
Abstract
We present a PDE-based framework that generalizes Group equivariant Convolutional Neural Networks (G-CNNs). In this framework, a network layer is seen as a set of PDE-solvers where geometrically meaningful PDE-coefficients become the layer’s trainable weights. Formulating our PDEs on homogeneous spaces allows these networks to be designed with built-in symmetries such as rotation in addition to the standard translation equivariance of CNNs. Having all the desired symmetries included in the design obviates the need to include them by means of costly techniques such as data augmentation. We will discuss our PDE-based G-CNNs (PDE-G-CNNs) in a general homogeneous space setting while also going into the specifics of our primary case of interest: roto-translation equivariance. We solve the PDE of interest by a combination of linear group convolutions and nonlinear morphological group convolutions with analytic kernel approximations that we underpin with formal theorems. Our kernel approximations allow for fast GPU-implementation of the PDE-solvers; we release our implementation with this article in the form of the LieTorch extension to PyTorch, available at https://gitlab.com/bsmetsjr/lietorch. Just like for linear convolution, a morphological convolution is specified by a kernel that we train in our PDE-G-CNNs. In PDE-G-CNNs, we do not use non-linearities such as max/min-pooling and ReLUs as they are already subsumed by morphological convolutions. We present a set of experiments to demonstrate the strength of the proposed PDE-G-CNNs in increasing the performance of deep learning-based imaging applications with far fewer parameters than traditional CNNs.
Similar content being viewed by others



Avoid common mistakes on your manuscript.
1 Introduction
In this work, we introduce PDE-based Group CNNs. The key idea is to replace the typical trifecta of convolution, pooling and ReLUs found in CNNs with a Hamilton–Jacobi type evolution PDE, or more accurately a solver for a Hamilton–Jacobi type PDE. This substitution is illustrated in Fig. 1 where we retain (channel-wise) affine combinations as the means of composing feature maps.
The PDE we propose to use in this setting comes from the geometric image analysis world [1,2,3,4,5,6,7,8,9,10,11,12]. It was chosen based on the fact that it exhibits similar behavior on images as traditional CNNs do through convolution, pooling and ReLUs. Additionally it can be formulated on Lie groups to yield equivariant processing, which makes our PDE approach compatible with Group CNNs [13,14,15,16,17,18,19,20,21,22,23,24,25]. Finally, an approximate solver for our PDE can be efficiently implemented on modern highly parallel hardware, making the choice a practical one as well.
Our solver uses the operator splitting method to solve the PDE in a sequence of steps, each step corresponding to a term of the PDE. The sequence of steps for our PDE is illustrated in Fig. 2. The morphological convolutions that are used to solve for the nonlinear terms of the PDE are a key aspect of our design. Normally, morphological convolutions are considered on \(\mathbb {R}^d\) [26, 27], but when extended to Lie groups such as SE(d) they have many benefits in applications (e.g., crossing-preserving flow [28] or tracking [29, 30]). Using morphological convolutions allows our network to have trainable non-linearities instead of the fixed non-linearities in (G-)CNNs.
The theoretical contribution of this paper consists of providing good analytical approximations to the kernels that go in the linear and morphological convolutions that solve our PDE. On \(\mathbb {R}^n\), the formulation of these kernels is reasonably straightforward, but in order to achieve group equivariance we need to generalize them on homogeneous spaces.
Instead of training kernel weights, our goal is training the coefficients of the PDE. The coefficients of our PDE have the benefit of yielding geometrically meaningful parameters from a image analysis point of view. Additionally, we will need (much) less PDE parameters than kernel weights to achieve a given level of performance in image segmentation and classification tasks, arguably the greatest benefit of our approach.

In a PDE-based CNN, we replace the traditional convolution, pooling and ReLU operations by a PDE solver. The inputs of a given layer serve as initial conditions for a set of evolution PDEs; the outputs consist of affine combinations of the solutions of those PDEs at a fixed point in time. The parameters of the PDE become the trainable weights (alongside the affine parameters) over which we optimize

Our Hamilton–Jacobi type PDE of choice contains a convection, diffusion, dilation and erosion term (CDDE for short). Through operator splitting, we solve for these terms separately by using resampling (for convection), linear convolution (for diffusion) and morphological convolution (for dilation and erosion)
This paper is a substantially extended journal version of [31] presented at the SSVM 2021 conference.
1.1 Structure of the Article
The structure of the article is as follows. We first place our work in its mathematical and deep learning context in Sect. 2. Then, we introduce the needed theoretical preliminaries from Lie group theory in Sect. 3 where we also define the space of positions and orientations \(\mathbb {M}_d\) that will allow us to construct roto-translation equivariant networks.
In Sect. 4, we give the overall architecture of a PDE-G-CNN and the ancillary tools that are needed to support a PDE-G-CNN. We propose an equivariant PDE that models commonly used operations in CNNs.
In Sect. 5, we detail how our PDE of interest can be solved using a process called operator splitting. Additionally, we give tangible approximations to the fundamental solutions (kernels) of the PDEs that are both easy to compute and sufficiently accurate for practical applications. We use them extensively in the PDE-G-CNNs GPU-implementations in PyTorch that can be downloaded from the GIT-repository: https://gitlab.com/bsmetsjr/lietorch.
Section 6 is dedicated to showing how common CNN operations such as convolution, max-pooling, ReLUs and skip connections can be interpreted in terms of PDEs.
We end our paper with some experiments showing the strength of PDE-G-CNNs in Sect. 7 and concluding remarks in Sect. 8.
The framework we propose covers transformations and CNNs on homogeneous spaces in general and as such we develop the theory in an abstract fashion. To maintain a bridge with practical applications, we give details throughout the article on what form the abstractions take explicitly in the case of roto-translation equivariant networks acting on \(\mathbb {M}_d\), specifically in 2D (i.e., \(d=2\)).
2 Context
As this article touches on disparate fields of study, we use this section to discuss context and highlight some closely related work.
2.1 Drawing Inspiration from PDE-Based Image Analysis
Since the Partial Differential Equations that we use are well known in the context of geometric image analysis [1,2,3,4,5,6,7,8,9,10,11], the layers also get an interpretation in terms of classical image-processing operators. This allows intuition and techniques from geometric PDE-based image analysis to be carried over to neural networks.
In geometric PDE-based image processing, it can be beneficial to include mean curvature or other geometric flows [32,33,34,35] as regularization and our framework provides a natural way for such flows to be included into neural networks. In the PDE layer from Fig. 2, we only mention diffusion as a means of regularization, but mean curvature flow could easily be integrated by replacing the diffusion sub-layer with a mean curvature flow sub-layer. This would require replacing the linear convolution for diffusion by a median filtering approximation of mean curvature flow [1].
2.2 The Need for Lifting Images
In geometric image analysis, it is often useful to lift images from a 2D picture to a 3D orientation score as in Fig. 3 and do further processing on the orientation scores [36]. A typical image processing task in which such a lift is beneficial is that of the segmentation of blood vessels in a medical image. Algorithms based on processing the 2D picture directly usually fail around points where two blood vessels cross, but algorithms that lift the image to an orientation score manage to decouple the blood vessels with different orientations as is illustrated in the bottom row of Fig. 3.
To be able to endow image processing neural networks with the added capabilities (such as decoupling orientations and guaranteeing equivariance) that result from lifting data to an extended domain, we develop our theory for the more general CNNs defined on homogeneous spaces, rather than just the prevalent CNNs defined on Euclidean space. One can then choose which homogeneous space to use based on the needs of one’s application (such as needing to decouple orientations). A homogeneous space is, given subgroup H of a group G, the manifold of left cosets, denoted by G/H. In the above image analysis example, the group G would be the special Euclidean group \(G = SE(d)\), the subgroup H would be the stabilizer subgroup of a fixed reference axis, and the corresponding homogeneous space G/H would be the space of positions and orientations \(\mathbb {M}_d \equiv \mathbb {R}^d \times S^{d-1}\), which is the lowest dimensional homogeneous space able to decouple orientations. By considering convolutional neural networks on homogeneous spaces such as \(\mathbb {M}_d\), these networks have access to the same benefits of decoupling structures with different orientations as was highly beneficial for geometric image processing [37,38,39,40,41,42,43,44,45,46,47,48,49,50,51].
Remark 1
(Generality of the architecture) Although not considered here, for other Lie groups applications (e.g., frequency scores [52, 53], velocity scores, scale orientation scores [54]) the same structure applies; therefore, we keep our theory in the general setting of homogeneous spaces G/H. This generality was also important in non-PDE-based learning [22], but also for PDE-based learning it is again beneficial.

Illustrating the process of lifting and projecting; in this case the advantage of lifting an image from \(\mathbb {R}^2\) to the 2D space of positions and orientations \(\mathbb {M}_2\) derives from the disentanglement of the lines at the crossings

Spatial CNNs, as used for image classification for example, are translation equivariant but not necessarily equivariant with respect to rotation, scaling and other transformations as the illustrative tags of the differently transformed apples images suggest. Building a G-CNN with the appropriately chosen group confers the network with all the equivariances appropriate for the chosen application. Our PDE-based approach is compatible with the group CNN approach [22] and so can confer the same symmetries
2.3 The Need for Equivariance
We require the layers of our network to be equivariant: a transformation of the input should lead to a corresponding transformation of the output, in other words: first transforming the input and then applying the network or first applying the network and then transforming the output should yield the same result. A particular example, in which the output transformation is trivial (i.e., the identity transformation), is that of invariance: in many classification tasks, such as the recognition of objects in pictures, an apple should still be recognized as an apple even if it is shifted or otherwise transformed in the picture as illustrated in Fig. 4. By guaranteeing equivariance of the network, the amount of data necessary or the need for data augmentation is reduced as the required symmetries are intrinsic to the network and need not be trained.
2.4 Related Work
G-CNNs After the introduction of G-CNNs by Cohen and Welling [13] in the field of machine and deep learning, G-CNNs became popular. This resulted in many articles on showing the benefits of G-CNNs over classical spatial CNNs. These works can be roughly categorized as
-
and steerable continuous G-CNNs [22,23,24,25, 57] that rely on Fourier transforms on homogeneous spaces [50, 58].
Both regular and steerable G-CNNs naturally arise from linear mappings between functions on homogeneous spaces that are placed under equivariance constraints [22, 24, 55, 57]. Regular G-CNNs explicitly extend the domain and lift feature maps to a larger homogeneous space of a group, whereas steerable CNNs extend the co-domain by generating fiber bundles in which a steerable feature vector is assigned to each position in the base domain. Although steerable operators have clear benefits in terms of computational efficiency and accuracy [59, 60], working with steerable representations puts constraints on nonlinear activations within the networks which limits the representation power of G-CNNs [57]. Like regular G-CNNs, the proposed PDE-G-CNNs do not suffer from this. In our proposed PDE-G-CNN framework, it is essential that we adopt the domain-extension viewpoint, as this allows to naturally and transparently construct scale space PDEs via left-invariant vector fields [12]. In general, this viewpoint entails that the domain of images is extended from the space of positions only, to a higher-dimensional homogeneous space, and originates from coherent state theory [61], orientation score theory [36], cortical perception models [39], G-CNNs [13, 20] and rigid-body motion scattering [62].
The proposed PDE-G-CNNs form a new, unique class of equivariant neural networks, and we show in Sect. 6 how regular continuous G-CNNs arise as a special case of our PDE-G-CNNs.
Probabilistic-CNNs Our geometric PDEs relate to \(\alpha \)-stable Lévy processes [50] and cost-processes akin to [26], but then on \(\mathbb {M}_{d}\) rather than \(\mathbb {R}^d\). This relates to probabilistic equivariant numerical neural networks [63] that use anisotropic convection-diffusions on \(\mathbb {R}^d\).
In contrast with these networks, the PDE-G-CNNs that we propose allow for simultaneous spatial and angular diffusion on \(\mathbb {M}_d\). Furthermore, we include nonlinear Bellman processes [26] for max pooling over Riemannian balls.
KerCNNs An approach to introducing horizontal connectivity in CNNs that does not require a Lie group structure was proposed by Montobbio et al. [64, 65] in the form of KerCNNs. In this biologically inspired metric model, a diffusion process is used to achieve intra-layer connectivity.
While our approach does require a Lie group structure, it is not restricted to diffusion and also includes dilation/erosion.
Neural Networks and Differential Equations The connection between neural networks and differential equations became widely known in 2017, when Weinan [66] explicitly explained the connection between neural networks and dynamical systems, especially in the context of the ultradeep ResNet [67]. This point of view was further expanded by Lu et al. [68], showing how many ultradeep neural networks can be viewed as discretizations of ordinary differential equations. The somewhat opposite point of view was taken by Chen et al. [69], who introduced a new type of neural network which no longer has discrete layers, them being replaced by a field parameterized by a continuous time variable. Weinan E also indicated a relationship between CNNs and PDEs, or rather with evolution equations involving a nonlocal operator. Implicitly, the connection between neural networks and differential equations was also explored by the early works of Chen et al. [70] who learn parameters in a reaction–diffusion equation. This connection between neural networks and PDEs was then made explicit and more extensive by Long et al. who made it possible to learn a much wider class of PDEs [71] with their PDE-Net. More recent work in PDE inspired neural networks includes [72, 73].
Basing neural network computations on PDEs formulated on manifolds also makes the processing independent with respect to the choice of coordinates on the manifold in the fashion of Weiler et al. [74].
More recent work in this direction includes integrating equivariant partial differential operators in steerable CNNs [75], drawing a strong analogy between deep learning and physics.
A useful aspect of the connection between neural networks and differential equations is the observation that the stability of the differential equation can give into the stability and generalization ability of the neural network [76]. Moreover, there are intriguing analogies with numerical PDE-approximations and specific network architectures (e.g. ResNets), as can be seen in the comprehensive overview article by Alt et al. [77].
The main contribution of our work in the field of PDE-related neural networks is that we implement and analyze geometric PDEs on homogeneous spaces, to obtain general group equivariant PDE-based CNNs whose implementations just require linear and morphological convolutions with new analytic approximations of scale space kernels.
3 Equivariance: Groups and Homogeneous Spaces
We want to design the PDE-G-CNN, and its layers, in such a way that they are equivariant. Equivariance essentially means that one can either transform the input and then feed it through the network, or first feed it through the network and then transform the output, and both give the same result. We will give a precise definition after introducing general notation.
3.1 The General Case
A layer in a neural network (or indeed the whole network) can be viewed as an operator from a space of real-valued functions defined on a space X to a space of real-valued functions defined on a space Y. It may be helpful to think of these function spaces as spaces of images.
We assume that the possible transformations form a connected Lie group G. Think for instance of a group of translations which shift the domain into different directions. The Lie group being connected excludes transformations such as reflections, which we want to avoid for the sake of simplicity. We further assume that the Lie group G acts smoothly on both spaces X and Y, which means that there are smooth maps \(\rho _X : G \times X \rightarrow X\) and \(\rho _Y: G \times Y \rightarrow Y\) such that for all \(g, h \in G\),
and
making \(\rho _X\) and \(\rho _Y\) group actions on their respective spaces.
Additionally we will assume that the group G acts transitively on the spaces, meaning that for any two elements of these spaces there exists a transformation in G that maps one to the other. This has as the consequence that X and Y can be seen as homogeneous spaces [78]. In particular, this means that after selecting a reference element \(x_0 \in X\) we can make the following isomorphism:
using the mapping
which is a bijection due to transitivity and the fact that
is a closed subgroup of G. Because of this, we will represent a homogeneous space as the quotient G/H for some choice of closed subgroup \(H = \text {Stab}_G(x_0)\) since all homogeneous spaces are isomorphic to such a quotient by the above construction.
In this article, we will restrict ourselves to those homogeneous spaces that correspond to those quotients G/H where the subgroup H is compact and connected. Restricting ourselves to compact and connected subgroups simplifies many constructions and still covers several interesting cases such as the rigid body motion groups SE(d).
The elements of the quotient G/H consist of subsets of G which we will denote by the letter p, these subsets are know as left cosets of H since every one of them consists of the set \(p=gH\) for some \(g \in G\), the left cosets are a partition of G under the equivalence relation
Under this notation, the group G consists of the disjoint union
The left coset that is associated with the reference element \(x_0 \in X\) is H, and for that reason we also alias it by \(p_0 := H\) when we want to think of it as an atomic entity rather than a set in its own right.
We will denote quotient map from G to G/H with \(\pi \):
Remark 2
(Principal homogeneous space) Observe that by choosing \(H=\left\{ e \right\} \) we get \(G/H \equiv G\), i.e., the Lie group is a homogeneous space of itself. This is called the principal homogeneous space. In that case, the group action is equivalent to the group composition. The numerical experiments we perform in this paper are on the principal homogeneous space \(\mathbb {R}^2 \times S^1\) of SE(2).
We will denote the group action/left-multiplication by an element \(g \in G\) by the operator \(L_g: G/H \rightarrow G/H\) given by
In addition, we denote the left-regular representation of G on functions f defined on G/H by \(\mathcal {L}_g\) defined by
A neural network layer is itself an operator (from functions on \(G/H_X\) to functions on \(G/H_Y\)), and we require the operator to be equivariant with respect to the actions on these function spaces.
Definition 1
(Equivariance) Let G be a Lie group with homogeneous spaces \(G/H_X\) and \(G/H_Y\). Let \(\Phi \) be an operator from functions (of some function class) on \(G/H_X\) to functions on \(G/H_Y\), then we say that \(\Phi \) is equivariant with respect to G if for all functions f (of that class) we have that:
or in words: the neural network commutes with transformations.
Most of the time we will have \(H_X = H_Y\) in our proposed neural networks; only the initial lifting layer and the final projection layer will be between different homogeneous spaces, as we will see later on.
3.2 Vector and Metric Tensor Fields
The particular operators that we will base our framework on are vector and tensor fields, if these basic building blocks are equivariant then our processing will be equivariant. We explain what left invariance means for these objects next.
For \(g \in G\) and \(p \in G/ H\), let \(T_p(G/H)\) be the tangent space at point p, then the pushforward
of the group action \(L_g\) is defined by the condition that for all smooth functions f on G/H and all \(\varvec{v} \in T_p(G/H)\) we have that
Remark 3
(Tangent vectors as differential operators) Other than the usual geometric interpretation of tangent vectors as being the velocity vectors \({\dot{\gamma }}(t)\) tangent to some differentiable curve \(\gamma :\mathbb {R} \rightarrow G/H\), we will simultaneously use them as differential operators acting on functions as we did in (8). This algebraic viewpoint defines the action of the tangent vector \({\dot{\gamma }}(t)\) on a differentiable function f as
In the flat setting of \(G=\left( \mathbb {R}^d,+\right) \), where the tangent spaces are isomorphic to the base manifold \(\mathbb {R}^d\), when we have a tangent vector \(\varvec{c} \in \mathbb {R}^d\) its application to a function is the familiar directional derivative:

See [79, §2.1.1] for details on this double interpretation.
Vector fields that have the special property that the push forward \((L_g)_*\) maps them to themselves in the sense that
for all differentiable functions f and where \(\varvec{v}:p \mapsto T_p \left( G/H \right) \) is a vector field are referred to as G-invariant.
Definition 2
(G-invariant vector field on a homogeneous space) A vector field \(\varvec{v}\) on G/H is invariant with respect to G if it satisfies
It is straightforward to check that (9) and (10) are equivalent and that these imply the following.
Corollary 3
(Properties of G-invariant vector fields) On a homogeneous space G/H, a G-invariant vector field \(\varvec{v}\) has the following properties:
-
1.
it is fully determined by its value \(\varvec{v}\vert _H \in T_H(G/H)\) in H,
-
2.
\(\forall h \in H: \left( L_h \right) _* \varvec{v}\vert _H = \varvec{v}\vert _H\).
We also introduce G-invariant metric tensor fields.
Definition 4
(G-invariant metric tensor field on G/H) A (0, 2)-tensor field \(\mathcal {G}\) on G/H is G-invariant if and only if
Recall that \(L_g p := g p\) and so the push-forward \(\left( L_{g} \right) _*\) maps tangent vector from \(T_p(G/H)\) to \(T_{g p}(G/H)\). Again it follows immediately from this definition that a G-invariant metric tensor field has similar properties as a G-invariant vector field.
Corollary 5
(Properties of G-invariant metric tensor fields) On a homogeneous space G/H, a G-invariant metric tensor field \(\mathcal {G}\) has the following properties:
-
1.
it is fully determined by its metric tensor \(\mathcal {G}\vert _{p_0}\) at \(p_0=H\),
-
2.
\(\forall h \in H,\, \forall \varvec{v}, \varvec{w} \in T_{p_0} \left( G/H \right) : \mathcal {G}\big \vert _{p_0} \left( \varvec{v}, \varvec{w} \right) = \mathcal {G}\big \vert _{p_0} \left( \left( L_h\right) _* \varvec{v}, \left( L_h \right) _* \varvec{w} \right) \).
Or in words, the metric (tensor) has to be symmetric with respect to the subgroup H.
A (positive definite) metric tensor field yields a Riemannian metric in the usual manner, as we recall next.
Definition 6
(Metric on G/H) Let \(p_1,p_2 \in G/H\) then:
As metrics and their smoothness play a role in our construction, we need to take into account where that smoothness fails.
Definition 7
The cut locus \({{\,\mathrm{cut}\,}}(p) \subset G/H\) or \({{\,\mathrm{cut}\,}}(g) \subset G\) is the set of points, respectively, group elements where the distance map from p resp. g is not smooth (excluding the point p and group element g themselves).
As long as we stay away from the cut locus, the infimum from Definition 6 gives a unique geodesic.
Being derived from a G-invariant tensor field gives the metric \(d_{\mathcal {G}}\) the same symmetries.
Proposition 8
(G-invariance of the metric on G/H) Let \(p_1,p_2 \in G/H\) away from each other’s cut locus, then we have:
Proof
We observe that we can make a bijection from the set of Lipschitz curves between \(p_1\) and \(p_2\) and between \(g p_1\) and \(g p_2\) simply by left multiplication by g one way and \(g^{-1}\) the other way. Due to (11), multiplying a curve with a group element preserves its length; hence, if \(\gamma :[0,1] \rightarrow G/H\) is the geodesic from \(p_1\) to \(p_2\), then \(g \gamma \) is the geodesic from \(g p_1\) to \(g p_2\), both having the same length. \(\square \)
A metric tensor field on the homogeneous space has a natural counterpart on the group.
Definition 9
(Pseudometric tensor field on G) A G-invariant metric tensor field \(\mathcal {G}\) on G/H induces a (pullback) pseudometric tensor field \(\tilde{\mathcal {G}}\) on G that is left invariant:
where \(\pi ^*\) is the pullback of the quotient map \(\pi \) from (4). This is equivalent to saying that for all \(\varvec{v},\varvec{w} \in T_g G\):
where \(\pi _*\) is the pushforward of \(\pi \).
This tensor field \(\tilde{\mathcal {G}}\) is left invariant by virtue of \(\mathcal {G}\) being G-invariant. It is also degenerate in the direction of H and so yields a seminorm on TG.
Definition 10
(Seminorm on TG) Let \(\varvec{v} \in T_g G\). Then, the metric tensor field \(\mathcal {G}\) on G/H induces the following seminorm:
In the same fashion, we have an induced pseudometric on G from the pseudometric tensor field on G.
Definition 11
(Pseudometric on G) Let \(g_1,g_2 \in G\). Then, we define:
This pseudometric has the property that \(d_{\tilde{\mathcal {G}}}(h_1,h_2)=0\) for all \(h_1,h_1 \in H\); in fact for all \(p \in G/H\) we have that \(d_{\tilde{\mathcal {G}}}(g_1,g_2)=0\) for all \(g_1,g_2 \in p\).
By requiring G and H to be connected, we get the following strong correspondence between the metric structure on the homogeneous space and the pseudometric structure on the group.
Lemma 12
Let \(g_1,g_2 \in G\) so that \(\pi (g_2)\) is away from the cut locus of \(\pi (g_1)\), then:
Moreover, if \(\gamma \) is a minimizing geodesic in the group G connecting \(g_1\) with \(g_2\), then \(\pi \circ \gamma \) is the unique minimizing geodesic in the homogeneous space G/H that connects \(\pi (g_1)\) with \(\pi (g_2)\).
Proof
Assuming it exists, let \(\gamma \in {{\,\mathrm{Lip}\,}}([0,1],G)\) be a minimizing geodesic connecting \(\gamma (0)=g_1\) with \(\gamma (1)=g_2\) and let \(\beta \in Lip([0,1],G/H)\) be the unique minimizing geodesic connecting \(\beta (0)=\pi (g_1)\) with \(\beta (1)=\pi (g_2)\). Because of the pseudometric on G, minimizing geodesics are not unique, i.e. \(\gamma \) is not unique. On G/H, we have a full metric and so staying away from the cut locus means \(\beta \) is both unique and minimizing.
Denote the length functionals with:

Observe that by construction of the pseudometric tensor field \(\tilde{\mathcal {G}}\) on G, we have: \({{\,\mathrm{Len}\,}}_G(\gamma )={{\,\mathrm{Len}\,}}_{G/H}(\pi \circ \gamma )\).
Now we assume \(\pi \circ \gamma \ne \beta \). Then, since \(\beta \) is the unique geodesic, we have
But then we can find some \(\gamma _{\mathrm {lift}} \in {{\,\mathrm{Lip}\,}}([0,1],G)\) that is a preimage of \(\beta \), i.e., \(\pi \circ \gamma _{\mathrm {lift}} = \beta \). The potential problem is that while \(\gamma _{\mathrm {lift}}(0) \in \pi (g_1)\) and \(\gamma _{\mathrm {lift}}(1) \in \pi (g_2)\), \(\gamma _{\mathrm {lift}}\) does not necessarily connect \(g_1\) to \(g_2\). But since the coset \(\pi (g_1)\) is connected, we can find a curve wholly contained in it that connects \(g_1\) with \(\gamma _{\mathrm {lift}}(0)\), call this curve \(\gamma _{\mathrm {head}} \in {{\,\mathrm{Lip}\,}}([0,1], \pi (g_1))\). Similarly we can find a \(\gamma _{\mathrm {tail}} \in {{\,\mathrm{Lip}\,}}([0,1], \pi (g_2))\) that connects \(\gamma _{\mathrm {lift}}(1)\) to \(g_2\). Both these curves have zero length since \(\pi \) maps them to a single point on G/H, i.e., \({{\,\mathrm{Len}\,}}_G(\gamma _{\mathrm {head}})={{\,\mathrm{Len}\,}}_G(\gamma _{\mathrm {tail}})=0\).
Now we can compose these three curves:

This new curve is again in \({{\,\mathrm{Lip}\,}}([0,1],G)\) and connects \(g_1\) with \(g_2\), but also:
which is a contradiction since \(\gamma \) is a minimizing geodesic between \(g_1\) and \(g_2\). We conclude \(\pi \circ \gamma = \beta \) and thereby:
\(\square \)
This result allows us to more easily translate results from Lie groups to homogeneous spaces.
We end our theoretical preliminaries by introducing the space of positions and orientations \(\mathbb {M}_d\).
3.3 Example: The Group SE(d) and the Homogeneous Space\(\mathbb {M}_d\)
Our main example and Lie group of interest are the Special Euclidean group SE(d) of the rotations and translations of \(\mathbb {R}^d\), in particular for \(d \in \left\{ 2,3 \right\} \). When we take \(H=\{ 0 \} \times SO(d-1)\), we obtain the space of positions and orientations
This homogeneous space and group will enable the construction of roto-translation equivariant networks. For the experiments in this paper, we restrict ourselves to \(d=2\), but we include the case \(d=3\) in some of our theoretical preliminaries.
As a set we identify \(\mathbb {M}_d\) with \(\mathbb {R}^d \times S^{d-1}\) and choose some reference direction \(\varvec{a} \in S^{d-1} \subset \mathbb {R}^d\) as the forward direction, we can set the reference point of the space as \(p_0 = \left( \varvec{0}, \varvec{a} \right) \). We can then see that elements of H are those rotations that map \(\varvec{a}\) to itself, i.e., rotations with the forward direction as their axis.
If we denote elements of SE(d) as translation/rotation pairs \(\left( \varvec{y},R\right) \in \mathbb {R}^d \times SO(d)\), then group multiplication is given by
and the group action on elements \(p=\left( \varvec{x}, \varvec{n} \right) \in \mathbb {R}^d \times S^{d-1} \equiv \mathbb {M}_d\) is given as
What the G-invariant vector field and metric tensor fields look like on \(\mathbb {M}_d\) is different for \(d=2\) than for \(d>2\). We first look at \(d>2\).
Proposition 13
Let \(d>2\) and let \(\partial _{\varvec{a}} \in T_{p_0}\left( \mathbb {M}_d \right) \) be the tangent vector in the reference point in the main direction \(\varvec{a} \in S^{d-1}\), specifically:
where \(f : \mathbb {M}_d \rightarrow \mathbb {R}\) is smooth in an open neighborhood of \(p_0=(0,\varvec{a})\); then, all SE(d)-invariant vector fields are spanned by the vector field:
with \(g_p \in p \in \mathbb {M}_d\).
Proof
For \(d > 3\), we can see that (17) are the only left-invariant vector fields since for all \(h \in H\) we have \(\left( g_p h\right) p_0=p\), and so in order to be well defined we must require \(\left( L_h \right) _* \varvec{v} = \varvec{v}\) on \(T_{p_0} \left( \mathbb {M}_d \right) \), and this is true for \(\partial _{\varvec{a}}\) (and its scalar multiples) but not true for any other tangent vectors at \(T_{p_0} \left( \mathbb {M}_d \right) \). \(\square \)
Proposition 14
For \(d>2\), the only Riemannian metric tensor fields on \(\mathbb {M}_d\) that are SE(d)-invariant are of the form:

with \(w_M, w_L, w_A > 0\) weighing the main, lateral and angular motion, respectively, and where the inner product, outer product and norm are the standard Euclidean constructs.
Proof
It follows that to satisfy the second condition of Corollary 5 at the tangent space \(T_{(\varvec{x},\varvec{n})}\) of a particular \((\varvec{x},\varvec{n})\) the metric tensor needs to be symmetric with respect to rotations about \(\varvec{n}\) both spatially and angularly (i.e., we require isotropy in all angular and lateral directions) which leads to the three degrees of freedom contained in (18) irrespective of d. \(\square \)
For \(d=2\), we represent the elements of \(\mathbb {M}_2\) with \((x,y,\theta ) \in \mathbb {R}^3\) where x, y are the usual Cartesian coordinates and \(\theta \) the angle with respect to the x-axis, so that \(\varvec{n}=(\cos \theta ,\sin \theta )^T\). The reference element is then simply denoted by (0, 0, 0).
It may be counter-intuitive but decreasing the number of dimensions to 2 gives more freedom to the G-invariant vector and metric tensor fields compared to \(d>2\). This is a consequence of the subgroup H being trivial, and so the symmetry conditions from Corollaries 3 and 5 also become trivial. The SE(2)-invariant vector fields are given as follows.
Proposition 15
On \(\mathbb {M}_2\), the SE(2)-invariant vector fields are spanned by the following basis:
Proof
For \(d=2\), we have \(\mathbb {M}_2 \equiv SE(d)\) and the group invariant vector fields on \(\mathbb {M}_2\) are exactly the left-invariant vector fields on SE(2) given by (19). \(\square \)
In a similar manner, SE(2)-invariant metric tensors are then given as follows.
Proposition 16
On \(\mathbb {M}_2\), the SE(2)-invariant metric tensor fields are given by:
for any choice of inner product \(\mathcal {G} \big \vert _{\left( 0,0,0\right) }\) at e.
Proof
Since \(SE(2) \equiv \mathbb {M}_2\), the G-invariant metric tensor fields are again exactly the left-invariant metric tensor fields. \(\square \)
This gives SE(2)-invariant metric tensor fields 6 degrees of freedom and hence 6 trainable parameters on \(\mathbb {M}_2\). Remarkably, the case \(d=2\) allows for more degrees of freedom than the case \(d=3\) where Proposition 14 applies. In our experiments so far, we have restricted ourselves to those metric tensors that are diagonal with respect to the frame from Proposition 15. A diagonal metric tensor would have just 3 degrees of freedom and have the same general form as (18), specifically:
We will expand into non-diagonal metric tensors in future work.
4 Architecture
4.1 Lifting and Projecting
The key ingredient of what we call a PDE-G-CNN is the PDE layer that we detail in the next section; however, to make a complete network we need more. Specifically we need a layer that transforms the network’s input into a format that is suitable for the PDE layers and a layer that takes the output of the PDE layers and transforms it to the desired output format. We call this input and output transformation lifting, respectively, projection; this yields the overall architecture of a PDE-G-CNN as illustrated in Fig. 5.
As our theoretical preliminaries suggest, we aim to do processing on homogeneous spaces, but the input and output of the network do not necessarily live on that homogeneous space. Indeed, in the case of images the data live on \(\mathbb {R}^2\) and not on \(\mathbb {M}_2\) where we propose to do processing.

Illustrating the overall architecture of a PDE-G-CNN (example: retinal vessel segmentation). An input image is lifted to a homogeneous space from which point on it can be fed through subsequent PDE layers (each PDE layer follow the structure of Fig. 2) that replace the convolution layers in conventional CNNs. Finally, the result is projected back to the desired output space
This necessitates the addition of lifting and projection layers to first transform the input to the desired homogeneous space and end with transforming it back to the required output space. Of course, for the entire network to be equivariant we require these transformation layers to be equivariant as well. In this paper, we focus on the design of the PDE layers, details on appropriate equivariant lifting and projection layers in the case of SE(2) is found in [20, 80].
Remark 4
(General equivariant linear transformations between homogeneous spaces) A general way to lift and project from one homogeneous space to another in a trainable fashion is the following. Consider two homogeneous spaces \(G/H_1\) and \(G/H_2\) of a Lie group G; let \(f: G/H_1 \rightarrow \mathbb {R}\) and \(k : G/H_2 \rightarrow \mathbb {R}\) with the following property:
where \(H_1\) is compact. Then, the operator \(\mathcal {T}\) defined by

transforms f from a function on \(G/H_1\) to a function on \(G/H_2\) in an equivariant manner (assuming f and k are such that the integral exists). Here the kernel k is the trainable part and \(\mu _G\) is the left-invariant Haar measure on the group.
Moreover, it can be shown via the Dunford–Pettis [81] theorem that (under mild restrictions) all linear transforms between homogeneous spaces are of this form.
Remark 5
(Lifting and projecting on \(\mathbb {M}_2\)) Lifting an image (function) on \(\mathbb {R}^2\) to \(\mathbb {M}_2\) can either be performed by a non-trainable Invertible Orientation Score Transform [36] or a trainable lift [20] in the style of Remark 4.
Projecting from \(\mathbb {M}_2\) back down to \(\mathbb {R}^2\) can be performed by a simple maximum projection: let \(f:\mathbb {M}_2 \rightarrow \mathbb {R}\), then
is a roto-translation equivariant projection as used in [20]. A variation on the above projection is detailed in [80, Ch. 3.3.3].
4.2 PDE Layer
A PDE layer operates by taking its inputs as the initial conditions for a set of evolution equations; hence, there will be a PDE associated with each input feature. The idea is that we let each of these evolution equations work on the inputs up to a fixed time \(T>0\). Afterward, we take these solutions at time T and take affine combinations (really batch normalized linear combinations in practice) of them to produce the outputs of the layer and as such the initial conditions for the next set of PDEs.
If we index network layers (i.e., the depth of the network) with \(\ell \) and denote the width (i.e., the number of features or channels) at layer \(\ell \) with \(M_{\ell }\), then we have \(M_{\ell }\) PDEs and take \(M_{\ell +1}\) linear combinations of their solutions. We divide a PDE layer into the PDE solvers that each apply the PDE evolution to their respective input channel and the affine combination unit. This design is illustrated in Fig. 1, but let us formalize it.
Let \(\left( U_{\ell ,c}\right) _{c=1}^{M_\ell }\) be the inputs of the \(\ell \)-th layer (i.e., some functions on G/H); let \(a_{\ell i j}\) and \(b_{\ell i} \in \mathbb {R}\) be the coefficients of the affine transforms for \(i=1 \ldots M_{\ell +1}\) and \(j=1 \ldots M_{\ell }\). Let each PDE be parametrized by a set of parameters \(\theta _{\ell j}\). Then, the action of a PDE layer is described as:
where \(\Phi _{T,\theta }\) is the evolution operator of the PDE at time \(T\ge 0\) and parameter set \(\theta \). We define the operator \(\Phi _{t,\theta }\) so that \((p,t) \mapsto \left( \Phi _{t,\theta } U \right) (p)\) satisfies the Hamilton–Jacobi type PDE that we introduce in just a moment. In this layer formula, the parameters \(a_{\ell i j}\), \(b_{\ell i}\) and \(\theta _{\ell j}\) are the trainable weights, but the evolution time T we keep fixed.
It is essential that we require the network layers and thereby all the PDE units to be equivariant. This has consequences for the class of PDEs that is allowed.
The PDE solver that we will consider in this article, illustrated in Fig. 2, computes the approximate solution to the PDE

Here, \(\varvec{c}\) is a G-invariant vector field on G/H (recall (17) and our use of tangent vectors as differential operators per Remark 3),  , \(\mathcal {G}_1\) and \(\mathcal {G}_2^\pm \) are G-invariant metric tensor fields on G/H, U is the initial condition and \(\Delta _{\mathcal {G}}\), and \(\Vert \cdot \Vert _{\mathcal {G}}\) denote the Laplace–Beltrami operator and norm induced by the metric tensor field \(\mathcal {G}\). As the labels indicate, the four terms have distinct effects:
, \(\mathcal {G}_1\) and \(\mathcal {G}_2^\pm \) are G-invariant metric tensor fields on G/H, U is the initial condition and \(\Delta _{\mathcal {G}}\), and \(\Vert \cdot \Vert _{\mathcal {G}}\) denote the Laplace–Beltrami operator and norm induced by the metric tensor field \(\mathcal {G}\). As the labels indicate, the four terms have distinct effects:
-
convection: moving data around,
-
(fractional) diffusion: regularizing data (which relates to subsampling by destroying data),
-
dilation: pooling of data,
-
erosion: sharpening of data.
This is also why we refer to a layer using this PDE as a CDDE layer. Summarized parameters of this PDE are given by \(\theta =\left( \varvec{c},\ \mathcal {G}_{1},\ \mathcal {G}^+_{2},\ \mathcal {G}^-_{2} \right) \). The geometric interpretation of each of the terms in (24) is illustrated in Fig. 6 for \(G = \mathbb {R}^2\) and in Fig. 7 for \(G=\mathbb {M}_2\).
Since the convection vector field \(\varvec{c}\) and the metric tensor fields \(\mathcal {G}_1\) and \(\mathcal {G}_2^{\pm }\) are G-invariant, the PDE unit, and so the network layer, is automatically equivariant.

Geometric interpretation of the terms of the PDE (24) illustrated for \(\mathbb {R}^2\). In this setting, the G-invariant vector field \(\varvec{c}\) is the constant vector field given by two translation parameters. For the other terms, we use Riemannian metric tensors parametrized by a positive definite \(2 \times 2\) matrix in the standard basis. The kernels used in the diffusion, dilation and erosion terms are functions of the distance map induced by the metric tensors

Geometric interpretation of the terms of the PDE (24) illustrated for \(\mathbb {M}_2\). In this setting, the G-invariant vector field \(\varvec{c}\) is a left-invariant vector field given by two translation and one rotation parameter. For the other terms, we use Riemannian metric tensors parametrized by a positive definite \(3 \times 3\) matrix in the left-invariant basis (the matrix does not need to be diagonal, but we keep that for future work). The kernels used in the diffusion, dilation and erosion terms are functions of the distance map induced by the metric tensors and are visualized by partial plots of their level sets
4.3 Training
Training the PDE layer comes down to adapting the parameters in the PDEs in order to minimize a given loss function (the choice of which depends on the application and we will not consider in this article). In this sense, the vector field and the metric tensors are analogous to the weights of this layer.
Since we required the convection vector field and the metric tensor fields to be G invariant, the parameter space is finite-dimensional as a consequence of Corollaries 3 and 5 if we restrict ourselves to Riemannian metric tensor fields.
For our main application on \(\mathbb {M}_2\), each PDE unit would have the following 12 trainable parameters:
-
3 parameters to specify the convection vector field as a linear combination of (19),
-
3 parameters to specify the fractional diffusion metric tensor field \(\mathcal {G}_1\),
-
and 3 parameters each to specify the dilation and erosion metric tensor fields \(\mathcal {G}_2^{\pm }\),
where the metric tensor fields are of the form (20) that are diagonal with respect to the frame from Proposition 15.
Surprisingly for higher dimensions, \(\mathbb {M}_d\) has less trainable parameters than for \(d=2\). This is caused by the SE(d)-invariant vector fields on \(\mathbb {M}_d\) for \(d \ge 3\) being spanned by a single basis element (per Proposition 13) instead of the three (19) basis elements available for \(d=2\). Since the left-invariant metric tensor fields are determined by only 3 parameters irrespective of dimensions, we count a total of 7 parameters for each PDE unit for applications on \(\mathbb {M}_d\) for \(d \ge 3\).
In our own experiments, we always use some form of stochastic gradient descent (usually ADAM) with a small amount of \(L^2\) regularization applied uniformly over all the parameters. Similarly, we stick to a single learning rate for all the parameters. Given that in our setting different parameters have distinct effects, treating all of them the same is likely far from optimal, however, we leave that topic for future investigation.
5 PDE Solver
Our PDE solver will consist of an iteration of time step units, each of which is a composition of convection, diffusion, dilation and erosion substeps. These units all take their input as an initial condition of a PDE and produce as output the solution of a PDE at time \(t=T\).
The convection, diffusion and dilation/erosion steps are implemented with, respectively, a shifted resample, linear convolution and two morphological convolutions, as illustrated in Fig. 8.
The composition of the substeps does not solve (24) exactly, but for small \(\Delta t\), it approximates the solution by a principle called operator splitting.
We will now discuss each of these substeps separately.
5.1 Convection
The convection step has as input a function \(U_1:G/H \rightarrow \mathbb {R}\) and takes it as initial condition of the PDE
The output of the layer is the solution of the PDE evaluated at time \(t=T\), i.e., the output is the function \(p \mapsto W_1(p,T)\).
Proposition 17
(Convection solution) The solution of the convection PDE (25) is found by the method of characteristics and is given by
where \(g_p \in p\) (i.e., \(g_p p_0=p\)) and \(\gamma _{\varvec{c}}:\mathbb {R} \rightarrow G\) is the exponential curve that satisfies \(\gamma _{\varvec{c}}(0)=e\) and
i.e., \(\gamma _{\varvec{c}}\) is the exponential curve in the group G that induces the integral curves of the G-invariant vector field \(\varvec{c}\) on G/H when acting on elements of the homogeneous space.
Note that this exponential curve existing is a consequence of the vector field \(\varvec{c}\) being G-invariant, such exponential curves do not exist for general convection vector fields.
Proof
now let \(\bar{U}:=\mathcal {L}_{\gamma _{\varvec{c}}(t)\,g_p^{-1}} U_1\), then
due to the G-invariance of \(\varvec{c}\) this yields
\(\square \)

Evolving the PDE through operator splitting, each operation corresponds to a term of (24)
In our experiments, Eq. (27) is numerically implemented as a resampling operation with trilinear interpolation to account for the off-grid coordinates.
5.2 Fractional Diffusion
The (fractional) diffusion step solves the PDE
As with (fractional) diffusion on \(\mathbb {R}^n\), there exists a smooth function
called the fundamental solution of the \(\alpha \)-diffusion equation, such that for every initial condition \(U_2\); the solution to the PDE (29) is given by the convolution of the function \(U_2\) with the fundamental solution \(K_{t}^{\alpha }\):
The convolution \(*_{G/H}\) on a homogeneous space G/H is specified by the following definition.
Definition 18
(Linear group convolution) Let \(p_0=H\) be compact, let \(f \in L^2 \left( G/H \right) \) and \(k \in L^1 \left( G/H \right) \) such that:
then, we define:

where \(\mu _H\) and \(\mu _G\) are the left-invariant Haar measures (determined up to scalar multiplication) on H, respectively, G.
Remark 6
In the remainder of this article, we refer the to the left-invariant Haar measure on G as ‘the Haar measure on G’ as right-invariant Haar measures on G do not play a role in our framework.
Remark 7
Compactness of H is crucial as otherwise the integral in the right-hand side of (31) does not converge. To this end, we note that one can always decompose (by Weil’s integral formula [82, Lem. 2.1]) the Haar measure \(\mu _{G}\) on the group as a product of a measure on the quotient G/H times the measure on the subgroup H. As Haar measures are determined up to a constant, we take the following convention: we normalize the Haar measure \(\mu _G\) such that
where \(\mu _{\mathcal {G}}\) is the Riemannian measure induced by \(\mathcal {G}\) and \(\mu _H\) is a choice of Haar measure on H. Thereby, (32) boils down to Weil’s integration formula:
whenever f is measurable. Since H is compact, we can indeed normalize the Haar measure \(\mu _H\) so that \(\mu _H(H)=1\).
In general, an exact analytic expression for the fundamental solution \(K_{t}^{\alpha }\) requires complicated steerable filter operators [50, Thm. 1 & 2], and for that reason we contend ourselves with more easily computable approximations. For now, let us construct our approximations and address their quality and the involved asymptotics later.
Remark 8
In the approximations, we will make use of logarithmic map as the inverse of the Lie group exponential map \(\exp _G\). Locally, such inversion can always be done by the inverse function theorem. Specifically, there is always a neighborhood \(V \subset T_e G\) of the origin so that \(\exp _G \vert _V\) is a diffeomorphism between V and \(W=\exp _G(V) \subset G\), where W is a neighborhood of e. Then we define the logarithmic map \(\log _G :W \rightarrow V\) by \(\text {exp}_G \circ \log _{G} = \text {id}_W\) and \( \log _{G} \circ \left. \text {exp}_G \right| _{V}=\text {id}_{V}\). For the moment, for simplicity, we assume \(V=T_e(G)\) in the general setting.Footnote 1
The idea is that instead of basing our kernels on the metric \(d_{\mathcal {G}}\) (which is hard to calculate [83]) we approximate it using the seminorm from Definition 10 (which is easy to calculate). We can use this seminorm on elements of the homogeneous space by using the group’s logarithmic map \(\log _G\). We can take the group logarithm of all the group elements that constitute a particular equivalence class of G/H and then pick the group element with the lowest seminorm:
Henceforth, we write this estimate as \(d_{\mathcal {G}} \left( p_0, p \right) \approx \rho _{\mathcal {G}}(p)\) relying on the following definition.
Definition 19
(Logarithmic metric estimate) Let \(\mathcal {G}\) be a G-invariant metric tensor field on the homogeneous space G/H, then we define
where \(\pi _*\) is the push-forward of the projection map \(\pi \) given by (4).
We can interpret this metric estimate as finding all exponential curves in G whose actions on the homogeneous space connect \(p_0\) (at \(t=0\)) to p (at \(t=1\)), and then, from that set we choose the exponential curve that has the lowest constant velocity according to the seminorm in Definition 10 and use that velocity as the distance estimate.
Summarizing, Definition 19 and Eq. (34), can be intuitively reformulated as: ‘instead of the length of the geodesic connecting two points of G/H, we take the length of the shortest exponential curve connecting those two points.’
The following lemma quantifies how well our estimate approximates the true metric.
Lemma 20
(Bounding the logarithmic metric estimate) For all \(p \in G/H\) sufficiently close to \(p_0\), we have
which has as a weaker corollary that for all compact neighborhoods of \(p_0\) there exists a \(C_{\mathrm {metr}}>1\) so that
for all p in that neighborhood. Note that the constant \(C_{\mathrm {metr}}\) depends on both the choice of compact neighborhood and the metric tensor field.
The proof of this lemma can be found in Appendix A.1.
Remark 9
(Logarithmic metric estimate in principal homogeneous spaces) When we take a principal homogeneous space such as \(\mathbb {M}_2 \equiv SE(2)\) with a left-invariant metric tensor field, the metric estimate simplifies to
hence, we see that this construction generalizes the logarithmic estimate, as used in [84, 85], to homogeneous spaces other than the principal.
Remark 10
(Logarithmic metric estimate for \(\mathbb {M}_2\)) Using the \((x,y,\theta )\) coordinates for \(\mathbb {M}_2\) and a left-invariant metric tensor field of the form (20), we formulate the metric estimate in terms of the following auxiliary functions called the exponential coordinates of the first kind:
The logarithmic metric estimate for SE(2) is then given by
this estimate is illustrated in Fig. 9 where it is contrasted against the exact metric.

Comparing the ‘exact’ Riemannian distance (top) obtained through numerically solving the Eikonal equation [29] versus the logarithmic metric estimate (bottom) on SE(2) endowed with a left-invariant Riemannian metric tensor field (20) with \(w_M=1\), \(w_L=2\), \(w_A=1/\pi \). The relative \(L^1\) error in the plotted volume is 0.20
We can see that the metric estimate \(\rho _{\mathcal {G}}\) (and consequently any function of \(\rho _{\mathcal {G}}\)) has the necessary compatibility property to be a kernel used in convolutions per Definition 18.
Proposition 21
(Kernel compatibility of \(\rho _{\mathcal {G}}\)) Let \(\mathcal {G}\) be a G-invariant metric tensor field on G/H, then we have
Note that, since we use left cosets, \(p h = p\) but \(h p \ne p\) in general, this requirement is not trivial. Proof of this proposition is included in Appendix A.2.
Now that we have developed and analyzed the logarithmic metric estimate; we can use it to construct an approximation to the diffusion kernel for \(\alpha =1\).
Definition 22
(Approximate \(\alpha =1\) kernel)
where \(\eta _t\) is a normalization constant for a given t; this can either be the \(L^1\) normalization constant or in the case of groups of polynomial growth one typically sets \(\eta _t=\mu _{\mathcal {G}}\left( B(p_0,\sqrt{t}) \right) ^{-1}\), see the definition of polynomial growth below .
On Lie groups of polynomial growth this approximate kernel be bounded from above and below by the exact kernels.
Definition 23
(Polynomial growth) A Lie group G with left-invariant Haar measure \(\mu _G\) is of polynomial growth when the volume of a sphere of radius r around \(g \in G\):
can be polynomialy bounded as follows: there exist constants \(\delta >0\) and \(C_{\mathrm {grow}}>0\) so that
take note that the exponent \(\delta \) is the same on both the lower and upper bound. Since \(\mu _G\) is left invariant, the choice of g does not matter.
Lemma 24
Let G be of polynomial growth, and let \(K_t^1\) be the fundamental solution to the \(\alpha =1\) diffusion equation on G/H, then there exist constants \(C\ge 1\) , \(D_1 \in (0,1)\) and \(D_2>D_{1}\) so that for all \(t>0\) the following holds:
for all \(p \in G/H\).
Proof
On a group of polynomial growth, we have \(\eta _t=\mu _{\mathcal {G}}\left( B(p_0,\sqrt{t}) \right) ^{-1}\). If G is of polynomial growth, we can apply [86, Thm. 2.12] to find that there exist constants \(C_1,C_2 >0\), and for all \(\varepsilon >0\) there exist a constant \(C_\varepsilon \) so that:
\(\square \)
Remark 11
(Left vs. right cosets) Note that Maheux [86] uses right cosets while we use left cosets. We can translate the results easily by inversion in view of \((gH)^{-1}=H^{-1} g^{-1}=H g^{-1}\). We then apply the result of Maheux to the correct (invertible) G-invariant metric tensor field on G/H.
Also note the different (but equivalent) way Maheux relates distance on the group with distance on the homogeneous space. While we use a pseudometric on G induced by a metric on G/H, Maheux uses a metric on G/H induced by a metric on G by:
for any choice of \(q_1 \in p_1\). We avoid having to minimize inside the cosets as in (39) thanks to the inherent symmetries in our pseudometric.
Now using the inequalities from Lemma 20, we obtain:
which leads to:
The group G being of polynomial growth also implies G/H is a doubling space [86, Thm. 2.17]. Using the volume doubling and reverse volume doubling property of doubling spaces [87, Prop. 3.2 and 3.3], we find that there exist constants \(C_3,C_4,\beta ,\beta '>0\) so that:
Applying these inequalities, we get:
and
; we obtain:
Reparametrizing t in both inequalities gives:
Finally, we fix \(\varepsilon >0\) and relabel constants:
observe that since \(\varepsilon >0\) and \(C_{\mathrm {metr}} \ge 1\), we have \(0<D_1< 1\). \(\square \)
Depending on the actually achievable constants, Lemma 24 provides a very strong or very weak bound on how much our approximation deviates from the fundamental solution. Fortunately in the SE(2) case, our approximation is very close to the exact kernel in the vicinity of the origin, as shown in Fig. 10. In our experiments, we sample the kernel on a grid around the origin; hence, this approximation is good for reasonable values of the metric parameters, which we may expect from Lemma 20 providing a second-order relative error.

Comparing the numerically computed heat kernel \(K_t^1\) (left) with our approximation \(K_t^{1,\mathrm {appr}}\) based on the logarithmic norm estimate (right) for \(G/H=SE(2)\). Shown here at \(t=1\) with the same metric as in Fig. 9. Especially in deep learning applications where discretization is very coarse, our approximation is sufficiently accurate as long as the spatial anisotropies \(w_M/w_L\) and \(w_L/w_M\) do not become too high. In this case, with \(w_L/w_M=2\) we have a relative \(L^2\) error of 0.23 in the plotted volume
Now let us develop an approximation for values of \(\alpha \) other than 1. From semi-group theory [88], it follows that semi-groups generated by taking fractional powers of the generator (in our case \(\Delta _{\mathcal {G}} \rightarrow -(-\Delta _{\mathcal {G}})^{\alpha }\)) amounts to the following key relation between the \(\alpha \)-kernel and the diffusion kernel:
for \(\alpha \in (0,1)\) and \(t>0\) where \(q_{t,\alpha }\) is defined as follows.
Definition 25
Let \(\mathcal {L}^{-1}\) be the inverse Laplace transform then
For explicit formulas of this kernel, see [88, Ch. IX:11 eq. 17]. Since \(e^{-t r^\alpha }\) is positive for all r, it follows that \(q_{t,\alpha }\) is also positive everywhere.
Now instead of integrating \(K_t^1\) to obtain the exact fundamental solution, we can replace it with our approximation \(K_t^{1,\mathrm {appr}}\) to obtain an approximate \(\alpha \)-kernel.
Definition 26
(Approximate \(\alpha \in (0,1)\) kernel) Akin to (40), we set \(\alpha \in (0,1)\), \(t>0\) and define:
for \(p \in G/H\).
The bounding of \(K_t^1\) we obtained in Lemma 24 transfers directly to our approximation for other \(\alpha \).
Theorem 27
Let G be of polynomial growth and let \(K_t^\alpha \) be the fundamental solution to the \(\alpha \in (0,1]\) diffusion equation on G/H, then there exists constants \(C\ge 1\) , \(D_1 \in (0,1)\) and \(D_{2}>D_{1}\) so that for all \(t>0\) and \(p \in G/H\) the following holds:
Proof
This is an consequence of Lemma 24 and the fact that \(q_{t,\alpha }\) is positive, applying the integral from (40) yields:

The other inequality works the same way. \(\square \)
Although the approximation (41) is helpful in the proof above it contains some integration and is not an explicit expression. Our initial experiments with diffusion for \(\alpha =1\) showed that (for the applications under consideration at least) adding diffusion did not improve performance. For that reason, we chose not to focus further on diffusion in this work. We leave developing a more explicit and computable approximation for diffusion kernels for \(0<\alpha <1\) for future work.
5.3 Dilation and Erosion
The dilation/erosion step solves the PDE
By a generalization of the Hopf–Lax formula [89, Ch.10.3], the solution is given by morphological convolution

for the \((+)\) (dilation) variant and

for the \((-)\) (erosion) variant, where the kernel \(k^{\alpha }_{t}\) (also called the structuring element in the context of morphology) is given as follows.
Definition 28
(Dilation/erosion kernels) The morphological convolution kernel \(k^{\alpha }_{t}\) for small times t and  is given by
is given by

with \(\nu _{\alpha }:=\left( \frac{2 \alpha - 1}{ \left( 2 \alpha \right) ^{2\alpha /(2\alpha -1)}} \right) \) and for  by
by

In the above definition and for the rest of the section, we write \(\mathcal {G}_2\) for either \(\mathcal {G}_2^+\) or \(\mathcal {G}_2^-\) depending on whether we are dealing with the dilation or erosion variant. The morphological convolution  (alternatively: the infimal convolution) is specified as follows.
(alternatively: the infimal convolution) is specified as follows.
Definition 29
(Morphological group convolution) Let \(f \in L^\infty \left( G/H \right) \), let \(k: G/H \rightarrow \mathbb {R} \cup \left\{ \infty \right\} \) be proper (not everywhere \(\infty \)), then we define:

Remark 12
(Grayscale morphology) Morphological convolution is related to the grayscale morphology operations \(\oplus \) (dilation) and \(\ominus \) (erosion) on \(\mathbb {R}^d\) as follows:

where \(f_1\) and \(f_2\) are proper functions on \(\mathbb {R}^d\). Hence, our use of the terms dilation and erosion, but mathematically we will only use  as the actual operation to be performed and avoid \(\oplus \) and \(\ominus \).
as the actual operation to be performed and avoid \(\oplus \) and \(\ominus \).
Combining morphological convolution with the structuring element \(k_t^\alpha \) allows us to solve (43).
Theorem 30
Let G be of polynomial growth, let  and let \(U_3 : G/H \rightarrow \mathbb {R}\) be Lipschitz. Then, \(W_3 : G/H \times (0,\infty ) \rightarrow \mathbb {R}\) given by
and let \(U_3 : G/H \rightarrow \mathbb {R}\) be Lipschitz. Then, \(W_3 : G/H \times (0,\infty ) \rightarrow \mathbb {R}\) given by

is Lipschitz and solves the \((-)\)-variant, the erosion variant, of the system (43) in the sense of Theorem 2.1 in [90], while

is Lipschitz and solves the \((+)\)-variant, the dilation variant, of system (43) in the sense of Theorem 2.1 in [90]. The kernels satisfy the semigroup property

for all \(s,t\ge 0\) and  .
.
Proof
The Riemannian manifold \((G/H, \mathcal {G}_2)\) is a proper length space, and therefore, the theory of [90] applies. Moreover, since G is of polynomial growth, we have that G/H is a doubling space [86, Thm. 2.17] and also admits a Poincaré constant [86, Thm. 2.18]. So we meet the additional requirements of [90, Thm. 2.3 (vii) and (viii)].
The Hamiltonian \(\mathcal {H}: \mathbb {R}_+ \rightarrow \mathbb {R}_+\) in [90] is given by \(\mathcal {H}(x)= x^{2\alpha }\). This Hamiltonian is indeed superlinear, convex, and satisfies \(\mathcal {H}(0) = 0\). The corresponding Lagrangian \(\mathcal {L}: \mathbb {R}_+ \rightarrow \mathbb {R}_+\) becomes
According to [90], the solution (in the sense of their Theorem 2.1) to the \((-)\)-variant of system (43) is given by

The \((+)\)-variant is proved analogously.
The semigroup property follows directly from [90, Thm 2.1(ii)]. \(\square \)
Remark 13
(Solution according to Balogh et al.) This theorem builds on the work by Balogh et al. [90] who provide a solution concept that is (potentially) different from the strong, weak or viscosity solution. The point of departure is to replace the norm of the gradient (i.e., the dual norm of the differential) with a metric subgradient, i.e., we replace \(\left\| \nabla _{\mathcal {G}_2} W (p,t) \right\| _{\mathcal {G}_2}\) by:
and we get a solution concept in terms of this slightly different notion of a gradient.
Remark 14
Unique viscosity solutions For the case  , we lose the superlinearity of the Hamiltonian and can no longer apply Balogh et al.’s approach [90]. The solution for
, we lose the superlinearity of the Hamiltonian and can no longer apply Balogh et al.’s approach [90]. The solution for  (46) converges pointwise to the solution for
(46) converges pointwise to the solution for  (47) as
(47) as  . However, the solution concept changes from that of Balogh et al. to that of a viscosity solution [91, 92]. In the general Riemannian homogeneous space setting, the result by Azagra [92, Thm 6.24] applies. It states that viscosity solutions of Eikonal PDEs on complete Riemannian manifolds are given by the distance map departing from the boundary of a given open and bounded set. As Eikonal equations directly relate to geodesically equidistant wavefront propagation on manifolds ( [93, ch. 3], [29, ch. 4,app. E], [89]) one expects that the solutions (44),(45) of (43) are indeed the viscosity solutions (for resp. the \(+\) and −-case) for
. However, the solution concept changes from that of Balogh et al. to that of a viscosity solution [91, 92]. In the general Riemannian homogeneous space setting, the result by Azagra [92, Thm 6.24] applies. It states that viscosity solutions of Eikonal PDEs on complete Riemannian manifolds are given by the distance map departing from the boundary of a given open and bounded set. As Eikonal equations directly relate to geodesically equidistant wavefront propagation on manifolds ( [93, ch. 3], [29, ch. 4,app. E], [89]) one expects that the solutions (44),(45) of (43) are indeed the viscosity solutions (for resp. the \(+\) and −-case) for  .
.
In many matrix Lie group quotients, like the Heisenberg group \(H(2d+1)\) studied in [94], or in our case of interest: the homogeneous space \(\mathbb {M}_d\) of positions and orientations) this is indeed the case. One can describe G-invariant vector fields via explicit coordinates and transfer HJB systems on G/H directly toward HJB-systems on \(\mathbb {R}^n\) or \(\mathbb {R}^d \times S^q\), with \(n=d+q=\text {dim}(G/H)\). Then, one can directly apply results by Dragoni [91, Thm.4] and deduce that our solutions, the dilations in (44) resp. erosions in (45), are indeed the unique viscosity solutions of HJB-PDE system (43) for the \(+\) and −-case, for all  . Details are left for future research.
. Details are left for future research.
To get an idea of how the kernel in (46) operates in conjunction with morphological convolution, we take \(G=G/H=\mathbb {R}\) and see how the operation evolves simple data, the kernels and results at \(t=1\) are shown in Fig. 12. Observe that with \(\alpha \) close to  (kernel and result in red) we obtain what amounts to an equivariant version of max/min pooling.
(kernel and result in red) we obtain what amounts to an equivariant version of max/min pooling.

Shapes of the level sets of the kernels on \(\mathbb {M}_2\) for solving fractional diffusion (\(K^{\alpha }_t\)) and dilation/erosion (\(k^{\alpha }_t\)) for various values of the trainable metric tensor field parameters \(w_M,w_L\) and \(w_A\). This shape is essentially what is being optimized during the training process of a metric tensor field on \(\mathbb {M}_2\)

In the center, we have kernels of the type (46) in \(\mathbb {R}\) (or the signed distance on a manifold of choice) for some  and \(t=1\), which solves dilation/erosion. For
and \(t=1\), which solves dilation/erosion. For  , this kernel converges to the type in (47), i.e., the solution is obtained by max/min pooling. On the left, we morphologically convolve a spike (in gray) with a few of these kernels; we see that if
, this kernel converges to the type in (47), i.e., the solution is obtained by max/min pooling. On the left, we morphologically convolve a spike (in gray) with a few of these kernels; we see that if  we get max pooling; conversely, we can call the case
we get max pooling; conversely, we can call the case  soft max pooling. On the right, we similarly erode a plateau, which for
soft max pooling. On the right, we similarly erode a plateau, which for  yields min pooling. The effects of these operations in the image processing context can also be seen in the last two columns of Fig. 6
yields min pooling. The effects of these operations in the image processing context can also be seen in the last two columns of Fig. 6
The level sets of the kernels \(k^{\alpha }_{t}\) for  are of the same shape as for the approximate diffusion kernels, see Fig. 11; for
are of the same shape as for the approximate diffusion kernels, see Fig. 11; for  these are the stencils over which we would perform min/max pooling.
these are the stencils over which we would perform min/max pooling.
Remark 15
The level sets in Fig. 11 are balls in \(G/H=\mathbb {M}_2\) that do not depend on \(\alpha \). It is only the growth of the kernel values when passing through these level sets that depends on \(\alpha \). As such, the example \(G/H=\mathbb {R}\) and Fig. 12 is very representative to the general G/H case. In the general G/H case, Fig. 11 still applies when one replaces the horizontal \(\mathbb {R}\)-axis with a signed distance along a minimizing geodesic in G/H passing through the origin. In that sense,  regulates soft-max pooling over Riemannian balls in G/H.
regulates soft-max pooling over Riemannian balls in G/H.
We can now define a more tangible approximate kernel by again replacing the exact metric \(d_{\mathcal {G}_2}\) with the logarithmic approximation \(\rho _{\mathcal {G}_2}\).
Definition 31
(Approximate dilation/erosion kernel) The approximate morphological convolution kernel \(k^{\alpha ,\mathrm {appr}}_{t}\) for small times t and  is given by
is given by
with \(\nu _{\alpha }:=\left( \frac{2 \alpha - 1}{ \left( 2 \alpha \right) ^{2\alpha /(2\alpha -1)}} \right) \) and for  by
by

We used this approximation in our parallel GPU-algorithms (for our PDE-G-CNNs experiments in Sect. 7). It is highly preferable over the ‘exact’ solution based on the true distance as this would require Eikonal PDE solvers ( [29, 95] which would not be practical for parallel GPU implementations of PDE-G-CNNs. Again the approximations are reasonable as long as the spatial anisotropy does not get too high, see Fig. 9 for an example.
Next we formalize the theoretical underpinning of the approximations in the upcoming corollary.
An immediate consequence of Definition 31 and Lemma 20 (keeping in mind that the kernel expressions in Definition 31 are monotonic w.r.t. \(\rho :=\rho _{\mathcal {G}_{2}}(p)\)) is that we can enclose our approximate morphological kernel with the exact morphological kernels in the same way as we did for the (fractional) diffusion kernel in Theorem 27. This proves the following Corollaries:
Corollary 32
Let  , then for all \(t>0\)
, then for all \(t>0\)
For the case  , the approximation is exact in an inner and outer region:
, the approximation is exact in an inner and outer region:

but in the intermediate region where \(\rho _{\mathcal {G}_2}(p)^{2 \alpha } > t\) and  we have
we have  while
while  .
.
Alternatively, instead of bounding by value we can bound in time, in which case we do not need to distinguish different cases of \(\alpha \).
Corollary 33
Let  then for all \(p \in G/H\) one has
then for all \(p \in G/H\) one has
With these two bounds on our approximate morphological kernels, we end our theoretical results.
6 Generalization of (Group-)CNNs
In this section, we point out the similarities between common (G-)CNN operations and our PDE-based approach. Our goal here is not so much claiming that our PDE approach serves as a useful model for analyzing (G-)CNNs, but that modern CNNs already bear some resemblance to a network of PDE solvers. Noticing that similarity, our approach is then just taking the next logical step by structuring a network to explicitly solve a set of PDEs.
6.1 Discrete Convolution as Convection and Diffusion
Now that we have seen how PDE-G-CNNs are designed we show how they generalize conventional G-CNNs. Starting with an initial condition U, we show how group convolution with a general kernel k can be interpreted as a superposition of solutions (27) of convection PDEs:

for any \(g_p \in p\), now change variables to \(q=g_p^{-1} g\) and recall that \(\mu _G\) is left invariant:

In this last expression, we recognize (27) and see that we can interpret \(p \mapsto U \left( g_p \,q p_0 \right) \) as the solution of the convection PDE (25) at time \(t=1\) for a convection vector field \(\varvec{c}\) that has flow lines given by \(\gamma _{\varvec{c}}(t)=\exp _G \left( - t \log _G q \right) p_0\) so that \((\gamma _{\mathbf {c}}(1))^{-1} p_0= q p_0\). As a result, the output \(k *_{G/H} U\) can then be seen as a weighted sum of solutions over all possible left invariant convection vector fields.
Using this result, we can consider what happens in the discrete case where we take the kernel k to be a linear combination of displaced diffusion kernels \(K_t^\alpha \) (for some choice of \(\alpha \)) as follows:
where for all i we fix a weight \(k_i \in \mathbb {R}\), diffusion time \(t_i \ge 0\) and a displacement \(g_i \in G\). Convolving with this kernel yields:

we change variables to \(h=g\, g_i\):

Here again we recognize \(q \mapsto U \left( g_q \, g_i^{-1} p_0 \right) \) as the solution (27) of the convection PDE at \(t=1\) with flow lines induced by \(\gamma _{\varvec{c}}(t)=\exp _G(t \log _G g_i)\). Subsequently, we take these solutions and convolve them with a (fractional) diffusion kernel with scale \(t_i\), i.e., after convection we apply the fractional diffusion PDE with evolution time \(t_i\) and finally make a linear combination of the results.
We can conclude that G-CNNs fit in our PDE-based model by looking at a single discretized group convolution as a set of single-step PDE units working on an input, without the morphological convolution and with specific choices made for the convection vector fields and diffusion times.
6.2 Max Pooling as Morphological Convolution
The ordinary max pooling operation commonly found in convolutional neural networks can also be seen as a morphological convolution with a kernel for  .
.
Proposition 34
(Max pooling) Let \(f \in L^\infty \left( G/H \right) \); let \(S \subset G/H\) be nonempty and define \(k_{S} : G/H \rightarrow \mathbb {R} \cup \left\{ \infty \right\} \) as:
Then,

We can recognize the morphological convolution as a generalized form of max pooling of the function f with stencil S.
Proof
Filling in (51) into Definition 29 yields:

\(\square \)
In particular cases, we recover a more familiar form of max pooling as the following corollary shows.
Corollary 35
(Euclidean Max Pooling) Let \(G=G/H=\mathbb {R}^n\) and let \(f \in C^0 \left( \mathbb {R}^n \right) \) with \(S \subset \mathbb {R}^n\) compact then:

for all \(x \in \mathbb {R}^n\).
The observation that max pooling is a particular limiting case of morphological convolution allows us to think of the case with  as a soft variant of max pooling, one that is better behaved under small perturbations in a discretized context.
as a soft variant of max pooling, one that is better behaved under small perturbations in a discretized context.
6.3 ReLUs as Morphological Convolution
Max pooling is not the only common CNN operation that can be generalized by morphological convolution as the following proposition shows.
Proposition 36
Let f be a compactly supported continuous function on G/H. Then, dilation with the kernel
equates to applying a Rectified Linear Unit to the function f:

Proof
Filling in k into the definition of morphological convolution:

due to the continuity and compact support of f its supremum exists, and moreover, we have \(\sup _{z \in G/H:z \ne p_0} f(z) = \sup _{y \in G/H} f(y)\), and thereby, we obtain the required result
\(\square \)
We conclude that morphological convolution allows us to:
-
do pooling in an equivariant manner with transformations other then translation,
-
do soft pooling that is continuous under domain transformations (illustrated in Fig. 12),
-
learn the pooling region by considering the kernel k as trainable,
-
effectively fold the action of a ReLU into trainable non-linearities.
6.4 Residual Networks
So-called residual networks [67] were introduced mainly as a means of dealing with the vanishing gradient problem in very deep networks, aiding trainability. These networks use so-called residual blocks, illustrated in Fig. 13, that feature a skip connection to group a few layers together to produce a delta-map that gets added to the input.

A residual block, like in [67], note the resemblance to a forward Euler discretization scheme
This identity + delta structure is very reminiscent of a forward Euler discretization scheme. If we had an evolution equation of the type
with some operator \(\mathcal {F}: L^{\infty }(M) \times M \rightarrow \mathbb {R}\), we could solve it approximately by stepping forward with:
for some time step \(\Delta t > 0\). We see that this is very similar to what is implemented in the residual block in Fig. 13 once we discretize it.
The correspondence is far from exact given that multiple channels are being combined in residual blocks, so we can not easily describe a residual block with a PDE. Still, our takeaway is that residual networks and skip connections have moved CNNs from networks that change data to networks that evolve data.
For this reason, we speculate that deep PDE-G-CNNs will not need (or have the same benefit from) skip connections; we leave this subject for future investigation. More discussion on the relation between residual networks and PDEs can be found in [77].
7 Experiments
To demonstrate the viability of PDE-based CNNs, we perform two experiments where we compare the performance of PDE-G-CNNs against G-CNNs and classic CNNs. We will be doing a vessel segmentation and digit classification problem: two straightforward applications of CNNs. Examples of these two applications are illustrated in Fig. 14.
The goal of the experiments is to compare the basic building blocks of different types of networks in clearly defined feed-forward network architectures. So we test networks of modest size only and do not just aim for the performance that would be possible with large-scale networks.

We perform a segmentation experiment on retinal vessel images and a classification experiment on rotation augmented digits
7.1 Implementation
We implemented our PDE-based operators in an extension to the PyTorch deep learning framework [98]. Our package is called LieTorch and is open source. It is available at https://gitlab.com/bsmetsjr/lietorch.
The operations we have proposed in the paper have been implemented in C++ for CPUs and CUDA for Nvidia GPUs but can be used from Python through PyTorch. Our package was also designed with modularity in mind: we provide a host of PyTorch modules that can be used together to implement the PDE-G-CNNs we proposed, but that can also be used separately to experiment with other architectures.
All the modules we provide are differentiable and so our PDE-G-CNNs are trainable through stochastic gradient descent (or its many variants) in the usual manner. In our experiments, we have had good results with using the ADAM [99] optimizer.
All the network models and training scripts used in the experiments are also available in the repository.
7.2 Design Choices
Several design choices are common to both experiments, we will go over these now.
First, we choose \(G/H=\mathbb {M}_2\) for our G-CNNs and PDE-G-CNNs and so go for roto-translation equivariant networks. In all instances, we lift to 8 orientations.
Second, we use the convection, dilation and erosion version of (24); hence, we refer to these networks as PDE-CNNs of the CDE-type. Each PDE-layer is implemented as in Fig. 1 with the single-pass PDE solver from Fig. 2 without the convolution. So no explicit diffusion is used, and the layer consists of just resampling and two morphological convolutions. Since we do the resampling using trilinear interpolation, this does introduce a small amount of implicit diffusion.
Remark 16
(Role of diffusion) In these experiments, we found no benefit to adding diffusion to the networks. Diffusion likely would be of benefit when the input data is noisy but neither datasets we used are noisy and we have not yet performed experiments with adding noise. We leave this investigation for future work.
Third, we fix \(\alpha =0.65\). We came to this value empirically; the networks performed best with \(\alpha \)-values in the range \(0.6-0.7\). Looking at Fig. 12, we can conjecture that \(\alpha =0.65\) is the “sweet spot” between sharpness and smoothness. When the kernel is too sharp (\(\alpha \) close to  ), minor perturbations in the input can have large effects on the output; when the kernel is too smooth (\(\alpha \) close to 1) the output will be smoothed out too much as well.
), minor perturbations in the input can have large effects on the output; when the kernel is too smooth (\(\alpha \) close to 1) the output will be smoothed out too much as well.
Fourth, all our networks are simple feed-forward networks.
Finally, we use the ADAM optimizer [99] together with \(L^2\) regularization uniformly over all parameters with a factor of 0.005.
7.3 DRIVE Retinal Vessel Segmentation
The first experiment uses the DRIVE retinal vessel segmentation dataset [96]. The object is the generate a binary mask indicating the location of blood vessels from a color image of a retina as illustrated in Fig. 14a.
We test 6- and 12-layer variants of a CNN, a G-CNN and a CDE-PDE-CNN. The layout of the 6-layer networks is shown in Fig. 15; the 12-layer networks simply add more convolution, group convolution or CDE layers. All the networks were trained on the same training data and tested on the same testing data.
The output of the network is passed through a sigmoid function to produce a 2D map a of values in the range [0, 1] which we compare against the known segmentation map b with values in \(\left\{ 0,1 \right\} \). We use the continuous DICE coefficient as the loss function:
where the sum \(\sum \) is over all the values in the 2D map. A relatively small \(\varepsilon =1\) is used to avoid divide-by-zero issues and the \(a \equiv b \equiv 0\) edge case.
The 6-layer networks were trained over 60 epochs, starting with a learning rate of 0.01 that we decay exponentially with a gamma of 0.95. The 12-layer networks were trained over 80 epochs, starting from the same learning rate but with a learning rate gamma of 0.96.
We measure the performance of the network by the DICE coefficient obtained on the 20 images of the testing dataset. We trained each model 10 times, the results of which are summarized in Table 1 and Fig. 16a.
We achieve similar or better performance than CNNs or G-CNNs but with a vast reduction in parameters. Scaling from 6 to 12 layers even allows us to reduce the total number of parameters of the PDE-G-CNN while still increasing performance; this is achieved by reducing the number of channels (i.e., the width) of the network, see also Table 2.

Schematic of the 6-layer models used on our segmentation experiments. Kernel sizes and number of feature channels in each layer are indicated, depth indicates that the data lives on \(\mathbb {M}_2\). Omitted are activation functions, batch normalization, padding and dropout modules. The 12-layer models are essentially the same but with double the number of layers but with reduced number of channels per layer (i.e., reduced width) for the CDE-PDE-CNN (hence the reduction in parameters going from 6 to 12 layers)

Comparison of PDE-based networks against conventional CNNs and group CNNs on segmentation and classification tasks
7.4 RotNIST Digit Classification

Schematic of the three models tested with the RotNIST data. Kernel sizes and number of feature channels in each layer are indicated. Omitted are activation functions, batch normalization and dropout modules
The second experiment we performed is the classic digit classification experiment. Instead of using the plain MNIST dataset, we did the experiment on the RotNIST dataset [97]. RotNIST contains the same images as MNIST but rotated to various degrees. Even though classifying rotated digits is a fairly artificial problem, we include this experiment to show that PDE-G-CNNs also work in a context very different from the first segmentation experiment. While our choice of PDEs derives from more traditional image processing methods, this experiment shows their utility in a basic image classification context.
We tested three networks: the classic LeNet5 CNN [100] as a baseline, a 4-layer G-CNN and a 4-layer CDE-PDE-CNN. The architectures of these three networks are illustrated in Fig. 17.
All three networks were trained on the same training data and tested on the same testing data. We train with a learning rate of 0.05 and a learning rate gamma of 0.96. We trained the LeNet5 model for 120 epochs and the G-CNN and CDE-PDE-CNN models for 60 epochs.
We measure the performance of the network by its accuracy on the testing dataset. We trained each model 10 times, the results of which are summarized in Table 3 and Fig. 16b.
We manage to get better performance than classic or group CNNs with far fewer parameters.
7.5 Computational Performance
Care was taken in optimizing the implementation to show that PDE-based networks can still achieve decent running times despite their higher computational complexity. In Table 4, we summarized the inferencing performance of each model we experimented with.
Our approach simultaneously gives us equivariance, a decrease in parameters and higher performance but at the cost of an increase in flops and memory footprint. While our implementation is reasonably optimized, it has had far less development time dedicated to it than the traditional CNN implementation provided by PyTorch/cuDNN, so we are confident more performance gains can be found.
In comparison with G-CNNs, our PDE-based networks are generally a little bit faster. Our G-CNN implementation is, however, less optimized compared to out PDE-G-CNN implementation. Were our G-CNN implementation equally optimized we expect G-CNNs to be slightly faster than the PDE-G-CNNs in our experiments.
8 Conclusion
In this article, we presented the general mathematical framework of geometric PDEs on homogeneous spaces that underlies our PDE-G-CNNs. PDE-G-CNNs allow for a geometric and probabilistic interpretation of CNNs opening up new avenues for the study and development of these types of networks. We showed that additionally, PDE-G-CNNs have increased performance with a reduction in parameters.
PDE-G-CNNs ensure equivariance by design. The trainable parameters are geometrically relevant: they are left-invariant vector and tensor fields.
PDE-G-CNNs have three types of layers: convection, diffusion and erosion/dilation layers. We have shown that these layers implicitly include standard nonlinear operations in CNNs such as max pooling and ReLU activation.
To efficiently evaluate PDE evolution in the layers, we provided tangible analytical approximations to the relevant kernel operators on homogeneous spaces. In this article, we have underpinned the quality of the approximations in Theorems 27 and 30.
With two experiments we have verified that PDE-G-CNNs can improve performance over G-CNNs in the context of automatic vessel segmentation and digit classification. Most importantly, the performance increase is achieved with a vast reduction in the amount of trainable parameters.
Notes
In our primary case of interest \(G=SE(2)\), we have \(V=\{\sum _{k=1}^3 c^k A_k \;|\; c^{3} \in [-\pi ,\pi )\}\).
References
Welk, M., Weickert, J.: PDE evolutions for M-smoothers: from common myths to robust numerics. In: International Conference on Scale Space and Variational Methods in Computer Vision, pp. 236–248. Springer (2019)
Fadili, J., Kutyniok, G., Peyré, G., Plonka-Hoch, G., Steidl, G.: Guest editorial: mathematics and image analysis. J. Math. Imaging Vis. 52(3), 315–316 (2015)
Peyré, G., Péchaud, M., Keriven, R., Cohen, L.D.: Geodesic methods in computer vision and graphics. Found. Trends. Comput. Graph. Vis. 5(3), 197–397 (2010)
Dubrovina-Karni, A., Rosman, G., Kimmel, R.: Multi-region active contours with a single level set function. IEEE PAMI 37(8), 1585–1601 (2015)
Burger, M., Sawatzky, A., Steidl, G.: First Order Algorithms in Variational Image Processing. Springer, Cham (2016)
Duran, J., Moeller, M., Sbert, C., Cremers, D.: Collaborative total variation: a general framework for vectorial tv models. SIAM SIIMS 9(1), 116–151 (2016)
Weickert, J., Grewenig, S., Schroers, C., Bruhn, A.: Cyclic schemes for PDE-based image analysis. Int. J. Comput. Vis. 118(3), 275–299 (2016)
Sapiro, G.: Geometric Partial Differential Equations and Image Analysis. Cambridge University Press, Cambridge (2001). https://doi.org/10.1017/CBO9780511626319
Sethian, J.: Level Set Methods and Fast Marching Methods. Cambridge University Press, Cambridge (1999)
Weickert, J.: Theoretical foundations of anisotropic diffusion in image processing. Comput. Suppl. 11, 221–236 (1996)
Morel, J., Solimini, S.: Variational Methods in Image Segmentation: With Seven Image Processing Experiments. Progress in Nonlinear Differential Equations and Their Applications. Birkhäuser, Basel (1995)
Duits, R., Burgeth, B.: Scale spaces on Lie groups. In: International Conference on Scale Space and Variational Methods in Computer Vision, pp. 300–312. Springer (2007)
Cohen, T.S., Welling, M.: Group equivariant convolutional networks. In: International of Conference on Machine Learning, pp. 2990–2999 (2016)
Dieleman, S., De Fauw, J., Kavukcuoglu, K.: Exploiting cyclic symmetry in convolutional neural networks (2016). arXiv preprint arXiv:1602.02660
Dieleman, S., Willett, K.W., Dambre, J.: Rotation-invariant convolutional neural networks for galaxy morphology prediction. Mon. Not. R. Astron. Soc. 450(2), 1441–1459 (2015)
Winkels, M., Cohen, T.S.: 3D G-CNNs for pulmonary nodule detection (2018). arXiv preprint arXiv:1804.04656
Worrall, D., Brostow, G.: Cubenet: Equivariance to 3D rotation and translation. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 567–584 (2018)
Bekkers, E.J., Loog, M., ter Haar Romeny, B.M., Duits, R.: Template matching via densities on the roto-translation group. IEEE Trans. Pattern Anal. Mach. Intell. 40(2), 452–466 (2017)
Oyallon, E., Mallat, S.: Deep roto-translation scattering for object classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2865–2873 (2015)
Bekkers, E.J., Lafarge, M.W., Veta, M., Eppenhof, K.A., Pluim, J.P., Duits, R.: Roto-translation covariant convolutional networks for medical image analysis. In: International Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 440–448. Springer (2018). arXiv:1804.03393
Weiler, M., Hamprecht, F.A., Storath, M.: Learning steerable filters for rotation equivariant cnns. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 849–858 (2018)
Cohen, T.S., Geiger, M., Weiler, M.: A general theory of equivariant cnns on homogeneous spaces. In: Advances in Neural Information Processing Systems, vol. 32 (2019)
Worrall, D.E., Garbin, S.J., Turmukhambetov, D., Brostow, G.J.: Harmonic networks: deep translation and rotation equivariance. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5028–5037 (2017)
Kondor, R., Trivedi, S.: On the generalization of equivariance and convolution in neural networks to the action of compact groups. In: Dy, J., Krause, A. (eds.) Proceedings of the 35th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 80, pp. 2747–2755. PMLR, Stockholmsmässan, Stockholm Sweden (2018). http://proceedings.mlr.press/v80/kondor18a.html
Esteves, C., Allen-Blanchette, C., Makadia, A., Daniilidis, K.: Learning SO(3) equivariant representations with spherical CNNs. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 52–68 (2018)
Akian, M., Quadrat, J.P., Viot, M.: Bellman processes. In: 11th International Conference on Analysis and Optimization of Systems Discrete Event Systems, pp. 302–311. Springer (1994)
Burgeth, B., Welk, M., Feddern, C., Weickert, J.: Morphological operations on matrix-valued images. In: European Conference on Computer Vision, pp. 155–167. Springer (2004)
Duits, R., Haije, T.D., Creusen, E., Ghosh, A.: Morphological and linear scale spaces for fiber enhancement in DW-MRI. J. Math. Imaging Vis. 46(3), 326–368 (2013)
Bekkers, E.J., Duits, R., Mashtakov, A., Sanguinetti, G.R.: A PDE approach to data-driven sub-Riemannian geodesics in SE(2). SIAM J. Imaging Sci. 8(4), 2740–2770 (2015)
Haije, T.C.D., Duits, R., Tax, C.M.: Sharpening fibers in diffusion weighted MRI via erosion. In: Visualization and Processing of Tensors and Higher Order Descriptors for Multi-valued Data, pp. 97–126. Springer (2014)
Duits, R., Smets, B., Bekkers, E.J., Portegies, J.M.: Equivariant deep learning via morphological and linear scale space PDEs on the space of positions and orientations. LNCS 12679, 27–39 (2021)
Citti, G., Franceschiello, B., Sanguinetti, G., Sarti, A.: Sub-Riemannian mean curvature flow for image processing. SIAM J. Imaging Sci. 9(1), 212–237 (2016)
Chambolle, A., Pock, T.: A first-order primal-dual algorithm for convex problems with applications to imaging. J. Math. Imaging Vis. 40(1), 120–145 (2011)
Chambolle, A., Pock, T.: Total roto-translational variation. Numer. Math. 142(3), 611–666 (2019). https://doi.org/10.1007/s00211-019-01026-w
Smets, B.M., Portegies, J., St-Onge, E., Duits, R.: Total variation and mean curvature PDEs on the homogeneous space of positions and orientations. J. Math. Imaging Vis. 63(2), 237–262 (2021)
Duits, R., Duits, M., van Almsick, M., ter Haar Romeny, B.: Invertible orientation scores as an application of generalized wavelet theory. Pattern Recognit. Image Anal. 17(1), 42–75 (2007)
Janssen, M.H.J., Janssen, A.J.E.M., Bekkers, E.J., Bescós, J.O., Duits, R.: Design and processing of invertible orientation scores of 3D images. J. Math. Imaging Vis. 60(9), 1427–1458 (2018). https://doi.org/10.1007/s10851-018-0806-0
Franceschiello, B., Mashtakov, A., Citti, G., Sarti, A.: Geometrical optical illusion via sub-Riemannian geodesics in the roto-translation group. Differ. Geom. Appl. 65, 55–77 (2019)
Citti, G., Sarti, A.: A cortical based model of perceptional completion in the roto-translation space. J. Math. Imaging Vis. 24(3), 307–326 (2006)
Duits, R., Franken, E.M.: Left invariant parabolic evolution equations on SE(2) and contour enhancement via invertible orientation scores, part I: linear left-invariant diffusion equations on SE(2). Q. Appl. Math. 68, 255–292 (2010)
Duits, R., Franken, E.M.: Left invariant parabolic evolution equations on SE(2) and contour enhancement via invertible orientation scores, part II: nonlinear left-invariant diffusion equations on invertible orientation scores. Q. Appl. Math. 68, 293–331 (2010)
Zhang, J., Duits, R., ter Haar Romeny, B., Sanguinetti, G.: Numerical approaches for linear left-invariant diffusions on SE(2), their comparisons to exact solutions, and their applications in retinal imaging. Numer. Math. Theory Methods Appl. 9(1), 1–50 (2016)
Boscain, U., Chertovskih, R.A., Gauthier, J.P., Remizov, A.O.: Hypoelliptic diffusion and human vision: a semidiscrete new twist. SIAM J. Imaging Sci. 7(2), 669–695 (2014)
Bertalmío, M., Calatroni, L., Franceschi, V., Franceschiello, B., Prandi, D.: A cortical-inspired model for orientation-dependent contrast perception: a link with Wilson-Cowan equations. In: Lellmann, J., Burger, M., Modersitzki, J. (eds.) Scale Space and Variational Methods in Computer Vision, pp. 472–484. Springer, Cham (2019)
Duits, R., Fuehr, H., Janssen, B., Florack, L., van Assen, H.: Evolution equations on Gabor transforms and their applications. ACHA 35(3), 483–526 (2013)
Barbieri, D., Citti, G., Cocci, G., Sarti, A.: A cortical-inspired geometry for contour perception and motion integration. J. Math. Imaging Vis. 49(3), 511–529 (2014)
Petitot, J.: The neurogeometry of pinwheels as a sub-Riemannian contact structure. J. Physiol. Paris 97, 265–309 (2003)
Felsberg, M., Forssen, P.E., Scharr, H.: Channel smoothing: efficient robust smoothing of low-level signal features. IEEE Trans. Pattern Anal. Mach. Intell. 28, 209–222 (2006)
Savadjiev, P., Strijkers, G., Bakermans, A., Piuze, E., Zucker, S., Siddiqi, K.: Heart wall myofibers are arranged in minimal surfaces to optimize organ function. PNAS 109(24), 9248–9253 (2012)
Duits, R., Bekkers, E., Mashtakov, A.: Fourier transform on the homogeneous space of 3D positions and orientations for exact solutions to linear PDEs. Entropy 21(1), 38 (2019)
Momayyez-Siahkal, P., Siddiqi, K.: 3D stochastic completion fields for fiber tractography. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (2009). https://doi.org/10.1109/CVPRW.2009.5204044
Duits, R., Führ, H., Janssen, B., Bruurmijn, M., Florack, L., van Assen, H.: Evolution equations on Gabor transforms and their applications. Appl. Comput. Harmon. Anal. 35(3), 483–526 (2013)
Boscain, U., Prandi, D., Sacchelli, L., Turco, G.: A bio-inspired geometric model for sound reconstruction. J. Math. Neurosci. 11(1), 1–18 (2021)
Baspinar, E., Citti, G., Sarti, A.: A geometric model of multi-scale orientation preference maps via Gabor functions. J. Math. Imaging Vis. 60(6), 900–912 (2018)
Bekkers, E.J.: B-Spline CNNs on Lie groups. In: International Conference on Learning Representations (2019)
Finzi, M., Stanton, S., Izmailov, P., Wilson, A.G.: Generalizing convolutional neural networks for equivariance to Lie groups on arbitrary continuous data. In: III, H.D., Singh, A. (eds.) Proceedings of the 37th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 119, pp. 3165–3176. PMLR (2020). http://proceedings.mlr.press/v119/finzi20a.html
Weiler, M., Cesa, G.: General E(2)-equivariant steerable CNNs. In: Advances in Neural Information Processing Systems, pp. 14334–14345 (2019)
Chirikjian, G.S., Kyatkin, A.B.: An operational calculus for the Euclidean motion group with applications in robotics and polymer science. J. Fourier Anal. Appl. 6(6), 583–606 (2000)
Franken, E., van Almsick, M., Rongen, P., Florack, L., ter Haar Romeny, B.: An efficient method for tensor voting using steerable filters. In: European Conference on Computer Vision, pp. 228–240. Springer (2006)
Reisert, M.: Group integration techniques in pattern analysis: a kernel view. Ph.D. thesis, Albert-Ludwigs-Universität Freiburg (2008)
Ali, S.T., Antoine, J.P., Gazeau, J.P., et al.: Coherent States, Wavelets and Their Generalizations, vol. 1. Springer, Berlin (2000)
Sifre, L., Mallat, S.: Rigid-motion scattering for texture classification (2014). arXiv preprint arXiv:1403.1687
Finzi, M., Bondesan, R., Welling, M.: Probabilistic numeric convolutional neural networks (2020). arXiv preprint arXiv:2010.10876
Montobbio, N.: A metric model of the visual cortex. Ph.D. thesis, Università di Bologna - Sorbonne Université (2019)
Montobbio, N., Bonnasse-Gahot, L., Citti, G., Sarti, A.: KerCNNs: biologically inspired lateral connections for classification of corrupted images (2019). arXiv preprint arXiv:1910.08336
Weinan, E.: A proposal on machine learning via dynamical systems. Commun. Math. Stat. 5(1), 1–11 (2017)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Lu, Y., Zhong, A., Li, Q., Dong, B.: Beyond finite layer neural networks: bridging deep architectures and numerical differential equations (2017). arXiv preprint arXiv:1710.10121
Chen, T.Q., Rubanova, Y., Bettencourt, J., Duvenaud, D.K.: Neural ordinary differential equations. In: Advances in Neural Information Processing Systems, pp. 6571–6583 (2018)
Chen, Y., Yu, W., Pock, T.: On learning optimized reaction diffusion processes for effective image restoration. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5261–5269 (2015)
Long, Z., Lu, Y., Ma, X., Dong, B.: PDE-net: Learning PDEs from data (2017). arXiv preprint arXiv:1710.09668
Ruthotto, L., Haber, E.: Deep neural networks motivated by partial differential equations. J. Math. Imaging Vis. 62(3), 352–364 (2020)
Shen, Z., He, L., Lin, Z., Ma, J.: Pdo-econvs: partial differential operator based equivariant convolutions. In: International Conference on Machine Learning, pp. 8697–8706. PMLR (2020)
Weiler, M., Forré, P., Verlinde, E., Welling, M.: Coordinate independent convolutional networks—isometry and gauge equivariant convolutions on Riemannian manifolds (2021). arXiv preprint arXiv:2106.06020
Jenner, E., Weiler, M.: Steerable partial differential operators for equivariant neural networks (2021). arXiv preprint arXiv:2106.10163
Haber, E., Ruthotto, L.: Stable architectures for deep neural networks. Inverse Prob. 34(1), 014004 (2017)
Alt, T., Peter, P., Weickert, J., Schrader, K.: Translating numerical concepts for PDEs into neural architectures (2021). arXiv preprint arXiv:2103.15419
Koda, T.: An introduction to the geometry of homogeneous spaces. In: Proceedings of the Thirteenth International Workshop on Differential Geometry, vol. 13, pp. 121–144 (2009)
Lee, J.M., Chow, B., Chu, S.C., Glickenstein, D., Guenther, C., Isenberg, J., Ivey, T., Knopf, D., Lu, P., Luo, F., et al.: Manifolds and differential geometry. Topology 643, 658 (2009)
Smets, B.: Geometric image denoising and machine learning. Master thesis, TU Eindhoven (2019). https://bmnsmets.com/publication/smets2019msc/
Arendt, W., Bukhvalov, A.V.: Integral representations of resolvents and semigroups. Forum Math. 6, 111–136 (1994)
Führ, H.: Abstract Harmonic Analysis of Continuous Wavelet Transforms. 1863. Springer, Berlin (2005)
Duits, R., Meesters, S.P., Mirebeau, J.M., Portegies, J.M.: Optimal paths for variants of the 2D and 3D Reeds–Shepp car with applications in image analysis. J. Math. Imaging Vis. 60, 1–33 (2018)
Portegies, J., Sanguinetti, G., Meesters, S., Duits, R.: New approximation of a scale space kernel on SE(3) and applications in neuroimaging. In: International Conference on Scale Space and Variational Methods in Computer Vision, pp. 40–52. Springer (2015)
Ter Elst, A., Robinson, D.W.: Weighted subcoercive operators on Lie groups. J. Funct. Anal. 157(1), 88–163 (1998)
Maheux, P.: Estimations du noyau de la chaleur sur les espaces homogenes. ESAIM Control Optim. Calc. Var. 8(1), 65–96 (1998)
Grigor’yan, A., Hu, J., Lau, K.S.: Heat kernels on metric spaces with doubling measure. In: Fractal Geometry and Stochastics IV, pp. 3–44. Springer (2009)
Yosida, K.: Functional Analysis. Springer, Berlin (1968)
Evans, L.C.: Partial Differential Equations, vol. 19. American Mathematical Society, Providence (2010)
Balogh, Z.M., Engulatov, A., Hunziker, L., Maasalo, O.E.: Functional inequalities and Hamilton–Jacobi equations in geodesic spaces. Potential Anal. 36(2), 317–337 (2012)
Dragoni, F.: Metric Hopf–Lax formula with semicontinuous data. Discrete Contin. Dyn. Syst. A 17(4), 713 (2007)
Azagra, D., Ferrera, J., López-Mesas, F.: Nonsmooth analysis and Hamilton–Jacobi equations on Riemannian manifolds. J. Funct. Anal. 220(2), 304–361 (2005)
Rund, H.: The Hamilton–Jacobi Theory in the Calculus of Variations: Its Role in Mathematics and Physics. Krieger Publishing Company, Malabar (1966)
Manfredi, J.J., Stroffolini, B.: A version of the Hopf–Lax formula in the Heisenberg group. Commun. Partial Differ. Equ. 27, 1139–1159 (2002)
Mirebeau, J.M., Portegies, J.: Hamiltonian fast marching: a numerical solver for anisotropic and non-holonomic eikonal PDEs. Image Process. On Line 9, 47–93 (2019)
Staal, J., Abràmoff, M.D., Niemeijer, M., Viergever, M.A., Van Ginneken, B.: Ridge-based vessel segmentation in color images of the retina. IEEE Trans. Med. Imaging 23(4), 501–509 (2004)
Baweja, C.: RotNIST (2018). https://github.com/ChaitanyaBaweja/RotNIST
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: Pytorch: an imperative style, high-performance deep learning library. In: Advances in Neural Information Processing Systems, pp. 8024–8035 (2019). www.ytorch.org
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization (2014). arXiv preprint arXiv:1412.6980
LeCun, Y., Boser, B., Denker, J.S., Henderson, D., Howard, R.E., Hubbard, W., Jackel, L.D.: Backpropagation applied to handwritten zip code recognition. Neural Comput. 1(4), 541–551 (1989)
Lee, J.: Introduction to Smooth Manifolds. Graduate Texts in Mathematics, 2nd edn. Springer, Berlin (2013). https://doi.org/10.1007/978-1-4419-9982-5_1
Acknowledgements
We gratefully acknowledge the Dutch Foundation of Science NWO for financial support (Duits: Geometric learning for Image Analysis, VI.C 202-031, Bekkers: Context Aware AI, VI nr.17290).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A
Appendix A
1.1 A.1 Proof of Lemma 20
The left inequality follows directly from the observation that \(\rho _{\mathcal {G}}(p)\) is exactly the Riemannian length of the curve
for \(t \in [0,1]\) and \(g_p = {{\,\mathrm{arg\,min}\,}}_{g \in p} \left\| \log _G g \right\| _{\tilde{\mathcal {G}}}\). This continuous curve connects \(p_0\) with p and as such has a greater length than the minimal length curve between those two points.
For the right inequality, consider the function \(F:T_e G \rightarrow \mathbb {R}\) given by
where we recall that \(\pi : G \rightarrow G/H\) was given by (4). With the goal of making a Taylor expansion for this function, we note that:
-
at the origin we have \(F(0)=0\),
-
due to the chain rule applied to the squaring we have
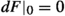 .
.
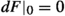 .
.Moreover, due to the to the G-invariance of \(d_{\mathcal {G}}\), the function F is even and consequently the 3rd order term of the Taylor expansion of F is zero.
For the second-order term, we are looking for the Hessian \(\mathcal {H}\) of F at \(v=0\). We split F into \(F_1 := \pi \circ \exp _G\) and \(F_2(p) := d_{\mathcal {G}}(p_0,p)^2\) and find the Hessian of the composed function is

Putting these facts together, we find:
where \(\Vert \cdot \Vert \) denotes some arbitrary norm on \(T_e G\).
Now we take a linear subspace V of \(T_e G\) that is independent from \(T_e H\) but so that the span of \(T_e H\) and V equals the entire \(T_e G\), so that \(T_e H \oplus V = T_e G\). Note that \(\tilde{\mathcal {G}}\vert _e\) is only degenerated along \(T_e H\), and so is a full norm when restricted to V, i.e., for all \(v \in V\), \(\tilde{\mathcal {G}}\vert _e(v,v) = 0\) only if \(v=0\). Therefore, there exists a \(c>0\) such that for all \(v \in V\),
and so by (53) we have:
Hence, for all \(v \in V\) close enough to 0 we have:
In a neighborhood of the origin, the Lie group exponential map \(\exp _G:T_e G \rightarrow G\) is a diffeomorphism to a neighborhood of e; at the same time \(\pi : G \rightarrow G/H\) is a smooth submersion by the Homogeneous Space Construction Theorem [101, Thm 21.17]. Consequently,  has full rank since \(\pi \circ \exp _G\) is a local diffeomorphism between two spaces (V and G/H) with the same dimension; it follows by the inverse function theorem that there exists a neighborhood \(V_0\) of 0 in V and a neighborhood \(P_0\) of \(p_0\) in G/H such that \(\pi \circ \exp _G\) is a diffeomorphism from \(V_0\) to \(P_0\). By possibly choosing \(V_0\) smaller, we may assume by (54) that there exists a \(C'>0\) such that for all \(v \in V_0\):
has full rank since \(\pi \circ \exp _G\) is a local diffeomorphism between two spaces (V and G/H) with the same dimension; it follows by the inverse function theorem that there exists a neighborhood \(V_0\) of 0 in V and a neighborhood \(P_0\) of \(p_0\) in G/H such that \(\pi \circ \exp _G\) is a diffeomorphism from \(V_0\) to \(P_0\). By possibly choosing \(V_0\) smaller, we may assume by (54) that there exists a \(C'>0\) such that for all \(v \in V_0\):
which, by using (55) yields
for all \(v \in V_0\) and \(C=C'\frac{c}{2}>0\).
Now take a \(p \in P_0\), then there exists a \(w \in V_0\) so that
Call \(g_p = \exp _G w\), then the previous inequality gives
Clearly \(g_p \in p\). Since \(\rho _{\mathcal {G}}(p)\) is the infinum of \(\Vert \log _G g \Vert \) for all \(g \in p\), it follows that \(\rho _{\mathcal {G}}(p)\) must also satisfy:
for all \(p \in P_0\), i.e., all p sufficiently close to \(p_0\).
As a corollary, we get that for any compact neighborhood \(K \subset G/H\) of \(p_0\)
for all \(p \in K\). We can see this by choosing \(C_1^2 = 1+C\,\sup _{p \in P_)} d_{\mathcal {G}}(p_0,p)^2\), then for all by choosing \(p \in P_0\) we have
Let \(K \subset G/H\) be compact so that it contains \(P_0\). Then, on \(\overline{K \setminus P_0}\) we have that both \(\rho _{\mathcal {G}}\) and \(d_{\mathcal {G}}(p_0,\cdot )\) are strictly positive, continuous and so bounded functions. Consequently,
and
for all \(p \in K\setminus P_0\), which leads to
for all \(p \in K \setminus P_0\). Now choose \(C_{\text {metr}} = \max \{ C_1, C_2 \}\), then we obtain the corollary. Remark that \(C_{\text {metr}}\) depends on both the parameters of the metric tensor field and the choice of K and so may become very large indeed. \(\square \)
1.2 A.2 Proof of Proposition 21
As a preliminary, we prove the following lemma.
Lemma For all \(g \in G\), let \(L_g: G \rightarrow G\) be the left group multiplication given by \(L_g h = g h\) and let \(R_g: G \rightarrow G\) be the right group multiplication given by \(R_g h = h g\). Let H be a closed subgroup of G with the projection map \(\pi :G \rightarrow G/H\) given by \(\pi (g)= g H\).
Then, for all \(h \in H\) we have the following relations for the push forwards:
-
1.
\(\pi _* \circ \left( R_h \right) _* = \pi _*\),
-
2.
\(\left( L_h \right) _* \circ \pi _* = \pi _* \circ \left( L_h \right) _*\).
Proof
-
1.
\(\pi \circ R_h = \pi \) since \(g h H = g H\),
-
2.
\(L_h \circ \pi = \pi \circ L_h\) since \(h ( g H)= (h g) H\).
\(\square \)
Now for the proof of Proposition 21. Consider the set of all exponential curves in the group whose action connects \(p_0 \in G/H\) to \(p \in G/H\):
We can then restate \(\rho _{\mathcal {G}}\) equivalently in terms of these curves as
since for each \(g \in p\) we have an exponential curve \(t \mapsto \exp _G(t \, \log _G g)\) in \(\Gamma _{p_0,p}\), and for each exponential curve \(\gamma \) in \(\Gamma _{p_0,p}\) we have \(\gamma (1) \in p\).
Let \(\gamma \in \Gamma _{p_0,p}\) and let \(h \in H\), then
-
1.
\(h \gamma (0) h^{-1} = h e h^{-1} =e\),
-
2.
\(h \gamma (1) h^{-1} p_0 =h \gamma (1) p_0 = h p\),
-
3.
\(h \gamma (a+b) h^{-1} = h \gamma (a) \gamma (b) h^{-1}=(h \gamma (a) h^{-1}) (h \gamma (b) h^{-1})\),
from which we conclude that \(h \gamma (\cdot ) h^{-1} \in \Gamma _{p_0,h p}\) and so there is a bijection between \(\Gamma _{p_0,p}\) and \(\Gamma _{p_0,h p}\) given by
Moreover, the bijection preserves the seminorm due to the G-invariance of \(\mathcal {G}\):
(using the previous lemma)
(using the G-invariance of \(\mathcal {G}\))
It follows that
\(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Smets, B.M.N., Portegies, J., Bekkers, E.J. et al. PDE-Based Group Equivariant Convolutional Neural Networks. J Math Imaging Vis 65, 209–239 (2023). https://doi.org/10.1007/s10851-022-01114-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10851-022-01114-x