
Abstract
In this paper, we consider extensions of the Maximum-Profit Public Transportation Route Planning Problem, or simply Maximum-Profit Routing Problem (MPRP), introduced in Armaselu and Daescu (Approximation algorithms for the maximum profit pick-up problem with time windows and capacity constraint, 2016. arXiv:1612.01038, Interactive assisting framework for maximum profit routing in public transportation in smart cities, PETRA, 13–16, 2017). Specifically, we consider MPRP with Time-Variable Supply (MPRP-VS), in which the quantity \(q_i(t)\) supplied at site i is linearly increasing in time t, as opposed to the original MPRP problem, where the quantity is constant in time. For MPRP-VS, our main result is a \(5.5 \log {T} (1 + \epsilon ) \left( 1 + \frac{1}{1 + \sqrt{m}}\right) ^2\) approximation algorithm, where T is the latest time window and m is the number of vehicles used. We also study the MPRP with Multiple Vehicles per Site, in which a site may be visited by a vehicle multiple times, which can have 2 flavors: with quantities fixed in time (MPRP-M), and with time-variable quantities (MPRP-MVS). Our algorithmic solution to MPRP-VS can also improve upon the MPRP algorithm in Armaselu and Daescu (2017) under certain conditions. In addition, we simulate the MPRP-VS algorithm on a few benchmark, real-world, and synthetic instances.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Consider a set S of n points in the plane, called sites. Each site \(S_i\) supplies a quantity \(q_i\) of a certain unit-priced product that needs to be collected and has an operating time window of \([s_i, e_i]\), where \(0 \le s_i \le e_i \le T\), for some constant \(T > 0\), \(\forall {i = 1, \dots , n}\). The distance \(d_{i,j}\) between sites \(S_i\) and \(S_j\) is the euclidean distance. We are also given a fleet of m vehicles \(V = \{v_1, \dots , v_m\}\), each having the same capacity Q. All vehicles are assumed to travel at unit speed and have unit fuel consumption per distance travelled. Only one vehicle may visit any given site and all vehicles must start and end their tour at the same given depot \(D(x_D, y_D)\). The goal is to compute, for every vehicle \(v_k\), a route \(R_k\) that collects a quantity \(q^k_i\) of the good such that the total profit of all routes is maximized, where the profit \(p_k\) of a route \(R_k\) is the total quantity collected \(q^k = \sum _{S_i \in R_k}{q^k_i}\) (called reward) minus the total distance \(d^k\) travelled via \(R_k\) (called cost). Such definition of profit makes sense since both the reward and the cost (and thus, the profit) can be measured in the same unit, e.g., in USD. We call this problem the Maximum Profit pick-up Routing Problem (MPRP).
MPRP was introduced in Armaselu and Daescu (2016, 2017), which focuses on the case with fixed quantities and only one vehicle per site.
In this paper, we consider a variant of MPRP with Variable Supply (MPRP-VS), in which quantities supplied at each site increases linearly in time. That is, for every site \(S_i\), the quantity \(q_i(t)\) of the good available at time t at site i, is assumed to be 0 outside the time window, and piecewise linearly increasing at the rate \(\rho _i\) within the time window.
We also consider the case where multiple vehicles may visit one site. In particular, we first study the MPRP problem with Multiple Vehicles Per Site and fixed quantities (MPRP-M), and then solve the MPRP problem with Multiple Vehicles Per Site and Time-Variable Quantities supplied (MPRP-MVS). A visit is a tuple \((i, k, t, q_{i,k,t})\) such that vehicle \(v_k\) visits a site \(S_i\) at time t and picks up a quantity \(0 < q_{i,k,t} \le q_i(t)\). Compared to the single vehicle versions, this adds the availability constraint that \(\sum _{1 \le k \le m, 0 \le u \le t}{q_{i,k,u}} \le q_i(t), \forall {i, t}\). However, a vehicle may not visit a site more than once.
MPRP is known to be strongly NP-hard (Armaselu and Daescu 2017). By extension, all the variants proposed above are also strongly NP-hard. That is, they have no algorithm running in time polynomial in the value of the input unless P = NP.
The problem arises in various public transportation settings such as cities (Armaselu and Daescu 2017), inter-city railway transportation, domestic or international flight, etc. In each such setting, one may be given a fleet of vehicles and a set of transportation hubs such as cities, stations, airports, etc., as well as the expected number of travellers per hub at any given time, and the goal is to schedule a set of routes, such as flight schedules, bus schedules, etc., to maximize the profit, i.e., maximize the difference between the revenue and the costs. Another important application is in for-profit waste pick-up, in which we are given the waste dump location, the reward is proportional to the amount of waste collected, and the goal is to schedule the garbage collecting vehicles to maximize the profit.
Table 1 provides a description of all notations used throughout this paper.
1.1 Related work
General graph TSP is proven to be hard to approximate within any constant factor (Sahni and Gonzalez 1976). However, TSP on special graphs, such as complete graphs with metric distances and euclidean distances, do have approximation algorithms. For instance, general metric TSP has a \(O(n^3)\) time 1.5-approximation algorithm by Christofides (1976). Euclidean metric TSP even has a PTAS achieving \(1 + \epsilon \) performance ratio via Arora’s \(O(n (\log n)^{O(1/\epsilon )})\) time algorithm (Arora 1998). On the other hand, metric TSP was shown to be APX-complete by Papadimitriou and Yannakakis (1993) and to date, the best known lower bound is 123/122 by Karpinski et al. (2005).
Various generalizations of TSP have also been considered. Bansal et. al introduced the Deadline-TSP and the Time Window-TSP problems (Bansal et al. 2004). In Deadline-TSP, every site \(S_i\) has a deadline \(D_i\), while in Time Window-TSP, every site \(S_i\) has a time window \([s_i, e_i]\). Both of these problems associate every site \(S_i\) with a reward \(q_i\) and ask for a single tour that maximized the total reward collected. For Deadline-TSP, they provide an \(O(\log n)\)-approximation algorithm, while for Time Window-TSP they describe an \(O(\log ^2 n)\)-approximation.
There are also variants involving multiple vehicles. Fisher et. al introduced the Vehicle Routing Problem with Time Windows and capacity constraints (VRPTW), in which customers have a demand \(q_i\) of the product, as well as operating time windows, and the m vehicles have non-uniform capacity constraints (Fisher et al. 1997). They solve this problem using a linear programming approach.
Golden et. al studied the Capacitated Arc Routing Problem (CARP) with uniform vehicle capacity where edges, rather than vertices, have customer demands, and the goal is to minimize the travelled distance subject to meeting all demands. They prove that CARP can be approximated within a constant factor when the triangle inequality is satisfied (Golden and Wong 1981). Later, van Bevern extended the result to general undirected graphs (van Bevern et al. 2014).
Wang et. al considered the Multi-Depot Vehicle Routing Problem (MDVRPTW) with Time Windows and Multi-type Vehicle Number Limits (Wang et al. 2008). The main difference in our problem is that the goal is to minimize the number of vehicles used (if feasible) or maximize the number of visited customers (if infeasible). Although they solve the problem using a genetic algorithm approach, their algorithm is iterative and has no performance guarantee with respect to the approximation factor.
Versions of vehicle routing with multiple vehicles per customer have also been considered. In Drexl (2012), Drexl does a comprehensive survey of variations of vehicle routing with multiple synchronization constraints (VRPMS), e.g. in which a customer may be visited by two vehicles (VRPTT) (Bredström and Rönnqvist 2008), or by 3 or more vehicles (Bürckert et al. 2000).
Armaselu and Daescu solved the fixed-supply, single-vehicle version of MPRP and provided an APX (Armaselu and Daescu 2016, 2017). The APX is a \(15 \log T\)-approximation and is achieved by an approach involving well-separated pair decompositions.
1.2 Our contributions
We give a constant-factor approximation algorithm for MPRP-VS, which uses clever reductions to some known problems. Specifically, our algorithm runs in \(O((\frac{n}{\epsilon ^2})^{11})\) time and has an approximation ratio of \(5.5 \log {T} (1 + \epsilon ) (1 + \frac{1}{1 + \sqrt{m}})^2\). In addition, our algorithm can be adapted to the MPRP problem to improve upon the algorithm in Armaselu and Daescu (2017), under certain assumptions about the quantities supplied.
The rest of the paper is structured as follows. In Sect. 2, we solve MPRP-VS and provide our experimental results for the MPRP-VS. Then, in Sect. 3, we solve MPRP-M. After that, in Sect. 4, we solve MPRP-MVS. Finally, in Sect. 5, we conclude and list some future directions.
2 MPRP-VS
MPRP-VS can be mathematically formulated as:
subject to
where \(t^k_i\) is the timestamp when vehicle \(v_k\) visits site \(S_i\). Here
-
(1)
is the profit maximization objective function,
-
(2)
is the first and last site visitation constraint,
-
(3)
is the capacity constraint,
-
(4)
is the time window constraint,
-
(5)
is the travelling constraint,
-
(6)
is the production constraint, and
-
(7)
is the per-site vehicle uniqueness constraint.
Note that the depot D is treated as the 0-th site.
We call the above Formulation 1.
Alternatively, one can formulate the problem as follows.
subject to
where \(x_{i,j,k,t} = 1\) if vehicle \(v_k\) arrives from \(S_i\) at \(S_j\) at time t. Here
-
(1)
is the profit maximization objective function,
-
(2)
is the capacity constraint,
-
(3)
is the time window constraint,
-
(4)
is the production constraint,
-
(5)
is the per-site vehicle uniqueness constraint,
-
(6)
is the tour connectivity constraint, and (7.1), (7.2) are the constraints enforcing starting and ending at the depot.
We call this alternative Formulation 2.
We assume that all sites start "empty", that is, \(q_i(s_i) = 0, \forall {1 \le i \le n}\). Further, we suppose the discrepancies in the quantities supplied are small, specifically \(q_i(e_i) \le \alpha q_j(e_j), \forall {i, j = 1, \dots , n}\), for some constant \(\alpha > 1\), and \(Q, q_i(l_i) \in {\mathbb {Z}}, \forall {1 \le i \le n}\).
Since the quantities supplied increase linearly in time, we have \(q_i(t) = \rho _i (t - s_i) = q_i(e_i) \frac{t - s_i}{e_i - s_i}\).
Note that, if \(Q \ge \sum _{i=1}^{n} q_i(e_i)\), then the capacity constraint is always satisfied. Thus, from now on, we also assume \(Q < \sum _{i=1}^{n} q_i(l_i)\).
In Sect. 2.1, we focus on a restricted one-vehicle case, show how to reduce it to the problem in Armaselu and Daescu (2016), and analyze the algorithm. After that, in Sect. 2.2, we generalize to multiple vehicles and provide the APX for the general case. Finally, in Sect. 2.3, we provide the results of the experimental simulation of our MPRP-VS solver.
2.1 One-vehicle case
We first consider a restricted version of the MPRP-VS problem, denoted MPRP-VS-1, in which only one vehicle is available and the goal is maximizing reward rather than profit. We show how to reduce MPRP-VS-1 to the MPRP problem with one vehicle (MPRP-1) where the goal is reward maximization rather the profit maximization.
Lemma 1
MPRP-VS-1 problem can be reduced to MPRP-1 within \(O(\frac{n}{\epsilon })\) time and a ratio of \((1+\epsilon )\), for any \(\epsilon > 0\). That is, the vehicle assigned for an instance I of MPRP-VS-1 collects a reward \(q^I \ge \frac{1}{1+\epsilon } q^J\), where \(q^J\) is the quantity collected by the vehicle assigned for J and J is the corresponding instance of MPRP-1.
Proof
Let I be an instance of the restricted MPRP-VS-1 problem. We construct an instance J of MPRP-1. Let \(\epsilon > 0\). For every site \(S_i\) on instance I, we consider the N intervals \(TW_{i,1}, \dots , TW_{i,N}\), with
\(TW_{i,\tau } = [e_i + \frac{l_i - e_i}{(1+\epsilon )^{N-\tau +1}}, e_i + \frac{l_i - e_i}{(1+\epsilon )^{N-\tau }}], \forall \tau = 1... N\).
Here N is the smallest integer such that \((1+\epsilon )^{N-1} \ge \alpha \), that is, \(N = 1 + \frac{\ln \alpha }{\epsilon }\) (see Fig. 1 for an illustration). Note that, the length of the interval containing timestamp t is a non-decreasing function of \(q_i(t)\). Indeed, \(\Vert TW_{i, 1}\Vert = \frac{l_i - e_i}{(1+\epsilon )^{N-1}}\), and \(\Vert W_{i, \tau }\Vert = \frac{\epsilon (l_i - e_i)}{(1+\epsilon )^{N-\tau +1}}, \forall \tau > 1\), which is increasing in \(\tau \). For each interval \(TW_{i,\tau }\), we add a site labeled \(S_{i, \tau }\) to J, with the same coordinates as site i and with fixed quantity \(q_{i, \tau } = q_i(l_i) \frac{\tau - 0.5}{N - 1}\) and time window \(W_{i,\tau }\). For every two nodes \(S_{i, \tau }, S_{j, \tau '}\) in J, the point-to-point distance \(d_J((i, \tau ), (j, \tau '))\) is defined as follows.
\(d_J((i, \tau ), (j, \tau ')) = {\left\{ \begin{array}{ll} d_I(i, j),&{} \text {if } i \ne j \\ 0, &{} \text {otherwise} \end{array}\right. } \)

The intervals \(W_{i, \tau }\) for \(\alpha = e^3, \epsilon = 0.5, \tau = 1 \dots 7\)
We approximately solve the optimization Subset-Sum problem, in which the goal is to find a set of numbers that add up to as close as possible to Q without exceeding Q. The input set of numbers for Subset-Sum will be \(\{ q_{i, \tau } \Vert i = 1 \dots n, \tau = 1 \dots N \}\). Denote by \(q_{SS}^J\) the set of numbers output by the Subset-Sum solver. We discard the sites whose quantities are not in \(q_{SS}^J\) from J (assuming wlong that quantities are distinct). At this point the construction of J is complete.
Using the reward-maximization algorithm in Bansal et al. (2004), we compute a routing \(R^J\) on J. Then, for every \(i = 1 \dots n\), we take the latest interval \(\tau _i\) for which \(S_{i, \tau _i} \in R^J\), and remove all nodes \(S_{i, \tau } \in R^J\) such that \(\tau \ne \tau _i\), to ensure that every site is visited only once.
Denote by \(R_0^J\) the resulting route and let \(R^I = \{ S_i \in S \Vert \exists \tau : S_{i, \tau } \in R_0^J \}, S^I = \{S_i \in S: i \in R^I\}, S^J = \{S_i \in S: S_{i, \tau _i} \in R^J\}\). By construction, \(S^I = S^J\). Moreover, for each site \(S_i\), the time interval \(TW_{i, \tau _i}\) in which \(R^I\) visits i is the same as the time window \(TW_{i, \tau _i}\). Also, we solve the Subset-Sum problem optimally in \(O^*(\min {Q \sqrt{n}, Q^{5/4}, \sum _i{q_{i, \tau }}})\), using the method in Koiliaris and Xu (2019), where \(O^*\) ignores a polylogarithmic factor. Since \(\sum _i{q_{i, \tau }} = O(\frac{\rho }{\epsilon } n T)\), the running time becomes \(O^*(\frac{\rho }{\epsilon } n T) = O^*(\frac{n}{\epsilon })\) time. The quantity \(q^I\) collected by \(R^I\) is at least \(q^J \cdot \beta \), with \(\beta = sup_{i,\tau }{\frac{q_{i, max}(\tau )}{q_{i, min}(\tau )}}\), where \(q_{i, max}(\tau )\) and \(q_{i, min}(\tau )\) are the maximum (respectively, minimum) quantity collectible in interval \(\tau \) of site \(i, \forall i, \tau \). It is easy to check that \(\beta = 1 + \epsilon \) by construction. Hence, the result follows. \(\square \)
2.2 MPRP-VS: general case
Now we show how to extend the reduction to solve the general MPRP-VS problem (for multiple vehicles).
Given an instance \(I^*\) of MPRP-VS with sites S, m vehicles of capcity Q and time windows \([s_1, e_1], \dots , [s_n, e_n]\), we do the following. First, decompose S into a set of subsets \(P_k\) for each vehicle \(v_k\). For each subset \(S_k\), create an instance \(I_k\) of MPRP-VS-1 with the set \(P_k\) of sites, the same capacity constraint Q and the same time windows. Then, for each instance \(I_k\), construct an instance \(J_k\) of MPRP-1 from \(I_k\), using the reduction in Sect. 2.1. Next, solve each instance \(J_k\) and denote by \(R_k\) the resulting route. For each site \(S_i\), if two or more vehicles visit \(S_i\), retain only the vehicle \(v_k\) that would collect the largest \(q_i^k\). After that, for each site \(S_i\) and vehicle \(v_k\), reassign \(S_i\) to \(R_k\) if and only if the profit would increase. Finally, remove all \(P_k\)’s from S and keep decomposing S until no more site-vehicle assignments are made.
For any route \(R_k\), denote by \(p(R_k)\) the profit obtained by \(R_k\).

In the following, we will describe the Decompose and Solve procedures of the MPRP-VS-General algorithm in detail. Note that the \(Reduce-MPRP-VS-1-to-MPRP-1(I_k)\) can be performed using the reduction in Sect. 2.1, while all other steps are straightforward.
The Decompose routine, which decomposes S into subsets, runs as follows. We first construct a well-separated pair decomposition (WSPD) W of the sites, using the separation factor \(\sigma = \sqrt{m}\). Note that W is a binary tree-like hierarchical clustering of the sites such that, for any pair \((S_i, S_j)\) of sites, exactly one pair \((A_k, B_k)\) of subsets in W s-separates them. That is, either \(S_i \in A_k, S_j \in B_k\) or viceversa. There are \(O(\sigma ^2 n)\) subsets in W, and each subset \(A_i\) or \(B_i\) is further decomposed into \(O(\sigma ^2)\) pairs of subsets \((A_{i+1}, B_{i+1}), \dots , (A_{i+\sigma ^2}, B_{i+\sigma ^2})\). Since this is a hierarchical pair decomposition, there are \(1 + O(\frac{\log n}{\log \sigma })\) levels in the hierarchy, and the union of the subsets on any level in the whole input set S. Assume wlog that the pairs of subsets are ordered by the total number of sites contained in them. After that, for every vehicle \(v_k\), we construct an instance \(I_k\) of MPRP-VS-1 where the set of sites is \(SS_k\) assigned to \(v_k\) as follows. For vehicles \(v_1, v_2\), assign subsets \(P_1 = A_1, P_2 = B_1\). For every \(k > 1\), for vehicles \(v_{2k-1}, v_{2k}\), assign subsets \(P_{2k-1} = A_{k}, P_{2k} = B_{k}\), and remove all sites in \(P_{2k-1}, P_{2k}\) from \(P_1, \dots , P_{2k-2}\). It is easy to check that no subsets are overlapping. Moreover, since the subgraph induced by the subsets is an s-spanner, it follows that any minimum-length routing algorithm on the induced subgraph outputs a total length of at most \(L = L^* \cdot (1 + \frac{1}{1 + \sigma })\), where \(L^*\) is the total length of a minimum-length routing on S. This gives us the following result.
Lemma 2
The total length of a minimum-length routing \(R_k\) for each subset \(P_k\) is at most \(L = L^* \cdot (1 + \frac{1}{1 + \sqrt{m}})\), where \(L^*\) is the total length of a minimum-length routing on S.
The Solve routine, i.e., solving an instance \(J_k\), operates as follows. First, compute a route \(R_k'\) that approximately maximizes the quantity collected from \(P_k\), using the algorithm in Bansal et al. (2004). After that, traverse \(R_k'\) and, for every two consecutive arcs \((S_i, S_j), (S, j, S_l)\), replace them by a single arc \((S_i, S_l)\) if and only if it meets and time windows and increases the profit. Denote the resulting route by \(R_k\). The following statement about \(R_k\) holds.
Lemma 3
\(R_k\) has a profit \(P(R_k) \ge \frac{P_k^*}{8 \ln {2} \log {T}}\), where \(P_k^*\) is the maximum profit obtainable by a tour visiting sites in \(R_k\) with capacity constraint Q.
Proof
With the algorithm in Bansal et al. (2004), \(r_k'\) picks up a total quantity of at least \(\frac{q_k^*}{8 \ln {2}\log {T}}\), where \(q_k^*\) is the total quantity collected by an optimal algorithm.
After arc replacements on \(R_k'\), the total profit of the resulting route \(R_k\) becomes
\(p_k = \sum _{S_i \in R_k}{q_i} - \sum _{(S_i, S_j) \in R_k}{d_{ij}} \ge \sum _{S_i \in R_k'}{q_i} - \sum _{(S_i, S_j) \in R_k'}{d_{ij}} \ge \frac{q_k^*}{8 \ln {2}\log {T}} - \sum _{(S_i, S_j) \in R_k'}{d_{ij}} \ge \frac{q_k^*}{8 \ln {2}\log {T}} - L_k \ge \frac{q_k^ - L_k}{8 \ln {2}\log {T}} \ge \frac{p_k^*}{8 \ln {2}\log {T}}\),
where \(L_k\) is the length of the shortest tour visiting all sites in \(R_k\) under capacity constraint Q. \(\square \)
Let \(P_t\) be S at the beginning of the t-th iteration.
Lemma 4
During some iteration t, after the second foreach of the algorithm, the total quantity \(q^t\) collected from \(P_t\) is at least \(\frac{q^*(t)}{(1 + \frac{1}{1 + \sqrt{m}})(1 + \epsilon )}\), where \(q^*(t)\) is the optimal quantity collectible from S(t).
Proof
Suppose on the contrary that, in any iteration t, the total quantity \(q^t\) collected after the second foreach is less than \(\frac{q^*(t)}{(1 + \frac{1}{1 + \sqrt{m}})(1 + \epsilon )}\). Then there exists a site \(s_i\) from which a quantity less than \(\frac{q_i^*}{(1 + \frac{1}{1 + \sqrt{m}})(1 + \epsilon )}\) is collected, where \(q_i^*\) is the quantity collected from \(S_i\) by the optimal MPRP-1 algorithm. By Lemma 1, it follows that the optimal MPRP-VS-1 algorithm collects a quantity less than \(\frac{q_i^*}{1 + \frac{1}{1 + \sqrt{m}}}\). Since the travel costs on \(P_t\) are at most \(1 + \frac{1}{1 + \sqrt{m}}\) times the optimal value, it follows that the algorithm misses a site \(S_i\) satisfying \(q_i^* > \frac{q^*(t)}{n}\) due to missing its time window. However, the last foreach of the algorithm ensures that, if a site is missed during an iteration, it will eventually be visited during a further iteration \(t'\). \(\square \)
We now analyze the performance of the algorithm.
By Lemma 2, the total distance travelled by all \(v_k\) on all \(SS_k\) is at most \(1 + \frac{1}{1 + \sqrt{m}}\) times higher than the optimal distance. By Lemma 1, for each \(v_k\), the quantity collected from all sites in \(SS_k\) is at least \(\frac{1}{1 + \epsilon }\) of the quanity collected by an MPRP-1 solver on \(SS_k\). Since \(r_k\) is the output of an MPRP-1 solver on \(SS_k\) and, by Lemma 3, the profit collected by \(r_k\) from \(SS_k\) has a profit at least \(\frac{1}{8 \ln {2}\log {T}}\) the optimal profit, it follows that the profit for each \(v_k\) is at least \(\frac{1}{1 + \epsilon } \cdot \frac{1}{8 \ln {2}\log {T}}\) times the optimal for an MPRP-VS-1 solver on \(SSS_k\). Now the profit of the algorithm on the original problem instance I would be \(\frac{1}{1 + \epsilon } \cdot \frac{1}{8 \ln {2}\log {T}}\) times the optimal in absence of time winodws. The extra tour length factor of \(1 + \frac{1}{1 + \sqrt{m}}\) may cause more than \(1 + \frac{1}{1 + \sqrt{m}}\) as much reward to be lost due to missing time windows. However, by Lemma 4, we collect a total quantity at least \(\frac{q^*}{(1 + \frac{1}{1 + \sqrt{m}})(1 + \epsilon )}\) while increasing travel costs at most \(1 + \frac{1}{1 + \sqrt{m}}\) times, where \(q^*\) is the optimal total quantity collectible for the problem instance.
That is, the total profit for the algorithm becomes at least
\(P = P^* \frac{1}{(1 + \epsilon )^2} \cdot \frac{1}{8 \ln {2}\log {T}} \cdot \frac{1}{(1 + \frac{1}{1 + \sqrt{m}})^2} = \frac{P^*}{8 \ln {2}\log {T} (1 + \epsilon )^2 (1 + \frac{1}{1 + \sqrt{m}})^2}\),
where \(P^*\) is the optimal profit for the problem instance.
Letting \(\delta = 2\epsilon + \epsilon ^2\), we get
\(P = \frac{P^*}{8 \ln {2}\log {T} (1 + \delta ) (1 + \frac{1}{1 + \sqrt{m}})^2}\).
Additionally, note that Step 2 produces a routing on a total of \(O(\frac{n}{\epsilon })\) sites. Since Step 3 takes \(O(N^{11})\) time when run on a et of N sites (Armaselu and Daescu 2017), it runs in \(O((\frac{n}{\epsilon })^{11})\) time in our case.
Since \(\epsilon = -1 + \sqrt{1 + \delta ^2} = \frac{\delta ^2}{1 + sqrt{1 + \delta ^2}} = \Theta (\delta ^2)\), we get a ruinning time of \(O((\frac{n}{\delta ^2})^{11})\).
Re-assigning \(\delta \) as \(\epsilon \), we can state the following result.
Theorem 5
For any parameter \(\epsilon \), MPRP-VS can be solved within \(O((\frac{n}{\epsilon ^2})^{11})\) time and has an approximation ratio of
\(8 \ln {2} \log {T} (1 + \epsilon ) (1 + \frac{1}{1 + \sqrt{m}})^2 \simeq 5.5 \log {T} (1 + \epsilon ) (1 + \frac{1}{1 + \sqrt{m}})^2\).
Notice that the algorithm presented in this paper can also be used to solve MPRP. When the quantities supplied at each site are constant in time, the decomposition step of the algorithm can be skipped, and \(I_k\) can be used to generate \(R_k\), instead of \(J_k\). Since the extra \(\frac{1}{(1 + \epsilon )^2}\) factor in the approximation ratio and the extra \(O(\frac{1}{\epsilon ^{22}})\) factor in the running time is due to the reduction from MPRP-VS-1 to MPRP-1, we obtain the following.
Corollary 6
MPRP can be solved in \(O(n^{11})\) time and has an approximation factor of \(\simeq 5.5 \log {T} (1 + \frac{1}{1 + \sqrt{m}})^2 \le 12.5 \log {T}\), assuming \(q_i(l_i) \le \alpha q_j(l_j), \forall {i, j = 1, \dots , n}\), for some constant \(\alpha > 1\), and \(Q, q_i(l_i) \in {\mathbb {Z}}, \forall {i = 1, \dots , n}\).
Note that this is an improvement over the algorithm in Armaselu and Daescu (2017) when the aforementioned assumption holds.
2.3 Experimental results
We ran \(MPRP-VS-General\) on a set of MPRP-VS instances in a Windows 10 environment running on CyberPower PC with Intel(R) Core(TM) i7-9700K CPU @ 3.60GHz and 32GB of RAM. The set contains 12 instances of the US tourism dataset (U. T. dataset) and 9 instances of Solomon’s benchmark, all tailored to MPRP-VS. In addition, the set contains 12 synthetic randomly generated datasets.
Similarly to the US tourism dataset tailored for the original MPRP (Armaselu and Daescu 2017), in the MPRP-VS-tailored dataset mentioned in this paper, each instance corresponds to a month. The sites \(S_i\) are major airports, the vehicles are aircraft, and the production rates \(\rho _i\) are the hourly ticket revenue collected at airport \(S_i\), averaged for that month. We assume a time window of 6 to 24 for all airports. The depot is taken to be Dallas, TX.
The instances from Solomon’s benchmark are labelled C, R, or RC, followed by a number. For all these instances, \(n = 100\).
Finally, the synthetic instances are labelled A, B, C, or D, followed by the number of sites (10, 30, or 50). The distances between sites are similar, however, the quantities and capacities are progressively larger going from A to D, while the time windows are shorter.
Table 2 shows, for each problem instance, the number of sites n, the latest time window end time T, the running time time in seconds, and the performance ratio \(\phi \) of \(MPRP-VS-General\). Here the performance ratio is defined as \(\phi = U / P\), where P and U are, respectively, the actual profit and the upper bound profit.
Note that the performance ratio \(\phi \) is typically much lower that the theoretical approximation ratio.
3 MPRP-M
Mathematically, MPRP-M can be formulated similarly as MPRP-VS. The only differences are:
-
(1)
There is no production constraint and the \(q^k_i\)’s (resp., \(q_i(t)\)’s) are replaced by \(q_i\), and
-
(2)
There is no per-site vehicle uniqueness constraint.
Formally, MPRP-M has a Formulation 1 as follows.
subject to
The alternate Formulation 2 would be
subject to
To solve MPRP-M, we come up with a reduction from to MPRP.
Let \(d(0, i) = d(i, 0)\) be the distance from the depot to site \(S_i, \forall {i: 1 \le i \le n}\).
An instance I of MPRP (or MPRP-M) can be described as a set \(I = (S = \{S_i: 1 \le i \le n\}, D = (x_0, y_0), d = \{d(i, j): 0 \le i < j \le n\}, T, Q, m)\), where \(S_i = (x_i, y_i, s_i, e_i, q_i)\).
A solution Sol to I is a set \(Sol = (R, F)\). Here R is a routing function assigning, to every pair of sites or depot \((i, j), 0 \le i, j \le n\), a number \(k(i, j): 0 \le k(i, j) \le m\), denoting the index of the vehicle operating the path from \(S_i\) to \(S_j\), or 0 if no such vehicle exists. F is a pickup function assigning, to every site \(S_i\) on vehicle \(v_k\)’s route, a quantity \(q^k_i \le q_i, Q\) to be picked up by \(v_k\).
A solution \(Sol'\) to \(I'\) is a routing function with the same properties as the function R in Sol.
Denote by MPRP (resp., \(MPRP-M\)) the set of MPRP (resp., MPRP-M) instances.
Starting from \(I = (\{(x_i, y_i, s_i, e_i, q_i): 1 \le i \le n\}, (x_0, y_0), \{d_{i,j}: 0 \le i < j \le n\}, T, Q, m) \in MPRP-M\), let \(I' = (\{(x_i, y_i, s_i, e_i, q_i): 1 \le i \le n\}, (x_0, y_0), \{d_{i,j}: 0 \le i < j \le n\}, T, Q, m) \in MPRP\). That is, \(I'\) has the same nodes and distances as I. We solve \(I'\) using the algorithm in Armaselu and Daescu (2017) and denote by \(Sol'\) the solution.
We transform the solution \(Sol'\) to an MPRP instance \(I'\), into a solution Sol to an MPRP-M instance I, as follows. For every vehicle \(v_k\) of \(I'\), let \(q^k\) be the total quantity collected by \(v_k\) from its assigned tour \(R'_k \in Sol'\). It may be possible that some sites in \(R'_k\) need to be visited multiple times in I, producing a new tour \(R_k \in Sol\). To figure out which ones need to, we look at tuples of sites \((S_u, S_{u'}, S_i, S_{i'}, S_j, S_{j'}) \in S^2 \times (S \cup D)^4\) in \(I'\) where
The goal is to maximize the total amount picked up from \(\tau '_k\) and \(\tau '_{k'} \cup \{S_u\}\). That is, denote by \(q^{k'}_{u'}\) the quantity assigned to be picked up by \(v_{k'}\) from \(S_{u'}\), by \(q^k_{u'}\) the quanity assigned to be picked up by \(v_{k}\) from \(S_{u'}\), and by \(q^k_u\) the quanity assigned to be picked up by \(v_{k}\) from \(S_{u}\). We have
and our goal is to maximize \(q^k_{u'} + q^{k'}_{u'} + q^k_u\). In order to do that, we set \(x = q^k_u, y = q^k_{u'}, z = q^{k'}_{u'}\), and we come to the following linear program.
After solving the linear program, we check the additional constraint \(x + y \le Q - q_k + q_{u'}\). If it is satisfied, we assign \(v_{k'}\) to pickup \(z^*\) from \(S_{u'}\), and \(v_k\) to pickup \(x^*\) from \(S_u\) and \(y^*\) from \(S_{u'}\) in Sol, where \((x^*, y^*, z^*)\) is a solution to the linear program. For Sol to achieve a better profit than \(Sol'\) through this re-assignment, the following need to hold.
-
1.
\(x^* + y^* + z^* - q_{u'} > d(i', i) + d(i, i'') - d(i', i'')\) and
-
2.
Insertion of \(S_i\) into \(R_{k'}\) in Sol does not introduce time window violations, i.e.
\(d(i', i) + d(i, i'') - d(i', i'') \le \min \{t^{k'}_{v'} - s_{v'}: S_{v'}\) before \(S_{i'}\) in \(R'_{k'}\} + \min \{e_{w'} - t^{k'}_ {w'}: S_{w'}\) after \(S_{j'}\) in \(R'_{k'}\}\),
where \(t^k_ i\) is the time when \(v_k\) visits \(S_i\).
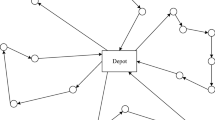
See Fig. 2 for an illustration of this re-assignment.

Tours of \(Sol'\) are depicted in solid lines and tours of Sol are depicted using dashed lines. \(v_k\) is assigned to pickup 35 from \(S_u\) and 20 from \(S_{u'}\), while \(v_{k'}\) is assigned to pickup 35 from \(S_{u'}\). Since time windows are not violated, Sol is more profitable than \(Sol'\)
For each vehicle \(v_k\) and site \(S_{u'} \in R'_k\), we look at all possible tuples \((S_u, S_i, S_{i'}, S_j, S_{j'}) \in S \times (S \cup D)^4\) satisfying the abovementioned additional constraints and solve the linear program to find the optimal quantities to pickup, then select the tuples that maximize the profit gain after re-assignment, and then perform the re-assignment.
One arising concern is that the order in which the pairs \((v_k, S_{u'})\) are selected produces different results. However, while this may happen, it may not impact the optimality of the re-assignment by more than a constant factor, as we shall see below.
Lemma 7
Let O be an ordering of the pairs \((v_k, S_{u'})\) and let \(\Delta (k, u')\) be the gain obtained through re-assignment when selecting pair \((v_k, S_{u'})\) (or 0, if re-assignment is infeasible). Then \(\sum _{k, S_{u'} \in R'_k} \Delta (k, u') = \Delta \in [C, 4 C]\), where C does not depend on O.
Proof
Note that
where \(S_i < S_j\) indicates that \(S_i\) is before \(S_j\) in \(R'_{k'}\).
Since \(x^* = q^k_u, y^* = q^k_{u'}, z^* = q^{k'}_{u'}\), we get
We have
Let
\(Q^* = \sum _{e_i - s_i: S_i \in R'_k} q_i, Q^e = \sum _k (e_i - t^k_ i: i \in R_k), Q^s = \sum _k (t^k_ i - s_i: i \in R_k)\).
Since \(\sum _{k, S_{u'} \in R'_k} \max \{0, q^k_u + q^k_{u'}\} \ge Q^*\), it follows that
Moreover, note that \(Q^s + Q^e = \sum _k(e_i - t^k_ i + t{k, i} - s_i) = \sum _k(e_i - s_i)\).
That is, \(\Delta \ge C = Q^* + \sum _k(e_i - s_i)\), where C does not depend on O.
Note that
since otherwise one would be able to create an optimal metric-space MST-based tour of cost \(> 2 C\), which is a contradiction of the result in Christofides (1976).
Thus,
Since
for sufficiently large \(\frac{\min {q_i}}{2 T}\), which is reasonable since T is constant, we get
That is, \(\Delta \le 4 C\). \(\square \)
Thus, we first run a MPRP solver to obtain a routing \(R'\) and then select the pairs \((v_k, S_{u'})\) in the order given by each \(R'_k\) for every k. For each of the O(mn) pairs, we inspect all possible \(O(n^5)\) tuples in O(n) time per tuple, which is the time required to verify constraint 2. That is, our reduction is done in \(O(m n^7)\) time.
As for the correctness of the reduction, suppose there exists a routing \(R''\) for \(I'\) yielding a profit increased by more than a factor of 4 compared to \(R'\). In order to do that, \(R''\) must pickup a quantity \(q''_{u'} >4 q_{u'}\) from some \(S_{u'}\). However, this implies that either \(S_{u'}\) is not re-assigned in R and thus gives an increased profit for \(I'\), or is re-assigned to one of \(S_u, S_i, S_{i'}, S_j, S_{j'}\) and thus gives an increased profit for one of these sites. Both options lead to a contradiction. Now suppose there exists a routing \(R''\) for I yielding an increased profit compared to R. In order for that to happen, either some site \(S_{u'}\) that was never added or involved in a re-assignment picks up a quantity \(q''_{u', k} > q^k_{u'}\), implying an increased profit for \(q''_{u'} > 4 q'_{u'}\) for \(S_{u'}\) in \(R'\), or some site \(S_{u'}\) involved in a re-assignment with \((S_u, S_i, S_{i'}, S_j, S_{j'})\) picks up a quantity \(q''_{u', k} > 4 q^k_{u'}\), implying a quantity was picked up from some site (wlog assumed to be \(S_u\)) in \(R''\) which is more than 4 times the one picked from the samee site in \(R'\). In both cases, a contradiction follows due to Lemma 1. Hence, we have reduced MPRP-M to MPRP within an approximation ratio of 4 in \(O(m n^7)\) time.
By using the \(\simeq 11 \log T\)-approximation for MPRP in Armaselu and Daescu (2017) for \(O(n^{11})\) time, we thus solve MPRP-M in \(O(n^{11})\) time.
We have proved the following result.
Theorem 8
MPRP-M can be solved in \(O(n^{11})\) time for an approximation ratio of \(\simeq 44 \log T\).
4 MPRP-MVS
MPRP-MVS can be formulated in a similar fashion as MPRP-VS and MPRP-M. Any formulation should have the production constraint present in MPRP-VS but lack the per-site vehicle uniqueness constraint. Just like in MPRP-VS, the \(q_i\)’s are a function of t and k.
Formulation 1 becomes
subject to
Similarly, Formulation 2 becomes
subject to
We adapt the algorithm in Sect. 2.2 for solving MPRP-VS, to work in our case, by using a similar reduction as the one from MPRP-M to MPRP described in the previous section, to reduce MPRP-MVS to MPRP-VS.
Given an instance \(I = (S = \{S_i: 1 \le i \le n\}, D = (x_0, y_0), d = \{d(i, j): 0 \le i < j \le n\}, T, Q, m)\) of MPRP-MVS, we apply the reduction in Sect. 2.2 to obtain an instance \(I'' \in MPRP-M\), and then solve MPRP-M using the algorithm in Sect. 3. Again, this is not straightforward since the approach in Sect. 2.2 depends on a single-vehicle assignment which is not the case here. Thus, we need a more insightful construction of \(I''\) than directly applying the approach in Sect. 2.2.
We proceed with a clever construction as follows. For each site \(S_i\), we split \([s_i, e_i]\) into \(N = 1 + \frac{\ln (1/\alpha )}{\epsilon }\) intervals, for some \(\epsilon > 0\), where \(\alpha > 1\) is the smallest constant such that \(q_i(e_i) \le \alpha q_j(e_j), \forall {i, j}\). Denote these intervals by \(TW_{i, \tau }: 1 \le l \le N\), i.e. \(TW_{i, \tau } = [s_i + \frac{e_i - s_i}{(1+\epsilon )^{N-l+1}}, s_i + \frac{e_i - s_i}{(1+\epsilon )^{N-l}}]\). After performing this split, we construct a set of sites \(S'\) where, for each original site \(S_i\), \(S'\) contains N sites \(S''_{i, \tau }, 1 \le \tau \le N\). To each newly constructed site \(S''_{i, l}\), we assign a quantity \(q'_{i, l} = q_i(e_i) \frac{l - 0.5}{N - 1}\) and a time window \(I_{i,l}\). We then run the MPRP-M Option 1 algorithm described in Sect. 3 on the transformed instance \(I'' = (S'', D, d, T, Q, m)\) (note that \(I'' \in MPRP-M\) since the sites in \(S''\) now supply constant quantities).
Denote by \(R''\) the routing obtained by running the MPRP-M algorithm on \(I''\). We now analyze the properties of \(R''\) to put a bound on its performance ratio.
Recall from Sect. 2.1 that an optimal MPRP algorithm run on \(S'\) may collect a quantity at least \(\frac{1}{1 + \epsilon }\) as much as an optimal MPRP-VS algorithm run on S. Since for \(m = 1\), an instance of MPRP-M also belongs to MPRP, and an instance of MPRP-MVS is also an instance of MPRP-VS, we get the following.
Lemma 9
For \(m = 1\), an optimal MPRP-M algorithm when run on \(S''\) may collect a quantity at least \(\frac{1}{1 + \epsilon }\) as high as an optimal MPRP-MVS algorithm when run on S.
By running the \(\frac{1}{44 \log T}\)-optimal MPRP-M algorithm in Sect. 3 on \(I''\), we get the following a profit at least \(\frac{1}{44 \log T (1 + \frac{1}{1 + \sqrt{m}})}\) as high as an optimal MPRP-MVS algorithm when run on I.
Since travel costs are less than the rewards generated by the quantities collected, a performance ratio of \(\frac{1}{1 + \epsilon }\) in the quantities induces a performance ratio of \(\frac{1}{1 + \epsilon }\) in the profits as well. Putting this together with the lemma above, we get the following.
Lemma 10
When run on \(I''\), the MPRP-M algorithm in Sect. 3 may obtain a profit at least \(\frac{1}{44 \log T (1 + \epsilon )(1 + \frac{1}{1 + \sqrt{m}})^2}\) as high as an optimal MPRP-MVS algorithm when run on I.
Note that the reduction described before Lemma 2 takes \(O(\frac{n}{\epsilon })\) time. Then, running MPRP-M on \(I''\) which has \(|S''| = O(\frac{n}{\epsilon })\) sites, takes \(O((\frac{n}{\epsilon })^{11})\) time. Thus, we have proved the following result.
Theorem 11
MPRP-MVS can be solved in \(O((\frac{n}{\epsilon })^{11})\) time within an approximation ratio of \(44 \log T (1 + \epsilon )(1 + \frac{1}{1 + \sqrt{m}})^2\).
5 Conclusions and future work
We presented an APX for the Maximum-Profit Routing Problem with Variable Supply (MPRP-VS). We also improve upon the results in Armaselu and Daescu (2017) for the Maximum-Profit Routing Problem (MPRP) under certain conditions. Furthermore, we solve the Multiple Vehicles per Site versions of the Maximum-Profit Routing Problem, specifically, the Fixed-Supply version (MPRP-M) and the Time-Variable Supply version (MPRP-MVS).
We leave for future consideration probablistic approaches for all versions of MPRP, e.g. algorithmic solutions whose output is, with high probability, within a certain bound of the optimum for the given instance. Proving negative results or lower bounds, e.g. inapproximability within a certain ratio, would also be of interest.
Data availibility
Not applicable.
References
Armaselu B, Daescu O (2016) Approximation algorithms for the maximum profit pick-up problem with time windows and capacity constraint. arXiv:1612.01038
Armaselu B, Daescu O (2017) Interactive assisting framework for maximum profit routing in public transportation in smart cities, PETRA, 13–16
Arora S (1998) Polynomial time approximation schemes for Euclidean traveling salesman and other geometric problems. J ACM 45(5):753–782
Bansal N, Blum A, Chawla S, Meyerson A (2004) Approximation algorithms for deadline-TSP and vehicle routing with time windows, STOC 166-174
Bredström D, Rönnqvist M (2008) Combined vehicle routing and scheduling with temporal precedence and synchronization constraints. Eur J Oper Res 191:19–29
Bürckert H, Fischer K, Vierke G (2000) Holonic transport scheduling with TELETRUCK. Appl Artif Intell 14:697–725
Christofides N (1976) Worst-case analysis of a new heuristic for the traveling salesman problem, N. Christofides. Worst-case analysis of a new heuristic for the travelling salesman problem, Management Sciences Research (388) report
Drexl M (2012) Synchronization in vehicle routing: a survey of vrps with multiple synchronization constraints. Transp Sci 46(3):297–316
Fisher ML, Jornstein KO, Madsen OB (1997) Vehicle routing with time windows: two optimization algorithms. Oper Res. https://doi.org/10.1287/opre.45.3.488
Golden BL, Wong RT (1981) Capacitated arc routing problems. Networks 11(3):305–315
Karpinski M, Lampis M, Schmied R (2005) New Inapproximability bounds for TSP. J Comput Syst Sci 81(8):1665–1677. https://doi.org/10.1016/j.jcss.2015.06.003. arXiv:1303.6437
Koiliaris K, Xu C (2019) Faster pseudopolynomial time algorithms for subset sum. ACM Trans Algorithms 15(3):40
Papadimitriou CH, Yannakakis M (1993) The traveling salesman problem with distances one and two. Math Oper Res 18:1–12. https://doi.org/10.1287/moor.18.1.1
Sahni S, Gonzalez T (1976) P-complete approximation problems. J ACM 23(3):555–565
Solomon’s Benchmark. (1987) https://www.sintef.no/projectweb/top/vrptw/100-customers/
U. T. dataset. (2013) https://github.com/Bogdy90/MPRP-VS-UT-dataset
van Bevern RR, Hartung S, Nichterlein A, Sorge M (2014) Constant-factor approximations for capacitated arc routing without triangle inequality. Oper Res Lett 42(4):290–292
Wang X, Xu C, Shang H (2008) Multi-depot vehicle routing problem with time windows and multi-type vehicle number limits and its genetic algorithm. WiCOM. https://doi.org/10.1109/WiCom.2008.1502
Acknowledgements
The author would like to thank Dr. Ovidiu Daescu for helpful discussions.
Funding
Not applicable.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares no competing interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Armaselu, B. Approximation algorithms for some extensions of the maximum profit routing problem. J Comb Optim 45, 26 (2023). https://doi.org/10.1007/s10878-022-00944-0
Accepted:
Published:
DOI: https://doi.org/10.1007/s10878-022-00944-0