
Abstract
In this paper, we propose a cubic regularized Newton method for solving the convex-concave minimax saddle point problems. At each iteration, a cubic regularized saddle point subproblem is constructed and solved, which provides a search direction for the iterate. With properly chosen stepsizes, the method is shown to converge to the saddle point with global linear and local superlinear convergence rates, if the saddle point function is gradient Lipschitz and strongly-convex-strongly-concave. In the case that the function is merely convex-concave, we propose a homotopy continuation (or path-following) method. Under a Lipschitz-type error bound condition, we present an iteration complexity bound of \({\mathcal {O}}\left( \ln \left( 1/\epsilon \right) \right) \) to reach an \(\epsilon \)-solution through a homotopy continuation approach, and the iteration complexity bound becomes \({\mathcal {O}}\left( \left( 1/\epsilon \right) ^{\frac{1-\theta }{\theta ^2}}\right) \) under a Hölderian-type error bound condition involving a parameter \(\theta \) (\(0<\theta <1\)).





Similar content being viewed by others
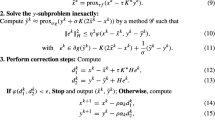

Data Availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Abadeh, S.S., Mohajerin Esfahani, P., Kuhn, D.: Distributionally robust logistic regression. In: Advances in Neural Information Processing Systems, pp. 1576–1584 (2015)
Arjovsky, M., Chintala, S., Bottou, L.: Wasserstein generative adversarial networks. In: Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia (2017)
Başar, T., Olsder, G.J.: Dynamic Noncooperative Game Theory. SIAM, Philadelphia (1998)
Ben-Israel, A., Greville, T.N.E.: Generalized Inverses: Theory and Applications, 2nd edn. Springer, New York (2003)
Ben-Tal, A., El Ghaoui, L., Nemirovski, A.: Robust Optimization, vol. 28. Princeton University Press, Princeton (2009)
Gao, R., Kleywegt, A.J.: Distributionally robust stochastic optimization with Wasserstein distance. arXiv preprint arXiv:1604.02199 (2016)
Gidel, G., Berard, H., Vignoud, G., Vincent, P., Lacoste-Julien, S.: A variational inequality perspective on generative adversarial networks. arXiv preprint arXiv:1802.10551 (2018)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Farley, D.W., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. In: Advances in Neural Information Processing Systems, pp. 2672–2680 (2014)
Jiang, B., Lin, T., Zhang, S.: A unified adaptive tensor approximation scheme to accelerate composite convex optimization. SIAM J. Optim. 30(4), 2897–2926 (2020)
Judd, K.L.: Numerical Methods in Economics. The MIT Press, Cambridge (1998)
Korpelevich, G.M.: The extragradient method for finding saddle points and other problems. Matecon 12, 747–756 (1976)
Lin, T., Jin, C., Jordan, M.: Near-optimal algorithms for minimax optimization. arXiv preprint arXiv:2002.02417 (2020)
Lu, T.T., Shiou, S.H.: Inverse of \(2\times 2\) block matrices. Comput. Math. Appl. 43, 119–129 (2003)
Mokhtari, A., Ozdaglar, A., Pattathil, S.: A unified analysis of extra-gradient and optimistic gradient methods for saddle point problems: proximal point approach. arXiv preprint arXiv:1901.08511 (2019)
Nemirovski, A.: Prox-method with rate of convergence \(o(1/t)\) for variational inequalities with Lipschitz continuous monotone operators and smooth convex-concave saddle point problems. SIAM J. Optim. 15(1), 229–251 (2004)
Yue, M.-C., Zhou, Z., Man-Cho So, A.: On the quadratic convergence of the cubic regularization method under a local error bound condition. SIAM J. Optim. 29(1), 904–932 (2019)
Nesterov, Y.: Accelerating the cubic regularization of Newton’s method on convex problems. Math. Program. 112(1), 159–181 (2008)
Nesterov, Y.: Dual extrapolation and its applications to solving variational inequalities and related problems. Math. Program. 109(2–3), 319–344 (2007)
Nesterov, Y.: Implementable tensor methods in unconstrained convex optimization. Math. Program. 186(1), 1–27 (2018)
Nesterov, Y.: Inexact basic tensor methods. CORE DP 23, 2019 (2019)
Nesterov, Y., Polyak, B.T.: Cubic regularization of newton method and its global performance. Math. Program. 108(1), 177–205 (2006)
Nesterov, Y., Scrimali, L.: Solving strongly monotone variational and quasi-variational inequalities. Available at SSRN 970903 (2006)
Nocedal, J., Wright, S.: Numerical Optimization. Springer Science & Business Media, New York (2006)
Ouyang, Y., Xu, Y.: Lower complexity bounds of first-order methods for convex-concave bilinear saddle-point problems. Math. Program. 185, 1–35 (2019)
Renegar, J.: A Mathematical View of Interior-Point Methods in Convex Optimization, vol. 3. SIAM, Philadelphia (2001)
Rockafellar, R.T.: Monotone operators and the proximal point algorithm. SIAM J. Control Optim. 14(5), 877–898 (1976)
Nisan, N., Roughgarden, T., Tardos, E., Vazirani, V.V. (eds.): Algorithmic Game Theory. Cambridge University Press, Cambridge (2007)
Taji, K., Fukushima, M., Ibaraki, T.: A globally convergent Newton method for solving strongly monotone variational inequalities. Math. Program. 58(1–3), 369–383 (1993)
Tseng, P.: On linear convergence of iterative methods for the variational inequality problem. J. Comput. Appl. Math. 60(1–2), 237–252 (1995)
Tseng, P.: On accelerated proximal gradient methods for convex-concave optimization. Unpublished Manuscript (2008)
von Neumann, J., Morgenstern, O.: Theory of Games and Economic Behavior (Commemorative Edition). Princeton University Press, Princeton (2007)
Wright, S.J.: Primal-Dual Interior-Point Methods. SIAM, Philadelphia (1997)
Zhang, G., Wu, K., Poupart, P., Yu, Y.: Newton-type methods for minimax optimization. arXiv preprint arXiv:2006.14592 (2020)
Zhang, J., Hong, M., Zhang, S.: On lower iteration complexity bounds for the saddle point problems. arXiv preprint arXiv:1912.07481 (2018)
Funding
None.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declares that they have no conflicts of interest/competing interests.
Code Availability
The codes analyzed during the current study are available from the corresponding author on reasonable request.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A Proofs of the Propositions and Theorems
Appendix A Proofs of the Propositions and Theorems
1.1 A.1 Proof of Proposition 2.1
With Assumption 2.1, we have
As a result, \(\frac{\mu }{2}\Big (\Vert x-x^*\Vert ^2 + \Vert y-y^*\Vert ^2\Big )\le f(x,y^*)-f(x^*,y)\). Denote \(z = (x;y)\) and \(z^* = (x^*;y^*)\). By the Lipschitzian Assumption 2.2, it holds that \( \Vert F(z)\Vert ^2=\Vert F(z)-F(z^*)\Vert ^2\le L^2\Vert z-z^*\Vert ^2\), which leads to the first half of our result
On the other hand, denote
With this notation, the duality gap can be rewritten as \(f(x,y^* (x))-f(x^*(y),y)\). By the first-order stationarity condition, we have
Applying the Lipschitz continuity condition yields
Similarly, \( f(x,y)\ge f(x,y^*(x))-\frac{L}{2}\Vert y^*(x)-y\Vert ^2\). Combining these two yields
Additionally, the strong convexity/strong concavity of f gives
resulting
Combining (32),(33) we the second half of the result:
\(\square \)
1.2 A.2 Proof of Proposition 3.3
We first prove that (8) can be achieved with small enough \(\gamma ^k\). Note that \(u^k,v^k\) are the solutions to the stationarity condition (7), which is equivalent to the following system:
where \(Q_1 = H_{xx}^k \succeq \mu I\) and \(Q_2 = -H_{yy}^k \succeq \mu I\) are positive definite matrices. Inner product the first equation in (34) with \(u^k\) and the second with \(v^k\) and then sum up the two, we get
Consequently, let \(b = \max \big \{\Vert g_x^k\Vert ,\Vert g_y^k\Vert \big \}\), we have
Note that \(\Vert u^k\Vert ^2+\Vert v^k\Vert ^2\ge \frac{1}{2}(\Vert u^k\Vert +\Vert v^k\Vert )^2\) and \(\Vert u^k\Vert ^3+\Vert v^k\Vert ^3\ge \frac{1}{4}(\Vert u^k\Vert +\Vert v^k\Vert )^3\). As a result,
Let \(\omega = \gamma ^k(\Vert u^k\Vert +\Vert v^k\Vert )\), then the above inequality is equivalent to \(\omega ^2 + 2\mu \omega - 4b\gamma ^k\le 0\). Solving this quadratic inequality yields that
We can see that the upper bound for \(\gamma ^k(\Vert u^k\Vert +\Vert v^k\Vert )\) is an increasing function of \(\gamma ^k\) with function values ranging from 0 to \(\infty \). This indicates that by making \(\gamma ^k\) small enough, condition (8) can then be satisfied.
Next, we proceed to prove descent result of Proposition 3.3. The proof of this part is based on the concept of the proof in [28]. By direct calculation,
Note that we added and subtracted the same three terms in the last equality. By rearranging the terms in the inner product, the first four terms on the RHS of (36) can be written as:
where inequality (ii) is because \(\gamma ^k\Vert u^k\Vert \le \mu \) and inequality (i) is due to
Similarly, for the last four terms of (36), we have
Adding (37) to the above inequality, combining with (36), we have \( \langle \nabla m(z^k),d^k\rangle \le -\frac{\mu ^2}{2}\Vert d^k\Vert ^2\), which completes the proof. \(\square \)
1.3 A.3 Proof of Theorem 3.1
First of all, we establish the descent lemma for the mapping F(z) by observing that:
Then with Assumption 2.2, we have the following inequality:
We can rewrite the expression for \(\nabla F(z^k)d^k\) using stationarity condition (7):
Putting the above identity back to (38) yields
Note that (9) indicates that \(\Vert d^k\Vert ^2 \le \frac{8L_m}{\mu ^4}(m(z^k)-m(z^{k+1}))=\frac{4}{\alpha \mu ^2}(m(z^k)-m(z^{k+1}))\), which further yields
where the last inequality is due to \( \Vert F(z)\Vert = \Vert F(z)-F(z^*)\Vert \le L D\) for \(\forall z\in \{z:m(z)\le m(z^0)\}.\) Define \(\beta = \left( \frac{L_2}{L_m}+\frac{4\bar{\gamma }}{\mu ^2}\right) L D\). Then combining (40) and (39) yields that
which results in:
Squaring both sides of (41) and dividing by half, we get the desired bound
Finally, taking \(\bar{\gamma }= \frac{L_2\mu ^2}{4L_m}\), we have \(\beta =\left( \frac{L_2}{L_m}+\frac{4\bar{\gamma }}{\mu ^2}\right) L D=\frac{2L_2L D}{L_m}=\frac{2L_2LD}{L^2+L_2LD}\le 2\), which further yields
\(\square \)
1.4 A.4 Proof of Lemma 5.1
Let \(x_t=(M+tI_m)^{-1}b\) for some \(t>0\). Suppose \(r=\text{ rank } (M)\). If \(r=m\) (namely M is invertible) then the lemma holds true trivially, by noting that \((M+tI_m)^{-1}=M^{-1}+{\mathcal {O}}(t)\) and \(\Vert x_t-x_s\Vert =\Vert {\mathcal {O}}(t)b-{\mathcal {O}}(s)b\Vert ={\mathcal {O}}(|s-t|)\) for small \(s,t>0\). Now, suppose \(r<m\), we shall show the same holds by establishing the dependency on t for \(x_t\). Let a singular value decomposition of M be
with \(\varLambda _r\) being an \(r\times r\) diagonal positive, and U and V are orthonormal matrices. The pseudo-inverse of M is \(M^+=V^\top \varLambda ^+ U\), where \(\varLambda ^+=\left( \begin{array}{cc} \varLambda _r^{-1} &{} 0_{r\times (m-r)} \\ 0_{(m-r)\times r} &{} 0_{(m-r)\times (m-r)} \end{array}\right) \). According to the theory of pseudo-inverse matrices (cf. [4]), \(L_0=\{x: Mx=b\}\not =\emptyset \) if and only if \(b=MM^+b\), or equivalently, the last \(m-r\) elements of Ub are zero; that is, \(U b=\left( \begin{array}{c} {\bar{b}}_r \\ 0_{m-r} \end{array}\right) \).
Now, let \(G=UV^\top \), which is also orthonormal, and introduce
In fact, observe that \(G_{22}\) is invertible. To see this, let us first examine the order of t in \(\det (M+tI_m)\). Note that \(\det (M+tI_m)\) is exactly the characteristic polynomial of the matrix \(-M\) (which has eigenvalues of opposite sign of M). Therefore, it can be written in the expression \(\prod \limits _{i=1}^r(t+\sigma _i)t^{m-r}\) for a rank-r matrix M with non-zero eigenvalues \(\sigma _i\), \(i=1,...,r\). Therefore, the dominant order of t in \(\det (M+tI_m)\) as \(t\rightarrow 0\) is \({\mathcal {O}}(t^{m-r})\). However, if \(G_{22}\) would be degenerate, then we can alternatively express the determinant as:
We can see that the middle term is at least O(t), since if it is of constant order, then the value converges to \(\det (G_{22})=0\) as \(t\rightarrow 0\), which is already a contradiction. Therefore, the above expression concludes that \(\det (M+tI_m)\) is at least of the order \(O(t^{m-r+1})\) for sufficiently small \(t>0\), which is a contradiction to the earlier conclusion. Therefore, \(G_{22}\) must be invertible.
In general, consider a \(2\times 2\) invertible block matrix \(\left( \begin{array}{cc} A &{} B \\ C &{} D \end{array}\right) \), where A and its Schur complement \(D-CA^{-1}B\) are invertible. Then (see [13]),
Substituting \(A=\varLambda _r + t G_{11}\), \(B=t G_{12}\), \(C=t G_{21}\) and \(D=t G_{22}\) into the above expression, we have
Therefore,
Since \(L_0=\{x: Mx=b\}\not =\emptyset \), it follows that \(M^+b \in L_0\). Let \(x_0:=M^+b = V^\top \left( \begin{array}{c} \varLambda _r^{-1} {\bar{b}} \\ -\varLambda _r^{-1} G_{12} G_{22}^{-1} {\bar{b}} \end{array}\right) \in L_0\), we have \(\Vert x_t - x_0\Vert =O(t)\). By the smoothness of the curve \(\{x_t: 0<t<\delta \}\), we actually have \(\Vert x_t-x_s\Vert =O(|t-s|)\) for sufficiently small positive t and s. \(\square \)
1.5 A.5 Proof of Lemma 5.6
First of all, note that since \(0<\lambda _k<1\), the sequence \(\{\nu _k\}\) is strictly decreasing. Let us first assume \(\nu _0>1\). Then for \(k<K\) such that \(\nu _k>1\), we can take \(\lambda _k=\lambda \) as a constant:
The above inequality can be verified by taking reciprocal on both sides and noting that \(\nu _k^{1-\theta }>1\). Indeed, for \( K>(4L_2C+2)^{\frac{1}{\theta }}\cdot \ln \nu _0\), we have \( \nu _K = (1-\lambda )^K\nu _0\le \exp (-K\lambda )\nu _0<1\).
Let us now focus on the case when \(\nu _k<1\). Without loss of generality, take \(\lambda _k\) as its upper bound in (24). Therefore we have
where \(\xi <1\) is a constant defined as
for \(\nu _k<1\).
Therefore, to establish the convergence of \(\{\nu _k\}\), we could instead establish the convergence of the following sequence:
for \(\theta \in (0,1)\).
The remaining part of this proof follows from the proof of Theorem 1 in [20].
Let us first note that the function \( f(x)=\frac{1}{(1+x)^p}\) is convex for \(x\ge -1\) and \(p>0\). Therefore, for \(x\ge -1\), we have \(f(x)=\frac{1}{(1+x)^p}\ge f(0)+f'(0)x=1-px\). Taking \(p=\frac{1-\theta }{\theta }>0\) and \(x=\frac{a_{k+1}-a_k}{a_k}>-1\), we obtain
Then
Summing up the above inequality from \(a_0\) to \(a_k\), we have
Therefore, \(a_k\le \left( \frac{1}{1+\frac{1-\theta }{\theta }\cdot k\xi }\right) ^{\frac{\theta }{1-\theta }}\). By the definition of \(C'\) in Lemma 5.6, we obtain \(\nu _k\le \left( \frac{1}{1+C'\cdot k}\right) ^{\frac{\theta }{1-\theta }}\), for all k such that \(\nu _k<1\). \(\square \)
Rights and permissions
About this article

Cite this article
Huang, K., Zhang, J. & Zhang, S. Cubic Regularized Newton Method for the Saddle Point Models: A Global and Local Convergence Analysis. J Sci Comput 91, 60 (2022). https://doi.org/10.1007/s10915-022-01819-6
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10915-022-01819-6