
Abstract
Bilevel optimization is an increasingly important tool to model hierarchical decision making. However, the ability of modeling such settings makes bilevel problems hard to solve in theory and practice. In this paper, we add on the general difficulty of this class of problems by further incorporating convex black-box constraints in the lower level. For this setup, we develop a cutting-plane algorithm that computes approximate bilevel-feasible points. We apply this method to a bilevel model of the European gas market in which we use a joint chance constraint to model uncertain loads. Since the chance constraint is not available in closed form, this fits into the black-box setting studied before. For the applied model, we use further problem-specific insights to derive bounds on the objective value of the bilevel problem. By doing so, we are able to show that we solve the application problem to approximate global optimality. In our numerical case study we are thus able to evaluate the welfare sensitivity in dependence of the achieved safety level of uncertain load coverage.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Bilevel optimization has become more and more important during the last years and decades. The reason is that this class of problems enables the modeler to describe hierarchical decision processes, which is often of great importance in practical applications. On the other hand, this ability also makes bilevel problems hard to solve—both in theory and practice. For instance, it is well known that even the easiest class of bilevel problems, i.e., models with linear lower and upper level, are strongly NP-hard [1] and even checking the local optimality of a given point is NP-hard [2]. Nevertheless, starting in the 1980’s, researchers developed increasingly powerful algorithms to tackle different challenging classes of bilevel problems; see, e.g., [3,4,5] for an overview of the field. The most recent trend is to consider more and more challenging bilevel models by also incorporating (mixed-)integer aspects [6,7,8,9,10], continuous nonconvexities [11, 12], or uncertainty modeling [13,14,15,16,17]. The resulting bilevel models usually are harder to solve if these complicating aspects appear in the lower level of the bilevel problem. For instance, a convex lower-level problem (that also satisfies a reasonable constraint qualification) can be replaced by its necessary and sufficient optimality conditions, leading to an equivalent single-level reformulation of the bilevel problem. This is of course not possible anymore if the lower-level problem does not possess compact optimality certificates as it is the case for mixed-integer or other nonconvex problems.
One main field of application for bilevel optimization are energy markets, where one often is faced with a hierarchical structure of decision making; see, e.g., the recent survey [18] of bilevel optimization applied in the energy sector. In this paper, we consider a simplified version of the European entry-exit gas market [19, 20], which can be modeled as a bilevel problem. The main goal of this market design is to decouple the trade and transport of natural gas. This is also reflected in the bilevel structure since the transport-related aspects are incorporated in the upper level, in which the transmission system operator (TSO) acts, while anticipating the market outcome that is determined in the lower-level problem. We refer to [21] for the derivation of this bilevel model and to [22, 23] for some further studies that tackle this bilevel model of the European gas market. All papers mentioned so far, however, make the assumption that all data of the model is deterministic. Obviously, this is not the case in practice. In particular, the future energy consumption is not known and it is rather standard to tackle such aspects using techniques from stochastic optimization.
Stochastic bilevel problems or, more generally, stochastic mathematical programs with equilibrium constraints (SMPECs), have been introduced in [24] and further investigated theoretically, e.g., in [25]. They have found numerous applications in specific electricity market models; see, e.g., [26]. In these models, the typical chronology of first- and second-stage decisions x, y accompanied by the observation of the random parameter \(\xi \) is \(x\!\curvearrowright \xi \curvearrowright \!y\). In this case, x is a here-and-now decision (before randomness is revealed) and y is a wait-and-see decision (reacting on randomness). This implies, in particular, that y can be chosen (as a function of x and \(\xi \)) such that the lower-level constraints are satisfied almost surely with respect to randomness for any x. However, in the gas market model we are considering in this paper, the chronology is \(x\curvearrowright y\curvearrowright \xi \), which means that both first- and second-stage decisions are of type here-and-now. In this case, the satisfaction of random lower-level constraints cannot be guaranteed almost surely in general, but only with a certain probability. This leads in a natural way to the use of probabilistic or chance constraints. The research on this topic is rather young. Exemplarily, we refer to the theoretical paper [27] devoted to a chance-constrained bilevel model in the chronology \(x\curvearrowright \xi \curvearrowright y\) we mentioned above and refer to the two papers [28, 29] dealing with the numerical solution of chance constraints as parts of bilevel problems. These latter articles make simplifying assumptions by restricting randomness to discrete measures or imposing individual rather than joint chance constraints; see also our critical discussion in the case study of Sect. 3.4. The main contribution of this paper is the consideration of joint chance constraints with continuous multivariate random distribution on the lower level of a bilevel problem.
We thus extend the deterministic setting to incorporate uncertain loads in the lower, i.e., the market, level of the bilevel problem. In the literature, gas buying firms are usually modeled using inverse market demand functions to model price elasticity. While this is a reasonable model in the deterministic setting, the bought quantities do not solely follow an economic rationale but also need to cover mostly random fluctuations in the day-ahead. This is not covered in the models in the literature and we capture this aspect by introducing a respective chance constraint in the lower level of the bilevel problem. On the other hand, we make simplifying assumptions such as considering a linear gas flow model as well as that we only consider passive networks to keep the model practically tractable and the presentation streamlined.
This extension of the model adds a significant mathematical challenge to the overall bilevel problem. Although the chance constraint is convex—and, thus, first-order optimality conditions are usable in general—it is not given in a closed form. Instead, only function and gradient evaluations are available and we have to design methods that can cope with such black-box functions. To the best of our knowledge, this problem class has not been considered so far in the literature.
In this setup, our contribution is the following. First, we study bilevel problems with a convex upper and lower level that contain a black-box constraint in the lower level in Sect. 2. Since a closed form of the latter is not available, one has to resort to iterative approaches that subsequently approximate the lower-level’s feasible set, which is possible by outer approximations since function evaluations and first-order information is available. Thus, the lower-level’s feasible set can only be approximated up to a certain prescribed tolerance. We discuss in detail that this makes it challenging (if possible at all) to ensure global optimality of the bilevel problem. Nevertheless we can show that, if our algorithm terminates, it terminates with a point that is approximate feasible for the lower level. Second, we present a chance-constrained extension of a simplified bilevel model of the European entry-exit gas market and also discuss the economic interpretation of the added chance constraint; cf. Sect. 3. For this application, we can further derive provably lower bounds by adjusting our method, which allows us to assess the quality of the obtained solutions. It turns out that we are always very close to a globally optimal solution of the chance-constrained bilevel problem. Third and finally, we present numerical results for the chance-constrained bilevel problem of the European gas market on an academic instance and discuss the effect of uncertainty on the results.
2 Bilevel problems with convex lower-level black-box constraints
2.1 Problem formulation
We consider convex bilevel problems of the form
in which the solution set of the convex lower-level problem is given by
The variable vector \(x\) denotes the \({n_x}\) upper-level (or leader) decisions and \(y\) denotes the \({n_y}\) lower-level (or follower) decisions. We assume that \(F : \mathbb {R}^{n_x}\times \mathbb {R}^{n_y}\rightarrow \mathbb {R}\), \(G : \mathbb {R}^{n_x}\times \mathbb {R}^{n_y}\rightarrow \mathbb {R}^{m_\mathrm {u}}\), \(f : \mathbb {R}^{n_x}\times \mathbb {R}^{n_y}\rightarrow \mathbb {R}\), \(g: \mathbb {R}^{n_x}\times \mathbb {R}^{n_y}\rightarrow \mathbb {R}^{m_{\ell }}\), and \(b: \mathbb {R}^{n_y}\rightarrow \mathbb {R}\) are convex and differentiable functions. Further, we suppose that \(b(y) \le 0\) is a black-box constraint for which we make the following assumptions.
Assumption 1
The black-box function \(b\) is convex and for all \((x, y) \!\in \!\{(x,y): G(x,y) \le 0, g(x, y) \le 0\}\),
-
(1)
we can evaluate the function \(b(y)\),
-
(2)
we can evaluate the gradient \(\nabla b(y)\), and
-
(3)
the gradient is bounded, i.e., \(\left\| \nabla b(y)\right\| \le K\) for a fixed \(K \in \mathbb {R}\).
Overall, the upper-level problem (1a–1c) is a convex minimization problem and for fixed upper-level variables \(x=\bar{x}\), the lower level is a convex minimization problem as well. In the case that the follower problem (2) has multiple solutions, i.e., \(S(x)\) is not a singleton, Problem (1) models the so-called optimistic bilevel solution, which realizes the lower-level solution \(y\in S(x)\) that minimizes the upper-level objective function F.
In the following, we denote the shared constraint set by
its projection onto the decision space of the leader by
and the feasible set of the lower-level problem for a fixed leader decision \(x=\bar{x}\) by
Further, we denote the optimal value function of the lower-level problem by
Using the latter, we rewrite Problem (1) as the equivalent single-level problem
2.2 Obstacles and pitfalls
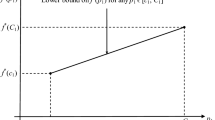
Besides being a bilevel problem, the main challenge of Problem (1), and also of Problem (3), is the black-box constraint \(b(y) \le 0\) in the lower-level problem. Typical methods for solving bilevel problems with convex lower levels replace the lower level with its necessary and sufficient optimality conditions in algebraic form. This is, however, not possible if the lower level contains a black-box function—i.e., a function for which an explicit expression is not available—since without such an expression, optimality conditions are also not available in closed form. Since later on, our method needs to employ global optimization solvers and since general-purpose global optimization software usually requires all constraints to be given in algebraic form (e.g., to derive suitable over- and underestimators), the considered back-box setting adds to the hardness of the bilevel problem at hand. As a remedy, we need to resort to iterative approaches, e.g., cutting-plane techniques [30] or outer approximation [31, 32], and the best we can expect is to fulfill the black-box constraint up to an a priori specified tolerance. In order to specify the quality of such solutions, we make use of the concepts of \(\delta \)-feasibility and \(\varepsilon \)-\(\delta \)-optimality known from global optimization; see, e.g., [33]. The same concept is also used in a bilevel-specific context in, e.g., [11], where the authors require this notion since they consider a nonconvex optimization problem in the lower level. In this paper, we use the following definition.
Definition 1
For \(\delta =(\delta _G, \delta _g, \delta _b, \delta _f) \in \mathbb {R}^{{m_\mathrm {u}}+{m_{\ell }}+2}_{\ge 0}\), a point \((\bar{x}, \bar{y}) \in \mathbb {R}^{{n_x}} \times \mathbb {R}^{n_y}\) is called \(\delta \)-feasible for Problem (1), if \(G(\bar{x}, \bar{y}) \le \delta _G\), \(g(\bar{x}, \bar{y}) \le \delta _g\), \(b(y) \le \delta _b\), and \(f(x,y) \le \varphi (x) + \delta _f\) hold. Moreover, for \(\varepsilon \ge 0\), a point \((x^*, y^*) \in \mathbb {R}^{{n_x}} \times \mathbb {R}^{n_y}\) is called \(\varepsilon \)-\(\delta \)-optimal for Problem (1), if it is \(\delta \)-feasible and if \(F(x^*,y^*) \le F^*+ \varepsilon \) holds, with \(F^*\) denoting the optimal objective function value of Problem (1).
We highlight that a \(\delta \)-feasible point \((\bar{x}, \bar{y})\) of Problem (1) is, in particular, \(\delta _f\)-\((\delta _g, \delta _b)\)-optimal for the lower-level problem (2) with fixed \(x=\bar{x}\). The point is \((\delta _g, \delta _b)\)-feasible because \(g(\bar{x}, \bar{y}) \le \delta _g\) as well as \(b(y) \le \delta _b\) hold and the objective function value is bounded by \(f(x, y) \le \varphi (x) + \delta _f\). If the functions f and g do not lead to further difficulties, we can choose \(\delta _f = \delta _g = 0\). If we can, in addition, also optimize exactly over F and G, then the best we can hope for in our bilevel setting is to obtain a 0-\(\delta \)-optimal solution of Problem (1) with \(\delta =(0, 0, \delta _b,0)\).
In practice, however, this turns out to be not so easy. We already mentioned that we can only expect to fulfill the black-box constraint up to a tolerance. Let us consider the following relaxation of the lower level for a given upper-level decision \(x=\bar{x}\):
We denote the optimal value function of this problem by \(\underline{\varphi }(x)\). Since Problem (4) is a relaxation of the original lower-level problem (2), \(\underline{\varphi }(x) \le \varphi (x)\) holds for all feasible \(x\in \Omega _\mathrm {u}\).
Virtually all solution techniques for bilevel problems with a convex lower-level problem exploit the single-level reformulation (3) or similar variants that express the optimal value function \(\varphi \) more explicitly, e.g., by using the optimality conditions of the convex lower-level problem. If we replace the lower-level problem with its relaxation (4) and derive a single-level reformulation in analogy to Problem (3), then we need to (i) relax Constraint (3c) and (ii) replace Constraint (3d) by \(f(x,y) \le \underline{\varphi }(x)\). If \(\underline{\varphi }(x) < \varphi (x)\) holds for any \(x\in \Omega _\mathrm {u}\), then such a “first-relax-then-reformulate” approach yields a single-level reformulation that is not a relaxation of the single-level reformulation (3). Thus, it is also not a relaxation of the original bilevel problem (1). Consequently, it is not clear whether and how \(\varepsilon \)-\(\delta \)-optimality can be guaranteed.
This observation is closely related to the missing independence of irrelevant constraints (IIC) property that is known from single-level optimization. In [34], it is shown that adding an inequality to the lower-level problem that is valid for the bilevel optimal solution may result in a better bilevel solution that is not feasible without the added valid inequality. We demonstrate this effect using a simple linear bilevel problem.
Example 1
The linear bilevel problem
possesses the optimal solution (2, 2) with objective function value 2. The inequality \(y\ge 1\) is valid but inactive for the optimal solution (2, 2). Adding this constraint to the lower level yields the problem
with optimal solution (0, 1) and objective value 0.
For our application, Example 1 particularly suggests that stopping a cutting-plane approach once the black-box constraint is fulfilled up to a \(\delta _b\)-tolerance may not yield a globally optimal solution. According to [34], a cutting-plane approach is only applicable, if the solution of the so-called high-point relaxation—the relaxation of the bilevel problem that disregards lower-level optimality—is also a solution of the original bilevel problem. This however means that we do not have a “real” bilevel problem in the first place. In [35], it is shown that a globally optimal solution of a bilevel problem remains locally optimal when adding valid inequalities to the lower level in case of inner semicontinuity of the solution set mapping \(S(x)\). Thus, under this restrictive assumption, a cutting-plane approach may at least yield locally optimal bilevel solutions.
In any case, determining an \(\varepsilon \)-optimality certificate, i.e., finding an \(\varepsilon \) such that \(F(x,y) \le F^*+ \varepsilon \) holds for \((x,y)\) derived by a cutting-plane algorithm is, in our opinion, an extremely challenging and up to now open task. Thus, the best we can hope for when applying a cutting-plane approach is to arrive at a \(\delta \)-feasible point with \(\delta =(0,0,\delta _b,0)\). In other words, the best we can hope for is an approximate heuristic for the bilevel problem with lower-level black-box constraints.
2.3 A “first-relax-then-reformulate”-approach to compute \(\delta \)-feasible points
In this section, we formalize a cutting-plane approach that proceeds in a “first-relax-then-reformulate” way. We will show that this approach can compute \(\delta \)-feasible points of Problem (1). After that, we briefly discuss why an intuitive extension, a “first-reformulate-then-relax” approach, fails.
Since the black-box constraint \(b(y) \le 0\) is convex, we can construct a sequence of linear outer approximations \((E^r,e^r)_{r\in \mathbb {N}}\) of the black-box constraint \(b(y) \le 0\) with the property
Such descriptions can be obtained, e.g., by a classic cutting-plane approach [30] that exploits the fact that the first-order Taylor approximation of \(b\) is a global underestimator of \(b\).
We note that for a given upper-level solution \(\bar{x} \in \Omega _\mathrm {u}\) and \(r\in \mathbb {N}\), the adapted lower-level problem
is a convex relaxation of the original lower-level problem (2). If we denote the optimal value function of Problem (6) by \(\underline{\varphi }^r(x)\), then the following lemma follows directly from (5).
Proposition 1
For every \(r\in \mathbb {N}\) and every upper-level decision \(x\in \Omega _\mathrm {u}\), it holds
We now follow a “first-relax-then-reformulate” approach by replacing the original lower-level problem (2) with its relaxation (6). This yields the following modified variant of the single-level reformulation (3):
For the practical tractability of Problem (7), we need the following assumption.
Assumption 2
For every upper-level decision \(\bar{x} \in \Omega _\mathrm {u}\) and every \(r\in \mathbb {N}\), Slater’s constraint qualification holds for the relaxed lower-level problem (6).
With Assumption 2, we can solve Problem (7) to global optimality, e.g., by replacing the optimal-value-function constraint (7d), which models the optimality of the relaxed lower level (6), and the lower-level primal feasibility with the necessary and sufficient KKT conditions of Problem (6). Note that such an explicit expression is not available for the Constraint (3d), because it would require explicit knowledge on the black-box function \(b\).
Following the discussion of the last section, we re-iterate that, although we relax the black-box constraint, we do not obtain a relaxation of Problem (3) due to the tightened constraint (7d); see Proposition 1. Still, we can exploit Problem (7) to compute a \(\delta \)-feasible point of Problem (1) as summarized in Algorithm 1.

After the initialization (Step 1), we enter a while-loop in which we first check, among others, for approximate feasibility w.r.t. the chance constraint. Inside the loop, we first update the linear outer approximation in Step 3. This can be achieved, e.g., by using the first-order Taylor approximation of the black-box function at the last iterate, which is possible due to Assumption 1. Then, we solve Problem (7) to obtain a point \((x^{r+1}, y^{r+1})\). In case Problem (7) is infeasible, we resort to the following feasibility problem:
We argued before that Problem (7) is not a relaxation of the single-level reformulation (3), because the optimality condition of the lower level is tightened. We thus relax the optimality of the lower level to compute a new iterate \((x^{r+1}, y^{r+1}, s)\). Since Problem (7) is infeasible, \(s > 0\) must hold.
Note also that Problem (8) must be feasible if Problem (3) is feasible. Consequently, if Problem (8) is infeasible, we can state that Problem (1) is infeasible. Otherwise, if Problem (7) or Problem (8) is feasible, we update \(\chi \) and \(r\).
Finally, note that Algorithm 1 only terminates if Problem (7) is feasible. This is ensured by the check on s in Step 2.
Theorem 1
If Algorithm 1 terminates, \((\bar{x},\bar{y})\) is \((0,0,\delta _b,0)\)-feasible for Problem (1).
Proof
The point \((\bar{x}, \bar{y})\) fulfills the constraints \(G(\bar{x},\bar{y}) \le 0\) and \(g(\bar{x},\bar{y}) \le 0\). Further, we have \(b(\bar{y})\le \delta _b\). Finally, \(\bar{y}\) is an optimal solution for the relaxed lower-level problem (6) for fixed \(\bar{x}\), i.e., \(f(\bar{x},\bar{y}) \le \underline{\varphi }^r(\bar{x})\). Due to Lemma 1, we thus know that \(f(\bar{x},\bar{y})\le \varphi (\bar{x})\) holds. In summary, \((\bar{x},\bar{y})\) is a \((0,0,\delta _b,0)\)-feasible point of Problem (1). \(\square \)
Note that we have to solve Problem (7) and (8) exactly and to global optimality to get a \((0,0,\delta _b,0)\)-feasible point as stated in the last theorem. While suitable convexity or even linearity assumptions on F, G, g, and f might render this feasible also for larger instances, this clearly underpins the hardness of the original problem addressed in this paper and, of course, puts a significant computational burden when it comes to real-world and large-scale instances. We also point out that Theorem 1 makes no statement regarding the convergence of Algorithm 1. In fact, convergence cannot be guaranteed. Consider, for example, the case in which Problem (7) is infeasible and for the solution \((x^{r+1},y^{r+1},s)\) of the feasibility problem (8) the black-box constraint is fulfilled, i.e., it holds \(b(y^{r+1}) \le 0\). Then, updating the linear outer approximation using the respective first-order Taylor approximation of \(b\) at \(y^{r+1}\) does not exclude the point \((x^{r+1},y^{r+1})\). In the new iteration, the algorithm then delivers either the same solution \((x^{r+1},y^{r+1},s)\) again—or we are lucky and the missing IIC property helps to find a new iterate: Adding the first-order Taylor approximation may change \(\bar{\varphi }^r(x)\) such that either Problem (7) might become feasible or the solution of Problem (8) differs from the previous iteration. In any way, Algorithm 1 may not terminate if such a lucky situation does not appear. However, we demonstrate in Sect. 3 that it works very well in practice.
We also note that Algorithm 1 requires to solve a bilevel problem in every iteration. In order to reduce the computational burden, we can initialize the algorithm with a tight initial linear outer approximation \(E^0 y\le e^0\), obtained, e.g., by an initial cut sampling phase.
Before we conclude this section, we briefly discuss a “first-reformulate-then-relax” approach. We already highlighted in the last section that there is not much hope to derive algorithms that yield more than a \(\delta \)-feasible point of Problem (1). We also discussed that for the “first-relax-then-reformulate” approach, the main problem is that Problem (7) is not a relaxation of Problem (1). However, Problem (8) might lead to the intuition that relaxing the optimality of the follower problem appropriately resolves this issue. Consequently, we may apply a “first-reformulate-then-relax” approach as follows.
Remark 1
We may first reformulate Problems (1–3) and then relax the black-box constraint (3c) and the optimality of the lower level (3d). We recap that the latter is necessary, because we cannot describe \(\varphi (x)\) explicitly. We therefore need to find functions \(\bar{\varphi }^r\) with
such that the problem
is a relaxation of Problem (1) for every \(r\in \mathbb {N}\). This would allow to compute 0-\(\delta \)-optimal points of Problem (1). It is, however, not clear how to derive suitable functions \(\bar{\varphi }^r\). One strategy might be to use a sequence \((H^r,h^r)_{r\in \mathbb {N}}\) of linear inner approximations of the lower-level problem such that
holds. By replacing the black-box constraint with the linear inner description, we would obtain the tightened lower-level problem
In order to use Problem (1) algorithmically, we need an explicit description of \(\bar{\varphi }^r(x)\). Therefore, we may use the KKT conditions or strong duality of Problem (10) and reformulate Problem (1) accordingly. This, in turn, requires Problem (10) to be feasible for every upper-level decision \(x\in \Omega _\mathrm {u}\), which could be fulfilled, e.g., for a sufficiently tight linear inner description \((H^r, h^r)\) of \(b(y) \le 0\) throughout its entire domain. This is not practicable from a computational point of view because such a linearization over the entire domain, in general, requires a significant amount of inequalities such that the resulting problem is very large. In addition, if such a sufficiently tight linear description over the entire domain would be available, we could directly use it to replace the lower level by its KKT conditions.
Remark 2
Let us finally comment on some possible extensions of the setting considered in this section.
-
(1)
We can easily add integer variables to the upper level of the original bilevel problem. The main rationale of the presented algorithm stays the same. The only difference is that a mixed-integer problem instead of continuous one needs to be solved in every iteration of the algorithm.
-
(2)
The same applies to more general, and maybe nonconvex, functions F and G in the upper level. The main rationale of the algorithm does not change if nonconvex functions are part of the upper level but the problem to be solved in each iteration of Algorithm 1 is harder. Moreover, one would have to consider an additional \(\varepsilon \)-\(\delta \) notion for the global optimization task of the upper level as well.
-
(3)
Finally, we presented the models and the algorithm in this section for a scalar black-box function b in the lower level. However, besides technical adaptions, nothing changes if b is an entire vector of black-box functions.
2.4 An academic example
In this section, we test Algorithm 1 on an academic instance. Since we are not aware of any bilevel test instances with black-box constraints, we use the following problem:
with
This example is taken from [36] and is contained in BASBLib, a library of bilevel test problems; see [37]. Problem (11) has a convex-quadratic objective function. In addition, the lower-level problem
is a convex-quadratic minimization problem over linear constraints. Note that we could replace the lower level by its necessary and sufficient KKT conditions and solve the resulting nonconvex single-level problem to global optimality by using the well-known mixed-integer linearization of the KKT complementarity conditions using big-M values. However, in order to apply Algorithm 1, we equivalently rewrite the lower-level problem (13) to
In this formulation, the “black-box function” \(b(y, t)\) fulfills Assumption 1. Overall, we apply Algorithm 1 to the following problem:
We first initialize \(\delta _b = 10^{-6}\), \(E^0=[0, 0]\), as well as \(e^0=0\) and enter the while-loop. In order to obtain \(E^1\) and \(e^1\), i.e., a tightening of the description of the black-box constraint, we solve the auxiliary problem
which is a relaxation of Problem (15). We obtain the solution \(\bar{x}=2.8\), \(\bar{y}=2.4\), and \({\bar{t}} = 0\), with corresponding objective value 0.2. Note that there is a strong ambiguity on the value of \({\bar{t}}\) in this situation, which is due to the fact that we moved the objective function of the lower-level problem into its constraint set. However, \({\bar{t}} = 0\) is a reasonable choice because we minimize t in the reformulated lower-level problem (14). Thus, we proceed with this value to illustrate the further behavior of our algorithm. In order to construct \(E^1\) and \(e^1\), we compute the first-order Taylor approximation at the point \((\bar{y}, {\bar{t}})\). With the gradient \(\nabla _yb(y, t) = 2y- 10\), \(\nabla _t b(y, t) = -1\), we obtain the inequality
which translates to \(E^1= [-5.2, -1]\) and \(e^1=-19.24\). We then solve the single-level problem (7) by describing \(\underline{\varphi }^1(x)\) with the linearized KKT conditions of the relaxed lower-level problem; see also the explanations after Assumption 2. We therefore use a big-M value of \(10^6\) in our computations. We obtain the solution \(\bar{x}=1\), \(\bar{y}=3\), \({\bar{t}}=3.64\) with objective function value 5 and \(\chi =0.36\).
Since the violation of the black-box constraint \(\chi \) exceeds the tolerance \(\delta _b\), we construct \(E^2=[-4,-1]\) and \(e^2-16\) by computing another gradient cut at \((\bar{x},\bar{y}, {\bar{t}})\). Updating and solving Problem (7) yields \({x}^*=1\), \({y}^*=3\), \({s}^*=4\) with corresponding objective value 5 and black-box constraint violation \(\chi =0\). According to Theorem 1, we found a \((0,0,\delta _b,0)\)-feasible point for Problem (15). Indeed, the point \(({x}^*,{y}^*)\) is a global optimum of the original problem Problem (11); see [37].
3 A European gas market model with chance constraints
In this section, we use the algorithmic approach developed in the previous section to solve a simplified model of the European entry-exit gas market with uncertain load modeling. We therefore take the model from [21] and extend it by a chance constraint to model uncertain loads. This results in a bilevel problem with a black-box constraint in the lower level; see Sect. 3.2. Afterward, we tailor the proposed solution approach to the specific setting of the considered gas market model and give some more details on the handling of the chance constraint, which is a black-box constraint as discussed in the previous section. Finally, we provide some algorithmic insights and discuss the obtained results from an applied perspective in Sect. 3.4.
In a nutshell, the European entry-exit gas market is organized as follows:
-
(1)
The transmission system operator (TSO) announces so-called technical capacities and booking price floors for every entry and exit node of the network to maximize the overall welfare.
-
(2)
Gas selling and buying firms located at entry and exit nodes, respectively, afterward sign capacity-right contracts (called bookings), which are limited by the technical capacities. The prices of these bookings are determined by the booking price floors set by the TSO plus a scarcity-based markup price.
-
(3)
The gas selling and buying firms then nominate entry and exit quantities on a day-ahead market. These nominations need to be balanced and are bounded above by the bookings. No other technical or physical restrictions are considered in this level.
-
(4)
The realized nominations are cost-optimally transported through the network by the TSO.
This setting is adequately captured by the four-level model developed in [21]. A peculiarity of the European gas market is the so-called robustness constraint. It requires that the TSO announces only those technical capacities that guarantee that every possibly occurring balanced nomination (i.e., entry and exit quantities match) that is restricted by the given set of bookings can indeed be transported through the network. This means, every such nomination needs to be physically and technically feasible. This leads to unnecessarily restrictive technical capacities, which themselves result in welfare losses (cf., e.g., [23]) on the one hand and in mathematically extremely challenging models (cf. [22, 38,39,40]) on the other hand. From a mathematical point of view, the robustness constraint can be seen as an adjustable robust constraint; see, e.g., [41, 42]. As shown in [23], an economically and algorithmically more reasonable approach is to require that only the actually realized nominations need to be transportable through the network. This is the setup we consider in what follows and we will come back to this aspect in the next section as well.
All papers published so far that tackle this four-level setup consider the deterministic case, i.e., exit nominations are purely driven by economic mechanisms that are modeled using inverse market demand functions to capture price elasticity. In what follows, we analyze the effects of uncertain demand. Before we do so in Sect. 3.2, we first recap the deterministic model from the literature in the next section.
3.1 A deterministic bilevel model
In Section 3 of [21] it is shown that the special structure of the four-level gas market model can be exploited to equivalently re-state it as a bilevel problem. In particular, the original second- and third-level problem, which model the profit- or surplus-maximizing bookings and nominations of the gas selling and buying firms, can be merged into a single level; see Theorem 5 in [21]. Moreover, the original fourth-level problem (i.e., the transportation level) can be merged into the original first level, in which the technical capacities and booking price floors are determined; see Theorem 7 in [21]. Before we state the resulting bilevel problem, we introduce some notation that is in line with [21, 23]. The gas network is modeled as a directed and connected graph \({G}= ({V}, {A})\) with nodes \({V}\) and arcs \({A}\). The node set is split into the set of entry nodes \({V}_+\subseteq {V}\) at which gas is supplied, the set of exit nodes \({V}_-\subseteq {V}\) at which gas is discharged, and the set of inner nodes \({V}_0\subseteq {V}\) without gas supply or withdrawal. Thus, \({V}= {V}_+\cup {V}_-\cup {V}_0\) holds. The model allows for multiple gas selling or gas buying firms \(i\in \mathcal {P}_u\) for \(u\in {V}_+\) or \(u\in {V}_-\), respectively. We denote the set of entry players by \(\mathcal {P}_+\mathrel {{\mathop :}{=}}\cup _{u\in {V}_+} \mathcal {P}_u\) and the set of exit players by \(\mathcal {P}_-\mathrel {{\mathop :}{=}}\cup _{u\in {V}_-} \mathcal {P}_u\). We consider multiple time periods \(t\in T\) with \(\left| T\right| < \infty \) of gas trading and transport and model the rational behavior of gas buying firms \(i\in \mathcal {P}_-\) based on linear inverse market demand functions \(P_{i, t}(q) = a_{i,t} - b_{i,t} q\) with \(a_{i,t}>0, b_{i,t} > 0\); see [43] for the economic background.Footnote 1 Further, we characterize gas selling firms using pairwise distinct variable costs of production \(c^\mathrm {var}_{i} > 0\), \(i\in \mathcal {P}_+\). When abstracting from the above mentioned robustness constraint, the bilevel reformulation of the four-level model from [21] is given by
where the lower level reads
In the upper level (18), the TSO specifies technical capacities \(q^\mathrm {TC}_u\) and booking price floors \(\underline{\pi }^\mathrm {book}_u\) for every entry and exit node \(u\in {V}_+\cup {V}_-\). The TSO uses the booking price floors to cover the transportation costs; see the bilinear constraint (18c). This constraint involves the bookings \(q^\mathrm {book}\), which are, together with the nominations \(q^\mathrm {nom}\), outcome of the lower-level problem; see Constraint (18e). The actual nominations are transported in a cost-optimal way through the network. To be more specific, the squared nodal pressures \(\pi \) and mass flows \(q\) on the arcs resulting from the nomination need to fulfill the technical network limitations denoted by \(\mathcal {F}(q^\mathrm {nom})\) such that the transportation costs \(c^\mathrm {trans}\) are minimized. The generic notation in Constraint (18d) allows to use various transportation models. In this paper, we use the modeling and notation that is used in [23]. For an arc \(a= (u, v)\), \(q_{a, t} > 0\) denotes the mass flow in the direction of the arc, i.e., from \(u\) to \(v\), and \(q_{a, t} < 0\) denotes flow in the opposite direction. The mass flow has to satisfy given bounds of the pipes:
In addition, we model mass balance at every node of the network using the constraints
where \(\delta ^{\text {out}}_u\) and \(\delta ^{\text {in}}_u\) represent outgoing and incoming edges at node \(u\), respectively. Moreover, the pressure loss law
couples the mass flows \(q_{a, t}\) on each arc with the squared pressures \(\pi _{u,t}, \pi _{v,t}\) at the incident nodes. The squared pressures are bounded by the squared pressure bounds
The function \(\Phi _a\) in (20) denotes the pressure loss function for arc \(a\in {A}\). In this paper, we make the following assumption, which is also used in [23].
Assumption 3
The pressure loss function \(\Phi _a\) is linear for all \(a\in {A}\).
We discuss this simplification of the physics model at the end of this subsection.
The transportation costs \(c^\mathrm {trans}\) generally arise from compensating pressure losses via controllable elements. However, in this paper, we only consider passive networks without controllable elements such as compressors or control valves. We also discuss the simplification of considering passive networks at the end of this subsection in more detail. To mimic transportation costs in our passive network model, we penalize squared pressure losses on all arcs of the network, i.e.,
where \(c^\mathrm {trans}_t>0\) is a given parameter and \(a=(u,v)\in {A}\), \(t\in T\). Note that the squared pressures \(\pi _{u,t}\), \(\pi _{v,t}\) are coupled to the mass flow \(q_{a,t}\) via Constraint (20).
In the lower-level problem (19), gas buyers and sellers choose their booking and nomination quantities to maximize their individual profit, i.e., each player solves individual maximization problems. It is shown in [21] that under the assumption of perfect competition, this is equivalent to the welfare maximizing problem (19), which consists of the merged second and third level of the original four-level model. We briefly shed some more light on the derivation of Problem (19). In the second level of the original four-level model, each player \(i\) chooses the bookings \(q^\mathrm {book}_i\) to maximize the anticipated outcome that is realized after trade in the third level. Under the assumption of perfect competition, the individual second-level problems can be equivalently reformulated as the aggregated second-level problem
in which the bookings of the players are bounded by the technical capacities that are set by the TSO in the upper level; see Constraint (19b). The nominations \(q^\mathrm {nom}_{i,t}\) that appear in the objective function (19a) result from the solution of the third level, where the actual interaction of gas buyers and sellers takes place.
In this third level, all players choose nominations restricted by their bookings (determined in the second level) to maximize their individual profit or surplus with respect to equilibrium market prices \(\pi ^\mathrm {nom}_t\). Under the assumption of perfect competition, all players act as price takers and, consequently, every gas seller \(i\in \mathcal {P}_+\) maximizes the profit in every time period \(t\!\in \!T\) as follows:
Similarly, every gas buyer \(i\in \mathcal {P}_-\) maximizes its surplus in every time period \(t\in T\):
The endogenously resulting equilibrium market price \(\pi _t^\mathrm {nom}\) ensures that the shared market-clearing condition (19d) is satisfied in every time period \(t\in T\). It is shown in [21] that the nomination level can be modeled as a mixed nonlinear complementarity problem (MNCP) by stacking the first-order optimality conditions of all Problems (23) and (24) and by further adding the market-clearing constraint (19d). The market price \(\pi _t^\mathrm {nom}\) is then exactly the dual variable of the market-clearing condition (19d). In Theorem 3 of [21] it is shown that the resulting MNCP can be recast as an equivalent welfare maximization problem. Further, in Theorem 5 of [21], it is shown that when integrating this problem into the second-level problem (22), one obtains Problem (19).
Overall, the upper-level objective maximizes total welfare (18a), which consists of exit player utilities minus the costs of the entry players and the transportation costs of the TSO. Since the inverse demand functions \(P_{i, t}\) are linear, the exit player utilities are concave-quadratic. In addition, the nonsmooth absolute values that appear in the transportation costs can be linearized with additional binary and continuous variables and constraints, exactly like it is done in Section 4 in [23]. After this linearization, we maximize a concave-quadratic objective function over linear and bilinear constraints in the upper level. For fixed upper-level decisions, the lower level is a continuous and concave-quadratic maximization problem.
Remark 3
We extend this setting by integrating uncertain loads into the lower level (19) in the next section. However, this means adding a further complicating aspect to an already challenging model. In this light, we also want to discuss the simplifications that we made in the modeling of the deterministic model. First, we simplified the transportation model by imposing Assumption 3, i.e., by assuming a linear pressure loss function. Using various other transportation models, e.g., the Weymouth equation [44, 45] is possible but results in additional nonlinear constraints, leading to further nonconvexities in the upper level. Second, we abstract from controllable elements such as compressors and instead use the proxy (21) to account for transportation costs that are mostly driven by these controllable elements. Allowing for active instead of passive networks requires additional integer variables in the upper level. Thus, we would obtain a nonconvex mixed-integer nonlinear problem in the upper level. Third and finally, we also simplified the market mechanism by abstracting from the robustness constraint. This constraint states that every balanced nomination that fulfills the technical capacities must be guaranteed to be transportable by the TSO. In [23], a characterization of feasible bookings from [38] is used to obtain a tractable reformulation of the robustness constraint. This characterization is only valid for passive networks with linear transportation models. It is further reported that adding the robustness constraint results in a significant computational burden.
Overall, we abstract from all these aspects because the primary focus of this paper is on the handling of black-box constraints in the lower level; see also the next section in which we extend the deterministic lower level by chance constraints. As discussed in Sect. 2.2, a setting with black-box constraints in a bilevel lower-level problem is very challenging. Dropping any of the mentioned simplifications further complicates this already demanding setting even more.
3.2 A probabilistic extension
We now extend the deterministic setting of the last section to capture demand uncertainties. In reality, exit players \(i\in \mathcal {P}_-\) nominate quantities \(q^\mathrm {nom}_{i,t}\) without exactly knowing the actual load \(\xi _{i,t}\) that they need to cover, say one day ahead. We assume that the load vector \(\xi =(\xi _{i,t})_{i\in \mathcal {P}_-, t\in T}\) has a log-concave cumulative distribution function. Thanks to Prékopa’s theorem [46, Theorem 4.2.1.], this is in particular true if the distribution has a log-concave density. It is well-known that many prominent multivariate distributions do have a log-concave distribution, e.g., (for any choice of parameters) Gaussian distributions and the uniform distribution on convex and compact sets, as well as (for a restricted range of parameters) Dirichlet, Gamma, Wishart, and log-normal distributions. In the following, we will assume that \(\xi \) obeys a multivariate Gaussian distribution, i.e., \(\xi \sim \mathcal {N}\left( m,\Sigma \right) \). We further assume that the TSO is interested in a fail-safe network and imposes a fee \(\mu \) on the exit players \(i\in \mathcal {P}_-\) to ensure that the realized loads are covered up to a specified safety level \(p\in [0,1]\). We model this by the following joint (over all times and exit players) probabilistic constraint
which we add to the lower-level problem (19). The left-hand side of (25) is nothing but the cumulative distribution function of \(\xi \) evaluated at the vector \(q_-^\mathrm {nom}\) of nominations at all exits and times. The mentioned log-concavity of this Gaussian distribution function implies that the log-transformed probabilistic load coverage constraint
is convex. Consequently, adding Constraint (26) to the lower-level problem (19) yields the extended lower-level problem
which is still convex.
In summary, we obtain the following probabilistic bilevel problem
Remark 4
Let us finally discuss in detail the economic interpretation of the probabilistic lower-level problem (27). We argued above that Constraint (25) models a situation, in which the TSO forces the exit players to fulfill a given safety level with respect to the actual loads \(\xi \) by imposing a sufficiently large fee \(\mu \). Thus, the maximization problem (24), which each gas buyer \(i\in \mathcal {P}_-\) solves in the third level, changes to
One can think of the fee \(\mu \) as the “price of the stochasticity”. Similarly to the deterministic case, we can again use the first-order optimality conditions to model the nomination level as an MNCP. In addition to the shared market-clearing condition (19d), we also need to add the further “clearing condition”
to the MNCP, which couples the fee \(\mu \) with the log-transformed chance constraint (26). The dual variable of the latter then corresponds to the fee \(\mu \). As in the deterministic case, we can recast the resulting MNCP as an equivalent maximization problem (given that the latter satisfies Slater’s constraint qualification). When integrating this problem into the second-level problem, we obtain Problem (27).
3.3 A tailored solution approach
The probabilistic bilevel model (28) is a problem in which the lower level is convex. However, we do not have a closed-form expression of the log-transformed chance constraint (26), which is part of the lower-level constraint set. In order to circumvent this difficulty, we tailor the solution approach for bilevel problems with black-box constrained lower levels from Sect. 2.3 to the specific setting of Problem (28). We therefore first give some more details on the log-transformed chance constraint (26).
The probability function h in (26) plays the role of the black-box constraint function b in (2). We are going to check next the satisfaction of Assumption 1 for h. By (26), we have that
where \(\Phi \) is a multivariate Gaussian distribution function. The basic requirement in Assumption 1 that h is convex, has already been verified above using the log-concavity of \(\Phi \). Proceeding with the three items of Assumption 1, the first two items claim the possibility to evaluate h along with its gradient at any given argument y. By (31), this amounts to evaluate \(\Phi \) and \(\nabla \Phi \) at any given nomination vector \(q_{-}^\mathrm {nom}\). As a multivariate Gaussian distribution function, \(\Phi \) is given as a multivariate integral. Therefore, one has no access to a closed formula but is constrained to sufficiently precise approximations. An efficient way to get fairly precise values of \(\Phi \) has been described and implemented by Genz [47].Footnote 2 Moreover, it is well-known (see, e.g., [48, Lemma 1]) that the partial derivatives of \(\Phi \) can be represented as
where \(m_i,\Sigma _{ii}\) are the corresponding components of the parameters \(m,\Sigma \) of the given Gaussian distribution and \({\tilde{\Phi }}\) is another Gaussian distribution function evaluated in one dimension less. Here, the parameters of \({\tilde{\Phi }}\) can be explicitly derived from the parameters \(m, \Sigma \) of \(\Phi \) and, similarly, the argument \({\tilde{u}}\) is an explicit function of the original argument u. Hence, one and the same code (as the one by Genz) may serve to provide values and gradients of the cumulative distribution function at any argument. This provides items (1) and (2) of Assumption 1. Another possibility to do so, and which we are using here, is the application of the spheric-radial decomposition of Gaussian random vectors, which applies not just to probabilities of random inequality systems with random left-hand side as in (25) but to arbitrary structures, preferably convex in the random vector. Values and gradients of the probability function can be determined simultaneously by evaluating certain spherical integrals. This approach has been intensively analyzed theoretically (see, e.g., [49, 50]) and successfully applied in practice [51].
It remains to justify item (3) of Assumption 1. By (26), we have that
where \(\Phi \) is a multivariate Gaussian distribution function. As such it is continuously differentiable and strictly positive, implying that
Since Assumption 1 refers in particular to all x, y satisfying the general constraint \(g(x,y)\!\le \! 0\), this implies in the concrete problem (28) the constraint \(q_{-}^\mathrm {nom}\ge 0\); see (19c). From the fact that distribution functions are non-decreasing with respect to the partial order of the space they are defined on, we infer that
Combining this with (32) and (33), one arrives at the desired boundedness property
where \(\Sigma ^{\min }\mathrel {{\mathop :}{=}}\min _i\Sigma _{ii}\) and where we used that \({\tilde{\Phi }}\) as a distribution function satisfies the relation \({\tilde{\Phi }}\le 1\).
Overall, the probabilistic bilevel problem (28) matches the setting of the general bilevel problem (1), the Assumptions 1 and 2, as well as its extensions as discussed in Remark 2 such that we obtain \(\delta \)-feasible points by applying Algorithm 1. The main steps in every iteration of Algorithm 1 are
-
(1)
to derive a tighter linear outer approximation \((E^r, e^r)\) and
-
(2)
to solve Problem (7) to global optimality.
In our setting, we can achieve the former by a classic cutting-plane approach [30]. In iteration \(r\), we use the point \(q^{r}_{-} = (q^\mathrm {nom}_{-})^{r}\), which is part of the solution provided by Algorithm 1 in iteration \(r-1\), as the linearization point. By exploiting that for convex functions, the first-order Taylor approximation is a global underestimator, we derive the cut
Thus, in iteration \(r\), we construct \(E^{r+1}\) by adding the row \(\nabla _{q^\mathrm {nom}_{-}}(q_{-}^{r})^\top q^\mathrm {nom}_{-}\) to \(E^r\) and construct \(e^{r+1}\) by adding the entry \(\nabla _{q^\mathrm {nom}_{-}}(q_{-}^{r})^\top q_{-}^{r} - h(q^{r}_{-})\) to \(e^r\). Consequently, we obtain the relaxation
of the lower-level problem (27) by replacing Constraint (26) with the Constraints in (35e).
As already discussed for the general bilevel problem (1), if Assumption 2 holds, then Task (2) from above can be achieved by replacing lower-level optimality, i.e., Constraint (7d), with the KKT conditions of the relaxed lower-level problem (6). In this way, we obtain an algorithmically tractable reformulation of Problem (7). For our application, the KKT conditions of the relaxed lower-level problem (35) consist of primal feasibility (35b–35e), the stationarity conditions
the complementarity conditions
and the nonnegativity conditions
Altogether, in every iteration of Algorithm 1 applied to Problem (28), we have to solve the problem
This problem contains several difficulties. First, although the primal constraints (35b–35e) of the relaxed lower-level problem are linear, the KKT complementarity constraints (36) are nonconvex. Fortunately, they can be expressed as a set of mixed-integer linear constraints by introducing additional binary variables and sufficiently large big-M values; see [52]. For a linear constraint \(a^\top x \le b\) and its dual variable \(\lambda \ge 0\), the complementarity condition \(\lambda (b - a^\top x) = 0\) can be linearized as follows:
This linearization is only correct, if the values \(M_p\) and \(M_d\) are large enough. On the other hand, too large values are also not desirable because the may cause numerical instabilities. In practice, these values are often derived heuristically, which may result in suboptimal solutions; see [53]. In fact, finding correct big-Ms may in general be as hard as solving the original bilevel problem [54]. Sometimes, however, problem-specific knowledge can be used to obtain correct big-M values; see, e.g., [22, 55, 56]. For the deterministic model that we discussed in Sect. 3.1, valid big-M values are derived from economic relationships in [23]. In the probabilistic setting, economic relationships are disturbed. Still, we can derive valid big-Ms in a similar way as it is done in [23] by exploiting technical limits of the network. For the only Lagrangian multiplier that does not appear in the deterministic setting, we derive a valid upper bound in Appendix B.
In addition, we are facing the bilinear upper-level constraint (18c). Hence, after having obtained the reformulation (40) of the complementarity conditions (37), we need to solve a mixed-integer maximization problem with a concave-quadratic objective function over linear and bilinear constraints in every iteration of Algorithm 1. Such problems can be solved by modern global solvers such as Gurobi, which tackle bilinear constraints by spatial branching [57]. We highlight that by design of spatial branching, a solution of Problem (39) fulfills Constraint (18c) only up to a pre-specified solver tolerance \(\delta _G>0\). Consequently, the solution we obtain from Algorithm 1 is a \((\delta _G,0,\delta _b,0)\)-feasible point of Problem (28); see also Remark 2.
Finally, we show how we can exploit structural properties of the specific model at hand to extend Algorithm 1. The extended variant is capable of computing a tight upper bound on the optimal objective function value of Problem (28) such that we get an ex-post guarantee regarding the optimality gap of the \(\delta \)-feasible solution obtained by Algorithm 1. To this end, we compare the KKT conditions (36–38) of the relaxed lower-level problem (35) with the KKT conditions of the original probabilistic lower level (27). The latter are given by primal feasibility (19b–19d) and (26), KKT stationarity (36a), (36c), and
KKT complementarity (37a–37c) and (30), as well as KKT nonnegativity conditions (38). We notice two differences when comparing the two sets of KKT conditions. First, instead of the single complementarity condition (30), we obtain the set of complementarity conditions (37d). Second, we note that in the stationarity condition (36b) we approximate the product \(\nabla _{q_{i,t}^\mathrm {nom}} h(q_{-}^\mathrm {nom}) \mu \) that appears in (41) by the sum \(\sum _{j=1}^{r} \nabla _{q_{i,t}^\mathrm {nom}}h(q^j_{-}) \mu _j\). As a consequence, the single-level problem (39) that we solve in every iteration \(r\) of Algorithm 1 (applied to Problem (28)) is neither a relaxation of Problem (28) nor is Problem (39) in iteration \(r\) a relaxation of Problem (39) in iteration \(r+ 1\). This is in line with the previous discussions in Sects. 2.2 and 2.3. However, by omitting the Constraints (36b), (37d), and (38c) from Problem (39), we obtain the desired relaxation.
Lemma 1
For every \(r\in \mathbb {N}\), the problem
is a relaxation of the probabilistic bilevel problem (28). In addition, Problem (42) in iteration \(r\) is a relaxation of Problem (42) in iteration \(r+1\).
The lemma follows directly from the construction of the problems. We note that Problem (42) relates to relaxing the optimal response of the exit players \(i\in \mathcal {P}_-\). For general bilevel problems, relaxing the optimality of the lower-level problem may result in weak bounds on the optimal objective value of the bilevel problem. In our application, however, we observe that the objective functions (18a) and (19a) of the two levels are rather aligned. In fact, the only difference is that in the upper level, we account for the transportation costs \(\sum _{t\in T}\sum _{a\in {A}}c^\mathrm {trans}(q_{a,t})\) of the TSO and in the lower level, we account for the booking costs \(\sum _{u\in {V}_+\cup {V}_-}\sum _{i \in \mathcal {P}_u} \underline{\pi }_u^\mathrm {book}q_i^\mathrm {book}\) of the players. These terms are forced to be equal by the upper-level constraint (18c). Thus, our working hypothesis is that relaxing the optimality of exit players as it is done in Problem (42) still yields a good approximation of the optimal response of the exit players. We thus expect that the bounds obtained by Problem (42) are rather tight. We solve Problem (42) iteratively as described in Algorithm 2.

Essentially, this directly applies Kelley’s cutting-plane approach [30] to the single level problem (42). Since the hypothesis is that the obtained bound is tight, we also expect that the cuts obtained in Algorithm 2 are useful for the original problem.
In practice, we thus proceed as follows. We invoke Algorithm 2 until it converges. We store the bound \(\bar{\varphi }^{\text {u}}\) and initialize \((E^0,e^0)\) in Algorithm 1 with all inequalities (35e) that we generated in Algorithm 2. This corresponds to extending Problem (42) to Problem (39), which we solve in every iteration of Algorithm 1. If Algorithm 1 then terminates with a \(\delta \)-feasible point of Problem (28), we compute the gap
which gives an ex-post optimality certificate. We analyze the quality of this gap in more detail in the next section.
3.4 Numerical study
In this section, we illustrate the proposed approach using the example of a specific instance of the probabilistic gas market model introduced in Sect. 3.2. We first give details on this instance, before we evaluate the approach from a computational point of view. Finally, we interpret the results that we obtain for various probability levels of the chance constraint.
3.5 Physical and economic setup
For our analysis, we consider a network with eleven nodes as shown in Fig. 1.

Gas network considered in the numerical study with variable costs \(c^\mathrm {var}_i\) (in EUR/(1000 Nm\(^{3}\)/h)) of entries, slopes \(b_i\) (in EUR/(1000 Nm\(^{3}\)/h)\(^{2}\)) of exits, and length \(L_a\) (in km) of pipes
Three of the nodes are entries at which gas is injected to the network, three others are exits at which gas is withdrawn from the network, and the remaining nodes are so-called inner nodes. The nodes are connected by eleven arcs and the network contains one cycle. The length \(L_a\) of each pipe is specified in Fig. 1. In addition, we assume an equal diameter \(D_a= {0.5}\,{\mathrm{m}}\), roughness \(k_a= {0.1}\,{\mathrm{mm}}\), and capacities \(q^\pm _a= \pm {266}{\mathrm{kg}\,\mathrm{s}^{-1}}\) for all pipes \(a\in {A}\). With respect to the flow model, we follow [23]. This means, we consider stationary gas flow, i.e., we abstract from temporal dependencies and only consider horizontal pipes. In this setting, we can use the pressure loss function
see, e.g., [45], in which the constant \(c = {340}\,{\mathrm{m}\mathrm{s}^{-1}}\) denotes the speed of sound in natural gas. The friction coefficient \(\lambda _a\) can be approximated by the formula of Nikuradse; see [45]:
Equation (43) is a suitable simplification of gas flow physics but is still nonlinear. In order to arrive at a linear approximation, see Assumption 3 and Remark 3, we replace \(\left| q_a\right| \) by a mean flow \(q^\text {mean}_a= {100}\,{\mathrm{kg}\,\mathrm{s}^{-1}}\). Again, exactly as done in [23], we set \(c^\mathrm {trans}_t=1\).
For all inner nodes \(u\), we have lower and upper pressure bounds of \({15}\,{\mathrm{bar}}\) and \({140}\,{\mathrm{bar}}\). At all entries we have a lower pressure bound of 20 bar. Further, at Entry 1 and Entry 2 we have an upper pressure bound of 80 bar, and at Entry 3 we have 160 bar. At Exit 1, Exit 2, and Exit 3, we have lower pressure bounds of 20 bar, 10 bar, and 5 bar, and all upper pressure bounds are set to 120 bar. We note that the pressure bounds are rather large such that the network is not very restrictive. The reason behind this choice is that we want to analyze the effect of uncertain loads. To this end, we analyze various choices of \(p \in [0,1]\) in the chance constraint (25). Hedging against the uncertainty increases nominated quantities, especially for p close to 1. Assuming large pressure bounds prevents technical infeasibilities that may otherwise result from large nominations.
In our example, we consider one player at each of the entry and exit nodes and \(\left| T\right| \!=\!12\) time steps, which refer to the months of a year. We thus set the initial willingness to pay, which corresponds to the intercepts \(a_{i,t}\), higher in winter months than in summer months. For a fixed time step \(\bar{t}\), fluctuations of the intercepts \(a_{i,\bar{t}}\) across the players \(i\in \mathcal {P}_-\) are rather small. We specify the exact choices for \(a_{i,t}\) in Table 2 in the appendix. In contrast to the intercepts, we assume that the price elasticity, i.e., the slopes \(b_{i,t}\) of the exit players, are constant over time, and specify \(b_i= b_{i,t}\) in Fig. 1. Exit 2 has a rather elastic demand, while the demand of Exit 3 is the least elastic. For the gas sellers, we set the variable costs to be constant over time as specified in Fig. 1. Entries 1 and 2 have similar variable costs, while Entry 3 has a significantly lower variable cost.
The vector \(\xi \) of loads at the exits is random and we assume that it follows a multivariate Gaussian distribution \(\xi \sim \mathcal {N}\left( m,\Sigma \right) \) with mean vector m and covariance matrix \(\Sigma \). In reality, also other types of distributions (e.g., log-normal, uniform, discrete) and mixtures thereof may be relevant [58, Chapter 13]. When specifying the parameters of this distribution, we do not rely on statistical data analysis of a concrete real-life network. We rather follow the idea that the mean vector of loads represents the equilibrium exit nominations for the deterministic bilevel model from Sect. 3.1, thus modeling an elastic demand, which changes only slowly over time. Hence, our mean load is—among other parameters—a consequence of the inverse demand functions \(P_{i,t}\) as specified in Table 2. For real-world problems, one would rather solve an inverse problem and calibrate the inverse demand functions in a way to derive a specific mean vector as a solution of the deterministic bilevel problem. We specify our actual choices of m and \(\Sigma \) in the appendix.
The load vector \(\xi \) itself can be understood as a random inelastic deviation from its mean, which is more relevant on the shorter time scale of a day-ahead market. This scattering around the mean is defined by the covariance matrix. In order to fix the covariance matrix, it is sufficient to define standard deviations of the single time- and node-components as well as correlations between these components. Orientation for both features can be obtained from general gas load data as analyzed in [58]. As a consequence, we built up our covariance matrix in a fairly heuristic way (zero correlation between exits at different times, common positive value of correlation between exits at fixed time, common relative standard deviation between exits, but constant over time). Clearly, the dimension of the random vector (or its multivariate distribution) is the same as that of the vector of exit nominations, namely 36 (3 exits combined with 12 time steps). All data required to reproduce our experiments are publicly available; see [59].
3.6 Computational analysis
In this section we briefly evaluate the tailored solution approach presented in Sect. 3.3 from a computational perspective. We implemented the approach in Python 3.7 and used Gurobi 9.1.1 to solve all involved optimization problems. All computations have been carried out on a compute cluster; see [60] for details on the installed hardware.
In order to have a benchmark, we first consider the deterministic model from Sect. 3.1, which can be solved by global solvers out-of-the-box after a classic single-level reformulation, e.g., using the KKT conditions of the lower level, has been applied. This model has 930 variables, thereof 282 binaries, and 1260 constraints. It is solved in 1.17 s and can thus be considered easy.
We now turn to the probabilistic model for various probability levels p of the chance constraint (25). The model sizes increase slightly compared to the deterministic model, because we obtain a new complementarity condition in every iteration of the algorithm. Since we linearize the complementarity conditions, we particularly obtain an additional binary variable in every iteration.
For our computations, we set \(\delta _b=10^{-3}\), i.e., we terminate Algorithm 1 and 2 if \(h(q^\mathrm {nom}_{-}) \le 10^{-3}\) holds. Preliminary results showed that it is very important to equip Algorithm 2 with initial cuts. The reason is that without an initial cut, we obtain a solution from the bounding problem (42), for which it is very likely that \(\mathbb {P}\left( \xi _{i,t}\le q_{i,t}^\mathrm {nom}\text { for all }i\in \mathcal {P}_-,\ t\in T\right) \) is close to zero. Consequently, we would linearize the chance constraints at the tails of the Gaussian distribution, where the gradient of the chance constraint is almost zero. For the log-transformed chance constraint (26), this results in partial derivatives going to infinity such that we cannot construct the cuts (34). The situation can be resolved by adding initial valid inequalities that bound the nominations appropriately from below. A straightforward way to achieve this is to exploit the p-quantile \(Q_{p}\) of the standard Gaussian distribution as follows:
These “quantile cuts” correspond to individual p-level constraints on load coverage for all exit players and for all time steps separately, i.e.,
which are clearly valid for the original chance constraint. Another approach is to add a single first-order cut (34) at a point \({\tilde{q}}_{-}^\mathrm {nom}\) with
for a given \(\delta _p > 0\). We can find such a point, e.g., via bisection. The latter approach turned out to be very effective in our computations such that we apply it by default.
In Table 1, we present the numbers of iterations and runtimes in total and separated for the three phases of our tailored algorithm, i.e., bisection to find an initial cut, the bounding procedure Algorithm 2, and the feasibility procedure Algorithm 1.
We observe several aspects in Table 1. First, in general, the larger fraction of the total iterations and runtimes is spent in the bounding procedure, while mostly only a few iterations are needed afterward to compute a \(\delta \)-feasible point. However, the bounding problems are rather cheap such that we cannot say that the bounding phase requires more runtime than the feasibility phase. Second, we cannot observe a relationship between the p-level and the total runtime, i.e., in general a larger p-level does not result in longer runtimes. The longer runtimes for \(p = 0.98\) and \(p=0.99\) are caused by a single iteration of Algorithm 1 that takes much more time than every other iteration. However, we do not see any explanation of these “outlier iterations” in terms of larger values of p. Third, we spent a significant amount of the runtime to find an initial cut via bisection. We already discussed that initial cuts are crucial for the applicability of the approach. However, the quantile cuts (44) can be added for free such that it appears to be a reasonable option to add these cuts. We shed some more light on this by discussing the evolution of the p-level over the iterations of our approach for both cases, i.e., using quantile cuts or running an initial bisection. By p-level, we mean the value of the original chance constraint (25) when it is evaluated at the solution of the respective iteration. Figure 2 demonstrates this comparison exemplary for the instance \(p=0.90\).

Evolution of the p-level and the ex-post computed gap over the iterations for the probabilistic model with \(p=0.9\)
We see that we start with a much higher p-level when we equip our approach with the bisection phase. This results in a faster convergence to the desired p-level. Ultimately, this reduction in iterations overcompensates the expensive bisection. This justifies to use the bisection instead of the quantile cuts.
Another conclusion from Fig. 2 can be drawn with respect to the usefulness of the cuts generated in the bounding phase. The vertical lines in Fig. 2 mark the end of the bounding phase. While it takes several iterations in the bounding phase to finally arrive at the desired p-level, we remain close to this p-level when entering the feasibility phase. This behavior can be observed for all tested instances and means that the cuts generated in the bounding phase are very useful in Algorithm 1, most likely because they linearize the log-transformed chance constraint around the \(\delta \)-feasible point to which we converge.
We now turn back to Table 1 and discuss the most important observation. Except \(p=0.99\), for which we terminate with a gap of \({0.187}\,\%\), we always terminate with a negligibly small gap that allows to consider the computed solutions to be approximate optimal. Thus, the computational results allow to use our tailored approach from Sect. 3.3 in a case study to analyze and interpret the effects of uncertain loads on economic quantities like nominations and total welfare.
3.7 Case study
In the following, we discuss the outcomes of our computations for different constraints on load coverage. The first instance is defined as the solution of the nominal problem without any load coverage constraint. As noted before, this solution corresponds to mean exit nominations. The second instance imposes individual 90 %-constraints on load coverage for all exit players and for all time steps as it is done in Constraint (44), respectively (45). As discussed, the advantage of this quantile-approach relies on the fact that it is as easy to obtain as the nominal solution, where the lower bound is just zero. The drawback is that these solutions—while yielding robust load coverage for each exit player and in each time step separately, may be far from guaranteeing robust load coverage for all exit players and times simultaneously. This observation—which will be supported by our results below—is not surprising because only a very restricted part of the underlying multivariate distribution is taken into account, i.e., no covariances between load components are considered. Our main interest is about the third instance, namely the joint (over all times and exits) probabilistic load coverage, which results in the probabilistic constraint (25). In contrast to the quantile-based solution, robust load coverage can be achieved. As seen in the last section, the robust solution of the chance-constrained problem comes at the cost of an additional computational burden. In the following we evaluate the impact of different probability levels \(p\in \left[ 0,1\right] \) as detailed in Table 1.

Time-dependent profiles of nominations at the three exits for the mean vector, the 0.9-quantile constraint and the probabilistic constraints with varying safety levels
Figure 3 shows the time-dependent profiles of nominations at the three exits for the mean vector, the 0.9-quantile constraint and the probabilistic constraints with safety levels from the indicated range. It can be observed how much nominations have to be increased in order to satisfy the desired safety. It can be seen that, while the mean profiles are just scaled/shifted versions of each other, which actually is a consequence of keeping the slopes of the inverse demand functions \(P_{i,t}\) in our model time-invariant, the other nomination profiles change their shape over time and exits.
Figure 4 provides a plot of total welfare (18a) and of the fee \(\mu \) for uniform load coverage occurring in (29) (also interpreted as the “price of stochasticity”) as a function of the chosen probability level. We reiterate that in our iterative solution approach, \(\mu \) is approximated by a series of \(\mu _j\). However, we can compute the “real” fee \(\mu \) ex-post via the KKT stationarity condition (41) of the original probabilistic lower-level problem (27). It can be seen that the loss of welfare is moderate when increasing the safety towards 0.9, whereas it severely decreases when driving safety further towards 1. A similar pattern is observed for the price of uniform load coverage. These diagrams suggest that in the given example, 90 % safety of load coverage would represent a reasonable compromise between the TSO’s interest in nominations covering the random load on the one hand and the welfare losses induced by this safety of load coverage.

Total welfare and price of load coverage as functions of safety level
The probabilistic effect of exit nominations is illustrated in Fig. 5: The black thick curves correspond to nominations according to mean (top), 0.9-quantile solution (middle), and probabilistic constraint for \(p=0.9 \) (bottom). In order to visualize load coverage by these nomination profiles, we simulated ten scenarios for load profiles according to the given multivariate Gaussian distribution. Note that each scenario is related to all exits and all times. Hence, for instance the three thin blue curves in the lower diagrams correspond to one scenario. Nominating according to the mean load not surprisingly yields that at each exit and each time the load of approximately one half of the scenarios is covered by the nomination. On the other hand, each of the ten scenarios is not covered by the nomination at some exit at some time (such scenarios not uniformly covered by the nomination are colored in the diagrams). This means that the TSO has to expect almost surely uncovered load in the network over the considered time horizon. In contrast, the quantile-based exit nomination guarantees at each exit and each time separately a load coverage for all but one (on average) scenarios, which corresponds well to the chosen 90 %-quantile. However, uniform load coverage is as poor as for the mean-based nomination: none of the ten scenarios is uniformly covered for all exits and times (i.e., all curves are colored). Things change when imposing a joint chance constraint: here, nine out of ten scenarios are uniformly covered by the corresponding nomination profile. Only one scenario (colored in blue) remains unsatisfied at Exits 1 and 3 at time 2. We note that the numbers of violating scenarios is random itself. Thus, repeating the analysis with a new sample of load scenarios might result in slightly different numbers. However, on average, it will reflect the true probabilities of violation. For instance, in a sample of 100 load scenarios (which we do not illustrate here for reasons of visibility), we found 100, 89, and 12 violating scenarios for the mean, the quantile, and the joint probabilistic solution, respectively.

Nomination profiles of Exit 1 (left), Exit 2 (middle) and Exit 3 (right) for mean (top), 0.9-quantile-solution (middle), and probabilistic constraint (\(p=0.9\)) (bottom) along with ten simulated load scenarios (colored: violating; gray: feasible)
Finally, the nomination counterparts of entries are plotted in Fig. 6 for six different safety instances.

Profiles of entry nominations for selected safety requirements
The arrangement in these diagrams is different from that of the exits in Fig. 3: Here, we opposed the three entries within each diagram. Three major observations can be made.
-
(1)
The sum of entry nominations increases with increasing safety required.
-
(2)
Entries 2 and 3 exhibit an almost constant time profile in all instances.
-
(3)
Both entries change their role from inactive to strongly active when increasing the safety level.
The first observation is not surprising since exit nominations increase as well and both entry and exit nominations have to be balanced. The second observation is due to technical limitations in combination with economic reasons. The maximum throughput of the network is limited mainly by pressure bounds. The technical capacities are set to ensure that the pressure bounds are fulfilled. Entry 2 and 3 have lower variable costs compared to Entry 1 such that it economically makes sense to use as much gas as possible from these two entries. Since total demand in most cases exceeds the technical capacities at Entries 2 and 3, we observe an almost constant profile.
Finally, we turn to observation 3, which is the least intuitive. For low safety levels, the cheapest entry, Entry 3, is supplying a lot of gas. With higher safety levels, Entry 3 is substituted by the significantly more expensive Entry 2, until Entry 3 is driven out of the market entirely. One possible explanation for this behavior might be as follows. Whenever Entry 3 supplies large amounts of gas, the pressure loss over Pipe 2 results in a low pressure at Node 1; see Fig. 1. When the nominations increase, more gas has to be transported from left to right—in particular, more gas than Entry 3 is able to deliver due to technical limitations. Thus, Entry 2, the second cheapest producer, needs to step in to supply Exit 2 and 3. However, the low pressure at Node 1 forces Entry 2 to “send” gas over Pipe 11 (and thus over Pipe 3 and Pipe 5 to Node 4) to satisfy all pressure loss constraints. This results in very high transportation costs compared to “sending” gas directly via Pipe 7 to Node 4. Consequently, with higher overall nominations, it becomes more attractive for the TSO to shut down Entry 3 entirely, because its cheaper production is overcompensated by higher overall transportation costs. This underlines also the complicated interplay of physics and economics.
4 Conclusion
We considered bilevel optimization problems with convex lower levels that involve black-box constraints, i.e., constraint functions for which no closed form is available. To tackle such problems, we developed a cutting-plane algorithm that can compute approximate bilevel-feasible points. Afterward, we applied this method to a bilevel model of the European gas market in which we model uncertain gas loads via a joint chance constraint in the lower level. Since such a constraint cannot be stated in closed form, this setting fits the setup of a bilevel problem with a lower-level black-box constraint. Using further problem-specific techniques we can also show that the computed approximate feasible points are indeed approximate optimal as well, which allowed to analyze the sensitivity of welfare outcomes in dependence of the achieved safety level for load coverage.
The considered setting is a rather new sub-field in bilevel optimization. Thus, many aspects can be elaborated on further in the future. Let us sketch two of them. First, it might be interesting to study a bilevel setting in which the lower-level black-box also depends on the leader’s decision. In the context of chance constraints, this can be seen as a variant of decision-dependent uncertainty in the lower-level problem. Second, we are sure that other algorithmic approaches to bilevel problems with black-box constraints are possible and every algorithmic improvement will be beneficial for tackling relevant problems from practice.
Notes
Thus, we can replace the integrals that appear in the objective function (18a), and also later on in other objective functions, using the explicit quadratic expression for the integral.
Codes are available at http://www.math.wsu.edu/faculty/genz/homepage.
References
Hansen, P., Jaumard, B., Savard, G.: New branch-and-bound rules for linear bilevel programming. SIAM J. Sci. Stat. Comput. 13.5, 1194–1217 (1992). https://doi.org/10.1137/0913069
Vicente, L., Savard, G., Júdice, J.: Descent approaches for quadratic bilevel programming. J. Optim. Theory Appl. 81.2, 379–399 (1994)
Dempe, S., Kalashnikov, V., Pérez-Valdés, G.A., Kalashnykova, N.: Bilevel Programming Problems. Springer (2015). https://doi.org/10.1007/978-3-662-45827-3
Dempe, S.: Foundations of Bilevel Programming. Springer, Berlin (2002)
Kleinert, T., Labbé, M., Ljubic, I., Schmidt, M.: A survey on mixed-integer programming techniques in bilevel optimization. EURO J. Comput. Optim. (2021). https://doi.org/10.1016/j.ejco.2021.100007
Moore, J.T., Bard, J.F.: The mixed integer linear bilevel programming problem. Oper. Res. 38.5, 911–921 (1990). https://doi.org/10.1287/opre.38.5.911
Fischetti, M., Ljubic, I., Monaci, M., Sinnl, M.: On the use of intersection cuts for bilevel optimization. Math. Programm. 172, 77–103 (2018). https://doi.org/10.1007/s10107-017-1189-5
Xu, P., Wang, L.: An exact algorithm for the bilevel mixed integer linear programming problem under three simplifying assumptions. Comput. Oper. Res. 41, 309–318 (2014). https://doi.org/10.1016/j.cor.2013.07.016
DeNegre, S.T., Ralphs, T.K.: A branch-and-cut algorithm for integer bilevel linear programs. In: Operations Research and Cyber-infrastructure, pp. 65–78. Springer, Berlin (2009)
Fischetti, M., Ljubic, I., Monaci, M., Sinnl, M.: A new general-purpose algorithm for mixed-integer bilevel linear programs. Oper. Res. 65.6, 1615–1637 (2017). https://doi.org/10.1287/opre.2017.1650
Mitsos, A., Lemonidis, P., Barton, P.I.: Global solution of bilevel programs with a nonconvex inner program. J. Glob. Optim. 42.4, 475–513 (2008). https://doi.org/10.1007/s10898-007-9260-z
Mitsos, A.: Global solution of nonlinear mixed-integer bilevel programs. J. Glob. Optim. 47.4, 557–582 (2010). https://doi.org/10.1007/s10898-009-9479-y
Burtscheidt, J., Claus, M., Dempe, S.: Risk-averse models in bilevel stochastic linear programming. SIAM J. Optim. 30.1, 377–406 (2020). https://doi.org/10.1137/19M1242240
Burtscheidt, J., Claus, M.: Bilevel linear optimization under uncertainty. In: Dempe, S., Zemkoho, A. (eds.) Bilevel Optimization: Advances and Next Challenges, pp. 485–511. Springer, Berlin (2020)
Yanikoglu, I., Kuhn, D.: Decision rule bounds for two-stage stochastic bilevel programs. SIAM J. Optim. 28.1, 198–222 (2018). https://doi.org/10.1137/16M1098486
Pita, J., Jain, M., Tambe, M., Ordóñez, F., Kraus, S.: Robust solutions to Stackelberg games: addressing bounded rationality and limited observations in human cognition. Artif. Intell. 174.15, 1142–1171 (2010). https://doi.org/10.1016/j.artint.2010.07.002
Beck, Y., Schmidt, M.: A robust approach for modeling limited observability in bilevel optimization. Oper. Res. Lett. 49.5, 752–758 (2021). https://doi.org/10.1016/j.orl.2021.07.010
Wogrin, S., Pineda, S., Tejada-Arango, D.A.: Applications of bilevel optimization in energy and electricity markets. In: Dempe, S., Zemkoho, A. (eds.) Bilevel Optimization: Advances and Next Challenges, pp. 139–168. Springer, Cham (2020)
European Parliament and Council of the European Union. Directive 2009/73/EC of the European Parliament and of the Council concerning common rules for the internal market in natural gas and repealing Directive 2003/55/EC. (2009)
European Parliament and Council of the European Union. Regulation No 715/2009 of the European Parliament and of the Council on conditions for access to the natural gas transmission networks and repealing Regulation No 1775/2005. July 13 (2009)
Grimm, V., Schewe, L., Schmidt, M., Zöttl, G.: A multilevel model of the European entry-exit gas market. Math. Methods Oper. Res. 89.2, 223–255 (2019). https://doi.org/10.1007/s00186-018-0647-z
Schewe, L., Schmidt, M., Thürauf, J.: Global optimization for the multilevel European gas market system with nonlinear flow models on trees. J. Glob. Optim. (2021). https://doi.org/10.1007/s10898-021-01099-8. (Forthcoming)
Böttger, T., Grimm, V., Kleinert, T., Schmidt, M.: The cost of decoupling trade and transport in the European entry-exit gas market with linear physics modeling. Eur. J. Oper. Res. (2021). https://doi.org/10.1016/j.ejor.2021.06.034
Patriksson, M., Wynter, L.: Stochastic mathematical programs with equilibrium constraints. Oper. Res. Lett. 25.4, 159–167 (1999). https://doi.org/10.1016/S0167-6377(99)00052-8
Shapiro, A., Xu, H.: Stochastic mathematical programs with equilibrium constraints, modelling and sample average approximation. Optimization 57.3, 395–418 (2008). https://doi.org/10.1080/02331930801954177
Henrion, R., Römisch, W.: On M-stationary points for a stochastic equilibrium problem under equilibrium constraints in electricity spot market modeling. Appl. Math. 52.6, 473–494 (2007). https://doi.org/10.1007/s10492-007-0028-z
Ivanov, S.: A bilevel stochastic programming problem with random parameters in the follower’s objective function. J. Appl. Ind. Math 12.4, 27–45 (2018). https://doi.org/10.1134/S1990478918040063
Yang, J., Zhang, M., He, B., Yang, C.: Bi-level programming model and hybrid genetic algorithm for flow interception problem with customer choice. Comput. Math. Appl. 57.11, 1985–1994 (2009). https://doi.org/10.1016/j.camwa.2008.10.035
Pramanik, S., Banerjee, D.: Chance constrained quadratic bi-level programming problem. Int. J. Modern Eng. Res. 2.4, 2417–2424 (2012)
Kelley, J.E., Jr.: The cutting-plane method for solving convex programs. J. Soc. Ind. Appl. Math. 8.4, 703–712 (1960). https://doi.org/10.1137/0108053
Duran, M.A., Grossmann, I.E.: An outer-approximation algorithm for a class of mixed-integer nonlinear programs. Math. Program. 36.3, 307–339 (1986). https://doi.org/10.1007/BF02592064
Fletcher, R., Leyffer, S.: Solving mixed integer nonlinear programs by outer approximation. Math. Program. 66.1, 327–349 (1994). https://doi.org/10.1007/BF01581153
Locatelli, M., Schoen, F.: Global optimization: theory, algorithms, and applications. SIAM (2013). https://doi.org/10.1137/1.9781611972672
Macal, C.M., Hurter, A.P.: Dependence of bilevel mathematical programs on irrelevant constraints. Comput. Oper. Res. 24.12, 1129–1140 (1997). https://doi.org/10.1016/S0305-0548(97)00025-7
Dempe, S., Lohse, S.: “Dependence Of Bilevel Programming On Irrelevant Data.” Preprint. (2011)
Clark, P., Westerberg, A.: Bilevel programming for steady-state chemical process design: I: fundamentals and algorithms. Comput. Chem. Eng. 14.1, 87–97 (1990). https://doi.org/10.1016/0098-1354(90)87007-C
Paulavicius, R., Adjiman, C.S.: BASBLib: a library of bilevel test problems. (2019). https://doi.org/10.5281/zenodo.3266835
Labbé, M., Plein, F., Schmidt, M.: Bookings in the European gas market: characterisation of feasibility and computational complexity results. Optim. Eng. 21.1, 305–334 (2020). https://doi.org/10.1007/s11081-019-09447-0
Labbé, M., Plein, F., Schmidt, M., Thürauf, J.: Deciding feasibility of a booking in the European gas market on a cycle is in P. Networks (2021). https://doi.org/10.1002/net.22003
Thürauf, J.: Deciding the Feasibility of a Booking in the European Gas Market is coNP-hard. Tech. rep (2020). http://www.optimization-online.org/DB_HTML/2020/05/7803.html
Ben-Tal, A., El Ghaoui, L., Nemirovski, A.: Robust Optimization. Princeton University Press, Princeton (2009)
Yanıkoglu, I., Gorissen, B.L., den Hertog, D.: A survey of adjustable robust optimization. Eur. J. Oper. Res. 277.3, 799–813 (2019). https://doi.org/10.1016/j.ejor.2018.08.031
Mas-Colell, A., Whinston, M.D., Green, J.R., et al.: Microeconomic Theory, vol. 1. Oxford University Press, New York (1995)
Weymouth, T.R.: Problems in natural gas engineering. Trans. Am. Soc. Mech. Eng. 34.1349, 185–231 (1912)
Fügenschuh, A., Geißler, B., Gollmer, R., Morsi, A., Pfetsch, M. E., Rövekamp, J., Schmidt, M., Spreckelsen, K., Steinbach, M. C.: “Physical and technical fundamentals of gas networks.” In: Evaluating Gas Network Capacities. Ed. by T. Koch, B. Hiller, M. E. Pfetsch, and L. Schewe. SIAM-MOS series on Optimization. SIAM, 2015. Chap. 2, pp. 17–44. https://doi.org/10.1137/1.9781611973693.ch2
Prékopa, A.: Stochastic Programming. Kluwer, Dordrecht (1995)
Genz, A., Bretz, F.: Computation of Multivariate Normal and t Probabilities. Lecture Notes in Statistics. Heidelberg: Springer-Verlag (2009). https://doi.org/10.1007/978-3-642-01689-9
van Ackooij, W., Henrion, R., Möller, A., Zorgati, R.: On probabilistic constraints induced by rectangular sets and multivariate normal distributions. Math. Methods Oper. Res. 71, 535–549 (2010). https://doi.org/10.1007/s00186-010-0316-3
van Ackooij, W., Henrion, R.: Gradient formulae for nonlinear probabilistic constraints with Gaussian and Gaussian-like distributions. SIAM J. Optim. 24.4, 1864–1889 (2014). https://doi.org/10.1137/130922689
van Ackooij, W., Henrion, R.: (Sub-)Gradient formulae for probability functions of random inequality systems under Gaussian distribution. SIAM/ASA J. Uncertain. Quantif. 5.1, 63–87 (2017). https://doi.org/10.1137/16M1061308
Heitsch, H.: On probabilistic capacity maximization in a stationary gas network. Optimization 69.3, 575–604 (2020). https://doi.org/10.1080/02331934.2019.1625353
Fortuny-Amat, J., McCarl, B.: A representation and economic interpretation of a two-level programming problem. J. Oper. Res. Soc. 32.9, 783–792 (1981). (JSTOR: 2581394)
Pineda, S., Morales, J.M.: Solving linear bilevel problems using big-Ms: not all that glitters is gold. IEEE Trans. Power Syst. (2019). https://doi.org/10.1109/TPWRS.2019.2892607
Kleinert, T., Labbé, M., Plein, F., Schmidt, M.: Technical note–there’s no free lunch: on the hardness of choosing a correct big-M in bilevel optimization. Oper. Res. 68.6, 1716–1721 (2020). https://doi.org/10.1287/opre.2019.1944
Siddiqui, S., Gabriel, S.A.: An SOS1-based approach for solving MPECs with a natural gas market application. Netw. Spat. Econ. 13.2, 205–227 (2013). https://doi.org/10.1007/s11067-012-9178-y
Kleinert, T., Schmidt, M.: Global optimization of multilevel electricity market models including network design and graph partitioning. Discret. Optim. 33, 43–69 (2019). https://doi.org/10.1016/j.disopt.2019.02.002
Horst, R., Tuy, H.: Global Optimization: Deterministic Approaches. Springer, Berlin (2013)
Koch, T., Hiller, B., Pfetsch, M. E., Schewe, L.: Evaluating Gas Network Capacities. Ed. by M. E. Pfetsch, T. Koch, L. Schewe, and B. Hiller. Philadelphia, PA: Society for Industrial and Applied Mathematics (2015). https://doi.org/10.1137/1.9781611973693
Heitsch, H., Henrion, R., Kleinert, T., Schmidt, M.: Data repository. https://github.com/m-schmidt-math-opt/bilevel-w-chance-constr-lowerlevel. (2021)
Regionales Rechenzentrum Erlangen. Woodcrest Cluster. https://hpc.fau.de/systems-services/systems-documentation-instructions/clusters/woody-cluster/ (visited on 02/15/2021)
Acknowledgements
This research has been performed as part of the Energie Campus Nürnberg and is supported by funding of the Bavarian State Government. We also thank the Deutsche Forschungsgemeinschaft for their support within projects A05, B04, and B08 in the “Sonderforschungsbereich/Transregio 154 Mathematical Modelling, Simulation and Optimization using the Example of Gas Networks”. In addition, the second author acknowledges support by the FMJH Program Gaspard Monge in optimization and operations research including support to this program by EDF.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 Appendix A: data
In Table 2 we specify the intercepts \(a_{i,t}\) and slopes \(b_i\) of the exit players.
We also specify the mean vector m of the multivariate Gaussian distribution of the load vector \(\xi \). For better readability, we denote the vector in parts \(m_i = (m_{i,t})_{t\in T}\) for all \(i\in \mathcal {P}_-\):
Finally, we denote the covariance matrix \(\Sigma \) of the loads \(\xi \). For better readability, we only denote the \(\left| T\right| \)-many \(\left| \mathcal {P}_-\right| \times \left| \mathcal {P}_-\right| \) nonzero blocks \(\Sigma _t\):
1.2 Appendix B: big-M
In this section, we derive an upper bound on the Lagrangian multipliers \(\mu _j\) as used in Sect. 3.2. To this end, we consider the stationarity condition (36b), i.e.,
First, we assume \(q_{i,t}^\mathrm {nom}> 0\) for all \(i \in \mathcal {P}_-\) and \(t\in T\), which is justified in the probabilistic setting: According to (44), we can bound the nominations of the exit players from below. With this, we obtain
From now on, we consider an arbitrary but fixed index j. Since the multivariate Gaussian distribution function \(\Phi \) is strictly positive, it follows from (32) that \(\nabla _{q_{i,t}^\mathrm {nom}}h(q^j_{-}) < 0\) holds for all \(i \in \mathcal {P}_-\), \(t\in T\), and \(j = 1, \dotsc , r\), we can solve for \(\mu _j\) and obtain
Note that all \(\nabla _{q_{i,t}^\mathrm {nom}}h(q^j_{-})\) for all \(i \in \mathcal {P}_-\), \(t\in T\), and \(j = 1, \dotsc , r\) are given (and negative) constants. Hence, to obtain a valid upper bound on \(\mu _j\) we first have to properly bound the other terms in the numerator. Since we divided by a negative number, a valid upper bound for \(\mu _j\) can be obtained by taking the smallest possible numerator. Due to \(b_{i,t} < 0\), a lower bound for
is given by
where \(\bar{q}_{i,t}^\mathrm {nom}\) is an upper bound for \(q_{i,t}^\mathrm {nom}\). Taking the network constraints into account, we can set
where \(u\in {V}\) is the node in the network at which player \(i \in \mathcal {P}_-\) is located.
Let us now further assume that the overall booking price is bounded above, i.e.,
for some \(L_2 > 0\) and all \(i \in \mathcal {P}_u\), \(u\in {V}_+\cup {V}_-\). Thus, with \(\gamma _{i,t}^+ \ge 0\) and (36a), we can also bound all \(\gamma _{i,t}^+\) from above by \(L_2\). By using (36c), we then see that
is a valid upper bound for the resulting market equilibrium price \(\pi ^\mathrm {nom}_t\).
The last term,
in the numerator gets as small as possible for \(\mu _k = 0\) for all \(k \in \{1, \dotsc , r\} \setminus \{j\}\) since \(\nabla _{q_{i,t}^\mathrm {nom}}h(q^k_{-}) < 0\).
Taking this all together, we see that
holds. Note that we can, in principle, do this derivation for every \(i \in \mathcal {P}_-\) and \(t\in T\) to get the tightest possible upper bound \(L^j\).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Heitsch, H., Henrion, R., Kleinert, T. et al. On convex lower-level black-box constraints in bilevel optimization with an application to gas market models with chance constraints. J Glob Optim 84, 651–685 (2022). https://doi.org/10.1007/s10898-022-01161-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10898-022-01161-z