
Abstract
The optimization problems with a sparsity constraint is a class of important global optimization problems. A typical type of thresholding algorithms for solving such a problem adopts the traditional full steepest descent direction or Newton-like direction as a search direction to generate an iterate on which a certain thresholding is performed. Traditional hard thresholding discards a large part of a vector, and thus some important information contained in a dense vector has been lost in such a thresholding process. Recent study (Zhao in SIAM J Optim 30(1): 31–55, 2020) shows that the hard thresholding should be applied to a compressible vector instead of a dense vector to avoid a big loss of information. On the other hand, the optimal k-thresholding as a novel thresholding technique may overcome the intrinsic drawback of hard thresholding, and performs thresholding and objective function minimization simultaneously. This motivates us to propose the so-called partial gradient optimal thresholding (PGOT) method and its relaxed versions in this paper. The PGOT is an integration of the partial gradient and the optimal k-thresholding technique. The solution error bound and convergence for the proposed algorithms have been established in this paper under suitable conditions. Application of our results to the sparse optimization problems arising from signal recovery is also discussed. Experiment results from synthetic data indicate that the proposed algorithm is efficient and comparable to several existing algorithms.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The optimization problem with a sparsity constraint
arises in many practical fields such as compressive sensing [20, 22, 37], signal processing [8], wireless communication [15], pattern recognition [33], to name a few. In the model (1), \(\Vert \cdot \Vert _0\) is called the ’\(\ell _0\)-norm’ which counts the number of nonzero entries of a vector. Depending on application, the function f(x) may take different specific forms. For instance, in compressed sensing scenarios, f(x) is usually taken as \(\left\| y-Ax\right\| _2^2\) which is an error metric for signal measurements. The problem (1) is known to be NP-hard, and the main difficulty for solving this problem lies in locating the position of nonzero entries of a feasible sparse vector at which f(x) is minimized.
The algorithms for solving (1) can be sorted into several categories including convex optimization methods, heuristic algorithms, and thresholding algorithms. The convex optimization methods include \(\ell _1\)-minimization [11, 14], reweighted \(\ell _1\)-minimization [13, 40], and dual-density-based reweighted \(\ell _1\)-minimization [37, 39, 41]. The heuristic-type methods include orthogonal matching pursuit (OMP) [10, 32, 34], compressive sampling matching pursuit (CoSaMP) [31], subspace pursuit (SP) [16, 17], and their variants. Thresholding-type algorithms attract much attention due to their easy implementation and low computational complexity [4, 6, 7, 9, 23, 27, 38].
The key step for thresholding-type iterative algorithms can be stated as
where \({{{\mathcal {T}}}}_k (\cdot )\) represents a thresholding operator that is used to produce a k-sparse vector, \(\lambda \) denotes the stepsize and d is a search direction at the current iterate \(x^p\). Throughout the paper, a vector x is said to be k-sparse if \(\Vert x\Vert _0 \le k\). Several thresholding operators are widely used in the literature, such as the hard thresholding [4, 6, 7, 9, 23, 27], soft thresholding [18, 21, 26, 28], and optimal k-thresholding [38, 42]. The steepest descent direction [5,6,7, 9, 24, 30] and Newton-type direction [29, 35, 43, 44] are two search directions that are used by many researchers.
Let \({{{\mathcal {H}}}}_k\) denote the hard thresholding operator which retains the largest k magnitudes and zeroes out other entries of a vector. By setting \({{{\mathcal {T}}}}_k = {{{\mathcal {H}}}}_k\) and \(d = -\nabla f(x)\), the iterative formula (2) is reduced to
where \(\nabla f (x^p)\) is the gradient of f at \(x^p\). The formula (3) is the well-known iterative hard thresholding (IHT) initially studied in [5, 6]. The IHT can be enhanced by either attaching an orthogonal projection (a pursuit step) to obtain the so-called hard thresholding pursuit (HTP) method [9, 23] or by using an adaptive stepsize strategy to yield the so-called normalized iterative hard thresholding (NIHT) [7]. While the algorithm (3) can reconstruct the vector under suitable conditions (see [6, 22, 36]), but as pointed in [38, 42], the operator \({{{\mathcal {H}}}}_k\) may cause certain numerical problems as well.
To improve the performance of IHT, Zhao [38, 42] recently proposed the optimal k-thresholding technique which stresses that thresholding of a vector should be performed simultaneously with objective function reduction in the course of iterations. Replacing \(\mathcal{H}_k\) by the optimal k-thresholding operator \({{{\mathcal {Z}}}}^{\#}_k\) in (3) leads to the following iterative optimal k-thresholding scheme:
The optimal k-thresholding of a vector \(u \in {\mathbb {R}}^n\) with respect to the objective function f(x) is defined as \(\mathcal{Z}^{\#}_k (u) := u \otimes w^*\) with
where \({\mathbf {e}} \in {\mathbb {R}}^{n}\) is the vector of ones and \(\otimes \) denotes the Hadamard product of two vectors. To avoid solving the above binary optimization problem, Zhao [38] suggests solving the tightest convex relaxation of (4) instead. That is, replacing the binary constraint by its convex hull, we obtain the following convex relaxation of the problem (4):
The vector \(u \otimes {\overline{w}}\) is called the relaxed optimal k-thresholding of u.
The hard thresholding operator in (3) discards a large important part of a vector when the vector is dense. This means some important information of the vector has been lost in the process of hard thresholding. As pointed out in [38, 42], the hard thresholding should be applied to a compressible vector instead of a dense vector in order to avoid a big loss of information. Note that the vector \(x^p - \lambda \nabla f(x^p)\) in (3) is usually dense since the search direction \(-\nabla f(x^p)\) is not necessarily sparse. This motivates us to adopt the partial gradient instead of the full gradient as a search direction in order to generate the following sparse or compressible vector:
on which some thresholding is then performed to generate the next iterate \(x^{p+1}\). In the above formula, the integer number \(q>0\) controls the number of elements extracted from the full gradient. In other words, we only use q significant entries of the gradient as our search direction. We may use the hard thresholding of \(u^p\) to produce an iterate satisfying the constraint of the problem (1). However, as we pointed out before, the optimal k-thresholding is more powerful and more efficient than the hard thresholding. This stimulates the following iterative scheme:
This is refer to as the partial gradient optimal thresholding (PGOT) algorithm in this paper, which is described in detail in Sect. 2. The enhanced version of PGOT is called the partial gradient relaxed optimal thresholding (PGROT). In order to maintain the k-sparsity of the iterate, a further enhancement of PGOT and PGROT can be made by adding a pursuit step to PGROT to eventually obtain the more efficient algorithm called the partial gradient relaxed optimal thresholding pursuit (PGROTP), which is treated as the final version of the proposed algorithm in the paper, actually being used to solve the problems. The solution error bound and convergence analysis for our algorithms with q in the range \(q \in [2k,n]\) are shown under the assumption of restricted isometry property (RIP). Simulations from synthetic data indicate that PGROTP algorithm is robust and comparable to several existing methods.
The paper is organized as follows. The algorithms are described in Sect. 2. The error bounds and global convergence of the proposed algorithms are established in Sect. 3. Numerical results are given in Sect. 4 and conclusions are given in Sect. 5.
1.1 Notations
We first introduce some notations used throughout the paper. \({\mathbb {R}}^n\) is the n-dimensional Euclidean space, and \({\mathbb {R}}^{m \times n}\) is the set of \(m \times n\) matrices. Vector \({\mathbf {e}}\) is the vector of ones. Denote [N] as the set \(\{1,\dots ,n\}\). Given a set \(\varOmega \subseteq [N]\), \({\overline{\varOmega }} {:}{=} [N] \backslash \varOmega \) denotes the complement set of \(\varOmega \), and \(|\varOmega |\) is the cardinality of set \(\varOmega \). For a vector \(x \in {\mathbb {R}}^n\), \(x_{\varOmega } \in {\mathbb {R}}^n\) denotes the vector obtained from x by retaining elements indexed by \(\varOmega \) and zeroing out the remaining ones. The set \({{\,\mathrm{supp}\,}}(x) = \{i: x_i \ne 0\}\) is called the support of x, \({{{\mathcal {L}}}}_k (x)\) denotes the support of \({{{\mathcal {H}}}}_k (x)\), and \(\mathcal{Z}^{\#}_k (\cdot )\) denotes the optimal k-thresholding operator. For a matrix A, \(A^T\) denotes its transpose. The notation \(\otimes \) represents the Hadamard product of two vectors, i.e., \(u \otimes v = [u_1v_1, \dots , u_nv_n]^T\). Given a number \(\alpha \), \(\lceil \alpha \rceil \) is the smallest integer number that is larger than or equal to \(\alpha \).
2 Algorithms
In this paper, we focus on the following specific objective function:
where A is a given \(m \times n\) matrix with \(m \ll n\), and y is a given vector. Using this quadratic function, the model (1) becomes
This problem has been widely used in data sparse representation, statistical regression, and signal reconstruction via compressive sensing and in many other application settings. The gradient of the function (6) is given as
By using the major part of this specific gradient, we define the \(u^p\) as follows:
where \(0 < q \le n\) is an integer number. The optimal thresholding of \(u^p\) with respect to the function (6) is given by \({{{\mathcal {Z}}}}^{\#}_k (u^p) = u^p \otimes w^*\), where
Thus the partial gradient optimal k-thresholding (PGOT) algorithm (5) for solving problem (7) can be stated as
For simplicity of algorithmic description and analysis, we set \(\lambda = 1\) throughout the rest of the paper. It should be stressed that in practical applications, suitable stepsize should be used in order to speed up the convergence of the algorithms. By the definition of \({{{\mathcal {Z}}}}_k^{\#}\), the PGOT algorithm can be described explicitly as follows.

To avoid solving the integer programming problem (OT), as suggested in [38], the binary constraint \(w \in \{0,1\}^n\) in (OT) can be relaxed to \(0 \le w \le {\mathbf {e}}\) so that we obtain the partial gradient relaxed optimal thresholding (PGROT) algorithm.

The solution \({\overline{w}}^p\) to (ROT) is not k-sparse in general. So the purpose of the final thresholding step in PGROT to restore the k-sparsity of iterate. It is worth emphasizing that the use of \({{{\mathcal {H}}}}_k\) here is different from the settings in traditional IHT, since the vector \(u^p\) generated by the partial gradient is \((k+q)\)-sparse instead of being a usually dense vector in IHT.
The PGROT can be further enhanced by including a pursuit step (i.e., an orthogonal projection step) to find a possibly better iterate than the point generated by PGROT. This consideration leads to so-called PGROTP algorithm which is described in Algorithm 3. In the next section, we perform a theoretical analysis for the proposed algorithms.

3 Error bound and convergence analysis
In this section, we establish the error bounds for the solution of the problem via the proposed algorithms. The purpose is to estimate the distance between the iterate \(x^p\), generated by the proposed algorithms, and the global solution of the problem (7). As an implication of the error bounds, the global convergence of our algorithms can be instantly obtained for the problem (7) in the scenarios of sparse signal recovery. Before going ahead, we first introduce the restricted isometry constant (RIC) of the matrix A.
Definition 1
[11, 22] The s-th order restricted isometry constant (RIC) \(\delta _s\) of a matrix \(A \in {\mathbb {R}}^{m \times n}\) is the smallest number \(\delta _s \ge 0\) such that
for all s-sparse vector x, where \(s>0\) is an integer number.
We usually say that matrix A satisfies the RIP of order s if \(\delta _s < 1\). It is well known that the random matrices such as Bernoulli and Gaussian matrices satisfy the RIP with an overwhelming probability [11, 12]. The following property of RIC is frequently used in the paper.
Lemma 1
[11, 23, 31] Suppose matrix A satisfy the RIP of order k. Given a vector \(u \in {\mathbb {R}}^n\) and a set \(\varOmega \subseteq [N]\), one has
-
(i)
\(\left\| {{\left( \left( I-A^{T} A\right) v\right) _{\varOmega }}} \right\| _{2} \le \delta _{t}\Vert u\Vert _{2} \) if \(|\varOmega \cup {{\,\mathrm{supp}\,}}(v)| \le t\).
-
(ii)
\(\left\| {{(A^T u)_{\varOmega }}} \right\| _2 \le \sqrt{1+\delta _t} \left\| {{u}} \right\| _2\) if \(|\varOmega | \le t\).
3.1 Main results for PGOT
The following two technical results concerning the properties of optimal k-thresholding and hard thresholding operators are useful.
Lemma 2
[38, 42] Let \(x^* \in {\mathbb {R}}^n\) be the solution to the problem (7) and denote by \(\eta = y-Ax^*\). Given an arbitrary vector \(u \in {\mathbb {R}}^n\), let \({{{\mathcal {Z}}}}^{\#}_k (u)\) be the optimal k-thresholding vector of u. Then for any k-sparse binary vector \(w^* \in \{0,1\}^n\) satisfying \({\text {supp}}(x^*) \subseteq {\text {supp}}(w^*)\), one has
This result can be found from the proof of Theorem 4.3 in [38].
Lemma 3
[36] Let \(q \ge s\) be an integer number. For any vector \(z \in {\mathbb {R}}^{n}\) and any s-sparse vector \(u \in {\mathbb {R}}^{n}\), one has
where \(\varLambda ={{\,\mathrm{supp}\,}}(u)\) and \(\varOmega ={{\,\mathrm{supp}\,}}\left( {\mathcal {H}}_{q}(z)\right) \).
When \(s \le q\), a s-sparse vector is also q-sparse. Thus Lemma 3 above follows exactly from Lemma 2.2 in [36]. We are ready to prove the error bound and global convergence of the algorithm PGOT.
Theorem 1
Let \(x^* \in {\mathbb {R}}^n\) be the solution of the problem (7) and \(\eta := y-Ax^*\). Let \(q \ge 2 k\) be a positive integer number. Suppose that the restricted isometry constant of A satisfies
where \(\alpha ^* \in (0,1)\) is the unique real root of the univariate equation
Then the sequence \(\left\{ x^{p}\right\} \) generated by PGOT satisfies that
where
is guaranteed under the condition (8), and the constant \(\tau \) is given as
In particular, if \(\eta =0\), the sequence \(\left\{ x^{p}\right\} \) generated by PGOT converges to \(x^*\).
Proof
Let \(\eta = y-Ax^*\) and \(u^p, x^{p+1}\) be the vectors generated at p-th iteration of PGOT, i.e., \(u^{p}=x^{p}+{\mathcal {H}}_{q}\left( A^{T}\left( y-A x^{p}\right) \right) \) and \(x^{p+1} = {{{\mathcal {Z}}}}^{\#}_k (u^p)\). Let \(w^* \in \{0,1\}^n\) be a k-sparse vector such that \({{\,\mathrm{supp}\,}}(x^*) \subseteq {{\,\mathrm{supp}\,}}(w^*)\). Applying Lemma 2 leads to
Denote by \(\varOmega := {{{\mathcal {L}}}}_q (A^{T}(y-A x^{p}) )\). It is easy to see that \(|{{\,\mathrm{supp}\,}}(x^*-x^p)| \le 2k\). Thus, if \(q \ge 2k\), by Lemma 3, we have
where \(S = {{\,\mathrm{supp}\,}}(x^*)\) and \(S^p = {{\,\mathrm{supp}\,}}(x^p)\). Given a vector \(v \in {\mathbb {R}}^n\) and two support sets \(\varLambda _1, \varLambda _2 \in [N]\). It is easy to verify \(\left\| {{v_{\varLambda _1 \cup \varLambda _2}}} \right\| _2 \le \left\| {{v_{\varLambda _1}}} \right\| _2 + \left\| {{v_{\varLambda _2}}} \right\| _2\). Therefore,
Noting that \(|{{\,\mathrm{supp}\,}}(x_S-x^p)| \le |S \cup S^p| \le 2k\). The second term on the right-hand side of (14) can be bounded. In fact, by Lemma 1, we have
Setting \(t = \left\lceil \frac{q}{k} \right\rceil \), the set \(\varOmega \) can be separated into t disjoint sets such that \(\varOmega = T_1 \cup T_2 \dots , T_t\), where \(|T_i| \le k\) for \(i=1,\dots ,t\), and \(T_i \cap T_j = \emptyset \) if \(i \ne j\). Thus we have
where the last inequality follows from Lemma 1 because \(|T_i \cup {{\,\mathrm{supp}\,}}(x^*-x^p)| \le 3k\). Since \(\delta _{2k} \le \delta _{3k}\), combining (13)–(16) leads to
Substituting (17) into (12) yields
where \(\rho \) and \(\tau \) are given as (10) and (11), respectively. Since \(\delta _k \le \delta _{2k} \le \delta _{3k}\), the constant \(\rho <1\) is ensured if
Squaring both sides of (19) and rearranging terms yield
The gradient of g with respect to \(\delta _{3k}\) is given as
Thus the function g is strictly and monotonically increasing over the interval \(\delta _{3k} \in (0,1]\). Note that
Thus there exists a unique real root \(\alpha ^*\) for the equation \(g(\alpha ^*)=0\) in [0, 1]. Therefore, \(\delta _{3k} < \alpha ^*\) ensures that the constant \(\rho <1\) in (18), and hence it follows from (18) that
which is exactly the desired error bound. In particular, when \(\eta =0\), it follows immediately from the above error bound that the sequence \(\{x^p\}\) generated by PGOT converges to \(x^*\) as \(p \rightarrow \infty \). \(\square \)
A more explicitly given RIC bound than (8) for PGOT can be derived as follows. Since \(\sqrt{\frac{1+\delta _{3k}}{1-\delta _{3k}}} < \frac{1+\delta _{3k}}{1-\delta _{3k}}\), the inequality (19) is guaranteed provided the following inequality is satisfied:
which can be written as
where
To guarantee (20), it is sufficient to require that
The right-hand side above is the positive root in [0, 1] of the quadratic equation \(\phi \delta _{3k}^2 + \left( \phi + 1 \right) \delta _{3k} - 1 = 0\). From the above analysis, we immediately obtain the following result.
Corollary 1
Let \(x^* \in {\mathbb {R}}^n\) be the solution of the problem (7) and \(\eta := y-Ax^*\). Let \(q \ge 2 k\) be a positive integer number. Suppose the restricted isometry constant of A satisfy
where
Then the sequence \(\left\{ x^{p}\right\} \) generated by PGOT satisfies that
where \(\rho <1\) and \(\tau \) are given by (10) and (11), respectively.
The bound (21) depends only on the given integer number q. It is easy to verify that, for instance, \(\delta _{3k} < 0.1517\) when \(q = 2k\), \(\delta _{3k} < 0.1211\) when \(2k < q \le 3k\), and \(\delta _{3k} < 0.1009\) when \(3k < q \le 4k\).
Theorem 1 demonstrates how far the iterate point \(x^{p+1}\) generated by PGOT is from the solution \(x^*\) of the problem (7). It shows that the bound of \(\Vert x^{p+1} - x^*\Vert _2\) depends on the value \(\Vert \eta \Vert _2 = \Vert y-Ax^*\Vert _2\). It is worth mentioning that the sparse optimization problems are a large class of problems arising from many different applications, such as statistical regression, data sparse representation, data compression, channel estimation in wireless communication. The main results established in this section are general enough to apply to these broad situations. For instance, in sparse signal recovery, \(y := Ax^*+\eta \) are the linear measurements of the signal \(x^*\). In this case, \(\Vert \eta \Vert _2 = \Vert y-Ax^*\Vert _2\) is the size of measurement error which would be small. In particular, \(\eta =0\) when measurements are accurate. For such a specific application, our main results can be further enhanced. See the discussion below in more detail.
3.1.1 Application to sparse signal recovery
Let \(x^*\) be a k-sparse signal to recover. To recover \(x^*\), we take the signal measurements \(y := Ax^*+\eta \) with a measurement matrix A, where \(\eta = y-Ax^*\) denotes the measurement error which is small. Recovering \(x^*\) from the measurements y can be exactly modeled as the optimization problem (7). From the results in Sect. 3.1, we immediately obtain the next result concerning sparse signal recovery.
Theorem 2
Let \(y:=A x^*+\eta \) be the measurements of the k-sparse signal \(x^* \in {\mathbb {R}}^{n}\) with measurement error \(\eta \). Let \(q \ge 2 k\) be a positive integer number. Suppose the restricted isometry constant of measurement matrix A satisfies one of the following conditions:
-
(i)
\(\delta _{3 k}<\alpha ^*\), where \(\alpha ^* \in (0,1)\) is the unique real root of (9),
-
(ii)
\(\delta _{3 k}\) satisfies (21).
Then the sequence generated by PGOT satisfies
where \(\rho \) and \(\tau \) are the same as (10) and (11), respectively. In particular, if the measurements are accurate, i.e., \(y=Ax^*\), then the sequence \(\{x^p\}\)generated by PGOT converges to \(x^*\).
From (22), we see that when the measurements are accurate enough, i.e., \(\Vert \eta \Vert _2\) is sufficient small, then \(x^{p+1} \approx x^*\). This means the \(x^{p+1}\) is a high-quality reconstruction of \(x^*\).
3.2 Main results for PGROT
Before analyzing the PGROT, we introduce the following lemma.
Lemma 4
[38] Let \(x^* \in {\mathbb {R}}^n\) be the solution to the problem (7) and \(\eta = y-Ax^*\) be the error. Denote \(S = {{\,\mathrm{supp}\,}}(x^*)\) and \(S^{p+1} = {{\,\mathrm{supp}\,}}(x^{p+1})\). Let \(u^p\) and \(w^p\) be the vector defined as in PGROT, and \(w^* \in \{0,1\}^n\) be a binary k-sparse vector such that \(S \subseteq {{\,\mathrm{supp}\,}}(w^*)\). Then
Theorem 3
Let \(x^* \in {\mathbb {R}}^n\) be the solution to the problem (7) and \(\eta = y-Ax^*\). Let \(q \ge 2 k\) be a positive integer number. Suppose the restricted isometry constant of matrix A satisfies
where \(\beta ^*\) is the unique real root of the equation
in (0, 1). Then the sequence \(\left\{ x^{p}\right\} \) generated by PGROT satisfies
where
is ensured under (23), and the constant \({\overline{\tau }}\) is given as
In particular, if \(\eta =0\), then the sequence \(\left\{ x^{p}\right\} \) generated by PGROT converges to \(x^*\).
Proof
Let \(x^{p+1}, u^p\) and \({\overline{w}}^p\) be defined in PGROT. Denote by \(S = {{\,\mathrm{supp}\,}}(x^*)\). Note that \(S^{p+1} = {{\,\mathrm{supp}\,}}(x^{p+1}) = {{\,\mathrm{supp}\,}}({{{\mathcal {H}}}}_k ({\overline{w}}^p \otimes u^p))\). By Lemma 3, we have
Note that \(w^*\) is a k-sparse binary vector satisfying \({{\,\mathrm{supp}\,}}(x^*) \subseteq {{\,\mathrm{supp}\,}}(w^*)\). By Lemma 4, we obtain
where the last inequality follows from
Based on (17), we have
where \(t = \left\lceil \frac{q}{k}\right\rceil \). Combining (27)–(29) yields
where \({\overline{\rho }}\) and \({\overline{\tau }}\) are given by (25) and (26), respectively. We now prove that (23) implies \({\overline{\rho }} < 1\). Due to the fact \(\delta _{k} \le \delta _{2k} \le \delta _{3k}\), to guarantee that \({\overline{\rho }} < 1\), it is sufficient to require
which, by squaring both sides and rearranging terms, is equivalent to \(g(\delta _{3k})<0\) where
The gradient of \(g(\delta _{3k})\) is given as
which is positive over the interval [0, 1]. This together with
implies that there exists a unique real positive root \(\beta ^* \in (0,1)\) satisfying \(g(\beta ^*)=0\). Therefore, the condition \(\delta _{3k} < \beta ^*\) guarantees the inequality (31), and thus ensures that \({\overline{\rho }} < 1\). Thus it follows from (30) that
When \(\eta =0\), the relation above implies that \(\left\| x^*-x^{p+1}\right\| _{2} \le {\overline{\rho }}^{p}\left\| x^*-x^{0}\right\| _{2} \rightarrow 0\) as \(p \rightarrow \infty \). Therefore, the sequence \(\{x^p\}\) generated by RPGOT in this case converges to the solution \(x^*\) of (7). \(\square \)
Similar to the discussion in the end of Sect. 3.1, an explicit bound of \(\delta _{3k}\) for PGROT can be given. Since \(\sqrt{\frac{1+\delta _{3 k}}{1-\delta _{3 k}}} < \frac{1+\delta _{3 k}}{1-\delta _{3 k}}\), a sufficient condition for (31) is
which is equivalent to
where
By the same analysis in Sect. 3.1, we immediately have the next corollary.
Corollary 2
Let \(x^* \in {\mathbb {R}}^n\) be the solution to the problem (7) and \(\eta := y-Ax^*\). Let \(q \ge 2 k\) be a positive integer number. Suppose the restricted isometry constant of matrix A satisfies
where
Then the sequence \(\left\{ x^{p}\right\} \) generated by PGROT satisfies
where \({\overline{\rho }}\) and \({\overline{\tau }}\) are given as (25) and (26), respectively.
Similar to Corollary 1, we may apply the above result (Theorem 3 and Corollary 2) to the scenario of sparse signal recovery via compressed sensing for which \(\eta = y-Ax^*\) is very small, and thus \(x^p \approx x^*\) when p is large enough. That is, the iterate \(x^p\) generated by PGROT is a quality approximation to the signal.
3.3 Main result for PGROTP
The error bound for the solution of (7) via PGROTP algorithm can be also established. The next lemma concerning a property of pursuit step is useful in this analysis.
Lemma 5
[38] Let \(x^* \in {\mathbb {R}}^n\) be the solution to the problem (7) and \(\eta = y-Ax^*\). The vector \(u \in {\mathbb {R}}^n\) is an arbitrary k-sparse vector. Then the optimal solution of the pursuit step
satisfies that
The main result for PGROTP algorithm is given as follows.
Theorem 4
Let \(x^* \in {\mathbb {R}}^n\) be the solution to the problem (7) and \(\eta = y-Ax^*\). Let \(q \ge 2 k\) be a positive integer number. Suppose the restricted isometry constant of matrix A satisfies
Then the sequence \(\left\{ x^{p}\right\} \) generated by PGROTP satisfies
where
is guaranteed by (32), and the constant \(\tau ^*\) is given as
In particular, when \(\eta =0\), the sequence \(\left\{ x^{p}\right\} \) generated by PGROTP converges to \(x^*\).
Proof
The PGROTP can be regarded as a combination of PGROT with a pursuit step. Denote \({\overline{x}}^{p+1}\) as the intermediate vector generated by PGROT. Based on the analysis of PGROT algorithm, we have
where \({\overline{\rho }}\) and \({\overline{\tau }}\) are the same as (25) and (26), respectively. By Lemma 5, we immediately have that
As \(\delta _k \le \delta _{2k} \le \delta _{3k}\), combining two inequalities above yields
where \(\rho ^*\) and \(\tau ^*\) are given in (34) and (35), respectively. To guarantee \(\rho ^* < 1\), i.e.,
it is sufficient to require that
which is exactly the assumption (33) of the theorem.
If \(\eta =0\), the sequence \(\left\{ x^{p}\right\} \) generated by PGROTP converges to \(x^*\) as \(p \rightarrow \infty \), since in this case, (33) is reduced to \(\left\| {{x^{p+1} - x^*}} \right\| _2 \le (\rho ^*)^p \left\| {{x^0-x^*}} \right\| _2\). \(\square \)
For sparse signal recovery, similar comments to that of Sect. 3.1.1 can be made to PGROTP. The discussion is omitted here. Before we close this section, we list a few RIC conditions in terms of \(\delta _{3k}\) for the proposed algorithms with different q, i.e., \(q=2k,3k,4k\). The results shown in Table 1 are derived based on (9), (24) and (32) for the q given as above, respectively. It is worth mentioning that, when \(q=n\), the partial gradient \({{{\mathcal {H}}}}_q(\nabla f(x))\) becomes the full gradient \(\nabla f(x)\), and the algorithms in this paper are reduced to the optimal k-thresholding (OT), relaxed optimal k-thresholding (ROT) and relaxed optimal k-thresholding pursuit (ROTP) algorithm, respectively. The sufficient conditions for the convergence of these algorithms were studied in [38, 42].
Remark 1
The iterative complexity of the interior point method for ROTP is about \(O\left( p m^{3}+p m n+p n^{3.5} L\right) \), as pointed out in [42], where p is the number of iterations and L is the size of the problem data encoding in binary. Solving quadratic optimization is the main cost for the ROTP algorithm. The algorithms proposed in this paper possess similar a computational complexity. To improve the chance for the solution of (ROT) to be binary or nearly binary, two or more relaxed optimal k-thresholding steps are employed by the algorithms in [38]. The partial-gradient-based algorithm in this paper is quite different from the strategy in [38]. The iterate generated by partial gradient methods is at most \((k+q)\)-sparse, based on which the vector derived from the relaxed k-optimal thresholding is more compressible than the one generated by those algorithms in [38].
4 Numerical experiments
Simulations via synthetic data are carried out to demonstrate the numerical performance of the PGROTP which is the main implementable algorithm proposed in this paper. We test the algorithm from four aspects: objective reduction, average number of iterations required for solving the problem (7), success frequency in vector reconstruction and phase transition in terms of success rate. The PGROTP with \(q=k, 2k, 3k\) and n are tested and compared. Unless otherwise stated, the measurement matrices used in experiments are Gaussian random matrices whose entries follow the standard normal distribution \({{{\mathcal {N}}}}(0,1)\). For sparse vectors, their entries also follow the \({{{\mathcal {N}}}}(0,1)\) and the position of nonzero entries of the vector follows the uniform distribution. All involved convex optimization problems were solved by CVX developed by Grant and Boyd [25] with solver ’Mosek’ [1].
4.1 Objective reduction
This experiment is used to investigate the objective-reduction performance of the PGROTP with different q, including \(q= k,2k,3k\) and n. We set \(A \in {\mathbb {R}}^{500 \times 1000}\) and \(y=Ax^*\), where \(x^*\) is a generated k-sparse vector. Thus \(x^*\) is a global solution of the problem (7). Figure 1 records the changes of the objective value \(\Vert y-Ax\Vert _2\) in the course of algorithm up to 70 iterations. Figure 1a, b include the results for the sparsity level \(\Vert x^*\Vert _0=162\) and 197, respectively. It can be seen that PGROTP is able to reduce the objective value during iterations. Moreover, this experiment also indicates that the optimal k-thresholding methods with partial gradients may perform better in objective reduction than the ones using full gradients in many situations.

Objective change in the course of iterations for PGROTP with different q, i.e., \(q = k, 2k, 3k, n\)
4.2 Number of iterations
Experiments were also performed to demonstrate the average number of iterations needed for PGROTP to solve the sparse optimization problems from the sparse vector reconstruction. The vector dimension is fixed to be 1000, and the size of the measurement matrix is \(m \times 1000\), where m takes the following a few different values: \(m = 300, 400, 500, 600\). The measurements \(y = Ax^*\) are accurate, where \(x^*\) is the sparse vector to recover. In this experiment, if the iterate \(x^p\) satisfies the criterion
then the algorithm terminates and the number of iterations p is recorded. If the algorithm within 50 iterations cannot meet the criterion (36), then the algorithm stops, and the number of iterations performed is recorded as 50. For each given sparsity level, the average number of iterations is obtained by attempting 50 trials. The outcomes are shown in Fig. 2 which indicate that the required iterations of PGROTP for vector reconstructions are usually low when the sparsity level of \(x^*\) is low, and that the number of iterations required for solving the problem increases as the sparsity level increases. This figure also shows that for a given sparsity level, the more measurements are required, the lower the average number of iterations are needed by the PGROTP to meet the reconstruction criterion (36).

Comparison of the average number of iterations required by PGROTP with different q
4.3 Sparse signal recovery
Simulations were also carried out to compare the success rates of the PGROTP algorithm in sparse vector reconstruction with several existing algorithms, such as \(\ell _1\)-minimization, subspace pursuit (SP), orthogonal matching pursuit (OMP) and ROTP2 (in [38, 42]). The size of the measurement matrix is still \({500 \times 1000}\). For every given ratio of the sparsity level k and n, the success rate of the algorithm is obtained by 50 random attempts. In this experiment, SP, ROTP2 and PGROTP(\(q=k\)) perform a total of 50 iterations, whereas OMP is performed k iterations. After performing the required number of iterations, the algorithm is counted as success if the condition (36) is satisfied. The success rates for accurate and inaccurate measurements are summarized in Fig. 3a, b, respectively. The inaccurate measurements are given by \(y=Ax^*+0.001\eta \), where \(\eta \) is a standard Gaussian vector. Compared with several existing algorithms, it can be seen that the PGROTP is robust and efficient for the sparse vector reconstruction in both noise and noiseless environments.

Comparisons of success rates of sparse signal reconstruction between several algorithms via Gaussian random matrices
4.4 Phase transition
Phase transition analysis was introduced by Donoho and Tanner [19]. Blanchard and Tanner [2] and Blanchard, Tanner and Wei [3] provided substantial analyses and experiments to compare the phase transition features of several compressed sensing algorithms. We also conducted such experiments to demonstrate the phase transition of PGROTP(\(q=k\)) and compare with \(\ell _1\)-minimization, SP and ROTP2 algorithms.
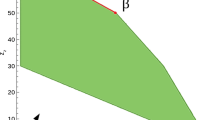
In this experiment, the length of the target vector \(x^*\) is fixed as \(n=2048\). We take 40 different sparsity levels uniformly from 1 to m, i.e., \(k = \left\lfloor \frac{1}{40} m\right\rfloor , \dots , \left\lfloor \frac{39}{40} m\right\rfloor , m\). For the number of measurements m, we require \(m \ge 40\) to ensure that there are 40 different sparsity levels. We take a total of 20 different values for the measurements, 10 uniformly from [40, 0.4n] and 10 from (0.4n, n]. The matrix A is a Gaussian random matrix whose entries follow the normal distribution \({{{\mathcal {N}}}}(0,1/\sqrt{m})\). The measurements of \(x^*\) are inexact, i.e., \(y = Ax^*+10^{-5}\eta \), where \(\eta \) is a standard Gaussian vector. The iterative algorithms terminate either when the criterion (36) is met, or the maximum of 30 iterations are reached. The algorithm is counted as success when (36) is satisfied. For each pair of (m, k), we use 10 trials to calculate the success rate and the average time consumption for success recoveries. In Figs. 4, 5, 6, the vertical axis represents over-sampling rate \(\rho = k/m\), while the horizontal axis represents under-sampling rate \(\delta = m/n\). The range of both \(\rho \) and \(\delta \) is between 0 and 1.

Phase transition of PGROTP with respect to success rate and CPU time under inexact measurements

Comparison of phase transition curves of \(\ell _1\)-minimization, SP, PGROTP and ROTP2 algorithms under inexact measurements in terms of success rates
Figure 4 demonstrates the phase transition regions of PGROTP in terms of success rates and CPU time for recovery success, respectively. The shaded area in Fig. 4a indicates the region for the recovery success of the algorithm. We can see from Fig. 4a that PGROTP has ability to recover the signal with relatively high \( \delta \) and \( \rho .\) Figure 4b shows that PGROTP takes more time to achieve recovery success when more measurements are used and when the signal is relatively dense.
We now compare the phase transition curves between \(\ell _1\)-minimization, SP, PGROTP and ROTP2 algorithms. We carry out the experiment in the same environment as that of Fig. 4. For every given \(\delta \), the logistic regression model is used to determine the specific success rate corresponding to \(\rho \). The phase transition curves can be obtained in terms of different level of success rates. Figure 5a, b demonstrate the curves for the success rates 0.9 and 0.5, respectively. Such curves delineate the regions where the algorithms can recover the target signal with a specific success rate and the region in which they cannot. In general, the higher the curve, the better the performance of the algorithm. Figure 5 indicates that PGROTP performs comparably to the other three algorithms. We also see that although PGROTP adopts a partial gradient direction, it maintains a similar performance to ROTP2 in sparse signal recovery.
Finally, we compare the performance of PGROTP and ROTP2 via time consumption ratio. Figure 6 shows the time ratios \(r=\frac{\text {time}(\text {ROTP2}(\delta ,\rho ))}{\text {time}(\text {PGROTP}(\delta ,\rho ))}\) over the phase transition region. The difference in time consumption between the two algorithms is more pronounced when more measurements are used to recover a sparse signal. Figure 6 clearly shows that when dealing with signals with low sparsity levels, the PGROTP algorithm can recover wide range of signals with less time than ROTP2. This does show that using the partial gradient information may help reduce the runtime of the optimal k-thresholding method.

Time consumption ratio of PGROTP and ROTP2
5 Conclusions and final remarks
Motivated by the recent optimal k-thresholding technique, we proposed the partial-gradient-based optimal k-thresholding methods for solving a class of sparse optimization problems. Under the restricted isometry property, we established a global error bound for the iterates produced by our algorithms. For sparse signal recovery, our results claim that the proposed algorithms with q satisfying \(2k \le q < n\) are guaranteed to recover the sparse vector. The optimal-thresholding-type algorithms usually require more time to solve the sparse optimization problem than traditional hard thresholding methods and existing heuristic algorithms. The primary computation time is solving quadratic optimization problems. However, the advantage of optimal-thresholding-type algorithms is that they are more stable, robust and have stronger reconstruction capability than existing heuristic methods. Although we focus on solving the specific model (7) in this paper, it is not difficult to extend the framework of the proposed algorithms to the general model (1). We leave this as future work.
References
Andersen, E. D., Andersen, K. D.: The MOSEK interior point optimizer for linear programming: an implementation of the homogeneous algorithm. High performance optimization. Springer, Boston, MA, 33, 197-232 (2000)
Blanchard, J.D., Tanner, J.: Performance comparisons of greedy algorithms in compressed sensing. Numer. Linear Algebra Appl. 22(2), 254–282 (2015)
Blanchard, J.D., Tanner, J., Wei, K.: CGIHT: conjugate gradient iterative hard thresholding for compressed sensing and matrix completion. Inform. Inference J. IMA 4(4), 289–327 (2015)
Blumensath, T.: Accelerated iterative hard thresholding. Signal Process. 92, 752–756 (2012)
Blumensath, T., Davies, M.: Iterative hard thresholding for sparse approximation. J. Fourier Anal. Appl. 14, 629–654 (2008)
Blumensath, T., Davies, M.: Iterative hard thresholding for compressed sensing. Appl. Comput. Harmon. Anal. 27, 265–274 (2009)
Blumensath, T., Davies, M.: Normalized iterative hard thresholding: guaranteed stability and performance. IEEE J. Sel. Top. Signal Process. 4, 298–309 (2010)
Boche, H., Calderbank, R., Kutyniok, G., Vybiral, J.: Compressed Sensing and its Applications. Springer, New York (2019)
Bouchot, J., Foucart, S., Hitczenki, P.: Hard thresholding pursuit algorithms: number of iterations. Appl. Comput. Harmon. Anal. 41, 412–435 (2016)
Cai, T., Wang, L.: Orthogonal matching pursuit for sparse signal recovery with noise. IEEE Trans. Inform. Theory 57(7), 4680–4688 (2011)
Candès, E., Tao, T.: Decoding by linear programming. IEEE Trans. Inform. Theory 51(12), 4203–4215 (2005)
Candès, E., Romberg, J., Tao, T.: Robust uncertainty principles: exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inform. Theory 52(2), 489–509 (2006)
Candès, E., Wakin, M., Boyd, S.: Enhancing sparsity by reweighted \(\ell _1\)-minimization. J. Fourier Anal. Appl. 14, 877–905 (2008)
Chen, S., Donoho, D., Saunders, M.: Atomic decomposition by basis pursuit. SIAM Rev. 43(1), 129–159 (2001)
Choi, J., Shim, B., Ding, Y., Rao, B., Kim, D.: Compressed sensing for wireless communications: useful tips and tricks. IEEE Commun. Surv. Tutor. 19(3), 1527–1549 (2017)
Dai, W., Milenkovic, O.: Subspace pursuit for compressive sensing: Closing the gap between performance and complexity. ILLINOIS UNIV AT URBANA-CHAMAPAIGN (2008)
Dai, W., Milenkovic, O.: Subspace pursuit for compressive sensing signal reconstruction. IEEE Trans. Inform. Theory 55, 2230–2249 (2009)
Donoho, D.: De-noising by soft-thresholding. IEEE Trans. Inform. Theory 41, 613–627 (1995)
Donoho, D., Tanner, J.: Observed universality of phase transitions in high-dimensional geometry, with implications for modern data analysis and signal processing. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 367(1906), 4273–4293 (2009)
Eldar, Y., Kutyniok, G.: Compressed Sensing: Theory and Applications. Cambridge University Press, Cambridge (2012)
Fornasier, M., Rauhut, H.: Iterative thresholding algorithms. Appl. Comput. Harmon. Anal. 25(2), 187–208 (2008)
Foucart, S., Rauhut, H.: A Mathematical Introduction to Compressive Sensing. Birkhäuser Basel (2013)
Foucart, S.: Hard thresholding pursuit: an algorithm for compressive sensing. SIAM J. Numer. Anal. 49(6), 2543–2563 (2011)
Garg, R., Khandekar, R.: Gradient descent with sparsification: an iterative algorithm for sparse recovery with restricted isometry property. In: Proceedings of the 26th annual international conference on machine learning (2009)
Grant, M., Boyd, S.: CVX: matlab software for disciplined convex programming. Version 1.21, (2017)
Huang, G., Wang, L.: Soft-thresholding orthogonal matching pursuit for efficient signal reconstruction. In: Proceedings of the 2013 IEEE international conference on acoustics, speech and signal processing. 2543–2547 (2013)
Khanna, R., Kyrillidis, A.: IHT dies hard: Provable accelerated iterative hard thresholding. Int. Conf. Artif. Intell. Stat. 188–198 (2018)
Liu, Y., Zhan, Z., Cai, J.F., et al.: Projected iterative soft-thresholding algorithm for tight frames in compressed sensing magnetic resonance imaging. IEEE Trans. Med. Imag. 35(9), 2130–2140 (2016)
Meng, N., Zhao, Y.-B.: Newton-type optimal thresholding algorithms for sparse optimization problems. arXiv preprint arXiv:2104.02371 (2021)
Meng, N., Zhao, Y.-B.: Newton-step-based hard thresholding algorithms for sparse signal recovery. IEEE Trans. Signal Process. 68, 6594–6606 (2020)
Needell, D., Tropp, J.: CoSaMP: iterative signal recovery from incomplete and inaccurate samples. Appl. Comput. Harmon. Anal. 26, 301–321 (2009)
Needell, D., Vershynin, R.: Signal recovery from incomplete and inaccurate measurements via regularized orthogonal matching pursuit. IEEE J. Sel. Top. Signal Process. 4(2), 310–316 (2010)
Patel, V., Chellappa, R.: Sparse representations, compressive sensing and dictionaries for pattern recognition. The First Asian Conference on Pattern Recognition, IEEE. 325–329 (2011)
Tropp, J., Gilbert, A.: Signal recovery from random measurements via orthogonal mathcing pursuit. IEEE Trans. Inform. Theory 53(12), 4655–4666 (2007)
Yuan, X.-T., Liu, Q.: Newton greedy pursuit: A quadratic approximation method for sparsity-constrained optimization. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 4122–4129 (2014)
Zhao, Y.-B., Luo, Z.-Q.: Improved Rip-based bounds for guaranteed performance of two compressed sensing algorithms. arXiv:2007.01451v3 (2020)
Zhao, Y.-B.: Sparse Optimization Theory and Methods. CRC Press, Boca Raton, FL (2018)
Zhao, Y.-B.: Optimal \(k\)-thresholding algorithms for sparse optimization problems. SIAM J. Optim. 30(1), 31–55 (2020)
Zhao, Y.-B., Kočvara, M.: A new computational method for the sparsest solutions to systems of linear equations. SIAM J. Optim. 25(2), 1110–1134 (2015)
Zhao, Y.-B., Li, D.: Reweighted \(\ell _1\)-minimization for sparse solutions to underdetermined linear systems. SIAM J. Optim. 22(3), 1065–1088 (2012)
Zhao, Y.-B., Luo, Z.-Q.: Constructing new reweighted \(\ell _1\)-algorithms for sparsest points of polyhedral sets. Math. Oper. Res. 42, 57–76 (2017)
Zhao, Y.-B., Luo, Z.-Q.: Analysis of optimal thresholding algorithms for compressed sensing. Signal Process. 187, 108148 (2021)
Zhou, S., Pan, L., Xiu, N.: Subspace Newton method for the \(\ell _0 \)-regularized optimization. arXiv:2004.05132 (2020)
Zhou, S., Xiu, N., Qi, H.: Global and quadratic convergence of Newton hard-thresholding pursuit. J. Mach. Learn. Res. 22(12), 1–45 (2021)
Acknowledgements
We would like to thank two reviewers for their helpful comments which help improve the paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was founded by the National Natural Science Foundation of China (NSFC) under the grant 12071307.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Meng, N., Zhao, YB., Kočvara, M. et al. Partial gradient optimal thresholding algorithms for a class of sparse optimization problems. J Glob Optim 84, 393–413 (2022). https://doi.org/10.1007/s10898-022-01143-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10898-022-01143-1