
Abstract
This paper is on the construction of structure-preserving, online-efficient reduced models for the barotropic Euler equations with a friction term on networks. The nonlinear flow problem finds broad application in the context of gas distribution networks. We propose a snapshot-based reduction approach that consists of a mixed variational Galerkin approximation combined with quadrature-type complexity reduction. Its main feature is that certain compatibility conditions are assured during the training phase, which make our approach structure-preserving. The resulting reduced models are locally mass conservative and inherit an energy bound and port-Hamiltonian structure. We also derive a wellposedness result for them. In the training phase, the compatibility conditions pose challenges, we face constrained data approximation problems as opposed to the unconstrained training problems in the conventional reduction methods. The training of our model order reduction consists of a principal component analysis under a compatibility constraint and, notably, yields reduced models that fulfill an optimality condition for the snapshot data. The training of our quadrature-type complexity reduction involves a semi-definite program with combinatorial aspects, which we approach by a greedy procedure. Efficient algorithmic implementations are presented. The robustness and good performance of our structure-preserving reduced models are showcased at the example of gas network simulations.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Conventional discretization methods, such as finite difference or finite element methods, are powerful tools for the numerical investigation of engineering applications. Nonetheless, they may reach their limits due to the high computational demand in many-query tasks of complex applications. Under certain circumstances, projection-based model reduction methods may help to break computational limits and speed up simulations profoundly [1, 27, 35]. In the linear case, a low dimension of the projection directly translates into an efficient reduced model. The supplementation by complexity reduction becomes necessary in the presence of nonlinearities. A prevailing approach to obtain reduced models is to train them towards given snapshot-data. The proper orthogonal decomposition [26, 43] and reduced basis method [37] are widely used examples for such model order reduction methods. As for the complexity reduction, we refer to the empirical interpolation method and its variants [6, 18] as well as to the quadrature-type approaches [4, 27].
While reduction methods have been successfully used in numerous applications, it is known that the standard approaches can suffer from poor results and stability issues for problems of complex structure. One major cause for the issues is that the reduced models may disregard fundamental structural properties of the model they approximate. These properties might include, e.g., conservation laws, dissipative relations or symplecticity. As a remedy, structure-preserving approximation methods have been developed, see, e.g., [1, 15, 19] for selected overviews. Problem-adapted space discretization approaches range from finite volume methods [44] to mixed finite element methods [10] or mimetic finite differences [28]. As for the time discretization, e.g., the symplectic and geometric integrators [33, 41] are famous structure-preserving methods. The development of structure-preserving reduction methods is a more recent topic. Frequency-based model order reduction methods for linear port-Hamiltonian models are discussed in [32, 54]. The works [13, 14] treat nonlinear Lagrangian dynamics by snapshot-based approaches, particularly also using empirical interpolation-type complexity reduction. The papers [1, 2, 49] investigate model order reduction methods that preserve canonical symplectic structure under certain compatibility conditions and thus yield reduced systems in Hamiltonian form. Additionally, complexity reduction by the discrete empirical interpolation method is considered, but this step is not strictly structure-preserving, i.e., it does not guarantee a Hamiltonian structure. A modification of the discrete empirical interpolation that allows for a Hamiltonian representation can be found in [16], but it inherits higher local errors due to an enforced symmetrization step it includes. In other contexts [27, 35], quadrature-type complexity reduction methods are used, which show to be structure-preserving in a more natural way.
In this paper, we construct structure-preserving and online-efficient reduced models for a nonlinear flow problem on networks. The problem is governed by the barotropic Euler equations with a friction term and inherits a port-Hamiltonian structure. It finds application in the context of gas transport networks. The efficient simulation, control and optimization of gas networks is an important topic as the wide range of publications in this direction shows. In [11] a model hierarchy of gradually simplified models is derived, whereby the isothermal (i.e., barotropic) Euler equations are the starting point. Strongly related are the contributions [20, 21], which apply adaptive model-switching in a gas simulation tool. Other approaches to speed up calculations include problem-adapted preconditioners [50] or concepts from discrete optimization [40]. Conventional snapshot-based model reduction methods have also been applied for gas networks [31, 38]. Our model reduction approach focuses on structure-preserving properties, i.e., local mass conservation, an energy bound and a port-Hamiltonian structure underlying the model problem. We establish these properties using compatibility conditions related to the mixed variational formulation [47], see also [22, 24]. While beneficial for the robustness and performance of the reduced models, the compatibility conditions pose a challenge in the training phase, as one faces constraints in the training problems related to the snapshot data. We aim for reduced models that fulfill an optimality condition under these compatibility constraints. The conventional model reduction approaches, cf. [6, 8, 42], are designed towards an optimality condition related to the snapshot data, but compatibility conditions are not taken into account, i.e., structural properties are generally not guaranteed. For some applications, more problem adapted approaches have been derived. In [3, 37, 52] inf-sup stable reduced models for the Stokes and Navier-Stokes equations are derived. This is done using a splitted procedure that treats the training towards the snapshot data and the inf-sup compatibility separately from each other. Consequently, no optimality condition related to the snapshot data can be guaranteed in this approach. Structure-preserving model order reduction methods that aim for optimal reduced models have been considered for canonical Hamiltonian systems, see [1, 49]. Conceptually, our approach shares most similarities with the latter approaches, which are also known as symplectic model reduction. However, the model problem we treat is quite different. Particularly, we cannot reformulate our problem as a canonical Hamiltonian system, we have to deal with network aspects, and our approximations rely on a mixed variational formulation. Regarding the model order reduction, we show that our training problem with its compatibility constraints can be attributed to an unconstrained principal component analysis, given appropriate norms are chosen. Based on this, we derive an efficient algorithmic implementation. Similarly, a training problem involving the snapshot data and constraints reflecting another compatibility condition is considered for the complexity reduction. It is a semi-definite program with combinatorial aspects, which we approach algorithmically by a greedy procedure. The performance of our proposed model reduction method is investigated numerically at the example of gas networks and compared to conventional, non-structure-preserving reduction methods. Moreover, we show a wellposedness result for our reduced models.
The structure of the paper is as follows. In sect. 2 we state the model problem and our notation concerning the network aspects. The approximation ansatz from [47] is shortly reviewed in Sect. 3. It is employed to set up the underlying full order model (space discretization) and also serves as a basis for the reduction steps. Our structure-preserving model order and the complexity reduction methods are derived and analyzed in Sects. 4 and 5, respectively. The numerical studies are presented in Sect. 6, and a wellposedness result for our reduced models is derived in Sect. 7.
2 Model Problem
This section introduces our nonlinear model problem, which describes, e.g., gas transportation networks [11, 36]. Moreover, the variational principle our approximations are based on is stated, and the notation concerning the network aspects is settled, cf. [23, 45].
Let a (gas pipe) network be described by a directed graph \(({{\mathcal {N}}},{\mathcal {E}})\) with sets of nodes \({{\mathcal {N}}} = \{\nu _1, \ldots , \nu _\ell \}\) and edges \({\mathcal {E}} = \{ e_1, \ldots , e_k \} \subset {{\mathcal {N}}} \times {{\mathcal {N}}}\). Each edge \(e\in {\mathcal {E}}\) is attached with a length \(l^e>0\) and a weight \(A^e>0\). The set of all edges adjacent to the node \(\nu \) is denoted by \({\mathcal {E}}(\nu ) = \{e\in {\mathcal {E}}: \, e= ( \nu , {\bar{\nu }}), \text { or } e=( {\bar{\nu }}, \nu ) \}\), and a weighted incidence mapping is defined by
The nodes are grouped into interior nodes \({{\mathcal {N}}}_0 \subset {{\mathcal {N}}}\) and boundary nodes \({{\mathcal {N}}}_\partial = {{\mathcal {N}}} {\backslash } {{\mathcal {N}}}_0\). Function spaces on the network are constructed by compositions of standard Sobolev spaces for every edge. The spatial domain of the union of edges is \(\Omega _{} = \{x: \, x\in e, \text { for } e\in {\mathcal {E}}\}\). Every edge \(e\) can be identified with an interval \((0,l^e)\) which is tacitly employed in the upcoming integral expressions. The space of square-integrable functions on \({\mathcal {E}}\) is given by \({\mathcal {L}}^2({\mathcal {E}}) = \left\{ b: \Omega _{}\rightarrow {\mathbb {R}} \text { with } b_{|e} \in {\mathcal {L}}^2(e) \text { for all } e\in {\mathcal {E}} \right\} \), where the subscript \(._{|e}\) indicates the restriction of a function to the edge \(e\). The respective scalar product and norm read \(\langle b, {\tilde{b}} \rangle = \sum _{e\in {\mathcal {E}}} A^e\int _eb \, {\tilde{b}} \, dx\) and \(|| b || = \sqrt{\langle b, b \rangle }\) for b, \({\tilde{b}} \in {\mathcal {L}}^2({\mathcal {E}})\). The weak (broken) derivative operator for functions on the network is defined by \((\partial _x b)_{|e} = \partial _x b_{|e}\) for \(e\in {\mathcal {E}}\). The space of functions with square-integrable weak broken derivative is given as \({\mathcal {H}}_{pw}^1({\mathcal {E}}) = \left\{ b\in {\mathcal {L}}^2({\mathcal {E}}) : \partial _x b \in {\mathcal {L}}^2({\mathcal {E}}) \right\} \). Accordingly, \({\mathcal {C}}_{pw}^k({\mathcal {E}}) = \left\{ b: \Omega _{} \rightarrow {\mathbb {R}} \text { with } b_{|e} \in {\mathcal {C}}^k(e) \text { for all } e\in {\mathcal {E}} \right\} \) denotes the space of piecewise k-times continuously differentiable functions, \(k\ge 0\). For \(b \in {\mathcal {H}}_{pw}^1({\mathcal {E}})\) we indicate node evaluations with squared brackets, i.e., \(b_{|e}[\nu ] \in {\mathbb {R}}\) for \(\nu \in {\mathcal {N}}\). The Sobolev space \({\mathcal {H}}_{div}^1({\mathcal {E}}) = \{b\in {\mathcal {H}}^1_{pw}({\mathcal {E}}) : \sum _{e\in {\mathcal {E}}(\nu ) } n^{e}[\nu ] b_{|e}[\nu ] = 0, \text { for } \nu \in {{\mathcal {N}}}_0 \}\) incorporates certain coupling conditions at inner nodes. The boundary nodes \({\mathcal {N}}_\partial = \{ \nu _1, \ldots , \nu _p \}\) are assumed to be connected to exactly one edge each. Thus, a boundary operator \({\mathcal {T}}^{ }: {\mathcal {H}}_{pw}^1({\mathcal {E}}) \rightarrow {\mathbb {R}}^{p}\) can be defined by \(\left[ {\mathcal {T}}^{ } b \right] _i = n^e[\nu _i] b_{|e}[\nu _i] \) for \(e\in {\mathcal {E}}(\nu _i)\), \( i =1,\ldots , p \) and \(b \in H^1_{pw}({\mathcal {E}})\).
We consider the barotropic Euler equations with friction governing density and velocity \(\rho ,v: [0,T]\times \Omega \rightarrow {\mathbb {R}} \) on the edges of the network,
Here, \(P'\) is the derivative of the pressure potential \(P:{\mathbb {R}}^+ \rightarrow {\mathbb {R}}\), which is a function exclusively of \(\rho \) in the barotropic case. We assume it to be strictly convex and twice continuously differentiable for all considered \(\rho \). Moreover, the friction term \({\tilde{r}}\) is assumed to be pointwise non-negative. Practically relevant choices for P and \({\tilde{r}}\) are presented in Sect. 6, cf. [5, 21, 29] for modeling details. The solution components are interconnected by the coupling conditions at \(\nu \in {\mathcal {N}}_0\)
The model is closed by appropriate boundary and initial conditions, e.g.,
and \(\rho (0,x) = \rho _0(x)\), \((\rho v)(0,x) = m_0(x)\) with suitable \(\rho _0,m_0 \in {\mathcal {C}}^1_{pw}({\mathcal {E}})\). Instead of the pressure potential, the flow can also be described by means of the pressure p given by \(p(\rho ) = \rho P'(\rho ) - P(\rho )\), cf., [5, 29]. The physical energy of the system is given by the Hamiltonian
Conservation of mass as well as of the Hamiltonian at inner nodes are ensured by the coupling conditions. Furthermore, for sufficiently smooth solutions, it can be shown that the Hamiltonian dissipates over time, up to the exchange with the boundary, i.e.,
with \({\mathbf{u}} = [u_{\nu _1}, \ldots , u_{\nu _p}]^T\). As is shown in [47], the energy dissipation (in-)equality can be derived from the variational principle stated in (3), cf. also Remark 2.1.
For a strong solution \((\rho ,v)\in {\mathcal {C}}^1([0,T];{\mathcal {C}}_{pw}^1({\mathcal {E}}) \times {\mathcal {C}}_{pw}^1({\mathcal {E}}))\) of (1) and the mass flux \(m=\rho v\), the variational principle
holds for all \(q\in {\mathcal {L}}^2({\mathcal {E}})\), \(w\in {\mathcal {H}}_{div}^1({\mathcal {E}})\), with r given by \(r(\rho ,m) = {\tilde{r}}(\rho ,m/\rho )\). The principle follows from (1) by standard arguments and the coupling conditions inherited in \({\mathcal {H}}_{div}^1({\mathcal {E}})\).
Remark 2.1
The dissipation (in-)equality (2) is a consequence of the more profound structural property that the barotropic Euler equations can be stated in port-Hamiltonian form. In particular, (1a) can be formally written as
with \(\nabla _\rho \tilde{{\mathcal {H}}}\) and \(\nabla _v \tilde{{\mathcal {H}}}\) denoting the functional derivatives of \(\tilde{{\mathcal {H}}}\) with respect to (w.r.t.) the variable \(\rho \) and v, respectively. The approximation procedure from [47], which we employ in this work, is designed to preserve the port-Hamiltonian structure on the discrete level. It crucially relies on the formulation of the variational principle (3) in terms of the mass flux m while still using the Hamiltonian formulation with its symmetries, as it is stated here.
3 Structure-Preserving Approximation Framework
The structure-preserving approximation concept from [45, 47] forms the theoretical basis of this work. We briefly present the concept and then discuss our specific choices for constructing the full order model and setting up the data-based reduction.
3.1 Generic Approximation Procedure
The structure-preserving approximation procedure developed in [45, 47] is based on the variational formulation (3). It is applicable to Galerkin projections with classical spatial finite element discretization and model order reduction as well as to complexity reduction of quadrature-type for the nonlinear terms. On all approximation levels local mass conservation and an energy bound for the approximations as well as the port-Hamiltonian structure indicated in Remark 2.1 are kept under mild assumptions.
Assumption 3.1
(Compatibility of spaces) Let \({\mathcal {V}}= {\mathcal {Q}}\times {\mathcal {W}}\subset {\mathcal {L}}^2({\mathcal {E}})\times {\mathcal {H}}_{div}^1({\mathcal {E}})\) be a finite dimensional subspace fulfilling the compatibility conditions
-
A1)
\({\mathcal {Q}}= \partial _x {\mathcal {W}}, \qquad \text { with } \partial _x {\mathcal {W}}= \left\{ \xi : \text {It exists } \zeta \in {\mathcal {W}}\text { with } \partial _x \zeta = \xi \right\} \),
-
A2)
\({\mathcal {K}} \subset {\mathcal {W}}\), with \({\mathcal {K}}=\{w\in {\mathcal {H}}^{1}_{div}({\mathcal {E}}): \, \partial _x w= 0 \}\).
The space \({\mathcal {K}}\) consists of the edge-wise constant functions fulfilling a certain coupling condition. Thus it only depends on the underlying topology and \(\mathtt {dim}({\mathcal {K}})=|{\mathcal {E}}|-|{\mathcal {N}}_0|\).
Assumption 3.2
(Compatibility of scalar product) Let the bilinear form \(\langle \cdot , \cdot \rangle _{*}: {\mathcal {L}}^2({\mathcal {E}}) \times {\mathcal {L}}^2({\mathcal {E}}) \rightarrow {\mathbb {R}}\) be such that the following holds:
-
A1)
For a constant \({\tilde{C}}\ge 1\) and \(||b||_{*}= \sqrt{\langle b,b \rangle _{{*}}}\), it holds \({{\tilde{C}}}^{-1} ||b||_{*}\le ||b|| \le {\tilde{C}} ||b||_{*}\) for all \(b \in {\mathcal {Q}}\cup {\mathcal {W}}\).
-
A2)
For any \(f \in {\mathcal {C}}_{pw}({\mathcal {E}})\) with \(f \ge 0\) it holds \(\langle f , 1 \rangle _{*}\ge 0\).
System 3.3
Assumptions 3.1 and 3.2 are supposed to hold. Given \((\rho _0,m_0) \in {\mathcal {Q}}\times {\mathcal {W}}\) and \({\mathbf{u}}: [0,T]\rightarrow {\mathbb {R}}^p\), find \((\rho ,m) \in {\mathcal {C}}^1([0,T];{\mathcal {Q}}\times {\mathcal {W}}) \) with \(\rho (0) = \rho _0\), \(m(0) =m_0\) and
for all \(q\in {\mathcal {Q}}\), \(w\in {\mathcal {W}}\). Further, \({\mathcal {H}}_{*}(\rho ,m) = \langle P(\rho )+ {m^2}/({2 \rho }), 1 \rangle _{*}\) is referred to as the Hamiltonian of the system.
Note that the density should satisfy \(\rho (t,x) > 0\) for \(t\ge 0\) and \(x \in \Omega \) for physical interpretability.
Theorem 3.4
(Energy bound, [47]) The energy dissipation (in-)equality is fulfilled by any solution \((\rho ,m)\) of System 3.3,
Note that the inequality in the energy bound is implied by the non-negativity of the map \(f \mapsto \langle f , 1 \rangle _{*}\). Our flow problem possesses the form of System 3.3 on each approximation level. At first, a Galerkin projection is constructed by mixed finite elements yielding the full order model (FOM). Subsequently, a second Galerkin projection is applied to obtain a reduced order model (ROM). Although the ROM is of much lower dimension than the FOM, it is unfortunately not more efficient, since the evaluation of the nonlinearities is not independent of the dimension of the FOM. Thus, a final complexity reduction step is performed that replaces the \({\mathcal {L}}^2\)-scalar product by a cheaper-to-evaluate bilinear form for all nonlinear expressions yielding the complexity-reduced model (CROM). In this sense, \(\langle \cdot , \cdot \rangle _{*}\) in System 3.3 is chosen as a complexity-reduced bilinear form (specified and denoted as \(\langle \cdot , \cdot \rangle _c\) below) for the CROM, otherwise for FOM and ROM it is considered as the \({\mathcal {L}}^2\)-scalar product \(\langle \cdot , \cdot \rangle \). In any case, \(\langle \cdot , \cdot \rangle _{*}\) is a scalar product and induces a norm on the spaces \({\mathcal {Q}}\) and \({\mathcal {W}}\), respectively, by Assumption 3.2. The energy dissipation (in-)equality (Theorem 3.4) ensures the stability of the model on each approximation level. Apart from that, System 3.3 inherits further structural properties. It preserves the port-Hamiltonian structure mentioned in Remark 2.1, and its solutions are locally mass conservative, i.e., \(\partial _t \rho = -\partial _x m\) holds in a pointwise sense. We refer to [45, 47] for details and proofs.
3.2 Specific Full Order Model and Data-Based Reduction Setting
Concerning the FOM we follow [24, 25] and use a mixed finite element space that is compatible in the sense of Assumption 3.1. A partitioning of the spatial domain \(\Omega \) into the cells \(K_1, \ldots , K_J\) is defined such that
and \(K_j \subset e\, \text { for {an} } e\in {\mathcal {E}} \text { for {any} } j=1,\ldots , J. \) The finite element ansatz space \( {\mathcal {V}}_{f}= {\mathcal {Q}}_{f} \times {\mathcal {W}}_{f}\), which we also refer to as FOM space, is given by
The functions in \({\mathcal {Q}}_{f}\) are piecewise constant and discontinuous, whereas \({\mathcal {W}}_{f}\) consists of piecewise linear, edgewise continuous functions and inherits the coupling conditions that relate to mass conservation at inner nodes.
The reduced models are trained towards data, the so-called snapshots, given as

The snapshots are typically selected (time) points of one or several solution trajectories of the FOM for appropriate training scenarios. In the model order reduction we seek for a low-dimensional subspace \({\mathcal {V}}_r = {\mathcal {Q}}_r \times {\mathcal {W}}_r\) of \({\mathcal {V}}_f\), \(\mathtt {dim}({\mathcal {V}}_r)\ll \mathtt {dim}({\mathcal {V}}_f)\), that fulfills Assumption 3.1 and in which the snapshot data is approximated with high fidelity. The subsequent complexity reduction aims for constructing a bilinear form \(\langle \cdot , \cdot \rangle _c\) that fulfills Assumption 3.2, whose evaluation-cost is independent of \(\mathtt {dim}({\mathcal {V}}_f)\), and for which  holds for \(\ell = 1, \ldots , L\) and \(w_r \in {\mathcal {W}}_r\) for the appearing nonlinear terms f. We use a quadrature-type approximation.
holds for \(\ell = 1, \ldots , L\) and \(w_r \in {\mathcal {W}}_r\) for the appearing nonlinear terms f. We use a quadrature-type approximation.
Our approach differs from most conventional data-based model reduction methods, e.g, [8, 18, 43], in that compatibility conditions are imposed to ensure the preservation of structural properties for the reduced systems, such as an energy bound (Theorem 3.4) or wellposedness (Sect. 7). In the training phase, the conditions pose an additional challenge, as they lead to constraints.
4 Realization of Model Order Reduction
In this section we formulate the data-based model reduction problem with compatibility conditions. It can be considered as a principal component analysis (PCA) with constraints. As will be shown, this constrained problem can be attributed to an underlying standard PCA given suitable norms are chosen. Based on that, we derive an efficient algorithmic implementation.
4.1 Constrained Principal Component Analysis
Our model order reduction follows the basic notion of proper orthogonal decomposition. The ROM space \({\mathcal {V}}_r\) is obtained by a PCA of the snapshot data, but in contrast to the standard approach, constraints related to the compatibility conditions are posed. To be able to treat the constraints efficiently, the choice of a proper scalar product \(\langle \cdot , \cdot \rangle _\diamond \) for \({\mathcal {W}}_{f}\) in the PCA will be crucial. We denote the respective induced norm by \(||\cdot ||_\diamond \), i.e., \(||w||_\diamond = \sqrt{\langle w, w\rangle _\diamond }\). Moreover, the orthogonal projection onto a subspace \({\mathcal {U}}_{}\) w.r.t. the scalar product \(\langle \cdot , \cdot \rangle \) and \(\langle \cdot , \cdot \rangle _\diamond \) is denoted by \(\Pi _{{\mathcal {U}}_{}}\) and \(\Pi _{{\mathcal {U}}_{}}^\diamond \), respectively. The general approximation problem we consider for the determination of the ROM space \({\mathcal {V}}_r\) reads as follows.
Problem 4.1
Let \({\mathcal {V}}_f = {\mathcal {Q}}_{f}\times {\mathcal {W}}_{f}\) be a FOM space compatible in the sense of Assumption 3.1. For the snapshots \((\rho ^\ell , m^\ell )\) as in (5) and \(n_1 \le N_1=\mathtt {dim}({\mathcal {Q}}_f)\), find a reduced space \({\mathcal {V}}_{r}= {\mathcal {Q}}_{r} \times {\mathcal {W}}_{r} \subset {\mathcal {V}}_f\) as solution to
Due to the compatibility conditions (Assumption 3.1), Problem 4.1 is a constrained optimization problem which might be quite involved to solve. We aim for the derivation of an equivalent unconstrained standard PCA. To remove the constraints, the underlying pure data approximation problem has to be separated from the question of compatibility.
Lemma 4.2
Let \({\mathcal {K}}=\{w\in {\mathcal {H}}^{1}_{div}({\mathcal {E}}): \, \partial _x w= 0 \}\) be as in Assumption 3.1. Then the bilinear form
is a scalar product on \({\mathcal {H}}^1_{div}({\mathcal {E}})\).
Proof
Using that \({\mathcal {K}}\) is the kernel of \(\partial _x: {\mathcal {H}}^1_{div}({\mathcal {E}})\rightarrow {\mathcal {L}}^2({\mathcal {E}}) \), the assertion is straightforward to show. We refer to [23], where the norm \(|| \cdot ||_\diamond \) is considered. \(\square \)
In view of Assumption 3.1, we introduce the orthogonal decomposition of \({\mathcal {W}}_{f}\) w.r.t. \(\langle \cdot , \cdot \rangle _\diamond \) into \({\mathcal {K}}\) and its orthogonal complement \({\mathcal {K}}^\perp \),
Furthermore, we define \(\partial _x^+:{\mathcal {Q}}_{f} \rightarrow {\mathcal {W}}_{f}\) as the right-inverse of the spatial derivative \(\partial _x: {\mathcal {W}}_{f} \rightarrow {\mathcal {Q}}_{f}\), which additionally fulfills \(\Pi ^\diamond _{{\mathcal {K}}} \partial _x^+ \equiv 0\). Note that \({\mathcal {K}}\) is the kernel of \(\partial _x\), and that \(\partial _x^+\) is well-defined and relates to a weighted Moore-Penrose inverse with weights given by the scalar product \(\langle \cdot , \cdot \rangle _\diamond \), cf. [7]. First, we show that the constraints can be formally removed for any choice of \(\langle \cdot , \cdot \rangle _\diamond \).
Theorem 4.3
Let the assumptions of Problem 4.1 hold. Then \({\mathcal {V}}_{r}={\mathcal {Q}}_{r} \times {\mathcal {W}}_{r} \subset {\mathcal {V}}_f\) is a solution to Problem 4.1, if and only if \({\mathcal {Q}}_{r}\) is a solution to
and it holds \({\mathcal {W}}_{r} = \partial _x^+ {\mathcal {Q}}_{r} \oplus {\mathcal {K}}\).
Proof
Let \({\mathcal {Q}}\times {\mathcal {W}}\subset {\mathcal {Q}}_{f} \times {\mathcal {W}}_{f}\) be a compatible reduced space in the sense of Assumption 3.1. Analogously as for the FOM, an orthogonal decomposition of \({\mathcal {W}}\) w.r.t. \(\langle \cdot , \cdot \rangle _\diamond \) can be performed, which yields \({\mathcal {W}}= ({\mathcal {W}}\cap {\mathcal {K}}^\perp ) \oplus {\mathcal {K}}\). From \(\partial _x {\mathcal {W}}= {\mathcal {Q}}\) it then follows that \({\mathcal {W}}= \partial _x^+ {\mathcal {Q}}\oplus {\mathcal {K}}\).
The orthogonal decomposition of the FOM implies \( || w||_\diamond ^2 = || \Pi ^\diamond _{{\mathcal {K}}^\perp } w||_\diamond ^2 + || \Pi ^\diamond _{{\mathcal {K}}} w||_\diamond ^2\) for any \(w\in {\mathcal {W}}_{f}\). Using this equality for the approximation error together with the compatibility \({\mathcal {K}} \subset {\mathcal {W}}\), it follows that \(||m^\ell - \Pi ^\diamond _{{\mathcal {W}}} m^\ell ||_\diamond ^2 = ||\Pi ^\diamond _{{\mathcal {K}}^\perp } m^\ell - \Pi ^\diamond _{{\mathcal {W}}\cap {\mathcal {K}}^\perp } \Pi ^\diamond _{{\mathcal {K}}^\perp } m^\ell ||_\diamond ^2 = ||\Pi ^\diamond _{{\mathcal {K}}^\perp } m^\ell - \Pi ^\diamond _{\partial _x^+ {\mathcal {Q}}} \Pi ^\diamond _{{\mathcal {K}}^\perp } m^\ell ||_\diamond ^2\) for \(\ell = 1,\ldots , L\). All in all, the compatibility conditions of Assumption 3.1 can be removed, and the unconstrained optimization problem is equivalent to Problem 4.1 in the sense of the theorem. \(\square \)
Among others, the theorem shows that the snapshots \(m^\ell \) should not be used directly in the PCA but should be altered first to \(\Pi ^\diamond _{{\mathcal {K}}^\perp } m^\ell \). Moreover note that the subproblem determining \({\mathcal {Q}}_r\) is unconstrained. However, its cost functional inherits terms with different norms depending on the choice of scalar product \(\langle \cdot , \cdot \rangle _\diamond \). For the specific choice (6), we can attribute the following standard PCA to the training problem.
Problem 4.4
Let \({\mathcal {V}}_f = {\mathcal {Q}}_{f}\times {\mathcal {W}}_{f}\) be a FOM space compatible in the sense of Assumption 3.1. For the snapshots \((\rho ^\ell , m^\ell )\) as in (5) and \(n_1 \le N_1=\mathtt {dim}({\mathcal {Q}}_f)\), find a reduced space \({\mathcal {Q}}_{r} \subset {\mathcal {Q}}_{f}\) as solution of
Theorem 4.5
Let \(\langle \cdot , \cdot \rangle _\diamond \) be the scalar product defined in (6). Then, \({\mathcal {V}}_r={\mathcal {Q}}_{r} \times {\mathcal {W}}_{r} \subset {\mathcal {V}}_f\) solves Problem 4.1, if and only if \({\mathcal {Q}}_{r}\) solves Problem 4.4 and \({\mathcal {W}}_{r} = \partial _x^+ {\mathcal {Q}}_{r} \oplus {\mathcal {K}}\).
Proof
As auxiliary result we show that for any compatible pair of spaces \({\mathcal {Q}}\), \({\mathcal {W}}\) it holds
By the definition of orthogonal projections, \(w_2 = \Pi _{\partial _x^+ {\mathcal {Q}}}^{\diamond } \Pi _{{\mathcal {K}}^\perp }^\diamond w\) for \(w\in {\mathcal {W}}\) is fully characterized by the two conditions \(w_2 \in \partial _x^+ {\mathcal {Q}}\) and \(\langle w_2 , {\tilde{w}} \rangle _\diamond = \langle \Pi _{{\mathcal {K}}^\perp }^\diamond w, {\tilde{w}} \rangle _\diamond \) for all \({\tilde{w}} \in \partial _x^+ {\mathcal {Q}}\). From \({\mathcal {W}}\cap {\mathcal {K}}^\perp = \partial _x^+ {\mathcal {Q}}\) it follows that
The last equivalence makes use of \({\mathcal {K}}\) being the kernel of \(\partial _x\). The full equivalence together with the fact \(\partial _x w_2 \in {\mathcal {Q}}\) yields that \(\partial _x w_2\) is the orthogonal projection of \(\partial _x w\) onto \({\mathcal {Q}}\), i.e., the result (7).
To show the equivalence of the minimization problems, we make use of the representation given in Theorem 4.3. Its cost function includes terms of the form \( || \Pi ^\diamond _{{\mathcal {K}}^\perp } m^\ell - \Pi ^\diamond _{\partial _x^+ {\mathcal {Q}}} \Pi ^\diamond _{{\mathcal {K}}^\perp }m^\ell ||_\diamond \). For our specific choice of inner product, it holds
whereby (7) has been used in the last step. From that the equivalence of the cost function of Problem 4.4 and the one stated in Theorem 4.3 can be concluded in a straightforward manner. Using Theorem 4.3 finishes the proof. \(\square \)
4.2 Structured Representations
For the algorithmic realization we introduce coordinate representations of the full and reduced order models.
4.2.1 Full Order Model
Consider the FOM space \({\mathcal {V}}_f = {\mathcal {Q}}_{f} \times {\mathcal {W}}_{f}\) with \(N = \mathtt {dim}({\mathcal {V}}_f) = N_1+N_2\). Let \(\{q^1,\ldots , q^{N_1}\}\) and \(\{w^1,\ldots , w^{N_2}\}\) be bases for \({\mathcal {Q}}_f\) and \({\mathcal {W}}_f\), respectively. The bijective mapping between the coordinate representation \({\mathbf{a}}= [{\mathbf{a}}_1^T, {\mathbf{a}}_2^T]^T \in {\mathbb {R}}^N\), \({\mathbf{a}}_i= [{\mathfrak {a}}_i^1, \ldots , {\mathfrak {a}}_i^{N_i}]^T \in {\mathbb {R}}^{N_i}\), and the function \((\rho ,m) \in {\mathcal {V}}_f\) is given by
The mass matrices for \({\mathcal {Q}}_f\) and \({\mathcal {W}}_f\) as well as the coordinate representation of \(\partial _x: {\mathcal {W}}_{f} \rightarrow {\mathcal {Q}}_{f}\) are defined by
The boundary operator \({\mathcal {T}}: {\mathcal {W}}_f \rightarrow {\mathbb {R}}^p\) has the coordinate representation \({\mathbf{B}} = \left[ {\mathcal {T}}w^1,\ldots , {\mathcal {T}}w^{N_2} \right] ^T\). Moreover, given \((\rho ,m) = \Psi ({\mathbf{a}})\in {\mathcal {V}}_f\), we define vectors related to the nonlinear expressions by
Then the FOM (System 3.3) can be equivalently described by the following algebraic representation.
System 4.6
(Algebraic representation of FOM) Given appropriate \({\mathbf{a}}_0 \in {\mathbb {R}}^{N}\) and \({\mathbf{u}}: [0,T]\rightarrow {\mathbb {R}}^p\), find \({\mathbf{a}} = [{\mathbf{a}}_1^T,{\mathbf{a}}_2^T]^T \in {\mathcal {C}}^1([0,T];{\mathbb {R}}^N)\) with \({\mathbf{a}}(0) = {\mathbf{a}}_0\) and
Remark 4.7
Related to System 4.6, the Hamiltonian H can be defined as \(H({\mathbf{a}}) = {\mathcal {H}}(\Psi ({\mathbf{a}}))\). Using this Hamiltonian, the system can be transformed into standard port-Hamiltonian form, see [47].
For \(m \in {\mathcal {W}}_f\), \(m = \sum _{j=1}^{N_2} w^j {\mathfrak {a}}_2^j\) with \({\mathbf{a}}_2 = [ {\mathfrak {a}}_2^1 ,\ldots , {\mathfrak {a}}_2^{N_2} ]^T \in {\mathbb {R}}^{N_2}\), the coordinate representation of \(\partial _x m \) in the basis of \({\mathcal {Q}}_f\) is given by
which can be concluded from Assumption 3.1 (\(\partial _x{\mathcal {W}}_f={\mathcal {Q}}_f\)).
4.2.2 Reduced Order Models
The projection of the FOM onto the low-dimensional ROM space \({\mathcal {V}}_r \subset {\mathcal {V}}_f\) can be equivalently described in the algebraic setting as projecting System 4.6 with a reduction matrix \({\mathbf{V}} \in {\mathbb {R}}^{N,n}\) and \(n=\mathtt {dim}({\mathcal {V}}_r) \ll N\). As we consider projections orthogonal w.r.t. the \({\mathcal {L}}^2\)-inner product, weighted orthogonal projections occur naturally in the coordinate representation. Accordingly the following definitions are helpful, cf., [7]. Given a symmetric positive definite matrix \({\mathbf{M}} \in {\mathbb {R}}^{N,N}\), we introduce the scalar product \(\langle \cdot , \cdot \rangle _{{\mathbf{M}}}\) and the respective norm \(\Vert \cdot \Vert _{{\mathbf{M}}}\), i.e., \(\langle {\mathbf{x}}, {\mathbf{y}} \rangle _{{\mathbf{M}}}={\mathbf{x}}^T {\mathbf{M}} {\mathbf{y}}\) and \(\Vert {\mathbf{x}} \Vert _{{\mathbf{M}}}=\sqrt{\langle {\mathbf{x}}, {\mathbf{x}} \rangle _{{\mathbf{M}}}}\) for any \({\mathbf{x}}, {\mathbf{y}} \in {\mathbb {R}}^N\). For any matrix \({\mathbf{V}} \in {\mathbb {R}}^{N,n}\) of full column rank, we refer to
as the weighted orthogonal projection w.r.t. \(\langle \cdot , \cdot \rangle _{{\mathbf{M}}}\), where \({\mathbf{V}}^{+,{\mathbf{M}}}\) particularly denotes the weighted left-inverse of \({\mathbf{V}}\). Note that \(\varvec{\Pi }_{{\mathbf{V}}}^{{\mathbf{M}}} \varvec{\Pi }_{{\mathbf{V}}}^{{\mathbf{M}}} = \varvec{\Pi }_{{\mathbf{V}}}^{{\mathbf{M}}} \) and \({{\texttt {im}}({\varvec{\Pi }_{\mathbf{V}}^{{\mathbf{M}}}})} = {{\texttt {im}}({{\mathbf{V}}})}\) as for any projection onto \({{\texttt {im}}({{\mathbf{V}}})}\) (image of \({\mathbf{V}}\)). Moreover, the weighted orthogonality condition \({\mathbf{V}}^T {\mathbf{M}} ({\mathbf{I}}- \varvec{\Pi }_{{\mathbf{V}}}^{{\mathbf{M}}}) = {\mathbf{0}}\) holds. In case of \({\mathbf{M}}={\mathbf{I}}\) identity matrix (implying the Euclidean scalar product and norm), we suppress the index \({\mathbf{M}}\).
Lemma 4.8
Let \({\mathcal {V}}_f\) fulfill Assumption 3.1 and \({\mathbf{Q}}\), \({\mathbf{J}}\) be as in (8). For a block-structured reduction matrix \({\mathbf{V}}\)

the space \({\mathcal {V}}_r ={\mathcal {Q}}_{r}\times {\mathcal {W}}_{r}:= {{\texttt {im}}({ {\mathbf{V}}_1})} \times {{\texttt {im}}({ {\mathbf{V}}_2})}\) fulfills Assumption 3.1, if and only if \({{\texttt {im}}({{\mathbf{Q}}{\mathbf{V}}_1})} = {{\texttt {im}}({{\mathbf{J}} {\mathbf{V}}_2})}\) and \(\text {ker}({\mathbf{J}})\subset {{\texttt {im}}({{\mathbf{V}}_2})}\) hold.
The compatibility condition of Assumption 3.1 on \({\mathcal {V}}_r\) can be recast as a compatibility condition on the reduction matrix \({\mathbf{V}}\) according to Lemma 4.8, as can be derived with the help of (10), cf., [25, 45]. The ROM and a reduced coordinate representation \({\mathbf{a}}_r\), \({\mathbf{V}} {\mathbf{a}}_r \approx {\mathbf{a}}\), are then characterized by a projected version of System 4.6. Its initial conditions \({\mathbf{a}}_r(0)\in {\mathbb {R}}^{n_1+n_2}\) are chosen as the \({\mathcal {L}}^2\)-projections of \({\mathbf{a}}_0=[{\mathbf{a}}_{0,1}^T,{\mathbf{a}}_{0,2}^T]^T\in {\mathbf {R}}^{N_1+N_2}\), accordingly.
System 4.9
(Algebraic representation of ROM) Given System 4.6 and a reduction matrix \({\mathbf{V}}\) as in Lemma 4.8, find \({\mathbf{a}}_r = [{\mathbf{a}}_{r,1}^T,{\mathbf{a}}_{r,2}^T]^T \in {\mathcal {C}}^1([0,T];{\mathbb {R}}^n)\), with \({\mathbf{a}}_r(0) = [({\mathbf{V}}_1^{+,{\mathbf{Q}}} {\mathbf{a}}_{0,1})^T,({\mathbf{V}}_2^{+,{\mathbf{W}}} {\mathbf{a}}_{0,2})^T]^T \) and
where the reduced state matrices are \({\mathbf{Q}}_{r} = {\mathbf{V}}_1^T {\mathbf{Q}}{\mathbf{V}}_1\), \({\mathbf{J}}_r = {\mathbf{V}}_1^T {\mathbf{J}} {\mathbf{V}}_2\) and \({\mathbf{B}}_{r} = {\mathbf{V}}_2^T {\mathbf{B}}\). The reduced nonlinearities are defined by \({\mathbf{f}}_r({\mathbf{a}}_r) = {\mathbf{V}}_2^T {\mathbf{f}}({\mathbf{V}} {\mathbf{a}}_r)\) for \({\mathbf{f}} \in \{ {\mathbf{f}}^\alpha , {\mathbf{f}}^\beta , {\mathbf{f}}^\gamma \}\).
4.3 Computation of Structure-Preserving Reduction Basis
To reformulate a PCA problem in a weighted norm in terms of the Euclidean norm, we make use of the following result, cf. [26]. Let \({\mathbf{M}} \in {\mathbb {R}}^{N,N}\) be a symmetric positive definite matrix and \({\mathbf{M}} = {\mathbf{L}}^T{\mathbf{L}}\). Then it holds
The relation follows from \(\Vert {\mathbf{x}} - \varvec{\Pi }_{{\mathbf{V}}}^{{\mathbf{M}}} {\mathbf{x}} \Vert _{\mathbf{M}} = \Vert {\mathbf{L}} ( {\mathbf{x}} - \varvec{\Pi }_{{\mathbf{V}}}^{{\mathbf{M}}} {\mathbf{x}} ) \Vert = \Vert {\mathbf{L}} {\mathbf{x}} - \varvec{\Pi }_{{\mathbf{L}}{\mathbf{V}}} {\mathbf{L}} {\mathbf{x}} \Vert \), as \(\varvec{\Pi }_{{\mathbf{V}}}^{{\mathbf{M}}} = {\mathbf{L}}^{-1} \varvec{\Pi }_{{\mathbf{L}}{\mathbf{V}}} {\mathbf{L}}\) according to the definition of the weighted orthogonal projection (11).
Theorem 4.10
Let \({\mathbf{Q}}\), \({\mathbf{J}}\) and \(\Psi \) be given as in Sect. 4.2. Let \({\mathbf{L }} \in {\mathbb {R}}^{N_1,N_1}\) be such that \({\mathbf{Q}}= {\mathbf{L }}^T {\mathbf{L }}\). Further, let the coordinate representations of the snapshots \((\rho ^\ell , m^\ell ) \in {\mathcal {V}}_f\) in (5) be given by
with \(n_1 \le \text {rank}({\mathbf{K}})\), \({\mathbf{K}} = {\mathbf{L }} [ {\mathbf{S}}_1 , {\mathbf{Q}}^{-1} {\mathbf{J}} {\mathbf{S}}_2]\). Then Problem 4.4 can be equivalently described by
Moreover, solutions \({\mathbf{V}}_1^*\) to this problem fulfill \({{\texttt {im}}({{\mathbf{V}}_1^*})} = {{\texttt {im}}({ {\mathbf{L}}^{-1}[\tilde{{\mathbf{v}}}_1,\ldots ,\tilde{{\mathbf{v}}}_{n_1} ]})}\), where the vectors \(\tilde{{\mathbf{v}}}_i\) denote the first left-singular vectors of the matrix \({\mathbf{K}}\).
Proof
The stated minimization problem relates to a coordinate representation of Problem 4.4 in the basis \(\{q^1, \ldots , q^{N_1}\}\) of \({\mathcal {Q}}_f\). This can be seen from the equalities
using (10). Let \({\mathbf{s}}^\ell \in {\mathbb {R}}^{N_1}\) for \(\ell = 1,\ldots , 2L\) be defined by \([{\mathbf{s}}^1,\ldots , {\mathbf{s}}^{2L}]= [{\mathbf{S}}_1 , {\mathbf{Q}}^{-1}{\mathbf{J}} {\mathbf{S}}_2]\). Then it holds
according to (12). Hence, \({\mathbf{V}}_1^*\) solves the problem of the theorem, if and only if \(\tilde{{\mathbf{V}}}_1^* = {\mathbf{L }} {\mathbf{V}}_1^*\) solves
The latter is a standard PCA problem and can be solved by the method of snapshots, cf. [42, 43]. It has a solution \(\tilde{{\mathbf{V}}}_1^* = [\tilde{{\mathbf{v}}}_1,\ldots ,\tilde{{\mathbf{v}}}_{n_1}]\) with \(\tilde{{\mathbf{v}}}_i\) as in the theorem. Consequently, \({\mathbf{V}}_1^*\) fulfills \({{\texttt {im}}({{\mathbf{V}}_1^*})} ={{\texttt {im}}({ {\mathbf{L}}^{-1}[\tilde{{\mathbf{v}}}_1,\ldots ,\tilde{{\mathbf{v}}}_{n_1} ]})}\). \(\square \)
In the following algorithm we summarize our procedure for constructing a reduction matrix \({\mathbf{V}}\), which yields an optimal reduction space in the sense of Problem 4.1. As the characterizations of \({\mathcal {V}}_r={\mathcal {Q}}_r\times {\mathcal {W}}_r\) in Lemma 4.8 and Theorem 4.3 suggest, the procedure separates into two parts. First, the space \({\mathcal {Q}}_r= {{\texttt {im}}({{\mathbf{V}}_1})}\) is determined according to Theorem 4.10. Then, \({\mathcal {W}}_r ={{\texttt {im}}({{\mathbf{V}}_2})}\) is derived using the compatibility conditions.
Algorithm 4.11
(Optimal compatible reduction basis)
INPUT:
-
Snapshot matrices for density and mass flux: \({\mathbf{S}}_1 \in {\mathbb {R}}^{N_1,L} \), \({\mathbf{S}}_2\in {\mathbb {R}}^{N_2,L}\)
-
Reduced dimension for density: \(n_1\)
-
System matrices according to (8): \({\mathbf{Q}}\), \({\mathbf{W}}\), \({\mathbf{J}}\)
OUTPUT: Reduction matrix: \({\mathbf{V}} \in {\mathbb {R}}^{N_1+N_2,n_1+n_2}\)
-
(1)
Calculate Cholesky factor \({\mathbf{L}} \in {\mathbb {R}}^{N_1,N_1}\) of \({\mathbf{Q}}\) with \({\mathbf{Q}}= {\mathbf{L}}^T {\mathbf{L}}\)
-
(2)
Determine \(\tilde{{\mathbf{V}}}_1 \in {\mathbb {R}}^{N_1,n_1}\) consisting of the first \(n_1\) left-singular vectors of \({\mathbf{K}}={\mathbf{L }} [ {\mathbf{S}}_1 , {\mathbf{Q}}^{-1} {\mathbf{J}} {\mathbf{S}}_2]\)
-
(3)
Determine matrices \({\mathbf{V}}_i \in {\mathbb {R}}^{N_i,n_i}\) for \(i=1,2\) (whose column vectors are orthonormal in the scalar products induced by \({\mathbf{Q}}\) and \({\mathbf{W}}\), respectively) with
$$\begin{aligned} {{\texttt {im}}({{\mathbf{V}}_1})}= & {} {{\texttt {im}}({{\mathbf{L}}^{-1} {\tilde{{\mathbf{V}}}}_1})}\\ {{\texttt {im}}({{\mathbf{V}}_2})}= & {} {\texttt {ker}({{\mathbf{J}}})} \oplus {{\texttt {im}}({{\mathbf{J}}^{\dag } ({\mathbf{Q}} {\mathbf{V}}_1)})}, \qquad where \, {\mathbf{J}}^{\dag } = {\mathbf{W}}^{-1} {\mathbf{J}}^T ({\mathbf{J}} {\mathbf{W}}^{-1} {\mathbf{J}}^T)^{-1} \end{aligned}$$ -
(4)
Set \({\mathbf{V}} = \begin{bmatrix} {\mathbf{V}}_1 &{} \\ &{} {\mathbf{V}}_2 \end{bmatrix}\)
end
In Step (3) of Algorithm 4.11, weighted scalar products are taken into account for better numerical stability. Particularly, \({\mathbf{J}}^{\dag }\) is the right-inverse of \({\mathbf{J}}\) weighted w.r.t. the scalar product induced by \({\mathbf{W}}\). Let us stress that the equality \({{\texttt {im}}({{\mathbf{V}}_2})} = {\texttt {ker}({{\mathbf{J}}})} \oplus {{\texttt {im}}({{\mathbf{J}}^{\dag } ({\mathbf{Q}} {\mathbf{V}}_1)})}\) as well as \({{\texttt {im}}({{\mathbf{V}}_1})}\) and \({{\texttt {im}}({{\mathbf{V}}_2})}\) are independent of the choice of scalar product in the absence of rounding errors. For convenience, we choose the dimension \(n_1\) of the ROM space as input parameter. Alternatively, a singular value based tolerance threshold could be used with respect to the data matrix \({\mathbf{K}}\).
Remark 4.12
The computational complexity of Algorithm 4.11 is comparable to the standard POD approach when implemented appropriately. Since \({\mathbf{Q}}\) is diagonal and \({\mathbf{W}}\) is tridiagonal, their Cholesky factorizations are of the same form. Step (2) scales only linearly in the dimension of the FOM when the method of snapshots [42, 43] is employed. In Step (3), the kernel \({\texttt {ker}({{\mathbf{J}}})}\) can be efficiently determined by a sparse LU-factorization [30]. Moreover, the right-inverse \({\mathbf{J}}^{\dag }\) does not have to be computed explicitly, but a few sparse linear equations can be solved instead, as can be seen using the Cholesky factorization of \({\mathbf{W}}\).
5 Quadrature-Type Complexity Reduction
Although the ROMs are typically of much lower dimension than the FOM, i.e., \(\mathtt {dim}({\mathcal {V}}_r) \ll N=\mathtt {dim}({\mathcal {V}}_f)\), they are in general not more efficient due to the lifting bottleneck related to the nonlinearities. The evaluation of the nonlinear integrals in System 3.3 scales with the number of finite elements \(K_{j}\), \(j=1,\ldots ,J\), and hence is not independent of the FOM dimension, since \(N=2J+\mathtt {dim}({\mathcal {K}})\), see, e.g., the friction term
We propose a complexity reduction by a quadrature-type approximation that restricts to integral evaluations at only few finite elements. It is trained towards the given snapshot data and, in contrast to conventional methods, regards compatibility conditions (Assumption 3.2). The resulting training problem is a semi-definite program with combinatorial aspects. We approach it algorithmically by a greedy procedure, as is generally done for complexity reduction.
Remark 5.1
The CROM distinguishes from the ROM only in the nonlinear terms. Its algebraic representation is similar to System 4.9, but \({\mathbf{f}}_r^\alpha \), \({\mathbf{f}}_r^\beta \), \({\mathbf{f}}_r^\gamma \) are substituted by complexity-reduced analogs.
5.1 Training Goal
The complexity reduction is done subsequently to the model order reduction and its training employs the ROM space \({\mathcal {V}}_r={\mathcal {Q}}_r \times {\mathcal {W}}_r\) explicitly. Similarly to [27, 35], we consider a complexity reduction of quadrature-type. We aim for a complexity-reduced bilinear form
that approximates \(\langle \cdot , \cdot \rangle \), satisfies Assumption 3.2 and realizes \(\langle \cdot , \cdot \rangle _{*}\) in System 3.3. In the training phase, we search for the index-set \(I\subset \{1,\ldots , J\}\) and weights \(\xi _i\ge 0\) for \(i\in I\). In particular, we aim for \(|I|=n_c\) with \(n_c \ll J\) small to ensure a reduced computational complexity for the CROM.
To formulate the training goal, we assume an appropriate collection of snapshots of all nonlinear integrands in the ROM to be given, i.e.,

The complexity reduction is desired to be of high fidelity for the snapshot data, i.e., \(\langle f^\ell , 1 \rangle _c\approx \langle f^\ell , 1 \rangle \) for \(\ell =1,\ldots ,{\bar{L}}\). Expressing that in a least-squares sense yields the following optimization problem for the training of the quadrature-rule.
Problem 5.2
Let nonlinear snapshot functions  be given as in (14). Let \(n_c \in \{1,\ldots , J \}\) and \({\tilde{C}} > 1\). Find an index-set \(I^*\subset \{1, \ldots , J \}\) and weights \(\xi ^*_i \in {\mathbb {R}}\) for \(i\in I^*\) as solution to the problem
be given as in (14). Let \(n_c \in \{1,\ldots , J \}\) and \({\tilde{C}} > 1\). Find an index-set \(I^*\subset \{1, \ldots , J \}\) and weights \(\xi ^*_i \in {\mathbb {R}}\) for \(i\in I^*\) as solution to the problem
The constraints reflect the compatibility condition of Assumption 3.2 that ensures structure preservation. In particular, the non-negativity of \(\xi _i\) directly implies the non-negativity of the function \(f \mapsto \langle f , 1 \rangle _c\).
As for the snapshots  , we consider the following mappings for
, we consider the following mappings for  , related to the three nonlinear integral expressions occurring in the ROM (System 3.3),
, related to the three nonlinear integral expressions occurring in the ROM (System 3.3),

with \(w_r^j\) for \( j = 1 , \ldots , n_2\) denoting the basis for \({\mathcal {W}}_r\). For the first two mappings, nonlinear snapshots are generated using the data set of the state snapshots  ,
,  , i.e., the snapshots the ROM is trained for. The third mapping appears in a time-derivative of the ROM. To treat this accordingly, we additionally assume that the state snapshots
, i.e., the snapshots the ROM is trained for. The third mapping appears in a time-derivative of the ROM. To treat this accordingly, we additionally assume that the state snapshots  consist of one or several solution trajectories in time. Particularly, given
consist of one or several solution trajectories in time. Particularly, given  and
and  are snapshots of the same trajectory at different time points \(t_{k-1}\) and \(t_{k}\), we collect the terms
are snapshots of the same trajectory at different time points \(t_{k-1}\) and \(t_{k}\), we collect the terms  for \(j = 1 , \ldots , n_2\), which relates to using a finite difference approximation on
for \(j = 1 , \ldots , n_2\), which relates to using a finite difference approximation on  at time \(t_k\). In case that
at time \(t_k\). In case that  represents one trajectory, we can approximate the time-derivative at \(L-1\) instances, and the collection of all nonlinear snapshots
represents one trajectory, we can approximate the time-derivative at \(L-1\) instances, and the collection of all nonlinear snapshots  has \({\bar{L}} = (3 L-1)n_2\) entries in total.
has \({\bar{L}} = (3 L-1)n_2\) entries in total.
Remark 5.3
By construction, the number of integrand-snapshots in  is significantly larger than the number of state snapshots
is significantly larger than the number of state snapshots  in (5). When the problem at hand is of very large scale, a pre-processing of
in (5). When the problem at hand is of very large scale, a pre-processing of  or other strategies to speed up the training phase might become necessary. We do not discuss this issue here but refer to [4, 35] for some attempts in this direction.
or other strategies to speed up the training phase might become necessary. We do not discuss this issue here but refer to [4, 35] for some attempts in this direction.
5.2 Greedy Implementation of Training
For algorithmic reasons, we rewrite Problem 5.2 in algebraic form. Let \(\varvec{\xi }= [\xi _1, \ldots , \xi _J]^T \in {\mathbb {R}}^J\) denote the extended vector of weights, which is composed of the weights \(\xi _i\) for \(i\in I\) used in the quadrature and the entries \(\xi _j=0\) for \(j\notin I\). With \({\mathbf{f}}^\ell \in {\mathbb {R}}^J\) defined by \([{\mathbf{f}}^\ell ]_i = \int _{K_i} f^\ell \,dx\) for the nonlinear integrands \(f^\ell \in {\mathcal {L}}^1({\mathcal {E}})\), \(\ell =1,...,{{\bar{L}}}\) in (14), we can rewrite the cost functional in terms of \(\varvec{\xi }\) and
The constraint in Problem 5.2 enforces a norm equivalence between the \({\mathcal {L}}^2\) norm and its complexity-reduced counterpart \(|| \cdot ||_c\). And as the ROM bases \(\{q_r^1,\ldots , q_r^{n_1}\}\) and \(\{w_r^1,\ldots , w_r^{n_2}\}\) are orthonormal in the \({\mathcal {L}}^2\) norm according to Algorithm 4.11, the related mass matrix becomes the unit matrix. Its complexity-reduced counterpart reads
from which it follows that \(|| \cdot ||_c\) is a norm on the ROM space, if and only if \({\mathbf{M}}_c\) is positive definite. The more specific constraint in Problem 5.2 can be expressed as a bound on the spectrum \(\sigma ({\mathbf{M}}_c)\) of \({\mathbf{M}}_c\), as can be shown using the estimate \(\Vert {\mathbf{M}}_c^{-1} \Vert _2^{1/2} \Vert {\mathbf{a}}_r\Vert \le ( {\mathbf{a}}_r^T {\mathbf{M}}_c {\mathbf{a}}_r)^{1/2} \le \Vert {\mathbf{M}}_c \Vert _2^{1/2} \Vert {\mathbf{a}}_r\Vert \), with \(\Vert {\mathbf{M}}_c \Vert _2\) denoting the spectral norm, cf. [42]. In sum, Problem 5.2 can be equivalently written as the constrained least squares problem
The constraint (17c) makes this a semi-definite program [55]. And inherently in the complexity reduction, there is a combinatorial aspect, in our case the selection of the index set I of active finite elements. Particularly the latter makes this problem too hard to be solved to global optimality. Thus, we rely on a greedy approximation, as most complexity reduction methods do, cf., [2, 6, 18], see also [4, 27] for quadrature-type approaches similar to ours. The basic idea is to alternate between enlarging the index set I by a greedy search and constructing an optimal weight for that fixed index set. Algorithm 5.4 summarizes the procedure. While the non-negativity constraint for the weights \(\xi _i\) is included explicitly, the eigenvalue constraint (17c) is only included as a safeguard at the end of the algorithm. As will be shown in the numerical results in Sect. 6, the latter condition is obtained by our greedy search for reasonable choices of \(n_c\) without further doing for our problem at hand.
Algorithm 5.4
(Greedy empirical quadrature weights)
INPUT:
-
Data matrix and vector as in (16): \({\mathbf{A}}\), \({\mathbf{b}}\)
-
Number of active finite elements: \(n_c\)
-
Constant: \({\tilde{C}} > 1\)
-
Complexity-reduced mass matrix as function of weights: \({\mathbf{M}}_c(\cdot )\)
OUTPUT: Vector of quadrature-weights: \(\varvec{\xi }^{n_c}\)
-
(1)
Define function \(F(\varvec{\xi }) = || {\mathbf{A}} \varvec{\xi }- {\mathbf{b}} ||^2\) with gradient \(\nabla F(\varvec{\xi }) = 2{\mathbf{A}}^T({\mathbf{A}} \varvec{\xi }- {\mathbf{b}})\)
-
(2)
Initialize \(I_0 = \{ \}\) and \(\varvec{\xi }^0 = {\mathbf{0}} \in {\mathbb {R}}^{J}\)
-
(3)
for \(k = 1:n_c\)
-
a)
Define set of candidates \(I_c = \{1, \ldots , J\} \setminus I_{k-1}\)
-
b)
Find \(j_{max} = \text {argmax}_{j\in I_c} -\left[ \nabla _{{}} F(\varvec{\xi }^{k-1}) \right] _j \)
-
c)
Set \(I_k = I_{k-1} \cup \{ j_{max} \}\)
-
d)
Find \(\varvec{\xi }^k\) as solution to
$$\begin{aligned} \min _{ \varvec{\xi }=[\xi _1,\ldots ,\xi _J]^T }&\,\, F(\varvec{\xi }) \\ \text {s.t.}&\,\, \xi _i \ge 0 \, \text { for } i \in I_k, \quad \xi _j = 0 \text { for } j \notin I_k \end{aligned}$$
endfor
-
a)
-
(4)
if \(\sigma \left( {\mathbf{M}}_{c}(\varvec{\xi })\right) \not \subset \left[ {\tilde{C}}^{-2}, {\tilde{C}}^2 \right] \)
Set \(n_c \hookleftarrow n_c+1\) and go to (3a)
endif
end
Let us note that only \(n_c\) columns or less of the data matrix \({\mathbf{A}}\) are used in most steps of the algorithm. The exception is Step (3b), where the gradient is evaluated once. It can be avoided to store the full matrix, if storage requirements are critical, cf., [9, 48] and Remark 5.3. Most importantly, the non-negative least-squares problem of Step (3d) needs only to be solved over very low-dimensional linear spaces. We do this using the built-in Matlab routine lsqnonneg in our implementation, which realizes an active-set method.
6 Numerical Results
For the numerical studies of this section we consider our model problem in parameter regimes relevant for gas distribution networks. The model equations are given by the isothermal Euler equations in a friction-dominated regime. The network parameters are extracted from the gaslib [53] with minor adaptions. Networks of pipes are considered, where each edge \(e\in {\mathcal {E}}\) represents a pipe of a cross-sectional area \(A^{e}= \pi /4\, (D^e)^2\). The \(A^{e}\) act as edge weights and are prescribed by the diameter \(D^e\). The reference values for density and mass flow are taken as \(\rho _\star =1~[\text {kg m}^{-3}]\) and \((Am)_\star = 1~[\text {kg s}^{-1}]\). An isothermal pressure law is used for p \([\text {Pa}]\), \(p(\rho ) = RT {\rho }/(1-RT\alpha \rho )\), with \(T= 283~[\text {K}]\), \(R = 518~[\text {J} (\text {kg K})^{-1}]\) and \(\alpha = -3 \cdot 10^{-8}~[\text {Pa}^{-1}]\), which implies the pressure potential \(P(\rho ) = RT \rho \log {\left( {(1-RT\alpha \rho )\rho _\star }/{\rho } \right) }\). The friction term is defined as \(r(\rho ,m) =\lambda |m|/(2D^e\rho ^2)\) with dimensionless friction parameter \(\lambda >0\) varied over the scenarios.
General boundary conditions are treated according to [47]. Specifically, for each mass flow boundary condition a Lagrange multiplier is added and also kept in the reduced models. The FOM is realized according to Sect. 3.2 using a uniform mesh on each pipe with the maximal spatial step size \(\Delta _x \le 200~[\text {m}]\). Time discretization is carried out by an implicit Euler method in the primitive variables \(\rho \) and v, cf., [47], with a constant time step \(\Delta _t = 1~[s]\), i.e., 3600 steps per hour of simulation time. The resulting nonlinear systems in each time step are solved by the Newton’s method. If this fixed-point iteration diverges for any time step, we consider this as a simulation-breakdown. Given the FOM solution  , the error of an approximation
, the error of an approximation  (obtained by a reduced model or orthogonal projection) is measured by the \({\mathcal {L}}^2\) norm in space and the supremum norm in time, yielding the relative error
(obtained by a reduced model or orthogonal projection) is measured by the \({\mathcal {L}}^2\) norm in space and the supremum norm in time, yielding the relative error  . All numerical results have been generated using MATLAB Version 9.1.0 (R2016b) on an Intel Core i5-7500 CPU with 16.0GB RAM.
. All numerical results have been generated using MATLAB Version 9.1.0 (R2016b) on an Intel Core i5-7500 CPU with 16.0GB RAM.
In Sect. 6.1 some qualitative properties of our complexity reduction approach are showcased at a smaller academic network scenario (diamond network). More quantitative studies with comparisons to other well-established, but non-structure-preserving, model reduction methods are presented in Sect. 6.2 using a network of realistic size.
6.1 Qualitative Study for Complexity Reduction
The topology and parameters for the academic network example (diamond network) are given in Fig. 1. For the friction factor, we consider two different choices \(\lambda = 0.01\) (high friction) and \(\lambda = 0.002\) (lower friction). At the two boundary nodes \(\nu _1\), \(\nu _2\), we prescribe the boundary conditions according to
with reference time \(t_\star = 1 [h]\) and the time-varying input profile

The initial values are chosen as the stationary solution related to the boundary conditions at \(t=0\). The FOM yields a system of dimension \(N=1922\), and the reduction methods (model order and complexity reduction) are trained towards 1000 equally distributed time snapshots of the solution trajectory of the FOM. The dimension of the ROM space \({\mathcal {V}}_r\) is fixed to \(n=14\). As regards the complexity reduction, we vary the parameter \(n_c\), as the qualitative behavior of this step is the focus in the upcoming.
For the two different cases of friction factor, the time evolution of the solution is visualized in Fig. 2. Hereby, the end of the edge \(e_2\) (at node \(\nu _4\)) is used as fixed spatial position. As to be expected, stronger damping effects are observed for larger \(\lambda \), especially for the density. Generally speaking, models with higher damping effects are mostly better suited for model reduction, but the effect seems rather minor in the parameter range we encounter in the context of gas transportation. For both choices of \(\lambda \), the CROMs with \(n_c=20\) produce very accurate time responses, see Fig. 2. But also when the complexity reduction is not well-resolved, as is the case for \(n_c=14\), stable simulations are produced, which is in accordance to our energy bound (Theorem 3.4). The relative errors over the full simulation with \(\lambda =0.002\) are shown Fig. 3-right. We observe that the error the complexity reduction step adds becomes negligible for \(n_c\ge 18\). Moreover, the compatibility condition on the spectrum of the complexity reduced mass matrix, \(\sigma ({\mathbf{M}}_{c}) \subset [{\tilde{C}}^{-2},{\tilde{C}}^2]\), is fulfilled for \(n_c \ge 12\) and moderately large \({\tilde{C}}\), as is indicated by the condition number of \({\mathbf{M}}_{c}\), see Table 1.

Diamond network with lengths [km] \(\{l^{e_i} :e_i\in {\mathcal {E}} \} = \{40 , 38 ,18 ,15 ,28 ,27 ,25\}\) and diameters [m] \(\{D^{e_i}: e_i\in {\mathcal {E}} \} = \{1.3 , 1, 1 , 1 , 1.3, 1.3 ,1\}\). The domain \( \{ e_i \in {\mathcal {E}}: \, i =1, \ldots , 4 \}\) is marked in magenta (Color figure online)

Diamond network, solutions and differences to the FOM at end of pipe \(e_2\), plotted over time

Diamond network, influence of ROM space on CROM. The space \(\tilde{{\mathcal {V}}}_r = {\mathcal {V}}_r + \tilde{{\mathcal {U}}}\) includes \(\mathtt {dim}(\tilde{{\mathcal {U}}})\)=4 artificial additional basis functions on edge \(e_3\). Left: Locations and values of quadrature-weights along edges \(e_1\) to \(e_4\) for \(n_c=20\), and \({\mathcal {V}}_r\) (top) or \(\tilde{{\mathcal {V}}}_r\) (bottom). The encircled weights are the ones on the support of \(\tilde{{\mathcal {U}}}\), and the cyan vertical lines indicate junctions. Right: Relative error \(E_T\) for different choices of \(n_c\)
An important qualitative property concerning the training of our complexity reduction method, which we want to showcase, is its adaption to the ROM space. To demonstrate that, we consider reduced models with an artificially enlarged ROM space given as \(\tilde{{\mathcal {V}}}_r = {\mathcal {V}}_r + \tilde{{\mathcal {U}}}\), where \(\tilde{{\mathcal {U}}}\) consists of functions with very local support. That is, two of the basis functions of the FOM for the density, which lie symmetrically around the midpoint of edge \(e_3\), are added to \({\mathcal {Q}}_r\), and the space \({\mathcal {W}}_r\) is supplemented according to Assumption 3.1-(A1). Thus \(\tilde{{\mathcal {V}}}_r\) is compatible, and it holds \(18 = \mathtt {dim}(\tilde{{\mathcal {V}}}_r)> \mathtt {dim}({{\mathcal {V}}}_r)=14\), but almost no improvement in terms of fidelity is observed for the scenario. In fact, the extension \(\tilde{{\mathcal {U}}}\) causes the complexity reduction to produce less accurate models with larger cond(\({\mathbf{M}}_c\)), at least for small \(n_c\), see Fig. 3-right and Table 1. The reason becomes evident when looking at the quadrature points obtained for the CROM without and with \(\tilde{{\mathcal {U}}}\). In Fig. 3-left the locations and values of the quadrature weights are visualized along the path of the edges \(e_1\) to \(e_4\) (marked in magenta in Fig. 1). When the space \(\tilde{{\mathcal {U}}}\) is added, we find three weights located on its support, see the encircled markers in the figure. Let us also mention that the weights do not cluster, the pairs that are observed around the junctions (the cyan vertical lines) lie on different pipes. Summarizing, the enrichment of the reduced space by \(\tilde{{\mathcal {U}}}\) hampers the complexity reduction, but our method still produces stable simulations. This illustrates that our training procedure promotes Assumption 3.2 and can cope with an enrichment of the reduction basis with elements chosen independently of the snapshot data. In more relevant scenarios, the space enrichment might be necessary due to compatibility conditions such as Assumption 3.1, and the effects on the complexity reduction can be expected to be less exaggerated. Let us stress that other complexity reduction methods, such as the empirical interpolation methods [6, 18], are trained independently of the choice of the ROM space and thus cannot adapt to it. Possibly related to that, we observe that the discrete interpolation method (DEIM) inherits stability issues when combined with our model order reduction approach, see the end of Sect. 6.2.
6.2 Comparison to Non-Structure-Preserving Reduction Methods
The benefits of our structure-preserving approach are demonstrated for a benchmark with a realistic gas network, illustrated in Fig. 4. The network is a slight modification of [53, GasLib-40], cf. [47]. Let us note that a few compressors and valves would be needed in an actual application. We do not consider these active elements for ease of presentation, as they are prescribed by low-order algebraic models, which would not be regarded during the reduction process anyway. The network consists of 38 pipes with diameters \(D^e\) between 0.4 and 1 \([\text {m}]\) and lengths \(l^e\) between 5 to 74 \([\text {km}]\). The total pipe length is 1008 \([\text {km}]\). Over the whole network, we set the friction factor to \(\lambda = 0.008\).

Topology of large network with boundary nodes \(\nu _i\), \(i=1,...,6\) (red circles). The spatial domain of the pipes \(\omega _j\), \(j=1,...,8\), a path from \(\nu _1\) to \(\nu _3\), is colored in magenta (Color figure online)
At the six boundary nodes \(\nu _i\), \(i=1,...,6\), we prescribe the following boundary conditions for \(t \in [0,5 t_\star ]\) and reference time \(t_\star = 1 [h]\),
with the input profile \({ u } \in \{ u_A, u_B \}\) varied over two cases according to
see Fig. 5. As initial condition the stationary solution belonging to the boundary conditions at \(t=0\) is taken. The FOM is a system of dimension \(N =10156\). The training of all reduction methods is realized with the trajectory of the FOM solution for Case A with 1000 equally distributed snapshots. Thus, we refer to Case A as the (perfectly) trained case and to Case B as the not trained one. In general, one can expect model reduction methods to perform worse in a not trained case, even more so if they do not have good stability qualities. In the upcoming, we first show temporal and spatial visualizations of the reference solution, which is given by the FOM. Then we compare our structure-preserving model order reduction approach against a conventional method, and subsequently do the same for the complexity reduction step.
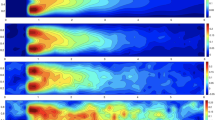
The time response of the FOM at the ends of pipe 2 and pipe 5 is shown in Fig. 6. Similarly as for the academic test scenario, we observe notable damping effects. The time response is smoothed out stronger at pipe-end 5 than at pipe-end 2, because the former has a larger distance to the driving boundary nodes. In Fig. 7, a spatial representation of the solution along the path from pipe 2 to pipe 8 (marked in magenta in Fig. 4) is shown for different time instances. The mass flows show to be discontinuous over junctions with more than two pipes meeting, as to be expected from the model. Apart from that, the spatial representations are rather smooth.

Input profiles used for the boundary conditions of the large network

Large network, temporal representation of reference solution at the ends of pipes \(e_2\) and \(e_5\), respectively (divided by cases for input profile)

Large network, spatial representation of reference solution with domain representing pipes 2-8 (marked in magenta in Fig. 4). The cyan vertical lines indicate junctions (Color figure online)

Large network, errors of ROMs and orthogonal projection onto the respective reduction space (Proj. \(\Pi _{{\mathcal {V}}_r}\)/\(\Pi _{{\mathcal {V}}_{BP}}\)), using our structure-preserving basis \({\mathcal {V}}_r\) and block-structured POD-basis \({\mathcal {V}}_{BP}\). Dimension FOM: \(N=10156\)
We compare our proposed model order reduction against a conventional block-structured POD, which is very similar to the approaches [31, 38] used in the gas network context. The reduction basis \({\mathcal {V}}_{BP}\) for the conventional method is obtained by separately applying a principal component analysis to the density- and mass flux-snapshots and extracting reduction spaces of the same dimension for them (\(n_1=n_2\)). This approach is preferable to applying POD onto the full state, but it is not structure-preserving in the sense of Assumption 3.1. In order to investigate the fidelity of the reduction spaces, independent of the stability properties of the reduced models, we additionally consider the \({\mathcal {L}}^2\)-projections of the FOM solutions onto the ROM spaces. The respective projectors are denoted by \(\Pi _{{\mathcal {V}}_{r}}\) and \(\Pi _{{\mathcal {V}}_{BP}}\), and they yield the pure projection errors. The relative errors are shown in Fig. 8. There is one scenario, where the conventional POD shows slightly better results than our method. That is, better projection errors are observed for the perfectly trained case for the reduced dimension n small (Fig. 8-left, \(n\le 50\)). This is not surprising, as taking the \({\mathcal {L}}^2\)-error favors \({\mathcal {V}}_{BP}\). Recall that our method is derived using another norm and regards compatibility conditions. Despite that, our reduction basis \({\mathcal {V}}_{r}\) has slightly better projection errors in the trained case when the dimension is chosen to be larger, and shows significantly smaller projection errors for all parameter choices in the not trained case. The theoretical advantage our approach has over the other is that it fulfills an optimality condition in the full state. We suppose that this is also the reason for the comparably low projection errors we observe. Practically more relevant is the comparison of the reduction errors. In this respect, our method outperforms the conventional reduction method much clearer, and we observe better errors for all dimensions n. The difference is most evident for the non-trained case, where the second smallest reduced order model with \({\mathcal {V}}_r\) is of higher fidelity than any of the reduced models for \({\mathcal {V}}_{BP}\), see Fig. 8-right. Further, we want to highlight the small gap between reduction- and projection-error for our proposed method compared to the conventional one, which strongly indicates the superior stability and robustness of our approach. Note that the relatively large number of basic functions required for reduction is due to the transport-dominated character of the underlying problem.

Large network, error of proposed complexity reduction CROM, non-structure-preserving DEIM. Underlying are ROMs of dimension \(n = 48\) (dashed-dotted lines) and \(n = 66\) (solid lines)
As regards the comparisons for the complexity reduction step, the starting point is a ROM obtained by our proposed model order reduction method. Our quadrature-type complexity reduction is compared to a non-structure preserving alternative, which we representatively choose as the discrete empirical interpolation method (DEIM) [17, 18]. For convenience, we denote the DEIM-space dimension used in the training as \(n_c\). Note that the parameter in our CROM, which we also denote by \(n_c\), has a quite different interpretation, which is the number of nonlinear integrals that need to be evaluated. The DEIM is not directly related to the integral expressions, but rather to the algebraic representation of the system, and needs several nonlinear integral evaluation for each \(n_c\), which makes it less online-efficient in our setting. We apply the DEIM to each nonlinearity separately, i.e, given the algebraic representation of the ROM (System 4.9), that means the terms \({\mathbf{f}}_r^\alpha \), \({\mathbf{f}}_r^\gamma \) and \(\tilde{{\mathbf{f}}}_r^\beta \) are separately complexity-reduced. The latter term \(\tilde{{\mathbf{f}}}_r^\beta \) is defined by \({\mathbf{f}}_r^\beta = {\mathbf{J}}^T \tilde{{\mathbf{f}}}_r^\beta \), and it is introduced as the resulting DEIM approach regards some of the structural properties of our model problem, cf., Remark 6.1 and [45, 47]. But let us emphasize that this DEIM approach still cannot guarantee port-Hamiltonian structure or a provable energy bound, in contrast to our quadrature-based approach. We test the complexity reduction methods for ROMs of dimensions \(n=48\) and \(n=66\), the resulting reduction errors are shown in Fig. 9. The first observation to be made is that DEIM yields in several parameter settings unstable results. Particularly in the untrained case, all DEIM models with \(n_c\le 92\) have either a simulation breakdown or very poor fidelity, and no consistent monotone decrease of the error with respect to \(n_c\) is obtained. Our CROM method shows to be much more robust and no simulation breakdowns occur. Let us also emphasize that we have a strong a priori indicator for stability for the CROM, which is the compatibility condition \(\sigma ({\mathbf{M}}_{c}) \subset [{\tilde{C}}^{-2},{\tilde{C}}^2]\) for a reasonably small constant \({\tilde{C}}\). As Table 2 shows, the condition is fulfilled in our experiments. Another difference of the complexity reduction methods we want to stress is that our quadrature-based complexity reduction in CROM depends stronger on the underlying ROM dimension n. Particularly, when perfectly trained and n is chosen large, the error of DEIM becomes negligible for \(n_c \approx 92\), whereas this holds only from \(n_c \approx 120\) on for the CROM, see Fig. 9-left with \(n=66\). However, this does not mean that DEIM is more efficient in this or any other setting. As mentioned above, more nonlinear integrals for each \(n_c\) have to be evaluated in DEIM than for CROM. This is directly reflected in the simulation times, which can be found in Table 3 for the untrained case. The DEIM models have runtimes between 432 to 482 seconds, as compared to the CROMs with about 126 to 152 seconds. Thus, the CROM is more than three times faster than DEIM for models of similar fidelity. Compared to the 2253.6 seconds runtime of FOM, CROM shows a speedup of about 16.
To summarize, our quadrature-based reduction yields significantly more robust and efficient results as DEIM when combined with our model order reduction approach. Moreover, the compatibility condition of Assumption 3.2 is conveniently promoted by our greedy training procedure in all our tests.
Remark 6.1
Instead of applying DEIM to \(\tilde{{\mathbf{f}}}^\beta \) as we did, one could apply it directly to \({\mathbf{f}}^\beta \). This alternative showed severe stability issues in our numerical tests. We assume this is related to a more profound loss of structural properties. Specifically, the anti-symmetry (symplectic structure) revolving around the terms \(-{\mathbf{J}}\) and \({\mathbf{J}}^T\) is destroyed by the more naive DEIM version, cf., [12, 49] for related discussions.
7 Wellposedness of Approximations
In this section, we derive a wellposedness result for our model order- and complexity-reduced approximation (CROM). The CROM is a realization of System 3.3, and its ansatz space \({\mathcal {V}}_r\) is a subspace of a finite element space \({\mathcal {V}}_f\) with partitioning \(K_1,\ldots ,K_J\) given as in (4). Further, the complexity-reduced bilinear form and Hamiltonian take, according to (13), the form
Here, we assume \(\xi _i>0\) instead of \(\xi _i \ge 0\) for technical reasons, which can be done w.l.o.g. by simply restricting I accordingly. The wellposedness result is established under the situation described in System 3.3 (i.e., for boundary conditions as in (1c)) and the following additional assumptions on the model problem.
Assumption 7.1
-
A1)
The pressure potential \(P: (0,M) \rightarrow {\mathbb {R}}\) for \(M>0\) is two times continuously differentiable. It holds \(P''(y) >0\), and \(y \le \max \{P(y),1 \}\) for \(y\in (0,M)\), and \(\lim _{y\rightarrow M} P(y) = \infty \).
-
A2)
The initial conditions \((\rho _0,m_0) \in {\mathcal {V}}_r\) are chosen such that \(\rho _{0}(x) \in (0,M)\) for \(x\in K_i\), \(i\in I\).
-
A3)
The friction model takes the form \(r(\rho ,m) = \rho ^{-2}\) (laminar friction model for gas pipelines).
Assumptions (A1)-(A2) assure that \({\mathcal {H}}_c\) is well-defined and yields a majorant for the norm of the solution. Moreover, it should be mentioned that P is also bounded from below by (A1). To establish a global existence result, we derive uniform boundedness of the solution and strict positivity of the density. The positivity of the density is needed to avoid zeros in the denominators of System 3.3. Our proof of that relies on (A2)-(A3). Further note that the restriction of the density to a single element \(K_i\), \(\rho (t)_{|K_i}\), is constant.
Remark 7.2
Similar results as the ones derived in this section can be established using other boundary conditions or friction/dissipation terms, but the derivations might get slightly more technical [45]. We also refer to [22, 39] for related results for other space discretizations of the Euler equations. However, the latter references do not treat model order and complexity reduction.
Lemma 7.3
Under the assumptions of this section, the solutions of System 3.3 fulfill \(\rho (t)_{|K_i} >0\) for \(t>0\) and \(i\in I\). Moreover, there exists a constant C, independent of the discretization parameters, such that
where \({\Delta _{x_i}}\) is the grid size of the finite element \(K_i\).
Proof
At several instances, we employ that \(\rho (t)_{|K_i}\) and \(\partial _x {{m}}_{|K_i}(t)\) are constant in space. As long as \(1/\rho (t)_{|K_i}\) is well-defined, it therefore holds
where the subscript \(K_i\) indicates a restriction of the spatial domain to one finite element. By the inverse estimate, there exists a constant C with \(||\partial _x m(t)||_{K_i} \le {C}/{{\Delta _{x_i}}} ||m(t)||_{K_i}\). Together with \(1/\rho (t)\) and \(\partial _x m(t)\) both being constant on \(K_i\), this yields
Setting together the two estimates, we thus get by the Gronwall lemma
It remains to bound \(\int _{0}^t c_{i}(s) ds \) for \(i \in I\). As a preparation, we introduce the auxiliary function \({\hat{{\mathcal {H}}}}( \rho , m) = {\mathcal {H}}_c( \rho ,m) + \max \left\{ 0 \, , \, -\text {inf}_{y\in (0,M)} P(y) \right\} \), which is a constant shift of the Hamiltonian \({\mathcal {H}}_c\) that takes only non-negative values. It fulfills the same energy-dissipation equality as \({\mathcal {H}}_c\), cf., Theorem 3.4. Assuming \(\rho (t)_{|K_i} > 0\) and \(i \in I\), we can follow
with R defined as in the lemma. The latter equality follows from integrating the energy dissipation equality for \({\hat{{\mathcal {H}}}}\) (Theorem 3.4) in time. Moreover, \(R(t)\ge 0\) holds for \(t\ge 0\), as the last equality also implies that R can be bounded from below by \( {\hat{{\mathcal {H}}}}\), which itself is non-negative. Now first applying the Jensen-inequality [51] and then inserting the former estimate yields
Inserting the latter bound on \(\int _{0}^t c_i(s) ds\) into the estimate obtained by the Gronwall lemma finishes the proof. \(\square \)
Remark 7.4
In the special case of \(\langle \cdot , \cdot \rangle _c\) chosen as the \({\mathcal {L}}^2\)-scalar product, we recover the case of pure Galerkin approximation, without complexity reduction. Lemma 7.3 then shows strict positivity of \(\rho (t)\) on all of the spatial domain. Such a result has been derived in [22] in a similar setting.
Note that positivity of \(\rho (t)_{|K_i}\) can only be guaranteed for \(i\in I\) by Lemma 7.3. This turns out to be sufficient, as the \(\rho (t)\) terms in the denominator are only evaluated for \(i\in I\). Next, we derive a boundedness result for the solution.
Theorem 7.5
Under the assumptions of this section, there exist constants \(C_1,C_2\), independent of the discretization parameters, such that for \((\rho ,m) \in {\mathcal {V}}_r\) with \(\rho _{|K_i}>0\) for \(i \in I\) it holds
Proof
Let \(k \in \text {argmax}_{i\in I} \rho _{|K_i}\), and let \({\bar{I}} = \{i\in I: \rho _{|K_i} > 1]\}\) w.l.o.g. be non-empty. Otherwise we trivially can bound the terms \(||\rho ||_c, \rho _{|K_k}\) by a constant. From Assumption 3.2 we get
By Assumption 7.1-(A1) it follows that the function P can be bounded from below (not necessarily by zero), which implies that there exists a constant \({\hat{c}}\) such that
Together, this shows that for some \({\hat{c}}_1,{\hat{c}}_2>0\) it holds
Similarly, it follows
where in the last step the same estimate on \(P(\rho _{|K_k} )\) as before has been used. With the help of Young’s inequality, it follows
Setting together the estimates for \(||\rho ||\) and ||m|| shows the assertion. \(\square \)
Notably, the bound on the \({\mathcal {L}}^2\) norms in Theorem 7.5 is almost independent of the discretization parameters. Only the quadrature weights of the complexity reduction step enter. To make the bound uniform, one has to require the quadrature weights to be bounded from below by a positive constant. The concluding result now reads as follows.
Theorem 7.6
Under the assumptions of this section, System 3.3 has a unique solution \((\rho ,m) \in {\mathcal {C}}^1([0,T);{\mathcal {Q}}\times {\mathcal {W}})\) for any \(T >0\).
Proof
Given the solution \((\rho ,m)\) exists up t, \(t>0\), we define \({\mathcal {F}}(t):= \left( \max _{i\in I}{\xi _i}^{-\frac{1}{2}}\right) \left[ C_1 {\mathcal {H}}_c(\rho (t),m(t)) + C_2 \right] \) with constants \(C_1, C_2\) as in Theorem 7.5. From the energy dissipation (Theorem 3.4) and the boundedness of the trace operator \({\mathcal {T}}\), it follows

for constants \(C_3,C_4>0\). Further, \(||\rho (t)||+|| m(t)|| \le {\mathcal {F}}(t)\) holds by Theorem 7.5. Thus, it holds by the former estimate that \({d}/{dt} {\mathcal {F}}(t) \le C_4 ||{\mathbf{u}}(t)|| {\mathcal {F}}(t)\). We follow by the Gronwall Lemma that \({\mathcal {F}}\) grows at most exponentially in time, and accordingly the same holds for the norm of the solution \((\rho ,m)\). By that existence of a continuously differentiable solution for any \(t>0\) can be deduced by the Peano existence theorem and the extension theorem for differential equations by standard arguments for ordinary differential equations, cf. [34]. \(\square \)
8 Conclusion
We proposed a snapshot-based model reduction approach for a nonlinear flow problem on networks that is governed by the barotropic Euler equations with friction. The approach consists of a structure-preserving modification of the proper orthogonal decomposition combined with a quadrature-type complexity reduction. It yields online-efficient reduced models with remarkable structure-preserving properties, i.e., local mass conservation, an energy bound and a port-Hamiltonian structure. These properties are established using a few compatibility conditions, which we assure by appropriate adaptions in the training phase. The involved implications and appropriate efficient algorithmic implementations were a main focus of this paper. Notably, our model order reduction spaces fulfill an optimality condition under the compatibility conditions. As we demonstrated on a realistic gas transportation network benchmark, our reduced models show superior stability and overall performance compared to more generic non-structure preserving model reduction approaches. Moreover, a wellposedness result for them was established under a few additional assumptions.
Data Availability
The MATLAB code used to generate the full order model data can be found under the DOI 10.5281/zenodo.6372667; see [46].
References
Afkham, B., Hesthaven, J.: Structure preserving model reduction of parametric Hamiltonian systems. SIAM J. Sci. Comput. 39(6), A2616–A2644 (2017)
Afkham, B., Hesthaven, J.: Structure-preserving model-reduction of dissipative Hamiltonian systems. J. Sci. Comput. 81(1), 3–21 (2019)
Ali, S., Ballarin, F., Rozza, G.: Stabilized reduced basis methods for parametrized steady Stokes and Navier-Stokes equations. Comput. Math 80(11), 2399–2416 (2020)
An, S.S., Kim, T., James, D.L.: Optimizing cubature for efficient integration of subspace deformations. ACM Trans. Graph. 27(5), 1–10 (2008)
Antonelli, P., Marcati, P.: The quantum hydrodynamics system in two space dimensions. Arch. Ration. Mech. Anal. 203(2), 499–527 (2012)
Barrault, M., Maday, Y., Nguyen, N.C., Patera, A.T.: An empirical interpolation method: Application to efficient reduced-basis discretization of partial differential equations. Comptes Rendus Mathematique 339(9), 667–672 (2004)
Ben-Israel, A., Greville, T.N.E.: Generalized Inverses: Theory and Applications, 2nd edn. Springer, New York (2001)
Benner, P., Mehrmann, V., Sorensen, D.C.: editors. Dimension Reduction of Large-Scale Systems. Lecture Notes in Computational Science and Engineering. Springer, 1 edition, (2005)
Blumensath, T., Davies, M.E.: Gradient pursuit for non-linear sparse signal modelling. In: 2008 16th European Signal Processing Conference, pages 1–5, (2008)
Boffi, D., Gastaldi, L.: editors. Mixed Finite Elements, Compatibility Conditions, and Applications. Lecture Notes in Mathematics. Springer, 1 edition, (2008)
Brouwer, J., Gasser, I., Herty, M.: Gas pipeline models revisited: Model hierarchies, nonisothermal models, and simulations of networks. Multiscale Model. Simul. 9(2), 601–623 (2011)
Buchfink, P., Bhatt, A., Haasdonk, B.: Symplectic model order reduction with non-orthonormal bases. Math. Comp. Appl 24(2), 43 (2019)
Carlberg, K., Bou-Mosleh, C., Farhat, C.: Efficient non-linear model reduction via a least-squares Petrov-Galerkin projection and compressive tensor approximations. Int. J. Numer. Methods Eng. 86(2), 155–181 (2011)
Carlberg, K., Tuminaro, R., Boggs, P.: Preserving Lagrangian structure in nonlinear model reduction with application to structural dynamics. SIAM J. Sci. Comput. 37(2), B153–B184 (2015)
Celledoni, E., Grimm, V., McLachlan, R.I., McLaren, D.I., O’Neale, D., Owren, B., Quispel, G.R.W.: Preserving energy resp. dissipation in numerical PDEs using the Average Vector Field method. J. Comput. Phys. 231(20), 6770–6789 (2012)
Chaturantabut, S., Beattie, C., Gugercin, S.: Structure-preserving model reduction for nonlinear port-Hamiltonian systems. SIAM J. Sci. Comput. 38(5), B837–B865 (2016)
Chaturantabut, S., Sorensen, D.C.: Nonlinear model reduction via discrete empirical interpolation. SIAM J. Sci. Comput. 32(5), 2737–2764 (2010)
Chaturantabut, S., Sorensen, D.C.: A state space error estimate for POD-DEIM nonlinear model reduction. SIAM J. Numer. Anal. 50(1), 46–63 (2012)
Christiansen, S.H., Munthe-Kaas, H.Z., Owren, B.: Topics in structure-preserving discretization. Acta Numerica 20, 1–119 (2011)
Domschke, P., Dua, A., Stolwijk, J.J., Lang, J., Mehrmann, V.: Adaptive refinement strategies for the simulation of gas flow in networks using a model hierarchy. Electron. Trans. Numer. Anal. 48, 97–113 (2018)
Domschke, P., Kolb, O., Lang, J.: Adjoint-based error control for the simulation and optimization of gas and water supply networks. Appl. Math. Comput. 259, 1003–1018 (2015)
Egger, H.: A robust conservative mixed finite element method for compressible flow on pipe networks. SIAM J. Sci. Comput 40(1), A108–A129 (2018)
Egger, H., Kugler, T.: Damped wave systems on networks: Exponential stability and uniform approximations. Numer. Math. 138(4), 839–867 (2018)
Egger, H., Kugler, T., Liljegren-Sailer, B.: Stability preserving approximations of a semilinear hyperbolic gas transport model. In: Hyperbolic Problems: Theory, Numerics, Applications, volume 10, pages 427–433. AIMS Series on Appl. Math, (2020)
Egger, H., Kugler, T., Liljegren-Sailer, B., Marheineke, N., Mehrmann, V.: On structure-preserving model reduction for damped wave propagation in transport networks. SIAM J. Sci. Comput. 40(1), A331–A365 (2018)
Fareed, H., Singler, J.R., Zhang, Y., Shen, J.: Incremental proper orthogonal decomposition for PDE simulation data. Comput. Math. Appl. 75(6), 1942–1960 (2018)
Farhat, C., Avery, P., Chapman, T., Cortial, J.: Dimensional reduction of nonlinear finite element dynamic models with finite rotations and energy-based mesh sampling and weighting for computational efficiency. Int. J. Numer. Meth. Eng. 98(9), 625–662 (2014)
Fisher, T.C., Carpenter, M.H.: High-order entropy stable finite difference schemes for nonlinear conservation laws: Finite domains. J. Comput. Phys. 252, 518–557 (2013)
Giesselmann, J., Lattanzio, C., Tzavaras, A.E.: Relative energy for the Korteweg theory and related Hamiltonian flows in gas dynamics. Arch. Ration. Mech. Anal. 223(3), 1427–1484 (2017)
Gotsman, C., Toledo, S.: On the computation of null spaces of sparse rectangular matrices. SIAM J. Matrix Anal. Appl. 30(2), 445–463 (2008)
Grundel, S., Jansen, L., Hornung, N., Clees, T., Tischendorf, C., Benner, P.: Model order reduction of differential algebraic equations arising from the simulation of gas transport networks. In: Progress in Differential-Algebraic Equations: Deskriptor 2013, pages 183–205. Springer, (2014)
Gugercin, S., Polyuga, R.V., Beattie, C.A., van der Schaft, A.: Interpolation-based \(H_2\) model reduction for port-Hamiltonian systems. In: Proceedings of the 48th IEEE Conference on Decision and Control, and the 28th Chinese Control Conference, Shanghai, pages 5362–5369, (2009)
Hairer, E., Lubich, C., Wanner, G.: Geometric Numerical Integration. Springer, 2nd edn. Springer, Heidelberg, Berlin (2006)
Hartman, P.: Ordinary Differential Equations, 2nd edn. Society for Industrial and Applied Mathematics, Philadelphia (2002)
Hernandez, J.A., Caicedo, M.A., Ferrer, A.: Dimensional hyper-reduction of nonlinear finite element models via empirical cubature. Comput. Methods Appl. Mech. Engrg. 313, 687–722 (2017)
Herran-Gonzalez, A., De La Cruz, J.M., Andres-Toro, B.D., Risco-Martin, J.L.: Modeling and simulation of a gas distribution pipeline network. Appl. Math. Model. 33(3), 1584–1600 (2009)
Hesthaven, J.S., Rozza, G., Stamm, B.: Certified Reduced Basis Methods for Parametrized Partial Differential Equations. SpringerBriefs in Mathematics. Springer, (2016)
Himpe, C., Grundel, S., Benner, P.: Model order reduction for gas and energy networks. J. Ind. Math 11(13), 2190–5983 (2021)
Karper, T.: Convergent finite differences for 1D viscous isentropic flow in Eulerian coordinates. Discrete Contin. Dyn. Syst. 7, 993–1023 (2014)
Koch, T., Hiller, B., Pfetsch, M., Schewe, L.: Evaluating Gas Network Capacities. MOS-SIAM, (2015)
Kotyczka, P., Lefevre, L.: Discrete-time port-Hamiltonian systems: A definition based on symplectic integration. Systems & Control Letters 133, 104530 (2019)
Kunisch, K., Volkwein, S.: Galerkin proper orthogonal decomposition methods for parabolic systems. Numer. Math. 90, 117–148 (2001)
Kunisch, K., Volkwein, S.: Galerkin proper orthogonal decomposition methods for a general equation in fluid dynamics. SIAM J. Numer. Anal. 40(2), 492–515 (2002)
LeVeque, R.J.: Finite Volume Methods for Hyperbolic Problems. Cambridge University Press, Cambridge (2002)
Liljegren-Sailer, B.: On Port-Hamiltonian Modeling and Structure-Preserving Model Reduction. PhD thesis, Universität Trier, (2020)
Liljegren-Sailer, B.: Code for the paper “On port-Hamiltonian approximation of a nonlinear flow problem on networks”. (2022). https://doi.org/10.5281/zenodo.6372667
Liljegren-Sailer, B., Marheineke, N.: On port-Hamiltonian approximation of a nonlinear flow problem on networks. SIAM J. Sci. Comput., in press, (2022)
Nguyen, T.T., Idier, J., Soussen, C., Djermoune, E.-H.: Non-negative orthogonal greedy algorithms. IEEE Transactions on Signal Processing 67(21), 5643–5658 (2019)
Peng, L., Mohseni, K.: Symplectic model reduction of Hamiltonian systems. SIAM J. Sci. Comput. 38(1), A1–A27 (2016)
Qiu, Y., Grundel, S., Stoll, M., Benner, P.: Efficient numerical methods for gas network modeling and simulation. Netw. Heterog. Media 15(4), 653–679 (2020)
Rockafellar, R., Wets, R.: Variational Analysis. Berlin, New York, Heidelberg (1998)
Rozza, G., Huynh, D.B.P., Manzoni, A.: Reduced basis approximation and a posteriori error estimation for Stokes flows in parametrized geometries: roles of the inf-sup stability constants. Numer. Mat. 125(1), 115–152 (2013)
Schmidt, M., Aßmann, D., Burlacu, R., Humpola, J., Joormann, I., Kanelakis, N., Koch, T., Oucherif, D., Pfetsch, M., Schewe, L., Schwarz, R., Sirvent, M.: GasLib - A Library of Gas Network Instances. Data 2(4), 40 (2017)
Wolf, T., Lohmann, B., Eid, R., Kotyczka, P.: Passivity and structure preserving order reduction of linear port-Hamiltonian systems using Krylov subspaces. Eur. J. Control 16(4), 401–406 (2010)
Wolkowicz, H., Saigal, R., Vandenberghe, L.: editors. Convex Analysis on Symmetric Matrices. Springer, 1 edition, (2000)
Funding
Open Access funding enabled and organized by Projekt DEAL. The support of the German Federal Ministry of Education and Research (BMBF) via the project EiFer is acknowledged. Moreover, we thank for the support of the DFG research training group 2126 on algorithmic optimization.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have not disclosed any competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liljegren-Sailer, B., Marheineke, N. On Snapshot-Based Model Reduction Under Compatibility Conditions for a Nonlinear Flow Problem on Networks. J Sci Comput 92, 62 (2022). https://doi.org/10.1007/s10915-022-01901-z
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10915-022-01901-z
Keywords
- Structure-preserving
- Nonlinear model reduction
- Proper orthogonal decomposition
- Empirical quadrature
- Gas networks