hat{\textbf{L}}\) are:
The iterates of \(\lambda ^{(k)}\) and \(\hat{\textbf{v}}^{(k)}\) for computing the first and second eigenpair are shown in Fig. 2. From this figure, we see that both the eigenvalue and the eigenvector converge linearly and the eigenvalue converges much faster than the eigenvector. Comparing the first and the second eigenpair, we see the convergence rate is the same. These conclusions are corresponding to our theory in Theorem 5 that \(\hat{\textbf{v}}^{(k)}\) converges to a strict dominant eigenvector at a rate of \({\tilde{O}}_D((\frac{1.382}{3.618})^k)\) and \(\lambda ^{(k)}\) converges to a strict dominant eigenvalue at a rate of \({\tilde{O}}_D((\frac{1.382}{3.618})^{2k})\).

Convergence rate of power method for the Laplacian matrix of a five-point circle
We further consider the Laplacian matrix of circles with 3, 6, and 10 points and list their eigenvalues and the number of iterations of the power method in Table 1. From this table, we see that all appreciable eigenvalues are real numbers and the smallest eigenvalues are all zeros. In our numerical experiments, we also find that the eigenvalues are the same for any \(\hat{\textbf{q}}\) and are all nonnegative real numbers. The following theorem indicates that the observations are true.
Theorem 9
Suppose \(\hat{\textbf{q}}\in \hat{\mathbb {U}}^n\) is a unit dual quaternion vector and
Then the eigenvalues of \(\hat{L}\) have closed-from as follows,
and they are independent of the choice of \(\hat{\textbf{q}}\).
Proof
Let \({\hat{S}}=\textrm{diag}(\hat{\textbf{q}})\). Then \({\hat{S}}\) is a unitary matrix, and
Hence, \(\hat{L}\) is similar with a circulant matrix that admits eigenvalues as (25) up to reordering. Since the eigenvalues are invariant under unitary transformation, (25) are also the eigenvalues of \(\hat{L}\). This completes the proof. \(\square \)
5.2 Eigenvalues of Laplacian Matrices of Random Graphs
We continue to consider the Laplacian matrix of a random graph \(G=(V,E)\). Assume that G is a sparse undirected graph and E is symmetric. The sparsity of G is \(s=m/n^2\), where \(m=|E|\) is the number of edges in E. In practice, we randomly generate \(\lceil \frac{m}{2}\rceil \) edges and let \(E=\{(i,j),(j,i):\text { if }(i,j) \text { is sampled}\}\). All results are repeated ten times with different choices of \(\hat{\textbf{q}}\), different E, and different initial values in the power method. The average results are reported. We show the results in Table 2. In this table,
where \(\lambda _i\) and \(\hat{\textbf{u}}_i\) are the limit points obtained by Algorithm 1 and \(n_0\) is the total number of eigenvalues obtained by Algorithm 2.
We also denote ‘\(n_{\text {iter}}\)’ as the average number of iterations and ‘Time (s)’ as the average CPU time in seconds for computing one eigenvalue.
From Table 2, we see that when \(n=10\), \(e_{\lambda }\) is less than \(10^{-7}\) and \(e_L\) is less than \(10^{-14}\). Similarly, when \(n=100\), the error in eigenvalues and the residue of the result matrices is less than \(1.1\times 10^{-3}\) and \(10^{-7}\), respectively. All results are obtained in less than 1.1 s. This shows the efficiency of the power method in computing all appreciable eigenvalues.
6 The Dominant Eigenvalue Method for SLAM
In this section, we first reformulate the SLAM problem as a rank-one dual quaternion matrix recovery problem. Then we present a two-block coordinate approach for solving this model.
At last, we present several numerical experiments to show the efficiency of our proposed method.
Given a directed graph \(G = (V, E)\) with n vertices and m edges, where each vertex \(i \in V\) corresponds to a robot pose \(\hat{q}_i \in {\hat{\mathbb {U}}}\) for \(i = 1, \ldots , n\), and each directed edge (arc) \((i, j) \in E\) corresponds to a relative measurement \(\hat{q}_{ij}\in \hat{\mathbb {U}}\). The aim of the SLAM problem is to find the best \(\hat{q}_i\) for \(i = 1, \ldots , n\), to satisfy \(\hat{q}_{ij} = (\hat{q}_i)^* \hat{q}_j\)
for \((i, j) \in E\) [5].
6.1 Reformulation
Denote \(\hat{\textbf{x}}=[\hat{q}_1,\dots ,\hat{q}_n]^*\in \hat{\mathbb {U}}^{n}\) as a unit dual quaternion vector, and \(\hat{\textbf{Q}}=(\hat{q}_{ij})\in \hat{\mathbb {U}}^{n\times n}\) as a dual quaternion matrix.
The aim of the SLAM problem is to find \(\hat{\textbf{x}}\) such that
Here, \((\hat{\textbf{Q}})_{E}\) denotes the set \(\{\hat{q}_{ij}: (i,j)\in E\}\). The variable \(\hat{\textbf{x}}\) can be computed by the least square model
The solution of (27) is not unique because \(\hat{\textbf{x}} \hat{\textbf{x}}^*=(\hat{\textbf{x}} \hat{q}) (\hat{\textbf{x}}\hat{q})^*\) for any \(\hat{q}\in \hat{\mathbb {U}}\).
Instead of solving (27) directly, we introduce the auxiliary variables \(\hat{\textbf{X}}\) to solve the following problem
Here,
In the following, we show the equivalence between problems (27) and (28).
Theorem 10
The optimization problems (27) and (28) are equivalent in the following senses:
-
(i)
If \(\hat{\textbf{x}}\) is an optimal solution of (27), then \(\hat{\textbf{X}} = \hat{\textbf{x}} \hat{\textbf{x}}^*\) is an optimal solution of (28). Furthermore, the optimal value of problems (27) and (28) are the same.
-
(ii)
Let \(\hat{\textbf{X}}\) be the optimal solution for (28). Then its rank-one decomposition \(\hat{\textbf{X}}=\lambda \hat{\textbf{u}}\hat{\textbf{u}}^*\) satisfies \(\lambda >0_D\). Furthermore, \(\hat{\textbf{x}} = \sqrt{\lambda }\hat{\textbf{u}}\) is an optimal solution of (27), and the optimal value of problems (27) and (28) are the same.
Proof
We first show that there is a one-to-one correspondence between \(\hat{\textbf{x}}\in \hat{\mathbb {U}}^{n\times 1}\) and \(\hat{\textbf{X}}\in C_1\cap C_2\). On one hand, suppose that \(\hat{\textbf{x}}\in \hat{\mathbb {U}}^{n\times 1}\). Then it follows from direct derivations that
On the other hand, suppose that \(\hat{\textbf{X}}\in C_1\cap C_2\). Then it follows from (21) that there exists \(\lambda \in \mathbb {D}\) and \(\hat{\textbf{u}}^*\hat{\textbf{u}}={\hat{1}}\) such that \(\hat{\textbf{X}} =\lambda \hat{\textbf{u}}\hat{\textbf{u}}^*\). By \(x_{ii} = \lambda \hat{u}_i \hat{u}_i^* ={\hat{1}},\) we have \(\lambda _{\textrm{st}}\tilde{u}_{i,\textrm{st}}\tilde{u}_{i,\textrm{st}}^* ={\tilde{1}}.\) Hence, \(\lambda _{\textrm{st}}>0\) and \(\lambda > 0_D\). By [18], we have \(\sqrt{\lambda }=\sqrt{\lambda _{\textrm{st}}} + \frac{\lambda _{\mathcal {I}}}{2\sqrt{\lambda _{\textrm{st}}}}\epsilon \). Let \(\hat{\textbf{x}}=\sqrt{\lambda }\hat{\textbf{u}}\). Then \(\hat{x}_i^*\hat{x}_i=\hat{1}\). Hence, \(\hat{\textbf{x}}\in \hat{\mathbb {U}}^{n\times 1}\).
(i) From (31) we have \(\hat{\textbf{X}} = \hat{\textbf{x}} \hat{\textbf{x}}^*\) is a feasible solution of (28). Suppose that \(\hat{\textbf{X}}\) is not an optimal solution. Denote the optimal solution as \(\hat{\textbf{X}}'\). Then \(\Vert P_E(\hat{\textbf{X}}'-\hat{\textbf{Q}})\Vert _F^2<\Vert P_E(\hat{\textbf{X}}-\hat{\textbf{Q}})\Vert _F^2\). It follows from the above discussion, there also exists \(\hat{\textbf{x}}'\in \hat{\mathbb {U}}^{n\times 1}\) such that \(\Vert P_E(\hat{\textbf{x}}'(\hat{\textbf{x}}')^*-\hat{\textbf{Q}})\Vert _F^2<\Vert P_E(\hat{\textbf{x}} \hat{\textbf{x}} ^*-\hat{\textbf{Q}})\Vert _F^2\). This contradicts the optimality of \(\hat{\textbf{x}}\).
(ii) Denote \(\hat{\textbf{x}} = \sqrt{\lambda }\hat{\textbf{u}}\). Then it is a feasible solution of (27). The optimality of \(\hat{\textbf{x}}\) can be obtained by the contradiction method similarly.
This completes the proof. \(\square \)
6.2 A Block Coordinate Descent Method
We introduce the auxiliary variables \(\hat{\textbf{X}}_1\) and \(\hat{\textbf{X}}_2\) to solve the following problem
The quadratic penalty approach is applied to reformulate (32) as
Then we compute \(\hat{\textbf{X}}_1\) and \(\hat{\textbf{X}}_2\) alternatively by the block coordinate descent method [26].
Specifically, at the k-th iteration, given \(\rho ^{(k-1)}\), \(\hat{\textbf{X}}_1^{(k-1)}\) and \(\hat{\textbf{X}}_2^{(k-1)}\), we compute \(\hat{\textbf{X}}_1^{(k)}\) as follows,
which has an explicit solution as \(\hat{x}_{1,ii}^{(k)}=1\) and
for all \(i\ne j\). Here, \(c_{ij}=\frac{1}{\delta _{E,ij}+\delta _{E,ji}+2\rho ^{(k-1)}}\), \(\delta _{E,ij}\) is equal to one if \((i,j)\in E\) and zero otherwise, and \(P_{\hat{\mathbb {U}}}(\cdot )\) is the projection onto the set of unit dual quaternion numbers defined by (6).
Then we compute \(\hat{\textbf{X}}_2^{(k)}\) as follows,
By (22), this problem admits an explicit solution as
where \(\lambda \) and \(\hat{\textbf{u}}\) are the dominant eigenvalue and eigenvector of \(\hat{\textbf{X}}_1^{(k)}\), respectively, which can be obtained by the power method (14).
We update the penalty parameter by
where \(\rho _1>1\) is a constant.
We summarize the block coordinate descent method for computing the SLAM problem in Algorithm 3.

A two-block coordinate descent algorithm for SLAM
6.3 Numerical Results for SLAM
We now consider solving the SLAM problem by our proposed model (28).
Denote \(\hat{\textbf{Q}}_0=\hat{\textbf{x}}\hat{\textbf{x}}^*\in \hat{\mathbb {U}}^{n\times n}\), the noise matrix as \(\hat{\textbf{N}}\), and
The parameters of Algorithm 3 are given as follows. The penalty parameters \(\rho ^{(0)}=0.01\) and \(\rho _1=1.1\). The maximal iteration is set to be 1000, and the parameter in the stopping criterion is \(\beta =10^{-5}\). All experiments are repeated ten times with different choices of \(\hat{\textbf{q}}\), different noises, and different initial values in Algorithm 3. We only report the average performance.
Firstly, consider the five-point circle SLAM problem with noisy observation (38). The results for different noise levels are given in Table 3. Here, ‘\(l_{\text {noise}}\)’ is the relative noise level defined by \(l_{\text {noise}}=\frac{\Vert \hat{\textbf{Q}}-\hat{\textbf{Q}}_0\Vert _{F^R}}{\Vert \hat{\textbf{Q}}_0\Vert _{F^R}}\), ‘\(e_x\)’ and ‘\(e_Q\)’ are the error measurements defined by \(e_x = \frac{\Vert \hat{\textbf{y}}_r - \hat{\textbf{x}}_r\Vert _{2^R}}{\Vert \hat{\textbf{x}}_r\Vert _{2^R}}\) and \(e_Q = \frac{\Vert \hat{\textbf{Q}}_0-\lambda \hat{\textbf{u}}\hat{\textbf{u}}^*\Vert _{F^R}}{\Vert \hat{\textbf{Q}}_0\Vert _{F^R}}\), where \(\hat{\textbf{x}}_r = \hat{\textbf{x}}\frac{\hat{x}_i}{|\hat{x}_i|}\), \(i=\mathop {\arg \max }\limits _{i=1,\dots ,n} |x_i|\), \(\hat{\textbf{y}} = \hat{\textbf{u}}\sqrt{\lambda }\), and \(\hat{\textbf{y}}_r = \hat{\textbf{y}}\frac{\hat{y}_i}{|\hat{y}_i|}\). ‘\(n_{\text {iter}}\)’ and ‘time (s)’ are the number of iterations and the total CPU time in seconds for implementing Algorithm 3 respectively. From Table 3, we can see that Algorithm 3 can return a solution with a reasonable error in one minute.
We continue to consider the SLAM problem of random graphs. Suppose the number of vertices is n and the observation rate is \(s=\frac{m}{n^2}\). The numerical results are shown in Table 4. When \(n=10\), all results can be obtained in less than one second. As the observation ratio increases, the error in \(\hat{\textbf{x}}\) and \(\hat{\textbf{Q}}\) and the number of iterations are all decreasing.
When \(n=100\), we have similar observations.
7 Final Remarks
In this paper, we proposed a power method for computing the dominant eigenvalue of a dual quaternion Hermitian matrix and showed the convergence and convergence rate. We used the Laplacian matrices from circles and random graphs to demonstrate the efficiency of the power method. Then we further studied the SLAM problem by a two blocks coordinate descent approach, where one block has a closed form solution and the other block can be obtained by the power method. Our results fill the blank of dual quaternion matrix computation and build relationship between the dual quaternion matrix theory and the SLAM problem. Adding the relation between the dual quaternion matrix theory and the formation control problem, established in [20], we see that the dual quaternion matrix has a solid application background and is worth being further studied.
Data Availibility Statement
The authors confirm that the data supporting the findings of this study are available within the article and its supplementary materials.
References
Bryson, M., Sukkarieh, S.: Building a robust implementation of bearing—only inertial SLAM for a UAV. J. Field Robot. 24, 113–143 (2007)
Bultmann, S., Li, K., Hanebeck, U.D.: Stereo visual SLAM based on unscented dual quaternion filtering. In: 2019 22th International Conference on Information Fusion (FUSION), 1–8 (2019)
Cadena, C., Carlone, L., Carrillo, H., Latif, Y., Scaramuzza, D., Neira, J., Reid, I., Leonard, J.J.: Past, present and future of simultaneous localization and mapping: toward the robust-perception age. IEEE Trans. Rob. 32, 1309–1332 (2016)
Carlone, L., Rosen, D. M., Calafiore, G.C., Leonard, J.J., Dellaert, F.: Lagrangian duality in 3D SLAM: verification techniques and optimal solutions. In: 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 125–132 (2015)
Carlone, L., Tron, R., Daniilidis, K., Dellaert, F.: Initialization techniques for 3D SLAM: a survey on rotation and its use in pose graph optimization. In: IEEE International Conference on Robotics and Automation (ICRA), 4597–4604 (2015)
Cheng, J., Kim, J., Jiang, Z., Che, W.: Dual quaternion-based graph SLAM. Robot. Auton. Syst. 77, 15–24 (2016)
Daniilidis, K.: Hand-eye calibration using dual quaternions. Int. J. Robot. Res. 18, 286–298 (1999)
Fan, J., Yuan, Y.: On the quadratic convergence of the Levenberg–Marquardt method without nonsingularity assumption. Computing 74, 23–39 (2005)
Fan, T., Murphey, T.D.: Majorization minimization methods for distributed pose graph optimization with convergence guarantees. In: 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 5058–5065 (2020)
Grisetti, G., Kümmerle, R., Stachniss, C., Burgard, W.: A tutorial on graph-based SLAM. IEEE Intell. Transp. Syst. Mag. 2(4), 31–43 (2010)
Golub, G.H., Van Loan, C.F.: Matrix Computations. Johns Hopkins Press (2013)
Kolda, T.G., Mayo, J.R.: Shifted power method for computing tensor eigenpairs. SIAM J. Matrix Anal. Appl. 32(4), 1095–1124 (2011)
Kümmerle, R., Grisetti, G., Strasdat, H. M., Konolige, K., Burgard, W.: G2o: a general framework for graph optimization. In: 2011 IEEE International Conference on Robotics and Automation, pp. 3607–3613 (2011)
Li, Y., Wei, M., Zhang, F.X., Zhao, J.L.: A structure-preserving method for the quaternion LU decomposition. Calcolo 54, 1553–1563 (2017)
Li, Y., Wei, M., Zhang, F., Zhao, J.: On the power method for quaternion right eigenvalue problem. J. Comput. Appl. Math. 345, 59–69 (2019)
Ling, C., He, H., Qi, L.: Singular values of dual quaternion matrices and their low-rank approximations. Numer. Funct. Anal. Optim. 43(12), 1423–1458 (2022)
Ng, M., Qi, L., Zhou, G.: Finding the largest eigenvalue of a nonnegative tensor. SIAM J. Matrix Anal. Appl. 31(3), 1090–1099 (2010)
Qi, L., Ling, C., Yan, H.: Dual quaternions and dual quaternion vectors. Commun. Appl. Math. Comput. 4, 1494–1508 (2022)
Qi, L., Luo, Z.: Eigenvalues and singular values of dual quaternion matrices. Pac. J. Optim. 19(2), 257–272 (2023)
Qi, L., Wang, X., Luo, Z.: Dual quaternion matrices in multi-agent formation control. Commun. Math. Sci. 21(7), 1865–1874 (2023)
Qi, L., Luo, Z., Wang, Q., Zhang, X.: Quaternion matrix optimization: motivation and analysis. J. Optim. Theory Appl. 193, 621–648 (2022)
Wang, X., Han, D., Yu, C., Zheng, Z.: The geometric structure of unit quaternion with application in kinematic control. J. Math. Anal. Appl. 389, 1352–1364 (2012)
Wei, E., Jin, S., Zhang, Q.: Autonomous navigation of mars probe using X-ray pulsars: modeling and results. Adv. Space Res. 51, 849–857 (2013)
Wei, T., Ding, W., Wei, Y.: Singular value decomposition of dual matrices and its application to traveling wave identification in the brain. SIAM J. Matrix Anal. Appl. 45, 634–660 (2024)
Williams, S.B., Newman, P., Dissanayake, G.: Autonomous underwater simultaneous localization and map building. In: IEEE International Conference on Robotics and Automation (ICRA), pp. 1793–1798 (2000)
Xu, Y., Yin, W.: A block coordinate descent method for regularized multiconvex optimization with applications to nonnegative tensor factorization and completion. SIAM J. Imag. Sci. 6(3), 1758–1789 (2013)
Yuan, X.-T., Zhang, T.: Truncated power method for sparse eigenvalue problems. J. Mach. Learn. Res. 14, 899–925 (2013)
Zhang, F.: Quaternions and matrices of quaternions. Linear Algebra Appl. 251, 21–57 (1997)
Funding
Open access funding provided by The Hong Kong Polytechnic University. This work was supported by the R &D project of Pazhou Lab (Huangpu) (Grant no. 2023K0603), the Natural Science Foundation of China (No. 12131004), and the Fundamental Research Funds for the Central Universities (Grant No. YWF-22-T-204).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cui, C., Qi, L. A Power Method for Computing the Dominant Eigenvalue of a Dual Quaternion Hermitian Matrix. J Sci Comput 100, 21 (2024). https://doi.org/10.1007/s10915-024-02561-x
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10915-024-02561-x
Keywords
- Dual quaternion Hermitian matrix
- Dominant eigenvalue
- Power method
- Simultaneous localization and mapping