
Abstract
Operator learning techniques have recently emerged as a powerful tool for learning maps between infinite-dimensional Banach spaces. Trained under appropriate constraints, they can also be effective in learning the solution operator of partial differential equations (PDEs) in an entirely self-supervised manner. In this work we analyze the training dynamics of deep operator networks (DeepONets) through the lens of Neural Tangent Kernel theory, and reveal a bias that favors the approximation of functions with larger magnitudes. To correct this bias we propose to adaptively re-weight the importance of each training example, and demonstrate how this procedure can effectively balance the magnitude of back-propagated gradients during training via gradient descent. We also propose a novel network architecture that is more resilient to vanishing gradient pathologies. Taken together, our developments provide new insights into the training of DeepONets and consistently improve their predictive accuracy by a factor of 10-50x, demonstrated in the challenging setting of learning PDE solution operators in the absence of paired input-output observations. All code and data accompanying this manuscript will be made publicly available at https://github.com/PredictiveIntelligenceLab/ImprovedDeepONets.














Similar content being viewed by others
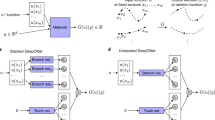


Data Availability
All methods needed to evaluate the conclusions in the paper are present in the paper and/or the Appendix. All code and data accompanying this manuscript will be made publicly available at https://github.com/PredictiveIntelligenceLab/ImprovedDeepONets.
References
Lanthaler, S., Mishra, S., Karniadakis, G.E.: Error estimates for DeepONet: a deep learning framework in infinite dimensions. arXiv preprint arXiv:2102.09618 (2021)
Kovachki, N., Lanthaler, S., Mishra, S.: On universal approximation and error bounds for fourier neural operators. arXiv preprint arXiv:2107.07562 (2021)
Yu, A., Becquey, C., Halikias, D., Mallory, M.E., Townsend, A.: Arbitrary-depth universal approximation theorems for operator neural networks. arXiv preprint arXiv:2109.11354 (2021)
Lu, L., Jin, P., Pang, G., Zhang, Z., Karniadakis, G.E.: Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nat. Mach. Intell. 3(3), 218–229 (2021)
Kovachki, N., Li, Z., Liu, B., Azizzadenesheli, K., Bhattacharya, K., Stuart, A., Anandkumar, A.: Neural operator: learning maps between function spaces. arXiv preprint arXiv:2108.08481 (2021)
Owhadi, H.: Do ideas have shape? Plato’s theory of forms as the continuous limit of artificial neural networks. arXiv preprint arXiv:2008.03920 (2020)
Kadri, H., Duflos, E., Preux, P., Canu, S., Rakotomamonjy, A., Audiffren, J.: Operator-valued kernels for learning from functional response data. J. Mach. Learn. Res. 17(20), 1–54 (2016)
Wang, S., Wang, H., Perdikaris, P.: Learning the solution operator of parametric partial differential equations with physics-informed DeepONets. Sci. Adv. 7(40), eabi8605 (2021)
Wang, S., Perdikaris, P.: Long-time integration of parametric evolution equations with physics-informed DeepONets. arXiv preprint arXiv:2106.05384 (2021)
Glorot, X., Bengio, Y.: Understanding the difficulty of training deep feedforward neural networks. In: Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, pp. 249–256. JMLR Workshop and Conference Proceedings (2010)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778 (2016)
Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: International conference on machine learning, pp. 448–456. PMLR (2015)
Salimans, T., Kingma, D.P.: Weight normalization: a simple reparameterization to accelerate training of deep neural networks. Adv. Neural Inf. Process. Syst. 29, 901–909 (2016)
LeCun, Y.A., Bottou, L., Orr, G.B., Müller, K.R.: Efficient backprop. In: Montavon, G., Orr, G.B., Müller, K.R. (eds.) Neural networks: tricks of the trade, pp. 9–48. Springer, Berlin (2012)
Di Leoni, P.C., Lu, L., Meneveau, C., Karniadakis, G., Zaki, T.A.: DeepONet prediction of linear instability waves in high-speed boundary layers. arXiv preprint arXiv:2105.08697 (2021)
Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A., Anandkumar, A.: Fourier neural operator for parametric partial differential equations. arXiv preprint arXiv:2010.08895 (2020)
Wang, S., Teng, Y., Perdikaris, P.: Understanding and mitigating gradient flow pathologies in physics-informed neural networks. SIAM J. Sci. Comput. 43(5), A3055–A3081 (2021)
Wang, S., Yu, X., Perdikaris, P.: When and why PINNs fail to train: a neural tangent kernel perspective. arXiv preprint arXiv:2007.14527 (2020)
McClenny, L., Braga-Neto, U.: Self-adaptive physics-informed neural networks using a soft attention mechanism. arXiv preprint arXiv:2009.04544 (2020)
Wang, S., Perdikaris, P.: Deep learning of free boundary and Stefan problems. J. Comput. Phys. 428, 109914 (2021)
Jacot, A., Gabriel, F., Hongler, C.: Neural tangent kernel: convergence and generalization in neural networks. In: Advances in Neural Information Processing Systems, pp. 8571–8580 (2018)
Du, S., Lee, J., Li, H., Wang, L., Zhai, X.: Gradient descent finds global minima of deep neural networks. In: International Conference on Machine Learning, pp. 1675–1685. PMLR (2019)
Allen-Zhu, Z., Li, Y., Song, Z.: A convergence theory for deep learning via over-parameterization. In: International Conference on Machine Learning, pp. 242–252. PMLR (2019)
Cao, Y., Fang, Z., Wu, Y., Zhou, D.-X., Gu, Q.: Towards understanding the spectral bias of deep learning. arXiv preprint arXiv:1912.01198 (2019)
Xu, Z.-Q.J., Zhang, Y., Luo, T., Xiao, Y., Ma, Z.: Frequency principle: Fourier analysis sheds light on deep neural networks. arXiv preprint arXiv:1901.06523 (2019)
Rahaman, N., Baratin, A., Arpit, D., Draxler, F., Lin, M., Hamprecht, F., Bengio, Y., Courville, A.: On the spectral bias of neural networks. In: International Conference on Machine Learning, pp. 5301–5310 (2019)
Lee, J., Xiao, L., Schoenholz, S., Bahri, Y., Novak, R., Sohl-Dickstein, J., Pennington, J.: Wide neural networks of any depth evolve as linear models under gradient descent. In: Advances in Neural Information Processing Systems, pp. 8572–8583 (2019)
Wang, S., Wang, H., Perdikaris, P.: On the eigenvector bias of Fourier feature networks: From regression to solving multi-scale PDEs with physics-informed neural networks. arXiv preprint arXiv:2012.10047 (2020)
Chen, T., Chen, H.: Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems. IEEE Trans. Neural Netw. 6(4), 911–917 (1995)
Baydin, A.G., Pearlmutter, B.A., Radul, A.A., Siskind, J.M.: Automatic differentiation in machine learning: a survey. J. Mach. Learn. Res. 18, 1–43 (2018)
Cai, S., Wang, Z., Lu, L., Zaki, T.A., Karniadakis, G.E.: Deepm &mnet: inferring the electroconvection multiphysics fields based on operator approximation by neural networks. arXiv preprint arXiv:2009.12935 (2020)
Iserles, A. A First Course in the Numerical Analysis of Differential Equations. Number 44. Cambridge University Press (2009)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Fort, S., Dziugaite, G.K., Paul, M., Kharaghani, S., Roy, D.M., Ganguli, S.: Deep learning versus kernel learning: an empirical study of loss landscape geometry and the time evolution of the neural tangent kernel. arXiv preprint arXiv:2010.15110 (2020)
Leclerc, G., Madry, A.: The two regimes of deep network training. arXiv preprint arXiv:2002.10376 (2020)
Duchi, J., Hazan, E., Singer, Y.: Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 12(7), 2121–2159 (2011)
Cai, T., Gao, R., Hou, J., Chen, S., Wang, D., He, D., Zhang, Z., Wang, L.: Gram–Gauss–Newton method: learning overparameterized neural networks for regression problems. arXiv preprint arXiv:1905.11675 (2019)
Zhang, G., Martens, J., Grosse, R.B.: Fast convergence of natural gradient descent for over-parameterized neural networks. In: Advances in Neural Information Processing Systems, 32 (2019)
van den Brand, J., Peng, B., Song, Z., Weinstein, O.: Training (overparametrized) neural networks in near-linear time. arXiv preprint arXiv:2006.11648 (2020)
Schoenholz, S.S., Gilmer, J., Ganguli, S., Sohl-Dickstein, J.: Deep information propagation. arXiv preprint arXiv:1611.01232 (2016)
Yang, Y., Perdikaris, P.: Physics-informed deep generative models. arXiv preprint arXiv:1812.03511 (2018)
Driscoll, T.A., Hale, N., Trefethen, L.N.: Chebfun Guide (2014)
Cox, S.M., Matthews, P.C.: Exponential time differencing for stiff systems. J. Comput. Phys. 176(2), 430–455 (2002)
Alnæs, M., Blechta, J., Hake, J., Johansson, A., Kehlet, B., Logg, A., Richardson, C., Ring, J., Rognes, M.E., Wells, G.N.: The fenics project version 1.5. Arch. Numer. Softw. 3(100), 9–23 (2015)
Shin, Y., Darbon, J., Karniadakis, G.E.: On the convergence of physics informed neural networks for linear second-order elliptic and parabolic type PDEs (2020)
Mishra, S., Molinaro, R.: Estimates on the generalization error of physics informed neural networks (PINNs) for approximating PDEs. arXiv preprint arXiv:2006.16144 (2020)
Mitusch, S.K., Funke, S.W., Dokken, J.S.: dolfin-adjoint 2018.1: automated adjoints for fenics and firedrake. J. Open Sour. Softw. 4(38), 1292 (2019)
Bradbury, J., Frostig, R., Hawkins, P., Johnson, M.J., Leary, C., Maclaurin, D., Necula, G., Paszke, A., VanderPlas, J., Wanderman-Milne, S., Zhang, Q.: JAX: composable transformations of Python+NumPy programs (2018)
Hunter, J.D.: Matplotlib: a 2D graphics environment. IEEE Ann. Hist. Comput. 9(03), 90–95 (2007)
Harris, C.R., Millman, K.J., van der Walt, S.J., Gommers, R., Virtanen, P., Cournapeau, D., Wieser, E., Taylor, J., Berg, S., Smith, N.J., et al.: Array programming with NumPy. Nature 585(7825), 357–362 (2020)
Funding
This work received support from DOE grant DE-SC0019116, AFOSR grant FA9550-20-1-0060, and DOE-ARPA grant DE-AR0001201.
Author information
Authors and Affiliations
Contributions
SW and PP conceptualized the research and designed the numerical studies. SW implemented the methods and conducted the numerical experiments. HW assisted with the numerical studies. PP provided funding and supervised all aspects of this work. SW and PP wrote the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
A Nomenclature
Table 8 summarizes the main symbols and notation used in this work.
B Hyper-parameter settings
See Table 9.
C Computational cost
Training: Table C summarizes the computational cost (hours) of training physics-informed DeepONet models with different network architectures and weighting schemes. All networks are trained using a single NVIDIA RTX A6000 graphics card (Table 10).
D Proof of Lemma 3.2
Proof
First we observe that \(\varvec{H}(\varvec{\theta })\) is a Gram matrix. Indeed, we define
Then by the definition of \(\varvec{H}(\varvec{\theta })\), we have
-
(a)
By the definition of a Gram matrix.
-
(b)
Let \(\Vert \varvec{H}(\varvec{\theta })\Vert _\infty = \langle v_i, v_j \rangle \) for some i, j and \(\langle v_k, v_k \rangle = \max _{1 \le k \le N^*} \varvec{H}_{kk}(\varvec{\theta }) \)/ for some k. Then we have
$$\begin{aligned} \max _{1 \le k \le N^*} \varvec{H}_{kk}(\varvec{\theta }) = \langle v_k, v_k \rangle \le \Vert \varvec{H}(\varvec{\theta })\Vert _\infty = \langle v_i, v_j \rangle \le \Vert v_i\Vert \Vert v_j\Vert \le \Vert v_k\Vert ^2 = \langle v_k, v_k \rangle . \end{aligned}$$(D.3)Therefore, we have
$$\begin{aligned} \Vert \varvec{H}(\varvec{\theta })\Vert _\infty = \max _{1\le k \le N^*} \varvec{H}_{kk}(\varvec{\theta }). \end{aligned}$$(D.4)
\(\square \)
E Proof of Lemma 3.4
Proof
Recall the definition of the loss function 3.6,
Now we consider the corresponding gradient flow
For \(1 \le j \le N^*\), note that
By Definition 3.1, 3.3, we conclude that
where \(\varvec{K}\) is a \(N^* \times N^*\) matrix whose entries are given by
\(\square \)
F Antiderivative
See Fig. 15.

Anti-derivative operator: Training loss convergence of DeepONet models using different loss schemes for \(4 \times 10^4\) 40,000 iterations of gradient descent using the Adam optimizer. Here we remark that all losses are weighted, and, therefore, the magnitude of these losses is not informative
G Advection equation

Advection equation: Training loss convergence of a DeepONet model using different DeepONet architectures and weighting schemes for \(3 \times 10^5\) iterations of gradient descent using the Adam optimizer. Here we remark that all losses are unweighted

Advection equation: Relative \(L^2\) error of physics-informed DeepONets represented by different architectures and trained using different fixed weights \(\lambda _{\text {bc}} = \lambda _{\text {ic}} = \lambda \in [10^{-2}, 10^{2}]\), averaged over the test data-set

Advection equation: Predicted solution of the best trained physics-informed DeepONet for three different examples in the test data-set
H Burger’s equation
See Figs. 19, 20, 21, 22 and 23.

Burger’s equation: Training loss convergence of a DeepONet models using different DeepONet architectures and weighting schemes for \(2 \times 10^5\) iterations of gradient descent using the Adam optimizer. Here we remark that all losses are unweighted

Burger’s equation: Relative \(L^2\) error of physics-informed DeepONets represented by different architectures and trained using different fixed weights \(\lambda _{\text {bc}} = \lambda _{\text {ic}} = \lambda \in [10^{-2}, 10^{2}]\), averaged over the test data-set

Burger’s equation (\(\nu = 0.01\)): Predicted solution of the best trained physics-informed DeepONet for three different examples in the test data-set

Burger’s equation (\(\nu = 0.001\)): Predicted solution of the best trained physics-informed DeepONet for three different examples in the test data-set

Burger’s equation (\(\nu = 0.0001\)): Predicted solution of the best trained physics-informed DeepONet for three different examples in the test data-set
I Stokes flow

Stokes equation: Training loss convergence of a DeepONet models using different DeepONet architectures and weighting schemes for \(2 \times 10^5\) iterations of gradient descent using the Adam optimizer. Here we remark that all losses are unweighted

Stokes equation: Predicted solution of the best trained physics-informed DeepONet for one example in the test data-set

Stokes equation: Predicted solution of the best trained physics-informed DeepONet for one example in the test data-set

Stokes equation: Predicted solution of the best trained physics-informed DeepONet for one example in the test data-set
Rights and permissions
About this article

Cite this article
Wang, S., Wang, H. & Perdikaris, P. Improved Architectures and Training Algorithms for Deep Operator Networks. J Sci Comput 92, 35 (2022). https://doi.org/10.1007/s10915-022-01881-0
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10915-022-01881-0