
Abstract
A sequentialquadratic Hamiltonian schemefor solving open-loop differential Nash games is proposed and investigated. This method is formulated in the framework of the Pontryagin maximum principle and represents an efficient and robust extension of the successive approximations strategy for solving optimal control problems. Theoretical results are presented that prove the well-posedness of the proposed scheme, and results of numerical experiments are reported that successfully validate its computational performance.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The sequential quadratic Hamiltonian (SQH) scheme has been recently proposed in [4,5,6,7] for solving nonsmooth optimal control problems governed by differential models. The SQH scheme belongs to the class of iterative methods known as successive approximations (SA) schemes that are based on the characterisation of optimality in control problems by the Pontryagin maximum principle (PMP); see [2, 27] and [12] for a recent detailed discussion. The initial development of SA schemes was inspired by the work of L. I. Rozonoèr [32], and originally proposed in different variants by H.J. Kelley, R.E. Kopp and H.G. Moyer [19] and by I.A. Krylov and F.L. Chernous’ko [20, 21]; see [11] for an early review.
The working principle of most SA schemes is the point-wise minimisation of the Hamilton-Pontryagin function introduced in the PMP theory. However, in their original formulation, the SA schemes appeared efficient but not robust with respect to the numerical and optimisation parameters. Twenty years later, a great improvement in robustness was achieved by Y. Sakawa and Y. Shindo [33, 34] by introducing a quadratic penalty of the control updates that resulted in an augmented Hamiltonian. In this latter formulation, the need of coupled updates of the state and control variables of the controlled system limited the application of the resulting method to small-size control problems. This limitation was resolved in the SQH approach where a sequential point-wise optimisation of an augmented Hamiltonian function is considered that defines a suitable update step for the control variable while the state function is updated after the completion of this step. Since the SQH iterative procedure has proved efficient and robust in solving (non-smooth) optimal control problems governed by ordinary- and partial-differential models, it is reasonable to investigate whether this procedure can be successfully extended to differential games.
The first component of a differential game is a differential model that governs the state of the considered system and is subject to different mechanisms of action representing the strategies of the players in the game. Furthermore, objective functionals and admissible set of actions are associated to each player, and in the game the purpose of each player is to minimise its own objective subject to the constraints given by the differential model and the admissible sets. Since we consider non-cooperative games, a suitable solution concept is the one proposed by J. F. Nash in [22, 23], where a so-called Nash equilibrium (NE) for static games with complete information is defined, that is, a configuration where no player can benefit from unilaterally changing its own strategy. In this framework, differential Nash games were pioneered by R. P. Isaacs [16]. However, contemporary to Isaacs’ book, there are the works [25, 26] where differential games are discussed in the framework of the maximum principle. Furthermore, in [1, 21], we find early attempts and comments towards the development of a SA scheme for differential games. Unfortunately, less attention was paid to this research direction and the further development of these schemes for differential games was left out.
It is the purpose of this work to contribute to this development by investigating a SQH scheme for solving open-loop non-zero-sum two-player differential Nash games. In particular, we consider linear-quadratic (LQ) Nash games that appear in the field of, e.g., economics and marketing [13, 18], and are very well investigated from the theoretical point of view; see, e.g., [8, 14, 15, 35]. Moreover, since the solution of unconstrained LQ Nash games can be readily obtained by solving coupled Riccati equations [3, 14], they provide a convenient benchmark for our method. However, we also consider extension of LQ Nash games to problems with tracking objectives, box constraints on the players’ actions, and actions’ costs that include L1 terms.
In the next section, we formulate a class of differential Nash games and their characterisation in the PMP framework. In particular, we notice that the point-wise PMP characterisation of a Nash equilibrium corresponds to the requirement that, at each time instant, the conditions of equilibrium of a finite-dimensional Nash game with two Hamilton-Pontryagin functions must be satisfied. In Section 3, we present our SQH method for solving differential Nash games and discuss its well-posedness. Specifically, we show that the adaptive choice of the weight of a Sakawa-Shindo-type penalisation can be successfully performed in a finite number of steps such that the proposed update criteria based on the Nikaido-Isoda function are satisfied.
Section 4 is devoted to numerical experiments that successfully validate our computational framework. In the first experiment, we consider a differential LQ Nash game and show that the SQH scheme provides a solution that is identical to that obtained by solving an appropriate Riccati system. In the second experiment, the same problem with the addition of the requirement that the players’ actions must belong to given bounded, closed, and convex sets is solved by the SQH scheme. In the third experiment, we extend the setting of the second experiment by adding weighted L1 costs of the players’ actions and verify that these costs promote sparsity. In the fourth experiment, we consider the case where each player’s functional corresponds to a tracking problem where the players aim at following different paths. Also in this case, constraints on the players’ actions and L1 costs are considered. We remark that all NE solutions are successfully computed with the same setting of values of the parameters entered in the SQH algorithm, that is, independently of the problem and of the chosen weights in the players’ cost functionals. A section of conclusion completes this work.
2 PMP Characterization of Nash Games
This section is devoted to the formulation of differential Nash games and the characterisation of their NE solution in the PMP framework. We discuss the case of two players, represented by their strategies \(\underline {u}_{1}\) and \( \underline {u}_{2}\), which can be readily extended to the case of N players, and assume the following dynamics:
where t ∈ [0,T], \(\underline {y} (t) \in \mathbb {R}^{n}\), and \(\underline {u}_{1} (t) \in \mathbb {R}^{m}\) and \(\underline {u}_{2}(t) \in \mathbb {R}^{m}\), m ≤ n. We assume that \(\underline {f}\) is such that for any choice of the initial condition \(\underline {y}_{0} \in \mathbb {R}^{n}\), and any \(\underline {u}_{1}, \underline {u}_{2} \in L^{2} (0,T;\mathbb {R}^{m})\), the Cauchy problem (1) admits a unique solution in the sense of Carathéodory; see, e.g., [3]. Furthermore, we assume that the map \((\underline {u}_{1},\underline {u}_{2}) \mapsto \underline {y}=\underline {y}(\underline {u}_{1},\underline {u}_{2})\), where \(\underline {y}(\underline {u}_{1},\underline {u}_{2})\) represents the unique solution to Eq. 1 with fixed initial conditions is continuous in \((\underline {u}_{1},\underline {u}_{2})\).
We refer to \(\underline {u}_{1}\) and \(\underline {u}_{2}\) as the game strategies of the players P1 and P2, respectively. The goal of P1 is to minimise the following cost (or objective) functional:
whereas P2 aims at minimising its own objective given by
We consider the cases of unconstrained and constrained strategies. In the former case, we assume \(\underline {u}_{1}, \underline {u}_{2} \in L^{2} (0,T;\mathbb {R}^{m})\), whereas in the latter case we assume that \(\underline {u}_{1}\) and \(\underline {u}_{2}\) belong, respectively, to the following admissible sets:
where \(K_{ad}^{(i)}\) are compact and convex subsets of \(\mathbb {R}^{m}\). We denote with \(U_{ad} = U_{ad}^{(1)} \times U_{ad}^{(2)} \) and \(U = L^{2}(0,T;\mathbb {R}^{m}) \times L^{2}(0,T;\mathbb {R}^{m}) \). Notice that we have a uniform bound on \(|\underline {y}(\underline {u}_{1},\underline {u}_{2})(t)|\), t ∈ [0,T], that holds for any \(\underline {u} \in U_{ad}\); see [9].
By using the map \((\underline {u}_{1},\underline {u}_{2}) \mapsto \underline {y}=\underline {y}(\underline {u}_{1},\underline {u}_{2})\), we can introduce the reduced objectives \(\tilde {J}_{1}(\underline {u}_{1},\underline {u}_{2}):=J_{1}(\underline {y}(\underline {u}_{1},\underline {u}_{2}),\underline {u}_{1},\underline {u}_{2})\) and \(\tilde {J}_{2}(\underline {u}_{1},\underline {u}_{2}):={J}_{2}(\underline {y}(\underline {u}_{1},\underline {u}_{2}),\underline {u}_{1},\underline {u}_{2})\). In this framework, a Nash equilibrium is defined as follows.
Definition 1
The functions \((\underline {u}_{1}^{*},\underline {u}_{2}^{*}) \in U_{ad}\) are said to form a Nash equilibrium (NE) for the game \((\tilde {J}_{1},\tilde {J}_{2}; U_{ad}^{(1)}, U_{ad}^{(2)})\), if it holds
(A similar Nash game is defined replacing Uad with U.)
We remark that existence of a NE point can be proved subject to appropriate conditions on the structure of the differential game, including the choice of T. For our purpose, we assume existence of a Nash equilibrium \((\underline {u}_{1}^{*},\underline {u}_{2}^{*}) \in U_{ad}\), and refer to [9] for a review and recent results in this field.
We remark that, if \(\underline {u}^{*}=(\underline {u}_{1}^{*},\underline {u}_{2}^{*})\) is a NE for the game, then it satisfies the following:
This fact implies that the NE point \(\underline {u}^{*}=(\underline {u}_{1}^{*},\underline {u}_{2}^{*})\) must fulfil the necessary optimality conditions given by the Pontryagin maximum principle applied to both optimisation problems stated in Eq. 5, alternatively (6).
In order to discuss these conditions, we introduce the following Hamilton-Pontryagin (HP) functions:
In terms of these functions, the PMP condition for the NE point \(\underline {u}^{*}=(\underline {u}_{1}^{*},\underline {u}_{2}^{*})\) states the existence of multiplier (adjoint) functions \(\underline {p}_{1}, \underline {p}_{2} : [0,T] \rightarrow \mathbb {R}^{n} \) such that the following holds:
for almost all t ∈ [0,T]. Notice that, at each t fixed, the problem (8) corresponds to a finite-dimensional Nash game.
In Eq. 8, we have \(\underline {y}^{*}=y(\underline {u}_{1}^{*},\underline {u}_{2}^{*})\), and the adjoint variables \(\underline {p}_{1}^{*}, \underline {p}_{2}^{*}\) are the solutions to the following differential problems:
where i = 1,2, \(\partial _{y} \phi (\underline {y})\) represents the Jacobian of ϕ with respect to the vector of variables \(\underline {y}\), and ⊤ means transpose. Similarly to Eq. 1, one can prove that Eqs. 9 and 10 are uniquely solvable, and the solution can be uniformly bounded independently of \(\underline {u} \in U_{ad}\).
We conclude this section introducing the Nikaido-Isoda [24] function \( \psi : U_{ad} \times U_{ad} \to \mathbb {R}\), which we use for the realisation of the SQH algorithm. We have
where \(\underline {u} = (\underline {u}_{1}, \underline {u}_{2}) \in U_{ad}\) and \(\underline {v} = (\underline {v}_{1}, \underline {v}_{2}) \in U_{ad}\). At the Nash equilibrium \( \underline {u}^{*} = (u_{1}^{*}, u_{2}^{*})\) it holds
for any \(\underline {v} \in U_{ad}\) and \(\psi (\underline {u}^{*},\underline {u}^{*})=0\).
3 The SQH Scheme for Solving Nash Games
In the spirit of the SA scheme proposed by Krylov and Chernous’ko [20], a SA methodology for solving our Nash game \((\tilde {J}_{1},\tilde {J}_{2}; U_{ad}^{(1)}, U_{ad}^{(2)})\) consists of an iterative process, starting with an initial guess \(({\underline {u}_{1}^{0}}, {\underline {u}_{2}^{0}}) \in U_{ad}\), and followed by the solution of our governing model (1) and of the adjoint problems Eqs. 9 and 10 for i = 1,2. Thereafter, a new approximation to the strategies \(\underline {u}_{1}\) and \(\underline {u}_{2}\) is obtained by solving, at each t fixed, the Nash game (8) and assigning the values of \((\underline {u}_{1}(t),\underline {u}_{2}(t))\) equal to the solution of this game.
We remark that this update step is well posed if this solution exists for t ∈ [0,T] and the resulting functions \(\underline {u}_{1}\) and \(\underline {u}_{2}\) are measurable. Clearly, this issue requires identifying classes of problems for which we can guarantee existence and uniqueness (or the possibility of selection) of a NE point. In this respect, a large class can be identified based on the following result given in [8], which is proved by an application of the Kakutani’s fixed-point theorem; see, e.g., [3] for references. We have
Theorem 3.1
Assume the following structure:
and
Furthermore, suppose that \(K_{ad}^{(1)}\) and \(K_{ad}^{(2)}\) are compact and convex, the function \(\underline {f}_{0}\), \({\ell _{i}^{0}}\) and the matrix functions M1 and M2 are continuous in t and \(\underline {y}\), and the functions \(\underline {u}_{1} \rightarrow {\ell _{1}^{1}}(t,\underline {u}_{1})\) and \(\underline {u}_{2} \rightarrow {\ell _{2}^{2}} (t,\underline {u}_{2})\) are strictly convex for any choice of t ∈ [0,T] and \(\underline {y} \in \mathbb {R}^{n}\).
Then, for any t ∈ [0,T] and any \(\underline {y}, \underline {p}_{1}, \underline {p}_{2} \in \mathbb {R}^{n}\), there exists a unique pair \((\tilde {\underline {u}}_{1},\tilde {\underline {u}}_{2}) \in K_{ad}^{(1)} \times K_{ad}^{(2)}\) such that
With the setting of this theorem, the map \((t,\underline {y},\underline {p}_{1},\underline {p}_{2}) \mapsto \left (u_{1}^{*}, u_{2}^{*} \right )\) is continuous [8]. Moreover, based on results given in [30], one can prove that the functions \((\underline {u}_{1}(t), \underline {u}_{2}(t))\) resulting from the SA update, starting from measurable \(({\underline {u}_{1}^{0}}(t), {\underline {u}_{2}^{0}}(t))\), are measurable. Therefore, the proposed SA update is well-posed and it can be repeated in order to construct a sequence of functions \(\left (({\underline {u}_{1}^{k}} ,{\underline {u}_{2}^{k}}) \right )_{k=0}^{\infty }\).
However, as already pointed out in [20] in the case of optimal control problems, it is difficult to find conditions that guarantee convergence of SA iterations to the solution sought. Furthermore, results of numerical experiments show a lack of robustness of the SA scheme with respect to the choice of the initial guess and of the numerical and optimisation parameters.
For this reason, further research effort was put in the development of the SA strategy, and an advancement was achieved by Sakawa and Shindo considering a quadratic penalty on the Hamiltonian [33, 34]. We remark that these authors related their penalisation strategy to that proposed by B. Järmark in [17], which is similar to the proximal scheme of R. T. Rockafellar discussed in [29].
For our purpose, we follow the same path of [33] and extend it to the case of Nash games as follows. Consider the following augmented HP functions:
where, in the iteration process, \(\underline {u} = (\underline {u}_{1}, \underline {u}_{2})\) is subject to the update step, and \(\underline {v} = (\underline {v}_{1}, \underline {v}_{2})\) corresponds to the previous strategy approximation; |⋅| denotes the Euclidean norm. The parameter 𝜖 > 0 represents the augmentation weight that is chosen adaptively along the iteration as discussed below.
Now, similar to the SA update illustrated above, suppose that the k th function approximation \(({\underline {u}_{1}^{k}}, {\underline {u}_{2}^{k}})\) and the corresponding \(\underline {y}^{k}\) and \({\underline {p}_{1}^{k}}, {\underline {p}_{2}^{k}}\) have been computed. For any fixed t ∈ [0,T] and 𝜖 > 0, consider the following finite-dimensional Nash game:
where \(\underline {y}^{k}=\underline {y}^{k}(t)\), \({\underline {p}_{1}^{k}}={\underline {p}_{1}^{k}}(t)\), \({\underline {p}_{2}^{k}}={\underline {p}_{2}^{k}}(t)\), and \(({\underline {u}_{1}^{k}}, {\underline {u}_{2}^{k}} )=({\underline {u}_{1}^{k}}(t), {\underline {u}_{2}^{k}}(t) )\).
It is clear that, assuming the structure specified in Theorem 3.1, the Nash game (14) admits a unique NE point, \((\tilde {\underline {u}}_{1}, \tilde {\underline {u}}_{2} ) \in K_{ad}^{(1)} \times K_{ad}^{(2)} \), and the sequence constructed recursively by the procedure:
is well defined.
Notice that, in this procedure, the solution to Eq. 14 depends on the value of 𝜖. Therefore, the issue arises whether, corresponding to the step k → k + 1, we can choose the value of this parameter such that the strategy function \(\underline {u}^{k+1}=(\underline {u}_{1}^{k+1}, \underline {u}_{2}^{k+1} ) \) represents an improvement on \(\underline {u}^{k}=({\underline {u}_{1}^{k}}, {\underline {u}_{2}^{k}} )\), in the sense that some convergence criteria towards the solution to our differential Nash problem are fulfilled.
For this purpose, we define a criterion that is based on the Nikaido-Isoda function. We require that
for some chosen ξ > 0. This is a consistency criterion in the sense that ψ must be non-positive, and if \((\underline {u}^{k+1}, \underline {u}^{k}) \rightarrow (\underline {u}^{*}, \underline {u}^{*})\), then we must have \(\lim _{k \to \infty }\psi (\underline {u}^{k+1}, \underline {u}^{k}) =0\). Furthermore, we require that the absolute value \(|\psi (\underline {u}^{k+1}, \underline {u}^{k})|\) monotonically decreases in the SQH iteration process.
In our SQH scheme, if the strategy update meets the two requirements above, then the update is taken and the value of 𝜖 is diminished by a factor ζ ∈ (0,1). If not, the update is discarded and the value of 𝜖 is increased by a factor σ > 1, and the procedure is repeated. Below, we show that a value of 𝜖 can be found such that the update is successful and the SQH iteration proceeds until an appropriate stopping criterion is reached.
Our SQH scheme for differential Nash games is implemented as follows:

In the following proposition, we prove that the Steps 1–6 of the SQH scheme are well posed. For the proof, we consider the assumptions of Theorem 3.1 with further simplifying hypothesis, which can be relaxed at the cost of more involved calculations.
Our purpose is to show that it is possible to find an 𝜖 in Algorithm 1 such that \(\tilde {\underline {u}}\) generated in Step 2 satisfies the criterion required in Step 5 for a successful update. We have
Proposition 3.2
Let the assumptions of Theorem 3.1 hold, and suppose that \(\underline {f}_{0}\), gi, ℓi, i = 1,2 are twice continuous differentiable and strictly convex in \(\underline {y}\) and \(\underline {u}\) for all t ∈ [0,T]. Moreover, let M1,M2 dependent only on t and suppose that \(\underline {f}_{0}\), ℓi and gi, i = 1,2, represent quadratic forms in \(\underline {u}\) and \(\underline {y}\) such that their Hessians are constant.
Let \((\tilde {\underline {y}}, \tilde {\underline {u}}_{1}, \tilde {\underline {u}}_{2})\), \((\underline {y}^{k}, {\underline {u}_{1}^{k}}, {\underline {u}_{2}^{k}})\) be generated by Algorithm 1, Steps 2–3, and denote \(\delta \underline {u} = \tilde {\underline {u}} - \underline {u}^{k}\). Then, there exists a 𝜃 > 0 independent of 𝜖 such that, for 𝜖 > 0 currently chosen in Step 2, the following inequality holds:
In particular, if 𝜖 > 𝜃 then \(\psi (\tilde {\underline {u}}, \underline {u}^{k})\leq 0 \).
Proof
Recall the definition of the Nikaido-Isoda function:
We focus on the first two terms involving J1; however, the same calculation applies to the last two terms with J2.
Notice that, with our assumptions, the function \(\underline {y}(\underline {u}_{1}, \underline {u}_{2})\) results differentiable. Denote \(\underline {y}^{k}=\underline {y}({\underline {u}_{1}^{k}}, {\underline {u}_{2}^{k}})\), \(\tilde {\underline {y}}=\underline {y}(\tilde {\underline {u}}_{1}, \tilde {\underline {u}}_{2})\) and \(\tilde {\underline {y}}_{1}^{k}=\underline {y}({\underline {u}_{1}^{k}}, \tilde {\underline {u}}_{2})\), \({\underline {p}_{1}^{k}}= \underline {p}_{1}({\underline {u}_{1}^{k}}, {\underline {u}_{2}^{k}})\), and define \(\delta \underline {y}_{1} := \tilde {\underline {y}} - \tilde {\underline {y}}_{1}^{k}\), and \(\delta \tilde {\underline {y}}_{1} := \tilde {\underline {y}}_{1}^{k} - \underline {y}^{k}\).
Consider the augmented Hamiltonian \(\mathcal {K}_{\epsilon }^{(1)}\) of player P1. Similar computations can be done with \(\mathcal {K}_{\epsilon }^{(2)}\). It holds
for any \(\underline {w} \in K_{ad}^{(1)}\). Hence, choosing \(\underline {w}={\underline {u}_{1}^{k}}\), we have
Now, compute
Notice that \(\tilde {\underline {y}} = \tilde {\underline {y}}_{1}^{k} + \delta \underline {y}_{1} \). By applying the mean value theorem to second order to the maps \(\underline {y} \mapsto {\mathscr{H}}_{1}(\cdot ,\underline {y},\cdot ,\cdot ,\cdot , \cdot )\) and \(\underline {y} \mapsto \underline {f}(\cdot , \underline {y}, \cdot , \cdot )\), and \(\underline {u}_{1} \mapsto \underline {f}(\cdot , \cdot ,\underline {u}_{1}, \cdot )\), we have
and
and
With these estimates, we continue the calculation above as follows. Notice that we add and subtract the term \(\epsilon |\delta \underline {u}|^{2}\).
Now, we consider the following integration by parts
Using this result in the previous calculation, we have
Applying again the mean value theorem to second order to the maps \(\underline {y} \mapsto {\mathscr{H}}_{1}(\cdot ,\underline {y}, \cdot ,\cdot ,\cdot ,\cdot )\) and \(\underline {y} \mapsto \mathcal {K}_{\epsilon }^{(1)}(\cdot ,\underline {y}, \cdot ,\cdot ,\cdot ,\cdot , \cdot ,\cdot )\), we get
and
With these results and replacing the expression of \(-({\underline {p}_{1}^{k}})^{\prime }\), we continue the calculation as follows:
where in the last integral we applied the mean value theorem to the maps \(\underline {y} \mapsto \partial _{y}{\ell _{1}^{0}}(\cdot , \underline {y})\) and \(\underline {y} \mapsto \partial _{y} \underline {f}_{0}(\cdot , \underline {y})\).
Therefore, we have shown that
With a similar computation, we also obtain
where \(\tilde {\underline {y}}_{2}^{k}=\underline {y}(\tilde {\underline {u}}_{1}, {\underline {u}_{2}^{k}})\), \(\delta \underline {y}_{2} := \tilde {\underline {y}} - \tilde {\underline {y}}_{2}^{k}\) and \(\delta \tilde {\underline {y}}_{2} := \tilde {\underline {y}}_{2}^{k} - \underline {y}^{k}\). Thus, we arrive at the following inequality:
Next, we notice that the solutions to the state and adjoint problems are uniformly bounded in [0,T] for any choice of \(\underline {u} \in U_{ad}\), and the following estimates hold:
Similarly,
see [9] for a proof. By using these estimates in Eq. 19, we obtain
where 𝜃 depends on the functions computed at the k th iteration but not on 𝜖. Thus, the claim is proved. □
We remark that in Step 2 of the SQH algorithm, the NE solution \(\tilde {\underline {u}}\) obtained in Step 2 depends on 𝜖 so that \( \| \tilde {\underline {u}} - \underline {u}^{k} \|_{L^{2}(0,T)}^{2} \) decreases as O(1/𝜖2). In order to illustrate this fact, consider the following optimisation problem:
where ν,𝜖 > 0. Clearly, the function f𝜖 is concave and its maximum is attained at \(\tilde u=(b + 2 \epsilon v)/(\nu + 2 \epsilon )\). Furthermore, we have
Now, subject to the assumptions of Proposition 3.2 and using the estimates in its proof, we can state that there exists a constant C > 0 such that
where C increases linearly with 𝜖. On the other hand, since the HP functions are concave, we have that \( \| \tilde {\underline {u}} - \underline {u}^{k} \|_{L^{2}(0,T)}^{2} \) decreases as O(1/𝜖2). Therefore, given the value Ψk in Step 5 of the SQH algorithm, it is always possible to choose 𝜖 sufficiently large such that \(|\psi (\tilde {\underline {u}},\underline {u}^{k}) | \le {\Psi }^{k}\).
In Algorithm 1, we have that \(\psi (\underline {u}^{k+1}, \underline {u}^{k}) \to 0\) as \(k \to \infty \). Thus, since \(\psi (\underline {u}^{k+1}, \underline {u}^{k}) \leq - \xi \|\underline {u}^{k+1} - \underline {u}^{k} \|_{L^{2}}^{2}\), it follows that \(\lim _{k} \| \underline {u}^{k+1} - \underline {u}^{k} \|_{L^{2}}^{2} = 0\) and hence the convergence criterion in Step 6 can be satisfied.
We remark that, subject to the assumptions of Proposition 3.2, if \(({\underline {u}_{1}^{k}}, {\underline {u}_{2}^{k}})\) generated by Algorithm 1 satisfies the PMP conditions, then Algorithm 1 stops returning \(({\underline {u}_{1}^{k}}, {\underline {u}_{2}^{k}})\).
4 Numerical Experiments
In this section, we present results of four numerical experiments to validate the computational performance of the proposed SQH scheme. We remark that in all these experiments the structure of the corresponding problems is such that in Step 2 of the SQH algorithm the update \(\tilde {\underline {u}}(t)\) at any fixed t can be determined analytically.
The first experiment exploits the possibility to compute open-loop NE solutions to linear-quadratic Nash games by solving a coupled system of Riccati equations [14]. Thus, we use this solution for comparison to the solution of the same Nash game obtained with the SQH method.
Our linear-quadratic Nash game is formulated as follows:
where
Therefore, \(\underline {y}(t) \in \mathbb {R}^{2}\) and \(\underline {u}_{i}(t) \in \mathbb {R}^{2}\), t ∈ [0,T].
The cost functionals are as follows:
i = 1,2, where the matrices Li(s),Di,Ni(s) are given by L1 = α1I2,L2 = α2I2, N1 = ν1I2,N2 = ν2I2, and D1 = γ1I2, and D2 = γ2I2, where I2 is the identity matrix in \(\mathbb {R}^{2}\). In the following experiment, we choose α1 = 1, α2 = 10, ν1 = 0.1, ν2 = 0.1, γ1 = 0 and γ2 = 0.
We consider the time interval [0,T], with T = 0.2, subdivided into N = 2000 subintervals and, on this grid, the state and adjoint equations are solved numerically by a midpoint scheme [3].
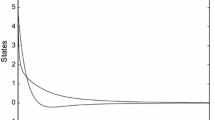
The initial guess \(\underline {u}^{0}\) for the SQH iteration are zero functions, and we choose 𝜖 = 10, ζ = 0.95, σ = 1.05, ξ = 10− 8, Ψ0 = 10, and \(\mathcal {K}= 10^{-14}\). With this setting, we obtain theNash strategies \((\underline {u}_{1}, \underline {u}_{2})\) depicted in Fig. 1 (left), which are compared with the solution obtained by solving the Riccati system as shown in Fig. 1 (right). We can see that the two sets of solutions overlap.

Strategies \(\underline {u}_{1}\) (left) and \(\underline {u}_{2}\) for the LQ Nash game obtained with the SQH scheme (top) and by solving the Riccati system (bottom)
Next, we consider the same setting but require that the players’ strategies are constrained by choosing \(K^{(i)}_{ad}= [-2,2] \times [-2,2]\), i = 1,2. With this setting, we obtain the strategies depicted in Fig. 2.

Strategies \(\underline {u}_{1}\) (left) and \(\underline {u}_{2}\) for the LQ Nash game with constraints on \(\underline {u}\) as obtained by the SQH scheme
In our third experiment, we consider a setting similar to the second experiment but add to the cost functionals a weighted L1 cost of the strategies. We have (written in a more compact form):
where i = 1,2; the terms with Di, i = 1,2, are omitted. We choose ν1 = 0.1, ν2 = 0.01, and β1 = 0.01, β2 = 0.1; the other parameters are set as in the first experiment. Furthermore, we require that the players’ strategies are constrained by choosing \(K^{(i)}_{ad}= [-10,10] \times [-10,10]\), i = 1,2. The strategies obtained with this setting are depicted in Fig. 3. Notice that the addition of L1 costs of the players’ actions promotes their sparsity.

Strategies \(\underline {u}_{1}\) (left) and \(\underline {u}_{2}\) for the Nash game with L2 and L1 costs and constraints on \(\underline {u}\) as obtained by the SQH scheme
In the next experiment, we consider a tracking problem where the cost functionals have the following structure:
where \(\bar {\underline {y}}^{i}\) denotes the trajectory desired by the Player Pi, i = 1,2. Specifically, we take
Notice that these trajectories are orthogonal to each other, that is, the two players have very different purposes. For the initial state, we take \(\underline {y}_{0}=(1/2,1/2)\).
In this fourth experiment, the values of the game parameters are given by α1 = 1, α2 = 10, ν1 = 10− 8, ν2 = 10− 6, β1 = 10− 8, β2 = 10− 6, and γ1 = 1 and γ2 = 1. Furthermore, we require that the players’ strategies are constrained by choosing \(K^{(i)}_{ad}= [-4,4] \times [-4,4]\), i = 1,2. In this experiment, we take T = 1 and N = 104 subdivision of [0,T] for the numerical approximation. The parameters of the SQH scheme remain unchanged. The results of this experiment are depicted in Fig. 4.

Strategies \(\underline {u}_{1}\) (top, left) and \(\underline {u}_{2}\) (top, right) for the Nash game with tracking functional as obtained by the SQH scheme. In the middle figures, the values of J1 and J2 along the SQH iterations (left) and the evolution of \(\underline {y}\) corresponding to \(\underline {u}_{1}\) and \(\underline {u}_{2}\) (right). In the bottom figures, the values of ψ (left) and of 𝜖 along the SQH iterations
For this concluding experiment, we report that the convergence criterion is achieved after 3593 SQH iterations, whereas the number of successful updates is 1686. Correspondingly, we see that ψ is always negative and its absolute value monotonically decreases, with ψ = − 1.70 × 10− 10 at convergence. On the other hand, we can see that the value of 𝜖 is changed along the iteration, while the values of the players’ functionals reach the Nash equilibrium. The CPU time for this experiment is 1151.4 s on a laptop computer.
5 Conclusion
A sequential quadratic Hamiltonian (SQH) scheme for solving open-loop differential Nash games was discussed. Theoretical and numerical results were presented that successfully demonstrated the well-posedness and computational performance of the SQH method applied to different Nash games governed by ordinary differential equations.
However, the applicability of the proposed method seems not restricted to these models and appears to be a promising technique for solving infinite-dimensional differential Nash game problems that have been considered recently in different fields of applied mathematics; see, e.g., [10, 28, 31].
References
Albul A, Sokolov B, Chernous’ko F. A method of calculating the control in antagonistic situations. USSR Comput Math Math Phys 1978;18(5):21–27.
Boltyanskiı̆ VG, Gamkrelidze RV, Pontryagin LS. On the theory of optimal processes. Dokl Akad Nauk SSSR (NS) 1956;110:7–10.
Borzì A. Modelling with ordinary differential equations: a comprehensive approach. Numerical analysis and scientific computing series. Abingdon and Boca Raton: Chapman & Hall/CRC; 2020.
Breitenbach T, Borzì A. On the SQH scheme to solve nonsmooth PDE optimal control problems. Numer Funct Anal Optim 2019;40:1489–1531.
Breitenbach T, Borzì A. A sequential quadratic Hamiltonian method for solving parabolic optimal control problems with discontinuous cost functionals. J Dyn Control Syst 2019;25:403–435.
Breitenbach T, Borzì A. The Pontryagin maximum principle for solving Fokker–Planck optimal control problems. Computational Optimization and Applied Mathematics 2020;76:499–533.
Breitenbach T, Borzì A. A sequential quadratic Hamiltonian scheme for solving non-smooth quantum control problems with sparsity. J Comput Appl Math 2020;369:112583.
Bressan A. Noncooperative differential games. Milan J Math 2011; 79(2):357–427.
Calà Campana F, Ciaramella G, Borzì A. 2020. Nash equilibria and bargaining solutions of differential bilinear games. Dynamic Games and Applications.
Chamekh R, Habbal A, Kallel M, Zemzemi N. A Nash game algorithm for the solution of coupled conductivity identification and data completion in cardiac electrophysiology. Mathematical Modelling of Natural Phenomena 2019;14 (2):15.
Chernous’ko FL, Lyubushin AA. Method of successive approximations for solution of optimal control problems. Optimal Control Applications and Methods 1982;3(2):101–114.
Dmitruk AV, Osmolovskii NP. On the proof of Pontryagin’s maximum principle by means of needle variations. J Math Sci 2016;218(5):581–598.
Dockner E, Jørgensen S, Van Long N, Sorger G. Differential games in economics and management science. Cambridge: Cambridge University Press; 2000.
Engwerda J. LQ dynamic optimization and differential games. Chichester: Wiley; 2005.
Friedman A. 1971. Differential games. Wiley-Interscience.
Isaacs R. Differential games: a mathematical theory with applications to warfare and pursuit, control and optimization. New York: Wiley; 1965.
Järmark B. 1975. A new convergence control technique in differential dynamic programming. Technical Report TRITA-REG-7502, The Royal Institute of Technology, Stockholm, Sweden, Department of Automatic Control.
Jørgensen S, Zaccour G. 2003. Differential games in marketing. Springer US.
Kelley HJ, Kopp RE, Moyer HG. Successive approximation techniques for trajectory optimization. Proc. IAS symp. on vehicle system optimization; 1961. p. 10–25. New York.
Krylov IA, Chernous’ko FL. On a method of successive approximations for the solution of problems of optimal control. USSR Comput Math Math Phys 1963;2(6):1371–1382. Transl of Zh Vychisl Mat Mat Fiz. 1962;2(6):1132–1139.
Krylov IA, Chernous’ko FL. An algorithm for the method of successive approximations in optimal control problems. USSR Comput Math Math Phys 1972;12(1):15–38.
Nash JF. Equilibrium points in n-person games. Proceedings of the National Academy of Sciences 1950;36(1):48–49.
Nash JF. Non-cooperative games. Ann Math 1951;54(2):286–295.
Nikaido H, Isoda K. Note on noncooperative convex games. Pacific Journal of Mathematics 1955;5:807–815.
Pontryagin LS. On the theory of differential games. Russian Mathematical Surveys 1966;21(4):193–246. Uspekhi Mat Nauk. 1966;21(4, 130):219–274.
Pontryagin LS. Linear differential games. SIAM Journal on Control 1974;12(2):262–267.
Pontryagin LS, Boltyanskiı̆ VG, Gamkrelidze RV, Mishchenko EF. The mathematical theory of optimal processes. New York-London: Wiley; 1962.
Roca Leon E, Le Pape A, Costes M, Desideri J-A, Alfano D. Concurrent aerodynamic optimization of rotor blades using a Nash game method. Journal of the American Helicopter Society 2016;61(2):13.
Rockafellar RT. Monotone operators and the proximal point algorithm. SIAM J Control Optim 1976;14(5):877–898.
Rockafellar RT, Wets RJ-B, Vol. 317. Variational analysis. Berlin Heidelberg: Springer-Verlag; 2009.
Roy S, Borzì A, Habbal A. Pedestrian motion modelled by Fokker-Planck Nash games. Royal Society Open Science 2017;4:170648.
Rozonoèr LI. Pontryagin maximum principle in the theory of optimum systems. Avtomat i Telemekh 1959;20:1320–1334. English Transl Automat Remote Control. 1959;20:1288–1302.
Sakawa Y, Shindo Y. On global convergence of an algorithm for optimal control. IEEE Trans Autom Control 1980;25(6):1149–1153.
Shindo Y, Sakawa Y. Local convergence of an algorithm for solving optimal control problems. J Optim Theory Appl 1985;46(3):265–293.
Varaiya P. N-person nonzero sum differential games with linear dynamics. SIAM Journal on Control 1970;8(4):441–449.
Acknowledgements
We are very grateful to Abderrahmane Habbal and Souvik Roy for many insightful discussions on the topic of differential games. We especially thank Andrei Fursikov for continued support of our work.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Campana, F.C., Borzì, A. On the SQH Method for Solving Differential Nash Games. J Dyn Control Syst 28, 739–755 (2022). https://doi.org/10.1007/s10883-021-09546-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10883-021-09546-1
Keywords
- Sequential quadratic Hamiltonian method
- Differential Nash games
- Pontryagin maximum principle
- Successive approximations strategy