
Abstract
Low-rank matrix recovery problem is difficult due to its non-convex properties and it is usually solved using convex relaxation approaches. In this paper, we formulate the non-convex low-rank matrix recovery problem exactly using novel Ky Fan 2-k-norm-based models. A general difference of convex functions algorithm (DCA) is developed to solve these models. A proximal point algorithm (PPA) framework is proposed to solve sub-problems within the DCA, which allows us to handle large instances. Numerical results show that the proposed models achieve high recoverability rates as compared to the truncated nuclear norm method and the alternating bilinear optimization approach. The results also demonstrate that the proposed DCA with the PPA framework is efficient in handling larger instances.
Similar content being viewed by others

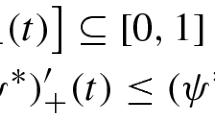
Avoid common mistakes on your manuscript.
1 Introduction
Matrix recovery problem concerns the construction of a matrix from incomplete information of its entries. This problem has a wide range of applications such as recommendation systems with incomplete information of users’ ratings or sensor localization problem with partially observed distance matrices (see, e.g., [4]). In these applications, the matrix is usually known to be (approximately) low-rank. Finding these low-rank matrices are theoretically difficult due to their non-convex properties. Computationally, it is important to study the tractability of these problems given the large scale of datasets considered in practical applications. Recht et al. [21] studied the low-rank matrix recovery problem using a convex relaxation approach which is tractable. More precisely, in order to recover a low-rank matrix \(\varvec{X}\in {\mathbb {R}}^{m\times n}\) which satisfies \(\mathcal{A}(\varvec{X})=\varvec{b}\), where the linear map \({{\mathcal {A}}}:\mathbb {R}^{m\times n}\rightarrow \mathbb {R}^p\) and \(\varvec{b}\in \mathbb {R}^p\), \(\varvec{b}\ne \varvec{0}\), are given, the following convex optimization problem is proposed:
where \(\displaystyle \left\Vert {\varvec{X}}\right\Vert _*=\sum _{i}\sigma _i({\varvec{X}})\) is the nuclear norm, the sum of all singular values of \({\varvec{X}}\). Recht et al. [21] showed the recoverability of this convex approach using some restricted isometry conditions of the linear map \({\mathcal {A}}\). In general, these restricted isometry conditions are not satisfied and the proposed convex relaxation can fail to recover the matrix \({\varvec{X}}\).
Low-rank matrices appear to be appropriate representations of data in other applications such as biclustering of gene expression data. Doan and Vavasis [7] proposed a convex approach to recover low-rank clusters using dual Ky Fan 2-k-norm instead of the nuclear norm. Ky Fan 2-k-norm is defined as
where \(\sigma _1\ge \cdots \ge \sigma _k\ge 0\) are the first k largest singular values of \(\varvec{A}\), \(k\le k_0=\text{ rank }(\varvec{A})\). The dual norm of the Ky Fan 2-k-norm is denoted by \(\Vert |\,\cdot \,|\Vert _{k,2}^\star \),
These unitarily invariant norms (see, e.g., Bhatia [3]) and their gauge functions have been used in sparse prediction problems [1], low-rank regression analysis [8] and multi-task learning regularization [12]. When \(k=1\), the Ky Fan 2-k-norm is the spectral norm, \(\left\Vert \varvec{A}\right\Vert =\sigma _1(\varvec{A})\), the largest singular value of \(\varvec{A}\), whose dual norm is the nuclear norm. Similar to the nuclear norm, the dual Ky Fan 2-k-norm with \(k>1\) can be used to compute the k-approximation of a matrix \(\varvec{A}\) (Proposition 2.9, [7]), which demonstrates its low-rank property. Motivated by this low-rank property of the (dual) Ky Fan 2-k-norm, which is more general than that of the nuclear norm, and its usage in other applications, we aim to utilize this norm to solve the matrix recovery problem.
In addition to the convex relaxation approach using nuclear norm, there have been many non-convex approaches for the matrix recovery problem. The recent survey paper by Nguyen et al. [18] surveys and extensively tests many of these methods. According to [18], a natural dichotomy distinguishes methods for which k is a priori unknown versus methods that prescribe k. Our proposed approach falls into the latter category. Among those methods that prescribe k, the next dichotomy is between methods based on nuclear-norm minimization versus those that attempt to directly minimize the residual \(\Vert {{\mathcal {A}}}({\varvec{X}})-\varvec{b}\Vert \) by carrying out some form of constraint-preserving descent on \({\varvec{X}}\). Methods based on nuclear-norm minimization generally have better recovery rates according to the experiments of [18].
Although our method is in neither of these categories, it is more similar to nuclear-norm based methods of [18] because it minimizes convex norms and does not maintain feasible iterates. Of the non-convex methods, the method with the best recovery rate according to [18] is called truncated nuclear norm minimization (TNN) by Hu et al. [10]. TNN minimizes the non-convex function \(\Vert {\varvec{X}}\Vert _* - \Vert |{\varvec{X}}|\Vert _{k,1}\), where \(\Vert |{\varvec{X}}|\Vert _{k,1}\) denotes the sum of the largest k singular values of \({\varvec{X}}\), the Ky Fan 1-k-norm. It should be observed that \(\Vert {\varvec{X}}\Vert _* - \Vert |{\varvec{X}}|\Vert _{k,1}\) is nonnegative and is the sum of singular values \(k+1,k+2,\ldots ,\min (m,n)\). Therefore, \(\Vert {\varvec{X}}\Vert _* - \Vert |{\varvec{X}}|\Vert _{k,1}=0\) if and only if \(\text {rank}({\varvec{X}})\le k\), hence TNN is an exact formulation of the original problem. We are going to compare our proposed approach with TNN among others.
1.1 Contributions and paper outline
In this paper, we focus on non-convex approaches for the matrix recovery problem using the (dual) Ky Fan 2-k-norm. Specifically, our contributions and the structure of the paper are as follows:
-
1.
We propose a Ky Fan 2-k-norm-based non-convex approach to solve the matrix recovery problem and discuss the proposed models in detail in Sect. 2.
-
2.
We develop numerical algorithms to solve those models in Sect. 3, which includes the framework for difference of convex functions algorithm (DCA) and a proximal point algorithm (PPA) framework to solve the (dual) Ky Fan 2-k-norm optimization problems.
-
3.
Numerical results are presented in Sect. 4 to compare the proposed approach with other approaches, including the convex relaxation approach and TNN, in terms of recoverability.
2 Ky Fan 2-k-norm-based models
The Ky Fan 2-k-norm is the \(\ell _2\)-norm of the vector of k largest singular values with \(k\le \min \{m,n\}\). Thus we have:
where \(\left\Vert \cdot \right\Vert _F\) is the Frobenius norm. Now consider the dual Ky Fan 2-k-norm and use the definition of the dual norm, we obtain the following inequality:
Thus we have:
It is clear that these inequalities become equalities if and only if \(\text {rank}(\varvec{A})\le k\). It shows that to find a low-rank matrix \({\varvec{X}}\) that satisfies \({{\mathcal {A}}}({\varvec{X}})=\varvec{b}\) with \(\text {rank}({\varvec{X}})\le k\), we can solve either the following optimization problem
or
It is straightforward to see that these non-convex optimization problems can be used to recover low-rank matrices as stated in the following theorem given the norm inequalities in (4).
Theorem 1
If there exists a matrix \({\varvec{X}}\in \mathbb {R}^{m\times n}\) such that \(\text{ rank }({\varvec{X}})\le k\) and \({{\mathcal {A}}}({\varvec{X}})=\varvec{b}\), then \({\varvec{X}}\) is an optimal solution of (5) and (6).
Given the result in Theorem 1, the exact recovery of a low-rank matrix using (5) or (6) relies on the uniqueness of the low-rank solution of \({\mathcal {A}}({\varvec{X}})=\varvec{b}\). Recht et al. [21] generalized the restricted isometry property of vectors introduced by Candès and Tao [5] to matrices and used it to provide sufficient conditions on the uniqueness of these solutions.
Definition 1
(Recht et al. [21]) For every integer k with \(1\le k\le \min \{m,n\}\), the k-restricted isometry constant is defined as the smallest number \(\delta _k({{\mathcal {A}}})\) such that
holds for all matrices \({\varvec{X}}\) of rank at most k.
Using Theorem 3.2 in Recht et al. [21], we can obtain the following exact recovery result for (5) and (6).
Theorem 2
Suppose that \(\delta _{2k}({\mathcal {A}})<1\) and there exists a matrix \({\varvec{X}}\in {\mathbb {R}}^{m\times n}\) which satisfies \({{\mathcal {A}}}({\varvec{X}})=\varvec{b}\) and \(\text {rank}({\varvec{X}})\le k\), then \({\varvec{X}}\) is the unique solution to (5) and (6), which implies exact recoverability.
The condition in Theorem 2 is indeed stronger than those obtained for the nuclear norm approach such as the condition of \(\delta _{5k}({{\mathcal {A}}})<1/10\) for exact recovery in Recht et al. [21, Theorem 3.3]. The non-convex optimization problems (5) and (6) use norm ratio and difference. When \(k=1\), the norm ratio and difference are computed between the nuclear and Frobenius norm. The idea of using these norm ratios and differences with \(k=1\) has been used to generate non-convex sparse generalizer in the vector case, i.e., \(m=1\). Yin et al. [24] investigated the ratio \(\ell _1/\ell _2\) while Yin et al. [25] analyzed the difference \(\ell _1-\ell _2\) in compressed sensing. Note that even though optimization formulations based on these norm ratios and differences are non-convex, they are still relaxations of \(\ell _0\)-norm minimization problem unless the sparsity level of the optimal solution is \(s=1\). Our proposed approach is similar to the idea of the truncated difference of the nuclear norm and Frobenius norm discussed in Ma et al [16]. Given a parameter \(t\ge 0\), the truncated difference is defined as
For \(t\ge k-1\), the problem of truncated difference minimization can be used to recover matrices with rank at most k given that \(\left\Vert {\varvec{X}}\right\Vert _{*,t-F}=0\) if \(\text {rank}({\varvec{X}})\le t+1\). Similar results for exact recovery as in Theorem 2 are provided in Theorem 3.7(a) in Ma et al [16]. Despite the similarity with respect to the recovery results, the problems (5) and (6) are motivated from a different perspective.
The proposed approach uses the inequality between the dual Ky Fan 2-k-norm and the Frobenius norm. Given the norm inequalities in (4), we can also generate different non-convex optimization problems using the Ky Fan 2-k-norm instead of its dual together with the Frobenius norm. These problems put the Ky Fan 2-k-norm in the non-convex objective term of the objective, which will be represented only via a (linear) approximation during the inner iterations of the DCA framework, which will be discussed in the next section. This is contrast to our method, where the dual Ky Fan 2-k norm appears in the convex term and therefore is exactly represented on outer iterations, which we believe is preferable. Note that if we use 1-norms, i.e., nuclear norm instead of Frobenius norm and Ky Fan 1-k-norm, \(\Vert |\cdot |\Vert _{k,1}\), instead of 2-k-norm, we get the TNN method directly from the difference model. We believe that, instead of the (dual) Ky Fan 1-k-norm, it is preferable in general to use the (dual) Ky Fan 2-k-norm given its property regarding rank-k approximation (see further remarks on this matter in [7]). This explains why the models (5) and (6) are proposed. We are now going to discuss how to solve these problems next.
3 Numerical algorithm
3.1 Difference of convex functions algorithms
We start with the problem (5). It can be reformulated as
with the change of variables \(z=1/\Vert |{\varvec{X}}|\Vert _{k,2}^{\star }\) and \(\varvec{Z}= {\varvec{X}}/\Vert |{\varvec{X}}|\Vert _{k,2}^{\star }\). The compact formulation is
where \({\mathcal {Z}}\) is the feasible set of the problem (8) and \(\delta _{{{\mathcal {Z}}}}(\cdot )\) is the indicator function of \(\mathcal Z\). The problem (9) is a difference of convex functions (d.c.) optimization problem (see, e.g. [19]). The difference of convex functions algorithm DCA proposed in [19] can be applied to the problem (9) as shown in Algorithm 1.
Algorithm 1
(DCA-R)
Step 1. Start with \((\varvec{Z}^0,z^0)=({\varvec{X}}^0/\Vert |{\varvec{X}}^0|\Vert _{k,2}^{\star },1/\Vert |{\varvec{X}}^0|\Vert _{k,2}^{\star })\) for some \({\varvec{X}}^0\) such that \({{\mathcal {A}}}({\varvec{X}}^0)=\varvec{b}\) and set \(s=0\).
Step 2. Update \((\varvec{Z}^{s+1},z^{s+1})\) as an optimal solution of the following convex optimization problem
Step 3. Set \(s\leftarrow s+1\) and repeat Step 2.
Let \({\varvec{X}}^s=\varvec{Z}^s/z^s\) and use the general convergence analysis of DCA (see, e.g., Theorem 3.7 in [20]), we can obtain the following convergence results.
Proposition 1
Given the sequence \(\{{\varvec{X}}^s\}\) obtained from the DCA for the problem (9), the following statements are true.
-
(i)
The sequence \(\displaystyle \left\{ \frac{\Vert |{\varvec{X}}^s|\Vert _{k,2}^{\star }}{\left\Vert {\varvec{X}}^s\right\Vert _F}\right\} \) is non-increasing and convergent.
-
(ii)
\(\displaystyle \left\Vert \frac{{\varvec{X}}^{s+1}}{\Vert |{\varvec{X}}^{s+1}|\Vert _{k,2}^{\star }}-\frac{{\varvec{X}}^{s}}{\Vert |{\varvec{X}}^{s}|\Vert _{k,2}^{\star }}\right\Vert _F\rightarrow 0 \) when \(s\rightarrow \infty \).
The convergence results show that the DCA improves the objective function value of the ratio minimization problem (5). The DCA can stop if \((\varvec{Z}^s,z^s)\in {{\mathcal {O}}}(\varvec{Z}^s)\), where \(\mathcal{O}(\varvec{Z}^s)\) is the set of optimal solution of (10) and \((\varvec{Z}^s,z^s)\) which satisfied this condition is called a critical point. Note that (local) optimal solutions of (9) can be shown to be critical points. The following proposition shows that an equivalent condition for critical points.
Proposition 2
\((\varvec{Z}^s,z^s)\in {{\mathcal {O}}}(\varvec{Z}^s)\) if and only if \({\varvec{Y}}=\varvec{0}\) is an optimal solution of the following optimization problem
Proof
Consider \({\varvec{Y}}\in \text{ Null }({{\mathcal {A}}})\), i.e., \(\mathcal{A}({\varvec{Y}})=\varvec{0}\), we then have:
We compute the objective function value in (10) for this solution and compare that of \((\varvec{Z}^s,z^s)\). We have: \(\displaystyle \langle \frac{{\varvec{X}}^s}{\Vert |{\varvec{X}}^s|\Vert _{k,2}^\star } , \frac{{\varvec{X}}^s+{\varvec{Y}}}{\Vert |{\varvec{X}}^s+{\varvec{Y}}|\Vert _{k,2}^\star } \rangle \le \langle \frac{{\varvec{X}}^s}{\Vert |{\varvec{X}}^s|\Vert _{k,2}^\star } , \frac{{\varvec{X}}^s}{\Vert |{\varvec{X}}^s|\Vert _{k,2}^\star } \rangle \) is equivalent to
When \({\varvec{Y}}=\varvec{0}\), we achieve the equality. We have: \((\varvec{Z}^s,z^s)\in {{\mathcal {O}}}(\varvec{Z}^s)\) if and only the above inequality holds for all \({\varvec{Y}}\in \text{ Null }({{\mathcal {A}}})\), which means \(f({\varvec{Y}};{\varvec{X}}^s)\ge f(\varvec{0};{\varvec{X}}^s)\) for all \({\varvec{Y}}\in \text{ Null }(\mathcal{A})\), where \(f({\varvec{Y}};{\varvec{X}})=\displaystyle \Vert |{\varvec{X}}+{\varvec{Y}}|\Vert _{k,2}^\star -\frac{\Vert |{\varvec{X}}|\Vert _{k,2}^\star }{\left\Vert {\varvec{X}}\right\Vert _F^2}\cdot \langle {\varvec{X}} , {\varvec{Y}} \rangle \). Clearly, it is equivalent to the fact that \({\varvec{Y}}=\varvec{0}\) is an optimal solution of (11).\(\square \)
The result of Proposition 2 shows the similarity between the norm ratio minimization problem (5) and the norm different minimization problem (6) with respect to the implementation of the DCA. It is indeed that the problem (6) is a DC optimization problem with the objective function as the difference between the dual Ky Fan 2-k-norm and the Frobenius norm together with a convex feasible set. Given that the linear approximation of the Frobenius norm is \(\left\Vert {\varvec{X}}+{\varvec{Y}}\right\Vert _F\approx \displaystyle \left\Vert {\varvec{X}}\right\Vert _F+\frac{1}{\left\Vert {\varvec{X}}\right\Vert _F}\langle {\varvec{X}} , {\varvec{Y}} \rangle \) for \({\varvec{X}}\ne \varvec{0}\), the DCA for (6) can be described as Algorithm 2 as follows.
Algorithm 2
(DCA-D)
Step 1. Start with some \({\varvec{X}}^0\) such that \(\mathcal{A}({\varvec{X}}^0)=\varvec{b}\) and set \(s=0\).
Step 2. Update \({\varvec{X}}^{s+1}={\varvec{X}}^s+{\varvec{Y}}\), where \({\varvec{Y}}\) is an optimal solution of the following convex optimization problem
Step 3. Set \(s\leftarrow s+1\) and repeat Step 2.
Note that in (12), we change the variable from \({\varvec{X}}\) to \({\varvec{Y}}={\varvec{X}}-{\varvec{X}}^s\), which results in the constraints \(\mathcal{A}({\varvec{Y}})=\varvec{0}\) for \({\varvec{Y}}\) given that \({{\mathcal {A}}}({\varvec{X}}^s)=\varvec{b}\). Now, it is clear that \({\varvec{X}}^s\) is a critical point for the problem (6) if and only if \({\varvec{Y}}\) is an optimal solution of (12). Both problems (11) and (12) can be written in the general form as
where \(\displaystyle \alpha ({\varvec{X}})=\frac{\Vert |{\varvec{X}}|\Vert _{k,2}^\star }{\left\Vert {\varvec{X}}\right\Vert _F^2}\) for (11) and \(\displaystyle \alpha ({\varvec{X}})=\frac{1}{\left\Vert {\varvec{X}}\right\Vert _F}\) for (12), respectively. Given that \(\mathcal{A}({\varvec{X}}^s)=\varvec{b}\), these problems can be written as
The following proposition shows that \({\varvec{X}}^s\) is a critical point of the problem (14) for many functions \(\alpha (\cdot )\) if \(\text {rank}({\varvec{X}}^s)\le k\).
Proposition 3
If \(\text {rank}({\varvec{X}}^s)\le k\), \({\varvec{X}}^s\) is a critical point of the problem (14) for any function \(\alpha (\cdot )\) which satisfies
Proof
If \(\text {rank}({\varvec{X}}^s)\le k\), we have: \(\alpha ({\varvec{X}}^s)=1/\Vert |{\varvec{X}}^s|\Vert _{k,2}\) since \(\Vert |{\varvec{X}}^s|\Vert _{k,2}=\left\Vert {\varvec{X}}^s\right\Vert _F=\Vert |{\varvec{X}}^s|\Vert _{k,2}^{\star }\). Given that
we have: \(\alpha ({\varvec{X}}^s)\cdot {\varvec{X}}^s\in \partial \Vert |{\varvec{X}}^s|\Vert _{k,2}^{\star }\). Thus for all \({\varvec{Y}}\), the following inequality holds:
It implies \({\varvec{Y}}=\varvec{0}\) is an optimal solution of the problem (13) since the optimality condition is
Thus \({\varvec{X}}^s\) is a critical point of the problem (14).\(\square \)
Proposition 3 shows that one can potentially use different functions \(\alpha (\cdot )\) such as \(\displaystyle \alpha ({\varvec{X}})=\frac{1}{\Vert |{\varvec{X}}|\Vert _{k,2}}\) for the sub-problem in the general DCA framework to solve the original problem. We are going to experiment with different pre-determined functions \(\alpha (\cdot )\) in the numerical section. Now, the generalized sub-problem (14) is a convex optimization problem, which can be formulated as a semidefinite optimization problem given the following calculation of the dual Ky Fan 2-k-norm provided in [7]:
In order to implement the DCA, one also needs to consider how to find the initial solution \({\varvec{X}}^0\). We can use the nuclear norm minimization problem (1), the convex relaxation of the rank minimization problem, to find \({\varvec{X}}^0\). A similar approach is to use the following dual Ky Fan 2-k-norm minimization problem to find \({\varvec{X}}^0\) given its low-rank properties:
This initial problem can be considered as an instance of (14) with \({\varvec{X}}^0=\varvec{0}\). Given that \(\langle {\varvec{X}}^0 , {\varvec{X}} \rangle =0\), one can set any value for \(\alpha (\varvec{0})\), e.g., \(\alpha (\varvec{0})=1\). It is equivalent to starting the iterative algorithm with \({\varvec{X}}^0=\varvec{0}\) one step ahead. All of these instances of (14) can be solved with a semidefinite optimization solver, which will not be efficient for large problem instances. In the next section, we will develop a primal-dual proximal point algorithm to solve (14).
3.2 Proximal point algorithm
Liu et al. [15] proposed a proximal point algorithm (PPA) framework to solve the nuclear norm minimization problem (1). We will develop a similar algorithm to solve the following general problem
where \(\varvec{C}\in \mathbb {R}^{m\times n}\) is a parameter, of which (14) is an instance.
This section is divided into four subsections as follows.
-
1.
We first write down the dual problem, its Moreau-Yoshida regularization, and finally a spherical quadratic approximation of the smooth term. Deriving the formulation of norm-plus-spherical is the main task needed in order to use the PPA framework.
-
2.
Next, we argue by symmetry that the norm-plus-spherical subproblem can be rewritten as a vector-norm optimization problem involving only the largest singular values of a certain matrix.
-
3.
This vector-norm optimization problem can be solved in closed form. This requires several technical results whose proofs are deferred to Appendix A.
-
4.
Finally, we summarize all the computations of the PPA method.
3.2.1 Deriving the norm-plus-spherical subproblem
The steps involved in setting up the PPA framework are formulating the dual, its Moreau-Yoshida regularization, and the quadratic approximation thereof. The dual problem can be written simply as \(\displaystyle \max _{{\varvec{z}}} g({\varvec{z}})\), where g is the concave function defined by
The Moreau-Yoshida regularization of g can be computed by applying the strong duality (or minimax theory) result in Rockafellar [22]:
The inner optimization problem can be solved easily with \({\varvec{y}}^*={\varvec{z}}+(\varvec{b}-{\mathcal {A}}({\varvec{X}}))\). Thus we can write down the Moreau-Yoshida regularization of g as follows:
where
The function \(\Psi _{\lambda }(\cdot ;{\varvec{z}})\) is convex and differentiable with the gradient \(\displaystyle \nabla _{\varvec{X}}\Psi _{\lambda }({\varvec{X}};{\varvec{z}})= -{\mathcal {A}}^*\left( {\varvec{z}}+\lambda (\varvec{b}-{\mathcal {A}}({\varvec{X}}))\right) \), which is Lipschitz continuous with modulus \(L=\lambda \left\Vert {\mathcal {A}}\right\Vert _2^2\). In order to find the proximal point mapping \(p_{\lambda }\) associated with g, we need to find an optimal solution \({\varvec{X}}^*\) for the inner minimization problem in (21) since \(p_\lambda ({\varvec{z}})={\varvec{z}}+\lambda (\varvec{b}-{\mathcal {A}}({\varvec{X}}^*))\). For a fixed \({\varvec{z}}\), the inner minimization problem we need to consider is
where \(P({\varvec{X}})=\Psi _{\lambda }({\varvec{X}};{\varvec{z}})\). As discussed in Liu et al. [15], we will use an accelerated proximal gradient (APG) algorithm for this problem. The APG algorithm in each iteration needs to solve the following approximation of the sum \(f({\varvec{X}})+P({\varvec{X}})\) at the current solution \(\varvec{Z}\):
where \(\displaystyle G_t(\varvec{Z})=\varvec{Z}-\frac{1}{t}\nabla P(\varvec{Z})\) and \(t>0\) is a parameter.
This problem has a unique solution \(S_t(\varvec{Z})\) given the strong convexity of the function. We have:
which means \(S_t(\varvec{Z})\) is the minimizer of the problem:
which is an instance of the following optimization problem
where \(\lambda =1/t>0\) and \(\displaystyle {\varvec{Y}}=G_t(\varvec{Z})-\frac{1}{t}\varvec{C}\) are parameters. For the nuclear norm minimization problem, the dual Ky Fan 2-k-norm is replaced by the nuclear norm and the resulting problem can be solved easily with the SVD decomposition and the shrinkage operator (see, e.g., Liu et al. [15] and references therein).
3.2.2 Reduction of the norm-plus-spherical problem to a convex vector-norm problem
Using the orthogonal invariance of \(\Vert |\cdot |\Vert _{k,2}^*\), we first prove that the optimal solution \({\varvec{X}}^*\) of (24) can be constructed from the optimal solution \({\varvec{x}}^*\) of the following optimization problem:
where \(\left\Vert {\varvec{x}}\right\Vert _{k,2}^*\) is the dual of the Ky Fan 2-k-vector norm of \({\varvec{x}}\), \(\displaystyle \left\Vert {\varvec{x}}\right\Vert _{k,2}=\left( \sum _{i=1}^k\left|x \right|_{(i)}^2\right) ^{\frac{1}{2}}\), with \(\left|x \right|_{(i)}\) is the \((n-i+1)\)-th order statistic of \(\left|{\varvec{x}} \right|\). \(\left\Vert \cdot \right\Vert _{k,2}^*\) is the corresponding symmetric gauge function of \(\Vert |\cdot |\Vert _{k,2}^*\) and the above result which we shall prove can actually be applied to any orthogonally invariant matrix norm \(\Vert |\cdot |\Vert \) and its corresponding symmetric gauge function \(\left\Vert \cdot \right\Vert \). We start with the following lemma.
Lemma 1
Consider the optimal solution \({\varvec{x}}^*\) of the following optimization problem:
where \(\left\Vert \cdot \right\Vert \) is a symmetric gauge function. The following statements are true.
-
(i)
If \({\varvec{y}}\ge \varvec{0}\) then \({\varvec{x}}^*\ge \varvec{0}\).
-
(ii)
If \(y_i\ge y_j\) then \(x_i^*\ge x_j^*\).
Proof
-
(i)
If \({\varvec{x}}^*\not \ge \varvec{0}\), without loss of generality, let us assume that \(x^*_1<0\). Construct the solution \({\varvec{x}}\) from \({\varvec{x}}^*\) by inverting the sign of the first element, \(x_1=-x_1^*>0\). We have: \(\left\Vert {\varvec{x}}\right\Vert =\left\Vert {\varvec{x}}^*\right\Vert \) and \(\left\Vert {\varvec{x}}-{\varvec{y}}\right\Vert _2\le \left\Vert {\varvec{x}}^*-{\varvec{y}}\right\Vert _2\). Thus \({\varvec{x}}\ne {\varvec{x}}^*\) is also an optimal solution of (26), which contradicts the uniqueness of the optimal solution \({\varvec{x}}^*\). Thus we have \({\varvec{x}}^*\ge \varvec{0}\).
-
(ii)
Assume that \(x_i^*<x_j^*\), we construct another solution \({\varvec{x}}\) as follows.
$$\begin{aligned} x_k=x_k^*,\,k\ne i,j,\quad x_i=x_j^*,\,x_j=x_i^*. \end{aligned}$$We have: \(\left\Vert {\varvec{x}}\right\Vert =\left\Vert {\varvec{x}}^*\right\Vert \) since \(\left\Vert .\right\Vert \) is a symmetric gauge function. We have:
$$\begin{aligned} \begin{array}{rl} \left\Vert {\varvec{x}}^*-{\varvec{y}}\right\Vert _2^2-\left\Vert {\varvec{x}}-{\varvec{y}}\right\Vert _2^2 &{}=(x_i^*-y_i)^2+(x_j^*-y_j)^2-(x_i^*-y_j)^2-(x_j^*-y_i)^2\\ \quad &{}=(x_i^*-x_j^*)(y_j-y_i)\ge 0. \end{array} \end{aligned}$$Thus \({\varvec{x}}\ne {\varvec{x}}^*\) is also an optimal solution of (26), which contradicts the uniqueness of the optimal solution \({\varvec{x}}^*\). Thus we have \(x_i^*\ge x_j^*\).
\(\square \)
We can now state the main result for the optimization problem with the general orthogonally invariant norm \(\Vert |.|\Vert \),
Proposition 4
If \({\varvec{Y}}=\varvec{U}\text{ Diag }(\varvec{\sigma }({\varvec{Y}}))\varvec{V}^T\) is a singular decomposition of \({\varvec{Y}}\), then the optimal solution \({\varvec{X}}^*\) of (27) can be calculated as
where \({\varvec{x}}^*\) is the optimal solution of (26) with \({\varvec{y}}=\varvec{\sigma }({\varvec{Y}})\).
Proof
Problem (27) with the general \(\Vert |.|\Vert \) has a unique optimal solution \({\varvec{X}}^*\) that satisfies the following optimality condition:
Similarly, the optimal solution \({\varvec{x}}^*\) satisfies the condition
We have: \({\varvec{y}}=\varvec{\sigma }({\varvec{Y}})\ge \varvec{0}\). Thus according to Lemma 1, \({\varvec{x}}^*\ge \varvec{0}\). Similarly, \(y_1\ge \ldots \ge y_n\) implies that \(x_1^*\ge \ldots \ge x_n^*\).
Now let us consider \({\varvec{X}}=\varvec{U}\text{ Diag }({\varvec{x}}^*)\varvec{V}^T\), we have: \(\varvec{\sigma }({\varvec{X}})={\varvec{x}}^*\). According to Ziȩtak [26], the subgradient of \(\Vert |.|\Vert \) is
where \({\varvec{X}}=\bar{\varvec{U}}\text{ Diag }(\varvec{\sigma }({\varvec{X}}))\bar{\varvec{V}}^T\) is any singular value decomposition of \({\varvec{X}}\). We have: \(\displaystyle \frac{1}{\lambda }({\varvec{y}}-{\varvec{x}}^*)\in \partial \left\Vert \varvec{\sigma }({\varvec{X}})\right\Vert \), thus
\({\varvec{X}}\) satisfies the optimality condition, thus \(\varvec{U}\text{ Diag }({\varvec{x}}^*)\varvec{V}^T\) is the (unique) optimal solution of (27).\(\square \)
3.2.3 Solution of the vector-norm problem
Proposition 4 shows that we can focus on (25). The following proposition is proved in Appendix A.
Proposition 5
The dual Ky Fan 2-k-vector norm can be computed using the following formulation:
where
We are now ready to solve the problem (25). The optimality condition for (25) can be written as follows:
We shall focus on the case \({\varvec{y}}=\sigma ({\varvec{Y}})\ge \varvec{0}\) and assume that \(y_1\ge \cdots \ge y_n\ge 0\). Using the formulation of \(\left\Vert \cdot \right\Vert _{k,2}^*\) stated in Proposition 5, we can compute the subgradient \(\partial \left\Vert \cdot \right\Vert _{k,2}^*\) as follows. If \({\varvec{y}}=\varvec{0}\), we have:
If \({\varvec{y}}\ne \varvec{0}\), compute \(i^*\in [0,k-1]\) using (29). For \(1\le j\le k-i^*-1\), we have:
Let assume that there are \(n_0\) zeros among the last \(n-k+i^*+1\) elements of \({\varvec{y}}\) starting from \((k-i^*)\)-th element. For \(k-i^*\le j\le n-n_0\), we have:
Finally we have:
where \(\varvec{e}_{n_0}\in \mathbb {R}^{n_0}\) is the vector of all ones.
Using the formulation of the subgradient at \({\varvec{x}}=\varvec{0}\) and the uniqueness of the optimal solution, we can show that if \(\left\Vert {\varvec{y}}\right\Vert _{k,2}\le \lambda \), then \({\varvec{x}}=\varvec{0}\) is the optimal solution of (25). Now consider the case \(\left\Vert {\varvec{y}}\right\Vert _{k,2}>\lambda \). According to Lemma 1, the optimal solution of (25) is nonnegative, i.e., \({\varvec{x}}\ge \varvec{0}\). Assuming that the values of \(i^*\) and \(n_0\) have been given, the optimality conditions can then be written as follows:
where \(\alpha =\left\Vert \varvec{x}\right\Vert _{k,2}^*/\lambda \), \(m_0=n-n_0-k+i^*+1\) and \(\varvec{I}_{m_0}\in \mathbb {R}^{m_0\times m_0}\) is the identity matrix. Using the Sherman-Morrison formula for the inverse of \(\displaystyle \varvec{I}_{m_0}+\frac{1}{(i^*+1)\alpha }\varvec{e}_{m_0}\varvec{e}_{m_0}^T\), we obtain the analytic formulation for \({\varvec{x}}\):
The unknown \(\alpha >0\) satisfies the following equation:
or equivalently
Given the relationship between \({\varvec{x}}\) and \({\varvec{y}}\), we have:
The function \(f(\alpha )\) is a (strictly) decreasing function on \([0,+\infty )\); therefore, the necessary conditions are \(f(0)>1\) and \(f(\alpha _{\max })<1\). If \(f(0)>1\) and \(f(\alpha _{\max })<1\), the value of \(\alpha \) can be found using the efficient binary search. Given the values of \(i^*\), \(n_0\), and \(\alpha \), the solution \({\varvec{x}}\) can be computed completely. Note that the optimal solution \({\varvec{x}}\) is unique, which guarantees that if all optimality conditions are satisfied and \(i^*\) is correct according to (29), we indeed obtain the unique optimal solution \({\varvec{x}}\).
3.2.4 PPA summary
The analyses in the preceding paragraphs result in Algorithm 3 that can be used to solve the problem (25).
Algorithm 3
(PROX)
Step 1. Compute \(\left\Vert {\varvec{y}}\right\Vert _{k,2}^*\). If \(\left\Vert {\varvec{y}}\right\Vert _{k,2}^*\le \lambda \), return \({\varvec{x}}=\varvec{0}\). Otherwise, continue.
Step 2. Iterate \(n_0=1:n\) and \(i^*=\max \{0,k-1+n_0-n\}:k-1\):
Step 2.1. Compute f(0) and \(f(\alpha _{\max })\). If \(f(0)>1\) and \(f(\alpha _{\max }))<1\), compute \(\alpha \) using (36) and go to Step 2.2. Otherwise, continue to the next iteration.
Step 2.2. Compute \({\varvec{x}}\) using (33), (34), and (35). If \({\varvec{x}}\ge \varvec{0}\), (32) and (29) are satisfied, return \({\varvec{x}}\). Otherwise, continue to the next iteration.
Algorithm 3 together with Proposition 4 allows us to solve the problem (24) using the SVD decomposition, which means that we can compute \(S_t(\varvec{Z})\) efficiently. The APG algorithm for solving (23) can then be described as follows. Given \(\tau _0=\tau _{-1}=1\) and \({\varvec{X}}^0={\varvec{X}}^{-1}\), each iteration includes the following steps
Step 1. Calculate \(\displaystyle {\varvec{Y}}^s={\varvec{X}}^s+\frac{\tau _{s-1}-1}{\tau _s}\left( {\varvec{X}}^{s}-{\varvec{X}}^{s-1}\right) \).
Step 2. Update \({\varvec{X}}^{s+1}=S_{t_s}({\varvec{Y}}^s)\) using Algorithm 3and Proposition 4.
Step 3. Update \(\displaystyle \tau _{s+1}=\frac{1}{2}\left( \sqrt{1+4\tau _s^2}+1\right) \).
The additional parameter \(\tau _s\) and how it is updated in each step are necessary for the convergence analysis of the APG algorithm when \(t_s\) is set to be L, the Lipschitz modulus of the gradient \(\nabla P({\varvec{Y}})\) (see, e.g., Beck and Teboulle [2]). We now can write down the proximal point algorithm (PPA) to solve the problem (18) as follows:
Algorithm 4
(PPA)
Given a tolerance \(\varepsilon >0\). Input \({\varvec{z}}^0\) and \(\lambda _0>0\). Set \(s=0\). Iterate:
Step 1. Find an approximate minimizer
where \(\Psi _{\lambda _s}({\varvec{X}}; {\varvec{z}}^s)\) is defined as in (22).
Step 2. Compute
Step 3. If \(\left\Vert ({\varvec{z}}^{s+1}-{\varvec{z}}^{s})/\lambda _s\right\Vert \le \varepsilon \); stop; else; update \(\lambda _s\) ; end.
The proximal parameter \(\lambda _s\) affects the convergence speeds of both inner optimization problem (37) and the whole PPA algorithm. Similar to the discussion in Doan et al. [6], one can initially fix \(\lambda _0\) and increase \(\lambda _s\) only when the outer algorithm converges too slowly as compared to the inner algorithm. One can use the relative convergence measure \(\displaystyle rel_o^s=\frac{\left\Vert \varvec{b}-{{\mathcal {A}}}({\varvec{X}}^s)\right\Vert }{\left\Vert \varvec{b}\right\Vert }\) for the outer algorithm and \(\displaystyle rel^s_i=\frac{\left\Vert {\varvec{X}}^s-{\varvec{X}}^{s-1}\right\Vert _F}{\left\Vert {\varvec{X}}^s\right\Vert _F}\) for the inner algorithm in deciding when to increase \(\lambda _s\). This PPA algorithm can then be used in Step 2 of the proposed DCA to solve the problem (10), which is an instance of (18). We are now ready to provide numerical results to demonstrate the effectiveness of the proposed approach.
4 Numerical results
In this section, we are going to discuss the proposed general DCA framework both in terms of computation and recoverability. Similar to Candès and Recht [4], we construct the following the experiment. We generate \(\varvec{M}\), an \(m\times n\) matrix of rank r, by sampling two \(m\times r\) and \(n\times r\) factors \(\varvec{M}_L\) and \(\varvec{M}_R\) with i.i.d. Gaussian entries and setting \(\varvec{M} = \varvec{M}_L\varvec{M}_R\). The linear map \({\mathcal {A}}\) is constructed with s independent Gaussian matrices \(\varvec{A}_i\) whose entries follows \({{\mathcal {N}}}(0,1/s)\), i.e.,
We now start with computational settings for the proposed DCA framework.
4.1 Computational settings
The proposed general DCA framework allows us to choose the function \(\alpha (\cdot )\) for the subproblem as well as the initial solution. In order to test different functions \(\alpha (\cdot )\), we generate \(K=50\) matrix \(\varvec{M}\) with \(m=50\), \(n=40\), and \(r=2\). The dimension of these matrices is \(d_r=r(m+n-r)=176\). For each \(\varvec{M}\), we generate s matrices for the random linear map with \(s=200\). We set the maximum number of iterations of the algorithm to be \(N_{\max } = 100\) together with the tolerance of \(\epsilon =10^{-6}\) for \(\left\Vert {\varvec{X}}^{s+1}-{\varvec{X}}^s\right\Vert _F\). For this experiment, the instances are solved using SDPT3 solver [23] for semi-definite optimization problems in Matlab with CVX [9]. The computer used for these numerical experiments is a 64-bit Windows 10 machine with 3.70GHz quad-core CPU, and 32GB RAM. We run the proposed DCA with \(k=r=2\) and three different pre-determined functions, \(\alpha _1({\varvec{X}})=\displaystyle \frac{1}{\left\Vert {\varvec{X}}\right\Vert _F}\), \(\displaystyle \alpha _2({\varvec{X}})=\frac{1}{\Vert |{\varvec{X}}|\Vert _{k,2}}\), and \(\displaystyle \alpha _3({\varvec{X}})=\frac{\Vert |{\varvec{X}}|\Vert _{k,2}^{\star }}{\left\Vert {\varvec{X}}\right\Vert _F^2}\). We use the solution obtained from the nuclear optimization formulation (1) as the initial solution for the proposed DCA in this experiment.
Figure 1a shows that all three functions \(\alpha (\cdot )\) perform similarly for most of the instances. However, for difficult instances which require a large number of iterations to converge, \(\alpha _3(\cdot )\) performs the worst as compared to the other two. There is one instance with which the DCA with \(\alpha _3(\cdot )\) does not converge after the maximum number of iterations. Given that \(\alpha _1(\cdot )\) performs slightly better than \(\alpha _2(\cdot )\) in all tested instances, we are going to use \(\alpha _1(\cdot )\) in subsequent experiments.

Computational performance of the DCA under different settings
The next experiment is used to test the options of initial solutions. In this experiment, we vary s from 180 to 500 and generate \(K=50\) instances for each value of s. We run the two variants of the proposed PCA, k2-nuclear with initial solution obtained from (1) and k2-zero with initial solution \({\varvec{X}}^0=\varvec{0}\) as discussed in Sect. 3.1. Figure 1b shows that two variants perform similarly in terms of average number of iterations for most sizes of the random linear map. k2-nuclear is better when the size of the linear map is large, which can be explained by the recoverability of the convex relaxation approach nuclear using the nuclear optimization formulation (1). We shall therefore use k2-nuclear in comparison with other approaches including nuclear in the next section.
4.2 Recoverability
In order to compare the proposed approach with others, we again generate \(K=50\) random instances with \(m=50\), \(n=40\), and \(r=2\) for different sizes of the linear map ranging from 180 to 500. In order to check whether the matrix \(\varvec{M}\) is recovered, we use the relative error \(\displaystyle \frac{\left\Vert {\varvec{X}}-\varvec{M}\right\Vert _F}{\left\Vert \varvec{M}\right\Vert _F}\) as the performance measure. The matrix \(\varvec{M}\) is considered to be recovered successfully if \(\displaystyle \frac{\left\Vert {\varvec{X}}-\varvec{M}\right\Vert _F}{\left\Vert \varvec{M}\right\Vert _F}\le \epsilon _t\), where the threshold \(\epsilon _t\) is set to be \(10^{-6}\) for these experiments. We compare our proposed approach k2-nuclear with nuclear and t-nuclear, an iterative algorithm proposed by Hu et al. [10] for the TNN method. Based on survey paper by Nguyen et al. [18], we also consider the alternating optimization approach proposed by Jain et al. [13] which is used to solve the following equivalent bilinear non-convex optimization problem:
Another approach that we consider is the greedy heuristic of atomic decomposition for minimum rank approximation (admira) proposed by Lee and Bresler [14], which aims to find k rank-one matrices representing the original matrix. Finally, in addition to nuclear, we consider schatten approach proposed by Mohan and Fazel [17] to solve the Schatten p-norm minimization problem with \(p=1/2\), one of the non-convex relaxation methods for which k is a priori unknown (see, e.g., Hu et al. [11]). The tolerance is again set at \(\epsilon =10^{-6}\) for \(\left\Vert {\varvec{X}}^{s+1}-{\varvec{X}}^s\right\Vert _F\) and the maximum number of iterations is set higher at \({\bar{N}}_{\max }=10000\) for these methods given that their (least-squares) subproblems require less computational efforts.
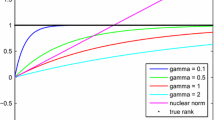
Figure 2a shows recovery probabilities given different sizes of the linear map. The results show that the proposed algorithm can recover exactly the matrix \(\varvec{M}\) with \(100\%\) rate when \(s\ge 200\) while the nuclear norm approach cannot recover any matrix at all, i.e., \(0\%\) rate, if \(s\le 300\). Both admira and schatten approaches cannot recover any matrix even though both of them converges with not very large number of iterations as shown in Fig. 2b. This result indicates that the greedy heuristic does not work well for exact recovery. Note that the schatten approach does not solve the non-convex Schatten p-norm optimization problem exactly, which might explain why it also does not perform well. The bilinear approach is better than the nuclear norm approach with \(100\%\) recovery rate when \(s\ge 300\). However, for small s, its recovery probability drops significantly to \(2\%\) for \(s=190\) and \(0\%\) for \(s=180\). The t-nuclear performs comparably with our proposed approach with \(100\%\) rate for \(s\ge 200\). For \(s=190\) and \(s=180\), our approach achieves better recovery rate of \(98\%\) and \(52\%\) respectively, as compared those of \(92\%\) and \(44\%\) for the t-nuclear approach.

Recovery performance of different algorithms given different sizes of the linear map
For all these three approaches, the average number of iterations increases significantly, especially for the bilinear approach, when the size of the linear map decreases. Both our approach and t-nuclear have similar average numbers of iterations. It is interesting to see that we only need 2 extra iterations when \(s=250\) or 1 extra iteration on average when \(s=300\) to obtain \(100\%\) recover rate when the nuclear norm optimization approach still cannot recover any of the matrices (\(0\%\) rate). The average numbers of iterations for bilinear are much higher, which implies that it has a much slower convergence rate. On the other hand, the computation time per iteration for bilinear is much lower than those for nuclear, t-nuclear, and our proposed approach. It can be explained by the fact that one needs to solve matrix norm minimization problems using SDPT3 in each iteration of these approaches why the solutions of least-squares subproblems of bilinear can be computed directly in Matlab. The computation times per iteration are shown in Fig. 3a while the average computation times are shown in Fig. 3b. It shows that bilinear is much more efficient when the size of the linear map is large. On the other hand, its average computation time increases significantly when the size of the linear map decreases. As compared with t-nuclear, the average computation time of our approach is higher even though the numbers of iterations are similar. One explanation might be that the dual Ky Fan 2-k-norm optimization problem is more difficult to solve than the nuclear norm optimization problem with the SDPT3 solver. We are going to test the proposed proximal point algorithm that can be used to solve the dual Ky Fan 2-k-norm optimization problem (14) for our proposed approach in the next section.

Computational performance of different algorithms given different linear map sizes
To conclude this section, we provide some additional recoverability tests with different rank settings including \(r=1\), \(r=5\) and \(r=10\). Note that when \(k=r=1\), the dual Ky Fan 2-k-norm is the nuclear norm and the objective function in (6) is \(\left\Vert {\varvec{X}}\right\Vert _*-\left\Vert {\varvec{X}}\right\Vert _F\) while that of the TNN method is \(\left\Vert {\varvec{X}}\right\Vert _*-\left\Vert {\varvec{X}}\right\Vert \), whose sub-problems are both nuclear norm optimization problems. We run the experiments with the following settings of (r, s): (1, 95), (2, 180), (5, 440), and (10, 820), in which the size of the linear map is quite close to the dimension \(d_r\). For all ranks, bilinear approach does not recover any matrix with this size of the linear map and the average number of iterations is very close to the maximum number of \({\bar{N}}_{\max }=10000\). Figure 4a shows the recovery probabilities of our proposed approach and t-nuclear. The results indicate that our proposed approach is slightly better than t-nuclear in general in terms of recovery with these small sizes of the linear map. It is interesting to see that there are instances with which one approach can recover the original matrix exactly while the other cannot. Figure 4b shows those instances for \(r=2\) (maximum number of iterations in general indicates no recovery and vice versa under these settings).

Recovery performance of k2 and t-nuclear for different ranks

Computational performance of k2 and t-nuclear for different ranks

Computational performance of k2-zero(sdp) and k2-zero(ppa)

Computational performance of k2-zero(ppa) for different matrix sizes
Figure 5a shows that the average numbers of iterations of our proposed approach are slightly higher than those of t-nuclear. The average computation times of our proposed approach are also higher as shown in Fig. 5b. When \(r=1\), the average computation time per iteration is still higher even though both sub-problems are nuclear norm minimization problems (10.54 seconds vs. 4.49 seconds). It might be explained by the fact that the sub-problem in our approach uses the general dual Ky Fan 2-k-norm for \(k=r=1\) whereas that in t-nuclear uses the function norm_nuc in CVX. In the next section, we are going to test whether the proposed proximal point algorithm can be used to solve subproblems in our proposed approach more efficiently.
4.3 Proximal point algorithm
In this section, we are going to test the proposed proximal point algorithm used to solve the subproblem (14). We start with the same initial setting of \(m=50\), \(n=40\), and \(r=2\) for the original matrix \(\varvec{M}\) and \(s=200\) for the random linear map. Instead of k2-nuclear, we run the proposed algorithm k2-zero with initial solution \({\varvec{X}}^0=\varvec{0}\), which is easier to set without the need of solving the nuclear norm optimization problem. We use the proximal point algorithm (ppa) for the sub-problems and compare it with the original algorithm which uses the interior-point method (sdp) for the semidefinite optimization formulation of the subproblem (14) for \(K=50\) instances. The tolerance is again set to be \(\epsilon =10^{-6}\) and the maximum number of iterations is \(N_{\max }=100\). The tolerance for the proximal point algorithm is set to be \(\epsilon _p=10^{-8}\) with the maximum number of iterations of \(N^p_{\max }=100\). We set \(\lambda _0=10\) and will increase \(\lambda _{s+1}=1.25\cdot \lambda _s\) if \(rel_o^s>5\cdot rel_i^s\). Figure 6a shows that in general the algorithm k2-zero(ppa) requires more iterations to converge than k2-zero(sdp). In terms of computation time, the algorithm k2-zero(ppa) is definitely better than k2-zero(sdp) in all instances. Figure 6b shows the average computation times for both variants of the proposed algorithm. In terms of accuracy, we plot the performance measure of relative error in Fig. 6c. The algorithm k2-zero(sdp) indeed has much higher accuracy for all instances. On the other hand, the algorithm k2-zero(ppa) also performs consistently and achieves relative errors below the threshold of \(\epsilon =10^{-6}\) for all instances, which is significant given that the proximal point algorithm only uses first-order information.
Next, we will run the algorithm k2-zero(ppa) for larger instances. We set \(m=n\) and vary it from 50 to 500 with \(r=5\) and \(s=\lceil 1.10\cdot d_r\rceil \), where \(d_r=r(m+n-r)\). Note that for \(m=500\), the decision matrix \({\varvec{X}}\) has the size of \(500\times 500\) and there are approximately 5500 dense linear constraints in \({\varvec{X}}\), which requires a substantial amount of memory for the representation of instance data and the execution of the algorithm. For these instances, the tolerance is set to be \(\epsilon =10^{-4}\) for \(\displaystyle \frac{\left\Vert {\varvec{X}}^{s+1}-{\varvec{X}}^s\right\Vert _F}{\max \{\left\Vert {\varvec{X}}^s\right\Vert _F,1\}}\), which is more consistent with respect to different instance sizes. The maximum number of iterations is kept at \(N_{\max }=100\) as before. For the proximal point algorithm, we set the tolerance \(\epsilon _p=10^{-6}\) and the maximum number of iterations \(N_{\max }^p=100\). Given these tolerances, the algorithm converges after approximately 14 iterations for all instances with 12 and 16 as the minimum and maximum, respectively. The relative errors are approximately \(10^{-4}\), which are shown in Fig. 7a for different matrix sizes. The computation time per iteration increases significantly from 2.5 to \(10^{4}\) seconds when the matrix size increases from \(m=50\) to \(m=500\) as shown in Fig. 7b.
5 Conclusion
We have proposed non-convex models based on the dual Ky Fan 2-k-norm for low-rank matrix recovery and developed a general DCA framework to solve the models. The computational results show that the proposed approach achieves high recoverability as compared to the truncated nuclear norm approach by Hu et al. [10] as well as the bilinear approach proposed by by Jain et al. [13], especially when the size of the linear map is small. We also demonstrate that the proposed proximal point algorithm is promising for larger instances.
Data Availability Declaration
The datasets generated during the current study are available from the corresponding author on reasonable request.
References
Argyriou, A., Foygel, R., Srebro, N.: Sparse prediction with the \(k\)-support norm. In: NIPS, pp. 1466–1474. (2012)
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imag. Sci. 1, 183–202 (2009)
Bhatia, R.: Matrix Analysis, Graduate Texts in Mathematics, vol. 169. Springer-Verlag, New York (1997)
Candès, E.J., Recht, B.: Exact matrix completion via convex optimization. Found. Comput. Math. 9(6), 717–772 (2009)
Candès, E.J., Tao, T.: Decoding by linear programming. IEEE Trans. Inform. Theory 51(12), 4203–4215 (2005)
Doan, X.V., Toh, K.C., Vavasis, S.: A proximal point algorithm for sequential feature extraction applications. SIAM J. Sci. Comput. 35(1), A517–A540 (2013)
Doan, X.V., Vavasis, S.: Finding the largest low-rank clusters with Ky Fan \(2\)-\(k\)-norm and \(\ell _1\)-norm. SIAM J. Optim. 26(1), 274–312 (2016)
Giraud, C.: Low rank multivariate regression. Electron. J. Stat. 5, 775–799 (2011)
Grant, M., Boyd, S.: CVX: Matlab Software for Disciplined Convex Programming, version 2.0 beta. http://cvxr.com/cvx (2013)
Hu, Y., Zhang, D., Ye, J., Li, X., He, X.: Fast and accurate matrix completion via truncated nuclear norm regularization. IEEE Trans. Patt. Anal. Mach. Intell. 35(9), 2117–2130 (2013). https://doi.org/10.1109/TPAMI.2012.271
Hu, Z., Nie, F., Wang, R., Li, X.: Low rank regularization: a review. Neural Netw. (2020)
Jacob, L., Bach, F., Vert, J.P.: Clustered multi-task learning: a convex formulation. NIPS 21, 745–752 (2009)
Jain, P., Netrapalli, P., Sanghavi, S.: Low-rank matrix completion using alternating minimization. In: Proceedings of the 45th Annual ACM Symposium on Theory of Computing, pp. 665–674. ACM (2013)
Lee, K., Bresler, Y.: ADMiRA: atomic decomposition for minimum rank approximation. IEEE Trans. Inform. Theory 56(9), 4402–4416 (2010)
Liu, Y.J., Sun, D., Toh, K.C.: An implementable proximal point algorithmic framework for nuclear norm minimization. Math. Program. 133(1–2), 399–436 (2012)
Ma, T.H., Lou, Y., Huang, T.Z.: Truncated \(\ell _{1-2}\) models for sparse recovery and rank minimization. SIAM J. Imag. Sci. 10(3), 1346–1380 (2017)
Mohan, K., Fazel, M.: Iterative reweighted algorithms for matrix rank minimization. J. Mach. Learn. Res. 13(1), 3441–3473 (2012)
Nguyen, L.T., Kim, J., Shim, B.: Low-rank matrix completion: a contemporary survey. IEEE Access 7, 94215–94237 (2019)
Pham-Dinh, T., Le-Thi, H.A.: Convex analysis approach to d.c. programming: theory, algorithms and applications. Acta Math. Viet. 22(1), 289–355 (1997)
Pham-Dinh, T., Le-Thi, H.A.: A d.c. optimization algorithm for solving the trust-region subproblem. SIAM J. Optim. 8(2), 476–505 (1998)
Recht, B., Fazel, M., Parrilo, P.: Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization. SIAM Rev. 52(3), 471–501 (2010)
Rockafellar, R.T.: Convex Analysis. Princeton University Press, Princeton, NJ (1970)
Toh, K.C., Todd, M.J., Tütüncü, R.H.: Sdpt3—a matlab software package for semidefinite programming, version 1.3. Optim. Methods Softw. 11(1-4), 545–581 (1999)
Yin, P., Esser, E., Xin, J.: Ratio and difference of \(\ell _1\) and \(\ell _2\) norms and sparse representation with coherent dictionaries. Commun. Inform. Syst. 14(2), 87–109 (2014)
Yin, P., Lou, Y., He, Q., Xin, J.: Minimization of \(\ell _1-\ell _2\) for compressed sensing. SIAM J. Sci. Comput. 37(1), A536–A563 (2015)
Ziȩtak, K.: Subdifferentials, faces, and dual matrices. Linear Algeb. Appl. 185, 125–141 (1993)
Acknowledgements
The authors would like to thank the anonymous referee for his/her helpful comments and suggestions.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work is partially supported by the Alan Turing Fellowship of the first author.
Appendix: Proof of Prop. 5
Appendix: Proof of Prop. 5
We start with some preliminary lemmas about the dual Ky Fan 2-k-vector norm, which can be written as follows:
Since \(\left\Vert .\right\Vert _{k,2}\) is a symmetric gauge function (and so is its dual norm), we can focus on \({\varvec{y}}\) that satisfies \(y_1\ge \ldots \ge y_n\ge 0\). We start with some properties of the optimal solution \({\varvec{x}}^*\) of (40).
Lemma 2
Consider the optimization problem in (40) with \({\varvec{y}}\) satisfying the above conditions. There exists an optimal solution \({\varvec{x}}^*\) that satisfies the following properties
-
(i)
\(x_1^*\ge \ldots \ge x_n^*\ge 0\).
-
(ii)
\(x_i^*=x_k^*\) for all \(i\ge k+1\).
Proof
-
(i)
Consider an optimal solution \({\varvec{x}}\) and assume there exists j such that \(x_j<0\). Construct a new solution \({\varvec{x}}^*\) from \({\varvec{x}}\) by inverting the sign of the j-th element, which means \(x_j^*=-x_j>0\). We have, \(\left\Vert .\right\Vert _{k,2}\) is a symmetric gauge function, thus \(\left\Vert {\varvec{x}}^*\right\Vert _{k,2}=\left\Vert {\varvec{x}}\right\Vert _{k,2}\le 1\) or \({\varvec{x}}^*\) is a feasible solution. In addition, \({\varvec{y}}^T{\varvec{x}}^*={\varvec{y}}^T{\varvec{x}}- 2x_jy_j\ge {\varvec{y}}^T{\varvec{x}}\). Thus \({\varvec{x}}^*\) is also an optimal solution, which means there exists a nonnegative optimal solution if \({\varvec{y}}\ge \varvec{0}\). Now consider an optimal solution \({\varvec{x}}\) and assume there exists \(i<j\) such that \(x_i<x_j\). Construct a new solution \({\varvec{x}}^*\) from \({\varvec{x}}\) by swapping two i-th and j-th elements, which means \(x_i^*=x_j\) and \(x_j^*=x_i\). Using the properties of the symmetric gauge function, we again can show that \({\varvec{x}}^*\) is a feasible solution. We also have, \({\varvec{y}}^T{\varvec{x}}^*={\varvec{y}}^T{\varvec{x}}+(x_i-x_j)(y_j-y_i)\ge {\varvec{y}}^T{\varvec{x}}\) since \(y_i\ge y_j\). Thus \({\varvec{x}}6*\) is an optimal solution and we have prove that there exists an optimal solution that satisfies \(x_1^*\ge \ldots \ge x_n^*\ge 0\) if \(y_1\ge \ldots \ge y_n\ge 0\).
-
(ii)
Consider an optimal solution \({\varvec{x}}^*\) that satisfies \(x_1^*\ge \ldots \ge x_n^*\ge 0\). We then have: \(x_i^*\le x_k^*\) for all \(i\ge k+1\). We can construct the solution \({\bar{{\varvec{x}}}}\) such that \({\bar{x}}_i=x_i^*\) for all \(i=1,\ldots ,k\) and \({\bar{x}}_i=x_k^*\) for all \(i\ge k+1\). We have: \(\left\Vert {\bar{{\varvec{x}}}}\right\Vert _{k,2}=\left\Vert {\varvec{x}}^*\right\Vert _{k,2}\le 1\) and \({\varvec{y}}^T{\bar{{\varvec{x}}}}\ge {\varvec{y}}^T{\varvec{x}}^*\). Thus \({\bar{{\varvec{x}}}}\) is also an optimal solution of the problem shown in (40).
\(\square \)
Applying Lemma 2, we can reformulate the problem (40) as follows:
Without the second constraint set, the optimal solution \({\varvec{x}}^*\) of the relaxation problem of (41) can be obtained by using Cauchy-Schwartz inequality:
where \(\displaystyle {\varvec{z}}=\left( y_1,\ldots ,y_{k-1},\sum _{i=k}^ny_i\right) \) (we can assume \({\varvec{z}}\ne \varvec{0}\)). Thus if \(\displaystyle y_{k-1}\ge \sum _{i=k}^ny_i\), \({\varvec{x}}^*\) is also the optimal solution of (41). We will prove that if \(\displaystyle y_{k-1}<\sum _{i=k}^ny_i\), then the optimal solution \({\varvec{x}}^*\) of (41) satisfies \(x_{k-1}^*=x_k^*\). The generalization of this statement will be shown later but in order to prove it, we first need the following lemma.
Lemma 3
Consider the following optimization problem
where \(a_1,a_2\ge 0\), \(a_1^2+a_2^2>0\), \(b>0\), and \(k\in \mathbb {Z}_+\).
-
(i)
If \(a_1\ge a_2\) then the optimal solution can be found by solving the relaxation problem by removing the second constraint.
-
(ii)
If \(a_1<a_2\) then the optimal solution satisfies \(x_1^*=x_2^*\).
Proof
-
(i)
Removing the second constraint, we can solve the relaxation using Cauchy-Schwartz inequality and the optimal solution satisfies the condition \(x_1\ge x_2\) since \(a_1\ge a_2\).
-
(ii)
We have:
$$\begin{aligned} \frac{1}{k+1}(a_1+ka_2)(x_1+kx_2)=(a_1x_1+ka_2x_2) + \frac{k}{k+1}(a_1-a_2)(x_2-x_1)\ge a_1x_1+ka_2x_2. \end{aligned}$$
The equality happens when \(x_1=x_2\) since \(a_1<a_2\). Solving the problem (42) with \(\displaystyle a_1=a_2=\frac{a_1+ka_2}{k+1}>0\), we obtain the optimal solution \({\varvec{x}}^*\) that satisfies \(x_1^*=x_2^*\). Thus
which implies that \({\varvec{x}}^*\) with \(x_1^*=x_2^*\) is also the optimal solution of (42) with the original parameters \(a_1\) and \(a_2\).\(\square \)
The structural property of the optimal solution of (41) can now be stated as follows.
Lemma 4
If \(\displaystyle y_{k-i}<\frac{1}{i}\left( \sum _{j=k-i+1}^ny_j\right) \) for an arbitrary i, \(i=1,\ldots ,k-1\), then there exists an optimal solution \({\varvec{x}}^*\) of (41) that satisfies the condition \(x_j^*=x_k^*\) for all \(j\ge k-i\).
Proof
We prove the statement by induction. Let \(i=1\), consider an optimal solution \({\varvec{x}}^*\) of (41) and the following optimization problem:
Applying Lemma 3, we obtain the optimal solution \({\bar{x}}_{k-1}={\bar{x}}_k\). We also have: \(2{\bar{x}}_k^2=(x_{k-1}^*)^2+(x_{k}^*)^2\) and \(x_{k-1}^*\ge x_k^*\). Thus \({\bar{x}}_{k}={\bar{x}}_{k-1}\le x_{k-1}^*\) (all values are nonnegative), which means \({\bar{x}}_{k-1}\le x_j^*\) for all \(j\le k-2\). Therefore, \((x_i^*,\ldots ,x_{k-2}^*,{\bar{x}}_k,{\bar{x}}_k)\) is also an optimal solution.
Now assume the statement is true for \(i<k-1\), we will prove that the statement is true for \(i+1\). We have: \(\displaystyle y_{k-i-1}<\frac{1}{i+1}\left( \sum _{j=k-i}^ny_j\right) \) and \(y_{k-i-1}\ge y_{k-i}\); therefore \(\displaystyle y_{k-i}<\frac{1}{i}\left( \sum _{j=k-i+1}^ny_j\right) \). Thus there exists an optimal solution \({\varvec{x}}^*\) that satisfies \(x_j^*=x_k^*\) for all \(j\ge k-i\). We consider the restricted optimization problem of (41):
which can be used to solve the original problem. It is equivalent to the following problem:
Similar to the case \(i=1\), we can construct the problem with two decision variable \(x_{k-i-1}\) and \(x_k\) from an optimal solution of the problem above and prove that the solution is \({\bar{x}}_{k-i-1}={\bar{x}}_k\). Thus the statement is true for \(i+1\), which means the statement is true for all i by induction.\(\square \)
Proof of Prop. 5. Without loss of generality, let consider \({\varvec{y}}\) that satisfies the condition \(y_1\ge \ldots \ge y_n\ge 0\). According to Lemma 4, with \(i^*\) defined in (29), there exists an optimal solution \({\varvec{x}}^*\) of (40) that satisfies \(x_i^*=x_{k-i^*}^*\) for all \(i\ge k-i^*+1\) and all values can be found by solving the following optimization problem with the Cauchy-Schwartz inequality:
Note that the index \(i=0\) always belongs to the considered set of indices. Thus we have:
which concludes the proof given that the above formulation can be easily extended for an arbitrary vector \({\varvec{y}}\). \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Doan, X.V., Vavasis, S. Low-rank matrix recovery with Ky Fan 2-k-norm. J Glob Optim 82, 727–751 (2022). https://doi.org/10.1007/s10898-021-01031-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10898-021-01031-0